

Adversarial Training for Mitigating Insider-Driven XAI-Based Backdoor Attacks


Abstract
1. Introduction
- We propose an insider-driven poison-label backdoor attack that adopts the use of model interpretability from explainable AI (XAI) to study the vulnerability of adversarial training when exploited by an insider.
- We performed comprehensive experiments to evaluate and analyze the robustness of adversarially trained tabular deep learning models against the insider-driven poison label attack.
Motivation
2. Related Work
2.1. Generative Adversarial Networks (GANs)
2.2. Adversarial Training
2.3. Explainable AI for Cybersecurity
2.4. Backdoor Attacks
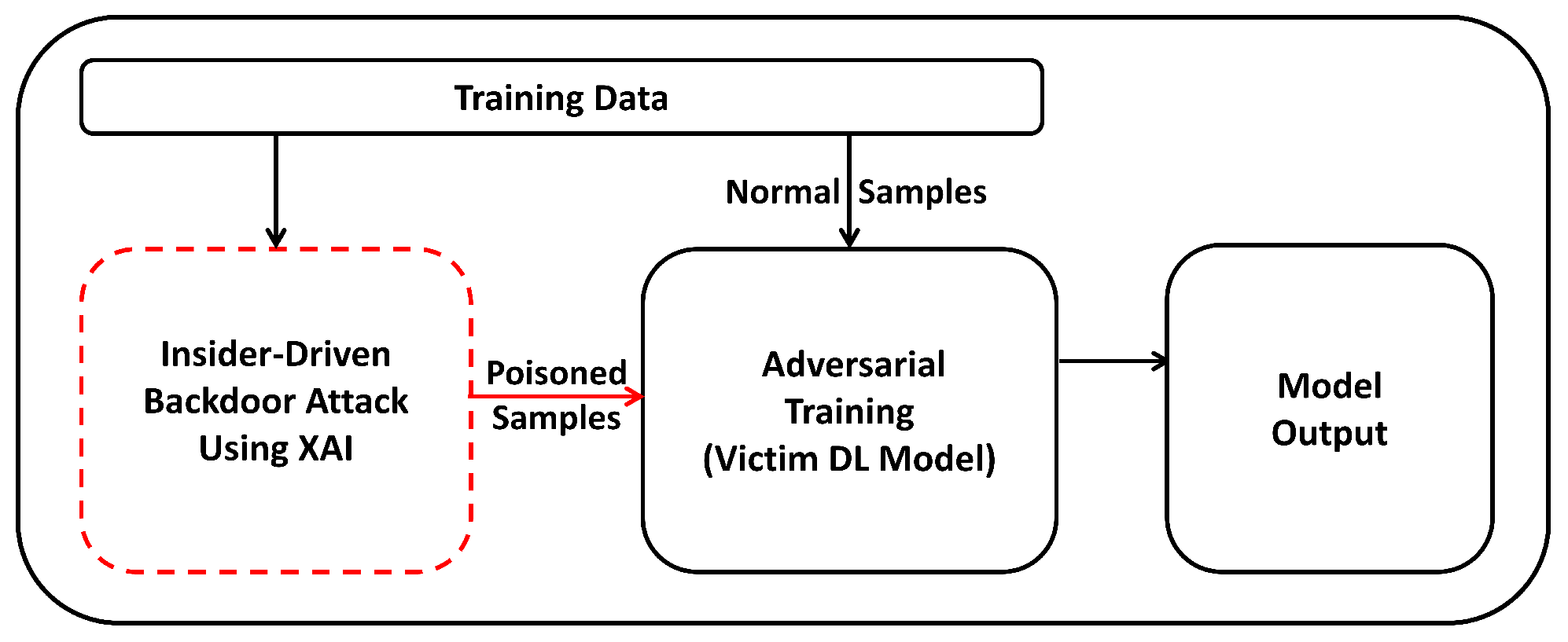
3. Proposed Approach
3.1. Insider-Driven Backdoor Attack Using XAI
3.1.1. Trigger Generation
| Algorithm 1: Insider-driven backdoor attack using XAI |
 |
3.1.2. Surrogate Model
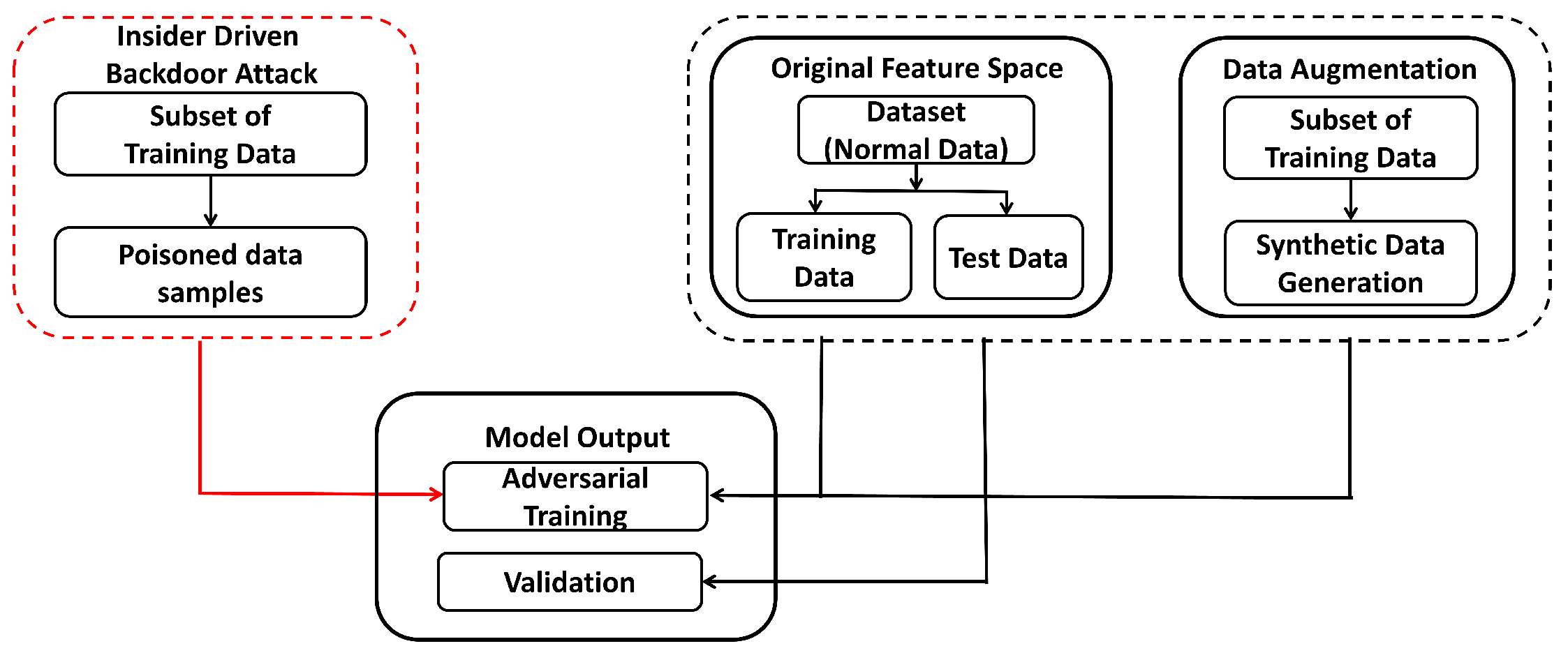
3.2. Adversarial Training
Training Models
4. Experiments
4.1. Dataset Description
4.2. Adversarial Training
4.2.1. Training Models
4.2.2. Performance Metrics
4.3. Discussion
4.3.1. Success of Attack
4.3.2. Effect of the Number of Poisoned Samples
4.4. Robustness Analysis of Backdoor in AT
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical Black-Box Attacks against Machine Learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security—ASIA CCS’17, Saadiyat Island, Abu Dhabi, 2–6 April 2017. [Google Scholar]
- Lin, Y.-S.; Lee, W.-C.; Celik, Z.B. What Do You See? Evaluation of Explainable Artificial Intelligence (XAI) Interpretability through Neural Backdoors. arXiv 2020, arXiv:2009.10639. [Google Scholar]
- Li, Y.; Jiang, Y.; Li, Z.; Xia, S.-T. Backdoor Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 5–22. [Google Scholar] [CrossRef] [PubMed]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. BadNets: Evaluating Backdooring Attacks on Deep Neural Networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Ali, H.; Khan, M.S.; Al-Fuqaha, A.; Qadir, J. Tamp-X: Attacking Explainable Natural Language Classifiers through Tampered Activations. Comput. Secur. 2022, 120, 102791. [Google Scholar] [CrossRef]
- Gayathri, R.; Sajjanhar, A.; Xiang, Y. Adversarial Training for Robust Insider Threat Detection. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022. [Google Scholar]
- Yan, Z.; Li, G.; TIan, Y.; Wu, J.; Li, S.; Chen, M.; Poor, H.V. DeHiB: Deep Hidden Backdoor Attack on Semi-Supervised Learning via Adversarial Perturbation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 10585–10593. [Google Scholar]
- Li, Z.; Jiang, H.; Wang, X. A novel reinforcement learning agent for rotating machinery fault diagnosis with data augmentation. Reliab. Eng. Syst. Saf. 2021, 253, 110570. [Google Scholar] [CrossRef]
- Švábenský, V.; Borchers, C.; Cloude, E.B.; Shimada, A. Evaluating the impact of data augmentation on predictive model performance. In Proceedings of the 15th International Learning Analytics and Knowledge Conference, Dublin, Ireland, 3–7 March 2025; pp. 126–136. [Google Scholar]
- Wang, A.X.; Chukova, S.S.; Simpson, C.R.; Nguyen, B.P. Challenges and opportunities of generative models on tabular data. Appl. Soft Comput. 2024, 166, 112223. [Google Scholar] [CrossRef]
- Kang, H.Y.J.; Ko, M.; Ryu, K.S. Tabular transformer generative adversarial network for heterogeneous distribution in healthcare. Sci. Rep. 2025, 15, 10254. [Google Scholar] [CrossRef]
- Lei, X.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Dou, H.; Chen, C.; Hu, X.; Xuan, Z.; Hu, Z.; Peng, S. PCA-SRGAN: Incremental orthogonal projection discrimination for face super-resolution. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1891–1899. [Google Scholar]
- Dou, H.; Chen, C.; Hu, X.; Jia, L.; Peng, S. Asymmetric CycleGAN for image-to-image translations with uneven complexities. Neurocomputing 2020, 415, 114–122. [Google Scholar] [CrossRef]
- Khazane, H.; Ridouani, M.; Salahdine, F.; Kaabouch, N. A Holistic Review of Machine Learning Adversarial Attacks in IoT Networks. Future Internet 2024, 16, 32. [Google Scholar] [CrossRef]
- Gao, Y.; Doan, B.G.; Zhang, Z.; Ma, S.; Zhang, J.; Fu, A.; Nepal, S.; Kim, H. Backdoor Attacks and Countermeasures on Deep Learning: A Comprehensive Review. arXiv 2020, arXiv:2007.10760. [Google Scholar]
- Cui, C.; Du, H.; Jia, Z.; Zhang, X.; He, Y.; Yang, Y. Data Poisoning Attacks with Hybrid Particle Swarm Optimization Algorithms against Federated Learning in Connected and Autonomous Vehicles. IEEE Access 2023, 11, 136361–136369. [Google Scholar] [CrossRef]
- Borgnia, E.; Cherepanova, V.; Fowl, L.; Ghiasi, A.; Geiping, J.; Goldblum, M.; Goldstein, T.; Gupta, A.K. Strong Data Augmentation Sanitizes Poisoning and Backdoor Attacks without an Accuracy Tradeoff. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Qiu, H.; Zeng, Y.; Guo, S.; Zhang, T.; Qiu, M.; Thuraisingham, B. DeepSweep: An Evaluation Framework for Mitigating DNN Backdoor Attacks Using Data Augmentation. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Hong Kong, China, 7–11 June 2021. [Google Scholar]
- Agarwal, G. Explainable AI (XAI) for Cyber Defense: Enhancing Transparency and Trust in AI-Driven Security Solutions. Int. J. Adv. Res. Sci. Commun. Technol. 2025, 5, 132–138. [Google Scholar] [CrossRef]
- Sahakyan, M.; Aung, Z.; Rahwan, T. Explainable Artificial Intelligence for Tabular Data: A Survey. IEEE Access 2021, 9, 135392–135422. [Google Scholar] [CrossRef]
- Eldrandaly, K.A.; Abdel-Basset, M.; Ibrahim, M.; Abdel-Aziz, N.M. Explainable and Secure Artificial Intelligence: Taxonomy, Cases of Study, Learned Lessons, Challenges and Future Directions. Enterp. Inf. Syst. 2022, 17, 2098537. [Google Scholar] [CrossRef]
- Liu, H.; Wu, Y.; Yu, Z.; Zhang, N. Please Tell Me More: Privacy Impact of Explainability through the Lens of Membership Inference Attack. IEEE Symp. Secur. Priv. 2024, 31, 4791–4809. [Google Scholar]
- Baniecki, H.; Biecek, P. Adversarial Attacks and Defenses in Explainable Artificial Intelligence: A Survey. arXiv 2023, arXiv:2306.06123. [Google Scholar] [CrossRef]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Saha, A.; Subramanya, A.; Pirsiavash, H. Hidden Trigger Backdoor Attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 9–11 February 2020; Volume 34, pp. 11957–11965. [Google Scholar]
- Ning, R.; Li, J.; Xin, C.; Wu, H. Invisible Poison: A Blackbox Clean Label Backdoor Attack to Deep Neural Networks. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021. [Google Scholar]
- Miller, D.J.; Xiang, Z.; Kesidis, G. Adversarial Learning Targeting Deep Neural Network Classification: A Comprehensive Review of Defenses against Attacks. Proc. IEEE 2020, 108, 402–433. [Google Scholar] [CrossRef]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Ning, R.; Xin, C.; Wu, H. TrojanFlow: A Neural Backdoor Attack to Deep Learning-Based Network Traffic Classifiers. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, Virtual, 2–5 May 2022. [Google Scholar]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Lundberg, S.M.; Erion, G.G.; Lee, S.-I. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Kadra, A.; Lindauer, M.; Hutter, F.; Grabocka, J. Well-Tuned Simple Nets Excel on Tabular Datasets. arXiv 2021, arXiv:2106.11189. [Google Scholar]
- Arik, S.Ö.; Pfister, T. TabNet: Attentive Interpretable Tabular Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 6679–6687. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Li, Y.; Zou, L.; Jiang, L.; Zhou, X. Fault Diagnosis of Rotating Machinery Based on Combination of Deep Belief Network and One-Dimensional Convolutional Neural Network. IEEE Access 2019, 7, 165710–165723. [Google Scholar] [CrossRef]
- Cmu.edu. Insider Threat Test Dataset. Available online: https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=508099 (accessed on 28 March 2025).
- Xiao, H.; Zhu, Y.; Zhang, B.; Lu, Z.; Du, D.; Liu, Y. Unveiling shadows: A comprehensive framework for insider threat detection based on statistical and sequential analysis. Comput. Secur. 2024, 138, 103665. [Google Scholar] [CrossRef]
- Gao, P.; Zhang, H.; Wang, M.; Yang, W.; Wei, X.; Lv, Z.; Ma, Z. Deep temporal graph infomax for imbalanced insider threat detection. J. Comput. Inf. Syst. 2025, 65, 108–118. [Google Scholar] [CrossRef]
- Gayathri, R.G.; Sajjanhar, A.; Xiang, Y.; Ma, X. Anomaly Detection for Scenario-Based Insider Activities Using CGAN Augmented Data. In Proceedings of the 2021 IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Shenyang, China, 20–22 October 2021. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | No of Instances | No. of Users | No. of Insiders | Scenarios | ||||
|---|---|---|---|---|---|---|---|---|
| Total | Mal. | S1 | S2 | S3 | S4 | |||
| v4.2 | 330,452 | 966 | 1000 | 70 | 30 | 30 | 10 | - |
| v5.2 | 1,048,575 | 906 | 2000 | 99 | 29 | 30 | 10 | 30 |
| Data | Model | Real | ||||
|---|---|---|---|---|---|---|
| P | R | F | K | M | ||
| V4 | RF | 0.496 | 0.704 | 0.500 | 0.505 | 0.555 |
| XGB | 0.754 | 0.748 | l0.739 | l0.920 | 0.921 | |
| LGB | 0.269 | 0.259 | 0.261 | 0.042 | 0.042 | |
| SNN_MLP | 0.276 | 0.870 | 0.289 | 0.069 | 0.187 | |
| SNN_1DCNN | 0.275 | 0.921 | 0.282 | 0.047 | 0.048 | |
| TabNet | 0.582 | 0.660 | 0.611 | 0.943 | 0.944 | |
| V5 | RF | 0.325 | 0.445 | 0.332 | 0.241 | 0.272 |
| XGB | 0.552 | 0.454 | 0.491 | 0.489 | 0.493 | |
| LGB | 0.309 | 0.230 | 0.247 | 0.147 | 0.148 | |
| SNN_MLP | 0.205 | 0.699 | 0.172 | 0.006 | 0.061 | |
| SNN_1DCNN | 0.204 | 0.738 | 0.158 | 0.008 | 0.055 | |
| TabNet | 0.295 | 0.204 | 0.183 | 0.006 | 0.031 | |
| Data | Model | ROS | SMOTE | VAE | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F | K | M | P | R | F | K | M | P | R | F | K | M | ||
| V4 | RF | 0.549 | 0.729 | 0.544 | 0.343 | 0.426 | 0.556 | 0.734 | 0.615 | 0.779 | 0.786 | 0.581 | 0.712 | 0.610 | 0.811 | 0.810 |
| XGB | 0.782 | 0.761 | 0.759 | 0.891 | 0.886 | 0.749 | 0.518 | 0.575 | 0.427 | 0.279 | 1.000 | 0.709 | 0.792 | 0.789 | 0.869 | |
| LGB | 0.368 | 0.866 | 0.419 | 0.156 | 0.290 | 0.391 | 0.793 | 0.422 | 0.071 | 0.193 | 0.420 | 0.80 | 0.481 | 0.201 | 0.32 | |
| SNN_MLP | 0.531 | 0.778 | 0.551 | 0.358 | 0.461 | 0.556 | 0.764 | 0.568 | 0.491 | 0.563 | 0.510 | 0.550 | 0.61 | 0.331 | 0.452 | |
| SNN_1DCNN | 0.277 | 0.921 | 0.289 | 0.061 | 0.174 | 0.44 | 0.793 | 0.517 | 0.487 | 0.557 | 0.45 | 0.801 | 0.53 | 0.5 | 0.462 | |
| TabNet | 0.373 | 0.491 | 0.298 | 0.086 | 0.086 | 0.742 | 0.487 | 0.508 | 0.367 | 0.462 | 0.341 | 0.440 | 0.54 | 0.381 | 0.420 | |
| V5 | RF | 0.317 | 0.456 | 0.341 | 0.225 | 0.261 | 0.253 | 0.464 | 0.287 | 0.175 | 0.234 | 0.280 | 0.481 | 0.312 | 0.190 | 0.24 |
| XGB | 0.208 | 0.719 | 0.181 | 0.008 | 0.059 | 0.207 | 0.714 | 0.189 | 0.012 | 0.073 | 0.220 | 0.731 | 0.21 | 0.021 | 0.08 | |
| LGB | 0.372 | 0.665 | 0.337 | 0.069 | 0.171 | 0.236 | 0.659 | 0.262 | 0.079 | 0.179 | 0.251 | 0.67 | 0.272 | 0.08 | 0.181 | |
| SNN_MLP | 0.231 | 0.606 | 0.252 | 0.089 | 0.177 | 0.221 | 0.614 | 0.234 | 0.048 | 0.131 | 0.240 | 0.622 | 0.261 | 0.054 | 0.146 | |
| SNN_1DCNN | 0.204 | 0.779 | 0.16 | 0.007 | 0.056 | 0.745 | 0.329 | 0.724 | 0.039 | 0.14 | 0.321 | 0.750 | 0.342 | 0.052 | 0.159 | |
| TabNet | 0.383 | 0.364 | 0.375 | 0.324 | 0.324 | 0.625 | 0.556 | 0.111 | 0.134 | 0.541 | 0.630 | 0.563 | 0.121 | 0.145 | 0.083 | |
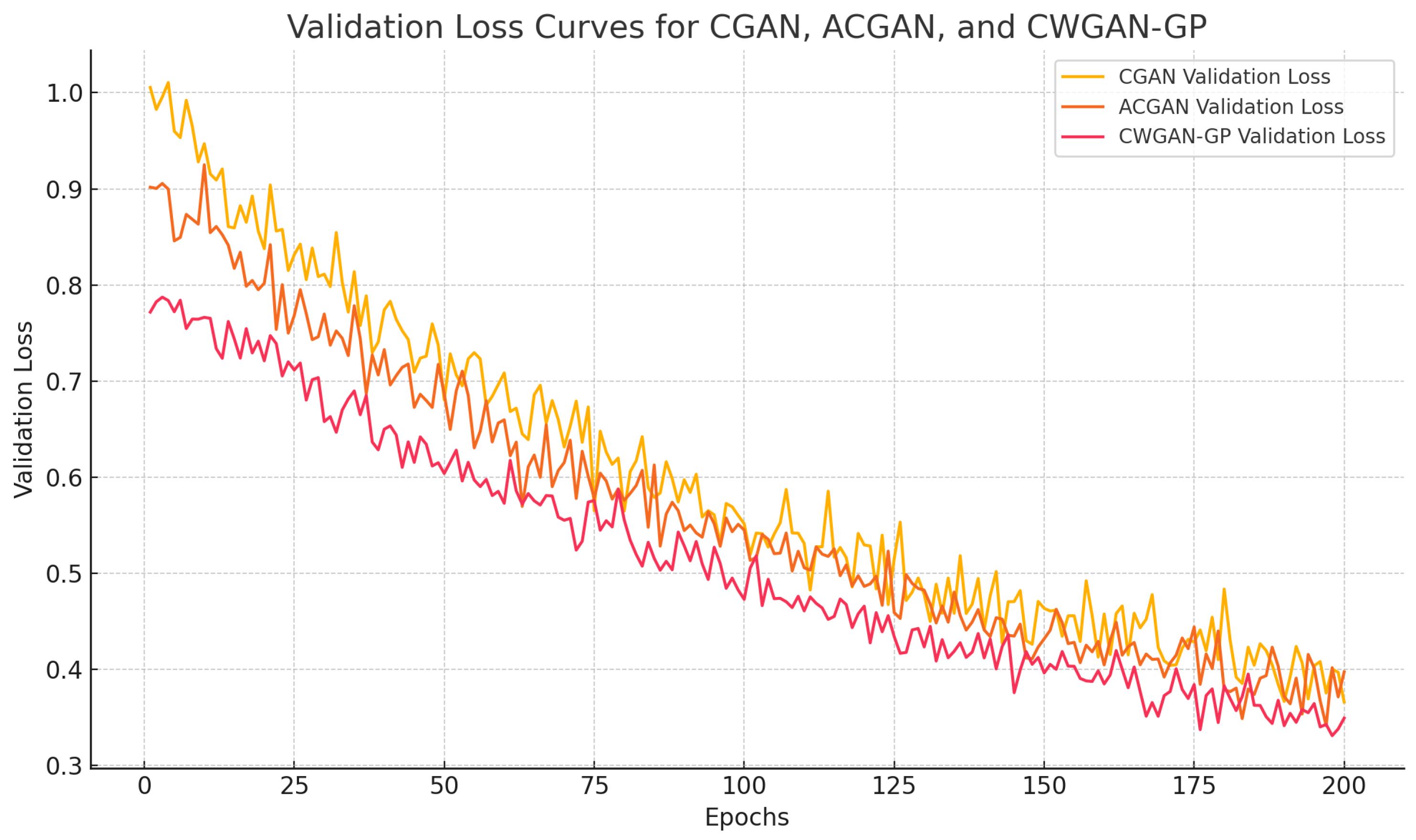
| Data | Model | CGAN | ACGAN | CWGANGP | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F | K | M | P | R | F | K | M | P | R | F | K | M | ||
| V4 | RF | 0.751 | 0.748 | 0.739 | 0.920 | 0.920 | 0.746 | 0.608 | 0.609 | 0.636 | 0.748 | 0.796 | 0.727 | 0.750 | 0.882 | 0.846 |
| XGB | 0.782 | 0.761 | 0.759 | 0.891 | 0.886 | 0.749 | 0.518 | 0.575 | 0.427 | 0.279 | 1.000 | 0.709 | 0.792 | 0.789 | 0.869 | |
| LGB | 0.714 | 0.875 | 0.773 | 0.545 | 0.567 | 0.718 | 0.716 | 0.696 | 0.816 | 0.818 | 0.930 | 0.712 | 0.768 | 0.803 | 0.816 | |
| SNN_MLP | 0.749 | 0.445 | 0.514 | 0.599 | 0.627 | 0.779 | 0.787 | 0.783 | 0.898 | 0.898 | 0.832 | 0.748 | 0.786 | 0.938 | 0.939 | |
| SNN_1DCNN | 0.569 | 0.429 | 0.482 | 0.612 | 0.653 | 0.750 | 0.647 | 0.916 | 0.916 | 0.919 | 0.804 | 0.722 | 0.752 | 0.752 | 0.762 | |
| TabNet | 0.708 | 0.635 | 0.667 | 0.900 | 0.903 | 0.792 | 0.973 | 0.861 | 0.722 | 0.744 | 0.935 | 0.757 | 0.789 | 0.890 | 0.840 | |
| V5 | RF | 0.465 | 0.447 | 0.454 | 0.428 | 0.428 | 0.683 | 0.511 | 0.540 | 0.606 | 0.643 | 0.815 | 0.748 | 0.779 | 0.935 | 0.936 |
| XGB | 0.998 | 0.751 | 0.816 | 0.948 | 0.949 | 1.000 | 0.629 | 0.732 | 0.861 | 0.869 | 0.994 | 0.763 | 0.820 | 0.963 | 0.963 | |
| LGB | 0.764 | 0.448 | 0.521 | 0.620 | 0.649 | 0.839 | 0.834 | 0.819 | 0.458 | 0.480 | 0.921 | 0.746 | 0.772 | 0.843 | 0.848 | |
| SNN_MLP | 0.588 | 0.389 | 0.454 | 0.588 | 0.636 | 0.815 | 0.748 | 0.779 | 0.935 | 0.936 | 0.875 | 0.747 | 0.798 | 0.940 | 0.941 | |
| SNN_1DCNN | 0.562 | 0.418 | 0.470 | 0.592 | 0.638 | 0.847 | 0.762 | 0.724 | 0.636 | 0.670 | 0.869 | 0.763 | 0.803 | 0.961 | 0.961 | |
| TabNet | 0.826 | 0.942 | 0.875 | 0.751 | 0.760 | 0.889 | 0.589 | 0.641 | 0.677 | 0.712 | 0.916 | 0.774 | 0.824 | 0.883 | 0.883 | |
| Model | Generator | Discriminator | Hyperparameters | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Layers | Units | Non-Linearity | Layers | Units | Non-Linearity | Optimizer | Epochs | Batch Size | |
| CGAN | Dense | 32 | LeakyReLU | Dense | 256 | LeakyReLU | Adam (lr = 0.0002, beta_1 = 0.5) | 300 | 64 |
| Dense | 64 | LeakyReLU | Dense | 128 | LeakyReLU | ||||
| Dense | 128 | Linear | Dense | 32 | LeakyReLU | ||||
| Dense | 1 | Sigmoid | |||||||
| ACGAN | Dense | 32 | LeakyReLU | Dense | 256 | LeakyReLU | Adam (lr = 0.0002, beta_1 = 0.5) | 300 | 64 |
| Dense | 64 | LeakyReLU | Dense | 128 | LeakyReLU | ||||
| Dense | 128 | Linear | Dense | 32 | LeakyReLU | ||||
| Dense | 1 | Sigmoid | |||||||
| CWGANGP | Dense | 20 | LeakyReLU | Dense | 100 | LeakyReLU | Adam (lr = 0.0002, beta_1 = 0.5) | 300 | 64 |
| Dense | 32 | LeakyReLU | Dense | 64 | LeakyReLU | ||||
| Dense | 64 | LeakyReLU | Dense | 32 | LeakyReLU | ||||
| Dense | 100 | Linear | Dense | 20 | LeakyReLU | ||||
| Dense | 1 | Sigmoid | |||||||
| Model | V4 | V5 | ||||||
|---|---|---|---|---|---|---|---|---|
| FGSM | DF | CW | JSMA | FGSM | DF | CW | JSMA | |
| RF | 0.512 | 0.561 | 0.550 | 0.489 | 0.408 | 0.549 | 0.522 | 0.463 |
| XGB | 0.999 | 0.452 | 0.635 | 0.612 | 0.750 | 0.701 | 0.667 | 0.636 |
| LGB | 0.633 | 0.571 | 0.619 | 0.571 | 0.615 | 0.612 | 0.655 | 0.539 |
| SNN_MLP | 0.459 | 0.616 | 0.474 | 0.489 | 0.549 | 0.625 | 0.761 | 0.750 |
| SNN_1DCNN | 0.5321 | 0.681 | 0.612 | 0.539 | 0.513 | 0.523 | 0.554 | 0.561 |
| TabNet | 0.734 | 0.714 | 0.762 | 0.716 | 0.704 | 0.725 | 0.681 | 0.702 |
| Data | Model | ASR % | CGAN | ACGAN | CWGANGP | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pdrop | Rdrop | Fdrop | Pdrop | Rdrop | Fdrop | Pdrop | Rdrop | Fdrop | |||
| V4 | RF | 90 | 0.026 | 0.016 | 0.014 | 0.038 | 0.079 | 0.023 | 0.002 | 0.307 | 0.244 |
| XGB | 100 | 0.018 | 0.313 | 0.238 | 0.075 | 0.164 | 0.154 | 0.2464 | 0.209 | 0.217 | |
| LGB | 96 | 0.057 | 0.238 | 0.126 | 0.056 | 0.271 | 0.276 | 0.077 | 0.035 | 0.026 | |
| SNN_MLP | 82 | 0.029 | −0.551 | −0.289 | 0.020 | 0.351 | 0.252 | 0.060 | 0.015 | 0.044 | |
| SNN_1DCNN | 96 | −0.027 | 0.189 | 0.226 | 0.002 | 0.068 | 0.319 | 0.005 | 0.347 | 0.290 | |
| TabNet | 92 | 0.038 | 0.134 | 0.243 | 0.072 | 0.435 | 0.255 | 0.043 | 0.340 | 0.322 | |
| V5 | RF | 90 | 0.056 | 0.139 | 0.135 | 0.241 | 0.065 | 0.101 | 0.008 | 0.009 | 0.008 |
| XGB | 100 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| LGB | 96 | 0.085 | 0.005 | 0.001 | 0.057 | 0.287 | 0.186 | 0.027 | 0.024 | 0.022 | |
| SNN_MLP | 86 | 0.011 | 0.049 | 0.049 | 0.008 | 0.310 | 0.262 | 0.001 | 0.220 | 0.174 | |
| SNN_1DCNN | 97 | 0.019 | −0.065 | −0.030 | 0.014 | 0.317 | 0.192 | 0.025 | 0.005 | 0.067 | |
| TabNet | 95 | 0.023 | 0.495 | 0.354 | 0.037 | 0.014 | −0.041 | 0.016 | 0.058 | 0.073 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gayathri, R.G.; Sajjanhar, A.; Xiang, Y. Adversarial Training for Mitigating Insider-Driven XAI-Based Backdoor Attacks. Future Internet 2025, 17, 209. https://doi.org/10.3390/fi17050209
Gayathri RG, Sajjanhar A, Xiang Y. Adversarial Training for Mitigating Insider-Driven XAI-Based Backdoor Attacks. Future Internet. 2025; 17(5):209. https://doi.org/10.3390/fi17050209
Chicago/Turabian StyleGayathri, R. G., Atul Sajjanhar, and Yong Xiang. 2025. "Adversarial Training for Mitigating Insider-Driven XAI-Based Backdoor Attacks" Future Internet 17, no. 5: 209. https://doi.org/10.3390/fi17050209
APA StyleGayathri, R. G., Sajjanhar, A., & Xiang, Y. (2025). Adversarial Training for Mitigating Insider-Driven XAI-Based Backdoor Attacks. Future Internet, 17(5), 209. https://doi.org/10.3390/fi17050209