
Survey on Image-Based Vehicle Detection Methods



Abstract
1. Introduction
2. Vehicle Detection Methods
2.1. Classical Vehicle Detection Methods
2.1.1. Feature Extraction Techniques
- Haar-like FeaturesHaar-like features are simple rectangular features used to detect edges, lines, and other visual patterns by computing the difference in pixel intensities between adjacent regions [31]. These features are particularly effective for capturing structural cues in vehicle shapes. The Haar-like feature F is calculated as follows:where denotes the pixel intensity at coordinate , and W and B represent the white and black rectangular regions, respectively. These features are evaluated across different scales and positions using an integral image for efficient computation. They are often combined with classifiers such as AdaBoost in early vehicle detection systems. Figure 4 illustrates typical Haar-like patterns used in vehicle detection tasks.
- HOG Feature ExtractionIn 2005, Dalal and Triggs [32] introduced the Histogram of Oriented Gradients (HOG), a descriptor that captures local object appearance and shape by encoding the distribution of intensity gradients or edge directions. HOG is particularly effective for detecting rigid objects such as vehicles, where edge and contour structures are prominent. The image is divided into small cells, and each cell’s histogram bins gradient orientations into predefined angle ranges (e.g., 0–180°), weighted by gradient magnitude. First, gradient magnitude and orientation are computed as follows:where and are the horizontal and vertical gradients, respectively.The image is then divided into cells, and orientation histograms are computed for each. These histograms are normalized over larger spatial blocks to improve invariance to illumination and contrast. The block normalization of the feature vector v is using L2-norm, is defined as follows:HOG features are widely used in vehicle detection systems due to their robustness in capturing structural information while being relatively efficient to compute.
- LBP Feature ExtractionLocal Binary Patterns (LBP) encode local texture patterns by comparing each pixel to its surrounding neighbors, making it robust to lighting variations. However, it is generally less effective in scenes with complex backgrounds or non-uniform textures [33].The LBP descriptor is defined as follows:where is the intensity of the center pixel, denotes the intensity of the neighboring pixel, P is the number of sampling points, and R is the radius of the neighborhood. The thresholding function is given by the following:The resulting binary values are combined into a single integer, forming a compact descriptor that captures local texture information. LBP is computationally efficient and suitable for real-time vehicle detection in well-lit environments.
- SIFT DetectionSIFT extracts local features from input images, ensuring invariance to scale and orientation. It identifies key points, such as edges and corners, using a Difference-of-Gaussian (DoG) filter across multiple scales. It then refines these key points and computes descriptors based on gradient orientation histograms within their neighborhoods [34]. It is a robust feature extraction method used to identify distinctive keypoints that remain invariant to scale, rotation, and illumination changes. The initial step involves computing the Difference of Gaussians (DoG) to detect potential keypoints:where denotes a Gaussian kernel with standard deviation , k is a scale multiplier, and is the input image. Following the DoG computation, SIFT performs keypoint localization, assigns orientations based on local gradient distributions, and generates a descriptor vector that encodes the spatial structure of gradients around each keypoint. These descriptors make SIFT particularly effective for detecting vehicles across varying scales, perspectives, and lighting conditions. While SIFT is computationally intensive, it remains influential for scale-invariant detection tasks.
2.1.2. Classical Classification Algorithms
- Support Vector Machine (SVM)The core concept of SVM is to identify an optimal hyperplane in a multidimensional feature space that best separates data points belonging to different classes [35]. This hyperplane serves as a decision boundary, partitioning the feature space into regions predominantly associated with one class or another. In vehicle detection, SVM is commonly trained to distinguish between vehicles (positive class) and non-vehicles (negative class).The optimal hyperplane is chosen to maximize the margin—the distance between the hyperplane and the nearest data points from each class (support vectors). When data are not linearly separable, SVM applies the kernel trick to map the input data into a higher-dimensional space where linear separation becomes feasible [36]. This enables SVM to handle non-linear classification tasks effectively. Variants of SVM include LSVM (Least Squares SVM), NLSVM (Non-Linear SVM), SSVM (Structural SVM), and NSVM (Normalized SVM), each offering specific adaptations for different data characteristics. A linear decision function can be expressed as follows:where w is the weight vector, I is the input feature vector, and b is the bias term.
- Adaptive Boosting (AdaBoost)AdaBoost is a powerful ensemble learning algorithm widely used in object detection, image classification, and other pattern recognition tasks [37]. The key idea is to combine multiple weak classifiers—each performing only slightly better than random guessing—into a single strong classifier with high accuracy. AdaBoost operates in a sequential manner, training each weak learner on the weighted version of the dataset. After each iteration, the weights of the misclassified examples are increased, forcing the next weak learner to focus more on the harder examples [38]. Correctly classified samples are assigned lower weights, reducing their influence in subsequent iterations. This adaptive re-weighting process ensures that the final ensemble is more focused on the difficult cases. Even if individual weak classifiers perform poorly, the combined model weighted by the accuracy of each learner can achieve excellent performance [39]. The sample weight update rule is the following:where is the weight of sample i at iteration t, is the true label, is the prediction from the weak learner, and is a normalization factor.Each weak learner is assigned a weight based on its classification error:where is the error rate of the weak classifier.The final strong classifier is defined as follows:where is the final strong classifier, T is the total number of weak classifiers, is the weight assigned to the weak classifier based on its accuracy, is the prediction of the weak classifier, and is the sign function that returns if the argument is positive and otherwise.
2.1.3. Motion-Based Vehicle Detection
- Techniques and AlgorithmsSeveral classical algorithms implement motion-based detection. Lefaix et al. [49] proposed a system that models dominant image motion, typically resulting from the ego-motion of a moving camera, and detects vehicles as motion outliers. This method also enables time-to-collision (TTC) estimation by analyzing the divergence of flow vectors. Some recent approaches explore the use of optical flow and epipolar geometry constraints to enhance motion sensitivity for detecting overtaking vehicles or lane changes. Techmer [50] introduced a real-time segmentation algorithm that tracks motion along pre-defined lane contours. This method simplifies the segmentation task by focusing only on relevant motion direction, making it both efficient and resistant to lighting variation.
- Applications and AdvantagesMotion-based techniques are widely used in:
- -
- Speed estimation and violation detection in traffic surveillance [51].
- -
- Lightweight embedded systems with limited computational capacity.
- -
- Challenging environments such as nighttime driving or adverse weather conditions.
These methods typically require fewer computational resources and are more resilient to occlusion and appearance variation than purely appearance-based approaches. For example, Jazayeri et al. [52] applied a Hidden Markov Model (HMM) to classify motion traces over time, achieving reliable vehicle detection in complex, cluttered scenes. - Challenges Despite their advantages, motion-based approaches have several limitations:
- -
- Susceptibility to false positives caused by camera shake or ego-motion instability.
- -
- Difficulty separating multiple vehicles moving in the same direction or at similar speeds.
- -
- Ineffectiveness in detecting stationary or parked vehicles.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Representative Techniques | References |
|---|---|---|
| Appearance-Based | HOG, LBP, SIFT, Haar + AdaBoost, Viola-Jones | [40,41,43,44] |
| Motion-Based | Background subtraction, Optical flow, Contour tracking, HMM | [42,47,49,50,52] |
| Hybrid/Heuristic | Pixel-based analysis, Hough + Haar-like, Shadow filtering | [46,48] |
2.1.4. Summary of Classical Vehicle Detection Methods
2.2. Deep Learning-Based Vehicle Detection Methods
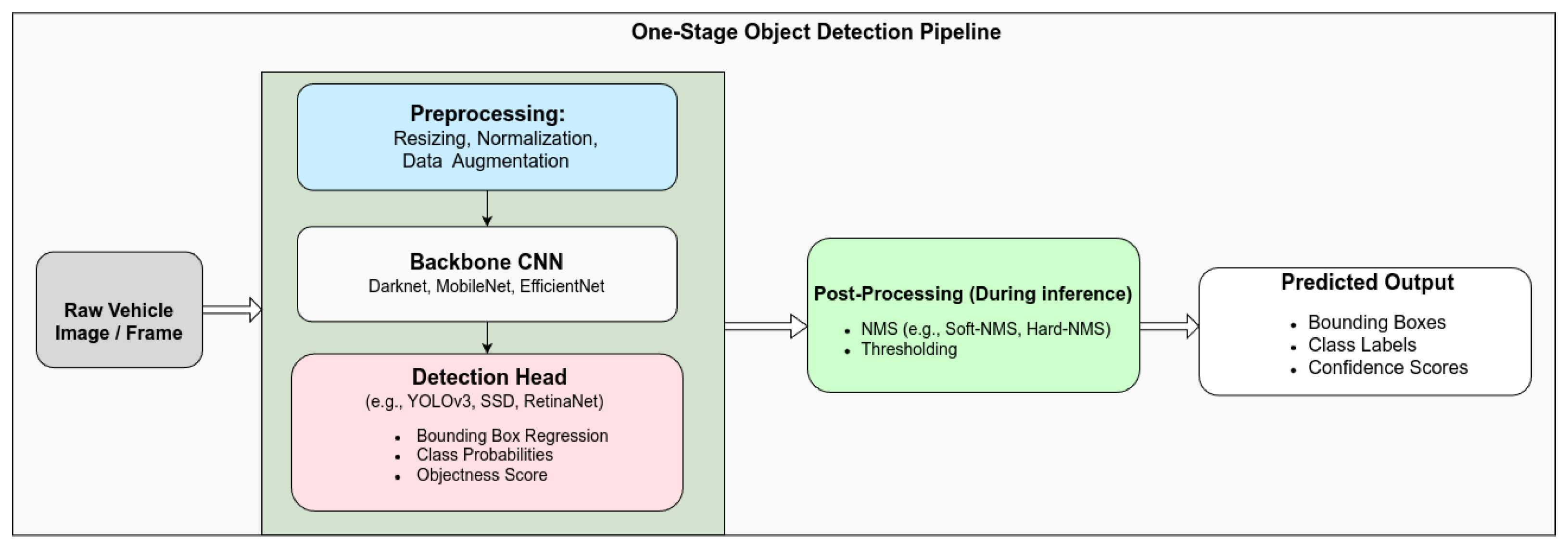
2.2.1. One-Stage Detectors
- YOLO Series AlgorithmsObject detection in real-time applications requires high-speed, accurate algorithms. YOLO (You Only Look Once) was introduced to meet real-time processing demands, with YOLOv1 [23] pioneering the first one-stage object detection algorithm. This series, including YOLO versions 2 and 3 [24,25], opened new opportunities for vehicle detection. Significant improvements have continued with YOLOv4 [59], YOLOv5 [65], YOLOv6 [26], YOLOv7 [27], YOLOX [66], PP-YOLOE [67], and the latest versions of YOLO including YOLOv8, YOLOv9, and YOLOv10 [68,69,70]. The YOLO architecture typically comprises the following three key components:
- -
- Backbone: Responsible for extracting low-level and high-level visual features from the input image.
- -
- Neck: Connects the backbone to the head and enhances spatial and semantic information across different scales using feature fusion modules such as PANet, BiFPN, or path aggregation blocks.
- -
- Head: Generates output predictions, including object classification, bounding box regression, instance segmentation, or pose estimation. Non-maximum suppression (NMS) is applied post-processing to remove redundant overlapping boxes.
Over the years, the YOLO series has evolved significantly, from YOLOv1 to the most recent YOLOv12 [65,68,69,70,71,72], with progressive improvements in accuracy, speed, and computational efficiency. These advances have made YOLO models increasingly suitable for real-time applications on edge devices. Table 3 and Figure 7 summarize the architectural progression across different YOLO versions. - Single Shot MultiBox Detector (SSD) algorithm [60] employs a feed-forward convolutional network to generate a fixed set of bounding boxes and confidence scores for object classes within those boxes. A non-maximum suppression step is then applied to refine the final detections. The SSD algorithm comprises two main components: the first extracts feature maps using the VGG16 network [73], and the second uses convolutional filters for object detection. As a one-stage object detection algorithm, SSD achieved a mean average precision (mAP) of 76.8 % on Pascal VOC 2007 at a speed of 19 frames per second (FPS), making it well-suited for real-time object detection due to its faster performance compared to two-stage algorithms. However, its accuracy is lower than those of two-stage detectors such as the Faster R-CNN series. Several lightweight backbone networks [74,75,76] have been developed to enhance the SSD algorithm’s Backbone. For instance, Chen et al. [77] optimized the SSD model to improve vehicle detection speed. They introduced an attention mechanism and bottom-up feature fusion using a deconvolution module by replacing VGG16 with MobileNetv2 [76] as the Backbone for feature extraction. Similarly, Zhang et al. [78] proposed an improved SSD-based model that enhances vehicle detection performance, enabling real-time detection of various types of vehicles. Table 3 provides a summary of different one-step approaches for vehicle detection tasks.SSD [60], originally built on VGG16, has benefited from lightweight backbones like MobileNet [76]. Enhancements such as attention modules and multi-scale feature layers have further improved detection accuracy [77,78]. Anchor-free methods like FCOS and CenterNet [79,80] remove the need for manually designed anchor boxes, simplifying training, which significantly enhances inference speed—an essential requirement for autonomous driving systems that rely on real-time perception.
2.2.2. Transformer-Based Methods
2.2.3. Gan-Based Methods
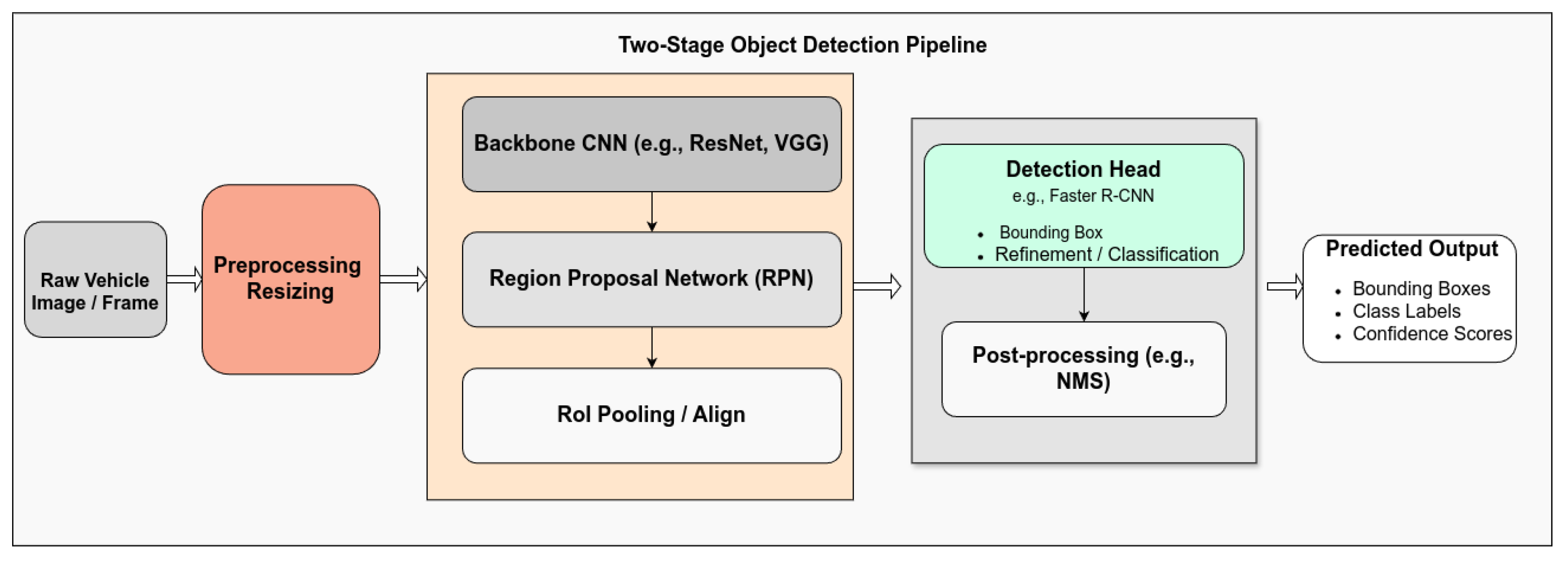
2.2.4. Two-Stage Detectors
2.2.5. Summary of Deep Learning Vehicle Detection Method
3. Application Areas
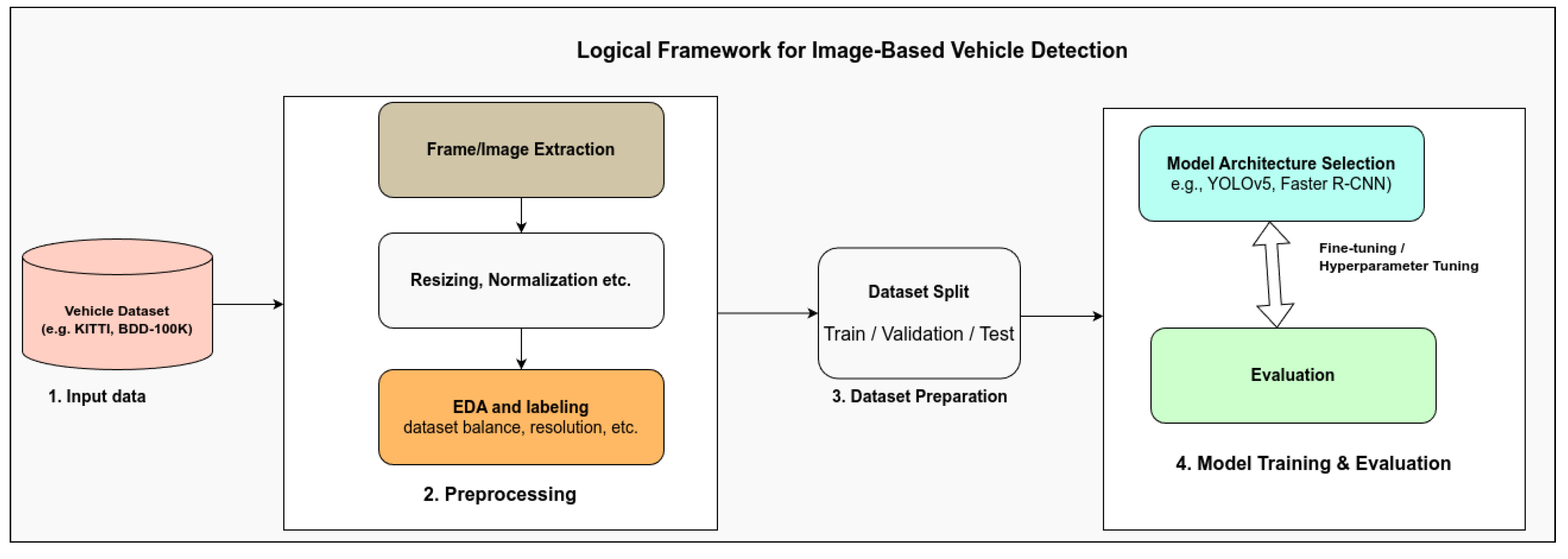
4. Datasets for Vehicle Detection Models Design
- Pascal VOC [117]: A foundational dataset with 20 object categories, including vehicles like cars, buses, bicycles, and motorcycles. It was used in early versions of YOLO (v1 and v2) and supports tasks such as object detection, segmentation, and classification.
- MS COCO [119]: A large-scale benchmark containing 91 object classes with five dedicated vehicle categories. It is widely used for training state-of-the-art models such as Faster R-CNN and the YOLO series.
- BDD100K [120]: A diverse driving dataset with 100,000 video clips captured under varied conditions. It includes ten classes and supports multiple tasks, including detection, segmentation, and lane marking. It is suitable for complex real-world driving environments.
- KITTI [121]: A widely used dataset for autonomous driving, providing both 2D and 3D annotations for object detection, tracking, and stereo vision. It includes real-world traffic scenes captured from a moving vehicle.
- Boxy Vehicle Detection [122]: One of the largest public datasets for freeway vehicle detection, containing 200,000 annotated images. It covers various weather conditions, traffic densities, and vehicle types, supporting large-scale training and evaluation.
5. Evaluation Metrics
- Precision (P): Measures the proportion of correctly predicted positive detections:where is the number of true positives and the number of false positives.
- Recall (R): Indicates the proportion of actual positives that are correctly detected:where denotes the number of false negatives.
- Intersection over Union (IoU): Represents the ratio of the overlap between predicted and ground truth bounding boxes to their union:where is the predicted bounding box and is the ground truth box. A detection is considered correct if IoU exceeds a predefined threshold (e.g., 0.5).
- Average Precision (AP): Quantifies the area under the precision-recall curve for a given class:where is the precision at recall level r. It captures the trade-off between precision and recall across different confidence scores.
- Mean Average Precision (mAP): The average of AP values over all object classes:where N is the number of classes and is the AP for class i. mAP is widely used to compare detection models comprehensively.
Model Optimization for Extreme Real-World Conditions
- Lightweight Backbone Integration: Efficient architectures such as MobileNet and GhostNet are increasingly adopted to enhance computational efficiency without significantly compromising detection accuracy. Models like MobileNet-SSDv2 deliver fast inference on embedded platforms with low power consumption [124]. Similarly, GhostNet-based variants, including GhostNet-SSD [125] and GS-YoloNet [126], reduce redundant computation by generating ghost feature maps, preserving spatial richness.
- Multi-Feature Fusion and Attention Mechanisms: Architectures such as SYGNet employ semantic-visual-guided GhostNet-YOLO to improve real-time detection in occluded or cluttered driving scenarios by fusing spatial and contextual information [127]. GS-YoloNet further enhances robustness using GhostShuffle and attention-based fusion techniques [126].
- Hybrid Architecture Strategies: Combining YOLOv4 with EfficientDet modules has shown improved detection performance under lighting variation and visual clutter. This is achieved through BiFPN and compound scaling, which balance detection accuracy and computational efficiency [8].
- Hardware-Aware Acceleration: TensorRT-optimized models such as YOLOv8-QSD demonstrate exceptional performance in low-light and small-object scenarios by leveraging quadrant spatial distribution encoding and depth-aware feature fusion [128].
- Backbone Benchmarking for Deployment: Comparative studies highlight that lightweight backbones (e.g., MobileNet) offer favorable trade-offs over heavier ones (e.g., ConvNeXt) in terms of speed, energy efficiency, and accuracy for edge deployments in vehicle detection tasks [129].
6. Challenges and Future Research Directions
- Dataset and Annotation Quality: Accurate and diverse labeling is essential for training effective vehicle detection models. Labeling errors or imbalances—particularly in single-stage detectors—can lead to biased learning and degraded performance [78].
- Complex Traffic Scenarios: Real-world traffic involves frequent occlusions, scale variations, and overlapping vehicles. Recent studies show that attention mechanisms—including spatial, channel-wise, and transformer-based—substantially improve robustness in these scenarios. Transformer models like RT-DETR and ViT variants capture long-range dependencies, while convolutional attention modules enhance feature discrimination in cluttered scenes [12,18,81,82].
- Environmental Variability: Illumination changes, shadows, and adverse weather (e.g., fog, rain) remain major obstacles. Solutions include synthetic data augmentation, domain adaptation, and deep sensor fusion techniques, which improve detection reliability under degraded visual conditions [130,131].
- Resource-Constrained Deployment: Real-time applications, particularly on UAVs or embedded systems, demand high efficiency. Lightweight models (e.g., YOLOv5, YOLOv6) combined with model compression techniques—such as pruning and quantization—are actively explored to address these constraints [88].
- Integration with V2X Communication: The integration of detection systems with Vehicle-to-Everything (V2X) networks can enhance cooperative perception and situational awareness. Future work should explore detection architectures capable of leveraging shared sensor data across connected vehicles and infrastructure [110]. Such multi-agent cooperation frameworks, as discussed in [11], depend critically on the reliability and timeliness of vehicle detection outputs, underscoring the importance of accurate, low-latency perception in MAS-based driving environments.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, Y.; Guo, Z.; Yu, H.; Zhao, Y. Real-time vehicle detection based on an improved YOLO model. Electronics 2020, 9, 583. [Google Scholar] [CrossRef]
- Kadim, Z.; Johari, K.M.; Samaon, D.F.; Li, Y.S.; Hon, H.W. Real-Time Deep-Learning Based Traffic Volume Count for High-Traffic Urban Arterial Roads. In Proceedings of the 2020 IEEE 10th Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang, Malaysia, 18–19 April 2020; pp. 53–58. [Google Scholar] [CrossRef]
- Liang, S.; Wu, H.; Zhen, L.; Hua, Q.; Garg, S.; Kaddoum, G.; Hassan, M.M.; Yu, K. Edge YOLO: Real-Time Intelligent Object Detection System Based on Edge-Cloud Cooperation in Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25345–25360. [Google Scholar] [CrossRef]
- Sun, Z.; Bebis, G.; Miller, R. On-road vehicle detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 694–711. [Google Scholar] [CrossRef]
- Shubho, F.H.; Iftekhar, F.; Hossain, E.; Siddique, S. Real-time traffic monitoring and traffic offense detection using YOLOv4 and OpenCV DNN. In Proceedings of the TENCON 2021—IEEE Region 10 Conference (TENCON), Auckland, New Zealand, 7–10 December 2021; pp. 46–51. [Google Scholar] [CrossRef]
- Liang, J.; Yang, K.; Tan, C.; Wang, J.; Yin, G. Enhancing High-Speed Cruising Performance of Autonomous Vehicles Through Integrated Deep Reinforcement Learning Framework. IEEE Trans. Intell. Transp. Syst. 2024, 26, 835–848. [Google Scholar] [CrossRef]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An Effective and Efficient Object Detector for Autonomous Driving. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Rajan, V.A.; Sakhamuri, S.; Nayaki, A.P.; Agarwal, S.; Aeron, A.; Lawanyashri, M. Optimizing Object Detection Efficiency for Autonomous Vehicles through the Integration of YOLOv4 and EfficientDet Algorithms. In Proceedings of the 2024 International Conference on Trends in Quantum Computing and Emerging Business Technologies (TQCEBT), Pune, India, 22–23 March 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Qiu, L. Real-Time Traffic Sign Detection System for Autonomous Driving Based on YOLO Algorithm. In Proceedings of the 2024 Cross Strait Radio Science and Wireless Technology Conference (CSRSWTC), Fuzhou, China, 19–21 April 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Sarda, A.; Dixit, S.; Bhan, A. Object Detection for Autonomous Driving Using YOLO (You Only Look Once) Algorithm. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 March 2021; pp. 1370–1374. [Google Scholar] [CrossRef]
- Liang, J.; Li, Y.; Yin, G.; Xu, L.; Lu, Y.; Feng, J.; Shen, T.; Cai, G. A MAS-Based Hierarchical Architecture for the Cooperation Control of Connected and Automated Vehicles. IEEE Trans. Veh. Technol. 2023, 72, 1559–1573. [Google Scholar] [CrossRef]
- Wang, B.; Wu, J.; Li, Q.; Huang, Y. A high-precision vehicle detection and tracking method based on the attention mechanism. Sensors 2023, 23, 1223. [Google Scholar] [CrossRef]
- Ammar, A.I.; Almazroi, A.A.; Alsharif, M.H.; Alhabib, M.; Anwer, A.H. A multi-stage deep-learning-based vehicle and license plate recognition system with real-time edge inference. Electronics 2023, 12, 1164. [Google Scholar] [CrossRef]
- Berwo, M.; Dey, N.; Ashour, A.S. Deep learning techniques for vehicle detection and classification from images/videos: A survey. Int. J. Imaging Syst. Technol. 2023, 33, 124–145. [Google Scholar] [CrossRef]
- Ragab, M.; Mohamed, M.; Saeed, R.A. Improved deep learning-based vehicle detection for urban applications using remote sensing imagery. Remote Sens. 2023, 15, 2372. [Google Scholar] [CrossRef]
- Chen, J.; Xu, W.; Xu, H.; Lin, F.; Sun, Y.; Shi, X. Fast vehicle detection using a disparity projection method. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2801–2813. [Google Scholar] [CrossRef]
- Soviany, P.; Ionescu, R.T. Frustratingly Easy Trade-off Optimization between Single-Stage and Two-Stage Deep Object Detectors. In Proceedings of the ECCV Workshops; Springer: Munich, Germany, 2018; pp. 552–568. [Google Scholar]
- Zhang, Y.; Liu, S.; Liu, Z.; Wang, X.; Wu, Z. RT-DETR: Real-Time DETR with Efficient Attention and Prompt Training. arXiv 2024, arXiv:2409.08475. [Google Scholar]
- Zhou, X.; Zhang, H.; Wang, B.; Zhang, Z.; Zhang, H.; Yang, M.; Lu, C. RT-DETR v3: Scalable and Real-Time End-to-End Object Detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. I-511–I-518. [Google Scholar] [CrossRef]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep Learning Strong Parts for Pedestrian Detection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar] [CrossRef]
- Premaratne, P.; Kadhim, I.J.; Blacklidge, R.; Lee, M. Comprehensive Review on Vehicle Detection, Classification and Counting on Highways. Neurocomputing 2023, 556, 126627. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Ke, Z. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Han, S.; Han, Y.; Hahn, H. Vehicle detection method using Haar-like feature on real-time system. World Acad. Sci. Eng. Technol. 2009, 59, 455–459. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support vector machines for classification. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Apress: Berkeley, CA, USA, 2015; pp. 39–66. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Rätsch, G.; Onoda, T.; Müller, K.-R. Soft margins for AdaBoost. Mach. Learn. 2001, 42, 287–320. [Google Scholar] [CrossRef]
- Joshi, A.J.; Porikli, F. Scene-adaptive human detection with incremental active learning. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2760–2763. [Google Scholar]
- Haselhoff, A.; Kummert, A.; Schneider, G. Radar-vision fusion for vehicle detection by means of improved Haar-like feature and AdaBoost approach. In Proceedings of the 2007 15th European Signal Processing Conference, Poznań, Poland, 3–7 September 2007; pp. 2070–2074. [Google Scholar]
- Moranduzzo, T.; Melgani, F. A SIFT-SVM method for detecting cars in UAV images. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 6868–6871. [Google Scholar]
- Tang, Y.; Zhang, C.; Gu, R.; Li, P.; Yang, B. Vehicle detection and recognition for intelligent traffic surveillance system. Multimed. Tools Appl. 2017, 76, 5817–5832. [Google Scholar] [CrossRef]
- Ali, J.E.; Rahmat, R.A.O.K. Developing and validating a real-time video-based traffic counting and classification. J. Eng. Sci. Technol. 2017, 12, 3215–3225. [Google Scholar]
- Cao, X.; Wu, C.; Yan, P.; Li, X. Linear SVM classification using boosting HOG features for vehicle detection in low-altitude airborne videos. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2421–2424. [Google Scholar]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A hybrid vehicle detection method based on Viola-Jones and HOG + SVM from UAV images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef]
- Niknejad, H.T.; Takeuchi, A.; Mita, S.; McAllester, D. On-road multivehicle tracking using deformable object model and particle filter with improved likelihood estimation. IEEE Trans. Intell. Transp. Syst. 2012, 13, 748–758. [Google Scholar] [CrossRef]
- Chávez-Aragón, A.; Laganiere, R.; Payeur, P. Vision-based detection and labelling of multiple vehicle parts. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1273–1278. [Google Scholar]
- Fawzy, N.; Obaya, M.; Ata, M.M.; Yousif, B.; Samra, A.S. A novel video processing algorithm for accurate vehicle detection and tracking. In Proceedings of the 2021 International Telecommunications Conference (ITC-Egypt), Alexandria, Egypt, 13–15 July 2021; pp. 1–4. [Google Scholar]
- Sun, Z.; Bebis, G.; Miller, R. On-road vehicle detection using Gabor filters and support vector machines. In Proceedings of the 2002 14th International Conference on Digital Signal Processing (DSP 2002), Santorini, Greece, 1–3 July 2002; Volume 2, pp. 1019–1022. [Google Scholar]
- Lefaix, G.; Marchand, E.; Bouthemy, P. Motion-based obstacle detection and tracking for car driving assistance. In Proceedings of the 16th International Conference on Pattern Recognition (ICPR), Québec City, QC, Canada, 11–15 August 2002; Volume 4, pp. 74–77. [Google Scholar] [CrossRef]
- Techmer, A. Real-time motion-based vehicle segmentation in traffic lanes. In Pattern Recognition (DAGM 2001); Springer: Berlin/Heidelberg, Germany, 2001; Volume 2191, pp. 202–207. [Google Scholar] [CrossRef]
- Musa, S.; Saad, M.H.M.; Ahmad, R.B.; Azemi, S.N.A.M. Motion-Based Vehicle Detection in Hsuehshan Tunnel Surveillance Video. Int. J. Image Graph. Signal Process. 2019, 11, 34–45. [Google Scholar] [CrossRef]
- Jazayeri, A.; Cai, H.; Zheng, J.Y.; Tuceryan, M. Vehicle detection and tracking in car video based on motion model. IEEE Trans. Intell. Transp. Syst. 2011, 12, 583–595. [Google Scholar] [CrossRef]
- Chauhan, N.K.; Singh, K. A review on conventional machine learning vs deep learning. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 347–352. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ouyang, L.; Wang, H. Vehicle target detection in complex scenes based on YOLOv3 algorithm. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Hubei, China, 19–20 April 2019; Volume 569, p. 052018. [Google Scholar]
- Espinosa, J.E.; Velastin, S.A.; Branch, J.W. Vehicle detection using AlexNet and Faster R-CNN deep learning models: A comparative study. In Advances in Visual Informatics: 5th International Visual Informatics Conference, IVIC 2017, Bangi, Malaysia, 28–30 November 2017; Springer: Cham, Switzerland, 2017; pp. 3–15. [Google Scholar]
- Wu, Y.-Y.; Tsai, C.-M. Pedestrian, bike, motorcycle, and vehicle classification via deep learning: Deep belief network and small training set. In Proceedings of the 2016 International Conference on Applied System Innovation (ICASI), Okinawa, Japan, 28 May–1 June 2016; pp. 1–4. [Google Scholar]
- Taek Lee, J.; Chung, Y. Deep learning-based vehicle classification using an ensemble of local expert and global networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 47–52. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, K.; Gui, X. Research on real-time detection of road vehicle targets based on YOLOv4 improved algorithm. In Proceedings of the 2022 3rd International Conference on Electronic Communication and Artificial Intelligence (IWECAI), Zhuhai, China, 14–16 January 2022; pp. 243–246. [Google Scholar]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef]
- Wu, Z.; Sang, J.; Zhang, Q.; Xiang, H.; Cai, B.; Xia, X. Multi-scale vehicle detection for foreground-background class imbalance with improved YOLOv2. Sensors 2019, 19, 3336. [Google Scholar] [CrossRef] [PubMed]
- Jocher, G. Ultralytics YOLOv5; Version 7.0; Ultralytics: Frederick, MD, USA, 2020; AGPL-3.0 License; Available online: https://github.com/ultralytics/yolov5 (accessed on 27 May 2025). [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An Evolved Version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8, version 8.0.0. License: AGPL-3.0. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 April 2025).
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. YOLOv10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chen, Z.; Guo, H.; Yang, J.; Jiao, H.; Feng, Z.; Chen, L.; Gao, T. Fast vehicle detection algorithm in traffic scene based on improved SSD. Measurement 2022, 201, 111655. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, X. Vehicle detection in the aerial infrared images via an improved YOLOv3 network. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 372–376. [Google Scholar]
- Zhou, T.; Bai, Y.; Feng, X.; Sun, L.; Fang, Q. A feature enhancement FCOS algorithm for dynamic traffic object detection. Connect. Sci. 2023, 35, 2321345. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, B.; Qiu, H.; Zhang, Z.; Peng, J. CenterNet-Auto: A multi-object visual detection algorithm for autonomous driving scenes based on improved CenterNet. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 743–755. [Google Scholar] [CrossRef]
- Fahad, I.A.; Arean, A.I.H.; Ahmed, N.S.; Hasan, M. Automatic Vehicle Detection using DETR: A Transformer-Based Approach for Navigating Treacherous Roads. arXiv 2025, arXiv:2502.17843. [Google Scholar]
- Zong, Z.; Xu, Y.; Guo, C. Real-Time Transformer-Based Object Detection for Autonomous Driving. arXiv 2024, arXiv:2502.17843. [Google Scholar] [CrossRef]
- Sun, Z.; Liu, C.; Qu, H.; Xie, G. A novel effective vehicle detection method based on Swin Transformer in hazy scenes. Mathematics 2022, 10, 2199. [Google Scholar] [CrossRef]
- Dong, X.; Shi, P.; Tang, Y.; Yang, L.; Yang, A.; Liang, T. Vehicle classification algorithm based on improved vision transformer. World Electr. Veh. J. 2024, 15, 344. [Google Scholar] [CrossRef]
- Wang, J.-G.; Wan, K.-W.; Yau, W.-Y.; Pang, C.H.; Lai, F.L. VAGAN: Vehicle-aware generative adversarial networks for vehicle detection in rain. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 363–368. [Google Scholar]
- Lin, C.-T.; Huang, S.-W.; Wu, Y.-Y.; Lai, S.-H. GAN-based day-to-night image style transfer for nighttime vehicle detection. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1286–1295. [Google Scholar] [CrossRef]
- Zheng, K.; Wei, M.; Sun, G.; Anas, B.; Li, Y. Vehicle synthesis generative adversarial networks (VS-GANs) for improved object detection in remote sensing images. ISPRS Int. J. Geo-Inf. 2019, 8, 390. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Ruan, W.; Liu, Y. Lightweight detection method based on improved YOLOv4. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022; pp. 46–49. [Google Scholar]
- Ding, X.; Yang, R. Vehicle and parking space detection based on improved YOLO network model. J. Phys. Conf. Ser. 2019, 1325, 012084. [Google Scholar] [CrossRef]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 51. [Google Scholar] [CrossRef]
- Fan, Y.-C.; Yelamandala, C.M.; Chen, T.-W.; Huang, C.-J. Real-time object detection for LiDAR based on LS-R-YOLOv4 neural network. J. Sens. 2021, 2021, 5576262. [Google Scholar] [CrossRef]
- Uus, J.; Krilavicius, T. Detection of different types of vehicles from aerial imagery. In Proceedings of the IVUS, Kaunas, Lithuania, 25 April 2019; pp. 80–85. [Google Scholar]
- Huang, Y.-Q.; Zheng, J.-C.; Sun, S.-D.; Yang, C.-F.; Liu, J. Optimized YOLOv3 algorithm and its application in traffic flow detections. Appl. Sci. 2020, 10, 3079. [Google Scholar] [CrossRef]
- Karungaru, S.; Dongyang, L.; Terada, K. Vehicle detection and type classification based on CNN-SVM. Int. J. Mach. Learn. Comput. 2021, 11, 304–310. [Google Scholar] [CrossRef]
- Simony, M.; Milzy, S.; Amendey, K.; Gross, H.-M. Complex-YOLO: An euler-region-proposal for real-time 3D object detection on point clouds. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Davis, T.; Nandana, K.V. Real-time 3D object detection on LiDAR point cloud using Complex-YOLO v4. Int. Res. J. Eng. Technol. 2022, 9, 716–721. [Google Scholar]
- Yang, Z.; Li, J.; Li, H. Real-time pedestrian and vehicle detection for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 179–184. [Google Scholar]
- Xu, X.; Xiong, H.; Zhan, L.; Królczyk, G.; Stanislawski, R.; Gardoni, P.; Li, Z. A new deep model for detecting multiple moving targets in real traffic scenarios: Machine vision-based vehicles. Sensors 2022, 22, 3742. [Google Scholar] [CrossRef]
- Xiong, C.; Yu, A.; Yuan, S.; Gao, X. Vehicle detection algorithm based on lightweight YOLOX. Signal Image Video Process. 2023, 17, 1793–1800. [Google Scholar] [CrossRef]
- Li, X.; Liu, Y.; Zhao, Z.; Zhang, Y.; He, L. A deep learning approach of vehicle multitarget detection from traffic video. J. Adv. Transp. 2018, 2018, 7075814. [Google Scholar] [CrossRef]
- Yayla, R.; Albayrak, E.; Yuzgec, U. Vehicle detection from unmanned aerial images with deep Mask R-CNN. Comput. Sci. J. Mold. 2022, 89, 148–169. [Google Scholar] [CrossRef]
- Rujikietgumjorn, S.; Watcharapinchai, N. Vehicle detection with sub-class training using R-CNN for the UA-DETRAC benchmark. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–5. [Google Scholar]
- Hsu, S.-C.; Huang, C.-L.; Chuang, C.-H. Vehicle detection using simplified Fast R-CNN. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018; pp. 1–3. [Google Scholar]
- Ahmed, S.H.; Raza, M.; Mehdi, S.S.; Rehman, I.; Kazmi, M.; Qazi, S.A. Faster R-CNN based vehicle detection and counting framework for undisciplined traffic conditions. In Proceedings of the 2021 IEEE 18th International Conference on Smart Communities: Improving Quality of Life using ICT, IoT and AI (HONET), Karachi, Pakistan, 11–13 October 2021; pp. 173–178. [Google Scholar]
- Tu, C.; Du, S. A hierarchical RCNN for vehicle and vehicle license plate detection and recognition. Int. J. Electr. Comput. Eng. 2022, 12, 731. [Google Scholar] [CrossRef]
- Tsai, C.-C.; Tseng, C.-K.; Tang, H.-C.; Guo, J.-I. Vehicle detection and classification based on deep neural network for intelligent transportation applications. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1605–1608. [Google Scholar]
- Nguyen, H. Improving Faster R-CNN framework for fast vehicle detection. Math. Probl. Eng. 2019, 2019, 3808064. [Google Scholar] [CrossRef]
- Azimjonov, J.; Özmen, A. A real-time vehicle detection and a novel vehicle tracking system for estimating and monitoring traffic flow on highways. Adv. Eng. Inform. 2021, 50, 101393. [Google Scholar] [CrossRef]
- Wang, L.; Zhong, H.; Ma, W.; Abdel-Aty, M.; Park, J. How many crashes can connected vehicle and automated vehicle technologies prevent: A meta-analysis. Accid. Anal. Prev. 2020, 136, 105299. [Google Scholar] [CrossRef]
- Trivedi, J.D.; Mandalapu, S.D.; Dave, D.H. Vision-based real-time vehicle detection and vehicle speed measurement using morphology and binary logical operation. J. Ind. Inf. Integr. 2022, 27, 100280. [Google Scholar] [CrossRef]
- Rios-Cabrera, R.; Tuytelaars, T.; Van Gool, L. Efficient Multi-Camera Vehicle Detection, Tracking, and Identification in a Tunnel Surveillance Application. Comput. Vis. Image Underst. 2012, 116, 742–753. [Google Scholar] [CrossRef]
- Muhammad, K.; Ullah, A.; Lloret, J.; Del Ser, J.; de Albuquerque, V.H.C. Deep Learning for Safe Autonomous Driving: Current Challenges and Future Directions. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4316–4336. [Google Scholar] [CrossRef]
- Boukerche, A.; Hou, Z. Object Detection Using Deep Learning Methods in Traffic Scenarios. ACM Comput. Surv. 2021, 54, 30. [Google Scholar] [CrossRef]
- Bakirci, E.; Altay, D.; Oztel, I.; Gungor, V.C. Vehicular mobility monitoring using remote sensing and deep learning on a UAV-based mobile computing platform. Drones 2025, 9, 11. [Google Scholar] [CrossRef]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision (ICCV), Bombay, India, 4–7 January 1998; pp. 555–562. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Behrendt, K. Boxy vehicle detection in large images. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. OTA: Optimal transport assignment for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 303–312. [Google Scholar]
- Chiu, Y.-C.; Tsai, C.-Y.; Ruan, M.-D.; Shen, G.-Y.; Lee, T.-T. Mobilenet-SSDv2: An improved object detection model for embedded systems. In Proceedings of the 2020 International Conference on System Science and Engineering (ICSSE), Tainan, Taiwan, 31 August–3 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, J.; Cong, W.; Li, H. Vehicle detection method based on GhostNet-SSD. In Proceedings of the 2020 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Zhangjiajie, China, 18–19 July 2020; pp. 200–203. [Google Scholar] [CrossRef]
- Wei, F.; Wang, W. GS-YoloNet: A Lightweight Network for Detection, Tracking, and Distance Estimation on Highways. In Proceedings of the 2024 IEEE 99th Vehicular Technology Conference (VTC2024-Spring), Antwerp, Belgium, 24–27 June 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, B.; Li, Y.; Gong, K.; Wen, Z.; Wang, S.; Dev, S. SYGNet: A SVD-YOLO Based GhostNet for Real-Time Driving Scene Parsing. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 2701–2705. [Google Scholar] [CrossRef]
- Wang, H.; Liu, C.; Cai, Y.; Chen, L.; Li, Y. YOLOv8-QSD: An Improved Small Object Detection Algorithm for Autonomous Vehicles Based on YOLOv8. IEEE Trans. Instrum. Meas. 2024, 73, 1–16. [Google Scholar] [CrossRef]
- Bihanda, Y.G.; Fatichah, C.; Yuniarti, A. Comparative Analysis of ConvNext and MobileNet on Traffic Vehicle Detection. In Proceedings of the 2023 IEEE 8th International Conference on Software Engineering and Computer Systems (ICSECS), Pahang, Malaysia, 19–21 September 2023; pp. 101–105. [Google Scholar] [CrossRef]
- Bijelic, M.; Gruber, T.; Mannan, F.; Kraus, F.; Ritter, W.; Dietmayer, K.; Heide, F. Seeing Through Fog Without Seeing Fog: Deep Sensor Fusion in the Absence of Labeled Training Data. Sensors 2020, 20, 2542. [Google Scholar] [CrossRef]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a LiDAR point cloud. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar] [CrossRef]





| References | Methods | Tasks Performed | Performance |
|---|---|---|---|
| [40] | SIFT and SVM | Vehicle detection and recognition | 65% |
| [41] | Haar-like features and AdaBoost | Vehicle detection and recognition | 97% |
| [42] | Background subtraction, shadow removal, pixel analysis | Vehicle detection and counting | 95% |
| [43] | Boosting HOG features, SVM | Detect moving vehicles | 90% |
| [44] | Viola-Jones (V-J) and HOG + SVM | Vehicle detection | 88.5% |
| [45] | LSVM + HOG | Multi-vehicle detection and tracking | 97% |
| [46] | Hough transform algorithm, Haar-like features | Detection and labeling of multiple vehicles | 95% |
| [47] | Background subtraction and frame difference | Moving vehicle detection | 95.5% |
| [48] | Feature extraction and classification for rear-view vehicle detection | Vehicle detection | 94.8% |
| Reference | Year | Version | Backbone | Head |
|---|---|---|---|---|
| [23] | 2015 | YOLOv1 | Custom | Custom |
| [24] | 2016 | YOLOv2 | Darknet-19 | Custom |
| [25] | 2018 | YOLOv3 | Darknet-53 | Custom |
| [59] | 2020 | YOLOv4 | CSPDarknet53 | Custom |
| [65] | 2020 | YOLOv5 | CSPDarknet | Custom |
| [26] | 2022 | YOLOv6 | EfficientRep | Custom |
| [27] | 2022 | YOLOv7 | YOLOv7Backbone | Custom |
| [68] | 2023 | YOLOv8 | YOLOv8CSPDarknet | Custom |
| [69] | 2024 | YOLOv9 | YOLOv9Backbone | DEKRHead |
| [70] | 2024 | YOLOv10 | YOLOv10Backbone | YOLOv10Head |
| [71] | 2024 | YOLOv11 | C3k2 + C2PSA | YOLOv11Head |
| [72] | 2025 | YOLOv12 | R-ELAN + A2C2f | YOLOv12Head |
| References | Dataset | Method | Performance |
|---|---|---|---|
| [78] | UA-DETRAC | DP-SSD | 77.94% |
| [77] | KITTI | SSD + (MobileNet v2, channel attention, deconvolution) | 84.81% |
| [88] | MS COCO | YOLOv5s, C3Ghost, CBAM | 72.40% |
| [89] | PASCAL VOC 2007 + 2012 | YOLOv4, MobileNetv1, ECA attention | 90.29% |
| [62] | KITTI | YOLOv4, CBM + CSP, Kmeans++ | 93.22% |
| [63] | BIT-Vehicle, CompCars | YOLOv2, k-means++ | 94.78% |
| [64] | BIT-Vehicle | YOLOv2, Rk-means++, Focal Loss | 97.30% |
| [90] | PASCAL VOC, MS COCO, PKLot | YOLOv3 | 93.30% |
| [55] | PASCAL VOC 2007 + 2012 | YOLOv3 | 89.10% |
| [91] | Vehicle dataset | YOLOv3, ORB algorithm | 87.80% |
| [92] | KITTI, PASCAL VOC | YOLOv4 | 97.70% |
| [93] | MAFAT tournament | YOLOv3 | 81.72% |
| [94] | DETRAC | YOLOv3 with SPP module | 98.80% |
| [95] | BIT-Vehicle | YOLOv2-tiny | 82.20% |
| [96] | KITTI | Complex-YOLO, E-RPN | 67.70% |
| [97] | KITTI | Complex-YOLO V4 | 79.00% |
| [7] | KITTI, BDD | YOLOv4, CSPDarknet53_dcn, PAN++ | 70.10% |
| [98] | KITTI | YOLOv2 | 61.30% |
| [99] | KITTI | YOLOv4, CBAM, Soft-NMS, DIoU | 81.23% |
| [5] | PoribohonBD, Dhaka-AI | YOLOv4 | 87.19% |
| [100] | BIT-Vehicle | YOLOX | 99.21% |
| [101] | VOC2007 | YOLOv2 | 90.00% |
| Reference | Dataset | Method | Performance |
|---|---|---|---|
| [103] | UA-DETRAC | R-CNN, Transfer Learning | 93.43% |
| [104] | SHRP 2 NDS | Fast R-CNN | 89.2% |
| [102] | UAV Images | Mask R-CNN | 93% |
| [105] | Pakistan Dataset | Faster R-CNN | 82.14% |
| [106] | CIFAR-10 | R-CNN | 98.5% |
| [107] | PASCAL VOC | Optimized Faster R-CNN | 90% |
| [108] | KITTI, LSVH | Faster R-CNN, Soft-NMS | 89.2% |
| Method | Model Type | Application Scenario | Strengths |
|---|---|---|---|
| YOLOv5/YOLOv7 | One-Stage | Real-time/Edge | Speed, Efficiency |
| Faster R-CNN | Two-Stage | High-Precision Detection | Accuracy, Localization |
| DETR/Swin | Transformer | Complex Scenes | Context Modeling |
| VAGAN/AugGAN | GAN-Based | Low-Light/Scarce Data | Data Augmentation |
| Dataset | Classes | Vehicle Types | Tasks | Annotation | #Img/Vid | Resolution |
|---|---|---|---|---|---|---|
| Pascal VOC | 20 | Car, Bus, Bicycle, Motorbike | Detection, Segmentation, Classification | Yes | ∼11,000 images | 384 × 480 to 500 × 375 |
| MS COCO | 91 | Bicycle, Car, Motorcycle, Bus, Truck | Detection, Segmentation, Classification | Yes | ∼330,000 images | Varies (avg. 640 × 480) |
| BDD100K | 10 | Car, Bus, Truck, Bike, Motorcycle | Detection, Segmentation, Lane Marking, Image Tagging | Yes | 100,000 video clips (40 s each) | 1280 × 720 |
| KITTI | 9 | Car, Van, Truck | Detection, Segmentation, Classification | Yes | ∼15,000 images, 200 videos | 1242 × 375 |
| Boxy Vehicle | 1 | Passenger Cars, Trucks, Car Carriers, Motorcycles | Vehicle Detection in Freeway Driving | Yes | 200,000 images | 5 MP (typically 1920 × 1080) |
| Limitation | Mitigation Strategy |
|---|---|
| Class imbalance (e.g., overrepresentation of cars) | Data resampling, synthetic data generation, loss reweighting |
| Poor diversity in weather/lighting | Data augmentation (e.g., rain, fog simulation), use of GANs |
| Low-quality or inconsistent annotations | Annotation refinement, human-in-the-loop labeling, weak supervision |
| Limited coverage of rare scenarios (e.g., accidents, occlusion) | Scenario simulation tools, collection of edge-case datasets |
| Domain-specific bias (e.g., specific cities or camera angles) | Domain adaptation, transfer learning, cross-dataset evaluation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adam, M.A.A.; Tapamo, J.R. Survey on Image-Based Vehicle Detection Methods. World Electr. Veh. J. 2025, 16, 303. https://doi.org/10.3390/wevj16060303
Adam MAA, Tapamo JR. Survey on Image-Based Vehicle Detection Methods. World Electric Vehicle Journal. 2025; 16(6):303. https://doi.org/10.3390/wevj16060303
Chicago/Turabian StyleAdam, Mortda A. A., and Jules R. Tapamo. 2025. "Survey on Image-Based Vehicle Detection Methods" World Electric Vehicle Journal 16, no. 6: 303. https://doi.org/10.3390/wevj16060303
APA StyleAdam, M. A. A., & Tapamo, J. R. (2025). Survey on Image-Based Vehicle Detection Methods. World Electric Vehicle Journal, 16(6), 303. https://doi.org/10.3390/wevj16060303