
MHBase: A Distributed Real-Time Query Scheme for Meteorological Data Based on HBase



Abstract
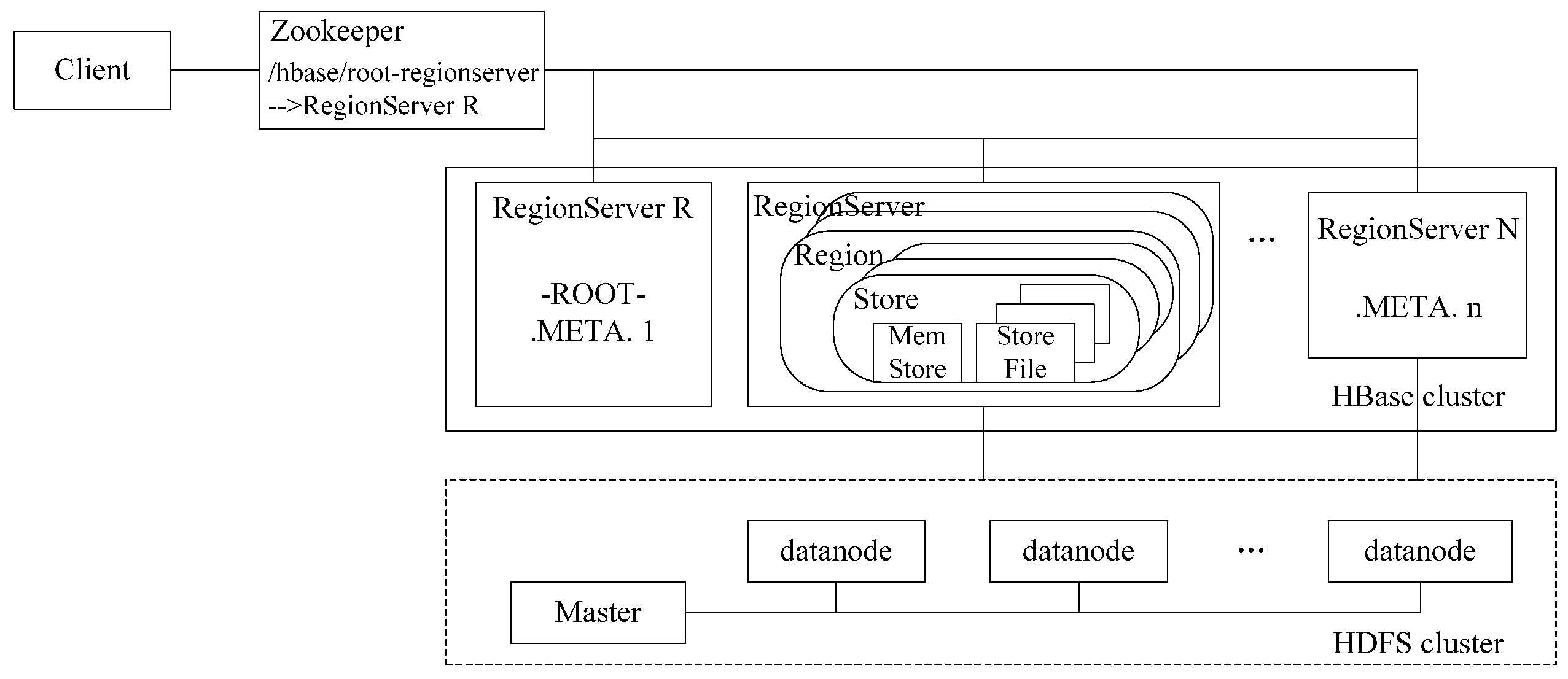
:1. Introduction
2. Related work
2.1. Distributed Architecture
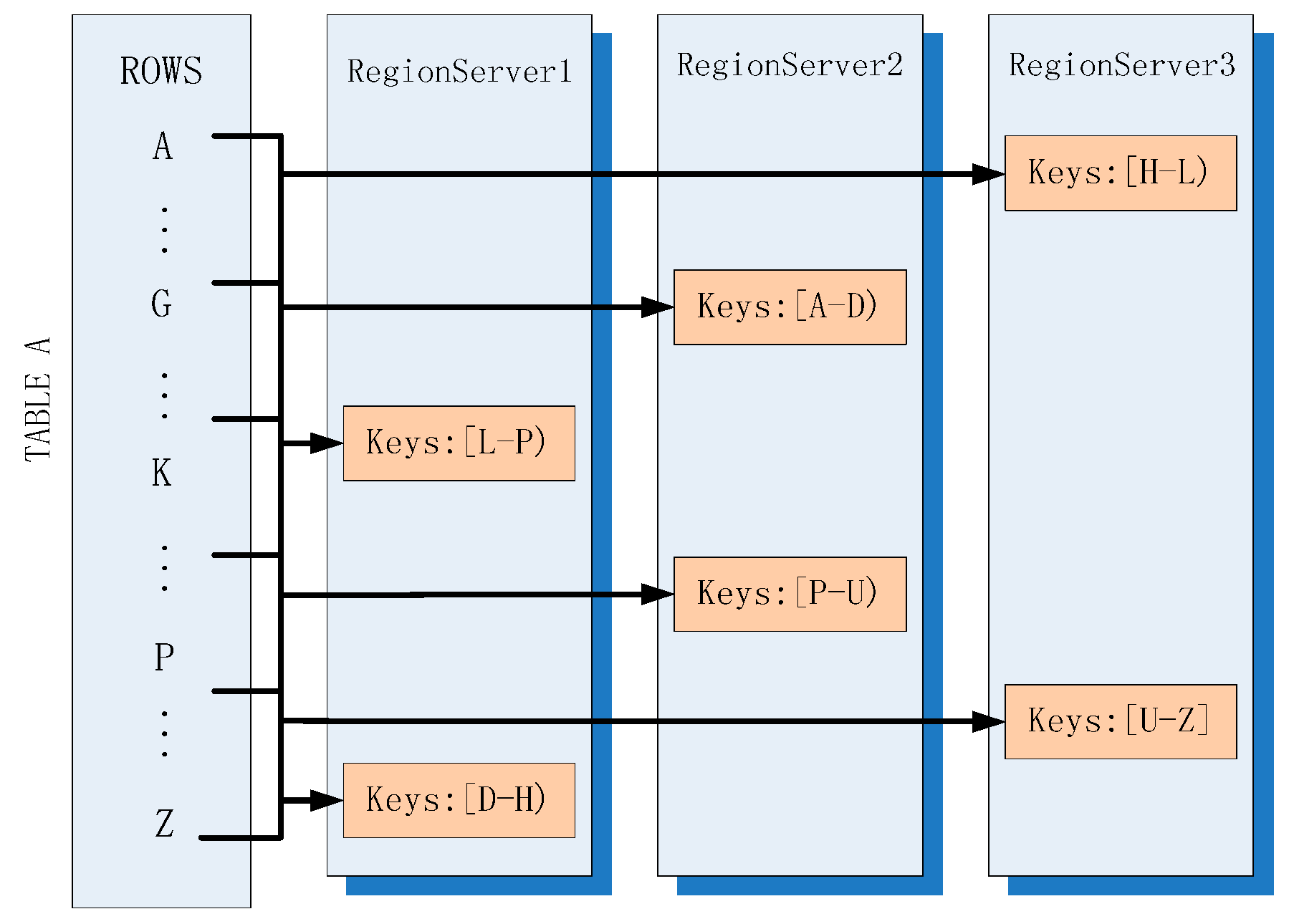
2.1.1. Horizontal Partitioning
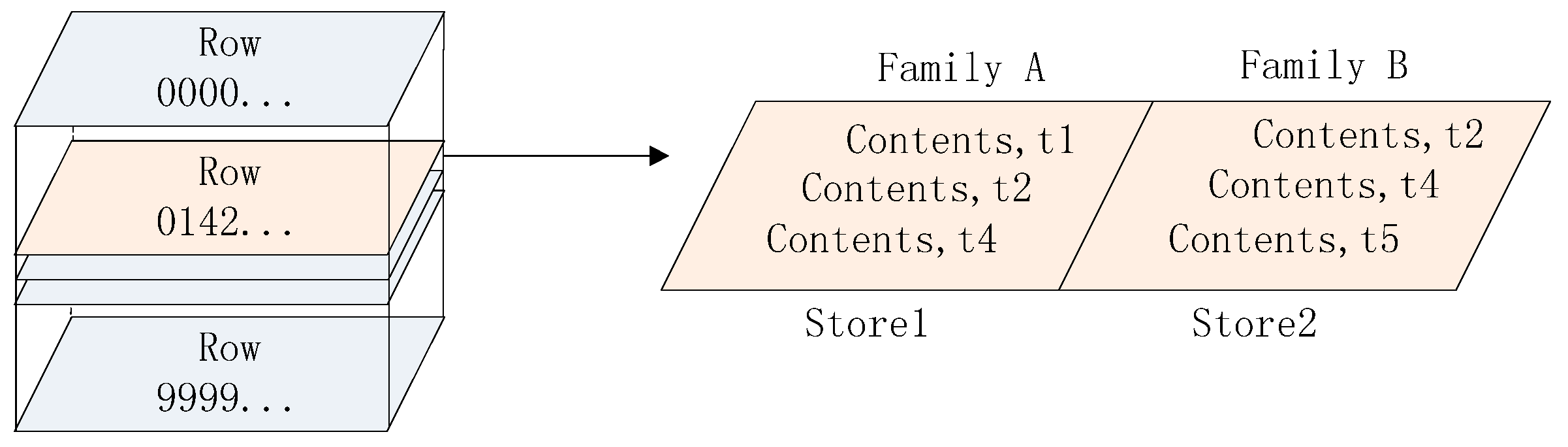
2.1.2. Vertical Partitioning
2.2. Meteorological Data Storage
2.3. Optimizing
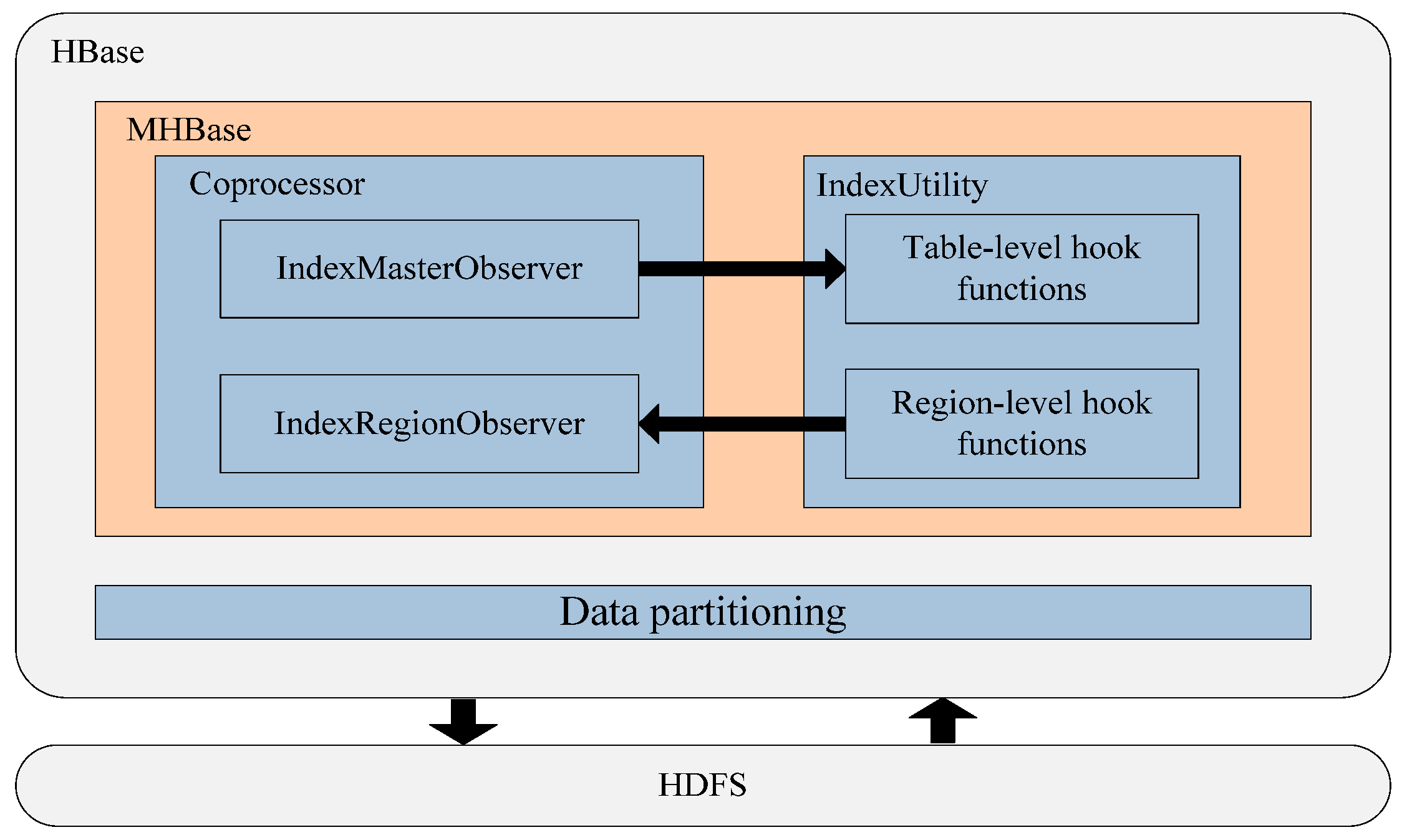
3. Proposed Design
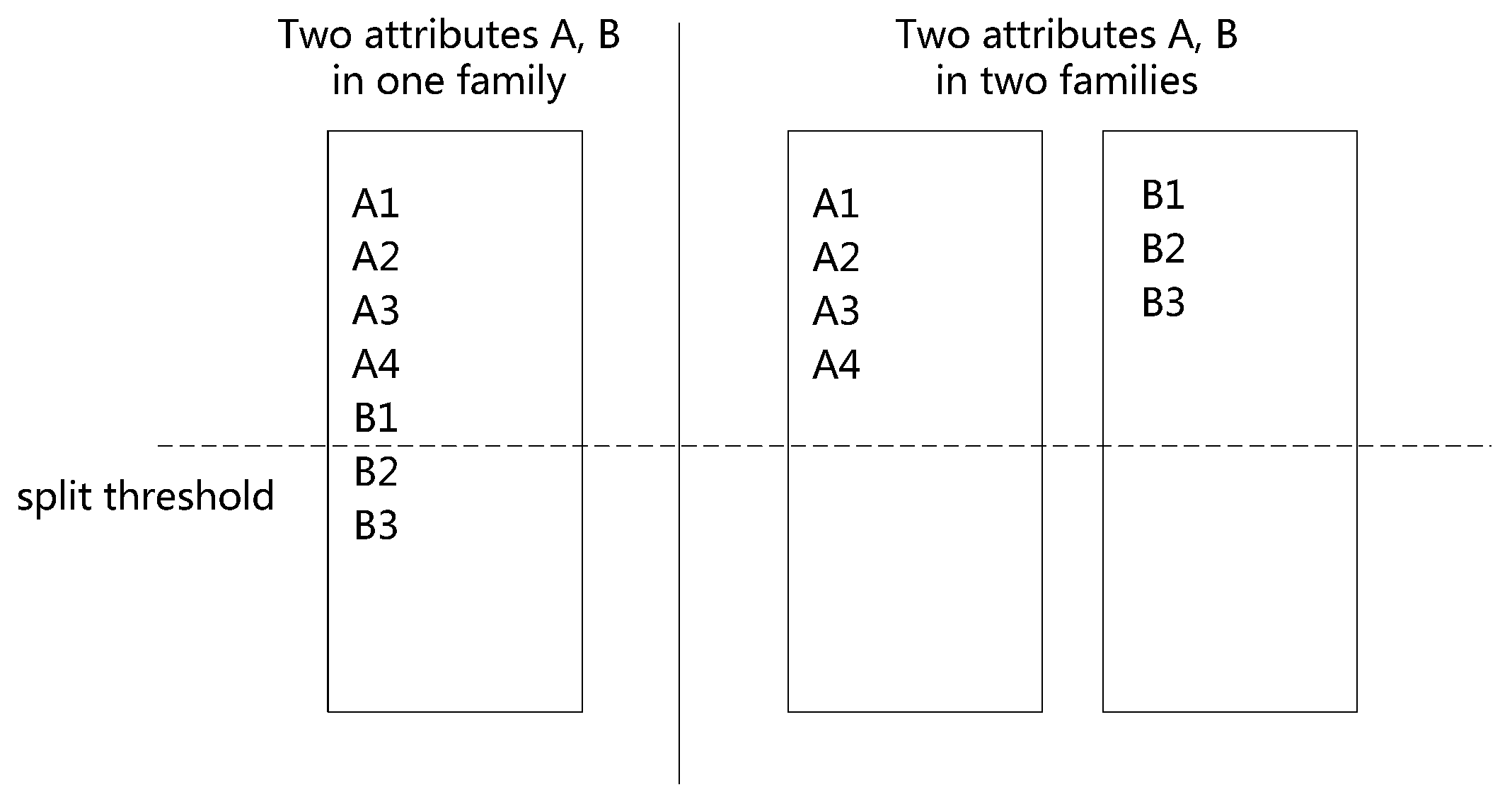
3.1. Data Partitioning
3.2. Index Model
3.2.1. Coprocessor
- (1)
- get the original rowkey: , split rowkey: and their length of region startkey , ;
- (2)
- calculate the length: = the length of ;
- (3)
- new byte [];
- (4)
- copy the combination of region startkey and the rest of original rowkey to new array.
3.2.2. Algorithms
3.2.2.1. Indexed Store Algorithm (ISA)
3.2.2.2. Indexed Retrieve Algorithm (IRA)
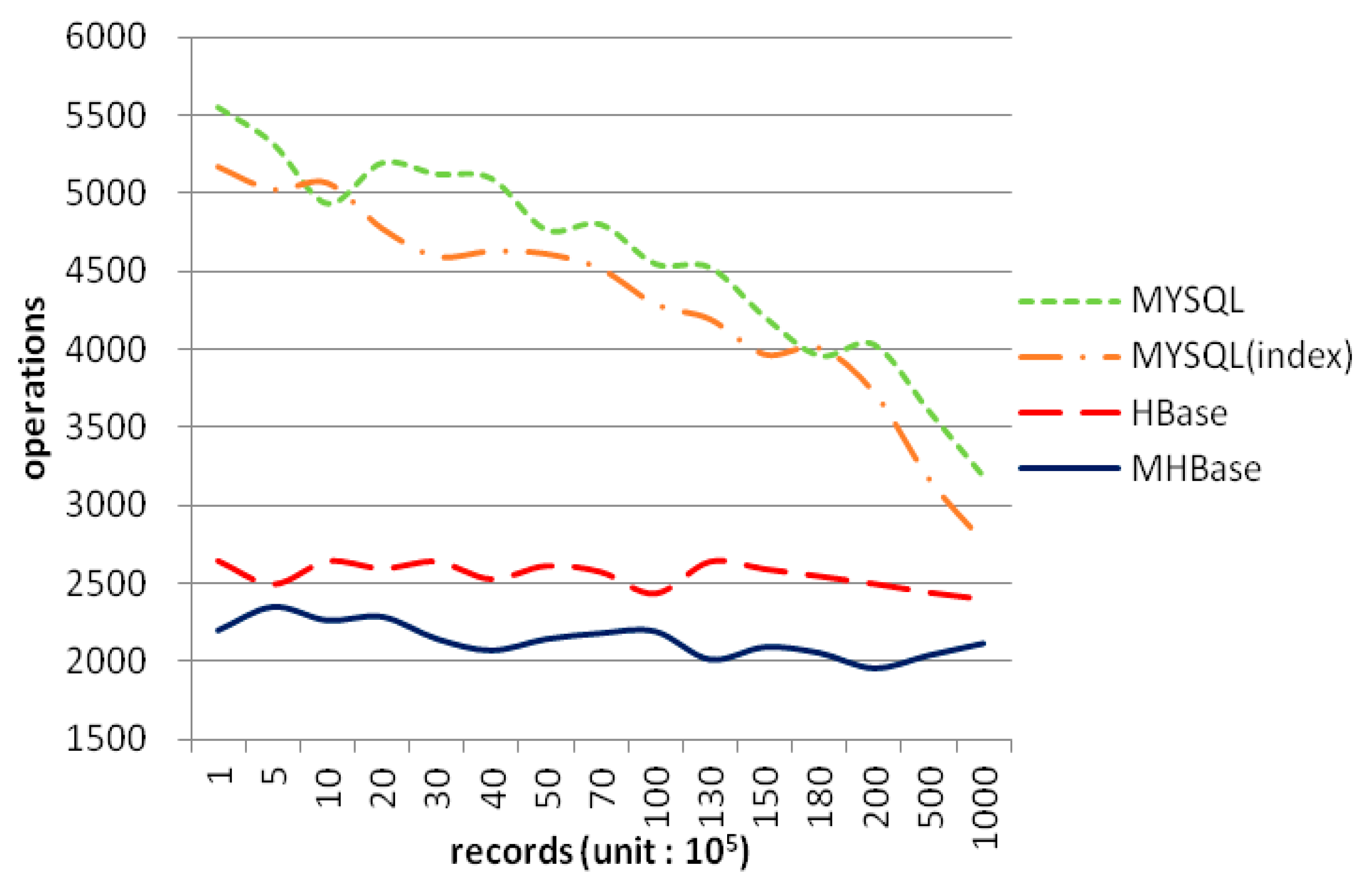
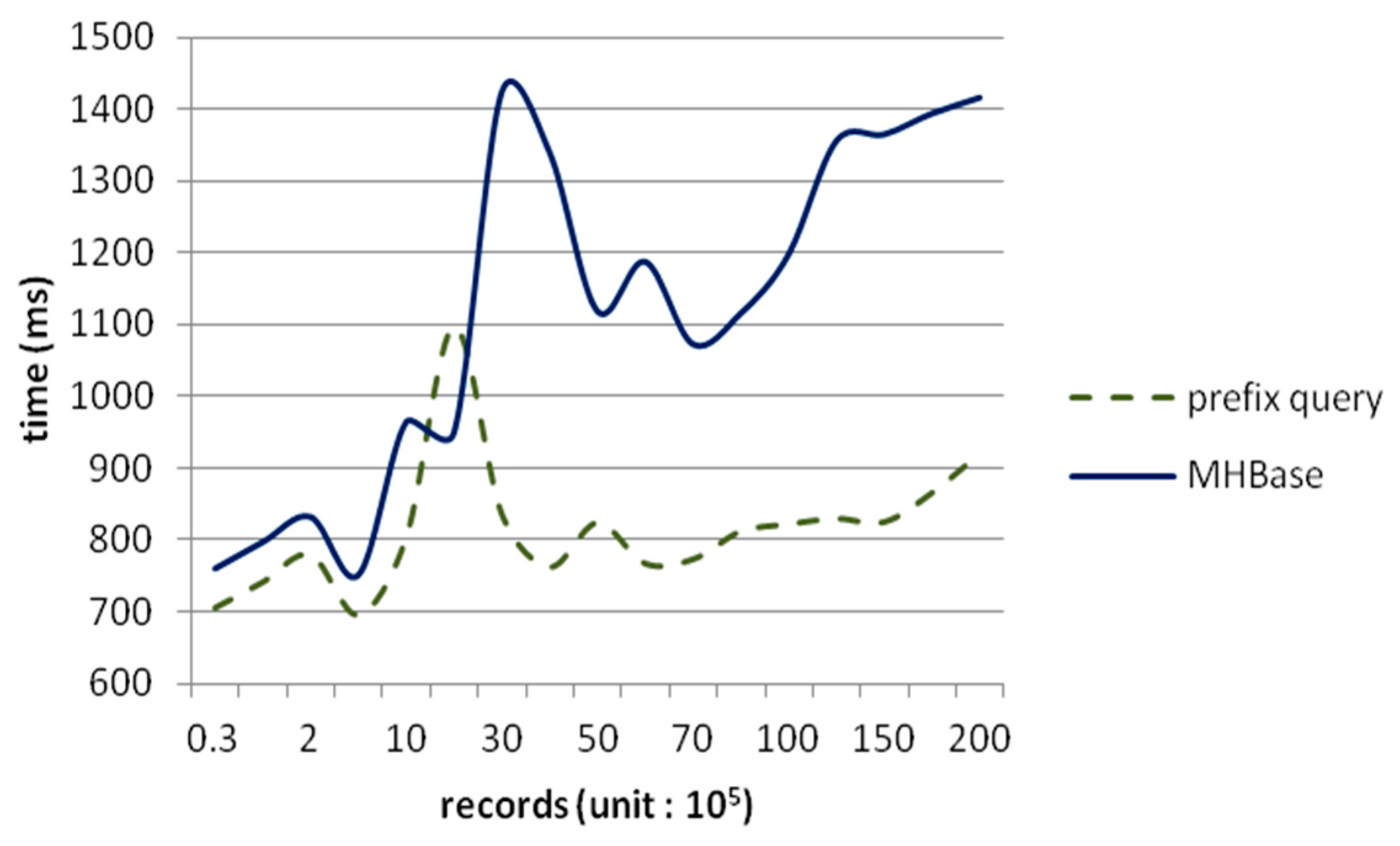
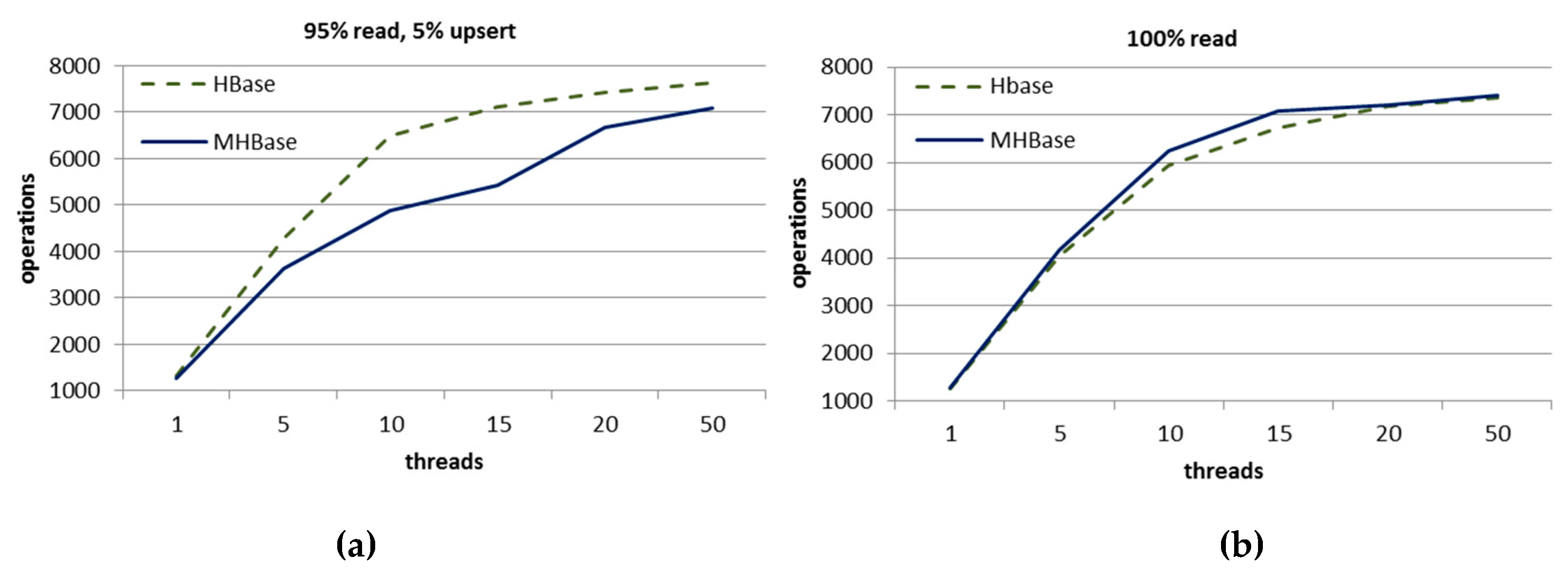
4. Experiments and Analyses
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| MHBase: | Meteorological data based on HBase |
| HBase: | Hadoop Database |
| IHBase: | Indexed HBase |
| HDFS: | the Hadoop Distributed File System |
| RDBMS: | Relational Database Management System |
| PAPD: | A Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions |
References
- Feldman, M.; Friedler, S.A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 10–13 August 2015; pp. 259–268.
- Gantz, J.; Reinsel, D. Extracting value from chaos. IDC iview 2011, 9–10. [Google Scholar]
- Islam, N.S.; Rahman, M.W.; Jose, J.; Rajachandrasekar, R.; Wang, H.; Subramoni, H.; Murthy, C.; Panda, D.K. High performance RDMA-based design of HDFS over InfiniBand. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Los Alamitos, CA, USA, 10–16 November 2012; p. 35.
- Ma, T.; Lu, Y.; Shi, S.; Tian, W.; Wang, X.; Guan, D. Data resource discovery model based on hybrid architecture in data grid environment. Concurr. Comp-Pract. E. 2015, 27, 507–525. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10.
- George, L. The region life cycle. In HBase: the definitive guide; George, L., Ed.; O’Reilly Media: Sebastopol, CA, USA, 2011; pp. 328–330. [Google Scholar]
- Li, D.; Wang, Y.; Xiong, A.; Ma, T. High Performance Computing Model for Processing Meteorological Data in Cluster System. J. Convergence Inf. Technol. 2011, 6, 92–98. [Google Scholar]
- Mattmann, C.A.; Waliser, D.; Kim, J.; Goodale, C.; Hart, A.; Ramirez, P.; Crichton, D.; Zimdars, P.; Boustani, M.; Lee, K.; et al. Cloud computing and virtualization within the regional climate model and evaluation system. Earth Sci. Inform. 2014, 7, 1–12. [Google Scholar] [CrossRef]
- Aravinth, M.S.S.; Shanmugapriyaa, M.S.; Sowmya, M.S.; Arun, M.E. An efficient HADOOP frameworks SQOOP and ambari for big data processing. IJIRST 2015, 1, 252–255. [Google Scholar]
- Rienecker, M.M.; Suarez, M.J.; Gelaro, R.; Todling, R.; Bacmeister, J.; Liu, E.; Bosilovich, M.G.; Schubert, S.D.; Takacs, L.; Kim, G.K.; et al. MERRA: NASA’s modern-era retrospective analysis for research and applications. J. Climate 2011, 24, 3624–3648. [Google Scholar] [CrossRef]
- Ghemawat, S.; Gobioff, H.; Leung, S.T. The Google file system. In Proceedings of the nineteenth ACM symposium on Operating systems principles, New York, NY, USA, 19–22 October 2003; Volume 37, pp. 29–43.
- Cattell, R. Scalable SQL and NoSQL data stores. ACM SIGMOD Record 2011, 39, 12–27. [Google Scholar] [CrossRef]
- Hunt, P.; Konar, M.; Junqueira, F.P.; Reed, B. ZooKeeper: Wait-free coordination for internet-scale systems. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 23–25 June 2010; p. 9.
- Zhao, Y.; Ma, T.; Liu, F. Research on index technology for group-by aggregation query in XML cube. Inf. Technol. J. 2010, 9, 116–123. [Google Scholar] [CrossRef]
- Aji, A.; Wang, F.; Vo, H.; Lee, R.; Liu, Q.; Zhang, X.; Saltz, J. Hadoop GIS: A high performance spatial data warehousing system over mapreduce. In Proceedings of the VLDB Endowment, Riva del Garda, Italy, 26–30 August 2013; pp. 1009–1020.
- Xie, X.; Xiong, Z.; Zhou, G.; Cai, G. On massive spatial data cloud storage and quad-tree index based on the Hbase. WIT. Trans. Inf. Commun. Technol. 2014, 49, 691–698. [Google Scholar]
- Zhang, C.; Zhao, T.; Anselin, L.; Li, W.; Chen, K. A Map-Reduce based parallel approach for improving query performance in a geospatial semantic web for disaster response. Earth. Sci. Inform. 2014, 8, 499–509. [Google Scholar] [CrossRef]
- Fong, L.L.; Gao, Y.; Guerin, X.; Liu, Y.G.; Salo, T.; Seelam, S.R.; Tan, W.; Tata, S. Toward a scale-out data-management middleware for low-latency enterprise computing. IBM. J. Res. Dev. 2013, 57, 1–6. [Google Scholar] [CrossRef]
- IHBase. Available online: http://github.com/ykulbak/ihbase (accessed on 8 July 2010).
- Chan, C.Y.; Ioannidis, Y.E. Bitmap index design and evaluation. In Proceedings of the 1998 ACM SIGMOD international conference on Management of data, New York, NY, USA, 1–4 June 1998; pp. 355–366.
- Hbase-solr-indexer. Available online: http://archive.cloudera.com/cdh5/cdh/5/hbase-solr-1.5-cdh5.3.3.tar.gz (accessed on 9 April 2015).
- The Intel Distribution for Apache Hadoop* Software. Available online: http://www.intel.com/content/www/uk/en/big-data/big-data-intel-distribution-for-apache-hadoop.html (accessed on 29 April 2013).
- Hindex. Available online: https://github.com/Huawei-Hadoop/hindex (accessed on 30 September 2013).
- Ge, W.; Huang, Y.; Zhao, D.; Luo, S.; Yuan, C.; Zhou, W.; Tang, Y.; Zhou, J. CinHBa: A secondary index with hotscore caching policy on Key-Value data store. In Proceedings of the 10th International Conference, Guilin, China, 19–21 December 2014; pp. 602–615.
- Foundation, A.S. Apache Phoenix. Available online: http://phoenix.apache.org (accessed on 8 April 2015).
- Romero, O.; Herrero, V.; Abelló, A.; Ferrarons, J. Tuning small analytics on Big Data: Data partitioning and secondary indexes in the Hadoop ecosystem. Inform. Syst. 2015, 54, 336–356. [Google Scholar] [CrossRef]
- Özsu, M.T.; Valduriez, P. Parallel Database Systems. In Principles of Distributed Database Systems; Özsu, M.T., Valduriez, P., Eds.; Springer: New York, NY, USA, 2011; pp. 497–550. [Google Scholar]
- George, P.S. [HBASE-2426] Introduce quick scanning row-based secondary indexes. Available online: https://issues.apache.org/jira/browse/HBASE-2426 (accessed on 8 April 2011).
- Shi, X. [HBASE-5723] Simple Design of Secondary Index. Available online: https://issues.apache.org/jira/browse/HBASE-5723 (accessed on 5 April 2012).
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM symposium on Cloud computing, New York, NY, USA, 10–11 June 2010; pp. 143–154.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Functions | Description |
|---|---|
| postOpen() | Called before region opens to read meta data and build indexes. |
| pre/postSplit() | Called before/after region splits to synchronize indexes. |
| postScannerOpen() | Used expanding scanner to query by indexes |
| prePut() | Called before put entry to update indexes |
| Number of Nodes | 4 |
|---|---|
| OS | Ubuntu 12.04 (32-bit) |
| Parameters | CPU: Intel Core2 Duo, 2.66GHz |
| Memory: 2 GB RAM | |
| Hard Disk: WDCWD2500 ( 250 G / 7200 / p / min) | |
| Configurations | HBase version: Based on HBase-0.94.8 |
| HBase configurations | |
| hbase.hregion.max.filesize: 10 G | |
| hbase.hregion.memstore.flush.size: 128 MB hbase.client.write.buffer: 2 M hbase.client.scanner.caching: 10 | |
| MySQL configurations | |
| MySQL version: 5.6.28 (64-bit) Cluster mode: Standalone Default storage engine: INNODB innodb_buffer_pool_size: 1230 M Transaction isolation: READ-COMITTED |
| Column | Data model |
|---|---|
| Rowkey | “StationNumber_year_month_day_hour_dataType” Examples: “210044001_2010_01_02_22_001” |
| Family1: w_meta | Qualifiers: country number (c_Number), longitude (LON), latitude (LAT), station style (style) Examples: “w_meta:c_Number = + 086”, “w_meta: LON = 118°46′40.0”E”, “w_meta: LAT = 32°03′42.0”N”, “w_meta:style = GROUND” |
| Family2: w_info | Qualifiers: maxTEMP, minTEMP, stationPRESS, clouds, windDirection, windSpeed, relativeHumidity, rainfall, observeYear, observeMonth, observeDay, observeHour, imgURL |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Xu, X.; Tang, M.; Jin, Y.; Shen, W. MHBase: A Distributed Real-Time Query Scheme for Meteorological Data Based on HBase. Future Internet 2016, 8, 6. https://doi.org/10.3390/fi8010006
Ma T, Xu X, Tang M, Jin Y, Shen W. MHBase: A Distributed Real-Time Query Scheme for Meteorological Data Based on HBase. Future Internet. 2016; 8(1):6. https://doi.org/10.3390/fi8010006
Chicago/Turabian StyleMa, Tinghuai, Xichao Xu, Meili Tang, Yuanfeng Jin, and Wenhai Shen. 2016. "MHBase: A Distributed Real-Time Query Scheme for Meteorological Data Based on HBase" Future Internet 8, no. 1: 6. https://doi.org/10.3390/fi8010006
APA StyleMa, T., Xu, X., Tang, M., Jin, Y., & Shen, W. (2016). MHBase: A Distributed Real-Time Query Scheme for Meteorological Data Based on HBase. Future Internet, 8(1), 6. https://doi.org/10.3390/fi8010006