
Low-Illumination Parking Scenario Detection Based on Image Adaptive Enhancement

Abstract
1. Introduction
- (1)
- When facing different low-illumination conditions, the parameters of the image enhancement algorithm can be adaptively adjusted to achieve different degrees of enhancement, enabling the downstream parking space and obstacle detection network to achieve higher detection accuracy;
- (2)
- The original feature pyramid network (FPN) structure of YOLOv5s is improved to a bidirectional feature pyramid network (BiFPN) structure, which significantly improves the detection ability of targets at different scales; the weighted feature fusion mechanism can dynamically adjust the contribution of each layer of features according to different input images, further optimizing the effect of feature fusion, and better working with the image adaptive enhancement module.
- (3)
- The image adaptive enhancement module and the detection module are cascaded to optimize the prediction parameters of the image adaptive enhancement module, taking into account the weighted loss that comprises both the matching similarity loss of the corner of parking spaces and the loss of obstacle detection results to achieve the purpose of adaptive enhancement, and ultimately make the image enhancement effect more and more conducive to the parking space corner and obstacle detection.
2. Related Work
2.1. Low-Illumination Image Enhancement
2.2. Parking Space Detection
2.3. Parking Scenario Obstacle Detection
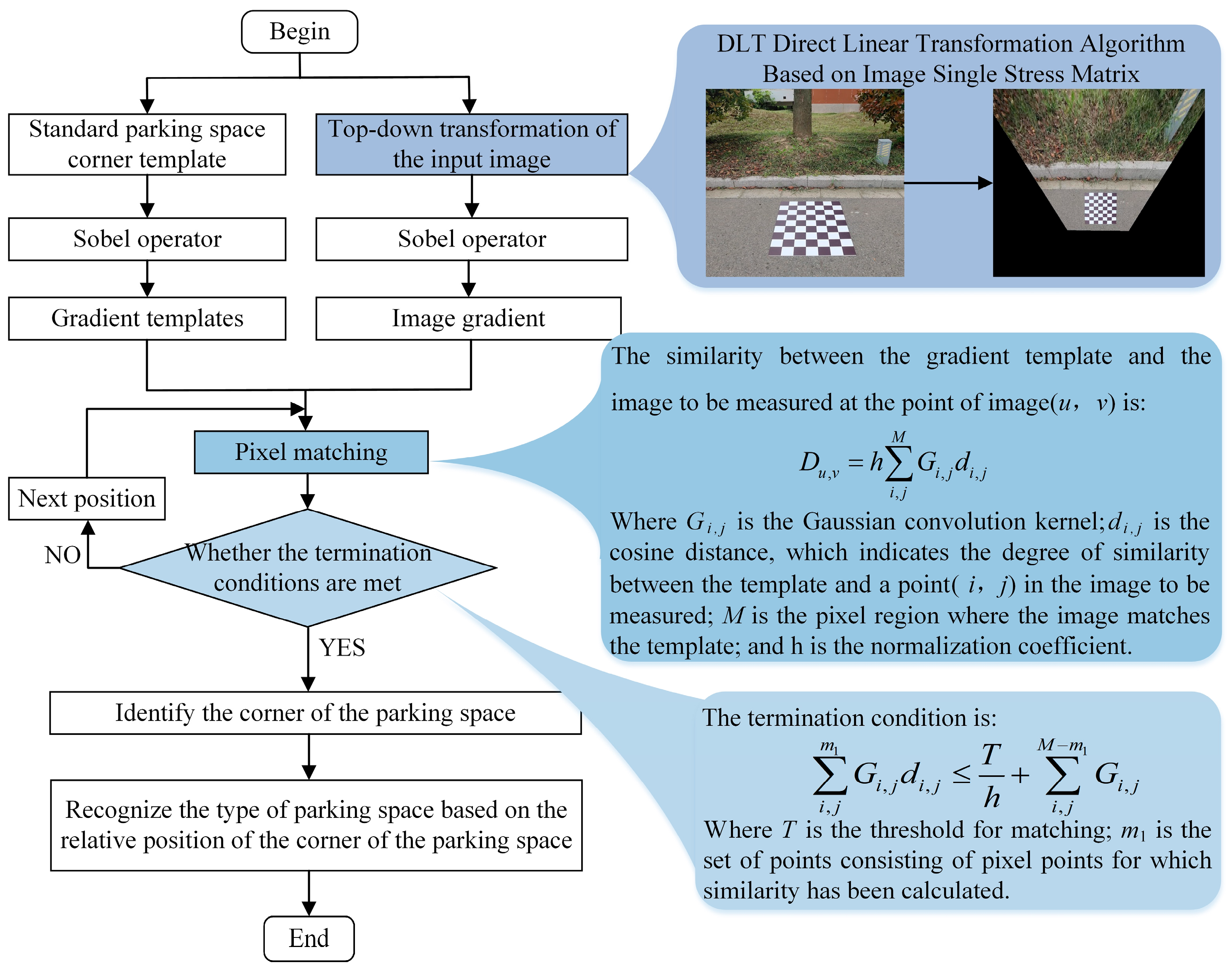
3. Detection Methods for Parking Spaces and Obstacles
3.1. Detection Process
| Algorithm 1: Available parking space detection | |
| 1: | Inputs: Low-illumination image L, adjustment coefficient α, brightness parameter γ, contrast threshold clipLimit |
| 2: | Output: Coordinates of available parking space C_out |
| 3: | Initialization: |
| 4: | P_out ← None # Coordinates of detected parking space |
| 5: | O_out ← None # Coordinates of detected obstacle |
| 6: | C_out ← None # Coordinates of available parking space |
| 7: | H ← None # Initial enhanced image |
| 8: | Step 1: Adaptive image enhancement |
| 9: | H, α, γ, clipLimit ← Adaptive_Enhancement(L, α, γ, clipLimit) |
| 10: | Step 2: Parking space detection and loss feedback |
| 11: | P_out, L_parking ← Detect_Parking_Spaces(H) |
| 12: | if P_out is None: |
| 13: | P_out ← “NO” |
| 14: | Step 3: Obstacle detection and loss feedback |
| 15: | O_out, L_obstacle ← Detect_Obstacles(H) |
| 16: | if O_out is None: |
| 17: | O_out ← “safe” |
| 18: | Step 4: Loss function minimization check |
| 19: | while not Is_Minimized(L_total = a·L_parking + b·L_obstacle): |
| 20: | H, α, γ, clipLimit ← Adaptive_Enhancement(L, α, γ, clipLimit) |
| 21: | P_out, L_parking ← Detect_Parking_Spaces(H) |
| 22: | O_out, L_obstacle ← Detect_Obstacles(H) |
| 23: | Step 5: Decision logic |
| 24: | if P_out == “NO”: |
| 25: | C_out ← None |
| 26: | Print(“NO parking”) |
| 27: | elif O_out == “safe”: |
| 28: | C_out ← P_out |
| 29: | Print(“Available parking space:”, C_out) |
| 30: | elif Is_Obstacle_In_Parking_Space(O_out, P_out): |
| 31: | C_out ← None |
| 32: | Print(“occupied”) |
| 33: | else: |
| 34: | C_out ← P_out |
| 35: | Print(“Available parking space:”, C_out) |
| 36: | Return C_out |
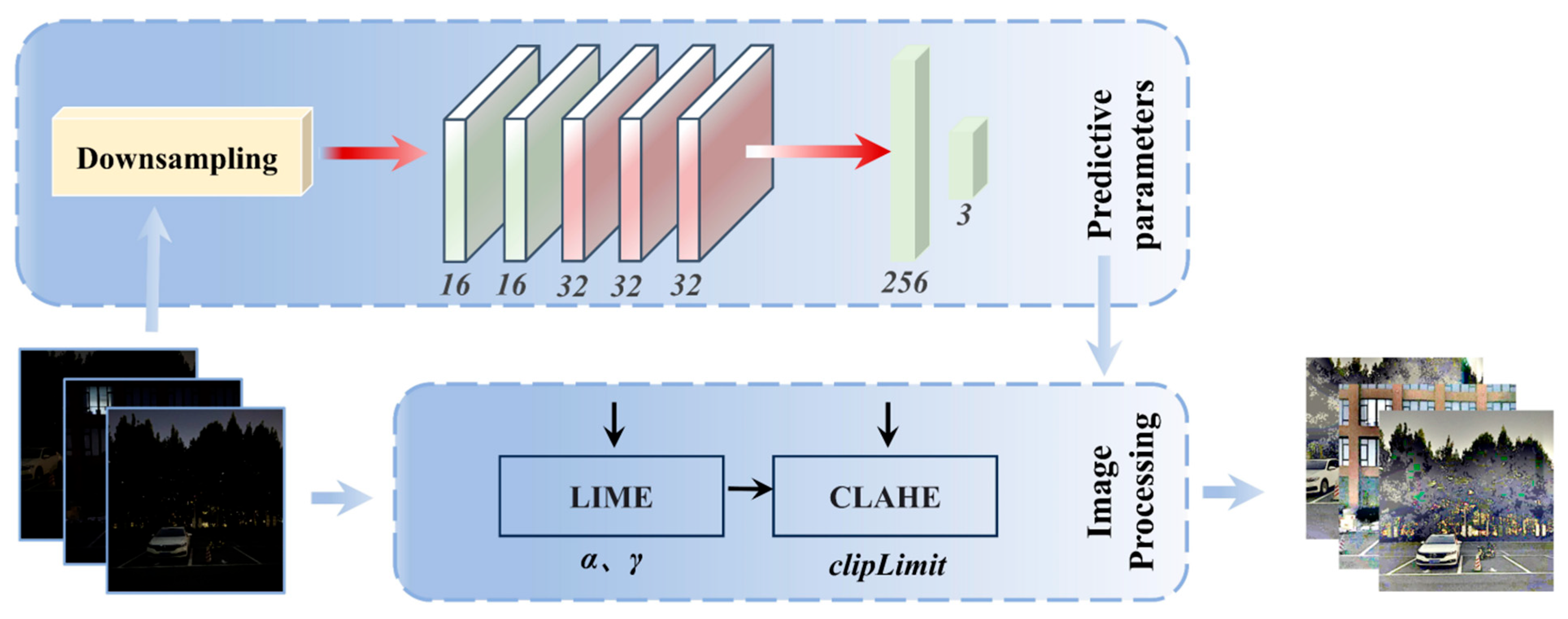
3.2. Image Adaptive Enhancement Module
| Algorithm 2: LIME | |
| 1: | Input: Low-illumination image L, adjustment coefficient α, brightness parameter γ |
| 2: | Output: Enhanced result M |
| 3: | Initialization: |
| 4: | W ← Construct_Weight_Matrix( ) |
| 5: | Step 1: Estimate initial luminance map Ti |
| 6: | Ti(x)←max Lc(x),c∈{R,G,B} |
| 7: | Step 2: Refine luminance map T using an exact solver algorithm |
| 8: | T←Refine_Luminance_Map(Ti) |
| 9: | Step 3: Apply gamma correction to T |
| 10: | T←Tγ |
| 11: | Step 4: Enhance L using T |
| 12: | M ← Enhance_Image(L, T) |
| 13: | Return M |
3.3. Improvement of Multi-Scale Feature Fusion
- (a)
- Adding bi-directional paths: By introducing bi-directional connections in feature pyramid networks at different scales, information exchange and fusion across layers are realized. This bi-directional connectivity is not limited to simple top-down and bottom-up paths but is more flexible and efficient in that each bi-directional path is considered as a feature network layer and can be repeated many times to achieve higher-level feature fusion [32].
- (b)
- Add weight learning module: At each feature fusion node, a weight learning module is added. This module learns the weights of each layer of features through convolutional operations and weights the features for fusion according to these weights so that the network can pay more attention to more informative features. The contribution of each level of features in the fusion process can be dynamically adjusted according to their importance, which makes the feature fusion more flexible and effective, improves the fusion effect, and further improves the accuracy of target detection.
- (c)
- Simplify feature fusion operations: Cross-scale connectivity is optimized by removing nodes with only one input edge, adding additional edges between input and output nodes in the same layer, and treating each bi-directional path as a feature network layer and repeating it multiple times. This simplified network structure and optimized cross-scale connectivity allow BiFPN to reduce computational complexity and increase detection speed while maintaining accuracy.
3.4. Joint Training
4. Tests and Analysis
4.1. Introduction to the Dataset and Test Environment
4.2. Parking Space Detection Experiment
- (a)
- Using the adaptive image enhancement method proposed in this paper, the parameters of the image enhancement algorithm can be adjusted adaptively in the face of different low-illumination conditions, and different degrees of enhancement can be achieved, so that the downstream parking space detection network achieves higher detection accuracy, significantly improves the detection performance, and obtains the highest accuracy of the detection of parking spaces.
- (b)
- After fusing the two algorithms for image enhancement, the parking space recognition accuracy is higher than that obtained by using a single image enhancement algorithm.
- (c)
- Although the average time consumed by the optimized algorithm during detection increases, real-time performance can still be guaranteed in low-speed scenarios of automatic parking.
4.3. Obstacle Detection Experiment
- (a)
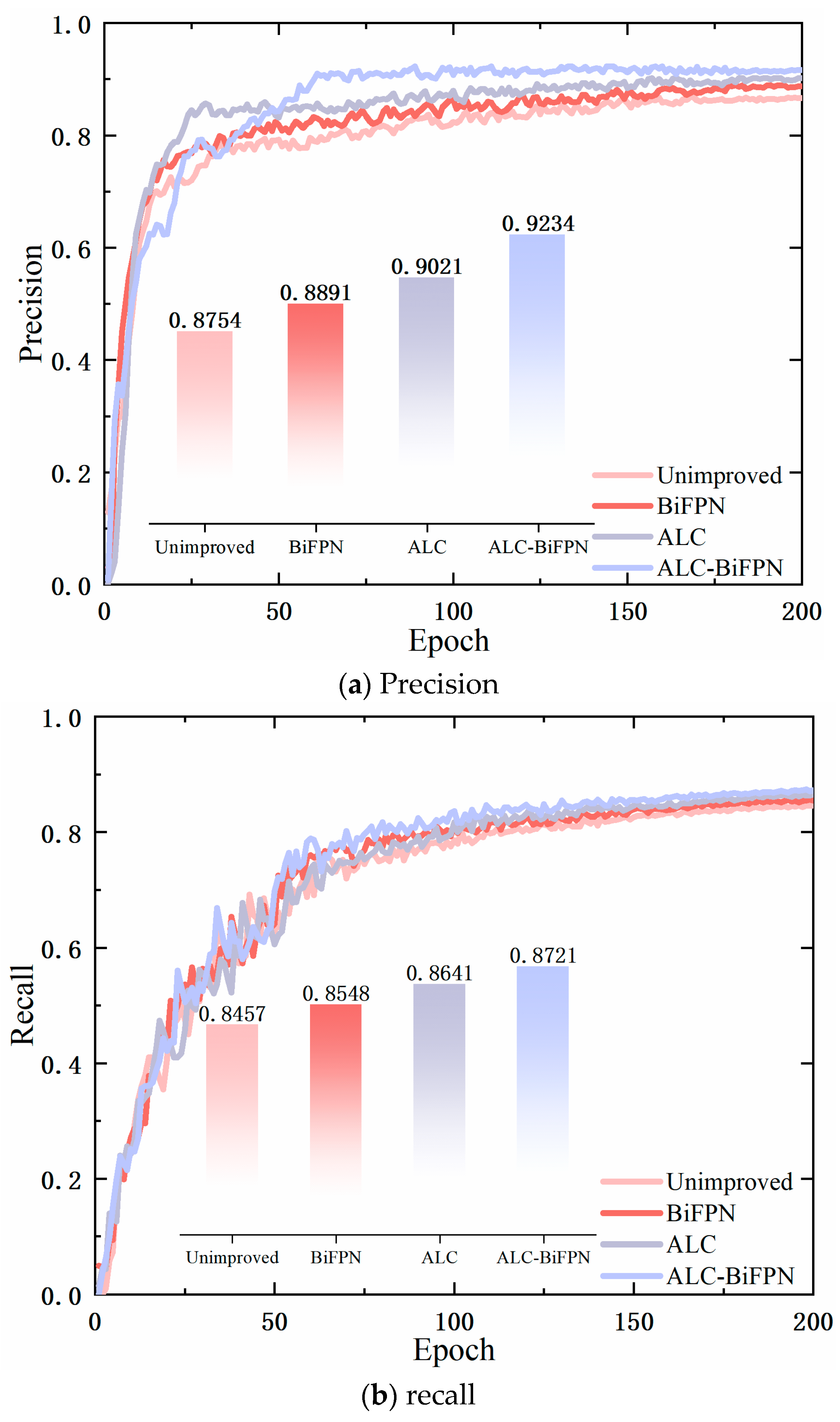
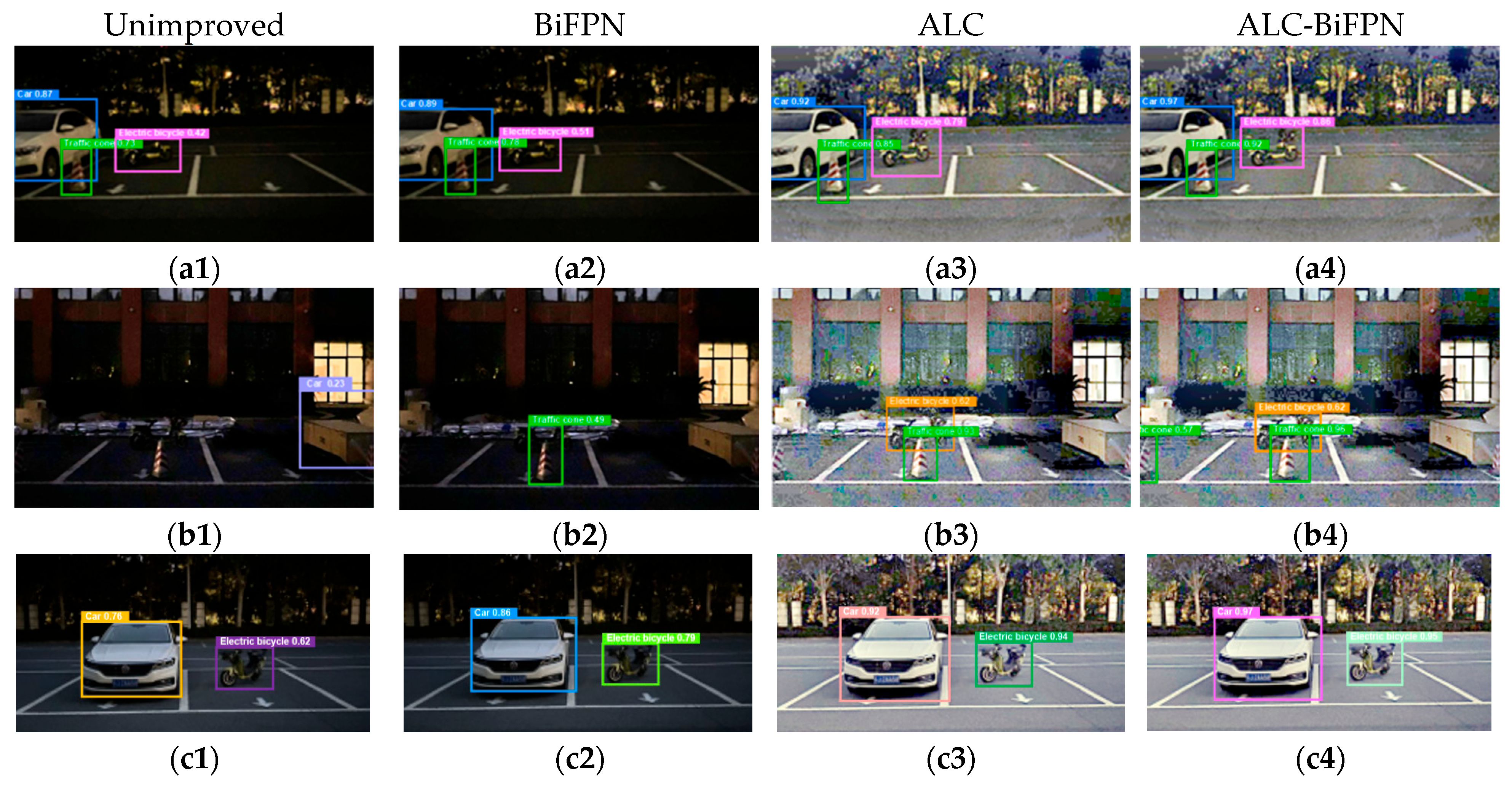
- In Experiment 2, the improvement in multi-scale feature fusion achieves a more comprehensive fusion of feature information and improves the network’s ability to capture the feature information of obstacles, and the mAP of obstacle detection is improved by 1.25%.
- (b)
- In Experiment 3, the image adaptive enhancement method proposed in this paper is used, which can adaptively adjust the parameters of the image enhancement algorithm when facing different low-illumination conditions, and the low-illumination image is adaptively enhanced, which improves the precision by 2.67%, the recall by 1.87%, and the mAP for obstacle detection by 2.95%, relative to the original network.
- (c)
- In Experiment 4, after simultaneously piggybacking the image adaptive enhancement method and the improvement strategy of multi-scale feature fusion into the network, the precision is improved by 4.8%, the recall is improved by 2.64%, and the mAP of obstacle detection is improved by 4.14%, which is significantly higher than that of both Experiment 3 with the image adaptive enhancement method alone and Experiment 2 with the improvement strategy of multi-scale feature fusion alone, which proves the effectiveness of the network improvement.
5. Conclusions
- (a)
- The method designs an image adaptive enhancement module, which consists of two parts: an adaptive parameter prediction module designed based on CNN and an image processing module fusing the LIME algorithm and the CLAHE algorithm, which enhances the image to different degrees by learning the global information of the input image.
- (b)
- The parking space and obstacle detection module of this method consists of two parts: parking space corner detection based on image gradient matching and parking scenario obstacle detection based on YOLOv5s. In this paper, the obstacle detection network is improved, and the original FPN structure is improved to a BiFPN structure, which enhances the feature fusion capability of the detection network when facing complex scenarios with the presence of multiple classes of detection targets.
- (c)
- The method cascades the image adaptive enhancement module with the parking space and obstacle detection module, and optimizes the prediction parameters of the image adaptive enhancement module, taking into account the weighted loss that comprises both the matching similarity loss of the corner of parking spaces and the loss of obstacle detection results to achieve the purpose of adaptive enhancement, and to make the effect of the image enhancement more conducive to the subsequent detection tasks.
- (d)
- In the task of detecting parking spaces and obstacles facing low illumination conditions, the method proposed in this paper has stronger robustness and higher detection accuracy compared to other detection methods. The experimental results on a merged parking scenario dataset show that the algorithm proposed in this paper achieves 95.46% recognition accuracy for parking spaces and 90.4% mean average precision for obstacles, which is better than the baseline algorithms. The research results of this paper have a certain significance for the development of automatic parking perception technology, and in our future work, we plan to add sensors such as LIDAR to increase the 3D spatial perception capability to improve the model’s performance in complex environments so that the model can be generalized to a wider range of unstructured environments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khalid, M.; Wang, K.; Aslam, N.; Cao, Y.; Ahmad, N.; Khan, M.K. From smart parking towards autonomous valet parking: A survey, challenges and future Works. J. Netw. Comput. Appl. 2021, 175, 102935. [Google Scholar] [CrossRef]
- Ayalew, W.; Menebo, M.; Merga, C.; Negash, L. Optimal path planning using bidirectional rapidly-exploring random tree star-dynamic window approach (BRRT*-DWA) with adaptive Monte Carlo localization (AMCL) for mobile robot. Eng. Res. Express 2024, 6, 035212. [Google Scholar] [CrossRef]
- Kedir, C.A.; Abdissa, C.M. PSO based linear parameter varying-model predictive control for trajectory tracking of autonomous vehicles. Eng. Res. Express 2024, 6, 035229. [Google Scholar] [CrossRef]
- Wendemagegn, Y.A.; Asfaw, W.A.; Abdissa, C.M.; Lemma, L.N. Enhancing trajectory tracking accuracy in three-wheeled mobile robots using backstepping fuzzy sliding mode control. Eng. Res. Express 2024, 6, 045204. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowl.-Based Syst. 2021, 213, 106617. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, C.; Wang, Y.; Ding, K.; Han, T.; Liu, H.; Tian, Y.; Xu, B.; Ju, M. Low Light Image Enhancement Based on Multi-Scale Network Fusion. IEEE Access 2022, 10, 127853–127862. [Google Scholar] [CrossRef]
- Huang, C.; Yang, S.; Luo, Y.; Wang, Y.; Liu, Z. Visual Detection and Image Processing of Parking Space Based on Deep Learning. Sensors 2022, 22, 6672. [Google Scholar] [CrossRef]
- Li, Y.; Mao, H.; Yang, W.; Guo, S.; Zhang, X. Research on Parking Space Status Recognition Method Based on Computer Vision. Sustainability 2023, 15, 107. [Google Scholar] [CrossRef]
- Ma, S.; Jiang, Z.; Jiang, H.; Han, M.; Li, C. Parking Space and Obstacle Detection Based on a Vision Sensor and Checkerboard Grid Laser. Appl. Sci. 2020, 10, 2582. [Google Scholar] [CrossRef]
- Mousania, Y.; Karimi, S.; Farmani, A. Optical remote sensing, brightness preserving and contrast enhancement of medical images using histogram equalization with minimum cross-entropy-Otsu algorithm. Opt. Quantum Electron. 2023, 55, 22. [Google Scholar] [CrossRef]
- Xiang, D.; Wang, H.H.; He, D.Y.; Zhai, C.K. Research on Histogram Equalization Algorithm Based on Optimized Adaptive Quadruple Segmentation and Cropping of Underwater Image (AQSCHE). IEEE Access 2023, 11, 69356–69365. [Google Scholar] [CrossRef]
- Yuan, Z.; Zeng, J.; Wei, Z.; Jin, L.; Zhao, S.; Liu, X.; Zhang, Y.; Zhou, G. CLAHE-Based Low-Light Image Enhancement for Robust Object Detection in Overhead Power Transmission System. IEEE Trans. Power Deliv. 2023, 38, 2240–2243. [Google Scholar] [CrossRef]
- Oishi, S.; Fukushima, N. Retinex-Based Relighting for Night Photography. Appl. Sci. 2023, 13, 19. [Google Scholar] [CrossRef]
- Zhou, F.; Sun, X.; Dong, J.Y.; Zhu, X.X. SurroundNet: Towards effective low-light image enhancement. Pattern Recognit. 2023, 141, 12. [Google Scholar] [CrossRef]
- Li, J.F.; Hao, S.; Li, T.S.; Zhuo, L.; Zhang, J. RDMA: Low-light image enhancement based on retinex decomposition and multi-scale adjustment. Int. J. Mach. Learn. Cybern. 2024, 15, 1693–1709. [Google Scholar] [CrossRef]
- Zhao, Z.J.; Xiong, B.S.; Wang, L.; Ou, Q.F.; Yu, L.; Kuang, F. RetinexDIP: A Unified Deep Framework for Low-Light Image Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1076–1088. [Google Scholar] [CrossRef]
- Liu, J.Y.; Xu, D.J.; Yang, W.H.; Fan, M.H.; Huang, H.F. Benchmarking Low-Light Image Enhancement and Beyond. Int. J. Comput. Vis. 2021, 129, 1153–1184. [Google Scholar] [CrossRef]
- Li, C.Y.; Guo, C.L.; Loy, C.C. Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4225–4238. [Google Scholar] [CrossRef]
- Pan, Y.N.; Li, Y.; Jin, J. Design and Implementation of Fully Convolutional Network Algorithm in Landscape Image Processing. Wirel. Commun. Mob. Comput. 2022, 2022, 9. [Google Scholar] [CrossRef]
- Li, X.F.; Wang, W.W.; Feng, X.C.; Li, M. Deep parametric Retinex decomposition model for low-light image enhancement. Comput. Vis. Image Underst. 2024, 241, 14. [Google Scholar] [CrossRef]
- Shih, S.E.; Tsai, W.H. A Convenient Vision-Based System for Automatic Detection of Parking Spaces in Indoor Parking Lots Using Wide-Angle Cameras. IEEE Trans. Veh. Technol. 2014, 63, 2521–2532. [Google Scholar] [CrossRef]
- Suhr, J.K.; Jung, H.G. Automatic Parking Space Detection and Tracking for Underground and Indoor Environments. IEEE Trans. Ind. Electron. 2016, 63, 5687–5698. [Google Scholar] [CrossRef]
- Suhr, J.K.; Jung, H.G. Full-automatic recognition of various parking slot markings using a hierarchical tree structure. Opt. Eng. 2013, 52, 14. [Google Scholar] [CrossRef]
- Yang, C.F.; Ju, Y.H.; Hsieh, C.Y.; Lin, C.Y.; Tsai, M.H.; Chang, H.L. iParking—A real-time parking space monitoring and guiding system. Veh. Commun. 2017, 9, 301–305. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhao, K.; Ren, X.X.; Kong, Z.Z.; Liu, M. Object detection on remote sensing images using deep learning: An improved single shot multibox detector method. J. Electron. Imaging 2019, 28, 7. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 25. [Google Scholar] [CrossRef]
- Huang, J.; Yang, F.; Chai, L. Multimodal Remote Sensing Image Registration Based on Adaptive Spectrum Congruency. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 14965–14981. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, T.; Yin, X.; Wang, X.; Zhang, K.; Xu, J.; Wang, D. An improved parking space recognition algorithm based on panoramic vision. Multimed. Tools Appl. 2021, 80, 18181–18209. [Google Scholar] [CrossRef]
- Guo, X.J.; Li, Y.; Ling, H.B. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tang, H.; Xu, X.; Xu, H.; Liu, S.; Ji, J.; Qiu, C.; Shen, Y. Lightweight ViT with Multiscale Feature Fusion for Driving Risk Rating Warning System. Adv. Theory Simul. 2024, 7, 2400586. [Google Scholar] [CrossRef]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the exclusively dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Y.; He, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv5-Fog: A Multiobjective Visual Detection Algorithm for Fog Driving Scenes Based on Improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 2515612. [Google Scholar] [CrossRef]
- Mai, J.W.; Li, H.; Kang, Y. Low-Light Object Detection Based on Feature Interaction Structure. Comput. Eng. Appl. 2024, 60, 224–232. [Google Scholar]
- Jiang, Z.; Xiao, Y.; Zhang, S.; Zhu, L.; He, Y.; Zhai, F. Low-Illumination Object Detection Method Based on Dark-YOLO. J. Comput. Aided Des. Comput. Grap 2023, 35, 441–451. [Google Scholar]
- Zhang, L.; Huang, J.; Li, X.; Xiong, L. Vision-based parking-slot detection: A DCNN-based approach and a large-scale benchmark dataset. IEEE Trans. Image Process. 2018, 27, 5350–5364. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodologies | MSE | PSNR | SSIM |
|---|---|---|---|
| LIME | 2.37 | 37.546 | 0.6458 |
| LIME + CLAHE | 0.5623 | 44.657 | 0.8046 |
| Methodologies | Average Elapsed Time/ms | Recognition Accuracy/% |
|---|---|---|
| LIME | 13.255 | 86.97 |
| CLAHE | 12.267 | 84.63 |
| LIME + CLAHE | 14.531 | 90.45 |
| ALC | 15.142 | 95.46 |
| Arithmetic | Number of Participants/106 | FLOPs/109 | Average Elapsed Time/ms | mAP/% |
|---|---|---|---|---|
| YOLOv5s | 7.02 | 15.82 | 9.80 | 86.32 |
| SSD | 138.36 | 15.47 | 15.63 | 76.0 |
| YOLOv5-Fog | 15.18 | 589.29 | 47.62 | 85.2 |
| FISNet | 47.0 | - | - | 88.3 |
| Dark-YOLO | - | - | - | 84.8 |
| ALC-BiFPN | 12.91 | 24.15 | 18.18 | 90.46 |
| Serial Number | Improvement Strategies | P/% | R/% | mAP/% | Number of Participants/106 | FLOPs/109 | Average Elapsed Time/ms | |
|---|---|---|---|---|---|---|---|---|
| ALC | BiFPN | |||||||
| 1 | 87.54 | 84.57 | 86.32 | 7.02 | 15.82 | 9.80 | ||
| 2 | √ | 88.91 | 85.48 | 87.57 | 8.97 | 18.63 | 10.36 | |
| 3 | √ | 90.21 | 86.41 | 89.72 | 10.76 | 21.02 | 8.34 | |
| 4 | √ | √ | 92.34 | 87.21 | 90.46 | 12.91 | 24.15 | 18.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, X.; Zhang, M.; Tang, H.; Xu, W.; Sun, B.; Zheng, Z. Low-Illumination Parking Scenario Detection Based on Image Adaptive Enhancement. World Electr. Veh. J. 2025, 16, 305. https://doi.org/10.3390/wevj16060305
Xu X, Zhang M, Tang H, Xu W, Sun B, Zheng Z. Low-Illumination Parking Scenario Detection Based on Image Adaptive Enhancement. World Electric Vehicle Journal. 2025; 16(6):305. https://doi.org/10.3390/wevj16060305
Chicago/Turabian StyleXu, Xixi, Meiqi Zhang, Hao Tang, Weiye Xu, Bowen Sun, and Zhu’an Zheng. 2025. "Low-Illumination Parking Scenario Detection Based on Image Adaptive Enhancement" World Electric Vehicle Journal 16, no. 6: 305. https://doi.org/10.3390/wevj16060305
APA StyleXu, X., Zhang, M., Tang, H., Xu, W., Sun, B., & Zheng, Z. (2025). Low-Illumination Parking Scenario Detection Based on Image Adaptive Enhancement. World Electric Vehicle Journal, 16(6), 305. https://doi.org/10.3390/wevj16060305