Racial Residential Segregation: Measuring Location Choice Attributes of Environmental Quality and Self-Segregation

Abstract
:1. Introduction
2. Literature Review
3. Empirical Methodology
3.1. Conceptual Model
3.2. Econometric Implementation
3.3. Counterfactual Segregation Analysis
4. Data Sources
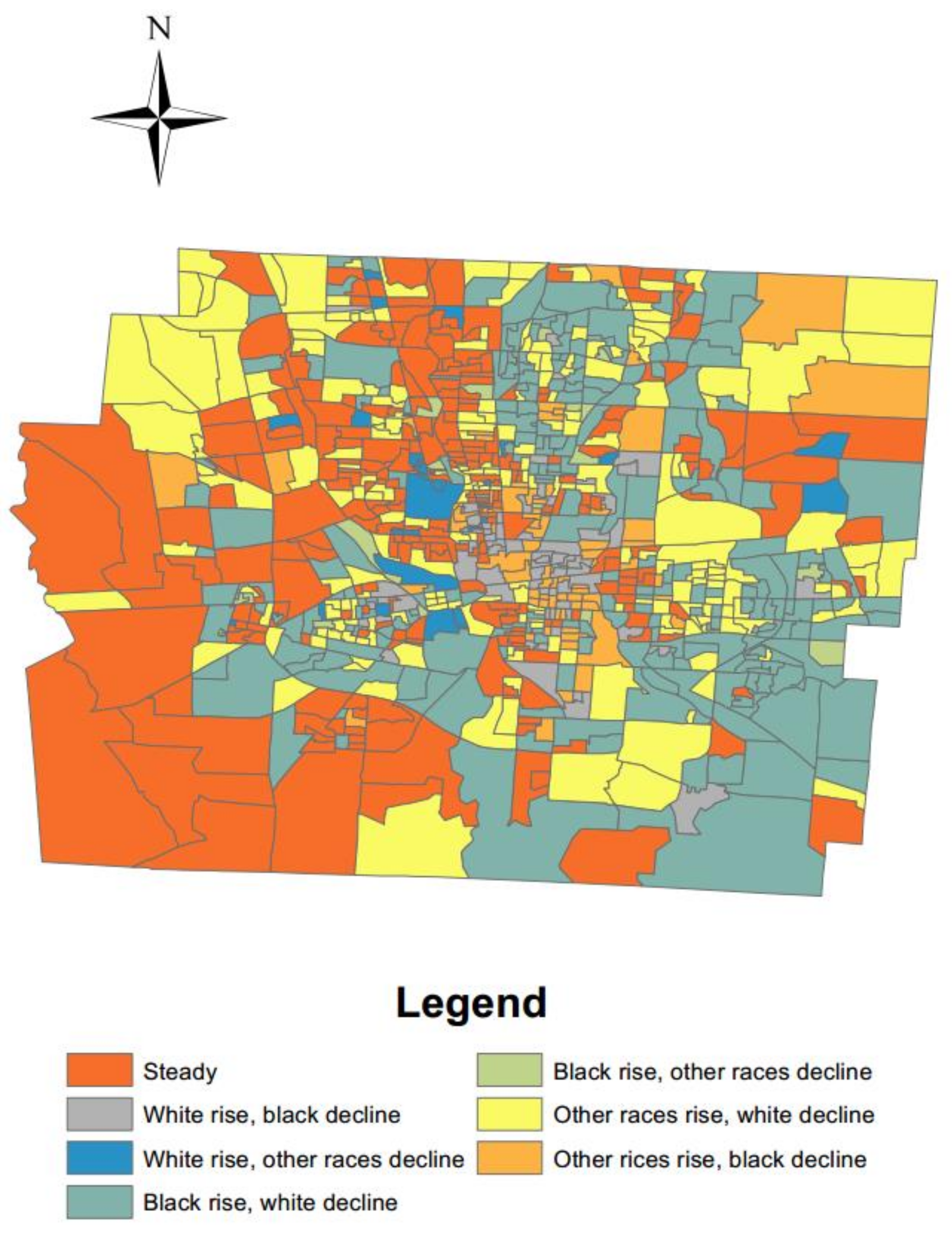
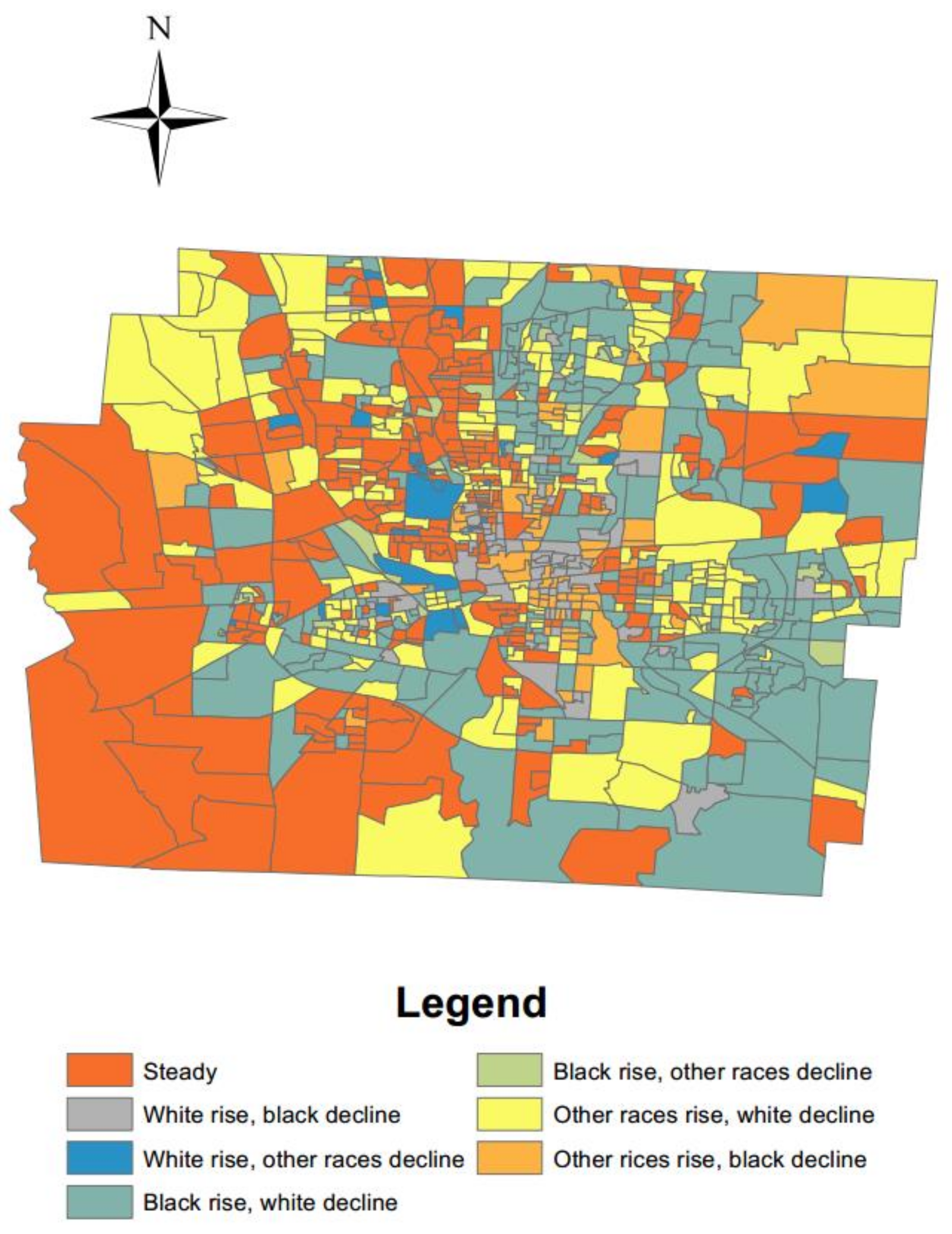
4.1. Neighborhood Attributes
4.2. Household and Housing Characteristics
5. Estimation Results
5.1. First Stage Estimation Results
5.2. Second Stage Estimation Results
5.3. Simulation Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
| Estimate | Std. Err. | |
|---|---|---|
| Interaction parameters from first stage estimation | ||
| Household Size ×Number of Bedrooms | 0.001 | 0.016 |
| Children in Family× School-district Ranking Score | 0.737 *** | 0.035 |
| Educational Attainment × School-district Ranking Score | 0.173 *** | 0.031 |
| Educational Attainment× Percent Black | −0.754 *** | 0.065 |
| Educational Attainment × Percent Other Races | −4.015 *** | 0.213 |
| Black × Percent Black | 7.085 *** | 0.057 |
| Black × Percent Other Races | −3.461 *** | 0.221 |
| Other Races × Percent Other Races | 1.965 *** | 0.020 |
| Other Races × Percent Black | −0.177 ** | 0.066 |
| Black × TRI Release | 0.590 *** | 0.052 |
| Other Races × TRI Release | 0.041 * | 0.054 |
| Household Income × TRI Release | −0.157 *** | 0.016 |
| Household Income × Percent Black | −0.868 *** | 0.012 |
| Household Income × Percent Other Races | −1.094 *** | 0.028 |
| Second-stage IV estimation results | ||
| House price ($10,000) | −0.403 *** | 0.012 |
| Number of Bedrooms | 2.410 *** | 0.088 |
| Fire Place | 1.559 *** | 0.066 |
| House Age | −0.718 *** | 0.024 |
| Air Conditioner | 1.064 *** | 0.059 |
| TRI Release | −0.684 *** | 0.129 |
| Percent Black population | −3.341 *** | 0.121 |
| Percent Other race population | −2.492 *** | 0.377 |
| School-district Ranking Score | 3.361 *** | 0.138 |
References
- Schaeffer, Y.; Cremer-Schulte, D.; Tartiu, C.; Tivadar, M. Natural amenity-driven segregation: Evidence from location choices in French metropolitan areas. Ecol. Econ. 2016, 130, 37–52. [Google Scholar] [CrossRef]
- Tiebout, C.M. A pure theory of local expenditures. J. Polit. Econ. 1956, 64, 416–424. [Google Scholar] [CrossRef]
- Epple, D.; Romer, T.; Sieg, H. Interjurisdictional Sorting and Majority Rule: An Empirical Analysis. Econometrica 2001, 69, 1437–1465. [Google Scholar] [CrossRef]
- Gamper Rabindran, B.S.; Timmins, C.; Banzhaf, S.; Walsh, R.P. Hazardous Waste Cleanup, Neighborhood Gentrification, and Environmental Justice: Evidence from Restricted Access Census Block Data. Am. Econ. Rev. 2011, 101, 620–624. [Google Scholar] [CrossRef]
- Banzhaf, H.S.; Walsh, P.R. Do People Vote with Their Feet? An Empirical Test of Tiebout. Am. Econ. Rev. 2008, 98, 843–863. [Google Scholar] [CrossRef]
- Schelling, T.C. Models of Segregation. Am. Econ. Rev. 1969, 59, 488–493. [Google Scholar]
- Schelling, T.C. Dynamic models of segregation. J. Math. Sociol. 1971, 1, 143–186. [Google Scholar] [CrossRef]
- Pancs, R.; Vriend, N.J.; Mary, Q.; Equilibria, M.N. Schelling’s Spatial Proximity Model of Segregation. J. Public Econ. 2007, 91, 1–24. [Google Scholar] [CrossRef]
- Caetano, G.; Maheshri, V. School segregation and the identification of tipping behavior. J. Public Econ. 2017, 148, 115–135. [Google Scholar] [CrossRef]
- Card, D.; Mas, A.; Rothstein, J. Tipping and the Dynamics of Segregation. Q. J. Econ. 2008, 123, 177–218. [Google Scholar] [CrossRef]
- Greenstone, M.; Gallagher, J. Does Hazardous Waste Matter? Evidence from the Housing Market and the Superfund Program. Q. J. Econ. 2008, 123, 951–1003. [Google Scholar] [CrossRef]
- Gamper-Rabindran, S.; Timmins, C. Does cleanup of hazardous waste sites raise housing values? Evidence of spatially localized benefits. J. Environ. Econ. Manage. 2013, 65, 345–360. [Google Scholar] [CrossRef]
- Banzhaf, H.S.; Walsh, R.P. Segregation and Tiebout sorting: The link between place-based investments and neighborhood tipping. J. Urban Econ. 2013, 74, 83–98. [Google Scholar] [CrossRef]
- Bayer, P.; Keohane, N.; Timmins, C. Migration and Hedonic Valuation: The Case of Air Quality. J. Environ. Econ. Manage. 2009, 58, 1–14. [Google Scholar] [CrossRef]
- Klaiber, A.H.; Phaneuf, D.J. Valuing Open Space in A Residential Sorting Model of the Twin Cities. J. Environ. Econ. Manage. 2010, 60, 57–77. [Google Scholar] [CrossRef]
- Bayer, P.; Fang, H.; McMillan, R. Separate when equal? Racial inequality and residential segregation. J. Urban Econ. 2014, 82, 32–48. [Google Scholar] [CrossRef]
- Hite, D. Environmental Equity. Growth Change 2000, 31, 40–58. [Google Scholar] [CrossRef]
- Ringquist, E.J. Assessing Evidence of Environmental Inequities: A Meta-Analysis. Soc. Polit. Anal. Manag. 2005, 24, 223–247. [Google Scholar] [CrossRef]
- Booth, J.M.; Teixeira, S.; Zuberi, A.; Wallace, J.M. Barrios, ghettos, and residential racial composition: Examining the racial makeup of neighborhood profiles and their relationship to self-rated health. Soc. Sci. Res. 2018, 69, 19–33. [Google Scholar] [CrossRef] [PubMed]
- Mohai, P.; Pellow, D.; Roberts, J.T. Environmental Justice. Annu. Rev. Environ. Resour. 2009, 34, 405–430. [Google Scholar] [CrossRef]
- Kravitz-Wirtz, N.; Crowder, K.; Hajat, A.; Sass, V. The Long-Term Dynamics of Racial/Ethnic Inequality in Neighborhood Air Pollution Exposure, 1990-2009. Du. Bois. Rev. 2016, 13, 237–259. [Google Scholar] [CrossRef] [PubMed]
- Mohai, P.; Bryant, B. Environmental Racism: Reviewing the Evidence. In Race and the Incidence of Environmental Hazards: A Time for Discourse; Westview Press: Boulder, CO, USA, 1992. [Google Scholar]
- Bader, M.; Warkentien, S. The Fragmented Evolution of Racial Integration since the Civil Rights Movement. Sociol. Sci. 2016, 3, 135–164. [Google Scholar] [CrossRef]
- Spiegel, S. Prison Race Rights: An Easy Case for Segregation. Calif. Law Rev. 2007, 95, 2261–2293. [Google Scholar]
- Glaeser, E.L.; Vigdor, J.L. Racial Segregation in the 2000 Census: Promising News. Brook. Insitution Surv. Ser. 2001, 1–16. [Google Scholar]
- Massey, D.S.; Denton, N.A. American Apartheid Segregation and the Making of the Underclass; Harvard University Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Jackson, K.T. Crabgrass Frontier The Suburbanization of America; Oxford University Press: New York, NY, USA, 1985. [Google Scholar]
- Sugrue, T.J. The Origins of the Urban Crisis: Race and Inequality in Postwar Detroit; Princeton University Press: Princeton, NJ, USA, 1996. [Google Scholar]
- Boustan, L.P. Racial Residential Segregation in American Cities. 2013. Available online: http://www.nber.org/papers/w19045.pdf (accessed on 8 April 2018).
- Kennedy, M.; Leonard, P. Dealing With Neighborhood Change: A Primer on Gentrification and Policy Choices. Brookings Inst. Cent. Urban Metrop. Policy 2001. [Google Scholar]
- Vigdor, J.L. Does Gentrification Harm the Poor? Brookings-whart. Pap. Urban Aff. 2002, 3, 133–182. [Google Scholar] [CrossRef]
- Bayer, P.; Ferreira, F.; McMillan, R. A Unified Framework for Measuring Preferences for Schools and Neighborhoods. J. Polit. Econ. 2007, 115, 588–638. [Google Scholar] [CrossRef]
- Bayer, P.; McMillan, R. Tiebout sorting and neighborhood stratification. J. Public Econ. 2012, 96, 1129–1143. [Google Scholar] [CrossRef]
- Bayer, P.; Robert, M.; Kim, R. An Equilibrium Model of Sorting in An Urban Housing Market. Available online: http://homes.chass.utoronto.ca/~mcmillan/methods.pdf (accessed on 8 April 2018).
- McFadden, D. Modelling the Choice of Residential Location. Transp. Res. Rec. 1978, 672, 72–77. [Google Scholar]
- McFadden, D. Conditional Logit Analysis of Qualitative Choice Behavior; Academic Press: New York, NY, USA, 1973; ISBN 0127761500. [Google Scholar]
- Berry, S.T. Estimating Discrete Choice Models of Product Differentiation. RAND J. Econ. 1994, 25, 242–262. [Google Scholar] [CrossRef]
- Massey, D.S. The Dimensions of Residential Segregation. Soc. Forces 1988, 67, 281–315. [Google Scholar] [CrossRef]
- Wilson, S.M.; Fraser-Rahim, H.; Williams, E.; Zhang, H.; Rice, L.; Svendsen, E.; Abara, W. Assessment of the distribution of toxic release inventory facilities in metropolitan Charleston: An environmental justice case study. Am. J. Public Health 2012, 102, 1974–1980. [Google Scholar] [CrossRef] [PubMed]
- Kalnins, A.; Dowell, G. Community Characteristics and Changes in Toxic Chemical Releases: Does Information Disclosure Affect Environmental Injustice? J. Bus. Ethics 2017, 145, 277–292. [Google Scholar] [CrossRef]
- Johnson, R.; Ramsey-White, K.; Fuller, C.H. Socio-demographic differences in toxic release inventory siting and emissions in metro Atlanta. Int. J. Environ. Res. Public Health 2016, 13. [Google Scholar] [CrossRef] [PubMed]
- Asadoorian, M.O. The Toxic Release Inventory: Public Awareness or Common Ignorance? Interdiscip. Environ. Rev. 2001, 3, 113–131. [Google Scholar] [CrossRef]
- Sanders, N.J. Toxic Assets: How the Housing Market Responds to Environmental Information Shocks. 2012. Available online: http://economics.wm.edu/wp/cwm_wp128.pdf (accessed on 8 April 2018).
- Mastromonaco, R. Do Environmental Right-to-Know Laws Affect Markets? Capitalization of Information in the Toxic Release Inventory. J. Environ. Econ. Manage. 2015, 71, 54–70. [Google Scholar] [CrossRef]
- Fishman, J.; Smith, V.K. Latent Tastes, Incomplete Stratification, and the Plausibility of Vertical Sorting Models. Environ. Resour. Econ. 2017, 66, 339–361. [Google Scholar] [CrossRef]
- Binner, A.; Day, B. How Property Markets Determine Welfare Outcomes: An Equilibrium Sorting Model Analysis of Local Environmental Interventions. Environ. Resour. Econ. 2017. [Google Scholar] [CrossRef]
- Tra, C.I.; Lukemeyer, A.; Neill, H. Evaluating the Welfare Effects of School Quality Improvements: A Residential Sorting Approach. J. Reg. Sci. 2013, 53, 607–630. [Google Scholar] [CrossRef]
- Krysan, M.; Couper, M.P.; Farley, R.; Forman, T. Does Race Matter in Neighborhood Preferences? Results from a Video Experiment. Am. J. Sociol. 2009, 115, 527–559. [Google Scholar] [CrossRef] [PubMed]
- Ananat, E.O. The Wrong Side(s) of the Tracks Estimating the Causal Effects of Racial Segregation on City Outcomes. Am. Econ. J. Appl. Econ. 2011, 3, 34–66. [Google Scholar] [CrossRef]
| Variable | Full Sample | Without TRI Release | With TRI Release | |||
|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | |
| Household Characteristics | ||||||
| Median Household Income ($10,000) | 6.326 | 3.304 | 6.438 | 3.348 | 4.866 | 2.082 |
| Household Size | 2.540 | 0.344 | 2.546 | 0.350 | 2.495 | 0.272 |
| Children in Family | 0.478 | 0.499 | 0.480 | 0.500 | 0.463 | 0.498 |
| Educational Attainment | 0.577 | 0.494 | 0.585 | 0.493 | 0.470 | 0.499 |
| White | 0.719 | 0.462 | 0.727 | 0.237 | 0.646 | 0.308 |
| Black | 0.199 | 0.399 | 0.191 | 0.233 | 0.270 | 0.309 |
| Other Races | 0.082 | 0.312 | 0.082 | 0.047 | 0.084 | 0.057 |
| N | 43,252 | 38,577 | 4675 | |||
| Housing Characteristics | ||||||
| House Price ($10,000) | 16.007 | 17.654 | 16.240 | 17.962 | 11.012 | 7.526 |
| Number of Bedrooms | 3.188 | 0.664 | 3.204 | 0.667 | 3.061 | 0.626 |
| House Age | 45.503 | 93.70 | 45.956 | 103.900 | 46.765 | 101.068 |
| Air Conditioner | 0.839 | 0.368 | 0.843 | 0.363 | 0.735 | 0.442 |
| Fireplace | 0.499 | 0.609 | 0.514 | 0.610 | 0.312 | 0.488 |
| N | 43,252 | 38,577 | 4675 | |||
| Neighborhood Attributes (N = 848) | ||||||
| Percent Census Block Group White | 0.676 | 0.270 | 0.688 | 0.261 | 0.566 | 0.320 |
| Percent Census Block Group Black | 0.237 | 0.267 | 0.224 | 0.257 | 0.345 | 0.321 |
| Percent Census Block Group Other Races | 0.087 | 0.058 | 0.087 | 0.058 | 0.089 | 0.062 |
| Toxic Release (1000 pounds) | 1.659 | 2.032 | 0 | 0 | 15.291 | 60.259 |
| School-district Ranking Score | 0.406 | 0.265 | 0.413 | 0.268 | 0.350 | 0.229 |
| N | 848 | 756 | 92 | |||
| Estimate | Std. Err. | |
|---|---|---|
| Interaction parameters from first stage estimation | ||
| Household Size × Number of Bedrooms | 0.005 | 0.016 |
| Children in Family× School-district Ranking Score | 0.740 *** | 0.035 |
| Educational Attainment × School-district Ranking Score | 0.173 *** | 0.031 |
| Educational Attainment × Percent Census Block Group Black | −0.760 *** | 0.065 |
| Educational Attainment × Percent Census Block Group Other Races | −4.018 *** | 0.213 |
| Black × Percent Census Block Group Black | 7.100 *** | 0.057 |
| Black × Percent Census Block Group Other Races | −3.404 *** | 0.221 |
| Other Races × Percent Census Block Group Other Races | 1.965 *** | 0.020 |
| Other Races × Percent Census Block Group Black | −0.182 ** | 0.066 |
| Black × TRI Release | 1.082 *** | 0.077 |
| Other Races × TRI Release | 0.194 ** | 0.082 |
| Household Income × TRI Release | −0.184 *** | 0.020 |
| Household Income× Percent Census Block Group Black | −0.869 *** | 0.012 |
| Household Income × Percent Census Block Group Other Races | −1.092 *** | 0.028 |
| Likelihood Ratio | 48,644 | |
| Estimate | Std. Err. | |
|---|---|---|
| Second-stage IV estimation results | ||
| House price ($10,000) | −0.417 *** | 0.013 |
| Number of Bedrooms | 2.494 *** | 0.092 |
| Fire Place | 1.628 *** | 0.070 |
| House Age | −0.727 *** | 0.025 |
| Air Conditioner | 1.107 *** | 0.061 |
| TRI Release | −0.732 *** | 0.093 |
| Percent Census Block Group Black | −3.435 *** | 0.127 |
| Percent Census Block Group Other Races | −2.239 *** | 0.393 |
| School-district Ranking Score | 3.507 *** | 0.145 |
| 0.37 | ||
| Panel A | |||||
| Observed Own-Race Exposure rate | Over-Exposure | ||||
| Household Race | Percent White | Percent Black | Percent other | ||
| White | 86.21% | 6.04% | 7.75% | 18.86% | |
| Black | 41.00% | 50.76% | 8.23% | 26.84% | |
| Other | 47.19% | 20.71% | 32.09% | 23.36% | |
| Panel B (switch off Heterogeneous Taste for TRI Emissions with Respect to Race) | |||||
| Simulation Results of Race Exposure Rate | Over-Exposure | Change in Own-Race “over-exposure” (Panel B – Panel A) | |||
| Household Race | Percent White | Percent Black | Percent Other | ||
| White | 85.28% | 7.09% | 7.63% | 17.93% | −0.93% |
| Black | 39.78% | 52.47% | 7.74% | 28.55% | 1.71% |
| Other | 45.99% | 22.27% | 31.73% | 23.00% | −0.36% |
| Panel C (switch off Heterogeneous Tastes for TRI Emissions with Respect to Race and Preferences for Own-Race Neighbors) | |||||
| Simulation Results of Race Exposure Rate | Over-Exposure | Change in Own-Race “over-exposure” (Panel C – Panel B) | |||
| Household Race | Percent White | Percent Black | Percent Other | ||
| White | 77.65% | 16.09% | 6.26% | 10.30% | −7.63% |
| Black | 44.06% | 36.20% | 19.74% | 12.28% | −16.37% |
| Other | 45.68% | 22.48% | 31.84% | 23.11% | 1.10% |
| Overall | 67.35% | 23.92% | 8.73% | ||
| Panel A: Observed Own-Race Over-Exposure rate | ||||
| Income Quantile | 1st Quantile | 2nd Quantile | 3rd Quantile | 4th Quantile |
| White | 15.44% | 16.81% | 18.62% | 21.55% |
| Black | 34.30% | 19.10% | 15.29% | 3.49% |
| Other | 20.80% | 16.31% | 14.67% | 26.85% |
| Panel B: Switch off Heterogeneous Taste for TRI Emissions with Respect to Race | ||||
| Income Quantile | 1st Quantile | 2nd Quantile | 3rd Quantile | 4th Quantile |
| White | 15.11% | 15.60% | 17.61% | 20.69% |
| Black | 35.68% | 20.80% | 18.10% | 6.89% |
| Other | 20.13% | 16.01% | 14.37% | 26.74% |
| Panel C: Switch off Heterogeneous Tastes for TRI Emissions with Respect to Race and Preferences for Own-Race Neighbors | ||||
| Income Quantile | 1st Quantile | 2nd Quantile | 3rd Quantile | 4th Quantile |
| White | 9.58% | 8.94% | 10.08% | 11.65% |
| Black | 14.08% | 10.60% | 9.13% | 6.60% |
| Other | 21.62% | 15.08% | 12.82% | 26.49% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Robinson, D.; Hite, D. Racial Residential Segregation: Measuring Location Choice Attributes of Environmental Quality and Self-Segregation. Sustainability 2018, 10, 1114. https://doi.org/10.3390/su10041114
Zhang Z, Robinson D, Hite D. Racial Residential Segregation: Measuring Location Choice Attributes of Environmental Quality and Self-Segregation. Sustainability. 2018; 10(4):1114. https://doi.org/10.3390/su10041114
Chicago/Turabian StyleZhang, Zhaohua, Derrick Robinson, and Diane Hite. 2018. "Racial Residential Segregation: Measuring Location Choice Attributes of Environmental Quality and Self-Segregation" Sustainability 10, no. 4: 1114. https://doi.org/10.3390/su10041114
APA StyleZhang, Z., Robinson, D., & Hite, D. (2018). Racial Residential Segregation: Measuring Location Choice Attributes of Environmental Quality and Self-Segregation. Sustainability, 10(4), 1114. https://doi.org/10.3390/su10041114