
Design and Development of a Spanish Hearing Test for Speech in Noise (PAHRE)


Abstract
1. Introduction
1.1. The Lombard Effect
1.2. Assessment of Signal-to-Noise Loss Using Speech-in-Noise Tests
2. Materials and Methods
2.1. PHASE 1: Familiarity Test
2.1.1. Purpose
2.1.2. Participants
2.1.3. Instruments
- (a)
- Following CORPES XXI corpus [59], nouns, verbs, adjectives, and adverbs were considered key words, in that these constitute 51.97% of all Spanish word classes. Taking into account the frequency of occurrence of each type of keyword, each list of six sentences with a total of 30 keywords was required to contain fifteen nouns, eight verbs, four adjectives, and three adverbs.
- (b)
- Given that studies vary regarding the number of words that an adult is likely to know (between 34,000 and 50,000 words), and to avoid the influence of factors such as age and socio-educational and cultural level, the lexicon was limited to some of the most familiar and frequently occurring words in the Spanish language. The selection of these was again based on CORPES XXI. Function words, punctuation marks, orthographic marks, fixed word combinations, abbreviations, acronyms, digits, proper names, and Anglicisms were excluded, until 3000 items were reached.
- (c)
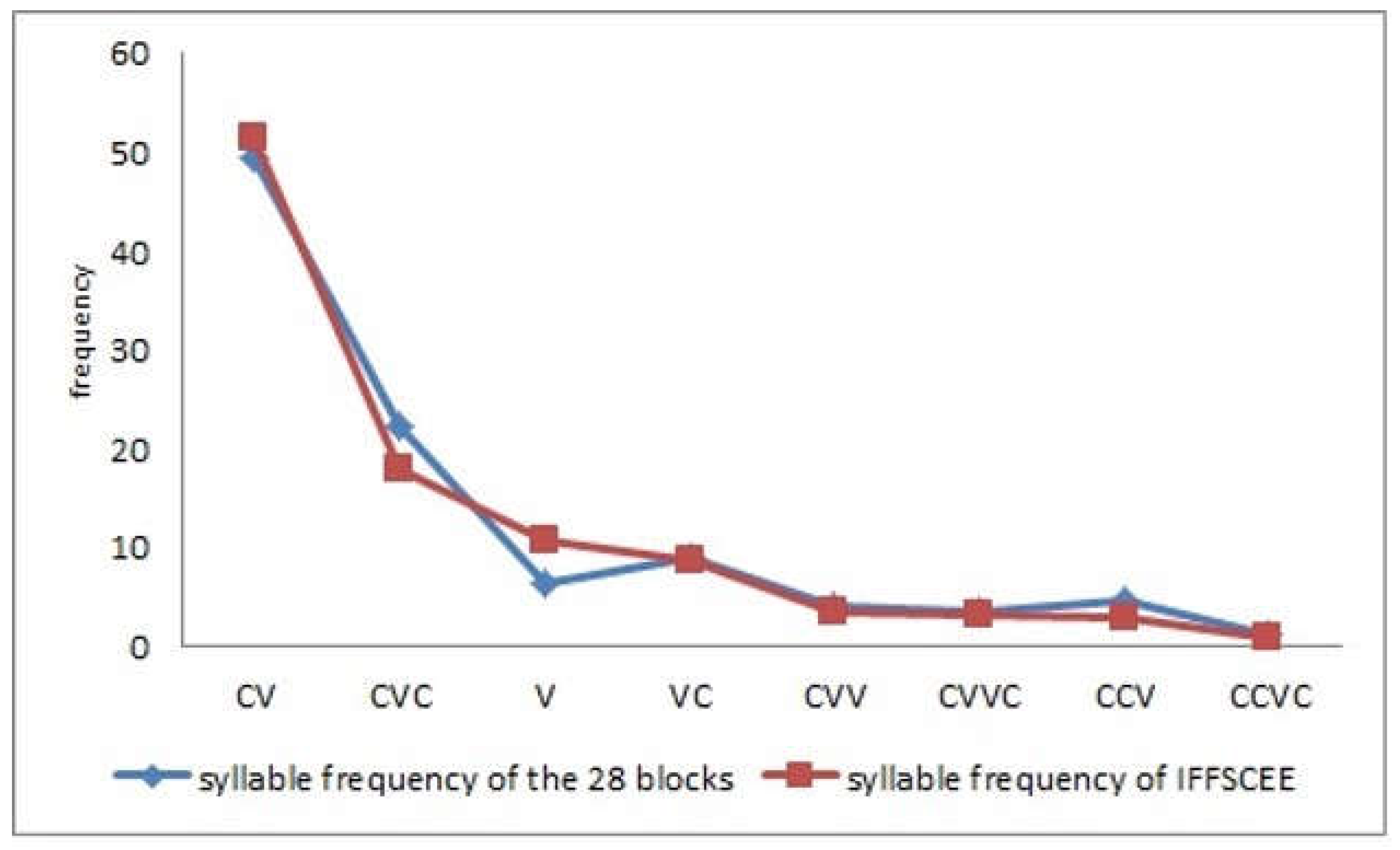
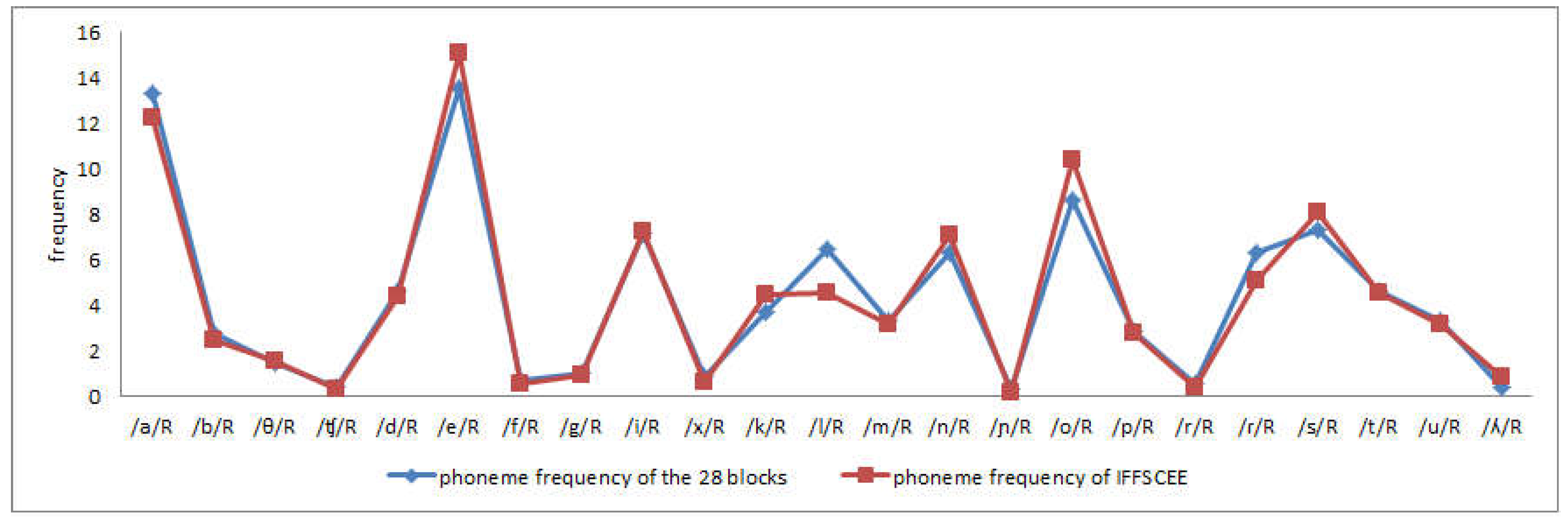
- To achieve a phonic and syllabic balance in each list of sentences, we followed the indications set out in the Inventory of Phonemic and Syllabic Frequencies of Spontaneous and Written Spanish (In Spanish, Inventario de Frecuencias Fonémicas y Silábicas del Castellano Espontáneo y Escrito, IFFSCEE) [60].
- (d)
- All sentences were expressed in the declarative form to avoid differences in intonation patterns.
- (e)
- At the syntactic level, the structure of most of the sentences was subject-verb-predicate.
- (f)
- Following Véliz et al. [61], the length and syntactic complexity of the sentences had to allow for their exact and immediate reproduction after their presentation in auditory mode, regardless of the age and working memory of the participants.
2.1.4. Procedure
2.1.5. Data Analysis
2.1.6. Results
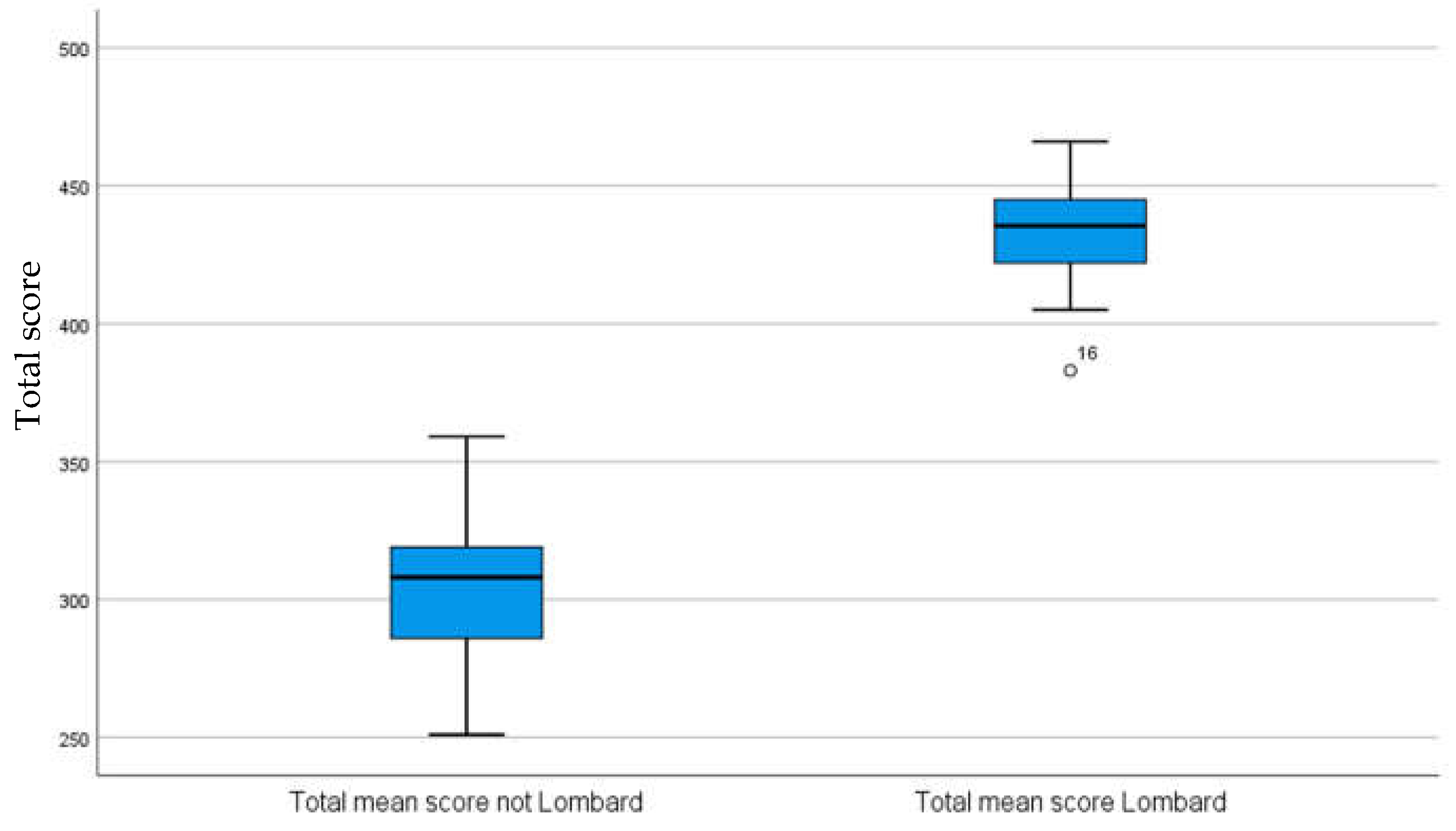
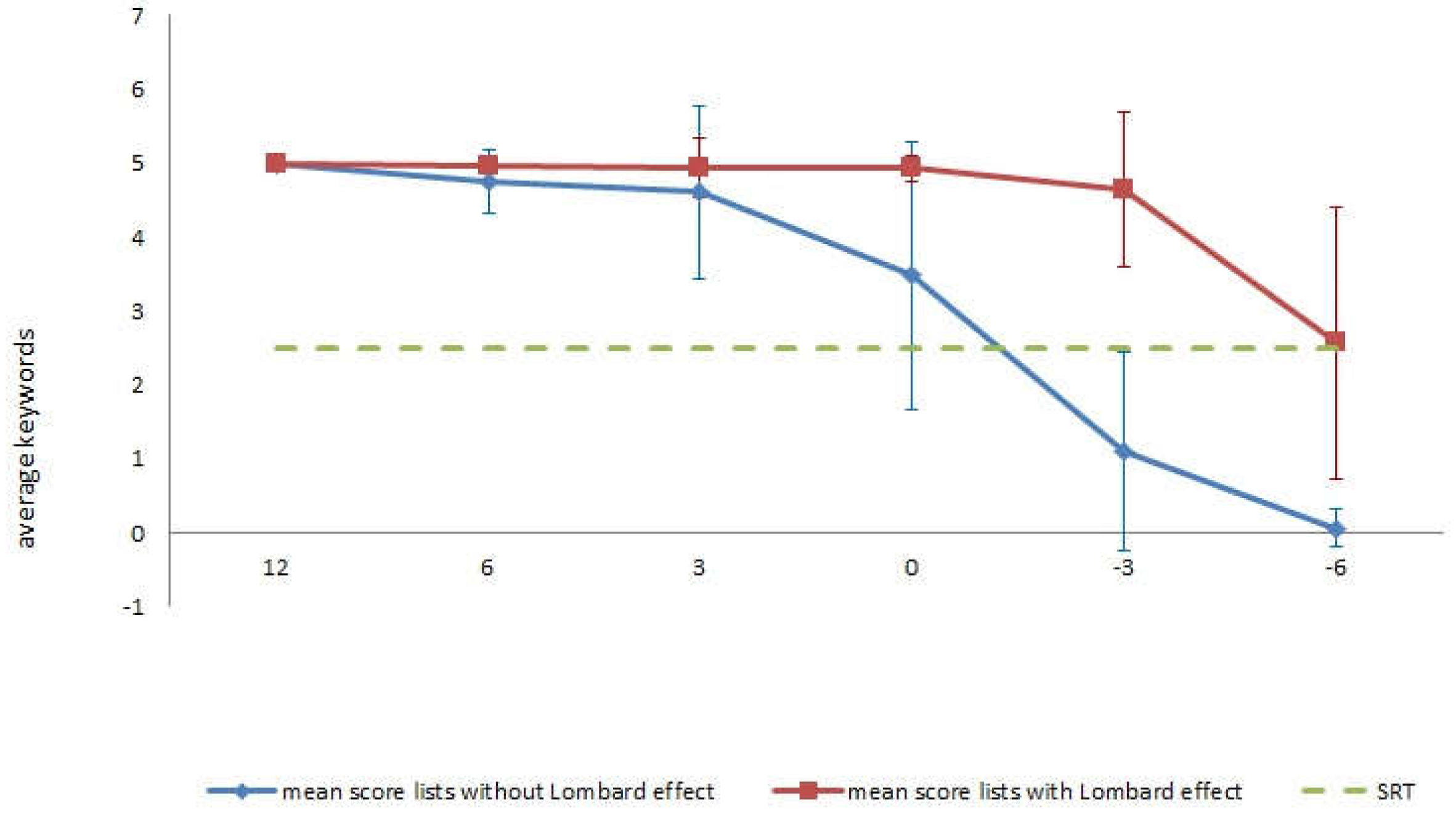
2.2. PHASE 2: Calculation of Intelligibility and Assessment of the Lombard Effect
2.2.1. Purpose
2.2.2. Participants
2.2.3. Instruments
2.2.4. Procedure
2.2.5. Data Analysis
2.2.6. Results
3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brungart, D.S. Informational and Energetic Masking Effects in Multitalker Speech Perception. In Speech Separation by Humans and Machines, 1st ed.; Divenyi, P., Ed.; Springer: Boston, MA, USA, 2005; pp. 261–267. [Google Scholar] [CrossRef]
- Garnier, M.; Henrich, N. Speaking in noise: How does the Lombard effect improve acoustic contrasts between speech and ambient noise? Comput. Speech Lang. 2014, 28, 580–597. [Google Scholar] [CrossRef]
- Lu, Y.; Cooke, M. The contribution of changes in F0 and spectral tilt to increased intelligibility of speech produced in noise. Speech Commun. 2009, 51, 1253–1262. [Google Scholar] [CrossRef]
- Stowe, L.M.; Golob, E.J. Evidence that the Lombard effect is frequency-specific in humans. J. Acoust. Soc. Am. 2013, 134, 640–647. [Google Scholar] [CrossRef] [PubMed]
- Summers, W.V.; Pisoni, D.B.; Bernacki, R.H.; Pedlow, R.I.; Stokes, M.A. Effects of noise on speech production: Acoustic and perceptual analyses. J. Acoust. Soc. Am. 1988, 84, 917–928. [Google Scholar] [CrossRef]
- Wilson, R.H.; McArdle, R. Speech signals used to evaluate functional status of the auditory system. J. Rehabil. Res. Dev. 2005, 42, 79–94. [Google Scholar] [CrossRef] [PubMed]
- Killion, M.C.; Niquette, P.A. What can the pure-tone audiogram tell us about a patient’s SNR loss? Hear. J. 2000, 53, 46–48. [Google Scholar] [CrossRef]
- Vermiglio, A.J.; Soli, S.D.; Freed, D.J.; Fisher, L.M. The relationship between high-frequency pure-tone hearing loss, hearing in noise test (HINT) thresholds, and the articulation index. J. Am. Acad. Audiol. 2012, 23, 779–788. [Google Scholar] [CrossRef]
- Akeroyd, M.A. Are individual differences in speech reception related to individual differences in cognitive ability? A survey of twenty experimental studies with normal and hearing-impaired adults. Int. J. Audiol. 2008, 47 (Suppl. S2), 53. [Google Scholar] [CrossRef]
- Killion, M.C. The SIN report: Circuits haven’t solved the hearing-in-noise problem. Hear. J. 1997, 50, 28–34. [Google Scholar] [CrossRef]
- Walden, T.C.; Walden, B.E. Predicting success with hearing aids in everyday living. J. Am. Acad. Audiol. 2004, 15, 342–352. [Google Scholar] [CrossRef]
- Wilson Richard, H.; McArdle Rachel, A.; Smith Sherri, L. An Evaluation of the BKB-SIN, HINT, QuickSIN, and WIN Materials on Listeners with Normal Hearing and Listeners with Hearing Loss. J. Speech Lang. Hear. Res. 2007, 50, 844–856. [Google Scholar] [CrossRef] [PubMed]
- Carhart, R.; Tillman, T.W. Interaction of Competing Speech Signals with Hearing Losses. Arch. Otolaryngol. 1970, 91, 273–279. [Google Scholar] [CrossRef] [PubMed]
- Lombard, E. Le signe de l’elevation de la voix. Ann. des Mal. de l’Oreille et du Larynx 1911, 37, 101–109. [Google Scholar]
- Lu, Y.; Cooke, M. Speech production modifications produced by competing talkers, babble, and stationary noise. J. Acoust. Soc. Am. 2008, 124, 3261–3275. [Google Scholar] [CrossRef]
- Junqua, J. The Lombard reflex and its role on human listeners and automatic speech recognizers. J. Acoust. Soc. Am. 1993, 93, 510–524. [Google Scholar] [CrossRef]
- Patel, R.; Schell Kevin, W. The Influence of Linguistic Content on the Lombard Effect. J. Speech Lang. Hear. Res. 2008, 51, 209–220. [Google Scholar] [CrossRef]
- Pittman Andrea, L.; Wiley Terry, L. Recognition of Speech Produced in Noise. J. Speech Lang. Hear. Res. 2001, 44, 487–496. [Google Scholar] [CrossRef]
- Šimko, J.; Beňuš, Š.; Vainio, M. Hyperarticulation in Lombard speech: Global coordination of the jaw, lips and the tongue. J. Acoust. Soc. Am. 2016, 139, 151–162. [Google Scholar] [CrossRef]
- Stanton, B.J.; Jamieson, L.H.; Allen, G.D. Acoustic-phonetic analysis of loud and Lombard speech in simulated cockpit conditions. In Proceedings of the ICASSP-88., International Conference on Acoustics, Speech, and Signal Processing, New York, NY, USA, 11–14 April 1988; Volume 1, pp. 331–334. [Google Scholar] [CrossRef]
- Summers, W.V.; Johnson, K.; Pisoni, D.B.; Bernacki, R.H. An addendum to ‘‘Effects of noise on speech production: Acoustic and perceptual analyses’’ [J. Acoust. Soc. Am. 84, 917–928 (1988)]. J. Acoust. Soc. Am. 1989, 86, 1717–1721. [Google Scholar] [CrossRef]
- Castellanos, A.; Benedí, J.; Casacuberta, F. An analysis of general acoustic-phonetic features for Spanish speech produced with the Lombard effect. Speech Commun. 1996, 20, 23–35. [Google Scholar] [CrossRef]
- Bosker, H.R.; Cooke, M. Enhanced amplitude modulations contribute to the Lombard intelligibility benefit: Evidence from the Nijmegen Corpus of Lombard Speech. J. Acoust. Soc. Am. 2020, 147, 721–730. [Google Scholar] [CrossRef] [PubMed]
- Cardemil, F.; Aguayo, L.; Fuente, A. Programas de rehabilitación auditiva en adultos mayores, ¿qué sabemos de su efectividad? Acta Otorrinolaringol. Esp. 2014, 65, 249–257. [Google Scholar] [CrossRef] [PubMed]
- Cardemil, M.F.; Aguayo, G.L.; Fuentes, L.E.; Muñoz, S.D.; Barría, E.T.; Fuente, C.A.; Rahal, E.M.; Yueh, B.; Rojas, C.G. Adherencia al uso de audífonos en adultos mayores con hipoacusia: Un ensayo clínico aleatorizado para evaluar un programa de rehabilitación auditiva. Rev. Otorrinolaringol. Cir. Cabeza Cuello. 2021, 81, 20–26. [Google Scholar] [CrossRef]
- Kim, T.S.; Chung, J.W. Evaluation of age-related hearing loss. Korean J. Audiol. 2013, 17, 50–53. [Google Scholar] [CrossRef]
- Stropahl, M.; Besser, J.; Launer, S. Auditory Training Supports Auditory Rehabilitation: A State-of-the-Art Review. Ear Hear. 2020, 41, 697–704. [Google Scholar] [CrossRef] [PubMed]
- Zendel, B.R.; West, G.L.; Belleville, S.; Peretz, I. Musical training improves the ability to understand speech-in-noise in older adults. Neurobiol. Aging. 2019, 81, 102–115. [Google Scholar] [CrossRef]
- Shi, L.F.; Doherty, K.A.; Kordas, T.M.; Pellegrino, J.T. Short-term and long-term hearing aid benefit and user satisfaction: A comparison between two fitting protocols. J. Am. Acad. Audiol. 2007, 18, 482–495. [Google Scholar] [CrossRef]
- Büchner, A.; Schwebs, M.; Lenarz, T. Speech understanding and listening effort in cochlear implant users—Microphone beamformers lead to significant improvements in noisy environments. Cochlear Implant. Int. 2020, 21, 1–8. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Z.; Dong, R.; Fu, X.; Wang, Y.; Wang, S. Effects of Wireless Remote Microphone on Speech Recognition in Noise for Hearing Aid Users in China. Front. Neurosci. 2021, 15, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Kalikow, D.N.; Stevens, K.N.; Elliott, L.L. Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. J. Acoust. Soc. Am. 1977, 61, 1337–1351. [Google Scholar] [CrossRef]
- Hagerman, B. Sentences for testing speech intelligibility in noise. Scand. Audiol. 1982, 11, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Smits, C.; Kapteyn, T.S.; Houtgast, T. Development and validation of an automatic speech-in-noise screening test by telephone. Int. J. Audiol. 2004, 43, 15–28. [Google Scholar] [CrossRef] [PubMed]
- Nilsson, M.; Soli, S.D.; Sullivan, J.A. Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise. J. Acoust. Soc. Am. 1994, 95, 1085–1099. [Google Scholar] [CrossRef]
- Wilson, R.H.; Abrams, H.B.; Pillion, A.L. A word-recognition task in multitalker babble using a descending presentation mode from 24 dB to 0 dB signal to babble. J. Rehabil. Res. Dev. 2003, 40, 321–327. [Google Scholar] [CrossRef]
- Killion, M.C.; Niquette, P.A.; Gudmundsen, G.I.; Revit, L.J.; Benerjee, S. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am. 2004, 116, 2395–2405. [Google Scholar] [CrossRef]
- Etymotic Research. Bamford-Kowal-Bench Speech-in-Noise Test (Version 1.03) [Audio CD]; Etymotic Research: Elk Grove Village, IL, USA, 2005. [Google Scholar]
- Duncan, K.; Aarts, N. A comparison of the HINT and Quick SIN tests. J. Speech Lang. Pathol. Audiol. 2006, 30, 86–94. [Google Scholar]
- Sultan, O.; Elmahallawi, T.; Kolkaila, E.; Lasheen, R. Comparison between Quick Speech in Noise Test (QuickSIN test) and Hearing in Noise Test (HINT) in Adults with Sensorineural Hearing Loss. Egypt. J. Ear Nose Throat Allied Sci. 2020, 21, 176–185. [Google Scholar] [CrossRef]
- Cox, R.M.; Alexander, G.C. The abbreviated profile of hearing aid benefit. Ear Hear. 1995, 16, 176–186. [Google Scholar] [CrossRef]
- Davidson, A.; Marrone, N.; Wong, B.; Musiek, F. Predicting Hearing Aid Satisfaction in Adults: A Systematic Review of Speech-in-noise Tests and Other Behavioral Measures. Ear Hear. 2021, 42, 1485–1498. [Google Scholar] [CrossRef]
- Spahr, A.J.; Dorman, M.F.; Litvak, L.M.; Van Wie, S.; Gifford, R.H.; Loizou, P.C.; Loiselle, L.M.; Oakes, T.; Cook, S. Development and validation of the AzBio sentence lists. Ear Hear. 2012, 33, 112–117. [Google Scholar] [CrossRef]
- Amiri, M.; Jarollahi, F.; Jalaie, S.; Sameni, S.J. A New Speech-in-Noise Test for Measuring Informational Masking in Speech Perception Among Elderly Listeners. Cureus 2020, 12, e7356. [Google Scholar] [CrossRef]
- Leclercq, F.; Renard, C.; Vincent, C. Speech audiometry in noise: Development of the French-language VRB (vocale rapide dans le bruit) test. Eur. Ann. Otorhinolaryngol. Head. Neck. Dis. 2018, 135, 315–319. [Google Scholar] [CrossRef]
- Ooster, J.; Krueger, M.; Bach, J.; Wagener, K.C.; Kollmeier, B.; Meyer, B.T. Speech Audiometry at Home: Automated Listening Tests via Smart Speakers with Normal-Hearing and Hearing-Impaired Listeners. Trends Hear. 2020, 24, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Sheikh Rashid, M.; Dreschler, W.A. Accuracy of an internet-based speech-in-noise hearing screening test for high-frequency hearing loss: Incorporating automatic conditional rescreening. Int. Arch. Occup. Environ. Health 2018, 91, 877–885. [Google Scholar] [CrossRef] [PubMed]
- Cárdenas, M.R.; Marrero, V. Cuaderno de Logoaudiometría; Universidad Nacional de Educación a Distancia—UNED: Madrid, Spain, 1994. [Google Scholar]
- Cox, R.M.; Alexander, G.C.; Gilmore, C. Development of the Connected Speech Test (CST). Ear Hear. 1987, 8, 119S–126S. [Google Scholar] [CrossRef]
- Villchur, E. Signal processing to improve speech intelligibility in perceptive deafness. J. Acoust. Soc. Am. 1973, 53, 1646–1657. [Google Scholar] [CrossRef]
- Pérez-González, P.; Gorospe, J.M.; Lopez-Poveda, E.A. A Castilian Spanish digit triplet identification test for assessing speech intelligibility in quiet and in noise*. Rev. de Acúst. 2013, 44, 13–24. [Google Scholar]
- Hochmuth, S.; Brand, T.; Zokoll, M.A.; Castro, F.Z.; Wardenga, N.; Kollmeier, B. A Spanish matrix sentence test for assessing speech reception thresholds in noise. Int. J. Audiol. 2012, 51, 536–544. [Google Scholar] [CrossRef] [PubMed]
- Huarte, A. The Castilian Spanish Hearing in Noise Test. Int. J. Audiol. 2008, 47, 369–370. [Google Scholar] [CrossRef]
- Cervera, T.; González-Alvarez, J. Test of Spanish sentences to measure speech intelligibility in noise conditions. Behav. Res. Methods 2011, 43, 459–467. [Google Scholar] [CrossRef][Green Version]
- Cervera, T. Elaboración de una versión reducida de las listas de frases en español (vr-LFE) para evaluar la percepción del habla con ruido. Rev. de Logop. Foniatr. y Audiol. 2014, 34, 32–39. [Google Scholar] [CrossRef]
- Aubanel, V.; Garcia Lecumberri, M.; Cooke, M. The Sharvard Corpus: A phonemically-balanced Spanish sentence resource for audiology. Int. J. Audiol. 2014, 53, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Marrero-Aguiar, V. La percepción del habla en ruido: Un reto para la lingüística y para la evaluación audiológica (estudio experimental). Rev. Esp. Linguist. Apl. 2015, 45, 129–151. [Google Scholar] [CrossRef]
- Cantos, P.; Sánchez, A. English and Spanish from a distributional and quantitative perspective: Equivalences and contrasts. Estud. Ingl. De La Univ. Complut. 2011, 19, 15–44. [Google Scholar] [CrossRef]
- Real Academia Española: Banco de datos, (CORPES XXI) Corpus del Español del Siglo XXI. Available online: https://apps2.rae.es/CORPES/view/inicioExterno.view;jsessionid=FB1727346FCE7759AF07F8A76AE8BDCB (accessed on 7 September 2020).
- Moreno Sandoval, A.; Toledano, D.T.; Curto, N.; Torre, R.d.l. Inventario de frecuencias fonémicas y silábicas del castellano espontáneo y escrito. In Proceedings of the IV Jornadas en tecnología del habla, Universidad de Zaragoza, Zaragoza, Spain, 8–10 November 2006; Buera, L., Lleida, E., Miguel, A. y Ortega A., Eds.; Universidad de Zaragoza: Zaragoza, Spain, 2006; pp. 77–81. [Google Scholar]
- Véliz, M.; Riffo, B.; Vásquez, A. Recuerdo inmediato de oraciones de sintaxis compleja en adultos jóvenes y mayores. Estud. Filol. 2009, 44, 243–258. [Google Scholar] [CrossRef][Green Version]
- Humes, L.E. Examining the validity of the World Health Organization’s long-standing hearing-impairment grading system for unaided communication in age-related hearing loss. Am. J. Audiol. 2019, 28, 810–818. [Google Scholar] [CrossRef]
- Stevens, G.; Flaxman, S.; Brunskill, E.; Mascarenhas, M.; Mathers, C.D.; Finucane, M. Global and regional hearing impairment prevalence: An analysis of 42 studies in 29 countries. Eur. J. Public Health. 2013, 23, 146–152. [Google Scholar] [CrossRef]
- Akeroyd, M.A.; Arlinger, S.; Bentler, R.A.; Boothroyd, A.; Dillier, N.; Dreschler, W.A.; Gagné, J.P.; Lutman, M.; Wouters, J.; Wong, L.; et al. International Collegium of Rehabilitative Audiology Working Group on Multilingual Speech Tests International Collegium of Rehabilitative Audiology (ICRA) recommendations for the construction of multilingual speech tests. ICRA Working Group on Multilingual Speech Tests. Int. J. Audiol. 2015, 54 (Suppl. S2), 17–22. [Google Scholar] [CrossRef]
- Casado Morente, J.C.; Adrián Torres, J.A.; Conde Jiménez, M.; Piédrola Maroto, D.; Povedano Rodríguez, V.; Muñoz Gomariz, E.; Cantillo Baños, E.; Jurado Ramos, A. Estudio objetivo de la voz en población normal y en la disfonía por nódulos y pólipos vocales. Acta Otorrinolaringol. Esp. 2001, 52, 476–482. [Google Scholar] [CrossRef]
- Elisei, N. Análisis acústico de la voz normal y patológica utilizando dos sistemas diferentes: ANAGRAF y PRAAT. Interdisciplinaria 2012, 29, 271–286. [Google Scholar] [CrossRef]
- González, J.; Cervera, T.; Miralles, J. Análisis acústico de la voz: Fiabilidad de un conjunto de parámetros multidimensionales. Acta Otorrinolaringol. Esp. 2002, 53, 256–268. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Hage, S.R.; Moss, C.F. The Lombard Effect: From Acoustics to Neural Mechanisms. Trends Neurosci. 2018, 41, 938–949. [Google Scholar] [CrossRef] [PubMed]
- Marrero-Aguiar, V.; Cruz, M.; Igualada, A. Los efectos del ruido sobre la percepción del habla. Aplicaciones audiométricas. In Panorama de la Fonética Española Actual; Penas Ibáñez, M.A., Nieto Jiménez, L., Eds.; Arco Libros: Madrid, Spain, 2013; pp. 367–378. [Google Scholar]
- Holder, J.T.; Levin, L.M.; Gifford, R.H. Speech Recognition in Noise for Adults with Normal Hearing: Age-Normative Performance for AzBio, BKB-SIN, and QuickSIN. Otol. Neurotol. 2018, 39, e972–e978. [Google Scholar] [CrossRef] [PubMed]
- Davidson, A.; Marrone, N.; Souza, P. Hearing Aid Technology Settings and Speech-in-Noise Difficulties. Am. J. Audiol. 2022, 31, 21–23. [Google Scholar] [CrossRef] [PubMed]
- Humes, L.E. Factors Underlying Individual Differences in Speech-Recognition Threshold (SRT) in Noise Among Older Adults. Front. Aging Neurosci. 2021, 13, 1–19. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
| Speech in Noise Tests | Stimulus Presentation | Signal-to-Noise Ratio | Approximate Application Time |
|---|---|---|---|
| Speech Perception in Noise test (SPIN) [32] | Multi-speaker background noise | Fixed SNR of +8 dB | |
| Matrix test [33] | Noise with spectral speech matching | Variable speech intensity and fixed noise intensity with variable SNR | 4–6 min with 8 min of pre-training |
| Digit in Noise test [34] | Multi-speaker background noise | Different versions | 3 min |
| Hearing in Noise test (HINT) [35] | Male speaker with spectrally matched noise weighted speech | Variable speech intensity in 2 dB steps and fixed noise intensity | 5–10 min |
| Words-in-Noise test (WIN) [36] | Female speaker with multi-speaker noise | Variable speech intensity and fixed noise intensity in 4 dB steps with SNR from +24 to 0 dB | |
| Quick Speech-in-Noise (QuickSIN) [37] | Female speaker with multi-speaker noise | Fixed speech intensity and variable noise intensity in 5 dB steps with SNR from +25 to 0 dB | 2–3 min |
| Bamford-Kowal-Bench Speech-in-Noise (BKB-SIN) [38] | Male speaker with multi-speaker noise | Fixed speech intensity and variable noise intensity in 3 dB steps with SNR of +21 to 0/−6 dB | 6 min |
| N | Average Age | ||
|---|---|---|---|
| Gender | Male | 11 | 46.91 |
| Female | 20 | 46.75 | |
| Total | 31 | 46.81 | |
| Level of education | Basic Education | 3 | |
| Intermediate Vocational Training | 3 | ||
| Advanced Vocational Training | 6 | ||
| Baccalaureate | 2 | ||
| University Studies | 14 | ||
| Master’s Degrees Courses | 3 | ||
| Total | 31 |
| List Sentences | r Phonemes | r Syllables |
|---|---|---|
| 1 | 0.97 ** | 0.98 ** |
| 2 | 0.91 ** | 0.99 ** |
| 3 | 0.91 ** | 0.96 ** |
| 4 | 0.91 ** | 0.98 ** |
| 5 | 0.95 ** | 0.98 ** |
| 6 | 0.92 ** | 0.97 ** |
| 7 | 0.96 ** | 0.98 ** |
| 8 | 0.91 ** | 0.98 ** |
| 9 | 0.96 ** | 0.99 ** |
| 10 | 0.92 ** | 0.99 ** |
| 11 | 0.97 ** | 0.99 ** |
| 12 | 0.94 ** | 0.96 ** |
| 13 | 0.92 ** | 0.99 ** |
| 14 | 0.92 ** | 0.98 ** |
| 15 | 0.96 ** | 0.91 ** |
| 16 | 0.97 ** | 0.95 ** |
| 17 | 0.96 ** | 0.96 ** |
| 18 | 0.93 ** | 0.97 ** |
| 19 | 0.88 ** | 0.98 ** |
| 20 | 0.94 ** | 0.98 ** |
| 21 | 0.94 ** | 0.99 ** |
| 22 | 0.93 ** | 0.99 ** |
| 23 | 0.93 ** | 0.99 ** |
| 24 | 0.90 ** | 0.98 ** |
| 25 | 0.97 ** | 0.98 ** |
| 26 | 0.93 ** | 0.95 ** |
| 27 | 0.95 ** | 0.95 ** |
| 28 | 0.96 ** | 0.97 ** |
| N | Average Age | ||
|---|---|---|---|
| Gender | Male | 13 | 48.23 |
| Female | 17 | 48.47 | |
| Total | 30 | 48.37 | |
| Level of Education | Basic Education | 5 | |
| Intermediate Vocational Training | 4 | ||
| Advanced Vocational Training | 7 | ||
| Baccalaureate | 1 | ||
| University Studies | 11 | ||
| Master’s Degrees Courses | 1 | ||
| PhD Degree | 1 | ||
| Total | 30 |
| RSR Levels (dB) | Z |
|---|---|
| L+12 − NL+12 | −1.26 |
| L+6 − NL+6 | −4.47 ** |
| L+3 − NL+3 | −4.52 ** |
| L0 − NL0 | −4.78 ** |
| L−3 − NL−3 | −4.79 ** |
| L−6 − NL−6 | −4.78 ** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Ferreiro, M.; Durán-Bouza, M.; Marrero-Aguiar, V. Design and Development of a Spanish Hearing Test for Speech in Noise (PAHRE). Audiol. Res. 2023, 13, 32-48. https://doi.org/10.3390/audiolres13010004
Rodríguez-Ferreiro M, Durán-Bouza M, Marrero-Aguiar V. Design and Development of a Spanish Hearing Test for Speech in Noise (PAHRE). Audiology Research. 2023; 13(1):32-48. https://doi.org/10.3390/audiolres13010004
Chicago/Turabian StyleRodríguez-Ferreiro, Marlene, Montserrat Durán-Bouza, and Victoria Marrero-Aguiar. 2023. "Design and Development of a Spanish Hearing Test for Speech in Noise (PAHRE)" Audiology Research 13, no. 1: 32-48. https://doi.org/10.3390/audiolres13010004
APA StyleRodríguez-Ferreiro, M., Durán-Bouza, M., & Marrero-Aguiar, V. (2023). Design and Development of a Spanish Hearing Test for Speech in Noise (PAHRE). Audiology Research, 13(1), 32-48. https://doi.org/10.3390/audiolres13010004