
Multi Stage Retrieval for Web Search During Crisis




Abstract
1. Introduction
- Architectural Design for Crisis-Specific Retrieval: We propose a novel multi-stage retrieval architecture that synergistically combines a lexical retrieval stage for efficient, broad recall with a subsequent dense retrieval stage for high-precision reranking. This cascaded design is specifically tailored to handle the high-volume, redundant, noisy, and time-sensitive data characteristic of crisis events, improving single-stage systems and generic multi-stage designs.
- LLM Independency: Our framework achieves state-of-the-art performance without relying on computationally expensive large language models (LLMs). This design choice prioritizes deployability and operational feasibility for resource-constrained emergency response scenarios, offering a practical alternative to LLM-based solutions while surpassing their effectiveness.
- Algorithmic Design for Extractive Summarization Support: The framework is designed to be fully extractive, ensuring that all retrieved information is directly traceable to source documents. This is a critical design choice for crisis management, where verifiability and trust are paramount, distinguishing our approach from abstractive methods that risk introducing unsupported information and hallucinations.
- Comparative Analysis: We provide a comprehensive empirical evaluation of our proposed pipeline against established single-stage lexical and dense retrieval baselines, as well as state-of-the-art models. Our results highlight a superior balance between retrieval effectiveness and computational efficiency, demonstrating the practical advantages of our architectural and algorithmic choices for the target domain.
2. Related Works
2.1. Text Retrieval
2.2. Deep Learning in Crisis Management
2.3. Retrieval in Crisis Management
3. Materials and Methods
3.1. Okapi BM25 Ranking Scheme
- is the Inverse Document Frequency of the query term . It measures the general importance of the term in the collection. A common formula for IDF isHere, N is the total number of documents in the collection, and is the number of documents containing the term . The addition of 1 inside the logarithm (or other variants like adding 0.5 to the numerator and denominator) is to prevent division by zero for terms not present in any document or to smooth the IDF values.
- represents the frequency of term in document D (i.e., term frequency).
- is the length of document D, measured as the total number of words (or tokens) in it.
- avgdl is the average document length across the entire collection.
- is a positive tuning parameter that controls the term frequency saturation. It dictates how quickly the contribution of a term’s frequency to the score diminishes as the frequency increases. A typical value for is between 1.2 and 2.0.
- b is another tuning parameter, usually between 0 and 1 (a common default is 0.75), which determines the degree of document length normalization. When , the scaling by document length is fully applied, and when , no length normalization is applied.
Data Structures
- Inverted Index: This is the primary data structure. It maps each unique term in the collection to a list (postings list) of documents that contain that term. Each entry in the postings list often stores the document ID and the term frequency within that document. The document frequencies (number of documents containing term ) can be derived from the length of these posting lists.
- Document Length Storage: An array or map is typically used to store the length for every document in the collection, indexed by document ID.
- Corpus Statistics Storage: Variables to hold global statistics such as the total number of documents N and the average document length avgdl.
3.2. Problem Statement
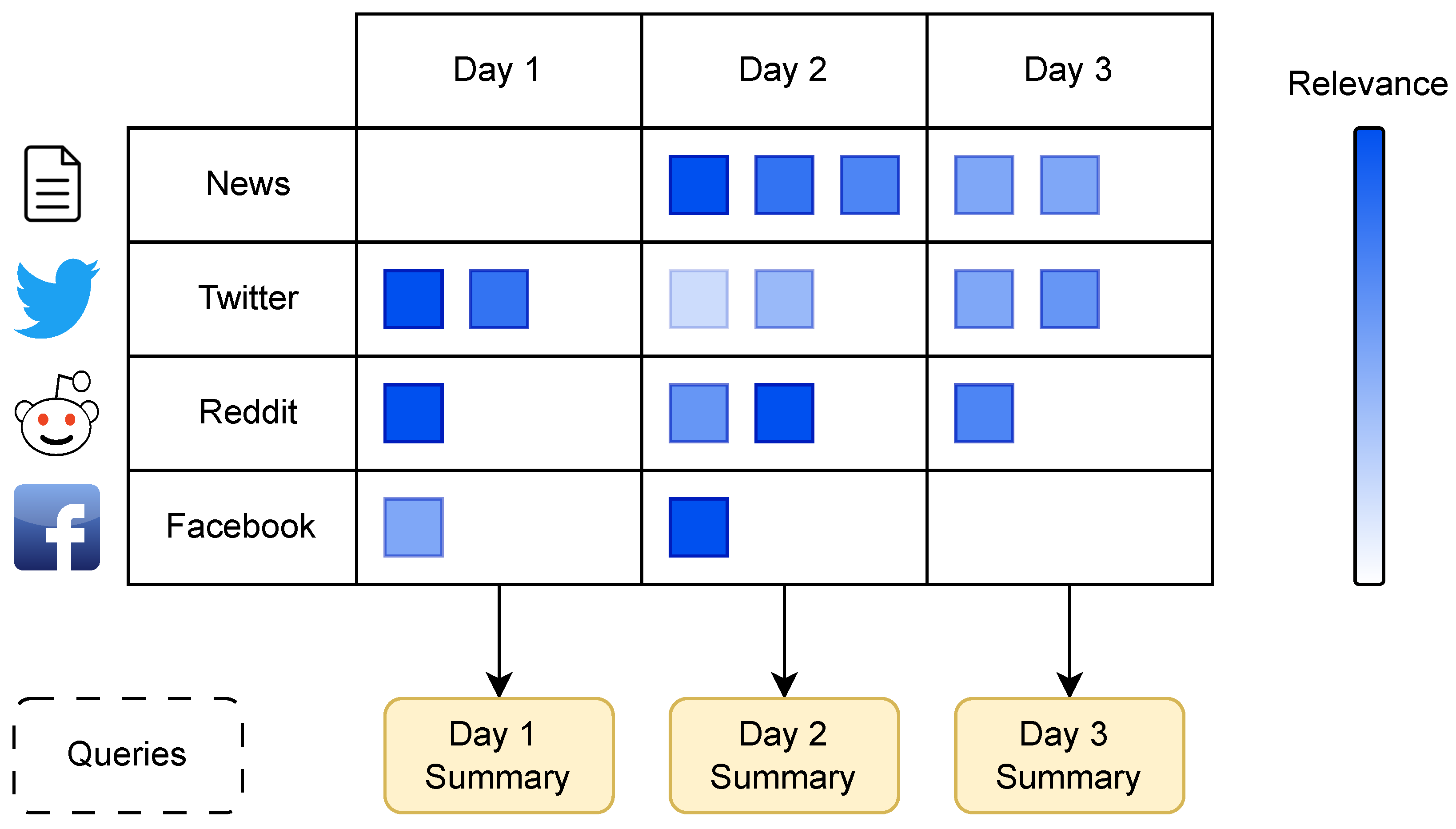
3.3. Dataset
- News: News articles are an excellent source of information during catastrophic events, and a small number of pieces were included in the dataset.
- Twitter: Twitter posts were collected based on keywords relevant to the events in the analysis.
- Reddit: Top-level posts with all subsequent comments were extracted from Reddit threads relevant to the emergency and included in the dataset.
- Facebook: Facebook posts from public pages are provided based on relevance to each disaster event.
- Wikipedia. It is the Wikipedia page for the given event, providing a high-level description.
- NIST Summary. It is created by NIST assessors from the documents present in the corpus. It is more detailed and tailored for the task.
3.4. Framework
3.5. Preprocessing
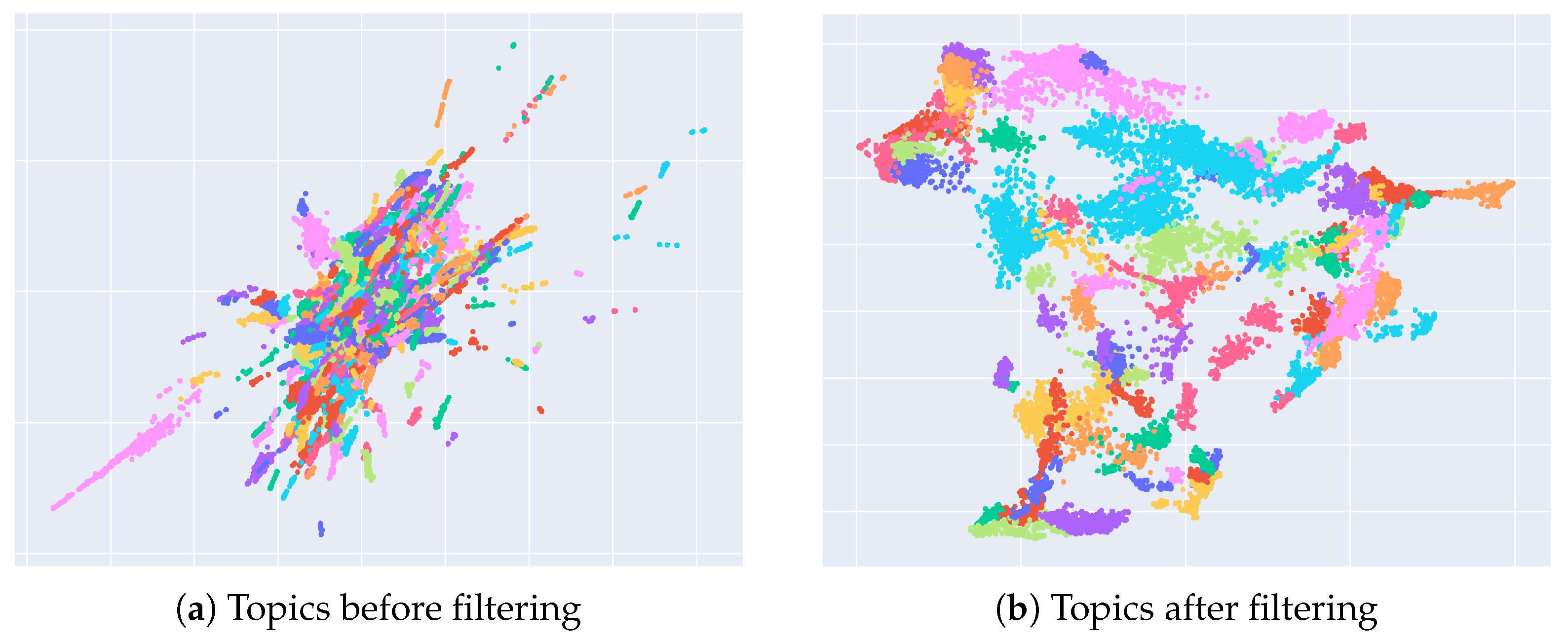
3.6. Topic Filtering
On 4 August 2020, a large amount of ammonium nitrate stored at the port of the city of Beirut, the capital of Lebanon, accidentally exploded, causing at least 180 deaths, 6000 injuries, US$10–15 billion in property damage, and leaving an estimated 300,000 people homeless.
3.7. Additional Queries
I need to refactor some queries in order to better capture the information by adding more context to them <LIST OF QUERIES>.
Can you analyze this list of queries and add at least 30 more that are related to the event <EVENT TYPE/GENERAL QUERIES> but are not present in the following list? <LIST OF QUERIES>
- Are there any security risks or criminal activities occurring due to the <EVENT>?
- What medical services are available for affected individuals?
- Are ATMs and banks functioning after the <EVENT>?
- Tornado: “Are there any reports of multiple tornadoes forming during the tornado?”
- Wildfire: “What weather conditions are affecting the wildfire’s spread?”
- Hurricane: “How far inland is flooding occurring due to the hurricane?”
- Flood: “Are any dams at risk of overflowing or failure due to the flood?”
- Storm: “How long is the storm expected to last?”
- Accident: “Has the air quality been affected by the accident?”
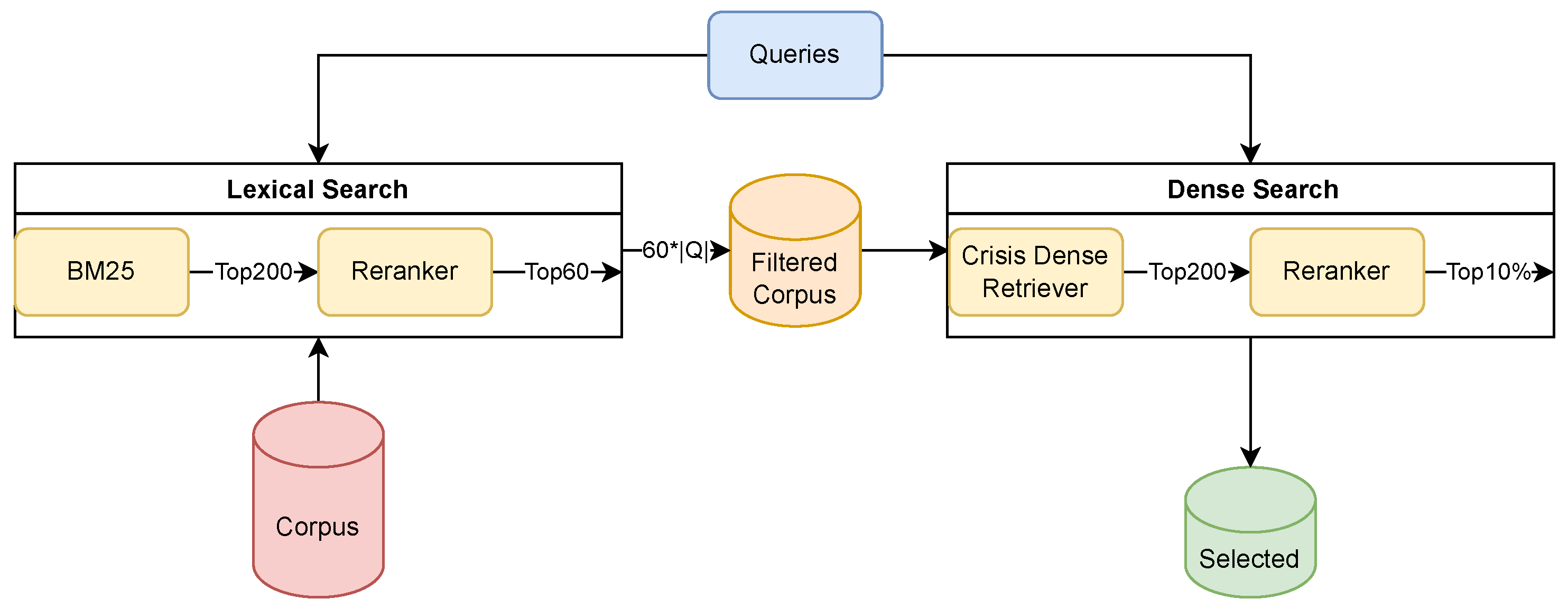
3.8. Multi Stage Retrieval
3.9. Summary
4. Results
4.1. Experimental Settings
4.2. Comparative Results
4.2.1. Competitors
4.2.2. Comment on the Results
4.3. Ablation Study
4.4. Results at the Event Level
5. Discussion
5.1. Summary of Findings
5.2. Comparison with Existing Methods
5.3. Impact on Crisis Management
5.4. Challenges and Limitations
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Heiss, R.; Nanz, A.; Matthes, J. Social Media Information Literacy: Conceptualization and Associations with Information Overload, News Avoidance and Conspiracy Mentality. Comput. Hum. Behav. 2023, 148, 107908. [Google Scholar] [CrossRef]
- Magnusson, M. Information Seeking and Sharing During a Flood: A Content Analysis of a Local Government’s Facebook Page. In Proceedings of the European Conference on Social Media: ECSM, Brighton, UK, 10–11 July 2014; Academic Conferences International Limited: Oxfordshire, UK, 2014; p. 169. [Google Scholar]
- World Health Organization. Communicating Risk in Public Health Emergencies: A WHO Guideline for Emergency Risk Communication (ERC) Policy and Practice; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Lamsal, R.; Read, M.R.; Karunasekera, S. Semantically Enriched Cross-Lingual Sentence Embeddings for Crisis-related Social Media Texts. In Proceedings of the International ISCRAM Conference, Münster, Germany, 25–29 May 2024. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Hyatt Regency, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Huang, D.; Cole, J.M. Cost-efficient domain-adaptive pretraining of language models for optoelectronics applications. J. Chem. Inf. Model. 2025, 65, 2476–2486. [Google Scholar] [CrossRef] [PubMed]
- Lu, R.S.; Lin, C.C.; Tsao, H.Y. Empowering large language models to leverage domain-specific knowledge in E-learning. Appl. Sci. 2024, 14, 5264. [Google Scholar] [CrossRef]
- Priya, S.; Bhanu, M.; Roy, S.; Dandapat, S.K.; Chandra, J. Multi-source domain adaptation approach to classify infrastructure damage tweets during crisis. Int. J. Data Sci. Anal. 2025. [Google Scholar] [CrossRef]
- Pereira, J.; Nogueira, R.; Lotufo, R.A. Large Language Models in Summarizing Social Media for Emergency Management. In Proceedings of the Thirty-Second Text REtrieval Conference Proceedings (TREC 2023), Gaithersburg, MD, USA, 14–17 November 2023; Soboroff, I., Ellis, A., Eds.; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2023; Volume 1328. [Google Scholar]
- Seeberger, P.; Riedhammer, K. Multi-Query Focused Disaster Summarization via Instruction-Based Prompting. In Proceedings of the Thirty-Second Text REtrieval Conference Proceedings (TREC 2023), Gaithersburg, MD, USA, 14–17 November 2023; Soboroff, I., Ellis, A., Eds.; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2023; Volume 1328. [Google Scholar]
- Jiao, J.; Park, J.; Xu, Y.; Sussman, K.; Atkinson, L. SafeMate: A Modular RAG-Based Agent for Context-Aware Emergency Guidance. arXiv 2025, arXiv:2505.02306. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar] [CrossRef]
- Moffat, A.; Zobel, J. Self-indexing inverted files for fast text retrieval. ACM Trans. Inf. Syst. 1996, 14, 349–379. [Google Scholar] [CrossRef]
- Yan, H.; Ding, S.; Suel, T. Inverted index compression and query processing with optimized document ordering. In Proceedings of the 18th International Conference on World Wide Web. ACM, 2009, WWW ’09, Madrid, Spain, 20–24 April 2009. [Google Scholar] [CrossRef]
- Berry, M.W.; Drmac, Z.; Jessup, E.R. Matrices, Vector Spaces, and Information Retrieval. SIAM Rev. 1999, 41, 335–362. [Google Scholar] [CrossRef]
- James, N.T.; Kannan, R. A survey on information retrieval models, techniques and applications. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2017, 7, 16–19. [Google Scholar] [CrossRef]
- Robertson, S.E. The probability ranking principle in IR. J. Doc. 1977, 33, 294–304. [Google Scholar] [CrossRef]
- Robertson, S.E.; Walker, S. Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval. In Proceedings of the SIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, Organised by Dublin City University; Springer: Berlin/Heidelberg, Germany, 1994; pp. 232–241. [Google Scholar]
- Robertson, S.; Zaragoza, H. The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends® Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Transier, F.; Sanders, P. Engineering basic algorithms of an in-memory text search engine. ACM Trans. Inf. Syst. 2010, 29, 1–37. [Google Scholar] [CrossRef]
- Akritidis, L.; Katsaros, D.; Bozanis, P. Improved retrieval effectiveness by efficient combination of term proximity and zone scoring: A simulation-based evaluation. Simul. Model. Pract. Theory 2012, 22, 74–91. [Google Scholar] [CrossRef]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6769–6781. [Google Scholar] [CrossRef]
- Nogueira, R.; Yang, W.; Cho, K.; Lin, J. Multi-Stage Document Ranking with BERT. arXiv 2019, arXiv:1910.14424. [Google Scholar]
- Lin, J.; Ma, X.; Lin, S.C.; Yang, J.H.; Pradeep, R.; Nogueira, R. Pyserini: A Python Toolkit for Reproducible Information Retrieval Research with Sparse and Dense Representations. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 11–15 July 2021; SIGIR ’21. pp. 2356–2362. [Google Scholar] [CrossRef]
- Bhat, R.A.; Sen, J.; Murthy, R.; P, V. UR2N: Unified Retriever and ReraNker. In Proceedings of the 31st International Conference on Computational Linguistics: Industry Track, Abu Dhabi, United Arab Emirates, 19–24 January 2025; pp. 595–602. [Google Scholar]
- Rezaei, M.R.; Hafezi, M.; Satpathy, A.; Hodge, L.; Pourjafari, E. AT-RAG: An Adaptive RAG Model Enhancing Query Efficiency with Topic Filtering and Iterative Reasoning. arXiv 2024, arXiv:2410.12886. [Google Scholar]
- Cambrin, D.R.; Colomba, L.; Garza, P. CaBuAr: California burned areas dataset for delineation [Software and Data Sets]. IEEE Geosci. Remote Sens. Mag. 2023, 11, 106–113. [Google Scholar] [CrossRef]
- Rege Cambrin, D.; Garza, P. QuakeSet: A Dataset and Low-Resource Models to Monitor Earthquakes through Sentinel-1. In Proceedings of the International ISCRAM Conference, Münster, Germany, 25–29 May 2024. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, G. Deep Q networks-based optimization of emergency resource scheduling for urban public health events. Neural Comput. Appl. 2022, 35, 8823–8832. [Google Scholar] [CrossRef]
- Chamola, V.; Hassija, V.; Gupta, S.; Goyal, A.; Guizani, M.; Sikdar, B. Disaster and Pandemic Management Using Machine Learning: A Survey. IEEE Internet Things J. 2021, 8, 16047–16071. [Google Scholar] [CrossRef]
- Long, Z.; McCreadie, R.; Imran, M. CrisisViT: A Robust Vision Transformer for Crisis Image Classification. In Proceedings of the 20th International Conference on Information Systems for Crisis Response and Management, Omaha, NE, USA, 28–31 May 2023; University of Nebraska at Omaha (USA): Omaha, NE, USA, 2023. [Google Scholar] [CrossRef]
- Acikara, T.; Xia, B.; Yigitcanlar, T.; Hon, C. Contribution of Social Media Analytics to Disaster Response Effectiveness: A Systematic Review of the Literature. Sustainability 2023, 15, 8860. [Google Scholar] [CrossRef]
- Buntain, C.; Hughes, A.L.; McCreadie, R.; Horne, B.D.; Imran, M.; Purohit, H. CrisisFACTS 2023-Overview Paper. In Proceedings of the Thirty-Second Text REtrieval Conference Proceedings (TREC 2023), Gaithersburg, MD, USA, 14–17 November 2023; Soboroff, I., Ellis, A., Eds.; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2023; Volume 1328. [Google Scholar]
- McCreadie, R.; Buntain, C. CrisisFacts: Building and evaluating crisis timelines. In Proceedings of the 20th International Conference on Information Systems for Crisis Response and Management. University of Nebraska at Omaha (USA), Omaha, NE, USA, 28–31 May 2023. [Google Scholar] [CrossRef]
- Salemi, H.; Senarath, Y.; Sharika, T.S.; Gupta, A.; Purohit, H. Summarizing Social Media & News Streams for Crisis-related Events by Integrated Content-Graph Analysis: TREC-2023 CrisisFACTS Track. In Proceedings of the Thirty-Second Text REtrieval Conference Proceedings (TREC 2023), Gaithersburg, MD, USA, 14–17 November 2023; Soboroff, I., Ellis, A., Eds.; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2023; Volume 1328. [Google Scholar]
- Burbank, V.; Conroy, J.M.; Lynch, S.; Molino, N.P.; Yang, J.S. Fast Extractive Summarization, Abstractive Summarization, and Hybrid Summarization for CrisisFACTS at TREC 2023. In Proceedings of the Thirty-Second Text REtrieval Conference Proceedings (TREC 2023), Gaithersburg, MD, USA, 14–17 November 2023; Soboroff, I., Ellis, A., Eds.; National Institute of Standards and Technology (NIST): Gaithersburg, MD, USA, 2023; Volume 1328. [Google Scholar]
- Rege Cambrin, D.; Cagliero, L.; Garza, P. DQNC2S: DQN-Based Cross-Stream Crisis Event Summarizer. In Advances in Information Retrieval; Springer Nature: Cham, Switzerland, 2024; pp. 422–430. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Grootendorst, M. KeyBERT: Minimal Keyword Extraction with BERT. 2020. Available online: https://zenodo.org/records/4461265 (accessed on 27 May 2025).
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- Huguet Cabot, P.L.; Navigli, R. REBEL: Relation Extraction By End-to-end Language generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 2370–2381. [Google Scholar] [CrossRef]
- Del Corro, L.; Gemulla, R. ClausIE: Clause-based open information extraction. In Proceedings of the 22nd International Conference on World Wide Web, New York, NY, USA, 18 May 2013; WWW ’13. pp. 355–366. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event ID | Name | Queries | Texts | Days |
|---|---|---|---|---|
| 001 | Lilac Wildfire 2017 | 52 | 51,015 | 9 |
| 002 | Cranston Wildfire 2018 | 52 | 30,535 | 6 |
| 003 | Holy Wildfire 2018 | 52 | 32,489 | 7 |
| 004 | Hurricane Florence 2018 | 51 | 376,537 | 15 |
| 005 | Maryland Flood 2018 | 48 | 41,770 | 4 |
| 006 | Saddleridge Wildfire 2019 | 52 | 38,369 | 4 |
| 007 | Hurricane Laura 2020 | 51 | 62,182 | 2 |
| 008 | Hurricane Sally 2020 | 51 | 116,303 | 8 |
| 009 | Beirut Explosion, 2020 | 56 | 468,178 | 7 |
| 010 | Houston Explosion, 2020 | 56 | 72,530 | 7 |
| 011 | Rutherford TN Floods, 2020 | 48 | 20,868 | 5 |
| 012 | TN Derecho, 2020 | 49 | 79,688 | 7 |
| 013 | Edenville Dam Fail, 2020 | 48 | 28,185 | 7 |
| 014 | Hurricane Dorian, 2019 | 51 | 556,233 | 7 |
| 015 | Kincade Wildfire, 2019 | 52 | 137,072 | 7 |
| 016 | Easter Tornado Outbreak, 2020 | 51 | 131,954 | 5 |
| 017 | Beirut Explosion, 2020 | 51 | 120,899 | 6 |
| 018 | Tornado Outbreak, 2020 March | 51 | 200,008 | 6 |
| Query | Relevant Document |
|---|---|
| What roads are closed? | Hwy 76 is closed both directions… |
| How many people have been injured? | Two civilians are being treated for burn injuries… |
| Where are wind speeds expected to be high? | …San Diego County as winds gust to 75 mph. |
| Topic | Score (%) | Selected |
|---|---|---|
| beirut explosion, beirut blast, beirut, beirut lebanon | 75.00 | ✓ |
| tonnes ammonium nitrate, tons ammonium nitrate | 67.34 | ✓ |
| cause explosion unknown, cause explosion unclear | 62.43 | ✓ |
| news updates, page latest updates, latest updates | 42.72 | ✗ |
| hope stay safe, hope okay safe, hope safe okay | 43.71 | ✗ |
| really scary, damn scary, terrifying scary | 44.64 | ✗ |
| NIST | Wiki | ||||||
|---|---|---|---|---|---|---|---|
| Run | Type | F1 | P | R | F1 | P | R |
| baseline.v1 [35,36] | E | 59.11 | 58.95 | 59.33 | 50.84 | 47.58 | 54.82 |
| FM-B [37] | E | 59.94 | 59.94 | 59.99 | 53.31 | 51.00 | 55.95 |
| occams extract [38] | E | 59.99 | 59.55 | 60.48 | 53.31 | 48.94 | 55.45 |
| nm-gpt35 [11] | A | 61.45 | 62.51 | 60.48 | 51.14 | 48.49 | 54.42 |
| llama 13b chat [12] | A | 65.00 | 64.74 | 65.29 | 53.63 | 50.95 | 56.69 |
| MSCR | E | 77.76 ± 2.54 | 76.71 ± 2.93 | 78.89 ± 2.58 | 72.69 ± 2.09 | 70.02 ± 3.19 | 75.64 ± 1.72 |
| Search Mode | Time (s) | NIST | Wiki | ||||
|---|---|---|---|---|---|---|---|
| F1 | P | R | F1 | P | R | ||
| Lexical (single-stage) | 913.50 ± 35.83 * | 77.47 ± 3.56 * | 76.54 ± 4.17 | 78.46 ± 3.22 * | 72.62 ± 3.10 | 70.00 ± 4.15 | 75.52 ± 2.59 |
| Dense (single-stage) | 1091.89 ± 1.09 * | 77.96 ± 2.57 | 76.83 ± 2.96 | 79.16 ± 2.68 | 72.66 ± 1.97 | 69.95 ± 3.05 | 75.67 ± 3.94 |
| MSCR | 1023.99 ± 4.16 | 77.76 ± 2.54 | 76.71 ± 2.93 | 78.89 ± 2.58 | 72.69 ± 2.09 | 70.02 ± 3.19 | 75.64 ± 1.72 |
| Event | NIST | Wikipedia | ||||
|---|---|---|---|---|---|---|
| F1 | P | R | F1 | P | R | |
| 009 | 79.35 ± 1.37 | 77.10 ± 2.11 | 81.74 ± 0.65 | 73.30 ± 0.96 | 72.52 ± 1.40 | 74.09 ± 0.63 |
| 010 | 76.17 ± 2.00 | 74.63 ± 2.92 | 77.81 ± 1.09 | 72.72 ± 2.27 | 70.70 ± 3.06 | 74.88 ± 1.37 |
| 011 | 78.86 ± 1.05 | 79.02 ± 1.04 | 78.70 ± 1.12 | — | — | — |
| 012 | 78.52 ± 1.29 | 77.63 ± 2.01 | 79.43 ± 0.77 | — | — | — |
| 013 | 76.22 ± 1.61 | 75.17 ± 2.13 | 77.30 ± 1.06 | 68.67 ± 1.18 | 65.48 ± 1.51 | 72.19 ± 0.77 |
| 014 | 76.41 ± 0.51 | 78.41 ± 0.48 | 74.51 ± 0.67 | 75.93 ± 0.24 | 76.38 ± 0.34 | 75.48 ± 0.15 |
| 015 | 78.48 ± 0.48 | 78.30 ± 0.82 | 78.67 ± 0.14 | 73.39 ± 0.19 | 70.27 ± 0.50 | 76.80 ± 0.24 |
| 016 | 77.01 ± 0.82 | 74.85 ± 0.96 | 79.30 ± 0.72 | 72.44 ± 0.30 | 70.87 ± 0.50 | 74.08 ± 0.11 |
| 017 | 80.26 ± 0.38 | 78.22 ± 0.47 | 82.40 ± 0.28 | 71.04 ± 0.47 | 65.27 ± 0.53 | 77.95 ± 0.49 |
| 018 | 81.45 ± 0.79 | 80.96 ± 0.81 | 81.94 ± 0.78 | 74.32 ± 0.31 | 70.93 ± 0.48 | 78.06 ± 0.38 |
| Mean | 78.27 ± 1.71 | 77.43 ± 1.92 | 79.18 ± 2.29 | 72.73 ± 2.03 | 70.30 ± 3.38 | 75.44 ± 1.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tcaciuc, C.C.; Rege Cambrin, D.; Garza, P. Multi Stage Retrieval for Web Search During Crisis. Future Internet 2025, 17, 239. https://doi.org/10.3390/fi17060239
Tcaciuc CC, Rege Cambrin D, Garza P. Multi Stage Retrieval for Web Search During Crisis. Future Internet. 2025; 17(6):239. https://doi.org/10.3390/fi17060239
Chicago/Turabian StyleTcaciuc, Claudiu Constantin, Daniele Rege Cambrin, and Paolo Garza. 2025. "Multi Stage Retrieval for Web Search During Crisis" Future Internet 17, no. 6: 239. https://doi.org/10.3390/fi17060239
APA StyleTcaciuc, C. C., Rege Cambrin, D., & Garza, P. (2025). Multi Stage Retrieval for Web Search During Crisis. Future Internet, 17(6), 239. https://doi.org/10.3390/fi17060239