
Improvement in Pavement Defect Scenarios Using an Improved YOLOv10 with ECA Attention, RefConv and WIoU

Abstract
1. Introduction
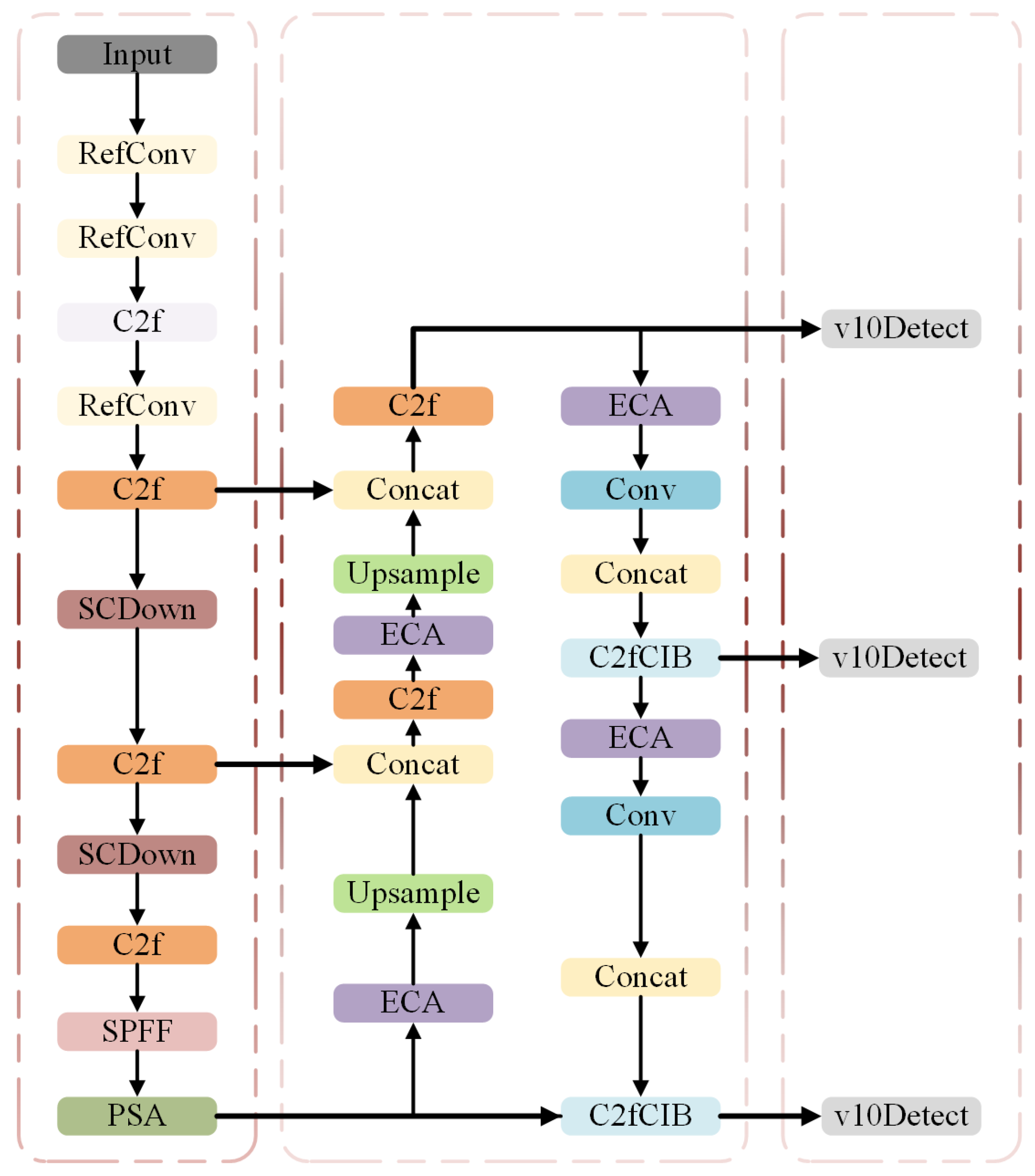
2. Theories and Methods
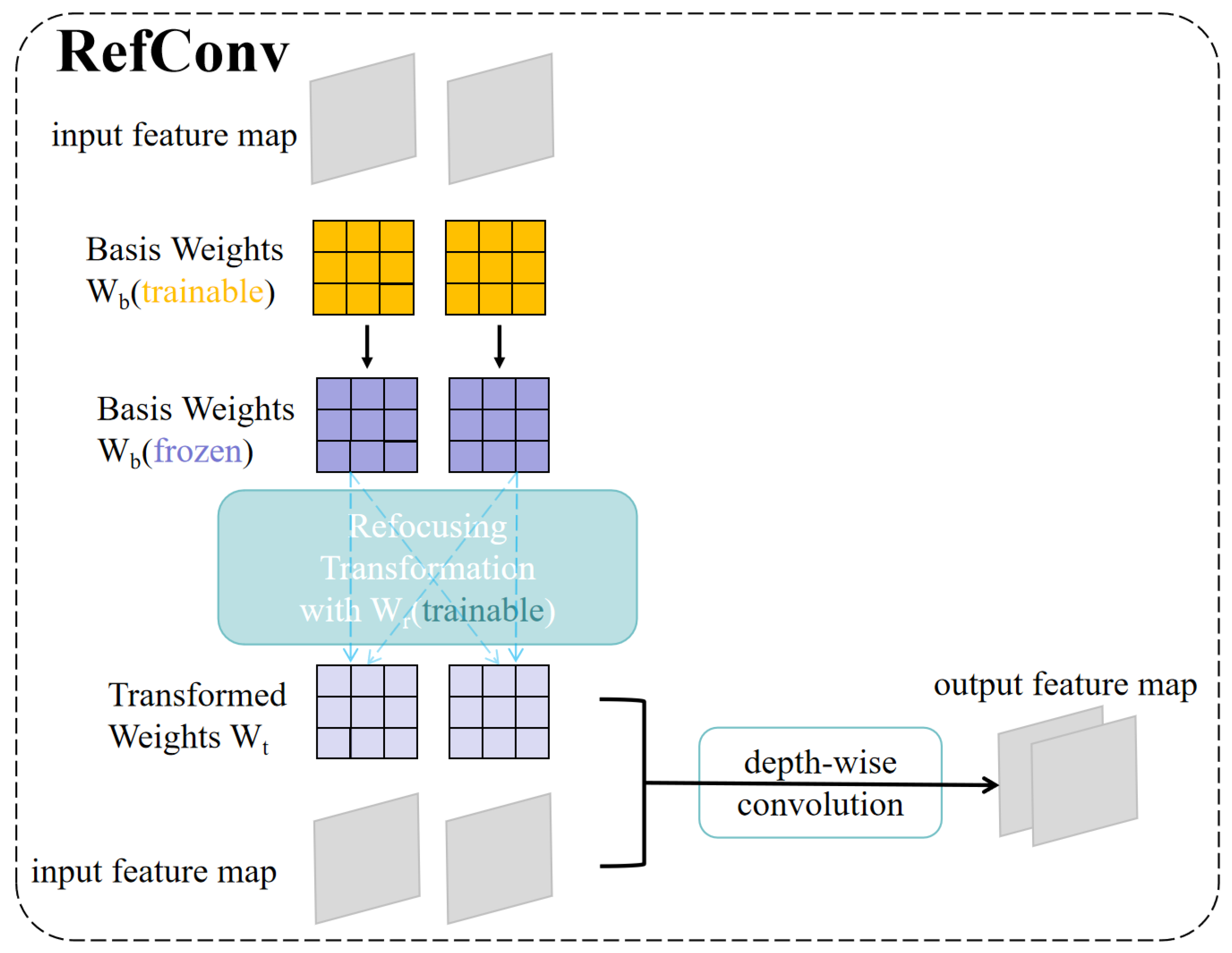
- Integration of the RefConv Module in Shallow Feature Extraction: By incorporating a dual-branch structure combining standard and dilated convolutions, along with residual connections, the RefConv module effectively fuses local and contextual information while enhancing feature flow. This significantly improves the model’s sensitivity to subtle texture defects such as cracks and spalling.
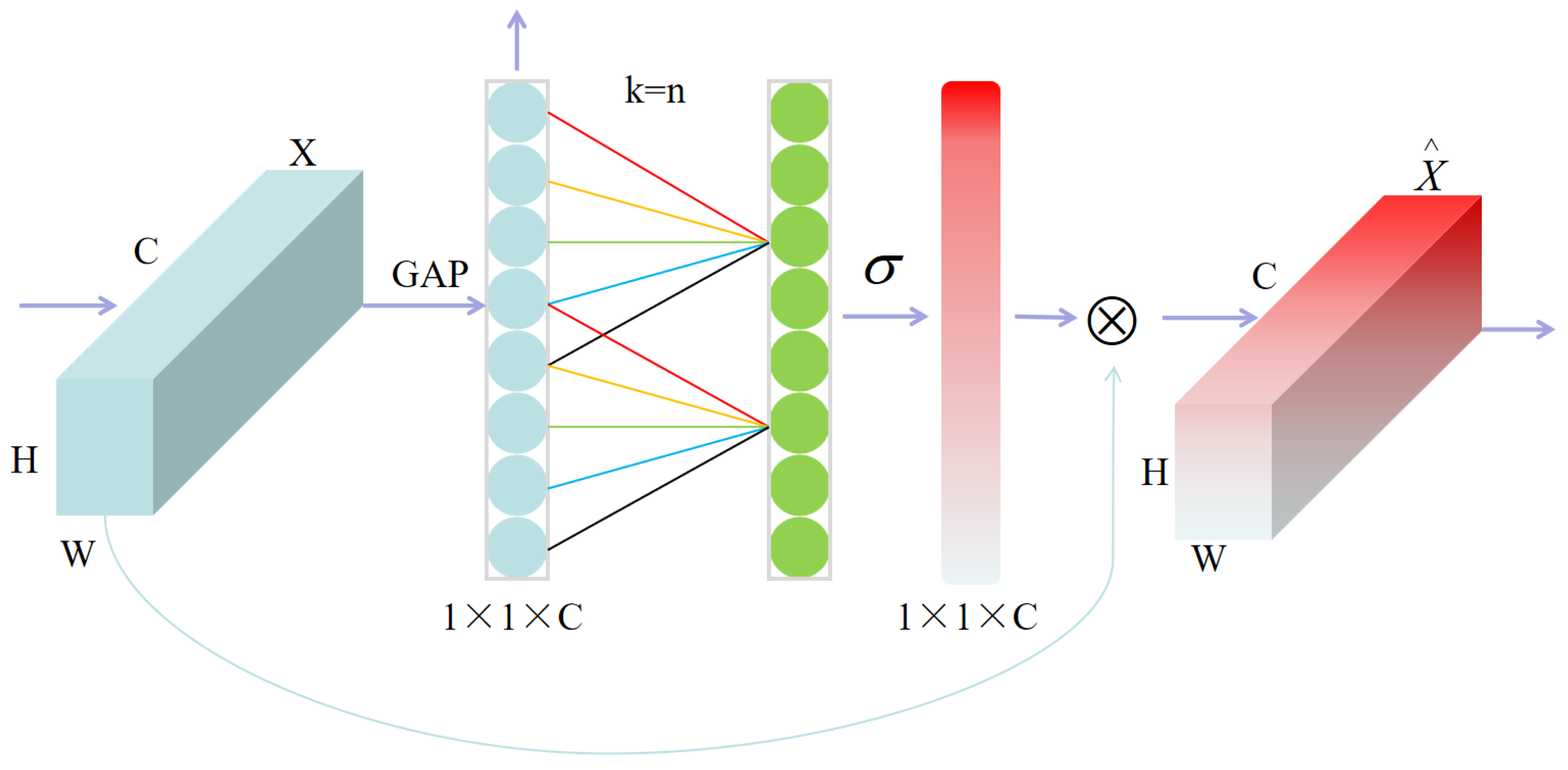
- Introduction of the ECA (Efficient Channel Attention) Mechanism in Multi-Scale Feature Fusion: Leveraging 1D local convolution, the ECA mechanism efficiently models inter-channel dependencies without the information loss typically caused by dimension reduction. This allows the model to focus more on discriminative channel responses in defect regions, improving detection precision.
- Adoption of the WIoU (Weighted IoU) Loss Function for Bounding Box Regression: By introducing a joint weighting mechanism that considers IoU, center distance, and aspect ratio differences, the WIoU loss effectively mitigates issues such as unstable convergence and sparse gradients in traditional IoU-based loss functions. This further enhances the model’s robustness and fitting capability for irregularly shaped targets.
2.1. ECA Attention
2.2. RefConv Convolution Module
2.3. WIoU Mechanism
3. Experimental Section
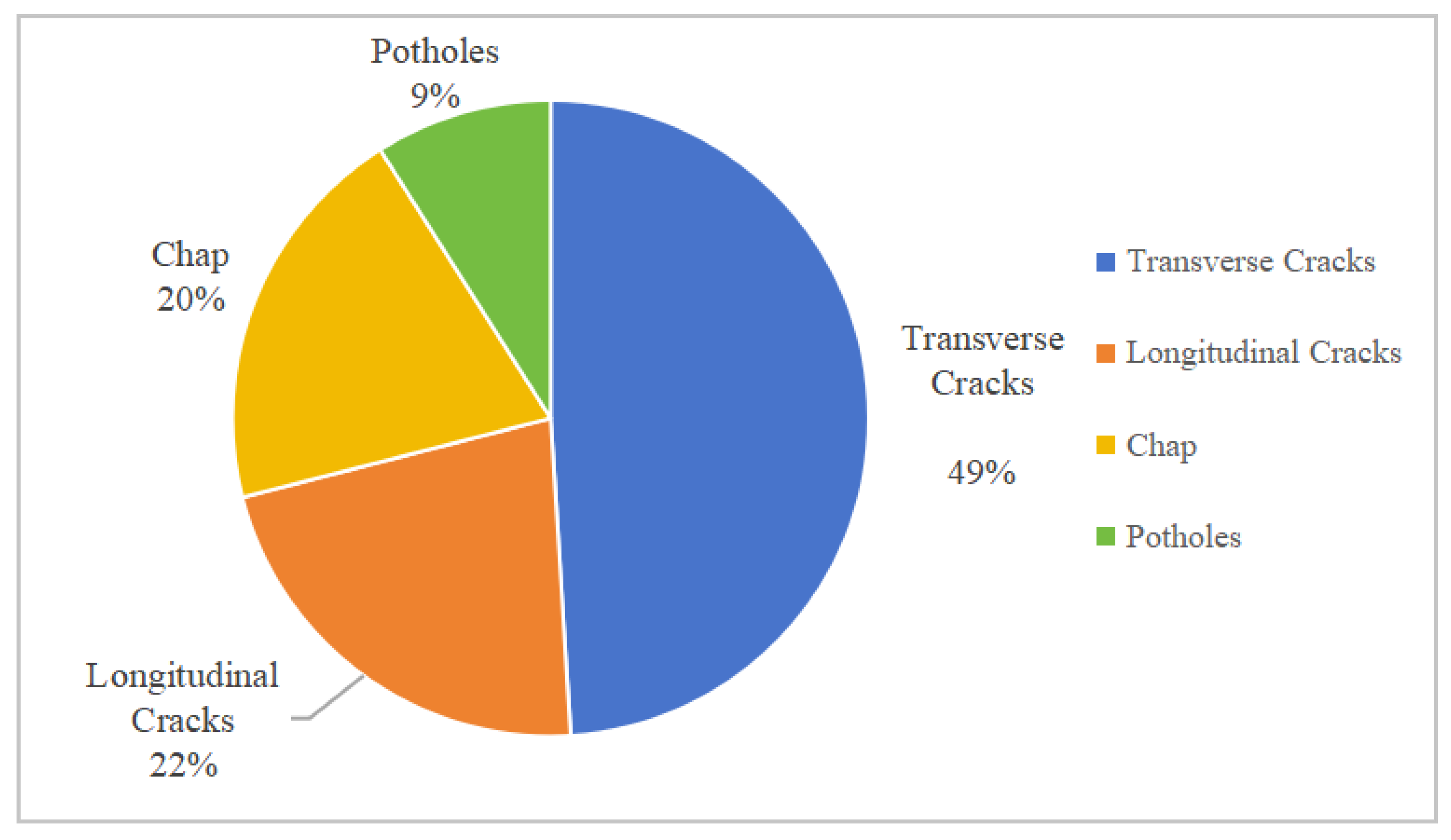
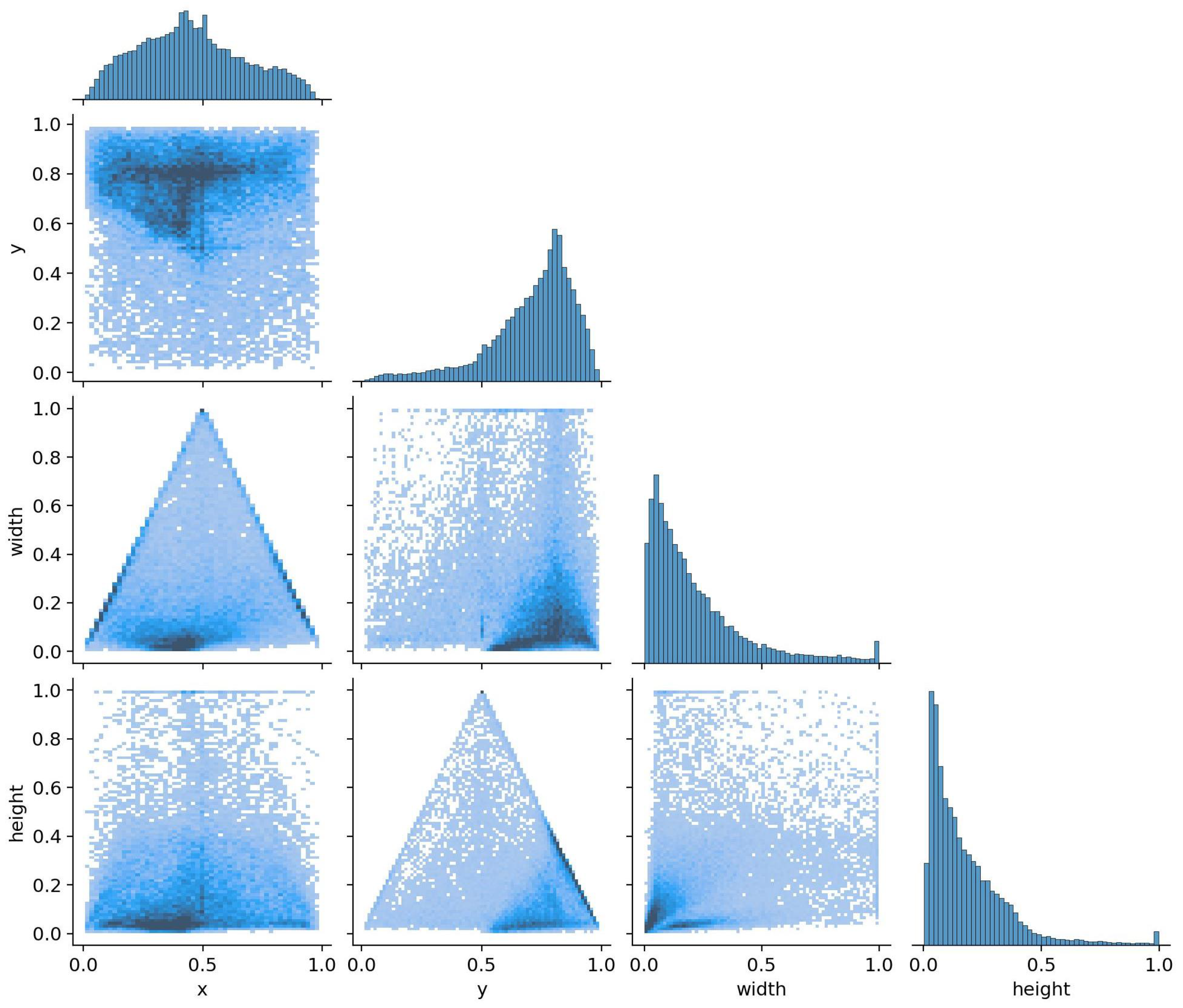
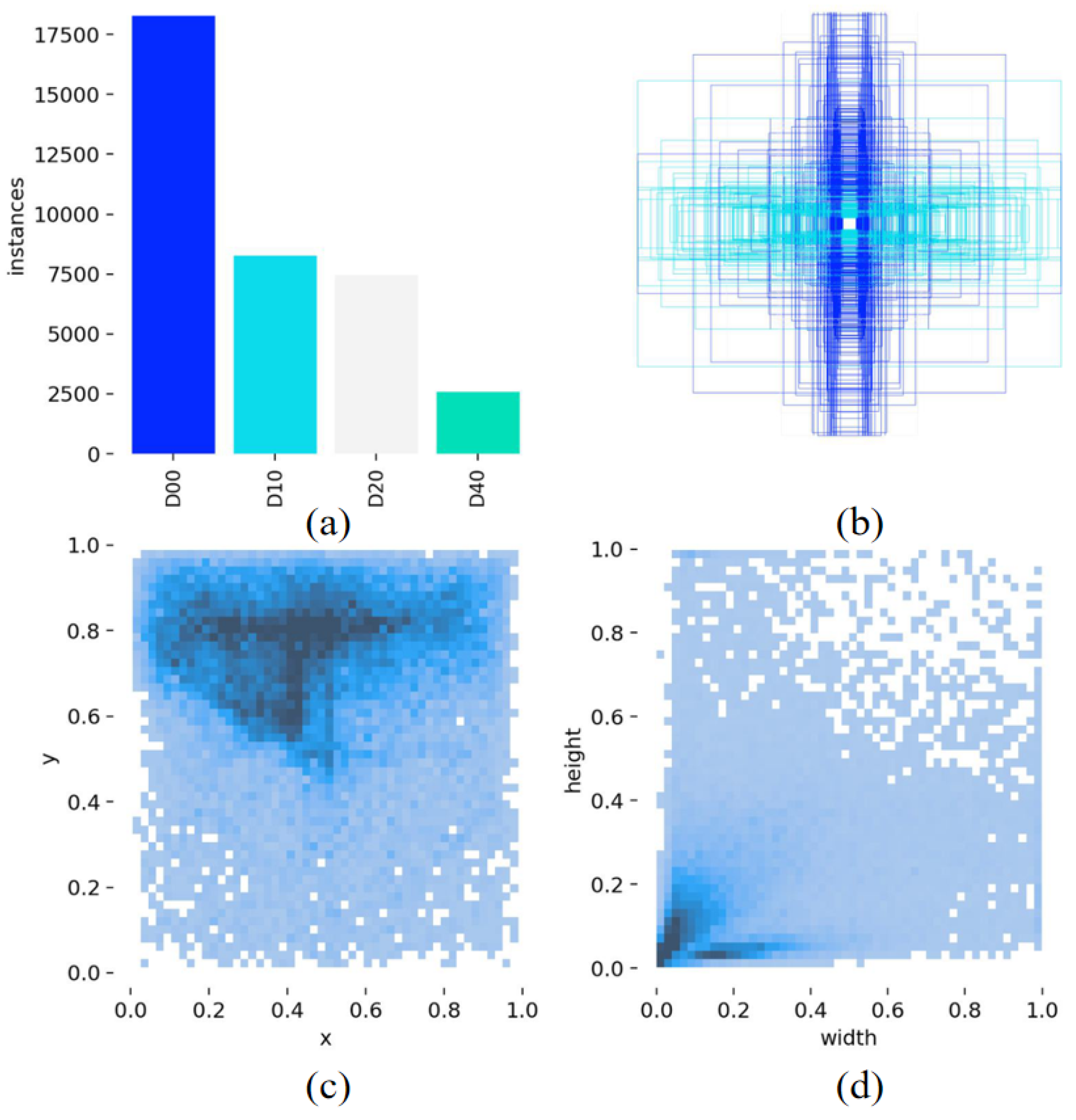
3.1. Dataset Content
3.2. Experimental Platform
3.3. Evaluation Metrics
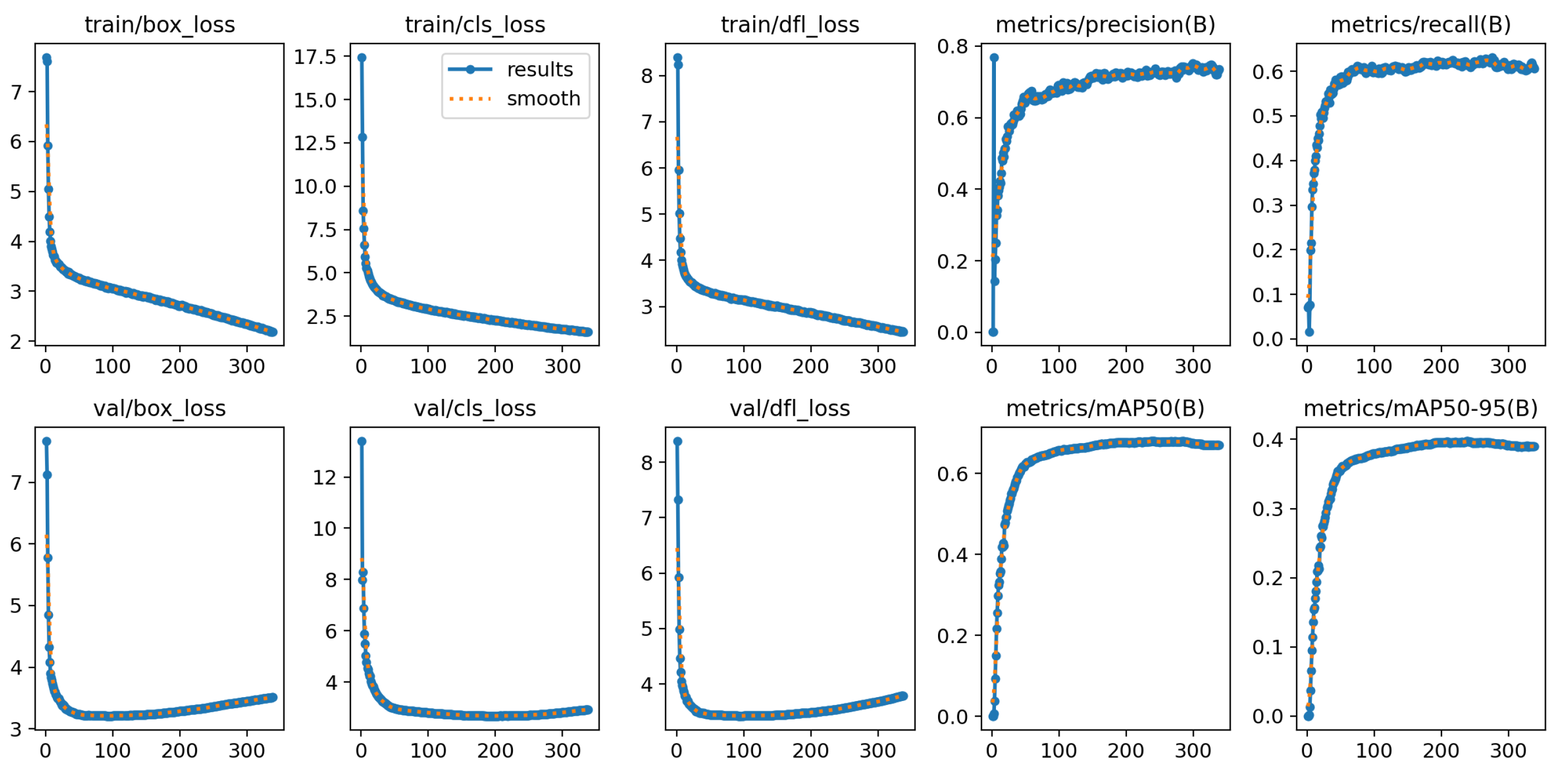
3.4. Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, R. Improved LKM-YOLOv10 Vehicle Licence Plate Recognition Detection System Based on YOLOv10. In Proceedings of the 2024 4th International Conference on Electronic Information Engineering and Computer Science (EIECS), Yanji, China, 27–29 September 2024; pp. 622–626. [Google Scholar]
- Haoyan, H.; Jinwu, T.; Haibin, W.; Xinyun, L. EAD-YOLOv10: Lightweight Steel Surface Defect Detection Algorithm Research Based on YOLOv10 Improvement. IEEE Access 2025, 13, 55382–55397. [Google Scholar] [CrossRef]
- Hu, Z.; Geng, Q.; Li, X.; Fu, Y. Study on Improved YOLOv10 Face Recognition Based on WF-EMA. In Proceedings of the 2024 5th International Symposium on Computer Engineering and Intelligent Communications (ISCEIC), Wuhan, China, 8–10 November 2024; pp. 563–566. [Google Scholar]
- Lodha, N.N.; Kalamkar, S.P.; Heda, L.M. Crowd Abnormal Behaviour Detection and Comparative Analysis Using YOLO Network. In Proceedings of the 2024 IEEE 9th International Conference for Convergence in Technology (I2CT), Pune, India, 5–7 April 2024; pp. 1–6. [Google Scholar]
- Qiao, N.; Jiang, Y.; Wang, J.; Xiong, W. A GPR Road Anomaly Interpretation System Based on YOLO Algorithm. In Proceedings of the 2024 Cross Strait Radio Science and Wireless Technology Conference (CSRSWTC), Macao, China, 4–7 November 2024; pp. 1–3. [Google Scholar]
- Chen, P.; Wang, Y.; Liu, H. GCN-YOLO: YOLO Based on Graph Convolutional Network for SAR Vehicle Target Detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 4013005. [Google Scholar] [CrossRef]
- Irham, A.; Kurniadi; Yuliandari, K.; Fahreza, F.M.A.; Riyadi, D.; Shiddiqi, A.M. AFAR-YOLO: An Adaptive YOLO Object Detection Framework. In Proceedings of the 2024 ASU International Conference in Emerging Technologies for Sustainability and Intelligent Systems (ICETSIS), Manama, Bahrain, 28–29 January 2024; pp. 594–598. [Google Scholar]
- Wang, H.; Song, X. DC-YOLO: A dual channel YOLO for small object defect detection of circuit boards. In Proceedings of the 2024 5th International Conference on Computer Vision, Image and Deep Learning (CVIDL), Zhuhai, China, 19–21 April 2024; pp. 1292–1296. [Google Scholar]
- Matsui, A.; Ishibashi, R.; Meng, L. YOLO-FG: YOLO-Based Visual Inspection for Fruits Grading. In Proceedings of the 2024 6th International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 21–24 August 2024; pp. 1–6. [Google Scholar]
- Kaymakcı, Z.E.; Akarsu, M.; Öztürk, C.N. Multiple Small-Scale Object Detection in Aerial Vehicle Images Using Standard or Optimized YOLO Detectors. In Proceedings of the 2023 International Conference on Innovations in Intelligent Systems and Applications (INISTA), Hammamet, Tunisia, 20–23 September 2023; pp. 1–5. [Google Scholar]
- Qu, X.; Zheng, Y.; Zhou, Y.; Su, Z. YOLO v8_CAT: Enhancing Small Object Detection in Traffic Light Recognition with Combined Attention Mechanism. In Proceedings of the 2024 10th International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2024; pp. 706–710. [Google Scholar]
- Xu, J.; Pan, F.; Han, X.; Wang, L.; Wang, Y.; Li, W. EdgeTrim-YOLO: Improved Trim YOLO Framework Tailored for Deployment on Edge Devices. In Proceedings of the 2024 4th International Conference on Computer Communication and Artificial Intelligence (CCAI), Xi’an, China, 24–26 May 2024; pp. 113–118. [Google Scholar]
- Hamzah, R.; Ang, L.; Roslan, R.; Teo, N.H.I.; Samad, K.A.; Samah, K.A.F.A. Comparing Modified Yolo V5 and Faster Regional Convolutional Neural Network Performance for Recycle Waste Classification. In Proceedings of the 2024 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Shah Alam, Malaysia, 29 June 2024; pp. 415–419. [Google Scholar]
- Yao, N.; Chen, W.; Qin, J.; Shan, G. Research on the Image Model of Substation UAV Inspection Based on the Improved YOLO Algorithm. In Proceedings of the 2024 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Shenzhen, China, 22–24 November 2024; pp. 61–64. [Google Scholar]
- Xiong, K.; Li, Q.; Meng, Y.; Li, Q. A Study on Weed Detection Based on Improved Yolo v5. In Proceedings of the 2023 4th International Conference on Information Science and Education (ICISE-IE), Zhanjiang, China, 15–17 December 2023; pp. 1–4. [Google Scholar]
- Liu, H. Fine-Grained Classification and Anomaly Detection System of Motion Injury Images Based on Improved YOLO Algorithm. In Proceedings of the 2024 International Conference on Data Science and Network Security (ICDSNS), Tiptur, India, 26–27 July 2024; pp. 1–5. [Google Scholar]
- Zhang, X.; Tang, Y.; Zhou, S.; Dong, S.; Zhou, H.; Hu, S. Improved YOLO algorithm for identifying abnormal states in electric energy metering devices. In Proceedings of the 2024 4th International Conference on Electrical Engineering and Control Science (IC2ECS), Nanjing, China, 27–29 December 2024; pp. 278–281. [Google Scholar]
- Zhang, D.; Liu, Z.; Wang, X.; Qi, J.; Zhou, Y.; Zhou, Q. Research on Aircraft Patrol Inspection Method Using UAV Based on YOLO Algorithm. In Proceedings of the 2024 4th International Conference on Electronic Information Engineering and Computer (EIECT), Shenzhen, China, 27–29 September 2024; pp. 412–415. [Google Scholar]
- Wu, J. Traffic Sign Detection in Autonomous Driving: Optimization Choices for YOLO Models. In Proceedings of the 2024 International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 16–18 August 2024; pp. 530–534. [Google Scholar]
- Liu, A.; Liu, Y.; Kifah, S. Deep Convolutional Neural Network for Enhancing Traffic Sign Recognition Developed on Yolo V5. In Proceedings of the 2024 International Conference on Advancements in Smart, Secure and Intelligent Computing (ASSIC), Bhubaneswar, India, 27–29 January 2024; pp. 1–6. [Google Scholar]
- Ding, Z.; Li, Y.; Hu, B.; Chen, Z.; Jia, H.; Shi, Y.; Zhang, X.; Zhu, X.; Feng, W.; Dong, C. ITD-YOLO: An Improved YOLO Model for Impurities in Premium Green Tea Detection. Foods 2025, 14, 1554. [Google Scholar] [CrossRef] [PubMed]
- Luo, Z.; Xu, H.; Xing, Y.; Zhu, C.; Jiao, Z.; Cui, C. YOLO-UFS: A Novel Detection Model for UAVs to Detect Early Forest Fires. Forests 2025, 16, 743. [Google Scholar] [CrossRef]
- Lv, R.; Hu, J.; Zhang, T.; Chen, X.; Liu, W. Crop-Free-Ridge Navigation Line Recognition Based on the Lightweight Structure Improvement of YOLOv8. Agriculture 2025, 15, 942. [Google Scholar] [CrossRef]
- Tariq, M.; Choi, K. YOLO11-Driven Deep Learning Approach for Enhanced Detection and Visualization of Wrist Fractures in X-Ray Images. Mathematics 2025, 13, 1419. [Google Scholar] [CrossRef]
- Liu, Y.; Li, S.; Zhou, L.; Liu, H.; Li, Z. Dark-YOLO: A Low-Light Object Detection Algorithm Integrating Multiple Attention Mechanisms. Appl. Sci. 2025, 15, 5170. [Google Scholar] [CrossRef]
- Zhong, H.; Zhang, Y.; Shi, Z.; Zhang, Y.; Zhao, L. PS-YOLO: A Lighter and Faster Network for UAV Object Detection. Remote Sens. 2025, 17, 1641. [Google Scholar] [CrossRef]
- Zhou, N.; Gao, D.; Zhu, Z. YOLOv8n-SMMP: A Lightweight YOLO Forest Fire Detection Model. Fire 2025, 8, 183. [Google Scholar] [CrossRef]
- Wang, Q.; Yan, N.; Qin, Y.; Zhang, X.; Li, X. BED-YOLO: An Enhanced YOLOv10n-Based Tomato Leaf Disease Detection Algorithm. Sensors 2025, 25, 2882. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Chen, Y.; Zhang, G.; Yang, C.; Teng, X.; Zhao, C. YOLO11-PGM: High-Precision Lightweight Pomegranate Growth Monitoring Model for Smart Agriculture. Agronomy 2025, 15, 1123. [Google Scholar] [CrossRef]
- Su, G.; Su, X.; Wang, Q.; Luo, W.; Lu, W. Research on X-Ray Weld Defect Detection of Steel Pipes by Integrating ECA and EMA Dual Attention Mechanisms. Appl. Sci. 2025, 15, 4519. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Type | Device Model |
|---|---|
| CPU | Intel® Core™ i7-13700KF |
| GPU | NVIDIA GeForce RTX 4080 |
| Operating system | Windows 11 64 bit |
| Memory | 32 GB |
| Training framework | Pytorch |
| ECA | RefConv | WIoU | P | R | mAP | mAP_0.5:0.95 |
|---|---|---|---|---|---|---|
| × | × | × | 70.1% | 58.5% | 64.2% | 34.2% |
| ◯ | × | × | 71.4% | 59.4% | 65.7% | 35.3% |
| × | ◯ | × | 72.2% | 61.7% | 66.3% | 35.7% |
| × | × | ◯ | 71.8% | 60.1% | 67.8% | 36.5% |
| ◯ | ◯ | ◯ | 72.9% | 62.1% | 68.2% | 39.8% |
| Class | P | R | mAP_0.5 | mAP_0.5:0.95 |
|---|---|---|---|---|
| all | 72.9% | 62.1% | 68.2% | 39.8% |
| TransverseCracks | 68.9% | 53.6% | 60.5% | 33.3% |
| LongitudinalCracks | 66.2% | 52.8% | 58.9% | 29.8% |
| Chap | 71.1% | 61.4% | 67.4% | 36.3% |
| Potholes | 85.3% | 80.7% | 86.1% | 59.8% |
| Model | P | R | mAP_0.5 | mAP_0.5:0.95 |
|---|---|---|---|---|
| YOLOv5 | 64.9% | 50.9% | 54.2% | 29.6% |
| YOLOv6 | 65.2% | 51.8% | 55.6% | 30.1% |
| YOLOv8 | 67.4% | 56.5% | 60.7% | 35.1% |
| YOLOv10 | 70.1% | 58.5% | 64.2% | 34.2% |
| YOLOv11 | 70.9% | 59.4% | 66.1% | 37.7% |
| Proposed | 72.9% | 62.1% | 68.2% | 39.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Lu, L.; Luo, H.; Wang, L. Improvement in Pavement Defect Scenarios Using an Improved YOLOv10 with ECA Attention, RefConv and WIoU. World Electr. Veh. J. 2025, 16, 328. https://doi.org/10.3390/wevj16060328
Zhang X, Lu L, Luo H, Wang L. Improvement in Pavement Defect Scenarios Using an Improved YOLOv10 with ECA Attention, RefConv and WIoU. World Electric Vehicle Journal. 2025; 16(6):328. https://doi.org/10.3390/wevj16060328
Chicago/Turabian StyleZhang, Xiaolin, Lei Lu, Hanyun Luo, and Lei Wang. 2025. "Improvement in Pavement Defect Scenarios Using an Improved YOLOv10 with ECA Attention, RefConv and WIoU" World Electric Vehicle Journal 16, no. 6: 328. https://doi.org/10.3390/wevj16060328
APA StyleZhang, X., Lu, L., Luo, H., & Wang, L. (2025). Improvement in Pavement Defect Scenarios Using an Improved YOLOv10 with ECA Attention, RefConv and WIoU. World Electric Vehicle Journal, 16(6), 328. https://doi.org/10.3390/wevj16060328