4. Experiments
4.1. Dataset Information
In this section, we present a detailed overview of the dataset used to develop ML models for diagnosing pediatric appendicitis. The dataset is derived from a retrospective study conducted at the Children’s Hospital St. Hedwig, with ethical approval from the University of Regensburg’s Ethics Committee [
17]. It encompasses 782 observations across 58 variables, covering patient demographics (age, sex, height, weight, BMI), clinical scoring systems (Alvarado Score and Pediatric Appendicitis Score), physical examination findings, laboratory test results, and detailed ultrasound observations. Key target variables of the dataset include:
- 1.
The patient’s diagnosis, histologically confirmed for operated patients. Conservatively managed patients were classified as having appendicitis if their AS or PAS was ≥4, and the appendix diameter was ≥6 mm.
- 2.
The management approach, determined by a senior pediatric surgeon, was categorized as either operative (appendectomy: laparoscopic, open, or conversion) or conservative (without antibiotics). Patients undergoing secondary surgery after initial conservative management were considered operatively managed.
- 3.
The severity of appendicitis, classified as uncomplicated (subacute, fibrosis) and complicated (phlegmonous, gangrenous, perforated, abscessed).
Upon initial exploration, we identified that 30.9% of the data were missing. Notably, variables related to ultrasound findings had at least 40% missing values, a common issue due to operator dependency and variability in emergency settings. Similarly, several urine laboratory tests exhibited high missing rates, likely due to their secondary importance in urgent care scenarios. To address these challenges, variables with over 40% missing data were excluded. As a result, our analysis was focused on a refined dataset comprising 782 observations and 39 variables. After this filtering process, all 782 observations were retained, while only variables with more than 40% missing values were excluded. As a result, the dataset used for modeling included 39 variables instead of the original 58. The remaining gaps (5.5%) were handled using multiple imputation with predictive mean matching (PMM) (m = 5, maxit = 50). While PMM improved data completeness, significant missingness persisted in “RBC in Urine”, “Ketones in Urine”, and “WBC in Urine” (206, 200, and 199 instances, respectively), indicating limitations in capturing predictive relationships.
To enhance imputation reliability, we increased imputations to m = 10, although substantial missing counts remained, prompting us to test other methods. We evaluated linear regression (PMM) and logistic regression (logreg) imputation methods; however, adjustments to the m parameter and model specifications did not fully resolve these gaps. Transitioning to k-nearest neighbors (k-NNs) imputation with Gower distance offered greater flexibility and effectively addressed all remaining missing values in mixed data types.
After preprocessing, statistical examination of the cleaned dataset revealed significant variability in patient characteristics. Key findings include:
Morphological characteristics: the cohort had a mean age of 11.35 years, an average height of 148.07 cm, and an average weight of 43.18 kg, with notable diversity in body mass. The average BMI was 18.89 kg/m2, ranging from underweight to obesity.
Clinical scores: the average AS was 5.96 and the PAS was 5.27, suggesting moderate appendicitis risk. Scores in this range typically indicate that further diagnostic studies may be necessary, as scores between 5 and 8 are inconclusive, while scores of 1 to 4 are usually negative, and scores of 9 to 10 are diagnostic of appendicitis.
Physical examination and laboratory tests: average body temperature was 37.41 °C, with some unusually low readings affecting the distribution. The mean WBC count was 12.70 × 109/L and the mean neutrophil percentage was 71.82%, reflecting typical inflammatory responses. CRP (a substance produced by the liver in response to inflammation; elevated levels of CRP indicate an ongoing inflammatory response, which is common in appendicitis) levels had a high right skew with a mean of 31.58 mg/L, indicating a mix of low and high values, consistent with inflammatory conditions.
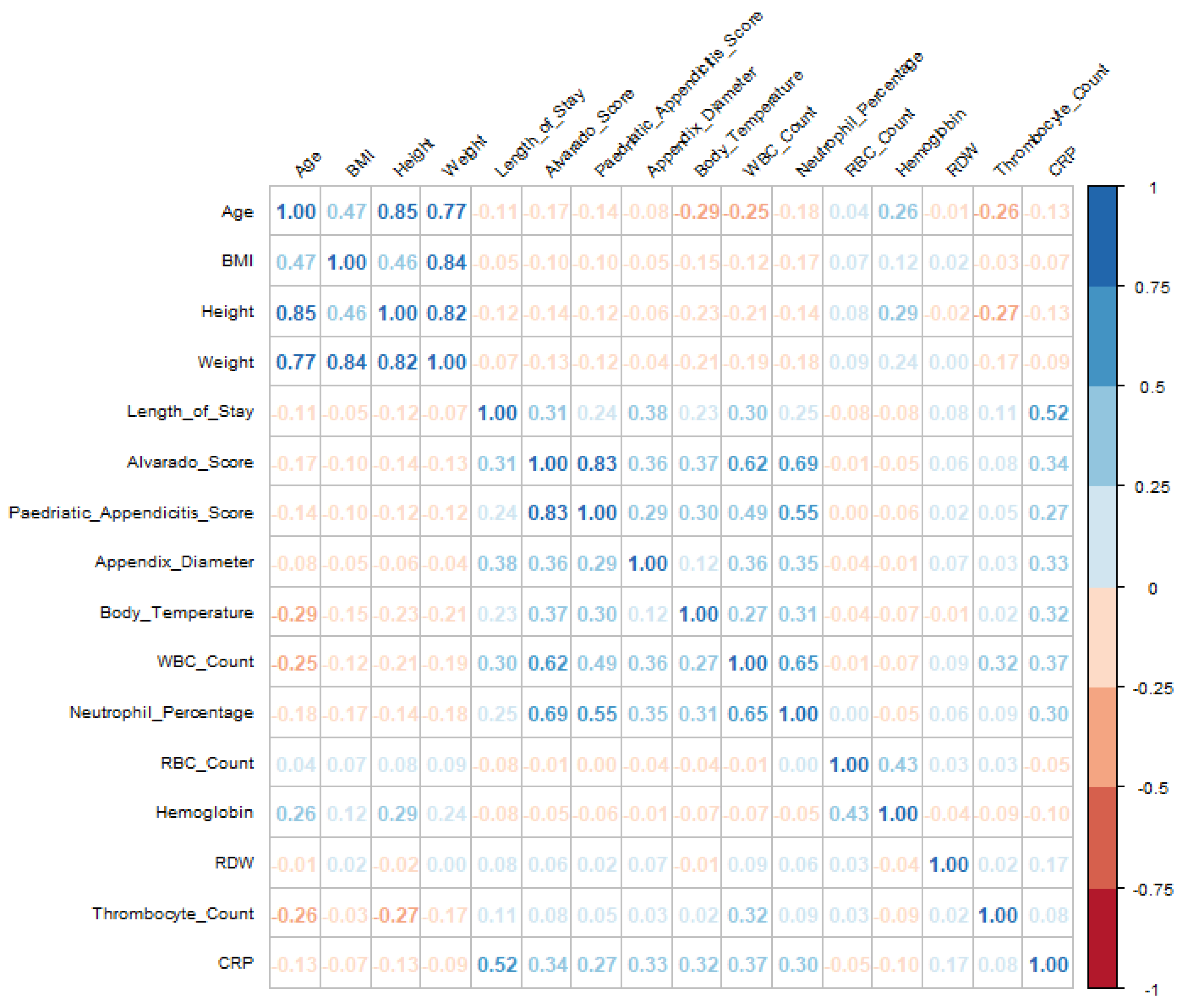
Visualizations, including boxplots and correlation matrices, provided valuable insights into the relationships among key variables, as shown in
Figure 1. Before imputation, high missingness limited our ability to analyze relationships among clinical scores, growth metrics, and inflammation markers. However, after preprocessing, the correlation matrix revealed clearer patterns, particularly among growth metrics and age, and between inflammation markers and clinical scores, supporting analyses related to hospital stays and patient outcomes. Notably, correlations between unrelated variables remained low (≤0.40), indicating that imputation preserved authentic variable relationships without inflating associations.
For instance, CRP initially showed a moderate positive correlation with length of stay (0.42), suggesting that higher CRP levels may be associated with longer hospitalizations. Similarly, body temperature demonstrated moderate correlations with both CRP (0.26) and neutrophil percentage (0.28), potentially indicating a link with inflammation. Post-imputation, these relationships were strengthened: the correlation between CRP and length of stay increased to 0.52, while body temperature’s correlations with CRP and neutrophil percentage rose to 0.32 and 0.31, respectively. This enhancement highlights the effectiveness of imputation in improving data reliability, thereby revealing clearer associations among these variables.
4.2. Exploratory Data Analysis
In the exploratory data analysis (EDA) phase, we thoroughly investigated the distributions and interrelationships of key target variables, as depicted by
Figure 2. Data were meticulously prepared and visualized using ggplot2 for data visualization, along with dplyr and tidyr for data manipulation, ensuring that actionable insights could be extracted. The analysis revealed that appendicitis was the predominant diagnosis, with 59.5% of patients confirmed to have the condition. Moreover, 61.8% of these cases were managed conservatively, reflecting a significant preference for non-surgical interventions. Severity analysis highlighted that 84.8% of appendicitis cases were classified as uncomplicated, underscoring the effectiveness of conservative management in these scenarios.
Patients diagnosed with appendicitis exhibited significantly higher clinical scores (median AS = 7, PAS = 6) compared with those without the condition (median AS = 5, PAS = 4), demonstrating the effectiveness of these diagnostic tools. Additionally, infection indicators such as WBC count (White Blood Cell, a standard measure in blood tests to check for infections or inflammation) and CRP levels were elevated in appendicitis cases (median WBC count = /L, CRP = 16.0 mg/L), indicating a strong inflammatory response. Further analysis of management strategies revealed that primary surgical management was associated with the highest clinical scores (median AS = 8, PAS = 7) and inflammatory indicators. Patients undergoing surgery also exhibited a higher prevalence of symptoms, such as lower right abdominal pain and nausea, compared with those managed conservatively. This suggests that more severe cases were appropriately triaged to surgical intervention, ensuring targeted and effective care. Finally, severity analysis showed that complicated appendicitis cases had higher median values for clinical scores (median AS = 8, PAS = 6), further validating the diagnostic scoring systems employed.
In summary, the EDA provided critical insights into the dataset, reinforcing the diagnostic utility of clinical scoring systems and highlighting key factors that influence management strategies, which will inform subsequent phases of this study.
4.3. Variable Selection
In this section, we employ several advanced techniques for feature selection and model interpretability, including Recursive Feature Elimination (RFE), Local Interpretable Model-agnostic Explanations (LIME), Shapley Additive Explanations (SHAPs), and Global Feature Explainability models such as RF and GBM. These methods collectively offer a comprehensive view of feature relevance, enhancing both model performance and interpretability.
4.4. Recursive Feature Elimination
RFE is a robust feature selection technique that iteratively fits a model and eliminates the least important features based on model coefficients or importance scores until the optimal subset of features is identified. This process enhances model accuracy and interpretability by reducing the feature space and mitigating the risk of overfitting. The RFE process involves two key steps:
- 1.
Filtering out incomplete cases: ensuring that only complete data are used for model training.
- 2.
Defining a cross-validation strategy: a 10-fold cross-validation approach is implemented to balance bias and variance using the refined dataset, which includes 792 observations and 39 variables after handling missing data and feature selection.
In the 10-fold cross-validation strategy, the dataset is randomly partitioned into 10 equal subsets. The model is trained using 9 of these folds (the training set), and the model’s performance is evaluated on the remaining 1 subset (the validation set). This process is repeated 10 times, with each fold serving as the validation set once, ensuring more reliable performance estimates.
The performance of the RFE process is evaluated using two metrics: accuracy and Cohen’s Kappa.
Diagnosis model: the model’s performance improved with the number of features, reaching optimal results with 19 features. It achieved an accuracy of 96.93% and a Kappa value of 0.9363. The most influential features include appendix diameter, appendix on US, length of stay, Diagnosis Presumptive, and peritonitis.
Management model: the optimal performance was achieved with 31 features, resulting in an accuracy of 91.95% and a Kappa value of 0.8340. Key features for distinguishing between management strategies include length of stay, appendix diameter, peritonitis, CRP, and neutrophil percentage.
Severity model: the model performed best with 11 features, attaining an accuracy of 93.60% and a Kappa value of 0.7416. The most critical features are length of stay, CRP, and WBC count, with neutrophil percentage and appendix diameter also playing significant roles.
Following feature selection, we used 19 features for the Diagnosis model, 31 features for the Management model, and 11 features for the Severity model. These selections were made based on Recursive Feature Elimination (RFE) to optimize predictive performance.
In summary, a larger number of features generally enhanced model accuracy and Kappa value for Diagnosis and Management, reflecting the complexity of these tasks. Conversely, the Severity model could be accurately predicted with fewer features, highlighting its more focused nature.
4.5. Local Feature Explainability
Local feature explainability methods provide insights into individual predictions by focusing on specific instances rather than the overall model. This subsection explores two prominent techniques: the Local Interpretable Model-agnostic Explanations (LIME) and Shapley Additive Explanations (SHAPs).
Datasets optimized through RFE were used to train RF models, ensuring explanations were based on the most relevant features.
The optimal number of trees for each target variable was determined by evaluating out-of-bag (OOB) error rates. Here are the findings:
Diagnosis model: with 450 trees, the model achieved an impressive OOB error rate of 3.45%, indicating high accuracy in distinguishing between appendicitis and non-appendicitis cases.
Management model: using 750 trees, this model had an OOB error rate of 7.93%. While effective at classifying common management strategies, it struggled with less frequent categories such as secondary surgical management, leading to higher error rates.
Severity model: employing 650 trees, this model attained a 6.27% OOB error rate, showing strong performance in identifying uncomplicated cases but facing challenges with complex cases.
LIME and SHAP were integrated with RF models using a custom model wrapper that supports prediction and model type identification, facilitating interpretable explanations:
LIME: provides local explanations by perturbing the input data and fitting a simple, interpretable model to these variations. This approach is useful for understanding individual predictions, such as those for specific patient cases.
SHAP: offers a theoretically grounded method for evaluating feature importance through Shapley values. It attributes contributions by considering all possible feature combinations, providing both local and global explanations.
While LIME and SHAP enhance interpretability, interpreting their results can be challenging, especially when explanations deviate from clinical expectations. Despite high performance metrics, individual case explanations might not always align with broader patterns, highlighting the need for generalizability and caution against data artifacts.
4.6. Global Feature Explainability
To complement insights from RFE, LIME, and SHAP, we performed a global feature importance analysis using RF and GBM, as per
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8. These techniques offer a comprehensive view of which features most significantly impact model performance across the entire dataset.
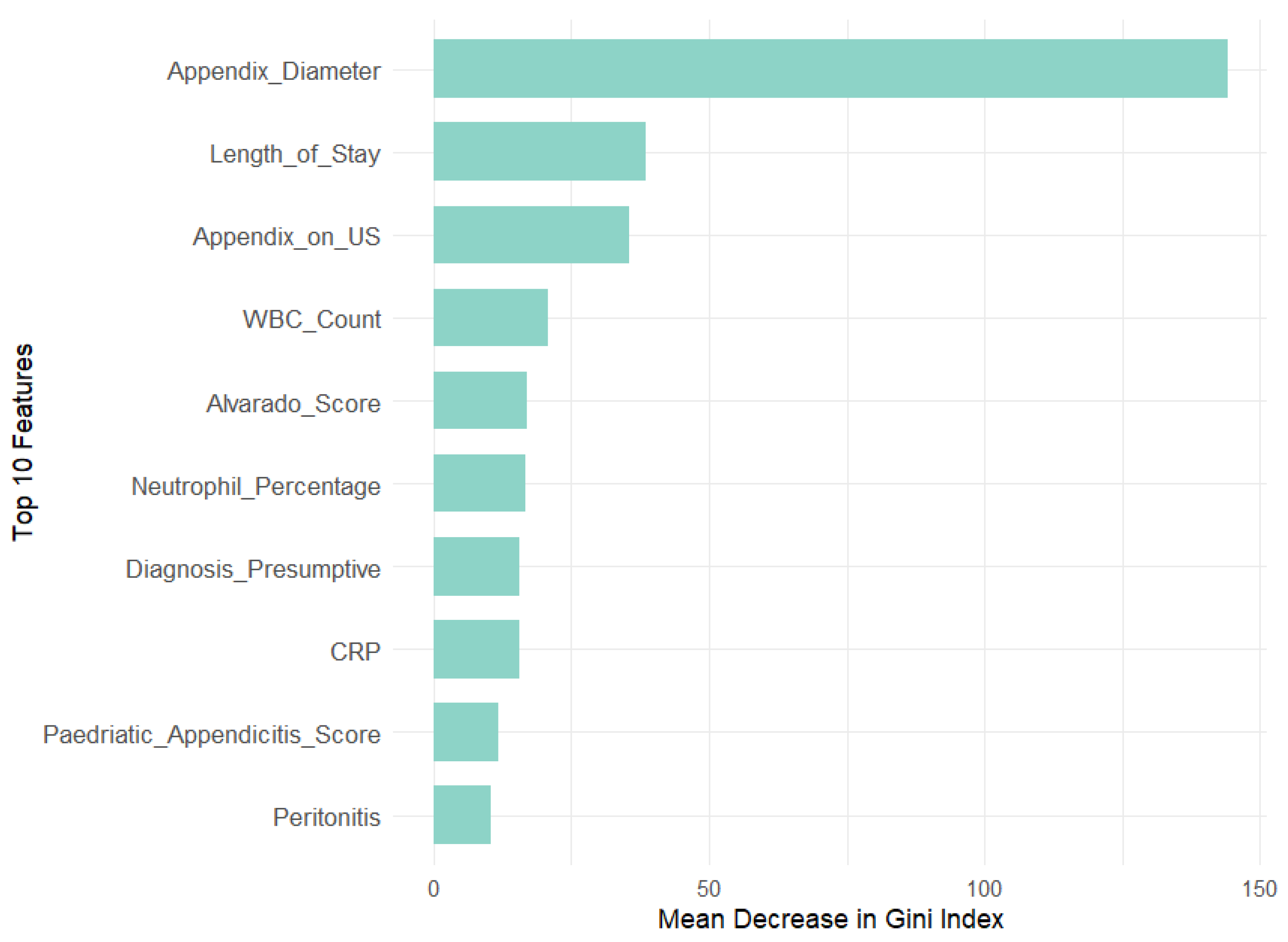
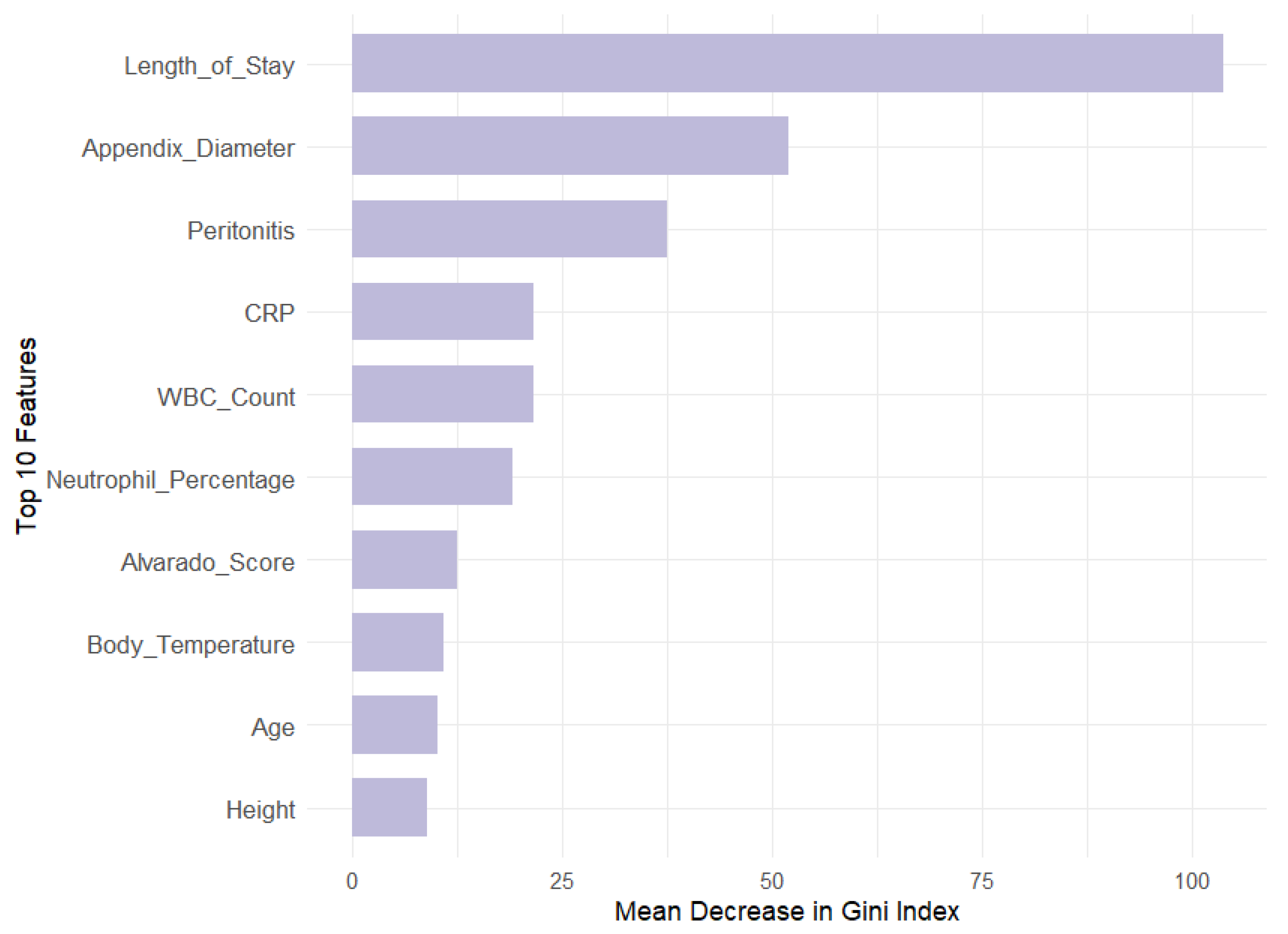
RF evaluates feature importance using the Mean Decrease in Gini (MDG), which quantifies how much a feature reduces uncertainty or impurity in the model’s predictions.
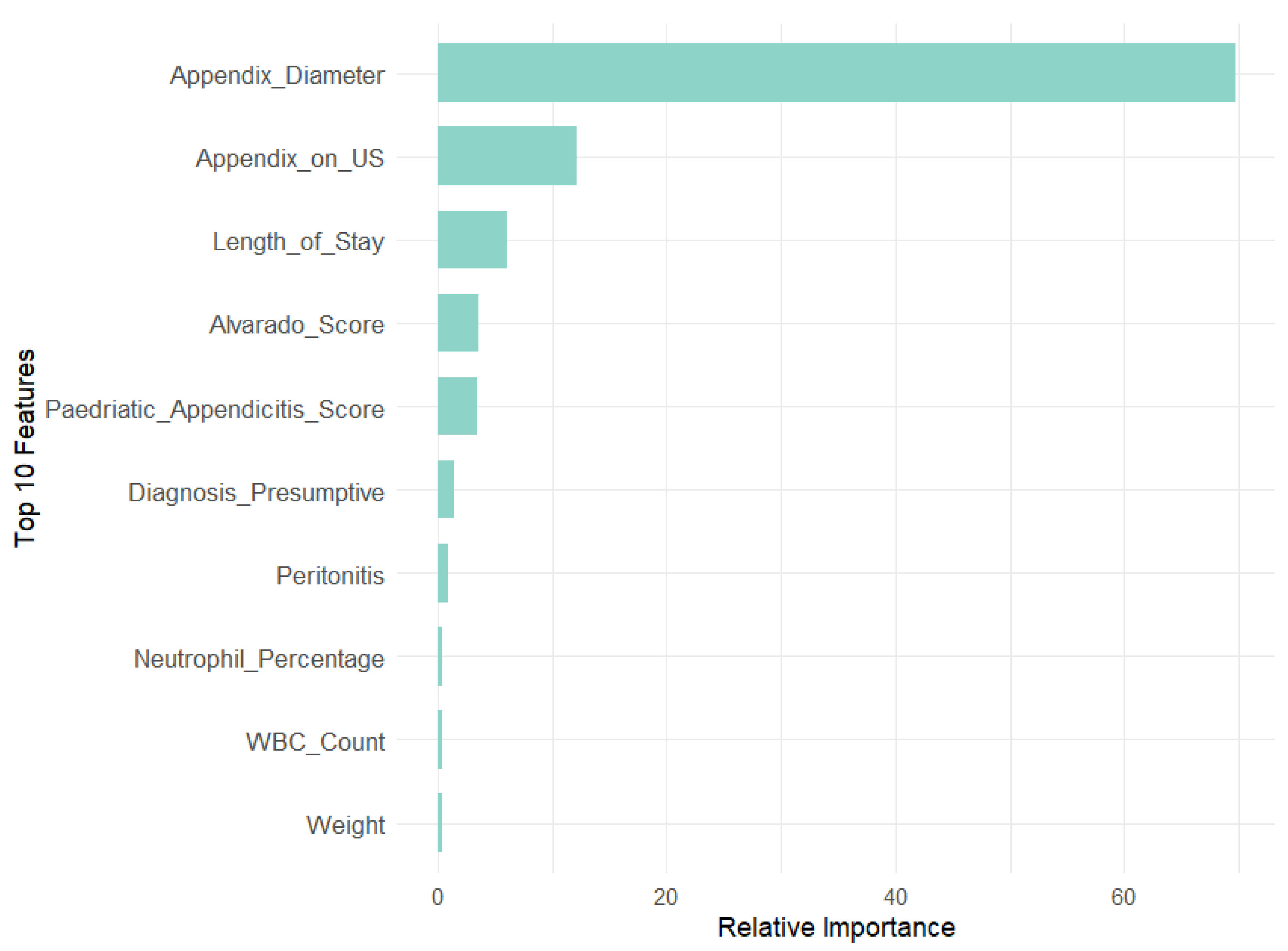
GBM captures complex interactions between features and assesses feature importance based on their cumulative contribution across all boosting rounds, evaluated through relative importance (RI).
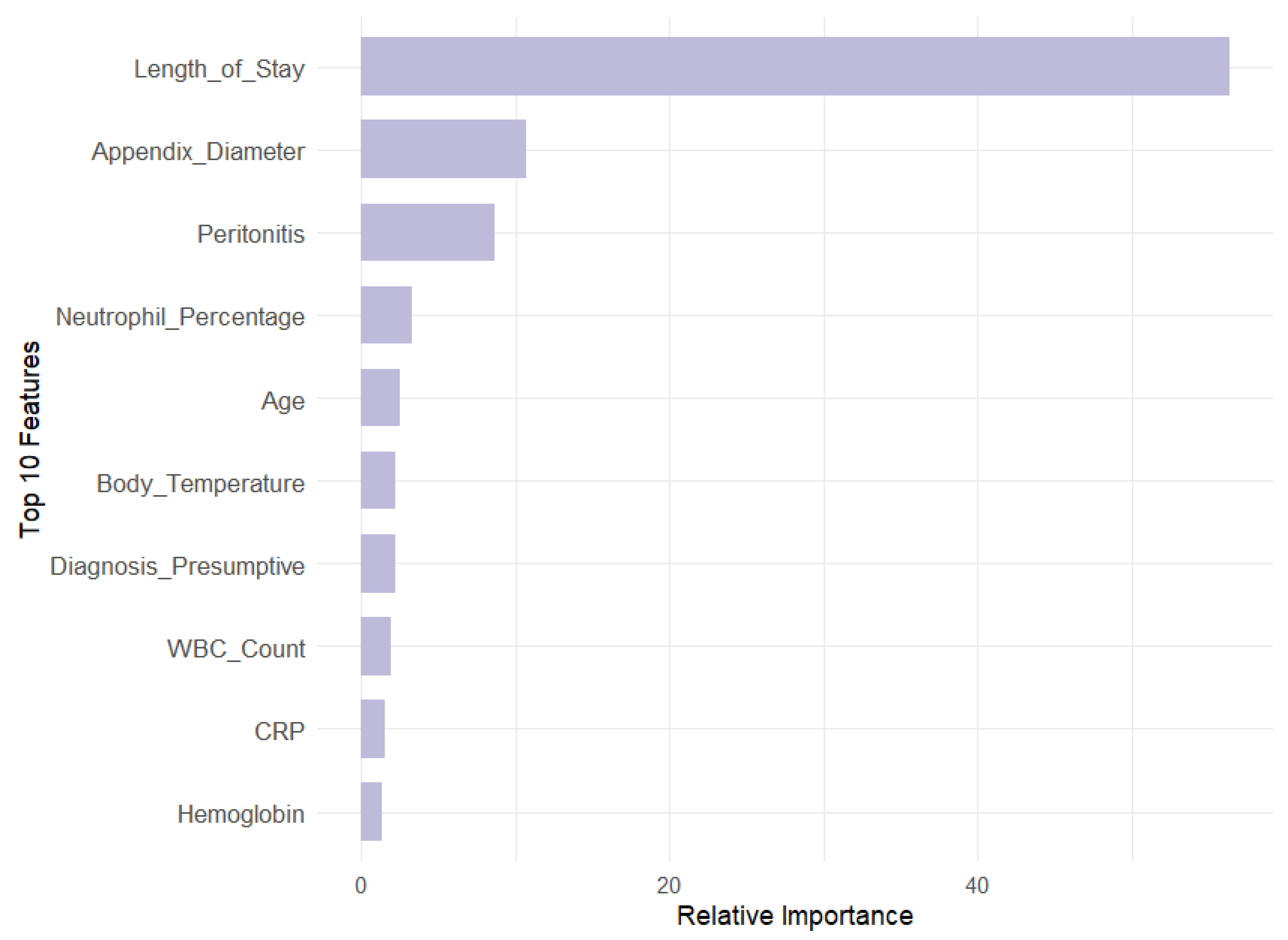
Our analysis revealed that appendix diameter is the most influential feature across all target variables in both models. It showed the highest Mean Decrease in Gini (147.71) and a substantial relative importance (69.73) for the Diagnosis target. Length of stay is also a significant predictor for Management (MDG = 104.79, RI = 55.44) and Severity (MDG = 74.34, RI = 57.83). In contrast, features like WBC count and neutrophil percentage are prominent in RF across all targets but exhibit lower relative importance in GBM, especially for Diagnosis (RI = 0.46 and 0.48, respectively). This suggests that GBM may underemphasize these features compared with RF. Additionally, peritonitis is moderately important in RF for Management (MDG = 38.31) but less significant in GBM (RI = 8.64).
Overall, RF highlights a broader range of important features, while gradient boosting machines focus on fewer features with higher relative importance. This contrast underscores the complementary strengths of these models: RF provides a wider array of significant predictors, whereas GBM emphasizes a few key variables with greater impact.
4.7. Models Parameters
Table 1 summarizes the key parameters used for each model. For logistic regression, no explicit hyperparameter tuning was required as the model was used with its default settings. In the case of random forest, the number of trees (‘ntree’) was set to 100 to strike a balance between performance and computational efficiency, while the number of features per split (‘mtry’) followed the standard heuristic of the square root of the total number of features. For XGBoost, the tree depth (‘max_depth’) was fixed at six to prevent overfitting while maintaining sufficient model complexity, and the learning rate (‘eta’) was set to 0.1 to ensure stable convergence. The number of boosting rounds (‘nrounds’) was determined through cross-validation, selecting a value of 100 based on optimal performance. For the Multilayer Perceptron, the number of hidden units (‘size’) was set to five after testing different values to prevent overfitting while preserving expressiveness, and the regularization weight (‘decay’) was introduced to improve generalization. The maximum number of iterations (‘maxit’) was set to 200 to allow sufficient training without excessive computational cost. These choices were informed by prior research, standard heuristics, and empirical evaluation, ensuring a trade-off between accuracy, interpretability, and efficiency.
The choice of models in the experiments reflects a well-considered approach to addressing the complexities of diagnosing pediatric appendicitis, given the need for both predictive accuracy and interpretability. LR was chosen as a foundational model due to its simplicity and effectiveness in binary classification problems, particularly in healthcare contexts where model interpretability is crucial. LR allows for clear insights into the influence of individual predictors, which is useful for clinicians needing to understand the relationship between clinical features and appendicitis diagnosis.
RFs were included because they offer a robust ensemble approach, capable of capturing complex relationships between features without overfitting, which is critical when dealing with potentially noisy medical data. The RF algorithm is particularly well-suited for datasets with many features, as it can handle high-dimensional spaces efficiently and produce reliable predictions. Moreover, the use of feature importance scores from the RF model adds another layer of interpretability, allowing the identification of the most relevant predictors for diagnosing appendicitis.
The inclusion of XGBoost demonstrates a commitment to maximizing predictive performance. XGBoost has become a popular model in ML due to its ability to handle a wide range of data types and its effectiveness in boosting weak learners to create strong, accurate models. In the context of this study, XGBoost was selected for its ability to optimize performance through hyperparameters such as learning rate and tree depth, making it particularly useful for refining predictions in a complex clinical dataset where nuanced decision boundaries are needed to differentiate between cases.
MLPs are known for their ability to model highly non-linear relationships, which may exist in complex medical datasets. While MLPs are often less interpretable than other models like LR or RFs, their capacity for handling intricate patterns in data makes them valuable in cases where traditional models may fall short. In this study, the MLP was employed to assess whether techniques based on neural networks could further enhance diagnostic precision, particularly in instances where other models might struggle to capture complex interactions between clinical features.
Other models could have been considered. However, they were ultimately not chosen due to various limitations that made them less suitable for the task at hand. For instance, Support Vector Machines (SVMs) are known for their robust performance in classification tasks, especially when dealing with complex boundaries between classes. While SVMs work well with smaller datasets and can handle non-linear relationships through kernel functions, they can be difficult to interpret, which is a crucial factor in clinical settings where the transparency of the decision-making process is valued. The need to balance interpretability with predictive power meant that SVM was not ideal for this study.
4.8. Model Train and Evaluation
This section details the process of preparing the dataset for model training and evaluation, focusing on feature selection, data splitting, and model optimization.
Data preparation involved encoding categorical variables as binary targets, ensuring consistent factor levels between training and testing sets, and defining feature subsets based on their relevance to the prediction task.
Key features identified through Recursive Feature Elimination (RFE) were organized into specific subsets, including Demographic and Morphological variables, Clinical Scoring and Historical features, Laboratory Tests and Imaging variables, Clinical Symptoms and Physical Observations features, and a Literature-Based group that incorporated insights from recent studies. After the feature selection process, the Diagnosis model included 19 features, the Management model used 31 features, and the Severity model was trained with 11 features. The models deployed were LR, RF, XGB, and MLP, and each model was trained with these tailored feature subsets for the specific target variables.
The models’ performance was assessed using confusion matrices, ROC curves, and AUC scores, providing a detailed analysis of their effectiveness. LR served as a baseline model due to its simplicity and interpretability, while RF and XGB offered greater power for capturing non-linear relationships and complex feature interactions. MLPs were tested for their ability to further improve performance through advanced pattern recognition. An SVM model was also evaluated but ultimately removed from the experiments due to issues with handling factor levels for the Management target.
Our findings demonstrated high AUC, accuracy, sensitivity, and specificity across these models, indicating that they effectively captured patterns in the data and met the project’s analytical goals. Key performance metrics from the experiments underscored the robustness of these algorithms, which successfully addressed the complexities of our clinical dataset and managed the mixed data types effectively. Given the success of these models, we concluded that additional, newer algorithms were unlikely to add substantial performance improvements without complicating interpretability.
We also observed that feature selection significantly impacted model performance across the different targets. For Diagnosis and Management, a larger feature set (19 and 31, respectively) contributed to greater model accuracy (96.93% and 91.95%) and Kappa values (0.9363 and 0.8340), aligning with the complexity of these tasks. Conversely, Severity was accurately predicted with a more focused subset of 11 variables, reflecting the specialized nature of this classification. This targeted approach to feature selection effectively optimized model performance, balancing accuracy and interpretability across all tasks.
To further validate the feature selection process, we compared the MDG and RI scores of excluded versus retained features, particularly metabolic and environmental factors. Results consistently showed lower importance scores for excluded features, reinforcing the robustness of our RFE-driven selection process. For the Diagnosis target, high-impact variables like appendix diameter (MDG = 147.71, RI = 69.73) greatly outperformed metabolic factors like WBC count (MDG = 20.66, RI = 0.46) and neutrophil percentage (MDG = 15.26, RI = 0.48), as well as environmental factors like age (MDG = 9.93, RI = 0.37) and BMI (MDG = 9.27, RI = 0.14). In the Management target, length of stay (MDG = 104.79, RI = 56.44) and appendix diameter (MDG = 51.22, RI = 10.75) similarly outweighed metabolic predictors like hemoglobin (MDG = 8.14, RI = 1.32) and environmental ones like body temperature (MDG = 11.02, RI = 0.25). Lastly, for Severity, dominant features such as length of stay (MDG = 74.34, RI = 57.83) and CRP (MDG = 34.10, RI = 14.45) far surpassed BMI (MDG = 10.40, RI = 3.01) and weight (MDG = 9.05, RI = 1.89).
These findings confirm that excluded metabolic and environmental factors have minimal impact on predictive accuracy, ensuring that retained variables represent the most critical predictors.
4.9. Model Comparison by Target Variable
The performance of the selected ML models was compared across three target variables, as shown in
Figure 9. The analysis involved extracting and evaluating key metrics, including AUC, accuracy, sensitivity, and specificity, across various feature subsets to identify the most effective combinations for each target.
For the Diagnosis target, LR, RF, and XGBoost models demonstrated superior discriminative power when using Laboratory and Imaging features, with AUCs reaching up to 0.9868 and accuracies around 94%. In contrast, models based on Demographic and Morphological features consistently underperformed, with AUCs as low as 0.5131 and accuracies just above 50%. MLPs further underscored the effectiveness of Laboratory and Imaging, and Literature-derived features in accurate diagnosis.
In the Management context, Clinical Symptoms and Observations, along with Literature-Based features, achieved the highest predictive accuracy across all models, with AUCs ranging from 0.9434 to 0.9596 and accuracies close to 90%. These features enabled robust discrimination between conservative and surgical management approaches. While Laboratory and Imaging features also performed well, with AUCs around 0.877 and accuracies of 80–83%, they were slightly less effective compared with the top-performing subsets. Demographic and Morphological features exhibited poor discriminative power, with AUCs between 0.4962 and 0.5867.
For Severity classification, models performed best using Literature-Based and Clinical Symptoms and Observations features, achieving near-perfect AUCs of 0.9986 and demonstrating strong sensitivity and specificity. LR, RF, XGBoost, and MLPs all highlighted these features as critical for accurate severity prediction. Conversely, Demographic and Morphological features were notably less effective, yielding AUCs as low as 0.4642, underscoring their limited utility in distinguishing severe from non-severe cases.
Overall, Laboratory and Imaging and Literature-Based feature sets consistently outperformed others across all three target variables, demonstrating their robustness and reliability. In contrast, Demographic and Morphological features consistently underperformed across all targets. The Clinical Symptoms and Observations feature set produced moderate to strong results depending on the target variable, reinforcing the need for careful feature selection in optimizing model performance.
4.10. Model Comparison by Model Type
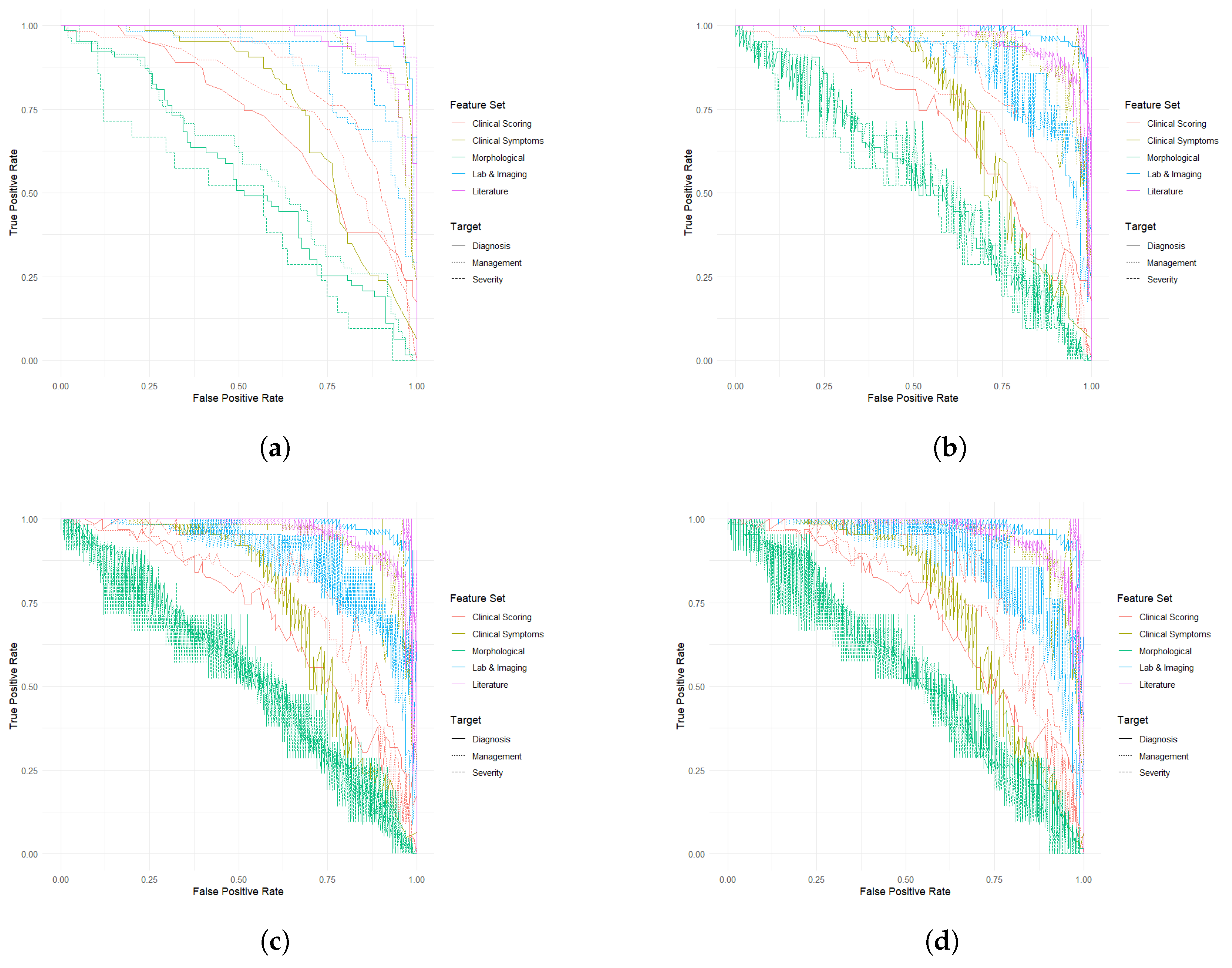
To thoroughly evaluate the performance of different ML models, as per
Figure 10, we compared their effectiveness across three target variables using different feature subsets, as depicted in
Figure 11. Key metrics, including AUC, accuracy, sensitivity, and specificity, were analyzed to determine the most effective feature combinations for each target.
For the Diagnosis target, all models exhibited superior performance with the Laboratory and Imaging and Literature-Based feature sets. LR and XGBoost reported similar AUC values for Laboratory and Imaging features (0.9862) and Literature features (0.9652), with RF also favoring these sets but with slightly different values (0.9868 and 0.9712, respectively). MLPs showed the highest AUCs for Laboratory and Imaging (0.9862) and Literature-Based features (0.9652). In contrast, models based on Demographic and Morphological features consistently underperformed, with the lowest AUC (0.5472) and accuracy (59.62%).
For Management, Clinical Symptoms and Observations and Literature-Based feature sets were notably effective across all models. LR and XGBoost achieved high AUCs of 0.9457 and 0.9585, respectively, for these feature sets. Similarly, RF ranked these features highly, though with slightly lower AUCs (0.9353 and 0.9596). The Demographic and Morphological feature set consistently performed poorly, reflecting its limited utility in predicting management strategies.
When predicting Severity, Literature-Based and Clinical Symptoms and Observations feature sets achieved the highest performance across all models. MLPs and XGBoost reported exceptional results for Literature-Based features, with AUCs of 0.9986 and 0.9965, respectively. LR and RF showed strong performance but with slightly lower AUC values compared with XGBoost and MLPs. Consistent with other targets, Demographic and Morphological features produced weaker results, particularly in distinguishing between severity levels.
One of the critical aspects of developing machine learning models for clinical applications is the careful selection of appropriate algorithms. In this study, we prioritized models that are well-suited for structured clinical data, including logistic regression (LR), random forest (RF), gradient boosting machines (GBMs), and Multilayer Perceptrons (MLPs). These models were chosen based on their ability to handle structured tabular data, their interpretability, and their established performance in medical decision support tasks.
The use of deep learning architectures such as Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs) was considered; however, such models typically require significantly larger datasets with high-dimensional features, such as imaging or sequential data, to generalize effectively. Given that our dataset consists primarily of structured clinical variables rather than unstructured data, deep learning models were not the primary focus of this study. Moreover, deep architectures often demand extensive hyperparameter tuning and increased computational resources, which may not be optimal for real-time clinical decision support in resource-limited settings.
Support Vector Machines (SVMs) were also considered due to their strong theoretical foundation in high-dimensional classification problems. However, in preliminary experiments, SVMs exhibited computational inefficiencies, particularly with larger sample sizes and feature-rich datasets. Additionally, tree-based ensemble models such as RF and GBM provided superior interpretability, an essential factor in clinical decision-making, allowing the identification of key predictive features contributing to diagnostic accuracy.
The selection of machine learning models is ultimately guided by the trade-off between predictive performance, interpretability, and computational feasibility. The findings of this study reinforce the suitability of ensemble learning methods for structured clinical data while acknowledging the potential for deep learning in more complex, multi-modal datasets.
Another key aspect of this study was the rigorous feature selection process, which ensured that only the most relevant predictors were included in the machine learning models. However, as with any data-driven approach, preprocessing decisions, such as handling missing values, can introduce potential biases that warrant careful consideration. Missing data were handled using established imputation techniques, including mean imputation for continuous variables and mode imputation for categorical variables when appropriate. While these methods prevent data loss and allow for the inclusion of a larger sample size, they also assume that missingness is random (Missing Completely at Random, MCAR), which may not always hold in clinical datasets. If certain variables have systematic missingness (e.g., laboratory test results not being recorded for milder cases), the imputation strategy could introduce bias, particularly by underrepresenting specific patient subgroups. Another critical preprocessing step was outlier detection and removal, which helps improve model robustness but may also lead to the exclusion of rare but clinically significant cases. For example, extreme values in laboratory markers could correspond to severe cases of appendicitis, and their removal could influence model sensitivity in detecting such cases. To mitigate these potential biases, we performed sensitivity analyses, comparing model performance with and without imputed values to assess the impact of missing data handling. The results indicated that, while imputation slightly affected individual feature importance rankings, overall model performance remained stable, suggesting that the selected imputation strategy did not substantially alter the predictive capabilities of the models.
A further challenge consists of the interpretability of complex models such as random forest, XGBoost, and Multilayer Perceptron, which, despite their high predictive power, often function as black-box systems. Clinicians require transparent decision-making processes to trust and effectively utilize ML-based recommendations. To address this, future research should focus on integrating explainability techniques to provide insights into how these models weigh different clinical features.
Another significant challenge is the deployment of ML models into hospital systems. Electronic Health Records (EHR) systems vary across institutions, requiring seamless integration of ML models to ensure real-time decision support without disrupting clinical workflows. Technical barriers such as data standardization, interoperability between different EHR platforms, and computational infrastructure requirements must be addressed before these models can be effectively implemented in a clinical setting.
Additionally, the success of ML applications in healthcare depends not only on technical feasibility but also on clinical adoption and training. Many healthcare professionals may be unfamiliar with ML-based decision support tools, necessitating targeted training programs to improve their understanding of model predictions and limitations. Without adequate training, there is a risk of either over-reliance on ML outputs or outright rejection due to skepticism. Future implementations should consider collaborative frameworks between data scientists and clinicians to ensure usability, trust, and proper interpretation of ML-driven insights.
Finally, ethical and regulatory considerations must be taken into account, particularly regarding model validation, patient data privacy, and liability in ML-assisted decision-making. Regulatory bodies require robust validation studies before ML models can be deployed in routine practice, emphasizing the need for multicenter external validation to ensure fairness, safety, and efficacy across diverse patient populations.
5. Conclusions and Future Work
This work addressed the diagnostic challenges of pediatric appendicitis through the application of machine learning (ML) techniques to enhance both diagnostic accuracy and patient management. Pediatric appendicitis is complex to diagnose due to age-related symptom variations, communication barriers, and the absence of standardized diagnostic guidelines, especially for children under five. These factors, coupled with non-specific symptoms in younger children and females, often result in misdiagnoses, delayed treatments, and unnecessary surgical interventions.
Our findings demonstrated that ML algorithms—including logistic regression (LR), random forest (RF), XGBoost, and Multilayer Perceptron (MLP)—achieved high AUC and accuracy values, confirming their robustness and reliability. Consistent with clinical expectations, key symptoms such as neutrophilia, nausea, loss of appetite, coughing pain, and migratory pain, along with established literature-based features like the Alvarado Score, Pediatric Appendicitis Score, appendix diameter, C-reactive protein, and White Blood Cell count emerged as the most effective predictors across all targets. In contrast, demographic and morphological factors such as age, height, weight, and BMI were less predictive, reinforcing the clinical perspective that symptomatology and specific biomarkers provide more direct diagnostic insights compared with general physical characteristics.
The main contribution of this work is demonstrating how ML can complement clinical decision-making by providing precise, data-driven insights into pediatric appendicitis. This approach has the potential to reduce negative appendectomies, improve diagnostic precision, and inform treatment strategies, ultimately leading to better patient outcomes.
However, several limitations need to be addressed in future research. One key challenge is the incomplete nature of the dataset, particularly regarding ultrasound imaging and laboratory results, which may affect model performance and predictive accuracy. To improve model robustness, future research should focus on collecting more comprehensive, high-quality clinical and imaging data.
A critical next step is the external validation of the proposed models. While the models performed well on the current dataset, generalizability must be confirmed by validating them on independent datasets from diverse clinical settings. This would ensure that the models maintain their predictive accuracy across varying patient populations and institutional protocols. Moreover, multicenter validation studies would help mitigate biases introduced by a single data source. Future research should also explore domain adaptation techniques to fine-tune the models for different clinical environments while maintaining diagnostic accuracy. Additionally, interpretability remains a challenge for complex ML models such as RF and XGBoost. Although these models achieved high predictive accuracy, their complexity can hinder adoption in clinical practice. Future efforts should aim to improve model transparency using explainability tools such as SHAPs (Shapley Additive Explanations) and LIME (Local Interpretable Model-Agnostic Explanations) to facilitate their integration into clinical workflows.
Lastly, exploring novel predictors, such as emerging biomarkers, genetic information, and detailed patient histories, may further enhance diagnostic accuracy, particularly in atypical cases. Future research should also investigate the ethical implications of ML-driven diagnostics, ensuring that AI applications in pediatric healthcare remain transparent, equitable, and aligned with clinical standards.
By addressing these challenges, future studies can advance the reliability and applicability of ML models in pediatric appendicitis diagnosis, paving the way for AI-assisted decision support tools that optimize patient care.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}