1. Introduction
With the development of water affair information, water affair data have the problems of multisource heterogeneity and a large quantity. There is a large amount of structured data in the database and a variety of unstructured data, such as text, images, and video, and the data storage locations are diverse. However, successful knowledge management relies on the construction and application of an effective knowledge graph for the formation and description of knowledge in specific areas, enabling the water affair industry to achieve an effective management of domain knowledge.
With the development of the Internet, network data content has undergone an explosive growth trend. Due to its large scale, substantial heterogeneity, and the loose organizational structure of Internet content, people find it challenging to meet the needs of accurate and efficient access to information and knowledge. The knowledge graph [
1] came into being and, with its strong semantic processing and open organization, laid a suitable foundation for knowledge organization and an intelligent application of the Internet era. A knowledge graph is essentially a semantic network; it is a graph-based data structure that consists of nodes and edges. Each node is an objective “entity” that exists in the world, and each edge marks a “relationship” between two entities. The knowledge graph is a large relational network that connects all kinds of different information and integrates them. In contrast to the previous ontology [
2], which focused on the upper and lower relations, the knowledge graph focuses on the semantic relationship. To put it simply, when the semantic relationship is merged into the ontology, a knowledge graph is formed. Thus, ontology is the conceptual model and logical basis of the knowledge graph [
3]. The hierarchy of a knowledge graph can be divided into two levels: a data layer and a pattern layer. The pattern layer of the knowledge graph is similar to the relationship and structure between concepts in the ontology. In the data layer of the knowledge graph, the storage is in various forms, and there is a graph database, which is stored in facts, as with Google’s Graphd and Trinity, which are typical graph databases. Data are also stored according to the resource description framework (RDF) triple, which is the basic expression of the fact according to the format of the “entity-relationship-entity” or “entity-attribute-attribute value” triplet. The entity relationship network formed by putting all of the data of the data layer and the structural relationship of the pattern layer together is the knowledge graph.
Traditional methods of knowledge graph construction include the skeleton method, the Toronto Virtual Enterprise Ontology Project (TOVE) method, the Methontology method, and the seven-step method. The skeleton method was proposed by Uschold [
4] based on the research and development experience of the enterprise ontology model. This method mainly includes the following processes: determining the domain and scope of the ontology application, analyzing and evaluating the target ontology, encoding the ontology and integrating with the ontology, evaluating the ontology, and assembling the document. The TOVE method [
5] was proposed by the University of Toronto Enterprise Integration Lab when constructing the Toronto Virtual Enterprise Ontology Project. This ontology includes the ontology of enterprise design, engineering, plan, and service, and uses first-order logic for integration. The Methontology method [
6] uses the concept of the ontology life cycle to organize the development process of the entire ontology. This method is divided into three phases: the management phase, the development phase, and the maintenance phase. The seven-step method [
7] is a classical method of ontology construction proposed by researchers at Stanford University. The seven-step method is a relatively logical method that first advocates the reuse of the existing ontology as much as possible, extracting the relationship between the concepts by a step-by-step method; the method then constructs the generic relationship between concepts, examining the relationship between concepts, and ultimately fills in the instance object of the concept.
At present, the construction methods and applications of various domain knowledge graphs have been developed. Chen et al. [
8] proposed a domain ontology construction model and a personalized knowledge search and recommendation system to enhance knowledge integration and application. Sulthana [
9] built an ontology with a neuro-fuzzy classification and evaluated the context and determined comments based on the ontology and context recommendation system. The proposed method was reported to improve the accuracy of the recommendation system. To solve the ambiguity problem, Run et al. [
10] proposed a financial news recommendation algorithm to help users find interesting articles. Uma et al. [
11] built a job recommendation system for job seekers by collecting work portal data. Castells et al. [
12] presented a comprehensive personalized retrieval framework where the advantages of ontologies are exploited in different parts of the retrieval cycle. Based on network encyclopedia resources, Kramer [
13] extracted more than two million conceptual concept networks from Wikipedia and mapped these concepts to more than three million terms. Shinzato and Torisawa [
14] proposed a method for automatically acquiring a relationship-assisted knowledge graph from HTML documents through the shortcomings of traditional methods. KnowItAll [
15] and Nell [
16] used iterative methods to learn high-quality triples from web page data to construct a knowledge graph.
However, these studies are not fully applicable to the construction and application of a water knowledge graph. At present, the monitoring data of water structure mainly exists in the Oracle database and composes millions of data volumes arranged in a complex structure. Unstructured data mainly include data sources such as text, images, and video. Based on the current distribution of water data and the demand for integrated data by water users, it is necessary to develop a model that can integrate a large number of multisource heterogeneous data points and apply them.
In this paper, for the user’s demand for water structural data and unstructured data integration, first, a model of water structured monitoring data and water unstructured text data is constructed to construct a knowledge graph. Then, an information recommendation system based on the water knowledge graph is constructed. Finally, according to the knowledge graph construction method, the recall rate, accuracy rate, and F comprehensive results are compared to evaluate the effectiveness and accuracy of the proposed method. At the same time, a set of verification data sets is used to verify the effectiveness of the information recommendation system based on the water knowledge graph.
The rest of this paper is organized as follows.
Section 2 presents the construction and application model of the water knowledge graph.
Section 3 proposes the construction of the water knowledge graph and the method of information recommendation.
Section 4 introduces the results of the construction and recommendation of the water knowledge graph and carries out the evaluation verification experiment.
Section 5 presents the conclusions and provides guidance for future work.
2. Materials and Methods
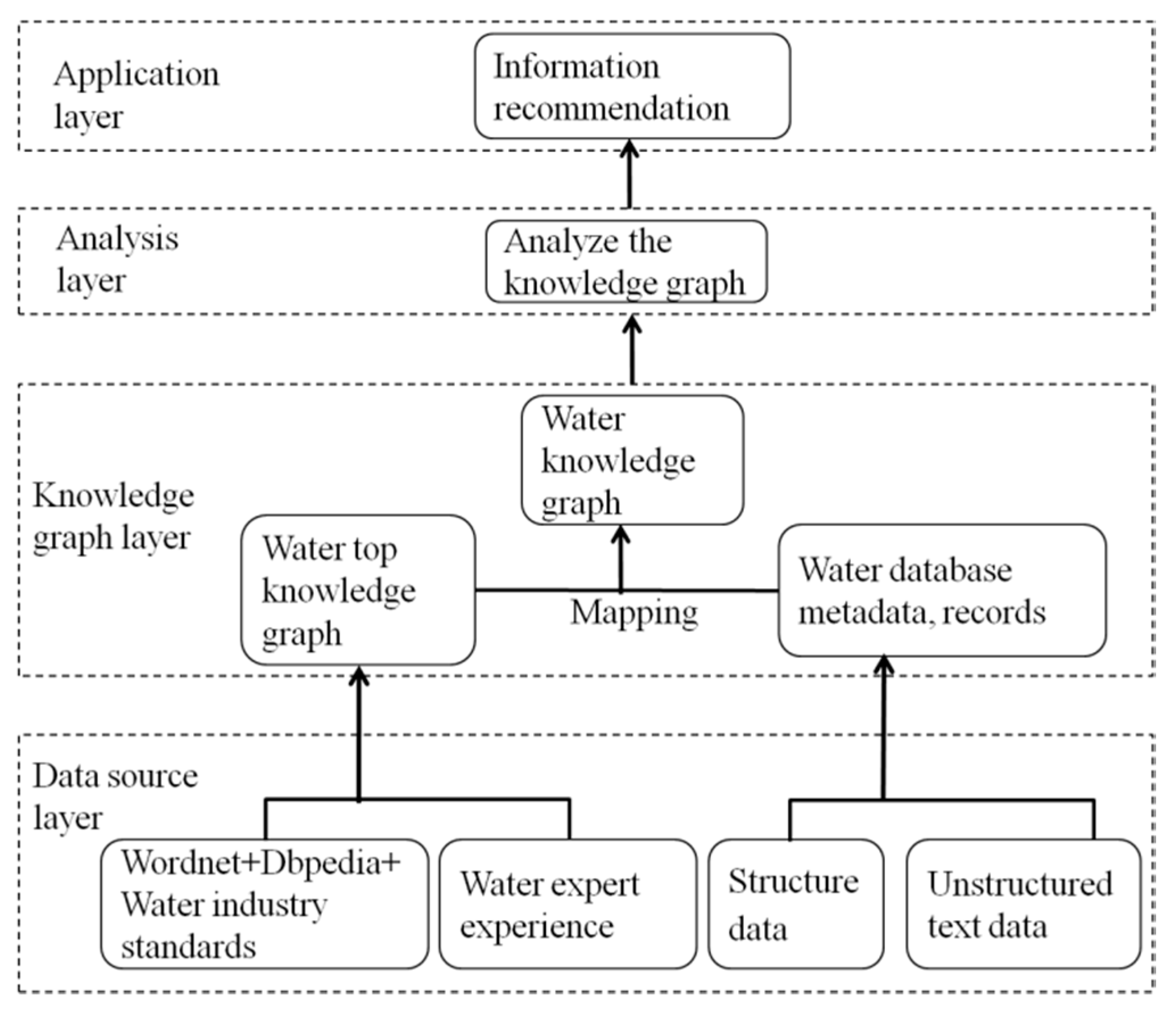
To realize the construction and recommendation of the water knowledge graph, this section establishes a personalized adaptation model of the water affair knowledge graph, as shown in
Figure 1. The model is mainly divided into four parts, namely, the data source layer, knowledge graph layer, reasoning layer, and application layer. Each part is discussed as follows. Data source layer: Wordnet dictionaries, Dbpedia thesaurus, water industry standards, and water expert experience are used to construct the top-level knowledge graph of water affairs. Structured monitoring data and unstructured text data are used to supplement the knowledge graph to form the final natural domain knowledge graph of water affairs. The knowledge graph layer mainly includes the construction of a top-level knowledge graph in the natural field of water affairs and the refinement of the knowledge graph in the natural fields of water affairs. The analytical layer analyzes the water affair knowledge graph and formulates an effective method of recommendation. Finally, the application layer mainly includes recommendations based on the knowledge graph of the water affair field.
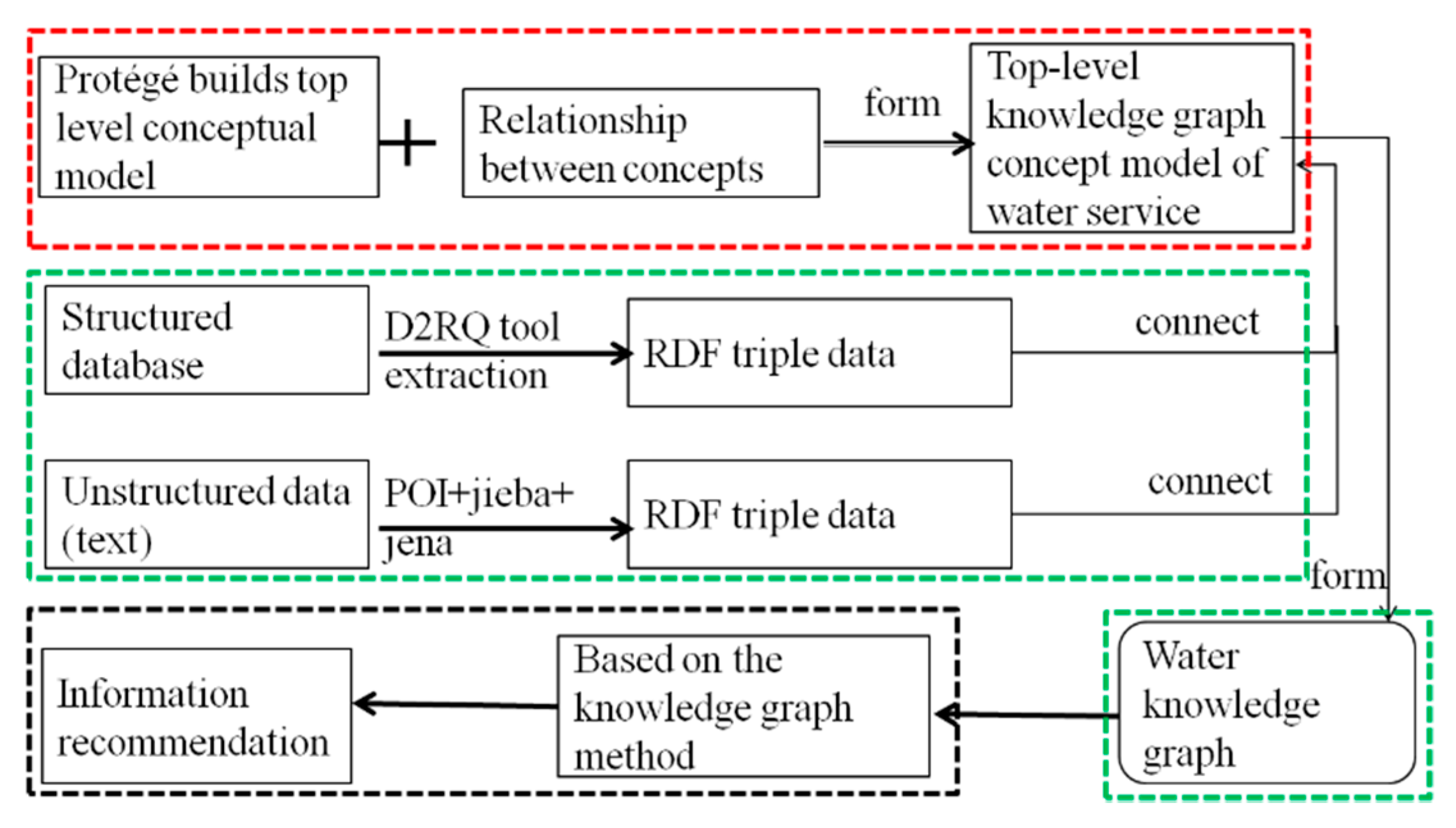
The technical model is shown in
Figure 2, where the red dashed box is the technical route of the data layer, the green dashed box is the technical route of the knowledge map construction layer, and the black dashed box is the technical route of the analysis layer and application layer. First, the Protégé (Stanford University, Stanford, CA, USA) ontology construction software is used to build a top-level conceptual model, and the conceptual model of the top knowledge graph of water affair is formed based on the relationship established between the concepts. Second, the D2RQ tool is used to extract the structured database to form the RDF triple data, and the text extraction tools (such as POI or jieba) are used to extract the unstructured text data to form the RDF triple data. In addition, the two sets of RDF triplet data are linked to the water affair top knowledge graph conceptual model to form a water affair knowledge graph. Finally, this paper creates a water affair information recommendation based on the methods of the knowledge graph.
2.1. Materials and Tools for the Construction of a Water Affair Knowledge Graph
2.1.1. Construction of the Top-Level Knowledge Graph of Water Affairs
The water affair knowledge graph construction process includes the construction of the top-level knowledge graph, extraction of the database, extraction of the text, and attachment of the knowledge graph. The construction of the top-level knowledge graph is a key link that directly affects the quality of the entire knowledge graph. This research mainly constructs the top-level knowledge graph of water resources based on the Wordnet [
17] dictionary, Dbpedia [
18] thesaurus, water industry standards, and water expert experience; the examples of their corresponding natural concepts and examples referred to herein are shown in
Table 1. The construction of the top-level knowledge graph of water affairs is completed in the Protégé tool [
19]. The content of the top-level knowledge graph of the water business constructed in this paper is shown in
Table 2, which mainly includes the concepts of water affairs and the hierarchical structure between the concepts.
2.1.2. Extraction Tools for Structured Monitoring Data
D2RQ [
20] is a tool used for a large number of structured data extractions; it extracts structured data and transforms them into RDF files for constructing a knowledge graph on the protégé platform. Due to the huge amount of water affair monitoring data, ordinary extraction methods cannot achieve large-scale structured data extraction. To achieve an effective extraction of structured data, this paper applies the D2RQ tool for extracting a large number of water structured monitoring data. The D2RQ language is implemented in the
Table 3.
2.1.3. Parsing Tools of Texts
POI [
21] is a tool for parsing text that can screen out nontext content such as tables and images in text, leaving only the contents of the text. Jieba [
22] is an open-source Python Chinese word segmentation tool that is divided into three modes: precise mode (default), full mode, and search engine mode. Jieba is more accurate than other commonly used open-source word segmentation tools (such as mmseg4j). Due to the large granularity of the experimental text concepts, this paper uses the precise mode of jieba to conduct our experiments. CN-Dbpedia [
23], a large-scale general-domain structured wiki developed and maintained by the Knowledge Factory laboratory of Fudan University, covers tens of millions of entities and hundreds of millions of relations. Jena has a Java API. As an ontology parsing tool, Jena converts the extracted text information into the RDF text format, which is used to realize ontology visualization in Protégé. This article uses these tools to parse water texts.
For the first time, CN-Dbpedia is applied to water data to improve the water affair knowledge graph. In addition, the combination of these tools greatly improves the efficiency and integrity of the construction of a water affair knowledge graph.
2.2. Construction Algorithms for a Water Affair Knowledge Graph
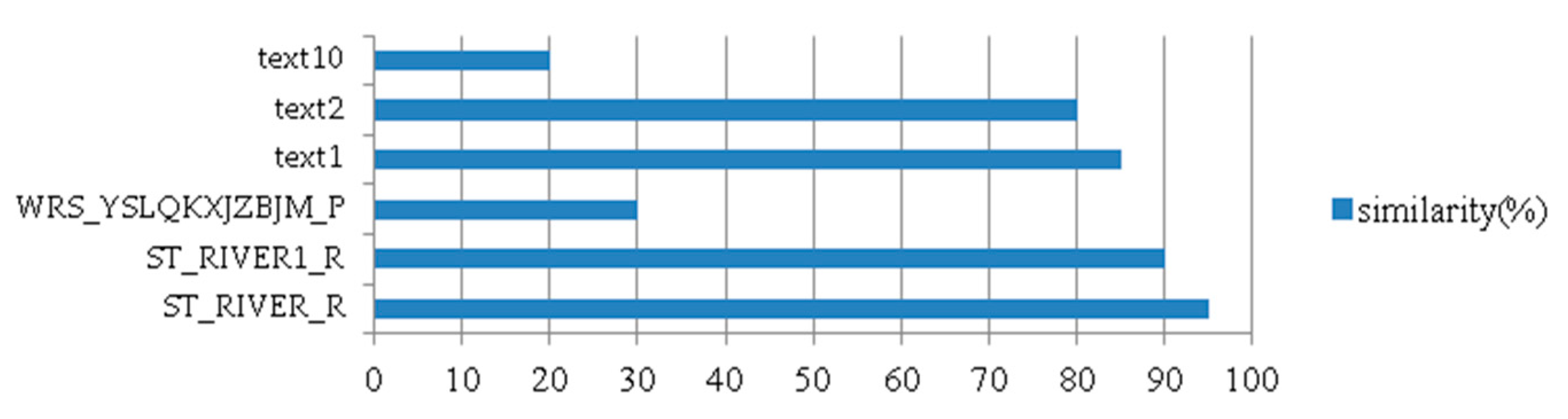
The mapping algorithm of a knowledge graph is the key to its construction. The algorithm maps the extracted table names of structured data tables, the content of unstructured texts, and the top-level knowledge graph of the constructed water service. Then, these data are integrated with the corresponding concepts to supplement the top-level knowledge graph of the water service with instances and attributes and attribute values. The mapping algorithm of the water affair knowledge graph is divided into an edit distance algorithm applied to the mapping of structured monitoring data and a latent Dirichlet allocation (LDA) text classification method used to map the unstructured text.
2.2.1. Edit Distance Algorithm
The edit distance is the minimum number of edit operations required to switch from one string to another. If the strings are more distant, then they are considered more different. Permissive editing operations include replacing one character with another, inserting one character, and deleting one character. The algorithm mainly adds the content of step1 on the basis of the original edit distance algorithm [
24], and this paper combines regularization with the original edit distance algorithm to realize the construction of the water affair structured data knowledge graph. The algorithmic process is as follows:
Step 1: First, the table name is formatted by regularization and conversion of all letters to lowercase, and the concept words in the table name are extracted;
Step 2: For two concept words to be compared, set one of them to be the source string s with length n and the other as target string t with length m. Based on these two strings, this paper constructs a matrix named d [m+1,n+1] and initializes the first row of the matrix to 0,1,2...n, and the first column is initialized to 0,1,2...m;
Step 3: Compare each pair of characters in s (i from 1 to n) and t (j from 1 to m);
Step 4: If , the edit cost ; if , the edit cost ;
Step 5: Set the value of the cell d[i,j] in the matrix by the following algorithm:
The value of the cell immediately above is incremented by 1, which is ;
The value of the left cell is incremented by 1, which is ;
The value of the diagonal cell is increased by the value of the edit cost, which is .
Step 6: Iterating the second, third, and fourth steps,
is the value of the last edit distance of the two concept words being compared. Then, the similarity between the two strings s and t is
2.2.2. LDA Text Classification Algorithm
The LDA topic model is a three-layer Bayesian production probability model proposed by D. M. Blei et al. in 2003. The model assumes that the text is a random mixture of a series of potential themes and that the topic is a mixture of all of the words in the vocabulary. The main difference between different texts is the different assortment of topics. The model implements the probability distribution at the document-subject level through the Dirichlet function. Documents are seen as a set of probabilistic topics that are combined with each other, and words have probabilities assigned to each topic. The algorithm improves the application of the original algorithm [
25] in step 4. In step 4, the frequency P of the occurrence of the i-th word in the document d is expressed as the similarity between the text
text and the concept c. The specific generation process is as follows:
Step 1: The word is the basic unit of text data and is a subitem of a word list indexed with . The vth word in the vocabulary is represented by a V-dimensional vector w, where for any , , and .
Step 2: A document is a sequence of N words, which is denoted by , where is the nth word in the sequence.
Step 3: A document set is a collection of M documents expressed as
. Assuming that there are k topics, the probability of the ith word
in document d can be expressed as follows:
where
is the latent variable, indicating that the ith word sink
is taken from this topic.
is the probability that the word
belongs to the subject j, and
gives the probability that the document d belongs to the subject j.
Step 4: The result
in (3) is used as the similarity between the document text and the concept c in the water affair knowledge graph:
The jth topic is expressed as a polynomial distribution
of V words in the vocabulary, and the text is represented as a random mixture
on K implicit topics, so the probability of the vocabulary w “occurring” in the text d is as follows:
This paper finds the maximum likelihood function by EM (expectation maximization algorithm):
The maximum likelihood estimators of Equation (5) are α and β, and the parameter values of α and β are estimated to determine the LDA model. The conditional probability distribution of where the text d “occurs” is as follows:
There are θ, β pairings, and the analytical formula cannot be calculated; thus, an approximate solution needs to be obtained. In the LDA model, an approximated inference algorithm such as Laplace approximation, variational inference, Gibbs sampling, or expectation propagation can be used to obtain the estimated parameter values.
2.2.3. Water Affair Knowledge Graph Recommendation Algorithm Based on the Semantic Distance
The “semantic distance” [
26] is a quantitative expression of the strength of the relationship between concepts. The definition of semantic similarity is based on the length of the path between concepts, which determines the degree of semantic similarity. The semantic distance and semantic similarity are different representations of the same relational features of a pair of concepts. If the semantic distance between two concepts is closer, then the concepts are considered more similar. The semantic similarity of concepts is related not only to the distance between concepts, but also to the depth of the concept in the knowledge graph. Considering these factors comprehensively, this paper proposes a water affair knowledge graph recommendation algorithm based on the semantic distance. The specific definition is as follows:
Step 1: For the two concepts
and
, if the semantic similarity is
and the semantic distance is
, then
where
is an adjustable parameter that represents the semantic distance value when the similarity is 0.5.
Step 2: Introduce the hierarchical depth of the node:
where
is the minimum depth of
and
. Thus, in the case where the path distances are the same, the nodes having deeper levels have higher similarities.
Step 3: Following reference [
27], this study set the parameter
and recommends the water affair knowledge graph area with a
value greater than 0.6.
The rules that the semantic similarity should follow are as follows: the range of the semantic similarity value of the concepts and is . When the two concepts are identical, their semantic similarity is 1; when the two concepts are completely different, their semantic similarity is close to zero.
4. Discussion
This paper proposes a knowledge graph construction method for combining water affair structured and unstructured data. This method is applicable to all data construction knowledge graphs similar to water affair structured and unstructured data, and the method has universality. Moreover, the recommendation system based on the knowledge graph can improve the efficiency of water affair information searches and provide a certain reference value for the accuracy of the construction of a water affair knowledge graph.
This paper proposes a method for constructing a knowledge graph of water affairs in the natural field by constructing a combined knowledge graph based on structured monitoring data in the water affair and unstructured text information. To realize the recommendation of water affair information, this paper also proposes a personalized recommendation method based on the natural field knowledge graph of water affair. Finally, these methods are tested and evaluated. The main results and contributions of this paper are summarized below:
(1) Construction of a top-level knowledge graph of water affair: This paper builds a top-level knowledge graph of water affair based on Wordnet, Dbpedia, water industry standards, and expert experience, and provides a solid foundation for building a complete water affair knowledge graph.
(2) Methodology for constructing a water affair knowledge graph: In this paper, the water affair knowledge graph is improved by the edit distance algorithm and the LDA text semantic similarity algorithm, and the water affair information recommendation algorithm based on the water affair knowledge graph is prepared.
(3) Methodology of a water affair knowledge graph recommendation based on semantic distance: The recommendation method considers the water affair knowledge graph to calculate the similarity of the water affair information, and the water affair knowledge graph information that exceeds a given threshold which is recommended.
5. Conclusions
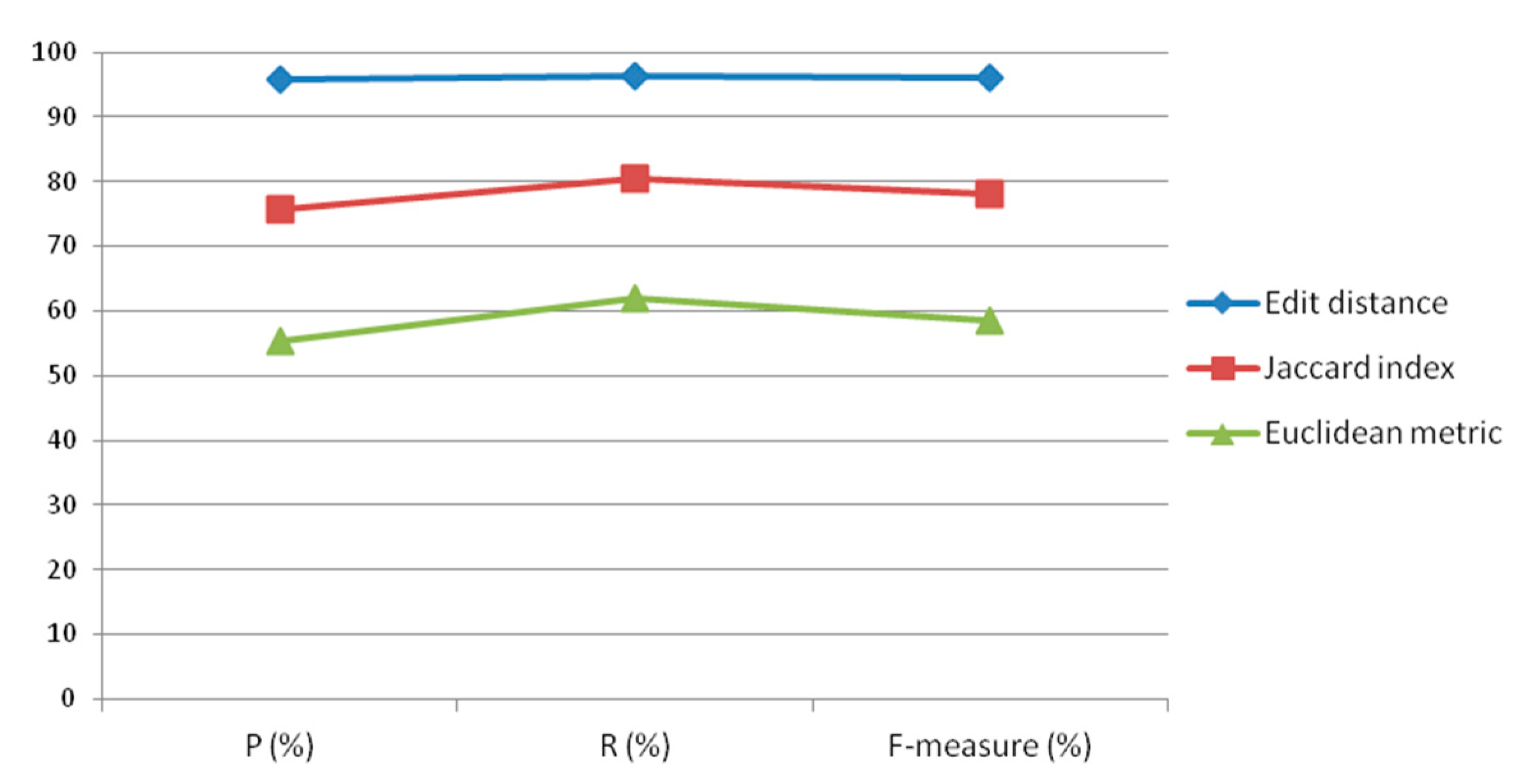
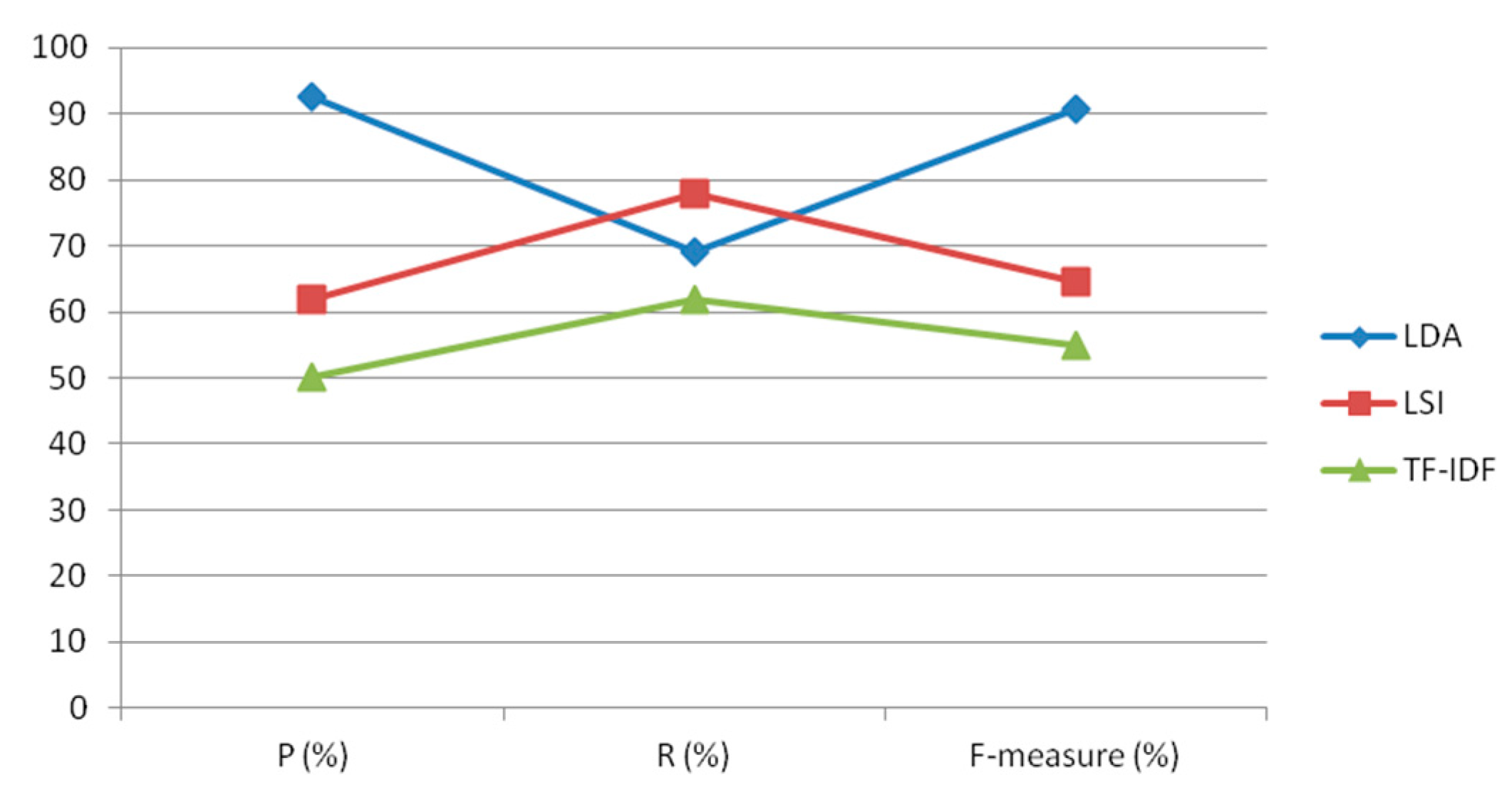
With the continuously increasing demand for water conservancy information in social production and life, the complexity of data involved in water conservancy information is increasing, which leads to challenges in data integration and low data utilization. To meet the needs of users for the integration of water data information, a method of constructing a knowledge graph by combining water affair structured and unstructured data is proposed. For meeting the needs of a water information search, an information recommendation system for a water affair knowledge graph is proposed. In this paper, the editing distance algorithm and LDA algorithm are used to construct the water affair-structured data and unstructured data combination knowledge graph, and the water affair-based knowledge graph is recommended based on the semantic distance algorithm. Finally, this paper uses the recall rate, accuracy rate, and F comprehensive results to compare the algorithms. The evaluation results in
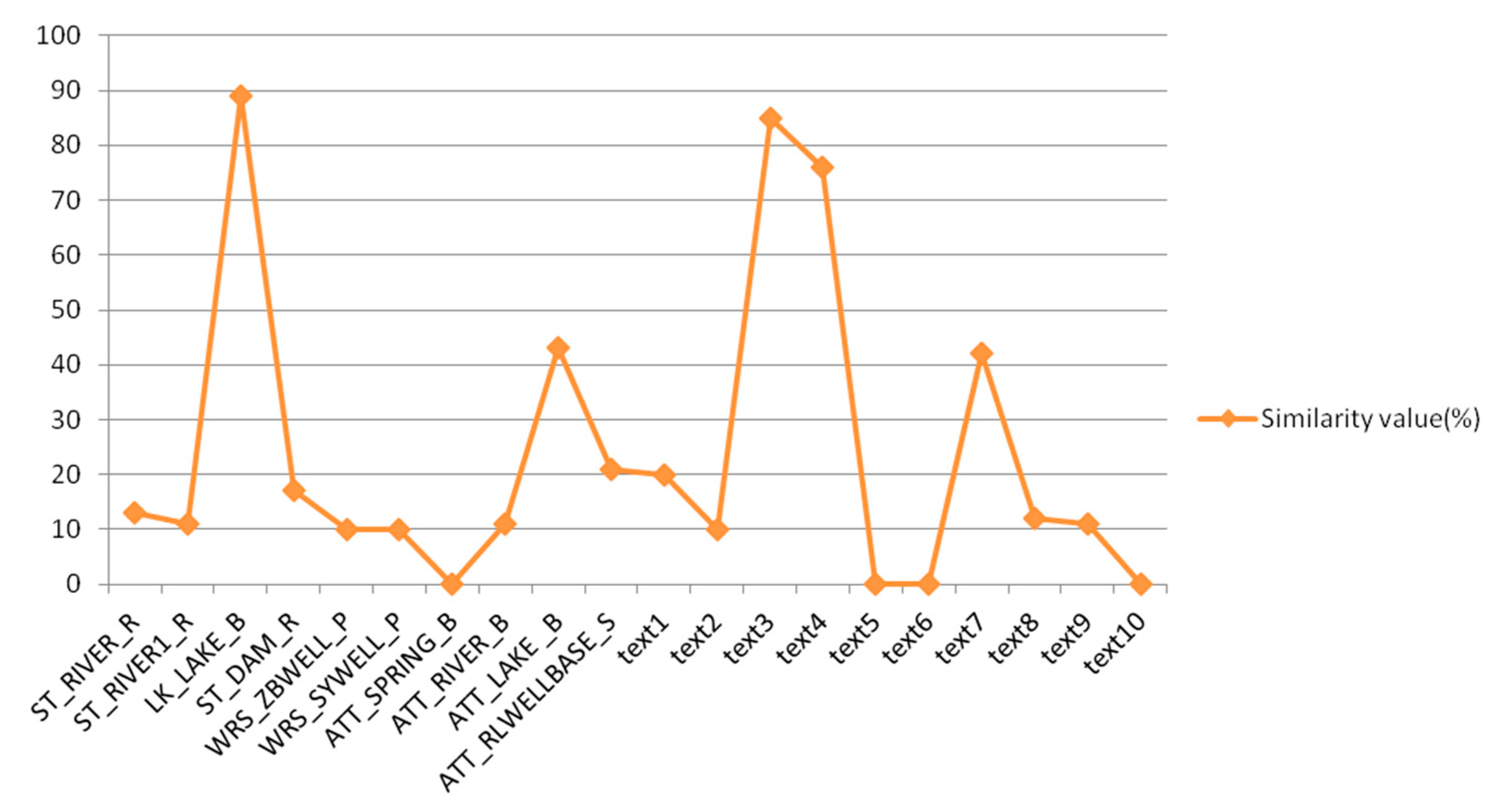
Section 3.4 shows that the evaluation results of the edit distance algorithm and the LDA algorithm are greater than that of the comparison algorithm, which verifies the validity and accuracy of the construction of the water affair knowledge graph. Furthermore, a set of water affair verification sets is used to verify the recommendation method, which proves the effectiveness of the recommended method. The results of this study promote the recommendation of water affair information. They also enhance the integrity of knowledge integration in the water affair sector and meet the user’s need for knowledge in the water affair sector, thereby increasing the practical value of the water affair knowledge graph.
Based on the models and methods proposed in this study, planned further work will proceed in two directions. In this study, the mapping of the knowledge graph is used to supplement the structure of the natural knowledge graph of water affair. However, due to the continuous improvement in technologies and processes, this method does not take into account the development of a knowledge graph in the water affair field. Therefore, a future domain knowledge graph adaptation should analyze and capture the concepts in the new water affair field knowledge graph. In addition, the present study also explored water affair information recommendation methods based on a knowledge graph of water affairs to recommend water affair information to users. However, this method is somewhat tedious to implement. Therefore, we seek better ways to increase the efficiency of the recommendation process.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}