
Navigating Data Corruption in Machine Learning: Balancing Quality, Quantity, and Imputation Strategies


Abstract
1. Introduction
- Modeling Performance Degradation: This study shows that performance degradation follows a diminishing-return pattern, well-captured by an exponential function, and reveal task-specific sensitivities.
- Imputation Trade-offs: This study demonstrates the boundary conditions where imputation is beneficial versus harmful, providing actionable guidelines for practitioners.
- Data Quantity–Quality Trade-offs: This study empirically shows that larger datasets can only partially offset corruption effects, with diminishing utility at high corruption levels.
2. Related Work
2.1. Types of Data Corruption
2.2. Impacts of Data Corruption
2.3. Data Imputation Techniques
- Impact of Data Corruption: What is the quantitative relationship between data corruption ratio and model performance? Can this relationship be consistently modeled across tasks?
- Effectiveness of imputation: How do different imputation methods compare in mitigating the effects of missing data? Is it possible to fully restore the utility of corrupted data through imputation?
- Trade-Off Between Data Quality and Quantity: Can larger datasets compensate for data corruption? How many additional data are required to offset quality issues and does the marginal utility of additional data diminish with increasing corruption level?
3. Learning with Corrupted Data
3.1. Experiment Design
3.1.1. NLP Supervised Learning (NLP-SL)
- The Matthews Correlation Coefficient (MCC) is used for CoLA;
- The average of Pearson and Spearman correlation coefficients is used for STSB;
- Test accuracy is used for the remaining tasks.
- Data missing: Each word in the training samples has a probability p of being replaced with a [MASK] token.
- Inserting noise: Each word in the training samples has a probability p of being replaced with a randomly selected word from the vocabulary.
3.1.2. Traffic Signal Control Deep Reinforcement Learning (Signal-RL)
- Vehicle missing: Each vehicle is not detected with probability p. This scenario is relevant in Vehicle-to-Everything (V2X) environments, where roadside units detect vehicles’ presence through communication channels like DSRC [28]. However, only a proportion of vehicles are equipped with onboard devices. This type of corruption is analogous to the data-missing scenario in the NLP-SL experiment.
- Inserting noise: Noise is added to the road occupancy state and rewards. Each road cell occupancy state has probability p of being replaced with random binary value. This scenario is relevant in environments where road occupancies are detected using computer-vision systems, which can introduce errors.
- Masking region: This special type of corruption is specific to traffic signal settings. The simulation environment assumes a lane length of 400 m. A masking-region ratio p means that the farthest m of each lane will be invisible to the model, simulating the range limitations of video cameras used for vehicle detection.
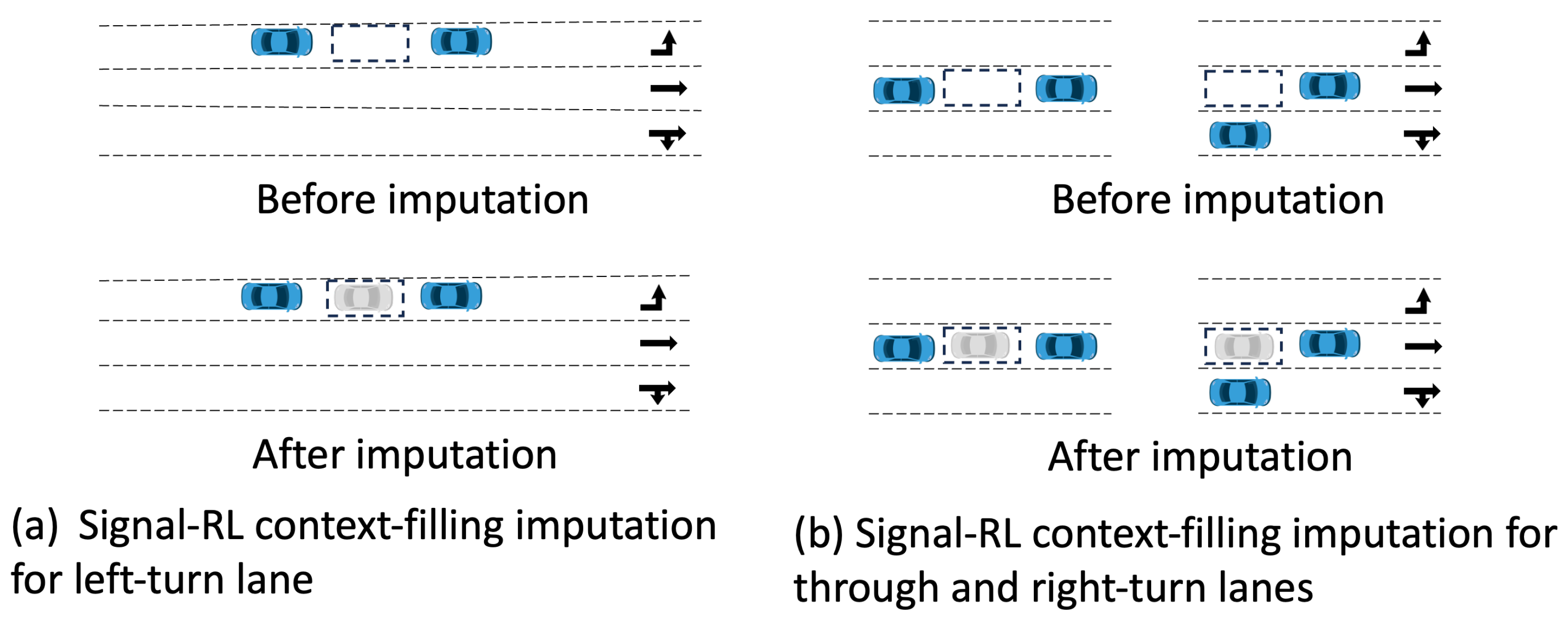
- Exact imputation: This scenario arises when the precise locations of missing data are known. A common example occurs in natural language processing (NLP), where missing words are explicitly marked with placeholders such as “[UNK]”.
- General imputation: In this case, the locations of missing data are unknown. For instance, in the Signal-RL experiment, vehicles may go undetected, leaving it unclear which elements of the state vector are corrupted. Imputing data under such conditions requires checking all possible locations, potentially introducing significantly more noise compared to exact imputation.
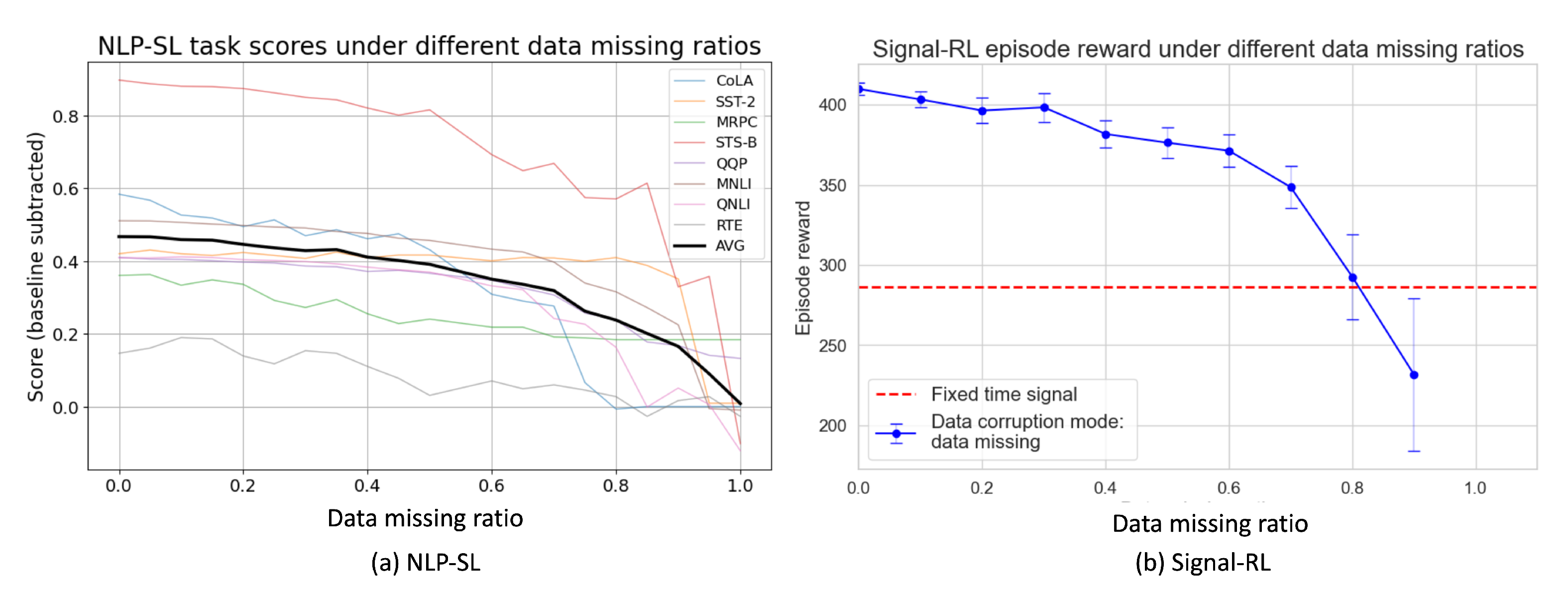
3.2. Observations
3.3. Explanation
4. Effectiveness of Data Imputation
4.1. Experiment Design
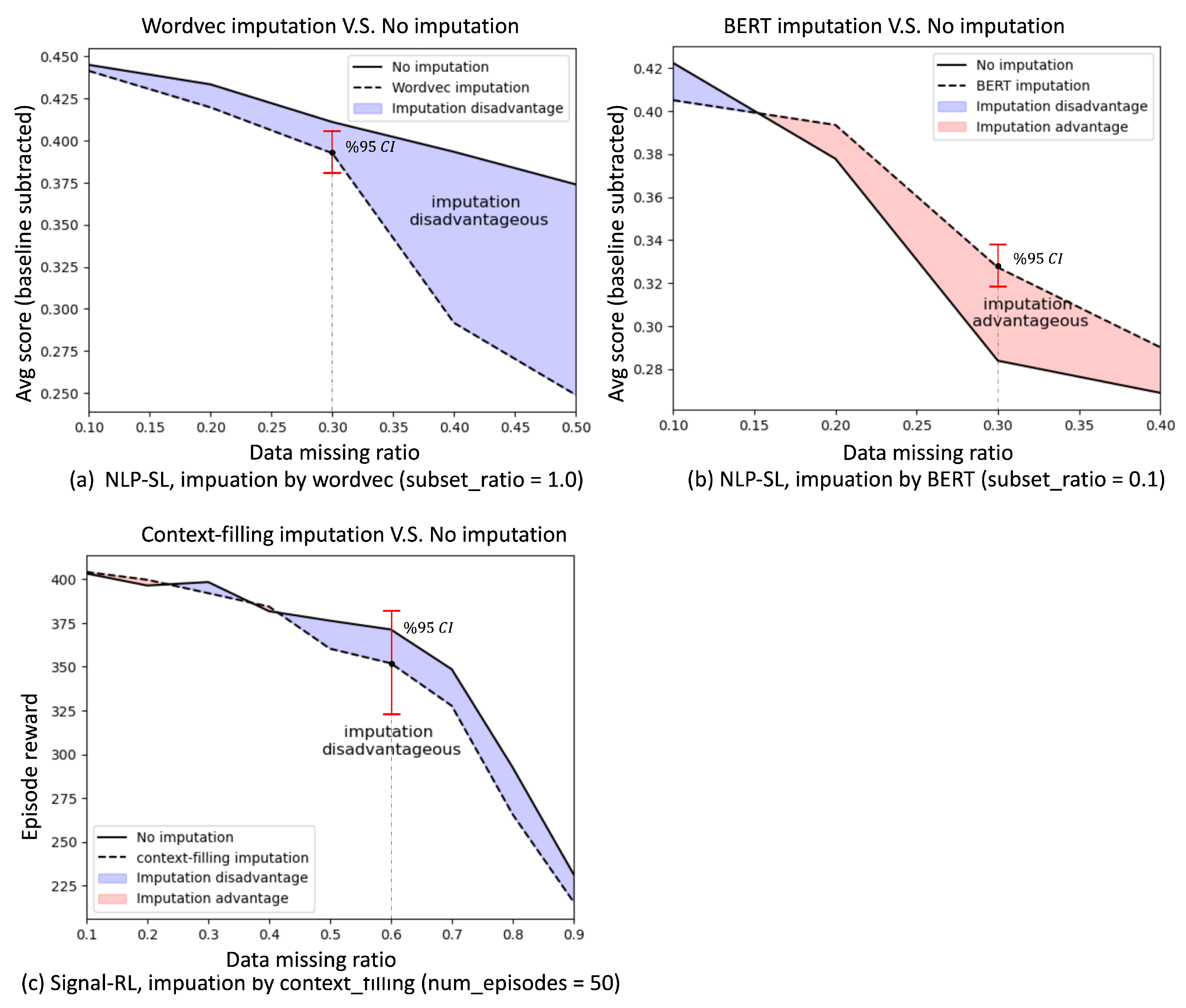
4.2. Observations
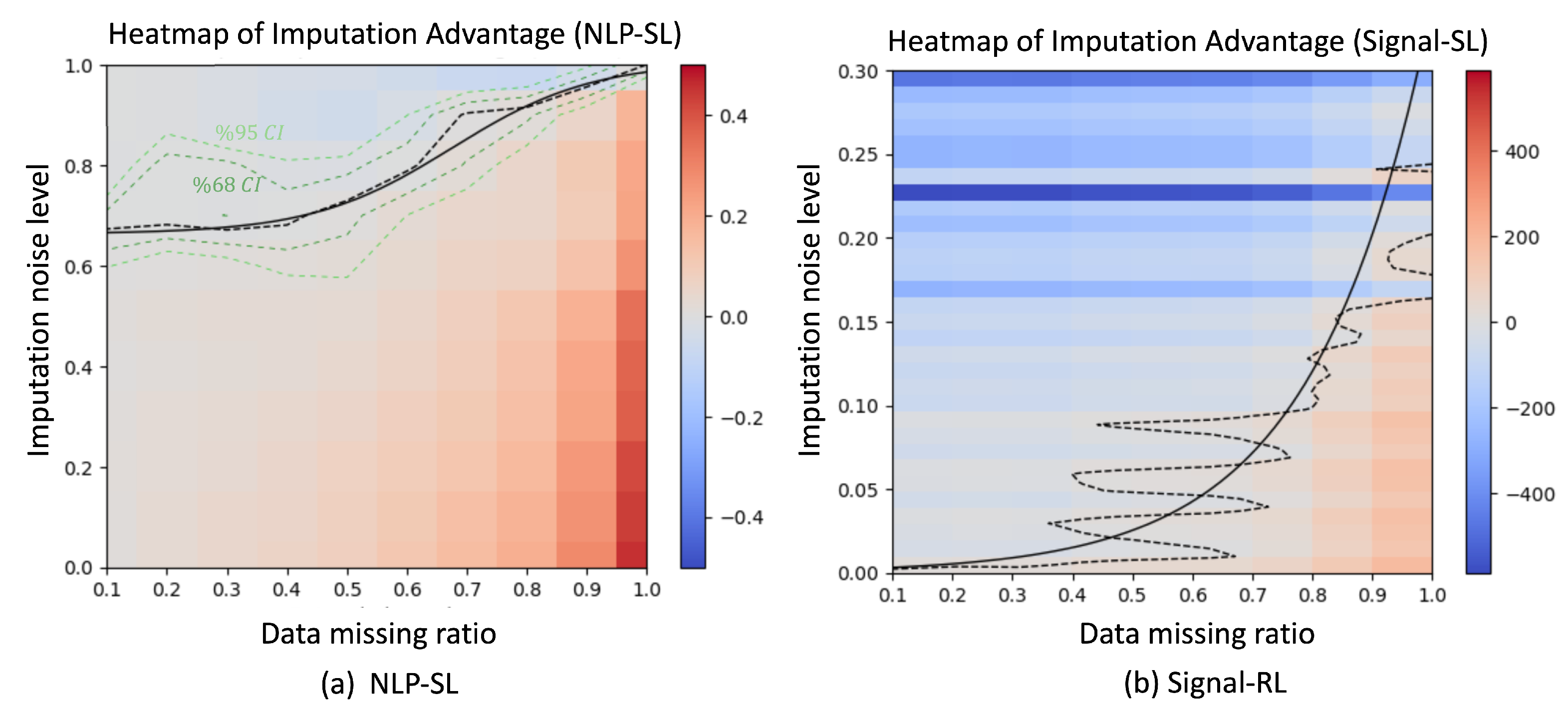
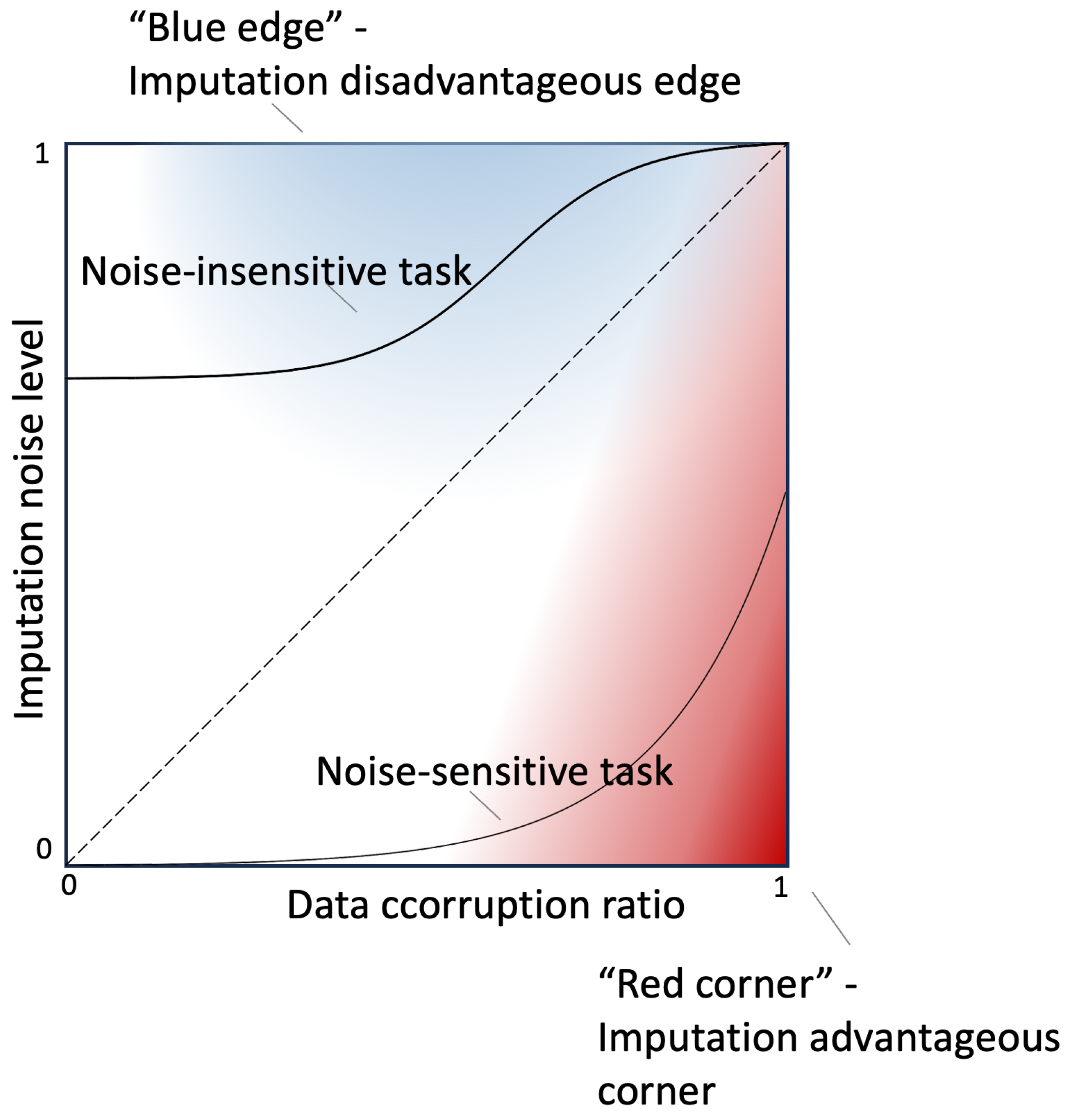
- Imputation advantageous corner: This region is located in the lower-right corner of the heatmap, where the data-missing ratio is high, and the imputation noise level is low. Accurate imputation in this region restores critical information, leading to significant improvements in model performance.
- Imputation disadvantageous edge: This region is near the edge where q = 1. When the imputation noise level approaches 1.0, the noise introduced during imputation overwhelms the model, leading to performance degradation. Interestingly, the greatest harm occurs when the data-missing ratio is around p = 0.6.
- Signal-RL Decision Boundary: The contour curve for the Signal-RL task lies much lower and is shifted to the right compared to the NLP-SL task. Moreover, the contour curve for Signal-RL is more ragged and fits to an exponential curve that starts at (0, 0) and intersects the line .
- NLP-SL Decision Boundary: The contour line for the NLP-SL task is smoother and fits well to a logistic function. When p in range , the decision boundary is relatively stable and remains around . For p in range , the contour line transitions into a sigmoid curve, with its midpoint around . This gradual transition reflects the trade-off between recovering critical information through accurate imputation and introducing ambiguities (e.g., incorrect word predictions) through noisy imputation.
- Noise-sensitive tasks: Tasks with contour curves below the diagonal (e.g., Signal-RL) are highly sensitive to noise, showing sharp performance degradation as imputation noise increases.
- Noise-insensitvie tasks: Tasks with contour curves above the diagonal (e.g., NLP-SL) are more robust to imputation noise.
5. Effectiveness of Enlarging Dataset
5.1. Experiment Design
5.2. Observations
6. Conclusions
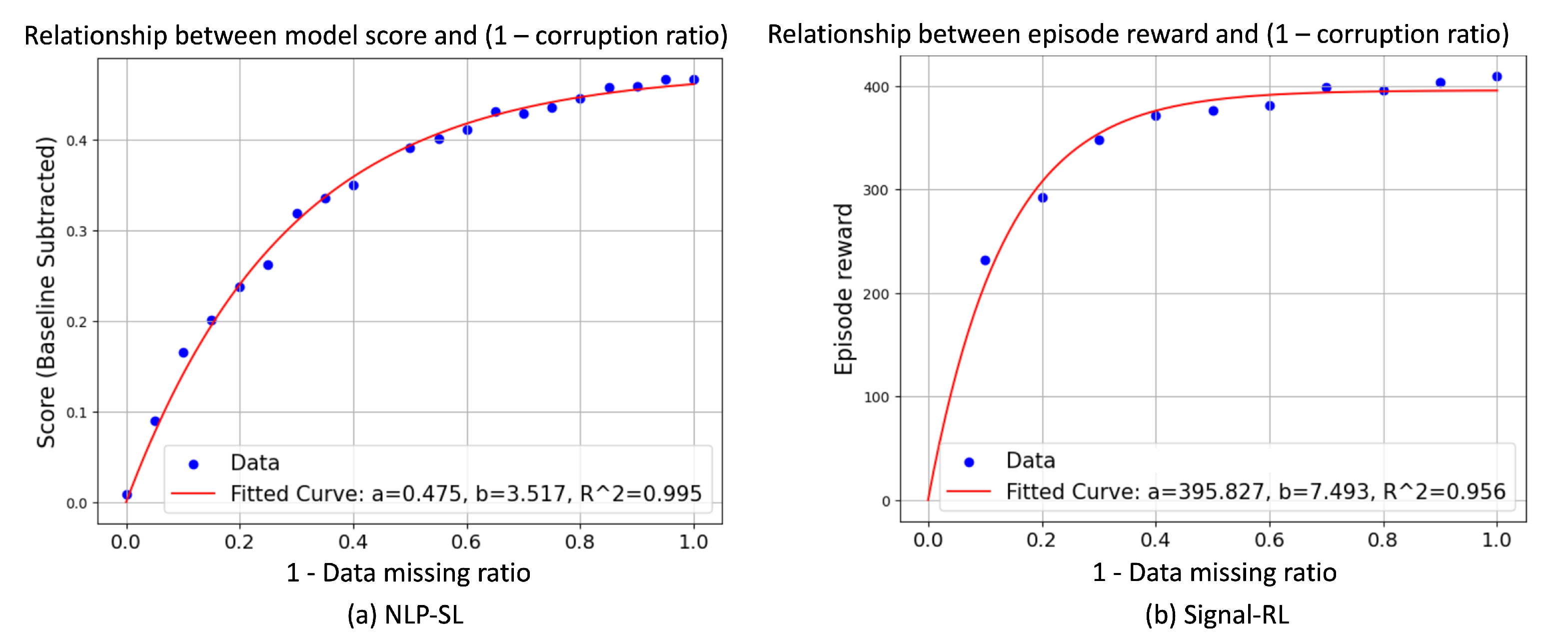
- Diminishing Returns in Data-Quality Improvement: Both NLP-SL and Signal-RL experiments revealed that model performance follows a diminishing return curve as data corruption decreases. The relationship between the model score S and data corruption level p is well modeled by the function:where parameter ; and is the model score when corruption ratio p = 0. This universal trend emphasizes the importance of balancing data quality and preprocessing efforts.
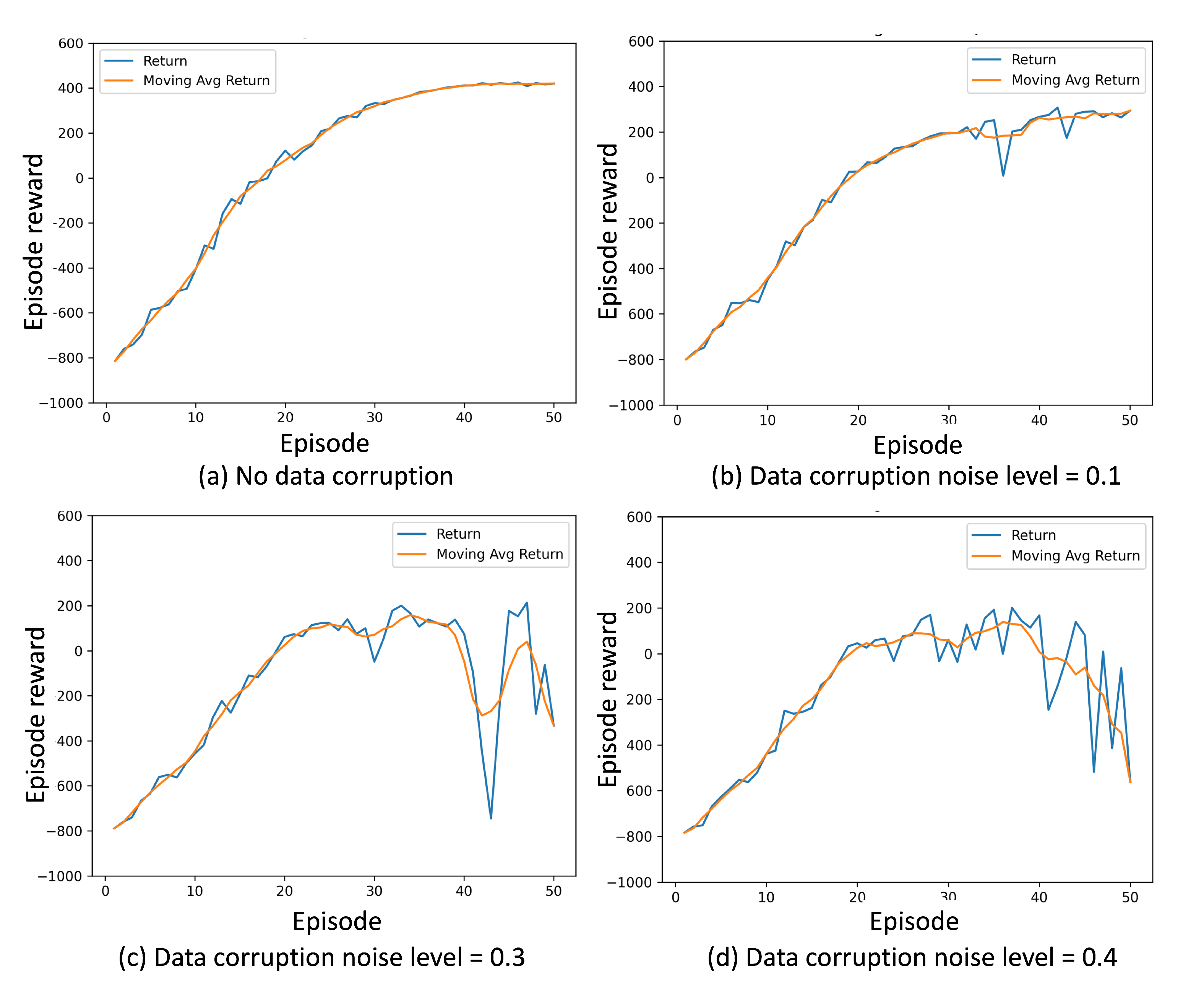
- Data Noise is More Detrimental than Missing Data: Our results demonstrate that noisy data are significantly more detrimental than missing data, leading to faster performance degradation and increased training instability. This was particularly evident in the reinforcement learning task, where inserting noise caused substantial fluctuations in both training and policy stability.
- Trade-offs in Data Imputation: Imputation methods can restore critical information for missing data but introduce a trade-off by potentially adding noise. The decision to impute depends on the imputation accuracy, the corruption ratio, and the nature of the task. The imputation advantage heatmap highlights two key regions:
- Imputation Advantageous Corner: A region where accurate imputation significantly boosts model performance.
- Imputation Disadvantageous Edge: A region where imputation noise outweighs its benefits, harming model performance.
- Two Types of Tasks Identified: Tasks are classified into two categories based on their sensitivity to noise:
- Noise-insensitive tasks: These tasks exhibit gradual performance degradation, with decision boundaries on the heatmap that can be effectively modeled using a sigmoid curve.
- Noise-sensitive tasks: These tasks exhibit sharp performance drops, with decision boundaries closely approximated by an exponential curve. This behavior is typical in deep reinforcement learning tasks. When only “general imputation” is available—as opposed to “exact imputation”—the sensitivity to noise tends to be further amplified.
- Limits of Enlarging Datasets: Increasing the dataset size partially mitigates the effects of data corruption but cannot fully recover the lost performance, especially under high noisy levels. Enlarging datasets does not entirely offset the detrimental effects of noisy data. The analysis showed that the number of samples required to achieve a certain performance level increases exponentially with the corruption ratio, confirming the exponential nature of the trade-off between data quality and quantity.
- Impact of Data Corruption on Learning Efficiency: Missing data hampers learning efficiency. To achieve the same performance level (if at all possible), the number of required samples—and hence training time—increases exponentially with the data-missing level.
- Empirical Rule on Data Importance: For traffic signal control tasks, approximately 30% of the data are critical for determining model performance, while the remaining 70% can be lost with minimal impact on performance. This observation provides practical guidance for prioritizing efforts in data collection and preprocessing. Note that the exact number may not apply to other tasks and, for many task, this kind of screening is not feasible.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | NLP-SL | Signal-RL |
|---|---|---|
| Model type | BERT | DQN |
| Architecture & model description | bert-base-uncased + classification_head Vocab Size: 30,522 (WordPiece) num_layers: 12 num_heads: 12 hidden_att: 768 hidden_ffn: 3072 | hidden_dims: [256, 48] State: road cell occupancy Action: next phase for next 6 s Action dim: 4 Step reward: Stop speed threshold: 0.3 m/s |
| Datasets | Pretraining: Wikitext, Bookcorpus Finetuning: GLUE | 50 simulation episodes (1 Episode = 1 h = 3600 steps) |
| Training config | (Pretraining) batch_size: 256 max_seq_len: 512 LR scheduler: linear warmup and decay weight_decay: 0.01 (Finetuning) (Seq: CoLA, SST2, MRPC, QQP, MNLI, QNLI, RTE, WNLI) num_epochs: [5, 3, 5, 16, 3, 3, 3, 6, 2] batch_size: [32, 64, 16, 16, 256, 256, 128, 8, 4] lr: [3e-5, 3.5e-5, 3e-5, 3e-5, 5e-5, 5e-5, 5e-5, 2e-5, 1e-5] weight_decay: 0.01 | num_episodes: 50 batch_size: 256 LR scheduler: linear decay with plateau Epsilon scheduler: linear decay with plateau Discounting : 0.98 target_update: 10 buffer_size: 10,000 |
 |
  |
References
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 3rd ed.; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- Emmanuel, T.; Maupong, T.; Mpoeleng, D.; Semong, T.; Mphago, B.; Tabona, O. A Survey on Missing Data in Machine Learning. J. Big Data 2021, 8, 1–37. [Google Scholar] [CrossRef] [PubMed]
- Brown, T.B. Language Models Are Few-shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-driven Exploration by Self-supervised Prediction. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2778–2787. [Google Scholar]
- Rubin, D.B. Inference and Missing Data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Moon, T.K.; Stirling, W.C. Mathematical Methods and Algorithms for Signal Processing; Prentice Hall: Upper Saddle River, NJ, USA, 2000; ISBN 0-201-36186-8. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.-G. Learning from Noisy Labels with Deep Neural Networks: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8135–8153. [Google Scholar] [CrossRef] [PubMed]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. SpanBERT: Improving Pre-training by Representing and Predicting Spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Devlin, J. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, 364, arXiv:1907.11692. [Google Scholar]
- Petroni, F.; Piktus, A.; Fan, A.; Lewis, P.; Yazdani, M.; De Cao, N.; Thorne, J.; Jernite, Y.; Karpukhin, V.; Maillard, J.; et al. KILT: A Benchmark for Knowledge Intensive Language Tasks. arXiv 2020, arXiv:2009.02252. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep Recurrent Q-learning for Partially Observable MDPs. AAAI Fall Symp. Ser. 2015, 45, 141. [Google Scholar]
- Bai, X.; Guan, J.; Wang, H. A Model-Based Reinforcement Learning with Adversarial Training for Online Recommendation. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level Control Through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Taylor, M.E.; Stone, P. Transfer Learning for Reinforcement Learning Domains: A Survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Zhou, Y.; Aryal, S.; Bouadjenek, M.R. Review for Handling Missing Data with Special Missing Mechanism. arXiv 2024, arXiv:2404.04905. [Google Scholar]
- Schafer, J.L.; Graham, J.W. Missing Data: Our View of the State of the Art. Psychol. Methods 2002, 7, 147–177. [Google Scholar] [CrossRef] [PubMed]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing Value Estimation Methods for DNA Microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Yuan, J.; Wang, R.; Zhang, Y. Missing Token Imputation Using Masked Language Models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event, 7–11 November 2021; pp. 1234–1240. [Google Scholar]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent Neural Networks for Multivariate Time Series with Missing Values. Sci. Rep. 2018, 8, 6085. [Google Scholar] [CrossRef] [PubMed]
- Tong, W.; Hussain, A.; Bo, W.X.; Maharjan, S. Artificial Intelligence for Vehicle-to-Everything: A Survey. IEEE Access 2019, 7, 10823–10843. [Google Scholar] [CrossRef]
- Feller, W. An Introduction to Probability Theory and Its Applications, 3rd ed.; Wiley: New York, NY, USA, 1991; Volume 1. [Google Scholar]
- Rakhmanov, A.; Wiseman, Y. Compression of GNSS Data with the Aim of Speeding Up Communication to Autonomous Vehicles. Remote Sens. 2023, 15, 2165. [Google Scholar] [CrossRef]



| Category | Method | Strengths/Weaknesses | Use Cases |
|---|---|---|---|
| Statistical-based [19,20] | Mean/Median/Mode | + Simple, fast − Ignores correlations, distorts variance | Small datasets, MCAR data |
| Maximum Likelihood | + Handles MAR data well − Computationally intensive | Surveys, clinical trials | |
| Matrix Completion | + Captures global structure − Requires low-rank assumption | Recommendation systems | |
| Bayesian Approach | + Incorporates uncertainty − Needs prior distributions | Small datasets with domain knowledge | |
| Machine Learning [21,22,23] | Regression-based | + Models feature relationships − Assumes linearity | Tabular data with correlations |
| KNN-based | + Non-parametric, local patterns − Sensitive to k, scales poorly | Small/medium datasets | |
| Tree-based | + Handles nonlinearity − Overfitting risk | High-dimensional data | |
| SVM-based | + Robust to outliers − Kernel choice critical | Nonlinear feature spaces | |
| Clustering-based | + Group-aware imputation − Depends on cluster quality | Data with clear subgroups | |
| Neural Network [24,25,26] | ANN-based | + Flexible architectures − Requires large data | Complex feature interactions |
| Flow-based | + Exact density estimation − High computational cost | Generative tasks | |
| VAE-based | + Handles uncertainty − Blurry imputations | Image/text incomplete data | |
| GAN-based | + High-fidelity samples − Training instability | Media generation | |
| Diffusion-based | + State-of-the-art quality − Slow sampling | High-stakes applications |
| Data-missing ratio | 0.0 | 0.05 | 0.1 | 0.15 | 0.2 |
| Model score | 0.4669 | 0.4663 | 0.4588 | 0.4572 | 0.4455 |
| Data-missing ratio | 0.25 | 0.3 | 0.35 | 0.4 | 0.45 |
| Model score | 0.4359 | 0.4283 | 0.4312 | 0.4106 | 0.4012 |
| Data-missing ratio | 0.5 | 0.6 | 0.65 | 0.7 | 0.75 |
| Model score | 0.3906 | 0.3501 | 0.3357 | 0.3186 | 0.2619 |
| Data-missing ratio | 0.8 | 0.85 | 0.9 | 0.95 | 1.0 |
| Model score | 0.2375 | 0.2008 | 0.1654 | 0.0897 | 0.0081 |
| Data missing ratio | 0.0 | 0.1 | 0.2 | 0.3 | 0.4 |
| Model score mean | 409.86 | 403.30 | 396.40 | 398.40 | 381.74 |
| Model score std | 3.83 | 5.04 | 7.92 | 8.97 | 8.44 |
| Data missing ratio | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 |
| Model score mean | 376.33 | 371.30 | 348.58 | 292.54 | 231.56 |
| Model score std | 9.62 | 10.05 | 13.25 | 26.44 | 47.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Ma, W. Navigating Data Corruption in Machine Learning: Balancing Quality, Quantity, and Imputation Strategies. Future Internet 2025, 17, 241. https://doi.org/10.3390/fi17060241
Liu Q, Ma W. Navigating Data Corruption in Machine Learning: Balancing Quality, Quantity, and Imputation Strategies. Future Internet. 2025; 17(6):241. https://doi.org/10.3390/fi17060241
Chicago/Turabian StyleLiu, Qi, and Wanjing Ma. 2025. "Navigating Data Corruption in Machine Learning: Balancing Quality, Quantity, and Imputation Strategies" Future Internet 17, no. 6: 241. https://doi.org/10.3390/fi17060241
APA StyleLiu, Q., & Ma, W. (2025). Navigating Data Corruption in Machine Learning: Balancing Quality, Quantity, and Imputation Strategies. Future Internet, 17(6), 241. https://doi.org/10.3390/fi17060241