An Integrated Dictionary-Learning Entropy-Based Medical Image Fusion Framework




Abstract
:1. Introduction
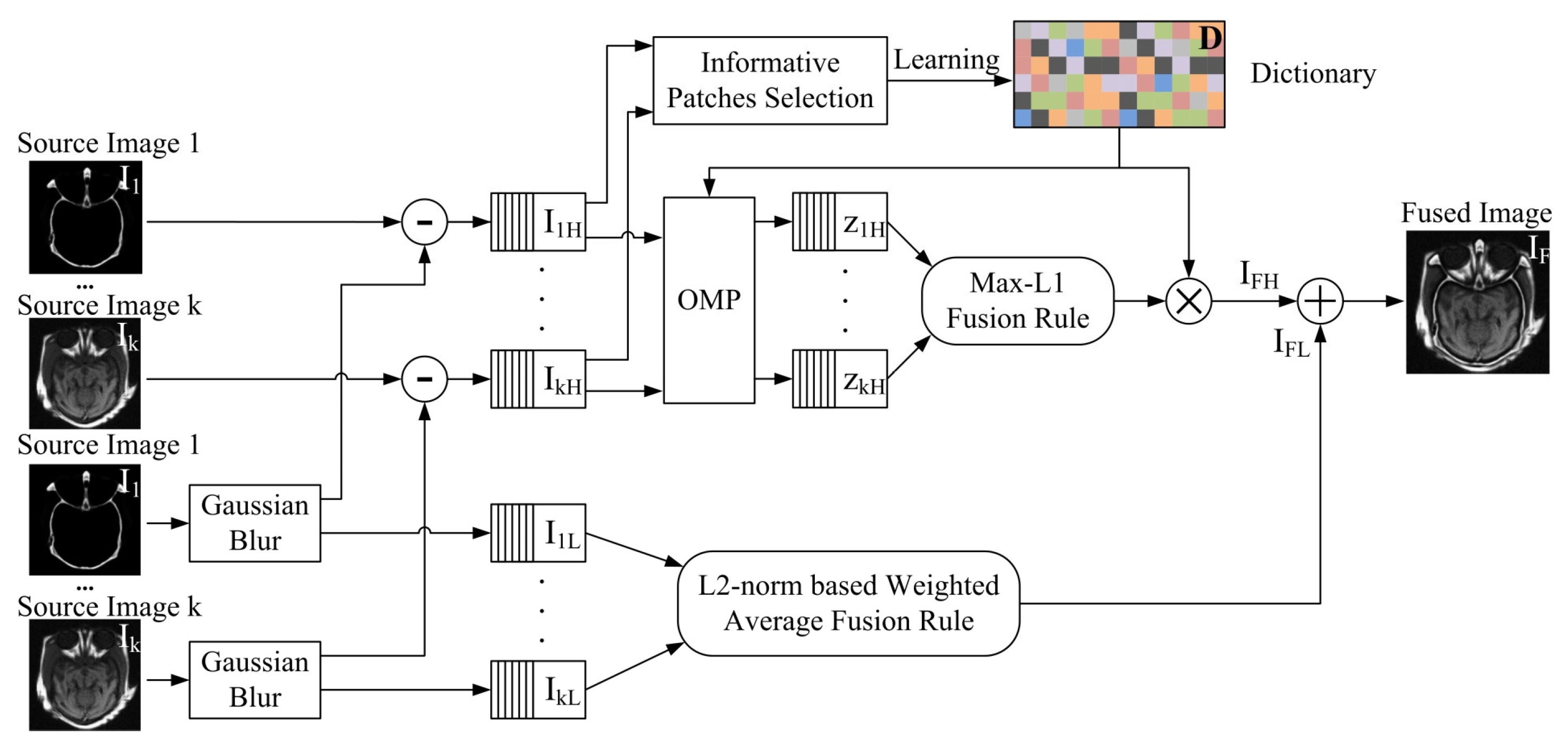
- Step 1 is a denoising process. Each input source image is smoothed by Gaussian filter that is robust to noise. Gaussian filter decomposes detailed information and noises from low-frequency image components. It ensures that high-frequency image components only contain detailed information and noises. It can adjust the sparse coefficients in sparse representation to achieve the image denoising. So sparse-representation based image fusion of high-frequency components can complete image denoising and fusion.
- Step 2 is a decomposition process of low-frequency and high-frequency components. The high-frequency components of each source image can be obtained, by subtracting the low-frequency components of original input source image. The low-frequency components only contain the source image information without details, and the high-frequency components include the detailed information of source image and noises.
- Step 3 is an image fusion process. L2-norm based weighted average method and an online dictionary-learning algorithm are applied to low-frequency and high-frequency components respectively.
- Step 4 is an integration process. The integrated image is obtained by merging the fused images of low-frequency and high-frequency components together.
- The low-frequency and high-frequency components of source image are discriminated by Gaussian filter and processed separately.
- An information-entropy based approach is used to select the informative image blocks for dictionary learning. An online dictionary-learning based image fusion algorithm is applied to fuse high frequency components of source image.
- An L2-norm based weighted average method is used to fuse low frequency components of source image.
2. Related Works
2.1. Image Fusion
2.2. Sparse Representation and Dictionary Learning
2.3. Medical Image Fusion
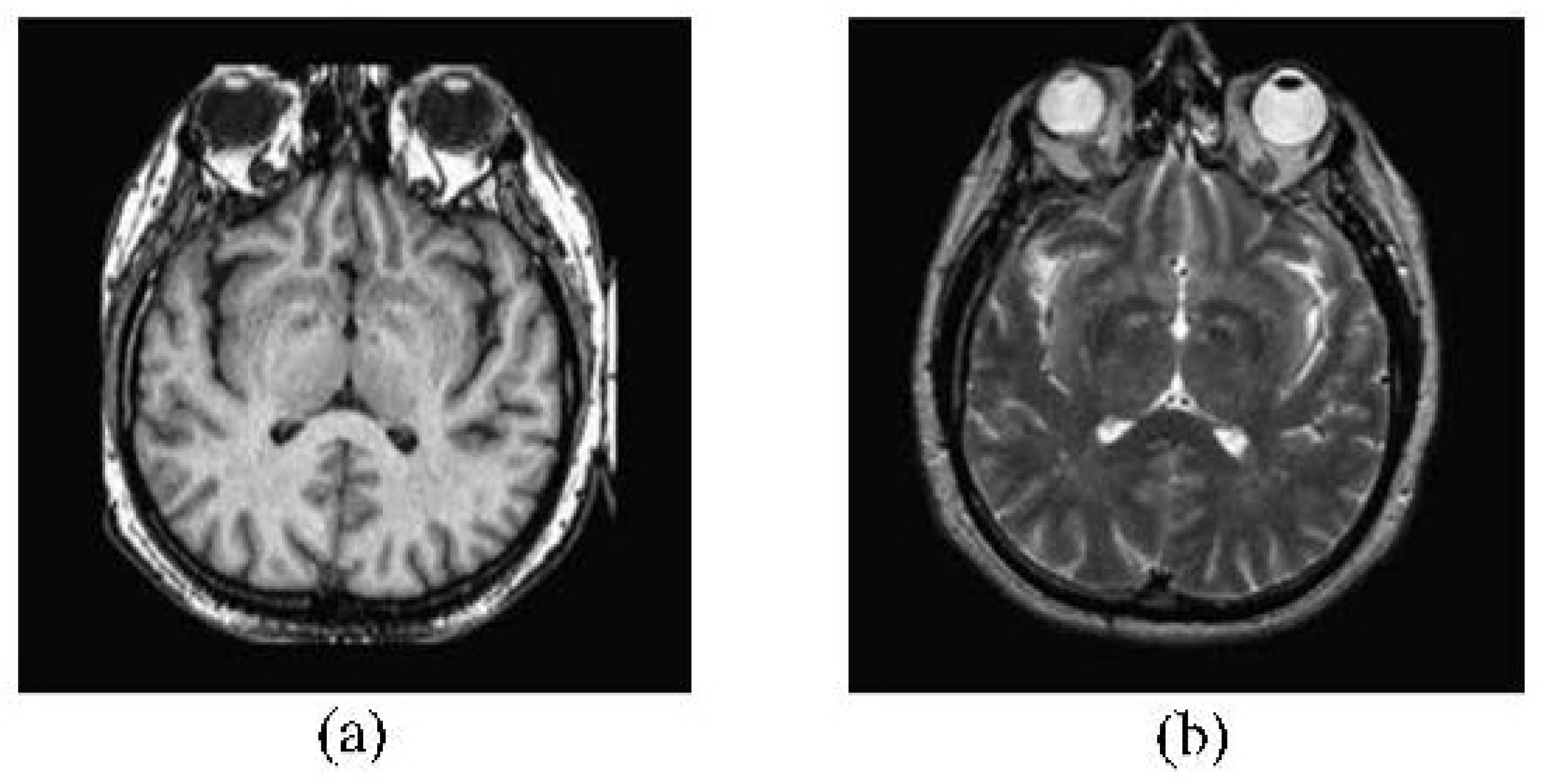
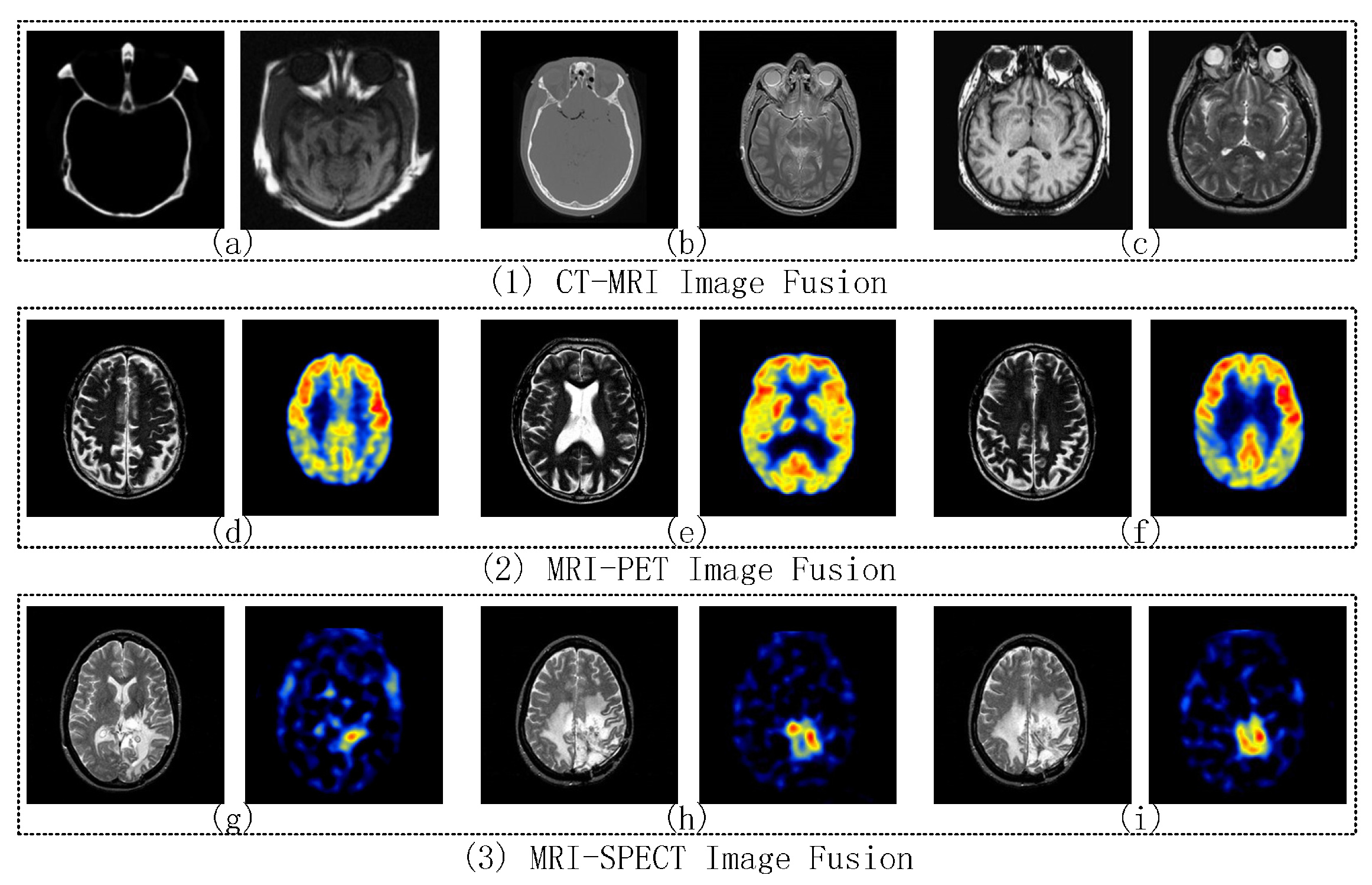
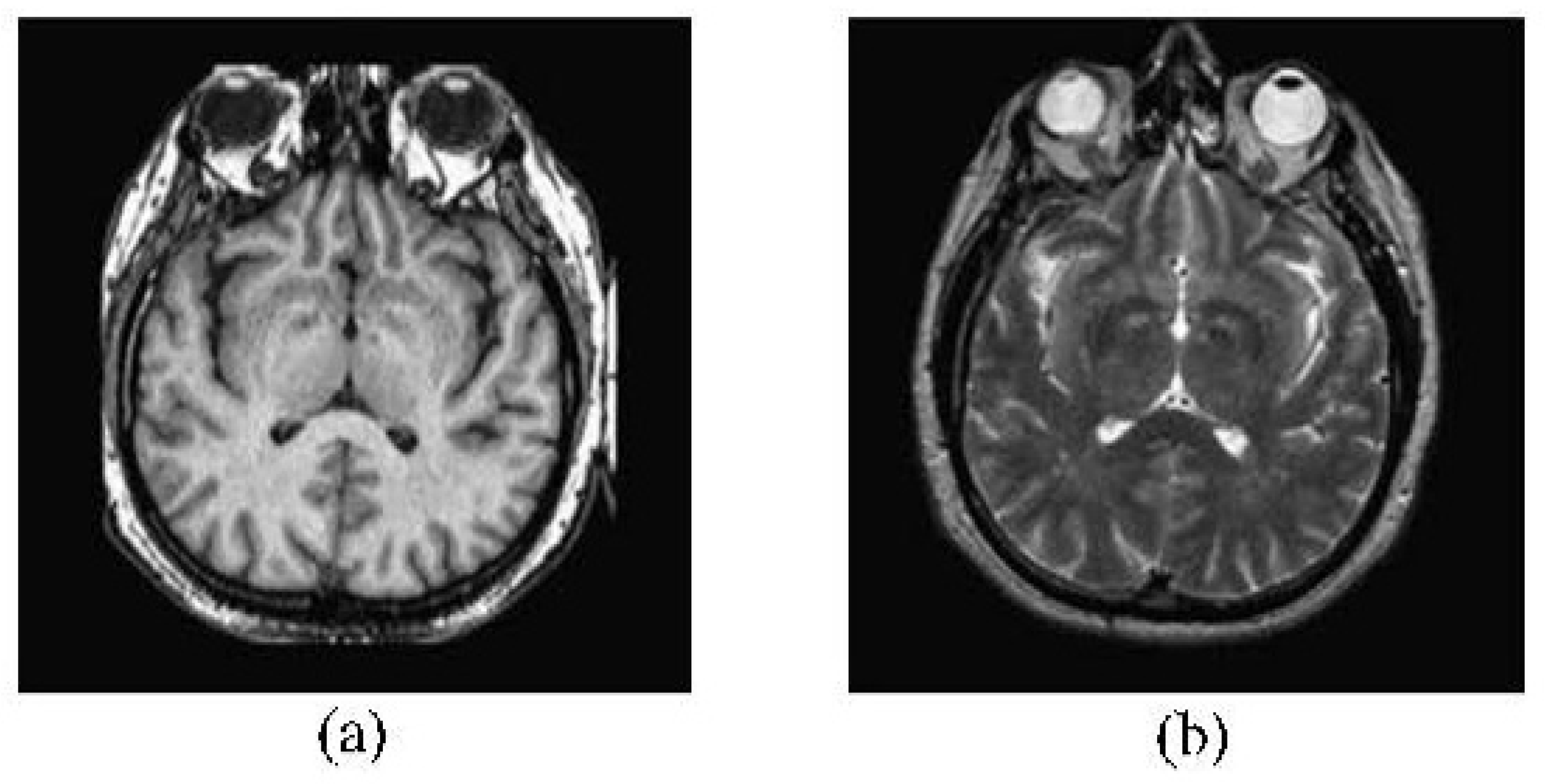
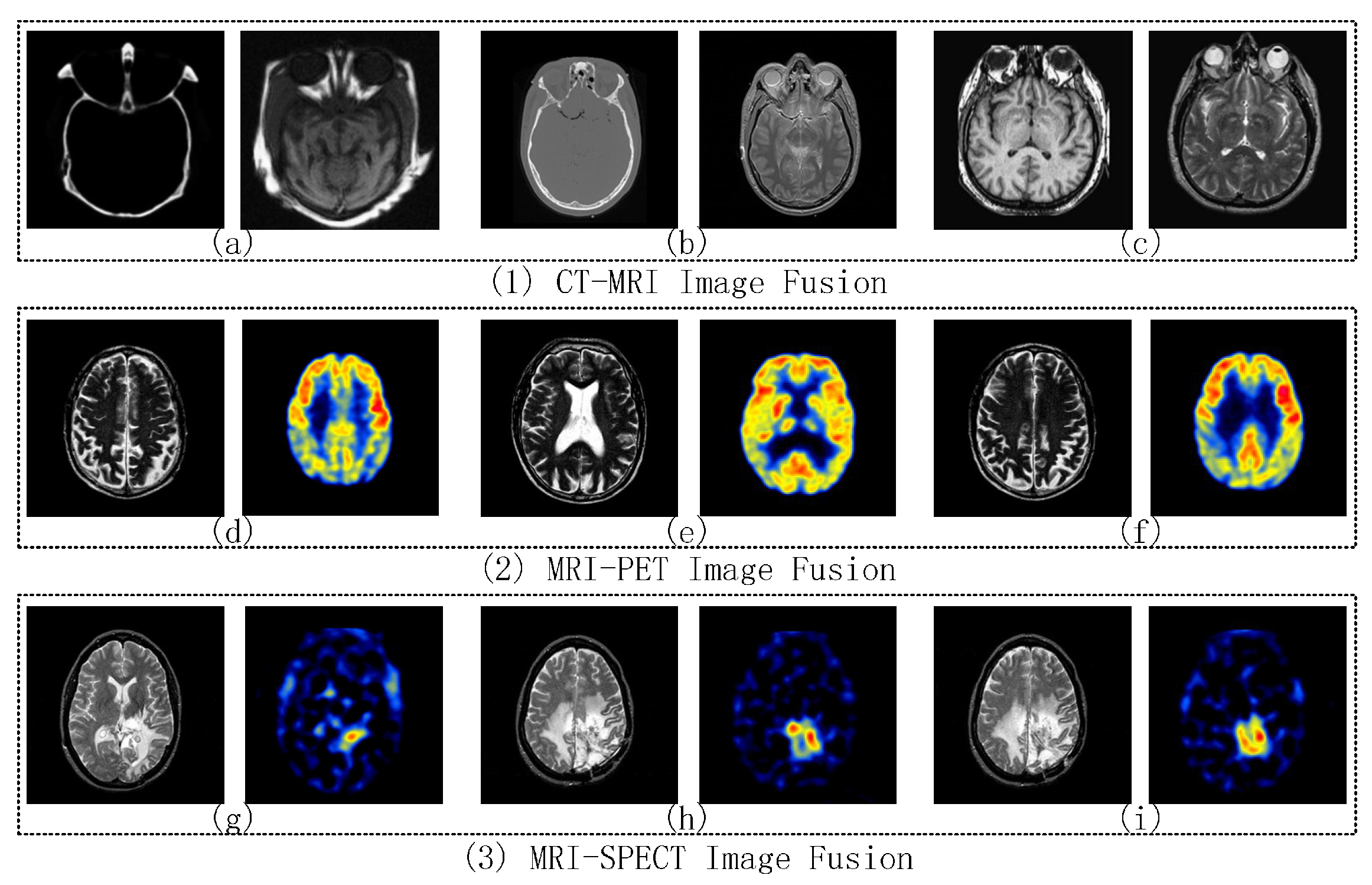
2.4. CT and MRI Images Fusion
2.5. MRI and PET Image Fusion
2.6. MRI and SPECT Image Fusion
3. Proposed Framework
3.1. Gaussian-Filter Based Decomposition
3.2. High-Frequency Components Fusion
3.2.1. Solution Discussion
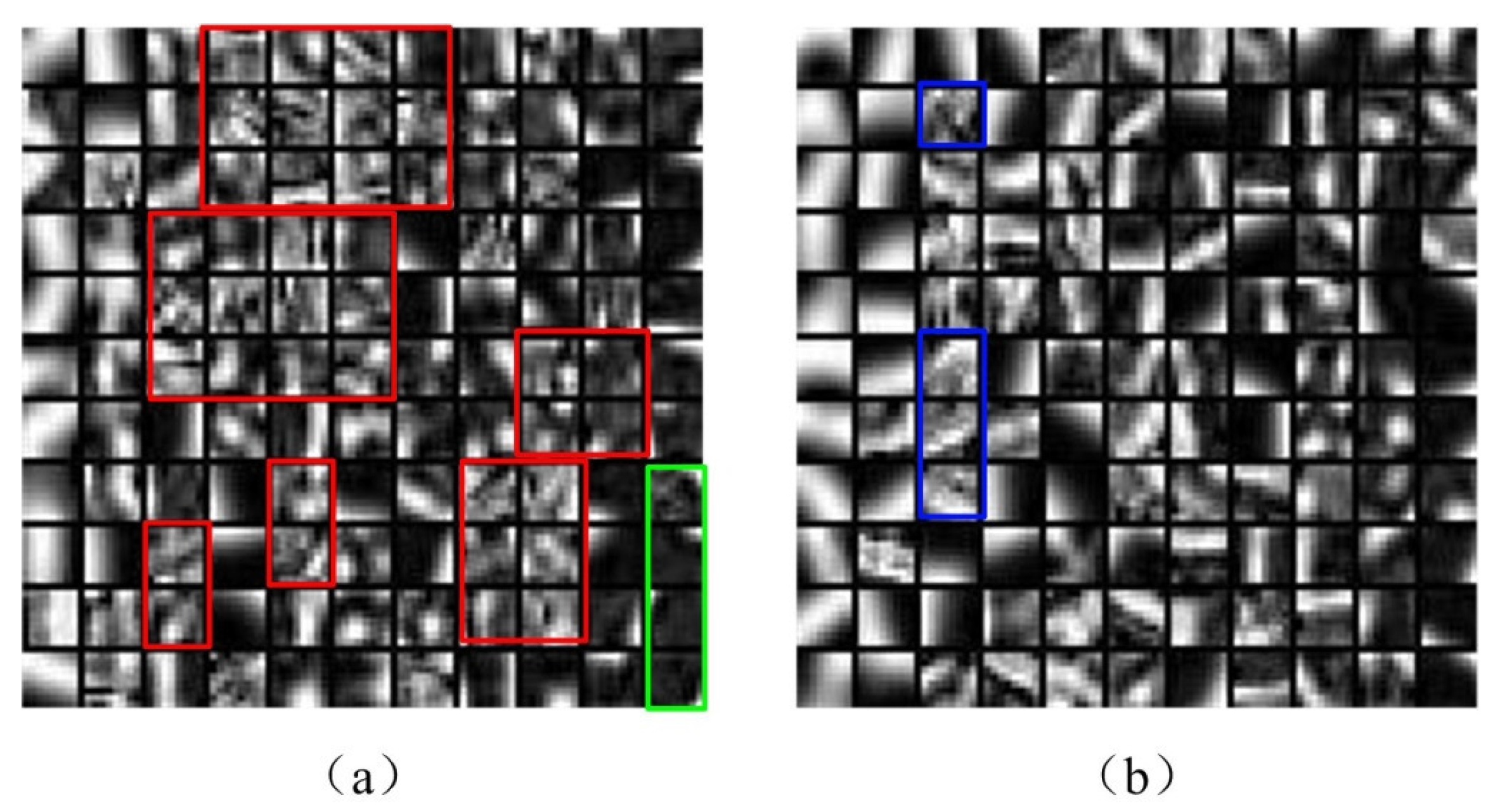
3.2.2. Dictionary Construction
| Algorithm 1 Image Block Entropy Calculation. |
| Input: |
| Gray-levels probability , |
| Output: |
| Entropy of image block, where |
| 1: |
| 2: for i = 1 to S do do |
| 3: Compute the entropy of number ith pixel in image block |
| 4: |
| 5: end for |
3.2.3. Sparse Coding and Coefficients Fusion
3.3. Low-Frequency Components Fusion
3.3.1. L2-Norm Based Fusion
3.3.2. Solution Discussion
3.4. Fused Components Merging
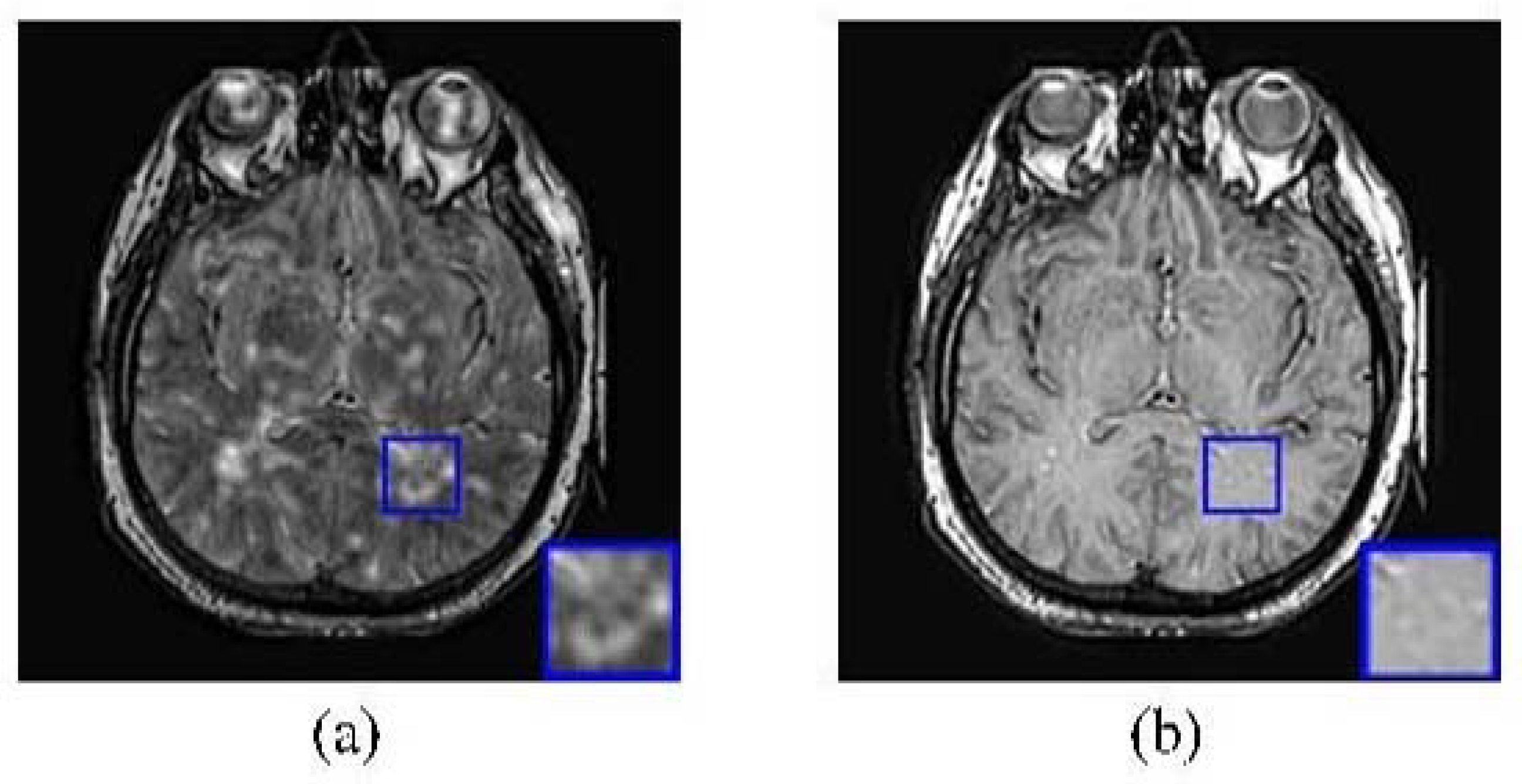
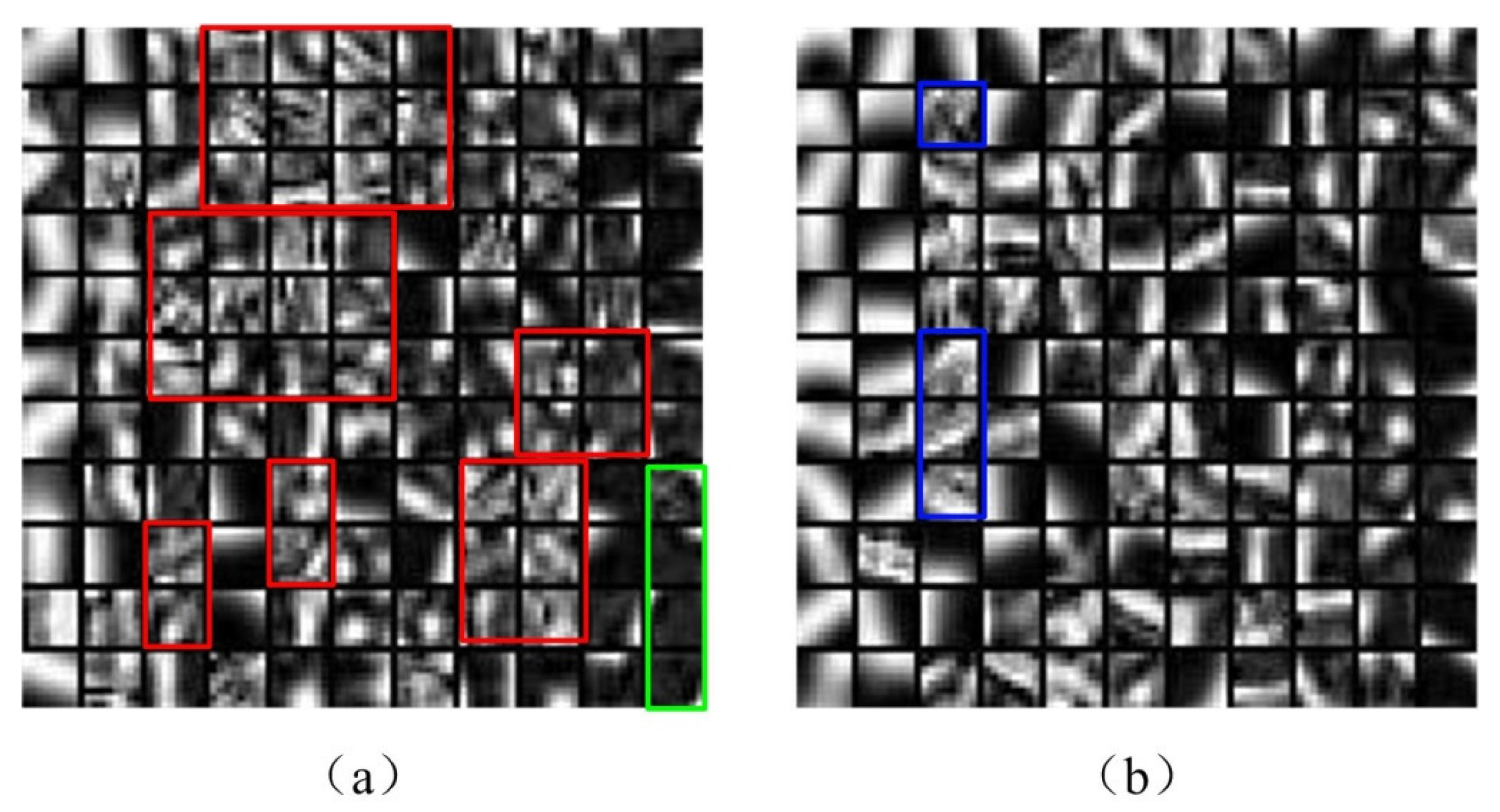
3.5. Comparison of Learned Dictionary
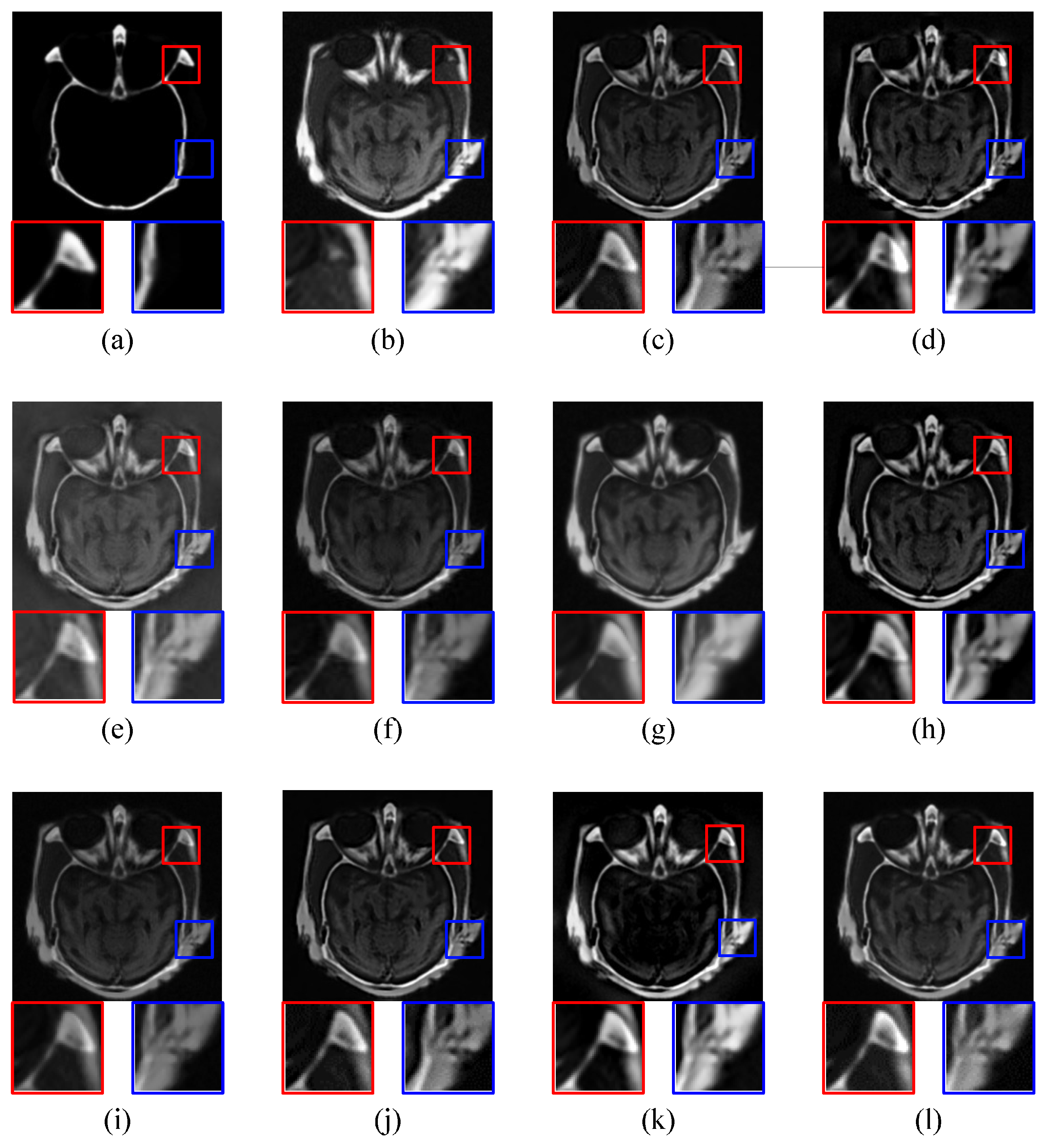
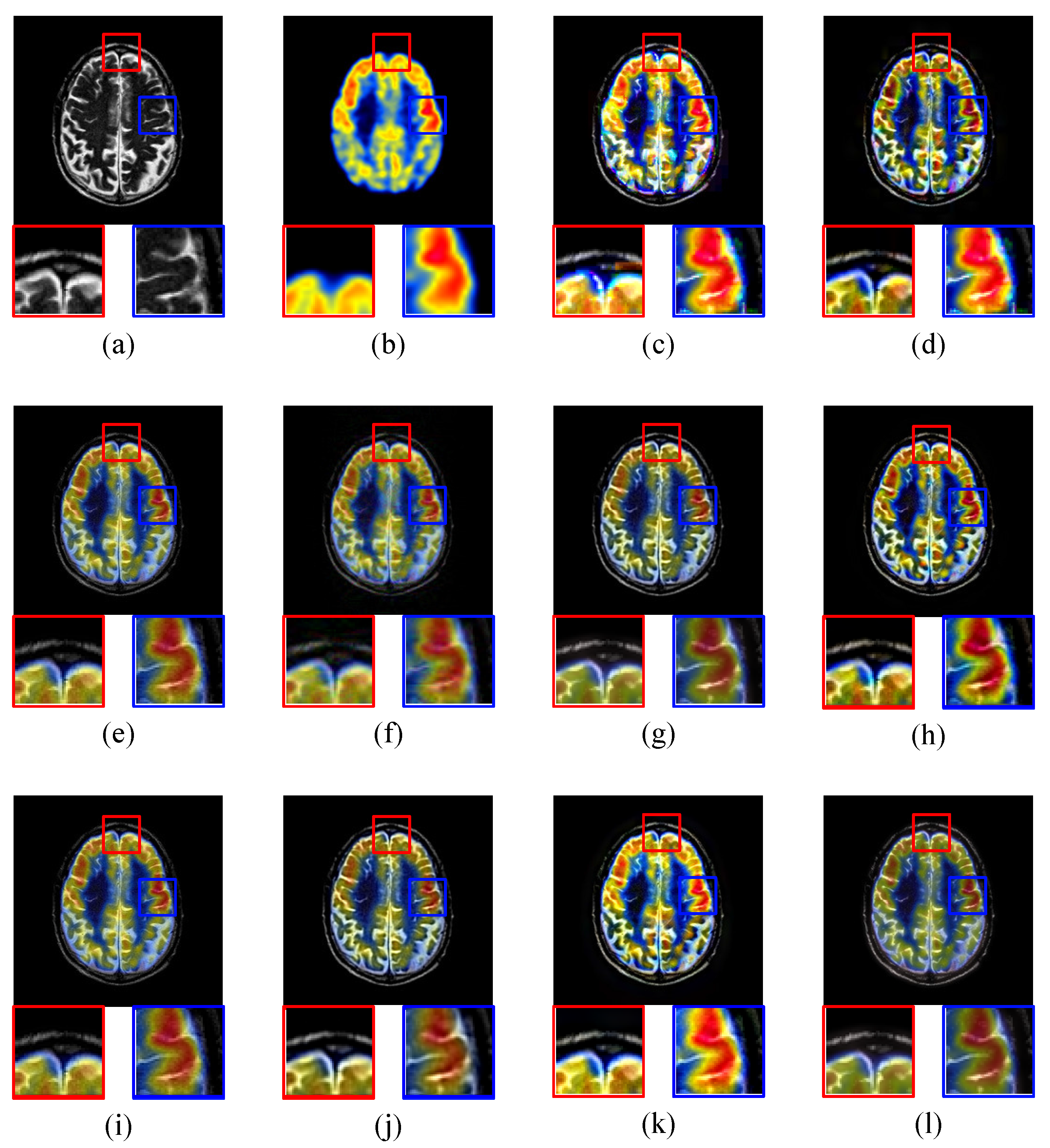
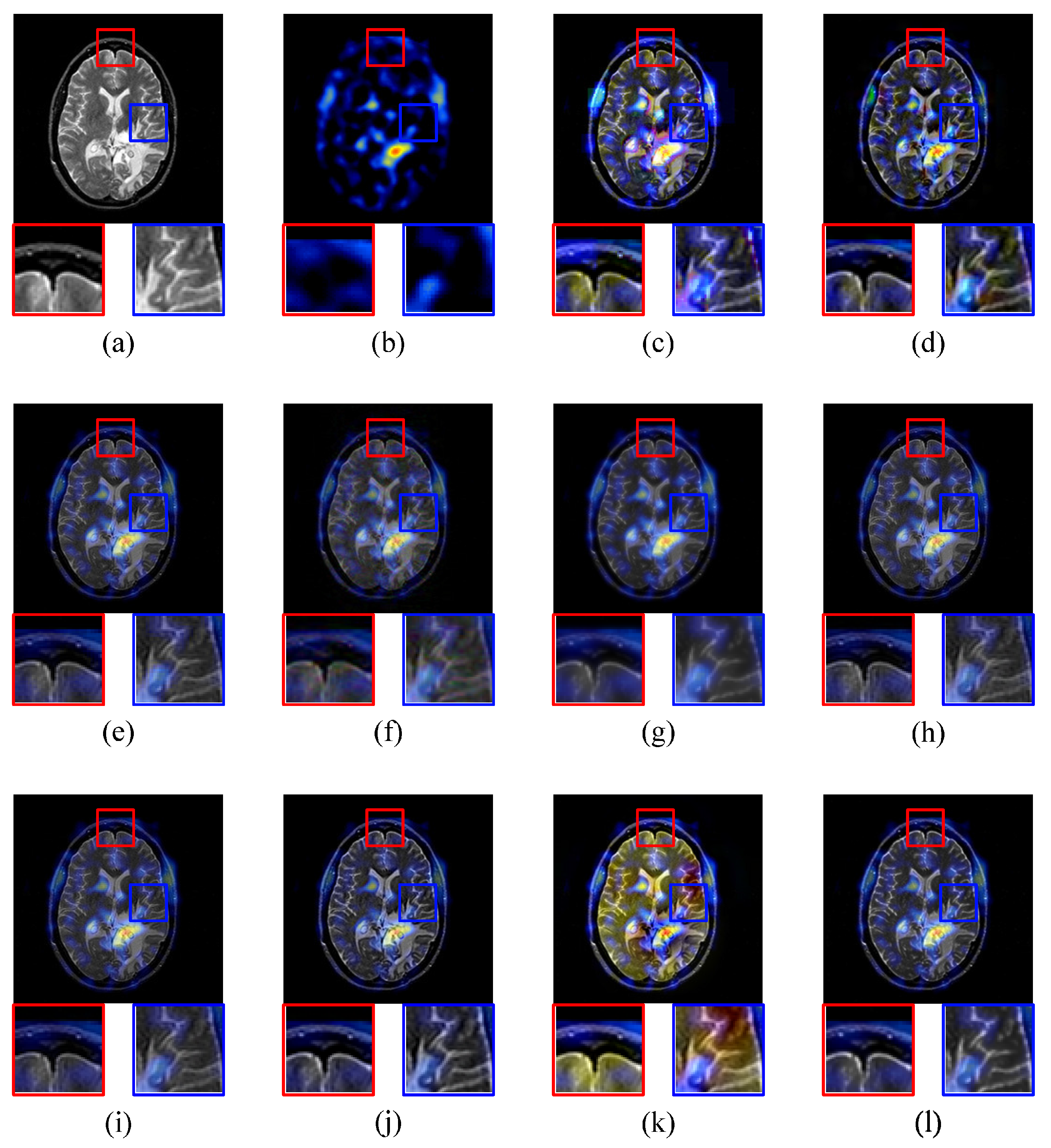
4. Experiments and Analysis
4.1. Experimental Setup
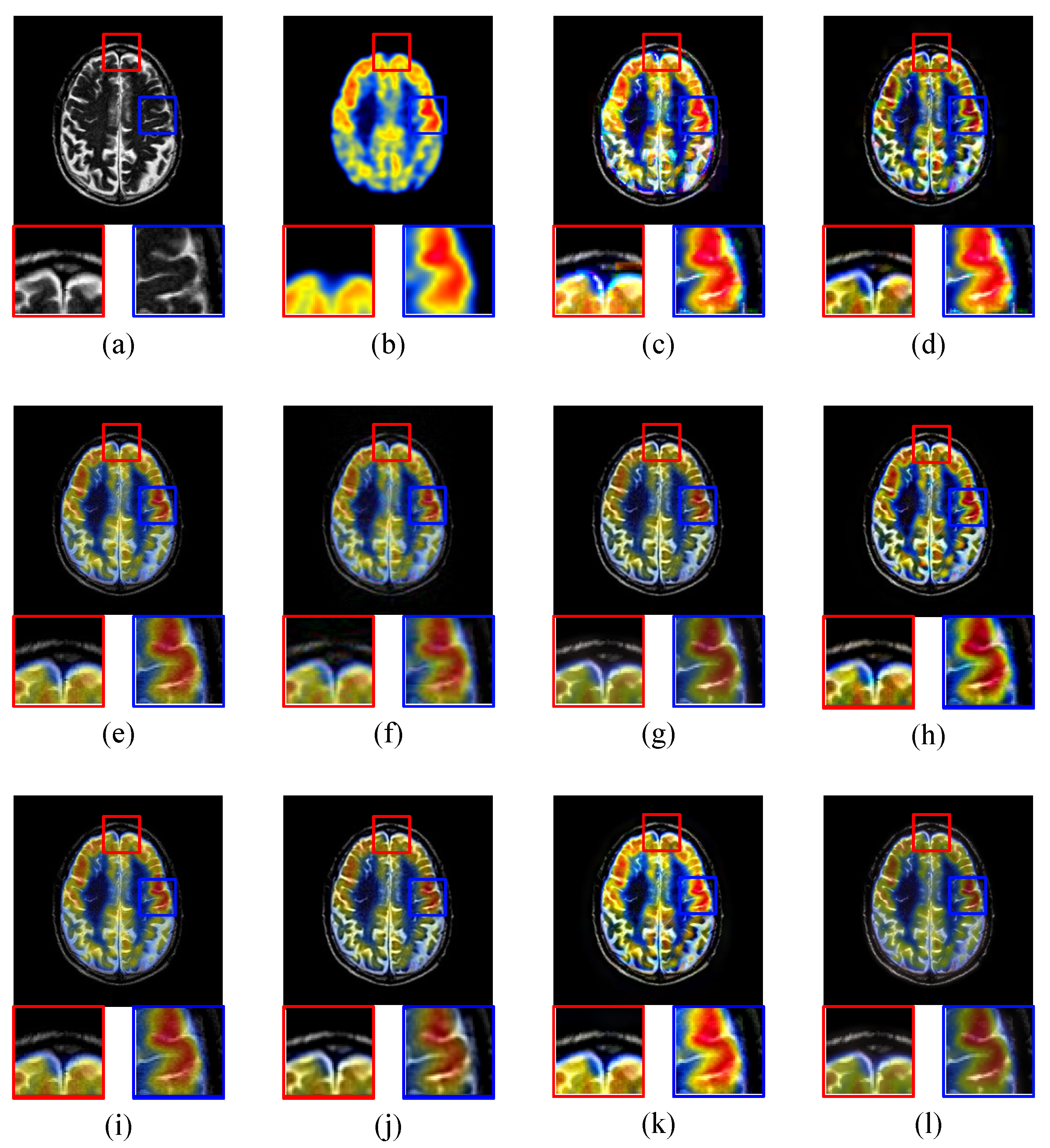
4.2. Image Quality Comparison
- AG computes the average gradients of each pixel in fused image, that shows the obvious degree of objects in the image. When AG gets larger, the difference between object and background increases [75].
- EI measures the strength of image local changes [76]. A higher EI value implies the fused image contains more intensive edges.
- edge strength represents the edge information associated with the fused image and visually supported by human visual system [77]. A higher value of value implies fused image contains better edge information.
- MI computes the information transformed from source images to fused images. When MI gets larger, the fused image gets more information from source images [78].
- VIF is a novel full-reference image quality metric [79]. VIF quantifies the information shared between the test and reference images based on the Natural Scene Statistics (NSS) theory and Human Visual System (HVS) model.
4.2.1. CT-MRI Image Fusion Comparative Experiments
4.2.2. MRI-PET Image Fusion Comparative Experiments
4.2.3. MRI-SPECT Image Fusion Comparative Experiments
4.2.4. Average Performance of Nine Image Fusion Comparative Experiments
4.2.5. Extension of Proposed Solution
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tsai, W.T.; Qi, G. DICB: Dynamic Intelligent Customizable Benign Pricing Strategy for Cloud Computing. In Proceedings of the 2012 IEEE Fifth International Conference on Cloud Computing (CLOUD), Honolulu, HI, USA, 24–29 June 2012; pp. 654–661. [Google Scholar]
- Tsai, W.T.; Qi, G.; Chen, Y. A Cost-Effective Intelligent Configuration Model in Cloud Computing. In Proceedings of the 2012 32nd International Conference on Distributed Computing Systems Workshops, Macau, China, 18–21 June 2012; pp. 400–408. [Google Scholar]
- Tsai, W.T.; Qi, G. Integrated fault detection and test algebra for combinatorial testing in TaaS (Testing-as-a-Service). Simulation Modelling Practice and Theory 2016, 68, 108–124. [Google Scholar] [CrossRef]
- Wikipedia, Magnetic Resonance Imaging. Available online: https://en.wikipedia.org/wiki/Magnetic_resonance_imaging (accessed on 1 October 2017).
- Wikipedia, Computed Tomography. Available online: https://en.wikipedia.org/wiki/CT_scan (accessed on 1 October 2017).
- RadiologyInfo, Positron Emission Tomography. Available online: https://www.radiologyinfo.org (accessed on 1 October 2017).
- Mayfield, Single Photon Emission Computed Tomography. Available online: https://www.mayfieldclinic.com/PE-SPECT.htm (accessed on 1 October 2017).
- May, K.A.; Georgeson, M.A. Blurred edges look faint, and faint edges look sharp: The effect of a gradient threshold in a multi-scale edge coding model. Vis. Res. 2007, 47, 1705–1720. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Qi, G.; Chai, Y.; Yin, H.; Sun, J. A Novel Visible-infrared Image Fusion Framework for Smart City. Int. J. Simul. Process Model. 2016, (in press). [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. Image denoising methods: A new nonlocal principle. SIAM Rev. 2010, 52, 113–147. [Google Scholar] [CrossRef]
- Vankawala, F.; Ganatra, A.; Patel, A. Article: A survey on different image deblurring techniques. Int. J. Comput. Appl. 2015, 116, 15–18. [Google Scholar]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000. [Google Scholar]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the 2009 International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Zhang, Y. Understanding image fusion. Photogramm. Eng. Remote Sens. 2004, 70, 657–661. [Google Scholar]
- Yang, B.; Li, S. Multifocus image fusion and restoration with sparse representation. IEEE Trans. Instrum. Meas. 2010, 59, 884–892. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Zhu, Z.; Sun, J.; Qi, G.; Chai, Y.; Chen, Y. Frequency Regulation of Power Systems with Self-Triggered Control under the Consideration of Communication Costs. Applied Sciences 2017, 7, 688. [Google Scholar] [CrossRef]
- Lee, H.; Battle, A.; Raina, R.; Ng, A.Y. Efficient sparse coding algorithms. In Proceedings of the 20th Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online learning for matrix factorization and sparse coding. J. Mach. Learn. Res. 2010, 11, 19–60. [Google Scholar]
- Qi, G.; Tsai, W.T.; Li, W.; Zhu, Z.; Luo, Y. A cloud-based triage log analysis and recovery framework. Simul. Model. Pract. Theory 2017, 77, 292–316. [Google Scholar] [CrossRef]
- Tsai, W.; Qi, G.; Zhu, Z. Scalable SaaS Indexing Algorithms with Automated Redundancy and Recovery Management. Int. J. Software Inform. 2013, 7, 63–84. [Google Scholar]
- Zhang, Q.; Fu, Y.; Li, H.; Zou, J. Dictionary learning method for joint sparse representation-based image fusion. Opt. Eng. 2013, 52. [Google Scholar] [CrossRef]
- Kim, M.; Han, D.K.; Ko, H. Joint patch clustering-based dictionary learning for multimodal image fusion. Inform. Fusion 2016, 27, 198–214. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Tsai, W.T.; Jin, C.; Qi, G.; Luo, J. Test-Algebra Execution in a Cloud Environment. In Proceedings of the 2014 IEEE 8th International Symposium on Service Oriented System Engineering, Oxford, UK, 7–11 April 2014; pp. 59–69. [Google Scholar]
- Tsai, W.T.; Luo, J.; Qi, G.; Wu, W. Concurrent Test Algebra Execution with Combinatorial Testing. In Proceedings of the 2014 IEEE 8th International Symposium on Service Oriented System Engineering, Washington, DC, USA, 7–11 April 2014; pp. 35–46. [Google Scholar]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inform. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Hyvärinen, A. Fast and robust fixed-point algorithms for independent component analysis. Neural Netw. IEEE Trans. 1999, 10, 626–634. [Google Scholar] [CrossRef] [PubMed]
- Zou, H.; Hastie, T.; Tibshirani, R. Sparse principal component analysis. J. Comput. Graph. Stat. 2006, 15, 265–286. [Google Scholar] [CrossRef]
- Nikolakopoulos, K.G. Comparison of nine fusion techniques for very high resolution data. Photogramm. Eng. Remote Sens. 2008, 74, 647–659. [Google Scholar] [CrossRef]
- Li, X.; Li, H.; Yu, Z.; Kong, Y. Multifocus image fusion scheme based on the multiscale curvature in nonsubsampled contourlet transform domain. Opt. Eng. 2015, 54. [Google Scholar] [CrossRef]
- Yang, Y.; Tong, S.; Huang, S.; Lin, P. Dual-tree complex wavelet transform and image block residual-based multi-focus image fusion in visual sensor networks. Sensors 2014, 14, 22408–22430. [Google Scholar] [CrossRef] [PubMed]
- Lemeshewsky, G.P. Multispectral multisensor image fusion using wavelet transforms. In Proceedings of the SPIE—The International Society for Optical Engineering, Orlando, FL, USA, 6 April 1999. [Google Scholar]
- Al-Azzawi, N.; Sakim, H.A.M.; Abdullah, A.K.W.; Ibrahim, H. Medical image fusion scheme using complex contourlet transform based on PCA. In Proceedings of the 2009 31st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Minneapolis, MN, USA, 3–6 September 2009. [Google Scholar]
- Chung, T.; Liu, Y.; Chen, C.; Sun, Y.; Chiu, N.; Lee, J. Intermodality registration and fusion of liver images for medical diagnosis. In Proceedings of the Intelligent Information Systems, IIS’97, Grand Bahama Island, Bahamas, 8–10 December 1997. [Google Scholar]
- Phegley, J.; Perkins, K.; Gupta, L.; Dorsey, J.K. Risk-factor fusion for predicting multifactorial diseases. Biomed. Eng. IEEE Trans. 2002, 49, 72–76. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.M.; Yao, J.; Bajwa, S.; Gudas, T. “Automatic” multimodal medical image fusion. In Proceedings of the 2003 IEEE International Workshop on Soft Computing in Industrial Applications, Provo, UT, USA, 17 May 2003. [Google Scholar]
- Zhu, Z.; Yin, H.; Chai, Y.; Li, Y.; Qi, G. A novel multi-modality image fusion method based on image decomposition and sparse representation. Inform. Sci. 2017, in press. [Google Scholar] [CrossRef]
- Olshausen, B.; Field, D. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Huang, K.; Aviyente, S. Sparse representation for signal classification. In Proceedings of the 20th Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006. [Google Scholar]
- Husoy, J.H.; Engan, K.; Aase, S. Method of optimal directions for frame design. In Proceedings of the 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing, Phoenix, AZ, USA, 15–19 March 1999. [Google Scholar]
- Rubinstein, R.; Zibulevsky, M.; Elad, M. Double sparsity: Learning sparse dictionaries for sparse signal approximation. IEEE Trans. Signal Process. 2010, 58, 1553–1564. [Google Scholar] [CrossRef]
- Yang, B.; Li, S. Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inform. Fusion 2012, 13, 10–19. [Google Scholar] [CrossRef]
- Nejati, M.; Samavi, S.; Shirani, S. Multi-focus image fusion using dictionary-based sparse representation. Inform. Fusion 2015, 25, 72–84. [Google Scholar] [CrossRef]
- Dong, W.; Li, X.; Zhang, D.; Shi, G. Sparsity-based image denoising via dictionary learning and structural clustering. In Proceedings of the 2011 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Chatterjee, P.; Milanfar, P. Clustering-based denoising with locally learned dictionaries. Trans. Image Process. 2009, 18, 1438–1451. [Google Scholar] [CrossRef] [PubMed]
- Mairal, J. Stochastic majorization-minimization algorithms for large-scale optimization. In Advances in Neural Information Processing Systems 26; Burges, C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K., Eds.; Neural Information Processing Systems Foundation: Brussels, Belgium, 2013; pp. 2283–2291. [Google Scholar]
- Zhu, Z.; Qi, G.; Chai, Y.; Chen, Y. A Novel Multi-Focus Image Fusion Method Based on Stochastic Coordinate Coding and Local Density Peaks Clustering. Future Internet 2016, 8, 53. [Google Scholar] [CrossRef]
- Qiu, Q.; Jiang, Z.; Chellappa, R. Sparse dictionary-based representation and recognition of action attributes. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Siyahjani, F.; Doretto, G. Learning a Context Aware Dictionary for Sparse Representation; Lecture Notes in Computer Science Book Series; Springer: Berlin/Heidelberg, Germany, 2013; pp. 228–241. [Google Scholar]
- Kong, S.; Wang, D. A dictionary learning approach for classification: Separating the particularity and the commonality. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Yang, M.; Zhang, L.; Feng, X.; Zhang, D. Fisher discrimination dictionary learning for sparse representation. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Zhang, Q.; Li, B. Discriminative K-SVD for dictionary learning in face recognition. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- James, M.L.; Gambhir, S.S. A molecular imaging primer: Modalities, imaging agents, and applications. Physiol. Rev. 2012, 92, 897–965. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Zhuang, D.; Huang, Y.; Fu, J. Advances in multi-sensor data fusion: Algorithms and applications. Sensors 2009, 9, 7771–7784. [Google Scholar] [CrossRef] [PubMed]
- Okada, T.; Linguraru, M.G.; Hori, M.; Suzuki, Y.; Summers, R.M.; Tomiyama, N.; Sato, Y. Multi-organ segmentation in abdominal CT images. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2012, 2012, 3986–3989. [Google Scholar] [PubMed]
- Lindeberg, T. Scale-space theory: A basic tool for analysing structures at different scales. J. Appl. Stat. 1994, 21, 225–270. [Google Scholar] [CrossRef]
- Wang, K.; Qi, G.; Zhu, Z.; Chai, Y. A Novel Geometric Dictionary Construction Approach for Sparse Representation Based Image Fusion. Entropy 2017, 19, 306. [Google Scholar] [CrossRef]
- Zhu, Z.; Qi, G.; Chai, Y.; Li, P. A Geometric Dictionary Learning Based Approach for Fluorescence Spectroscopy Image Fusion. Applied Sciences 2017, 7, 161. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J.M. On iMage Denoising Methods; Technical Report, Technical Note; Centre de Mathematiques et de Leurs Applications (CMLA): Paris, France, 2004. [Google Scholar]
- Wikipedia, Gaussian Blur. Available online: https://en.wikipedia.org/wiki/Gaussian_blur (accessed on 1 October 2017).
- Aharon, M.; Elad, M. Sparse and redundant modeling of image content using an image-signature-dictionary. SIAM J. Imaging Sci. 2008, 1, 228–247. [Google Scholar] [CrossRef]
- Zuo, Q.; Xie, M.; Qi, G.; Zhu, H. Tenant-based access control model for multi-tenancy and sub-tenancy architecture in Software-as-a-Service. Front. Comput. Sci. 2017, 11, 465–484. [Google Scholar] [CrossRef]
- Tsai, W.T.; Qi, G. Integrated Adaptive Reasoning Testing Framework with Automated Fault Detection. In Proceedings of the 2015 IEEE Symposium on Service-Oriented System Engineering, Redwood City, CA, USA, 30 March–3 April 2015; pp. 169–178. [Google Scholar]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inform. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Liu, Z.; Chai, Y.; Yin, H.; Zhou, J.; Zhu, Z. A novel multi-focus image fusion approach based on image decomposition. Inform. Fusion 2016, 35, 102–116. [Google Scholar] [CrossRef]
- Wu, Y.; Vansteenberge, J.; Mukunoki, M.; Minoh, M. Collaborative representation for classification, sparse or non-sparse? CoRR 2014, arXiv:1403.1353. [Google Scholar]
- Image Fusion Organization, Image Fusion Source Images. Available online: http://www.imagefusion.org (accessed on 20 October 2015).
- Johnson, K.A.; Becker, J.A. The Whole Brain Atlas. Available online: www.med.harvard.edu/aanlib/home.html (accessed on 17 June 2016).
- Hwang, B.M.; Lee, S.; Lim, W.T.; Ahn, C.B.; Son, J.H.; Park, H. A fast spatial-domain terahertz imaging using block-based compressed sensing. J. Infrared Millim. Terahertz Waves 2011, 32, 1328–1336. [Google Scholar] [CrossRef]
- Zheng, Y.; Essock, E.A.; Hansen, B.C.; Haun, A.M. A new metric based on extended spatial frequency and its application to DWT based fusion algorithms. Inform. Fusion 2007, 8, 177–192. [Google Scholar] [CrossRef]
- Anantrasirichai, N.; Achim, A.; Bull, D.; Kingsbury, N. Mitigating the effects of atmospheric distortion using DT-CWT fusion. In Proceedings of the 19th IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012. [Google Scholar]
- Liu, Z.; Yin, H.; Chai, Y.; Yang, S.X. A novel approach for multimodal medical image fusion. Expert Syst. Appl. 2014, 41, 7425–7435. [Google Scholar] [CrossRef]
- Chen, H.; Huang, Z. Medical Image feature extraction and fusion algorithm based on K-SVD. In Proceedings of the 9th IEEE International Conference on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), Guangdong, China, 8–10 November 2014. [Google Scholar]
- Kumar, U.; Dasgupta, A.; Mukhopadhyay, C.; Joshi, N.; Ramachandra, T. Comparison of 10 multi-sensor image fusion paradigms for IKONOS images. Int. J. Res. Rev. Comput. Sci. 2011, 2, 40–47. [Google Scholar]
- Dixon, T.D.; Canga, E.F.; Nikolov, S.G.; Troscianko, T.; Noyes, J.M.; Canagarajah, C.N.; Bull, D.R. Selection of image fusion quality measures: Objective, subjective, and metric assessment. J. Opt. Soc. Am. A 2007, 24, B125–B135. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Xydeas, C.; Petrović, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Sheikh, H.; Bovik, A. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Manchanda, M.; Sharma, R. A novel method of multimodal medical image fusion using fuzzy transform. J. Vis. Commun. Image Represent. 2016, 40, 197–217. [Google Scholar] [CrossRef]
- James, A.P.; Dasarathy, B.V. Medical image fusion: A survey of the state of the art. Inform. Fusion 2014, 19, 4–19. [Google Scholar] [CrossRef]
- Xu, X.; Shan, D.; Wang, G.; Jiang, X. Multimodal medical image fusion using PCNN optimized by the QPSO algorithm. Appl. Soft Comput. 2016, 46, 588–595. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
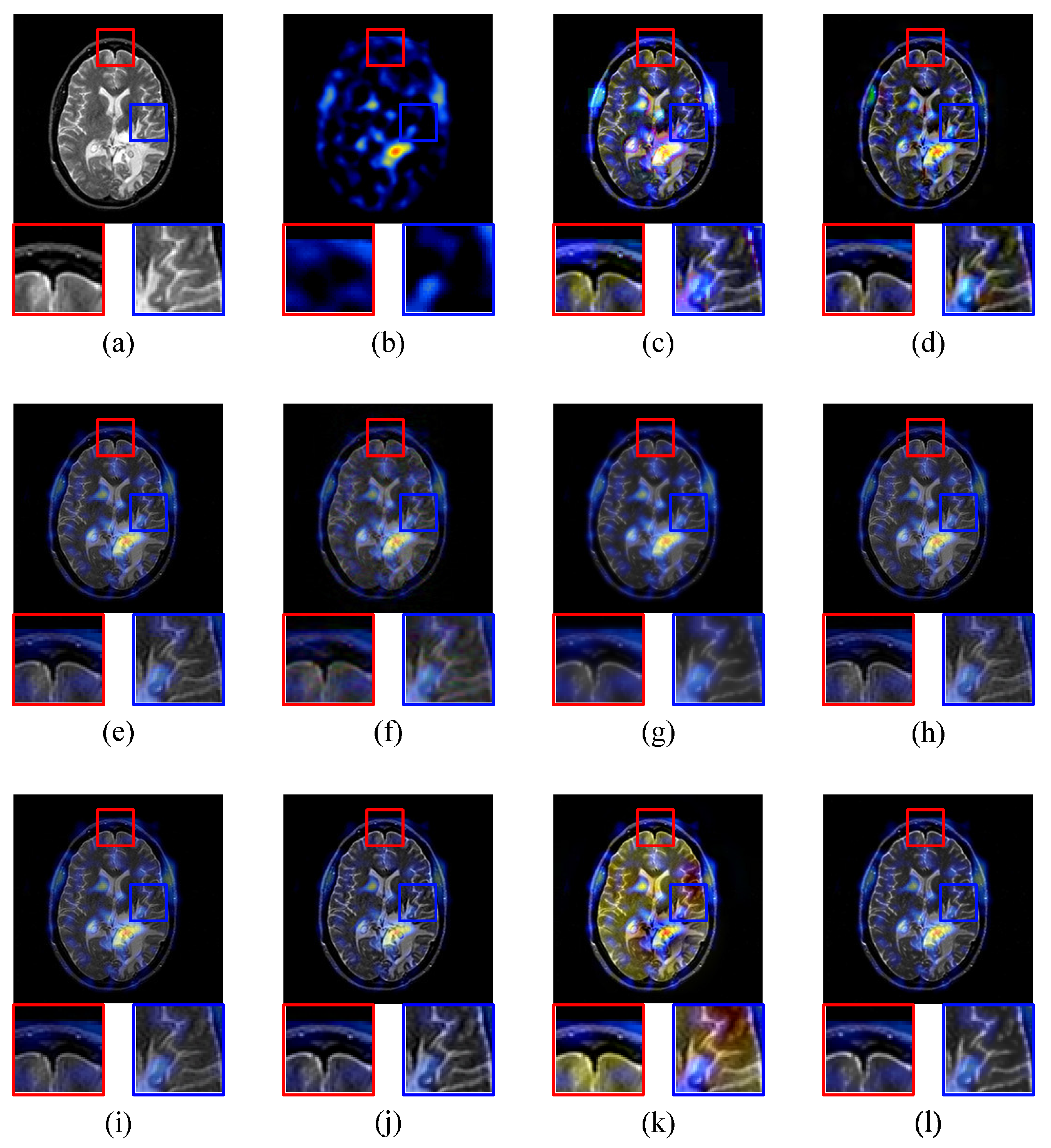{kind=link}
{kind=link}
{kind=link}
| AG | EI | MI | VIF | ||
|---|---|---|---|---|---|
| BSD | 7.1738 | 76.9148 | 0.6595 | 2.1021 | 0.4021 |
| DWT | 6.1569 | 56.8719 | 0.6284 | 1.3327 | 0.2952 |
| DT-CWT | 4.2628 | 46.2560 | 0.5097 | 1.2463 | 0.2632 |
| CS-DCT | 3.5918 | 38.7132 | 0.5063 | 2.0268 | 0.3046 |
| KSVD-OMP | 4.2109 | 46.0699 | 0.7762 | 2.5085 | 0.3493 |
| MFR | 6.0671 | 62.1495 | 0.7442 | 2.7284 | 0.3691 |
| SRDL | 4.6062 | 53.2307 | 0.7238 | 2.6084 | 0.3417 |
| JPC | 6.1482 | 64.5306 | 0.7264 | 2.5146 | 0.3908 |
| MST-SR | 4.4807 | 49.1622 | 0.6843 | 2.4708 | 0.3261 |
| Proposed IDLE | 6.1330 | 65.6209 | 0.8428 | 3.0158 | 0.4097 |
| AG | EI | MI | VIF | ||
|---|---|---|---|---|---|
| BSD | 6.7133 | 69.2493 | 0.3069 | 1.8505 | 0.2611 |
| DWT | 6.8695 | 70.8721 | 0.3128 | 1.7715 | 0.2447 |
| DT-CWT | 4.9488 | 47.1991 | 0.3147 | 1.8667 | 0.2954 |
| CS-DCT | 4.1109 | 42.9211 | 0.2955 | 1.8330 | 0.2694 |
| KSVD-OMP | 3.5764 | 36.7095 | 0.2840 | 1.7970 | 0.2842 |
| MFR | 4.9026 | 47.9372 | 0.3155 | 1.8673 | 0.3096 |
| SRDL | 5.0374 | 49.1628 | 0.3163 | 1.8571 | 0.3142 |
| JPC | 4.6936 | 47.6084 | 0.3184 | 1.8647 | 0.3086 |
| MST-SR | 3.7241 | 38.9104 | 0.2894 | 1.8163 | 0.2907 |
| Proposed IDLE | 4.7137 | 48.0413 | 0.3199 | 1.8744 | 0.3161 |
| AG | EI | MI | VIF | ||
|---|---|---|---|---|---|
| BSD | 5.8505 | 59.7385 | 0.7180 | 1.5139 | 0.2951 |
| DWT | 4.6099 | 57.2050 | 0.6397 | 1.3106 | 0.2766 |
| DT-CWT | 3.8157 | 37.3078 | 0.7079 | 1.6847 | 0.3212 |
| CS-DCT | 3.0988 | 31.6784 | 0.3601 | 1.4818 | 0.2695 |
| KSVD-OMP | 2.7215 | 38.1780 | 0.6497 | 1.6565 | 0.2898 |
| MFR | 4.5781 | 51.8703 | 0.7174 | 1.7067 | 0.3196 |
| SRDL | 4.8603 | 51.3517 | 0.7219 | 1.6973 | 0.3244 |
| JPC | 4.7361 | 52.5702 | 0.7196 | 1.7102 | 0.3227 |
| MST-SR | 3.8729 | 43.7209 | 0.6173 | 1.5927 | 0.2681 |
| Proposed IDLE | 4.7295 | 52.0081 | 0.7317 | 1.7192 | 0.3265 |
| AG | EI | MI | VIF | ||
|---|---|---|---|---|---|
| BSD | 5.5369 | 56.6304 | 0.3293 | 1.8758 | 0.2837 |
| DWT | 5.4205 | 55.1206 | 0.3585 | 1.2852 | 0.2471 |
| DT-CWT | 4.4082 | 45.0176 | 0.4376 | 1.6371 | 0.2847 |
| CS-DCT | 3.6498 | 36.8703 | 0.3974 | 1.8496 | 0.2745 |
| KSVD-OMP | 3.6265 | 39.9752 | 0.5382 | 1.8416 | 0.2984 |
| MFR | 5.1247 | 52.1774 | 0.5653 | 2.0934 | 0.3204 |
| SRDL | 4.9845 | 5.1983 | 0.5537 | 1.9416 | 0.3279 |
| JPC | 5.2903 | 55.0743 | 0.6149 | 1.9773 | 0.3395 |
| MST-SR | 4.0817 | 44.1942 | 0.5142 | 1.9237 | 0.3076 |
| Proposed IDLE | 5.2374 | 53.9238 | 0.6291 | 2.1045 | 0.3426 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, G.; Wang, J.; Zhang, Q.; Zeng, F.; Zhu, Z. An Integrated Dictionary-Learning Entropy-Based Medical Image Fusion Framework. Future Internet 2017, 9, 61. https://doi.org/10.3390/fi9040061
Qi G, Wang J, Zhang Q, Zeng F, Zhu Z. An Integrated Dictionary-Learning Entropy-Based Medical Image Fusion Framework. Future Internet. 2017; 9(4):61. https://doi.org/10.3390/fi9040061
Chicago/Turabian StyleQi, Guanqiu, Jinchuan Wang, Qiong Zhang, Fancheng Zeng, and Zhiqin Zhu. 2017. "An Integrated Dictionary-Learning Entropy-Based Medical Image Fusion Framework" Future Internet 9, no. 4: 61. https://doi.org/10.3390/fi9040061
APA StyleQi, G., Wang, J., Zhang, Q., Zeng, F., & Zhu, Z. (2017). An Integrated Dictionary-Learning Entropy-Based Medical Image Fusion Framework. Future Internet, 9(4), 61. https://doi.org/10.3390/fi9040061