1. Introduction
A typical current development is the move to the Cloud, driven by the goal of saving cost or substantially enhancing the number and kinds of services offered. While the existing players can reduce cost, new entrants use services with a rich set of capabilities that they could not afford before. This commoditization of services has led to an increasing number of active players, including so-called “prosumers”. A whole new community seeks to provide new and niche services. At the same time, we have seen a whole range of new network architectures and approaches appear.
This has however come at a cost: moving computation and storage outside the domain of the company, or even from the average user’s home, means that we need to “trust” that those running these services behave as is expected and do not misuse the outsourced resources. There will be a wide range of trust levels, including both established players with a track record and initially untrusted new entrants, who may come and go quickly. Even these must have an opportunity to succeed in the future digital environment. New architectures to handle trust in a heterogeneous environment will be needed. In this context, Security, privacy, trust and identity are strongly interrelated.
The paper presents an enhanced security, privacy and trust architecture supporting the flexible integration of independent third parties building upon work done in the EU projects SWIFT [
1] and Daidalos [
2], in particular its concepts of Virtual Identity and Identity Aggregator or Broker, but going beyond using new approaches which support stronger notions of trust. It deals with both infrastructure and service aspects. The architecture supports an identity-enabled Future Internet and encompasses both control and management functions. The target of the architecture is to make real people, objects (things), as well as services the end-points of communications. The heterogeneous infrastructure, to which these end-points are connected, should support awareness and control of trust levels, as well privacy, and thus support the privacy and trust levels of services and applications.
People are now used to using digital identities to access networks and services, either via user name and password combinations, or via (U)SIM cards. Not quite as common is the use of digital certificates. With the upcoming Cloud environment, the number of distributed digital identities per person is exploding and becoming unmanageable. This is accompanied by a fragmentation both regarding the technologies used and underlying methods of use. From the usability point of view, we need to allow applications using a specific identity solution and technology to connect to applications and domains that use different identity technologies. These issues have been addressed e.g., by the identity aggregator approach in SWIFT.
The paper is structured as follows.
Section 2 shows the general problems that exist today and shows link to how related work has addressed the problem.
Section 3 shows the proposed architecture.
Section 4 illustrates an example scenario.
Section 5 concludes the paper with a summary.
2. State-of-the-Art and Related Work
To be able to ensure reliable and trusted communication and use of services, we need to be able to control what happens both in the infrastructure and for the end points, services for example. Regarding the infrastructure, trust has been focused on security measures, e.g., dealing with securing individual channels via IPSEC or through end-to-end SSL encryption. Network Address Translation (NAT) has addressed network autonomy and security by decoupling the internal network from the Internet [
3]. Approaches such as HIP (Host Identity Protocol) have separated identification and identities from the addresses (locators) that point to where a device is attached. HIP uses cryptographic host identifiers with a global name space between the IP and transport layers [
4]. The EU FP6 Ambient Networks project is based on such a separation of locator, identifier and administrative domains [
4,
5]. Related approaches are PONA [
6] and MILSA [
7]. Some have suggested completely eliminating layering [
8] to overcome layering violations of the TCP/IP architecture. Others adopt a content- or information-centric approach [
9,
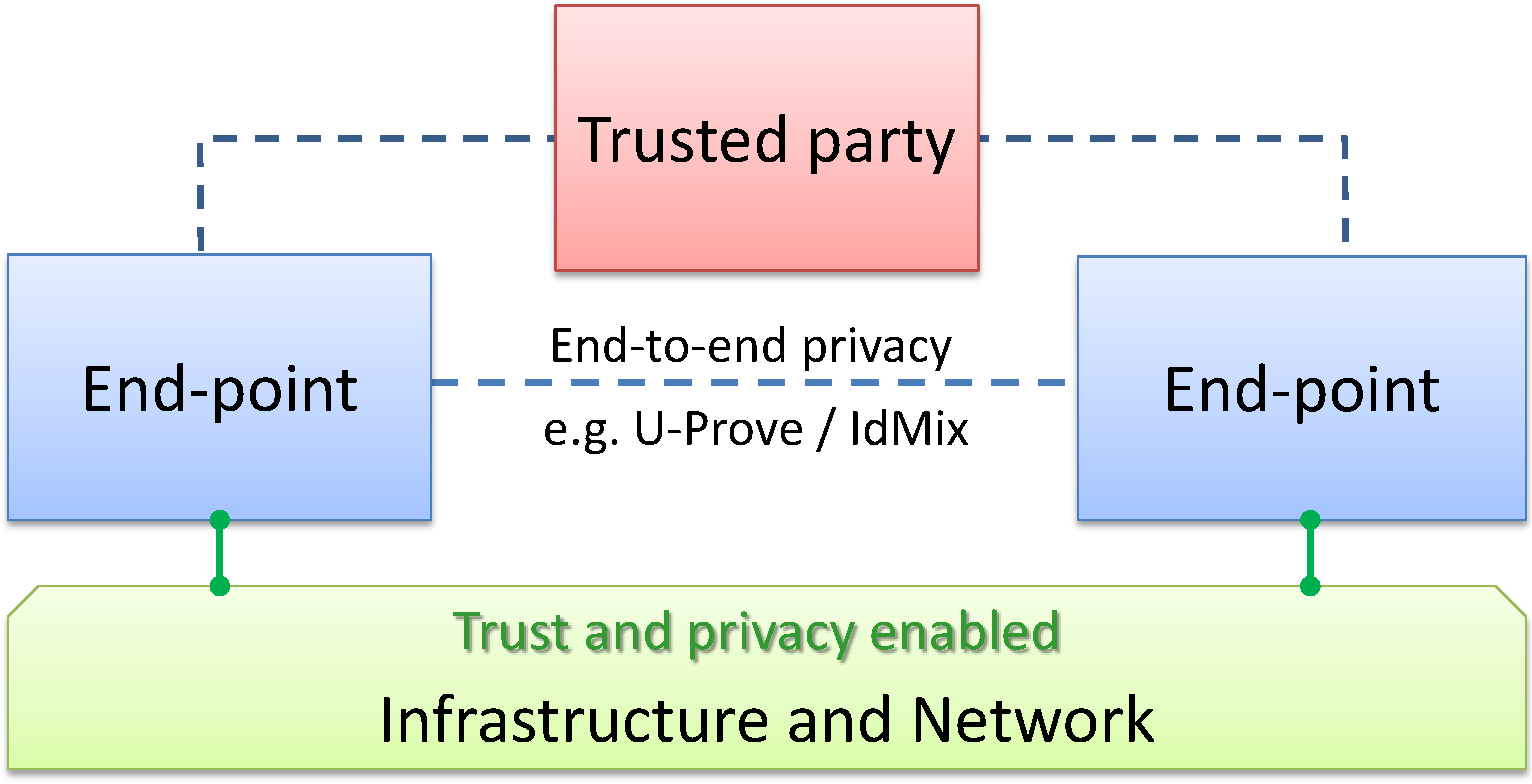
10] connecting information consumers with information producers. Building on this work, our goal on the infrastructure side is to enable reliable Virtual Infrastructure Sessions (VIS) connecting two or more end-points of the communication, represented by virtual identities as defined in SWIFT and Daidalos, to support privacy, with an architecture that allows us to control and understand trust related to the infrastructure and the end-points. We have not specifically addressed solutions, such as U-Prove and IDMix from the EU projects ABC4Trust or Prime/Primelife. These address privacy in the context of services and applications, not the network or the infrastructure. They may thus be seen as complementary or orthogonal approaches to the one described here, see
Figure 1.
Figure 1.
Supporting trust and privacy via the infrastructure.
Figure 1.
Supporting trust and privacy via the infrastructure.
Much work including in standards has been done on the identity side of things. ITU-T Recommendation (X.1250) on global identity management [
11] defines identity as the “Representation of an entity (or group of entities) in the form of one or more information elements, which allow the entity(s) to be uniquely recognized within a context to the extent that is necessary (for the relevant applications).” For privacy, we need to handle (and restrict) Personally Identifiable Information (PII), which is “the information pertaining to any living person which makes it possible to identify such individual (including the information capable of identifying a person when combined with other information even if the information does not clearly identify the person)” [
12]. More on the application and end-point side, federated identity management systems are based on the SAMLv2 [
13] Liberty Alliance [
14] and Shibboleth [
15] models, that support identity management, authentication and authorization. We differentiate between an identifier and an identity that includes attributes of the entity to enable communication between endpoints based on identifiers, possibly pseudonyms, as well as attributes, such as connecting with any entity with the property representative of bank x (not necessarily human). The use of pseudonyms and attributes help making identification more difficult.
3. Proposed Architecture
The Internet was designed as a support infrastructure to allow people to communicate freely when the computer was on its way to become the preferred tool to handle all sorts of information about people, public records, enterprise data, medical, things. Barriers to finding information have been torn down, and the Internet has moved to the center of business, social, educational, cultural and global issues.
Along the way, we have neglected why we needed an Internet in the first place: for people to communicate. The Internet became the storage place for information, the infrastructure to where one plugs to and, inevitably, the bottleneck of our communications infrastructure. Because we see this Internet as an abstract entity to where one “plugs-in”, it has become increasing difficult to scale services to the billions of users and their digital entities that the Internet will hold and serve.
We propose a different approach to the Internet based on previous work [
16,
17,
18,
19]. If we go back to how we started this discourse, the Internet is for people to communicate. They may be communicating in real-time or over-time. They may be using writing, speech, video, pictures, documents which include graphs and tables. They may be doing so in a business context, social context, for entertainment, for medical reasons. They even may be doing all these things at once, but all the information, data, they put in will only make sense in two contexts: their own and whoever receives it. Our approach is to design a Next Generation Internet, one which conceptually starts at the user consuming a service, identified and addressed by a virtual identifier acting as a portal to all the services the current Internet supports, and more. Our approach is to create a scalable digital communication infrastructure which mirrors the structure we have always had in the real world: people talking to people, objects, and in general digital identities communicating with each other.
To bind these concepts together, we have created a concept called Virtual Infrastructure Sessions (VIS). A VIS is a channel over which one or more (virtual) identities communicate. It encompasses all the levels from application to transport necessary to transmit bits from one identity to the other and also the purpose for that communication. We distinguish between three parts: the virtual identities, which mark the endpoints and support privacy, the intent, which determines the purpose for the communication and the VIS, which is the channel over which communication is achieved. The intent is an abstraction of what some entity wants to do, such as a user wanting to make a phone call to some other user, or a user wanting to download some specific information, which brings the virtual identity and the VIS together for a specific purpose.
In most ways, the VIS can be seen as having the same properties as an identity. It can be identified, most times differently depending on the administrative domain and the level at which it is being addressed, it can be manipulated by a control layer, which permits functions such as connection establishment, the addition of identities to the communication and the query of parameters of the communication to be performed and it aggregates the same properties of security and privacy normally attributed to identities: authentication, authorization, minimum disclosure and trust.
3.1. Architecture Description
For us to get a better understanding of how the concepts of Identity and VIS can be instantiated in the existing Internet architecture, we propose the following separation of functions into three levels: Application, VIS and connectivity.
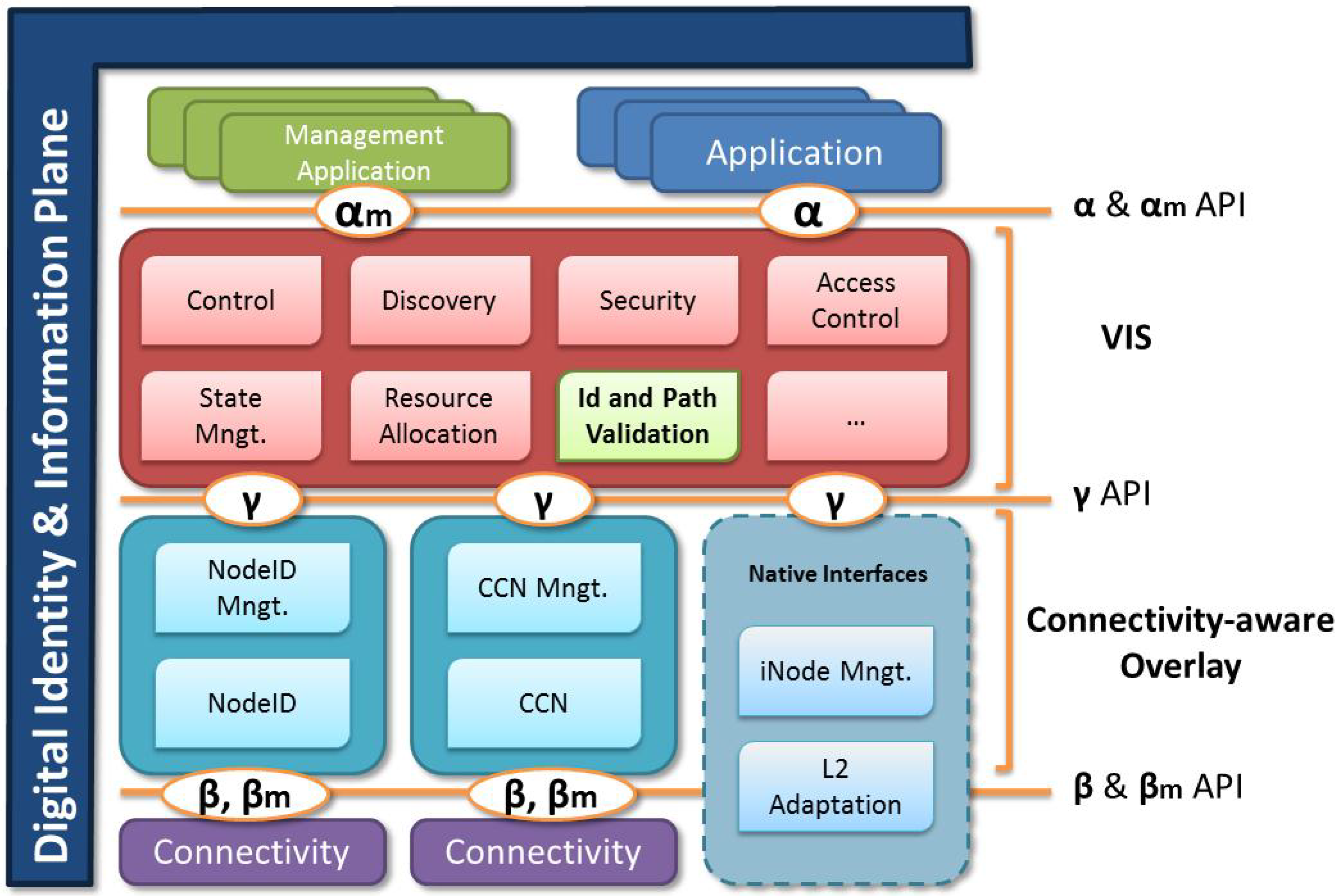
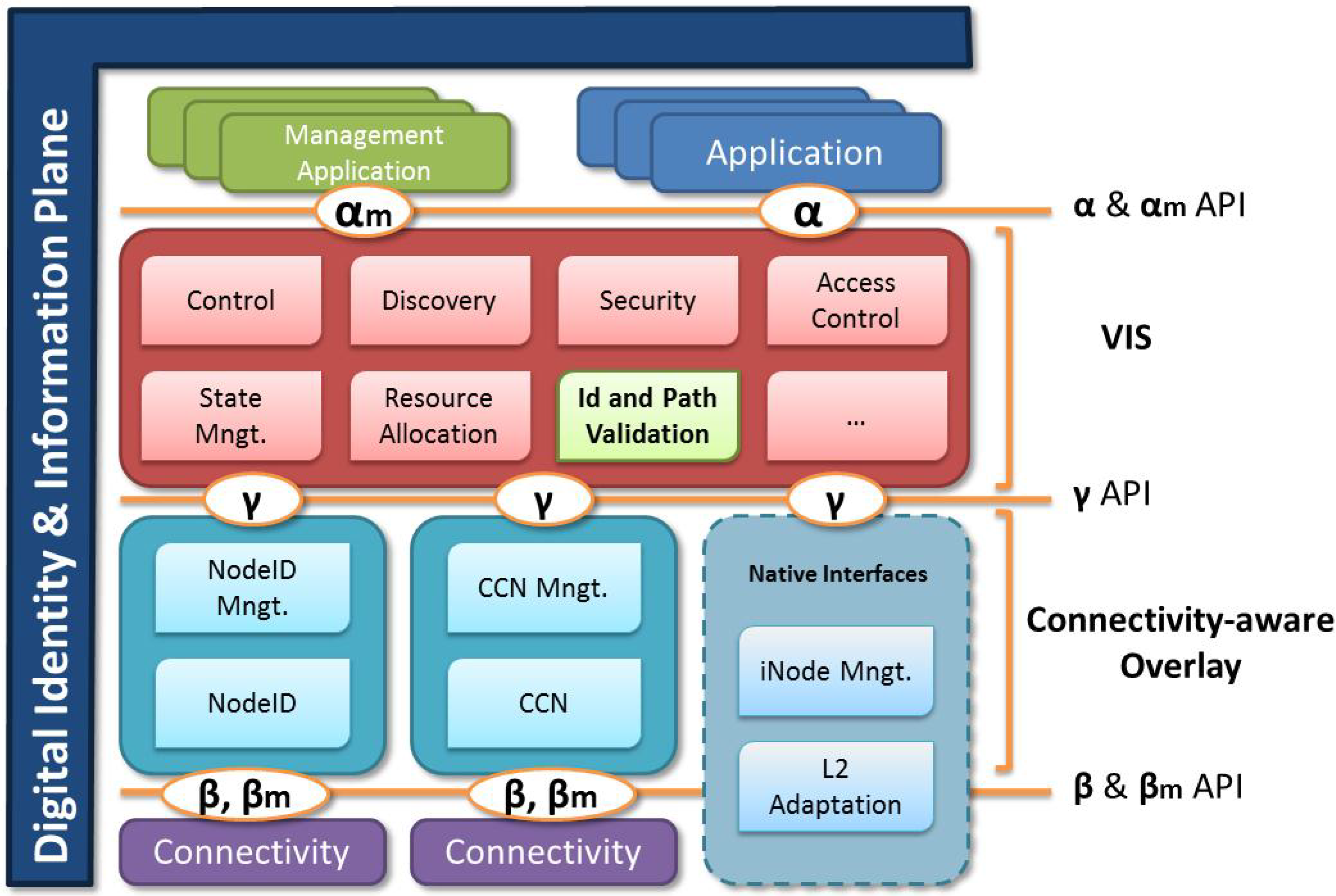
Figure 2 describes the proposed alignment for these interfaces or APIs, which builds on ideas developed for MANA [
20].
Figure 2.
Future Internet identity architecture using Virtual Infrastructure Sessions.
Figure 2.
Future Internet identity architecture using Virtual Infrastructure Sessions.
The first step for session establishment is the discovery of the identity or identities we want to communicate with. Much like the Internet today, one can assume that discovering the domain name of a service endpoint can be done through the use of search engines or through assumed prior knowledge (e.g., google.com). The domain can then be used to identify a specific identity in the domain using a lookup mechanism such as a directory. We believe that for the purposes of the architecture, such mechanisms can be varied and heterogeneous, which is also why we do not offer further details about its instantiation in this paper. It is important at this stage that the result obtained from the lookup be compatible with the Identity Management (IDM) system. This is usually not a problem since most IDM systems are identifier agnostic. Once the identifier is obtained, a second discovery mechanism, at the connectivity layer can be used to find a path or route to the endpoint based on the context of the communication.
3.2. Virtual Infrastructure Session
The VIS is created as soon as the endpoints and intention are known. It offers a distributed querying and control layer distributed across the different domains which functions like an Identity Management system. Identifiers are mapped according to the domain and layer of the request. A URL might become an IP or a MAC address depending on the layer at which the data is indexed. The advantage of this system is that it is agnostic to the protocols offering a general purpose API to deal with data about a communication at all levels. In sum, a VIS has an identity of its own. Below is a description of the interfaces and their main functions:
Application (Alpha) API: The alpha API provides applications with the controls to create new VISs, populate them and use them to transport data at an application level. The API uses the identities and intents, together with the context of the access to provide discovery and session setup.
Control (Gama) API: This API provides VIS with a mechanism to interact with domain specific control layer. For example, it could be used to setup QoS or pinholes to allow for traffic to traverse across domains. Since our architecture could potentially use many different types of transport, the API ensures compatibility between Internet, Content Centric Networking, NodeID, etc. In some extreme cases, there might be no Beta API since the transport layer supports this architecture natively.
Transport (Beta) API: In cases where transport is not native, this API ensures the communication and abstraction between the different control layer protocols and the actual transport.
Each of these APIs vary from simple to complex depending on the functions to be supported, and are designed to be open for future extensions. The intention is to reuse existing protocols and standards as far as possible and only extend these when needed. The overall architecture may thus also be seen as a framework that encompasses the existing state of the art.
3.3. Privacy and Trust Support
One of the key motivations behind this architecture has been to enable privacy and trust. This done via two means:
Identity Validation Component: The VIS has an identity validation component owned by specific provider that validates identities, which may not go as far as identification, but may be content with the validation of attributes or claims that the end-points must fulfill. The provider is thus able to assess whether or not the end-points are valid, thus providing an important barrier to phishing attacks. Of course, this depends on the provider itself being trustworthy and certified. This validation component will communicate via the Alpha API, is designed to communicate with a wide range of Identity Management systems, and is open to enhancements to cope with new developments in Identity Management. Validations are performed using Identity Management protocols that guarantee privacy e.g., using pseudonyms. To each identity in a domain, a different local identifier is used and mapped at the borders using a name resolution mechanism built into the IDM platform. A partial recovery of the data and identification of the user can be perform by the correlation of the pseudonyms at the different domains, which allows for legal interception and fulfills other regulatory requirements without compromising privacy on the day to day operations. Attribute based access control will support the setting up of connections.
Path Validation Component: Not all the routers and nodes that are used by the VIS are necessarily owned by the provider of the VIS. This component will communicate via the Gamma API and need to check the identity of the nodes and their trustworthiness. As above, Identity Management protocols will be used to negotiate the security parameters related to the VIS for each particular communication. Identities of the network entities of a VIS, and their policies, are parameters that will need negotiation. Based on these results, the setup of the VIS will adjust which nodes have access to the transported data including end-point addresses, and which do not. As the internal end-points of the VIS themselves may not be (fully) trusted, the user will be notified about the level of trust that should be assumed and what levels of assurance exist.
For both the trustworthiness of end-points of a communication, e.g., services, as well as for the trustworthiness of internal nodes and routers, hierarchical schemes, such as via certification authorities, as well as reputation systems may be used, such as those proposed in [
21]. Security functions will ensure the necessary privacy, and prevent an uncontrolled disclosure of identity data. Cryptographic techniques regarding private information retrieval may be applied [
22,
23].
While we have focused on the privacy and trust components, others will be supported, see
Figure 1, such as dealing with access control and resource allocation, both of which are not dealt with here.
3.4. Security Enforcement
The VIS provides the interfaces both for the network, service and discovery components. In this architecture design privacy is intrinsically dealt with by creating the separation, or in some cases distributed, of the knowledge of identities, intents, networks and service operations. In this architecture, different layers behave independently but share a VIS. In addition to its role of providing a privacy layer, the VIS is also a point for policy enforcement and allows for fine grain control on discovery and access to information about the VIS based on identity or intent information. For example, the VIS can be setup in a way that the separation of data ensures the communication between participants remains anonymous; while preserving the right to be part of the VIS through the identity layer (and associated credentials).
5. Conclusions
A large amount of effort has been put into identity management and the federation of such systems, and a large number of solutions exist today. However, some of the fundamental problems related to being able to trust both the infrastructure and the end-points at the other end remain inadequately addressed. For many applications and scenarios, this may be the blocking factor that differentiates success from failure. We have presented an architecture based on Virtual Infrastructure Sessions (VIS) that allows for a flexible build-up of a trusted connectivity between 2 or more end-points. The architecture provides a more controlled way of ensuring reliable connectivity without linking a lot of the data or identities, supporting privacy, while at the same time ensuring via security mechanisms that control the VIS that the sessions can be trusted and are not susceptible to be hijacked via man-in-the-middle attacks. Thus both privacy and trust are supported.
This paper has consolidated some of the findings of the EU projects SWIFT and Daidalos and enhanced the architectures developed there to cope with supporting trust and privacy from the infrastructure. It goes well beyond the contributions of these projects, since it takes a more consistent view on how identities can be used beyond the endpoints, and establishes a perspective on how communication can be perceived both from the endpoints and the nodes in between. Potentially, this approach can lead to more intelligent networks with reduced control messaging and a more coherent cross-application protocol stack. We will work on validating this architecture via new projects, such as EU FP7 ATTPS, which will be building the infrastructure for trials. In this context, we will also need to focus on a range of possible attack scenarios to ensure that the claim of support of privacy and trust is actually validated.

{kind=link}
{kind=link}
{kind=link}