TSKT-ORAM: A Two-Server k-ary Tree Oblivious RAM without Homomorphic Encryption †

Abstract
:1. Introduction
- Communication efficiency: Under a practical scenario, the communication cost per data query is about 22 blocks–46 blocks when and the block size bits for some constant . In practice, this is lower or comparable to constant communication ORAM constructions C-ORAM and CNE-ORAM. Furthermore, in TSKT-ORAM, there is no server-server communication cost incurred.
- Low access delay: Compared to both the C-ORAM and CNE-ORAM schemes with constant client-server communication cost, TSKT-ORAM has a low access latency.
- Small data block size requirement: Compared to C-ORAM and CNE-ORAM, TSKT-ORAM only requires each data block size KB.
- Constant storage at the client: TSKT-ORAM only requires the client storage to store a constant number of data blocks, while each server needs to store data blocks.
- Low failure probability guarantee: TSKT-ORAM is proven to achieve a failure probability given system parameter .
2. Related Work
2.1. Oblivious RAM
2.2. Private Information Retrieval
2.3. Hybrid ORAM-PIR Designs
2.4. Multi-Server ORAMs
3. Problem Definition
- private read ;
- private write .
- retrieval from a location, denoted as ;
- uploading to a location, denoted as .
- security parameter λ;
- two arbitrary equal-length sequences of private data access denoted as , , ⋯〉 and , , ⋯〉; and
- two sequences of the client’s access to storage locations that correspond to and , denoted as , and , .
- and are computationally indistinguishable; and
- the construction fails with a probability no greater than .
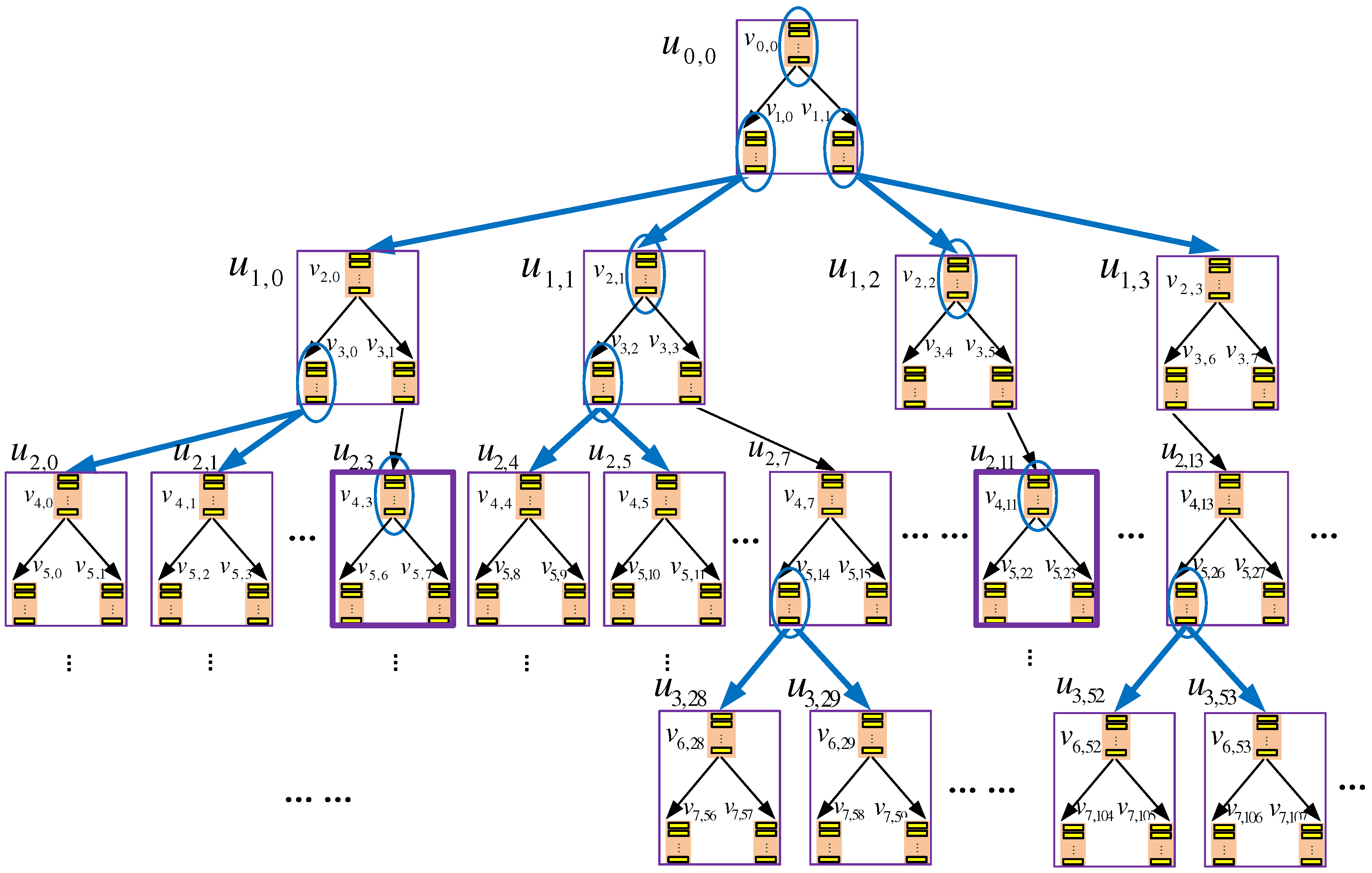
4. Preliminary Construction: TSBT-ORAM
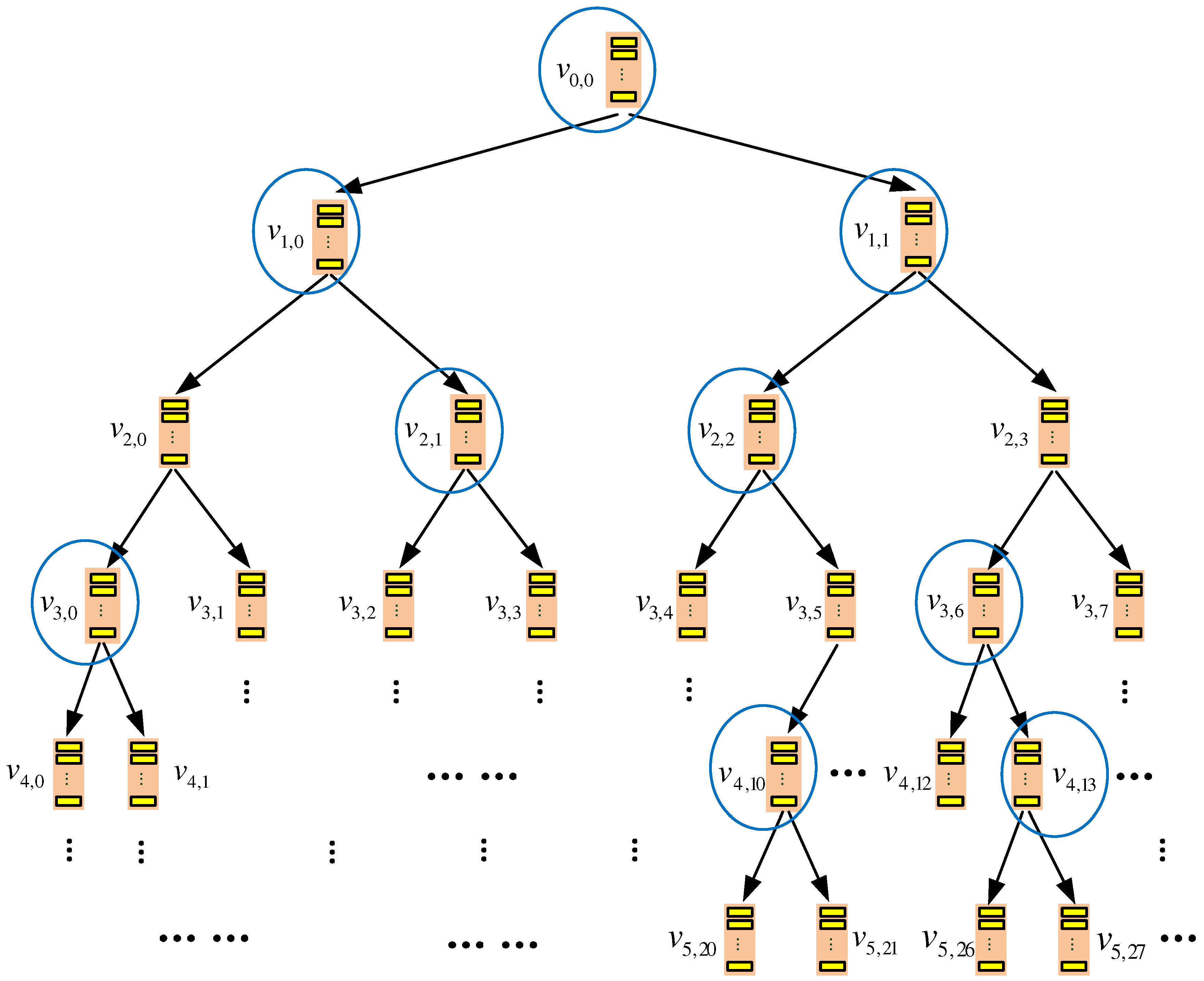
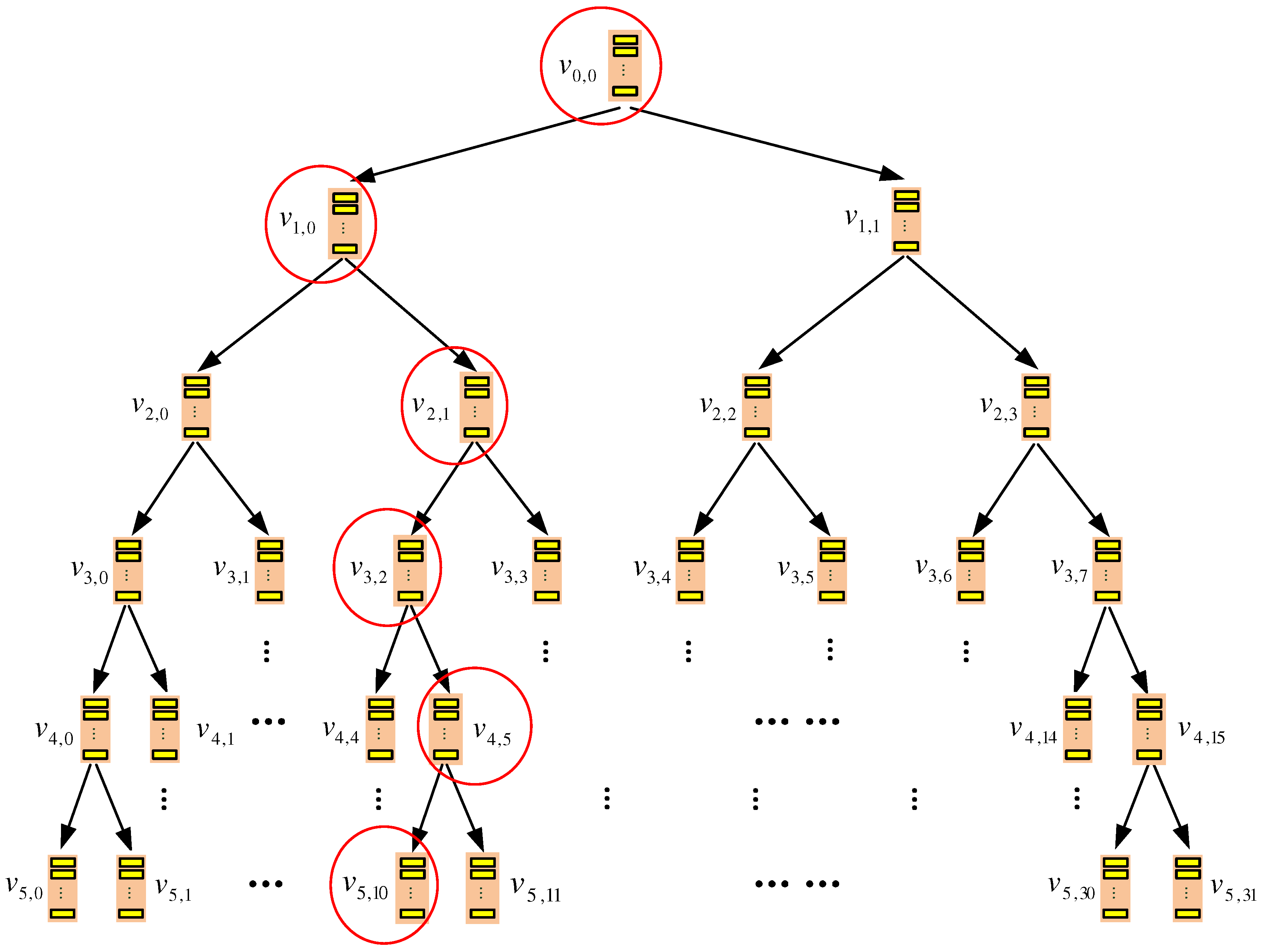
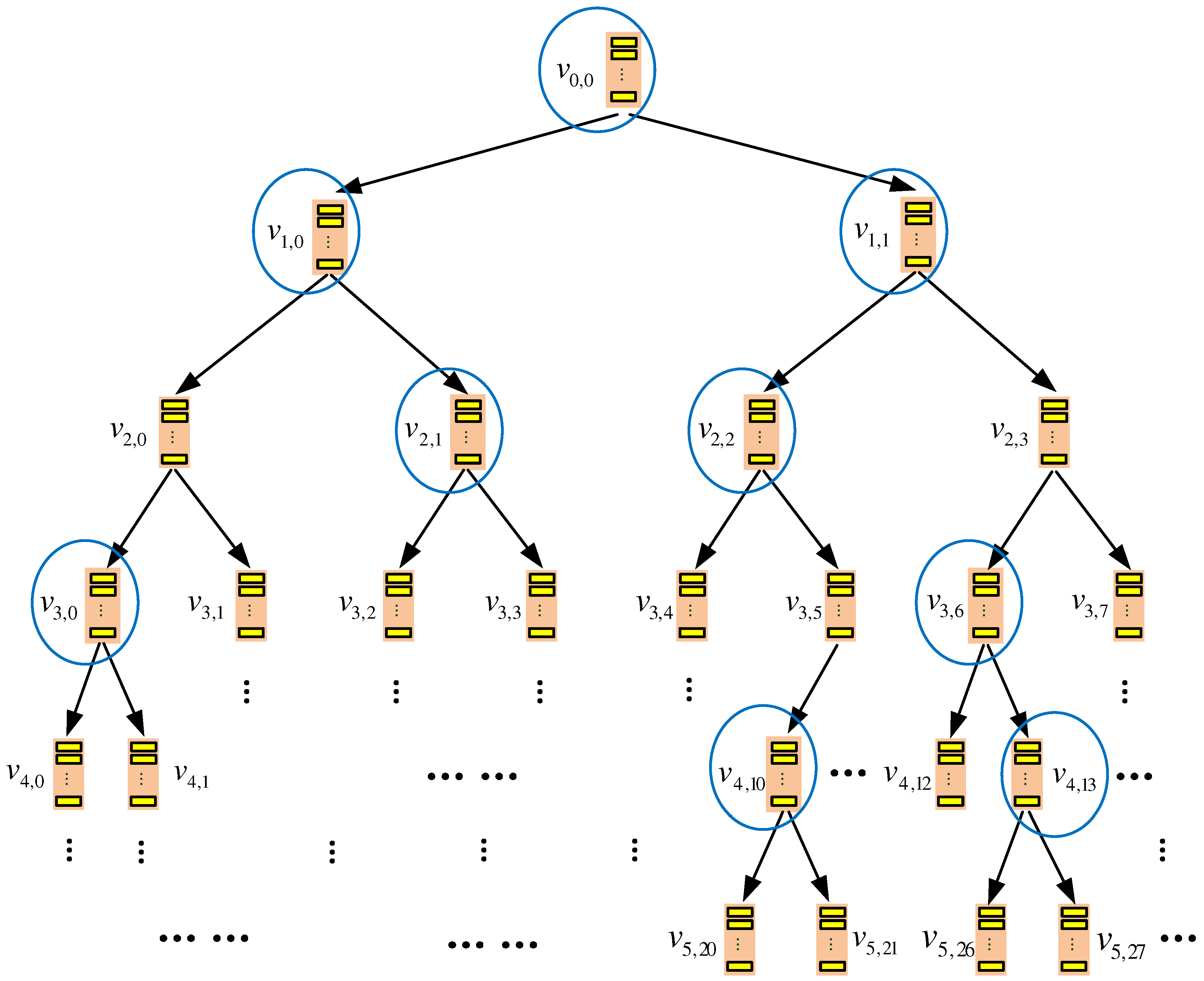
4.1. Storage Organization
4.1.1. Server-Side Storage
4.1.2. Client-Side Storage
4.2. Data Query Process
4.2.1. Client’s Launching of Query
- is generated randomly.
- is first made as a copy of . Further, if the query target is in node (supposing the offset of in the block is m), bit m of is flipped.
4.2.2. Servers’ Response to Query
4.2.3. Client’s Computation of the Query Result
4.3. Data Eviction Process
4.3.1. Basic Idea
- which real data block is evicted from an evicting node should be hidden;
- which one of two child nodes of an evicting node that receives the evicted real data block should be hidden.
- For each evicting node (e.g., ), the position where the evicted data block resides should be hidden from any server.
- For each receiving node (e.g., ), each position that can be used to receive the evicted data block should be selected with an equal probability. In other words, each position of the receiving node should have an equal probability to be written during data eviction. This way, the behavior of a receiving node is independent of whether it receives a real or dummy block.
4.3.2. Oblivious Retrieval of Evicted Data Block
4.3.3. Oblivious Receiving of Evicted Data Block
- Case I: D is a real data block.Without loss of generality, suppose D needs to be evicted to ; meanwhile, a dummy block needs to be evicted to to achieve obliviousness. To reduce the communication cost, D is treated also as the dummy data block when evicted to .
- Case II: D is a dummy data block. In this case, D is evicted to both and as a dummy data block.
- : This part is used by the node to store the latest evicted data blocks, which could be dummy or real, from its parent.
- : This part is used to store each real data block that still remains in the node after more than (dummy or real) blocks have been evicted to the node since the arrival of this real block. Since the number of real data blocks stored in any node is at most , this part may contain dummy blocks.
- : This is the storage space other than and in the node. This part contains only dummy data blocks.
- If D should be evicted to (i.e., D is assigned to the path passing ), one position in partition of node is randomly picked to receive D, and meanwhile, one position in partition or of node is randomly picked to receive a dummy block.
- Otherwise (i.e., D should be evicted to ), one position in partition of is randomly picked to receive D, while one position in partition or of is randomly picked to receive a dummy block.
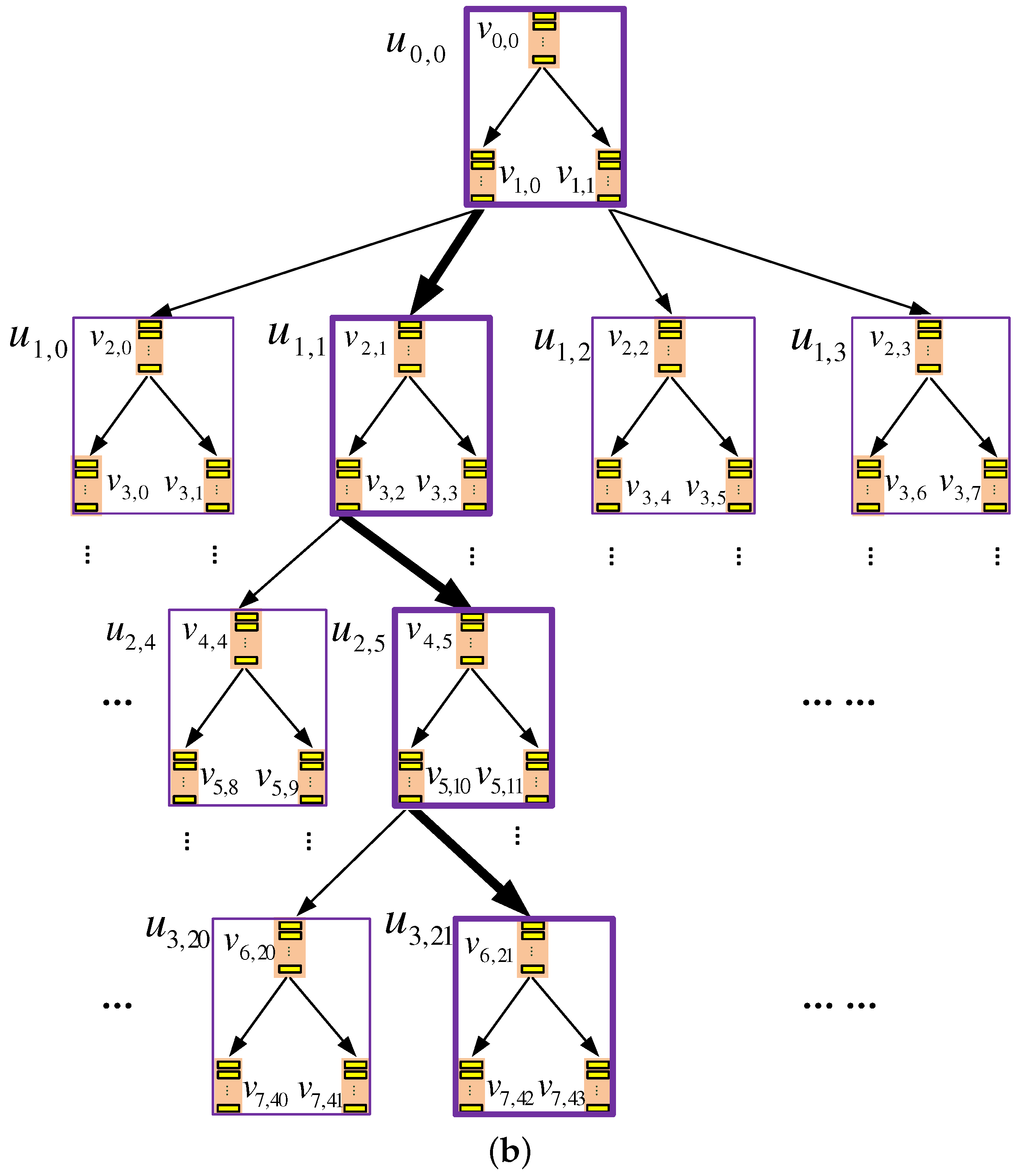
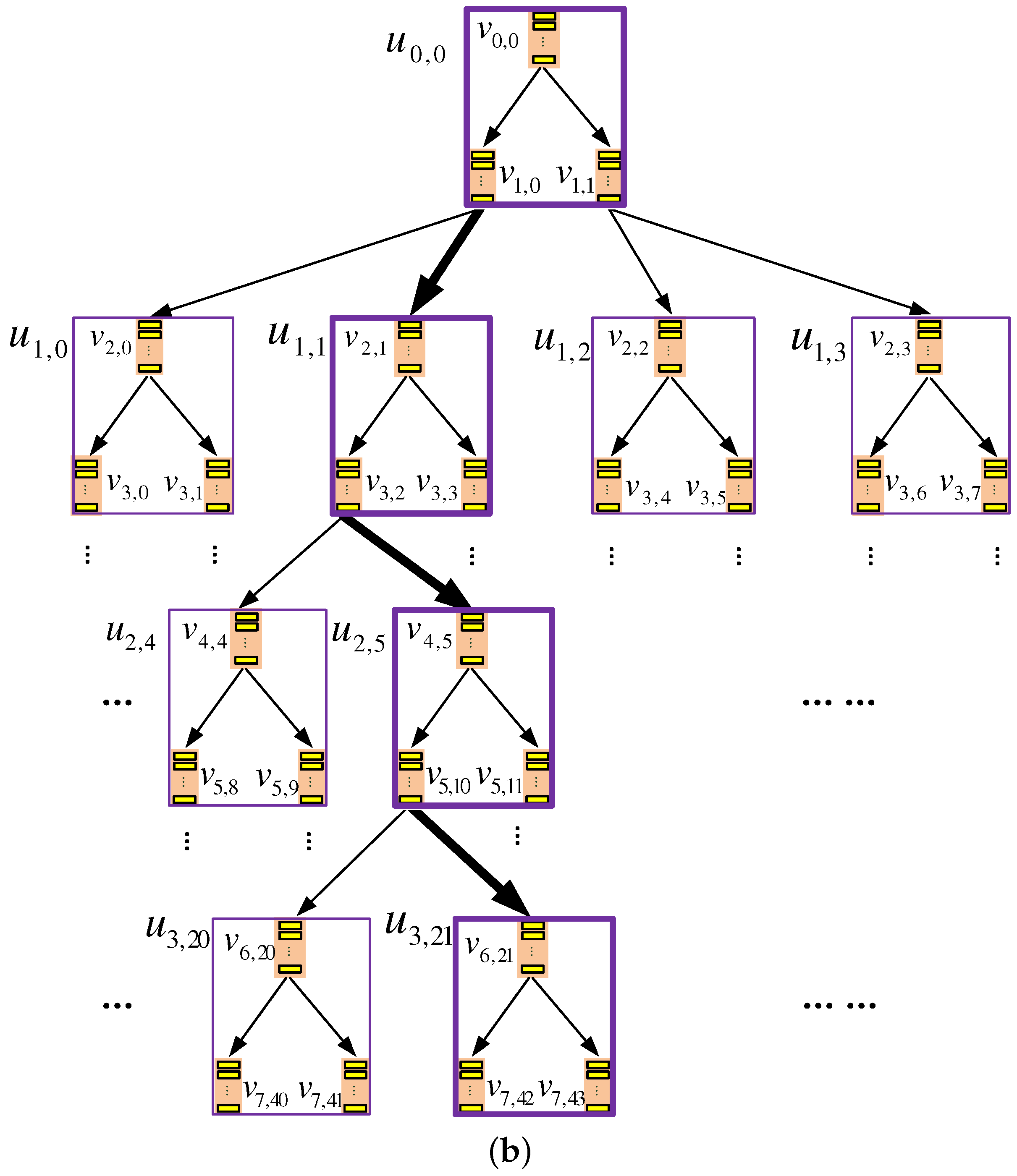
5. Final Construction: TSKT-ORAM
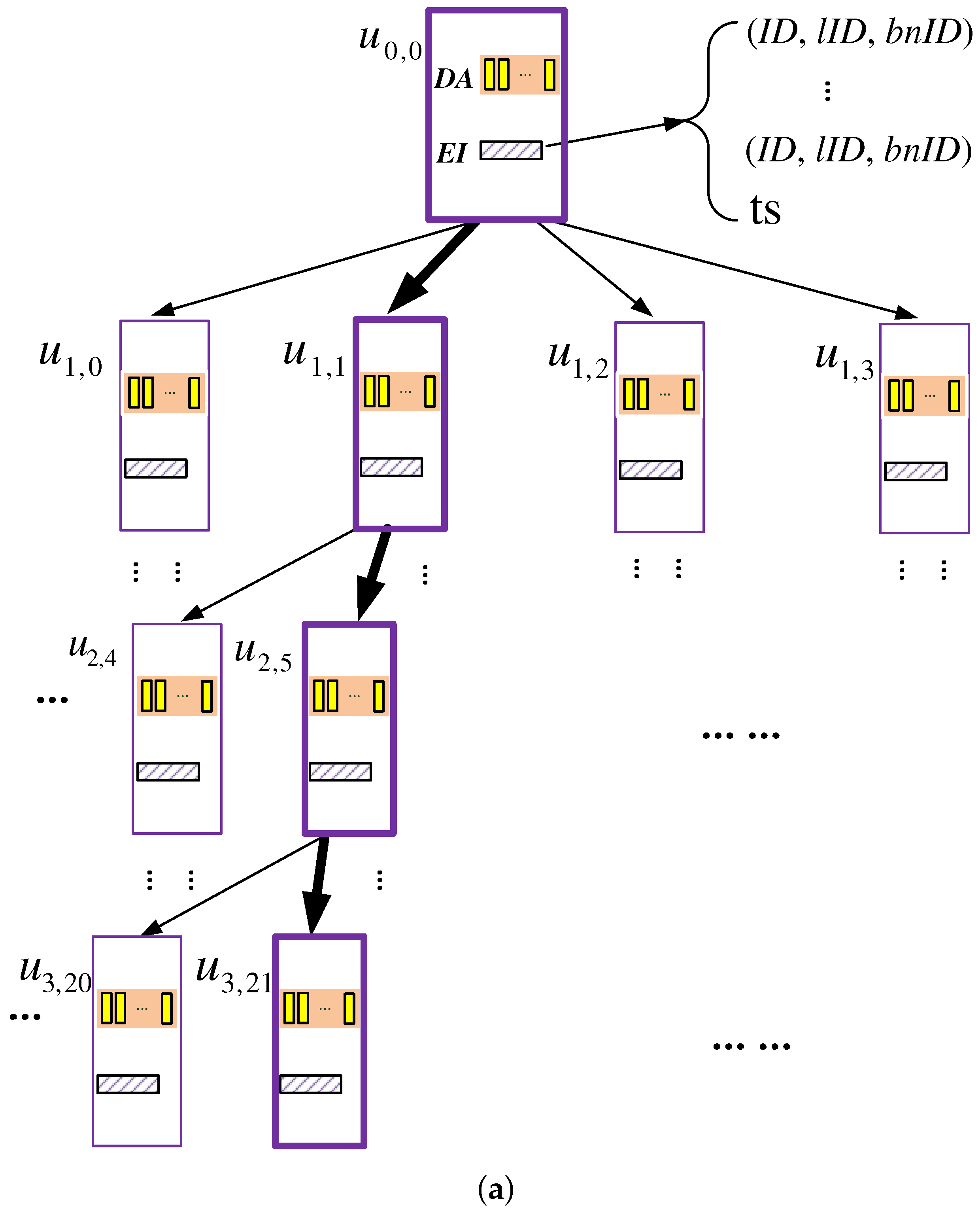
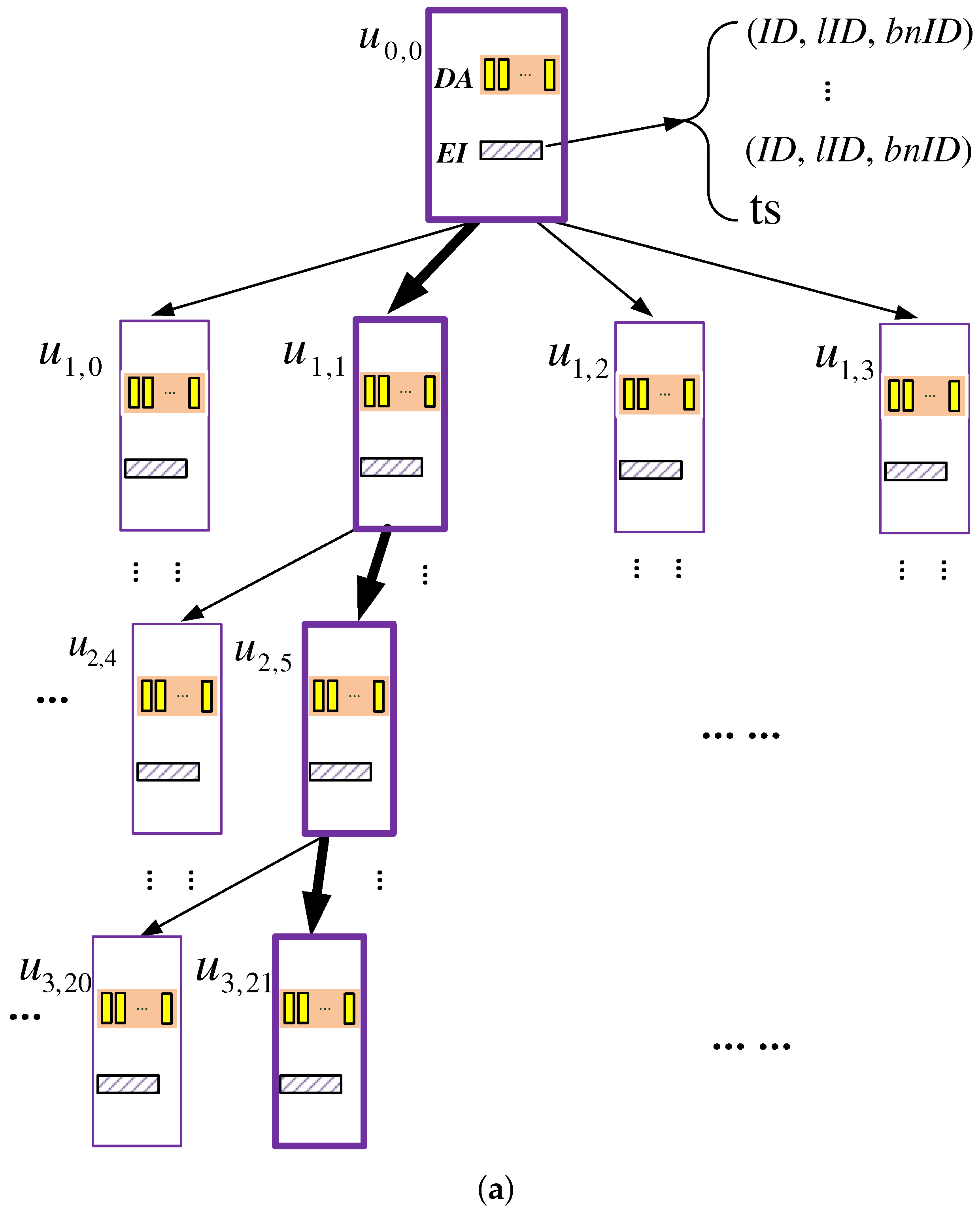
5.1. Storage Organization
- Data array (DA): a data container that stores data blocks, where c is a system parameter. As c gets larger, the failure probability of the scheme gets smaller, and meanwhile, more storage space gets consumed; hence, an appropriate value should be picked for c. As demonstrated by the security analysis presented later, when , the failure probability can be upper-bounded by . Therefore, we use four as the default value of c.
- Encrypted index table (EI): a table of entries recording the information for each block stored in the DA. Specifically, each entry is a tuple of format , which records the following information of each block:
- −
- : ID of the block;
- −
- : ID of the leaf k-node to which the block is mapped;
- −
- : ID of the b-node (within ) to which the block logically belongs.
In addition, the EI has a ts field, which stores a time stamp indicating when this k-node was accessed the last time.
5.2. Client-Side Storage
5.3. System Initialization
5.4. Data Query
5.5. Data Eviction
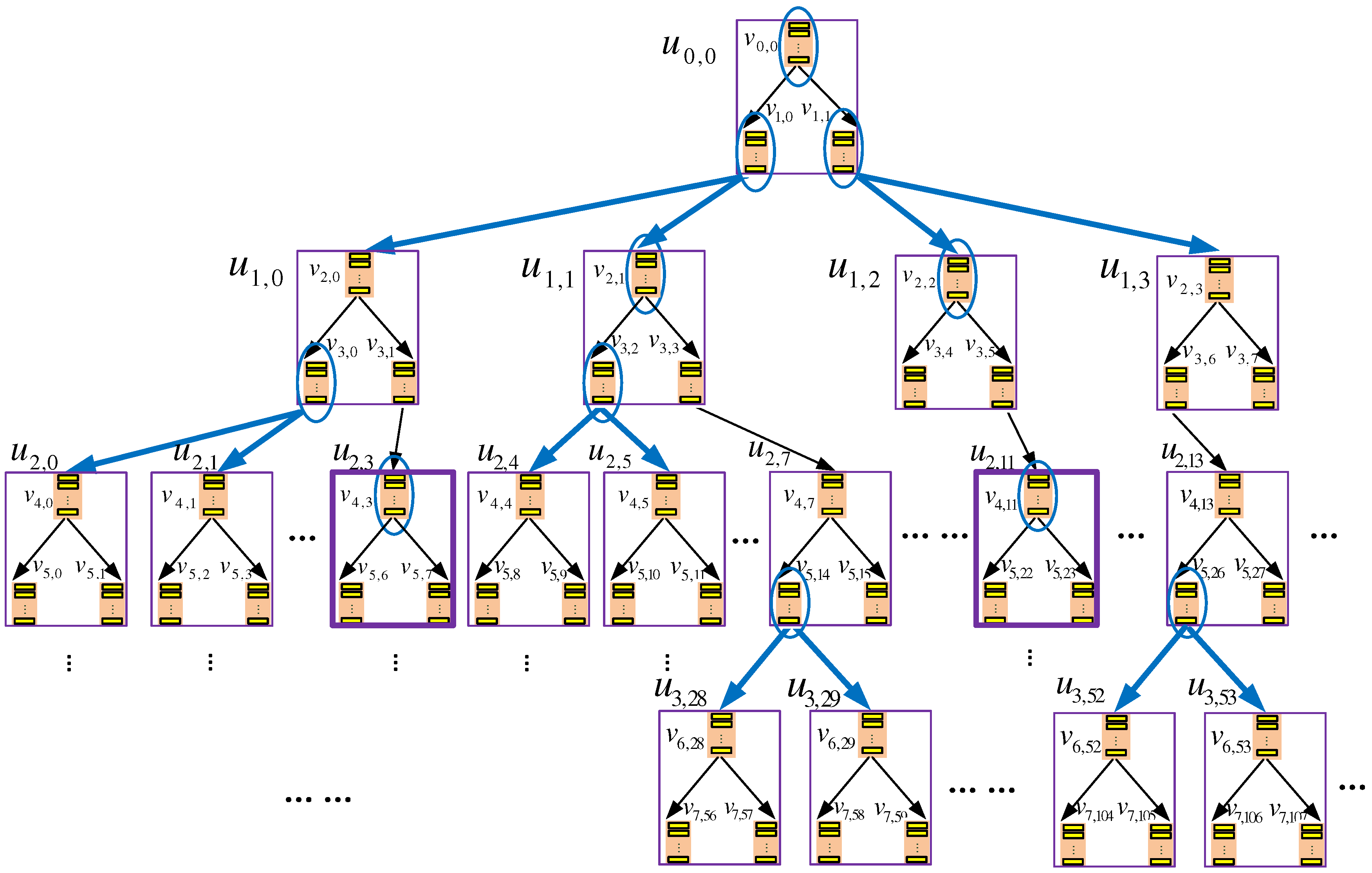
5.5.1. Overview
5.5.2. The Algorithm
- Phase I, selecting b-nodes for inter-k-node eviction: In this phase, the client randomly selects two b-nodes from each layer on the binary tree; that is, each selected b-node must be on the bottom layer of the binary subtree within a certain non-leaf k-node. Each selected b-node needs to evict a data block to its child nodes, which are in other k-nodes. Hence, the eviction has to be an inter k-node eviction and should be conducted immediately.
- Phase II, conducting delayed intra-k-node evictions: Each inter-k-node eviction planned in the previous phase involves three k-nodes: the k-node that contains the evicting b-node and the two other k-nodes that contain the child b-nodes of the evicting b-node. Before the inter-k-node eviction is executed, we need to make sure that the three involved k-nodes have completed all delayed evictions within them, and this is the purpose of this phase.More specifically, the following three steps should be taken for each k-node, denoted as , which is involved in an inter-k-node eviction planned in the previous phase. Note that, here, l denotes the layer of the k-node on the k-ary tree.
- The client downloads the EI of , decrypts it and extracts the value of field .
- The client computes . Note that, counts the number of queries issued by the client, which is also the number of eviction processes that have been launched, and is the discrete timestamp for the latest access of . Hence, r is the number of eviction processes for which may have delayed its intra-k-node evictions.
- The client simulates the r eviction processes to find out and execute the delayed intra-k-node evictions. In particular, for each of the eviction processes:
- (a)
- The client randomly selects two b-nodes from each binary-tree layer . Note that layer is not a leaf binary-tree layer within a k-node, and therefore, any b-node selecting from the layer only has child nodes within the same k-node; in other words, the eviction from the selected b-node must be an intra-k-node eviction.
- (b)
- For each previously selected b-node that is within k-node , one data block is picked from it, and the field of the block is updated to one of its child nodes that the block can be evicted to; this way, the delayed eviction from the selected b-node is executed.
- After the previous step completes, all the delayed evictions within k-node have been executed. Therefore, the field in the EI of is updated to .
- Phase III, conducting inter-k-node evictions: For each inter-k-node eviction planned in the first phase, its involved k-nodes should have conducted all of their delayed evictions in the second phase. Hence, the planned inter-k-node eviction can be conducted now. Essentially, each selected evicting b-node should evict one of its data blocks from the DA space of its k-node to the DA space of the k-node containing the child b-node that accepts the block, and the eviction should be oblivious. The detail is similar to the oblivious data eviction process in TSBT-ORAM that is elaborated in Section 4.3 and therefore is skipped here.
6. Security Analysis
- data blocks are stored in each DA;
- ;
- ; and
- .
- According to the query and eviction algorithms, sequences and should have the same format; that is, they contain the same number of observable accesses, and each pair of corresponding accesses has the same access type.
- According to Lemma 2, the sequence of locations (i.e., k-nodes) accessed by each query process is uniformly random and thus independent of the client’s private data request.
- According to Lemma 3, the sequence of locations (i.e., k-nodes) accessed by each eviction process after a query process is also independent of the client’s private data request.
7. Comparisons
7.1. Asymptotic Comparisons
7.2. Practical Comparisons
7.2.1. Communication Cost
7.2.2. Computational Cost
7.2.3. Access Delay Comparison
7.2.4. Storage Cost
8. Conclusions
Author Contributions
Conflicts of Interest
References
- Islam, M.S.; Kuzu, M.; Kantarcioglu, M.K. Access pattern disclosure on searchable encryption: Ramification, attack and mitigation. In Proceedings of the NDSS Symposium, San Diego, CA, USA, 5–8 February 2012. [Google Scholar]
- Chor, B.; Goldreich, O.; Kushilevitz, E.; Sudan, M. Private information retrieval. In Proceedings of the 36th FOCS 1995, Milwaukee, WI, USA, 23–25 October 1995. [Google Scholar]
- Beimel, A.; Ishai, Y.; Kushilevitz, E.; Raymond, J.F. Breaking the barrier for information-theoretic private information retrieval. In Proceedings of the 43rd FOCS 2002, Vancouver, BC, Canada, 16–19 November 2002. [Google Scholar]
- Chor, B.; Gilboa, N. Computationally private information retrieval. In Proceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing, El Paso, TX, USA, 4–6 May 1997. [Google Scholar]
- Gertner, Y.; Ishai, Y.; Kushilevitz, E.; Malkin, T. Protecting data privacy in private information retrieval schemes. In Proceedings of the 30th Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998. [Google Scholar]
- Goldberg, I. Improving the robustness of private information retrieval. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 20–23 May 2007. [Google Scholar]
- Kushilevitz, E.; Ostrovsky, R. Replication is not needed: Single database, computationally-private information retrieval (extended abstract). In Proceedings of the FOCS 1997, Miami, FL, USA, 19–22 October 1997. [Google Scholar]
- Cachin, C.; Micali, S.; Stadler, M. Computationally private information retrieval with polylogarithmic communication. In Proceedings of the Eurocrypt 1999, Prague, Czech Republic, 2–6 May 1999. [Google Scholar]
- Lipmaa, H. An oblivious transfer protocol with log-squared communication. In Proceedings of the ISC 2005, Berlin, Germany, 9–11 June 2005. [Google Scholar]
- Trostle, J.; Parrish, A. Efficient computationally private information retrieval from anonymity or trapdoor groups. In Information Security; Springer: Heidelberg, Germany, 2011; Volume 6531, pp. 114–128. [Google Scholar]
- Hoffstein, J.; Pipher, J.; Silverman, J.H. NTRU: A ring-based public key cryptosystem. In Algorithmic Number Theory; Springer: Heidelberg, Germany, 1998; Volume 1423, pp. 267–288. [Google Scholar]
- Goldreich, O.; Ostrovsky, R. Software protection and simulation on oblivious RAMs. J. ACM 1996, 43, 431–473. [Google Scholar] [CrossRef]
- Goodrich, M.T.; Mitzenmacher, M. Mapreduce parallel cuckoo hashing and oblivious RAM simulations. arXiv, 2010; arXiv:1007.1259. [Google Scholar]
- Goodrich, M.T.; Mitzenmacher, M.; Ohrimenko, O.; Tamassia, R. Privacy-preserving group data access via stateless oblivious RAM simulation. In Proceedings of the SODA 2012, Kyoto, Japan, 17–19 January 2012. [Google Scholar]
- Goodrich, M.T.; Mitzenmacher, M. Privacy-preserving access of outsourced data via oblivious RAM simulation. In Proceedings of the ICALP 2011, Zurich, Switzerland, 4–8 July 2011. [Google Scholar]
- Goodrich, M.T.; Mitzenmacher, M.; Ohrimenko, O.; Tamassia, R. Oblivious RAM simulation with efficient worst-case access overhead. In Proceedings of the CCSW 2011, Chicago, IL, USA, 21 October 2011. [Google Scholar]
- Kushilevitz, E.; Lu, S.; Ostrovsky, R. On the (in)security of hash-based oblivious RAM and a new balancing scheme. In Proceedings of the Twenty-Third Annual ACM-SIAM Symposium on Discrete Algorithms, Kyoto, Japan, 17–19 January 2012. [Google Scholar]
- Pinkas, B.; Reinman, T. Oblivious RAM revisited. In Proceedings of the CRYPTO 2010, Santa Barbara, CA, USA, 15–19 August 2010. [Google Scholar]
- Williams, P.; Sion, R. Building castles out of mud: Practical access pattern privacy and correctness on untrusted storage. In Proceedings of the CCS 2008, Alexandria, VA, USA, 27–31 October 2008. [Google Scholar]
- Williams, P.; Sion, R.; Tomescu, A. PrivateFS: A parallel oblivious file system. In Proceedings of the CCS 2012, Releigh, NC, USA, 16–18 October 2012. [Google Scholar]
- Williams, P.; Sion, R.; Tomescu, A. Single round access privacy on outsourced storage. In Proceedings of the CCS 2012, Releigh, NC, USA, 16–18 October 2012. [Google Scholar]
- Shi, E.; Chan, T.H.H.; Stefanov, E.; Li, M. Oblivious RAM with O((logN)3) worst-case cost. In Proceedings of the ASIACRYPT 2011, Seoul, Korea, 4–8 December 2011. [Google Scholar]
- Stefanov, E.; van Dijk, M.; Shi, E.; Fletcher, C.; Ren, L.; Yu, X.; Devadas, S. Path ORAM: An extremely simple oblivious RAM protocol. In Proceedings of the CCS 2013, Berlin, Germany, 4–8 November 2013. [Google Scholar]
- Stefanov, E.; Shi, E. ObliviStore: High performance oblivious cloud storage. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 19–23 May 2013. [Google Scholar]
- Stefanov, E.; Shi, E.; Song, D. Towards practical oblivious RAM. In Proceedings of the NDSS 2011, San Diego, CA, USA, 6–9 February 2011. [Google Scholar]
- Gentry, C.; Goldman, K.; Halevi, S.; Julta, C.; Raykova, M.; Wichs, D. Optimizing ORAM and using it efficiently for secure computation. In Proceedings of the PETS 2013, Bloomington, IN, USA, 10–23 July 2013. [Google Scholar]
- Stefanov, E.; Shi, E. Multi-Cloud Oblivious Storage. In Proceedings of the CCS 2013, Berlin, Germany, 4–8 November 2013. [Google Scholar]
- Wang, X.; Huang, Y.; Chan, T.H.H.; Shelat, A.; Shi, E. SCORAM: Oblivious RAM for secure computations. In Proceedings of the CCS 2014, Scotsdale, AZ, USA, 3–7 November 2014. [Google Scholar]
- Moataz, T.; Mayberry, T.; Blass, E.O. Constant communication ORAM with small blocksize. In Proceedings of the CCS 2015, Denver, CO, USA, 12–16 October 2015. [Google Scholar]
- Moataz, T.; Blass, E.O.; Mayberry, T. Constant Communication ORAM without Encryption. In IACR Cryptology ePrint Archive; International Association for Cryptologic Research: Rüschlikon, Switzerland, 2015. [Google Scholar]
- Lipmaa, H.; Zhang, B. Two new efficient PIR-writing protocols. In Proceedings of the ACNS 2010, Beijing, China, 22–25 June 2010. [Google Scholar]
- Mayberry, T.; Blass, E.O.; Chan, A.H. Efficient private file retrieval by combining ORAM and PIR. In Proceedings of the NDSS 2014, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Lu, S.; Ostrovsky, R. Distributed Oblivious RAM for Secure Two-Party Computation. In IACR Cryptology ePrint Archive 2011/384; International Association for Cryptologic Research: Rüschlikon, Switzerland, 2011. [Google Scholar]
- Freier, A.; Karlton, P.; Kocher, P. The Secure Sockets Layer (SSL) Protocol Version 3.0; RFC 6101; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2011. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ORAM | C-SComm.Cost | S-SComm. Cost | Client Stor.Cost | Server Stor. Cost | # of Servers |
|---|---|---|---|---|---|
| T-ORAM [22] | N.A. | 1 | |||
| Path ORAM [23] | N.A. | 1 | |||
| * P-PIR [32] | N.A. | 1 | |||
| * C-ORAM [29] | N.A. | 1 | |||
| MS-ORAM [33] | 2 | ||||
| MSS-ORAM [27] | 2 | ||||
| CNE-ORAM [30] | N.A. | 4 | |||
| TSKT-ORAM | N.A. | 2 |
| CNE-ORAM | TSKT-ORAM | |
|---|---|---|
| Communication Cost | ~ | |
| Computational Cost |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Ma, Q.; Zhang, W.; Qiao, D. TSKT-ORAM: A Two-Server k-ary Tree Oblivious RAM without Homomorphic Encryption. Future Internet 2017, 9, 57. https://doi.org/10.3390/fi9040057
Zhang J, Ma Q, Zhang W, Qiao D. TSKT-ORAM: A Two-Server k-ary Tree Oblivious RAM without Homomorphic Encryption. Future Internet. 2017; 9(4):57. https://doi.org/10.3390/fi9040057
Chicago/Turabian StyleZhang, Jinsheng, Qiumao Ma, Wensheng Zhang, and Daji Qiao. 2017. "TSKT-ORAM: A Two-Server k-ary Tree Oblivious RAM without Homomorphic Encryption" Future Internet 9, no. 4: 57. https://doi.org/10.3390/fi9040057
APA StyleZhang, J., Ma, Q., Zhang, W., & Qiao, D. (2017). TSKT-ORAM: A Two-Server k-ary Tree Oblivious RAM without Homomorphic Encryption. Future Internet, 9(4), 57. https://doi.org/10.3390/fi9040057