
An Algorithmic Study of Transformer-Based Road Scene Segmentation in Autonomous Driving

Abstract
1. Introduction
2. Preparation and Processing of the Datasets
2.1. Datasets
2.2. Data Preprocessing
3. Model Architecture
3.1. Encoding Block
3.2. Decoding Block
4. Analysis of the Experimental Results
4.1. Evaluation Indicators
- (1)
- Runtime: The runtime includes the training time and testing time of the network model. Since the runtime depends on the hardware devices and the backend implementation, it is difficult to provide the exact runtime in some cases. However, providing information about the hardware on which the algorithm runs and the runtime is helpful for evaluating the effectiveness of the method and ensuring that the fastest execution method is tested in the same environment.
- (2)
- Exact value: Semantic image segmentation is essentially a classification problem, i.e., the pixels are segmented according to the semantic information in the image. The binary classification confusion matrix is shown in Table 2. The rows represent the prediction results of the classification algorithm, and the columns represent the real categories of the samples. The meanings of the four forms in the table are as follows: True Positive (TP): the sample category is positive, and the prediction result is true; False Positive (FP): the sample category is negative, but the prediction result is positive, which is a misclassification; False Negative (FN): the sample category is positive, but the prediction result is negative, which is an omission; True Negative (TN): the sample category is positive, but the prediction result is negative, which is an omission.
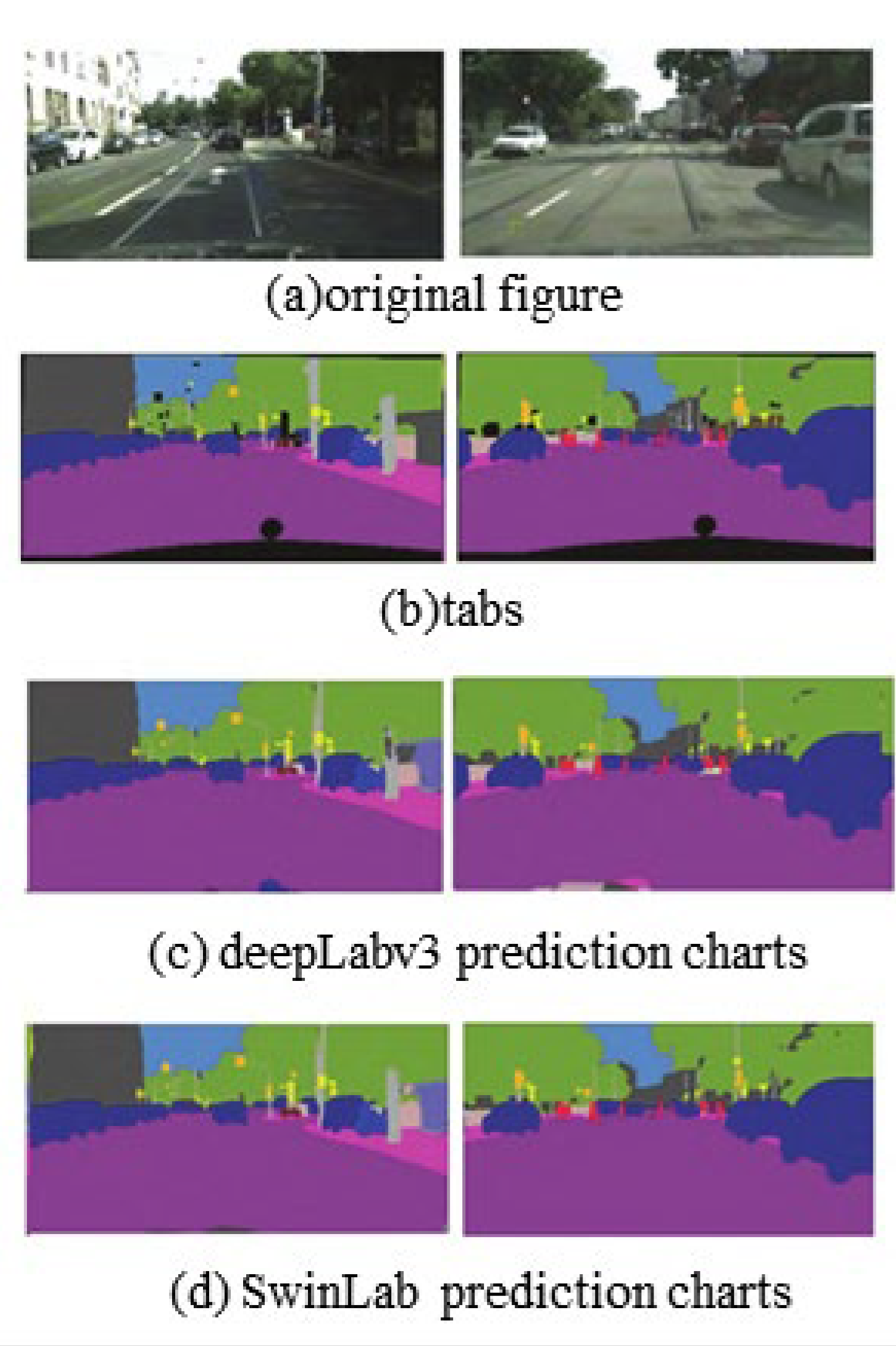
4.2. Experimental Results
5. Conclusions and Outlook
5.1. Conclusions
5.2. Outlook
- (1)
- Accuracy. In the Transformer-based image semantic segmentation algorithm proposed in this paper, the number of parameters is small, which is mainly due to the multi-head attention mechanism module and the lightweight decoding part. Therefore, there are still many parameters worthy of optimization to increase the accuracy of the network, such as how to further reduce the exponential amount of computation, model prediction, image preprocessing, training strategy, and so on.
- (2)
- Dataset. The datasets used in this paper are the more commonly used datasets for semantic segmentation, namely Cityscapes and VOC 2012, which are both based on the precise labeling of the training images to complete the learning of the fixed model, although the generalization ability is limited to a certain extent, and the segmentation ability of the images with large differences in the inputs needs to be further improved. The cost of manual annotation is also high, and semi-supervised or fully supervised learning based on Transformer is also a major research direction for the future.
- (3)
- Practical application. The model proposed in this paper achieves satisfactory results in terms of the number of parameters, but the CNN model is already very mature in practical application, while the practical application of Transformer in industrial scenarios needs to be further explored and researched, and there are still many practical problems to be solved.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sevak, J.S.; Kapadia, A.D.; Chavda, J.B.; Shah, A.; Rahevar, M. Survey on semantic image segmentation techniques. In Proceedings of the 2017 International Conference on Intelligent SUSTAINABLE systems (ICISS), Palladam, India, 7–8 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 306–313. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Kaymak, Ç.; Uçar, A. A brief survey and an application of semantic image segmentation for autonomous driving. In Handbook of Deep Learning Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 161–200. [Google Scholar]
- Taran, V.; Gordienko, Y.; Rokovyi, A.; Alienin, O.; Stirenko, S. Impact of ground truth annotation quality on performance of semantic image segmentation of traffic conditions. In Advances in Computer Science for Engineering and Education II; Springer International Publishing: New York, NY, USA, 2020; pp. 183–193. [Google Scholar]
- Kamann, C.; Rother, C. Benchmarking the robustness of semantic segmentation models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8828–8838. [Google Scholar]
- Rottmann, M.; Maag, K.; Chan, R.; Hüger, F.; Schlicht, P.; Gottschalk, H. Detection of false positive and false negative samples in semantic segmentation. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1351–1356. [Google Scholar]
- Kamann, C.; Rother, C. Benchmarking the robustness of semantic segmentation models with respect to common corruptions. Int. J. Comput. Vis. 2021, 129, 462–483. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Frémont, V.; Rodríguez, S.A. Color-based road detection and its evaluation on the KITTI road benchmark. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 31–36. [Google Scholar]
- Banik, B.; Alam, F.I. A robust approach to the recognition of text based Bangla road sign. In Proceedings of the 2014 International Conference on Informatics, Electronics & Vision (ICIEV), Dhaka, Bangladesh, 23–24 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–7. [Google Scholar]
- Peng, W.; Jian, W.; Yuan, Z.; Jixiang, L.; Peng, Z. Research on Robustness Tracking of Maneuvering Target for Bionic Robot. Int. J. Secur. Its Appl. 2015, 9, 67–76. [Google Scholar] [CrossRef]
- Jing, P.; Zheng, W.; Xu, Q. Vision-based mobile robot’s environment outdoor perception. In Proceedings of the 3rd International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2019; pp. 1–5. [Google Scholar]
- Qin, Y.; Chen, Y.; Lin, K. Quantifying the effects of visual road information on drivers’ speed choices to promote self-explaining roads. Int. J. Environ. Res. Public Health 2020, 17, 2437. [Google Scholar] [CrossRef] [PubMed]
- Firkat, E.; Zhang, J.; Wu, D.; Yang, M.; Zhu, J.; Hamdulla, A. ARDformer: Agroforestry road detection for autonomous driving using hierarchical transformer. Sensors 2022, 22, 4696. [Google Scholar] [CrossRef] [PubMed]
- Duan, S. Semantic segmentation of point cloud based on graph neural network. In Proceedings of the Third International Conference on Computer Vision and Pattern Analysis (ICCPA 2023), Hangzhou, China, 7–9 April 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12754, pp. 357–361. [Google Scholar]
- Hamandi, M.; Seneviratne, L.; Zweiri, Y. Static hovering realization for multirotor aerial vehicles with tiltable propellers. J. Mech. Robot. 2024, 16, 031004. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| category name | background | aeroplane | bicycle | bird | boat | bottle | bus | car | cat | chair | cow |
| category index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| category name | diningtable | dog | horse | motorbike | person | pottedplant | sheep | sofa | train | tvmonitor | |
| category index | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
| Prediction/Truth | True Results (Positive) | True Results (Negative) |
|---|---|---|
| Projected results (positive) | TP | FN |
| Projected results (negative) | FP | TN |
| Method | Backbone | Params (M) | Flops (G) | MioU (%) | |
|---|---|---|---|---|---|
| Cityscapes | VOC 2012 | ||||
| DeepLabv3 | MobileNetv2 | 18.70 | 75.37 | 69.67 | 54.69 |
| ResNet-50 | 68.21 | 270.25 | 75.61 | 62.89 | |
| ResNet-101 | 87.21 | 384.15 | 75.93 | 64.48 | |
| SwinLab | Transformer | 29.31 | 30.61 | 77.61 | 64.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, H.; Lei, J. An Algorithmic Study of Transformer-Based Road Scene Segmentation in Autonomous Driving. World Electr. Veh. J. 2024, 15, 516. https://doi.org/10.3390/wevj15110516
Cui H, Lei J. An Algorithmic Study of Transformer-Based Road Scene Segmentation in Autonomous Driving. World Electric Vehicle Journal. 2024; 15(11):516. https://doi.org/10.3390/wevj15110516
Chicago/Turabian StyleCui, Hao, and Juyang Lei. 2024. "An Algorithmic Study of Transformer-Based Road Scene Segmentation in Autonomous Driving" World Electric Vehicle Journal 15, no. 11: 516. https://doi.org/10.3390/wevj15110516
APA StyleCui, H., & Lei, J. (2024). An Algorithmic Study of Transformer-Based Road Scene Segmentation in Autonomous Driving. World Electric Vehicle Journal, 15(11), 516. https://doi.org/10.3390/wevj15110516