
Advancing TinyML in IoT: A Holistic System-Level Perspective for Resource-Constrained AI

 ,
, 
Abstract
1. Introduction
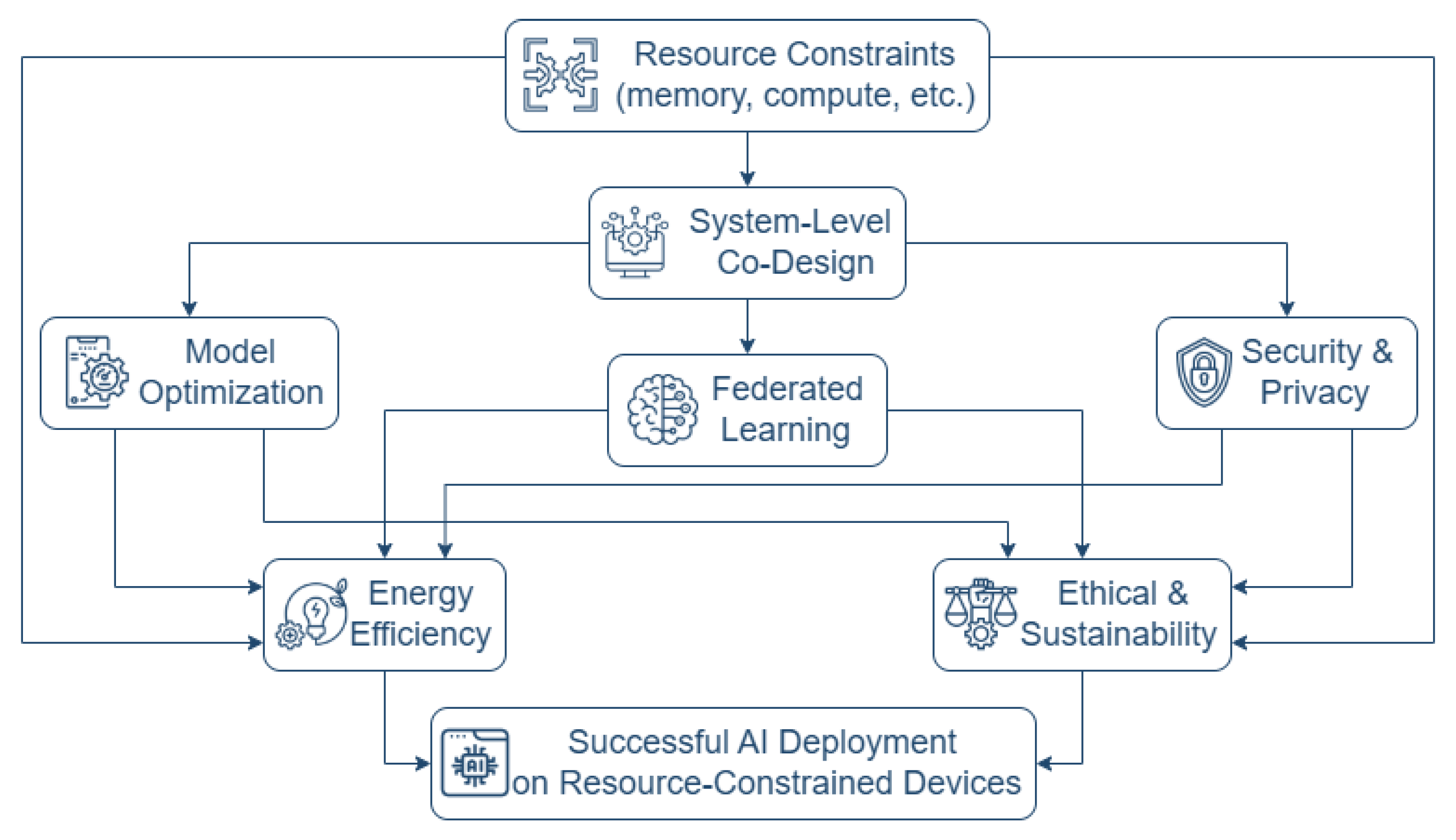
- A comprehensive analysis of the fundamental challenges inherent in deploying AI on resource-constrained hardware, including computational limits, memory constraints, energy efficiency, real-time requirements, data security, and reliability;
- An in-depth examination of state-of-the-art methodologies and emergent techniques enabling TinyML, covering model compression strategies (quantization, pruning, knowledge distillation), specialized software frameworks, hardware accelerators, and distributed learning paradigms like federated learning;
- An illustration of the significant opportunities and transformative potential of resource-constrained AI across diverse application domains, including healthcare, smart cities, smart agriculture, and Industry 4.0, highlighting the unique demands of each context;
- A discussion of critical cross-cutting themes vital for responsible deployment, such as data security, privacy, ethical considerations, and environmental sustainability in the context of edge AI;
- Identification of pressing research gaps and future directions, offering a roadmap for advancing the field of TinyML and resource-constrained AI systems.
2. Background and Motivation
2.1. The Evolution of TinyML
- Hardware Advancements: While still constrained, modern microcontrollers offer increasing computational capabilities, including specialized instructions or small accelerators suitable for integer-based AI operations [16]. The development of ultra-low-power specialized hardware such as application-specific integrated circuits (ASICs) and field-programmable gate arrays (FPGAs) tailored for AI inference on embedded systems has also been crucial [15,19].
- Software Framework Innovation: The emergence of specialized frameworks and toolchains like TensorFlow Lite for Microcontrollers, microTVM, and CMSIS-NN has abstracted away some of the low-level hardware complexities, making it feasible for developers to optimize and deploy models on these constrained platforms [8,20,21].
2.2. Defining Resource-Constrained Devices
2.3. Significance of On-Device AI
3. Key Challenges in AI for Constrained Devices
3.1. Computational and Memory Limitations
3.2. Energy Efficiency and Thermal Management
3.3. Real-Time Constraints
3.4. Data Security and Privacy
3.5. Model Generalization vs. Specialization
3.6. Reliability and Fault Tolerance
4. Emerging Solutions and State-of-the-Art Approaches
4.1. Model Compression Techniques
4.2. TinyML Frameworks
4.3. Hardware Accelerators and Architectures
4.4. Federated Learning and Edge AI
4.5. Security Mechanisms and Lightweight Encryption
4.6. Software and System Optimizations
5. Opportunities and Cross-Cutting Themes
5.1. Healthcare and Wearables
5.2. Smart Cities and Infrastructure
5.3. Agriculture and Environmental Monitoring
5.4. Industry 4.0 and Predictive Maintenance
5.5. Ethical and Sustainability Considerations
6. Future Directions
6.1. Dynamic Model Adaptation and On-Device Training
6.2. Co-Design of Hardware and Algorithms
6.3. Advanced Security and Trust Mechanisms
6.4. Privacy-Preserving Learning at Scale
6.5. Resilience and Reliability for Real-World Environments
6.6. Benchmarking and Standardization
6.7. Opportunities and Future Outlook
6.8. Key Insights for TinyML Researchers
- Ethical and Sustainable Deployments: Large-scale IoT expansions demand addressing fairness, bias, environmental impact, and responsible data management, ensuring TinyML’s long-term societal benefits [22].
7. Conclusions
Funding
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Satyanarayanan, M. The emergence of edge computing. Computer 2017, 50, 30–39. [Google Scholar] [CrossRef]
- Shi, R.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Li, S.; Da Xu, L.; Zhao, S. The internet of things: A survey. Inf. Syst. Front. 2015, 17, 243–259. [Google Scholar] [CrossRef]
- Bayoudh, K. A survey of multimodal hybrid deep learning for computer vision: Architectures, applications, trends, and challenges. Inf. Fusion 2023, 105, 102217. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Warden, P.; Situnayake, D. TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Micro-Controllers; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Xu, L.D.; He, W.; Li, S. Internet of Things in industries: A survey. IEEE Trans. Ind. Informat. 2014, 10, 2233–2243. [Google Scholar] [CrossRef]
- Koomey, G. Growth in Data Center Electricity Use 2005 to 2010; Analytics Press: Oakland, CA, USA, 2011; Available online: https://alejandrobarros.com/wp-content/uploads/old/4363/Growth_in_Data_Center_Electricity_use_2005_to_2010.pdf (accessed on 3 February 2025).
- Dehrouyeh, F.; Yang, L.; Ajaei, F.B.; Shami, A. On TinyML and cybersecurity: Electric vehicle charging infrastructure use case. IEEE Access 2024, 12, 108703–108730. [Google Scholar] [CrossRef]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Han, H.; Siebert, J. TinyML: A Systematic review and synthesis of existing research. In Proceedings of the 2022 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 21–24 February 2022. [Google Scholar] [CrossRef]
- Venkataramanaiah, S.K.; Ma, Y.; Yin, S.; Nurvithadhi, E.; Dasu, A.; Cao, Y.; Seo, J.-S. DeepX: A software accelerator for low-power deep learning inference on mobile devices. In Proceedings of the 15th International Conference on Information Processing in Sensor Networks (IPSN), Vienna, Austria, 11–14 April 2016; pp. 1–12. [Google Scholar]
- Reddi, V.J.; Plancher, B.; Kennedy, S.; Moroney, L.; Warden, P.; Suzuki, L.; Agarwal, A.; Banbury, C.; Banzi, M.; Bennett, M.; et al. Widening access to applied machine learning with TinyML. Harv. Data Sci. Rev. 2022, 4. [Google Scholar] [CrossRef]
- Johnvictor, A.C.; Poonkodi, M.; Sankar, N.P.; Vs, T. TinyML-based lightweight AI healthcare mobile chatbot deployment. J. Multidiscip. Heal. 2024, 17, 5091–5104. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Krishna, T.; Emer, J.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Wiese, P.; İsLamoğlu, G.; Scherer, M.; Macan, L.; Jung, V.J.; Burrello, A.; Conti, F.; Benini, L. Toward Attention-based TinyML: A heterogeneous accelerated architecture and automated deployment flow. IEEE Micro. 2025, 1. [Google Scholar] [CrossRef]
- Sudharsan, B.; Salerno, S.; Nguyen, D.-D.; Yahya, M.; Wahid, A.; Yadav, P.; Breslin, J.G.; Ali, M.I. TinyML Benchmark: Executing fully connected neural networks on commodity microcontrollers. In Proceedings of the 2021 IEEE World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June 2021–31 July 2021. [Google Scholar] [CrossRef]
- Andalib, N.; Selimi, M. Exploring local and cloud-based training use cases for embedded Machine Learning. In Proceedings of the 2024 Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 11–14 June 2024. [Google Scholar] [CrossRef]
- Tsoukas, V.; Boumpa, E.; Giannakas, G.; Kakarountas, A. A review of Machine Learning and TinyML in healthcare. In Proceedings of the Panhellenic Conference on Informatics, Volos, Greece, 26–28 November 2021. [Google Scholar] [CrossRef]
- Elhanashi, A.; Dini, P.; Saponara, S.; Zheng, Q. Advancements in TinyML: Applications, limitations, and impact on IoT devices. Electronics 2024, 13, 3562. [Google Scholar] [CrossRef]
- Zhang, Y.; Wijerathne, D.; Li, Z.; Mitra, T. Power-performance characterization of TinyML systems. In Proceedings of the 2022 IEEE International Conference on Computer Design (ICCD), Lake Tahoe, NV, USA, 23–26 October 2022. [Google Scholar] [CrossRef]
- Bai, L.; Zhao, Y.; Huang, X. A CNN accelerator on FPGA using depthwise separable convolution. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef]
- Arpaia, P.; Capobianco, L.; Caputo, F.; Cioffi, A.; Esposito, A.; Isgrò, F.; Moccaldi, N.; Pau, D.; Siorpaes, D.; Toscano, E. Accurate energy measurements for Tiny Machine Learning workloads. In Proceedings of the 2024 IEEE International Workshop on Metrology for eXtended Reality, AI and Neural Engineering (MetroXRAINE), St Albans, UK, 21–23 October 2024. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Tsoukas, V.; Gkogkidis, A.; Boumpa, E.; Kakarountas, A. A Review on the emerging technology of TinyML. ACM Comput. Surv. 2024, 56, 1–37. [Google Scholar] [CrossRef]
- Alajlan, N.; Ibrahim, D.M. TinyML: Adopting tiny machine learning in smart cities. J. Auton. Intell. 2024, 7. [Google Scholar] [CrossRef]
- Yang, L.T.; Lei, S.; Jianing, C.; Amine, F.M.; Jun, W.; Edmond, N.; Kai, H. A survey on smart agriculture: Development modes, technologies, and security and privacy challenges. IEEE/CAA J. Autom. Sin. 2021, 8, 273–302. [Google Scholar] [CrossRef]
- Ren, H.; Anicic, D.; Runkler, T.A. TinyOL: TinyML with Online-Learning on microcontrollers. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021. [Google Scholar] [CrossRef]
- Schizas, N.; Karras, A.; Karras, C.; Sioutas, S. TinyML for Ultra-Low Power AI and large scale IoT deployments: A systematic review. Future Internet 2022, 14, 363. [Google Scholar] [CrossRef]
- Pavan, M.; Caltabiano, A.; Roveri, M. On-device subject recognition in UWB-radar data with Tiny Machine Learning. In Proceedings of the CPS Summer School PhD Workshop 2022, Sardinia, Italy, 19–23 September 2022. [Google Scholar]
- Yousefpour, A.; Ishigaki, G.; Jue, J.P. Fog computing: Towards minimizing delay in the Internet of Things. In Proceedings of the IEEE International Conference on Edge Computing (EDGE), Honolulu, HI, USA, 25–30 June 2017; pp. 17–24. [Google Scholar]
- Adafruit. Adafruit EdgeBadge—TensorFlow Lite for Microcontrollers. 2025. Available online: https://www.adafruit.com/product/4400 (accessed on 5 February 2025).
- Arducam. Pico4ML-BLE TinyML Dev Kit User Manual. 2025. Available online: https://www.arducam.com/downloads/B0330-Pico4ML-BLE-User-Manual.pdf (accessed on 5 February 2025).
- Arduino. Arduino Nano 33 BLE Sense Datasheet. 2025. Available online: https://docs.arduino.cc/resources/datasheets/ABX00031-datasheet.pdf (accessed on 5 February 2025).
- STMicroelectronics. B-L475E-IOT01A-STM32L4 Discovery Kit IoT Node. 2025. Available online: https://www.st.com/en/evaluation-tools/b-l475e-iot01a.html (accessed on 5 February 2025).
- Systems, E. ESP32-S3-DevKitC-1. 2025. Available online: https://docs.espressif.com/projects/esp-dev-kits/en/latest/esp32s3/esp32-s3-devkitc-1/index.html (accessed on 5 February 2025).
- Himax. Himax WE-I Plus EVB Endpoint AI Development Board. 2025. Available online: https://www.sparkfun.com/himax-we-i-plus-evb-endpoint-ai-development-board.html (accessed on 5 February 2025).
- NVIDIA. Jetson Nano Developer Kit Downloads. 2025. Available online: https://developer.nvidia.com/embedded/downloads (accessed on 5 February 2025).
- Arduino. Portenta H7 Datasheet. 2025. Available online: https://docs.arduino.cc/resources/datasheets/ABX00042-ABX00045-ABX00046-datasheet.pdf (accessed on 5 February 2025).
- Pi, R. Raspberry Pi 4 Model B Datasheet. 2025. Available online: https://datasheets.raspberrypi.com/rpi4/raspberry-pi-4-datasheet.pdf (accessed on 5 February 2025).
- Pi, R. Raspberry Pi Pico Datasheet. 2025. Available online: https://datasheets.raspberrypi.com/pico/pico-datasheet.pdf (accessed on 5 February 2025).
- Studio, S. Get Started with Seeeduino XIAO. 2025. Available online: https://wiki.seeedstudio.com/Seeeduino-XIAO/ (accessed on 5 February 2025).
- Sony. Spresense Products. 2025. Available online: https://developer.sony.com/spresense/products (accessed on 5 February 2025).
- SparkFun. SparkFun Edge Hookup Guide. 2025. Available online: https://learn.sparkfun.com/tutorials/sparkfun-edge-hookup-guide/all (accessed on 5 February 2025).
- Corp, S. Syntiant TinyML. 2025. Available online: https://www.digikey.com/en/products/detail/syntiant-corp/SYNTIANT-TINYML/15293343 (accessed on 5 February 2025).
- Studio, S. Get Started with Wio Terminal. 2025. Available online: https://wiki.seeedstudio.com/Wio-Terminal-Getting-Started/ (accessed on 5 February 2025).
- Abadade, Y.; Benamar, N.; Bagaa, M.; Chaoui, H. Empowering healthcare: TinyML for precise lung disease classification. Future Internet 2024, 16, 391. [Google Scholar] [CrossRef]
- Zaidi, S.A.R.; Hayajneh, A.M.; Hafeez, M.; Ahmed, Q.Z. Unlocking edge intelligence through Tiny Machine Learning (TinyML). IEEE Access 2022, 10, 100867–100877. [Google Scholar] [CrossRef]
- Nurvitadhi, E.; Venkatesh, G.; Sim, J.; Marr, D.; Huang, R.; Hock, J.O.G.; Liew, Y.T.; Srivatsan, K.; Moss, D.; Subhaschandra, S.; et al. Can FPGAs beat GPUs in accelerating next-generation deep neural networks? In Proceedings of the ACM/SIGDA International Symposium Field-Programmable Gate Arrays (FPGA), Monterey, CA, USA, 22–24 February 2017; pp. 5–14. [Google Scholar]
- Conde, J.; Munoz-Arcentales, A.; Alonso, L.; Salvacha, J.; Huecas, G. Enhanced FIWARE-Based architecture for Cyber-physical systems with Tiny Machine Learning and Machine Learning operations: A Case Study on Urban Mobility Systems. IEEE IT Prof. 2024, 26, 55–61. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Capogrosso, L.; Cunico, F.; Cheng, D.S.; Fummi, F.; Cristani, M. A Machine Learning-oriented survey on Tiny Machine learning. IEEE Access 2024, 12, 23406–23426. [Google Scholar] [CrossRef]
- Alaa, R.; Hussein, E.; Al-libawy, H. Object detection algorithms implementation on embedded devices: Challenges and suggested solutions. Kufa J. Eng. 2024, 15, 148–169. [Google Scholar] [CrossRef]
- Abadade, Y.; Temouden, A.; Bamoumen, H.; Benamar, N.; Chtouki, Y.; Hafid, A.S. A comprehensive survey on TinyML. IEEE Access 2023, 11, 96892–96922. [Google Scholar] [CrossRef]
- Datta, A.; Pal, A.; Marandi, R.; Chattaraj, N.; Nandi, S.; Saha, S. Real-Time air quality predictions for smart cities using TinyML. In Proceedings of the International Conference of Distributed Computing and Networking, Chennai, India, 4–7 January 2024. [Google Scholar] [CrossRef]
- Rb, M.; Tuchel, P.; Sikora, A.; Mueller-Gritschneder, D. A continual and incremental learning approach for TinyML On-device Training Using Dataset Distillation and Model Size Adaption. In Proceedings of the 2024 IEEE International Conference on Industrial Cyber-Physical Systems (ICPS), St. Louis, MO, USA, 12–15 May 2024. [Google Scholar] [CrossRef]
- Karras, A.; Giannaros, A.; Karras, C.; Theodorakopoulos, L.; Mammassis, C.S.; Krimpas, G.A.; Sioutas, S. TinyML algorithms for big data management in large-scale IoT systems. Future Internet 2024, 16, 42. [Google Scholar] [CrossRef]
- Lin, J.; Zhu, L.; Chen, W.-M.; Wang, W.-C.; Han, S. Tiny Machine Learning: Progress and futures [Feature]. IEEE Solid-State Circuits Mag. 2023, 23, 8–34. [Google Scholar] [CrossRef]
- Chen, T.; Moreau, T.; Jiang, Z.; Zheng, L.; Yan, E.; Cowan, M.; Shen, H.; Wang, L.; Hu, Y.; Ceze, L.; et al. TVM: End-to-end optimization stack for deep learning. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 1–15. [Google Scholar]
- Oufettoul, H.; Chaibi, R.; Motahhir, S. TinyML applications, research challenges, and future research directions. In Proceedings of the 2024 International Conference on Learning Technologies & Technologies (LTT), London, UK, 17–18 April 2024. [Google Scholar] [CrossRef]
- Zhang, J.; Li, J. Improving the performance of openCL-based FPGA accelerator for convolutional neural network. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2783–2794. [Google Scholar]
- Jaiswal, S.; Goli, R.; Kumar, A.; Seshadri, V.; Sharma, R. MinUn: Accurate ML inference on microcontrollers. In Proceedings of the ACM SIGPLAN Conference on Languages, Compilers, and Tools for Embedded Systems, San Diego, CA, USA, 14 June 2022. [Google Scholar] [CrossRef]
- Ovtcharov, K.; Ruwase, O.; Kim, J.-Y.; Fowers, J.; Strauss, K.; Chung, E.S. Accelerating Deep Convolutional Neural Networks Using Specialized Hardware. Microsoft Research: Redmond, WA, USA, White Paper, February 2015. Available online: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/CNN20Whitepaper.pdf (accessed on 5 February 2025).
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tuts. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Kim, K.; Jang, S.; Park, J.-H.; Lee, E.; Lee, S.-S. Lightweight and energy-efficient deep learning accelerator for real-time object detection on edge devices. Sensors 2023, 23, 1185. [Google Scholar] [CrossRef] [PubMed]
- Gallager, R.G. A perspective on multiaccess channels. IEEE Trans. Inf. Theory 1985, 31, 124–142. [Google Scholar] [CrossRef]
- Costan, V.; Devadas, S. Intel SGX Explained. Cryptology ePrint Archive, Paper 2016/086, 2016. Available online: https://eprint.iacr.org/2016/086 (accessed on 5 February 2025).
- King, S.; Nadal, S. PPCoin: Peer-to-Peer Crypto-Currency with Proof-of-Stake. Documento Técnico Auto-Publicado, 19 de Agosto de 2012. Available online: https://decred.org/research/king2012.pdf (accessed on 5 February 2025).
- Al Faruque, M.; Mancini, L.V. Energy management-as-a-service over fog computing platform. IEEE Internet Things J. 2016, 3, 161–169. [Google Scholar] [CrossRef]
- Azimi, I.; Anzanpour, A.; Rahmani, A.M.; Pahikkala, T.; Levorato, M.; Liljeberg, P.; Dutt, N. Hich: HIERARCHICAL fog-assisted computing architecture for healthcare IoT. ACM Trans. Embed. Comput. Syst. 2020, 19, 1–29. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Jiang, L.; Xie, S.; Zhang, Y. Intelligent edge computing for IoT-based energy management in smart cities. IEEE Netw. 2019, 33, 111–117. [Google Scholar] [CrossRef]
- Xu, K.; Zhang, H.; Li, Y.; Zhang, Y.; Lai, R.; Liu, Y. An ultra-low power TinyML system for real-time visual processing at edge. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 2640–2644. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tuts. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Neethirajan, M. Recent advances in wearable sensors for animal health management. Sens. Bio-Sens. Res. 2017, 12, 15–29. [Google Scholar] [CrossRef]
- Yin, S.; Li, X.; Gao, H. Data-based techniques focused on modern industry: An overview. IEEE Trans. Ind. Electron. 2015, 62, 657–667. [Google Scholar] [CrossRef]
- Crawford, K. The Hidden Biases in Big Data. Harvard Business Review. Available online: https://hbr.org/2013/04/the-hidden-biases-in-big-data (accessed on 5 February 2025).
- Yang, T.-C.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. NetAdapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Computer Vision Association (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Horowitz, M. Computing’s energy problem (and what we can do about it). In Proceedings of the IEEE International Solid-State Circuits Conference—Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 10–14. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May 2009–2 June 2009; pp. 169–178. [Google Scholar]
- Signoretti, G.; Silva, M.; Andrade, P.; Silva, I.; Sisinni, E.; Ferrari, P. An evolving TinyML compression algorithm for IoT environments based on data eccentricity. Sensors 2021, 21, 4153. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]

{kind=link}
| Characteristic/Paradigm | Centralized (Cloud) AI | General Edge AI (Gateways, Edge Servers) | TinyML (Ultra-Low-Power Embedded) | References |
|---|---|---|---|---|
| Primary processing location | Remote data centers | Near data source (gateways, local servers) | On the device itself (microcontrollers, embedded systems) | [1,2,8,14] |
| Typical hardware | High-performance GPUs, TPUs, CPUs, large memory | Servers, industrial PCs, powerful embedded systems | Microcontrollers (MCUs), digital signal processors (DSPs), small ASICs/FPGAs, limited memory | [1,15,16,19] |
| Resource constraints | Minimal (relative to task complexity) | Moderate (power, size, cost, some memory/compute) | Severe (extreme limits on power, memory, compute, size, cost) | [15,16,23,24] |
| Key drivers/rationale | Handle large datasets, train complex models, centralized control | Reduce latency, reduce bandwidth, improve privacy, enable semi-real-time response | Maximize energy efficiency, minimize latency to microseconds, preserve privacy on device, enable massive low-cost deployment | [4,12,13,17] |
| Latency (typical) | High (requires data transmission) | Moderate (local processing reduces round-trip) | Very low (processing happens instantly on device) | [4,17,18] |
| Privacy (data location) | Low (raw data often sent to cloud) | Improved (data stay closer to source, can be filtered) | Highest (raw data remain on device) | [12,13,25] |
| Bandwidth requirement | High (requires streaming raw data) | Reduced (data can be pre-processed/filtered) | Very low (only results or events sent) | [4,11] |
| Energy consumption (per inference/task) | High (powerful hardware) | Moderate | Very low (targeting microwatts/milliwatts) | [18,19,26] |
| Training paradigm | Centralized (large-scale data) | Centralized or federated learning | Centralized (model trained elsewhere), federated learning (emerging) | [1,9,27] |
| Key enabling techniques | Large models, distributed training | Model compression, specialized hardware, edge orchestration | Extreme model compression (quantization, pruning, distillation), specialized frameworks (TFLite Micro, microTVM), hardware co-design, lightweight security | [6,8,12,19,28] |
| Typical applications | Complex vision, natural language processing (NLP), large recommender systems | Local analytics, video processing, data aggregation | Simple tasks: keyword spotting, anomaly detection, sensor fusion, basic image recognition | [17,22,29,30] |
| Board | MCU | Main Features | Dimensions | Applications | References |
|---|---|---|---|---|---|
| Adafruit EdgeBadge | ATSAMD51J19 | ARM Cortex-M4F, 120 MHz, 512 KB flash, 192 KB SRAM | 86.3 × 54.3 mm | Edge-based image recognition and processing using TinyML | [35] |
| Arducam Pico4ML-BLE | RP2040 | Dual-core ARM Cortex-M0+, 133 MHz, 2 MB flash, 264 KB SRAM | 51 × 21 mm | Data collection and lightweight image processing with TinyML models | [36] |
| Arduino Nano 33 BLE Sense | nRF52840 | Cortex-M4, 64 MHz, 1 MB flash, 256 KB SRAM | 45 × 18 mm | Voice recognition and motion sensing for IoT edge applications | [37] |
| B-L475E-IOT01A Discovery kit | STM32L4 | ARM Cortex-M4, 80 MHz, 1 MB flash, 128 KB SRAM | 61 × 89 × 9 mm | Direct cloud-connected IoT applications with TinyML for data pre-processing | [38] |
| ESP32-S3-DevKitC | ESP32-S3-WROOM-1 | 32-bit Xtensa dual-core, 240 MHz, 8 MB flash, 512 KB SRAM | 63 × 25 × 8 mm | Rapid prototyping of IoT systems with TinyML for real-time tasks | [39] |
| Himax WE-I | HX6537-A | ARC 32-bit DSP, 400 MHz, 2 MB flash, 2 MB SRAM | 40 × 40 mm | High-performance image and voice sensing with ambient analysis for smart systems | [40] |
| Jetson Nano | N/A | Quad-core ARM A57, 1.43 GHz, N/A flash, 4 GB SRAM | 70 × 45 mm | AI-driven robotics and computer vision with TinyML for autonomous systems | [41] |
| Portenta H7 | STM32H747 | Cortex-M7 & Cortex-M4, 480 & 240 MHz, 16 MB NOR flash, 8 MB SRAM | 62 × 25 mm | Advanced computer vision, robotics, and lab setups for AI experimentation | [42] |
| Raspberry Pi 4 Model B | BCM2711 | Quad-core Cortex-A72, 1.5 GHz, N/A flash, 2–8 GB SRAM | 56.5 × 86.6 mm | Robotics and smart home automation with AI and TinyML at the edge | [43] |
| Raspberry Pi Pico | RP2040 | Dual-core ARM Cortex-M0+, up to 133 MHz, 2 MB flash, 264 KB SRAM | 51 × 21 mm | Wake-word detection and lightweight TinyML edge processing | [44] |
| Seeeduino XIAO | SAMD21G18 | ARM Cortex-M0+, up to 48 MHz, 256 KB flash, 32 KB SRAM | 20 × 17.5 × 3.5 mm | Wearable device prototyping and real-time analytics with TinyML | [45] |
| Sony Spresense | CXD5602 | ARM Cortex-M4F (×6 cores), 156 MHz, 8 MB flash, 1.5 MB SRAM | 50 × 20.6 mm | Sensor data analysis and image processing for advanced AI systems | [46] |
| SparkFun Edge | Apollo3 | ARM Cortex-M4F, up to 96 MHz, 1 MB flash, 384 KB SRAM | 40.6 × 40.6 mm | Ultra-low-power motion sensing for IoT edge applications with TinyML | [47] |
| Syntiant TinyML | NDP101 | Cortex-M0+, 48 MHz, 256 KB flash, 32 KB SRAM | 24 × 28 mm | Speech recognition and sensor interfacing for TinyML edge tasks | [48] |
| Wio Terminal | ATSAMD51P19 | ARM Cortex-M4F, 120 MHz, 4 MB flash, 192 KB SRAM | 72 × 57 mm | Remote control and monitoring systems with TinyML for low-latency tasks | [49] |
| Dimension | Quantization | Pruning | References |
|---|---|---|---|
| Memory footprint | High reduction (e.g., 4–8×) by reducing numerical precision | Moderate–high reduction by removing entire weights/channels | [69,70] |
| Hardware acceleration | Typically straightforward to accelerate with integer ops | Dependent on kernel support for sparse operations | [71] |
| Accuracy impact | Generally small if calibrated or fine-tuned; can degrade if precision is too aggressive | Can be significant if excessively pruned without careful retraining | [72] |
| Deployment complexity | Often simpler (e.g., post-training quantization or quant-aware training) | Requires re-training or iterative search for optimum sparsity | [20] |
| Real-world speedups | Typically consistent on integer-friendly hardware; improved throughput/latency | Highly dependent on structured vs. unstructured pruning and hardware’s ability to exploit sparsity | [71] |
| Framework | Core Features | Pros | Cons | References |
|---|---|---|---|---|
| TFLite Micro | Optimized for 8-bit quant Minimal runtime & memory usage | Mature ecosystem Large user community & docs Wide device support | May require manual tuning for advanced tasks C++ heavy | [8] |
| microTVM | Compiler-level optimizations Automated code generation. | Flexible & hardware-agnostic Supports multiple back-ends | Steep learning curve Some features in active dev | [20] |
| Edge Impulse | Cloud-based pipeline Automated machine learning (AutoML) & sensor data ingestion | Rapid prototyping No/low-code approach Integrated IDE | Cloud dependency Possible vendor lock-in | [73] |
| CMSIS-NN | Hand-optimized kernels for ARM MCUs | Very fast conv & activation routines Directly integrates with MCU ecosystem | Primarily ARM-focused Less feature-rich than TFLM/microTVM | [21] |
| Device | Architecture | Frequency (MHz) | RAM (KB/MB) | TinyML Capability | References |
|---|---|---|---|---|---|
| ESP32-S3 | Xtensa LX7 (dual-core) | 240 | 512 KB | Medium (basic audio and simple inferences) | [39] |
| Raspberry Pi Pico | ARM Cortex-M0+ | 133 | 264 KB | Low (only very lightweight models) | [44] |
| Arduino Nano 33 BLE Sense | ARM Cortex-M4 | 64 | 256 KB | High (sensor integration and embedded ML) | [37] |
| Jetson Nano | ARM Cortex-A57 | 1420 | 4 GB | Very high (deep learning and computer vision) | [41] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pazmiño Ortiz, L.A.; Maldonado Soliz, I.F.; Guevara Balarezo, V.K. Advancing TinyML in IoT: A Holistic System-Level Perspective for Resource-Constrained AI. Future Internet 2025, 17, 257. https://doi.org/10.3390/fi17060257
Pazmiño Ortiz LA, Maldonado Soliz IF, Guevara Balarezo VK. Advancing TinyML in IoT: A Holistic System-Level Perspective for Resource-Constrained AI. Future Internet. 2025; 17(6):257. https://doi.org/10.3390/fi17060257
Chicago/Turabian StylePazmiño Ortiz, Leandro Antonio, Ivonne Fernanda Maldonado Soliz, and Vanessa Katherine Guevara Balarezo. 2025. "Advancing TinyML in IoT: A Holistic System-Level Perspective for Resource-Constrained AI" Future Internet 17, no. 6: 257. https://doi.org/10.3390/fi17060257
APA StylePazmiño Ortiz, L. A., Maldonado Soliz, I. F., & Guevara Balarezo, V. K. (2025). Advancing TinyML in IoT: A Holistic System-Level Perspective for Resource-Constrained AI. Future Internet, 17(6), 257. https://doi.org/10.3390/fi17060257