1. Introduction
The rapid development of autonomous driving technologies has significantly elevated the importance of 3D perception systems in this field. As the demand for autonomous systems to comprehensively understand their surroundings grows, 3D object detection has emerged as a cornerstone technology for enabling safe and efficient navigation. Traditional 3D detection approaches rely on lidar sensors, leveraging point cloud data for object recognition and localization, with representative algorithms including Lvp [
1], VoxelNet [
2], and PV-RCNN [
3]. While lidar offers advantages in precision and stability, the inherent sparsity of point clouds leads to a sharp decline in detection performance for distant targets. Furthermore, its prohibitive cost and hardware requirements have constrained its application in large-scale autonomous driving systems. According to Robesense’s latest financial data, the average unit price of lidar products for advanced driver-assistance system (ADAS) applications in the first quarter of 2024 was USD 358 [
4]. Industry-related research reports indicate that the unit price of ordinary surround-view automotive camera modules ranges from USD 20 to USD 28, while the unit price of ADAS automotive camera modules ranges from USD 41 to USD 69 [
5,
6]. The challenges posed by these budgetary limitations have spurred research into monocular 3D object detection. This method strives to enable accurate 3D awareness utilizing only one camera sensor. With the automotive industry progressing toward higher levels of automation, the development of cost-effective and robust 3D detection solutions has become increasingly critical. Motivated by these economic and practical considerations, recent research has shifted focus toward advancing monocular 3D detection techniques, as explored in the following sections.
Recent years have witnessed remarkable advancements in monocular 3D detection techniques. These methodologies can be broadly categorized into three paradigms: direct regression, depth-guided estimation, and pseudo-lidar point cloud generation. Direct regression approaches bypass intermediate representations by leveraging geometric priors and uncertainty-aware depth estimation to predict 3D bounding box parameters (center coordinates, dimensions, and orientation) directly from RGB images. Pioneering works such as MonoCon [
7] and MonoDLE [
8] map image features to 3D space through keypoint detection and geometric constraints. SMOKE [
9] eliminates traditional 2D detection branches, instead employing a single-stage network to jointly estimate keypoints and 3D attributes, achieving real-time inference at 30 frames per second (FPS). MonoDGP [
10] deals with model prediction by revolving around geometric errors. Recent innovations, including MonoCAPE [
11], introduce coordinate-aware position embedding generators to enhance the model’s spatial understanding, addressing the historical neglect of spatial context in earlier methods. MonoDiff [
12] employs a diffusion-based framework for monocular 3D detection and pose estimation, improving feature representation without requiring additional annotation costs. However, the interdependency of predicted parameters (e.g., depth and center offsets) often amplifies estimation errors, posing a persistent challenge.
Building on the challenges of direct regression, another prominent paradigm within monocular 3D detection is depth-guided estimation, which integrates depth estimation as an auxiliary task to strengthen spatial reasoning. For instance, AuxDepthNet [
13] presents a depth-fusion transformer architecture designed to effectively combine visual information with depth data. The architecture incorporates a depth position mapping unit (DPM) alongside an auxiliary depth feature unit (ADF). By guiding the fusion process with depth cues, the network achieves holistic integration of visual and depth-related characteristics, leading to dependable and optimized detection. Exploiting Ground Depth Estimation [
14] designs a transformer-based RGB-D fusion network to effectively unify RGB and depth information. MonoDFNet [
15] further incorporates multi-branch depth prediction and weight-sharing modules to enhance depth information acquisition and integration. While MonoGRNet [
16] and D4LCN [
17] utilize sparse depth supervision or depth-adaptive convolutions to minimize computational overhead, their performance remains constrained by the accuracy of pretrained depth estimators—depth prediction errors propagate into 3D detection, particularly for distant or occluded objects.
In contrast to depth-guided methods that leverage depth as an auxiliary feature, the pseudo-lidar framework adopts a different strategy by transforming depth estimates into a 3D point cloud. Early implementations like pseudo-lidar [
18] project depth maps into point clouds and apply point-based detectors such as Frustum PointNet [
19]. Subsequent works [
20,
21] enhance robustness through multimodal fusion with low-cost beam lidar. Am3d [
22] and Mono3D_PiDAR [
23] extract point cloud frustums from pseudo-lidar data using 2D detection masks, while Sparse Query Dense [
24] improves data richness through synthetic point clouds. To address the high computational demands of pseudo-lidar methods, Meng et al. [
25] propose a lightweight detection framework that achieves minimal latency, ensuring real-time performance. Gao et al. [
26] introduced a 2D detection mask channel as a guiding layer by reshaping the representation of pseudo-lidar to facilitate 3D object detection. This method has achieved good results on several datasets, particularly making breakthrough progress on the KITTI dataset, demonstrating its potential in autonomous driving applications. However, the Pseudo-lidar method also faces challenges, especially the structural mismatch between depth estimation and the real scene. This mismatch affects the geometric authenticity of the point cloud, leading to a decrease in object detection accuracy [
18,
21].
In order to solve the above problems, this paper proposes a pseudo-lidar optimization method based on multi-scale attention mechanism MSFNet3D, which aims to improve the multi-scale feature representation capability of depth estimation, optimize the efficiency of cross-modal feature fusion, and generate more accurate point cloud data through semantic guidance. Specifically, in this paper, a multi-scale channel spatial attention module (MS_CBAM) is designed to enhance the network’s ability to extract multi-scale geometric information through hierarchical feature pyramid and adaptive weight allocation mechanism so as to effectively alleviate the problem of multi-scale feature loss in traditional depth estimation. Secondly, this paper proposes a dynamic fusion strategy based on local gradient consistency, which can dynamically adjust the feature fusion between RGB images and depth maps according to the local gradient information so as to improve the expression ability of cross-modal features. Finally, a semantic-guided point cloud generation method is introduced in this paper. The semantic features extracted from the instance segmentation network are embedded into the pseudo-lidar point cloud generation process to enhance the semantic attributes of the point cloud so that the target detection network can identify and distinguish different types of objects more accurately.
The organization of this paper is as follows: In
Section 2, the MSFNet3D algorithm is designed in detail.
Section 3 introduces the experimental setup and comparative analysis and verifies the effectiveness of the module through ablation experiment. Limitations of our approach are presented in
Section 4, along with a discussion of necessary future work.
Section 5 summarizes the key contributions of this paper and underscores its potential impact on the advancement of autonomous driving technology.
2. MSFNet3D: Framework and Operational Flow
2.1. System Framework
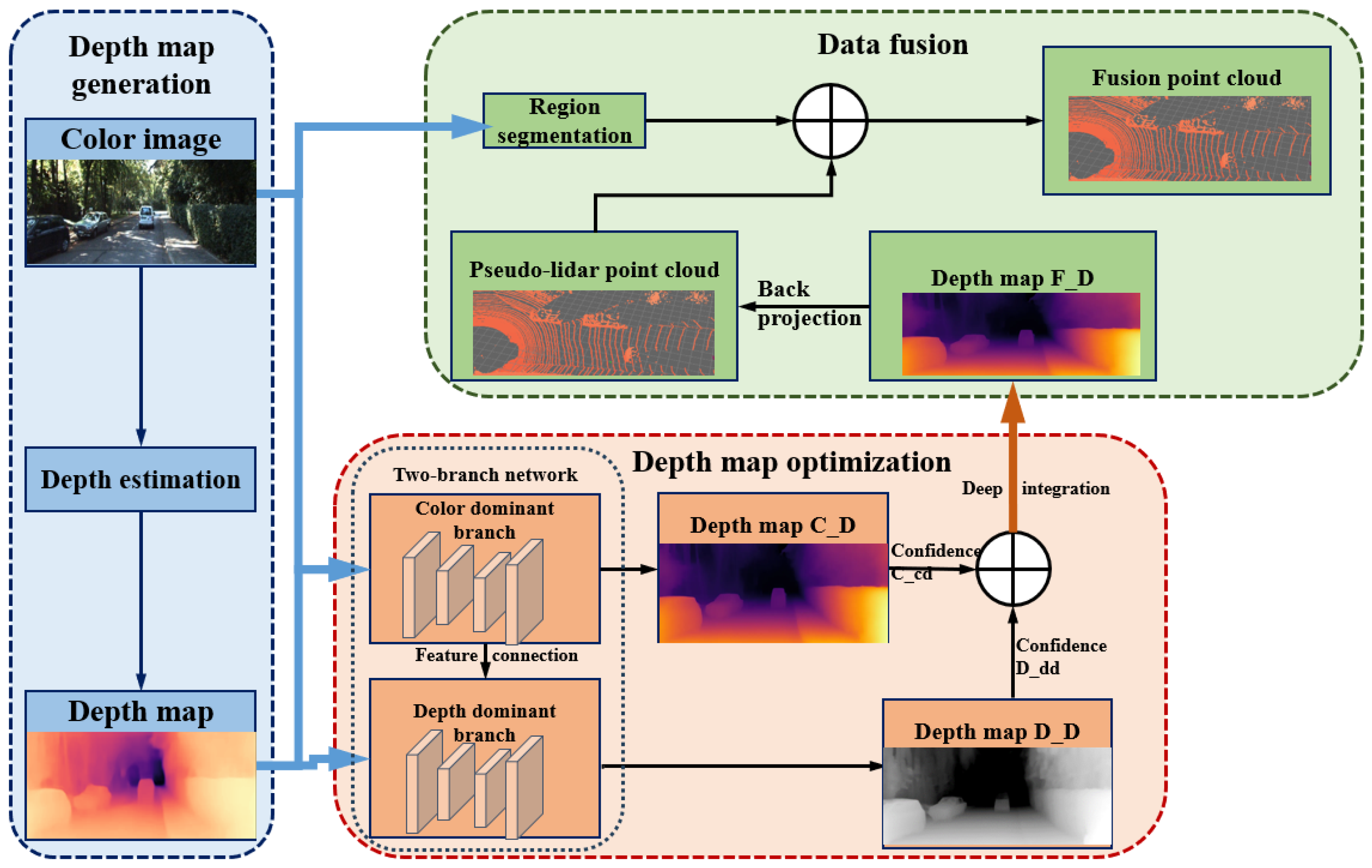
MSFNet3D primarily comprises three stages: a depth map generation network, pseudo-point cloud semantic fusion generation, and 3D detection.
As illustrated in
Figure 1, initially, a robust depth estimation network generates depth maps. Subsequently, based on the PENET [
27] encoder embedded with MS_CBAM and consistency weight, a dual-branch feature fusion is performed through the dynamic interaction of color-dominant and depth-dominant pathways to optimize the depth map, resulting in a high-precision depth map. A pseudo-point cloud is generated, enhanced by target region augmentation guided by Mask R-CNN [
28]. The final stage utilizes mature 3D detection techniques to identify objects within the scene.
2.2. MS_CBAM
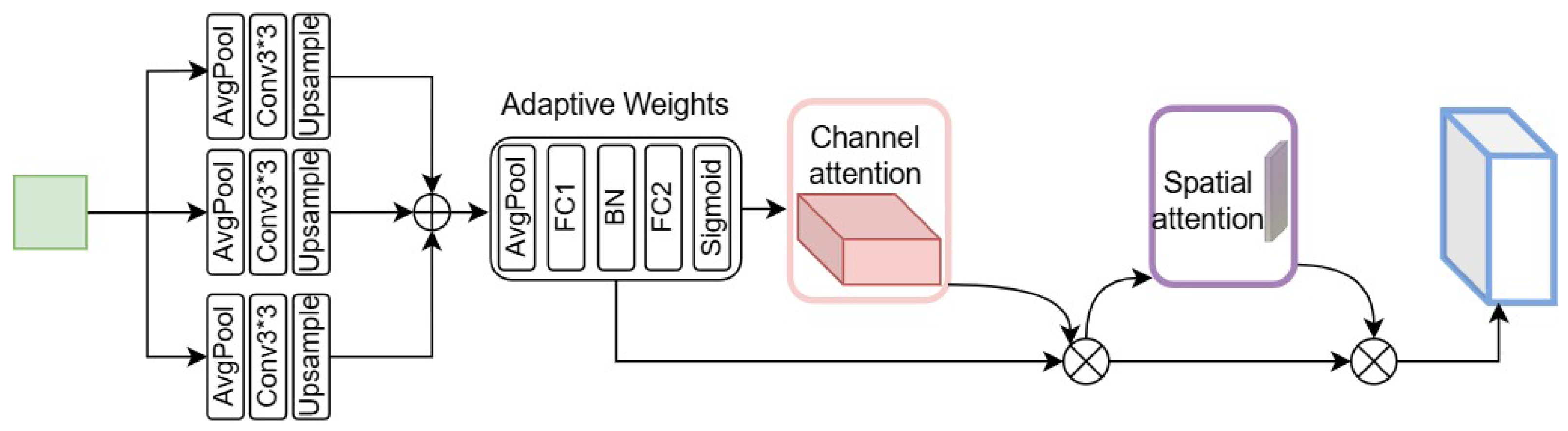
Precise depth estimation requires the effective capture of features at various scales and the enhancement of information-rich feature expressions. To this end, we propose a novel multi-scale channel spatial attention module (MS_CBAM). Based on the Convolutional Block Attention Module (CBAM) [
29], this module introduces a multi-scale feature extraction mechanism and an adaptive weight allocation strategy so as to more effectively utilize contextual information and focus on important features.
The structure of MS_CBAM, as shown in
Figure 2, mainly includes three parts: multi-scale feature extraction, adaptive weight allocation, and channel and spatial attention mechanisms.
The multi-scale feature extraction module employs average pooling operations with downsampling ratios of 2, 4, and 8, ensuring comprehensive coverage of scene geometry. Each scale of pooling operation is followed by a 3 × 3 convolution and a bilinear interpolation operation to restore the original spatial dimension and adjust the number of channels. Following this, the multi-scale feature maps are combined, resulting in a more integrated and complete representation of the data. At the same time, in order to effectively fuse the multi-scale features, we introduce an adaptive weight allocation strategy. The strategy uses a global average pooling layer and two fully connected layers to learn the weight of the feature map of each scale. These weights are activated by a sigmoid function to ensure that their values are between 0 and 1. Subsequently, the learned weights are multiplied by the corresponding multi-scale feature maps to achieve adaptive feature fusion. This adaptive weighting strategy enables the network to dynamically emphasize information-rich scales while suppressing less-relevant scales. Then, the module uses channel and spatial attention processes to refine the fused multi-scale features.
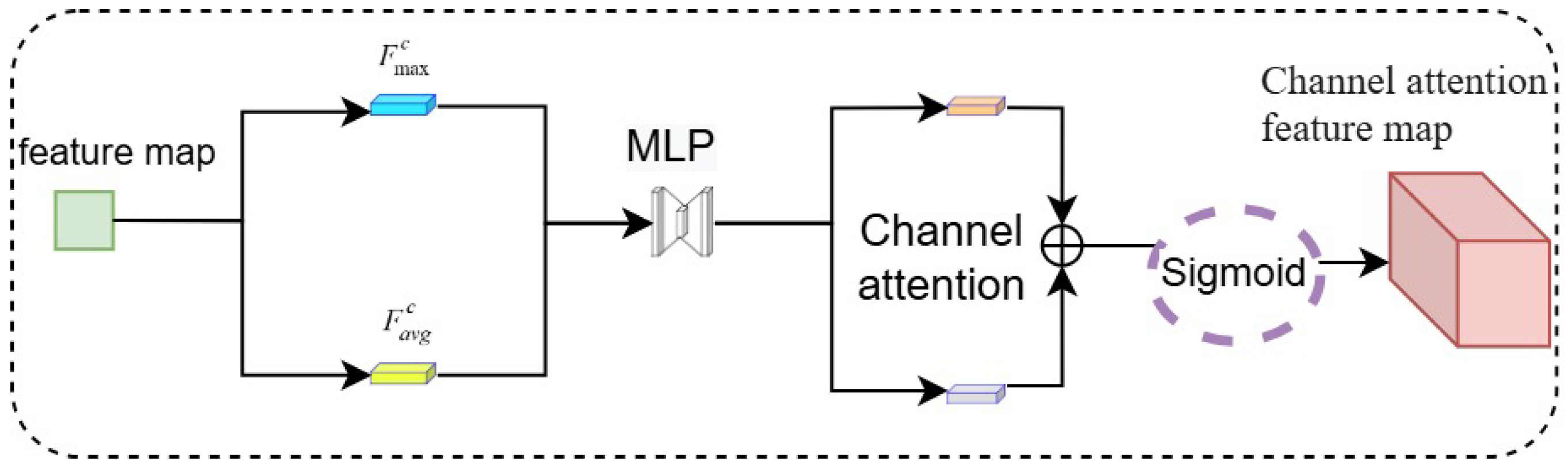
As shown in
Figure 3, the channel attention module applies global average pooling and global maximum pooling, with the output of each pooling operation then being directed to its own dedicated fully connected layer. Following the summation of the outputs from the two fully connected layers, a sigmoid activation is employed to create the channel attention weights. The mathematical formulation is provided in Equation (1).
where
denotes the channel attention weights,
is the sigmoid activation function,
and
represent the weight matrices of the fully connected layers within the multilayer perceptron (MLP), and r is the reduction ratio (controlling the number of parameters in the MLP).
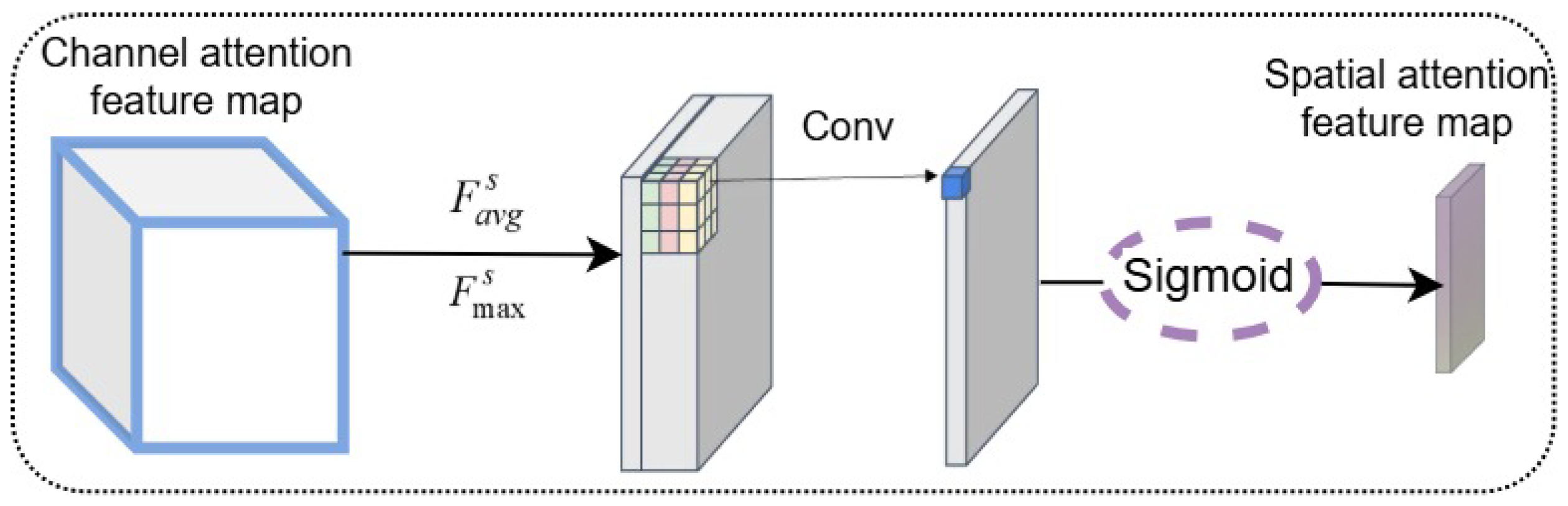
These channel attention weights are multiplied with the corresponding multi-scale features. After the channel attention processing, the spatial attention branch takes the channel-weighted features and performs average and max pooling across the channel dimension. As illustrated in
Figure 4, the resulting pooled maps are then concatenated. The combined feature representation is subsequently processed with a 7 × 7 convolution, and a sigmoid activation is applied to produce the spatial attention weights, as mathematically expressed in Equation (2).
where
denotes the spatial attention weights,
and
represent the intermediate feature map within the spatial attention module, and
signifies a convolution operation with a 7 × 7 kernel. To obtain the final output feature map, an element-wise multiplication is carried out, combining the spatial attention weights and the initial feature representation.
Through the integration of multi-scale feature extraction, adaptive weight allocation, and channel and spatial attention mechanisms, the MS_CBAM module effectively enhances salient feature representations and significantly improves the network’s ability to perceive information across various scales while suppressing irrelevant features. This provides a more discriminative feature representation for downstream depth completion tasks. Furthermore, the lightweight design of MS_CBAM ensures high efficiency despite the introduction of additional computational overhead, making it suitable for integration within large convolutional neural networks.
Then, we integrate the proposed MS_CBAM module into the PENet encoder architecture. The original PENet encoder uses strided convolution for downsampling in the BasicBlockGeo module and fuses features of different scales through skip connections. We replace the first 3 × 3 convolutional layer (when the stride is 2) in the BasicBlockGeo module with the MS_CBAM module so that it can extract multi-scale features and perform channel and spatial attention weighting while downsampling.
Specifically, we set the stride of the MS_CBAM module to 2, enabling it to perform downsampling operations. For the residual connection part, we keep the original 1 × 1 convolution and BatchNormalization operations to maintain the function of the residual connection and use an MS_CBAM module with a stride of 1 to process the residual path to further enhance multi-scale feature fusion. The integration method of the MS_CBAM module is shown in
Figure 5.
We believe that integrating the MS_CBAM module into the PENet encoder can better capture contextual information at different scales and enhance important feature expressions, thereby enhancing the precision of the generated pseudo-lidar point cloud.
2.3. Consistency Weight
Discrepancies in depth accuracy and detail representation exist between depth maps generated from depth estimation and their corresponding RGB images, stemming from inherent differences in input modalities and data distributions. To mitigate this and enhance the quality of depth estimation after fusing these sources, we introduce “Consistency Weights”, a weight adjustment method based on local consistency differences. Consistency Weights dynamically adjust the contribution of features from the color-guided and depth-guided branches, promoting more adaptive feature fusion and thereby improving the quality of the final depth map. These weights are generated dynamically by comparing local regions, integrating both pixel value differences and gradient information from the depth map and RGB image. Since depth maps and RGB images have differing value ranges, a normalization step is first applied to the pixel values of the depth map,
D, and the RGB image,
I, mapping them to the range [0, 1], as shown in Equation (3).
where
represents the normalized depth map,
is the minimum value, and
is the maximum value within the depth map.
represents the normalized RGB image pixel values, with
and
being the minimum and maximum values, respectively.
Image gradient computation is commonly used to detect edges and regions of significant change. Furthermore, depth map pixel values, corresponding to the distance from the point to the camera center, can represent spatial variations via their gradient. Therefore, to obtain a richer feature representation, a 3 × 3 Sobel operator is applied to both the depth map and RGB image, as formulated in Equation (4).
where
and
denote the horizontal and vertical gradients of the depth map
D, respectively;
and
denote the corresponding gradients for the RGB image.
Following normalization and gradient computation, to obtain a more comprehensive representation, pixel value differences and gradient information from the depth map and RGB image are integrated and compared within local regions, as formulated in Equation (5).
After obtaining the local region comparison results, these values are used to assign the weights
. This assignment is formulated in Equation (6).
In the proposed architecture, a consistency weighting mechanism is applied to the dual-branch network (the color-dominated branch and the depth-dominated branch) to dynamically adjust the contribution ratio during the feature fusion process. The final fused feature is calculated according to the following Equation (7):
where C_D and D_D represent the features extracted from the color-guided and depth-guided branches, respectively, while F_D denotes the fused feature. Through the consistency weight W, the model can adaptively adjust the feature ratio from both branches based on local region differences, thereby enhancing the flexibility and adaptability of feature fusion.
In the implementation, to ensure dimensional compatibility between the consistency weight and the network’s feature map, a broadcasting mechanism is employed to extend the weight tensor.
2.4. Integrated Dual-Branch Network Architecture
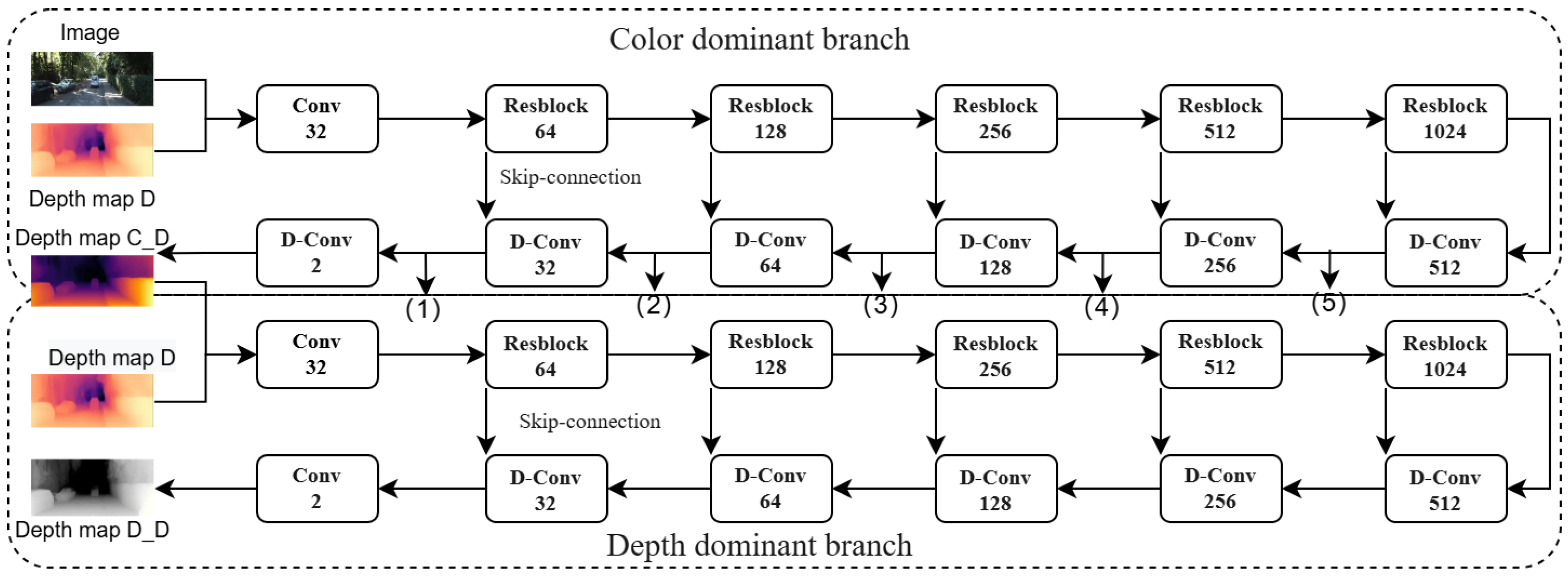
To further refine the depth maps, we introduce a dual-branch network, integrating the MS-CBAM and the consistency weighting mechanism into its architecture. This dual-branch network effectively processes and integrates complementary information from RGB images and initial depth maps. Furthermore, the MS-CBAM and consistency weighting mechanism enhance the network’s capacity to capture intricate details within the depth maps. Illustrated in
Figure 6, the dual-branch network architecture consists of a color-dominant branch and a depth-dominant branch. Within this architecture, multi-scale features (1) to (5) extracted from the color-dominant branch are fused with depth features in the depth-dominant branch.
With the RGB image and depth map D as input, the color-dominated branch employs a 5-level encoder-decoder architecture to extract multi-scale representations. It learns depth around the boundary by capturing color features and structural information in the color image, generating a dense depth map C_D and a confidence map C_cd. Fed with the dense depth map C_D and the depth map D, the depth-dominated branch concatenates color-dominated decoder features with its own encoder features, outputting the dense depth map D_D and confidence map D_cd. The confidence map is generated by a convolutional neural network running in parallel with the backbone network, consisting of feature extraction layers and confidence prediction layers. By combining the dense depth map, the confidence map, and the consistency weight, the final dense depth map F_D is obtained through fusion, as described in Equation (8).
After obtaining the dense depth map F_D with size H×W, a pixel grid of the same size as F_D is generated, and the position of each pixel is computed. Depth points with a value of zero or invalid points generally lack valid depth information. These points tend to increase unnecessary computational load and introduce noise. Therefore, an effective depth mask valid_mask = (D > 0) is applied to the depth map and the pixel grid to remove invalid depth values and their corresponding pixels.
2.5. Pseudo-Point Cloud Generation
Our approach adheres to the technical framework of pseudo-lidar, necessitating the conversion of the fused depth map F_D into a 3D point cloud representation. Utilizing the camera’s intrinsic matrix, each pixel (
u,
v) in the image is mapped to 3D space using the following back-projection formula:
Here,
represents the pixel’s location relative to the camera center,
is the vertical focal length, and
is the horizontal focal length. We obtain a three-dimensional point cloud
by transforming pixel positions to their corresponding locations in 3D space through back-projection, where
N signifies the aggregate pixel population. The resulting pseudo-lidar point cloud is then used for 3D object detection. After mapping the depth map to 3D space, an initial point cloud
Pr is obtained, with each point
Pi in the point cloud containing coordinate information
.
Despite its cost-effectiveness for 3D object detection, pseudo-lidar generates relatively coarse point cloud. This lower point cloud quality leads to reduced object detection accuracy compared to using lidar-derived point cloud. To address this, the Pseudo-lidar++ [
21] approach was developed. By refining the network used for depth prediction and optimizing its loss function, this method achieves better object detection for objects at a distance. The system also incorporates a four-beam lidar sensor for pseudo-point cloud data calibration. However, this method still relies on lidar, making it unsuitable for 3D detection with monocular cameras alone. We address this limitation by integrating an image segmentation network to segment objects, generating a semantic point cloud that is subsequently fused with the pseudo-point cloud, enhancing its characteristics. In this work, we use Mask R-CNN [
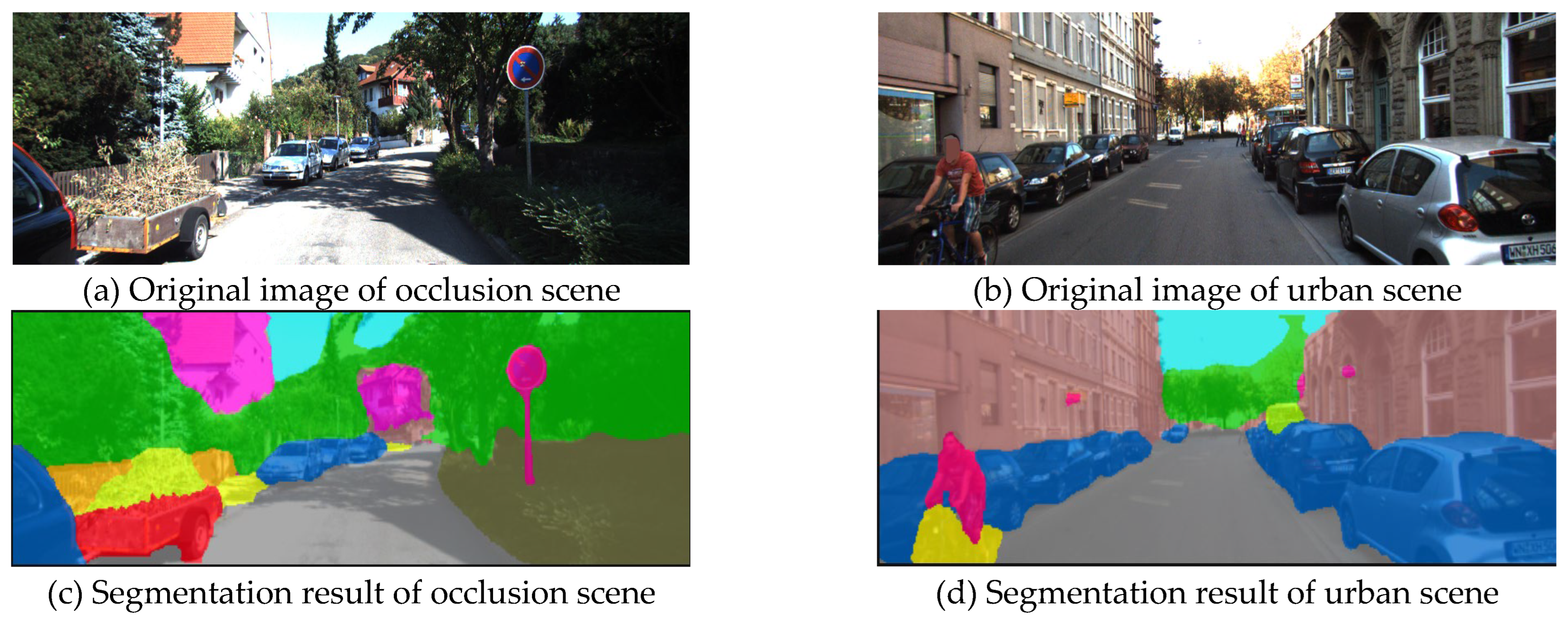
28] to process the RGB image, and the segmented result is shown in
Figure 7.
To develop a more detailed semantic description for every point, semantic features from the RGB image are projected into the point cloud space. This projection is limited to the masks of vehicles, pedestrians, and bicycles. For each point
Pi, its corresponding pixel coordinates (
ui,
vi) in the RGB image are computed using the inverse projection formula based on the depth map. The RGB-based semantic feature F
rgb(
ui,
vi) at that pixel location is then assigned to
Pi. For the point cloud cluster projected from the 2D mask into 3D space, the minimum and maximum coordinates of all points are identified to generate an axis-aligned bounding box, characterized by its center
and dimensions
. A monocular 3D object detection model (this article uses the MonoRun [
30]) is employed to predict the 3D bounding box parameters (center, size, and orientation) of the target. The next step involves projecting the eight corner vertices that define the predicted 3D bounding box onto the point cloud plane. As illustrated in
Figure 8, the red box represents the detection from the monocular 3D object detection model, while the green box indicates the bounding box generated from the segmentation mask.
For each object instance, the intersection-over-union (IoU) between its segmentation area and the projected bounding box is calculated. Instances with an IoU threshold below 0.5 are considered false detections. Specifically, for each 3D point
Pi, its source pixel coordinates are evaluated to determine whether they fall within the mask region of a high-IoU target. If true,
Pi is labeled as a foreground point; otherwise, it is treated as a non-foreground point and all non-foreground points are discarded. The initial pseudo point cloud
Pr is fused with the semantic features to obtain the final semantically enhanced point cloud
Psem. The fusion process is expressed as follows:
where
is the RGB semantic feature corresponding to point
Pi.
2.6. Loss Fuction
The loss function proposed in this paper consists of two key components: the depth optimization network loss
and the gradient consistency regularization loss
. The depth optimization network loss follows the loss function used by the PENet network. The model is trained using this loss, and supervision signals are applied during the intermediate stages of the depth optimization process, as expressed in Equation (11):
where
and
are hyperparameters set empirically. The complete loss function is given in Equation (12). Since the ground truth includes invalid pixels, only those pixels with valid depth values are considered:
where
denotes the ground truth used for supervision. To ensure consistency between the depth map and RGB image, especially in the edge regions, we introduce a gradient consistency regularization loss term:
where
and
represent the gradients of the predicted depth map and the RGB image, respectively.
The final combined loss function is expressed as follows:
5. Conclusions
In this paper, we propose MSFNet3D, an advanced monocular 3D inspection framework designed to solve the problem of the quality limitation of pseudo-lidar point cloud. Firstly, the constructed multi-scale channel spatial attention module (MS_CBAM) breaks through the limitation of scale sensitivity of traditional attention mechanisms. This module significantly enhances the ability of depth estimation network to analyze complex scenes through hierarchical feature pyramid structure and adaptive weight allocation strategy. Secondly, the proposed dynamic consistency weight achieves optimized coupling of pixel-level image features and depth features through local gradient consistency analysis and differentiable weighting, which effectively mitigates the feature conflict issue caused by fixed-weight fusion in dual-branch networks, demonstrating enhanced robustness in dense traffic scenarios. In addition, the semantic-guided point cloud optimization strategy enhances the semantic interpretability of point cloud by fusing the result of instance segmentation with pseudo-point cloud data and verifies the key role of semantic information in 3D reconstruction.
These advancements not only push the boundaries of monocular 3D perception but also present a cost-effective solution for electric vehicle manufacturers. The method in this paper can use an 800 M monocular camera, which can save about 80% of the cost compared with the vehicle lidar. Our approach aligns with the industry’s urgent demand for affordable yet reliable autonomous driving technologies.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}