
A Complete EDA and DL Pipeline for Softwarized 5G Network Intrusion Detection


Abstract

1. Introduction
- Apply exploratory data analysis techniques to better understand the considered dataset’s characteristics.
- Propose a complete DL pipeline for softwarized 5G network intrusion detection.
- Evaluate the performance of the different algorithms and compare them to other literature works.
2. Related Work
2.1. General ML-Based Security Works
2.2. ML-Based 5G Network Security Works
3. Proposed Approach
3.1. Description
- (1)
- Data Preprocessing Module: The first module of the framework is the “data preprocessing” module. It aims to adequately prepare the input data in such a manner that it maximizes the performance of the subsequent modules. It consists of three steps, namely “data cleaning”, “data encoding”, and “data normalization”.
- (a)
- Data Cleaning: The first step of data preprocessing is data cleaning. Data cleaning refers to the process of “fixing systematic problems or errors in messy data” [41]. The goal is that the quality of data is improved so that the underlying ML and DL models built upon the data are also of high quality [42]. This process consists of two main steps, error detection and error repair [41,42]. In this work, two main data cleaning techniques are used, namely feature deletion and mean/mode replacement (a statistical technique) [43]. More specifically, features that have a high correlation between missing values and the output label are deleted, as these are considered to be extraneous to the analysis. For other features with some missing values, mean/mode replacement is used. It is worth noting that, for categorical features, missing values are replaced with the mode of the feature. On the other hand, the missing values of numerical features are replaced with the mean value [43]. This is carried out to insure that numerical bias is not added by the data cleaning process when employing error repair techniques.
- (b)
- Data Encoding: The second step of data preprocessing is data encoding. This refers to the process of transforming data/features from one format into another. Typically, this is performed to transform categorical features into numerical or integer features. In this work, two different data encoding techniques are used. The first is “one-hot encoding”, which is used for the input categorical features [44]. This technique adds a new feature column for every potential value of an input feature using a binary indicator (i.e., either 0 or 1) to represent if the value matches the category or not [44]. The second technique is “label encoding”, which is used for the output categorical target label feature [45]. In this case, the target label value is assigned a higher integer if it appears more often, as this reflects the importance and probability of an attack. Therefore, this combination of data encoding insures that regular categorical input features, in which the order of the values is not essential, are represented adequately, without leading the underlying ML/DL algorithm to misinterpret their importance (through using one-hot encoding), while simultaneously guaranteeing that the order is accounted for in the output target label encoding (through label encoding).
- (c)
- Data Normalization: The third step of data preprocessing is data normalization. This refers to the process of scaling the features so that they have similar ranges [46]. This is performed to ensure that the ML/DL models trained are not biased to particular features, due to them having differing magnitudes in their values. To that end, this work proposed using a custom hybrid data normalization, to ensure consistent scaling of the features and consequently facilitating the convergence of the underlying ML/DL models. More specifically, this work proposed using “min-max normalization” for one-hot encoded features and “Z-score normalization” for regular numerical features (which often follow a Gaussian distribution [47]).In the case of “min-max normalization”, the scaled features can be calculated as follows [46]:where for data point X, is the original value of feature i, is the scaled value of the feature, is the minimum of the feature, and is the maximum value for the feature among the data points. As a result, all the min-max normalized features have a unified scale between 0 and 1 [46].In the case of “Z-score normalization”, the scaled features can be calculated as follows [46]:where for data point X, is the original value of feature i, is the scaled value of the feature, is the mean, and is the standard deviation of feature i. As a result, all the z-score normalized features have a unified scale with zero mean and unit standard deviation [46].
- (2)
- Feature Selection Module: The second module of the framework is the “feature selection” module. It aims to select important features, with the goal of reducing the computational complexity of the overall framework. The importance of this module is amplified by the presence of the data encoding step (specifically the one-hot encoding) in the previous module. To that end, the “mutual information” feature selection technique is considered in this work.
- (a)
- Mutual Information: Mutual information feature selection is the process of selecting the features that provide the highest amount of information for the output target label. Mutual information is defined as “the amount of information that a random variable contains in another random variable” [48]. In this case, the mutual information (referred to as ) between each of the input features and the output target label is calculated using the following equation [48]:where is the joint probability density function, and and are the marginal probability density functions of variables X (in this case one of the input features) and Y (in this case the output target label). The benefit of using mutual information feature selection is threefold [49]. The first is that it is not constrained by real-valued random variables, as it computes both the joint distribution and the marginal distribution [49]. This means it can deal with both continuous (numerical) and discrete data (numerical or categorical) [50]. This is crucial in this case, since all the features are either discrete numerical or categorical features. Thus, calculation of the mutual information score is easily applied. The second benefit is that it is capable of measuring both linear and non-linear relationships, which is also essential in such environments where many of the features exhibit non-linear behavior [49]. The third advantage is that this technique ensures invariability to any reversible and differentiable data transformations, which is also important given some of the techniques employed, such as data encoding [49]. Thus, mutual information feature selection is suitable for the application and the type of data observed in this work, as there are no scenarios that could pose difficulties for its implementation.
- (3)
- DL-based Intrusion Detection Module: The third module of the framework is the “DL-based intrusion detection” module. This module focuses on using three different types of DL models for softwarized 5G network intrusion detection, namely “dense autoencoder neural network”, “convolutional neural network”, and “recurrent neural network” models.
- (a)
- Dense Autoencoder Neural Network Model: The first DL model is the dense autoencoder neural network model. This model uses an autoencoder to enhance a dense neural network (DNN) model. An autoencoder is a type of unsupervised deep learning model that uses a combination of backpropagation and compression to reconstruct an output as accurately as possible [51,52]. It allows for an accurate latent representation of the original features, while minimizing the effects of linearity [51,52]. On the other hand, a DNN is a fully connected supervised learning neural network model, in which each neuron in each layer is connected to every other neuron in previous and subsequent layers [53]. The autoencoder component is used for feature extraction, while the DNN component learns the characteristics for accurate prediction. Hence, this model leverages the power of DL to learn complex patterns and representations from the input data, while reducing its dimensionality, thereby improving the computational efficiency and generalization performance.
- (b)
- Convolutional Neural Network Model: The second DL model considered is the convolutional neural network (CNN) model. CNNs are a type of feedforward neural network that can extract features using convolution operations [54,55]. Convolution operations are basically an inner product computation between the weight vector and the vectorized version of the input feature set of the previous layer in the neural network architecture [56]. The advantage of CNNs compared to other deep neural network models are threefold, namely allowing for local connections, which eliminates the need for a fully connected architecture; facilitating weight sharing, which reduces the number of parameters to be determined; and achieving dimensionality reduction by using a pooling layer to reduce the amount of data needed, while retaining useful information [54,55,56]. This makes them a reliable and attractive option for many applications and fields.
- (c)
- Recurrent Neural Network Model: The third DL model considered is the recurrent neural network (RNN) model. RNNs are a feedforward neural network architecture with at least one feedback loop [57,58]. The goal is to achieve some form of “memory” regarding the learning process [57,58]. Consequently, RNNs are able to perform “temporal processing” and “learn sequences”, i.e., they are capable of dealing with time-sequence data and can identify patterns that repeat over time [57,58]. This represents an advantage over other DL-based models and architectures, as they are able to not just learn patterns within a data sample, but also across several sequential data samples [59]. This makes them suitable for a variety of applications, such as natural language process, audio and video data processing, stock prediction, and cybersecurity [60].
3.2. Computational Complexity
4. Dataset Description, Exploration, and Discussion
4.1. General Description
4.2. Data Pre-Processing
4.2.1. Data Cleaning
4.2.2. Data Encoding
4.2.3. Data Normalization
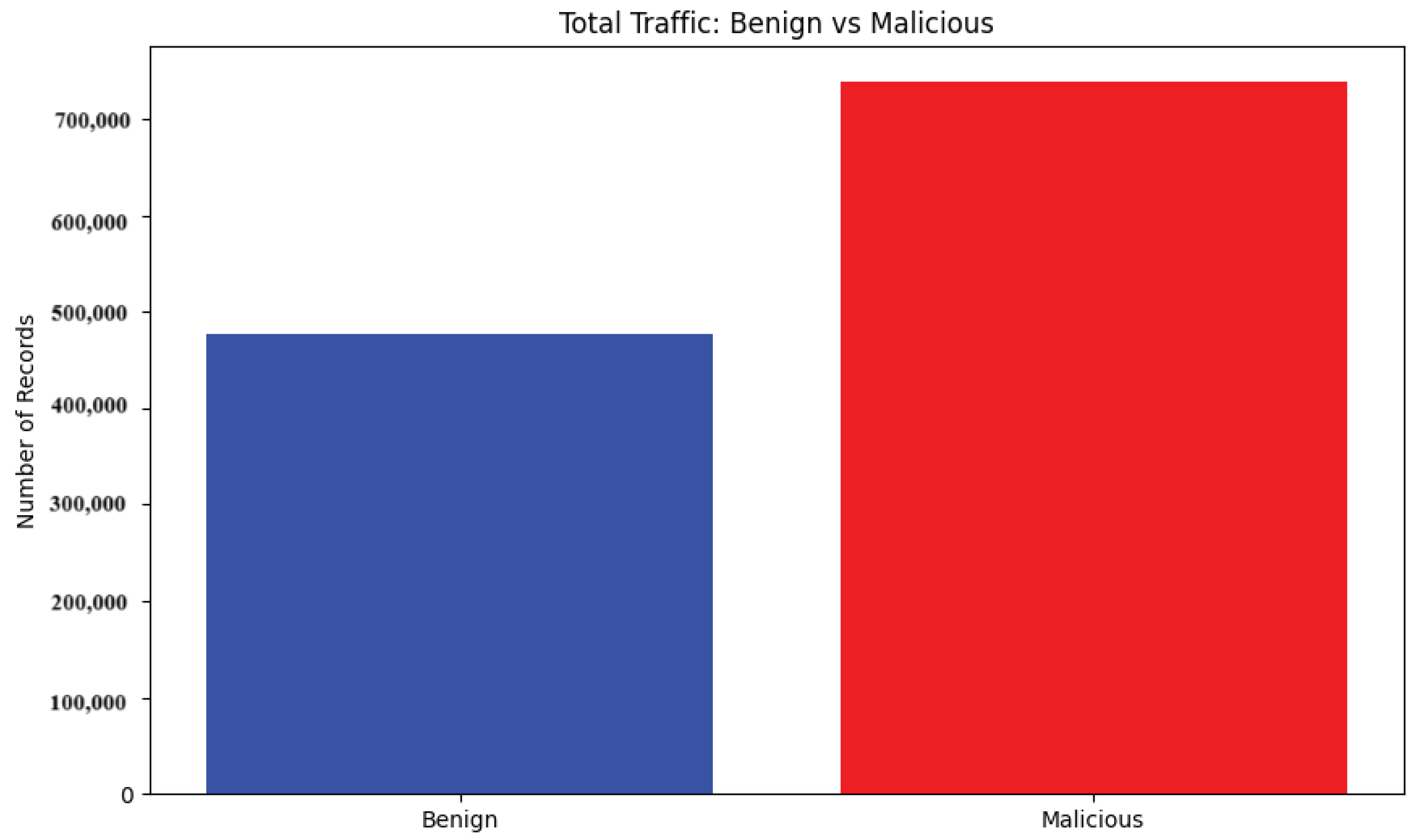
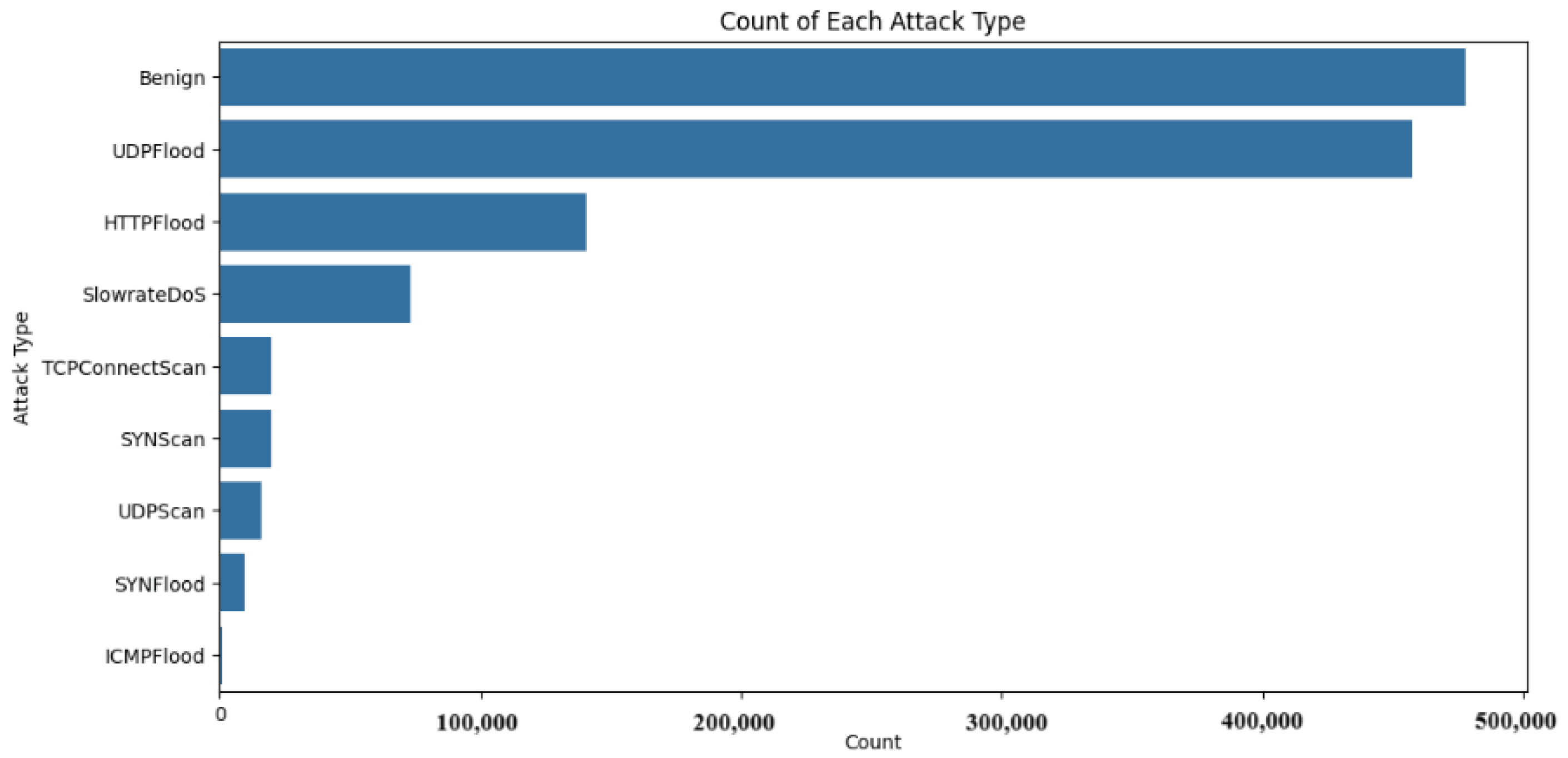
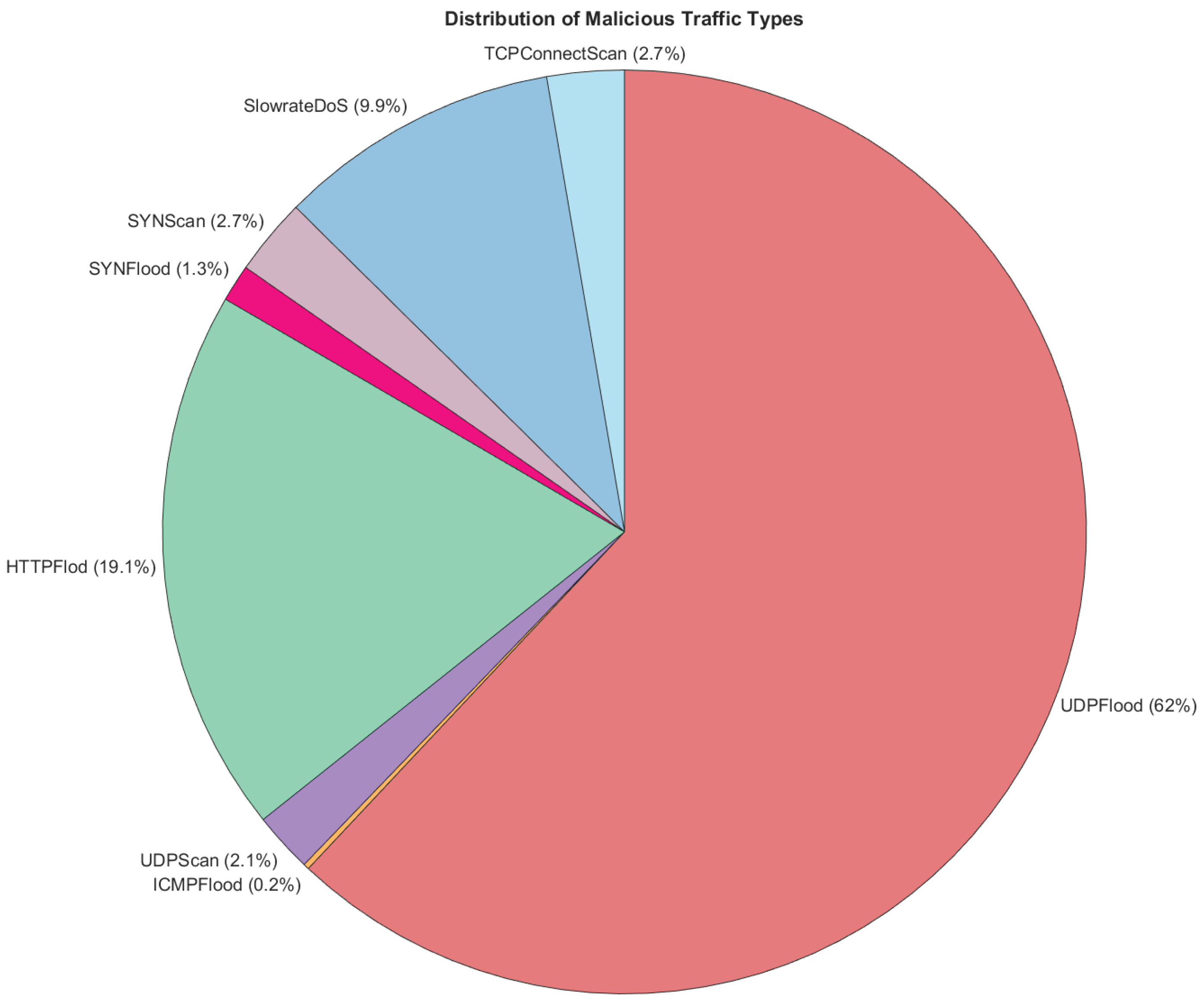
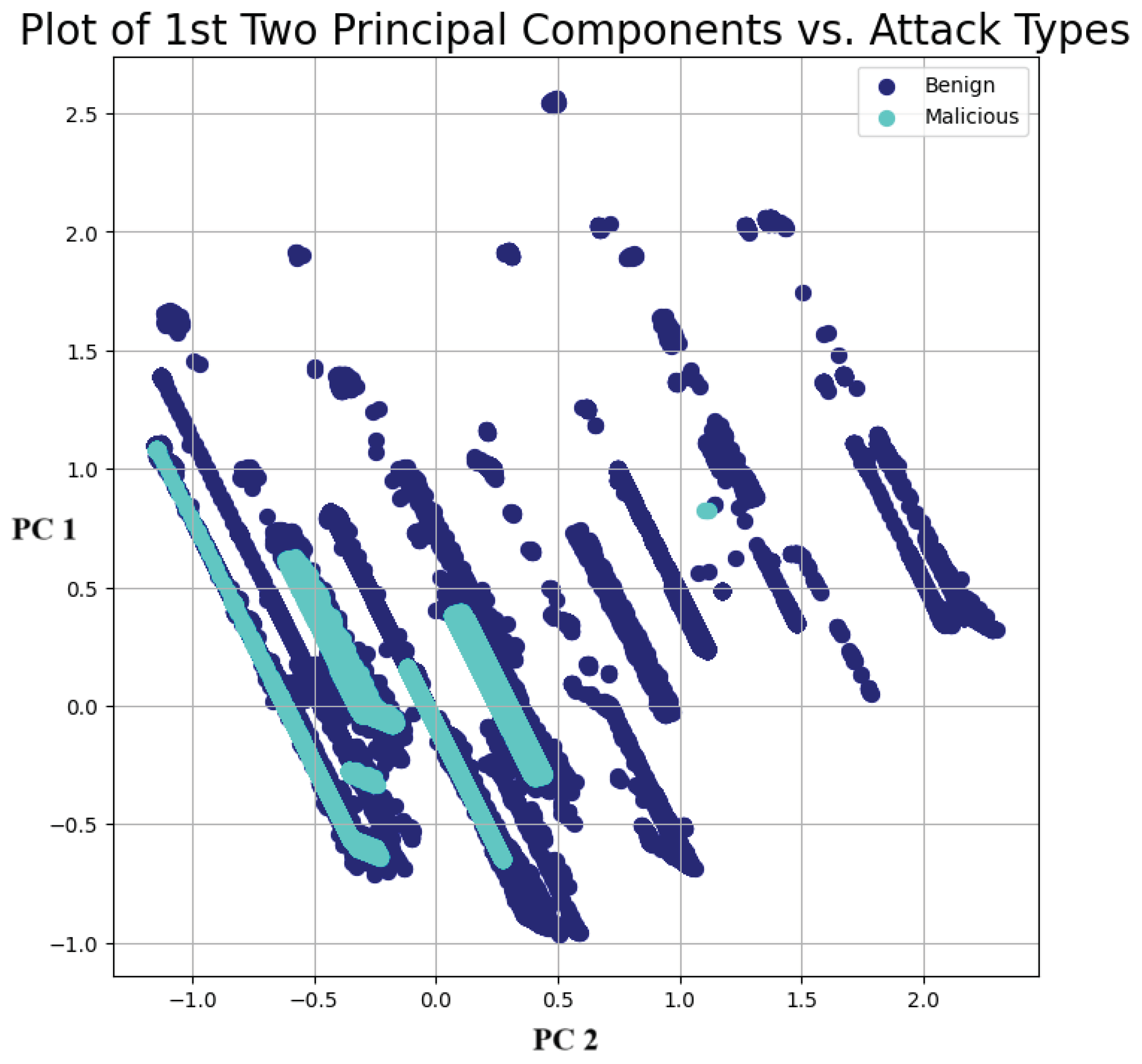
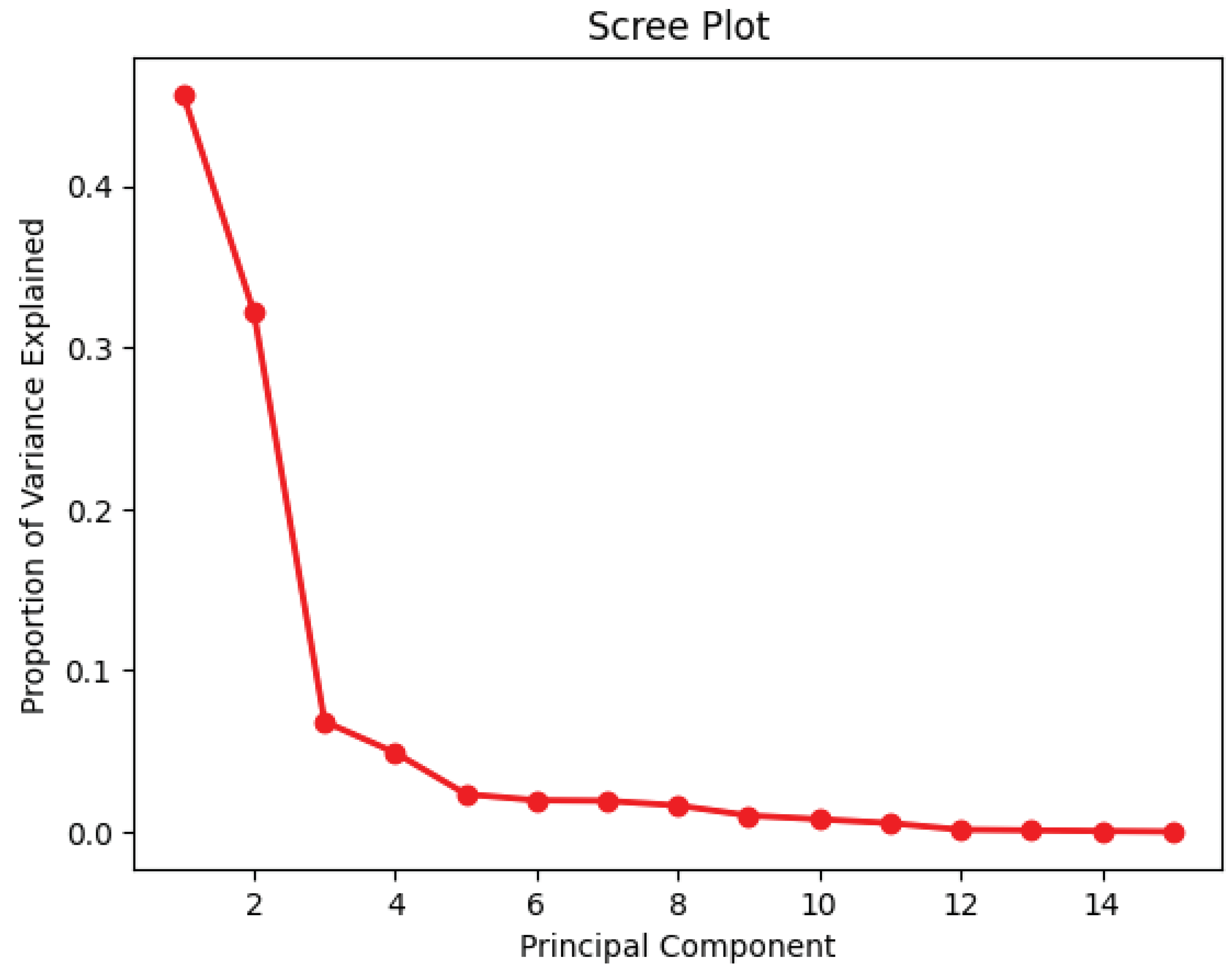
4.3. Exploratory Data Analysis Discussion
5. Experimental Results and Discussion
5.1. Experiment Setup
5.2. Performance Metrics
5.3. DL Architecture Implementations
5.3.1. Dense Autoencoder Neural Network Architecture
5.3.2. Convolutional Neural Network Architecture
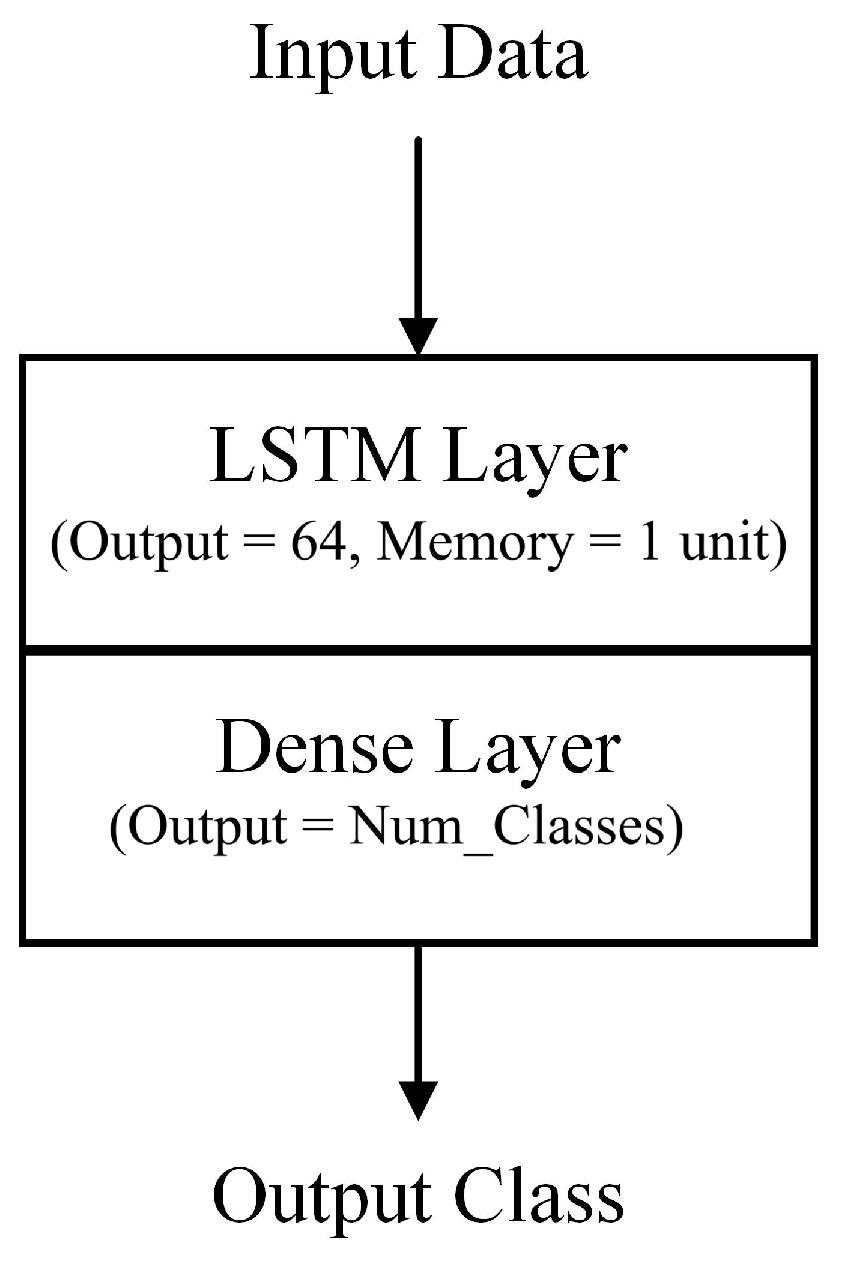
5.3.3. Recurrent Neural Network Architecture
5.4. DL-Based Framework’s Results and Discussion
5.4.1. Binary Classification Scenario
5.4.2. Multi-Class Classification Scenario
6. Conclusions and Future Works
Funding
Data Availability Statement
Conflicts of Interest
References
- Moubayed, A.; Javadtalab, A.; Hemmati, M.; You, Y.; Shami, A. Traffic-Aware OTN-over-WDM Optimization in 5G Networks. In Proceedings of the 2022 IEEE International Mediterranean Conference on Communications and Networking (MeditCom), Athens, Greece, 5–8 September 2022; pp. 184–190. [Google Scholar] [CrossRef]
- Moubayed, A.; Manias, D.M.; Javadtalab, A.; Hemmati, M.; You, Y.; Shami, A. OTN-over-WDM optimization in 5G networks: Key challenges and innovation opportunities. Photonic Netw. Commun. 2023, 45, 49–66. [Google Scholar] [CrossRef]
- International Telecommunication Union. Measuring Digital Development: Facts and Figures 2020; Technical report; International Telecommunication Union: Geneva, Switzerland, 2020. [Google Scholar]
- International Telecommunication Union. Setting the Scene for 5G: Opportunities & Challenges; Technical report; International Telecommunication Union: Geneva, Switzerland, 2018. [Google Scholar]
- Feldmann, A.; Gasser, O.; Lichtblau, F.; Pujol, E.; Poese, I.; Dietzel, C.; Wagner, D.; Wichtlhuber, M.; Tapiador, J.; Vallina-Rodriguez, N.; et al. A year in lockdown: How the waves of COVID-19 impact internet traffic. Commun. ACM 2021, 64, 101–108. [Google Scholar] [CrossRef]
- The World Bank. How COVID-19 Increased Data Consumption and Highlighted the Digital Divide; Technical report; The World Bank: Washington, DC, USA, 2021. [Google Scholar]
- Taylor, P. Monthly Internet Traffic in the U.S. 2018–2023; Technical report; Statista: New York, NY, USA, 2023. [Google Scholar]
- Condoluci, M.; Mahmoodi, T. Softwarization and virtualization in 5G mobile networks: Benefits, trends and challenges. Comput. Netw. 2018, 146, 65–84. [Google Scholar] [CrossRef]
- Lake, D.; Wang, N.; Tafazolli, R.; Samuel, L. Softwarization of 5G networks–Implications to open platforms and standardizations. IEEE Access 2021, 9, 88902–88930. [Google Scholar] [CrossRef]
- Doffman, Z. Cyberattacks on IOT Devices Surge 300% in 2019, ‘Measured in Billions’ Report Claims. Forbes, 14 September 2019. [Google Scholar]
- Lefebvre, M.; Nair, S.; Engels, D.W.; Horne, D. Building a Software Defined Perimeter (SDP) for Network Introspection. In Proceedings of the 2021 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Heraklion, Greece, 9–11 November 2021; pp. 91–95. [Google Scholar] [CrossRef]
- Hindy, H.; Brosset, D.; Bayne, E.; Seeam, A.K.; Tachtatzis, C.; Atkinson, R.; Bellekens, X. A Taxonomy of Network Threats and the Effect of Current Datasets on Intrusion Detection Systems. IEEE Access 2020, 8, 104650–104675. [Google Scholar] [CrossRef]
- Nti, I.K.; Narko-Boateng, O.; Adekoya, A.F.; Somanathan, A.R. Stacknet Based Decision Fusion Classifier for Network Intrusion Detection. Int. Arab. J. Inf. Technol. 2022, 19, 478–490. [Google Scholar]
- Muthiya, D.E.R. Design and Implementation of Crypt Analysis of Cloud Data Intrusion Management System. Int. Arab. J. Inf. Technol. 2020, 17, 895–905. [Google Scholar]
- Ghazal, T.M.; Hasan, M.K.; Abdullah, S.N.H.S.; Bakar, K.A.A.; Al-Dmour, N.A.; Said, R.A.; Abdellatif, T.M.; Moubayed, A.; Alzoubi, H.M.; Alshurideh, M.; et al. Machine Learning-Based Intrusion Detection Approaches for Secured Internet of Things. In The Effect of Information Technology on Business and Marketing Intelligence Systems; Alshurideh, M., Al Kurdi, B.H., Masa’deh, R., Alzoubi, H.M., Salloum, S., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 2013–2036. [Google Scholar] [CrossRef]
- Moubayed, A.; Aqeeli, E.; Shami, A. Detecting DNS Typo-Squatting Using Ensemble-Based Feature Selection Classification Models. IEEE Can. J. Electr. Comput. Eng. 2021, 44, 456–466. [Google Scholar] [CrossRef]
- Yang, L.; Moubayed, A.; Shami, A.; Boukhtouta, A.; Heidari, P.; Preda, S.; Brunner, R.; Migault, D.; Larabi, A. Forensic Data Analytics for Anomaly Detection in Evolving Networks. In Innovations in Digital Forensics; World Scientific: Singapore, 2023; pp. 99–137. [Google Scholar]
- Aburakhia, S.; Tayeh, T.; Myers, R.; Shami, A. A Transfer Learning Framework for Anomaly Detection Using Model of Normality. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 4–7 November 2020; pp. 55–61. [Google Scholar] [CrossRef]
- He, K.; Kim, D.D.; Asghar, M.R. Adversarial Machine Learning for Network Intrusion Detection Systems: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2023, 25, 538–566. [Google Scholar] [CrossRef]
- Vanin, P.; Newe, T.; Dhirani, L.L.; O’Connell, E.; O’Shea, D.; Lee, B.; Rao, M. A Study of Network Intrusion Detection Systems Using Artificial Intelligence/Machine Learning. Appl. Sci. 2022, 12, 1752. [Google Scholar] [CrossRef]
- Manderna, A.; Kumar, S.; Dohare, U.; Aljaidi, M.; Kaiwartya, O.; Lloret, J. Vehicular network intrusion detection using a cascaded deep learning approach with multi-variant metaheuristic. Sensors 2023, 23, 8772. [Google Scholar] [CrossRef] [PubMed]
- Maseer, Z.K.; Yusof, R.; Bahaman, N.; Mostafa, S.A.; Foozy, C.F.M. Benchmarking of Machine Learning for Anomaly Based Intrusion Detection Systems in the CICIDS2017 Dataset. IEEE Access 2021, 9, 22351–22370. [Google Scholar] [CrossRef]
- Alamleh, A.; Albahri, O.; Zaidan, A.; Albahri, A.; Alamoodi, A.; Zaidan, B.; Qahtan, S.; Alsatar, H.; Al-Samarraay, M.S.; Jasim, A.N. Federated learning for IoMT applications: A standardization and benchmarking framework of intrusion detection systems. IEEE J. Biomed. Health Inform. 2022, 27, 878–887. [Google Scholar] [CrossRef] [PubMed]
- Injadat, M.; Salo, F.; Nassif, A.B.; Essex, A.; Shami, A. Bayesian Optimization with Machine Learning Algorithms Towards Anomaly Detection. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar] [CrossRef]
- Musa, U.S.; Chhabra, M.; Ali, A.; Kaur, M. Intrusion Detection System using Machine Learning Techniques: A Review. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; pp. 149–155. [Google Scholar] [CrossRef]
- Yang, L.; Moubayed, A.; Shami, A.; Heidari, P.; Boukhtouta, A.; Larabi, A.; Brunner, R.; Preda, S.; Migault, D. Multi-Perspective Content Delivery Networks Security Framework Using Optimized Unsupervised Anomaly Detection. IEEE Trans. Netw. Serv. Manag. 2022, 19, 686–705. [Google Scholar] [CrossRef]
- Alzahrani, A.O.; Alenazi, M.J. Designing a network intrusion detection system based on machine learning for software defined networks. Future Internet 2021, 13, 111. [Google Scholar] [CrossRef]
- Salo, F.; Injadat, M.; Moubayed, A.; Nassif, A.B.; Essex, A. Clustering Enabled Classification using Ensemble Feature Selection for Intrusion Detection. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 276–281. [Google Scholar]
- You, X.; Zhang, C.; Tan, X.; Jin, S.; Wu, H. AI for 5G: Research directions and paradigms. Sci. China Inf. Sci. 2019, 62, 1–13. [Google Scholar] [CrossRef]
- Afaq, A.; Haider, N.; Baig, M.Z.; Khan, K.S.; Imran, M.; Razzak, I. Machine learning for 5G security: Architecture, recent advances, and challenges. Ad Hoc Netw. 2021, 123, 102667. [Google Scholar] [CrossRef]
- Park, J.H.; Rathore, S.; Singh, S.K.; Salim, M.M.; Azzaoui, A.; Kim, T.W.; Pan, Y.; Park, J.H. A comprehensive survey on core technologies and services for 5G security: Taxonomies, issues, and solutions. Hum.-Centric Comput. Inf. Sci 2021, 11, 2–22. [Google Scholar]
- Fang, H.; Wang, X.; Tomasin, S. Machine learning for intelligent authentication in 5G and beyond wireless networks. IEEE Wirel. Commun. 2019, 26, 55–61. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Erpek, T.; Shi, Y. Adversarial machine learning for 5G communications security. Game Theory Mach. Learn. Cyber Secur. 2021, 270–288. [Google Scholar]
- Usama, M.; Ilahi, I.; Qadir, J.; Mitra, R.N.; Marina, M.K. Examining machine learning for 5G and beyond through an adversarial lens. IEEE Internet Comput. 2021, 25, 26–34. [Google Scholar] [CrossRef]
- Suomalainen, J.; Juhola, A.; Shahabuddin, S.; Mämmelä, A.; Ahmad, I. Machine learning threatens 5G security. IEEE Access 2020, 8, 190822–190842. [Google Scholar] [CrossRef]
- Ramezanpour, K.; Jagannath, J. Intelligent zero trust architecture for 5G/6G networks: Principles, challenges, and the role of machine learning in the context of O-RAN. Comput. Netw. 2022, 217, 109358. [Google Scholar] [CrossRef]
- Alamri, H.A.; Thayananthan, V.; Yazdani, J. Machine Learning for Securing SDN based 5G network. Int. J. Comput. Appl. 2021, 174, 9–16. [Google Scholar] [CrossRef]
- Li, J.; Zhao, Z.; Li, R. Machine learning-based IDS for software-defined 5G network. IET Networks 2018, 7, 53–60. [Google Scholar] [CrossRef]
- Qu, Y.; Zhang, J.; Li, R.; Zhang, X.; Zhai, X.; Yu, S. Generative adversarial networks enhanced location privacy in 5G networks. Sci. China Inf. Sci. 2020, 63, 1–12. [Google Scholar] [CrossRef]
- Brownlee, J. Data Preparation for Machine Learning: Data Cleaning, Feature Selection, and Data Transforms in Python; Machine Learning Mastery: Vermont, VIC, Australia, 2020. [Google Scholar]
- Li, P.; Rao, X.; Blase, J.; Zhang, Y.; Chu, X.; Zhang, C. CleanML: A Study for Evaluating the Impact of Data Cleaning on ML Classification Tasks. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 13–24. [Google Scholar] [CrossRef]
- Lin, W.C.; Tsai, C.F. Missing value imputation: A review and analysis of the literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- Al-Shehari, T.; Alsowail, R.A. An insider data leakage detection using one-hot encoding, synthetic minority oversampling and machine learning techniques. Entropy 2021, 23, 1258. [Google Scholar] [CrossRef]
- Dahouda, M.K.; Joe, I. A Deep-Learned Embedding Technique for Categorical Features Encoding. IEEE Access 2021, 9, 114381–114391. [Google Scholar] [CrossRef]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Chen, J.; Wu, D.; Zhao, Y.; Sharma, N.; Blumenstein, M.; Yu, S. Fooling intrusion detection systems using adversarially autoencoder. Digit. Commun. Netw. 2021, 7, 453–460. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, X.; Zhu, R. Feature selection based on mutual information with correlation coefficient. Appl. Intell. 2022, 52, 5457–5474. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, J.; Yao, K.; Xu, M.; Cao, Y. A variable selection method based on mutual information and variance inflation factor. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 268, 120652. [Google Scholar] [CrossRef]
- Rupak, B.R., II. Mutual Information Score—Feature Selection; Medium: San Francisco, CA, USA, 2022. [Google Scholar]
- Rezvy, S.; Petridis, M.; Lasebae, A.; Zebin, T. Intrusion detection and classification with autoencoded deep neural network. In Proceedings of the International Conference on Security for Information Technology and Communications; Springer: Cham, Switzerland, 2018; pp. 142–156. [Google Scholar]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Olivares-Mercado, J.; Portillo-Portilo, J.; Avalos, J.G.; Garcia Villalba, L.J. Detecting cryptojacking web threats: An approach with autoencoders and deep dense neural networks. Appl. Sci. 2022, 12, 3234. [Google Scholar] [CrossRef]
- Mudadla, S. Deep Neural Networks vs Dense Neural Networks; Medium: San Francisco, CA, USA, 2023. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Ketkar, N.; Moolayil, J.; Ketkar, N.; Moolayil, J. Convolutional neural networks. In Deep Learning with Python: Learn Best Practices of Deep Learning Models with PyTorch; Apress: New York, NY, USA, 2021; pp. 197–242. [Google Scholar]
- Ghiasi-Shirazi, K. Generalizing the convolution operator in convolutional neural networks. Neural Process. Lett. 2019, 50, 2627–2646. [Google Scholar] [CrossRef]
- Bullinaria, J.A. Recurrent neural networks. Neural Comput. Lect. 2013, 12, 1–20. Available online: https://www.cs.bham.ac.uk/~jxb/INC/l12.pdf (accessed on 30 July 2024).
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, H.; Zhang, J.; Gao, Z.; Wang, J.; Yu, P.S.; Long, M. PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 2208–2225. [Google Scholar] [CrossRef]
- Tyagi, A.K.; Abraham, A. Recurrent Neural Networks: Concepts and Applications; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Estevez, P.A.; Tesmer, M.; Perez, C.A.; Zurada, J.M. Normalized Mutual Information Feature Selection. IEEE Trans. Neural Netw. 2009, 20, 189–201. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, M.; Horton, M.; Paneliya, H.; Kallakuri, U.; Homayoun, H.; Mohsenin, T. On the complexity reduction of dense layers from o (n2) to o (nlogn) with cyclic sparsely connected layers. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Habib, G.; Qureshi, S. Optimization and acceleration of convolutional neural networks: A survey. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 4244–4268. [Google Scholar] [CrossRef]
- Akpinar, N.J.; Kratzwald, B.; Feuerriegel, S. Sample complexity bounds for recurrent neural networks with application to combinatorial graph problems. arXiv 2019, arXiv:1901.10289. [Google Scholar]
- Samarakoon, S.; Siriwardhana, Y.; Porambage, P.; Liyanage, M.; Chang, S.Y.; Kim, J.; Kim, J.; Ylianttila, M. 5G-NIDD: A Comprehensive Network Intrusion Detection Dataset Generated over 5G Wireless Network. arXiv 2022, arXiv:2212.01298. [Google Scholar] [CrossRef]
- 5GTN. Available online: https://5gtnf.fi/ (accessed on 30 March 2024).
- Bagui, S.; Li, K. Resampling imbalanced data for network intrusion detection datasets. J. Big Data 2021, 8, 6. [Google Scholar] [CrossRef]
- Balla, A.; Habaebi, M.H.; Elsheikh, E.A.A.; Islam, M.R.; Suliman, F.M. The Effect of Dataset Imbalance on the Performance of SCADA Intrusion Detection Systems. Sensors 2023, 23, 758. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Camizuli, E.; Carranza, E.J. Exploratory data analysis (EDA). In The Encyclopedia of Archaeological Sciences; John Wiley & Sons: Hoboken, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Mukhiya, S.K.; Ahmed, U. Hands-On Exploratory Data Analysis with Python: Perform EDA Techniques to Understand, Summarize, and Investigate Your Data; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- QRATOR Labs. 2023 DDoS Attacks Statistics and Observations. 20 May 2024. Available online: https://qrator.net/blog/details/2023-ddos-attacks-statistics-and-observations (accessed on 30 July 2024).
- Sharma, A.; Rani, R. Classification of Cancerous Profiles Using Machine Learning. In Proceedings of the International Conference on Machine Learning and Data Science (MLDS’17), Noida, India, 14–15 December 2017; pp. 31–36. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|
| Dense Autoenconder Neural Network | 1.0 | 1.0 | 1.0 | 1.0 | 904 | 41 |
| Convolutional Neural Network | 0.9994 | 0.9996 | 0.9993 | 0.9995 | 864 | 83 |
| Recurrent Neural Network | 0.9981 | 0.9981 | 0.9981 | 0.9981 | 1005 | 12 |
| KNN [65] | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 61 | 8 |
| Random Forest [65] | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 59 | 8 |
| Model | Accuracy | Precision | Recall | F1-Score | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|
| Dense Autoencoder Neural Network | 0.9975 | 0.9971 | 0.9970 | 0.9970 | 1177 | 42 |
| Convolutional Neural Network | 0.9984 | 0.9984 | 0.9983 | 0.9984 | 1043 | 203 |
| Recurrent Neural Network | 0.9981 | 0.9981 | 0.9981 | 0.9981 | 1334 | 182 |
| KNN [65] | 0.9923 | 0.9923 | 0.9923 | 0.9923 | 2066 | 360 |
| Random Forest [65] | 0.9963 | 0.9963 | 0.9963 | 0.9963 | 521 | 5 |
| Model | Attack Type | Overall Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Dense Autoencoder Neural Network | Benign | 0.9975 | 0.99974 | 0.99998 | 0.99988 |
| HTTP Flood | 0.99094 | 0.99573 | 0.99334 | ||
| ICMP Flood | 0.98854 | 1.00000 | 0.99423 | ||
| SYN Flood | 0.99283 | 0.85521 | 0.91892 | ||
| SYN Scan | 0.99663 | 0.99734 | 0.99702 | ||
| Slowrate DoS | 0.99667 | 0.99733 | 0.99700 | ||
| TCP Connect Scan | 0.93626 | 0.99634 | 0.96537 | ||
| UDP Flood | 1.00000 | 1.00000 | 1.00000 | ||
| UDP Scan | 0.99706 | 0.99664 | 0.99685 | ||
| Convolutional Neural Network | Benign | 0.9984 | 0.9993 | 0.9999 | 0.9996 |
| HTTP Flood | 0.9612 | 0.9975 | 0.9790 | ||
| ICMP Flood | 0.9958 | 1.0000 | 0.9979 | ||
| SYN Flood | 0.9958 | 0.9984 | 0.9971 | ||
| SYN Scan | 0.9992 | 0.9962 | 0.9977 | ||
| Slowrate DoS | 0.9949 | 0.9907 | 0.9928 | ||
| TCP Connect Scan | 0.9968 | 0.9983 | 0.9975 | ||
| UDP Flood | 0.9999 | 0.9993 | 0.9996 | ||
| UDP Scan | 1.0000 | 0.9972 | 0.9986 | ||
| Recurrent Neural Network | Benign | 0.9981 | 0.9993 | 0.9998 | 0.9995 |
| HTTP Flood | 0.9939 | 0.9949 | 0.9944 | ||
| ICMP Flood | 0.9958 | 1.0000 | 0.9979 | ||
| SYN Flood | 0.9958 | 0.9995 | 0.9976 | ||
| SYN Scan | 0.9944 | 0.9969 | 0.9959 | ||
| Slowrate DoS | 0.9901 | 0.9890 | 0.9895 | ||
| TCP Connect Scan | 0.9978 | 0.9951 | 0.9965 | ||
| UDP Flood | 0.9998 | 0.9994 | 0.9996 | ||
| UDP Scan | 0.9987 | 0.9928 | 0.9958 | ||
| KNN [65] | Benign | 0.9923 | 1.00000 | 0.99941 | 0.99971 |
| HTTP Flood | 0.96652 | 0.97041 | 0.96846 | ||
| ICMP Flood | 1.00000 | 1.00000 | 1.00000 | ||
| SYN Flood | 0.99656 | 0.99246 | 0.99450 | ||
| SYN Scan | 0.99403 | 0.99667 | 0.99535 | ||
| Slowrate DoS | 0.93403 | 0.93582 | 0.93492 | ||
| TCP Connect Scan | 0.98946 | 0.99867 | 0.99404 | ||
| UDP Flood | 1.00000 | 1.00000 | 1.00000 | ||
| UDP Scan | 0.99958 | 0.99790 | 0.99874 | ||
| Random Forest [65] | Benign | 0.9963 | 1.00000 | 1.00000 | 1.00000 |
| HTTP Flood | 0.98157 | 0.98845 | 0.98500 | ||
| ICMP Flood | 1.00000 | 1.00000 | 1.00000 | ||
| SYN Flood | 0.99658 | 0.99863 | 0.99760 | ||
| SYN Scan | 0.99933 | 0.99601 | 0.99767 | ||
| Slowrate DoS | 0.97736 | 0.96435 | 0.97081 | ||
| TCP Connect Scan | 0.99801 | 0.99867 | 0.99834 | ||
| UDP Flood | 1.00000 | 1.00000 | 1.00000 | ||
| UDP Scan | 0.99707 | 0.99832 | 0.99770 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moubayed, A. A Complete EDA and DL Pipeline for Softwarized 5G Network Intrusion Detection. Future Internet 2024, 16, 331. https://doi.org/10.3390/fi16090331
Moubayed A. A Complete EDA and DL Pipeline for Softwarized 5G Network Intrusion Detection. Future Internet. 2024; 16(9):331. https://doi.org/10.3390/fi16090331
Chicago/Turabian StyleMoubayed, Abdallah. 2024. "A Complete EDA and DL Pipeline for Softwarized 5G Network Intrusion Detection" Future Internet 16, no. 9: 331. https://doi.org/10.3390/fi16090331
APA StyleMoubayed, A. (2024). A Complete EDA and DL Pipeline for Softwarized 5G Network Intrusion Detection. Future Internet, 16(9), 331. https://doi.org/10.3390/fi16090331