Climate Change Communication in an Online Q&A Community: A Case Study of Quora


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Regression Model for Count Data
2.3. The Explanatory Variables
2.3.1. Textual Features
2.3.2. Auxiliary Features
3. Results
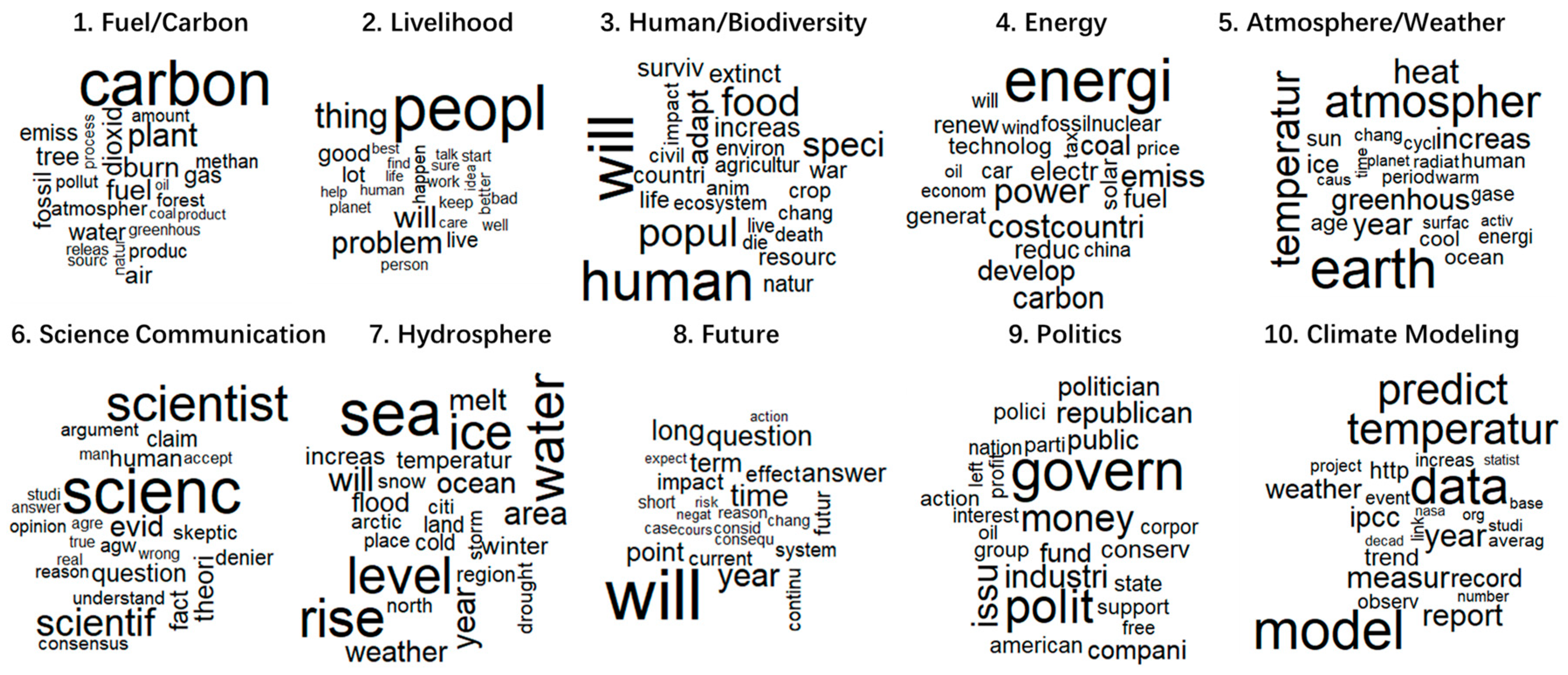
3.1. Major Topics in Answers
3.2. Regression Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Topic | Most Frequent Terms | Label | Proportion |
|---|---|---|---|
| 1 | will, energi-, peopl-, countri-, power, fuel, carbon, emiss-, coal, cost, develop, fossil, problem, reduc-, oil | energy, fuel, carbon, energy policy | 0.265 |
| 2 | earth, atmospher-, heat, carbon, human, greenhous-, water, increas-, temperatur-, air, plant, natur-, ocean, planet, energi- | earth, atmosphere, weather | 0.196 |
| 3 | will, year, ice, temperatur-, level, rise, sea, weather, increas-, water, area, time, age, ocean, chang- | ice, sea level | 0.223 |
| 4 | scienc-, peopl- scientist, question, human, scientif-, model, data, will, evid-, answer-, thing, fact, theori-, polit- | science, science communication | 0.317 |
| Topic | Most Frequent Terms | Label | Proportion |
|---|---|---|---|
| 1 | carbon, energi-, fuel, fossil, coal, plant, power, gas, emiss-, solar, burn, electr-, generat-, sourc-, nuclear | energy, fuel, carbon | 0.112 |
| 2 | will, human, peopl-, live, life, chang-, planet, popul-, natur-, food, speci-, happen, earth, bad, impact | impacts on human life and the earth | 0.135 |
| 3 | countri-, will, develop-, cost, emiss-, econom-, govern, energi-, china, carbon, money, tax, nation, price, reduc- | economy, policy | 0.108 |
| 4 | temperatur-, earth, atmospher-, year, increas-, heat, greenhouse-, ice, ocean, sun, age, time, cool, period, gase | earth, atmosphere, weather | 0.127 |
| 5 | peopl-, polit-, scienc-, issu-, denier, govern, republican, deni-, public, denial, industri-, politician, fact, real, fund | politics, science communication | 0.126 |
| 6 | sea, water, rise, level, ice, area, weather, year, will, increas-, ocean, flood | hydrosphere | 0.128 |
| 7 | thing, question, answer, good, time, point, problem, well, term, year, work, long, start, lot, people | question, future | 0.138 |
| 8 | scientist, scienc-, model, data, scientif-, predict, evid-, theori-, ipcc, studi-, report, claim, observ-, agw, consensus | climate science | 0.126 |
| Topic | Most Frequent Terms | Label | Proportion |
|---|---|---|---|
| 1 | carbon, plant, dioxid-, tree, emiss-, forest, burn, air, pollut-, produc-, fuel, methan-, water, product, grow | carbon cycling | 0.065 |
| 2 | peopl-, thing, problem, issu-, care, person, live, lot, good, work, feel, control, educ-, time, idea | livelihood | 0.095 |
| 3 | atmospher-, earth, heat, greenhouse-, temperatur-, gase, sun, energi-, water, increas-, radiat-, surfac-, cool, gas, amount | earth, atmosphere, weather | 0.077 |
| 4 | will, human, chang-, happen, natur, planet, life, earth, time, popul-, year, speci-, long, live, problem | human, nature, species | 0.118 |
| 5 | energi-, power, fuel, coal, fossil, electr-, oil, renew-, generat-, solar, nuclear, will, car, cost, gas | energy | 0.083 |
| 6 | level, increas-, rise, sea, ocean, temperatur-, degre-, year, will, average-, rate, water, countri-, land, higher | marine climate | 0.058 |
| 7 | scienc-, scientist, scientif-, polit-, denier, public, skeptic, republican, deni-, consensus, denial, claim, industri-, accept, opinion | science communication | 0.090 |
| 8 | ice, year, age, melt, period, temperatur-, warm, time, cold, warmer, arctic, ago, glacier, earth, polar | ice, temperature | 0.066 |
| 9 | water, area, flood, citi-, weather, drought, region, will, place, rain, storm, exterm-, winter, north, day | weather, water disaster | 0.072 |
| 10 | question, answer, point, reason, understand, fact, well, thing, read, man, interest, real, evid-, good, matter | question | 0.102 |
| 11 | countri-, develop, govern, carbon, emiss-, econom-, money, nation, tax, cost, will, industry, market, china, compani- | economy, policy | 0.091 |
| 12 | model, data, predict, temperatur-, report, theori-, scienc-, ipcc, year, scientist, measur-, observ, scientif-, studi-, weather | climate modeling | 0.082 |
Appendix B
Appendix C
- Any individual molecule of CO2 may cycle in or out of the atmosphere relatively frequently. Vegetation and phytoplankton take in huge amounts of CO2 every year, and release much of that CO2 back to the atmosphere the same year. That CO2 hasn’t actually been “removed” from the atmosphere, it has only gone for a short trip and then returns.
- The key issue from a climate change perspective is how long does it take for the large amount of added CO2 to leave the atmosphere for good. That actually takes place gradually over hundreds of years (before it’s mostly gone). That’s because the carbon has to find its way into permanent repositories of carbon that aren’t part of the annual carbon cycle. This could be into the deep ocean, or it could be mineralized…there are a number of ways CO2 leaves the “daily and yearly” cycle. But it does take a long time. That’s why people are concerned that climate change is effectively permanent, at least on the scale of a couple hundred years once we’ve made the leap.
- All references to international aviation and maritime emissions disappeared from the final draft, apparently cutting these sectors loose. It’s quite a switch from years of efforts to pull these rapidly growing emissions into the global framework of an agreement. And they were in there in most of the drafts circulated up to the very end.
- All references to black carbon and short-lived forcers have apparently disappeared. I suspect people will argue they’re included implicitly, but there has been such a big focus recently on trying to get countries to think about “quick action” measures on things like black carbon (which have a short-term greenhouse gas potential thousands of times greater than CO2) and methane that it’s surprising there is no reference.
References
- Kirilenko, A.P.; Molodtsova, T.; Stepchenkova, S.O. People as sensors: Mass media and local temperature influence climate change discussion on Twitter. Glob. Environ. Chang. Hum. Policy Dimens. 2015, 30, 92–100. [Google Scholar] [CrossRef]
- Tvinnereim, E.; Flottum, K. Explaining topic prevalence in answers to open-ended survey questions about climate change. Nat. Clim. Chang. 2015, 5, 744. [Google Scholar] [CrossRef]
- Hart, P.S.; Nisbet, E.C.; Myers, T.A. Public attention to science and political news and support for climate change mitigation. Nat. Clim. Chang. 2015, 5, 541–545. [Google Scholar] [CrossRef]
- Oreskes, N. Beyond the ivory tower—The scientific consensus on climate change. Science 2004, 306, 1686. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.Q.; Leiserowitz, A.A.; Maibach, E.W.; Roser-Renouf, C. Attention to Science/Environment News Positively Predicts and Attention to Political News Negatively Predicts Global Warming Risk Perceptions and Policy Support. J. Commun. 2011, 61, 713–731. [Google Scholar] [CrossRef]
- Jiang, H.C.; Qiang, M.S.; Lin, P. Assessment of online public opinions on large infrastructure projects: A case study of the Three Gorges Project in China. Environ. Impact Assess. Rev. 2016, 61, 38–51. [Google Scholar] [CrossRef]
- Williams, S.A.; Terras, M.M.; Warwick, C. What do people study when they study Twitter? Classifying Twitter related academic papers. J. Doc. 2013, 69, 384–410. [Google Scholar] [CrossRef]
- Schober, M.F.; Pasek, J.; Guggenheim, L.; Lampe, C.; Conrad, F.G. Research Synthesis Social Media Analyses for Social Measurement. Public Opin. Q. 2016, 80, 180–211. [Google Scholar] [CrossRef] [PubMed]
- Groves, R.M. Three Eras of Survey Research. Public Opin. Q. 2011, 75, 861–871. [Google Scholar] [CrossRef]
- Presser, S.; McCulloch, S. The growth of survey research in the United States: Government-sponsored surveys, 1984–2004. Soc. Sci. Res. 2011, 40, 1019–1024. [Google Scholar] [CrossRef]
- Ashley, C.; Tuten, T. Creative Strategies in Social Media Marketing: An Exploratory Study of Branded Social Content and Consumer Engagement. Psychol. Mark. 2015, 32, 15–27. [Google Scholar] [CrossRef]
- Gainsbury, S.M.; Delfabbro, P.; King, D.L.; Hing, N. An Exploratory Study of Gambling Operators’ Use of Social Media and the Latent Messages Conveyed. J. Gambl. Stud. 2016, 32, 125–141. [Google Scholar] [CrossRef] [PubMed]
- Mavragani, A.; Tsagarakis, K.P. YES or NO: Predicting the 2015 GReferendum results using Google Trends. Technol. Forecast. Soc. Chang. 2016, 109, 1–5. [Google Scholar] [CrossRef]
- Van de Belt, T.H.; Engelen, L.J.; Verhoef, L.M.; van der Weide, M.J.A.; Schoonhoven, L.; Kool, R.B. Using Patient Experiences on Dutch Social Media to Supervise Health Care Services: Exploratory Study. J. Med. Int. Res. 2015, 17. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Martin, B.; Richards, E. Scientific knowledge, controversy, and public decision-making. In Handbook of Science and Technology Studies; Jasanoff, S., Markle, G.E., Petersen, J.C., Pinch, T., Eds.; Sage: Thousand Oaks, CA, USA, 1995; pp. 506–526. [Google Scholar]
- Funtowicz, S.O.; Ravetz, J.R. Science for the post-normal age. Futures 1993, 25, 739–755. [Google Scholar] [CrossRef]
- Nowotny, H.; Scott, P.; Gibbons, M. ‘Mode 2′ revisited: The new production of knowledge—Introduction. Minerva 2003, 41, 179–194. [Google Scholar] [CrossRef]
- Flottum, K.; Gjesdal, A.M.; Gjerstad, O.; Koteyko, N.; Salway, A. Representations of the future in English language blogs on climate change. Glob. Environ. Chang. Hum. Policy Dimens. 2014, 29, 213–222. [Google Scholar] [CrossRef]
- Sharman, A. Mapping the climate skeptical blogosphere. Glob. Environ. Chang. Hum. Policy Dimens. 2014, 26, 159–170. [Google Scholar] [CrossRef]
- Crompton, H. Mode 2 knowledge production: Evidence from orphan drug networks. Sci. Public Policy 2007, 34, 199–211. [Google Scholar] [CrossRef]
- Trench, B. Scientists’ Blogs: Glimpses Behind the Scenes. In The Sciences’ Media Connection—Public Communication and Its Repercussions; Rödder, S., Franzen, M., Weingart, P., Eds.; Springe: Berlin, Germany, 2012; Volume 28, pp. 273–289. [Google Scholar]
- Itkonen, J.V.A. Social ties and concern for global warming. Clim. Chang. 2015, 132, 173–192. [Google Scholar] [CrossRef]
- Kirilenko, A.P.; Stepchenkova, S.O. Public microblogging on climate change: One year of Twitter worldwide. Glob. Environ. Chang. Hum. Policy Dimens. 2014, 26, 171–182. [Google Scholar] [CrossRef]
- Papworth, S.K.; Nghiem, T.P.L.; Chimalakonda, D.; Posa, M.R.C.; Wijedasa, L.S.; Bickford, D.; Carrasco, L.R. Quantifying the role of online news in linking conservation research to Facebook and Twitter. Conserv. Biol. 2015, 29, 825–833. [Google Scholar] [CrossRef] [PubMed]
- Bennett, W.L.; Segerberg, A. Digital media and the personalization of collective action social technology and the organization of protests against the global economic crisis. Inf. Commun. Soc. 2011, 14, 770–799. [Google Scholar] [CrossRef]
- Jin, J.H.; Li, Y.J.; Zhong, X.J.; Zhai, L. Why users contribute knowledge to online communities: An empirical study of an online social Q&A community. Inf. Manag. 2015, 52, 840–849. [Google Scholar] [CrossRef]
- Rughinis, R.; Matei, S.; Marinescu-Nenciu, A.P.; Rughinis, C. Computer-Supported Collaborative Questioning. Regimes of Online Sociality on Quora. In Regimes of Online Sociality on Quora. In Proceedings of the 9th Iberian Conference on Information Systems and Technologies (Cisti 2014), Barcelona, Spain, 18–21 June 2014. [Google Scholar] [CrossRef]
- Yeung, K. Quora Now Has 100 Million Monthly Visitors up from 80 Million in January. Available online: http://venturebeat.com/2016/03/17/quora-now-has-100-million-monthly-visitors-up-from-80-million-in-january/ (accessed on 28 March 2016).
- Alexa Webpage: Web Traffic Statistics of Quora. Available online: http://www.alexa.com/siteinfo/www.quora.com (accessed on 15 April 2016).
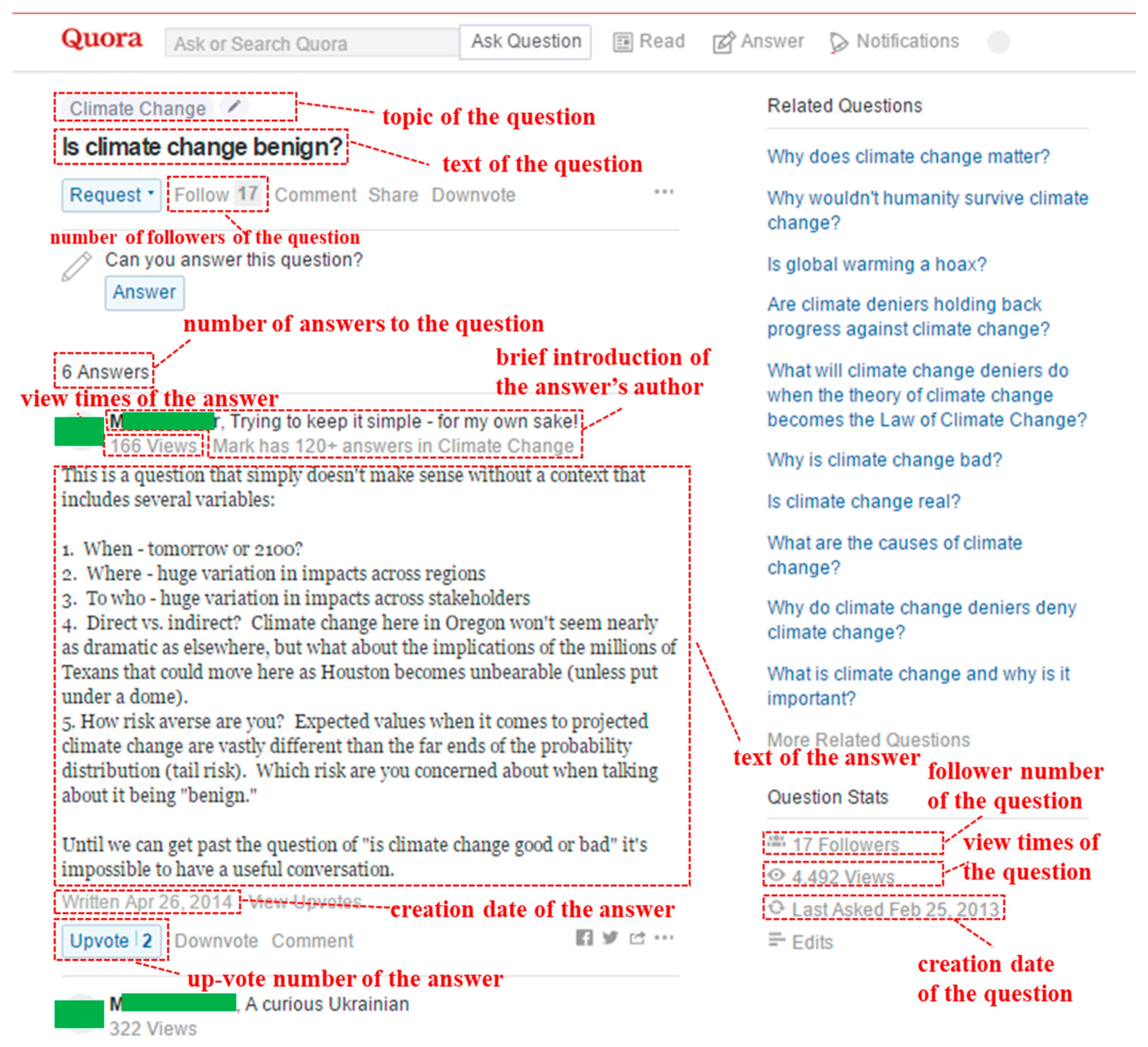
- Quora Webpage: Question Page of “Is Climate Change Benign”. Available online: https://www.quora.com/Is-climate-change-benign (accessed on 28 March 2016).
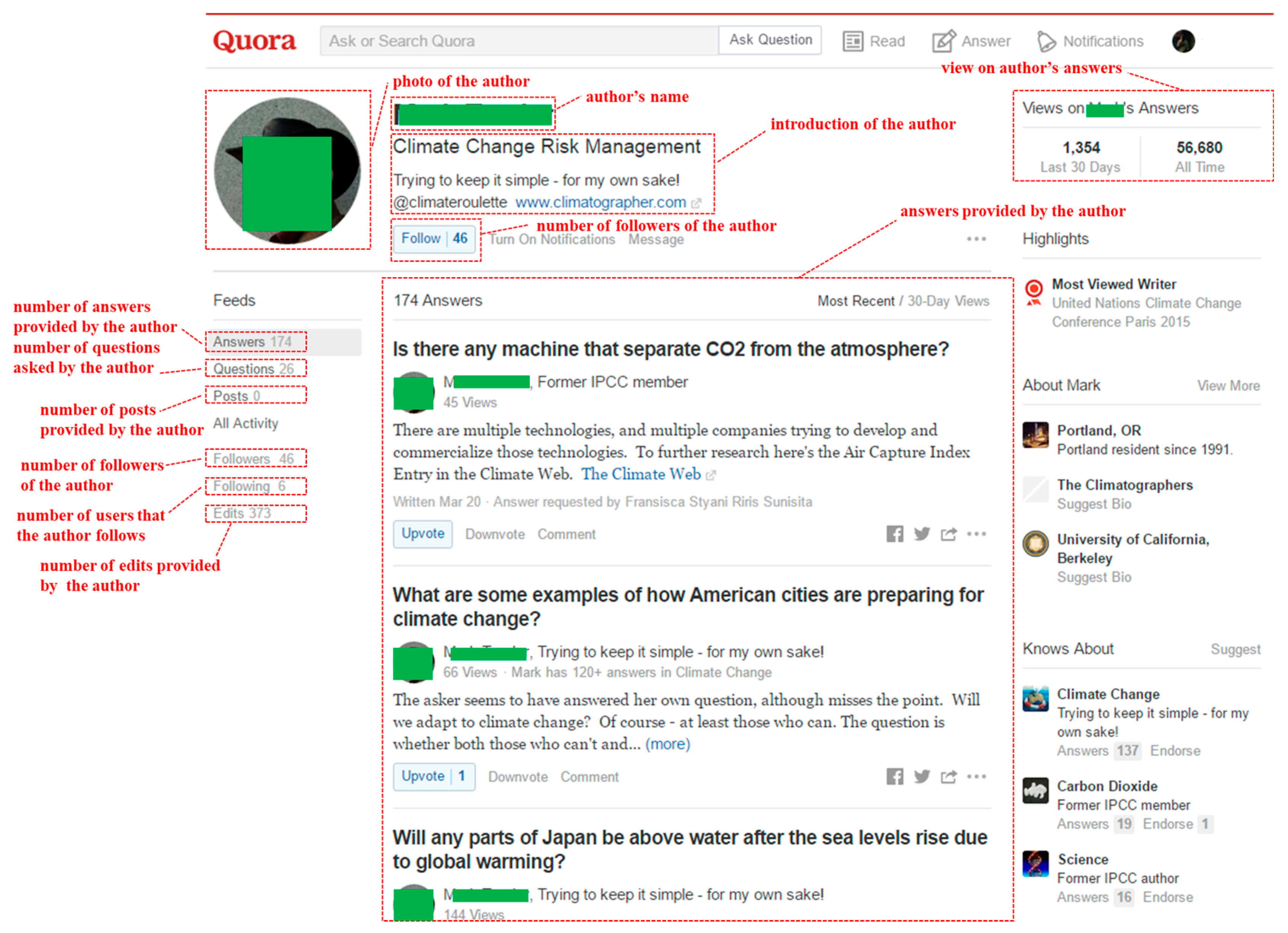
- Quora Webpage: An Author’s Profile in Quora. Available online: https://www.quora.com/profile/Mark-Trexler (accessed on 28 March 2016).
- Bubela, T.; Nisbet, M.C.; Borchelt, R.; Brunger, F.; Critchley, C.; Einsiedel, E.; Geller, G.; Gupta, A.; Hampel, J.; Hyde-Lay, R.; et al. Science communication reconsidered. Nat. Biotechnol. 2009, 27, 514–518. [Google Scholar] [CrossRef] [PubMed]
- Myers, T.A.; Maibach, E.W.; Roser-Renouf, C.; Akerlof, K.; Leiserowitz, A.A. The relationship between personal experience and belief in the reality of global warming. Nat. Clim. Chang. 2013, 3, 343–347. [Google Scholar] [CrossRef]
- Nisbet, E.C.; Hart, P.S.; Myers, T.; Ellithorpe, M. Attitude Change in Competitive Framing Environments? Open-/Closed-Mindedness, Framing Effects, and Climate Change. J. Commun. 2013, 63, 766–785. [Google Scholar] [CrossRef]
- Entman, R.M. Framing: Toward clarification of a fractured paradigm. J. Commun. 1993, 43, 51–58. [Google Scholar] [CrossRef]
- Giorgi, S.; Weber, K. Marks of Distinction: Framing and Audience Appreciation in the Context of Investment Advice. Adm. Sci. Q. 2015, 60, 333–367. [Google Scholar] [CrossRef]
- Jang, W.Y. News as propaganda: A comparative analysis of US and Korean press coverage of the Six-Party Talks, 2003–2007. Int. Commun. Gaz. 2013, 75, 188–204. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Lucas, C.; Leder-Luis, J.; Gadarian, S.K.; Albertson, B.; Rand, D.G. Structural Topic Models for Open-Ended Survey Responses. Am. J. Political Sci. 2014, 58, 1064–1082. [Google Scholar] [CrossRef]
- De Battisti, F.; Ferrara, A.; Salini, S. A decade of research in statistics: A topic model approach. Scientometrics 2015, 103, 413–433. [Google Scholar] [CrossRef]
- Marwick, A.E.; Boyd, D. I tweet honestly, I tweet passionately: Twitter users, context collapse, and the imagined audience. New Media Soc. 2011, 13, 114–133. [Google Scholar] [CrossRef]
- Su, Z.; Meng, T.G. Selective responsiveness: Online public demands and government responsiveness in authoritarian China. Soc. Sci. Res. 2016, 59, 52–67. [Google Scholar] [CrossRef] [PubMed]
- Houts, P.S.; Doak, C.C.; Doak, L.G.; Loscalzo, M.J. The role of pictures in improving health communication: A review of research on attention, comprehension, recall, and adherence. Patient Educ. Couns. 2006, 64, 393–394. [Google Scholar] [CrossRef]
- Davis, C.; Hyde, J.; Bangdiwala, S.; Nelson, J. An example of dependencies among variables in a conditional logistic regression. In Modern Statistical Methods in Chronic Disease Epidemiology; Moolgavkar, S., Prentice, R., Eds.; Wiley: New York, NY, USA, 1986; pp. 140–147. [Google Scholar]
- Intergovernmental Panel on Climate Change (IPCC). Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Core Writing Team, Pachauri, R.K., Meyer, L.A., Eds.; IPCC: Geneva, Switzerland, 2014; p. 151.
- Jabr, W.; Mookerjee, R.; Tan, Y.; Mookerjee, V.S. Leveraging Philanthropic Behavior for Customer Support: The Case of User Support Forums. MIS Q. 2014, 38, 187–208. [Google Scholar] [CrossRef]
- Miaou, S.-P. The relationship between truck accidents and geometric design of road sections: Poisson versus negative binomial regressions. Accid. Anal. Prev. 1994, 26, 471–482. [Google Scholar] [CrossRef]
- Bertot, J.C.; Jaeger, P.T.; Hansen, D. The impact of polices on government social media usage: Issues, challenges, and recommendations. Gov. Inf. Q. 2012, 29, 30–40. [Google Scholar] [CrossRef]
- Bonson, E.; Torres, L.; Royo, S.; Flores, F. Local e-government 2.0: Social media and corporate transparency in municipalities. Gov. Inf. Q. 2012, 29, 123–132. [Google Scholar] [CrossRef]
- Lorenzoni, I.; Leiserowitz, A.; Doria, M.D.; Poortinga, W.; Pidgeon, N.F. Cross-national comparisons of image associations with “global warming’’ and “climate change’’ among laypeople in the United States of America and Great Britain. J. Risk Res. 2006, 9, 265–281. [Google Scholar] [CrossRef]
- Smith, N.; Leiserowitz, A. The Rise of Global Warming Skepticism: Exploring Affective Image Associations in the United States Over Time. Risk Anal. 2012, 32, 1021–1032. [Google Scholar] [CrossRef] [PubMed]
- Gillard, R. Unravelling the United Kingdom’s climate policy consensus: The power of ideas, discourse and institutions. Glob. Environ. Chang. Hum. Policy Dimens. 2016, 40, 26–36. [Google Scholar] [CrossRef]
- Harrison, K.; Sundstrom, L.M. The comparative politics of climate change. Glob. Environ. Politics 2007, 7, 1–18. [Google Scholar] [CrossRef]
- Wasko, M.M.; Faraj, S. Why should I share? Examining social capital and knowledge contribution in electronic networks of practice. MIS Q. 2005, 29, 35–57. [Google Scholar] [CrossRef]
- Simon, H.A. Designing Organizations for an Information-Rich World. Comput. Commun. Public Interest 1971, 70, 37–72. [Google Scholar]
- Huberman, B.A.; Romero, D.M.; Wu, F. Crowdsourcing, attention and productivity. J. Inf. Science 2009, 35, 758–765. [Google Scholar] [CrossRef]
- Rui, H.X.; Whinston, A. Information or attention? An empirical study of user contribution on Twitter. Inf. Syst. E-Bus. Manag. 2012, 10, 309–324. [Google Scholar] [CrossRef]
- Jacobson, S.; Myung, E.; Johnson, S.L. Open media or echo chamber: The use of links in audience discussions on the Facebook pages of partisan news organizations. Inf. Commun. Soc. 2016, 19, 875–891. [Google Scholar] [CrossRef]
- Pearce, W.; Holmberg, K.; Hellsten, I.; Nerlich, B. Climate change on Twitter: Topics, communities and conversations about the 2013 IPCC Working Group 1 report. PLoS ONE 2014, 9, e94785. [Google Scholar] [CrossRef] [PubMed]
- Williams, H.T.; McMurray, J.R.; Kurz, T.; Lambert, F.H. Network analysis reveals open forums and echo chambers in social media discussions of climate change. Glob. Environ. Chang. 2015, 32, 126–138. [Google Scholar] [CrossRef]
- Yadav, D.; Vatsa, M.; Singh, R.; Tistarelli, M. Bacteria Foraging Fusion For Face Recognition Across Age Progression. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops (Cvprw), Portland, OR, USA, 23–28 June 2013; pp. 173–179. [Google Scholar] [CrossRef]
- Rutter, C.M.; Gatsonis, C.A. A hierarchical regression approach to meta-analysis of diagnostic test accuracy evaluations. Stat. Med. 2001, 20, 2865–2884. [Google Scholar] [CrossRef] [PubMed]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical Dirichlet processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]



| Variable Name | Description | Mean | Min | Max | Std. Dev. |
|---|---|---|---|---|---|
| Author followers | follower number of the author | 1572 | 0 | 157,228 | 5244 |
| Text length | number of characters of answer text | 966 | 6 | 19,275 | 1146 |
| Image number | number of images in the answer | 0.13 | 0 | 20 | 0.64 |
| Question followers | follower number of the question | 11 | 0 | 262 | 31 |
| Existing days | number of existing days of the answer | 268 | 1 | 2101 | 191 |
| Topic | Most Frequent Terms | Label | Proportion |
|---|---|---|---|
| 1 | carbon, plant, fuel, burn, dioxid-, tree, fossil, air, gas, water, emiss-, atmospher-, produc-, methan-, forest | Fuel/Carbon | 0.078 |
| 2 | people, thing, problem, will, good, live, lot, happen, better, bad, person, keep, planet, work, start | Livelihood | 0.124 |
| 3 | will, human, food, popul-, speci-, adapt, increas-, extinct, surviv-, resourc-, countri-, life, war, natur-, environ- | Human/Biodiversity | 0.082 |
| 4 | energi-, power, cost, emiss-, countri-, carbon, develop, coal, fuel, electr-, reduc-, renew-, solar-, technolog-, generat- | Energy | 0.110 |
| 5 | earth, atmospher-, temperatur-, heat, year, increas-, greenhous-, ice, sun, age, ocean, cool, human, gase, energi- | Atmosphere/Weather | 0.100 |
| 6 | scienc-, scientist, scientif-, evid-, theori-, fact, question, human, claim, denier, skeptic, agw, consensus, understand, argument | Science Communication | 0.114 |
| 7 | sea, rise, water, level, ice, will, area, year, ocean, melt, weather, flood, increas-, winter, temperatur- | Hydrosphere | 0.109 |
| 8 | will, year, time, long, question, answer, term, point, impact, futur-, effect, current, continu-, system, short | Future | 0.103 |
| 9 | govern, polit-, money, issu-, industri-, republican, public, fund, compani-, politician, conserv-, polici-, American, state, action | Politics | 0.098 |
| 10 | model, data, predict, temperatur-, year, measur-, report, ipcc, weather, record, trend, http, observ-, increas-, event | Climate Modeling | 0.080 |
| Variables | Poisson Model | Negative Binomial Model | ||
|---|---|---|---|---|
| β | Z-Value | β | Z-Value | |
| Intercept | −4.530 *** | −361.068 | −4.188 *** | −104.342 |
| Topic 1 | 0.628 *** | 49.212 | 0.105 * | 2.068 |
| Topic 2 | −0.145 *** | −10.222 | −0.212 *** | −5.090 |
| Topic 3 | 0.143 *** | 8.899 | 0.228 *** | 4.732 |
| Topic 4 | 0.384 *** | 28.325 | 0.138 ** | 3.051 |
| Topic 5 | −0.003 | −0.239 | −0.027 | −0.601 |
| Topic 6 | 0.085 *** | 6.530 | 0.451 *** | 10.454 |
| Topic 7 | 0.238 *** | 18.149 | −0.073 | −1.606 |
| Topic 8 | −0.258 *** | −12.633 | −0.144 ** | −2.684 |
| Topic 9 | 0.615 *** | 48.625 | 0.348 *** | 7.978 |
| Topic 10 | 0.505 *** | 36.255 | 0.187 *** | 3.746 |
| Author followers | 0.234 *** | 398.605 | 0.625 *** | 46.722 |
| Text length | 0.195 *** | 75.294 | 0.334 *** | 23.505 |
| Image number | 0.099 *** | 64.832 | 0.102 *** | 7.308 |
| Question followers | 0.056 *** | 24.063 | 0.102 *** | 7.464 |
| Sample size | 10,393 | 10,393 | ||
| Log likelihood | −84,785 | −25,313 | ||
| AIC | 169,600 | 50,658 | ||
| BIC | 169,709 | 50,774 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, H.; Qiang, M.; Zhang, D.; Wen, Q.; Xia, B.; An, N. Climate Change Communication in an Online Q&A Community: A Case Study of Quora. Sustainability 2018, 10, 1509. https://doi.org/10.3390/su10051509
Jiang H, Qiang M, Zhang D, Wen Q, Xia B, An N. Climate Change Communication in an Online Q&A Community: A Case Study of Quora. Sustainability. 2018; 10(5):1509. https://doi.org/10.3390/su10051509
Chicago/Turabian StyleJiang, Hanchen, Maoshan Qiang, Dongcheng Zhang, Qi Wen, Bingqing Xia, and Nan An. 2018. "Climate Change Communication in an Online Q&A Community: A Case Study of Quora" Sustainability 10, no. 5: 1509. https://doi.org/10.3390/su10051509
APA StyleJiang, H., Qiang, M., Zhang, D., Wen, Q., Xia, B., & An, N. (2018). Climate Change Communication in an Online Q&A Community: A Case Study of Quora. Sustainability, 10(5), 1509. https://doi.org/10.3390/su10051509