
Measuring Speech Intelligibility with Romanian Synthetic Unpredictable Sentences in Normal Hearing


 ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Selecting Words for Each Category of Phonetic Material
2.2. Text-To-Speech System (TTS), Creation of Files, Audiometric Testing System
2.3. Subjects, Test Set-Up, and Parameters
2.4. Statistical Analysis
3. Results
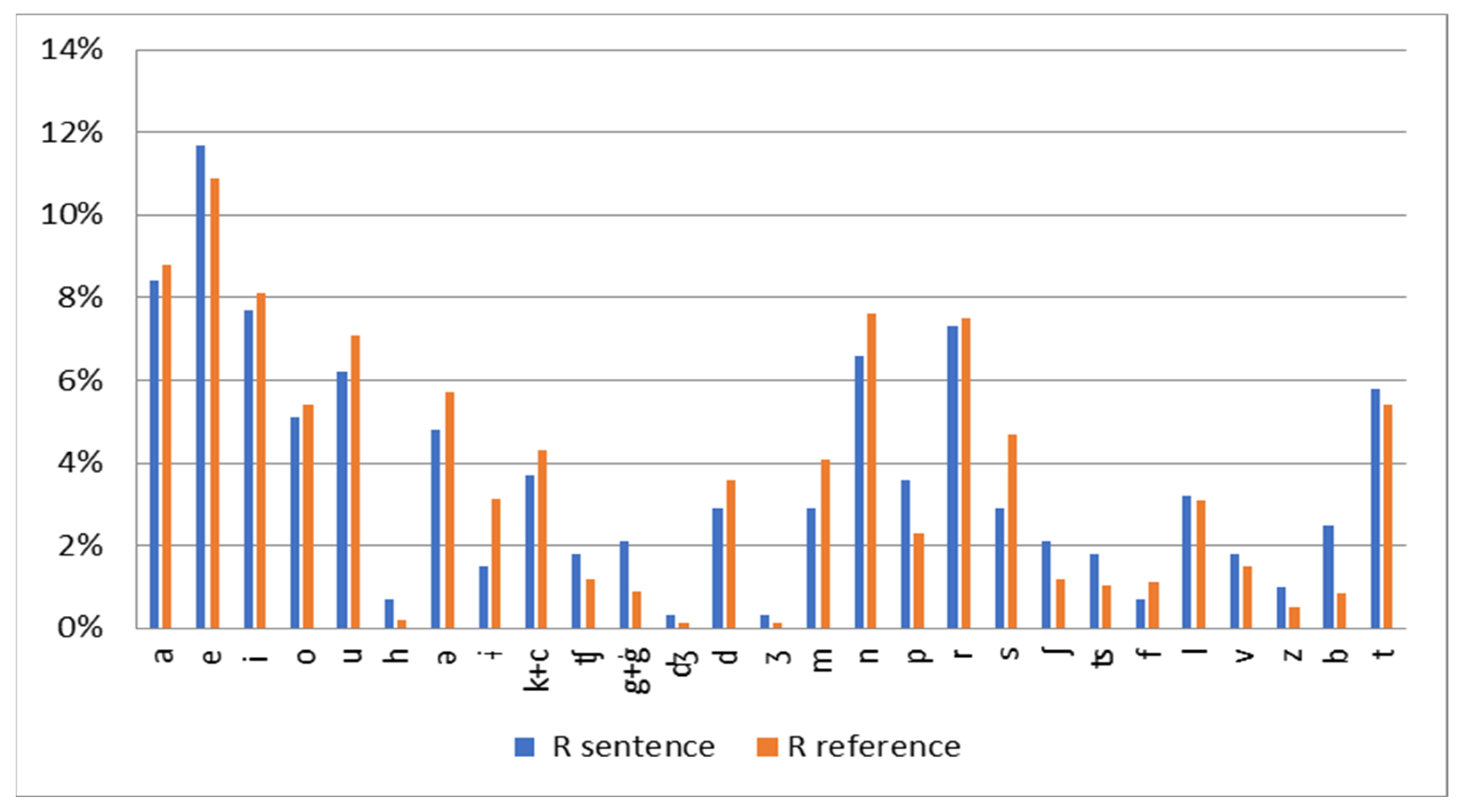
3.1. Phonetic Material
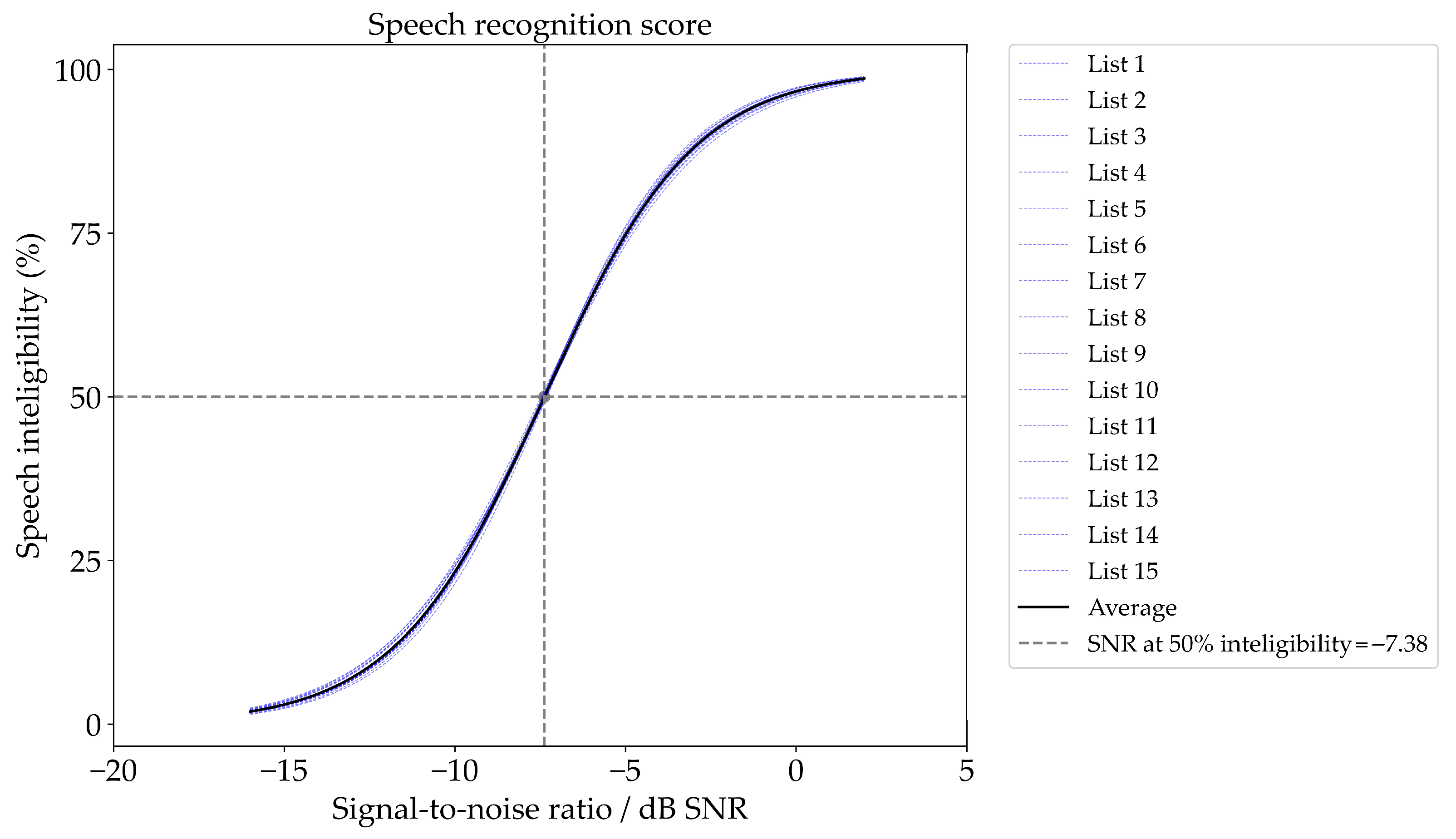
3.2. Speech Recognition at Different SNRs, the Psychometric Function with Fixed SNR
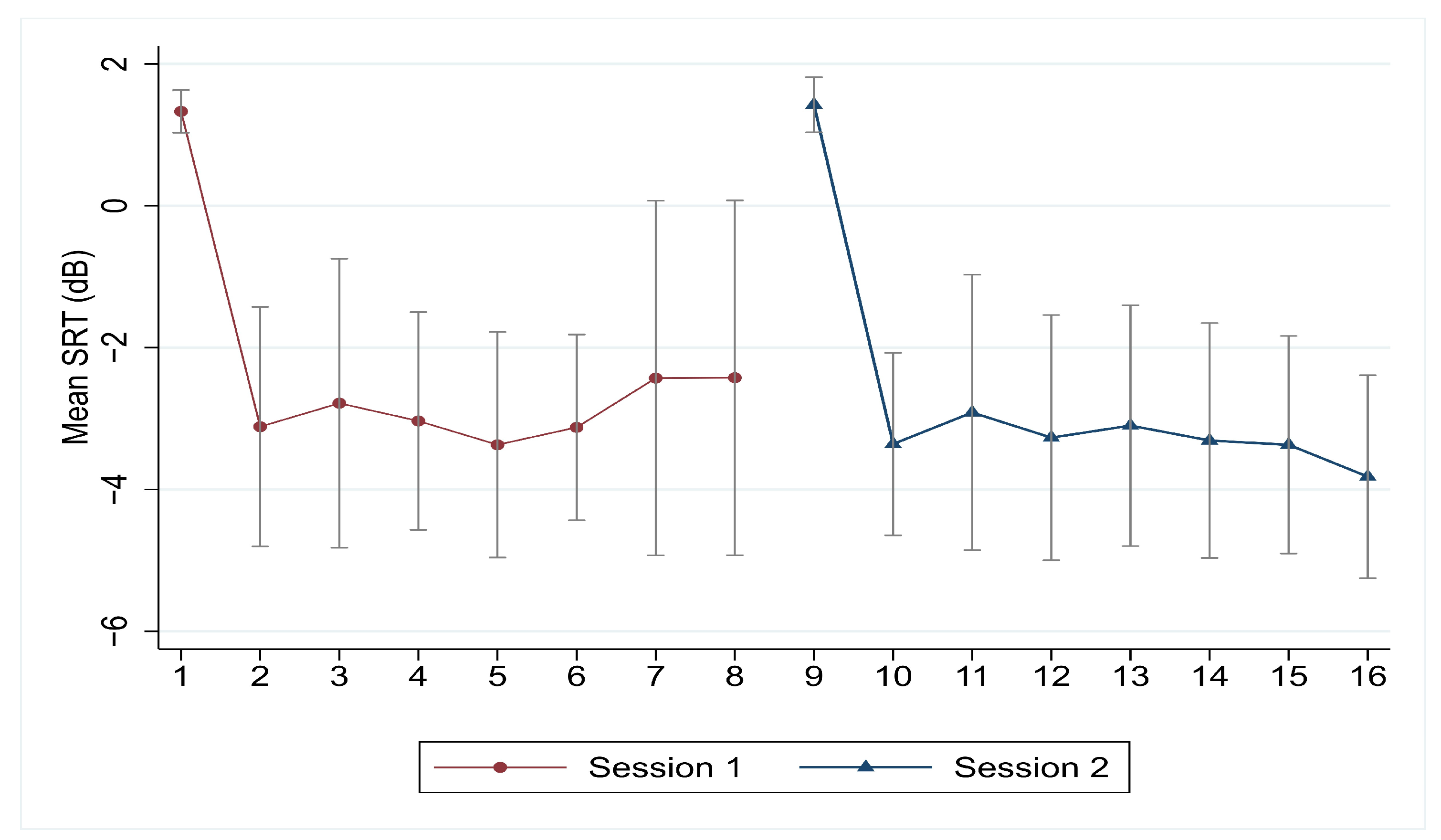
3.3. Measuring Speech Intelligibility with Adaptive SNR Procedure
4. Discussion
4.1. Methodological Differences Between Studies Using Fixed and Adaptive SNR
4.2. SRT50 and Slope Analysis
4.3. Learning Effect
4.4. Comparing Word Categories and Recognition Performance
4.5. Perceptual Equivalence of Lists: SRT50 and Scoring Consistency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Reynard, P.; Lagacé, J.; Joly, C.A.; Dodelé, L.; Veuillet, E.; Thai-Van, H. Speech-in-Noise Audiometry in Adults: A Review of the Available Tests for French Speakers. Audiol. Neurootol. 2022, 27, 185–199. [Google Scholar] [CrossRef] [PubMed]
- Billings, C.J.; Olsen, T.M.; Charney, L.; Madsen, B.M.; Holmes, C.E. Speech-in-Noise Testing: An Introduction for Audiologists. Semin. Hear. 2023, 45, 55–82. [Google Scholar] [CrossRef] [PubMed]
- Taylor, B. Speech-in-noise tests: How and why to include them in your basic test battery. Hear. J. 2003, 56, 40,42–46. [Google Scholar] [CrossRef]
- Joly, C.A.; Reynard, P.; Mezzi, K.; Bakhos, D.; Bergeron, F.; Bonnard, D.; Borel, S.; Bouccara, D.; Coez, A.; Dejean, F.; et al. Guidelines of the French Society of Otorhinolaryngology-Head and Neck Surgery (SFORL) and the French Society of Audiology (SFA) for Speech-in-Noise Testing in Adults. Eur. Ann. Otorhinolaryngol. Head Neck Dis. 2022, 139, 21–27. [Google Scholar] [CrossRef] [PubMed]
- Canzi, P.; Manfrin, M.; Locatelli, G.; Nopp, P.; Perotti, M.; Benazzo, M. Development of a novel Italian speech-in-noise test using a roving-level adaptive method: Adult population-based normative data. Acta Otorhinolaryngol. Ital. 2016, 36, 506–512. [Google Scholar] [CrossRef] [PubMed]
- Puglisi, G.E.; Warzybok, A.; Hochmuth, S.; Visentin, C.; Astolfi, A.; Prodi, N.; Kollmeier, B. An Italian matrix sentence test for the evaluation of speech intelligibility in noise. Int. J. Audiol. 2015, 54 (Suppl. 2), 44–50. [Google Scholar] [CrossRef] [PubMed]
- Kollmeier, B.; Warzybok, A.; Hochmuth, S.; Zokoll, M.; Uslar, V.; Brand, T.; Wagener, K.C. The multilingual matrix test: Principles, applications and comparison across languages –a review. Int. J. Audiol. 2015, 54 (Suppl. 2), 3–16. [Google Scholar] [CrossRef] [PubMed]
- Akeroyd, M.A.; Arlinger, S.; Bentler, R.A.; Boothroyd, A.; Dillier, N.; Dreschler, W.A.; Gagné, J.P.; Lutman, M.; Wouters, J.; Wong, L.; et al. ICRA recommendations for the construction of multilingual speech tests. Int. J. Audiol. 2015, 54 (Suppl. 2), 17–22. [Google Scholar] [CrossRef] [PubMed]
- Jansen, S.; Luts, H.; Wagener, K.C.; Kollmeier, B.; Del Rio, M.; Dauman, R.; James, C.; Fraysse, B.; Vormès, E.; Frachet, B.; et al. Comparison of three types of French speech-in-noise tests: A multi-center study. Int. J. Audiol. 2012, 51, 164–173. [Google Scholar] [CrossRef] [PubMed]
- Hochmuth, S.; Brand, T.; Zokoll, M.A.; Castro, F.Z.; Wardenga, N.; Kollmeier, B.A. Spanish matrix sentence test for assessing speech reception thresholds in noise. Int. J. Audiol. 2012, 51, 536–544. [Google Scholar] [CrossRef]
- Speech in Noise (SIN) Test. Available online: https://www.interacoustics.com/audiometers/equinox/support/speech-in-noise-sin-test (accessed on 28 November 2023).
- Nuesse, T.; Wiercinski, B.; Brand, T.; Holube, I. Measuring Speech Recognition With a matrix Test Using Synthetic Speech. Trends 2019, 23, 2331216519862982. [Google Scholar] [CrossRef]
- Ibelings, S.; Brand, T.; Holube, I. Speech Recognition and Listening Effort of Meaningful Sentences Using Synthetic Speech. Trends 2022, 26, 23312165221130656. [Google Scholar] [CrossRef] [PubMed]
- Cozma, S.; Dascalu, C.G.; Radulescu, L.; Martu, C.; Bitere, O.; Martu, D.; Olariu, R. Audiological Clinical Validation of New Original Romanian Speech Audiometry Materials for Evaluation of Communication Abilities in Children of Primary School Age. Rev. Cercet. Interv. Soc. 2016, 55, 47–62. [Google Scholar]
- Van de Heyning, P.; Távora-Vieira, D.; Mertens, G.; Van Rompaey, V.; Rajan, G.P.; Müller, J.; Hempel, J.M.; Leander, D.; Polterauer, D.; Marx, M.; et al. Towards a Unified Testing Framework for Single-Sided Deafness Studies: A Consensus Paper. Audiol. Neurootol. 2016, 21, 391–398. [Google Scholar] [CrossRef]
- Pantaleo, A.; Murri, A.; Cavallaro, G.; Pontillo, V.; Auricchio, D.; Quaranta, N. Single-Sided Deafness and Hearing Rehabilitation Modalities: Contralateral Routing of Signal Devices, Bone Conduction Devices, and Cochlear Implants. Brain Sci. 2024, 14, 99. [Google Scholar] [CrossRef] [PubMed]
- Aldè, M.; Zanetti, D.; Ambrosetti, U.; Monaco, E.; Gasbarre, A.M.; Pignataro, L.; Cantarella, G.; Barozzi, S. Unilateral Sensorineural Hearing Loss in Children: Etiology, Audiological Characteristics, and Treatment. Children 2024, 11, 324. [Google Scholar] [CrossRef] [PubMed]
- ISO8253-3; Acoustics-Audiometric Test Methods-Part 3 Speech Audiometry. International Organization for Standardization: Geneva, Switzerland, 2022. Available online: https://www.iso.org/obp/ui/#iso:std:iso:8253:-3:ed-3:v1:enISO8253-3:2022(EN) (accessed on 23 October 2023).
- Alexandra, R.-A. Fonostatistica Limbii Române; Ed Academiei Republicii Socialiste: Bucureşti, Romania, 1968; pp. 73–112. [Google Scholar]
- Chitoran, I. The Phonology of Romanian, 1st ed.; De Gruyter: Berlin, Germany, 2013; pp. 21–41. Available online: https://www.perlego.com/book/653661/the-phonology-of-romanian-pdfChitoranI (accessed on 15 October 2023).
- Iordan, I.; Robu, V. Limba Română Contemporană; Ed Didactică și Pedagocică: București, Romania, 1978; pp. 114–178. [Google Scholar]
- Toma, I.; Silvestru, E. Sinteze De Limba Română: Actualizări Teoretice şi Aplicaţii; Ed Niculescu: București, Romania, 2007; pp. 15–32. [Google Scholar]
- Dan, T.; Verginica, B.M.; Elena, I.; Vasile, P.; Radu, I.; Nils, D.; Maria, M.; Mihaela, O. Little Strokes Fell Great Oaks: Creating CoRoLa, the Reference Corpus of Contemporary Romanian. Rev. Roum. De Linguist. 2019, 64, 227–240. Available online: https://dspace.bcu-iasi.ro/handle/123456789/32122 (accessed on 24 October 2023).
- Kerlinger, F.N. Foundations of Behavioral Research; Holt, Rinehart & Winston: New York, NY, USA, 1964. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Erlbaum: Hillsdale, NJ, USA, 1988. [Google Scholar]
- Brand, T.; Kollmeier, B. Efficient adaptive procedures for threshold and concurrent slope estimates for psychophysics and speech intelligibility tests. J. Acoust. Soc. Am. 2002, 111, 2801–2810. [Google Scholar] [CrossRef] [PubMed]
- Ahsanul, K.; Giurgiu, M. A Romanian Corpus for Speech Perception and Automatic Speech Recognition NEHIPISIC’11. In Proceedings of the 10th WSEAS International Conference on Electronics, Hardware, Wireless and Optical Communications, and 10th WSEAS International Conference on Signal Processing, Robotics and Automation, and 3rd WSEAS International Conference on Nanotechnology, and 2nd WSEAS International Conference on Plasma-Fusion-Nuclear Physics, Cambridge, UK, 20–22 February 2011; pp. 323–326. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Verb | Numeral | Object | Adjective | English Translation |
|---|---|---|---|---|---|
| Mihai/mi’hai/ | vinde/‘vin.de/ | zero/‘ze.ro/ | mașini/‘ma.ʃi.ni/ | cuminți/kuˈminʦʲ/ | Michael sells zero good cars. |
| Costel/ˈkos.tel/ | anunță/aˈnun.t͡sə/ | două/ˈdo.wə/ | scaune/ˈska.u̯ne/ | magice/maˈd͡ʒi.t͡ʃe/ | Costel announces two magic chairs |
| Florin/floʼrin/ | cumpără/kumpə.rə/ | trei/trej/ | sticle/ˈsti.kle/ | maro/ˈma.ro/ | Florin buys three brown bottles. |
| Alex/aˈleks/ | prinde/ˈprin.de/ | patru/ˈpatru/ | păpuși/ˈpəpuʃ/ | albastre/alˈbas.tre/ | Alex catches four blue dolls. |
| Ștefan/ʃteˈfan/ | dorește/doˈreʃ.te/ | cinci/ʧinʧʲ/ | jucării/ʒuˈkə.rij/ | verzi/ˈver.zʲ/ | Stephen wants five green toys. |
| Sandu/ˈsan.du/ | învață/ˈɨn.va.t͡sə/ | șase/ˈʃa.se/ | becuri/ˈbe.ku.ri/ | galbene/ɡalˈbe.ne/ | Sandu learns six yellow bulbs. |
| Ionuț/joˈnut͡s/ | saltă/ˈsal.tə/ | șapte/ˈʃap.te/ | ghete/ˈɡe.te/ | grăbite/ɡrəˈbi.te/ | John jumps seven hurry boots. |
| Bogdan/ˈboɡ.dan/ | începe /ˈint͡ʃe.pe/ | opt/opt/ | haine/ˈhaj.ne/ | drăguțe/drəˈɡut͡se/ | Bogdan starts eight nice clothes. |
| Petru/ˈpe.tru/ | îmbracă/ˈim.bra.kə/ | nouă/ˈno.wə/ | vapoare/vaˈpo̯a.re/ | violet/vi.oˈlet/ | Peter puts on nine purple ships. |
| Tudor/tuʼdor/ | cheamă/ˈkea.mə/ | zece/ˈze.t͡ʃe/ | globuri/ˈɡlo.bu.ri/ | urâte/uˈrɨte/ | Tudor calls ten ugly globes. |
| List | Slope (%) | SRT50 | SI (%) by SNR | ||
|---|---|---|---|---|---|
| −4 dB | −7 dB | −10 dB | |||
| 1 | 11.32 | −7.33 | 81.88 | 53.73 | 22.98 |
| 2 | 10.94 | −7.47 | 82.04 | 55.13 | 24.84 |
| 3 | 11.81 | −7.42 | 83.42 | 54.95 | 22.82 |
| 4 | 11.60 | −7.36 | 82.64 | 54.21 | 22.74 |
| 5 | 11.40 | −7.33 | 82.00 | 53.70 | 22.80 |
| 6 | 12.02 | −7.41 | 83.72 | 54.86 | 22.32 |
| 7 | 11.59 | −7.33 | 82.42 | 53.86 | 22.52 |
| 8 | 10.65 | −7.36 | 80.70 | 53.80 | 24.50 |
| 9 | 10.98 | −7.38 | 81.55 | 54.20 | 24.05 |
| 10 | 11.47 | −7.44 | 82.89 | 55.02 | 23.59 |
| 11 | 11.16 | −7.43 | 82.24 | 54.83 | 24.14 |
| 12 | 12.03 | −7.31 | 83.07 | 53.66 | 21.47 |
| 13 | 10.91 | −7.38 | 81.35 | 54.10 | 24.15 |
| 14 | 11.61 | −7.39 | 82.84 | 54.52 | 22.94 |
| 15 | 11.52 | −7.36 | 82.44 | 54.11 | 22.84 |
| Mean | 11.40 | −7.38 | 82.35 | 54.31 | 23.25 |
| SD | 0.39 | 0.05 | 0.77 | 0.51 | 0.89 |
| Name | Verb | Numeral | Object | |
|---|---|---|---|---|
| Verb | 0.000 | |||
| Numeral | 0.276 | 0.000 | ||
| Object | 0.000 | 0.000 | 0.000 | |
| Adjective | 0.000 | 0.000 | 0.000 | 0.013 |
| Session 1 | List 15 | List 1 | List 2 | List 3 | List 4 | List 5 | List 6 | List 7 |
| SRT mean | 1.33 | −3.12 | −2.79 | −3.04 | −3.37 | −3.13 | −2.43 | −2.43 |
| SRT change | 4.45 | −0.33 | 0.25 | 0.34 | −0.25 | −0.69 | −0.01 | |
| SRT aggregated change | 4.45 | 4.12 | 4.37 | 4.70 | 4.46 | 3.76 | 3.76 | |
| Session 2 | List 15 | List 8 | List 9 | List 10 | List 11 | List 12 | List 13 | List 14 |
| SRT mean | 1.43 | −3.36 | −2.92 | −3.27 | −3.10 | −3.31 | −3.37 | −3.82 |
| SRT change | 4.79 | −0.45 | 0.36 | −0.17 | 0.21 | 0.06 | 0.45 | |
| SRT aggregated change | 4.79 | 4.34 | 4.70 | 4.53 | 4.74 | 4.80 | 5.25 |
| List No 15 | List 1 | List 2 | List 3 | List 4 | List 5 | List 6 | |
|---|---|---|---|---|---|---|---|
| List 1 | <0.001 | ||||||
| List 2 | <0.001 | 1.000 | |||||
| List 3 | <0.001 | 1.000 | 1.000 | ||||
| List 4 | <0.001 | 1.000 | 1.000 | 1.000 | |||
| List 5 | <0.001 | 1.000 | 1.000 | 1.000 | 1.000 | ||
| List 6 | <0.001 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| List 7 | <0.001 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| List No 15 | List 8 | List 9 | List 10 | List 11 | List 12 | List 13 | |
|---|---|---|---|---|---|---|---|
| List 8 | <0.001 | ||||||
| List 9 | <0.001 | 1.000 | |||||
| List 10 | <0.001 | 1.000 | 1.000 | ||||
| List 11 | <0.001 | 1.000 | 1.000 | 1.000 | |||
| List 12 | <0.001 | 1.000 | 1.000 | 1.000 | 1.000 | ||
| List 13 | <0.001 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |
| List 14 | <0.001 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Astefanei, O.; Cozma, S.; Martu, C.; Serban, R.; Butnaru, C.; Moraru, P.; Musat, G.; Radulescu, L. Measuring Speech Intelligibility with Romanian Synthetic Unpredictable Sentences in Normal Hearing. Audiol. Res. 2024, 14, 1028-1044. https://doi.org/10.3390/audiolres14060085
Astefanei O, Cozma S, Martu C, Serban R, Butnaru C, Moraru P, Musat G, Radulescu L. Measuring Speech Intelligibility with Romanian Synthetic Unpredictable Sentences in Normal Hearing. Audiology Research. 2024; 14(6):1028-1044. https://doi.org/10.3390/audiolres14060085
Chicago/Turabian StyleAstefanei, Oana, Sebastian Cozma, Cristian Martu, Roxana Serban, Corina Butnaru, Petronela Moraru, Gabriela Musat, and Luminita Radulescu. 2024. "Measuring Speech Intelligibility with Romanian Synthetic Unpredictable Sentences in Normal Hearing" Audiology Research 14, no. 6: 1028-1044. https://doi.org/10.3390/audiolres14060085
APA StyleAstefanei, O., Cozma, S., Martu, C., Serban, R., Butnaru, C., Moraru, P., Musat, G., & Radulescu, L. (2024). Measuring Speech Intelligibility with Romanian Synthetic Unpredictable Sentences in Normal Hearing. Audiology Research, 14(6), 1028-1044. https://doi.org/10.3390/audiolres14060085