
Output from Statistical Predictive Models as Input to eLearning Dashboards

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Some LMSs have “what if” algorithms that allow students to assess the level of performance needed to achieve a certain course grade. Those “what if” routines are based solely on the algebra of the final grade calculation; i.e., they are deterministic. We propose a messaging system that is probabilistic; it produces predictions using statistical methods that model uncertainty.
- The proposed system can be designed to produce longitudinal information so that students can track their progress over time and, importantly, see for themselves how their behavior impacts outcomes.
- Our methodology incorporates as much numerical information as possible about individual student characteristics.
- The envisioned system can be designed to be either reactive or proactive or both, allowing developers to design a system as complex as needed for the learning environment at hand.
2. Predictive Models and Methods
- Traditional statistical inference is a secondary focus of predictive models so that diagnostics and remedies that speak to the quality of inferential evidence (e.g., multicollinearity) are of secondary importance in prediction settings; inference tends to be front-and-center in most explanatory research.
- Large numbers of observations are welcomed in predictive modeling settings, since they accommodate the use of cross-validation (holdout samples) for model selection. Large sample sizes, on the other hand, can detract from the interpretability of inferential outcomes from explanatory models since hypotheses are routinely rejected in large enough samples [31,32].
- Explanatory research, which typically focuses on aggregates, handles outliers by minimizing their impact via exclusion or outlier-resistant methods. Outliers are of special interest in predictive models, since they are often the ones we want to find: the fraudulent credit card charge or the struggling student.
- Overfitting is a known risk with predictive modeling. Models that are overfit produce good in-sample predictions but inadequate out-of-sample predictions; i.e., they perform worse than expected once we put them into practice. To mitigate overfitting, predictive modelers use methods such as cross-validation that are not often seen in explanatory work.
3. Applying Predictive Models to an eLearning Messaging System
3.1. The Development Phase
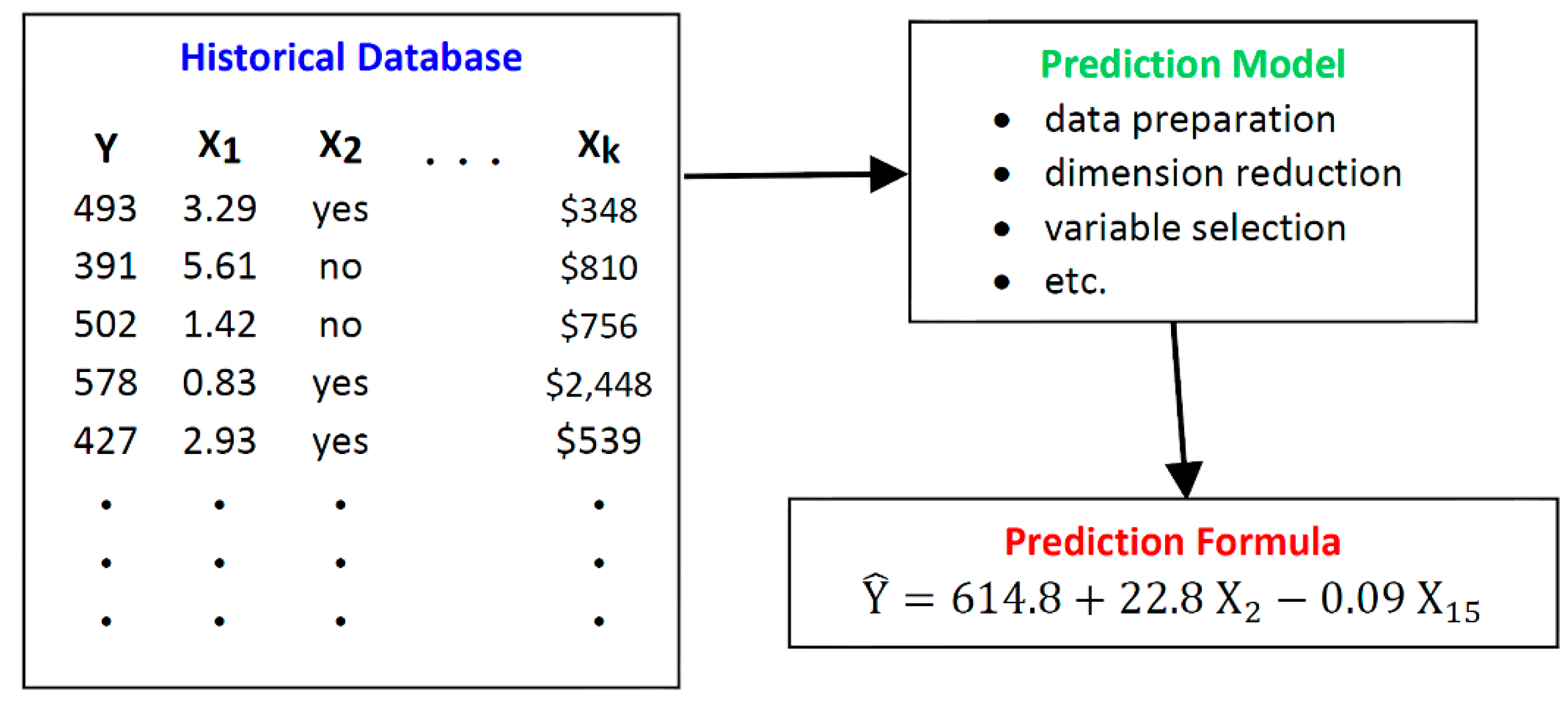
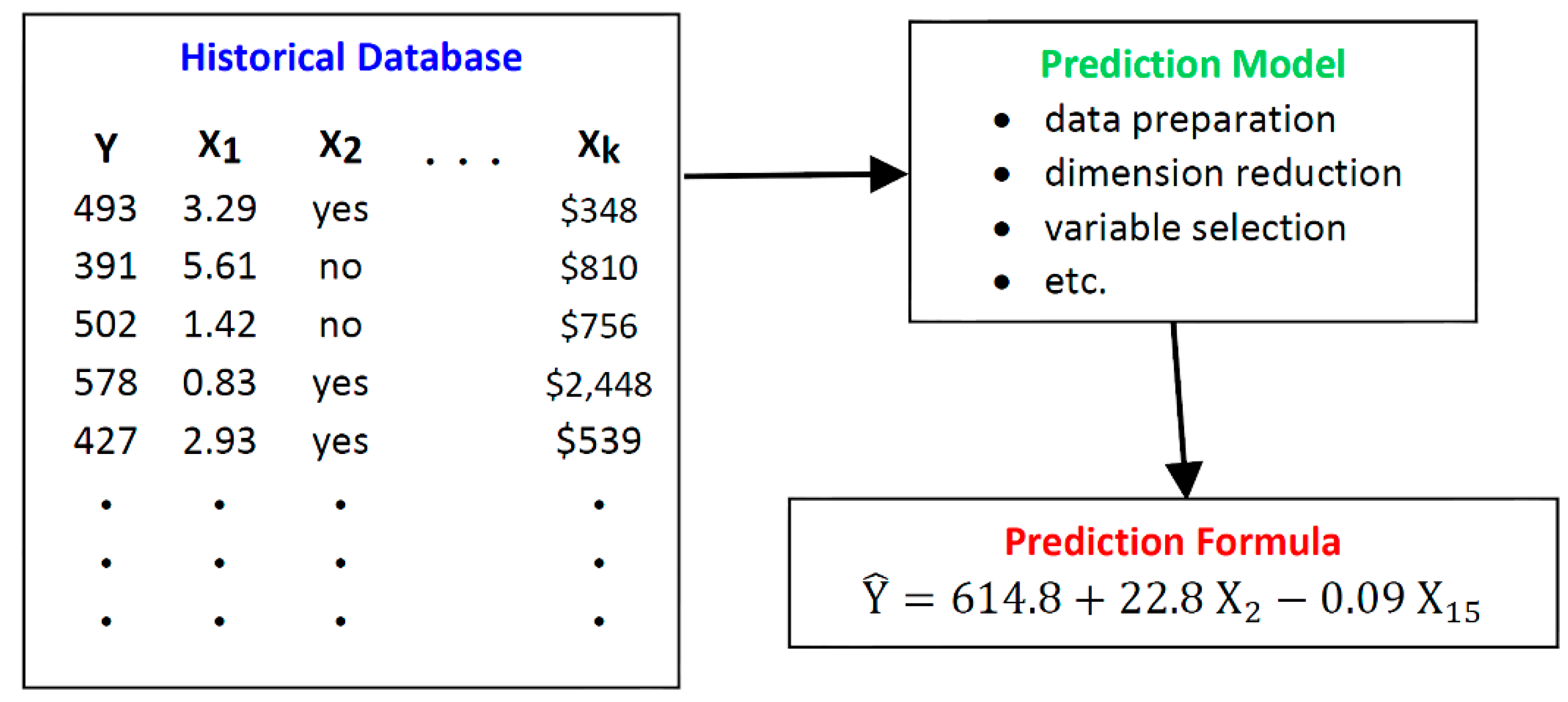
3.1.1. The Historical Database
3.1.2. The Prediction Model
3.1.3. The Prediction Formula or Algorithm
- If [Experience ≤ 5] and [Grade ≤ 85] then [Probability of Passing = 40.6%],
- If [Experience ≤ 5] and [Grade > 85] then [Probability of Passing = 51.1%],

3.2. The Implementation Phase

3.2.1. The Current Database
- The current database does not contain a field for the dependent variable, since the purpose of the system is to estimate those unknown values for each current student; i.e., there is no column of numbers for the dependent variable in the current database in Figure 3.
- The current database almost certainly contains fewer input variables than is found in the historical database because model derivation usually means variable elimination. The current database will include fields only for the variables used in the prediction formula or algorithm.
- The current database contains different records—those characterizing the current students.
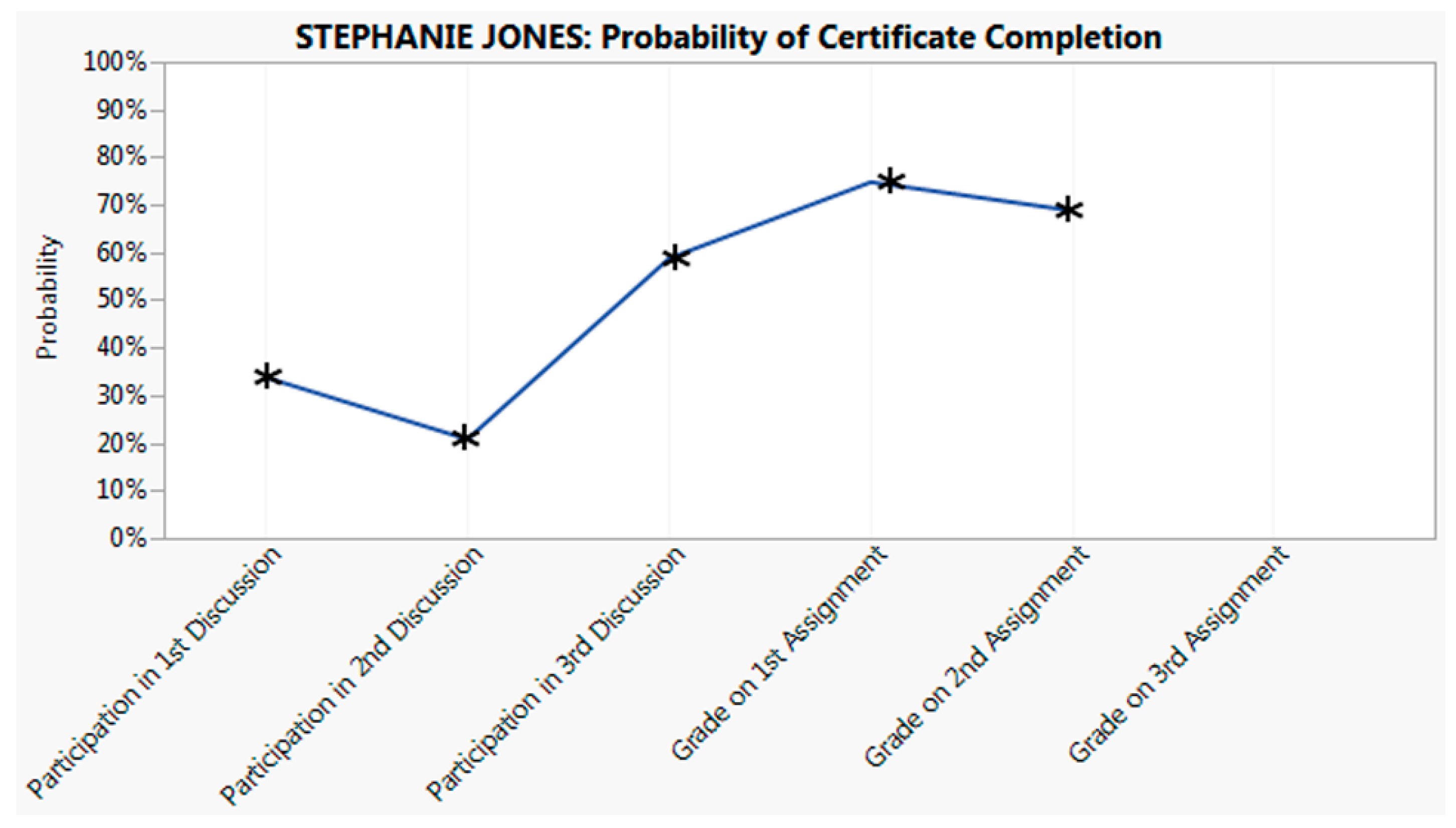
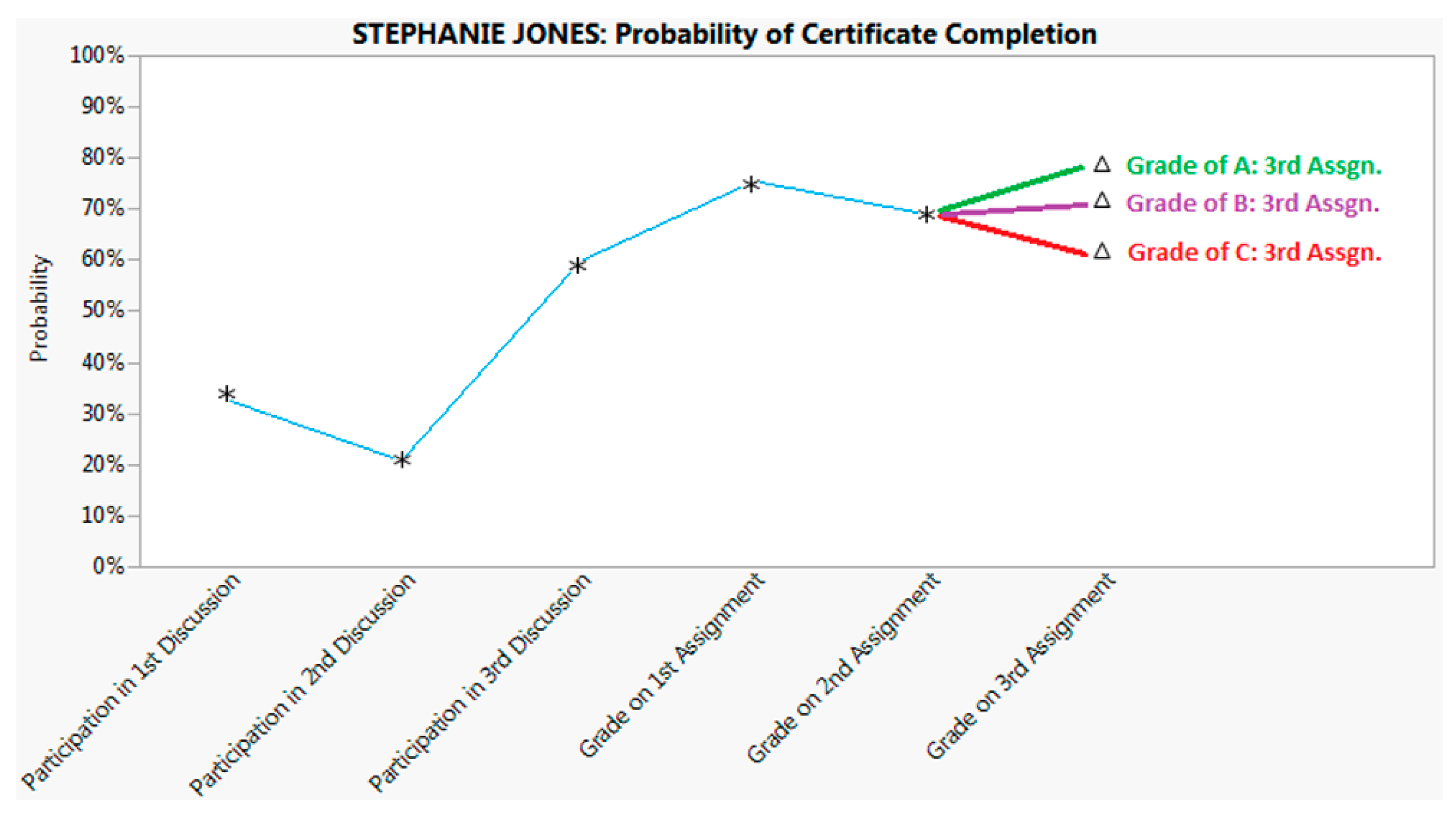
3.2.2. The Dashboard
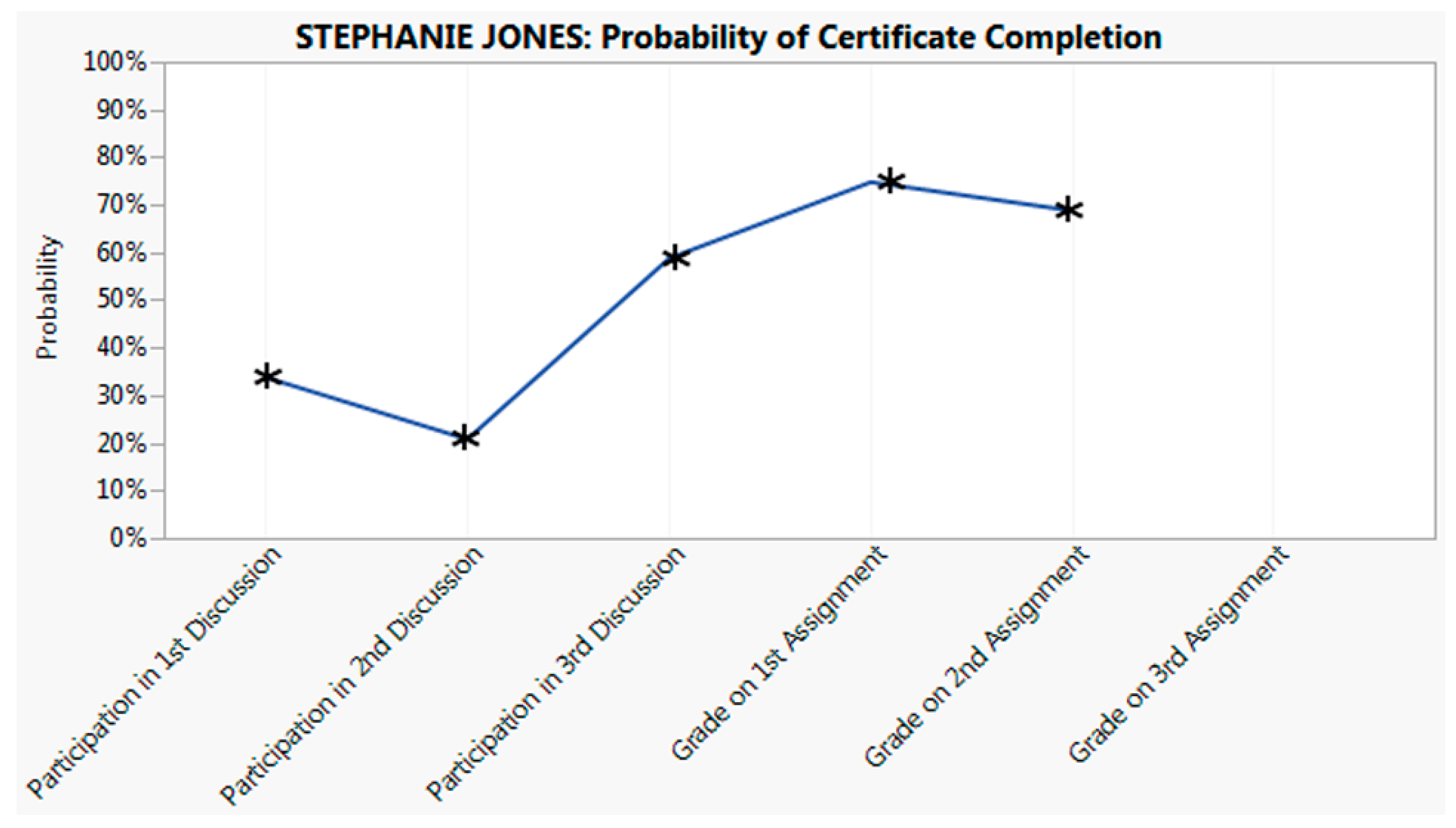
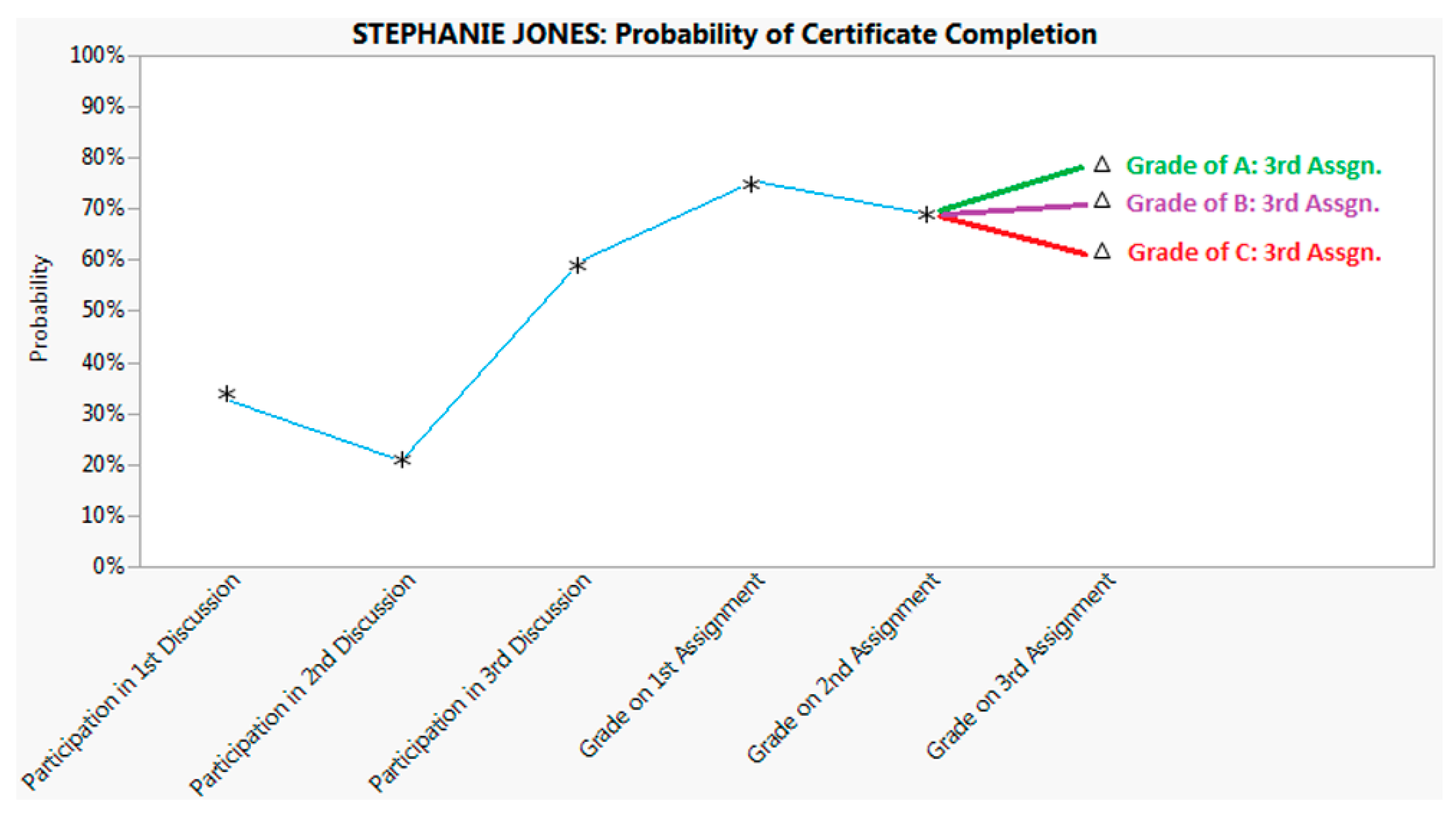
3.3. The Assessment Phase
- Did students see the information? This relates to where the information is displayed in the LMS—on the home page, at the top of the grade book, within a pop-up window, via a link buried somewhere inside the course, or elsewhere.
- Did students understand the information? If the messages are text-based, are they clearly worded? If graphical, is the presentation obvious to even untrained consumers?
- Did students believe the information? Once students embrace the probabilistic nature of the information provided, they are then in the position to assess its credibility. Interested students might be referred to a description of the process by which the information is generated.
- Did the students value the information? Did messages come too often or not often enough? Were students curious enough to return to longitudinal displays to track their progress?
4. Resource Implications
5. Unresolved Issues and Future Research
- No student involvement. Many universities have Institutional Review Boards or equivalents that will release legally-protected student information once it has been anonymized. That information might include things like age, ethnicity, prior academic performance, and financial status. That data source might be used for the historical database.
- Minimal student involvement. Students might grant the release of legally-protected information. This would require, from students, nothing more than consent.
- Moderate student involvement. Students might provide information about themselves that is not available from existing sources—e.g., whether the student is caring for aging parents or number of hours worked. This might require, from students, the completion of a survey.
- Maximum student involvement. Students might actively seek out information about themselves that not even they know. For example, students might be asked to determine their personality type or learning styles using publicly-available online assessments such as the International Personality Item Pool (http://www.personal.psu.edu/~j5j/IPIP/) or the Felder-Soloman Index of Learning Styles (http://www.engr.ncsu.edu/learningstyles/ilsweb.html) [39,40,41]. In this scenario, students would complete the questionnaires online, receive the results, and report them to the instructor or database manager.
6. Final Thoughts
Acknowledgments
Conflicts of Interest
References
- Hardesty, L. Lessons learned from MITx’s prototype course. MIT News. 2012. Available online: http://newsoffice.mit.edu/2012/mitx-edx-first-course-recap-0716 (accessed on 10 February 2015).
- Liyanagunawardena, T.R.; Adams, A.A.; Williams, S.A. MOOCs: A systematic study of the published literature 2008–2012. Int. Rev. Res. Open Distance Learn. 2013, 14, 202–227. [Google Scholar]
- Yang, D.; Sinha, T.; Adamson, D.; Rose, C.P. Turn on, tune in, drop out: Anticipating student dropouts in massive open online courses. In Proceedings of the 2013 NIPS Data-Driven Education Workshop, Lake Tahoe, NV, USA, 9–10 December 2013; Available online: http://lytics.stanford.edu/datadriveneducation/papers/yangetal.pdf (accessed on 9 February 2015).
- Ho, A.D.; Reich, J.; Nesterko, S.; Seaton, D.T.; Mullaney, T.; Waldo, J.; Chaung, I. HarvardX and MITx: The First Year of Open Online Courses. HarvardX and MITx Working Paper No. 1. Available online: http://dx.doi.org/10.2139/ssrn.2381263 (accessed on 27 May 2015).
- Liyanagunawardena, T.R.; Parslow, P.; Williams, S.A. Dropout: MOOC participants’ perspective. In Proceedings of the European MOOC Stakeholder’s Summit 2014, Lausanne, Switzerland, 10–12 February 2014.
- Rosen, R.J. Overblown-Claims-of-Failure Watch: How not to gauge the success of online courses. Available online: http://www.theatlantic.com/technology/archive/2012/07/overblown-claims-of-failure-watch-how-not-to-gauge-the-success-of-online-courses/260159/ (accessed on 18 May 2015).
- Daniel, J. Making Sense of MOOCs: Musings in a Maze of Myth, Paradox and Possibility. J. Interact. Med. Educ. 2012, 3. [Google Scholar] [CrossRef]
- Levy, Y. Comparing dropouts and persistence in e-learning courses. Comput. Educ. 2007, 48, 185–204. [Google Scholar] [CrossRef]
- Brady, L. Fault lines in the terrain of distance education. Comput. Compos. 2001, 18, 347–358. [Google Scholar] [CrossRef]
- Carr, S. As distance education comes of age, the challenge is keeping the students. Available online: http://chronicle.com/article/As-Distance-Education-Comes-of/14334 (accessed on 30 January 2015).
- Parker, A. A study of variables that predict dropout from distance educations. Int. J. Educ. Technol. 1999, 2. Available online: http://education.illinois.edu/ijet/v1n2/parker/index.html (accessed on 28 January 2015). [Google Scholar]
- Jaggars, S.S.; Edgecombe, N.; Stacey, G.W. What We Know about Online Course Outcomes. Research Overview, Community College Research Center, Teachers College, Columbia University: New York, USA, April 2013. Available online: http://ccrc.tc.columbia.edu/publications/what-we-know-online-course-outcomes.html (accessed on 28 January 2015).
- Boettcher, J.V. Online Course Development: What Does It Cost? Campus Technol. 2004. Available online: http://campustechnology.com/Articles/2004/06/Online-Course-Development-What-Does-It-Cost.aspx?aid=39863&Page=1 (accessed on 29 January 2015). [Google Scholar]
- Jewett, F. A framework for the comparative analysis of the costs of classroom instruction. In Dollars, Distance, and Online Education: The New Economics of College Teaching and Learning; Finkelstein, M.J., Frances, C., Jewett, F.I., Scholz, B.W., Eds.; Oryx Press: Phoenix, AZ, USA, 2000; pp. 85–122. [Google Scholar]
- Young, J.R. Inside the Coursera contract: How an upstart company might profit from free courses. Chron. High. Educ. 2012. Available online: http://chronicle.com/article/How-an-Upstart-Company-Might/133065/?cid=at&utm_source=at&utm_medium=en (accessed on 1 February 2015). [Google Scholar]
- Campaign for the Future of Higher Education. The “Promises” of Online Education: Reducing Costs. CFHE Working Paper, Posted 16 October 2013. Available online: http://futureofhighered.org/wp-content/uploads/2013/10/Promises-of-Online-Higher-Ed-Reducing-Costs1.pdf (accessed on 1 February 2015).
- Kay, J.; Reimann, P.; Diebold, E.; Kummerfeld, B. MOOCs: So many learners, so much potential. IEEE Intell. Syst. 2013, 28, 70–77. [Google Scholar] [CrossRef]
- Subban, P. Differentiated instruction: A research basis. Int. Educ. J. 2006, 7, 935–947. [Google Scholar]
- Siefert, J.W. Data mining and homeland security: An overview. Congressional Research Service Report for Congress. Report #31798. 5 June 2007. Available online: https://epic.org/privacy/fusion/crs-dataminingrpt.pdf (accessed on 19 February 2015).
- Rygielski, C.; Wang, J.-C.; Yen, D.C. Data mining techniques for customer relationship management. Technol. Soc. 2002, 24, 483–502. [Google Scholar] [CrossRef]
- Nichols, J. Not Just the NSA: Politicians are Data Mining the American Electorate. Nation 2013. Available online: http://www.thenation.com/blog/174759/not-just-nsa-politicians-are-data-mining-american-electorate (accessed on 21 February 2015). [Google Scholar]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C: Appl. Rev. 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Arnold, K. Signals: Applying academic analytics. Available online: http://www.educause.edu/ero/article/signals-applying-academic-analytics (accessed on 27 May 2015).
- Lieblein, E. Critical factors for successful delivery of online programs. Internet High. Educ. 2000, 3, 161–174. [Google Scholar] [CrossRef]
- Smith, M.A.; Kellogg, D.L. Required collaborative work in online courses: A predictive modeling approach. Decis. Sci. J. Innov. Educ. 2015, in press. [Google Scholar]
- Pappano, L. The Year of the MOOC. The New York Times. 2012. Available online: http://edinaschools.org/cms/lib07/MN01909547/Centricity/Domain/272/The%20Year%20of%20the%20MOOC%20NY%20Times.pdf (accessed on 4 February 2015).
- Bali, M. MOOC pedagogy: Gleaning good practice from existing MOOCs. MERLOT J. Online Learn. Teach. 2014, 10. Available online: http://jolt.merlot.org/vol10no1/bali_0314.pdf (accessed on 3 February 2015). [Google Scholar]
- Ertmer, P.A.; Richardson, J.C.; Belland, B.; Camin, D. Using peer feedback to enhance the quality of student online postings: An exploratory study. J. Comput.-Med. Commun. 2007, 12, 412–433. [Google Scholar] [CrossRef]
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Shmueli, G.; Koppius, O.R. Predictive analytics in information systems research. MIS Q. 2011, 35, 553–572. [Google Scholar] [CrossRef]
- Sawyer, A.G.; Peter, J.P. The significance of statistical significance tests in marketing research. J. Mark. Res. 1983, 20, 122–133. [Google Scholar] [CrossRef]
- Lin, M.; Lucas, H.C.; Shmueli, G. Research commentary—Too big to fail: Large samples and the p-value problem. Inf. Syst. Res. 2013, 24, 906–917. [Google Scholar] [CrossRef]
- Hand, D.J.; Manilla, H.; Smyth, P. Principles of Data Mining; The MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Linoff, G.S.; Berry, M.J.A. Data Mining Techniques for Marketing, Sales, and Customer Relationship Management, 3rd ed.; Wiley: Indianapolis, IN, USA, 2011. [Google Scholar]
- Shmueli, G.; Patel, N.R.; Bruce, P.C. Data Mining for Business Intelligence: Concepts, Techniques, and Applications, 2nd ed.; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Walsh, S. Applying Data Mining Techniques Using SAS Enterprise Miner; SAS Publishing: Cary, NC, USA, 2005. [Google Scholar]
- Tanes, Z.; Arnold, K.E.; King, A.S.; Remnet, M.A. Using Signals for appropriate feedback: Perceptions and practices. Comput. Educ. 2011, 57, 2414–2422. [Google Scholar] [CrossRef]
- Arnold, K.E.; Tanes, Z.; King, A.S. Administrative perspectives of data-mining software signals: Promoting student success and retention. J. Acad. Adm. High. Educ. 2010, 6, 29–39. [Google Scholar]
- Felder, R.M. Learning and teaching styles in engineering education. Eng. Educ. 1988, 78, 674–681. [Google Scholar]
- Gow, A.J.; Whiteman, M.C.; Pattie, A.; Deary, I.J. Goldberg’s “IPIP” big-five factor markers: Internal consistency and concurrent validation in Scotland. Personal. Individ. Differ. 2005, 39, 317–329. [Google Scholar] [CrossRef]
- Socha, A.; Cooper, C.A.; McCord, D.M. Confirmatory factor analysis of the M5–50: An implementation of the International Personality Item Pool Set. Psychol. Assess. 2010, 22, 43–49. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Smith, M.A. Output from Statistical Predictive Models as Input to eLearning Dashboards. Future Internet 2015, 7, 170-183. https://doi.org/10.3390/fi7020170
Smith MA. Output from Statistical Predictive Models as Input to eLearning Dashboards. Future Internet. 2015; 7(2):170-183. https://doi.org/10.3390/fi7020170
Chicago/Turabian StyleSmith, Marlene A. 2015. "Output from Statistical Predictive Models as Input to eLearning Dashboards" Future Internet 7, no. 2: 170-183. https://doi.org/10.3390/fi7020170
APA StyleSmith, M. A. (2015). Output from Statistical Predictive Models as Input to eLearning Dashboards. Future Internet, 7(2), 170-183. https://doi.org/10.3390/fi7020170