Spatial Layout of Multi-Environment Test Sites: A Case Study of Maize in Jilin Province

 ,
,  , ,
, , 
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
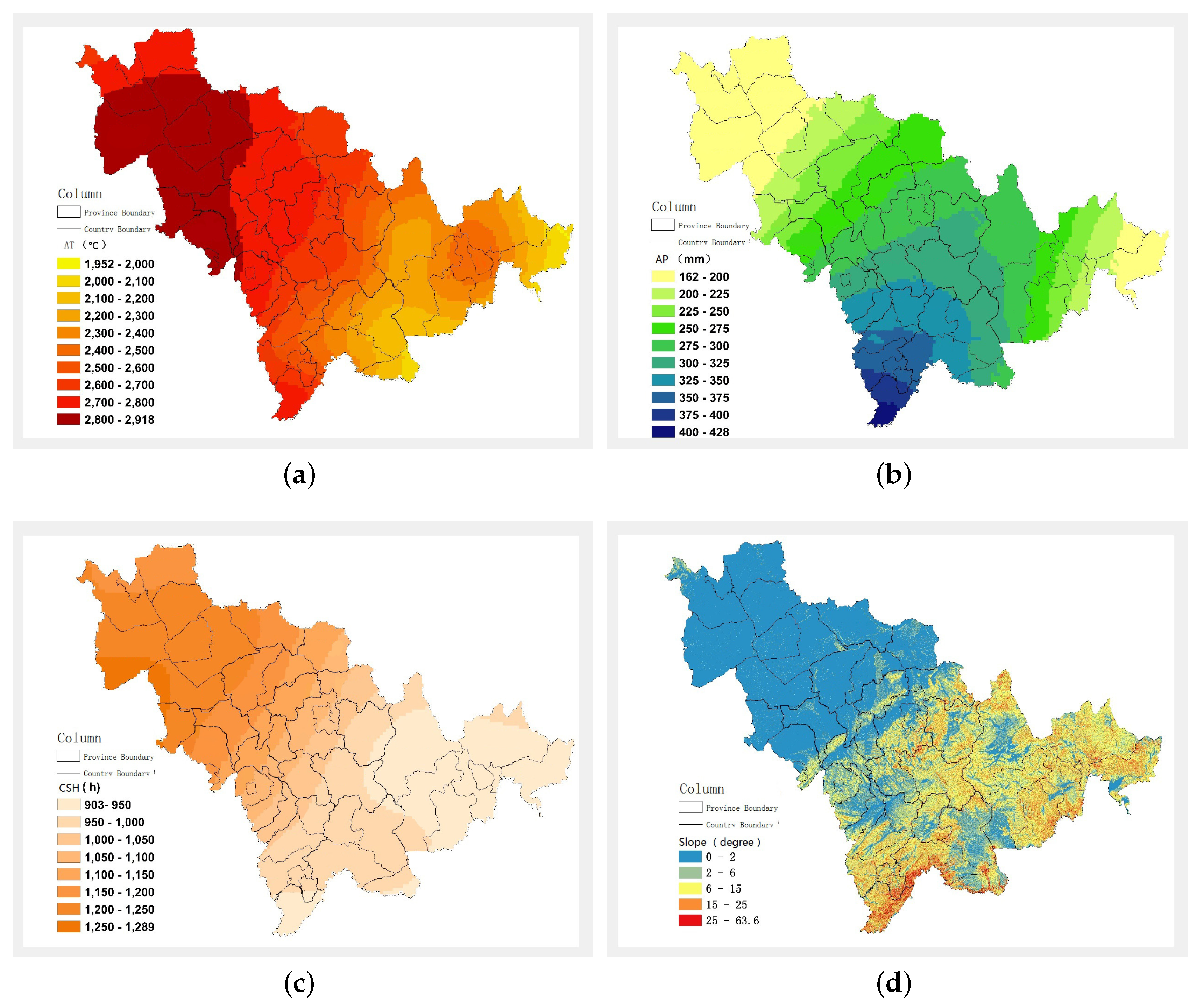
2.1. Index System Construction
- Accumulated temperature (AT) which refers to the accumulation daily average temperature (t) from sowing to maturity is formulated as:
- Accumulated Precipitation (AP) which refers to accumulation of precipitation during whole grown period is formulated as:refers to daily i precipitation (units:mm)
- Cumulative Sunshine Hours (CSH) which refers to accumulation of sunshine hours during whole grown period is formulated as:
- Elevation and Slope
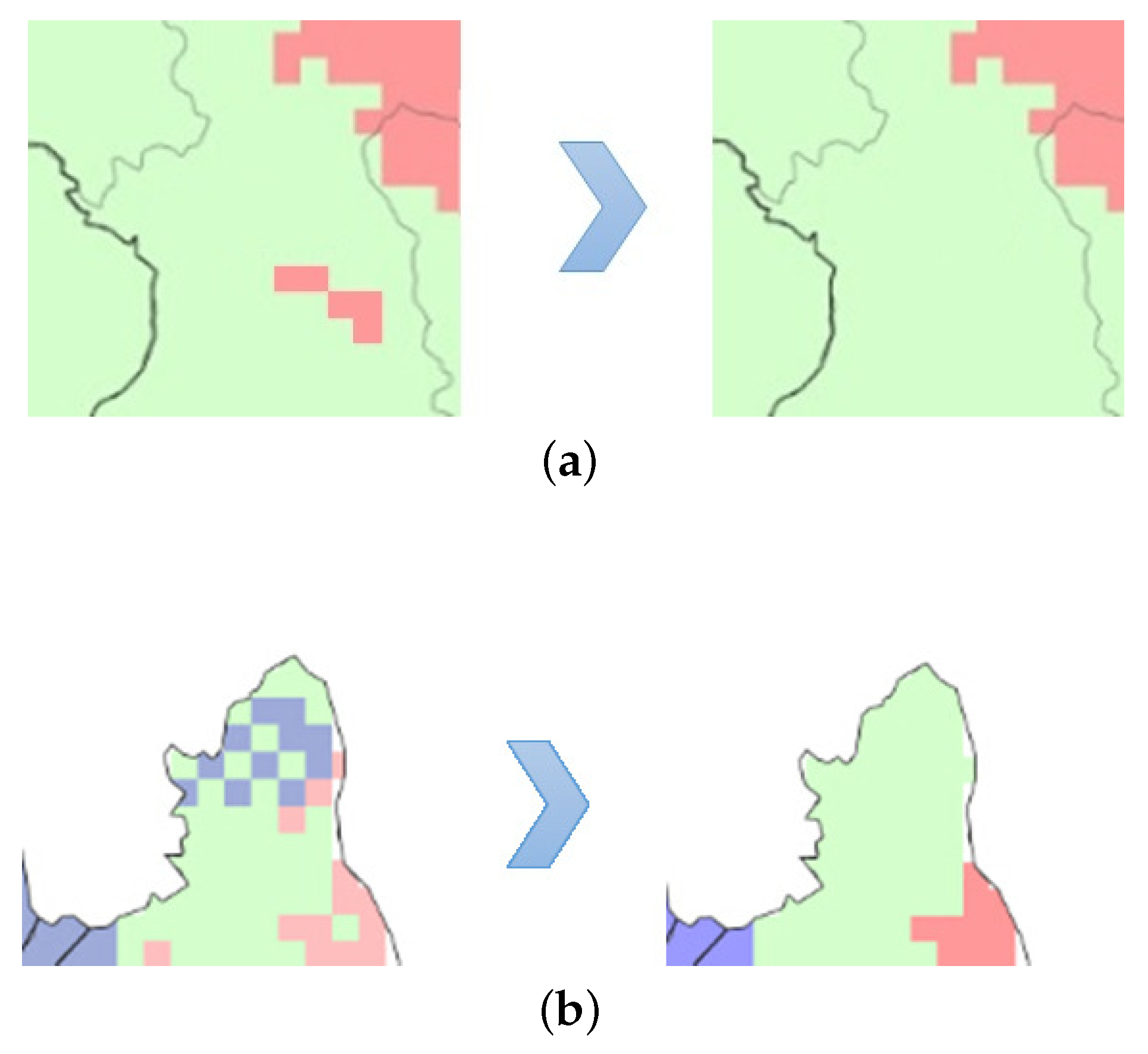
2.2. Data Pre-Processing
2.3. Spatial Clustering
2.4. Sample Strategy
3. Results
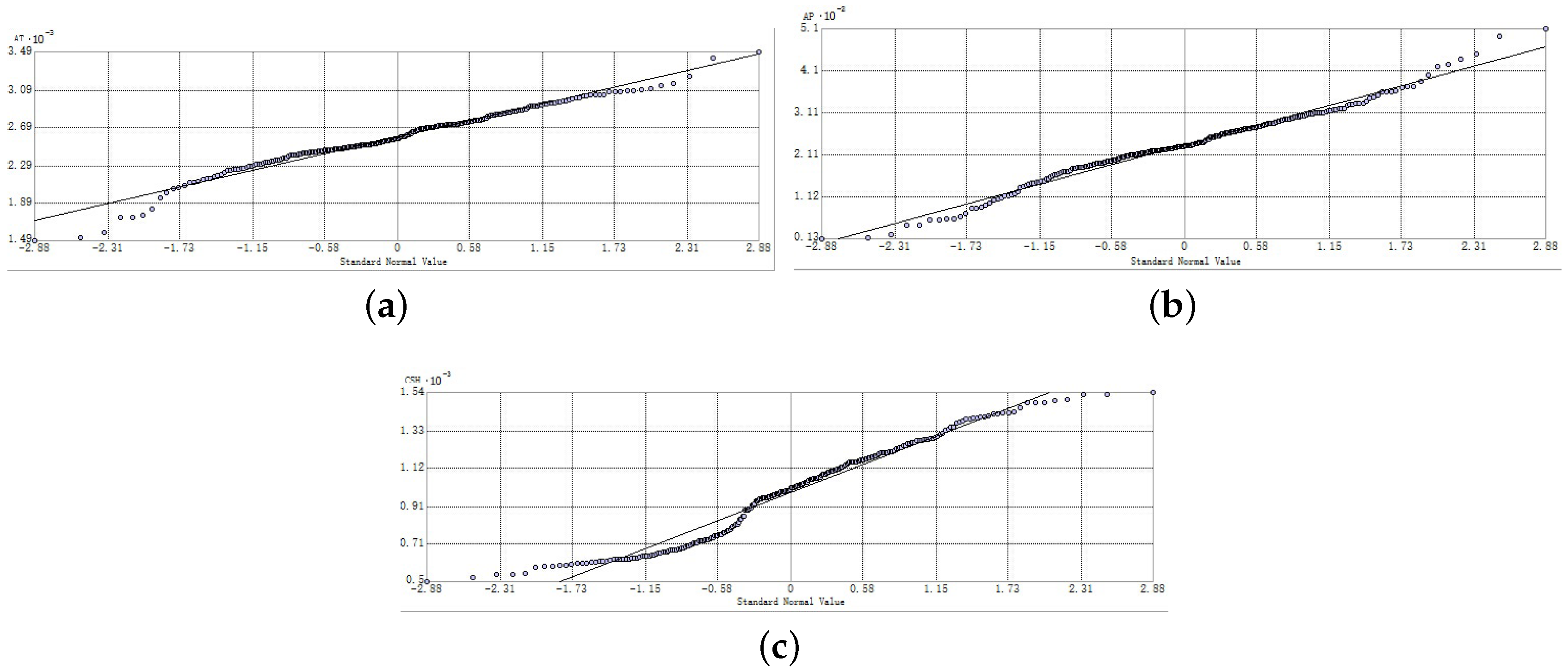
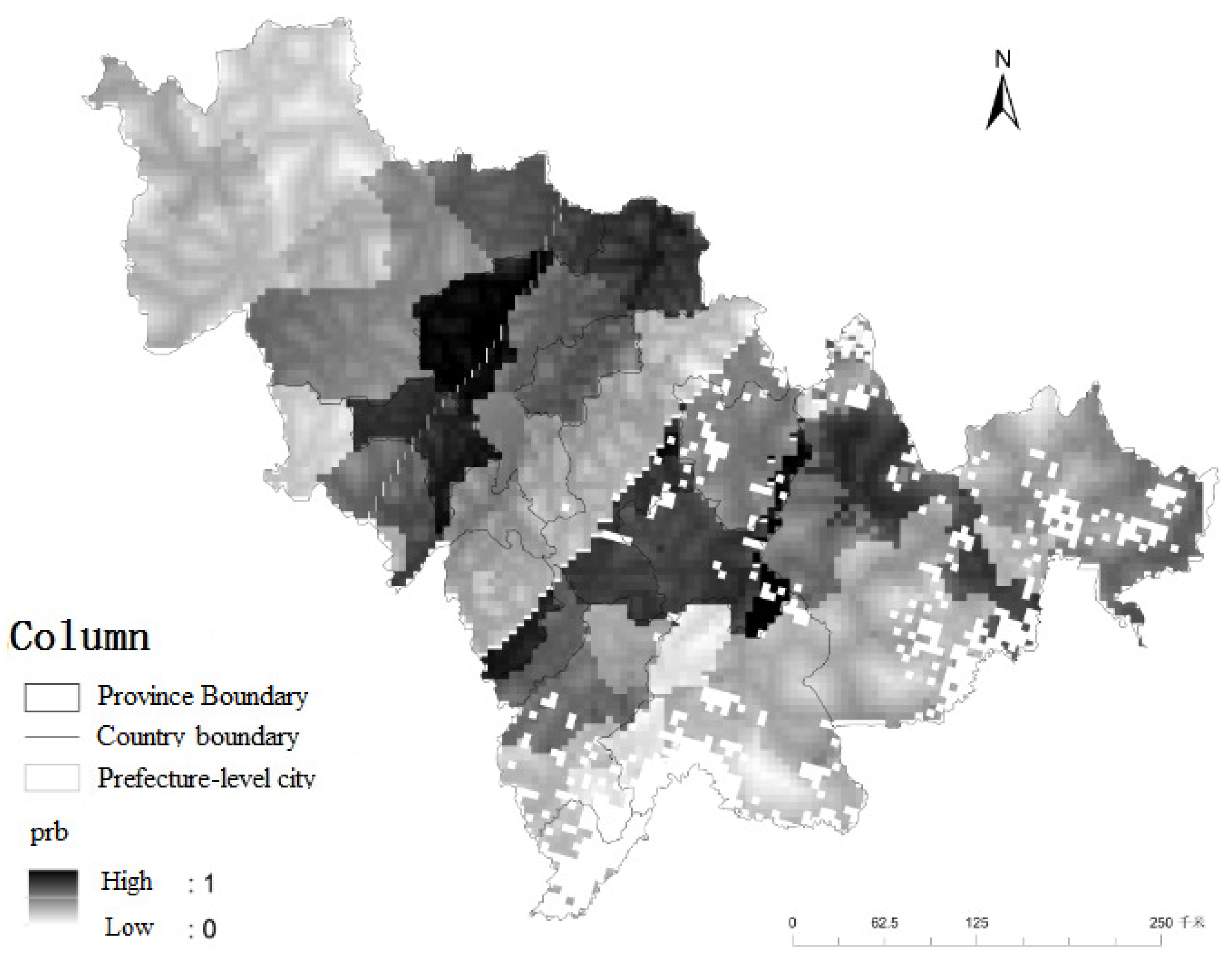
3.1. Data Processing
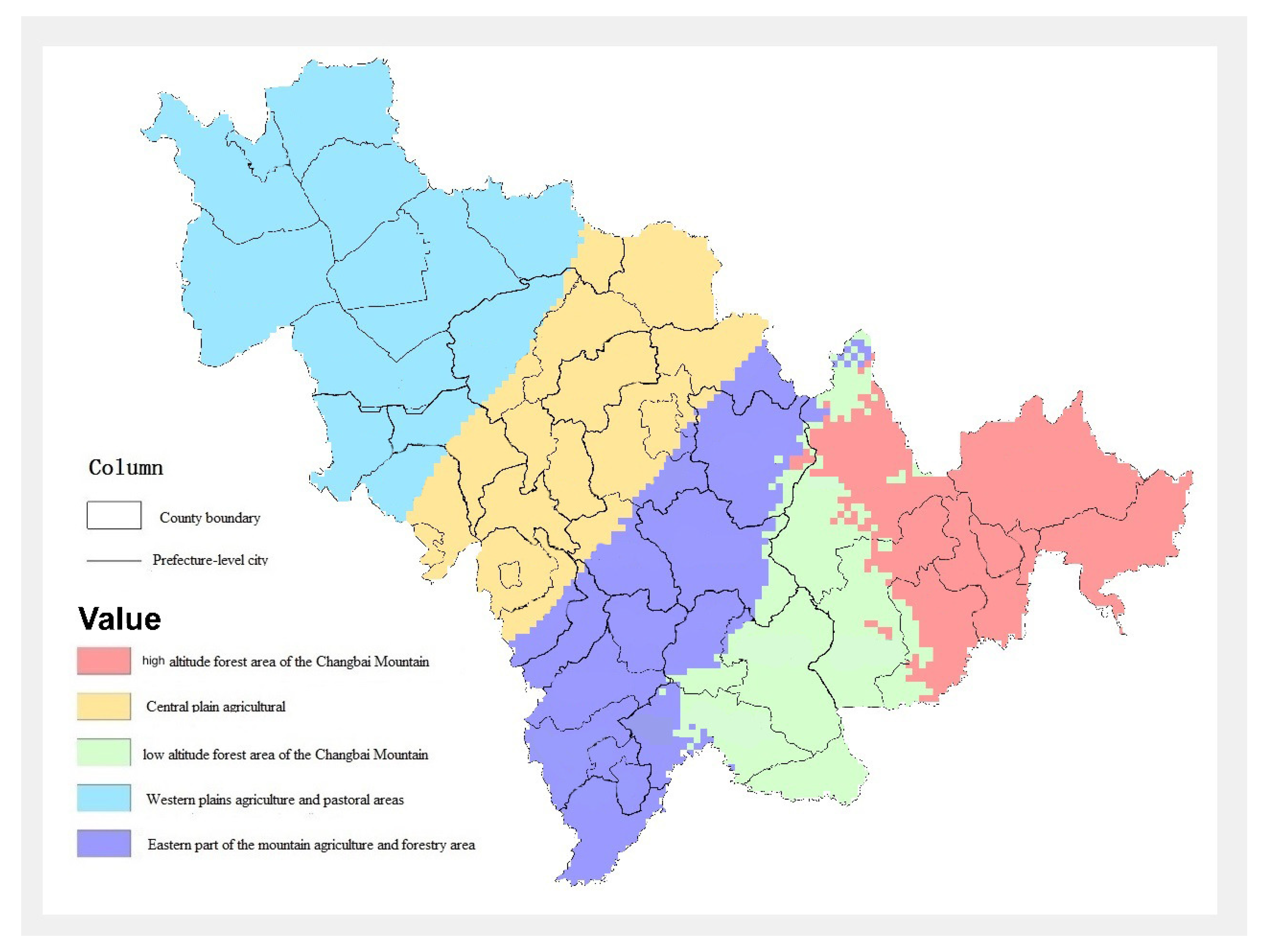
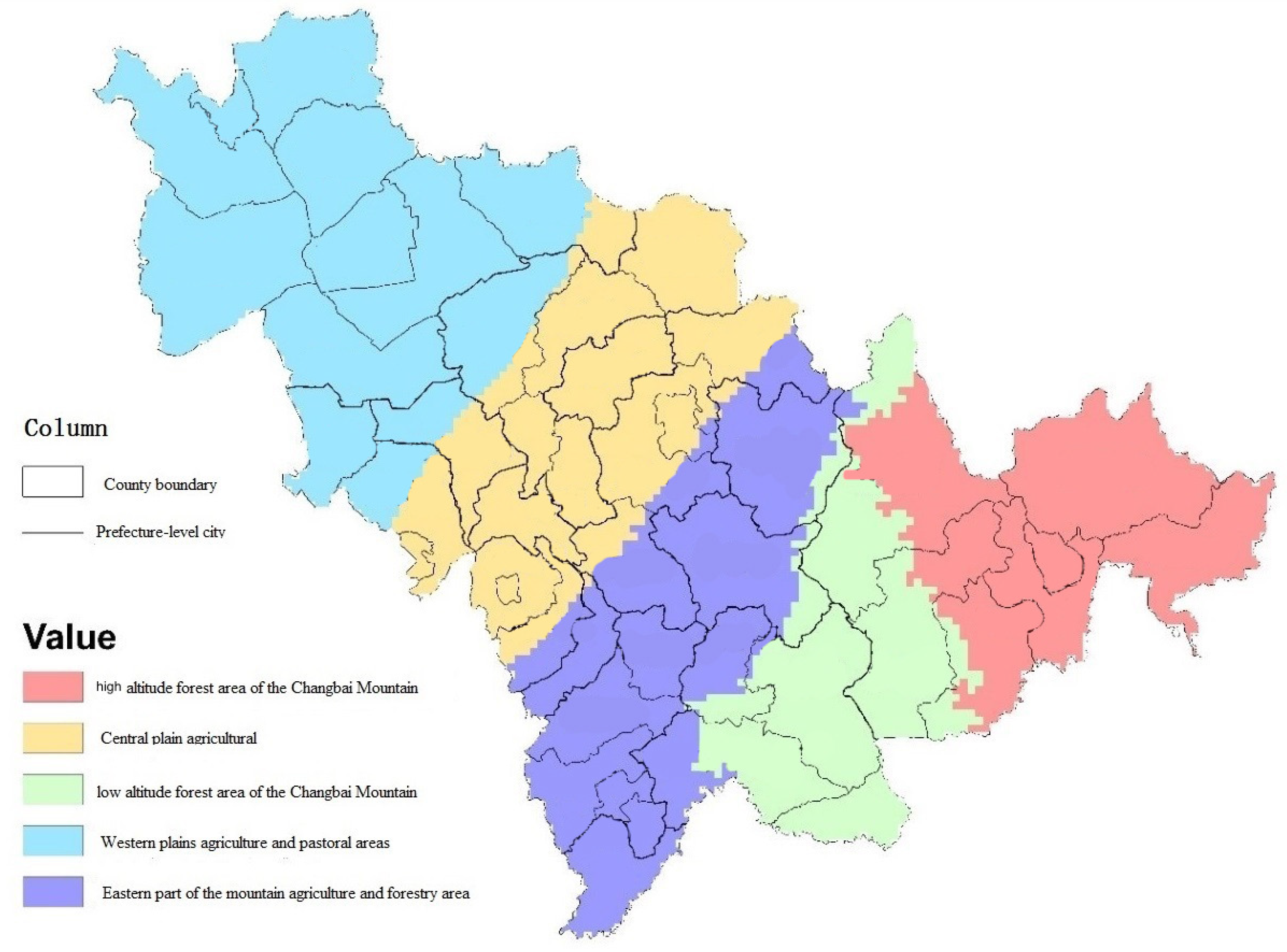
3.2. Multi-Environments Clustering
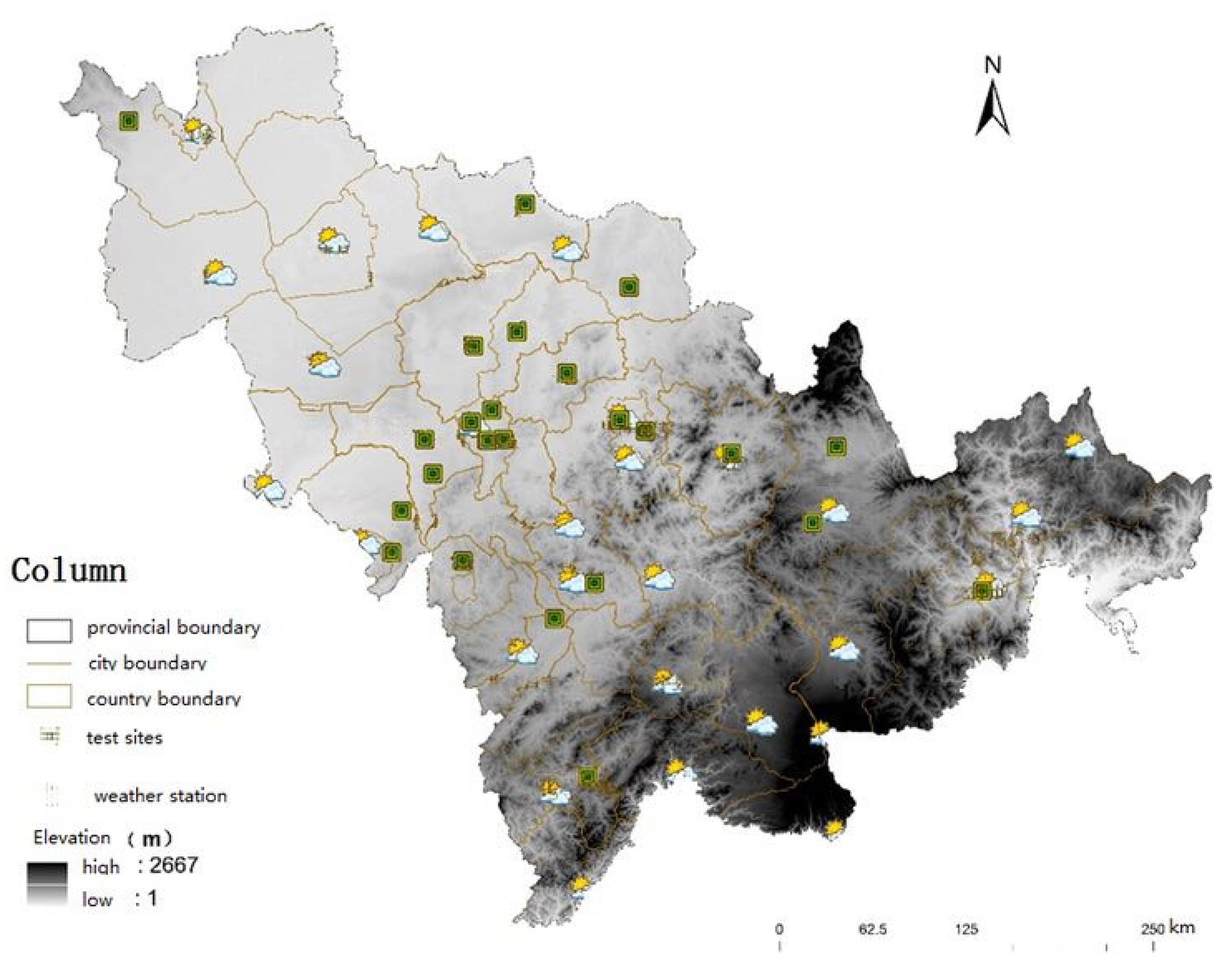
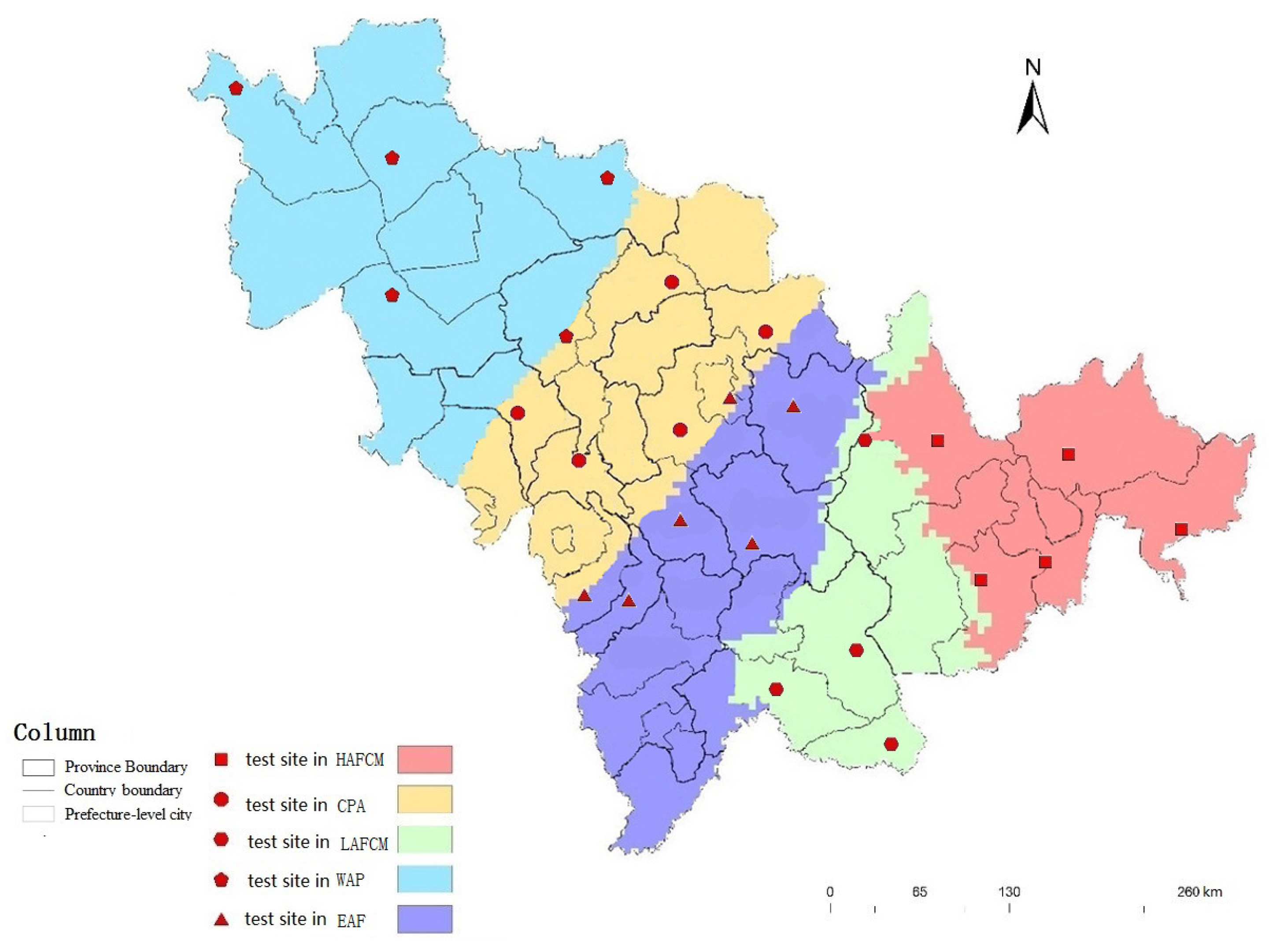
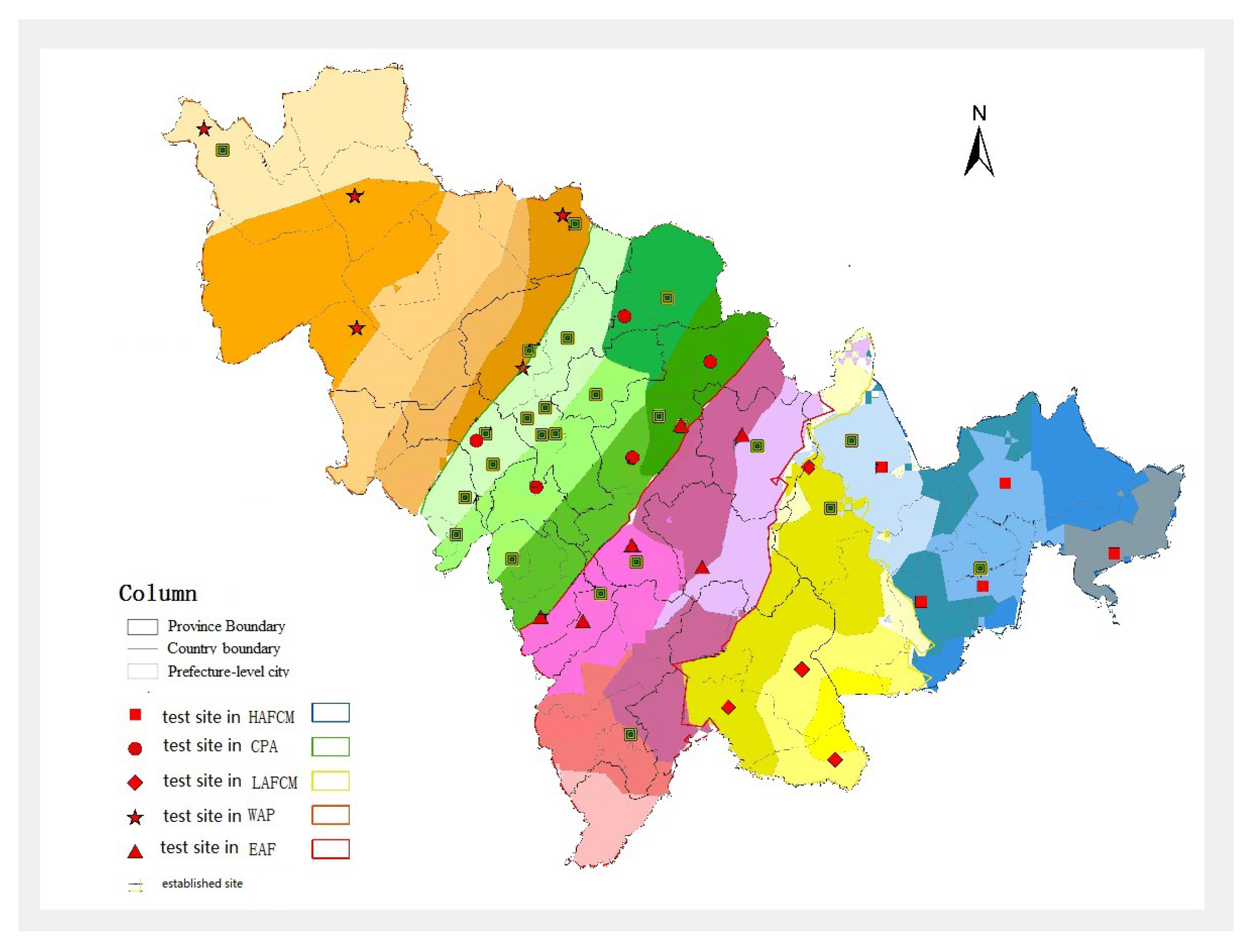
3.3. Test Sites Layout
4. Discussion
4.1. Clustering Attribute Statistics
4.2. Planting Environmental Representation
4.3. Comparison Number of Test Sites
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| AT | Accumulated temperature |
| AP | Accumulated Precipitation |
| CSH | Cumulative Sunshine Hours |
| LD | linear dichroism |
| HAFCM | High Altitude Forest area of the Changbai Mountain |
| LAFCM | Low Altitude Forest area of the Changbai Mountain |
| EAF | Eastern part of the mountain Agriculture and Forestry Area |
| CPA | Central Plains Agricultural |
| WAP | Western plain Agriculture and Pastoral Area |
References
- Cooper, M.; Messina, C.D.; Podlich, D.; Totir, L.R.; Baumgarten, A.; Hausmann, N.J.; Wright, D.; Graham, G. Predicting the future of plant breeding: Complementing empirical evaluation with genetic prediction. Crop Pasture Sci. 2014, 65, 311–336. [Google Scholar] [CrossRef]
- Burnham, L.; King, B.H.; Deline, C.; Barkaszi, S.; Sahm, A.; Stein, J. The US DOE Regional Test Center Program: Driving Innovation Quality and Reliability; Technical Report; Sandia National Laboratories (SNL-NM): Albuquerque, NM, USA, 2015.
- Gale, F.; Jewison, M.; Hansen, J. Prospects for China’s corn yield growth and imports. Curr. Politics Econ. North. West. Asia 2016, 25, 479–521. [Google Scholar]
- Fufeng, Q.; Jun, Y.; Torres, D.A.P. Comparison of Corn Production Costs in China, the US and Brazil and Its Implications. Agric. Sci. Technol. 2016, 17, 731–736. [Google Scholar]
- Li, J.; Zhang, X.; Sun, S.; Wang, S. Analysis of maize variety in national maize main production area using SSR technique I. evaluation of distinctness and uniformity of maize variety. Yumi Kexue (J. Maize Sci.) 2006, 14, 3842. [Google Scholar]
- Beyene, Y.; Semagn, K.; Crossa, J.; Mugo, S.; Atlin, G.N.; Tarekegne, A.; Meisel, B.; Sehabiague, P.; Vivek, B.S.; Oikeh, S.; et al. Improving maize grain yield under drought stress and non-stress environments in sub-Saharan Africa using marker-assisted recurrent selection. Crop Sci. 2016, 56, 344–353. [Google Scholar] [CrossRef]
- Harrison, M.T.; Tardieu, F.; Dong, Z.; Messina, C.D.; Hammer, G.L. Characterizing drought stress and trait influence on maize yield under current and future conditions. Glob. Chang. Biol. 2014, 20, 867–878. [Google Scholar] [CrossRef] [PubMed]
- Naveed, M.; Mitter, B.; Reichenauer, T.G.; Wieczorek, K.; Sessitsch, A. Increased drought stress resilience of maize through endophytic colonization by Burkholderia phytofirmans PsJN and Enterobacter sp. FD17. Environ. Exp. Bot. 2014, 97, 30–39. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, J.; Mu, J. Exploring the relationships between climatic variables and climate-induced yield of spring maize in Northeast China. Agric. Ecosyst. Environ. 2015, 207, 79–90. [Google Scholar] [CrossRef]
- Meng, Q.; Hou, P.; Lobell, D.B.; Wang, H.; Cui, Z.; Zhang, F.; Chen, X. The benefits of recent warming for maize production in high latitude China. Clim. Chang. 2014, 122, 341–349. [Google Scholar] [CrossRef]
- Lobell, D.B.; Hammer, G.L.; Chenu, K.; Zheng, B.; McLean, G.; Chapman, S.C. The shifting influence of drought and heat stress for crops in northeast Australia. Glob. Chang. Biol. 2015, 21, 4115–4127. [Google Scholar] [CrossRef] [PubMed]
- Deb, P.; Shrestha, S.; Babel, M.S. Forecasting climate change impacts and evaluation of adaptation options for maize cropping in the hilly terrain of Himalayas: Sikkim, India. Theor. Appl. Climatol. 2015, 121, 649–667. [Google Scholar] [CrossRef]
- Yu, W.; Chen, H. Study on precise comprehensive agricultural climate regional planning of summer maize in Henan Province. Meteorol. Environ. Sci. 2010, 33, 14–19. [Google Scholar]
- Gong, L.; Wang, C.; Wang, P.; Lv, S.; Wang, J.; Dai, S. Variation of climate suitability of maize in the Northeast of China. J. Maize Sci. 2013, 21, 140–146. [Google Scholar]
- Wang, D.; Li, G.; Mo, Y.; Cai, M.; Bian, X. Effect of Planting Date on Accumulated Temperature and Maize Growth under Mulched Drip Irrigation in a Middle-Latitude Area with Frequent Chilling Injury. Sustainability 2017, 9, 1500. [Google Scholar] [CrossRef]
- Dai, L.; Li, C.; Wei, R. Climatic suitability of summer corn and its changes in Hebei province. Ecol. Environ. Sci. 2011, 20, 1031–1036. [Google Scholar]
- Wang, L.; Xiong, W.; Wen, X.; Feng, L. Effect of climatic factors such as temperature, precipitation on maize production in China. Trans. Chin. Soc. Agric. Eng. 2014, 30, 138–146. [Google Scholar]
- Zhao, Z.; Qu, Y.; Liu, Z.; Wu, R.; Xia, Y.; Li, S.; Zhang, X. Spatial distribution of interaction effect between variety and environment on maize yield. Trans. Chin. Soc. Agric. Eng. 2015, 31, 232–238. [Google Scholar]
- Cooper, M.; Smith, O.; Merrill, R.; Arthur, L.; Podlich, D.; Löffler, C. Integrating breeding tools to generate information for efficient breeding: Past, present, and future. In Plant Breeding: The Arnel R. Hallauer International Symposium; Wiley Online Library, 2008; pp. 141–154. [Google Scholar]
- Crosbie, T.M.; Eathington, S.R.; Johnson, G.R.; Edwards, M.; Reiter, R.; Stark, S.; Mohanty, R.G.; Oyervides, M.; Buehler, R.E.; Walker, A.K.; et al. Plant breeding: Past, present, and future. In Plant Breeding: The Arnel R. Hallauer International Symposium; Wiley Online Library: Hoboken, NJ, USA, 2006; pp. 3–50. [Google Scholar]
- Butruille, D.V.; Birru, F.H.; Boerboom, M.L.; Cargill, E.J.; Davis, D.A.; Dhungana, P.; Dill, G.M.; Dong, F.; Fonseca, A.E.; Gardunia, B.W.; et al. Maize breeding in the United States: Views from within Monsanto. Plant Breed. Rev. 2015, 39, 199–282. [Google Scholar]
- Liu, Z.; Yang, J.; Li, S.; Wang, H.; Li, L.; Zhang, X.; Zhu, D. Optimal method of transforming observables into relative values for multi-environment trials in maize. Trans. Chin. Soc. Agric. Eng. 2011, 27, 205–209. [Google Scholar]
- Delmelle, E. Optimization of Second-Phase Spatial Sampling Using Auxiliary Information. Ph.D. Thesis, The State University of New York, Buffalo, NY, USA, 2005. [Google Scholar]
- Fischer, M.M.; Wang, J. Spatial Data Analysis: Models, Methods and Techniques; Springer Science & Business Media: Luxemburg, Germany, 2011. [Google Scholar]
- Wang, J.F.; Stein, A.; Gao, B.B.; Ge, Y. A review of spatial sampling. Spat. Stat. 2012, 2, 1–14. [Google Scholar] [CrossRef]
- Liu, T.; Wang, J.; Xu, C.; Ma, J.; Zhang, H.; Xu, C. Sandwich mapping of rodent density in Jilin Province, China. J. Geogr. Sci. 2018, 28, 445–458. [Google Scholar] [CrossRef]
- Wang, J.F.; Jiang, C.S.; Hu, M.G.; Cao, Z.D.; Guo, Y.S.; Li, L.F.; Liu, T.J.; Meng, B. Design-based spatial sampling: Theory and implementation. Environ. Model. Softw. 2013, 40, 280–288. [Google Scholar] [CrossRef]
- Grafström, A.; Lundström, N.L.; Schelin, L. Spatially balanced sampling through the pivotal method. Biometrics 2012, 68, 514–520. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.F.; Zhang, T.L.; Fu, B.J. A measure of spatial stratified heterogeneity. Ecol. Indic. 2016, 67, 250–256. [Google Scholar] [CrossRef]
- Hou, P.; Liu, Y.; Xie, R.; Ming, B.; Ma, D.; Li, S.; Mei, X. Temporal and spatial variation in accumulated temperature requirements of maize. Field Crops Res. 2014, 158, 55–64. [Google Scholar] [CrossRef]
- Liu, Z.; Qu, Y.; Zhao, Z.; Li, S.; Zhang, X. Temporal and spatial law of promotion center moving and diffusion of excellent maize varieties. Trans. Chin. Soc. Agric. Eng. 2018, 34, 178–185. [Google Scholar]
- Zhao, Z.; Zhang, X.; Liu, Z.; Yao, X.; Li, S.; Zhu, D. Spatial sampling of multi-environment trials data for station layout of maize variety. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–6. [Google Scholar]
- Bezdek, J.C. A convergence theorem for the fuzzy ISODATA clustering algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1980, PAMI-2, 1–8. [Google Scholar] [CrossRef]
- Abbas, A.W.; Minallh, N.; Ahmad, N.; Abid, S.A.R.; Khan, M.A.A. K-Means and ISODATA Clustering Algorithms for Landcover Classification Using Remote Sensing. Sindh Univ. Res. J.-SURJ (Sci. Ser.) 2016, 48, 315–318. [Google Scholar]
- Chen, Z.; Chen, Y.; Hu, L.; Wang, S.; Jiang, X.; Ma, X.; Lane, N.D.; Campbell, A.T. ContextSense: Unobtrusive discovery of incremental social context using dynamic bluetooth data. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, WA, USA, 13–17 September 2014; pp. 23–26. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Moran I | Variance | Z points |
|---|---|---|---|
| AT | 0.531548 | 0.006411 | 6.951109 |
| AP | 0.656345 | 0.006324 | 8.567889 |
| CSH | 0.685310 | 0.006488 | 8.818582 |
| Number of Clusters | semi- | |
|---|---|---|
| 9 | 0.926 | |
| 8 | 0.911 | 0.015 |
| 7 | 0.904 | 0.007 |
| 6 | 0.891 | 0.013 |
| 5 | 0.880 | 0.009 |
| 4 | 0.826 | 0.054 |
| 3 | 0.787 | 0.039 |
| 2 | 0.663 | 0.124 |
| Type | Range AT | Mean | Range AP | Mean | Range CSH | Mean | Range Elevation | Mean |
|---|---|---|---|---|---|---|---|---|
| LAFCM | 1950–2500 | 2300 | 180–300 | 240 | 900–970 | 926 | 2–1481 | 600 |
| HAFCM | 2040–2500 | 2250 | 250–360 | 300 | 900–1000 | 953 | 330–2670 | 860 |
| EAF | 2330–2770 | 2570 | 280–430 | 340 | 920–1050 | 980 | 90–1500 | 500 |
| CPA | 2600–2900 | 2740 | 240–330 | 280 | 1030–1180 | 1110 | 130–850 | 240 |
| WAP | 2630–2920 | 2830 | 160–260 | 200 | 1170–1280 | 1217 | 100–640 | 160 |
| Type | Established Sites | Our Method |
|---|---|---|
| HAFCM | 2 | 5 |
| LAFCM | 1 | 4 |
| EAF | 4 | 6 |
| CPA | 13 | 5 |
| WAP | 3 | 5 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Zhe, L.; Zhang, X.; Zan, X.; Yao, X.; Wang, S.; Ye, S.; Li, S.; Zhu, D. Spatial Layout of Multi-Environment Test Sites: A Case Study of Maize in Jilin Province. Sustainability 2018, 10, 1424. https://doi.org/10.3390/su10051424
Zhao Z, Zhe L, Zhang X, Zan X, Yao X, Wang S, Ye S, Li S, Zhu D. Spatial Layout of Multi-Environment Test Sites: A Case Study of Maize in Jilin Province. Sustainability. 2018; 10(5):1424. https://doi.org/10.3390/su10051424
Chicago/Turabian StyleZhao, Zuliang, Liu Zhe, Xiaodong Zhang, Xuli Zan, Xiaochuang Yao, Sijia Wang, Sijing Ye, Shaoming Li, and Dehai Zhu. 2018. "Spatial Layout of Multi-Environment Test Sites: A Case Study of Maize in Jilin Province" Sustainability 10, no. 5: 1424. https://doi.org/10.3390/su10051424
APA StyleZhao, Z., Zhe, L., Zhang, X., Zan, X., Yao, X., Wang, S., Ye, S., Li, S., & Zhu, D. (2018). Spatial Layout of Multi-Environment Test Sites: A Case Study of Maize in Jilin Province. Sustainability, 10(5), 1424. https://doi.org/10.3390/su10051424