Abstract
This study presents a deep generative model designed to predict intermediate stages in the drawing process of character illustrations. To enhance generalization and robustness, the model integrates a variational bottleneck based on the Variational Autoencoder (VAE) and employs Gaussian noise augmentation during training. We also investigate the effect of U-Net-style skip connections, which allow for the direct propagation of low-level features, on autoregressive sequence generation. Comparative experiments with baseline models demonstrate that the proposed VAE with noise augmentation outperforms both CNN- and RNN-based baselines in long-term stability and visual fidelity. While skip connections improve local detail retention, they also introduce instability in extended sequences, suggesting a trade-off between spatial precision and temporal coherence. The findings highlight the advantages of probabilistic modeling and data augmentation for sequential image generation and provide practical insights for designing intelligent drawing support systems.
1. Introduction
Recent advances in generative AI have accelerated the development of intelligent systems capable of producing high-quality images across diverse creative and technical domains. While many of these models, including diffusion models [1,2] and GANs [3,4,5], are optimized to generate final outputs with exceptional realism, the underlying process of image creation—particularly the intermediate stages of drawing—remains largely underexplored. This omission is notable, as constructing an image step by step encodes valuable structural and stylistic information that is especially important in educational and assistive contexts.
To address this gap, our previous research proposed a drawing support system that sequentially generates intermediate stages in the drawing process using a convolutional encoder–decoder model trained on a custom dataset of rasterized character sketches (Figure 1) [6]. While the model showed promising results, particularly when trained with noise-augmented images to mitigate recursive error accumulation, its deterministic architecture lacked the expressive flexibility and probabilistic reasoning needed to capture the complex variations of human-like drawing behavior. In the present study, the term “high-quality image generation” is defined more broadly than in conventional works. Specifically, it refers not only to the visual fidelity of each generated frame but also to the long-term temporal consistency and generalization capacity of entire sequences. This broader definition emphasizes stable evolution across drawing stages and the preservation of coherent creative intent, which are essential for drawing support applications.
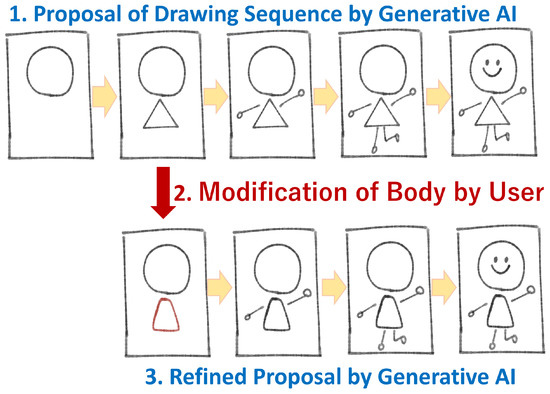
Figure 1.
Schematic diagram of system. This figure is reused from Matsumoto et al., 2025 published in Applied Sciences [6], under the terms of the CC BY 4.0 license.
In this study, we extend the previous approach by incorporating a probabilistic framework based on Variational Autoencoders (VAEs), which introduce latent variable modeling through learned mean and variance representations. This framework enables stochastic sampling during generation, allowing for richer variation and improved robustness. We further examine the effectiveness of combining this probabilistic architecture with skip connections inspired by the U-Net model, which is widely recognized for its ability to preserve spatial detail in image reconstruction tasks.
We evaluate two variants of the proposed model:
- 1.
- A VAE-based architecture that introduces probabilistic sampling to enhance generation diversity and stability.
- 2.
- A skip-connected VAE (hereafter referred to as VAE+U-Net) that combines latent sampling with the direct transfer of low-level features to the decoder to improve reconstruction quality.
Both models are trained under two strategies: standard training with clean image sequences and training with noise-augmented data. The latter improves generalization and reduces error accumulation during recursive generation. For both models, we conducted comparative experiments using two training strategies: standard training with clean image sequences and training with noise-augmented image data. The latter aims to improve generalization and reduce error accumulation during recursive generation. Our results show that the VAE-based architecture trained with noise augmentation achieves the best overall performance. While skip connections can help preserve fine details in early frames, we observed that they can also markedly reduce accuracy in longer sequences due to amplified error accumulation, indicating a trade-off between local fidelity and temporal coherence.
This research contributes to the growing field of interactive drawing support systems and offers insight into the benefits of integrating stochastic modeling, structural connectivity, and data augmentation. The methods explored here have potential applications in educational tools, real-time sketching assistants, and accessibility-focused creative systems.
The rest of the paper is organized as follows. Section 2 reviews related work on image generation, including VAE- and U-Net-based models and their applications in sequential generation and drawing support. Section 3 introduces the proposed model architectures, focusing on the integration of variational bottlenecks and skip connections. Section 4 describes the experimental design, including dataset preparation, training protocols, and baseline comparisons. Section 5 presents the quantitative and qualitative results across multiple models and generation lengths. Section 6 provides a detailed discussion of the findings and design implications. Finally, Section 7 concludes the paper and outlines future research directions.
2. Related Works
In this section, we review prior studies relevant to our research. The review is organized into four areas: (1) image generation with Variational Autoencoders (VAEs), (2) image generation using U-Net architectures, (3) applications of generative models in drawing support systems, and (4) the positioning of our study within the existing literature.
2.1. Image Generation Using Variational Autoencoders
Variational Autoencoders (VAEs) [7] are a class of deep generative models that combine neural networks with variational inference to learn a probabilistic latent representation of input data. VAEs consist of an encoder and a decoder , trained to maximize the evidence lower bound (ELBO):
The reparameterization trick [7] allows gradients to backpropagate through stochastic nodes by expressing z as follows:
which enables efficient optimization via stochastic gradient descent.
Many extensions have been proposed to improve the generative performance of VAEs. NVAE [8] introduces a hierarchical structure with multiple stochastic layers to enhance expressiveness. VQ-VAE and its successor VQ-VAE-2 [9,10] discretize the latent space via vector quantization, achieving high fidelity and diversity in generated images.
Further refinements, such as Residual Quantization VAEs [11] and reparameterization-based latent feature quantization [12], improve the accuracy and stability of reconstruction. Comparative evaluations by Wei et al. [13] highlight the trade-offs among InfoVAE, -VAE [14], and VQ-based methods in reconstruction quality, disentanglement, and diversity.
The applications of VAEs extend beyond general image synthesis. For instance, Liu [15] applied VAEs to tasks such as underwater image enhancement and dark image recovery, demonstrating strong quantitative performance.
Collectively, these works demonstrate the efficacy of VAEs as a foundation for diverse and controllable image generation, motivating our use of a probabilistic framework.
2.2. Image Generation Using U-Net Architectures
U-Net is a convolutional neural network originally designed for biomedical image segmentation [16]. Its encoder–decoder structure with skip connections enables it to capture both semantic features and fine-grained spatial details, making it effective in reconstruction-oriented image generation.
In conditional image generation, U-Net has been widely adopted. The Pix2Pix framework [17] uses a U-Net-based generator in a conditional GAN setting for image-to-image translation, where skip connections directly propagate low-level features to improve sharpness and coherence. SPADE [18] extends this idea with spatially adaptive normalization, allowing semantic maps to guide generation.
U-Net has also been integrated into VAEs to improve reconstruction. For example, Baur et al. [19] proposed a symmetric U-Net VAE for MRI reconstruction and anomaly detection. In high-resolution diffusion models, Rombach et al. [20] used a U-Net denoiser in the latent space, enabling efficient training and sampling.
Variants such as UNet++ [21] and 3D U-Net [22] extend the architecture to medical synthesis and volumetric segmentation. Temporal adaptations like TC-UNet [23] and MCNet [24] show U-Net’s versatility for video prediction and temporal modeling.
In industrial applications, Kim et al. [25] combined CycleGAN-based augmentation with U-Net segmentation for weakly supervised defect detection on periodic textures. These findings underscore the flexibility of U-Net, motivating its inclusion in our model.
Recent studies have also shown that U-shaped encoder–decoder architectures are effective beyond medical imaging. For instance, Li et al. [26] proposed a lightweight U-shaped encoder–decoder for pavement crack detection in civil engineering, demonstrating versatility in infrastructure inspection. In addition, new architectural improvements continue to emerge: U-Net v2 [27] rethinks skip connections for richer semantic information, and UDTransNet [28] integrates transformer-based attention to enhance feature fusion. These studies highlight the broad applicability and ongoing evolution of U-shaped architectures, further motivating our investigation of U-Net-style skip connections in sequential image generation.
2.3. Image Generation Using Sequential Generation Models
Beyond convolutional encoder–decoder and diffusion-based designs, sequential generation models have been widely studied for spatiotemporal prediction tasks such as video frame forecasting and dynamic image generation. These models capture temporal dependencies using recurrent or memory-based mechanisms.
A foundational approach is the ConvLSTM [29], which integrates LSTM-style memory into convolutional layers to jointly model spatial and temporal dynamics. Building on this, PredRNN [30] introduced dual-memory structures with spatiotemporal alignment, which became a widely used benchmark. Extensions like Dual-ConvLSTM [31] have demonstrated adaptability to tasks beyond video, such as vision–language alignment.
In addition, transformer-based sequence generation models have also been explored. For example, TimeSformer [32] introduces a space–time attention mechanism to capture both spatial and temporal dependencies in video tasks, demonstrating strong performance in modeling long-term consistency. Such transformer-based approaches represent a promising direction for autoregressive image sequence generation, complementing recurrent architectures.
More recently, diffusion-based models have achieved state-of-the-art results in high-fidelity image synthesis. DDPM [33] and LDM [20] reconstruct images via iterative denoising, producing high-quality results in unconditional and conditional settings. Extensions such as blended diffusion [34], low-light generation [35], and hybrid ConvLSTM–diffusion models for neuron segmentation [36] illustrate the versatility of this approach.
While our previous study [6] showed that a lightweight encoder–decoder could generate sketches faster than PredRNN, it lagged in quality. In this paper, we extend that work by introducing variational inference and skip-connected architectures, demonstrating improvements in both quality and efficiency.
2.4. Research on Generative AI for Character Image Generation and Drawing Support
Advances in generative AI have significantly influenced character design and sketching support. Tools like Sketchar [37] highlight the potential of generative systems to assist non-experts in prototyping and refining characters. Similarly, GANs and VAEs have been applied to anime-style and hand-drawn character generation [38,39], achieving strong performance measured by Fréchet Inception Distance (FID) and Inception Score (IS).
Beyond static image generation, process-oriented models have been proposed to support drawing itself. AI Sketcher [40] integrates CNN-based encoding and influence layers for stroke-level guidance, addressing the limitations of earlier models like Sketch-RNN. Sketch-pix2seq [41] combines convolutional and recurrent layers to jointly model the spatial and temporal aspects of sketching.
Generative AI has also been integrated into co-creative and educational tools. DesignAID [42], for example, combines large language models with image generation to help users explore diverse visual concepts. In education, systems have been proposed to record and replay drawing processes [43] or to provide real-time instructional support through robotic gestures [44].
Most prior work has focused either on generating final images or on assisting composition and ideation. In contrast, our study emphasizes generating the intermediate drawing process itself. Moreover, unlike previous works that primarily target applications, this paper focuses on model-level enhancements—such as VAE-based sampling and U-Net-style skip connections—to improve the quality and controllability of generated sequences. These advances allow our system to function as both a generative backbone and an interactive drawing support tool.
2.5. Positioning of This Study
As reviewed above, prior research in generative AI for character design and drawing support has primarily focused on application-level tools (e.g., sketch assistants and ideation systems) or domain-specific frameworks based on GANs and sequence models. While these contributions are valuable, they often target final image generation or user-facing features without deeply modifying the generative architecture itself.
In contrast, our study approaches the problem from a model-level perspective. Building upon our earlier encoder–decoder framework [6], we introduce two key enhancements: a VAE-style latent sampling mechanism to improve generalization and skip connections inspired by U-Net to preserve spatial detail.
These modifications are both theoretically motivated and empirically validated against our prior model and a state-of-the-art predictor, PredRNN. The results demonstrate improved generation quality while maintaining computational efficiency.
Thus, this work occupies a unique position at the intersection of generative architecture research and sketch-based AI applications. It contributes a lightweight yet high-performing model that can serve as a foundation for drawing support systems requiring both temporal consistency and user interactivity.
3. Proposed Architecture
This section describes the proposed generative model architecture, which extends a baseline encoder–decoder framework with two key components: variational latent sampling and skip connections. These enhancements are designed to improve both the diversity and spatial coherence of generated images, particularly in the context of sequential drawing generation.
3.1. Overview of the Architecture
The model follows a convolutional encoder–decoder design that maps an input image to a latent representation and reconstructs the corresponding output. As shown in Figure 2, the architecture consists of three main modules: (1) a convolutional encoder, (2) a variational bottleneck, and (3) a decoder with skip connections.
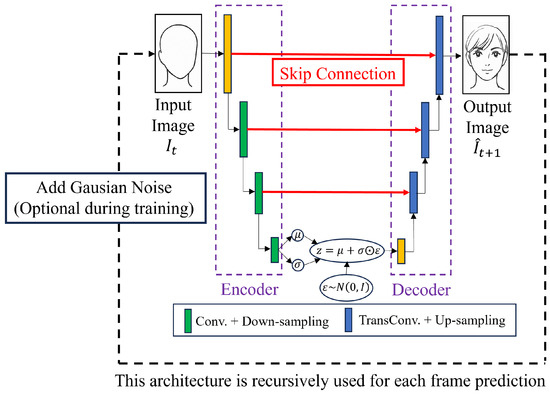
Figure 2.
Architecture of the proposed model. Black arrows indicate the forward data flow, and red arrows represent skip connections between corresponding encoder and decoder layers.
The encoder comprises stacked convolutional layers that progressively downsample the input while extracting hierarchical features. These features are mapped to a latent distribution through two parallel fully connected layers, producing vectors and that represent the mean and standard deviation of a Gaussian distribution. A latent vector z is then sampled using the reparameterization trick [7]:
where and are the mean and standard deviation vectors predicted by the encoder, is a random noise vector sampled from the standard normal distribution, and ⊙ denotes element-wise multiplication.
The decoder reconstructs an image from z using a series of transposed convolutional layers. To preserve spatial details lost during downsampling, skip connections are introduced between corresponding encoder and decoder layers, following the U-Net design [16]. These connections allow the decoder to leverage fine-grained features from earlier encoding stages.
3.2. Training Objective
The model is trained to minimize a composite loss function that balances reconstruction fidelity and latent regularization. Specifically, the total loss L consists of a pixel-wise reconstruction loss and the Kullback–Leibler divergence between the learned latent distribution and a standard normal prior:
The reconstruction loss is defined as the mean squared error (MSE) between the predicted image and the ground truth x. The KL divergence is given by the following:
The hyperparameter controls the strength of regularization, allowing for a trade-off between reconstruction accuracy and latent space disentanglement.
3.3. Input and Output Formats
The model is designed for sequential image prediction. At each step, the input represents the current drawing state, and the output predicts the next state. During training, pairs of consecutive frames are used to learn the transition dynamics.
For the final input frame , the model is trained to reproduce the same image as output, i.e., , to stabilize autoregressive generation and prevent out-of-distribution behavior at the sequence endpoint.
This formulation supports both one-step prediction and autoregressive generation, enabling flexible integration into real-time drawing support systems.
4. Experimental Setup
This section describes the experimental design used to evaluate the proposed generative model. We detail the dataset construction process, model architectures, training methodology, and baseline comparisons. Because publicly available datasets of stepwise drawing sequences are scarce and unsuitable for our purposes, we constructed a custom dataset of character illustrations specifically for this study.
4.1. Dataset Construction
To assess the model’s ability to generate intermediate drawing states, we built a custom dataset of sequential images from the drawing processes of ten original characters. Each character was illustrated by a single designer using a digital drawing tool with layer-based editing. The drawing of each character was divided into six stages, with details incrementally added from rough outlines to completed illustrations.
Figure 3 shows the ten character designs used for training. Figure 4 and Figure 5 illustrate the drawing sequences of the top-left and top-right characters in Figure 3. To improve visibility and reduce ambiguity during training, all images were rendered with a green background, as many characters included light-colored elements.

Figure 3.
Illustrations of the ten character designs used for training.
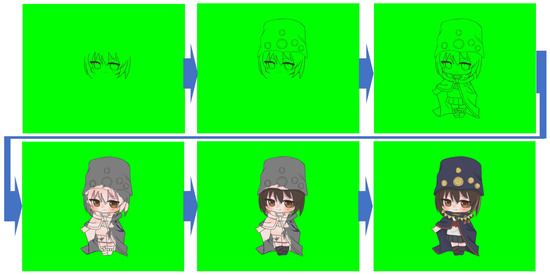
Figure 4.
Drawing sequence of the top-left character shown in Figure 3.
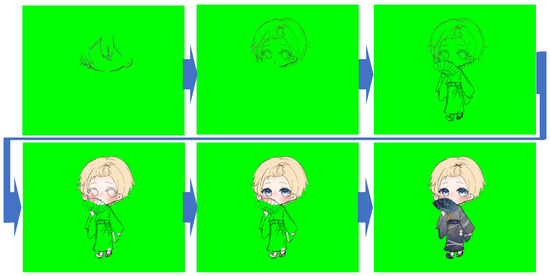
Figure 5.
Drawing sequence of the top-right character shown in Figure 3.
All images were resized to pixels to match the model architecture, which applies five stages of downsampling and upsampling. Each dataset entry consists of six sequential frames representing the drawing progression.
4.2. Model Architecture
The models evaluated in this study are based on convolutional encoder–decoder networks implemented in PyTorch (ver. 2.7.0). Three architectural variants were tested:
- Baseline CNN: A standard convolutional encoder–decoder.
- VAE: The baseline model with a variational bottleneck for stochastic latent sampling.
- VAE+U-Net: A skip-connected extension of the VAE using U-Net-style skip connections to preserve spatial detail.
Each encoder comprises five convolutional layers with ReLU activations and progressively increasing channel sizes. The decoder mirrors this structure with five transposed convolutional layers. In the VAE+U-Net model, skip connections link each encoder layer to its corresponding decoder layer.
Table 1 and Table 2 summarize the encoder and decoder parameters. The final output is a three-channel RGB image predicting the next stage in the drawing sequence.

Table 1.
Encoder architecture parameters. Abbreviations: InCh = Input Channels; OutCh = Output Channels; Ksize = Kernel Size; Strd = Stride; Pad = Padding.
Table 2.
Decoder architecture parameters. Abbreviations: InCh = Input Channels; OutCh = Output Channels; Ksize = Kernel Size; Strd = Stride; Pad = Padding; OutPad = Output Padding.
4.3. Training Procedure
Two training strategies were employed to analyze the effect of data augmentation:
- 1.
- Standard Training: Each of the 10 characters (6 stages each) yields 60 image pairs . In our previous work [6], the Baseline CNN trained without noise augmentation showed markedly lower performance. Therefore, in this study we omit the standard training condition for the Baseline CNN.
- 2.
- Noise-Augmented Training: For the Baseline CNN, each of the 60 base images was augmented with 99 noisy variants using Gaussian noise, resulting in 6000 training samples (as in our previous work [6]). For the VAE and VAE+U-Net, each base image was augmented with nine noisy variants, yielding 600 samples in total.
All models were trained until convergence, with epoch counts determined by observing validation loss saturation. Table 3 lists the configurations.
Table 3.
Number of training epochs per model and training condition.
To ensure fairness, all models used the same architecture within their category and were trained with stochastic gradient descent (SGD) at a fixed learning rate of 0.01. The batch size was 8 for standard training and 64 for noise-augmented training. Training was conducted on a workstation with an NVIDIA RTX 4080 GPU and 32 GB RAM.
The objective function was mean squared error (MSE) between the prediction and ground truth. For VAE-based models, an additional KL divergence term was included to regularize the latent space, as defined in Section 3.2.
4.4. Baseline: PredRNN
To contextualize our model’s performance, we compared it against PredRNN [30], a widely used spatiotemporal predictor. We employed its official PyTorch implementation, adapted to our dataset.
Training and evaluation conditions matched those of our model. Performance was assessed using three metrics:
- PSNR (Peak Signal-to-Noise Ratio).
- SSIM (Structural Similarity Index).
- LPIPS (Learned Perceptual Image Patch Similarity).
These metrics were computed frame-by-frame across entire predicted sequences, providing a detailed view of image quality and temporal consistency.
5. Experimental Results
This section evaluates the effectiveness of the proposed models. We first present frame-wise quantitative results using SSIM, PSNR, and LPIPS to assess image quality over sequential predictions (Section 5.1). We then report per-character scores at the final output frame to highlight model-wise differences (Section 5.2). Finally, we provide qualitative comparisons for representative characters that exhibited notable performance differences (Section 5.3).
5.1. Frame-Wise Quantitative Evaluation
We conducted a frame-wise analysis using Structural Similarity Index Measure (SSIM), Peak Signal-to-Noise Ratio (PSNR), and Learned Perceptual Image Patch Similarity (LPIPS). The evaluation was performed on generated sequences of five predicted frames (i.e., frames 1–5), where the initial image served as the input and predictions – were compared against –.
Figure 6, Figure 7 and Figure 8 show results across five steps for all models. Among them, the VAE trained with noise augmentation achieved the highest SSIM/PSNR and the lowest (best) LPIPS, indicating stronger fidelity and perceptual quality. These gains suggest that the variational bottleneck, together with robustness to noisy inputs, improves long-horizon stability.
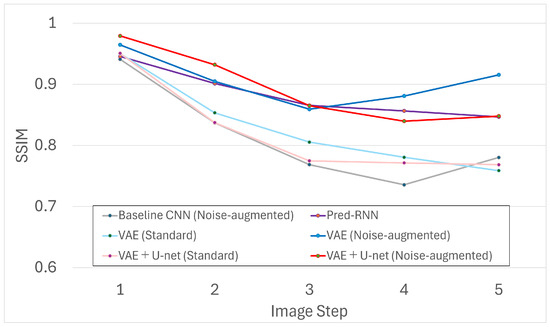
Figure 6.
Frame-wise SSIM scores across five predicted steps.
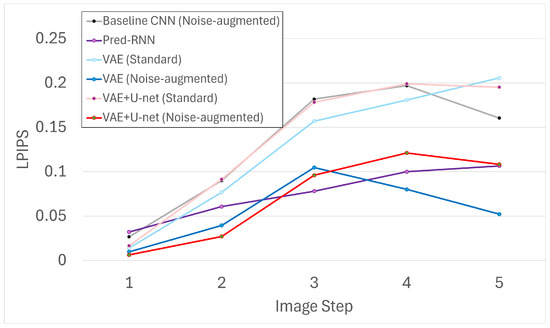
Figure 7.
Frame-wise LPIPS scores across five predicted steps.
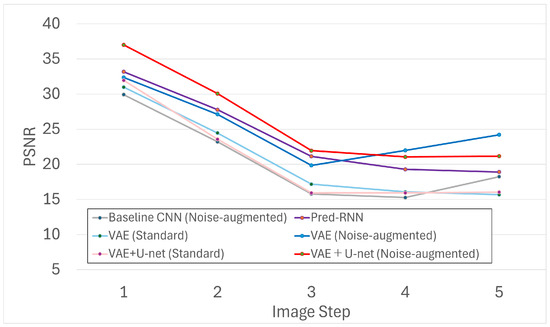
Figure 8.
Frame-wise PSNR scores across five predicted steps.
As expected, quality declines as the prediction step increases. This trend reflects error accumulation, where small discrepancies at earlier steps compound and manifest as structural distortions in later frames. Even so, the VAE and VAE+U-Net models with noise augmentation maintained relatively high SSIM/PSNR at later steps, whereas the Baseline CNN—despite noise augmentation—dropped sharply beyond the second step.
To probe longer horizons, we extended generation to 14 frames and evaluated the same metrics for VAE and VAE+U-Net (with and without noise). The results are shown in Figure 9, Figure 10 and Figure 11.
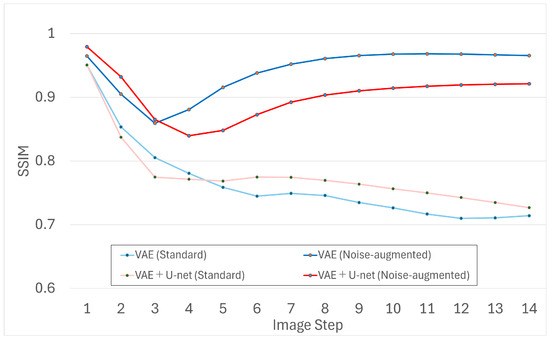
Figure 9.
SSIM scores for 14-frame generation with VAE and VAE+U-Net.
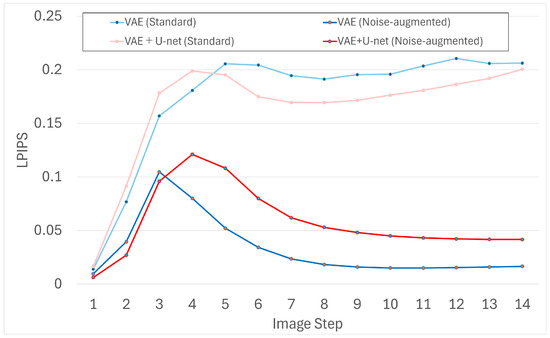
Figure 10.
LPIPS scores for 14-frame generation with VAE and VAE+U-Net.
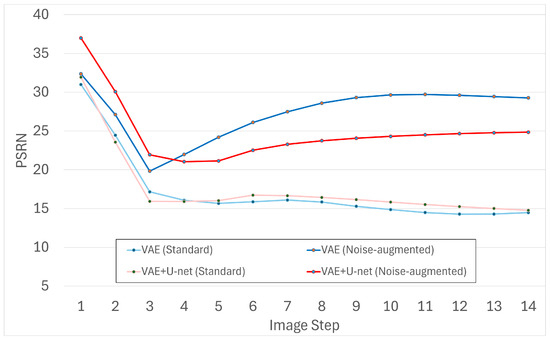
Figure 11.
PSNR scores for 14-frame generation with VAE and VAE+U-Net.
The extended evaluation confirms the same pattern. Noise-augmented models—particularly the VAE—mitigate cumulative error more effectively, yielding more stable and detailed outputs even beyond the five-frame training horizon. Models trained without noise tended to accumulate artifacts or stagnate earlier.
5.2. Quantitative Comparison on Final Frame
To compare the final predicted images (), we computed character-wise SSIM, LPIPS, and PSNR for three models: VAE (Noise-Augmented), VAE+U-Net (Noise-Augmented), and PredRNN. Table 4 summarizes the results. The best value per metric is highlighted in red, and the overall best-performing model per character appears in the rightmost column.
Table 4.
Quantitative evaluation of final frame () for each character. Best values are highlighted in red.
Overall, the VAE achieved the best performance in 5 out of 10 characters (#1, #2, #5, #9, #10). In these cases, the gap between them and the other models was substantial. For example, on character #2, the VAE reached 31.57 dB PSNR, compared with 16.95 dB and 16.94 dB for VAE+U-Net and PredRNN. This trend indicates strong robustness where structural clarity is low or features are subtle.
When VAE+U-Net or PredRNN performed best (#3, #4, #6–#8), the VAE remained competitive with small margins. For instance, on character #6, VAE+U-Net achieved 33.04 dB PSNR, while the VAE still obtained high perceptual quality (SSIM 0.95, LPIPS 0.03).
These results suggest an asymmetric relationship: when the VAE is best, competing models often fail conspicuously; when it is not best, the VAE remains close to the top performer. The combination of a variational bottleneck and U-Net-style skip connections further improved performance on several characters (e.g., #3, #6, #7), indicating complementary benefits beyond those achieved by a temporal predictor such as PredRNN.
5.3. Qualitative Evaluation
We further compared the visual outputs of the VAE and VAE+U-Net models trained with noise augmentation. Figure 12, Figure 13, Figure 14 and Figure 15 present the predictions: Figure 12 shows the VAE at the 5th frame, Figure 13 the VAE+U-Net at the 5th frame, Figure 14 the VAE at the 14th frame, and Figure 15 the VAE+U-Net at the 14th frame.

Figure 12.
VAE (Noise-augmented): Output at frame 5.

Figure 13.
VAE+U-Net (Noise-augmented): Output at frame 5.

Figure 14.
VAE (Noise-augmented): Output at frame 14.

Figure 15.
VAE+U-Net (Noise-augmented): Output at frame 14.
Both models maintain visual consistency across frames, but the VAE consistently produced clearer, more stable character shapes at later time steps. The VAE+U-Net, while sometimes preserving fine details in early frames (e.g., frame 5), often degraded over long horizons, showing fragmented or distorted forms by frame 14. These observations align with the quantitative trends and the discussion in Section 6: skip connections can propagate low-level features that, in autoregressive settings, exacerbate error accumulation and destabilize global structure over time. Overall, the VAE-only model exhibited superior robustness and reliability in long-term generation.
6. Discussion
This study investigated how a variational autoencoder (VAE) and U-Net-style skip connections affect the quality and robustness of sequential image generation for character drawing processes. The experiments yield several findings and point to promising directions for future work.
6.1. Advantages of Variational Bottleneck and Noise Augmentation
Introducing a variational bottleneck enables the model to encode probabilistic representations of intermediate drawing states, reducing overfitting to limited patterns and supporting more plausible, diverse transitions. The benefit is most apparent when combined with noise-augmented training: the VAE (noise-augmented) consistently outperformed other models, especially for long-horizon generation beyond the fifth frame.
Gaussian noise acted as a regularizer, improving generalization to unseen or ambiguous drawing states. This was particularly helpful at later steps, where small deviations otherwise accumulate and degrade output quality. Although the Baseline CNN also gained from noise, its performance plateaued after the second frame, unlike the VAE-based models, which continued to produce coherent structures.
Across Figure 6, Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11, all models showed a gradual decline in performance as the number of generation steps increased. This degradation can be attributed to error accumulation, where small deviations at earlier steps compound over time, leading to structural collapse or loss of detail in later frames. The VAE model, by leveraging probabilistic latent sampling and noise augmentation, effectively reduced this cumulative effect, resulting in greater stability and quality in long-term generation. It is also worth noting that the quantitative metrics used in this study (PSNR, SSIM, LPIPS) primarily capture pixel- or feature-level similarity and may not fully reflect higher-level aspects such as the reasonableness of the drawing process or the coherence of creative intent. Future work will therefore incorporate user studies or subjective evaluations to provide a more comprehensive understanding of perceived quality in sequential drawing generation.
6.2. Effects of Skip Connections in Sequential Prediction
U-Net-style skip connections were introduced to preserve spatial detail. The results, however, indicate a trade-off. While skip connections improved detail retention in some cases (e.g., higher LPIPS gains for certain characters), they also increased the risk of structural collapse in longer sequences, suggesting that the direct propagation of low-level features can interfere with the abstraction needed for temporal consistency.
In qualitative evaluations (Section 5.3), the U-Net-enhanced model often produced artifacts or disjointed features after the fifth frame—effects not observed in the simpler, VAE-only model. This implies that, although effective in segmentation and restoration, skip connections may not always be suitable for autoregressive generation where controlled abstraction and compression are critical.
From a theoretical perspective, autoregressive generation requires progressively abstracting and compressing information so that each prediction depends on temporally coherent high-level representations. Direct propagation of low-level features via skip connections can bypass this abstraction, causing the decoder to rely excessively on local details that do not align across time steps. As a result, small inconsistencies are amplified and accumulate as artifacts in long sequences. This contrasts with image restoration or segmentation, where retaining fine-grained spatial details is beneficial because predictions are conditioned on the full input at once. Therefore, in sequential prediction, skip connections can interfere with the formation of globally consistent temporal dynamics.
To further clarify this point, future work could incorporate feature map visualizations or attention map analyses. Such analyses would show how skip connections selectively transmit low-level spatial information and where they might disrupt global temporal modeling. By highlighting which regions or features dominate in the decoder across steps, these visualizations could help explain why skip connections sometimes cause structural artifacts in long-term predictions.
6.3. Limitations and Future Extensions
Despite the performance gains, several limitations remain. First, the current model does not include recurrent structures such as ConvLSTM or PredRNN, which are effective for temporal dependency modeling. Our prior work [6] showed that PredRNN achieved higher accuracy in some cases, albeit with longer inference. Integrating recurrent mechanisms into the VAE framework is a promising direction to better capture long-term dependencies without sacrificing stochasticity.
Second, all experiments used relatively small images (160 × 128 pixels). While this choice favored computational feasibility and architectural compatibility, real-world applications (e.g., sketch-based design tools) often require higher resolutions. Future work will therefore evaluate the proposed models on higher-resolution inputs (e.g., 256 × 256 or 512 × 512) to verify scalability and practical utility in real-world drawing environments.
Third, the dataset contained six stages per character. Although this supports learning local transitions, it limits modeling of long-range dependencies. As shown in Section 5.1, the VAE-based model was capable of generating up to 14 frames; increasing the number of intermediate states (e.g., 10–20 per character) could enable smoother, more realistic transitions. In addition, the dataset is relatively small (10 characters, 6 stages each) and not publicly available, which limits generalizability and reproducibility. We constructed a custom dataset because public resources such as QuickDraw or Sketch-RNN primarily provide stroke-level vector data rather than rasterized stepwise images. Our task required consistent intermediate raster images to capture structural transitions across stages, which are not directly available in those datasets. Future work should expand the dataset in scale and diversity, and make it publicly accessible to support reproducibility and broader comparison.
Fourth, while this study compared against a baseline CNN and PredRNN, it did not include more advanced sequence-generation architectures such as transformer-based models (e.g., TimeSformer [32]) and diffusion models (e.g., DDPM [33], LDM [20]). Incorporating these approaches would allow for a more comprehensive evaluation of scalability and generalization.
7. Conclusions and Future Work
This study introduced a deep generative framework for modeling the intermediate drawing stages of character illustrations. By incorporating a variational bottleneck (VAE), U-Net-style skip connections, and noise-augmented training into an encoder–decoder architecture, we aimed to improve generalization and visual coherence in sequential generation.
The experimental results demonstrated the following:
- The VAE with noise augmentation outperformed both the baseline CNN and PredRNN across SSIM, PSNR, and LPIPS, particularly in long-sequence generation tasks (up to 14 frames).
- U-Net skip connections had mixed effects: they preserved local details in some cases but occasionally degraded later frames due to error accumulation.
- Noise augmentation consistently improved robustness and generalization across all architectures, serving as an effective regularizer.
These findings suggest that the proposed model provides a promising approach for sequential image generation in drawing support systems. Unlike existing models that focus solely on final outputs, our framework represents the full drawing process, offering potential benefits for both educational and creative applications.
Future research will extend this work in the following directions:
- 1.
- Incorporating Recurrent Structures: The current model lacks explicit temporal memory. Integrating modules such as ConvLSTM or attention-based recurrence into the VAE could enhance long-term consistency while retaining generative flexibility.
- 2.
- Scaling to Higher-Resolution Outputs: Extending the model to higher resolutions (e.g., 256 × 256 or larger) will increase its applicability in real-world illustration and design environments.
- 3.
- Increasing the Number of Drawing Stages: Our dataset currently contains six stages per character. Expanding to finer-grained sequences (e.g., 10–20 stages) would improve long-horizon modeling.
- 4.
- Supporting Interactive and Real-Time Generation: Developing a co-creative interface that allows users to input partial drawings and receive real-time continuations will enhance the system’s usability for education and creativity.
- 5.
- Exploring Domain Transfer and Style Control: Future work will examine whether the framework generalizes to domains such as manga, architectural sketches, or animation. Adding style-conditioning mechanisms could enable user control over visual tone.
In summary, the proposed model offers a practical and extensible framework for generative modeling of the sketching process. By expanding its resolution, dataset scope, and interactive features, it has the potential to serve as a foundation for future AI-assisted drawing environments.
Author Contributions
Conceptualization, A.N. and S.N.; methodology, A.N.; software, A.N.; validation, A.N., H.M., K.C. and S.N.; formal analysis, S.N.; investigation, A.N.; data curation, A.N.; writing—original draft preparation, A.N.; writing—review and editing, A.N. and S.N.; visualization, H.M. and K.C.; supervision, S.N.; project administration, S.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by JSPS KAKENHI Grant Number JP23K11277.
Data Availability Statement
The dataset used in this study consists of hand-created drawing process images and is not publicly available due to privacy and copyright considerations, as the hand-drawn data constitutes the personal intellectual property of the creators. However, the data may be made available from the corresponding author upon reasonable request.
Acknowledgments
We would like to thank the members of the Nishide Laboratory at Kyoto Tachibana University for their support in preparing the dataset and experimental setup. During the preparation of this manuscript, the authors used ChatGPT (OpenAI, GPT-4.0, May 2025) to verify ideas and improve clarity. All authors reviewed and edited the output and take full responsibility for the content.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| VAE | Variational Autoencoder |
| U-Net | U-shaped Convolutional Neural Network |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index |
| LPIPS | Learned Perceptual Image Patch Similarity |
| RNN | Recurrent Neural Network |
| PredRNN | Predictive Recurrent Neural Network |
| GAN | Generative Adversarial Network |
| GPU | Graphics Processing Unit |
| SGD | Stochastic Gradient Descent |
| MSE | Mean Squared Error |
| RGB | Red-Green-Blue (color space) |
| FID | Fréchet Inception Distance |
| IS | Inception Score |
References
- Ho, J.; Saharia, C.; Chan, W.; Fleet, D.J.; Norouzi, M.; Salimans, T. Cascaded Diffusion Models for High Fidelity Image Generation. J. Mach. Learn. Res. 2022, 23, 2249–2281. [Google Scholar]
- Chen, H.; Xiang, Q.; Hu, J.; Ye, M.; Yu, C.; Cheng, H.; Zhang, L. Comprehensive Exploration of Diffusion Models in Image Generation: A Survey. Artif. Intell. Rev. 2025, 58, 99. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Zhang, X.S. MEF-GAN: Multi-Exposure Image Fusion via Generative Adversarial Networks. IEEE Trans. Image Process. 2020, 29, 7203–7216. [Google Scholar]
- Kang, M.; Shin, J.; Park, J. StudioGAN: A Taxonomy and Benchmark of GANs for Image Synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15725–15742. [Google Scholar] [CrossRef]
- Sorin, V.; Barash, Y.; Konen, E.; Klang, E. Creating Artificial Images for Radiology Applications Using Generative Adversarial Networks (GANs) – A Systematic Review. Acad. Radiol. 2020, 27, 1175–1185. [Google Scholar] [CrossRef]
- Matsumoto, H.; Nakamura, A.; Nishide, S. Learning and Generation of Drawing Sequences Using a Deep Network for a Drawing Support System. Appl. Sci. 2025, 15, 7038. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Vahdat, A.; Kautz, J. NVAE: A Deep Hierarchical Variational Autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- van den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural Discrete Representation Learning. Adv. Neural Inf. Process. Syst. 2017, 30, 1–9. [Google Scholar]
- Razavi, A.; van den Oord, A.; Vinyals, O. Generating Diverse High-Fidelity Images with VQ-VAE-2. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Yu, J.; Li, X.; Koh, J.Y.; Zhang, H.; Pang, R.; Qin, J.; Ku, A.; Xu, Y.; Baldridge, J.; Wu, Y. Vector-Quantized Image Modeling with Improved VQGAN. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 25–29 April 2022; pp. 1–13. [Google Scholar]
- Sun, M.; Wang, W.; Zhu, X.; Liu, J. Reparameterizing and Dynamically Quantizing Image Features for Image Generation. Pattern Recognit. 2024, 146, 109962. [Google Scholar]
- Wei, R.; Garcia, C.; El-Sayed, A.; Peterson, V.; Mahmood, A. Variations in Variational Autoencoders: A Comparative Evaluation. IEEE Access 2020, 8, 153651–153670. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. Beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–13. [Google Scholar]
- Liu, J. Research on the Application of Variational Autoencoder in Image Generation. ITM Web Conf. 2025, 70, 02001. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic Image Synthesis with Spatially-Adaptive Normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2337–2346. [Google Scholar]
- Baur, C.; Wiestler, B.; Albarqouni, S.; Navab, N. Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images. arXiv 2018, arXiv:1804.04488. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis (DLMIA) Workshop, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Ovadia, O.; Oommen, V.; Kahana, A.; Peyvan, A.; Turkel, E.; Karniadakis, G.E. Real-time Inference and Extrapolation with Time-Conditioned UNet: Applications in Hypersonic Flows, Incompressible Flows, and Global Temperature Forecasting. Comput. Methods Appl. Mech. Eng. 2025, 441, 117982. [Google Scholar] [CrossRef]
- Villegas, R.; Yang, J.; Hong, S.; Lin, X.; Lee, H. Decomposing Motion and Content for Natural Video Sequence Prediction. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–12. [Google Scholar]
- Kim, M.; Jo, H.; Ra, M.; Kim, W.-Y. Weakly-Supervised Defect Segmentation on Periodic Textures Using CycleGAN. IEEE Access 2020, 8, 176202–176216. [Google Scholar] [CrossRef]
- Zhu, G.; Liu, J.; Fan, Z.; Yuan, D.; Ma, P.; Wang, M.; Sheng, W.; Wang, K.C.P. A Lightweight Encoder–Decoder Network for Automatic Pavement Crack Detection. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 1743–1765. [Google Scholar] [CrossRef]
- Peng, Y.; Sonka, M.; Chen, D.Z. U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation. arXiv 2023, arXiv:2311.17791. [Google Scholar]
- Wang, H.; Cao, P.; Yang, J.; Zaiane, O. Narrowing the semantic gaps in U-Net with learnable skip connections: The case of medical image segmentation. Neural Netw. 2024, 178, 106546. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Yu, P.S. PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12345–12357. [Google Scholar] [CrossRef]
- Zuo, Y.; Li, L.; Wang, Y.; Qiao, Y. Dual Convolutional LSTM Network for Referring Image Segmentation. IEEE Trans. Multimedia 2022, 25, 2501–2513. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is Space-Time Attention All You Need for Video Understanding? In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 813–824. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Avrahami, O.; Bahat, Y.; Dekel, T. Blended Diffusion for Text-driven Editing of Natural Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18208–18218. [Google Scholar]
- Chan, K.C.K.; Xie, J.; Lu, W.; Loy, C.C. GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14257–14266. [Google Scholar]
- Zhou, J.; Liu, Y.; Zhu, Y.; Zhang, Z.; Li, R. Accurately 3D Neuron Localization Using 2D Conv-LSTM Super-Resolution Segmentation. IET Image Process. 2023, 17, 1234–1246. [Google Scholar] [CrossRef]
- Ling, L.; Chen, X.; Wen, R.; Li, T.; LC, R. Sketchar: Supporting Character Design and Illustration Prototyping Using Generative AI. Proc. ACM Hum.-Comput. Interact. 2024, 8, 337. [Google Scholar] [CrossRef]
- Noor, N.Q.M.; Zabidi, A.; Jaya, M.I.B.M.; Ler, T.J. Performance Comparison between Generative Adversarial Networks (GAN) Variants in Generating Anime/Comic Character Images—A Preliminary Result. In Proceedings of the IEEE International Symposium on Industrial Electronics (ISIE), Ulsan, Korea, 18–21 June 2024; pp. 248–252. [Google Scholar]
- Kırbıyık, Ö.; Simsar, E.; Cemgil, A.T. Comparison of Deep Generative Models for the Generation of Handwritten Character Images. In Proceedings of the 27th Signal Process. Commun. Appl. Conf., Sivas, Turkey, 24–26 April 2019; pp. 1–4. [Google Scholar]
- Cao, N.; Yan, X.; Shi, Y.; Chen, C. AI-Sketcher: A Deep Generative Model for Producing High-Quality Sketches. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 2564–2571. [Google Scholar]
- Chen, Y.; Tu, S.; Yi, Y.; Xu, L. Sketch-pix2seq: A Model to Generate Sketches of Multiple Categories. arXiv 2017, arXiv:1709.04121. [Google Scholar]
- Cai, A.; Rick, S.R.; Heyman, J.; Zhang, Y.; Filipowicz, A.; Hong, M.K.; Klenk, M.; Malone, T. DesignAID: Using Generative AI and Semantic Diversity for Design Inspiration. In Proceedings of the ACM Collective Intelligence Conference, Delft, The Netherlands, 7–9 November 2023; pp. 1–11. [Google Scholar]
- Nagai, T.; Kayama, M.; Itoh, K. A Drawing Learning Support System Based on the Drawing Process Model. Interact. Technol. Smart Educ. 2014, 11, 146–164. [Google Scholar] [CrossRef]
- Hiroi, Y.; Ito, A. A Robotic System for Remote Teaching of Technical Drawing. Educ. Sci. 2023, 13, 347. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).