7R Data Value Framework for Open Data in Practice: Fusepool

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Open Government
The Citizen asked the National Research Council a simple question: What’s this joint study that you and NASA are doing on falling snow? The federal department never agreed to an interview. It sent an email instead, with technical details on equipment but without much information on the nature of the project. It never even explained the study’s topic. Before sending even that modest response, however, it took a small army of staffers—11 of them by our count—to decide how to answer, and dozens of emails back and forth to circulate the Citizen’s request, discuss its motivation, develop their response, and “massage” its text.
1.1.1. Political Efficiency
1.1.2. Open Government Data
1.1.3. Current Shortcomings
- only 7% of datasets surveyed are open in machine-readable forms and under open licenses;
- rarely available are politically or economically important datasets for holding governments and companies accountable or for improving entrepreneurship and policy;
- much statistical data is available only as highly aggregated, with unclear or restrictive licenses;
- even in countries with OGD policies, for almost half of the questions asking for impacts, no examples were given, and the overall impact score was 1.7 out of 10.
1.2. Linked Data
- (1)
- available on the Internet;
- (2)
- machine-readable (i.e., interpreted by software);
- (3)
- in non-proprietary data formats;
- (4)
- in the RDF (Resource Description Framework) data format; and
- (5)
- interlinked to other data by pointing at it (via hyperlinks).
1.2.1. Data Structures and Models
1.2.2. Web of Linked Data
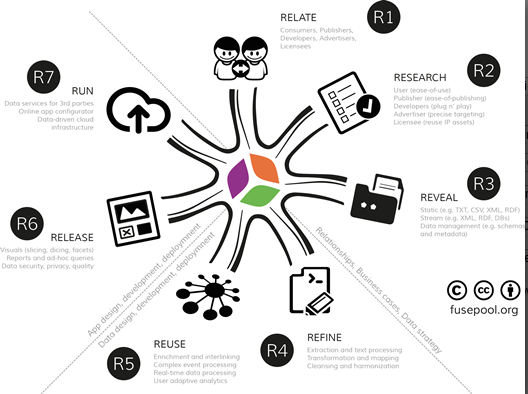
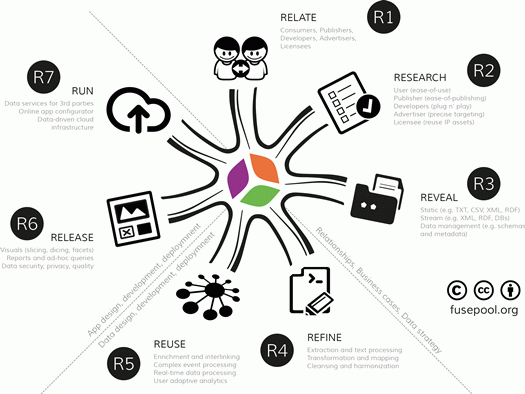
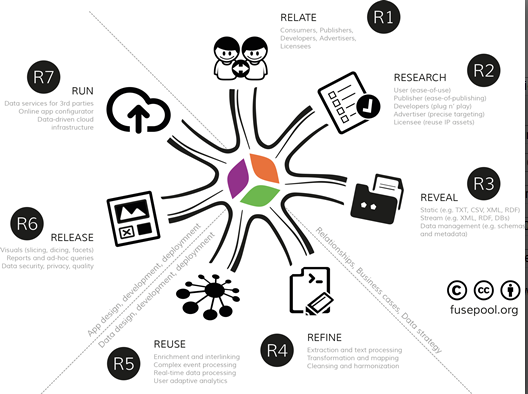
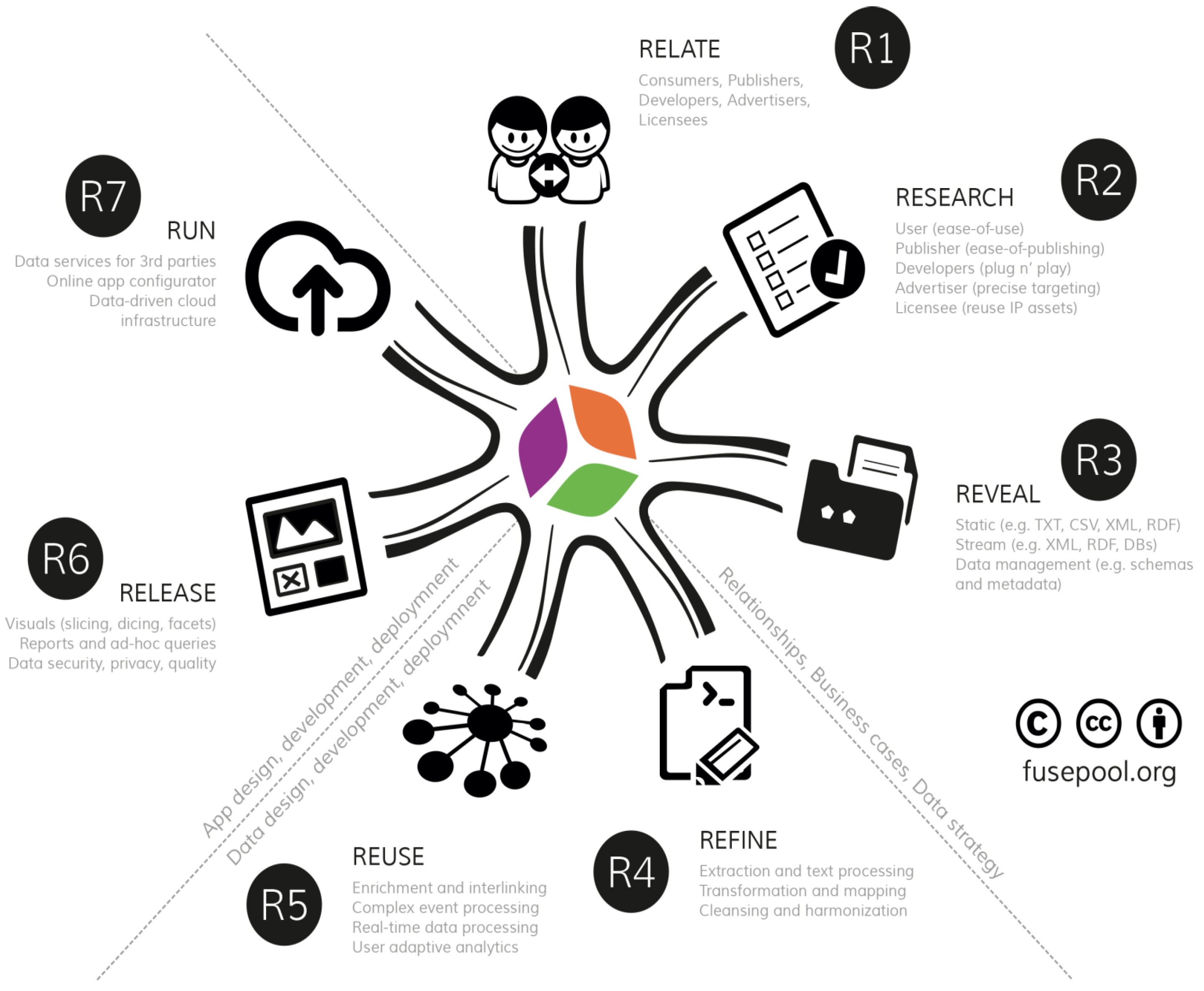
2. 7R Data Value Framework
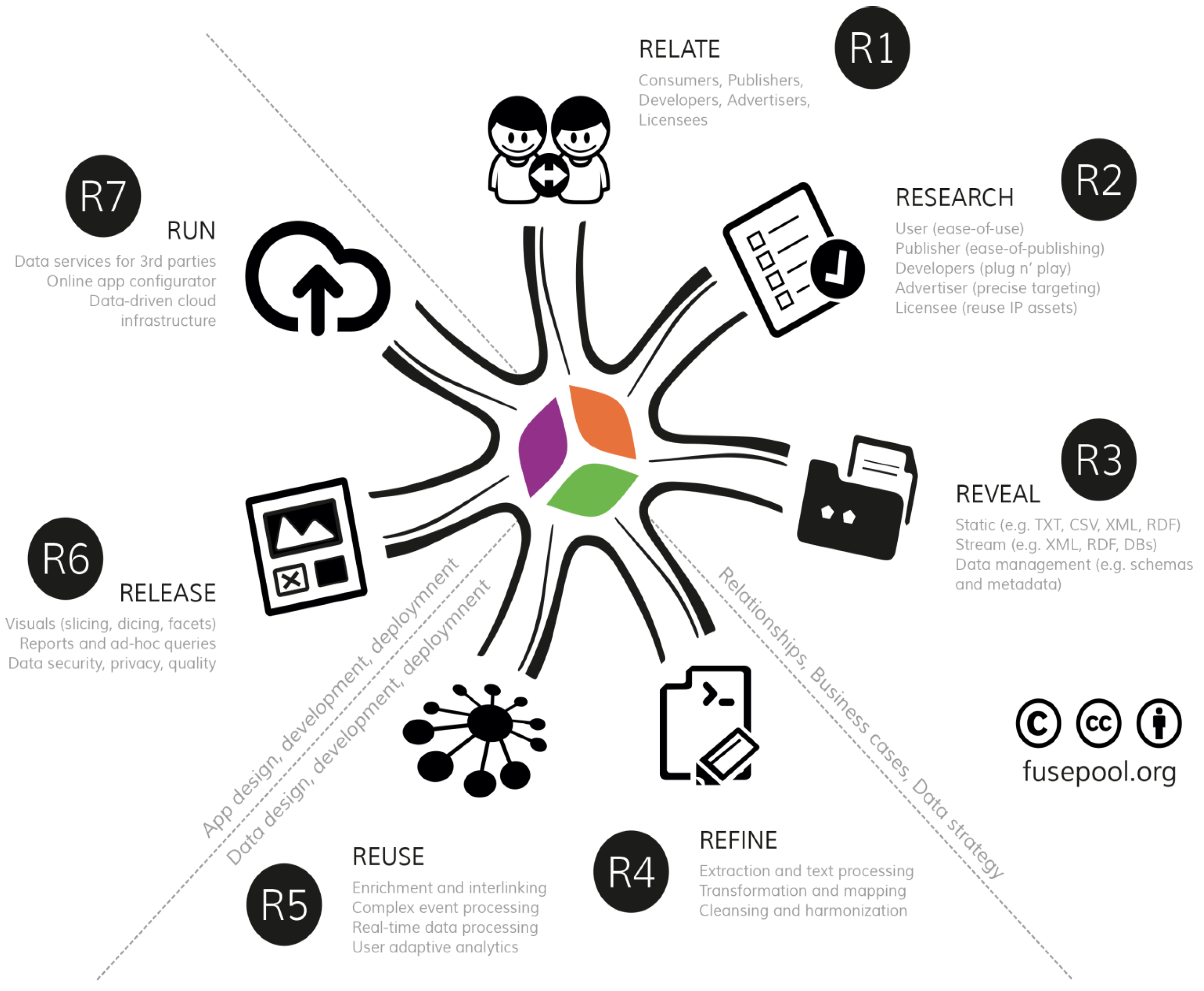
2.1. Stakeholder Relationships, Business Cases and Data Strategy
2.1.1. R1 (Relate): Stakeholder Relationships
- Data publishers: have an interest to make their data interlink across datasets;
- Data developers: create data models and business cases based on Fusepool data;
- Software developers: create new data enhancers for the Fusepool open-source platform;
- Expert users: professional users who annotate and curate data to improve data quality;
- Consumers: use Fusepool in their business and workflows (may also be part of “the crowd”).
2.1.2. R2: Researching Business Cases and Requirements
2.1.3. R3: Revealing Data
2.2. Data Design, Development and Deployment
2.2.1. R4 (Refine): Data Rationalization, Staging and Semantics
2.2.2. R5 (Reuse): Advanced Enrichment and Predictive Analytics
- are defined externally to the application through data creation and use case processes in a data management layer;
- orchestrate internal and external integration and sharing of data assets; and
- leverage both steady-state data assets in repositories and services in a flexible, audited model.
2.3. Application Design, Development and Deployment
2.3.1. R6 (Release): GUI, Data Visualizations, Apps
2.3.2. R7 (Run): Running Scalable Data-Driven Apps
3. 7R Data Value Framework in Practice
3.1. Stakeholder Relationships, Business Cases and Data Strategy
3.1.1. R1 (Relate): Stakeholder Engagement
- Internal and external discussion and finalization of the tasks to be performed by applicants;
- Launch and promotion of the Open Call with tasks, selection criteria and important dates;
- Application period of 30 to 60 days during which applications are submitted within deadline;
- Selection process based on internal and external discussion and transparent communication;
- Signing of contracts with successful candidates and kick-off followed by one or more events.
3.1.2. R2: Researching Requirements
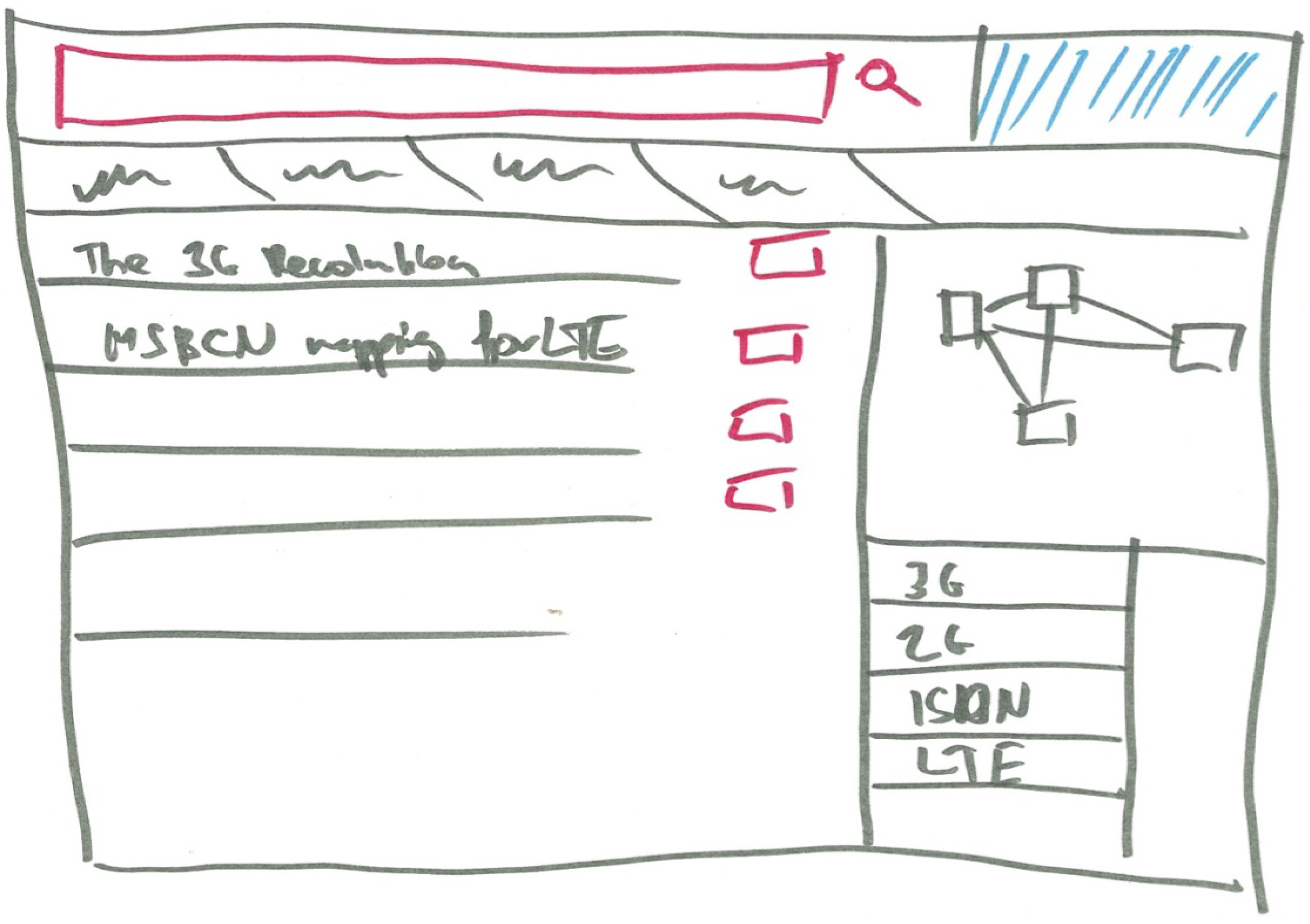
- Mapping and clustering functions (cluster visualization of documents);
- trending and classification functions (e.g., for patents/PubMed);
- predictive analytics to improve search results;
- annotation functions for users (required for predictive analytics);
- multi-language facilities for search, filtering, notifications;
- hiding functionalities for lay users, suggestions for advanced users;
- showing organizations, person names, and locations;
- overview of all data pooled in the platform;
- connecting people to documents, to optimize searching.
EXAMPLE: Patent Explorer Use Case
Rationale
- Avoid duplication of R&D efforts and spending: Patents are the broadest source of technical information. Many companies do not disclose their R&D results in any other form. Looking up patents therefore is an efficient way to avoid duplication of R&D work; up to 30% of all expenditure in R&D is wasted on redeveloping existing inventions;
- Gather business intelligence: Patent information not only reveals the state-of-the-art in certain technology areas, but also enables monitoring the innovation strategies of competitors and other players at a very early stage.
Use Case
- (1)
- Felix enters a text string describing the research and starts the search;
- (2)
- Felix views retrieved entities ranked based on the relevance score of searched entities;
- (3)
- Felix limits retrieved entities to “patent” (displayed are only the patents);
- (4)
- Felix leaves the default display type of retrieved entities at “landscape”;
- (5)
- In the resulting map of patent clusters (described by the most frequently occurring terms in them), Felix hovers over a patent in a cluster and views description and metadata.
User Stories
- “a service for our customers to boost competitive intelligence … [by] monitor[ing] the status of their technology and possible competitors in the area in which they undertake their activity”;
- “patent analysis is not easy and there are not many tools that could help us, so Fusepool patent analysis … could be a great resource to be more effective in the search”;
- “provide [our] clients with patent tips for close-to-market opportunities (in preparing Technology Offers/Request for the Enterprise Europe Network Marketplace)”;
- “The most important feature is definitely around the collection, gathering and processing of various sources of information in the intellectual property sector, possibly also interlinked with other areas of product development such as research funding and collaboration opportunities”;
- “PatentExplorer will help scope our clients’ ideas into a minimal prototype that is not infringing on already granted rights”
- PatentExplorer (PublicationExplorer): Millions of patents are freely available in XML, with the majority in English, German and French related to the medical domain. All patents have the base properties with patent classification codes. Millions of medical journal articles for establishing prior articles are freely available in XML with the base properties;
- FundingFinder: Funding includes available public and private tenders or calls for proposals. Following the guidelines by the data publishers, some of the funding datasets are available to data subscribers only;
- PartnerMatch (ExpertMatch): Fusepool PartnerMatch helps find partners with similar or complementary capabilities for product research and development. Following the guidelines by the data publishers, some of the partner datasets are available to data subscribers only.
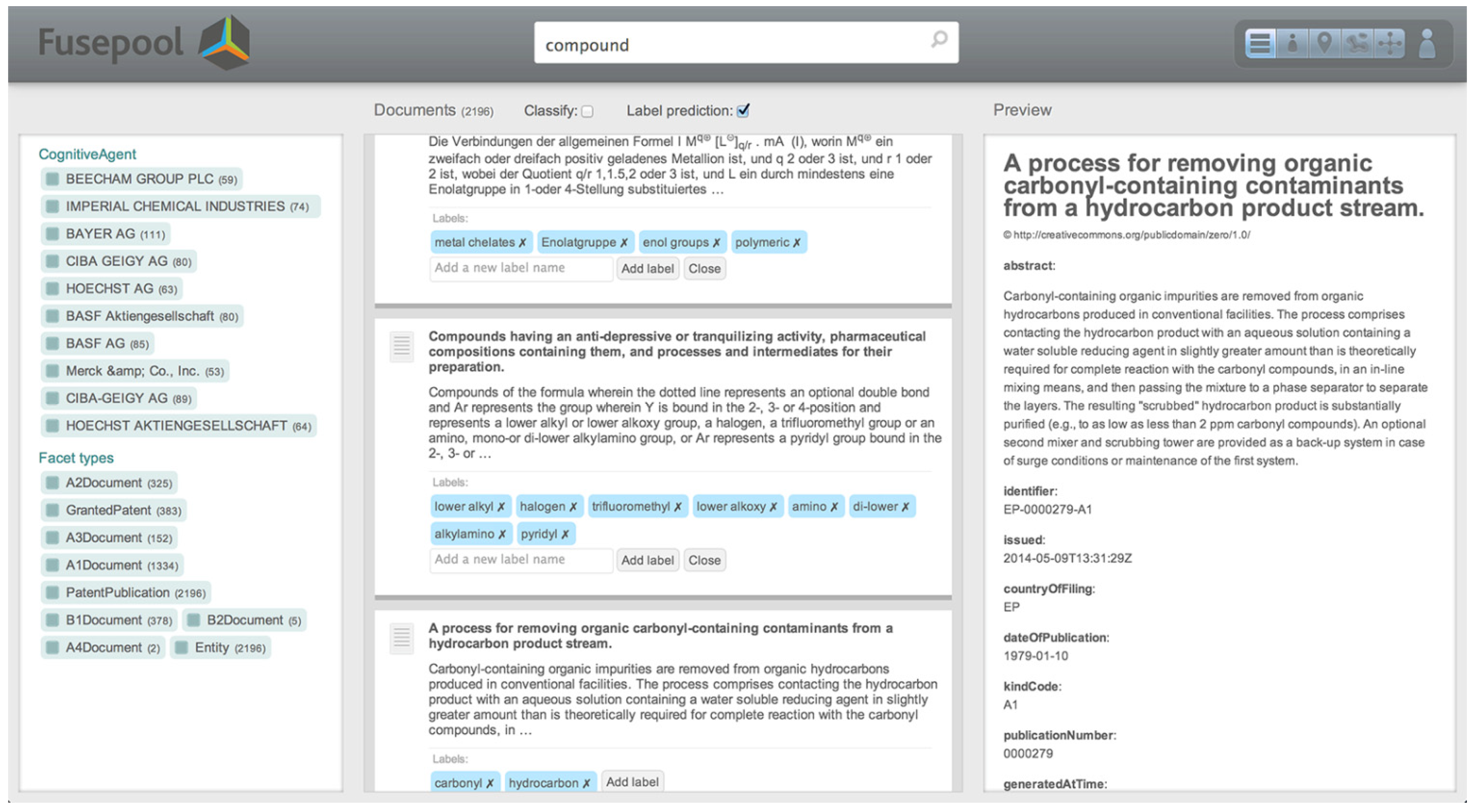
- Searching and retrieving information: The search engine uses the search index of all information available to identify and rank the most relevant results based on a scoring algorithm. The resulting screen is split into two sections, a large one for displaying the search results and a smaller one for displaying parameters to refine the search results;
- Limiting retrieved entities or retrieving related information: The user limits the search results by clicking on one of the facets and/or extends the results to retrieve related information by clicking on one or more entities;
- Providing feedback or annotations to a result: The user “writes” back to the data pool by adding personal annotations and customizations that can be shared among multiple users. For example, predicted labels automatically describe patent clusters, but a user may choose to give it a more descriptive name and share that label with colleagues.
3.1.3. R3: Revealing Data
- Patents: A patent document has metadata attributes, such as the inventors, patent application status, publication date, country, claims and description. There are four major classification systems for patents. These taxonomies come with around 150,000 concepts. Patent documents can be downloaded from the European Patent Office or the United States Patent and Trademark Office in XML format. MAREC (Matrixware Research Collection) contains a corpus of over 19 million patents in XML format from the World Intellectual Property Organization (WIPO);
- Publications: PubMed is an archive of biomedical and life sciences articles published by different journals. The National Library of Medicine at the U.S. National Institute of Health maintains the archive. The articles are freely accessible from the PubMed website according to its release policy. A free license to use this dataset was requested and approved. The dataset is divided in folders, each containing articles from a journal. The XML document contains bibliographic information, such as title, abstract, authors and affiliation, license, citations, classifications and identifiers (DOI, digital object identifiers);
- Funding opportunities: The European Commission funds research and innovation programs through specific calls to which companies and research organizations apply. A call belongs to challenges that target one or more objectives. A company or organization must search in the portal among these objectives to which call it wants to participate. Each call has a title or number, description, publication date and deadline, area, funding scheme, budget allocated and topics. EUresearch, a Swiss organization that supports companies and institutions applying to research grants, has provided the dataset as a schema-free spreadsheet.
3.2. Data Design, Development and Deployment
3.2.1. R4 (Refine): Data Rationalization, Staging and Semantics
EXAMPLE: Data processing and analytics components
- Data life cycle (DLC): DLC implements the processing chain for data imports for RDF mapping, interlinking and smushing into the RDF content graph;
- DLC patents: Java OSGi bundle with the DLC components needed to process patent data including the service to transform patents from MAREC XML format to RDF;
- Dictionary matching algorithm: Implementation of a dictionary-matching algorithm as Fusepool enhancer engine that outputs RDF triples from extracted entities from text documents;
- SILK linking: OSGi bundle that wraps the SILK Link Discovery Framework for the interlinked service into the Fusepool platform.
3.2.2. R5 (Reuse): Advanced Enrichment and Predictive Analytics
3.3. Application Design, Development and Deployment
3.3.1. R6 (Release): GUI, Data Visualizations, Apps
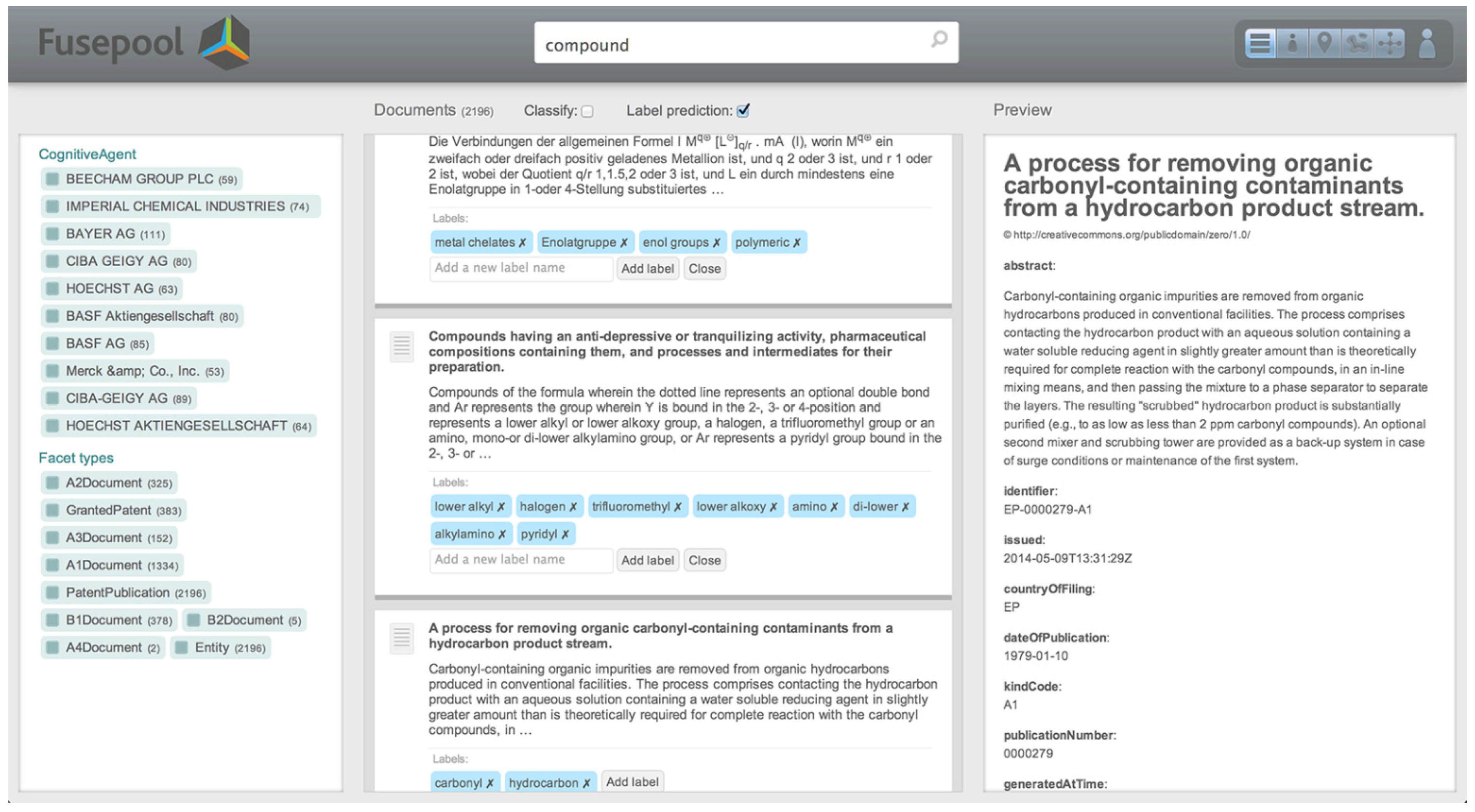
3.3.2. R7 (Run): Running Scalable Data-Driven Apps
- Apache Stanbol: The result from a previous project, Stanbol offers a wide range of tools to discover entities in unstructured text documents. The Stanbol enhancers provide an extensible mechanism to process and semantically enrich content, including components for transformation to text, as well as for natural language processing;
- OSGi component architecture: OSGi specifies component architecture for the local interaction within a Java virtual machine. OSGi promotes modularization of the application providing a model for versioned libraries, as well as service architecture. The Fusepool platform relies on the core OSGi specification, as well as on the declarative service specification of the OSGi compendium [25]. The latter allows it to easily build services extending platform functionality;
- Authentication and authorization: In effect, Apache Stanbol had no authentication or access control mechanisms. The adopted approach leverages existing security mechanisms built into the Java Platform and some libraries from Apache Clerezza. All security-related code was contributed to the Apache Stanbol project and accepted by the Stanbol community and part of the Stanbol distribution;
- Search and indexing: Apache Lucene and Apache Solr are fast and scalable indexing and search tools running on the Java platform. Lucene provides basic search and indexing. Solr frontends Lucene with an HTTP interface.
- CPU clock usage hours;
- Persistent storage levels;
- I/O requests, API requests;
- Data transfer (outbound).
- Cost of storing a document?
- Cost of one entity extraction?
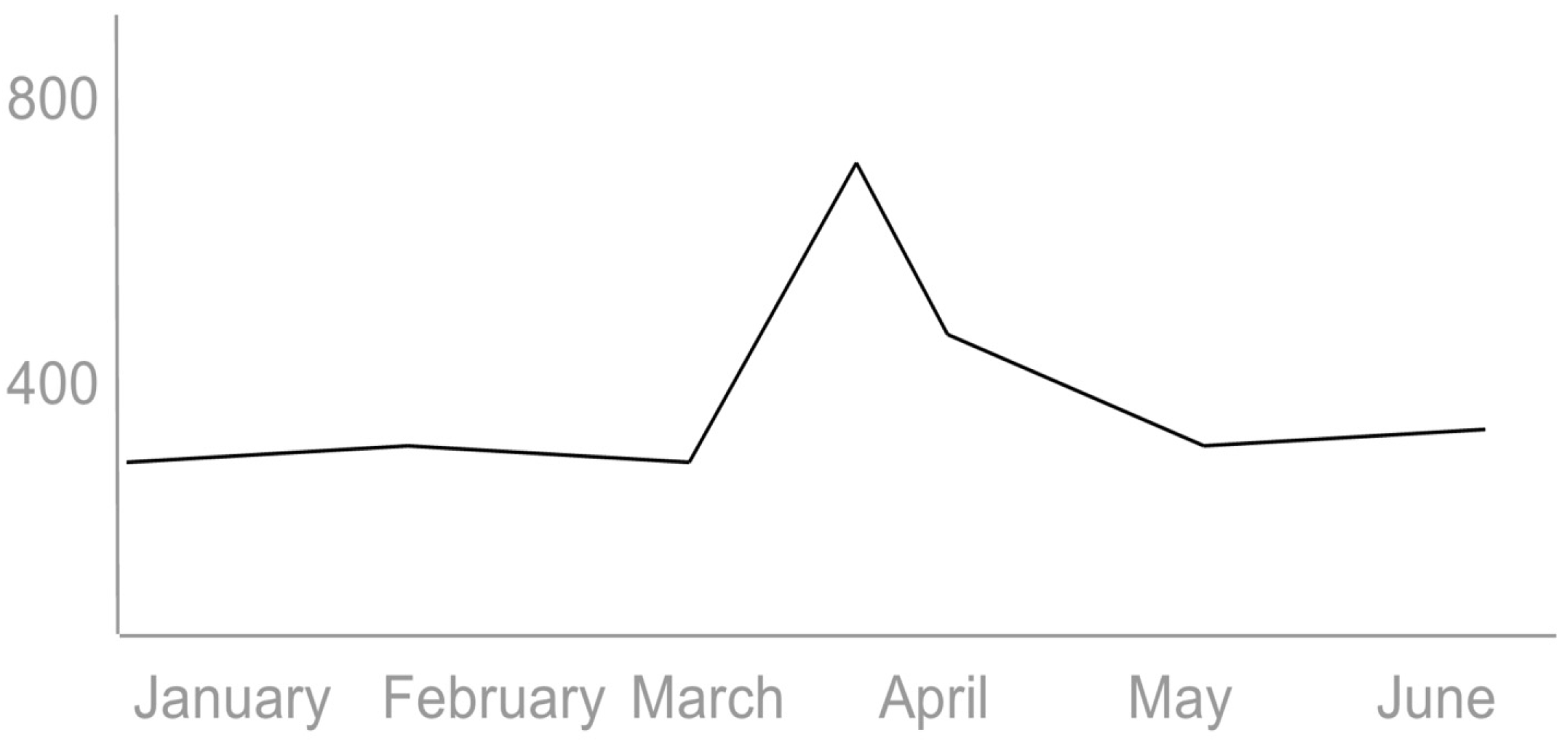
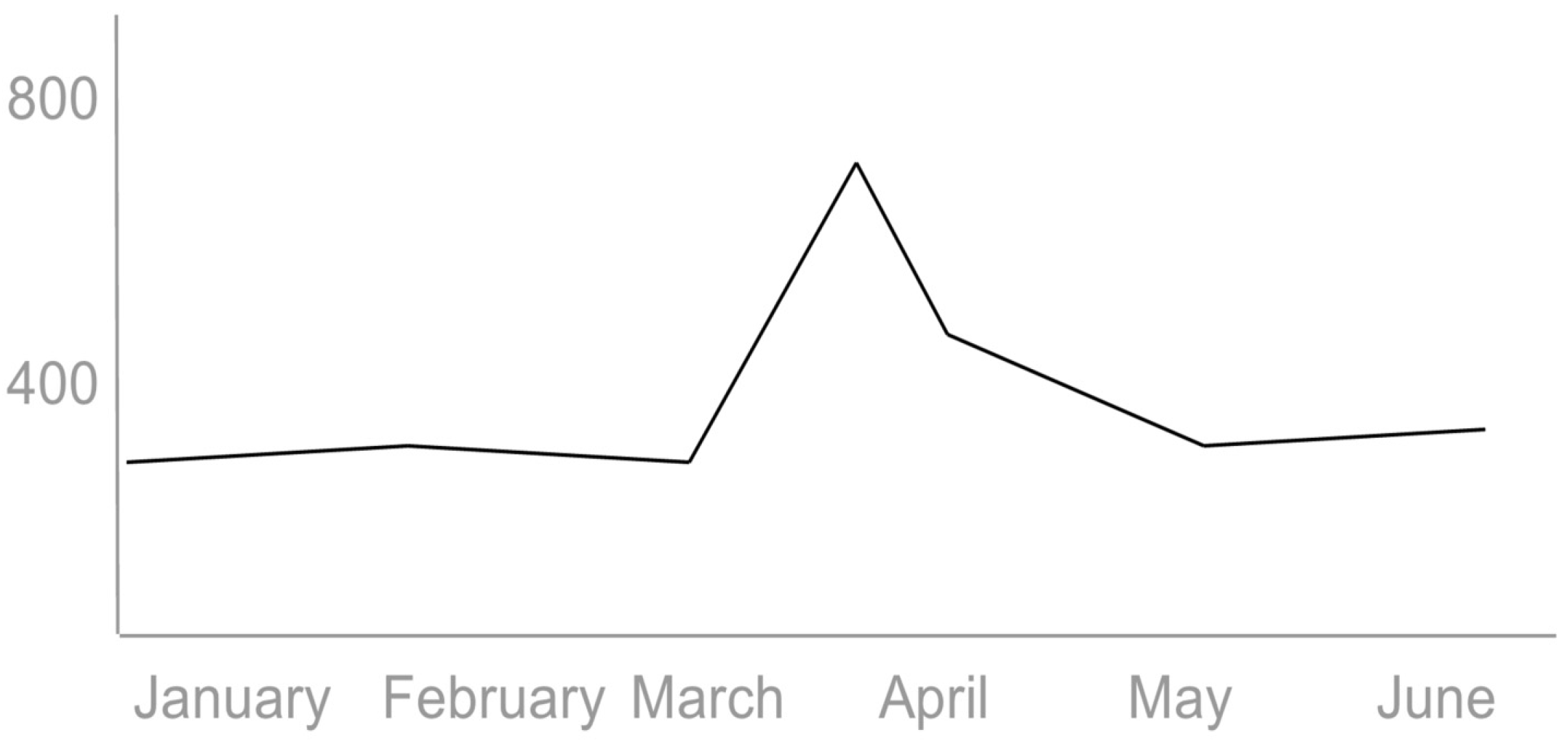
- Cost of one entity interlinking? Figure 4 below shows a spike in costs during the high volume of interlinking activity on the Fusepool cloud platform hosted on Amazon Web Services.
- Cost of supporting one user?
- Functions and usage (e.g., interlinking);
- Components and services (e.g., SILK);
- Track cost factors over time (e.g., CPU, data store);
- Link resource usage (e.g., time, downloads) to cost factors (e.g., Amazon bill).
4. Discussion
4.1. Fusepool in Practice
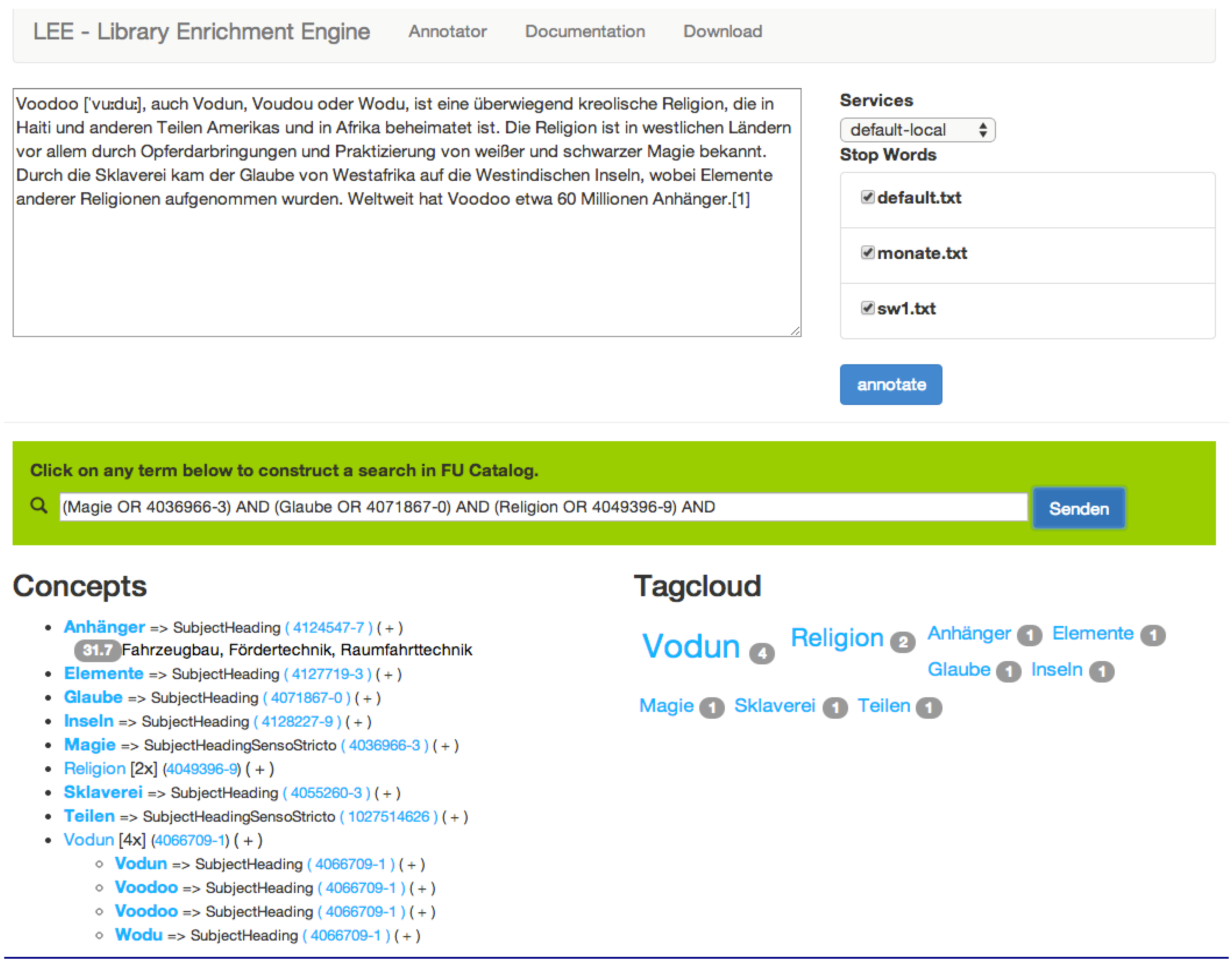
4.1.1. Content Lookup and Discovery Engine by the Libraries of Free University of Berlin
- tools supporting library staff in the time consuming task of manual subject indexing;
- new services that improve results and attract usage of library online search systems.
- Library staff: support in the time-consuming task of manual indexing the acquired materials. It should be possible to suggest identifiers based on the text input of book reviews, table of contents, abstracts and full texts;
- Researchers: suggestions of related content for their research topics. It should be possible to start research at any location in the WWW (not only library catalogue). Users want to collect significant text phrases and get suggestions of related content available in their library;
- Publishers/authors: improve the findability of their content by adding controlled keywords (i.e., concept identifiers) easily. Their contents should be scanned automatically for phrases that can be represented with unique identifiers.
- showing most used concepts in a tag cloud, based on their appearance in the text;
- gathering synonyms of a concept into a group labeled with the preferred denotation; and
- providing background information about each concept to support the process of choosing correct concepts between homonyms.
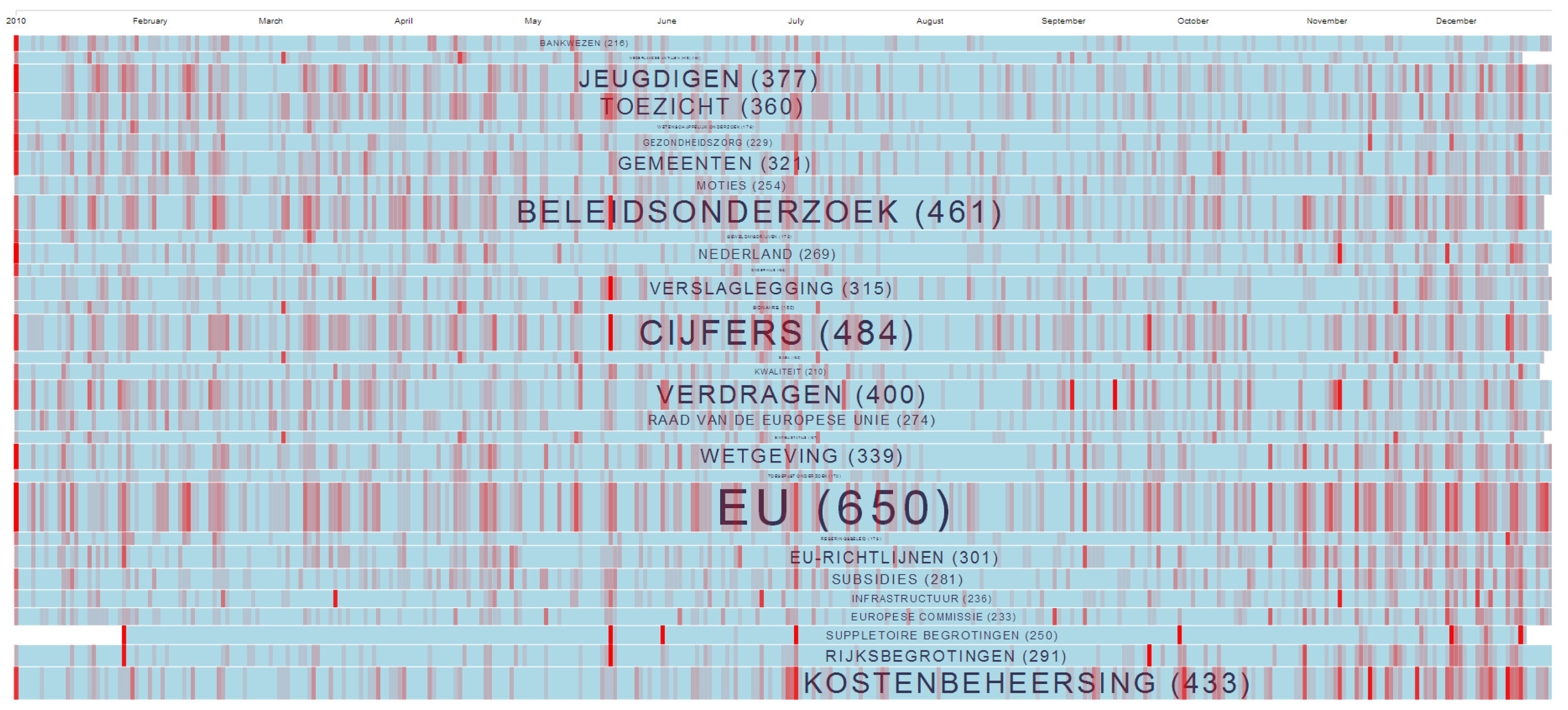
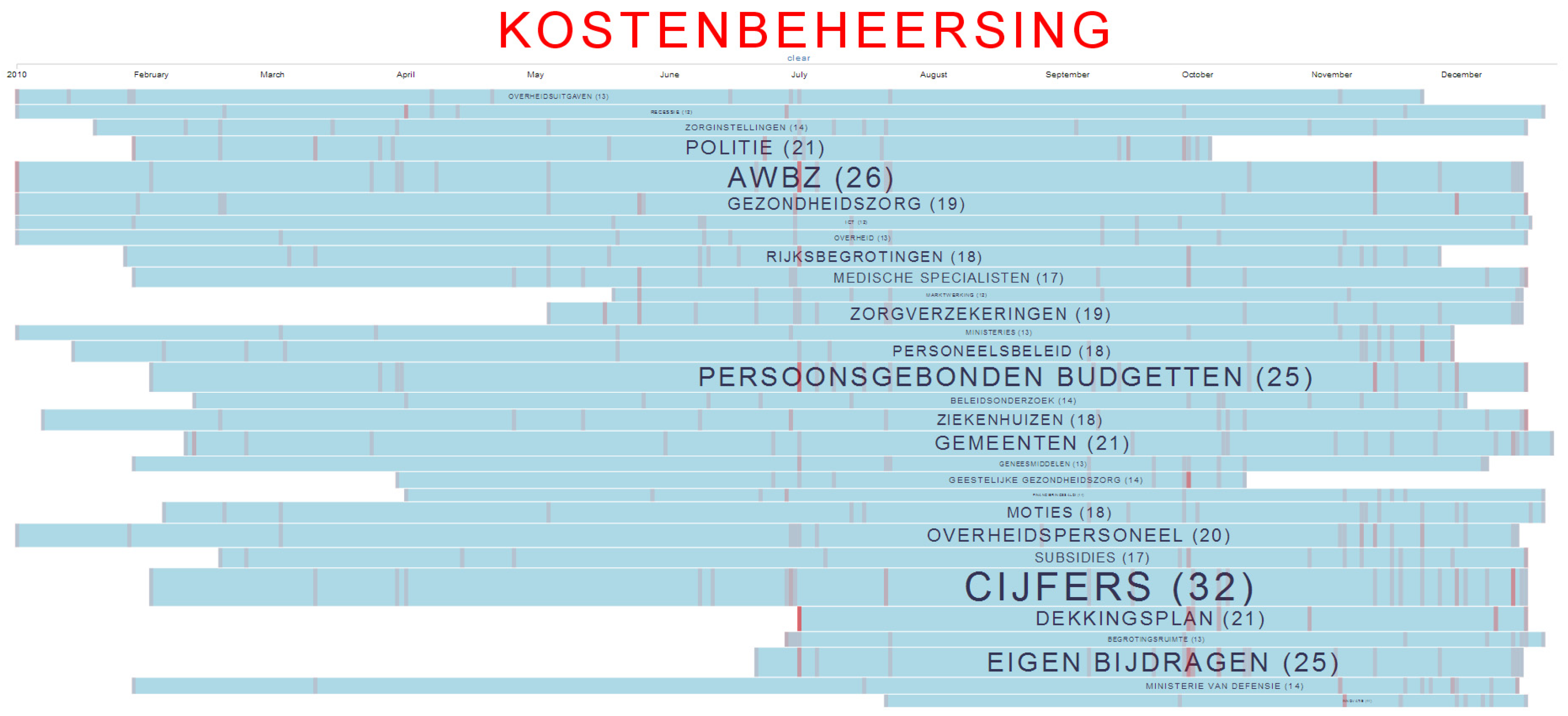
4.1.2. Weyeser’s Data Transparency Mash-Up for the Dutch Parliament
- single entry for parliamentary documents and visualization of the evolution of topics over time;
- amend the platform with new tools to visually analyze the results and emerging patterns.

5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Australian Bureau of Statistics. A Guide for Using Statistics for Evidence Based Policy. Available online: http://www.abs.gov.au/ausstats/abs@.nsf/lookup/1500.0chapter32010 (accessed on 16 March 2014).
- World Wide Web Consortium (W3C). Linked Data Platform 1.0. Available online: http://www.w3.org/TR/ldp (accessed on 16 March 2014).
- Spears, T. Canadian bureaucracy and a joint study with NASA. Available online: http://www.ottawacitizen.com/technology/Canadian+bureaucracy+joint+study+with+NASA/6493201/story.html (accessed on 16 March 2014).
- Wildavsky, A. The political economy of efficiency. Public Adm. Rev. 1966, 26, 292–310. [Google Scholar] [CrossRef]
- Cerny, P.G. Reconstructing the political in a globalizing world: States, institutions, actors and governance. In Globalization and the Nation-State; Buelens, F., Ed.; Edward Elgar: Cheltenham, UK, 1999; pp. 89–137. [Google Scholar]
- Cerny, P.G. Multi-nodal politics: Toward a political process theory of globalization. In Proceedings of the Annual Conference of the International Political Economy Society, Stanford, CA, USA, 9–10 November 2007.
- Wittman, D. Why democracies produce efficient results. J. Political Econ. 1989, 97, 1395–1424. [Google Scholar]
- Kaschesky, M.; Riedl, R. Top-Level Decisions Through Public Deliberation on the Internet: Evidence from the Evolution of Java Governance. In Proceedings of the 2009 10th Annual International Conference on Digital Government Research, Puebla, Mexico, 17–20 May 2010; pp. 42–55.
- Cucciniello, M.; Nasi, G.; Valotti, G. Assessing Transparency in Government: Rhetoric, Reality and Desire. In Proceedings of the 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 2451–2461.
- Lathrop, D.; Ruma, L. Open Government: Transparency, Collaboration and Participation in Practice; Lathrop, D., Ruma, L., Eds.; O’Reilly Media: Sebastopol, CA, USA, 2010. [Google Scholar]
- Davies, T. Open Data Barometer—2013 Global Report. Released 31/10/2013. Web Foundation & Data Institute. Available online: http://www.opendataresearch.org/dl/odb2013/Open-Data-Barometer-2013-Global-Report.pdf (accessed on 16 March 2014).
- Neuroni, A.; Riedl, R.; Brugger, J. Swiss Executive Authorities on Open Government Data—Policy Making Beyond Transparency and Participation. In Proceedings of the 46th Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013; pp. 1911–1920.
- Alani, H.; Dupplaw, D.; Sheridan, J.; O’Hara, K.; Darlington, J.; Shadbolt, N.; Tullo, C. Unlocking the Potential of Public Sector Information with Semantic Web Technology. In Proceedings of the Semantic Web Conference, Busan, Korea, 24 August 2007; Volume 4825, pp. 708–721.
- Klischewski, R. Identifying Informational Needs for Open Government: The Case of Egypt. In Proceedings of the 2012 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012; pp. 2482–2490.
- Dawes, S.S. Stewardship and usefulness: Policy principles for information-based transparency. Gov. Inform. Quart. 2010, 27, 377–383. [Google Scholar] [CrossRef]
- Heckmann, D. Open government—Retooling democracy for the 21st Century. In Proceedings of the 44th Hawaii International Conference on System Sciences (HICSS), Kauai, HI, USA, 4–7 January 2011; pp. 1–11.
- Berners-Lee, T. Five Principles of Linked Data. Available online: http://www.w3.org/DesignIssues/LinkedData.html (accessed on 16 March 2014).
- West, M.; Fowler, J. Developing High Quality Data Models; Morgan Kaufmann: Burlington, MA, USA, 2011. [Google Scholar]
- World Wide Web Consortium (W3C). Linked Data Cookbook. Available online: http://www.w3.org/2011/gld/wiki/Linked_Data_Cookbook (accessed on 16 March 2014).
- World Wide Web Consortium (W3C). Semantic Web Activity. Available online: http://www.w3.org/2001/sw/Activity (accessed on 16 March 2014).
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web. Scientific American Magazine, 17 May 2001; 35–43. [Google Scholar]
- Evelson, B.; Yuhanna, N. Craft Your Future State BI Reference Architecture; Forrester Research Inc.: Cambridge, MA, USA, 2012. [Google Scholar]
- Linstedt, D. Physical Data Models and Ontologies. Available online: http://danlinstedt.com/datavaultcat/physical-data-models-and-ontologies (accessed on 16 March 2014).
- Beyer, M. Leading the Logical Data Warehouse Charge Has Its Challenges. Available online: http://blogs.gartner.com/merv-adrian/2012/02/24/guest-post-leading-the-logical-data-warehouse-charge-has-its-challenges (accessed on 16 March 2014).
- OSGi Alliance. OSGi Service Platform Service Compendium. Available online: http://www.osgi.org/download/r4v42/r4.cmpn.pdf (accessed on 16 March 2014).
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Kaschesky, M.; Selmi, L. 7R Data Value Framework for Open Data in Practice: Fusepool. Future Internet 2014, 6, 556-583. https://doi.org/10.3390/fi6030556
Kaschesky M, Selmi L. 7R Data Value Framework for Open Data in Practice: Fusepool. Future Internet. 2014; 6(3):556-583. https://doi.org/10.3390/fi6030556
Chicago/Turabian StyleKaschesky, Michael, and Luigi Selmi. 2014. "7R Data Value Framework for Open Data in Practice: Fusepool" Future Internet 6, no. 3: 556-583. https://doi.org/10.3390/fi6030556
APA StyleKaschesky, M., & Selmi, L. (2014). 7R Data Value Framework for Open Data in Practice: Fusepool. Future Internet, 6(3), 556-583. https://doi.org/10.3390/fi6030556