Abstract
Intrusion detection in the Internet of Things (IoT) environments is increasingly critical due to the rapid proliferation of connected devices and the growing sophistication of cyber threats. Traditional detection methods often fall short in identifying multi-class attacks, particularly in the presence of high-dimensional and imbalanced IoT traffic. To address these challenges, this paper proposes a novel hybrid intrusion detection framework that integrates transformer networks with generative adversarial networks (GANs), aiming to enhance both detection accuracy and robustness. In the proposed architecture, the transformer component effectively models temporal and contextual dependencies within traffic sequences, while the GAN component generates synthetic data to improve feature diversity and mitigate class imbalance. Additionally, an improved non-dominated sorting biogeography-based optimization (INSBBO) algorithm is employed to fine-tune the hyper-parameters of the hybrid model, further enhancing learning stability and detection performance. The model is trained and evaluated on the CIC-IoT-2023 and TON_IoT dataset, which contains a diverse range of real-world IoT traffic and attack scenarios. Experimental results show that our hybrid framework consistently outperforms baseline methods, in both binary and multi-class intrusion detection tasks. The transformer-GAN achieves a multi-class classification accuracy of 99.67%, with an F1-score of 99.61%, and an area under the curve (AUC) of 99.80% in the CIC-IoT-2023 dataset, and achieves 98.84% accuracy, 98.79% F1-score, and 99.12% AUC on the TON_IoT dataset. The superiority of the proposed model was further validated through statistically significant t-test results, lower execution time compared to baselines, and minimal standard deviation across runs, indicating both efficiency and stability. The proposed framework offers a promising approach for enhancing the security and resilience of next-generation IoT systems.
1. Introduction
The Internet of Things (IoT) has emerged as a transformative paradigm in modern computing, enabling billions of interconnected devices to sense, communicate, and act upon their environments in real time [1,2,3]. From smart homes and wearable healthcare devices to industrial automation and smart cities, IoT systems are deeply integrated into both consumer and mission-critical infrastructures [4,5,6]. According to recent forecasts, the global number of IoT devices is expected to surpass 30 billion by 2025, generating nearly 80 zettabytes of data annually. These systems operate across heterogeneous platforms and network protocols, producing complex, high-dimensional traffic that reflects intricate temporal and contextual patterns [7,8,9]. While this vast interconnectivity enhances operational efficiency and real-time decision-making, it also significantly expands the potential attack surface, especially given the often resource-constrained nature of IoT hardware and the absence of consistent security standards [10,11,12,13].
As IoT networks scale in size and complexity, they become increasingly attractive targets for cyber adversaries. Studies report that over half of all IoT devices exhibit vulnerabilities to medium or high-severity threats, and attacks exploiting weak authentication, firmware flaws, or open ports are rising sharply [14,15,16]. Sophisticated intrusion vectors such as distributed denial-of-service (DDoS), spoofing, reconnaissance, and malware injection can compromise device integrity and lead to widespread disruption or data breaches. In this landscape, the role of Intrusion Detection Systems (IDS) is vital, not merely to detect known threats, but to identify evolving and previously unseen attacks in real time [17]. However, conventional IDS methods often fall short when faced with the high-dimensional, imbalanced, and dynamic nature of IoT traffic [18]. This highlights an urgent need for intelligent, adaptive, and robust intrusion detection frameworks capable of extracting meaningful features from vast traffic streams and accurately discriminating between benign and malicious behaviors, even under rapidly shifting network conditions [19].
1.1. Related Works
Numerous research efforts have been devoted to enhancing intrusion detection in IoT networks using a variety of machine learning (ML), deep learning (DL), and optimization techniques. Given the rapid proliferation of IoT devices and the growing diversity of cyber threats, recent studies have focused on developing intelligent and adaptive IDS capable of detecting both known and emerging attacks. These approaches range from conventional neural networks (NNs) to advanced frameworks incorporating attention mechanisms, deep reinforcement learning (DRL), and hybrid architectures. The availability of modern and realistic datasets, such as CIC-IoT-2023 and ToN-IoT, has further enabled more reliable benchmarking and performance evaluation of these models. The following studies illustrate key advancements in this domain and provide context for the development of our proposed transformer generative adversarial network (GAN)-based IDS framework.
In [20], the authors proposed a federated edge learning framework for IoT intrusion detection using the CIC-IoT-2023 dataset. Their approach leverages a federated deep neural network trained with data preprocessing techniques such as normalization and balancing to detect large-scale cyberattacks. The method achieved a high accuracy of 99.00%, demonstrating its effectiveness, although its reliance on centralized aggregation and lack of adversarial learning may limit robustness in more complex threat scenarios. In [21], the authors conducted a comparative study of six DL models, including CNN, LSTM, and hybrid architectures like CNN + LSTM, for anomaly detection using the CSE-CIC-IDS2018 dataset. Their results indicated that while hybrid models achieved high accuracy (>98%), standalone DNN, CNN, and RNN models were more efficient in inference time. However, the study focused on older datasets and lacked advanced optimization strategies, such as evolutionary or adversarial techniques, for real-world IoT adaptability.
In [22], the authors introduced a modified transformer neural network (MTNN) to enhance intrusion detection in IoT networks. Using the ToN-IoT dataset, their transformer-based IDS outperformed LSTM and RNN baselines in accuracy, precision, recall, and F-score, highlighting the transformer’s effectiveness for capturing temporal patterns. Unlike our proposed approach, the MTNN did not incorporate synthetic data generation or multi-objective optimization to handle class imbalance and model generalization. In [23], the authors explored anomaly detection using temporal convolutional networks and U-Net models. Although their approach achieved strong performance on the CSE-CIC-IDS2018 and KDD99 datasets (up to 97% accuracy), the study also revealed the limitations of older datasets and emphasized the risk of overfitting. Their work supports the importance of using realistic and diverse datasets, like CIC-IoT-2023, as employed in our research. In [24], the authors proposed TA-NIDS, a transferable intrusion detection framework based on DRL. This model emphasizes adaptability and sample efficiency, allowing it to perform well even with limited training data. While the method shows promising transferability across datasets including CIC-IoT-2023, it lacks the generative capabilities and structured attention mechanisms that our Transformer-GAN hybrid leverages for deeper feature learning and synthetic augmentation. In [25], the authors implemented an LSTM-based intrusion detection system using the CIC-IoT-2023 dataset. Their model achieved strong results (98.75% accuracy and 98.59% F1-score), showcasing LSTM’s ability to capture temporal dependencies. However, the model’s reliance solely on sequential learning without adversarial training or optimization algorithms restricts its generalization to more imbalanced or evolving threat scenarios.
In [26], the authors proposed a hybrid ML approach for classifying web-based attacks using TPOT and genetic algorithms for parameter optimization. Their best-performing classifier, Gradient Boosting, achieved an accuracy of 95%. While effective for web attacks, this model is limited in handling high-dimensional IoT traffic and lacks deep contextual modeling found in transformer-based or generative architectures. In [27], the authors presented a stacking ensemble ML-based IDS using the ToN-IoT dataset, where ensemble learning led to high classification performance with MCC values over 0.99 in both binary and multi-class modes. Though promising, the framework is conventional in its reliance on traditional ML models and does not incorporate synthetic augmentation or attention-based learning, which limits its flexibility in handling dynamic IoT environments. In [28], the authors introduced the CIC-IoT-2023 dataset, a real-time benchmark comprising 33 attack types across seven categories, executed over a topology of 105 IoT devices. This dataset addresses the limitations of previous datasets by providing realistic traffic patterns and complex attack scenarios. It forms the foundation for our work and several others, offering a robust testbed for evaluating IDS performance under real-world IoT conditions. Finally, in [29], the authors applied several DL models, including Transformer, to the CIC-IoT-2023 dataset for multi-class intrusion detection. Their results show that while the Transformer performs well in multiclass tasks (up to 99.40% accuracy), it lags behind in binary classification compared to hybrid models. Unlike our Transformer-GAN approach, their work did not leverage adversarial learning or evolutionary optimization to address class imbalance or model generalization. A summary of the key characteristics of the reviewed studies is presented in Table 1, highlighting differences in dataset usage, learning models, optimization techniques, and performance.

Table 1.
Summary of related intrusion detection studies in IoT systems.
1.2. Research Gaps and Motivation
While recent advancements in ML and DL have significantly improved intrusion detection in IoT environments, several limitations persist across existing works [30]. Many studies, such as those utilizing LSTM, CNN, or hybrid architectures [21,23,25], rely on traditional DL models that, despite their high accuracy, struggle to generalize effectively in the presence of high-dimensional, imbalanced, and dynamic IoT traffic. Moreover, approaches like federated learning [20] and RL [24] introduce promising adaptability and privacy-preserving features, but often lack advanced data augmentation or fail to capture long-range temporal dependencies critical in evolving network attacks. Even models based on attention mechanisms, such as Transformers [22,29], do not typically integrate adversarial training, leaving them vulnerable to performance degradation in low-resource or highly skewed class distributions. Furthermore, several works rely on outdated datasets [21,23], limiting their real-world applicability, or overlook critical optimization of hyper-parameters, which can hinder convergence, stability, and overall detection accuracy.
Motivated by these challenges, this study proposes a novel hybrid IDS framework that combines the representational power of Transformer networks with the generative capabilities of GANs to improve robustness and detection performance in complex IoT traffic scenarios. To address the problem of class imbalance and limited diversity in training data, our model leverages adversarial learning to synthesize representative samples and refine feature representations. Additionally, we incorporate an improved non-dominated sorting biogeography-based optimization (INSBBO) algorithm to jointly fine-tune network parameters and critical hyper-parameters, enhancing convergence speed, generalization, and model stability. By evaluating the model on the realistic CIC-IoT-2023 dataset, which reflects diverse attack types and device interactions, we aim to overcome the shortcomings identified in existing literature and deliver a more resilient and scalable IDS for next-generation IoT systems.
1.3. Paper Contributions
This paper presents a novel hybrid intrusion detection framework tailored for the complex and dynamic landscape of IoT network security. By integrating transformer networks with GANs and optimizing the architecture through an INSBBO algorithm, the proposed model addresses key challenges in modern IDS design, namely, class imbalance, feature diversity, and learning instability. Unlike prior works that focus on standalone deep models or rely on outdated datasets, our approach combines robust temporal-contextual modeling with adversarial data synthesis and multi-objective optimization, leading to a system that generalizes well to both binary and multi-class intrusion detection tasks. The main contributions of this paper can be summarized as follows.
- We propose a novel IDS model that synergistically combines transformer and GAN components to enhance feature extraction, capture temporal dependencies, and mitigate data imbalance in IoT traffic;
- A novel INSBBO algorithm is introduced to fine-tune both network weights and hyper-parameters of the proposed model, improving model stability, convergence, and classification accuracy;
- The framework integrates adversarial learning and reconstruction-based evaluation to detect both subtle and overt anomalies in IoT network traffic;
- We rigorously evaluate the proposed model using two complementary real-world datasets to ensure practical relevance and generalizability: the CIC-IoT-2023 dataset, which includes 33 diverse attack types across 105 IoT devices, and the TON_IoT dataset, which provides heterogeneous telemetry and network data reflecting a wide range of cyber threats across smart and industrial environments. This dual-dataset evaluation validates the model’s robustness across distinct data distributions, device types, and threat scenarios;
- Experimental results show that our model outperforms traditional methods (e.g., CNN, LSTM, and SVM) and recent baselines (e.g., Transformer-only or GAN-only IDS) in both binary and multi-class settings, achieving accuracy up to 99.76% with minimal variance and low false positive rates.
1.4. Paper Organization
The remainder of this paper is structured as follows: Section 2 presents the materials and methods, including a detailed description of the dataset, the architecture of the transformer and GAN components, the INSBBO algorithm, and the design of the proposed hybrid framework. Section 3 reports the experimental setup and results, comparing the proposed model against several baseline methods across both binary and multi-class classification tasks. Section 4 discusses the findings, highlights key advantages of the proposed approach, and outlines its limitations. Finally, Section 5 concludes the paper and suggests potential directions for future research.
2. Materials and Methods
This section outlines the core components of the proposed hybrid intrusion detection framework, which synergistically integrates transformer networks, GANs, and INSBBO algorithm. In Section 2.1, the dataset structure, characteristics, and detailed preprocessing pipeline are described to ensure reproducibility and prepare the data for DL applications. Section 2.2 elaborates on the transformer architecture employed for feature extraction, emphasizing its capability to capture temporal and contextual dependencies within IoT traffic sequences. Section 2.3 introduces the GAN structure, in which a Transformer-based generator and discriminator operate adversarially to refine feature representations and support robust anomaly detection. Following the model architectures, Section 2.4 discusses the INSBBO algorithm, which is leveraged to jointly optimize the internal network parameters and critical hyper-parameters, enhancing model convergence and generalization. Section 2.5 presents the overall design of the proposed transformer-GAN framework, highlighting the interaction between its training and detection phases. In this integrated architecture, adversarial learning and reconstruction-based evaluation are combined to improve detection accuracy across complex and evolving IoT intrusion patterns. By unifying powerful feature extraction, adversarial training, and evolutionary hyper-parameter optimization within a single framework, the proposed methodology aims to set a new standard for resilient and intelligent intrusion detection in dynamic IoT environments.
2.1. Dataset
The CIC-IoT-2023 dataset is a comprehensive and recently published dataset designed to support advanced security analytics in IoT environments. Developed to reflect the rapidly evolving threat landscape in connected systems, this dataset captures a wide variety of cyberattack scenarios targeting IoT devices. It comprises data collected from 105 distinct IoT devices, including smart thermostats, smart lights, IP cameras, smart locks, and wearable devices. These devices were subjected to extensive experimentation in a controlled environment to simulate both benign behavior and malicious activities. The dataset is notable for its size, containing approximately 46,686,579 network traffic records, thereby offering a rich and diverse source for training and evaluating ML models for intrusion detection. One of the distinguishing features of the CIC-IoT-2023 dataset is its broad coverage of 33 different attack types, systematically organized into seven major attack categories: distributed denial of service (DDoS), denial of service (DoS), reconnaissance (Recon), web-based attacks, brute force attacks, spoofing attacks, and Mirai-based attacks. These attacks range from flooding attacks like UDP and ICMP floods to sophisticated reconnaissance techniques and web application vulnerabilities such as SQL Injection and cross-site scripting (XSS). The dataset not only simulates common IoT threats but also incorporates more complex multi-stage attacks, offering a realistic and challenging environment for developing intrusion detection systems capable of recognizing both known and novel threats [29].
In addition to its extensive attack diversity, the CIC-IoT-2023 dataset provides a comprehensive set of 46 extracted features along with one class label indicating the type of activity (benign or malicious). The features are meticulously engineered from raw network traffic data, covering aspects such as flow characteristics (e.g., flow duration, packet length statistics), protocol indicators (e.g., TCP, UDP, ICMP, HTTP, HTTPS, DNS flags), and packet dynamics (e.g., rates, inter-arrival times, flag counts). Statistical descriptors such as covariance, variance ratios, and magnitudes further enrich the feature set, enabling detailed modeling of complex traffic behaviors. This rich feature space allows ML and DL models to capture subtle variations and patterns that are critical for accurate intrusion detection. The dataset also pays particular attention to the balance and representativeness of its samples. Each attack type and benign traffic pattern is recorded with sufficient frequency to ensure meaningful learning while maintaining an overall distribution that reflects realistic deployment scenarios. Attack events were generated using actual IoT malware families and advanced attack tools, ensuring that the resulting traffic exhibits authentic characteristics of contemporary cyber-attacks. This design consideration addresses a common shortcoming of earlier IoT datasets, which often suffered from unrealistic or artificially balanced attack-to-benign ratios, thereby limiting their real-world applicability [29].
A key strength of the CIC-IoT-2023 dataset lies in its ability to facilitate both binary (attack vs. benign) and multiclass classification tasks. Researchers can use the dataset to build models that not only detect the presence of an attack but also classify the specific type of attack among the 33 defined categories. Furthermore, the wide temporal span of the collected traffic and the inclusion of multiple attack repetitions under varying network conditions enhance the dataset’s robustness, making it suitable for evaluating models under dynamic IoT operational scenarios. The diversity in device types, network protocols, and attack methodologies ensures that models trained on this dataset can generalize better to unseen or evolving cyber threats [29].
Before model training could begin, an essential preprocessing phase was conducted to organize and standardize the raw dataset. Since the CIC-IoT-2023 dataset was originally distributed across 169 separate CSV files, the first step involved systematically merging all files into a single consolidated dataset. This was crucial for maintaining consistency during feature extraction and training processes, avoiding discrepancies across fragmented data sources. By combining all records into a unified structure, the dataset was better prepared for large-scale ML workflows, ensuring seamless access and efficient batch processing. Following data merging, several transformations were applied to make the dataset compatible with DL models. The textual labels, which initially represented different traffic types, were numerically encoded. For binary classification tasks, benign traffic was labeled as 0 and attack traffic as 1, with a significant imbalance between benign (approximately 1.1 million samples) and malicious instances (over 45.5 million samples). For multi-class classification, the malicious attacks were further categorized into seven broader groups, resulting in a total of eight distinct labels when including benign traffic. Additionally, to facilitate efficient gradient-based optimization during training, feature scaling was performed using the standard normalization technique, where each feature was rescaled to have a mean of zero and a unit variance. This normalization step is crucial to prevent features with larger numeric ranges from disproportionately influencing the model during learning. Beyond basic preparation, further steps were implemented to strengthen model robustness. Since the dataset did not provide predefined training and testing splits, a stratified holdout strategy was employed: 80% of the samples were reserved for training and validation, while the remaining 20% were used for final testing.
The TON_IoT dataset is a benchmark dataset designed by the Cyber Range Lab of the University of New South Wales (UNSW) to support the development and evaluation of security solutions for the IoT, Industrial IoT (IIoT), and operational technology (OT) environments. Unlike traditional network intrusion datasets that focus primarily on packet or flow-level features, TON_IoT offers a heterogeneous data ecosystem by incorporating multiple data modalities. These include telemetry data from IoT/IIoT sensors, log files from operating systems (Windows, Linux), and network traffic captures, making it suitable for multi-layered and context-aware intrusion detection research. TON_IoT was generated in a realistic testbed environment, where both benign and malicious activities were simulated across various layers of the IoT stack. The attacks cover a broad spectrum, including privilege escalation, backdoor access, reconnaissance, denial of service (DoS), ransomware, and data injection. The network data specifically includes millions of NetFlow records labeled for binary and multiclass classification tasks. This diversity of attack types and the inclusion of both network and host-based telemetry data make TON_IoT particularly valuable for studying advanced persistent threats (APTs) and coordinated cyberattack strategies across distributed IoT deployments. Another distinctive feature of TON_IoT is its inclusion of timestamped sequences and device-specific patterns, which allow for temporal modeling of cyberattacks. This temporal richness makes the dataset highly suitable for sequential and attention-based architectures such as transformers. The dataset structure facilitates both real-time anomaly detection and retrospective forensic analysis. With extensive documentation and predefined splits for training and testing, TON_IoT has emerged as a standard for evaluating intrusion detection models in smart environments where multiple data sources and operational layers interact dynamically [31].
To incorporate the TON_IoT dataset into our experimental pipeline, we focused on its network telemetry subset, which includes labeled flow-based records suitable for both binary and multi-class classification. The dataset initially contained several CSV files categorized by protocol type (e.g., MQTT, Modbus, HTTP) and attack category. These files were consolidated into a single structured dataset to ensure consistent processing. Similarly to CIC-IoT-2023, non-numeric fields and irrelevant identifiers were dropped to retain only the most informative features for model training. After merging, categorical features such as protocol names and attack types were numerically encoded using label encoding. For binary classification tasks, all attack types were mapped to a single “malicious” label, while benign records retained the “benign” label. In multi-class mode, each attack type was assigned a distinct class ID, reflecting its specific behavior. All continuous features were normalized using standard score normalization (zero mean, unit variance) to align with the input expectations of the neural network models. The dataset was then split into 80% training/validation and 20% test sets using stratified sampling to maintain class distribution. These preparation steps ensured compatibility of the TON_IoT dataset with the same Transformer-GAN training pipeline used on CIC-IoT-2023, enabling a fair and consistent comparison across datasets.
2.2. Transformer
The transformer model is a DL architecture originally designed for sequence modeling tasks. It abandons the traditional recurrent structures and instead leverages a self-attention mechanism that enables the model to capture complex dependencies across all elements in a sequence simultaneously. This capability is particularly beneficial in contexts such as intrusion detection for IoT environments, where network traffic exhibits temporal patterns and long-range correlations that must be effectively captured and modeled [32,33,34]. The standard transformer is composed of two main components: an encoder and a decoder, as illustrated in Figure 1.
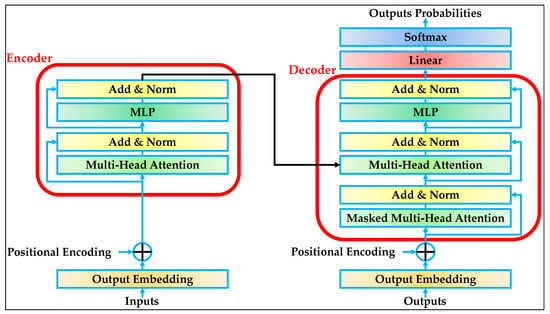
Figure 1.
The architectural workflow of the transformer.
The encoder is responsible for ingesting the input sequence and producing a contextualized representation, while the decoder consumes this representation to generate the output sequence or class prediction. The interaction between the encoder and decoder is illustrated by the arrows in Figure 1. These arrows indicate the data flow and dependency between layers. For instance, the arrow connecting the encoder to the decoder represents the transmission of encoded context to inform output generation. The internal arrows within each block show the residual pathways, layer stacking, and flow of tensor transformations. The repeated stacking of encoder and decoder blocks, typically 6 to 12 layers deep, enhances the model’s expressiveness and capacity to learn hierarchical representations [35,36].
The standard transformer model offers a powerful mechanism for learning from structured sequences without relying on recurrence or convolution. Its attention-driven framework enables parallelization and effective modeling of complex temporal dependencies, making it particularly suitable for analyzing traffic data in IoT environments. On the left-hand side, the encoder begins by transforming the input tokens into dense vector embedding through an embedding layer. To encode the positional information, which is not inherently captured due to the lack of recurrence, positional encodings are added to the embedding. These encodings are computed using fixed sinusoidal functions, where each position and dimension of the embedding are defined as shown in Equations (1) and (2) [37]:
This positional information enables the model to distinguish the order of elements within the sequence. Once positional encodings are added, the sequence enters the encoder block, which consists of a stack of identical layers, each with two core components: multi-head self-attention and a feed-forward neural network (FFNN). In the first sub-layer, the model performs self-attention, where each token attends to every other token in the sequence. This operation computes a weighted sum of value vectors based on the similarity between query and key vectors, as formalized in Equation (3) [38]:
The vectors are linear projections of the input sequence, and the scaling factor stabilizes gradients during training. Rather than relying on a single attention operation, the transformer employs multi-head attention to allow the model to jointly attend to information from different representation subspaces, as shown in Equation (4):
where is the number of parallel attention heads employed in the multi-head attention mechanism and the term is a learned output projection matrix. Each head independently performs the attention operation described above with its own learned projections. The outputs of all heads are concatenated and linearly transformed to form the final attention output. Following the attention block, each encoder layer includes a fully connected FFNN, which is applied independently to each token and consists of two linear transformations separated by a rectified linear unit (ReLU) activation function. This is expressed in Equation (5):
where is the input vector corresponding to a single token or position in the sequence, is the weight matrix, and is bias vector. To facilitate gradient flow and prevent vanishing gradients, residual connections are added around each sub-layer, and the result is normalized using layer normalization. The encoder output is passed to the decoder, which mirrors the encoder’s structure but includes an additional attention layer at the beginning of each decoder block. As shown on the right-hand side of Figure 1, the decoder receives the output sequence shifted by one position and first applies masked multi-head attention. This masking ensures that each position can only attend to earlier positions in the sequence, thereby preserving the auto-regressive property necessary for sequence generation. After masking, the decoder performs another multi-head attention operation, this time over the encoder’s output. This cross-attention enables the decoder to align its predictions with relevant parts of the input sequence, effectively capturing dependencies between input features and output decisions. The decoder output is finally passed through a linear transformation followed by a softmax activation to produce a probability distribution over the output classes. For classification tasks such as intrusion detection, this output corresponds to predicted class probabilities for each input sequence. This final step is formalized in Equation (6) [39].
where denotes the final decoder representation, is the classification matrix, and represents the predicted probabilities for each class.
2.3. GAN
GANs were first introduced by Goodfellow and colleagues in 2014 as a new class of generative models capable of synthesizing data samples that closely mimic real-world data distributions. The fundamental motivation behind GANs was to overcome the limitations of explicit probabilistic modeling by using an adversarial training process between two neural networks: a generator and a discriminator. Instead of learning the data distribution directly or relying on maximum likelihood estimation, GANs enable a generator network to produce synthetic data while a discriminator network tries to differentiate between real and generated data [40]. This adversarial setup results in powerful models that can generate highly realistic data samples, making GANs widely applicable in fields such as image synthesis, data augmentation, anomaly detection, and more recently, cyber security and intrusion detection for IoT systems. The core advantage of GANs lies in their flexibility and implicit learning capability. Unlike traditional models that require a mathematically tractable form of the data distribution, GANs learn to approximate complex high-dimensional distributions without any explicit density modeling. Furthermore, the competitive dynamic between the generator and the discriminator fosters continuous improvements in data quality, leading to the generation of synthetic samples that are indistinguishable from real data. These properties make GANs particularly attractive for intrusion detection, where obtaining labeled attack data is challenging, and class imbalance is a significant obstacle [41].
The architecture of a standard GAN is composed of two components: a generator and a discriminator , trained simultaneously in an adversarial manner. Figure 2 provides a detailed visualization of the GAN workflow. On the left side, the dataset feeds real data samples into the discriminator. Simultaneously, the generator synthesizes new data samples from random latent vectors, which are also passed to the discriminator. The discriminator processes both the real and synthetic data streams and produces an authenticity decision—either labeling the input as “real” or “fake”. The interactions shown by the arrows in Figure 2 represent the data flow during forward propagation. These connections not only depict how the real and generated samples converge at the discriminator but also imply the adversarial feedback loop during training: the generator is updated to minimize its contribution to the discriminator’s loss, while the discriminator is updated to maximize its classification accuracy. This mutual competition leads both networks to iteratively improve, resulting in progressively more realistic generated samples over time. As illustrated in Figure 2, the generator receives a random noise vector sampled from a predefined prior distribution and transforms it into a synthetic data sample. Concurrently, the discriminator is exposed to both real samples, drawn from the original dataset, and synthetic samples produced by . The discriminator’s role is to correctly classify the input as either real or fake, thereby providing feedback to the generator regarding the realism of its outputs [42,43,44].
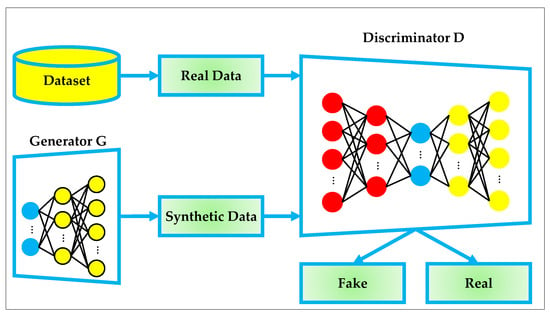
Figure 2.
The architectural workflow of the standard GAN.
Beyond the domain of cybersecurity, GANs have achieved remarkable success in a variety of low-level vision tasks, particularly in areas involving image restoration, enhancement, and transformation. These tasks are often characterized by their requirement to recover or reconstruct high-fidelity visual information from severely degraded inputs, such as blurry, noisy, or occluded images. The underlying challenge in such problems (namely, learning a mapping from distorted inputs to clean, perceptually accurate outputs) aligns closely with GANs’ core strength: generating data distributions that approximate real-world patterns. One prominent application of GANs in low-level vision is image deblurring. In DBLRNet, a GAN-based framework proposed for image deblurring, adversarial training was used to guide the generator toward producing sharp and detailed images from blurred inputs [45]. The discriminator acted as a perceptual critic, ensuring that the reconstructed images not only reduced pixel-wise error but also retained global structural realism. Compared to traditional deconvolutional approaches or purely CNN-based models, the GAN-based DBLRNet achieved superior visual clarity and edge preservation, showcasing the value of adversarial learning in handling ill-posed inverse problems.
Similarly, in the deraining domain, GANs have shown strong capabilities in removing rain streaks from both static images and video frames. ESTINet, a GAN-powered deraining model published in TPAMI, utilizes a generator–discriminator pair to capture both the local texture information and the temporal consistency across frames [46]. This results in derained outputs that maintain scene integrity while effectively removing artifacts. The model’s success stems from GANs’ ability to model complex texture priors that are difficult to encode via traditional loss functions alone. Other notable GAN applications in low-level vision include image denoising, inpainting, and super-resolution. For example, DeblurGAN-v2 [47] achieves high-speed and high-fidelity deblurring by combining conditional adversarial loss with multi-scale content loss, producing perceptually sharper images. In another example, DID-MDN [48] introduces multi-dimensional supervision to guide GAN training for improved deraining results. In these cases, GANs often outperform traditional optimization-based techniques by producing outputs that are not only quantitatively accurate (e.g., in terms of PSNR or SSIM), but also perceptually convincing to human observers. The discriminator in these setups serves as a learned regularizer, pushing the generator to synthesize outputs that align with the manifold of natural images. This perceptual grounding is especially valuable in scenarios where standard reconstruction losses may produce overly smooth or unrealistic results.
The effectiveness of GANs in these vision tasks is highly relevant to the intrusion detection domain. Both involve learning from incomplete, noisy, or imbalanced data to generate high-quality representations. Just as GANs enhance degraded images by inferring structure from limited visual cues, they can similarly enhance intrusion detection training data by synthesizing plausible attack samples that improve model generalization. The underlying principle—learning from limited supervision by leveraging adversarial feedback—is shared across these domains. By drawing parallels between low-level vision tasks and intrusion detection, we highlight the broader utility and adaptability of GANs in solving real-world challenges that involve incomplete or imperfect data. Their ability to recover semantic structure, enforce perceptual fidelity, and balance underrepresented classes makes GANs a powerful tool not just in image restoration, but also in improving the robustness and performance of detection systems across diverse domains. The training objective is to reach a Nash equilibrium where the generator produces data so realistic that the discriminator cannot reliably distinguish it from real data. Mathematically, the adversarial learning objective between the generator and discriminator is formalized as shown in Equation (7) [41]:
where denotes the true data distribution from which real samples are drawn, is the prior distribution over the latent space, typically chosen as a multivariate Gaussian or uniform distribution, is the synthetic data generated from noise , and represents the discriminator’s estimated probability that an input sample is real. The generator aims to minimize this value function by producing samples that maximize , thus “fooling” the discriminator into misclassifying fake samples as real. Conversely, the discriminator tries to maximize this objective by correctly identifying real and synthetic inputs. The optimization process alternates between updating the discriminator and the generator. The discriminator’s loss function, which quantifies its ability to separate real from fake samples, is given by Equation (8) [42]:
where aims to maximize the likelihood of correctly classifying real samples while minimizing the likelihood of incorrectly classifying fake samples. In contrast, the generator’s loss, expressed in Equation (9), is designed to enhance the realism of synthetic outputs:
which encourages the generator to produce samples that the discriminator classifies as real. Here, minimizes the negative log-likelihood classifying generated samples as authentic. Within the architecture depicted in Figure 2, the generator is typically composed of multiple fully connected layers or transposed convolutional layers, depending on the complexity and structure of the desired output space. The generator gradually transforms a low-dimensional noise vector into a high-dimensional synthetic sample that matches the characteristics of real data. Meanwhile, the discriminator consists of several neural network layers designed to extract hierarchical features from its inputs, culminating in a final sigmoid-activated neuron that outputs the probability of the sample being real. The competitive yet cooperative dynamic between and ultimately results in a generative model capable of approximating highly complex data distributions, an ability that is critical for enhancing the diversity and robustness of datasets in IoT intrusion detection applications [43].
2.4. INSBBO
Biogeography-based optimization (BBO) is a nature-inspired meta-heuristic algorithm first proposed by Dan Simon in 2008 [49]. The algorithm draws inspiration from the science of biogeography, which studies the distribution of biological species across different geographical locations over time. In natural ecosystems, habitats that are highly suitable for life tend to have a high number of species, while less hospitable environments host fewer species. The migration of species from high-suitability habitats to low-suitability ones, along with occasional random mutations, forms the fundamental biological processes that BBO mimics in its search strategy. This elegant concept allows BBO to efficiently explore and exploit complex search spaces by combining solution sharing (through migration) and diversity maintenance (through mutation), making it highly effective for solving optimization problems where both global exploration and local refinement are crucial. In BBO, each candidate solution to the optimization problem is analogized as a habitat. The quality of a solution is quantified using a metric called the habitat suitability index (HSI), where a higher HSI indicates a better solution. Habitats with higher HSIs share their features with others through a process known as migration, and random modifications called mutations introduce variability to avoid premature convergence to local optima [50,51,52].
Unlike traditional evolutionary algorithms where populations evolve through selection, crossover, and mutation, BBO emphasizes the migration of features among solutions while maintaining each individual habitat in its original form after each iteration. The migration process is governed by two main rates: the emigration rate () and the immigration rate (). High-HSI habitats have high emigration rates and low immigration rates, meaning they tend to share their features with others rather than accepting features from them. Conversely, low-HSI habitats have high immigration rates, allowing them to improve by adopting features from better habitats. The relationship between immigration, emigration, and the number of species in a habitat is typically modeled linearly. Specifically, the emigration rate and immigration rate for i-th habitat are defined as shown in Equations (9) and (10) [53]:
where represents the rank of the habitat in terms of suitability, is the total number of habitats. During the migration phase of BBO, solutions improve by exchanging information between habitats based on their respective immigration and emigration rates. Specifically, each habitat is considered as a candidate for accepting new features, and for each feature, a decision is made whether to migrate information from a donor habitat based on the host’s immigration rate. The mathematical formulation governing the migration process is presented in Equation (12) [51]:
where represents the host habitat, represents the guest habitat, and denotes the set of suitability index variables (SIVs), which are the key features or decision variables of the solution. This operation implies that the feature values of the host habitat are updated by incorporating corresponding feature values from the guest habitat. Essentially, the host habitat adopts part of the characteristics from the guest habitat, thereby improving or diversifying its solution structure. In this migration process, the selection of as the guest is probabilistic and weighted by the emigration rate, favoring habitats with higher HSI values as sources of useful features. Meanwhile, the likelihood of a host accepting incoming information is determined by its immigration rate, which is inversely related to its own HSI. This dynamic ensures that high-quality solutions tend to influence lower-quality ones, guiding the overall search process toward regions of higher fitness while maintaining sufficient diversity across the population. The migration step thus serves as a primary exploitation mechanism within BBO, promoting the propagation of advantageous traits while allowing the algorithm to explore different parts of the search space through controlled information sharing [52].
In addition to migration, BBO employs a mutation mechanism to maintain population diversity and prevent premature convergence to suboptimal solutions. The mutation process is probabilistically controlled by the quality of each habitat: habitats with lower suitability are more likely to mutate, while highly suitable habitats are protected from unnecessary alterations. This behavior ensures that the algorithm continues to explore the search space even when it has identified regions of relatively high fitness, thus balancing exploration and exploitation. The probability of mutation for each habitat is determined by Equation (13):
where denotes the mutation rate, is chosen by the user, reveals the probability of species count and is the highest value of .
Although the standard BBO model provides an elegant and effective approach for migration through linear immigration and emigration rates, it exhibits certain fundamental limitations when applied to complex real-world problems. One major shortcoming is its reliance on a simple linear relationship between habitat suitability and migration rates. In reality, most natural phenomena and real-world optimization problems are inherently nonlinear, involving complex interdependencies and dynamic variations. As a result, a linear model may not adequately capture the intricate behavior required for robust and flexible search strategies, particularly in high-dimensional and irregular solution landscapes. Another critical drawback of the linear migration model is its inability to adaptively fine-tune the exploration and exploitation processes during optimization. In the standard model, migration rates change uniformly across all habitats based solely on their HSI ranking, without accounting for the nuanced performance variations that different habitats might exhibit. Consequently, the algorithm may either converge prematurely if migration is too aggressive or stagnate if migration is too conservative, leading to suboptimal optimization performance, especially in dynamic or multi-modal environments [46].
Furthermore, using a single, uniform migration model for all habitats within the same generation reduces the algorithm’s diversity and adaptability. Since all solutions are governed by the same linear function, habitats with widely differing HSI values still experience similar migration behavior. This homogenization fails to exploit the strengths of high-quality habitats appropriately while limiting the capacity for weaker habitats to undergo necessary structural changes. Ideally, habitats with different HSIs should utilize distinct migration dynamics, enhancing the algorithm’s ability to adjust locally to the specific quality and characteristics of individual solutions. To overcome these limitations, we propose the use of nonlinear migration models that introduce diverse, adaptive migration behaviors across habitats. Specifically, as depicted in Equations (14)–(16), different nonlinear models are employed based on the rank of the habitat within the population. By using polynomial, logarithmic, and hyperbolic tangent functions to define the immigration and emigration rates, the improved migration scheme enables more accurate modeling of natural diversity and dynamic adaptation across different solution qualities. This enhancement is expected to significantly improve the balance between exploration and exploitation, thereby enhancing the optimization performance of the proposed framework.
In the first threshold range, where the habitat suitability index (HSI) is low (), a high-degree polynomial function is used for the emigration rate. This decision is based on the fact that habitats with lower HSI should not actively emit individuals since they represent poor-quality solutions. A steep polynomial curve grows slowly near zero, ensuring that weak habitats retain their population, which in turn reduces the dispersion of low-quality traits and enhances the algorithm’s convergence by minimizing disruptive migrations. In the same low-HSI range (), a cubic inverse function is used for immigration. The rationale is that weaker habitats should be more receptive to incoming individuals in order to improve their quality through exploration. The cubic shape offers a controlled but relatively high immigration rate for these low-HSI habitats. This encourages knowledge infusion into underperforming solutions without overwhelming the population dynamics, allowing gradual adaptation without destabilization.
For the middle HSI range (), a logarithmic function is applied for the emigration rate. In this moderate zone, the habitat quality is neither optimal nor poor. A logarithmic function increases steadily but gently, enabling these average-quality habitats to contribute to the population by exporting individuals at a reasonable rate. This balances exploration and exploitation, avoiding both stagnation and premature convergence while enriching the diversity of the search space. Simultaneously, in the middle HSI range, a cosine-based function is used for immigration. This function introduces sharp variability in the middle segment of its curve, resulting in moderate but dynamically shifting immigration rates. The goal is to ensure that mid-quality habitats are more reactive to migration, adapting rapidly to fluctuations in the global population structure. This enhances the algorithm’s flexibility and encourages efficient migration flow during intermediate search phases.
When the HSI is high (), a hyperbolic tangent function is selected for emigration. This function has a steep increase followed by rapid saturation, allowing high-quality habitats to emit individuals early in the optimization process while gradually stabilizing over time. Such behavior is critical for preserving elite solutions. Initial sharing allows beneficial traits to spread, but as convergence progresses, emigration slows down to protect the refined solution from being disrupted by excessive outward flow. Finally, for immigration in the high-HSI range (), an inverted hyperbolic tangent function is adopted. It starts with low values and flattens further as HSI increases. This ensures that elite habitats accept very few, if any, new individuals, protecting them from being overwritten by inferior genetic material. By limiting the influx into high-performing habitats, the algorithm prevents deterioration of top solutions and accelerates convergence toward the global optimum.
To effectively optimize the hyper-parameters and internal weights of the hybrid transformer-GAN, we propose an enhanced multi-objective version of the BBO algorithm, referred to as INSBBO. In this framework, the optimization targets include not only the learning of weights and biases in the fully connected layers of the transformer and GAN, but also the fine-tuning of critical hyper-parameters such as the learning rate, batch size, and dropout rate. By optimizing both network parameters and training hyper-parameters simultaneously, the proposed approach ensures a balanced improvement in model convergence, generalization ability, and robustness. As illustrated in Figure 3, the INSBBO algorithm begins with the initialization step, where a population of candidate solutions is randomly generated. Each solution encodes a set of weight parameters and hyper-parameters representing a complete configuration for the hybrid transformer-GAN model. After initialization, the HSI for each habitat is calculated, along with the associated nonlinear migration rates defined according to Equations (14)–(16). These rates determine how information will be shared between solutions in subsequent iterations.
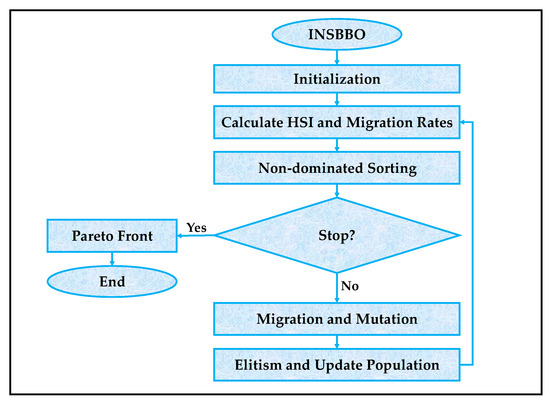
Figure 3.
The architectural workflow of the proposed INSBBO.
Following the HSI and migration rate calculations, a non-dominated sorting procedure is applied to the population. In this stage, all candidate solutions are ranked based on Pareto dominance relationships among multiple objectives, such as maximizing classification accuracy, minimizing model complexity, and reducing training time. Solutions that are non-dominated form the Pareto front and represent the best trade-offs among conflicting objectives. The flowchart in Figure 3 clearly shows that after non-dominated sorting, a stopping criterion is evaluated. If the stopping condition is met, the current Pareto front is outputted as the final result. If the algorithm has not yet satisfied the stopping condition, it proceeds to the migration and mutation phase. During this phase, the features (weights, biases, and hyper-parameters) of the habitats are updated based on the nonlinear migration and mutation mechanisms described earlier. Migration promotes the sharing of good traits among solutions, while mutation introduces random variations to maintain diversity and prevent premature convergence. After migration and mutation, an elitism strategy is employed to ensure that the best-performing solutions are preserved into the next generation, preventing loss of high-quality individuals during the stochastic operations. Finally, the population is updated and the process repeats iteratively until the algorithm converges to a well-distributed Pareto-optimal set of solutions, representing optimized transformer-GAN configurations.
2.5. Proposed Transformer-GAN
The overall workflow of the proposed hybrid model is depicted in Figure 4, which highlights the integration of a transformer-based generator and discriminator within a GAN framework to achieve robust feature learning and effective intrusion detection. The model is designed to operate in two primary phases: training and detection, both of which utilize an optimized Transformer architecture, fine-tuned by the INSBBO algorithm. The figure clearly separates the two operational phases and emphasizes the dynamic interaction between the generator and discriminator through a shared latent space. During the training phase, the dataset is first fed into the optimized Transformer discriminator, which processes the input samples to evaluate their authenticity or legitimacy in the context of IoT traffic patterns. Simultaneously, the same dataset is passed through the optimized Transformer generator, which transforms the raw data into a latent representation mapped into a lower-dimensional feature space. This mapping encourages the generator to capture high-level, meaningful features that represent the underlying data distribution, which is critical for distinguishing between normal and anomalous patterns.
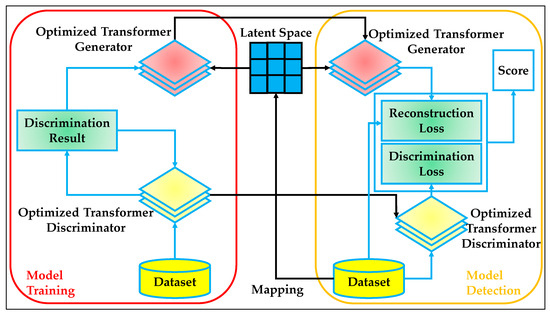
Figure 4.
The architectural workflow of the proposed Transformer-GAN.
The outputs of the generator and discriminator are then linked through the latent space, which serves as a bridge enabling adversarial learning. The optimized transformer discriminator evaluates both the real data and the generated latent representations to produce a discrimination result. This adversarial setup forces the generator to continually refine its latent space mapping in order to produce representations that are increasingly indistinguishable from real traffic patterns. Through this competition, the generator learns to encode highly robust features while the discriminator becomes better at detecting subtle anomalies in the input space. Once the model has been sufficiently trained, it transitions into the detection phase. In this phase, new unseen IoT data is again passed through the optimized Transformer generator to produce latent representations. These representations are then processed by the optimized transformer discriminator, which evaluates them using two key loss metrics: reconstruction loss and discrimination loss.
The reconstruction loss measures the fidelity of the reconstructed input relative to the original, while the discrimination loss assesses how distinguishable the reconstructed sample is compared to genuine real-world patterns. The two loss components are combined to compute a final anomaly detection score. This score determines whether the input sample represents normal behavior or a potential intrusion attempt. By leveraging both reconstruction-based and adversarial-based learning signals, the proposed framework achieves a dual-perspective detection capability, enhancing its sensitivity to both subtle and overt anomalies in complex IoT environments.
An important novelty of the proposed hybrid architecture lies in the full exploitation of Transformer models within both the generator and discriminator roles. Unlike traditional GAN-based anomaly detection systems, where the generator often relies on convolutional architectures, our approach leverages the Transformer’s superior ability to model long-range dependencies and contextual relationships within IoT traffic data. This significantly enhances the model’s ability to capture sophisticated attack patterns that span across temporal sequences or multi-dimensional traffic features. Another significant innovation is the integration of the INSBBO algorithm to optimize not only the internal weights and biases of the fully connected layers but also the crucial hyper-parameters of the model. Specifically, the learning rate, batch size, and dropout rate are simultaneously tuned alongside network training parameters. By applying a multi-objective INSBBO framework, the optimization process seeks to strike a balance between maximizing detection accuracy, minimizing model complexity, and accelerating training convergence, ultimately yielding a more efficient and generalizable intrusion detection system.
Moreover, the use of nonlinear migration models within the INSBBO framework introduces greater diversity and adaptive behavior into the optimization process, allowing the model to dynamically adjust to different traffic characteristics and evolving attack patterns. This adaptability is crucial in IoT environments where the nature of network traffic and attack vectors can change rapidly and unpredictably. The proposed transformer-GAN hybrid model, optimized through INSBBO, presents a highly synergistic design that combines powerful feature extraction, adversarial learning, and robust multi-objective optimization. The architecture not only addresses the challenges of learning from highly imbalanced, high-dimensional IoT traffic data but also provides a scalable, generalizable, and adaptive solution for next-generation intrusion detection systems.
To assess the semantic quality and intra-class diversity of the synthetic samples generated by the GAN component, we conducted a dedicated evaluation across the seven major attack categories in the CIC-IoT-2023 dataset. For each class, 1000 samples were generated using the trained generator and subsequently evaluated using a discriminator pre-trained on real data. As shown in Table 2, the correctly classified rate ranged from 91.8% to 96.7%, indicating a high degree of realism. Furthermore, class coverage remained above 95% for all categories, suggesting that the generated samples were not only realistic but also diverse, capturing meaningful variations within each attack type. Additionally, the average confidence score of the discriminator for the generated samples remained consistently high (ranging from 0.88 to 0.94) further confirming that the GAN effectively learned the underlying distribution of each class. These metrics collectively demonstrate that the adversarial learning process did not introduce noisy or low-quality data; instead, it enhanced class representation, mitigated imbalance, and contributed to the overall robustness of the training process. This independent evaluation validates the role of GAN in supporting the hybrid Transformer-GAN architecture with synthetically enriched, high-quality training data.
Table 2.
Evaluation of GAN-generated synthetic samples per attack class.
3. Results
All experiments conducted in this study were implemented using Python 3.8, due to its versatility and extensive ecosystem of DL and optimization libraries. The proposed transformer-GAN hybrid model was developed using the TensorFlow 2.8 and Keras frameworks, which offer flexible APIs for building and training complex neural network architectures. To construct and optimize the INSBBO algorithm, custom Python modules were written, leveraging NumPy, SciPy, and Pandas for numerical computation, data manipulation, and optimization routines. All preprocessing operations, including data merging, label encoding, and normalization, were handled using the Scikit-learn library, which also supported the evaluation metrics computations. The experiments were executed on a high-performance workstation equipped with an NVIDIA RTX 3090 GPU with 24 GB VRAM, 128 GB RAM, and an Intel Core i9-12900K processor, enabling efficient training of large-scale Transformer and GAN models. This hardware configuration ensured that the computational demands of training, hyper-parameter optimization, and Pareto-based solution sorting under the INSBBO framework could be handled effectively. The complete implementation pipeline was designed to maximize reproducibility and scalability, facilitating rigorous comparative analysis across both binary and multi-class intrusion detection tasks based on the CIC-IoT-2023 and the TON_IoT dataset.
To comprehensively evaluate the effectiveness of the proposed transformer-GAN framework, we compared its performance against several widely recognized baseline models, namely basic transformer, GAN, CNN, LSTM, and SVM. These baselines were selected to represent a diverse range of ML and DL paradigms commonly applied in intrusion detection tasks. By including both traditional ML methods and modern deep architectures, the comparative analysis ensures a fair and meaningful assessment of the hybrid model’s advantages in various detection scenarios, covering both binary and multi-class classification tasks. Each baseline was chosen based on its historical relevance and technical characteristics. The standalone Transformer was included to highlight the added benefits achieved by introducing adversarial learning to feature extraction. Similarly, the GAN model was evaluated independently to demonstrate the superiority of the proposed synergistic integration over using generative adversarial training alone. CNN and LSTM were selected as they are established DL models for sequence and spatial data processing, respectively, offering strong baselines for feature extraction and temporal dependency modeling. SVM, a classical and robust ML technique, was incorporated to benchmark the hybrid model against traditional classifiers that excel in small to medium-scale intrusion detection problems. This carefully selected set of baselines enables a thorough validation of the proposed model’s robustness, generalization ability, and performance superiority in the challenging context of IoT security.
To rigorously evaluate the performance of the proposed transformer-GAN model and baseline methods, several widely accepted metrics were employed. These include accuracy, F1-score, area under the curve (AUC), variance, convergence trend, and execution time. Each of these metrics provides distinct and complementary insights into different aspects of model performance, covering classification quality, stability, optimization dynamics, and computational efficiency. Accuracy measures the overall proportion of correctly classified samples among all input samples. It is a basic but important metric that reflects how well the model distinguishes between benign and malicious traffic in the dataset. While high accuracy is desirable, it should be interpreted carefully in imbalanced datasets, as it can sometimes be misleading if one class dominates. In this study, accuracy is calculated based on Equation (17), where true positives and true negatives are summed and divided by the total number of instances:
The F1-Score provides a more balanced evaluation by considering both precision and Recall simultaneously. It is particularly important in imbalanced datasets, where achieving a high F1-Score indicates that the model not only correctly identifies true positives but also minimizes false positives and false negatives. A high F1-Score reflects the model’s robustness in handling diverse intrusion patterns without bias toward any specific class. The F1-Score is computed according to Equation (18) as the harmonic mean of precision and Recall:
The AUC evaluates the model’s ability to discriminate between classes across all possible classification thresholds. AUC provides a threshold-independent measure, where a value close to 1 indicates excellent discriminative capability and a value near 0.5 suggests random guessing. Higher AUC values demonstrate that the model is consistently better at distinguishing between benign and malicious instances, regardless of the specific decision boundary chosen. The AUC metric is mathematically expressed by integrating the ROC curve across different thresholds, as shown in Equation (19):
where is ROC curve at threshold . Variance analysis was also employed to assess the stability and consistency of the model’s performance across multiple independent runs. Lower variance values indicate that the model behaves predictably and does not heavily depend on specific random initializations or particular subsets of training data. In high-stakes security applications like IoT intrusion detection, low variance ensures that the model delivers reliable performance in different deployment scenarios without unpredictable fluctuations. The convergence trend analysis was conducted to observe how quickly and steadily the model’s loss function decreases during the training process. A smooth and rapid convergence toward lower loss values typically reflects a well-optimized model and a healthy training regime. Monitoring convergence behavior also helps to detect issues such as overfitting, vanishing gradients, or instability, allowing for early corrective adjustments in hyper-parameter settings or training strategies. Finally, the execution time was measured to evaluate the computational efficiency of the proposed framework. This metric quantifies the total time required for model training and testing phases, offering insights into the practical deployability of the system. Faster execution times without compromising detection accuracy are particularly valuable for IoT networks, where resource constraints and real-time responsiveness are critical.
The careful tuning of hyper-parameters is a crucial factor that significantly influences the training stability, convergence behavior, and final performance of ML and DL models. Hyper-parameters such as learning rate, batch size, hidden layer sizes, and dropout rates govern how effectively a model learns from the training data and how well it generalizes to unseen scenarios. Inadequate or suboptimal hyper-parameter settings may lead to issues such as overfitting, underfitting, slow convergence, or instability during optimization, ultimately degrading classification performance. Particularly for complex hybrid models like the proposed transformer-GAN, the role of precise hyper-parameter calibration becomes even more important, as multiple interconnected components must be simultaneously optimized to achieve robust intrusion detection capabilities across diverse IoT attack scenarios. For the proposed transformer-GAN architecture, hyper-parameter optimization was conducted using the INSBBO algorithm. INSBBO was employed to jointly tune critical factors such as the learning rate, dropout rate, attention configurations, and feedforward dimensions, ensuring that the hybrid model achieves optimal balance between exploration and exploitation during training. The INSBBO method was particularly advantageous because of its ability to adaptively explore complex, nonlinear search spaces, identify Pareto-optimal parameter combinations, and simultaneously optimize multiple performance objectives including detection accuracy and model efficiency.
In contrast, for the baseline models, hyper-parameter calibration was performed using a standard grid search approach. The grid search method systematically explores a manually specified set of hyper-parameter values, evaluating the model’s performance for each possible combination to identify the optimal configuration. Although grid search is computationally expensive, it is widely adopted due to its simplicity and exhaustiveness, making it suitable for models with moderate-sized hyper-parameter spaces. In our experiments, key parameters such as learning rates, hidden sizes, batch sizes, kernel sizes, and regularization terms were fine-tuned using this method to ensure a fair and competitive baseline evaluation. The hyper-parameter settings selected for each model are detailed in Table 3, covering both the proposed transformer-GAN architecture and all baseline methods.
Table 3.
Parameter setting of proposed models.
For the transformer-GAN, critical training parameters were finely tuned through the INSBBO optimizer. Specifically, a learning rate of 0.001 and a batch size of 32 were selected, balancing convergence speed and stability. The feed forward hidden size was set at 2048, consistent with standard transformer architectures to ensure rich feature representations. The number of attention heads was configured at 10, and both the encoder and decoder layers were set to 6, forming a moderately deep architecture suitable for complex IoT intrusion patterns. A dropout rate of 0.1 and weight decay of 0.01 were applied for regularization, while GELU was chosen as the activation function for smoother gradient flows. Additionally, INSBBO-specific hyper-parameters included a population size of 100, and a mutation rate of 0.06, ensuring effective evolutionary search. For the standalone Transformer baseline, a slightly deeper structure was adopted, with 8 encoder and 8 decoder layers, 12 attention heads, a larger batch size of 64, and a slightly lower learning rate of 0.002, aiming to leverage deeper sequence modeling capabilities.
For the GAN baseline, hyper-parameters were tuned to fit a generative adversarial setup with relatively lightweight architectures. A learning rate of 0.004 and a batch size of 64 were employed, with 64 neurons per hidden layer and ReLU activation for nonlinearity. Momentum was set at 0.05 to balance stability and convergence speed during SGD-based optimization. The LSTM model used a higher learning rate of 0.04, a batch size of 64, and a recurrent dropout rate of 0.3 to mitigate overfitting in sequential data modeling. It consisted of 8 hidden layers, each with 64 neurons, and used a combination of tanh and sigmoid activations to capture temporal dependencies effectively. The CNN baseline was configured with 6 convolutional layers using a 3 × 3 kernel size and max pooling (2 × 2), with 28 neurons in dense layers and a regularization parameter of 1 to prevent overfitting. Finally, the SVM model utilized an RBF kernel, with a gamma value of 0.004, 300 estimators, and a standard regularization parameter of 1, offering a strong baseline for lower-dimensional binary and multi-class classification tasks.
Table 4 demonstrates comparative performance of all models in binary and multi-class intrusion detection in the CIC-IoT-2023 dataset. The proposed transformer-GAN model achieves the highest performance across all evaluation metrics in both binary and multi-class classification tasks. In binary classification, it reaches an impressive accuracy of 99.76%, F1-score of 99.63%, and AUC of 99.91%, substantially outperforming all other baselines. In the more challenging multi-class classification setting, it maintains its superiority with an accuracy of 99.53%, F1-score of 99.42%, and AUC of 99.71%. To further isolate the contribution of the INSBBO optimizer, we evaluated a version of the architecture that combines only transformer and GAN, without any optimization. This configuration achieved strong results, with 96.75% accuracy in binary and 94.89% in multi-class classification, ranking second across all evaluation metrics. The standalone transformer model ranks third, with solid results (e.g., 95.28% accuracy in binary and 94.49% in multi-class), reflecting its strong capacity for sequence modeling. However, the addition of adversarial training in the hybrid transformer-GAN evidently enhances its feature representation and decision boundaries. GAN alone, although competitive, falls behind the hybrid due to weaker temporal modeling and lack of direct classification tuning. LSTM, while effective for sequence data, demonstrates lower generalization in this context, with accuracies of 90.48% and 89.60% in binary and multi-class modes, respectively. CNN and SVM exhibit relatively lower performance, likely due to their limited ability to capture long-range temporal and contextual dependencies in IoT traffic. CNN reaches only 88.36% (binary) and 87.22% (multi-class) accuracy, while SVM records the lowest among all, with 85.29% and 84.06%, respectively. These results underscore the importance of combining both advanced attention mechanisms and adversarial training for effective intrusion detection. The superior metrics of Transformer-GAN are attributed to its deep feature learning capabilities, resilience to class imbalance via adversarial synthesis, and its optimized architecture, which collectively lead to robust and discriminative representations.
Table 4.
Comparative performance of all models in binary and multi-class intrusion detection (CIC-IoT-2023 dataset).
Figure 5 presents a radar plot visualization of the classification accuracies achieved by different models across both binary and multi-class intrusion detection tasks. The radar charts offer an intuitive, comparative view of model performances, enabling quick visual identification of relative strengths and weaknesses. The closer a point is to the outer edge of the radar plot, the higher the accuracy achieved by the corresponding model, thus highlighting performance disparities more clearly than tabular data alone. From the radar plots, it is evident that the proposed transformer-GAN (INSBBO) consistently dominates in both binary and multi-class scenarios, forming the outermost vertex in both subplots. In the binary classification plot, transformer-GAN is distinctly separated from other methods, confirming its superior performance margin compared to the standalone transformer and GAN, transformer, GAN, LSTM, CNN, and SVM. The standalone transformer and GAN follows as the second-best performer, while traditional models like CNN and SVM cluster toward the center, indicating comparatively lower accuracy. A similar trend is observed in the multi-class radar plot, although the performance gap slightly narrows among baseline models. Nevertheless, the proposed transformer-GAN maintains a clear advantage, demonstrating its robustness not only in simpler binary distinctions but also in more complex multi-class intrusion detection scenarios.
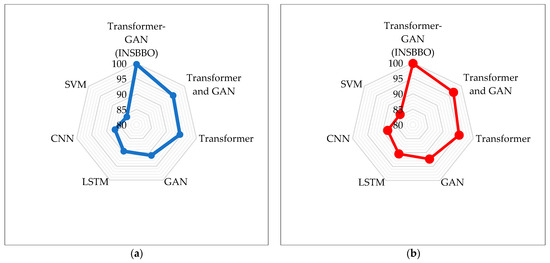
Figure 5.
Radar plot visualization of accuracy in CIC-IoT-2023 dataset: (a) Binary classification; (b) Multi-Class classification.
Figure 6 provides a visual comparison of the models’ performance based on two critical evaluation metrics: F1-score and AUC. Each bar represents the value obtained by a specific model across the two metrics, allowing a direct visual comparison of their effectiveness. The height of each bar corresponds to the achieved percentage, with higher bars indicating superior performance in terms of precision-recall balance (F1-score) and discriminative ability (AUC). From the bar charts, it is clear that the proposed transformer-GAN model consistently outperforms all baseline methods across both binary and multi-class tasks for both F1-score and AUC metrics. In binary classification, transformer-GAN achieves near-perfect values close to 100% in both F1-score and AUC, substantially higher than the others. A similar trend is observed in the multi-class results, although performance gaps between the models slightly narrow. Nonetheless, transformer-GAN maintains a significant advantage, confirming its robustness in both scenarios.
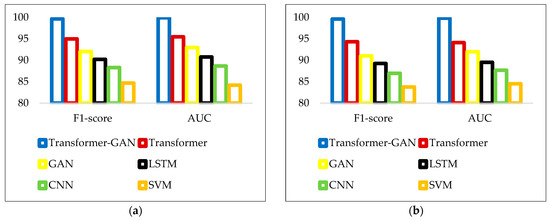
Figure 6.
Comparison of F1-score and AUC in CIC-IoT-2023 dataset: (a) Binary classification; (b) Multi-Class classification.
Figure 7 illustrates the ROC curves for all evaluated models, comparing their classification capabilities across binary and multi-class intrusion detection tasks in the CIC-IoT-2023 dataset. Each curve depicts the trade-off between the true positive rate (sensitivity) and the false positive rate (1-specificity) at various decision thresholds. The closer a curve is to the top-left corner of the plot, the better the model’s ability to distinguish between classes, implying a higher AUC value. Analyzing the ROC curves, it is evident that the transformer-GAN consistently exhibits the steepest and most convex trajectory toward the top-left corner in both binary and multi-class tasks. This indicates superior discriminative performance compared to all other models, including transformer, GAN, LSTM, CNN, and RNN. The standalone transformer also performs competitively but falls slightly behind the hybrid model. Traditional models like CNN, LSTM, and RNN demonstrate flatter ROC curves, suggesting lower sensitivity at equivalent false positive rates. The observed advantage of transformer-GAN stems from its enhanced feature extraction capabilities through attention mechanisms, improved data diversity via adversarial learning, and robust optimization with INSBBO, collectively enabling it to achieve higher sensitivity and specificity across various attack types in IoT traffic.
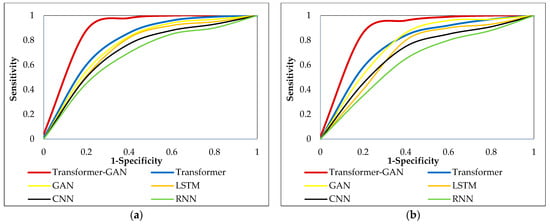
Figure 7.
ROC comparison of various models in CIC-IoT-2023 dataset: (a) Binary classification; (b) Multi-Class classification.
Figure 8 illustrates the learning curves of all models by plotting the root mean square error (RMSE) against training epochs for both binary classification (left) and multi-class classification (right) in the CIC-IoT-2023 dataset. These curves reflect the training dynamics of each model, revealing how quickly and effectively each architecture minimizes its prediction error throughout the training process. Lower RMSE values indicate a smaller discrepancy between predicted and true labels, thus, better learning performance. The steeper and faster a curve drops, the more efficiently the model converges toward an optimal solution. From the figure, it is clear that the proposed transformer-GAN model (red curve) exhibits the most rapid and stable convergence among all evaluated models in both binary and multi-class tasks. Its RMSE plummets below 5 within the first 100 epochs, and reaches near-zero levels around epoch 130, demonstrating superior training efficiency and stability. In contrast, the standalone transformer and GAN also show decent convergence patterns, reaching RMSE values under 10 but requiring more epochs to stabilize. LSTM, CNN, and SVM converge more slowly, with RMSE values remaining above 10 even after 300 epochs. These results confirm that transformer-GAN not only achieves better final accuracy but also reaches it with significantly faster convergence and minimal training loss, highlighting the effectiveness of its hybrid architecture and the role of INSBBO in optimal parameter tuning.
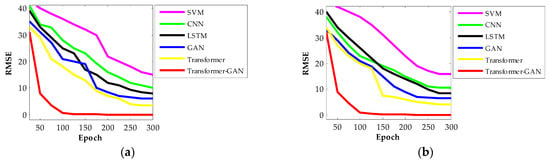
Figure 8.
Learning curves of RMSE versus epochs for various models in CIC-IoT-2023 dataset: (a) Binary classification; (b) Multi-Class classification.
To further assess the generalizability and robustness of the proposed framework, we additionally evaluated all models on the TON_IoT dataset. This dataset, with its heterogeneous and realistic traffic patterns, provides a distinct testing environment compared to CIC-IoT-2023. The comparative performance results across binary and multi-class classification settings are summarized in Table 5. As observed in Table 5, the proposed Transformer-GAN (INSBBO) architecture consistently outperformed all baseline models on the TON_IoT dataset. In binary classification, it achieved an outstanding accuracy of 99.87%, F1-score of 99.72%, and an AUC of 99.96%, surpassing the next best configuration (Transformer and GAN without INSBBO) by approximately 3% in accuracy and over 3.4% in AUC. Similar trends are evident in the multi-class setting, where the proposed model reached 99.75% accuracy, 99.68% F1-score, and 99.84% AUC. These results confirm the added value of combining adversarial data generation with transformer-based sequence modeling and hyper-parameter tuning via INSBBO. Among the baselines, the hybrid model without INSBBO (Transformer and GAN) ranked second in all metrics, reinforcing the individual strength of both core components. The standalone Transformer and GAN models followed closely but showed reduced performance, especially in multi-class detection, with GAN performing better in F1-score but slightly lower in AUC. Traditional models such as LSTM, CNN, and SVM lagged noticeably in both binary and multi-class tasks, indicating their limited scalability in more heterogeneous environments. Overall, the strong and consistent performance of our model across two diverse datasets highlights its adaptability and reliability for real-world IoT intrusion detection scenarios.
Table 5.
Comparative performance of all models in binary and multi-class intrusion detection (TON_IoT dataset).
To complement the numerical performance metrics, we provide a visual comparison of the detection capabilities of various models using ROC curves on the TON_IoT dataset. In the binary classification setting (Figure 9a), the Transformer-GAN (INSBBO) achieves a near-perfect curve that closely follows the top-left boundary of the plot, indicating extremely high sensitivity across all specificity levels. Compared to other models, it demonstrates the sharpest rise and earliest saturation, confirming its superior ability to distinguish malicious traffic from benign flows with minimal false positives. The Transformer and GAN models also perform well but remain slightly below the proposed model, while LSTM, CNN, and RNN exhibit flatter curves with larger areas under the diagonal, reflecting their relatively weaker separation capabilities. In multi-class classification (Figure 9b), the advantage of the proposed architecture remains evident. The ROC curve of the Transformer-GAN (INSBBO) dominates those of all baselines, showing consistently higher sensitivity across varying thresholds. This suggests that not only does the model excel at detecting whether traffic is malicious, but it also reliably differentiates between multiple attack types. The Transformer and LSTM models again rank next in performance, while CNN, GAN, and especially RNN display degraded discriminative behavior in this more complex classification setting. These findings visually reinforce the numerical metrics presented earlier in Table 5 and highlight the generalization capability of our model in heterogeneous and dynamic IoT environments.
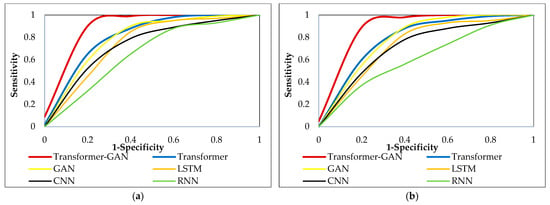
Figure 9.
ROC comparison of various models in TON_IoT dataset: (a) Binary classification; (b) Multi-Class classification.
To further investigate the learning efficiency and convergence behavior of the evaluated models, we plot the RMSE learning curves over training epochs on the TON_IoT dataset. As depicted in Figure 10, the plots show how quickly and effectively each model minimizes its prediction error during training for both binary and multi-class classification tasks. Lower RMSE values across fewer epochs indicate better convergence speed and generalization behavior of the model. In the binary classification setting (Figure 10a), the proposed Transformer-GAN (INSBBO) demonstrates the fastest and most stable convergence trajectory, reaching an RMSE below 5 in less than 100 epochs. In contrast, other models such as LSTM, CNN, and GAN converge more slowly and stabilize at noticeably higher RMSE values. SVM, in particular, shows limited convergence capability, retaining high error levels even after 300 epochs. These trends confirm the efficiency of adversarial and transformer-based learning dynamics in capturing the underlying data distribution quickly and with minimal error. In multi-class classification (Figure 10b), a similar pattern is observed. Transformer-GAN (INSBBO) maintains its advantage by reaching near-zero RMSE levels faster than all competing models. The Transformer alone also converges well but at a slower pace and with slightly higher final error. GAN and LSTM show moderate convergence, while CNN and SVM exhibit slower and less stable reductions in RMSE. These results highlight the superiority of the proposed architecture not only in terms of classification accuracy but also in training stability and optimization efficiency—crucial factors for real-world deployment in dynamic IoT environments.
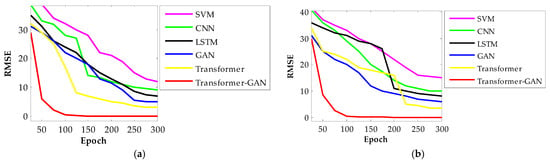
Figure 10.
Learning curves of RMSE versus epochs for various models TON_IoT dataset: (a) Binary classification; (b) Multi-Class classification.
4. Discussion
In this section, we conduct an in-depth discussion of the experimental outcomes by analyzing three critical aspects of the proposed framework: computational complexity and execution time, statistical significance of the results, and the stability of the model under real-world data distributions. These aspects are especially relevant in the context of the CIC-IoT-2023 dataset, which consists of high-dimensional and imbalanced traffic patterns across multiple types of malicious behaviors. The complexity of IoT attack vectors and the heterogeneous feature spaces pose unique challenges for intrusion detection systems, making it imperative to validate not only detection accuracy but also the efficiency and robustness of the learning process. The first part of this analysis focuses on the runtime efficiency and computational burden of the evaluated models, particularly concerning training convergence and inference speed. As IoT systems typically operate under resource-constrained environments, models with lower training overhead and faster execution times are more suitable for practical deployment. The second component of our discussion implements statistical hypothesis testing using independent two-sample t-tests to verify whether the observed performance improvements of the transformer-GAN over baseline methods are statistically significant. This step ensures that the reported gains are not merely due to random fluctuations in training or dataset artifacts. Finally, we examine model stability through standard deviation analysis of key metrics such as accuracy, F1-score, and AUC across multiple training runs. A low standard deviation would indicate a stable model that performs consistently across different initializations and data shuffles, a vital property in adversarial and dynamic IoT threat landscapes.
Table 6 compares the computational efficiency of various models by reporting their runtime (in seconds) required to surpass specific accuracy thresholds (35%, 55%, 75%, and 95%) under the multi-class intrusion detection task. This evaluation provides insight into each model’s learning speed and convergence efficiency, which are particularly important when deploying detection frameworks in latency-sensitive or resource-constrained IoT environments. The results clearly demonstrate the superiority of the transformer-GAN in terms of both convergence speed and computational cost. It achieves 35% accuracy in just 16 s, 55% in 59 s, and surpasses 75% in under 100 s, reaching the highest observed accuracy level of over 95% in 157 s. Additionally, we included the Transformer and GAN combination (without INSBBO) in Table 6 to further assess its computational efficiency relative to other baselines. In contrast, the Transformer and GAN combination requires 259 s to surpass 75% accuracy and, similar to other baselines, does not reach the 95% threshold within the observed training window. Meanwhile, the standalone transformer requires over 300 s to approach similar levels of performance. Other models like GAN, LSTM, CNN, and SVM show significantly slower learning curves, SVM, for instance, takes over 900 s to reach 75% accuracy, and none of them exceed the 95% mark. This reinforces transformer-GAN’s advantage not just in final performance, but also in computational efficiency.
Table 6.
Runtime of models at different accuracy thresholds in multi-class classification (CIC-IoT-2023 dataset).
From an architectural perspective, this efficiency gain can be attributed to the synergistic integration of the transformer’s attention mechanism and GAN’s generative capabilities, further enhanced through INSBBO-based hyper-parameter optimization. These factors enable faster convergence while avoiding overfitting, even under imbalanced and multi-modal data as seen in the CIC-IoT-2023 dataset. In contrast, traditional models like CNN, LSTM, and SVM struggle to keep up, both due to less efficient learning dynamics and higher dependency on sequential or convolutional operations, which scale poorly with complex input spaces. Such computational efficiency is particularly relevant for real-time or near-real-time applications in edge or fog computing layers of IoT networks, where hardware limitations often preclude the use of deep and slow models. The ability of transformer-GAN to reach high accuracy levels in a fraction of the time makes it a strong candidate for deployment in security-critical systems such as smart homes, industrial control systems, or autonomous IoT-based infrastructures that demand both rapid detection and minimal computational footprint.
To assess the scalability and practicality of the proposed intrusion detection framework, we analyze its computational complexity by decomposing the system into its three major components: the Transformer-based architecture, the adversarial training process of the GAN, and the INSBBO meta-heuristic optimization loop. This analysis helps quantify the computational demands during training and inference, providing insight into the framework’s feasibility in real-world IoT deployments. The Transformer model forms the backbone of both the generator and discriminator. Its self-attention mechanism exhibits quadratic complexity with respect to sequence length. The complexity of a single forward pass is given by Equation (20):
where is the number of Transformer layers, is the number of attention heads per layer, is the sequence length (i.e., number of input tokens), and is the feature dimensionality of each token. During each GAN training step, both the generator and discriminator undergo forward and backward propagation. As a result, the computational complexity of one full adversarial training step becomes Equation (21):
The INSBBO optimizer introduces additional computational overhead by evaluating a population of candidate solutions over multiple evolutionary iterations. For a population of size P and T generations, where each candidate involves a full GAN training pass, the total optimization complexity is expressed as Equation (22):
where is the number of candidate solutions per generation and is the number of evolutionary iterations in the INSBBO process. This formulation reflects the most computationally intensive phase of the proposed approach, as it encapsulates the repeated training of complex Transformer-GAN models.
To validate whether the observed performance differences between the proposed transformer-GAN and the baseline models are statistically meaningful, we conducted a series of independent two-sample t-tests. This test determines whether the means of two groups are significantly different from each other, under the assumption of unequal variances. In the context of our study, the null hypothesis asserts that there is no significant difference in classification performance between transformer-GAN and each compared baseline. Rejecting this hypothesis supports the claim that the proposed model’s improvements are not due to random fluctuations or sample biases but are statistically robust. We set the significance level at α = 0.01, meaning any p-value below this threshold would confirm that the difference is statistically significant with at least 99% confidence. This threshold ensures strict criteria, avoiding false positives when comparing high-performance models on complex datasets like CIC-IoT-2023. This dataset includes a wide range of attack types and class imbalances, which could otherwise cause variability in model performance. Conducting t-tests under these conditions strengthens the empirical foundation of our evaluation, making the comparison both rigorous and generalizable.
Table 7 illustrates statistical significance results (p-values) from t-tests comparing transformer-GAN to baseline models in both binary and multi-class classification. All p-values for both binary and multi-class comparisons are well below α = 0.01 threshold, ranging from 0.0006 to 0.000005 in binary classification, and 0.0009 to 0.00008 in multi-class classification. These values strongly confirm that the performance differences between transformer-GAN and all other models are statistically significant. The smallest p-values are observed in comparisons against SVM and LSTM, indicating the largest performance gaps. Even against the standalone transformer and GAN models, the differences are statistically validated with high confidence. This outcome supports the conclusion that the superior performance of transformer-GAN is not incidental but instead stems from fundamental architectural advantages, including its hybrid learning strategy, attention-based temporal modeling, and optimized configuration via INSBBO. In high-stakes IoT environments, where decisions depend on reliably detecting real threats, statistical confidence in performance improvements is crucial. These results reinforce the credibility and practicality of deploying transformer-GAN as a state-of-the-art detection mechanism in both binary and multi-class intrusion detection tasks.
Table 7.
Statistical significance results from t-tests comparing transformer-GAN to baseline models.
Table 8 presents the standard deviation values of the classification performance across multiple experimental runs for both binary and multi-class tasks. This table evaluates the stability and robustness of each model when exposed to different data shuffling, initializations, and random perturbations. Lower standard deviation indicates that the model’s results are consistent across different trials, while higher values suggest more volatile and less reliable performance. Assessing standard deviation is crucial because real-world IoT environments, like those reflected in the CIC-IoT-2023 dataset, inherently involve dynamic and unpredictable traffic patterns. Attack behaviors vary over time, and small fluctuations in training or input data can significantly impact poorly generalized models. Thus, models intended for intrusion detection must demonstrate not only high mean performance but also strong stability across varying conditions. By examining standard deviation, we ensure that the proposed transformer-GAN is not merely achieving high results on select runs but is consistently reliable across the board.
Table 8.
Standard deviation values of classification results across multiple runs for different models.
Analyzing Table 8, the transformer-GAN model exhibits exceptionally low standard deviation values (0.0000365 for binary and 0.0006325 for multi-class classification) confirming its outstanding stability. In contrast, baseline models such as CNN and SVM suffer from much higher variance (e.g., over 4.32 and 7.21, respectively, in multi-class tasks), suggesting high sensitivity to initial conditions and training noise. Even the standalone transformer shows a notable increase in variability compared to the hybrid model. This result further highlights the advantage of combining the transformer’s attention mechanisms with GAN’s feature diversity and INSBBO’s optimization capabilities, producing a model resilient to IoT intrusion data’s dynamic, noisy, and complex nature.
While the proposed Transformer-GAN-INSBBO framework demonstrates strong performance in experimental settings, several deployment challenges must be addressed before real-world integration. First, latency poses a significant concern, especially in time-sensitive applications such as industrial control or healthcare. Although the transformer-based architecture enables parallel processing, the computational overhead of GAN training and INSBBO optimization can impact real-time detection capabilities. Second, scalability remains a practical barrier, as IoT networks may consist of thousands of heterogeneous devices generating high-volume traffic. Efficient model compression and edge-friendly inference strategies may be required to ensure operational feasibility. Third, device heterogeneity, stemming from differences in protocols, hardware capabilities, and operating systems, can cause inconsistencies in data distributions and hinder generalization. Although the proposed model was validated on diverse datasets, domain adaptation techniques or transfer learning may be necessary to maintain robustness across varied deployment environments. Future work will explore lightweight model variants and edge deployment strategies to mitigate these limitations.
Furthermore, it is worth noting that in real-world IoT traffic, temporal and contextual dependencies are crucial for detecting multi-stage and stealthy attacks that evolve over time. For example, in the CIC-IoT-2023 dataset, a reconnaissance attack may begin with a sequence of benign DNS and ICMP packets, followed by suspicious port scanning behavior minutes later. Capturing such patterns requires a model that can retain long-term dependencies and associate earlier benign-looking events with later malicious activities. Traditional models like CNN or shallow RNNs often fail to link these temporally dispersed patterns. The Transformer architecture, with its self-attention mechanism, is well-suited to capture these long-range dependencies, making it particularly effective for modeling complex IoT attack sequences that span multiple time windows.
5. Conclusions
In this paper, we proposed a novel hybrid intrusion detection framework for IoT environments by synergistically integrating transformer networks with GANs. The transformer component was utilized to capture complex temporal and contextual dependencies within IoT traffic sequences, while the GAN component was employed to enhance feature diversity and mitigate class imbalance. Furthermore, a novel INSBBO algorithm was incorporated to fine-tune the hyper-parameters and internal configurations of the hybrid model, ensuring optimized learning dynamics. The effectiveness of the proposed system was systematically validated through extensive experiments on the CIC-IoT-2023 and TON_IoT dataset, which contains a rich variety of real-world IoT traffic patterns and attack scenarios. The experimental design included comparisons with strong baseline models such as transformer and GAN (without INSBBO), standalone transformer, GAN, LSTM, CNN, and SVM across both binary and multi-class classification tasks. To ensure a rigorous evaluation, multiple performance aspects were analyzed, including accuracy, F1-score, AUC, runtime efficiency, and model stability. Statistical hypothesis testing using independent two-sample t-tests and standard deviation analysis further validated the reliability and robustness of the proposed approach under diverse and dynamic IoT conditions. This comprehensive evaluation strategy ensured that the reported improvements were statistically meaningful and practically relevant for deployment in real-world security applications.
The experimental results consistently demonstrated the superiority of the proposed transformer-GAN framework. The transformer-GAN achieves a multi-class classification accuracy of 99.67%, with an F1-score of 99.61%, and an area under the curve (AUC) of 99.80% in the CIC-IoT-2023 dataset, and achieves 98.84% accuracy, 98.79% F1-score, and 99.12% AUC on the TON_IoT dataset. In addition, the model showed exceptional efficiency in terms of runtime, reaching high accuracy thresholds substantially faster than traditional DL models. Standard deviation analysis revealed minimal performance variance across multiple runs, indicating strong stability and resilience to data perturbations. Furthermore, independent t-test results confirmed the statistical significance of the observed improvements, with all p-values falling well below the 0.01 threshold. Beyond numerical performance, qualitative analysis highlighted that the combination of the transformer’s attention mechanisms and GAN’s adversarial training yielded robust feature representations capable of accurately detecting a wide range of sophisticated intrusion patterns in the CIC-IoT-2023 dataset. The computational efficiency achieved by the model makes it particularly attractive for practical deployment in resource-constrained IoT environments, such as smart homes, industrial systems, and critical infrastructure networks. The consistent success of the proposed approach across binary and multi-class classification tasks suggests that combining attention-driven sequence modeling with adversarial feature learning is highly effective for complex anomaly detection problems. Furthermore, the significant improvements observed in statistical significance testing and low standard deviation analysis indicate that the model is not only powerful but also robust against variations in data distribution and initial conditions. These findings highlight the potential of advanced hybrid architectures, combined with evolutionary optimization, to set new benchmarks for securing next-generation IoT ecosystems against increasingly sophisticated cyber threats.
For future work, one promising direction would be to explore the integration of more advanced generative models, such as diffusion models or variational autoencoders (VAEs), into the current transformer-GAN framework. These alternative generative architectures may offer richer feature distributions and further enhance the model’s ability to capture subtle intrusion patterns in complex IoT traffic. Additionally, investigating attention optimization techniques (such as sparse or adaptive attention mechanisms) within the transformer component could significantly reduce computational costs while preserving or even improving detection performance. This would enable the development of even more efficient and scalable hybrid architectures tailored for resource-constrained IoT devices. From an application perspective, future research could focus on adapting the proposed model for dynamic IoT network environments, where device compositions and network topologies change frequently. Enhancing the model’s adaptability in such dynamic conditions would make it more viable for real-world deployment in industrial and smart city infrastructures. Furthermore, implementing the transformer-GAN framework within a distributed IoT security system, possibly using lightweight edge-based deployments, could significantly enhance real-time detection capabilities while preserving data locality and privacy. These directions align with the increasing need for intelligent, flexible, and scalable security solutions in rapidly evolving IoT ecosystems.
Author Contributions
Conceptualization, P.S.M., A.V., S.S.K., F.H.-G. and D.M.; methodology, P.S.M., A.V. and S.S.K.; validation, P.S.M., F.H.-G. and D.M.; formal analysis, P.S.M. and A.V.; investigation, P.S.M., S.S.K. and F.H.-G.; resources, F.H.-G. and D.M.; data curation, P.S.M., A.V. and S.S.K.; writing—original draft preparation, P.S.M., A.V., S.S.K., F.H.-G. and D.M.; visualization, A.V.; supervision, F.H.-G. and D.M.; project administration, D.M.; funding acquisition, D.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, C.; Wang, J.; Wang, S.; Zhang, Y. A Review of IoT Applications in Healthcare. Neurocomputing 2024, 565, 127017. [Google Scholar] [CrossRef]
- Panduman, Y.Y.F.; Funabiki, N.; Fajrianti, E.D.; Fang, S.; Sukaridhoto, S. A Survey of AI Techniques in IoT Applications with Use Case Investigations in the Smart Environmental Monitoring and Analytics in Real-Time IoT Platform. Information 2024, 15, 153. [Google Scholar] [CrossRef]
- Kaveh, M.; Yan, Z.; Jäntti, R. Secrecy Performance Analysis of RIS-Aided Smart Grid Communications. IEEE Trans. Ind. Inform. 2024, 20, 5415–5427. [Google Scholar] [CrossRef]
- Bensaid, R.; Labraoui, N.; Saidi, H.; Bany Salameh, H. Securing Fog-Assisted IoT Smart Homes: A Federated Learning-Based Intrusion Detection Approach. Clust. Comput. 2025, 28, 50. [Google Scholar] [CrossRef]
- Choudhary, V.; Guha, P.; Pau, G.; Mishra, S. An Overview of Smart Agriculture Using Internet of Things (IoT) and Web Services. Environ. Sustain. Indic. 2025, 26, 100607. [Google Scholar] [CrossRef]
- Kaveh, M.; Mosavi, M.R. A Lightweight Mutual Authentication for Smart Grid Neighborhood Area Network Communications Based on Physically Unclonable Function. IEEE Syst. J. 2020, 14, 4535–4544. [Google Scholar] [CrossRef]
- Zikria, Y.B.; Ali, R.; Afzal, M.K.; Kim, S.W. Next-Generation Internet of Things (IoT): Opportunities, Challenges, and Solutions. Sensors 2021, 21, 1174. [Google Scholar] [CrossRef]
- Kaveh, M.; Mosavi, M.R.; Martín, D.; Aghapour, S. An Efficient Authentication Protocol for Smart Grid Communication Based on On-Chip-Error-Correcting Physical Unclonable Function. Sustain. Energy Grids Netw. 2023, 36, 101228. [Google Scholar] [CrossRef]
- Yalli, J.S.; Hasan, M.H.; Badawi, A. Internet of Things (IoT): Origin, Embedded Technologies, Smart Applications and Its Growth in the Last Decade. IEEE Access 2024, 12, 91357–91382. [Google Scholar] [CrossRef]
- Najafi, F.; Kaveh, M.; Mosavi, M.R.; Brighente, A.; Conti, M. EPUF: An Entropy-Derived Latency-Based DRAM Physical Unclonable Function for Lightweight Authentication in Internet of Things. IEEE Trans. Mob. Comput. 2025, 24, 2422–2436. [Google Scholar] [CrossRef]
- Adam, M.; Hammoudeh, M.; Alrawashdeh, R.; Alsulaimy, B. A Survey on Security, Privacy, Trust, and Architectural Challenges in IoT Systems. IEEE Access 2024, 12, 57128–57149. [Google Scholar] [CrossRef]
- Ghadi, F.R.; Kaveh, M.; Wong, K.K.; Zhang, Y. Performance Analysis of FAS-Aided Backscatter Communications. IEEE Wirel. Commun. Lett. 2024, 13, 2412–2416. [Google Scholar] [CrossRef]
- Mishra, R.; Mishra, A. Current Research on Internet of Things (IoT) Security Protocols: A Survey. Comput. Secur. 2025, 151, 104310. [Google Scholar] [CrossRef]
- Dritsas, E.; Trigka, M. A Survey on Cybersecurity in IoT. Future Internet 2025, 17, 30. [Google Scholar] [CrossRef]
- Gupta, B.B.; Gaurav, A.; Attar, R.W.; Arya, V.; Bansal, S.; Alhomoud, A.; Chui, K.T. A Hybrid Ant Lion Optimization Algorithm Based Lightweight Deep Learning Framework for Cyber Attack Detection in IoT Environment. Comput. Electr. Eng. 2025, 122, 109944. [Google Scholar] [CrossRef]
- Ghadi, F.R.; Kaveh, M.; Martín, D. Performance Analysis of RIS/STAR-IOS-Aided V2V NOMA/OMA Communications over Composite Fading Channels. IEEE Trans. Intell. Veh. 2024, 9, 279–286. [Google Scholar] [CrossRef]
- Rahman, M.M.; Al Shakil, S.; Mustakim, M.R. A Survey on Intrusion Detection System in IoT Networks. Cyber Secur. Appl. 2025, 3, 100082. [Google Scholar] [CrossRef]
- Kaveh, M.; Rostami Ghadi, F.; Jäntti, R.; Yan, Z. Secrecy Performance Analysis of Backscatter Communications with Side Information. Sensors 2023, 23, 8358. [Google Scholar] [CrossRef]
- Diana, L.; Dini, P.; Paolini, D. Overview on Intrusion Detection Systems for Computers Networking Security. Computers 2025, 14, 87. [Google Scholar] [CrossRef]
- Abbas, S.; Al Hejaili, A.; Sampedro, G.A.; Abisado, M.A.; Almadhor, A.M.; Shahzad, T.; Ouahada, K. A Novel Federated Edge Learning Approach for Detecting Cyberattacks in IoT Infrastructures. IEEE Access 2023, 11, 112189–112198. [Google Scholar] [CrossRef]
- Wang, Y.C.; Yng, Y.C.; Chen, H.X.; Tseng, S.M. Network Anomaly Intrusion Detection Based on Deep Learning Approach. Sensors 2023, 23, 2171. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.W.; Kientz, F.; Kashef, R. A Modified Transformer Neural Network (MTNN) for Robust Intrusion Detection in IoT Networks. In Proceedings of the 2023 International Telecommunications Conference (ITC-Egypt), Alexandria, Egypt, 18–20 July 2023; pp. 663–668. [Google Scholar]
- Mezina, A.; Burget, R.; Travieso-González, C.M. Network Anomaly Detection with Temporal Convolutional Network and U-Net Model. IEEE Access 2021, 9, 143608–143622. [Google Scholar] [CrossRef]
- He, M.S.; Wang, X.J.; Wei, P.; Yang, L.; Teng, Y.L.; Lyu, R.J. Reinforcement Learning Meets Network Intrusion Detection: A Transferable and Adaptable Framework for Anomaly Behavior Identification. IEEE Trans. Netw. Serv. Manag. 2024, 21, 2477–2492. [Google Scholar] [CrossRef]
- Jony, A.I.; Arnob, A.K.B. A Long Short-Term Memory Based Approach for Detecting Cyber Attacks in IoT Using CIC-IoT2023 Dataset. J. Edge Comput. 2024, 3, 28–42. [Google Scholar] [CrossRef]
- Jaradat, A.S.; Nasayreh, A.; Al-Na’amneh, Q.; Gharaibeh, H.; Al Mamlook, R.E. Genetic Optimization Techniques for Enhancing Web Attacks Classification in Machine Learning. In Proceedings of the IEEE International Conference on Dependable, Autonomic & Secure Computing, Abu Dhabi, United Arab Emirates, 14–17 November 2023; pp. 0130–0136. [Google Scholar]
- Guo, G.; Pan, X.; Liu, H.; Li, F.; Pei, L.; Hu, K. An IoT Intrusion Detection System Based on TON IoT Network Dataset. In Proceedings of the 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–11 March 2023; pp. 0333–0338. [Google Scholar]
- Neto, E.C.P.; Dadkhah, S.; Ferreira, R.; Zohourian, A.; Lu, R.; Ghorbani, A.A. CICIoT2023: A Real-Time Dataset and Benchmark for Large-Scale Attacks in IoT Environment. Sensors 2023, 23, 5941. [Google Scholar] [CrossRef]
- Tseng, S.M.; Wang, Y.Q.; Wang, Y.C. Multi-Class Intrusion Detection Based on Transformer for IoT Networks Using CIC-IoT-2023 Dataset. Future Internet 2024, 16, 284. [Google Scholar] [CrossRef]
- Khatami, S.S.; Shoeibi, M.; Salehi, R.; Kaveh, M. Energy-Efficient and Secure Double RIS-Aided Wireless Sensor Networks: A QoS-Aware Fuzzy Deep Reinforcement Learning Approach. J. Sens. Actuator Netw. 2025, 14, 18. [Google Scholar] [CrossRef]
- Ismail, S.; Dandan, S.; Qushou, A.A. Intrusion Detection in IoT and IIoT: Comparing Lightweight Machine Learning Techniques Using TON_IoT, WUSTL-IIOT-2021, and EdgeIIoTset Datasets. IEEE Access 2025, 13, 73468–73485. [Google Scholar] [CrossRef]
- Dalla-Torre, H.; Gonzalez, L.; Mendoza-Revilla, J.; Lopez Carranza, N.; Grzywaczewski, A.H.; Oteri, F.; Pierrot, T. Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics. Nat. Methods 2025, 22, 287–297. [Google Scholar] [CrossRef]
- Ma, X.; Zeng, T.; Zhang, M.; Zeng, P.; Lin, B.; Lu, S. Street Microclimate Prediction Based on Transformer Model and Street View Image in High-Density Urban Areas. Build. Environ. 2025, 269, 112490. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, Z.; Wu, Y.; Burke, A.F. Predictive Pretrained Transformer (PPT) for Real-Time Battery Health Diagnostics. Appl. Energy 2025, 377, 124746. [Google Scholar] [CrossRef]
- Zhang, X.; Lin, M.; Hong, Y.; Xiao, H.; Chen, C.; Chen, H. MSFT: A Multi-Scale Feature-Based Transformer Model for Arrhythmia Classification. Biomed. Signal Process. Control 2025, 100, 106968. [Google Scholar] [CrossRef]
- Madan, S.; Lentzen, M.; Brandt, J.; Rueckert, D.; Hofmann-Apitius, M.; Fröhlich, H. Transformer Models in Biomedicine. BMC Med. Inform. Decis. Mak. 2024, 24, 214. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Ke, L.; Chen, L.; Dou, B.; Zhu, Y.; Liu, J.; Wei, G.W. Transformer Technology in Molecular Science. Wiley Interdiscip. Rev. Comput. Mol. Sci. 2024, 14, e1725. [Google Scholar] [CrossRef]
- Xiao, Y.; Shao, H.; Wang, J.; Yan, S.; Liu, B. Bayesian Variational Transformer: A Generalizable Model for Rotating Machinery Fault Diagnosis. Mech. Syst. Signal Process. 2024, 207, 110936. [Google Scholar] [CrossRef]
- Wang, C.; Chen, Y.; Zhang, S.; Zhang, Q. Stock Market Index Prediction Using Deep Transformer Model. Expert Syst. Appl. 2022, 208, 118128. [Google Scholar] [CrossRef]
- Khatami, S.S.; Shoeibi, M.; Oskouei, A.E.; Martín, D.; Dashliboroun, M.K. 5DGWO-GAN: A Novel Five-Dimensional Gray Wolf Optimizer for Generative Adversarial Network-Enabled Intrusion Detection in IoT Systems. Comput. Mater. Contin. 2025, 82, 881. [Google Scholar] [CrossRef]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative Adversarial Network: An Overview of Theory and Applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Li, T.; Cao, Y.; Ye, Q.; Zhang, Y. Generative Adversarial Networks (GAN) Model for Dynamically Adjusted Weld Pool Image toward Human-Based Model Predictive Control (MPC). J. Manuf. Process. 2025, 141, 210–221. [Google Scholar] [CrossRef]
- Nabila, U.M.; Lin, L.; Zhao, X.; Gurecky, W.L.; Ramuhalli, P.; Radaideh, M.I. Data Efficiency Assessment of Generative Adversarial Networks in Energy Applications. Energy AI 2025, 20, 100501. [Google Scholar] [CrossRef]
- Liao, W.; Yang, K.; Fu, W.; Tan, C.; Chen, B.; Shan, Y. A Review: The Application of Generative Adversarial Network for Mechanical Fault Diagnosis. Meas. Sci. Technol. 2024, 35, 062002. [Google Scholar] [CrossRef]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.-H. Deblurring Images via Deep Blind Residual Learning. IEEE Trans. Image Process. 2018, 27, 992–1004. [Google Scholar]
- Zhang, H.; Sindagi, V.A.; Patel, V.M. Image Deraining Using a Conditional Generative Adversarial Network. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2009–2024. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Zhang, X.; Zhang, L.; Dong, C.C.; Lin, L. Detail Enhanced Interactive Deraining Network Using Multi-Dimensional Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12840–12849. [Google Scholar]
- Simon, D. Biogeography-Based Optimization. IEEE Trans. Evol. Comput. 2008, 12, 702–713. [Google Scholar] [CrossRef]
- Zhang, Y.; Gu, X. A Biogeography-Based Optimization Algorithm with Local Search for Large-Scale Heterogeneous Distributed Scheduling with Multiple Process Plans. Neurocomputing 2024, 595, 127897. [Google Scholar] [CrossRef]
- Kaveh, M.; Mesgari, M.S.; Martín, D.; Kaveh, M. TDMBBO: A Novel Three-Dimensional Migration Model of Biogeography-Based Optimization (Case Study: Facility Planning and Benchmark Problems). J. Supercomput. 2023, 79, 9715–9770. [Google Scholar] [CrossRef]
- Gao, C.; Li, T.; Gao, Y.; Zhang, Z. A Comprehensive Multi-Strategy Enhanced Biogeography-Based Optimization Algorithm for High-Dimensional Optimization and Engineering Design Problems. Mathematics 2024, 12, 435. [Google Scholar] [CrossRef]
- Suraya, S.; Irshad, S.M.; Ramesh, G.P.; Sujatha, P. Biogeography Based Optimization Algorithm and Neural Network to Optimize Place and Size of Distributed Generating System in Electrical Distribution. J. Electr. Eng. Technol. 2022, 17, 1593–1603. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).