1. Introduction
In today’s Industry 4.0 landscape, equipment, processes, and decision support systems (DSS) are seamlessly interconnected, with a vast amount of sensor data continuously collected in real time. This interconnectivity facilitates various applications (e.g., predictive maintenance), ultimately transforming traditional manufacturing into agile, data-driven systems. The IoT plays a pivotal role in this technological shift, utilizing sensor displacements and platforms to connect devices and gather data seamlessly, enabling intelligent analytics through AI. According to Bonomi et al. [
1], IoT facilitates the structuring of complex ecosystems, enabling data processing through five distinct layers (sensing, network, storage, learning, and application). The comprehensive review by Killeen and Parvizimosaed [
2] also supports the structured logic mentioned by Bonomi, highlighting the crucial functions of the layers in the IoT pipeline, from the data source to the extraction of information. In most IoT architectures, the sensing layer gathers data through sensors and actuators, representing the physical part of the system, and disseminates data through the network layer, which extends the computation to other apparatuses such as cloud or fog systems. Then, the storage layer is responsible for caching and preserving data, while the learning layer employs information retrieval through advanced algorithms or data analysis. The DSS is supported by the application layer. It utilizes the valuable insight presented in a human-interpretable way to enhance practical applications or to be integrated into larger systems (e.g., networking, security, intelligent IoT). Although the layered IoT architecture mentioned above is relevant in many domains (from medical to agriculture), it is particularly beneficial when adopted in critical domains where timing responsiveness is pivotal (e.g., industrial maintenance). PdM, clearly born from the combination of AI and IoT, represents the paradigm shift from traditional maintenance strategies. The adoption of data-driven methodologies permits the forecasting of a system’s future state, ergo estimating the machine degradation pattern (prognosis) [
3,
4]. Conversely, this intelligent approach allows more complex anomaly detection methodologies (diagnosis) while seeking to optimize maintenance schedules, reduce unplanned downtime, and minimize production costs.
Historically, this transformation originated from the past industrial revolutions. It commenced with simple strategies, such as reactive maintenance based on visual inspections by trained craftsmen and preventive maintenance based on planned routine operations, scheduled inspections, and performance monitoring [
5]. In the last century, condition-based monitoring (CbM) appeared as a pioneering data-driven approach to more effectively monitoring the health and performance of machinery through sensors. It emerged as a branch of mechanical engineering, as highlighted in the seminal work by Den [
6], and then was embraced as a branch of statistics, emphasizing the importance of data analysis in maintenance decision-making processes [
7]. The operational deployment of this approach involves several critical steps, with parameter selection representing a pivotal stage to identify the most relevant variables indicating the condition of the machinery [
8]. By processing the set of selected parameters, it is possible to generate potential condition indicators that represent the statistical properties of the process by providing quantifiable measures of equipment health [
9]. Subsequently, quality control charts, baselines, and thresholds are set for monitoring deviations from normal operating conditions [
10]. In practice, the later stage involves statistical techniques to determine these control limits, identifying regions of in-control conditions, thereby highlighting abnormal behavior in the alternative machinery’s performance. The final phase of CbM comprises effective continuous monitoring with real-time data flow, intending to trigger alerts and maintenance actions when certain thresholds are exceeded [
11], representing a comprehensive, data-driven management system. The CbM approach facilitates the construction of a diagnostic framework capable of timely fault detection, possibly minimizing sudden production interruptions, proactively identifying potential issues and root causes, allowing timely maintenance interventions, and enhancing the reliability and efficiency of manufacturing processes. The integration of modern and complex sensor apparatus has significantly improved the effectiveness of CbM techniques, enhancing the understanding of machinery health and contributing to operational efficiency, making these well-oiled strategies even more adaptable in the actual maintenance context; however, uncertainties inherent in analytics due to the more complex technological processes coupled with the time constraints under which decisions must be made pose significant challenges and limitations to its applicability. These limitations have catalyzed the development of PdM and its sophisticated variants, positioning them as innovative drivers for maintenance management systems promising to improve maintenance strategies and decision-making processes further.
Technically, the PdM strategies significantly depend on robust and reliable data flow. Through IoT platforms, the analytics can be conducted at the level of individual machines, manufacturing cells, factories, or across entire networks of factories via cloud solutions. However, these data sets are often fragmented across different systems and exist as isolated data islands, or “silos”, which feature varying semantics and formats, making them hardly interoperable and challenging to amalgamate within a PdM framework [
12]. Christou et al. introduce a digital platform designed explicitly for PdM to address these challenges. This platform provides comprehensive support for implementing PdM applications, minimizing the effort required for deployment. The platform achieves this through middleware functions that streamline data collection, facilitate advanced data analytics, and complete the feedback loop by configuring other systems based on assets’ predictive insights [
12].
Methodologically, the effectiveness of PdM systems relies heavily on the analytical capabilities provided by various data mining and machine learning techniques. These systems analyze datasets to derive predictive insights about the lifetime of assets, focusing on parameters such as RUL and time to end of life (EoL). Studies by Paolanti et al. (2018) explore the use of diverse machine learning methods in PdM, emphasizing their crucial role in the field [
13]. In this context, neural networks have also been identified as particularly effective for these applications.
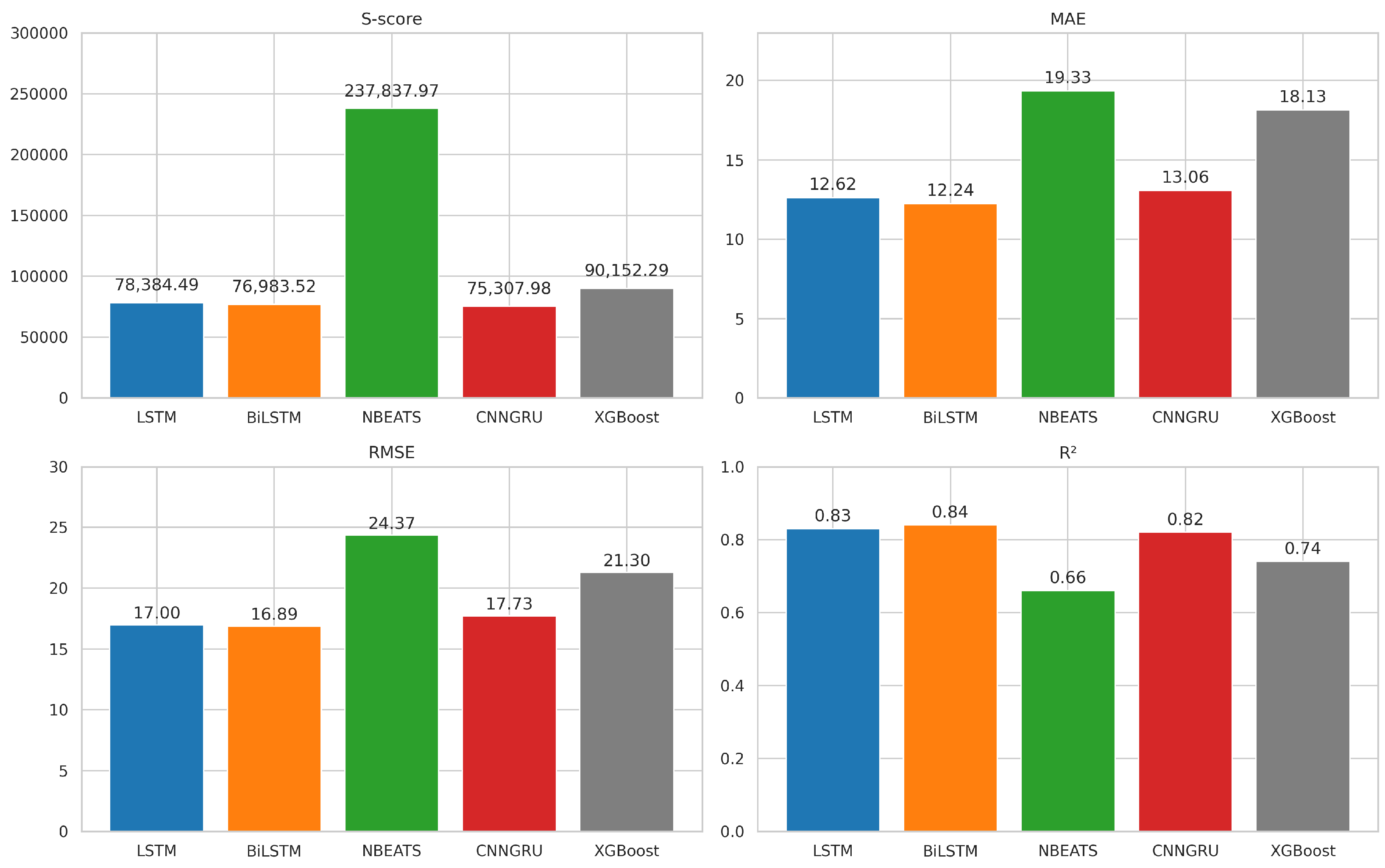
Generally, in the actual PdM research panorama, several algorithms and learning strategies have been utilized to predict the RUL [
14], ranging from SL to DL architectures. Among the principal algorithms found in the literature, are statistical models such as Prophet [
15], machine learning techniques like Extreme Gradient Boosting (XGBoost) [
16], and other decision tree-based variants. Additionally, DL methodologies like Long Short-Term Memory (LSTM), Bidirectional LSTM (BiLSTM), Neural Basis Expansion Analysis for Time Series (N-BEATS), and Convolutional Neural Network-Gated Recurrent Unit (CNN-GRU) have been extensively applied, with significant contributions to PdM outcomes [
17,
18,
19,
20]. These approaches underscore the importance of selecting the correct algorithm based on the system and dataset’s characteristics. This is crucial, as the performance of these algorithms can significantly affect the accuracy of the RUL predictions and the overall efficiency of the maintenance strategy. However, data scarcity in PdM for critical systems such as aircraft engines is still a significant barrier to developing predictive models in real applications. In addressing this issue, Saxena et al. (2008) have contributed to the field by introducing the CMAPSS dataset [
21] along with simulation paradigms and guidelines. This dataset, developed through damage propagation modeling for aircraft engine run-to-failure simulation, has become a pivotal resource for researchers and practitioners in the field of prognostics and health management, allowing for the realistic simulation and testing of PdM models and providing a vital tool at the disposal of the scientific community. Nonetheless, the field of PdM is still in need of more generalized AI research, as mentioned by Fink et al. (2020), which discusses the potential and challenges of deploying DL within prognostics and health management, emphasizing the need for future research to address the complex patterns in the data and effectively implement data-driven strategies [
22]. Additionally, Tiddens et al. (2015) highlight the slow adoption rate of AI-powered prognostic strategies in decision-making, remarking on the significant gap between their potential benefits and their practical applications, highlighting the need for an intermediate framework that translates data into actionable maintenance decisions, offering more explicit guidance on practical maintenance actions [
23].
While these areas have seen significant progress, a comprehensive methodological framework for reliable PdM tasks is still needed. Punctual or multi-horizon forecasting poses stringent limitations on the practical usage of the PdM algorithm in real-world conditions, both when integrated into larger optimization procedures (involving multiple components, plants, and other data sources) and even as an effective DSS serving engineers and domain experts. Moreover, sensor misreading, noise, and missingness can amplify the negative impact of these practices in a real setting, remarking the need for a more reliable solution that extends the algorithm’s forecasting power.
UQ has recently emerged as an interesting practice in time series analysis and forecasting. It refers to the unpredictability associated with future values of a data sequence due to various factors such as randomness, external influences, and incomplete information. Managing and quantifying uncertainty in time series forecasting is crucial for decision-making processes across diverse domains, including PdM, permitting the construction of a more sophisticated predictive framework that is even more essential when applied to industrial critical components or workflows. In this context, Conformal Prediction is established solidly among the most widely used techniques for estimating confidence intervals due to its practical potential (it does not require explicit assumptions about the predictive algorithm) and flexibility (it works without a predefined data distribution), opening a new potential era for refined DSS supplied by a reliable CI.
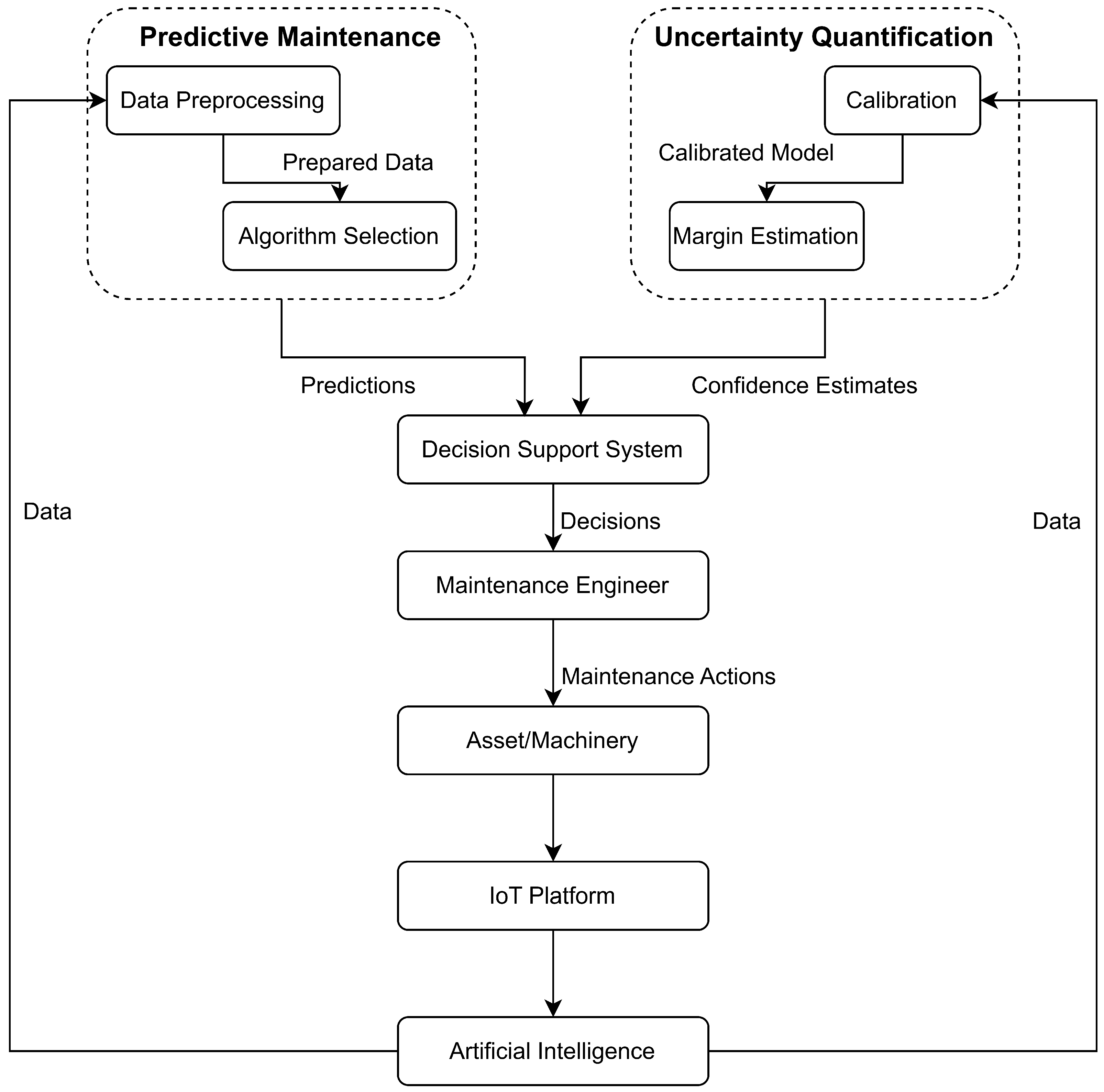
This work leverages a comprehensive overview that highlights the extensive development of research of IoT systems in PdM to offer a methodological approach to algorithm selection and CI evaluation, as presented in
Figure 1, offering a tailored framework for robust IoT-enabled PdM, leading to more efficient and secure maintenance operations. In detail, the study aims to show that when sensor streams exhibit non-stationary behavior and the underlying degradation process is explicitly modeled, embedding a clamp-regulated, one-sided Conformal Prediction layer into the RUL-estimation pipeline produces statistically valid yet markedly tighter lower-bound uncertainty intervals than representative distribution-based benchmarks.
This manuscript is articulated in the following sections:
Section 1 Introduction—motivation and problem statement
Section 2 Time series analysis in predictive maintenance—survey of RUL models.
Section 3 CI estimation in predictive maintenance—limits of current UQ methods.
Section 4 CMAPSS dataset—benchmark dataset description.
Section 5 Robust conformal prognostic for reliable predictive maintenance.
Section 6 Experimental result and performance evaluation.
Section 7 Discussion—practical IoT implications.
Section 8 Conclusion—key findings and future work.
2. Time Series Analysis in Predictive Maintenance
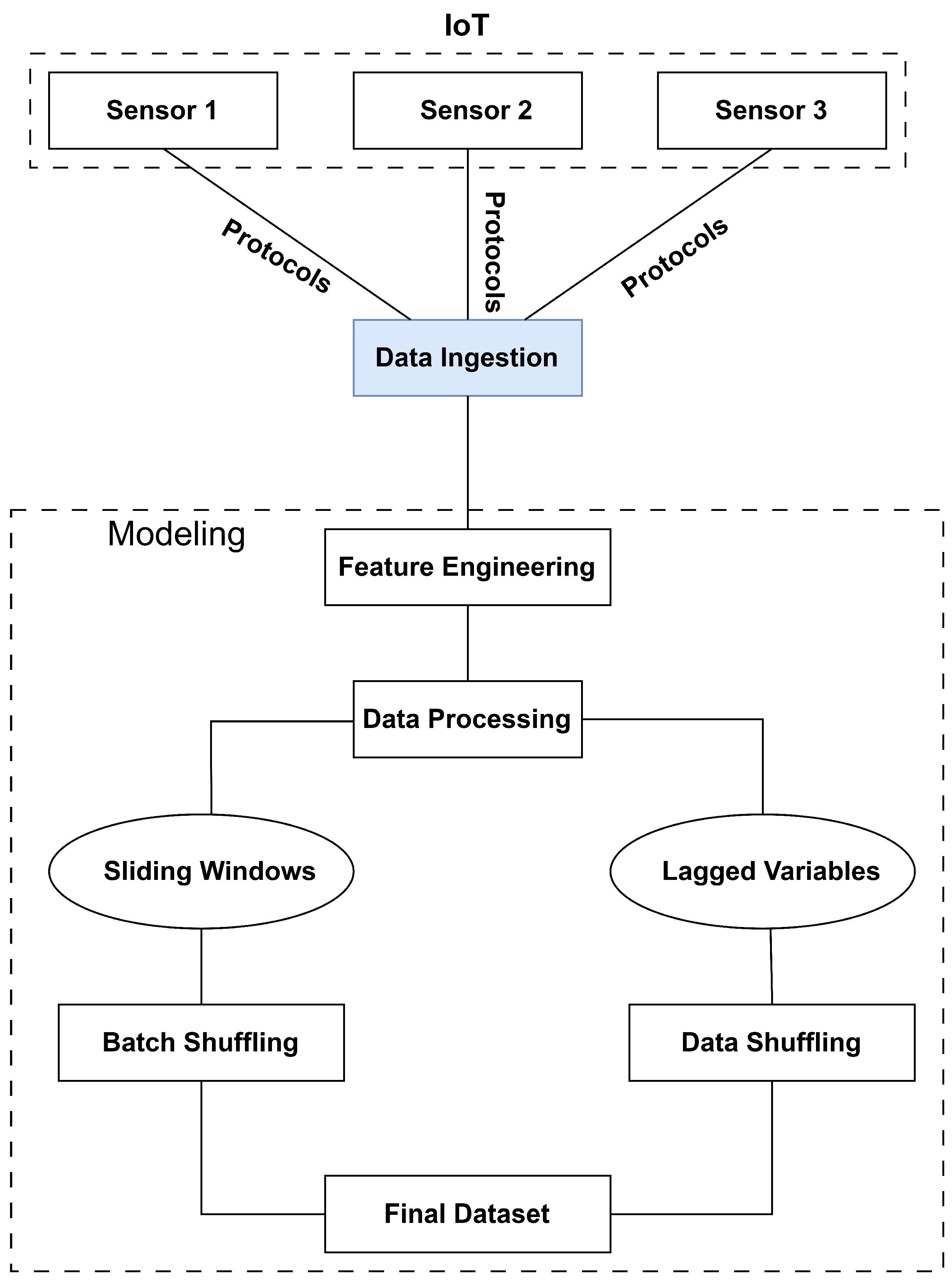
At the juncture between AI and IoT in the field of PdM, the data ensemble is the pivotal starting point in PdM data modeling by integrating historical and real-time data to form a rich dataset that underpins the PdM strategy. Through the meticulous data workflow presented in
Figure 2, the IoT platforms offer sophisticated data processing techniques to synchronize and merge data flowing from multiple machines. Additionally, the platform ensures the applicability of AI models, which can access all necessary information for accurate prediction.
Through this comprehensive data structure, the development of predictive models that can accurately forecast potential machine failures using a time series analysis framework empowers organizations to make timely and informed maintenance decisions.
The last critical data processing step is transforming raw time series data into a format suitable for predictive analysis. The primary techniques utilized in this context are sliding windows and lagged variables. The sliding window technique processes time series data by employing a fixed-size window that traverses the data points sequentially, capturing contiguous subsets of the original series. Mathematically, given a time series
and a window size
w, the subsets analyzed are presented in the following equations.
The choice of window size is critical since a too-small window might miss significant trends. In contrast, a window that is too large could oversmooth essential data fluctuations, so it should be adequately regulated by the previous correlation analysis. Similar to the sliding window, the lagged variables approach is also particularly practical in capturing the temporal dynamics. It works by shifting the time series backward by one or more periods, making it suitable for those predictive models that do not operate with a three-dimensional data batch structure. The process is mathematically described as:
where shift is the number of periods the data is moved backward. This technique emphasizes shifting data feature-wise, offering an alternative to the three-dimensional data structure typically formed by the batches in the sliding window approach.
Focusing on the PdM practices, the main aim of this research is to predict the RUL with its progressive failure process. However, one principal peculiarity regarding PdM practices is the absence of a specific target value, as highlighted by [
24]. Their work emphasizes that degradation modeling always relies on inferring the target variable from historical data rather than having explicit labels for failure events. Health prognostics is one of the core tasks in CBM, which aims to predict the RUL of machinery based on the historical and ongoing degradation trends observed through condition monitoring information [
25,
26,
27].
In machinery, a prognostic program generally consists of four technical processes, i.e., data acquisition, health indicator (HI) construction, health stage (HS) division, and RUL prediction. It is crucial in PdM to model the target variable (e.g., RUL or degradation state), as this forms the foundation for training predictive models and establishing CI around the predictions. Among the various techniques of RUL extraction, linear modeling is often used in the early stages of RUL estimation, where degradation trends are generally used in simple linear assumptions. This linear degradation modeling can be refined through survival analysis, which provides a probabilistic framework for estimating the time until failure, defining an early RUL value, and then truncating the linear RUL value, defining “in-control regions”.
In PdM, survival analysis estimates how long a machine or its components will continue to operate effectively before failure. This estimation helps organizations plan maintenance activities proactively, thereby reducing downtime and extending the equipment’s lifespan. The Kaplan–Meier estimator, which measures the fraction of units operating over a certain amount of time without failure, provides a robust framework for understanding the machinery lifespan and failure rates.
where
is the number of failures observed, and
is the number of units at risk at time
.
Early RUL phase: initially, when a machine is new or has been recently maintained, the probability of failure is low, and thus, the RUL can be assumed to be relatively constant or decreasing very slowly.
Degradation phase: As the equipment ages and wear accumulates, the RUL decreases more rapidly. This phase can be modeled using a linear degradation function informed by the failure rates derived from the Kaplan–Meier analysis reaching the unit EoL.
In the above formulation, T represents the transition time between the early RUL phase and the degradation phase, and k is a constant, calibrated based on historical data analyzed using the Kaplan–Meier estimator, that quantifies the degradation rate. By integrating survival analysis with the piecewise linear degradation functions, PdM models can more accurately estimate when machinery is likely to fail, not considering or learning patterns that are not probably presenting failure status but just focusing on the start of anomalous sensor drifts.
3. CI Estimation in Predictive Maintenance
In real-world situations, machine learning or AI applications are often incorrect or unreliable because of various factors, such as insufficient or incomplete data, issues arising during the modeling process, or simply the randomness and complexities of the underlying problem. These problems are critical in estimating the RUL and constructing intervals for prognostic outcomes.
CI presents a range of possible values derived from sample data, providing a measure of uncertainty around the prediction value that reflects the variability inherent in sampling [
28]. CI estimation, presented in Equation (
6), is divided into three key components: calibration, residual analysis, and margin estimation. Calibration involves adjusting or fine-tuning the model parameters to ensure the predictions align as closely as possible with the observed data, with the residual analysis focusing on examining the differences between the observed values and the model’s predicted values [
29]. At the same time, margin estimation refers to calculating the range around the predicted value in which the actual value is expected to lie, given a certain confidence level. The formula for a CI is as follows:
where
is the sample estimate,
z represents the critical value corresponding to the desired confidence level, and
is the standard error of the estimate.
In classical statistical learning models, like ARIMA (Auto-Regressive Integrated Moving Average), CI is estimated based on the assumption that residuals are usually distributed by calculating the standard error of the forecast from the fitted model and estimating the CI by adding and subtracting the product of the critical value and the standard error from the predicted value [
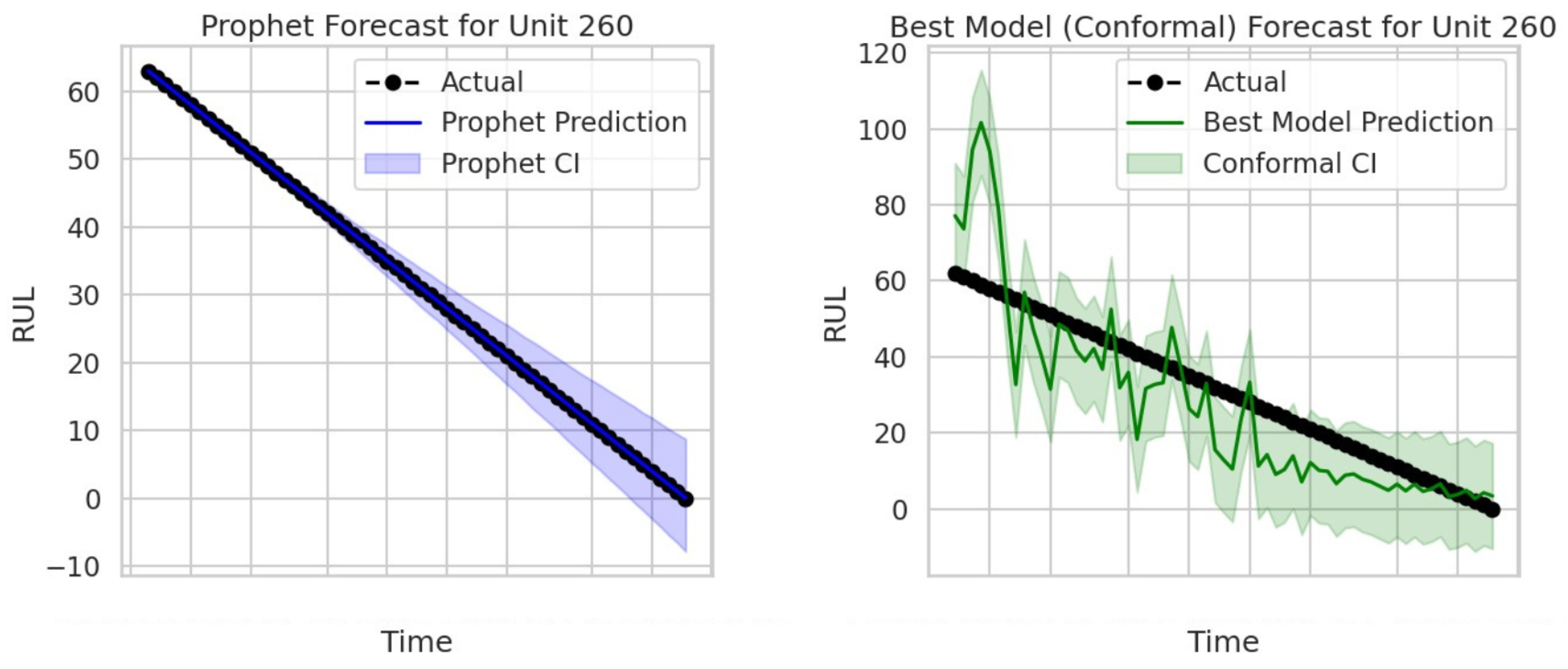
30]. In probabilistic frameworks like Prophet, CI is estimated using simulation over multiple possible future scenarios by sampling from the calibration distribution and using those simulated forecasts to compute empirical percentiles, defining the CI. In contrast, frameworks like CP present more flexible capabilities since they provide post-hoc uncertainty evaluation, adapting to any underlying forecasting model.
In the following part of this section, a detailed analysis of Prophet and Conformal strategy is presented, highlighting their internal workflows and remarking on the pros and cons when applied for uncertainty quantification in the domain of PdM.
3.1. Prophet
Prophet is an open-source forecasting tool developed by Facebook (now Meta) for time series data [
31], designed to be easy to use, interpretable, and capable of handling common time series patterns such as trends, seasonality, and holidays. Principally, Prophet falls under the umbrella of the probabilistic paradigm, leveraging Bayesian posterior inference to estimate uncertainty in the forecast, not requiring forcing the time series into a stationary state (e.g., integrating the lags) and well-handling missingness and noise in the data. The time series for a piecewise linear multiplicative
prophet model can be shown in Equation (
7):
where
is the error term, and
,
, and
represent the trend, seasonal, and holiday terms.
Trend component: The trend component is denoted as
, which represents the non-periodic and long-term changes in the value of a time series. It captures the underlying pattern or direction of the data over time, excluding short-term fluctuations or seasonal variations. A piecewise linear function is a common approach to modeling
, which estimates the trend as a series of connected linear segments. The mathematical formulation for
is presented through Equation (
8):
where the following is true:
- −
k: initial growth rate;
- −
: vector of rate adjustments at changepoints;
- −
: indicator vector for changepoints;
- −
m: offset parameter;
- −
: vector of offset adjustments at changepoints, defined as .
Seasonal component: The function
represents the seasonal component. It captures the seasonal effects in the data, such as daily, weekly, or yearly patterns.
uses a Fourier series to model these seasonal effects, a mathematical tool that decomposes periodic functions into a sum of sine and cosine terms. For seasonality modeling, the Fourier series is defined as in Equation (
9).
where the following is true:
- −
N is the order of the Fourier series;
- −
P is the period of the seasonality;
- −
and are coefficients;
- −
t is the time variable.
Holidays component: The holiday component, denoted by
. It models the effects of holidays or special events on the time series. Unlike regular seasonality, holidays often occur on irregular schedules and can significantly impact the data. To account for these effects, Prophet uses binary variables to indicate whether a given time point
t falls on a holiday. Each holiday
i is assigned a coefficient
, quantifying its impact on the time series. The overall holidays component is then calculated as the sum of these effects for all relevant holidays. The mathematical expression for
is provided in the Equation (
10).
where the following is true:
- −
: holidays component at time t;
- −
: coefficient representing the impact of holiday i;
- −
: indicator function that equals 1 if t falls on holiday i and 0 otherwise.
In Prophet, CI can be estimated using two primary approaches: Monte Carlo sampling and posterior predictive distributions. Monte Carlo sampling generates multiple future scenarios by randomly sampling from the model’s parameters, while posterior predictive distributions directly simulate forecasts based on the fitted model’s uncertainty. Then, these simulated forecasts are used to compute empirical percentiles (e.g., 95% CI corresponds to the 2.5th and 97.5th percentiles), which define the CI.
3.2. Conformal Prediction
CP is a robust machine learning framework that provides valid confidence measurements for individual predictions. Predictions made by ML or DL often come without the UQ, which is required for confident and reliable decision-making in the real world. Quantifying uncertainty is a prerequisite for explainability and trust in machine learning models. Using any model within the CP framework generates predictions and quantifies the confidence in those predictions. Several different approaches to quantifying uncertainty exist, such as statistical methods, Bayesian methods, and fuzzy logic methods [
32].
Statistical methods are widely used for UQ and involve using probability distributions to model the uncertainty in data and prediction. Bayesian methods use prior knowledge and data to update beliefs about the uncertainty in predictions. Fuzzy logic involves using sets and membership functions to represent uncertainty in a system. Considering the CP framework, there are three primary approaches to estimating CI, such as NCP (Naive Conformal Prediction), BCP (Bootstrapping-Based Conformal Prediction), and WCP (Weighted Conformal Prediction) [
33,
34,
35].
To perform CP, the first critical step is to calculate the nonconformity score, which measures how unusual or non-conforming the observed data are compared with the predicted values. Generally, it measures how much the model’s prediction deviates from reality. NCP is the most straightforward approach to estimating the nonconformity score. It computed the nonconformity score for each data point by the difference between observed values and predicted values. It is computed directly using this formula:
where
is the observed value for the
i-th data point and
is the predicted value from the model for input
.
However, in BCP, the nonconformity score is calculated by resampling techniques. For each BCP sample
b, the nonconformity score is computed by the same formula as in NCP. In BCP, multiple samples are generated from the original dataset. For each sample of BCP, the nonconformity score is calculated as the absolute difference between the predicted and observed values. The formula for calculating the nonconformity score of the BCP sample is
where
is the model trained on the
i-th BCP sample.
The WCP is the extent of the NCP, which assigns weight
to calibration points. By assigning weight
, the CP reflects the importance of the
i-th calibration point (e.g., based on time proximity, relevance, or domain-specific knowledge). The formula for calculating the nonconformity score using weight is
where
is the weight reflecting the relative importance.
After computing the nonconformity scores for the three different approaches—NCP, BCP, and WCP—the next step is to calculate the quantile threshold using the significance level . This threshold ensures that the CI achieves the desired coverage probability. The specific method for determining the threshold varies depending on the approach, but all rely on the -th quantile of the nonconformity scores.
In NCP, the quantile threshold is determined as
where
is the
-th quantile of the calibration scores and
represents the set of nonconformity scores.
For BCP sample
b, the quantile threshold is determined as
where
B is the total number of BCP samples.
For WCP, the nonconformity score is calculated using the weight
. So, a weighted quantile is used to compute the threshold as follows:
where the weighted_quantile accounts for the relative importance of each score based on the assigned weights.
The final formula for computing the CI is the same for all three methods. To calculate the CI, include all candidate values
Y that satisfy
, where
is the nonconformity score for the new prediction and
is the quantile threshold computed differently depending on the methods as the following formula:
This formula states that the probability of true response falling within the predicted confidence set is at least ().
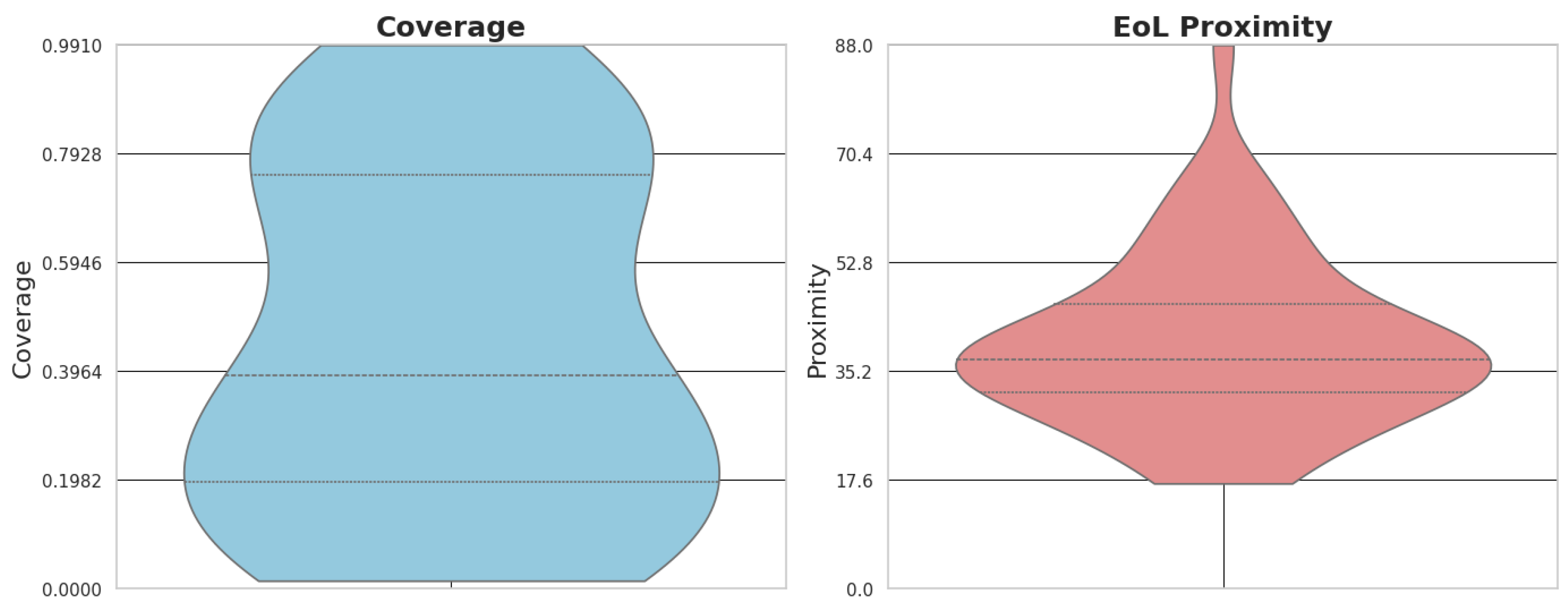
From the performance evaluation perspective, the key metrics for CP are margin, coverage, and average width. Margin is defined as the quantile of the absolute errors or nonconformity scores, which is computed on a calibration set. If a score is taken from the target coverage percentile, then this score will be added to and subtracted from the point prediction to form the prediction interval. A higher margin result is always a wider interval, which represents the prediction intervals with more stability and reliability. In comparison, a lower margin generates narrow intervals that provide more precise estimates but are less robust. Coverage measures the robustness of the predicted interval. It refers to the proportion of times when the actual value falls within the predicted CI.
The coverage value is presented in Equation (
19), where
N is the total number of predictions,
is the indicator function that evaluates to 1 if the condition is true (and 0 otherwise), and
is the point prediction for the
ith sample. The
m is the margin, which determines how well the predicted intervals capture the actual value. Lowering the coverage value means that its prediction intervals often fail to capture the actual values. In contrast, a higher coverage value indicates that actual values fall within the prediction intervals. The average width measures the size of the predicted intervals. It is calculated simply as the mean of the widths of all prediction intervals. Narrower intervals are more precise but may sacrifice coverage, while wider intervals are less accurate but more reliable. The calibration set is central to this process. It is used to compute the nonconformity scores that define the margin, ensuring that the selected margin reflects the model’s performance on unseen data. This allows the integrity of the performance assessment to be maintained, as the metrics computed on the test set are not influenced by the margin selection process.
In the above sections, we have explained the Prophet and CP methodologies to compute CI for predicted values. It is visible that these two approaches have different patterns when calculating CI. Prophet incorporates seasonality, trends, and holidays through simulation-based methods (e.g., Monte Carlo sampling or posterior predictive distributions), while CP relies on nonconformity scores and quantile thresholds in different methods (e.g., NCP, BCP, and WCP) to perform CI even under non-exchangeability conditions and data drifts.
4. Commercial Modular Aeropropulsion Simulation System (CMAPSS) Dataset
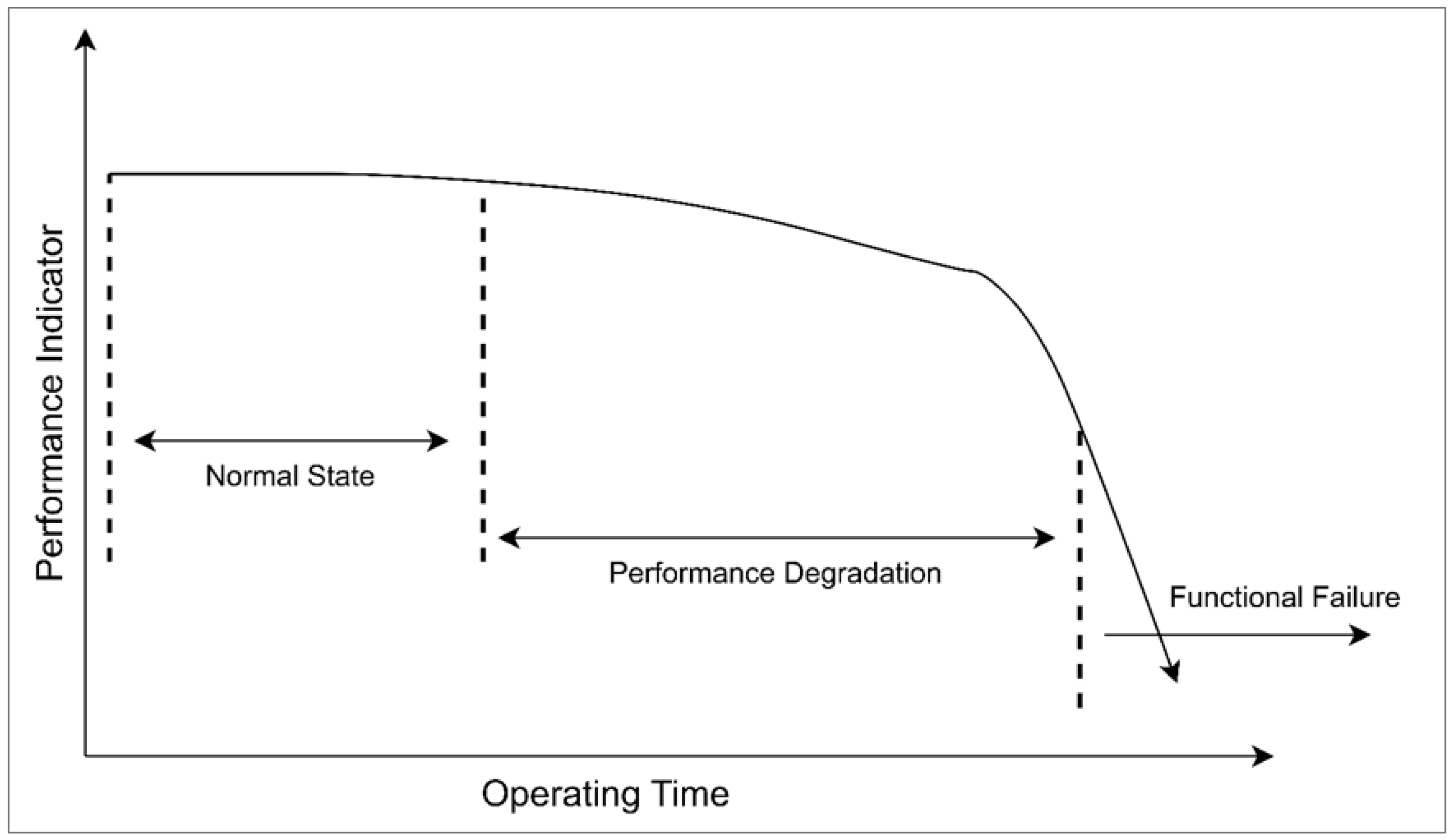
The CMAPSS simulated datasets [
21], courtesy of the NASA Center of Excellence, represent a typical ensemble of a jet engine (turbofan) that operates with a faulty and complex wear system. This dataset presents a pivotal and trusted data source for diagnostic and prognostic analysis, allowing the RUL prediction of each separate unit, thereby modeling their specific and progressive failure processes. Generally, engine failure refers to mechanical degradation resulting from variations in output sensor parameters caused by damage or wear, with its pattern following a typical evolutionary trajectory, which can be depicted by the curve shown in
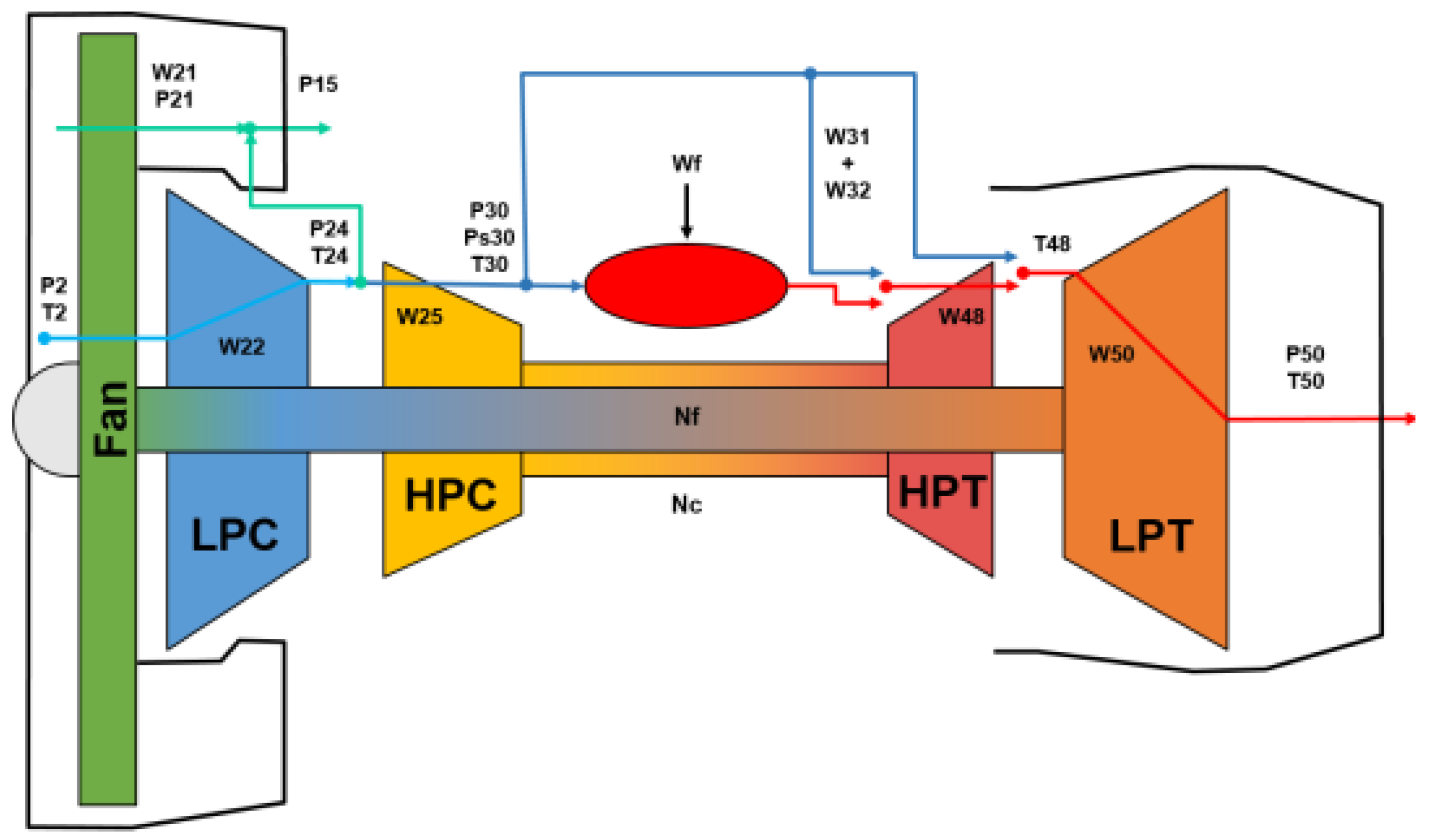
Figure 3. This curve illustrates the gradual decline in jet performance over time, supporting the analysis and prediction of engine RUL. Particularly, the CMAPSS software involves the simultaneous failures of up to five rotating sub-components, which are presented in
Figure 4: fan, low-pressure compressor (LPC), high-pressure compressor (HPC), low-pressure turbine (LPT), and high-pressure turbine (HPT). In addition to component-level failures, the CMAPSS simulation environment incorporates various flight conditions that can significantly influence engine performance, including parameters such as altitude, Mach number, and throttle resolve angle (TRA), which permit more realistic modeling of a wide range of operational scenarios.
Other relevant variants of the CMAPSS have been proposed by Chao et al. [
36], leveraging a more tailored and structured approach intended to represent a small fleet of aircraft better by taking advantage of the CMAPSS tool, which presents an extension of the original dataset but captures similar patterns and trends in the data, de facto incorporating its predecessor. The generation process adopted by the authors is presented in Algorithm 1.
Specifically, FD001 and FD002 consist of 100 engine units each, whereas FD003 and FD004 consist of 260 and 249 units, respectively. The specific measurements present various operational parameters, such as fuel flow, fan speed, and various temperatures and pressures throughout the turbofan engine system. These datasets could be mainly grouped into two classes, as presented in
Table 1:
Single operational condition: FD1–FD3 presents a single working condition, indicating that the data were captured at specific flight settings (Mach, TRA, Altitude).
Multiple operational condition: FD2–FD4 presents six working conditions, indicating that the data were captured at different flight settings (Mach, TRA, Altitude).
| Algorithm 1: Generate Degradation Data |
![Futureinternet 17 00244 i001]() |
| return Output time series of observables for each operational cycle (hours) [21].
|
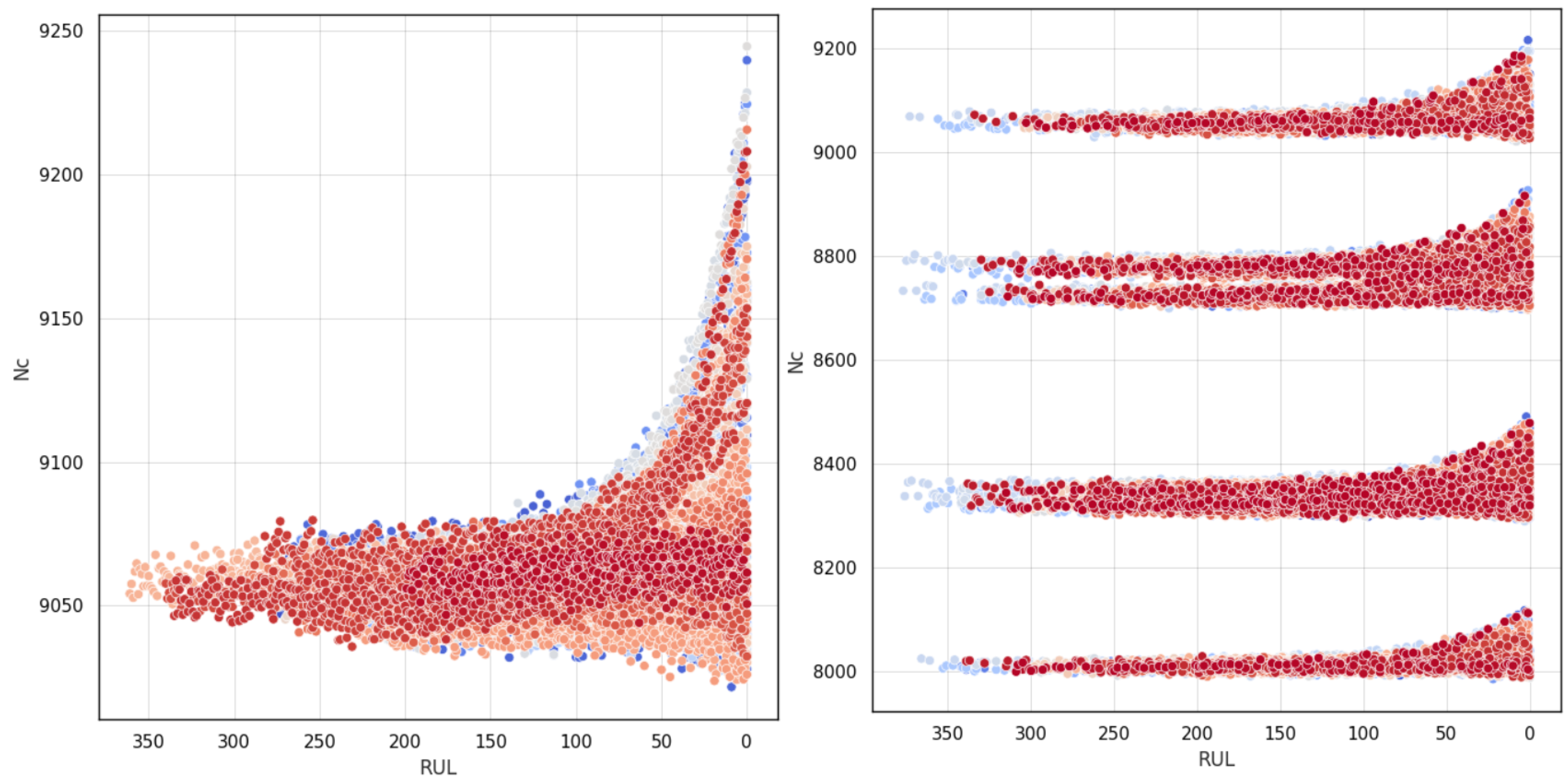
The main differences between these two classes of datasets can also be visually inspected through
Figure 5. The FD1 dataset represents a singular failure modality and operational condition, while the FD2 dataset presents the same failure condition through different operational settings. In the above-mentioned figure of the RUL, presented on the axis, it is calculated following Equation (
20). Basically, it represents the reverse of the number of cycles as hours [
21], which is a known parameter that sets the granularity of the sensor series from the beginning till the EoL.
The integration of survival analysis presented in
Section 2 allows us to leverage the insights gained from the Kaplan–Meier estimation to establish a more detailed RUL extraction procedure. In contrast, the CMAPSS training dataset collects the machine’s entire lifespan from the operational start to EoL without a clear indication of the RUL, which represents the latent degradation target.
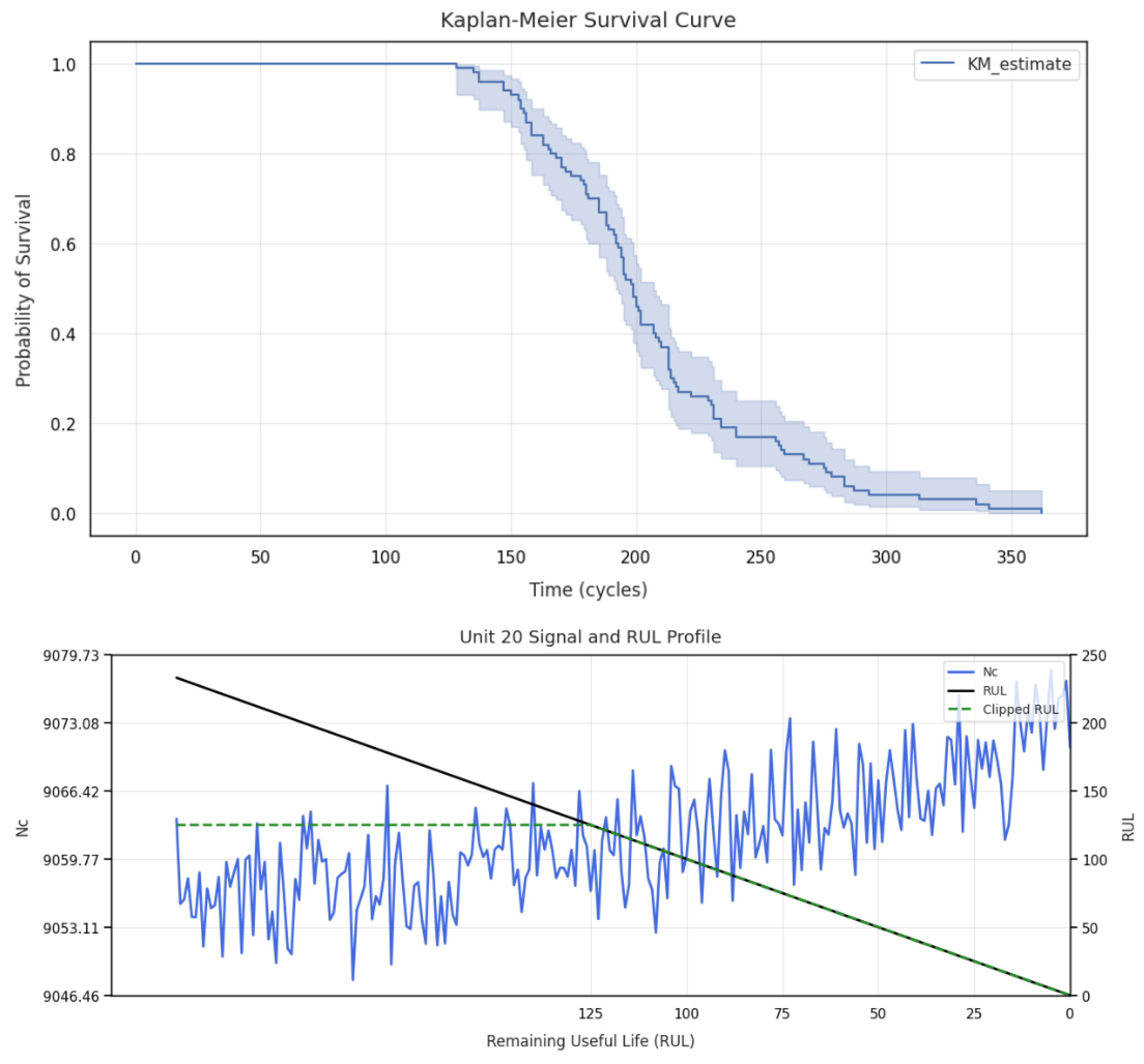
The results from the tailored survival analysis, through Kaplan–Meier estimation curves, define different time (operational cycles) thresholds (for the two different classes of datasets, FD1–FD3 (single operational conditions) and FD2–FD4 (multiple operational condition), when the survival probability starts to decrease, standing at cycle 125 for the first set and cycle 150 for the second set.
Figure 6, which refers to the FD1 dataset, clearly shows how the survival threshold and the sensor drift (Nc sensor) are correlated, thereby giving the possibility of a more refined degradation analysis and RUL extraction, which determines better model training and performance, mitigating pitfalls related to internal parameter modifications in far EoL conditions.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}