A Hierarchical Feature Extraction Model for Multi-Label Mechanical Patent Classification


Abstract
1. Introduction
- A novel hybrid hierarchical feature extraction model (HFEM) for multi-label mechanical patent classification is introduced, which applies deep learning algorithms to patent feature extraction and classification.
- A CNN-based n-gram feature extractor is proposed to automatically extract features from a lengthy patent text full of technical and legal terminologies. A long dependency feature extraction model based on bidirectional LSTM is proposed to uncover sequential correlations from higher-level sequence representations.
- We compared HFEM with CNN, LSTM, and BiLSTM. It is shown that HFEM outperforms other compared models in terms of precision, recall and the weighted harmonic mean of precision and recall (F1) scores.
2. Related Works
2.1. Feature Extraction from Text
2.2. Patent Classification
2.3. Deep Learning in Text Feature Extraction
3. Deep-Learning-Based Hierarchical Feature Extraction Model for Patent Classification
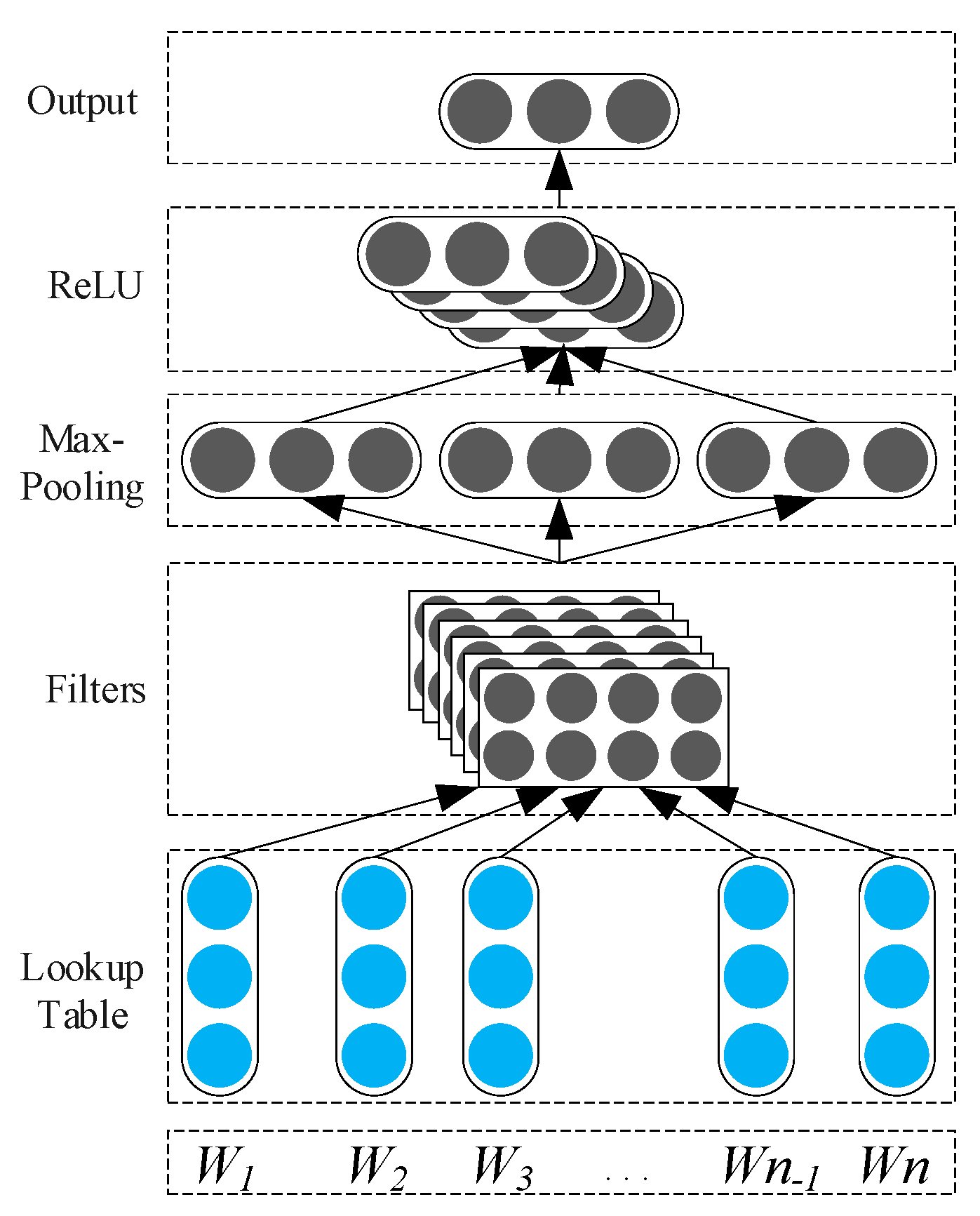
3.1. N-Gram Feature Extraction Based on CNN
3.2. Long Dependency Feature Extraction Based on Bidirectional LSTM
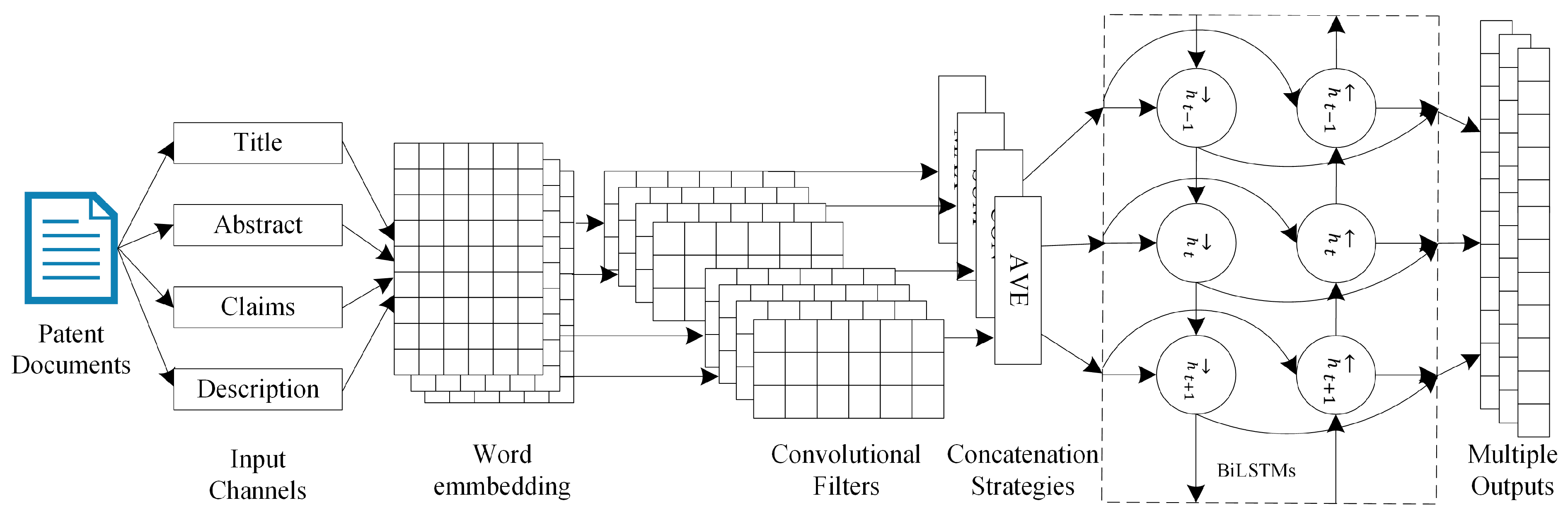
3.3. The Architecture of the Hierarchical Feature Extraction Model and Algorithm
- (1)
- Split the document into four sections, keep the top 150 words of each section.
- (2)
- Initialize the text with pertained word embedding by looking up the word embedding lookup table, then each patent document is represented by four matrices with dimension 150 × 100.
- (3)
- The four matrices are fed in to four independent CNN channels, each channel applies 128 filters with the dimensions of 3 × 100. The convolutional operation converts four input channels into four feature maps with the dimension of 148 × 128.
- (4)
- Concatenation, maximum, average, and summation strategies are employed to join the feature maps. After four concatenation operations, four kinds of feature maps are obtained with the dimension of 592 × 128, 148 × 128, 148 × 128, and 148 × 128 respectively.
- (5)
- The four feature maps are fed into four BiLSTM networks with 128 forward and backward LSTM neurons. After the BiLSTM network, each feature map is reduced to a matrix of 1 × 256.
- (6)
- Sigmoid function is utilized to calculate the feature vector’s probabilities for each label.
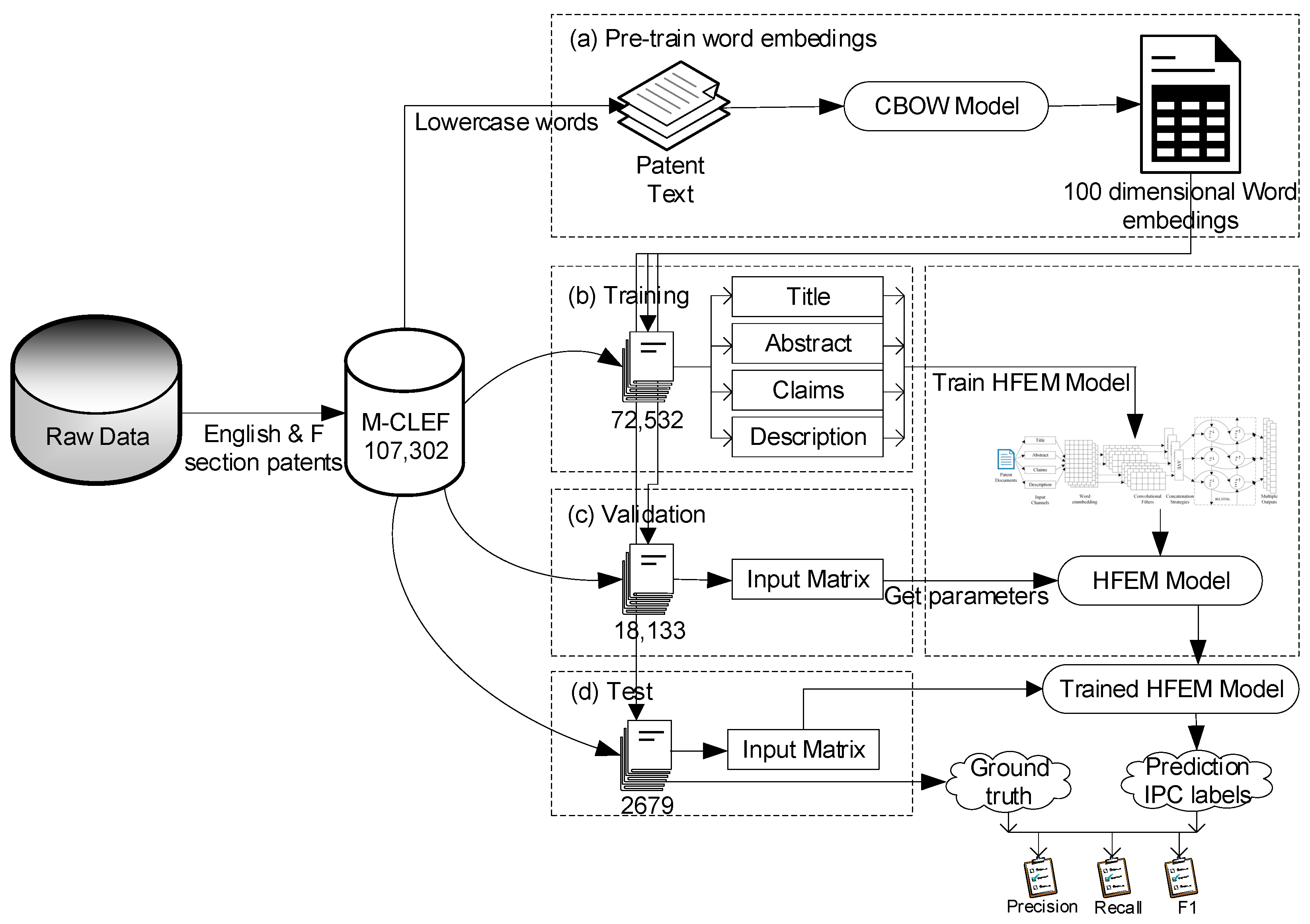
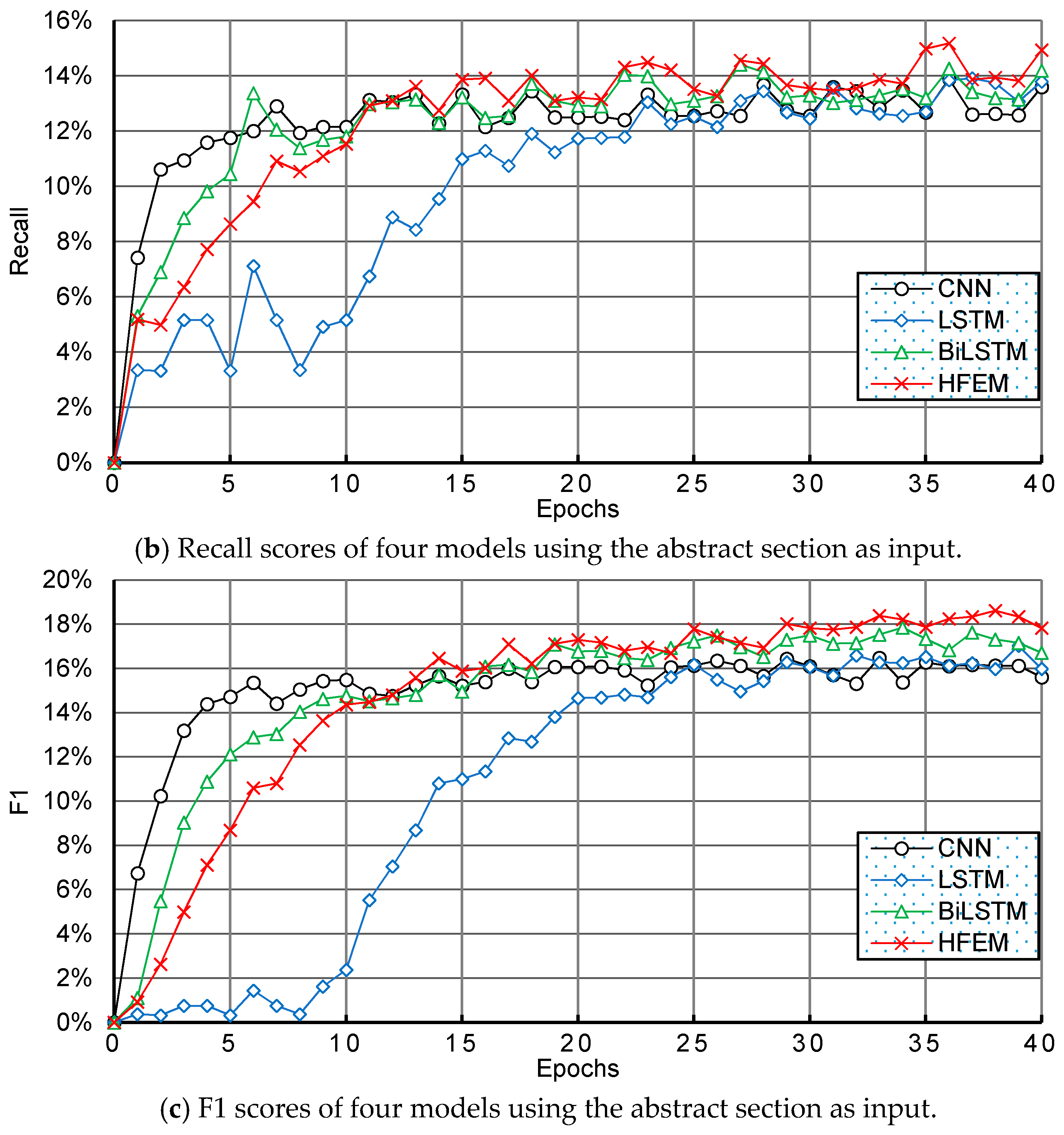
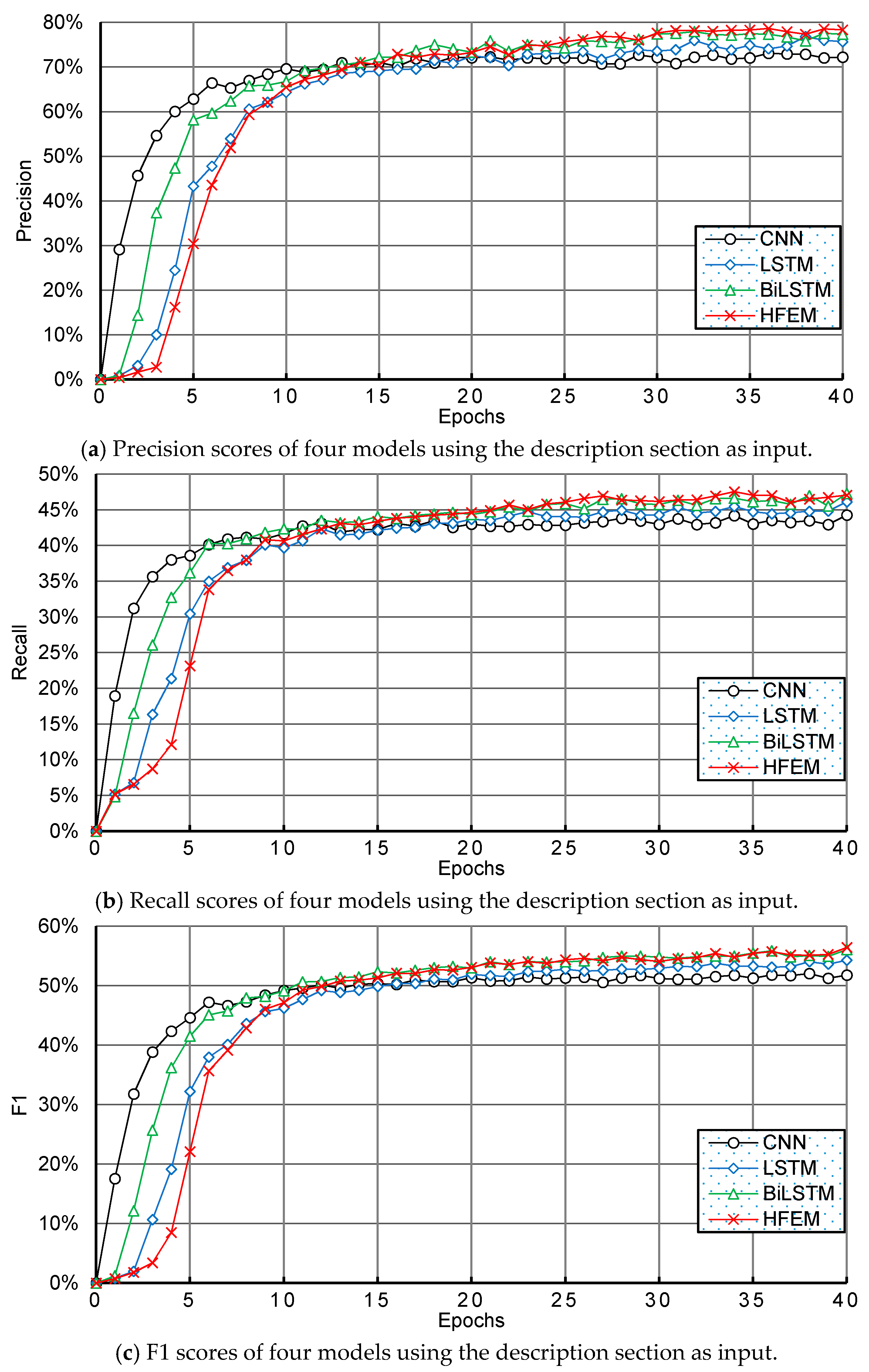
4. Datasets and Evaluation Metrics
5. Performance Analysis of HFEM with Different Concatenation Strategies
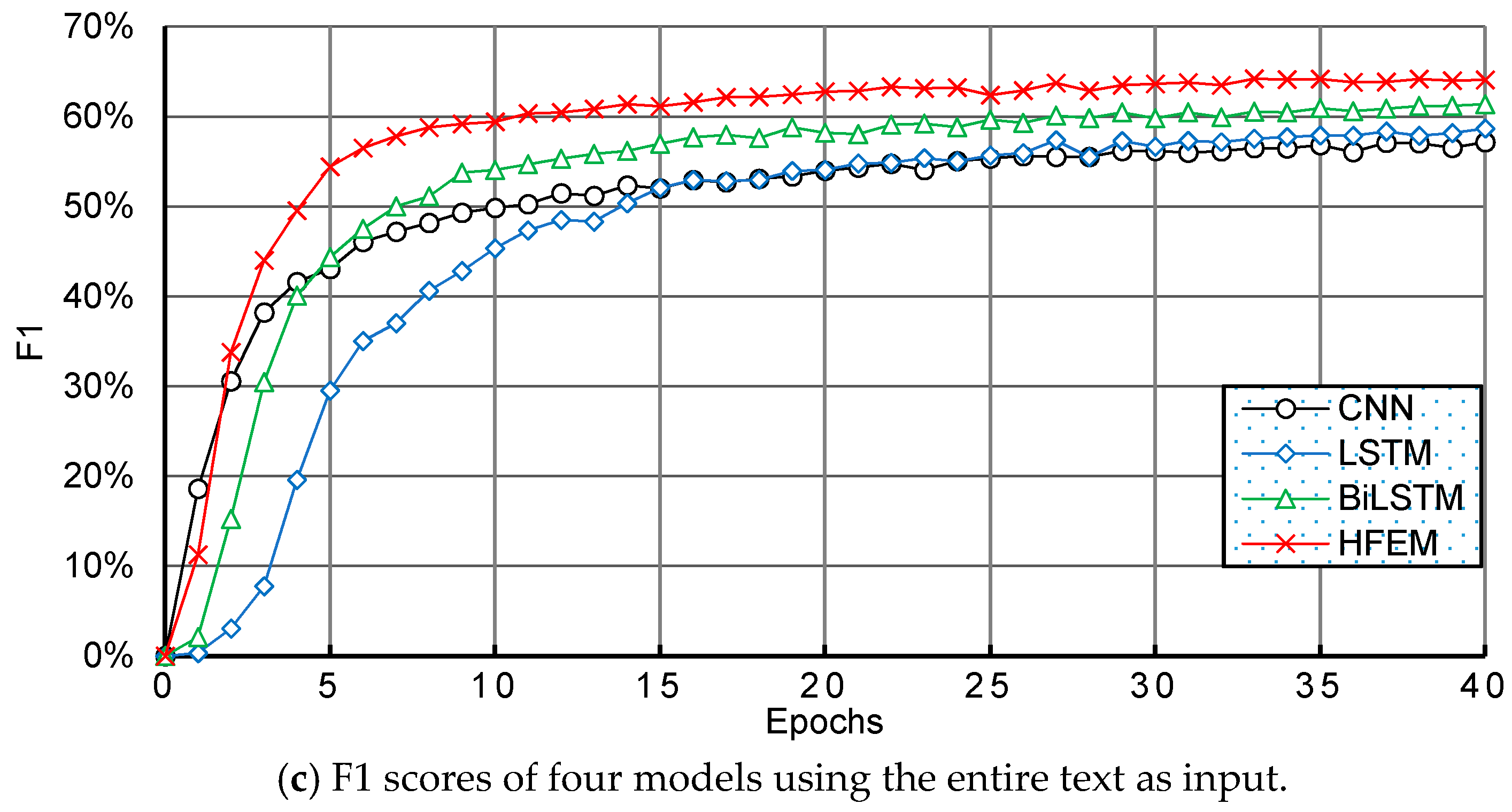
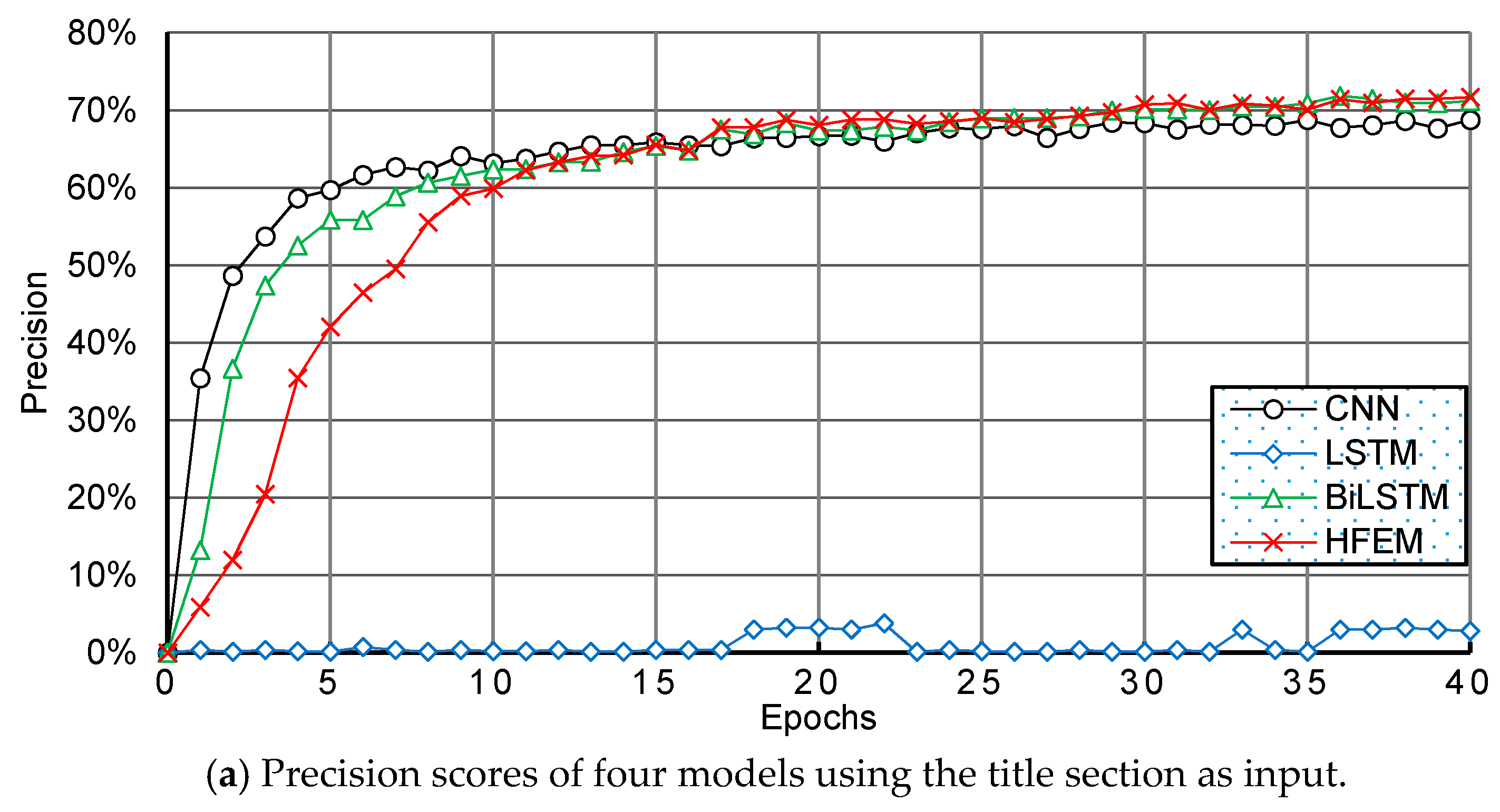
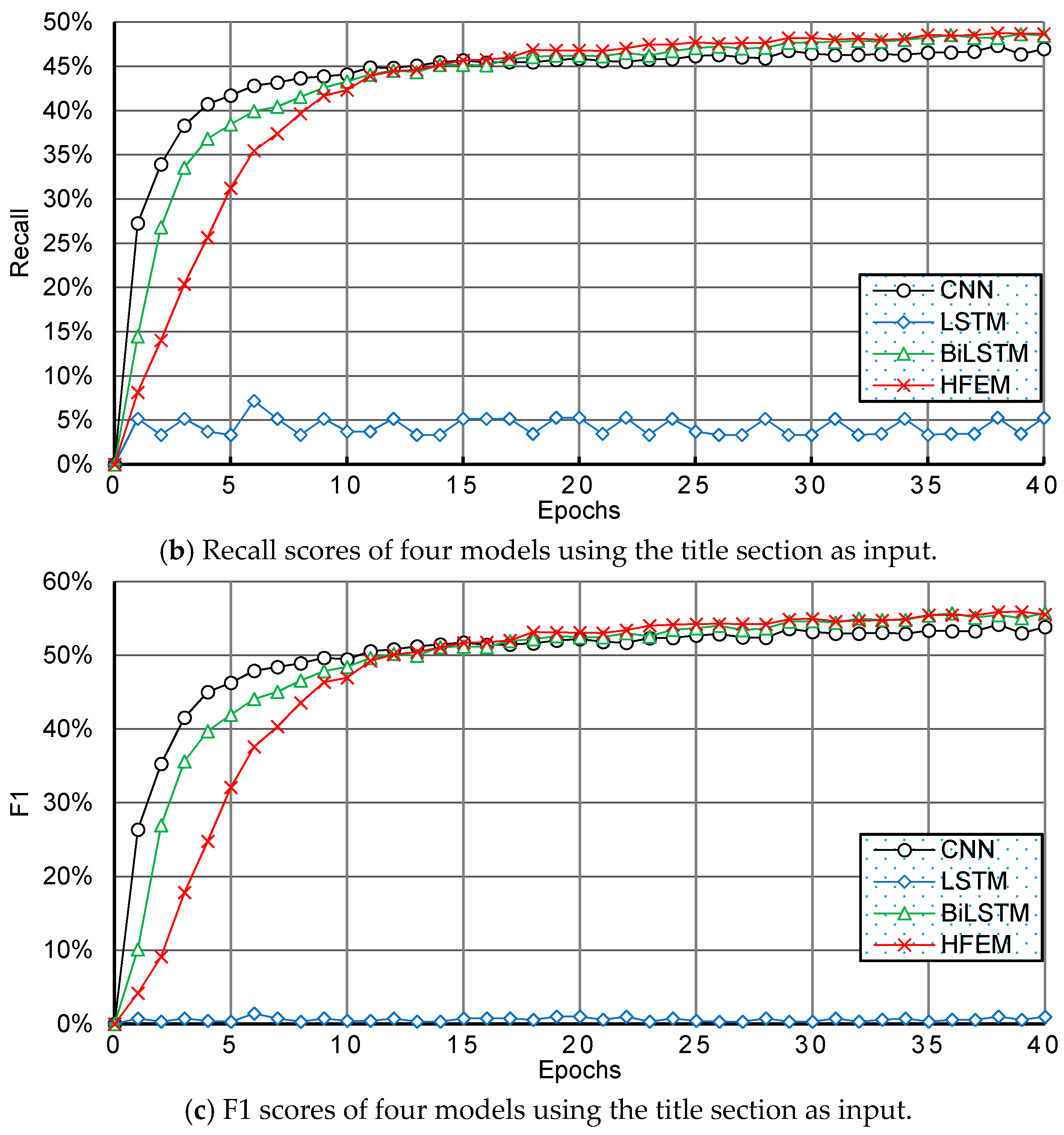
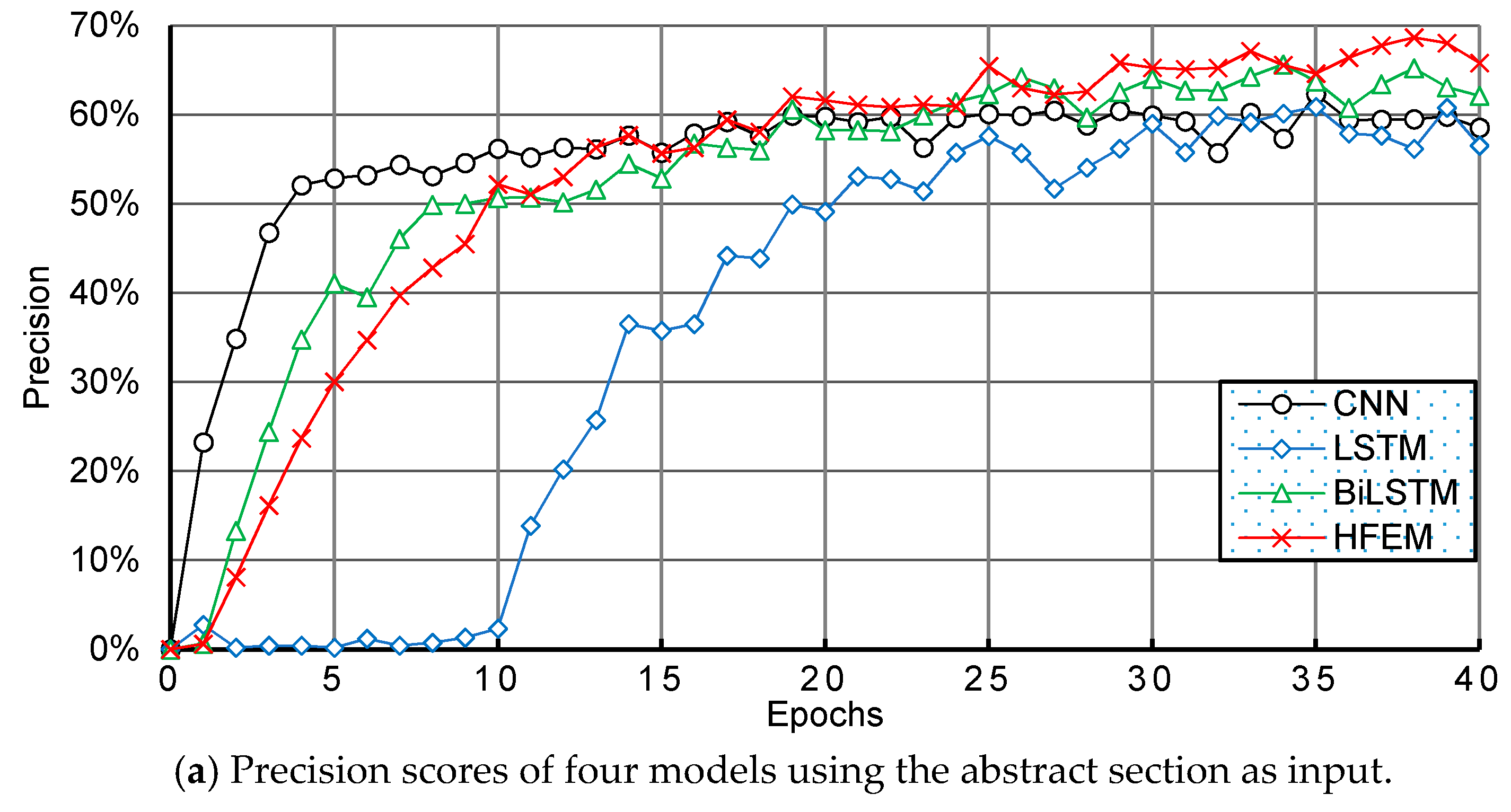
6. Comparison and Analysis with Other Methods
6.1. Experimental Setup
- CBOW+CNN: We converted patent text using word embeddings pre-trained with the CBOW algorithm into the input matrix and then trained a CNN model with 128 filters for classifying mechanical patent documents.
- CBOW+LSTM: We converted patent text using word embeddings pre-trained with the CBOW algorithm into the input matrix and then trained an LSTM model with 128 memory LSTM units for classifying mechanical patent documents.
- CBOW+BiLSTM: We converted patent text using word embeddings pre-trained with the CBOW algorithm into the input matrix and trained a BiLSTM model with 128 forward and backward LSTM units for classifying mechanical patent documents.
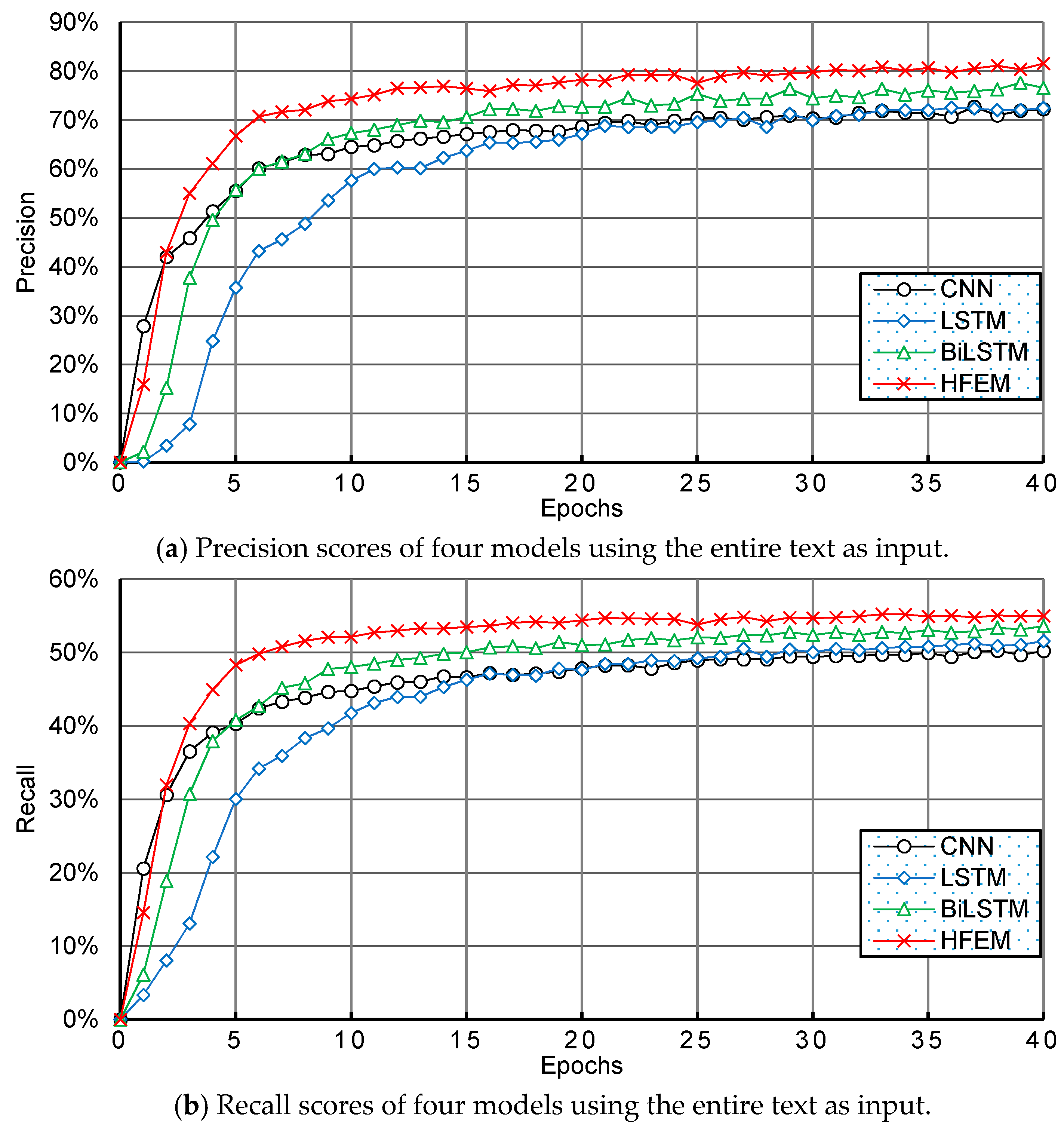
6.2. Experimental Results and Discussion
7. Conclusions
Acknowledgments
Author Contributions
References
- Park, Y.; Yoon, J.; Phillips, F. Application technology opportunity discovery from technology portfolios: Use of patent classification and collaborative filtering. Technol. Forecast. Soc. Chang. 2017, 118, 170–183. [Google Scholar] [CrossRef]
- Cong, H.; Tong, L.H. Grouping of TRIZ Inventive Principles to facilitate automatic patent classification. Expert Syst. Appl. 2008, 34, 788–795. [Google Scholar] [CrossRef]
- D’hondt, E.; Verberne, S. Patent classification on subgroup level using Balanced Winnow. In Current Challenges in Patent Information Retrieval; Springer: Berlin, Germany, 2017; pp. 299–324. [Google Scholar]
- Al Shamsi, F.; Aung, Z. Automatic patent classification by a three-phase model with document frequency matrix and boosted tree. In Proceedings of the IEEE 5th International Conference on Electronic Devices, Systems and Applications (ICEDSA), Ras Al Khaimah, UAE, 6–8 December 2016. [Google Scholar]
- Stutzki, J.; Schubert, M. Geodata supported classification of patent applications. In Proceedings of the Third International ACM SIGMOD Workshop on Managing and Mining Enriched Geo-Spatial Data, San Francisco, CA, USA, 26 June 2016. [Google Scholar]
- Lim, S.; Kwon, Y. IPC Multi-label Classification Based on the Field Functionality of Patent Documents. In Proceedings of the 12th International Conference on Advanced Data Mining and Applications (ADMA 2016), Gold Coast, QLD, Australia, 12–15 December 2016; Springer: Berlin, Germany, 2016. [Google Scholar]
- Wu, J.L.; Chang, P.C.; Tsao, C.C.; Fan, C.Y. A patent quality analysis and classification system using self-organizing maps with support vector machine. Appl. Soft Comput. 2016, 41, 305–316. [Google Scholar] [CrossRef]
- D’hondt, E.; Verberne, S.; Koster, C.; Boves, L. Text Representations for Patent Classification. Comput. Linguist. 2013, 39, 755–775. [Google Scholar] [CrossRef]
- Meng, L.E.; He, Y.; Li, Y. Research of Semantic Role Labeling and Application in Patent Knowledge Extraction. In Proceedings of the IPaMin 2014 Co-Located with Konvens 2014 1st International Workshop on Patent Mining and Its Applications (IPaMin@ KONVENS), Cincinnati, OH, USA, 6–7 October 2014. [Google Scholar]
- Noh, H.; Jo, Y.; Lee, S. Keyword selection and processing strategy for applying text mining to patent analysis. Expert Syst. Appl. 2015, 42, 4348–4360. [Google Scholar] [CrossRef]
- Joung, J.; Kim, K. Monitoring emerging technologies for technology planning using technical keyword based analysis from patent data. Technol. Forecast. Soc. Chang. 2017, 114, 281–292. [Google Scholar] [CrossRef]
- Taeyeoun, R.; Yujin, J.; Byungun, Y. Developing a Methodology of Structuring and Layering Technological Information in Patent Documents through Natural Language Processing. Sustainability 2017, 9, 2117. [Google Scholar]
- Kim, G.; Lee, J.; Jang, D.; Park, S. Technology Clusters Exploration for Patent Portfolio through Patent Abstract Analysis. Sustainability 2016, 8, 1252. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 5–10 December 2013. [Google Scholar]
- Kuang, S.; Davison, B.D. Learning Word Embeddings with Chi-Square Weights for Healthcare Tweet Classification. Appl. Sci. 2017, 7, 846. [Google Scholar] [CrossRef]
- Zeng, Y.; Yang, H.; Feng, Y. A convolution BiLSTM neural network model for Chinese event extraction. In Proceedings of the International Conference on Computer Processing of Oriental Languages, Kunming, China, 2–6 December 2016; Springer: Berlin, Germany, 2016. [Google Scholar]
- Kiperwasser, E.; Goldberg, Y. Simple and Accurate Dependency Parsing Using Bidirectional LSTM Feature Representations. arXiv, 2016; arXiv:1603.04351v3. [Google Scholar]
- Derieux, F.; Bobeica, M. Combining Semantics and Statistics for Patent Classification. In Proceedings of the CLEF 2010 LABs and Workshops, Notebook Papers, Padua, Italy, 22–23 September 2010. [Google Scholar]
- Benson, C.L.; Magee, C.L. A hybrid keyword and patent class methodology for selecting relevant sets of patents for a technological field. Scientometrics 2013, 96, 69–82. [Google Scholar] [CrossRef]
- Brants, T.; Franz, A. Web 1T 5-gram Version 1. Linguistic Data Consortium. Available online: https://catalog.ldc.upenn.edu/ldc2006t13 (accessed on 13 January 2018).
- Lim, J.; Choi, S.; Lim, C.; Kim, K. SAO-Based Semantic Mining of Patents for Semi-Automatic Construction of a Customer Job Map. Sustainability 2017, 9, 1386. [Google Scholar] [CrossRef]
- Zhang, D.; Xu, H. Chinese comments sentiment classification based on word2vec and SVM perf. Expert Syst. Appl. 2015, 42, 1857–1863. [Google Scholar] [CrossRef]
- Xu, H.; Dong, M.; Zhu, D. Text Classification with Topic-based Word Embedding and Convolutional Neural Networks. In Proceedings of the 7th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 2–5 October 2016. [Google Scholar]
- Verberne, S.; D’hondt, E. Patent Classification Experiments with the Linguistic Classification System LCS in CLEF-IP 2011. In Proceedings of the CLEF 2011 Notebook Papers/Labs/Workshop, Amsterdam, The Netherlands, 19–22 September 2011. [Google Scholar]
- Li, Z.; Tate, D.; Lane, C.; Adams, C. A framework for automatic TRIZ level of invention estimation of patents using natural language processing, knowledge-transfer and patent citation metrics. Comput. Aided Des. 2012, 44, 987–1010. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. A survey of randomized algorithms for training neural networks. Inf. Sci. 2016, 364, 146–155. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995; Volume 3361. [Google Scholar]
- Llamas, J.; M Lerones, P.; Medina, R.; Zalama, E.; Gómez-García-Bermejo, J. Classification of Architectural Heritage Images Using Deep Learning Techniques. Appl. Sci. 2017, 7, 992. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv, 2014; arXiv:1408.5882. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Piroi, F.; Lupu, M.; Hanbury, A.; Zenz, V. CLEF-IP 2011: Retrieval in the intellectual property domain. In Proceedings of the CLEF 2011 Labs and Workshop, Notebook Papers, Amsterdam, The Netherlands, 19–22 September 2011. [Google Scholar]
- Han, T.L.; He, C.; Shen, L. Automatic classification of patent documents for TRIZ users. World Pat. Inf. 2006, 28, 6–13. [Google Scholar]
- Chollet, Franois, and others, Keras, in GitHub. 2015. Available online: https://github.com/keras-team/keras (accessed on 13 January 2018).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | # of Documents | Average # Labels per Document | # of Categories |
|---|---|---|---|
| Training dataset | 72,532 | 1.4 | 96 |
| Validation dataset | 18,133 | 1.4 | 96 |
| Test dataset | 2679 | 1.5 | 93 |
| HFEM | ||||
|---|---|---|---|---|
| channel names | title | abstract | claims | description |
| training epochs | 40 | |||
| input size | 150 × 100 | 150 × 100 | 150 × 100 | 150 × 100 |
| # of filters | 128 | |||
| filter size | 3 × 100 | |||
| activation layer | ReLU | |||
| concatenation strategies | Concatenation | Maximum | Average | Summation |
| memory size | 128 | |||
| activation layer | Sigmoid | |||
| # of target classes | 96 | |||
| Strategies | Precison Top 1 (%) | Precison Top 5 (%) | Precison Top 10 (%) | Recall Top 1 (%) | Recall Top 5 (%) | Recall Top 10 (%) | F1 Top 1 (%) | F1 Top 5 (%) | F1 Top 10 (%) |
|---|---|---|---|---|---|---|---|---|---|
| Single channel | 78.93 | 31.31 | 18.21 | 54.57 | 89.49 | 94.6 | 62.8 | 45.26 | 29.71 |
| Concatenation | 80.54 | 31.69 | 19.04 | 54.99 | 90.28 | 95.59 | 63.97 | 46.55 | 30.8 |
| Maximum | 79.81 | 31.92 | 19.28 | 54.77 | 91.05 | 96.01 | 63.52 | 46.32 | 30.22 |
| Average | 80.26 | 31.63 | 19.02 | 54.89 | 90.67 | 95.98 | 63.58 | 46.1 | 30.69 |
| Summation | 80.21 | 31.88 | 19.04 | 54.87 | 90.88 | 96.31 | 63.65 | 45.95 | 30.82 |
| Hyper-Parameters | CNN | LSTM | BiLSTM |
|---|---|---|---|
| training epochs | 40 | 40 | 40 |
| input size | 600 × 100 | 600 × 100 | 600 × 100 |
| # of filters | 128 | - | - |
| memory size | - | 128 | 128 |
| max-pooling size | 2 | - | - |
| # of target classes | 96 | 96 | 96 |
| Algorithms | P@1% | P@5% | P@10% | R@1% | R@5% | R@10% | F1@1% | F1@5% | F1@10% |
|---|---|---|---|---|---|---|---|---|---|
| CNN | 71.34 | 29.89 | 17.43 | 50.08 | 86.81 | 92.93 | 57.02 | 43.09 | 28.35 |
| LSTM | 74.44 | 30.53 | 18.44 | 51.96 | 86.14 | 92.96 | 59.26 | 43.72 | 29.73 |
| BiLSTM | 77.71 | 30.96 | 18.83 | 53.57 | 88.1 | 94.67 | 61.55 | 44.53 | 30.24 |
| HFEM | 80.54 | 31.69 | 19.04 | 54.99 | 90.28 | 95.59 | 63.97 | 46.55 | 30.8 |
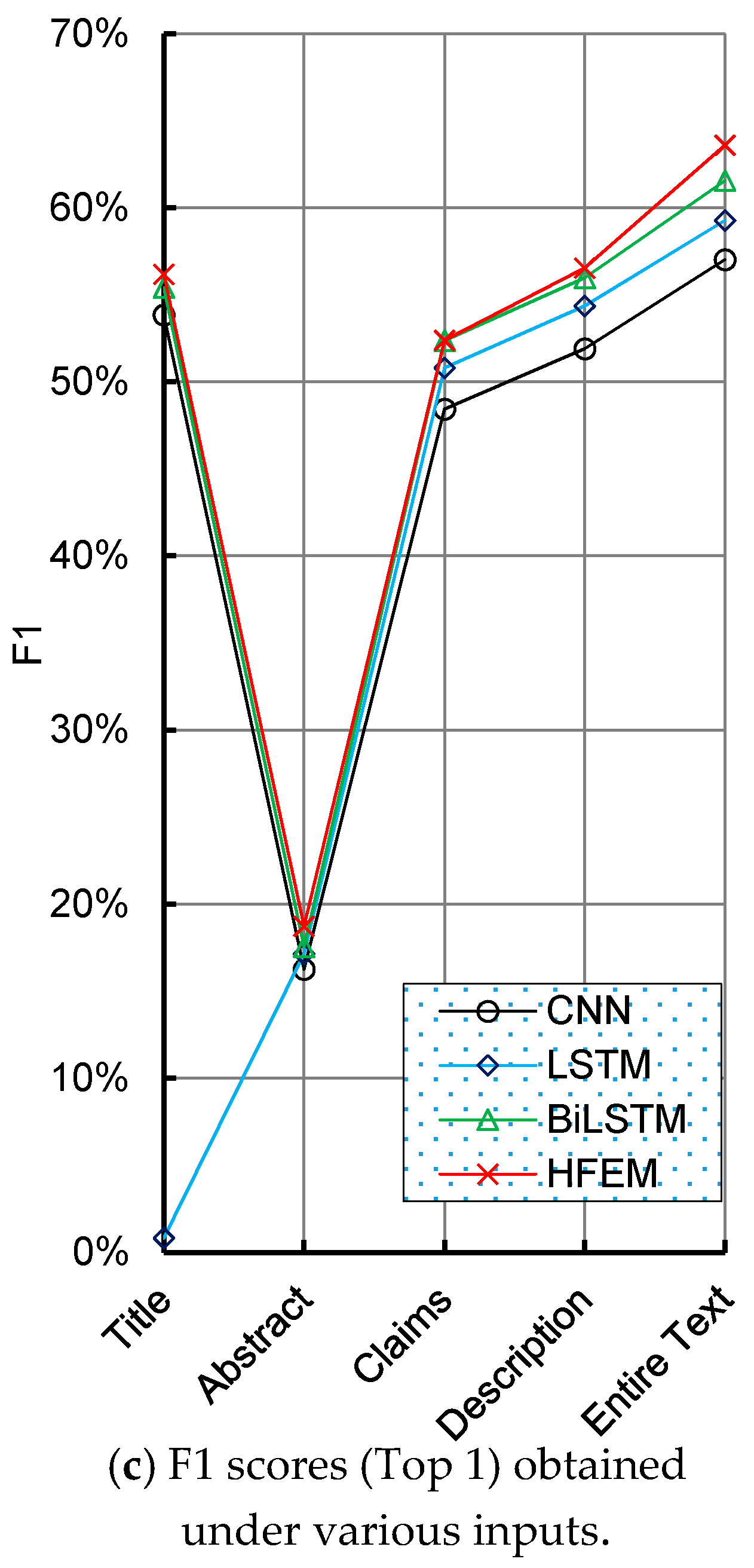
| Metrics | Algorithms | Input Schemes | ||||
|---|---|---|---|---|---|---|
| Title | Abstract | Claims | Description | Entire Text | ||
| Precision Top 1 | CNN | 68.67% | 60.36% | 67.54% | 73.21% | 71.75% |
| LSTM | 3.08% | 62.68% | 71.60% | 76.98% | 73.82% | |
| BiLSTM | 71.22% | 65.19% | 74.16% | 79.22% | 77.02% | |
| HFEM | 72.22% | 69.09% | 74.81% | 79.62% | 81.55% | |
| Recall Top 1 | CNN | 46.98% | 13.44% | 41.19% | 43.79% | 50.07% |
| LSTM | 4.54% | 13.74% | 42.44% | 45.46% | 51.96% | |
| BiLSTM | 48.66% | 13.89% | 43.75% | 46.50% | 53.58% | |
| HFEM | 49.06% | 14.18% | 43.81% | 47.29% | 55.02% | |
| F1 Top 1 | CNN | 53.85% | 16.26% | 48.43% | 51.91% | 57.02% |
| LSTM | 0.81% | 17.16% | 50.80% | 54.36% | 59.27% | |
| BiLSTM | 55.40% | 17.54% | 52.37% | 55.98% | 61.55% | |
| HFEM | 56.18% | 18.73% | 52.38% | 56.55% | 63.60% | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Li, S.; Hu, J.; Yang, G. A Hierarchical Feature Extraction Model for Multi-Label Mechanical Patent Classification. Sustainability 2018, 10, 219. https://doi.org/10.3390/su10010219
Hu J, Li S, Hu J, Yang G. A Hierarchical Feature Extraction Model for Multi-Label Mechanical Patent Classification. Sustainability. 2018; 10(1):219. https://doi.org/10.3390/su10010219
Chicago/Turabian StyleHu, Jie, Shaobo Li, Jianjun Hu, and Guanci Yang. 2018. "A Hierarchical Feature Extraction Model for Multi-Label Mechanical Patent Classification" Sustainability 10, no. 1: 219. https://doi.org/10.3390/su10010219
APA StyleHu, J., Li, S., Hu, J., & Yang, G. (2018). A Hierarchical Feature Extraction Model for Multi-Label Mechanical Patent Classification. Sustainability, 10(1), 219. https://doi.org/10.3390/su10010219