
Social Networking Privacy—Who’s Stalking You? †

Abstract
:
1. Introduction
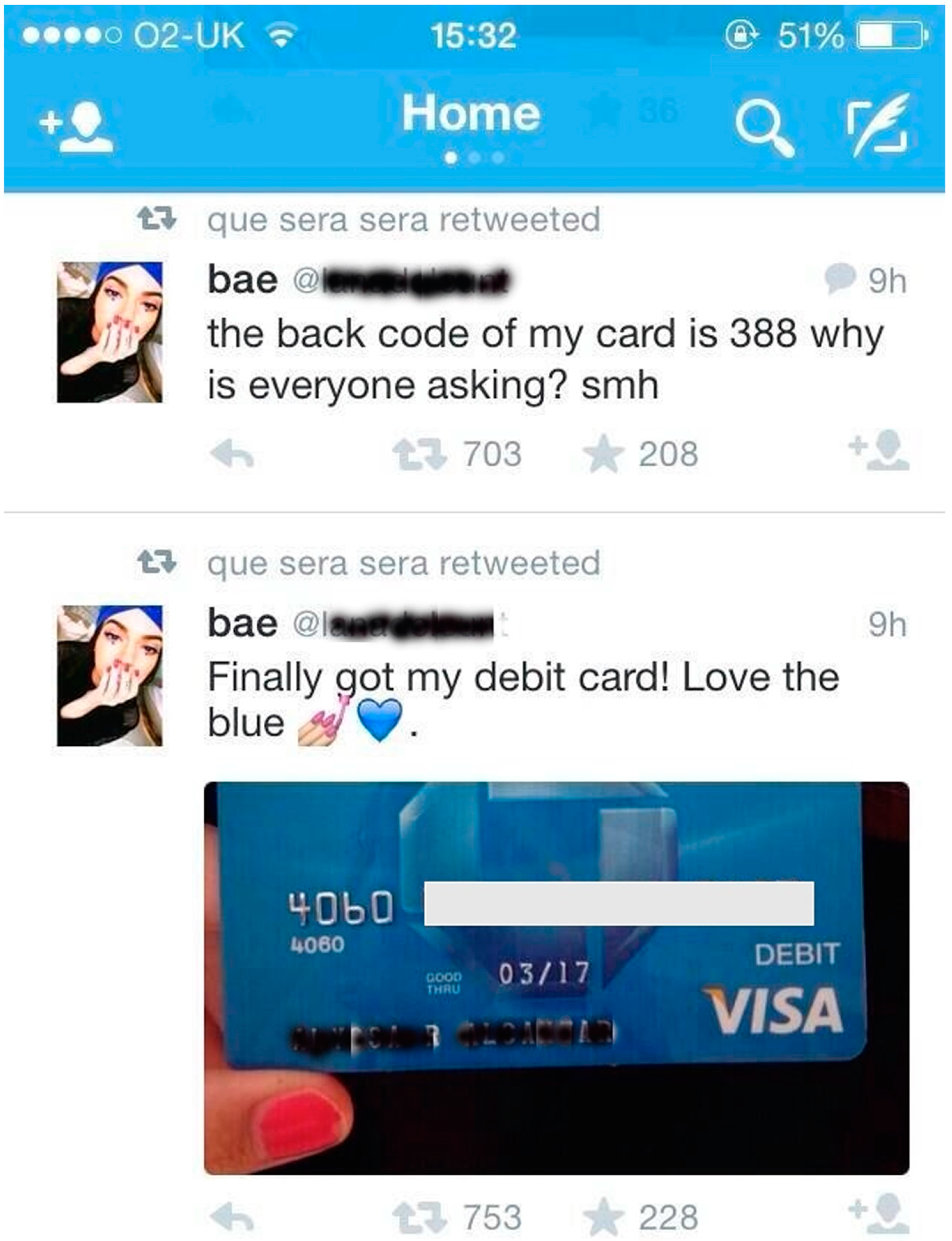
1.1. The Privacy Debate
1.2. Geo-Location Tagging
1.3. Related Literature
2. Review of the Tools
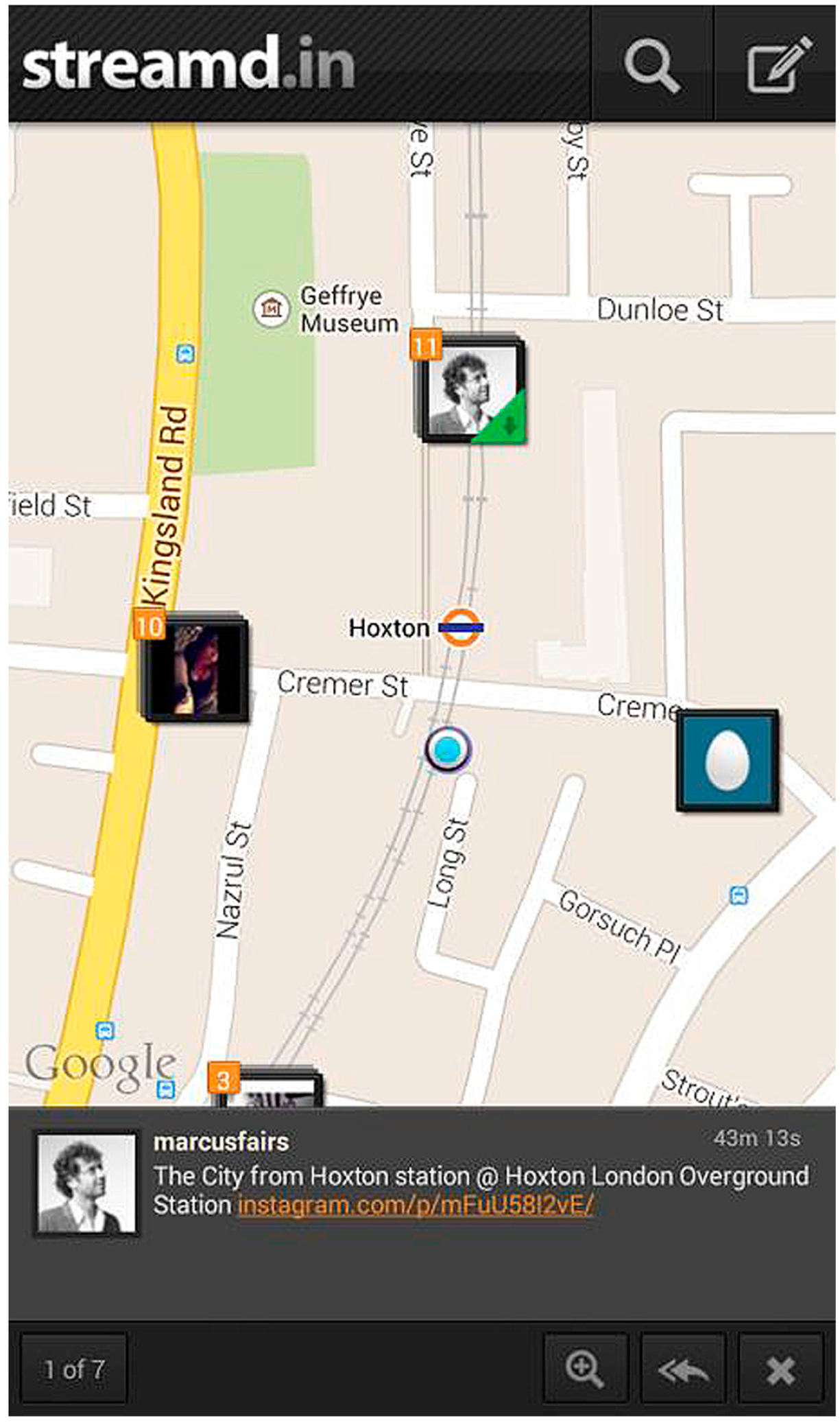
2.1. Streamd.in Application
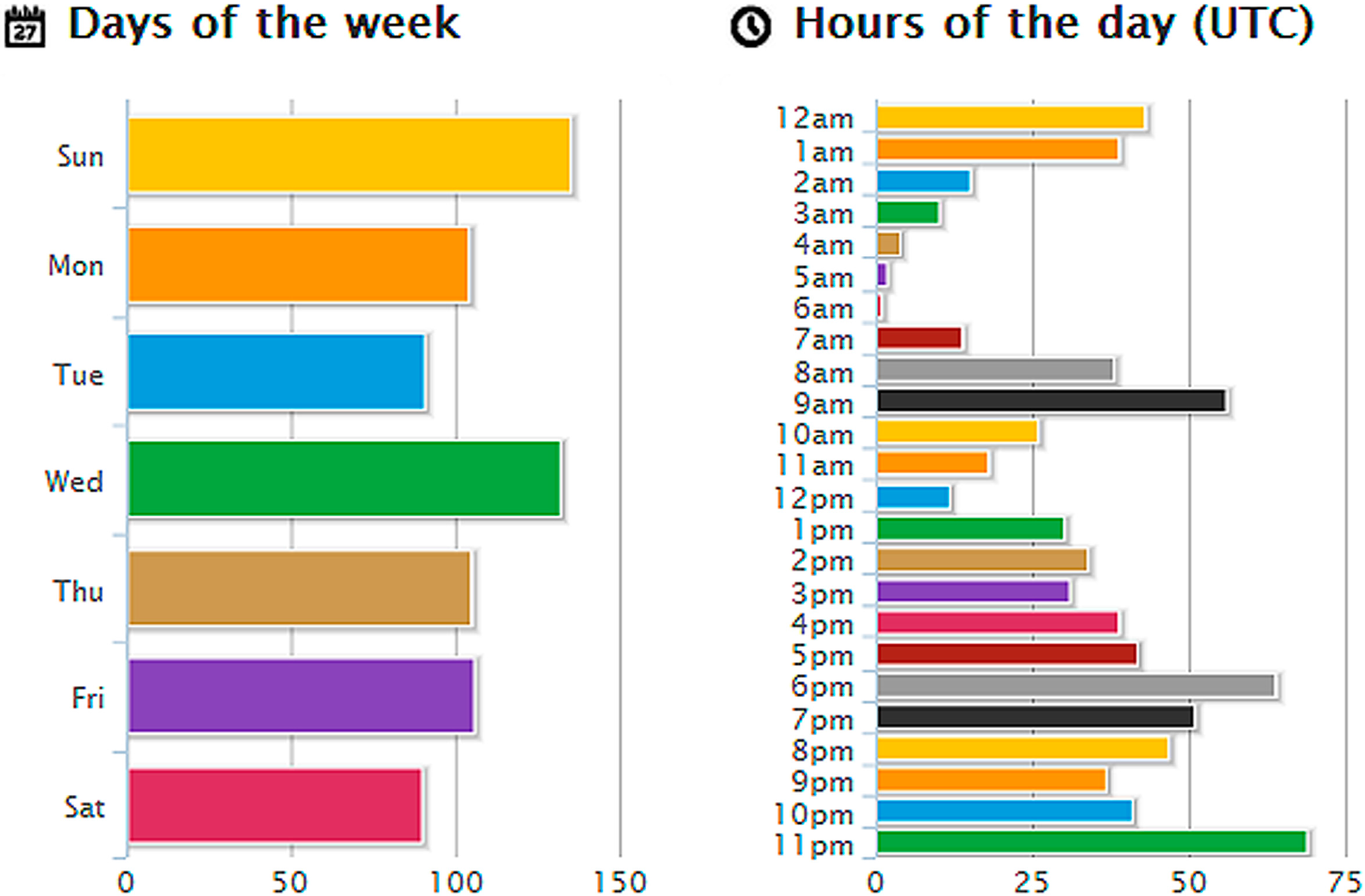
2.2. Twitonomy Application
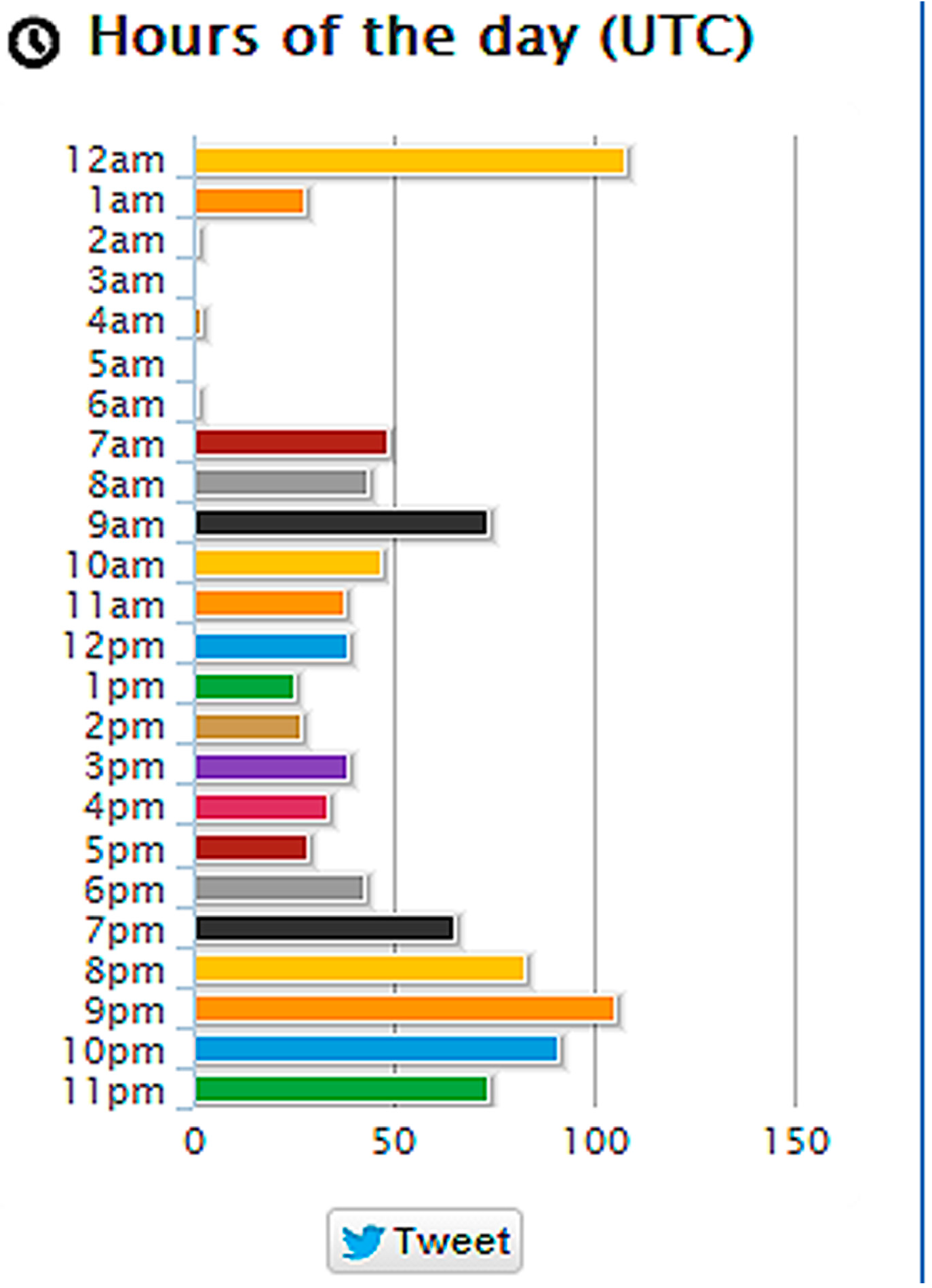
2.3. Creepy Application
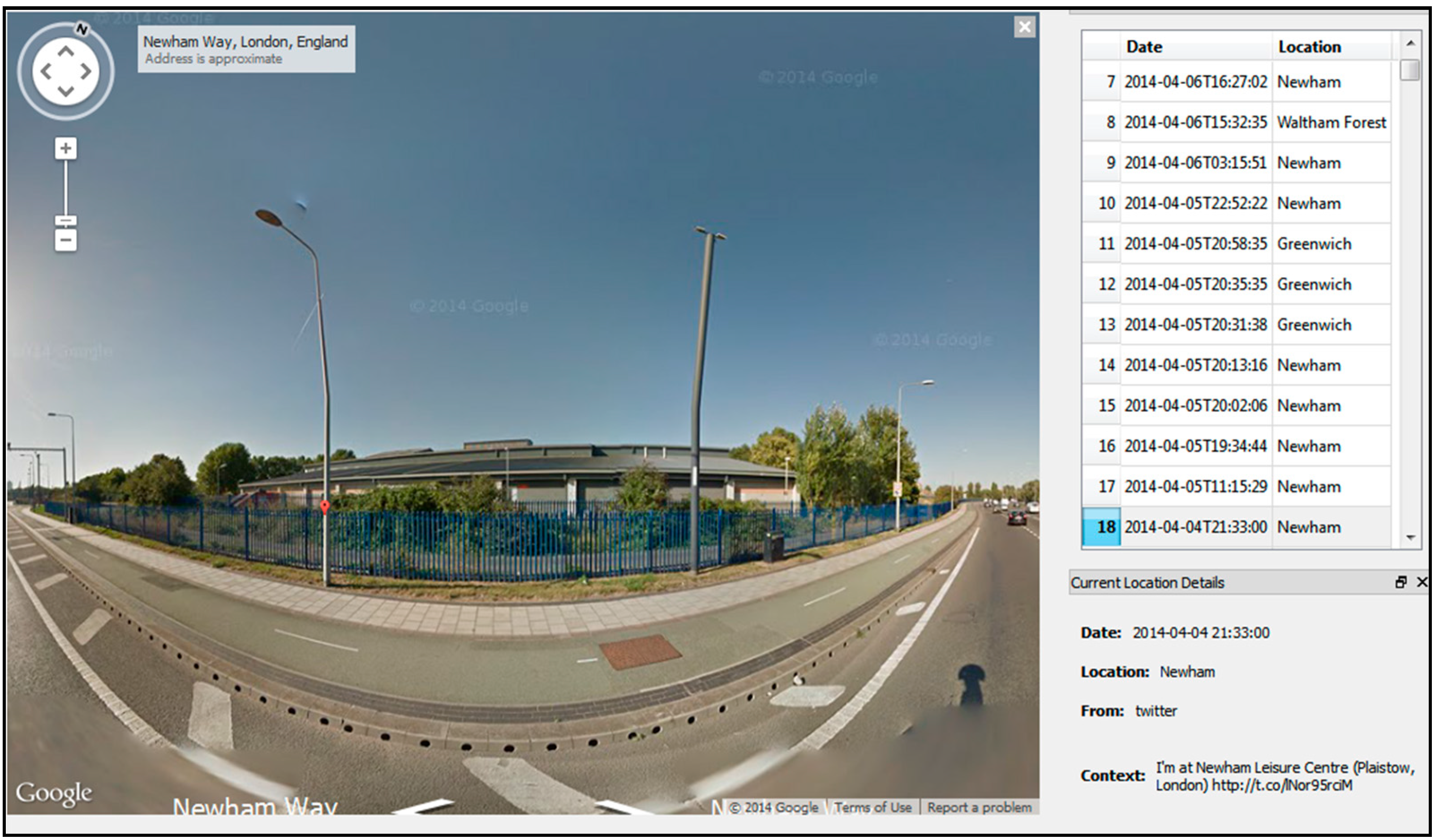
3. The Experiments
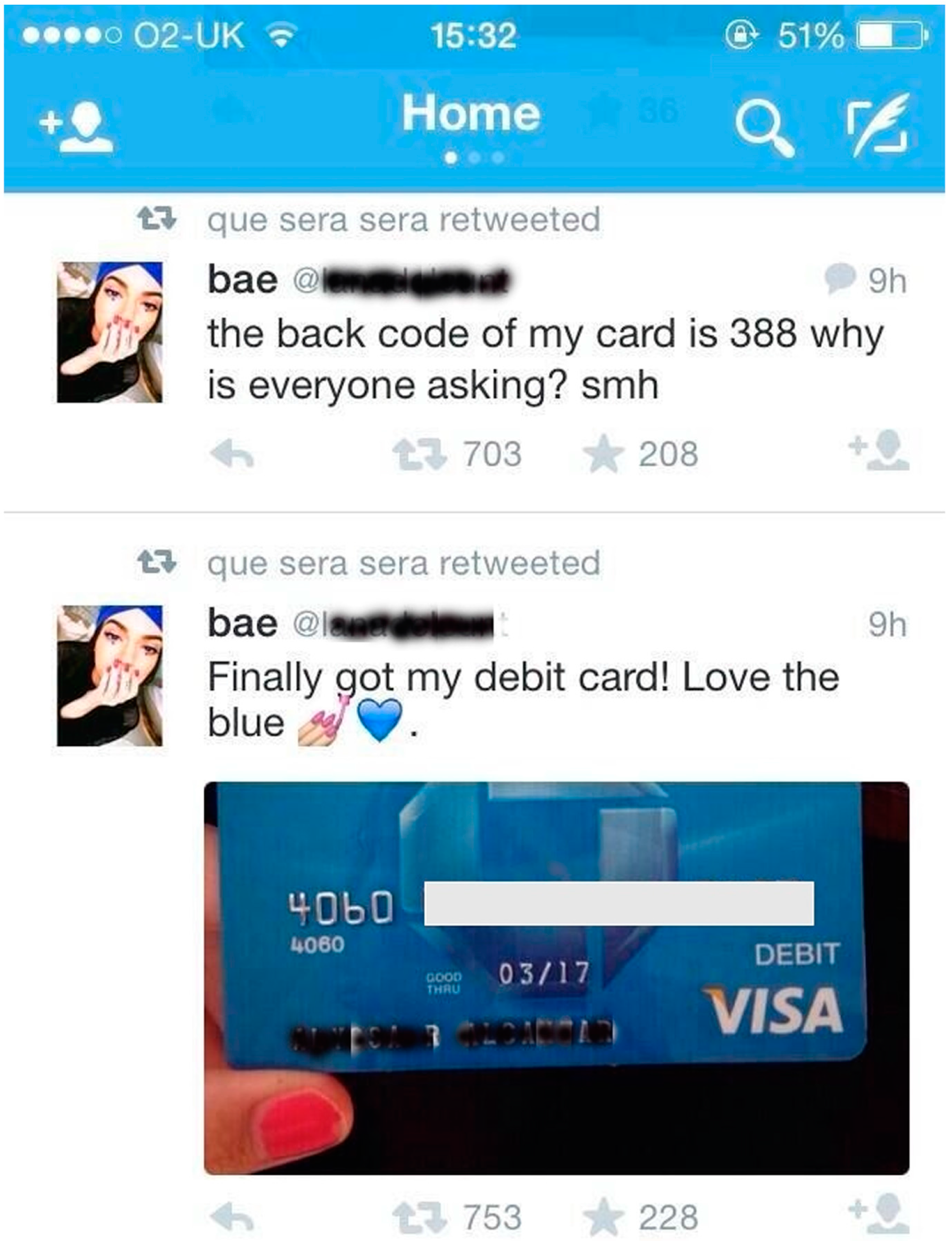
3.1. Preliminary Study

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vulnerabilities | Number of Twitter Users from Sample |
|---|---|
| Displayed real name | 59 users (65.5%) |
| Real name as username | 33 users (36.7%) |
| Real name and geotag posts | 47 users (43.3%) |
| Shared self-images | 85 users (94.4%) |
| Specified link to other site | 39 users (43.3%) |
| Same username on multiple platforms | 30 users (33.3%) |
| Above five hundred followers | 61 users (67.8%) |
| Above five hundred following | 54 users (60%) |
| Type of information leaked | Number of users |
|---|---|
| Whereabouts information | 7,000,000 + users |
| Credit/Debit Card photos | 1,186 users |
| Flight Tickets | 2,514 users |
| Other Tickets with sensitive data | 1,808,801 |
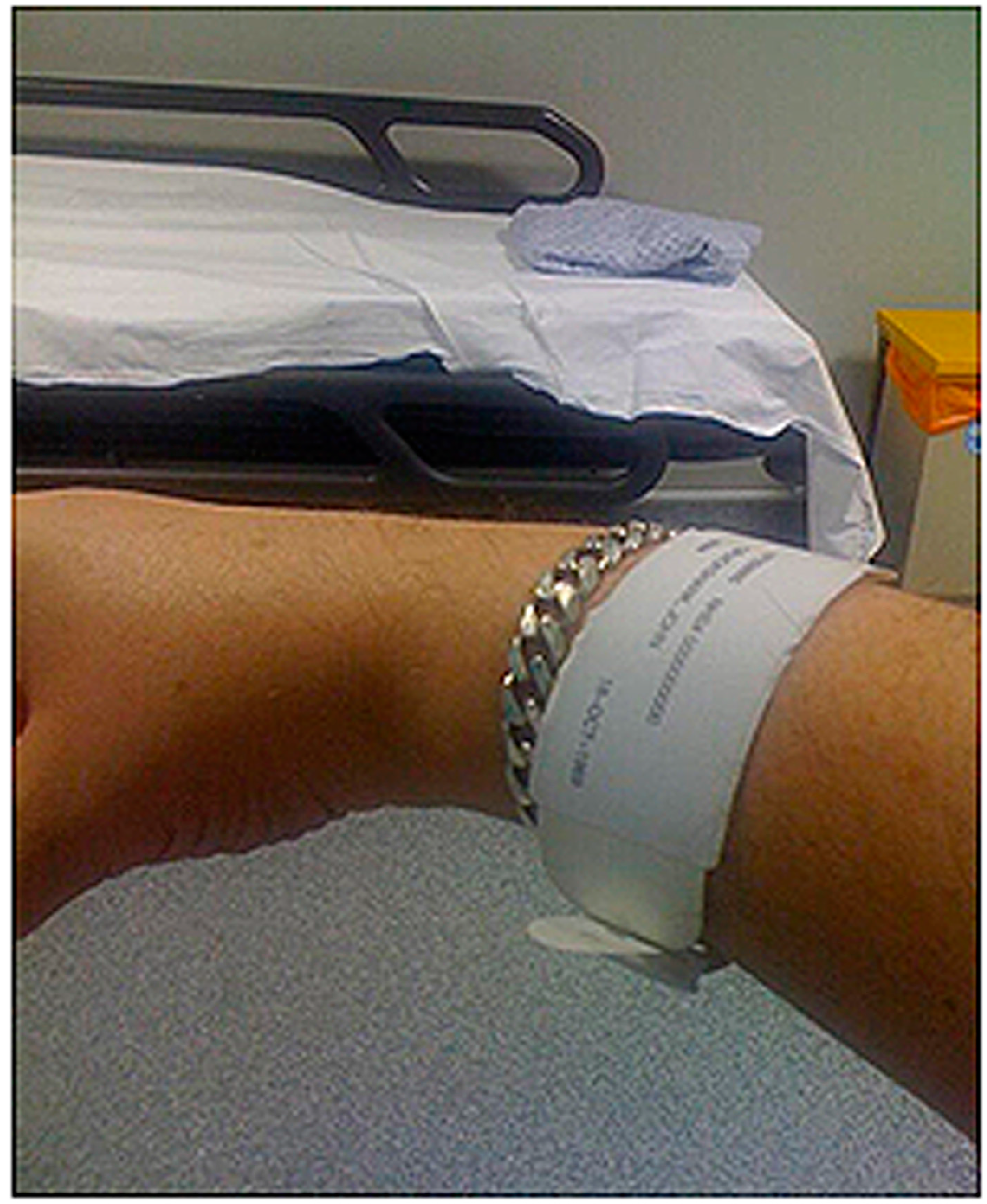
| Hospital ID band with full name | Approximately 39,503 users |
| Using hashtag #Homesweethome | Approximately 4 million posts |
| Using hashtag #Offtowork | Approximately 350,000 posts |
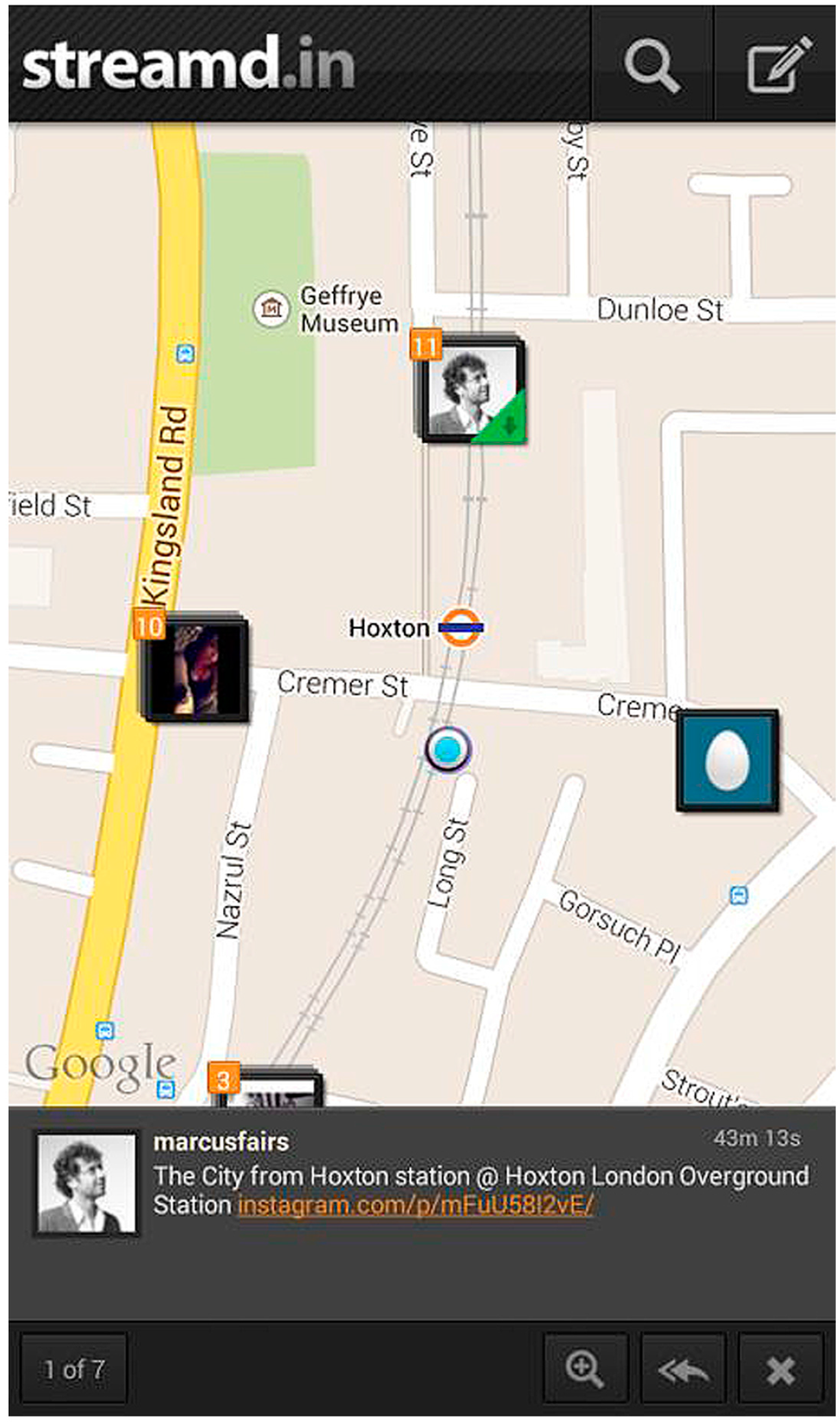
3.2. Experiment 1—Streamd.in
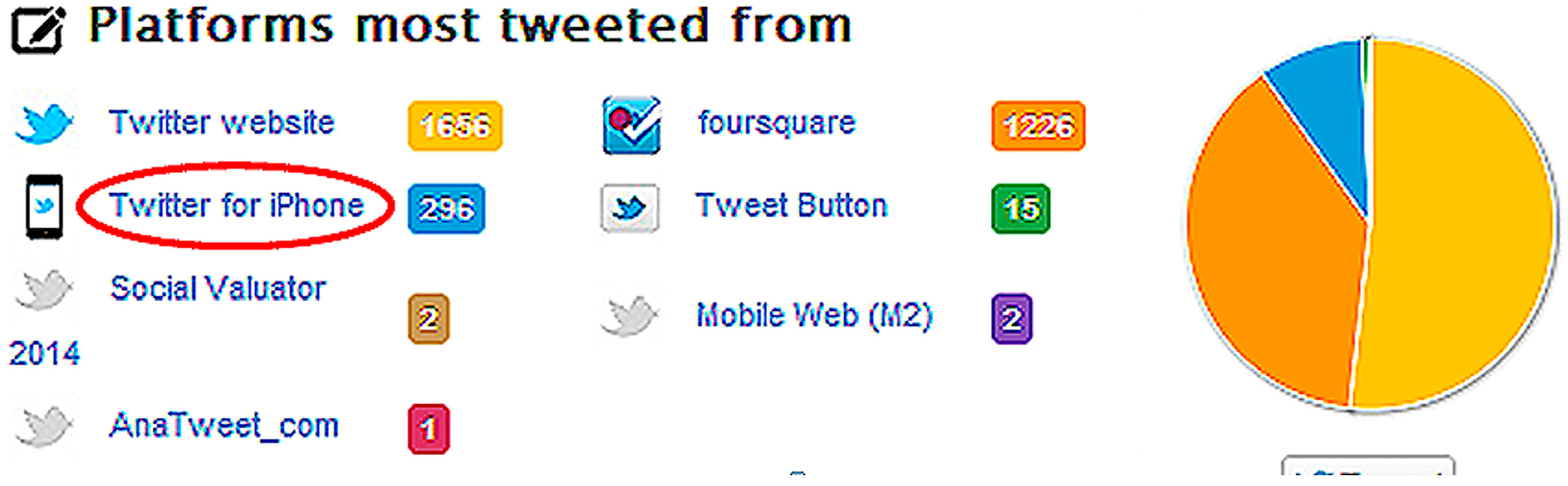
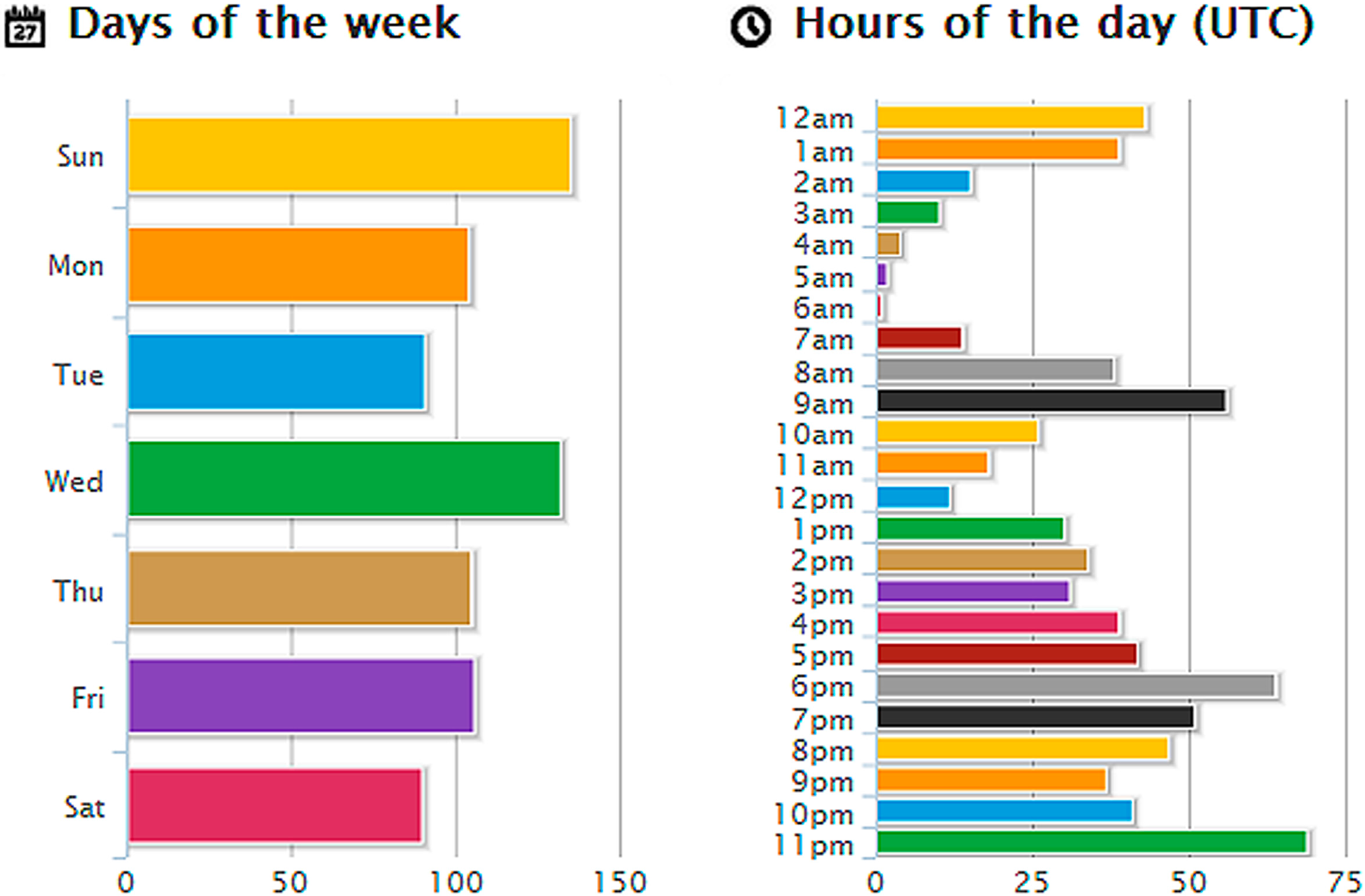
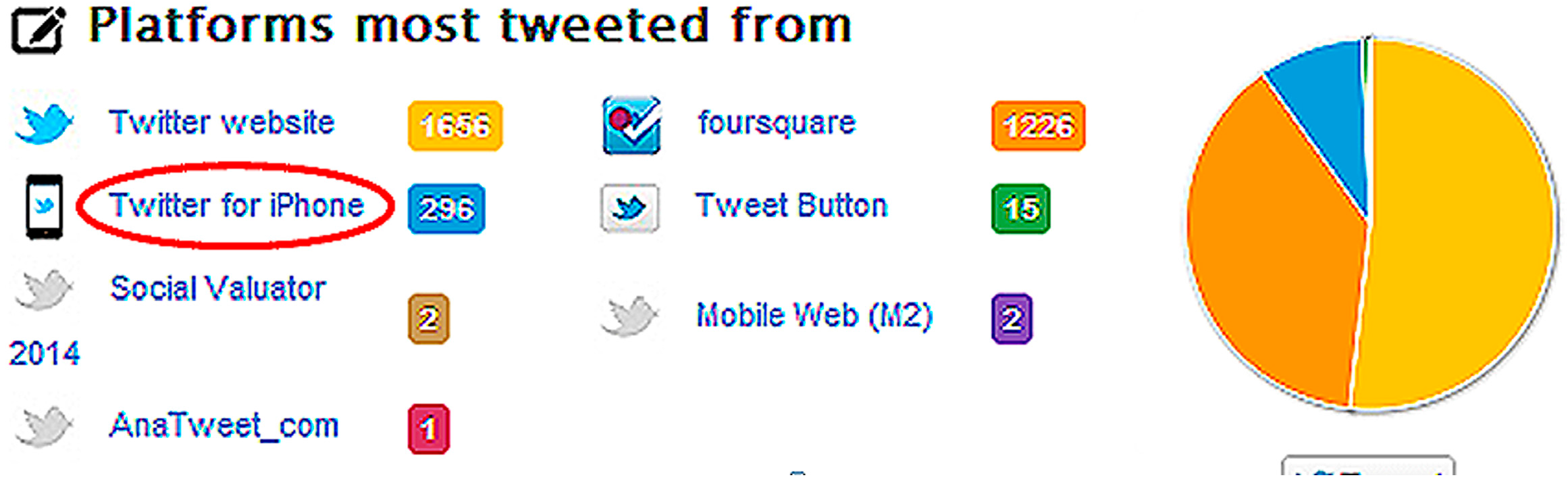
3.3. Experiment 2—Twitonomy
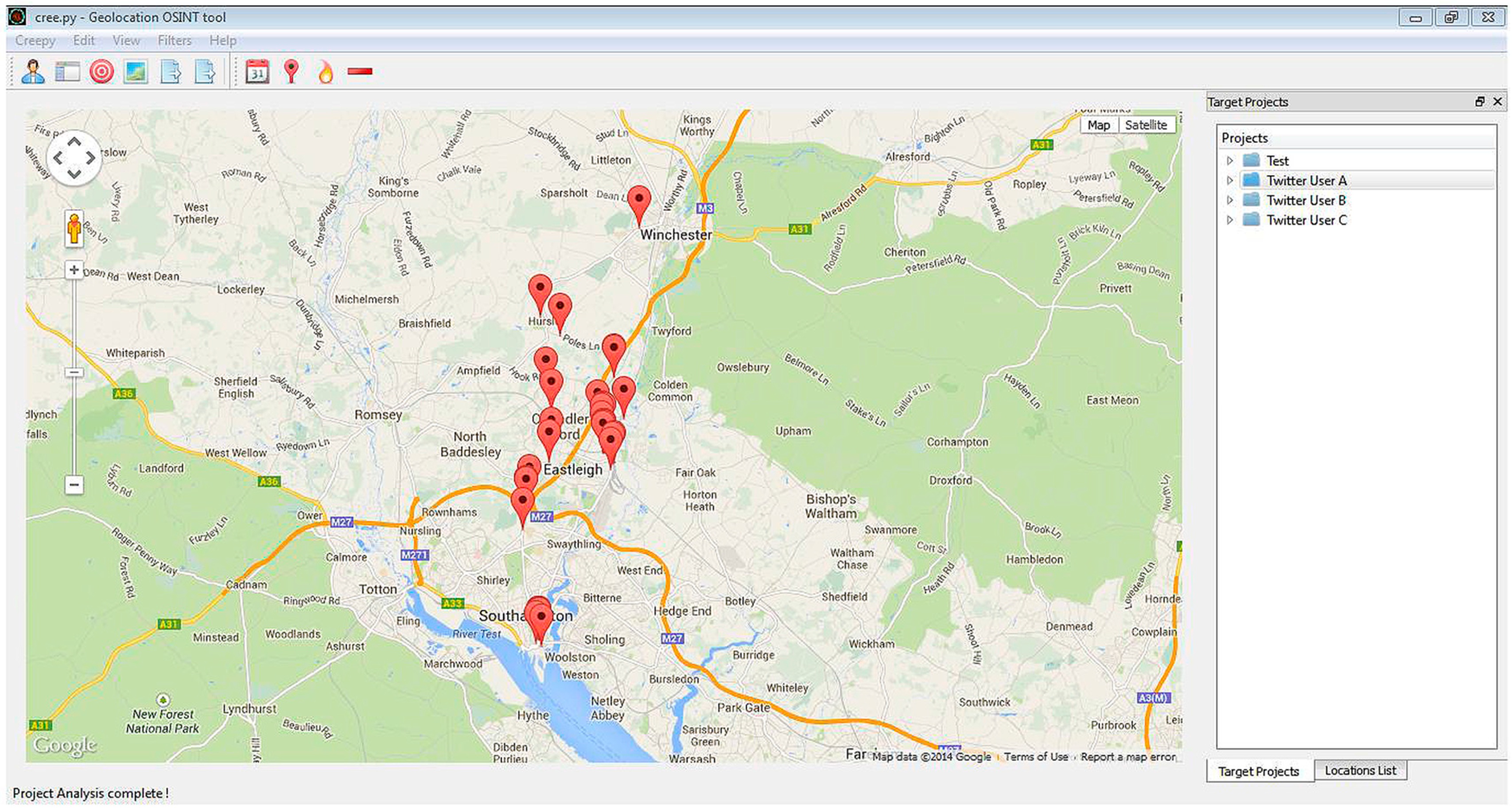
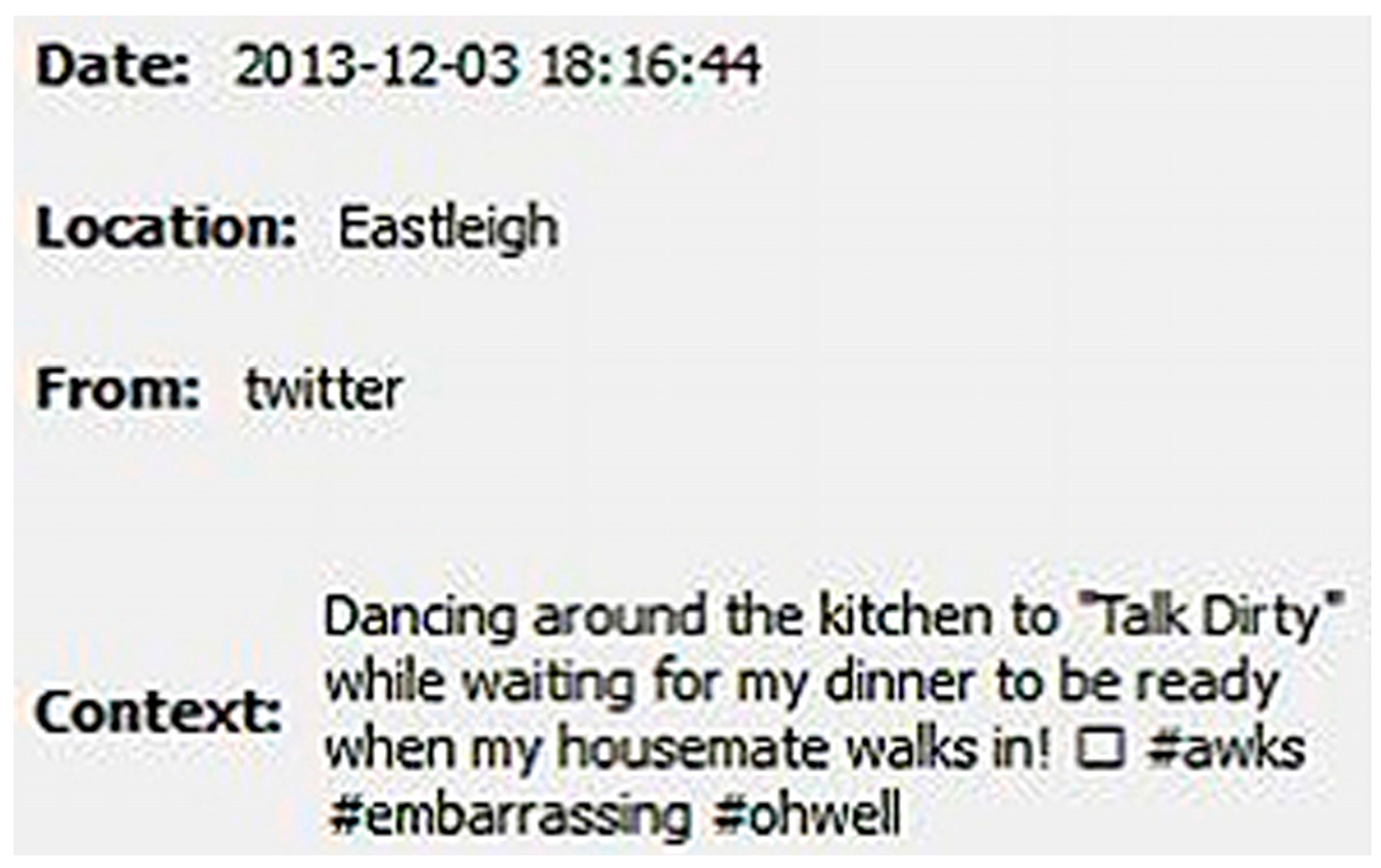
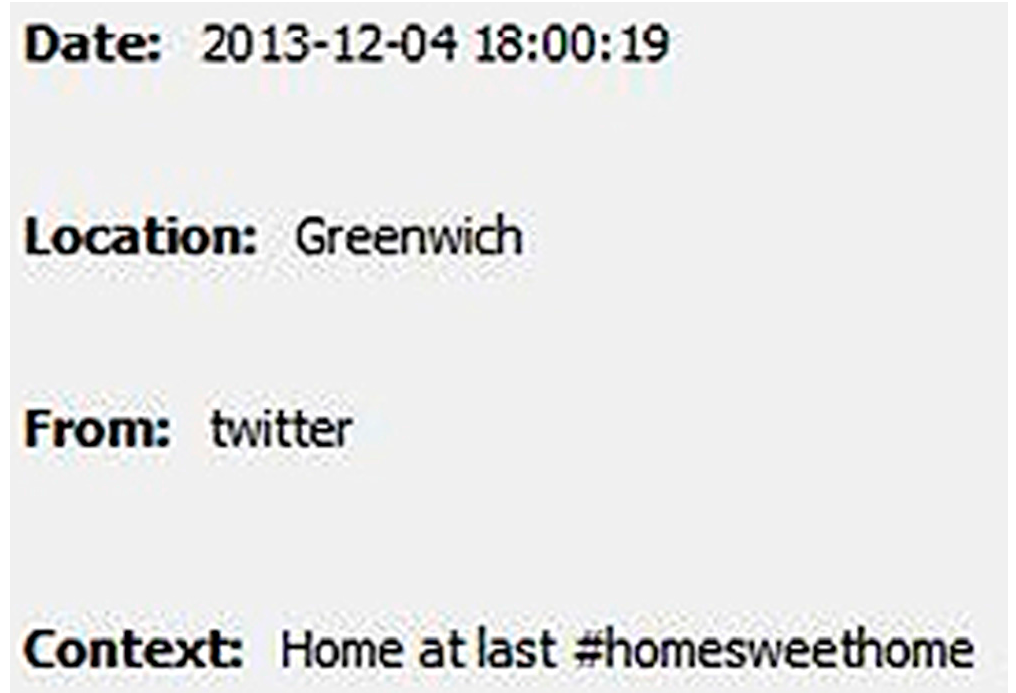
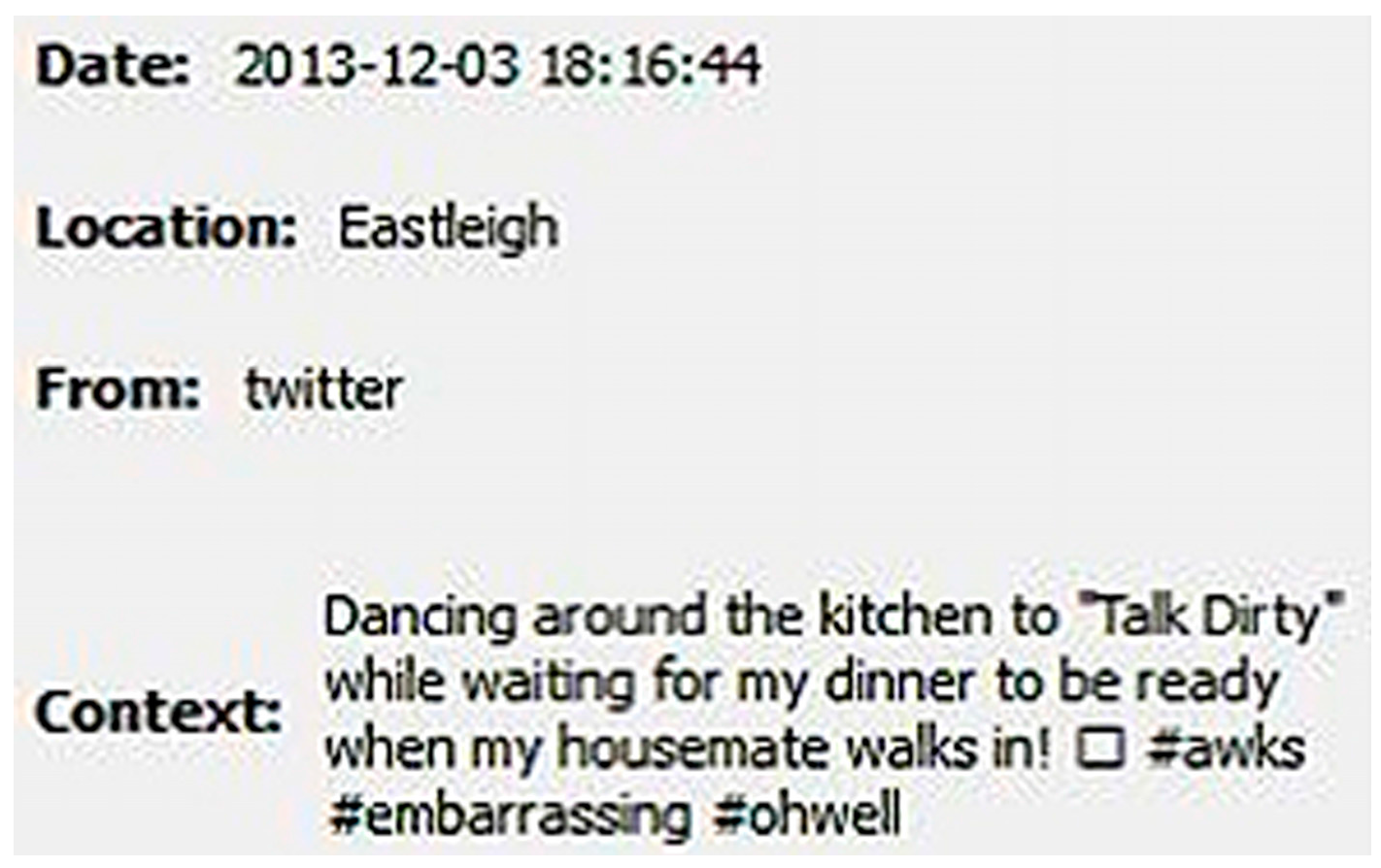
3.4. Experiment 3—Creepy

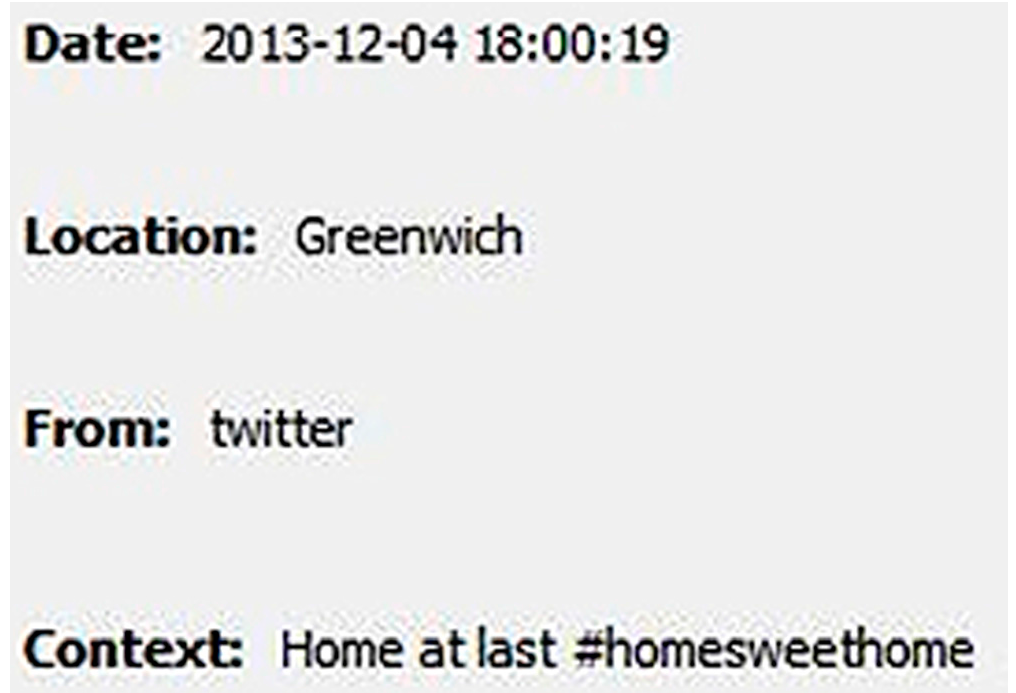

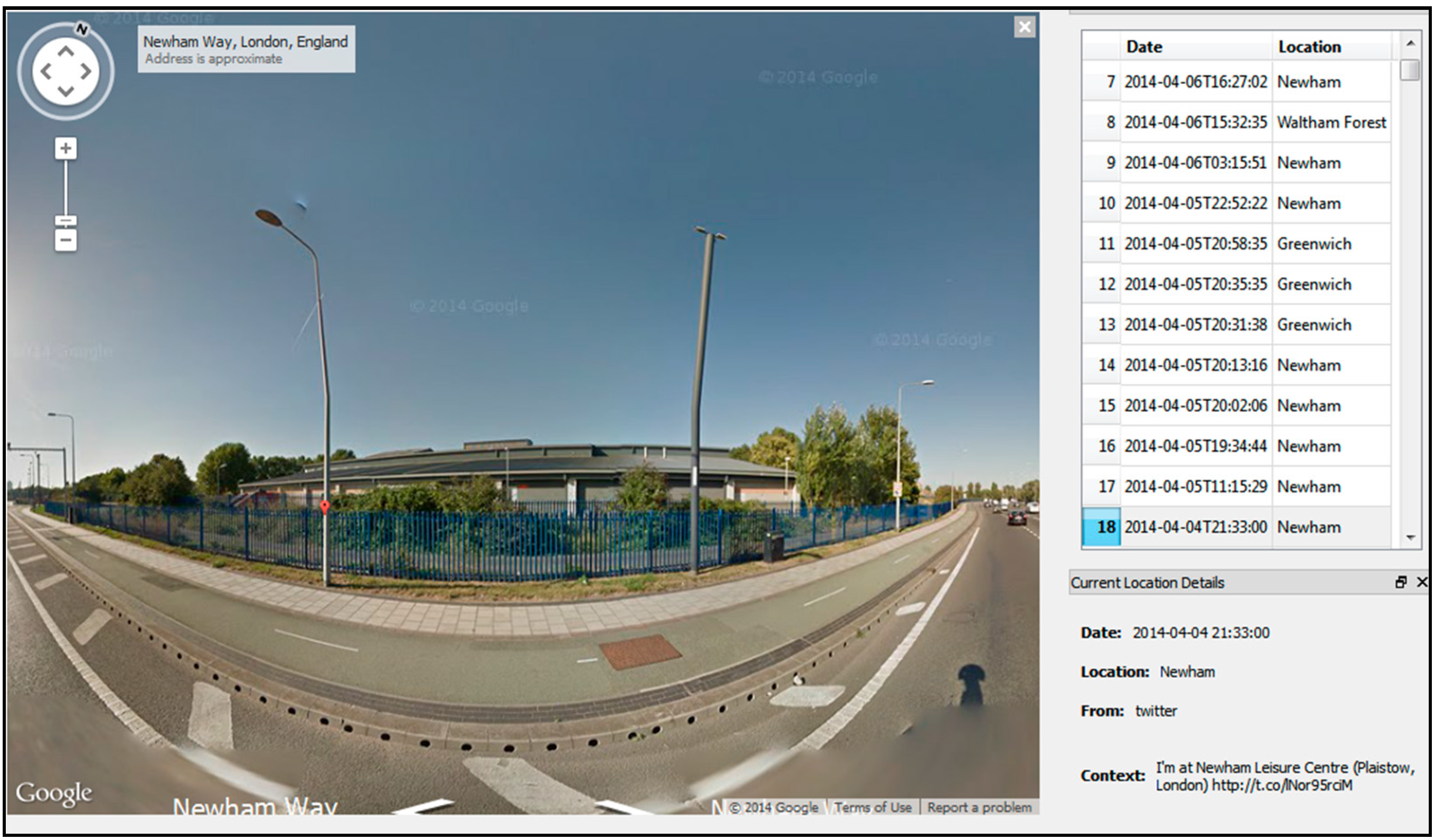
3.5. Experiment 4—Other Social Networks
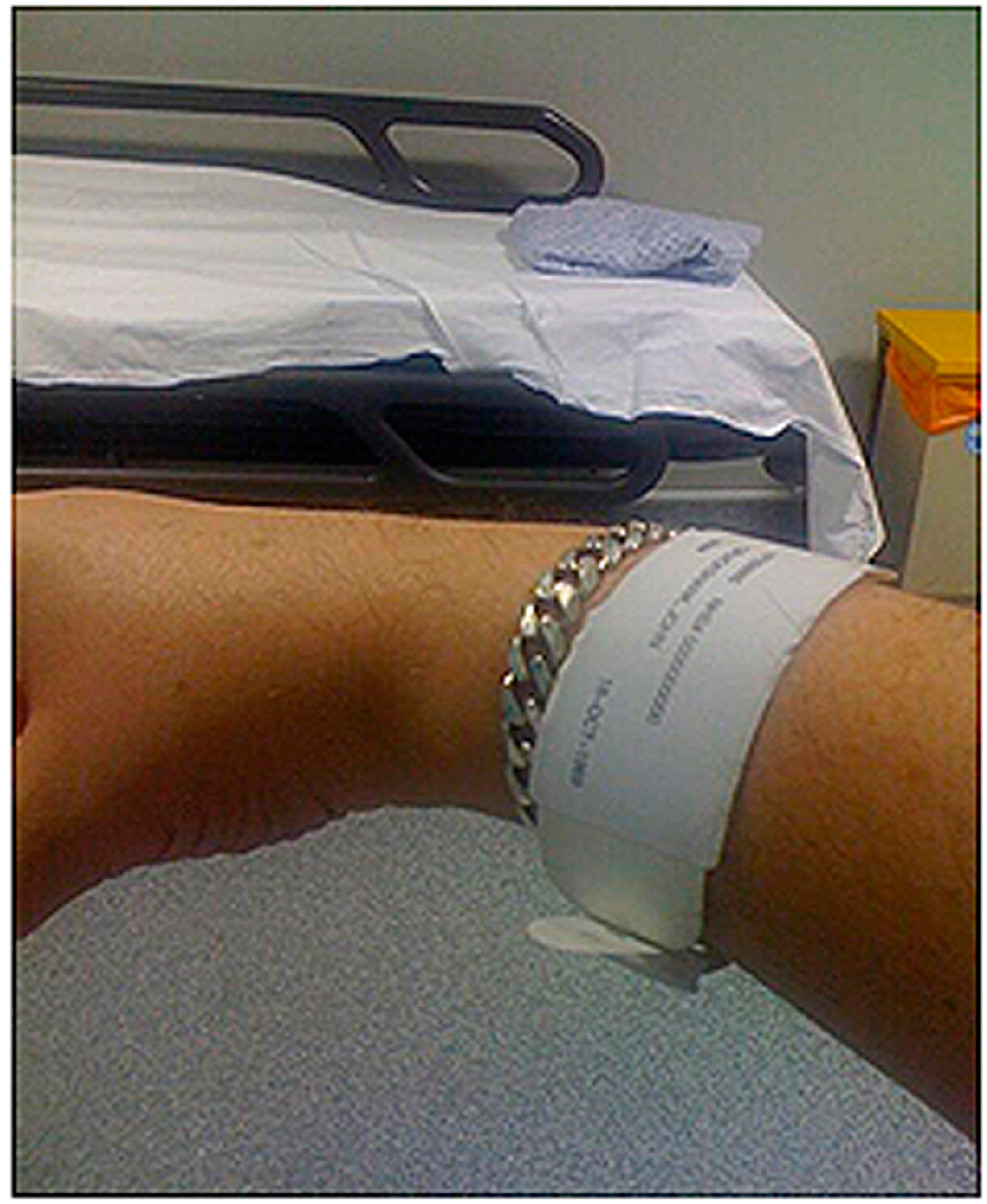

3.6. Evaluation
4. Recommendations
- If using Twitter is important to limit the amount of information added to an individual’s profile, so do not include where you live even if it is only the city.
- Avoid using your full name. This will reduce the chance of identity theft from Twitter and other social networks. Use an alias or at the very most only initials.
- Avoid using an actual profile picture of yourself. Use a cartoon or a picture of yourself when very young which will make it more difficult to identify you in person.
- Set your profile to private “Protect my Tweets” which is located in the “Security and privacy” settings. This will allow only your permitted followers to view your tweets, as followers have to be accepted by the user, unlike on public accounts.
- Remove geo-location tagging on tweets. If some tweets already have geo-location data attached to them Twitter has a function to delete this data.
- Do not provide your phone number.
- Remove “Let others find me by my email address” as this is another piece of information that can lead to the disclosure of personal information.
- Do not connect your Twitter account with any other social media sites, such as Facebook to avoid unintentional sharing information.
- Limit the amount of Apps that have access to your profile. Always question whether it is necessary to give access.
- Be very selective about what you put in your tweets and always check to make sure you are not accidentally giving away personal information.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Discover Twitter—What is Twitter and How to Use It. Available online: https://discover.twitter.com/ (accessed on 4 February 2014).
- Ball, J.; Lewis, P. Twitter and the Riots: How the News Spread. The Guardian, 7 December 2011. Available online: http://www.theguardian.com/uk/2011/dec/07/twitter-riots-how-news-spread (accessed on 4 August 2014).
- Proctera, R.; Crump, J.; Karstedt, S.; Voss, A.; Cantijoch, M. Reading the riots: what were the police doing on Twitter? Polic. Soc.: Int. J. Res. Policy 2013, 23, 413–436. [Google Scholar]
- Twitter Statistics. Available online: http://www.statisticbrain.com/twitter-statistics (accessed on 18 February 2014).
- Stone, B. Location, Location, Location. 20 August 2009. Available online: https://blog.twitter.com/2009/location-location-location (accessed on 20 February 2014).
- Vicente, C.R.; Freni, D.; Bettini, C.; Jensen, C.S. Location-related privacy in geo-social networks. IEEE Internet Comput. 2011, 15, 20–27. [Google Scholar] [CrossRef]
- Jenkins, L.R.; Gan, D.E. Investigation into the privacy issues of using social media. In Proceedings of the CFET 2014—7th International Conference on Cybercrime, Forensics, Education and Training, Christ Church Canterbury, UK, 10–11 July 2014. ISBN:97801909067158.
- Luo, W.; Liu, J.; Liu, J.; Fan, C. An analysis of security in social networks. In Proceedings of the 2009 8th IEEE International Conference on Dependable, Autonomic and Secure Networking, Chengdu, China, 12–14 December 2009.
- Abdulhamid, S.M.; Ahmad, S.; Waziri, V.O.; Jibril, F.N. Privacy and National Security Issues in Social Networks: The Challenges. Int. J. Comput. Internet Manag. 2011, 19, 14–20. [Google Scholar]
- Hajli, N.; Lin, X. Exploring the security of information sharing on social networking sites: The role of perceived control of information. J. Bus. Ethics 2014. [Google Scholar] [CrossRef]
- Edwards, A. Teenage Youth Crime Commissioner Who Quit over Offensive Tweets is Questioned by Special Branch. Available online: http://www.dailymail.co.uk/news/article-2312044/Paris-Brown-Foul-mouthed-youth-commissioner-quit-offensive-tweets-questioned-police-caution.htm (accessed on 20 April 2013).
- Reuters. Twitter Told to Improve Security. Available online: http://www.pcpro.co.uk/news/security/368542/twitter-told-to-improve-security (accessed on 8 July 2011).
- Brinkmann, M. Twitter Improves Account Security, Improves Password Reset. Available online: http://www.ghacks.net/2014/05/09/twitter-improves-account-security-improves-password-reset/ (accessed on 9 May 2014).
- Srinivasan, S. Lack of Privacy Awareness in Social Networks. ISACA J. 2012, 6. Available online: http://www.isaca.org/Journal/Past-Issues/2012/Volume-6/Pages/Lack-of-Privacy-Awareness-in-Social-Networks.aspx (accessed on 20 February 2014). [Google Scholar]
- Twitter Privacy Policy 2014. Available online: https://twitter.com/privacy (accessed on 4 February 2014).
- Madden, M. Privacy management on social media sites. In Pew Internet Report; Pew Research Center: Washington, DC, USA, 2012; pp. 1–20. Available online: http://pewinternet.org/Reports/2012/Privacy-management-on-social-media.aspx (accessed on 23 November 2014).
- Bennett, S. Social Media And Crime—How Secure Is Your Information? Covering the World of Social Media. Available online: http://www.adweek.com/socialtimes/social-media-crime/491227?red=at (accessed on 25 September 2013).
- Welter, A. Social Media and Crime, Crime Wire. Available online: http://www.instantcheckmate.com/crimewire/social-media-and-crime-2/#prettyPhoto (accessed on 21 August 2013).
- Hardwick, L. How to Improve Your Twitter Security and Privacy. Available online: https://nakedsecurity.sophos.com/2014/08/26/how-to-improve-your-twitter-security-and-privacy/ (accessed on 26 August 2013).
- Neagu, A. Twitter Security Tips: How to Improve your Twitter Security and Privacy in 10 Easy Steps. Available online: https://heimdalsecurity.com/blog/twitter-security-privacy-essential-guide (accessed on 13 November 2014).
- Hannay, P.; Baatard, G. GeoIntelligence: Data mining locational social media content for profiling and information gathering. In Proceedings of the 2nd International Cyber Resilience Conference, School of Computer and Information Science, Security Research Centre, Edith Cowan University, Perth, Western Australia, 1–2 August 2011; Available online: http://data.openduck.com/wp-posts/2012/09/paper-geo/geointelf.pdf (accessed on 10 December 2013).
- Valli, C.; Hannay, P. Geotagging Where Cyberspace Come to Your Place. Openduck 2010, 1–4. Available online: http://data.openduck.com/wp-posts/2010/07/paper-geotagging/valli-hannay-geotagging.pdf (accessed on 10 December 2013). [Google Scholar]
- Paske, B.; Lyle, J. Follow you follow me: Using location tracking to mitigate multi-device privacy threats. In Proceedings of the Workshop on Multi-device App Middleware, Montreal, QC, Canada, 3–7 December 2012; Article No. 4. pp. 1–6. [CrossRef]
- Thomas, L.; Briggs, P.; Little, L. Location tracking via social networking sites. In Proceedings of the 5th Annual ACM Web Science Conference (ACM WebSci14), Paris, France, 2–4 May 2013; pp. 405–412. [CrossRef]
- Brownlee, J. This Creepy App Isn’t Just Stalking Women without Their Knowledge, It’s A Wake-up Call about Facebook Privacy. Available online: http://www.cultofmac.com/157641/this-creepy-app-isnt-just-stalking-women-without-their-knowledge-its-a-wake-up-call-about-facebook-privacy/ (accessed on 20 February 2014).
- Palmer, S. How Twitter is being used by Australian engineering academic units. In Proceedings of the 24th 2013 Australasian Association for Engineering Education Conference, Griffith School of Engineering, Griffith University, Brisbane, Australia, 8–11 December 2013.
- Forgie, S.E.; Duff, J.P.; Ross, S. Twelve tips for using Twitter as a learning tool in medical education. In US Natl. Lib. Med.; 2013; 35, pp. 8–14. Available online: http://www.ncbi.nlm.nih.gov/pubmed/23259608 (accessed on 12 August 2014). [Google Scholar] [CrossRef]
- Visser, R.D.; Evering, L.C.; Barrett, D.E. #TwitterforTeachers: The Implications of Twitter as a Self-Directed Professional Development Tool for K–12 Teachers. J. Res. Technol. Educ. 2014, 46, 396–413. [Google Scholar] [CrossRef]
- Carpenter, J.P.; Krutka, D.G. How and why educators use twitter: A survey of the field. J. Res. Technol. Educ. 2014, 46, 414–434. [Google Scholar] [CrossRef]
- Prestridge, S. A focus on students’ use of Twitter—Their interactions with each other, content and interface. Act. Learn. High. Educ. 2014, 15, 101–115. [Google Scholar] [CrossRef]
- Junco1, R.; Elavsky, C.M.; Heiberger, G. Putting twitter to the test: Assessing outcomes for student collaboration, engagement and success. Br. J. Educ. Technol. 2013, 44, 273–287. [Google Scholar] [CrossRef]
- Pentina, I.; Zhang, L.; Basmanova, O. Antecedents and consequences of trust in a social media brand: A cross-cultural study of Twitter. Comput. Hum. Behav. 2013, 29, 1546–1555. [Google Scholar] [CrossRef]
- Visa, F. Twitter as a Reporting Tool for Breaking News—Journalists tweeting the 2011 UK riots. Digit. Journal. 2013, 1, 27–47. [Google Scholar] [CrossRef]
- Hermida, A.; Lewis, S.C.; Zamith, R. Sourcing the Arab Spring: A Case Study of Andy Carvin’s Sources on Twitter during the Tunisian and Egyptian Revolutions. J. Comput. Mediat. Commun. 2014, 19, 479–499. [Google Scholar] [CrossRef]
- Malleson, N.; Andresen, M.A. The impact of using social media data in crime rate calculations: Shifting hot spots and changing spatial patterns. Cartogr. Geogr. Inf. Sci. 2015, 42, 112–121. [Google Scholar] [CrossRef]
- Gabielkov, M.; Rao, A.; Legout, A. Studying social networks at scale: Macroscopic anatomy of the Twitter Social Graph. In Proceedings of the 2014 ACM International Conference on Measurement and Modeling of Computer Systems, (SIGMETRICS '14), Austin, TX, USA, 16–20 June 2014; Volume 42, pp. 277–288. [CrossRef]
- Graham, M.; Hale, S.A.; Gaffney, D. Where in the World Are You? Geo-location and Language Identification in Twitter. Prof. Geogr. 2014, 42, 277–288. [Google Scholar] [CrossRef]
- Jeong, Y.; Coyle, E. What Are You Worrying About on Facebook and Twitter? An Empirical Investigation of Young Social Network Site Users’ Privacy Perceptions and Behaviors. J. Interact. Advertising 2014. [Google Scholar] [CrossRef]
- Davis, K.; James, C. Tweens’ conceptions of privacy online: implications for educators. Learn. Media Technol. 2013, 38, 4–25. [Google Scholar] [CrossRef]
- Zhang, H.; Choudury, M.D.; Grudin, J. Creepy but Inevitable? In Proceedings of the Evolution of Social Networking, CSCW ’14, Baltimore, ML, USA, 15–19 February 2014; Available online: http://dx.doi.org/10.1145/2531602.2531643 (accessed on 15 August 2014).
- Mao, H.; Shuai, X.; Kapadia, A. Loose Tweets: An Analysis of Privacy Leaks on Twitter. In Proceedings of the 10th Annual ACM Workshop on Privacy in the Electronic Society, Chicago, IL, USA, 17–21 October 2011; pp. 1–12, ISBN:978-1-4503-1002-4.
- Mearns, G.; Simmonds, R.; Richardson, R.; Turner, M.; Watson, P.; Missier, P. Tweet My Street: A Cross-Disciplinary Collaboration for the Analysis of Local Twitter Data. Future Internet 2014, 6, 378–396. [Google Scholar] [CrossRef]
- Ryoo, K.; Moon, S. Inferring Twitter user locations with 10 km accuracy. In Proceedings of the Companion Publication of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 643–648, ISBN:978-1-4503-2745-9.
- Jin, L.; Chen, Y.; Wang, T.; Hui, P.; Vasilakos, A.V. Understanding User Behavior in Online Social Networks: A Survey. IEEE Commun. Mag. 2013, 51, 144–150. [Google Scholar]
- Shi, Z.; Ru, H.; Whinston, A.B. Content Sharing In a Social Broadcasting Environment: Evidence from Twitter. MIS Q. 2014, 38, 123–142. [Google Scholar]
- Yang, Z.; Guo, J.; Cai, K.; Tang, J.; Li, J.; Zhang, L.; Su, Z. Understanding retweeting behaviors in social networks, CIKM’10. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010.
- Zhang, J.; Liu, B.; Tang, J.; Chen, T.; Li, J. Social Influence Locality for Modeling Retweeting Behaviors. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2761–2767.
- Wang, J.; Wang, L.; Wu, W. Predicting information popularity degree in microblogging diffusion networks. Int. J. Multimed. Ubiquitous Eng. 2014, 9, 21–30. [Google Scholar] [CrossRef]
- Lee, K.; Mahmud, J.; Chen, J.; Zhou, M.; Nichols, J. Who will retweet this? Automatically Identifying and Engaging Strangers on Twitter to Spread Information. In Proceedings of the 19th International Conference on Intelligent User Interfaces, New York, NY, USA, 24–27 February 2014; pp. 247–256.
- Pervin, N.; Takeda, H.; Toriumi, F. Factors Affecting Retweetability: An Event-Centric Analysis on Twitter. In Proceedings of the International Conference on Information Systems (ICIS) 2014, Auckland, New Zealand, 14–17 December 2014.
- Lia, J.; Pengb, W.; Lia, T.; Sunb, T.; Lic, Q.; Xuc, J. Social network user influence sense-making and dynamics prediction. Expert Syst. Appl. 2014, 41, 5115–5124. [Google Scholar] [CrossRef]
- Liu, G.; Shi, C.; Chen, Q.; Wu, B.; Qi, J. A Two-Phase Model for Retweet Number Prediction. In Proceedings of the Web-Age Information Management—15th International Conference, WAIM 2014, Macau, China, 16–18 June 2014; Volume 8485, pp. 781–792.
- Macskassy, S.A.; Michelson, M. Why do People Retweet? Anti-Homophily Wins the Day? In Proceedings of the International Conference on Weblogs and Social Media (ICWSM), Barcelona, Spain, 17–21 July 2011.
- StreamdIn API. Available online: http://download.cnet.com/StreamdIn/3000–12941_4–75695954.html (accessed on 20 February 2014).
- Shetty, N. Streamd.in—Tweets on Google maps in an Awesome Way. 2010. Available online: http://www.twi5.com/streamd-in-tweets-on-google-maps-in-an-awesome-way/8666/ (accessed on 1 February 2015).
- Twitonomy: Twitter #Analytics and Much More. Available online: http://www.twitonomy.com/index.php Twitonomy.com (accessed on 12 February 2014).
- Creepy API. Available online: http://ilektrojohn.github.io/creepy (accessed on 12 February 2014).
- Kakavas, Y. Creepy, the Geo-location Information Aggregator, 2011—InfoSec Institute. Available online: http://resources.infosecinstitute.com/creepy/ (accessed on 31 January 2014).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, D.; Jenkins, L.R. Social Networking Privacy—Who’s Stalking You? Future Internet 2015, 7, 67-93. https://doi.org/10.3390/fi7010067
Gan D, Jenkins LR. Social Networking Privacy—Who’s Stalking You? Future Internet. 2015; 7(1):67-93. https://doi.org/10.3390/fi7010067
Chicago/Turabian StyleGan, Diane, and Lily R. Jenkins. 2015. "Social Networking Privacy—Who’s Stalking You?" Future Internet 7, no. 1: 67-93. https://doi.org/10.3390/fi7010067
APA StyleGan, D., & Jenkins, L. R. (2015). Social Networking Privacy—Who’s Stalking You? Future Internet, 7(1), 67-93. https://doi.org/10.3390/fi7010067