The ARCOMEM Architecture for Social- and Semantic-Driven Web Archiving


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Use Cases and Requirements
2.1. Broadcaster Use Case
- How did people talk about the elections, parties or the people involved?
- How are opinions distributed in relation to demographic user data and is it changing over time?
- Who are the most active Twitter users?
- What did they talk about?
- What videos were most popular on Facebook?
2.2. Parliament Use Case
- What is the public opinion on crucial social events?
- How has the public opinion on a key person evolved?
- Who are the opinion leaders?
- What is their impact and influence?
2.3. Derived Requirements
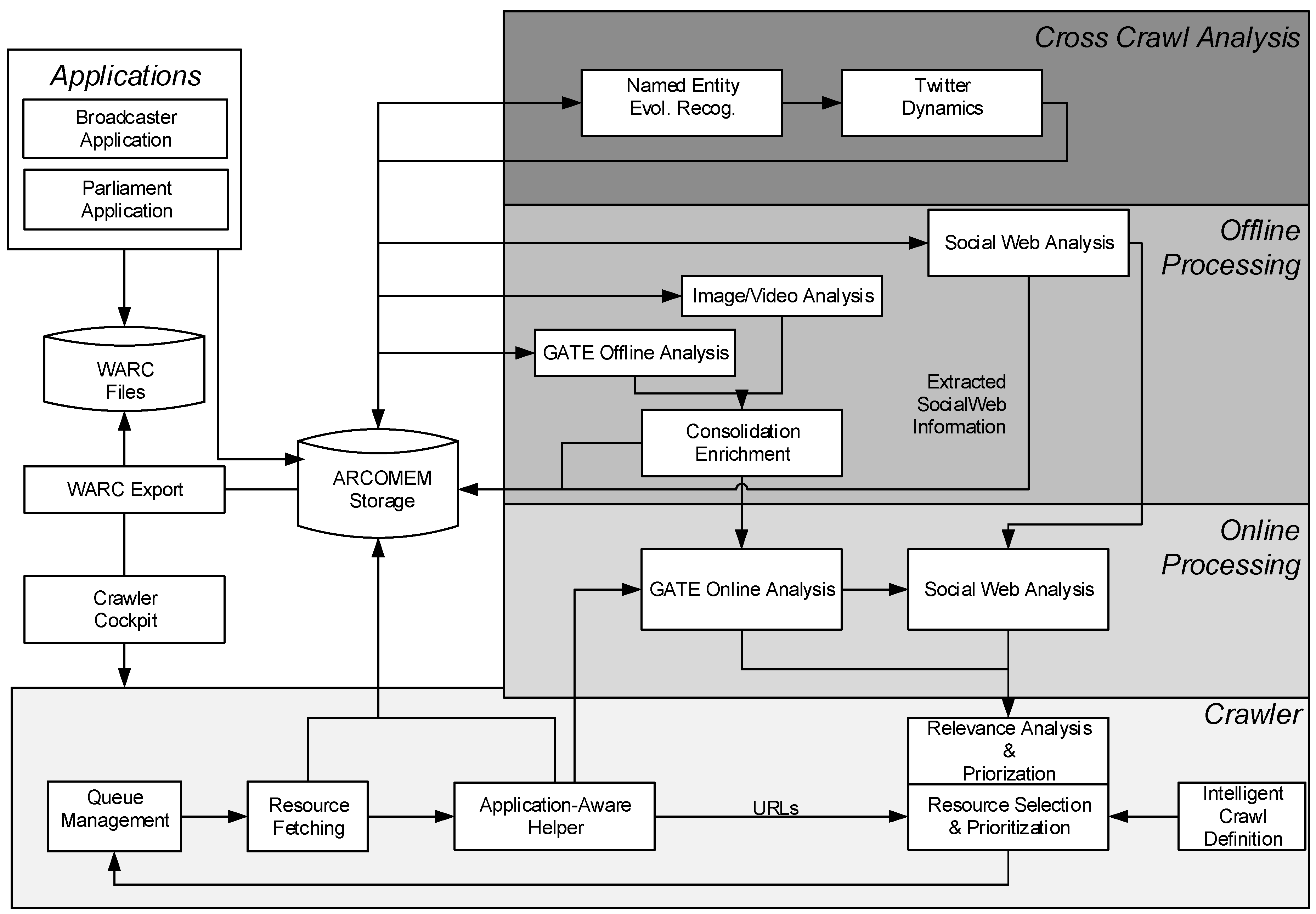
3. Approach and Architecture

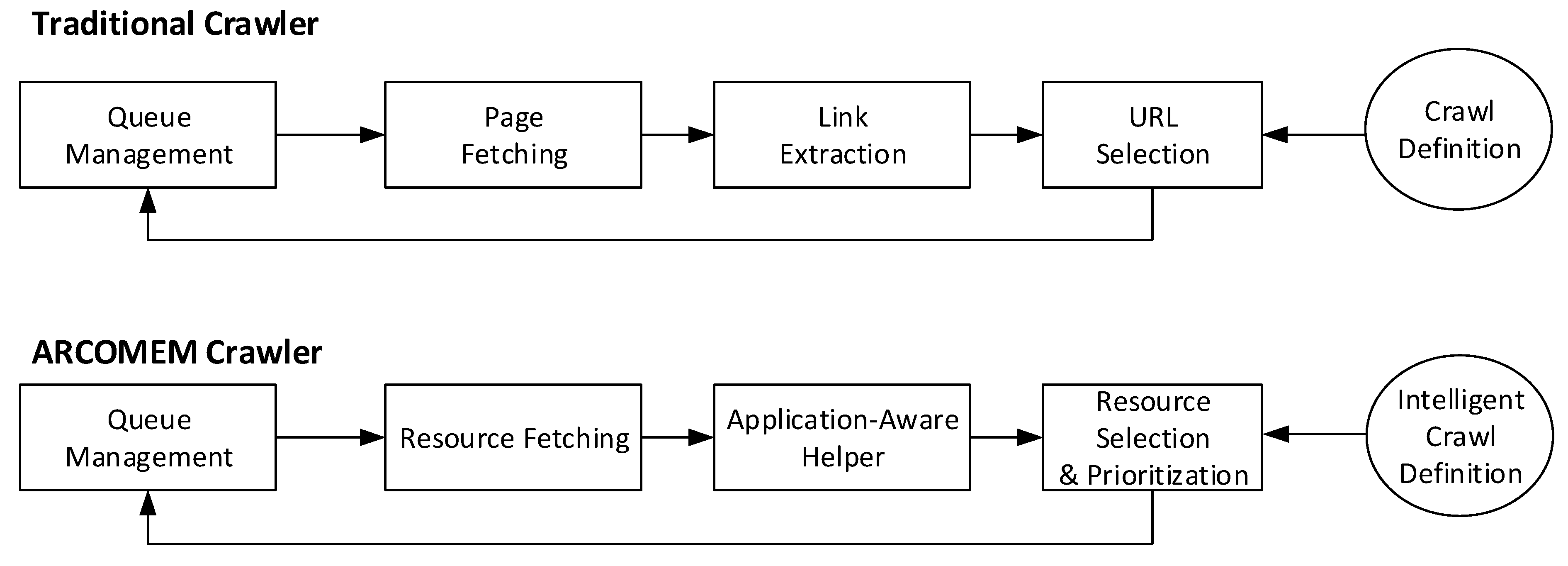
3.1. Crawling Level
3.2. Online Processing Level
3.3. Offline Processing Level
3.4. Cross Crawl Analysis Level
3.5. Applications
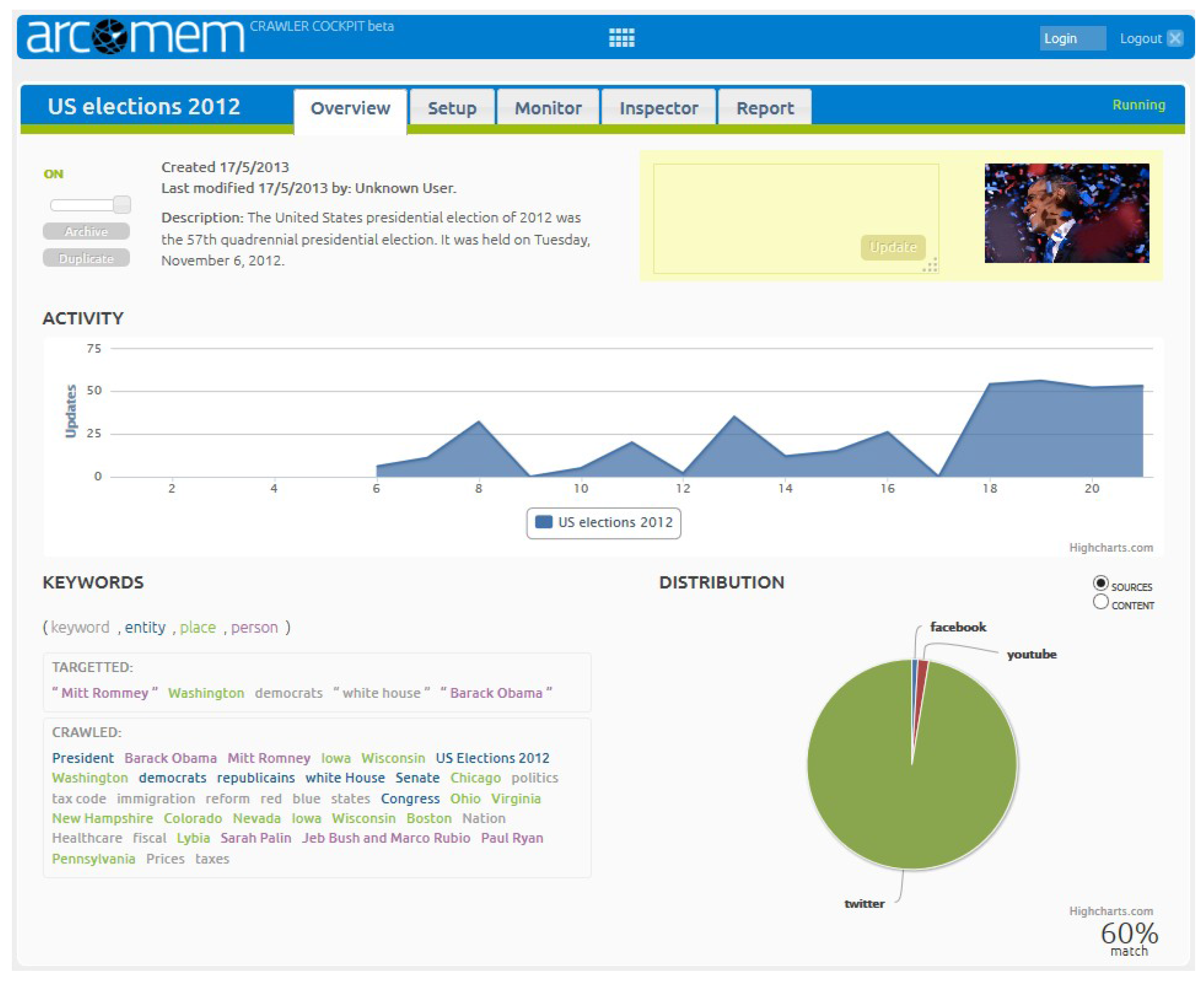

4. ARCOMEM Data Management
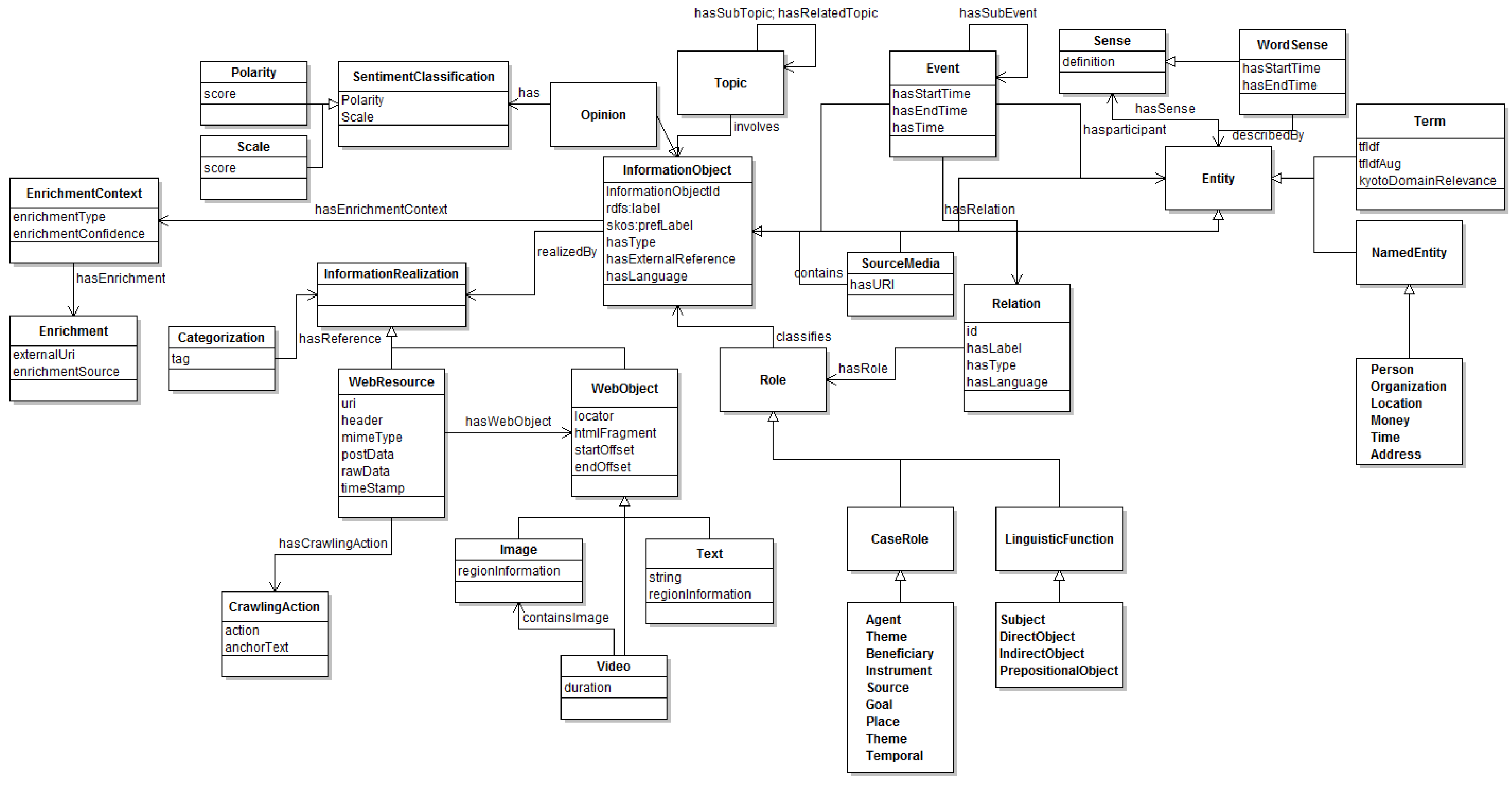
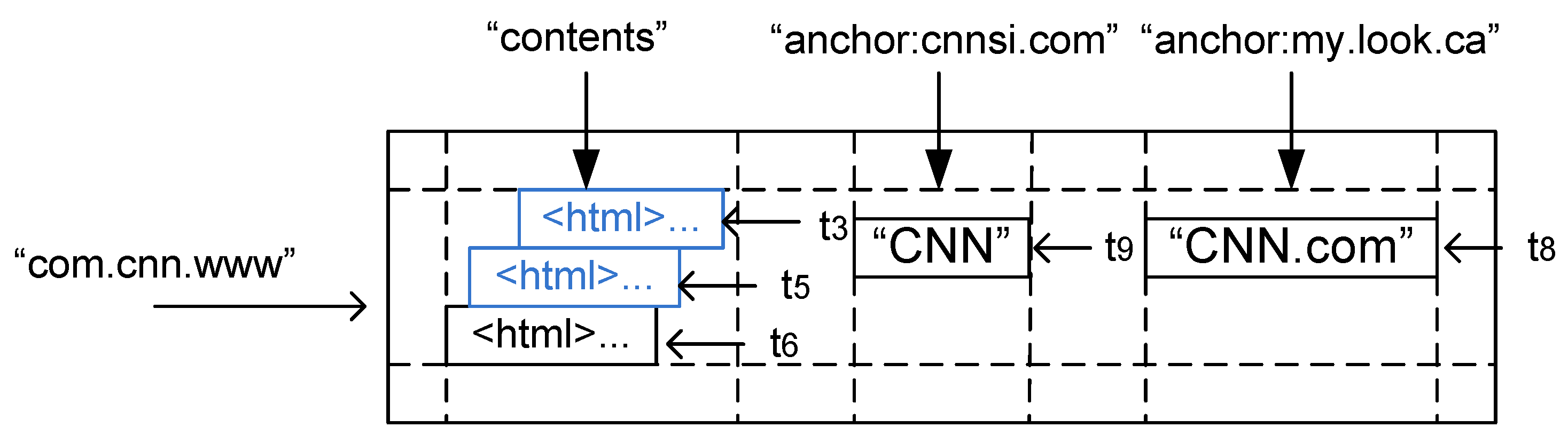
4.1. ARCOMEM Data Model

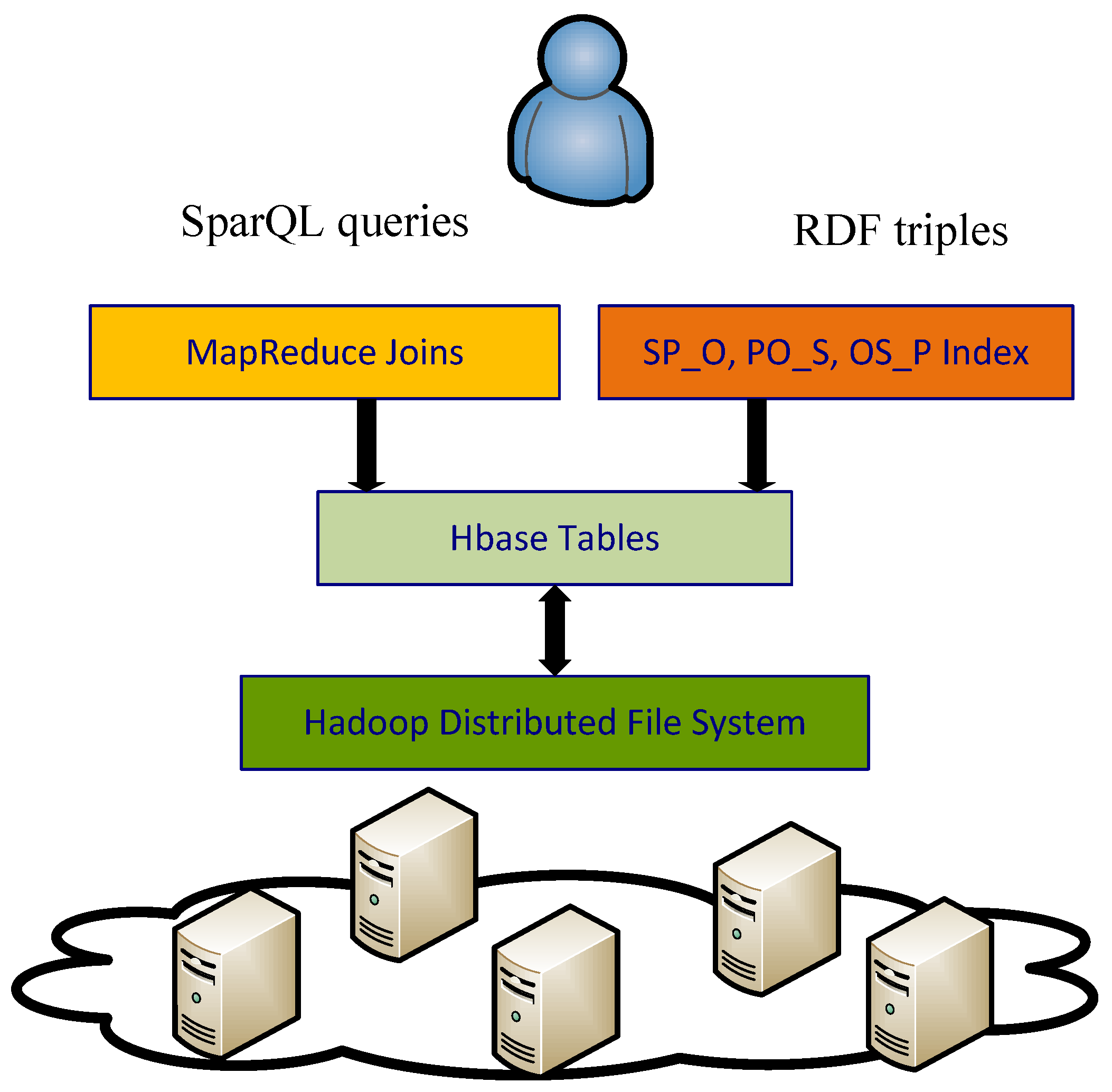
4.2. ARCOMEM Storage
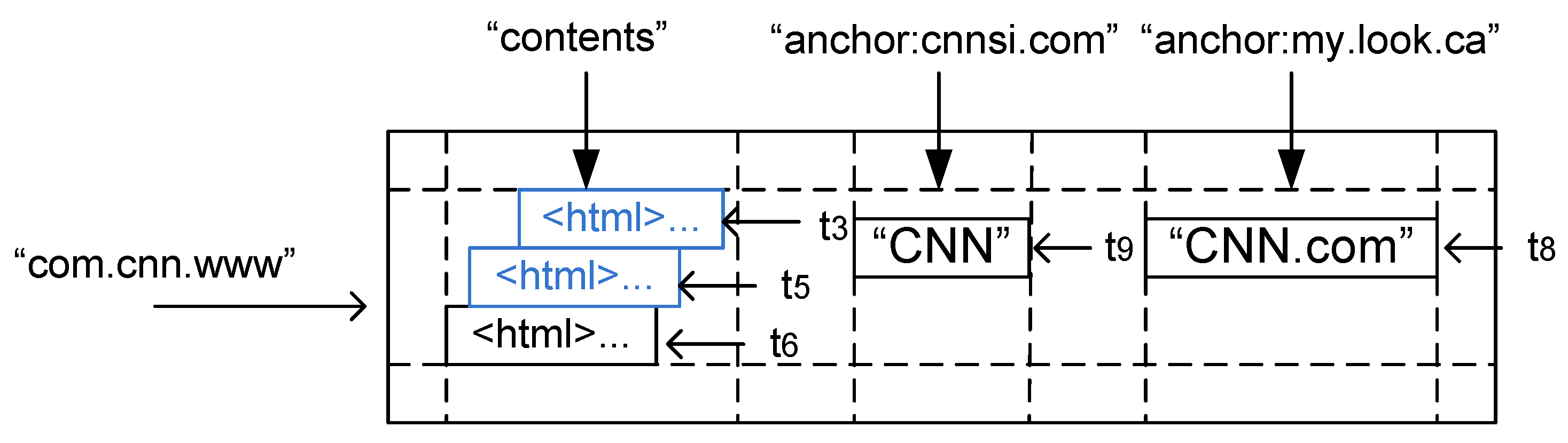
4.2.1. The ARCOMEM Object Store
4.2.2. The ARCOMEM Knowledge Base

5. Analysis for Crawl Guidance and Enrichment
5.1. Content Analysis
5.2. Data Enrichment and Consolidation
5.3. Social Web Analysis
5.3.1. Cultural Dynamics
5.3.2. Twitter Domain Expert Detection
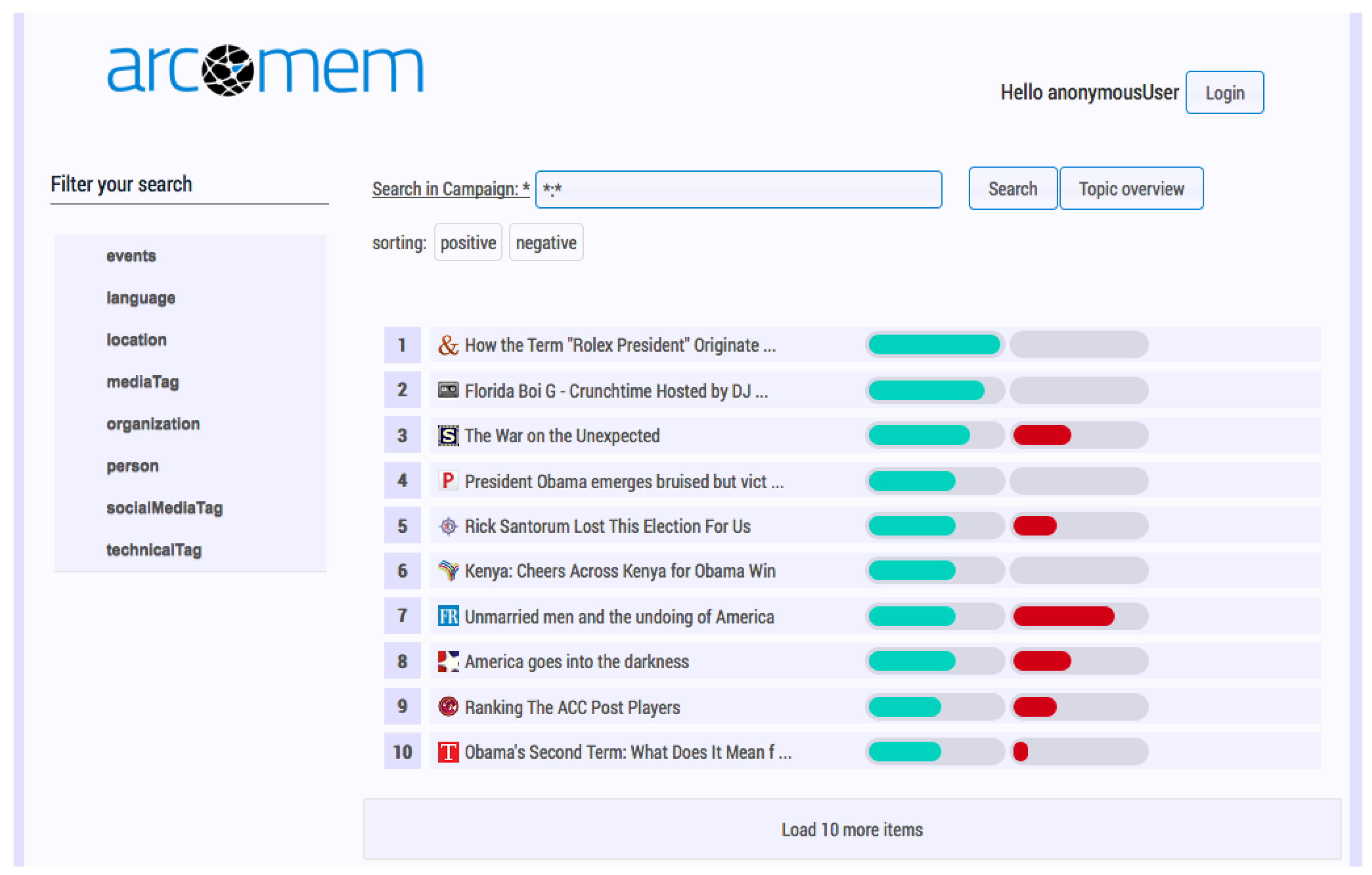
5.3.3. Responses to News
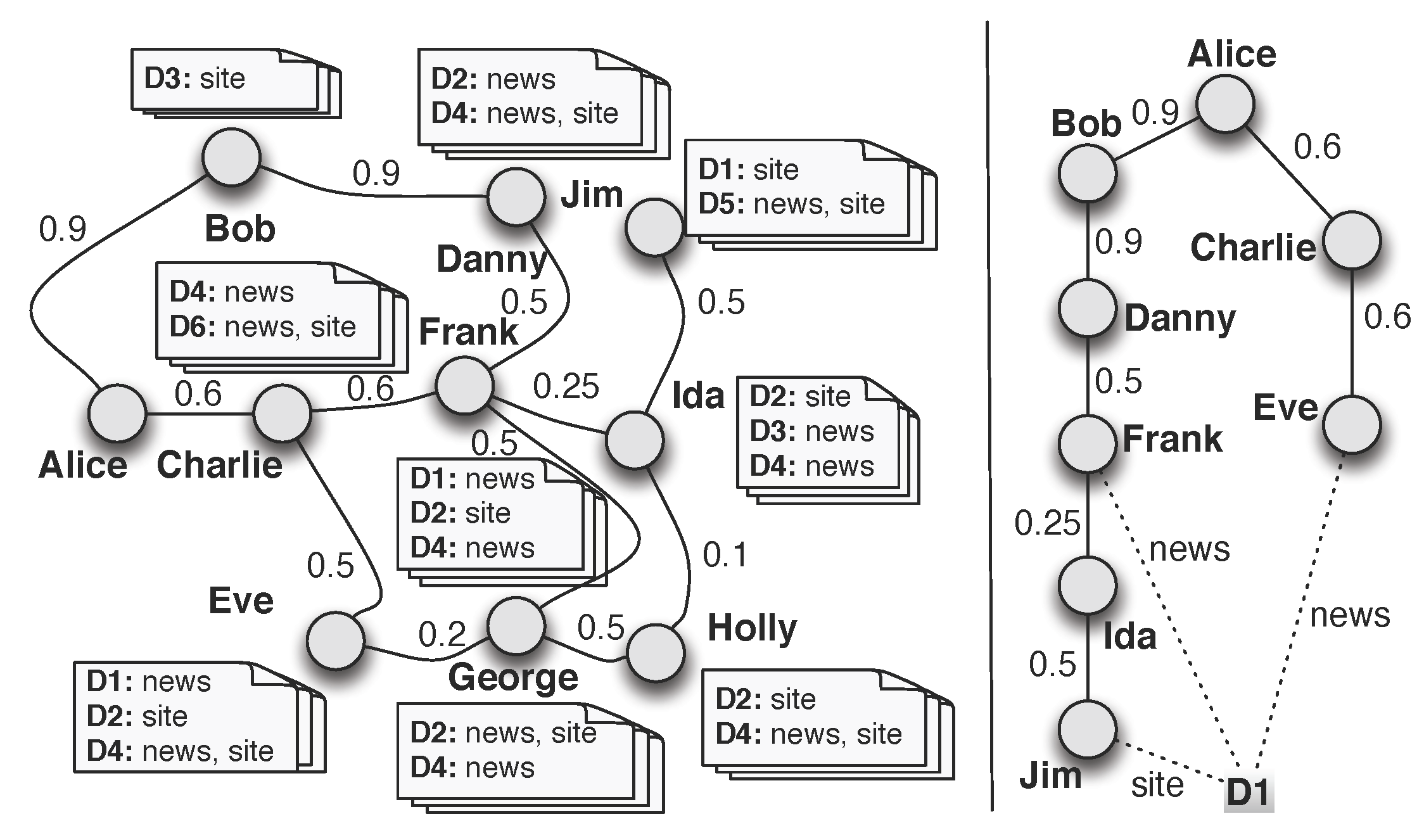
5.3.4. Context-Aware Search
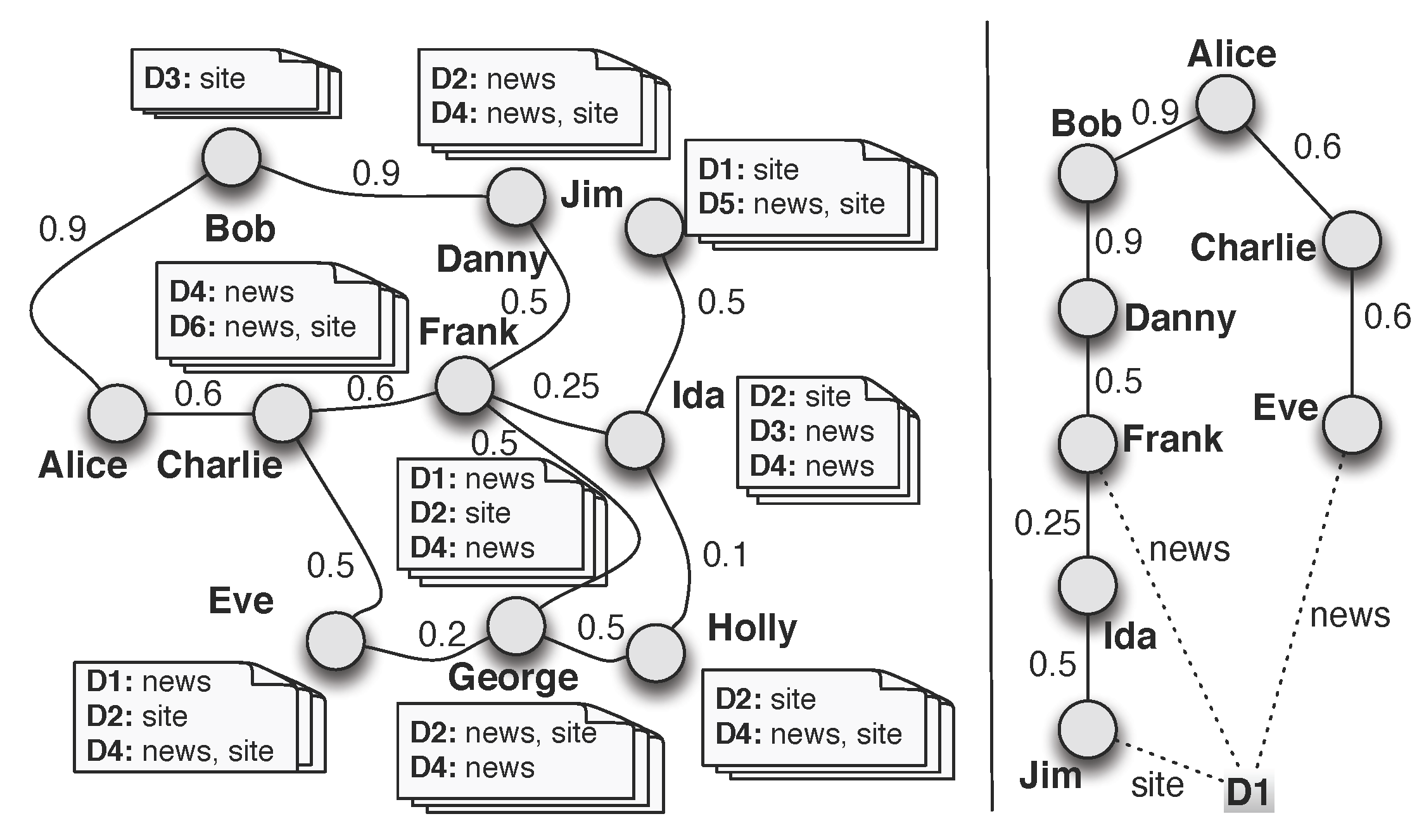
- we allow full scoring personalization, where potentially each user of the system can define their own way to rank items.
- we can iterate over the relevant users more efficiently, sparing the potentially huge disk volumes required by existing techniques, while also having the potential to run faster; as a bonus, most social networks could fit in main memory in practice.
- social link updates are no longer an issue; in particular, when the social network depends on user actions (e.g., the tagging history), we can keep it up-to-date and, by it, all the proximity values at any given moment, with little overhead.
5.4. Cross Crawl Analysis
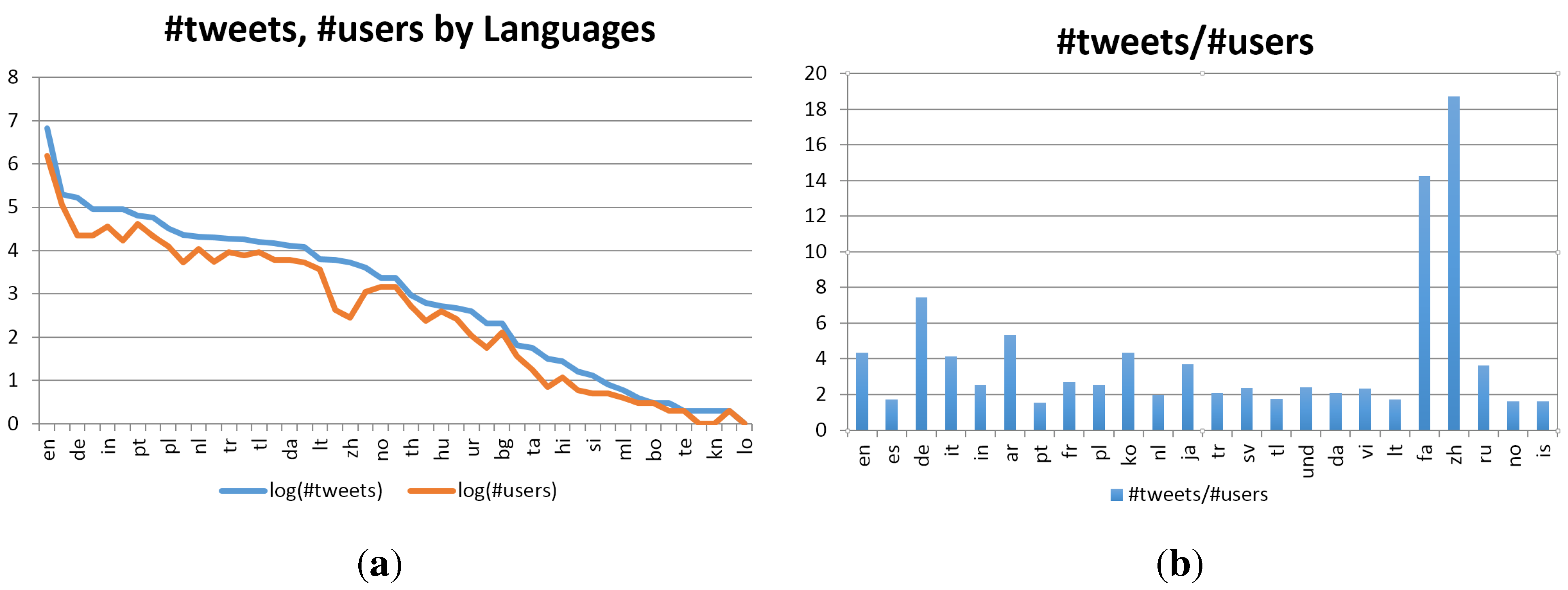
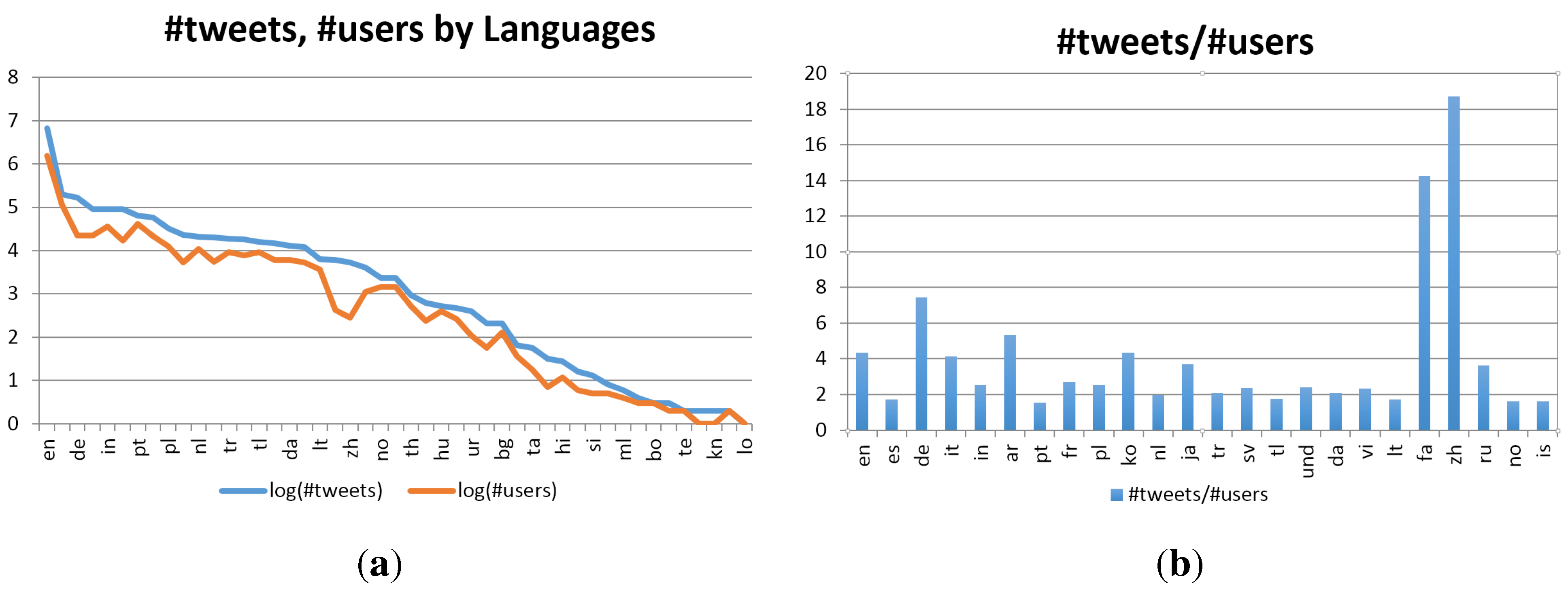
5.4.1. Language Dynamics
5.4.2. Twitter Dynamics
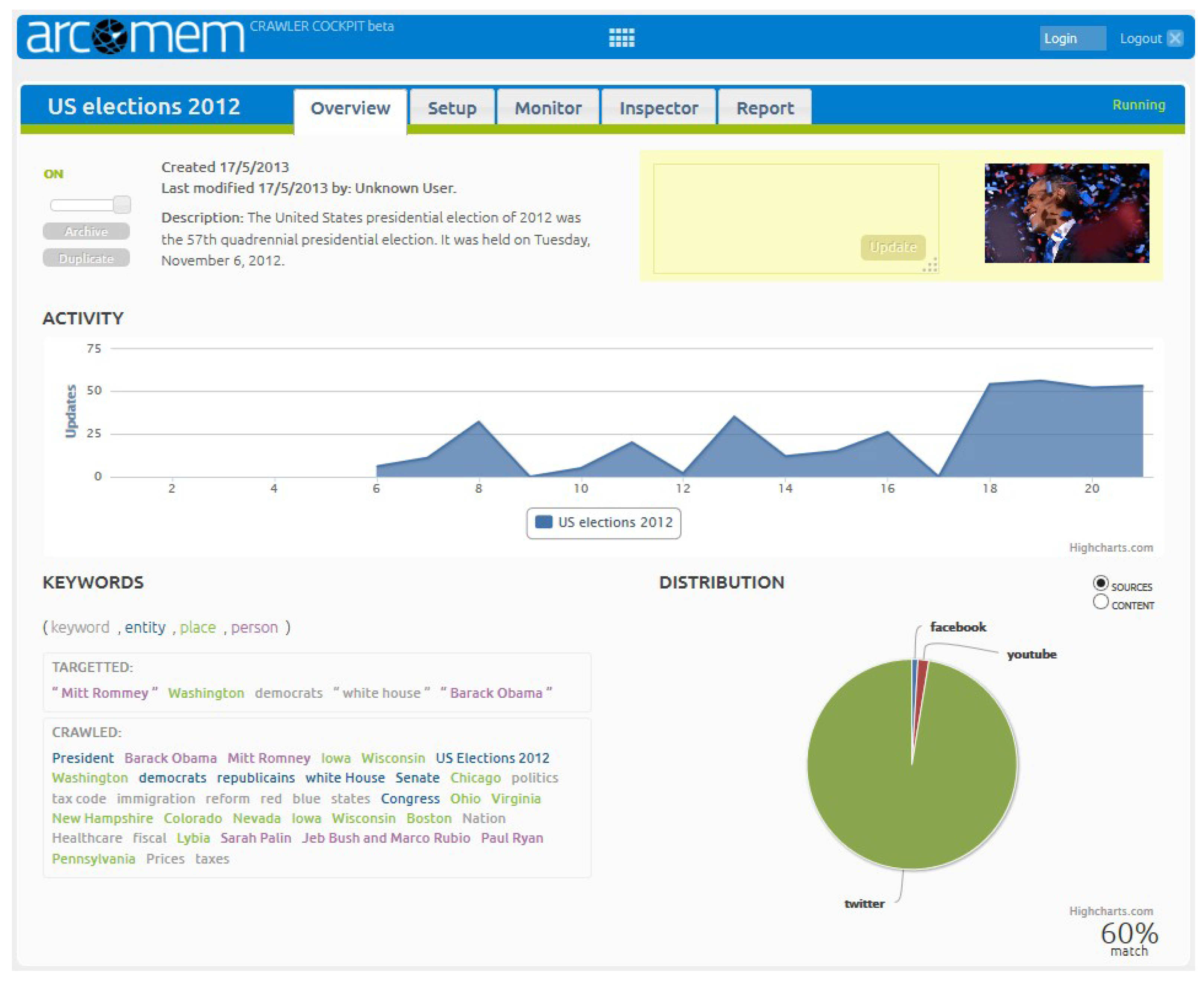
5.5. Crawler Guidance
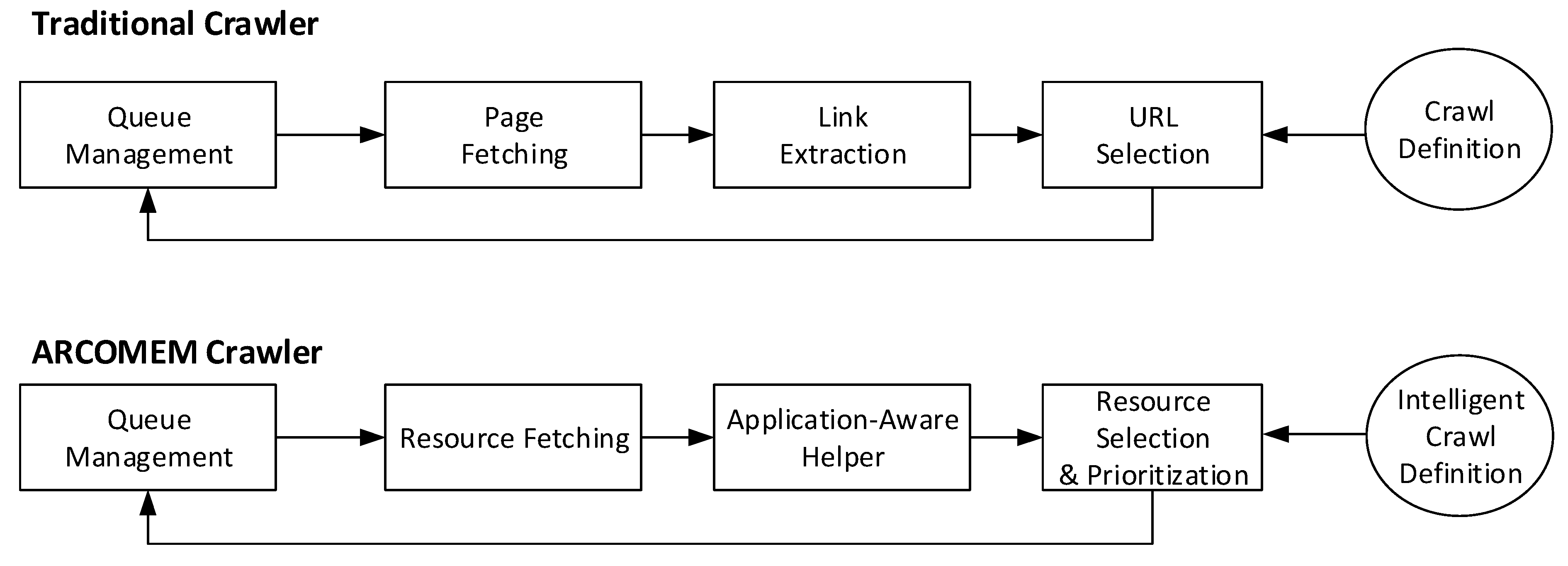
6. Implementation
7. Related Work
8. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Blue Ribbon Task Force on Sustainable Digital Preservation and Access. Sustainable Economics for a Digital Planet, ensuring Long-Term Access to Digital Information. Available online: http://brtf.sdsc.edu/biblio/BRTF_Final_Report.pdf (accessed on 23 October 2014).
- ARCOMEM: Archiving Communities Memories. Available online: http://www.arcomem.eu/ (accessed on 10 April 2014).
- Ntoulas, A.; Cho, J.; Olston, C. What’s New on the Web? The Evolution of the Web from a Search Engine Perspective. In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17–20 May 2004.
- Gomes, D.; Miranda, J.; Costa, M. A Survey on Web Archiving Initiatives. In Proceedings of the 15th International Conference on Theory and Practice of Digital Libraries (TPDL), Berlin, Germany, 26–28 September 2011.
- Risse, T.; Dietze, S.; Peters, W.; Doka, K.; Stavrakas, Y.; Senellart, P. Exploiting the Social and Semantic Web for Guided Web Archiving. In Proceedings of the 16th International Conference on Theory and Practice of Digital Libraries (TPDL), Paphos, Cyprus, 23–27 September 2012.
- The ARCOMEM Consortium. ARCOMEM system release. Available online: http://sourceforge. net/projects/arcomem/ (accessed on 25 July 2014).
- ISO. ISO 28500:2009 Information and Documentation—WARC File Format. Available online: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=44717 (accessed on 23 October 2014).
- Demidova, E.; Barbieri, N.; Dietze, S.; Funk, A.; Holzmann, H.; Maynard, D.; Papailiou, N.; Peters, W.; Risse, T.; Spiliotopoulos, D. Analysing and Enriching Focused Semantic Web Archives for Parliament Applications. Futur. Internet 2014, 6, 433–456. [Google Scholar] [CrossRef]
- McGuinness, D.L.; van Harmelen, F. (Eds.) OWL Web Ontology Language. Available online: http://www.w3.org/TR/owl-features/ (accessed on 23 October 2014).
- Lee, C. Open Archival Information System (OAIS) Reference Model. Available online: http://www.tandfonline.com/doi/abs/10.1081/E-ELIS3-120044377 (accessed on 23 October 2014).
- Resource Description Framework (RDF). Available online: http://www.w3.org/RDF/ (accessed on 23 October 2014).
- Scherp, A.; Franz, T.; Saathoff, C.; Staab, S. F-A Model of Events based on the Foundational Ontology DOLCE + DnS Ultralight. In Proceedings of the International Conference on Knowledge Capturing (K-CAP), Redondo Beach, CA, USA, 1–4 September 2009.
- Shaw, R.; Troncy, R.; Hardman, L. LODE: Linking Open Descriptions of Events. In Proceedings of the 4th Asian Semantic Web Conference (ASWC), Shanghai, China, 6–9 December 2009.
- The ARCOMEM Consortium. ARCOMEM Data Model. Available online: http://www.gate.ac.uk/ns/ontologies/arcomem-data-model.owl (accessed on 23 October 2014).
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Apache Foundation. The Apache HBase Project. Available online: http://hbase.apache.org/ (accessed on 23 October 2014).
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A Distributed Storage System for Structured Data. ACM Trans. Comput. Syst. 2008. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Lake Tahoe, NV, USA, 3–7 May 2010.
- Papailiou, N.; Konstantinou, I.; Tsoumakos, D.; Koziris, N. H2RDF: Adaptive Query Processing on RDF Data in the Cloud. In Proceedings of the 21st International Conference Companion on World Wide Web (Companion Volume), Lyon, France, 16–20 April 2012.
- Papailiou, N.; Konstantinou, I.; Tsoumakos, D.; Karras, P.; Koziris, N. H2RDF+: High-performance distributed joins over large-scale RDF graphs. In Proceedings of the IEEE International Conference on Big Data, Santa Clara, CA, USA, 6–9 October 2013.
- Weiss, C.; Karras, P.; Bernstein, A. Hexastore: Sextuple indexing for semantic Web data management. Proc. VLDB Endow. 2008, 1, 1008–1019. [Google Scholar] [CrossRef]
- Cunningham, H.; Maynard, D.; Bontcheva, K.; Tablan, V. GATE: A Framework and Graphical Development Environment for Robust NLP Tools and Applications. In Proceedings of the 40th Anniversary Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–12 July 2002.
- TermRaider term extraction tools. Available online: https://gate.ac.uk/sale/tao/splitch23.html#sec:creole:termraider (accessed on 23 October 2014).
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; Bizer, C. DBpedia—A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia. Semantic Web Journal 2014. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge. In Proceedings of the ACM SIGMOD Conference (SIGMOD’08), Vancouver, Canada, 9–12 June 2008.
- Nunes, B.P.; Dietze, S.; Casanova, M.; Kawase, R.; Fetahu, B.; Nejdl, W. Combining a co-occurrence-based and a semantic measure for entity linking. In Proceeedings of the 10th Extended Semantic Web Conference (ESWC), Montpellier, France, 26–30 May 2013.
- Demidova, E.; Oelze, I.; Nejdl, W. Aligning Freebase with the YAGO Ontology. In Proceedings of the 22nd ACM International Conference on Conference on Information and Knowledge Management (CIKM), San Francisco, CA, USA, 27 October–1 November 2013.
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A Core of Semantic Knowledge. In Proceedings of the 16th International World Wide Web Conference, Banff, Alberta, Canada, 8–12 May 2007.
- Poblete, B.; Gavilanes, R.O.G.; Mendoza, M.; Jaimes, A. Do all birds tweet the same?: Characterizing Twitter around the world. In Proceedings of the 20th ACM Conference on Information and Knowledge Management (CIKM), Glasgow, UK, 24–28 October 2011.
- Siehndel, P.; Kawase, R. TwikiMe!—User Profiles That Make Sense. In Proceedings of the ISWC 2012 Posters & Demonstrations Track, Boston, MA, USA, 11–15 November 2012.
- Kawase, R.; Siehndel, P.; Pereira Nunes, B.; Herder, E.; Nejdl, W. Exploiting the wisdom of the crowds for characterizing and connecting heterogeneous resources. In Proceedings of the 25th ACM Conference on Hypertext and Social Media, Santiago, Chile, 1–4 September 2014.
- Wikipedia Miner Toolkit. Available online: http://wikipedia-miner.cms.waikato.ac.nz/ (accessed on 23 October 2014).
- Milne, D.; Witten, I.H. An open-source toolkit for mining Wikipedia. Artif. Intell. 2013, 194, 222–239. [Google Scholar] [CrossRef]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a Social Network or a News Media? In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010.
- Stajner, T.; Thomee, B.; Popescu, A.M.; Pennacchiotti, M.; Jaimes, A. Automatic selection of social media responses to news. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Chicago, IL, USA, 11–14 August 2013.
- Maniu, S.; Cautis, B. Taagle: Efficient, personalized search in collaborative tagging networks. In Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), Scottsdale, AZ, USA, 20–24 May 2012.
- Maniu, S.; Cautis, B. Efficient Top-K Retrieval in Online Social Tagging Networks. CoRR. 2011. abs/1104.1605. Available online: http://arxiv.org/abs/1104.1605 (accessed on 23 October 2014).
- Tahmasebi, N.; Gossen, G.; Kanhabua, N.; Holzmann, H.; Risse, T. NEER: An Unsupervised Method for Named Entity Evolution Recognition. In Proceedings of the 24th International Conference on Computational Linguistics (COLING), Mumbai, India, 8–15 December 2012.
- Tahmasebi, N.; Niklas, K.; Theuerkauf, T.; Risse, T. Using Word Sense Discrimination on Historic Document Collections. In Proceedings of the 10th ACM/IEEE Joint Conference on Digital Libraries (JCDL), Gold Coast, Queensland, Australia, 21–25 June 2010.
- O’Connor, B.; Balasubramanyan, R.; Routledge, B.R.; Smith, N.A. From Tweets to Polls: Linking Text Sentiment to Public Opinion Time Series. In Proceedings of the 4th International Conference on Weblogs and Social Media (ICWSM), Washington, DC, USA, 23–26 May 2010.
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent Twitter Sentiment Classification. In Proceedingsa of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011.
- Plachouras, V.; Stavrakas, Y. Querying Term Associations and their Temporal Evolution in Social Data. In VLDB Workshop on Online Social Systems (WOSS), Istanbul, Turkey, 31 August 2012.
- Mohr, G.; Stack, M.; Ranitovic, I.; Avery, D.; Kimpton, M. Introduction to heritrix, an archival quality Web crawler. In Proceedings of the 4th International Web Archiving Workshop, Bath, UK, 16 September 2004.
- Plachouras, V.; Carpentier, F.; Faheem, M.; Masanès, J.; Risse, T.; Senellart, P.; Siehndel, P.; Stavrakas, Y. ARCOMEM Crawling Architecture. Future Internet 2014, 6, 518–541. [Google Scholar] [CrossRef]
- Arvidson, A.; Lettenström, F. The Kulturarw Project—The Swedish Royal Web Archive. Electron. Libr. 1998, 16, 105–108. [Google Scholar] [CrossRef]
- International Internet Preservation Consortium (IIPC). Available online: http://netpreserve.org/ (accessed on 23 October 2014).
- Masanès, J. Web Archiving; Springer: Berlin, Germany, 2006; pp. I–VII, 1–234. [Google Scholar]
- Living Web Archives Project. Available online: http://www.liwa-project.eu/ (accessed on 23 October 2014).
- Cho, J.; Garcia-Molina, H.; Page, L. Efficient crawling through URL ordering. In Proceedings of the 7th International Conference on World Wide Web, Brisbane, Australia, 14–18 April 1998.
- Baeza-Yates, R.; Castillo, C.; Marin, M.; Rodriguez, A. Crawling a Country: Better Strategies Than Breadth-first for Web Page Ordering. In Proceedings of Special Interest Tracks and Posters of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005.
- Chakrabarti, S.; van den Berg, M.; Dom, B. Focused Crawling: A New Approach to Topic-specific Web Resource Discovery. Comput. Netw. 1999, 31, 1623–1640. [Google Scholar] [CrossRef]
- Menczer, F.; Pant, G.; Srinivasan, P. Topical Web crawlers: Evaluating adaptive algorithms. ACM Trans. Internet Technol. 2004, 4, 378–419. [Google Scholar] [CrossRef]
- Laranjeira, B.; Moreira, V.; Villavicencio, A.; Ramisch, C.; Finatto, M.J. Comparing the Quality of Focused Crawlers and of the Translation Resources Obtained from them. In Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC), Reykjavik, Iceland, 26–31 May 2014.
- Pandey, S.; Olston, C. User-centric Web Crawling. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005.
- Barford, P.; Canadi, I.; Krushevskaja, D.; Ma, Q.; Muthukrishnan, S. Adscape: Harvesting and Analyzing Online Display Ads. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014.
- Boanjak, M.; Oliveira, E.; Martins, J.; Mendes Rodrigues, E.; Sarmento, L. TwitterEcho: A Distributed Focused Crawler to Support Open Research with Twitter Data. In Proceedings of the Workshop on Social Media Applications in News and Entertainment (SMANE 2012), at the ACM 2012 International World Wide Web Conference, Lyon, France, 16 April 2012.
- Psallidas, F.; Ntoulas, A.; Delis, A. Soc Web: Efficient Monitoring of Social Network Activities. In Proceedings of the 14th International Web Information Systems Engineering Conference, Nanjing, China, 13–15 October 2013.
- Blackburn, J.; Iamnitchi., A. An architecture for collecting longitudinal social data. In IEEE ICC Workshop on Beyond Social Networks: Collective Awareness, Budapest, Hungary, 9 June 2013.
- Isele, R.; Umbrich, J.; Bizer, C.; Harth, A. LDSpider: An open-source crawling framework for the Web of Linked Data. In Proceedings of 9th International Semantic Web Conference (ISWC) Posters and Demos, Shanghai, China, 9 November 2010.
- Slug: A Semantic Web Crawler. Available online: http://www.ldodds.com/projects/slug/ (accessed on 23 October 2014).
- Internet Archive. NutchWAX. Available online: http://archive-access.sourceforge.net/projects/nutch/ (accessed on 30 January 2012).
- Apache Nutch—Highly extensible, highly scalable Web crawler. Available online: http://nutch.apache.org/ (accessed on 23 October 2014).
- Gomes, D.; Cruz, D.; Miranda, J.A.; Costa, M.; Fontes, S.A. Search the Past with the Portuguese Web Archive. In Proceedings of the 22nd International Conference on World Wide Web (Companion Volume), Rio de Janeiro, Brazil, 13–17 May 2013.
- Internet Archive. Wayback. Available online: http://archive-access.sourceforge.net/projects/wayback/ (accessed on 30 January 2012).
- Spaniol, M.; Weikum, G. Tracking Entities in Web Archives: The LAWA Project. In Proceedings of the 21st International Conference Companion on World Wide Web (Companion Volume), Lyon, France, 16–20 April 2012.
- Big UK Domain Data for the Arts and Humanities. Available online: http://buddah.projects.history.ac.uk/ (accessed on 23 October 2014).
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Risse, T.; Demidova, E.; Dietze, S.; Peters, W.; Papailiou, N.; Doka, K.; Stavrakas, Y.; Plachouras, V.; Senellart, P.; Carpentier, F.; et al. The ARCOMEM Architecture for Social- and Semantic-Driven Web Archiving. Future Internet 2014, 6, 688-716. https://doi.org/10.3390/fi6040688
Risse T, Demidova E, Dietze S, Peters W, Papailiou N, Doka K, Stavrakas Y, Plachouras V, Senellart P, Carpentier F, et al. The ARCOMEM Architecture for Social- and Semantic-Driven Web Archiving. Future Internet. 2014; 6(4):688-716. https://doi.org/10.3390/fi6040688
Chicago/Turabian StyleRisse, Thomas, Elena Demidova, Stefan Dietze, Wim Peters, Nikolaos Papailiou, Katerina Doka, Yannis Stavrakas, Vassilis Plachouras, Pierre Senellart, Florent Carpentier, and et al. 2014. "The ARCOMEM Architecture for Social- and Semantic-Driven Web Archiving" Future Internet 6, no. 4: 688-716. https://doi.org/10.3390/fi6040688
APA StyleRisse, T., Demidova, E., Dietze, S., Peters, W., Papailiou, N., Doka, K., Stavrakas, Y., Plachouras, V., Senellart, P., Carpentier, F., Mantrach, A., Cautis, B., Siehndel, P., & Spiliotopoulos, D. (2014). The ARCOMEM Architecture for Social- and Semantic-Driven Web Archiving. Future Internet, 6(4), 688-716. https://doi.org/10.3390/fi6040688