2. Background and Related Works
Recently, several studies have shed light on fairness issues [
21], including unfairness in TCP and extreme unfairness, also known as starvation. In [
18], the authors presented experimental evidence demonstrating that achieving equal bandwidth distribution among network users is challenging. Instead, users often experience unfairness or a low share of available bandwidth, with at least one user receiving extremely low or zero bandwidth. This phenomenon, known as “TCP Starvation”, is evident not only in delay-bounded congestion control algorithms but also in loss-based CCAs.
CCAs are crucial in network protocols, influencing data transmission performance and fairness. Traditionally, loss-based congestion control algorithms such as NewReno, CUBIC, and Compound TCP have been widely used. These algorithms adjust the congestion window size in response to packet loss, signaling network congestion. However, their reactive nature often leads to suboptimal performance as delay increases, posing challenges to maintaining fairness among flows [
25].
In recent years, delay-bounding congestion control algorithms have garnered attention for their ability to control network traffic delay. Unlike their loss-based counterparts, delay-bounding algorithms prioritize delay as the primary congestion indicator. This approach is particularly advantageous for real-time and interactive applications requiring low latency. Notable delay-bounding algorithms include Vegas, FAST, BBR, PCC, and Copa, each with distinct design principles and mechanisms for delay control.
2.1. TCP Fairness and ML Approaches
Inter-flow fairness, ensuring equitable distribution of network resources among competing flows, is a fundamental aspect of congestion control. However, achieving fairness poses challenges, as highlighted by recent studies. These studies identify scenarios where starvation can occur despite efforts to maintain fairness, particularly in delay-bounding congestion control algorithms. Recently proposed solutions, including reinforcement learning-based approaches that aim to optimize host CCAs and bottleneck Active Queue Management (AQM) schemes [
26], such as leveraging Deep Deterministic Policy Gradient (DDPG) [
27] and Asynchronous Advantage Actor Critic (A3C) [
28], aim to simultaneously improve throughput and ensure fairness [
19].
Network delay variations significantly impact congestion control algorithm performance and fairness among flows. Factors contributing to delay variations challenge traditional throughput and fairness models. Comparative studies of TCP congestion control mechanisms emphasize the benefits of loss-based algorithms for latency-sensitive flows and the fairness issues of delay-based algorithms [
29,
30]. Empirical evidence highlights the potential for unfairness in delay-bounding congestion control algorithms, particularly when non-congestive network delay variations exceed certain thresholds. Improved fairness and performance have been achieved through adaptive and stable delay control algorithms. These advancements aim to address issues such as bufferbloat [
31], which can lead to unfairness in network performance [
32].
Metrics for fairness evaluation play a crucial role in assessing network protocols. Throughput fairness, delay fairness, jitter fairness, and loss fairness are key metrics used to evaluate the distribution of network resources among flows. These metrics help identify potential issues and guide the development of fairer congestion control algorithms [
3].
ML and DRL frameworks for TCP offer promising avenues for improving congestion control algorithm fairness and performance. These frameworks enable the development of models that optimize network resource allocation while considering various QoE metrics. Integrating ML/DRL into congestion control algorithm selection processes can lead to more efficient and equitable network experiences [
3,
33,
34].
Traditional rule-based approaches, which employ predefined rules and logical conditions, often struggle under varying network conditions due to their lack of flexibility. Heuristic methods, while relying on rule-of-thumb strategies and practical experience, can also fall short in complex and dynamic environments because they lack the ability to adapt to real-time changes [
35]. Thus, instead of directly comparing DRL methods against these more rigid approaches, we chose to focus on a DRL-based dynamic switching mechanism. This approach leverages DRL’s ability to continually learn and adapt to varying network conditions, offering a significant advantage over static evaluation functions or less flexible methods.
2.2. Closest Works in Literature
Arun et al. [
18] highlighted that delay-bounding CCAs like Vegas, FAST, BBR, PCC, and Copa, while designed to ensure high network utilization and fairness, can lead to starvation under certain conditions, particularly when non-congestive delay variations exceed twice the equilibrium delay range. Their experiments with BBR, PCC Vivace, and Copa demonstrated that these CCAs may not effectively address inter-flow fairness in scenarios with significant delay variations, suggesting the need for CCAs to account for non-congestive jitter to prevent starvation. Similarly, Zhang et al. [
3] addressed the gap between QoS optimization and actual application needs, proposing “Floo”, a QoE-oriented mechanism that dynamically selects the most suitable CCA using reinforcement learning to improve web service performance by optimizing Request Completion Times.
Yamazaki et al. [
36] reviewed the evolution of TCP variants, emphasizing the limitations of fixed-logic approaches in dynamic network environments and highlighting the potential of adaptive solutions like QTCP, a Q-learning-based TCP, despite its fairness issues. Zhang et al. [
37] discussed the importance of congestion control mechanisms in maintaining Internet stability, noting the limitations of traditional loss-based algorithms and the advancements in algorithms like BBRv2, Vivace, Copa, and C2TCP, which aim to balance high throughput with low delays. Finally, Xiao et al. [
38] introduced “TCP-Drinc”, a DRL-based approach that addresses the shortcomings of traditional TCP variants by adjusting the congestion window size using state features, demonstrating improved throughput and delay while maintaining fairness.
2.3. Deep Reinforcement Learning in TCP
Recent research has extensively explored the application of DRL and ML techniques to address fairness and performance issues in wireless networks and TCP congestion control.
In wireless networks, DRL-based approaches have demonstrated significant potential across various scenarios. For instance, DRL has been used to improve throughput and reduce collision rates in IEEE 802.11 networks by optimizing contention window parameters [
39]. These techniques also enhance fairness and Quality of Service in wireless scheduling problems while maximizing system throughput [
40]. In wireless mesh networks, a distributed network monitoring mechanism using Q-learning has been proposed to improve TCP fairness and throughput for starved flows [
41]. Additionally, DRL-based MAC protocols have shown the ability to coexist with other MAC protocols while maximizing sum throughput or achieving proportional fairness, even without prior knowledge of the other protocols’ operating principles [
42]. These studies underscore the transformative potential of DRL in mitigating network unfairness and starvation issues across various wireless network scenarios.
Similarly, DRL and ML approaches have been applied to enhance fairness and efficiency in TCP congestion control. DRL techniques have improved fairness and performance in both single-flow and multi-flow scenarios [
19,
20]. These methods aim to optimize convergence properties such as fairness, fast convergence, and stability while maintaining high performance [
20]. Researchers have also addressed the selfish behavior of learning-based congestion control algorithms by proposing new mechanisms that enhance fairness without compromising throughput and latency [
36]. Furthermore, ML-based estimation of competing flows’ congestion control algorithms has been explored to improve per-flow fairness in environments where multiple congestion control algorithms coexist [
43]. Another DRL-based approach, TCP-Drinc [
38], has been proposed to improve traditional TCP variants by adjusting the congestion window size using extracted state features and addressing challenges like delayed feedback and multi-agent competition, showing improved throughput and delay while maintaining fairness.
Moreover, RL-based approaches that aim to optimize host CCAs and bottleneck AQM schemes [
26], such as leveraging Deep Deterministic Policy Gradient (DDPG) [
27] and Asynchronous Advantage Actor-Critic (A3C) [
28], have been proposed to simultaneously improve throughput and ensure fairness [
19].
These studies highlight the potential of ML and DRL techniques to significantly enhance fairness and efficiency in TCP congestion control across diverse network environments. Existing DRL research has primarily focused on two approaches to enhance network performance, fairness, and to prevent starvation. The first approach involves optimizing traditional rule-based CCAs’ functionality, such as the optimization of contention window parameters [
38,
39,
40], convergence properties [
20], and CCA and AQM [
27,
28]. The second approach involves designing DRL-based algorithms, such as TCP-Drinc [
38], Aurora [
44], and Astraea [
20]. These efforts have mitigated many networking problems and reduced complexities.
However, implementing DRL in TCP is not straightforward. Some approaches are only available offline [
20], require rigorous training for CCA, and demand high CPU resources, which are often lacking [
45]. Additionally, existing approaches cannot guarantee fairness among competing flows as they are still in the development phase [
46]. Despite these challenges, multiple studies have already demonstrated that DRL-based approaches are becoming increasingly promising in TCP.
Upon reviewing the existing ML-, RL-, and DRL-based approaches in TCP, we identified the need for a novel approach to further address persistent network issues. While several DRL-based TCP protocols and optimization strategies have been proposed, no prior research has explored the dynamic switching between available CCAs to enhance network performance, improve flow fairness, and prevent starvation, especially in heterogeneous environments, such as in WiFi networks. This paper introduces a DRL-based dynamic switching mechanism designed to tackle these persistent TCP issues. Our results demonstrate significant improvements in key performance metrics such as throughput, RTT, jitter, packet loss, fairness, and the prevention of throughput starvation.
Despite advancements in congestion control algorithms, several challenges remain unresolved. A comprehensive understanding of how delay-bounding algorithms adapt to non-congestive network delay variations, the thresholds and characteristics of non-congestive jitter, and the development of ML/DRL frameworks to quantify and mitigate fairness issues is essential. Addressing these gaps will advance the development of congestion control algorithms and contribute to enhanced network performance and fairness [
19].
In this study, we focused on TCP unfairness by analyzing the underlying mathematical principles, conducting real-world network tests, and dynamically switching CCAs using DRL techniques. This involved assessing current CCAs’ performance under varying network conditions and dynamically selecting the optimal CCA when significant disparities in throughput, latency, loss rate, and sending rate were observed among competing flows. To the best of our knowledge, this is the first study to investigate the dynamic switching of CCAs using DRL to improve flow performance and prevent starvation. Therefore, this research aims to contribute to the field by providing a DRL-based approach that dynamically switches CCAs based on historical network data to better understand and respond to network fluctuations, ultimately improving flow performance and preventing starvation.
3. Mathematical Interpretation of Unfairness and Starvation in Representative CCAs
Multiple TCP CCAs exist, but all have the common core philosophy of improving users’ experience in reliable data transformation. Some of the CCAs explicitly in use are Bottleneck Bandwidth and Round-trip propagation time (BBR), Performance-oriented Congestion Control (PCC) Vivace, Vegas, Copa, CUBIC, NewReno, and Reno. In this section, we aim to provide a detailed discussion of four key CCAs: BBR, PCC Vivace, CUBIC, and Copa. The exposition will elucidate the comprehensive functioning of each TCP variant, shedding light on their overall behavior and how they respond to packet loss and variations in RTT across flows.
Before moving to the detailed mathematical interpretation, we briefly explain the hypotheses formulated later in this section. Three key hypotheses are made for each selected CCA:
Equal Loss with Varying RTT: This hypothesis aims to investigate how a CCA manages flows with different RTTs when they experience the same level of packet loss. Specifically, it evaluates whether disparities in RTTs result in unequal congestion window allocation under identical loss conditions. The primary purpose is to ascertain whether variations in RTT alone can lead to unfairness in congestion window sizes across different flows.
Equal RTT with Varying Loss: In this hypothesis, the focus is on how varying levels of packet loss impact the congestion window of flows with the same RTT. It examines whether changes in packet loss lead to fairness issues or potential starvation in flows that experience identical network delays. The objective is to investigate whether packet loss alone can disrupt fairness and lead to differential treatment of flows.
Starvation Hypothesis: This hypothesis examines extreme cases of unfairness, where one flow significantly underperforms compared to another due to variations in RTT or packet loss. The aim is to assess the worst-case scenarios for fairness and evaluate how effectively the CCA prevents starvation.
“TCP Starvation” [
18] is a critical phenomenon that can significantly impact network performance and fairness. It occurs when a TCP flow with a longer RTT receives a disproportionately smaller share of bandwidth/observed ratio compared to flows with shorter RTT. This can lead to degraded throughput, increased latency, and unfair resource allocation.
TCP CUBIC performs the window growth functions in a cubic function. It sets a Maximum Window () at the point where the packet loss occurred. Then, the congestion window decreases multiplicatively. It recovers the performance quickly and enters the congestion-avoidance phase. Up to the inflection point, the window size increases in concave style. However, it adjusts the window size after the congestion is detected and maintains stabilized networks at before entering convex-style growth of the window size. Concave and convex styles of window adjustments assist CUBIC to stand out from the other existing congestion control algorithms, improving protocol and network stability by maintaining high network utilization. Improvements are possible as the window size remains stable around by forming a plateau. The detailed derivation are provided at the end of this paper. With extensive analytic modeling, we consider two cases to explain the causes of unfairness and starvation.
Case i: Considering two CUBIC flows with different RTTs,
and
, and experiencing the same loss
p, we can evaluate how the congestion windows
and
evolve as
using (
1); if
, then
, which explain the key reason for the observed unfairness.
Case ii: Considering two CUBIC flows with the same RTTs,
, and experiencing different losses,
and
, we can evaluate how the congestion windows
and
evolve:
If , then .
As we know, Starvation is an extreme case of unfairness; the two cases discussed above will have the following consequences:
Case i: If , where ;
Case ii: If , where .
PCC Vivace borrows the PCC architecture: a utility function framework and a learning rate-control algorithm and perceives both modules uniquely. This utility function rewards throughput to maximize performance and minimize latency, while it penalizes when packet loss occurs and increases latency [
14,
15]. The learning rate-control algorithm provides an opportunity for the sender to select the sending rates that allow the senders to learn their performance through statistic aggregation, such as achieved throughput, latency, and loss rate of packets. Then based on the numerical utility value, they determine the sending rate [
15]. The following equation helps to find out the utility value. With detailed derivation deferred to the
Appendix A, we consider two cases to explain the causes of unfairness and starvation.
Case i: Considering two PCC flows with different RTTs,
and
, and experiencing the same loss
p, we can evaluate how the congestion windows
and
evolve as
If , then .
Case ii: Considering two PCC flows with same RTTs,
, and experiencing different losses,
and
, we can evaluate how the congestion windows
and
evolve:
If , then .
As we know, Starvation is an extreme case of unfairness; the two cases discussed above will have the following consequences:
Case i: If
, where
Case ii: If
, where
BBR has a strong influence on congestion control, which measures the available Bottleneck Bandwidth (Btlbw) and lowest RTT [
47]. By using those measurements, BBR creates a network path model to increase the delivery rate and decrease latency [
47]. The BBR congestion control algorithm also measures the maximum delivery rate and minimum transmission delay to find Kleinrock’s optimal operating point [
48], also known as Bandwidth Delay Product (BDP). During this period, the delivery rate remains unchanged but RTT increases. With extensive mathematical modeling detailed at the end of this paper, we consider cases to explain the causes of unfairness and starvation as follows.
Case i: Considering two BBR flows with different RTTs,
and
, and experiencing the same loss
p, we can evaluate how the congestion windows
and
evolve as
Case ii: Considering BBR flows with the same RTTs,
, and experiencing different losses
and
, we can evaluate how the congestion windows
and
evolve
If , then .
As we know, Starvation is an extreme case of unfairness; the two cases discussed above will have the following consequences:
Case i: If , where
Case ii: If , where
Copa is a delay-based end-to-end congestion control mechanism. It observes the delay evolution to detect the existing buffer fillers and reacts with an additive increase/multiplicative decrease [
16]. While the detailed maths are deferred to the end of this paper, we obtain the equilibrium congestion window
as
We consider two cases to explain the causes of unfairness and starvation.
Case i: Considering two Copa flows with different RTTs,
and
, and experiencing the same loss,
p, we can evaluate how the congestion windows
and
evolve as
If , then .
Case ii: Considering Copa flows with same RTTs,
, and experiencing different losses
and
, we can evaluate how the congestion windows
and
evolve:
If , then .
As we know, Starvation is an extreme case of unfairness; the two cases discussed above will have the following consequences:
Case i: If , where
Case ii: If , where
Figure 1a highlights the possibilities of flow starvation under different TCP variants and congestion levels. An n represents the loss ratio, whereas the ratio observed by TCP flows reflects the relative bandwidth allocation among the various flows of the PCC Vivace, BBR, Copa, and CUBIC. Since n represents the loss ratio, higher n values mean more packet loss, which indicates the intensity of congestion in the network. Each pair of color-coded lines corresponds to two flows using the same TCP variants and highlights how the bandwidth ratio between those flows varies as the loss ratio increases.
In
Figure 1b, the RTT Ratio (n) quantifies the difference in Round-Trip Times between competing flows, with higher values pointing to greater disparities. As the n increases, lines for flows with longer RTT curves move downwards, indicating declining bandwidth ratios. The ratio observed by TCP flows measures bandwidth distribution among flows, and values falling significantly below 1 suggest starvation for the corresponding flows. Notably, different TCP protocols, such as PCC, BBR, Copa, and CUBIC, demonstrate distinct behaviors concerning starvation.
Based on our analysis of plots and equations associated with different TCP algorithms, our hypothesis regarding resource allocation disparity seems to hold true. We initially hypothesized that regardless of design principles aiming for TCP-friendliness, low latency, low loss, and higher throughput, fairness issues related to resource allocation still arise. Our observations within a specific congested network environment suggest that packets experience significant queuing delays, leading to delivery time extensions or packet drops, even when certain flows manage to deliver packets without issues. This scenario represents a “starvation state” for some flows, and such intra- and inter-variant unfairness negatively impacts overall network performance.
4. System Model of Proposed TCP-Switching Mechanism
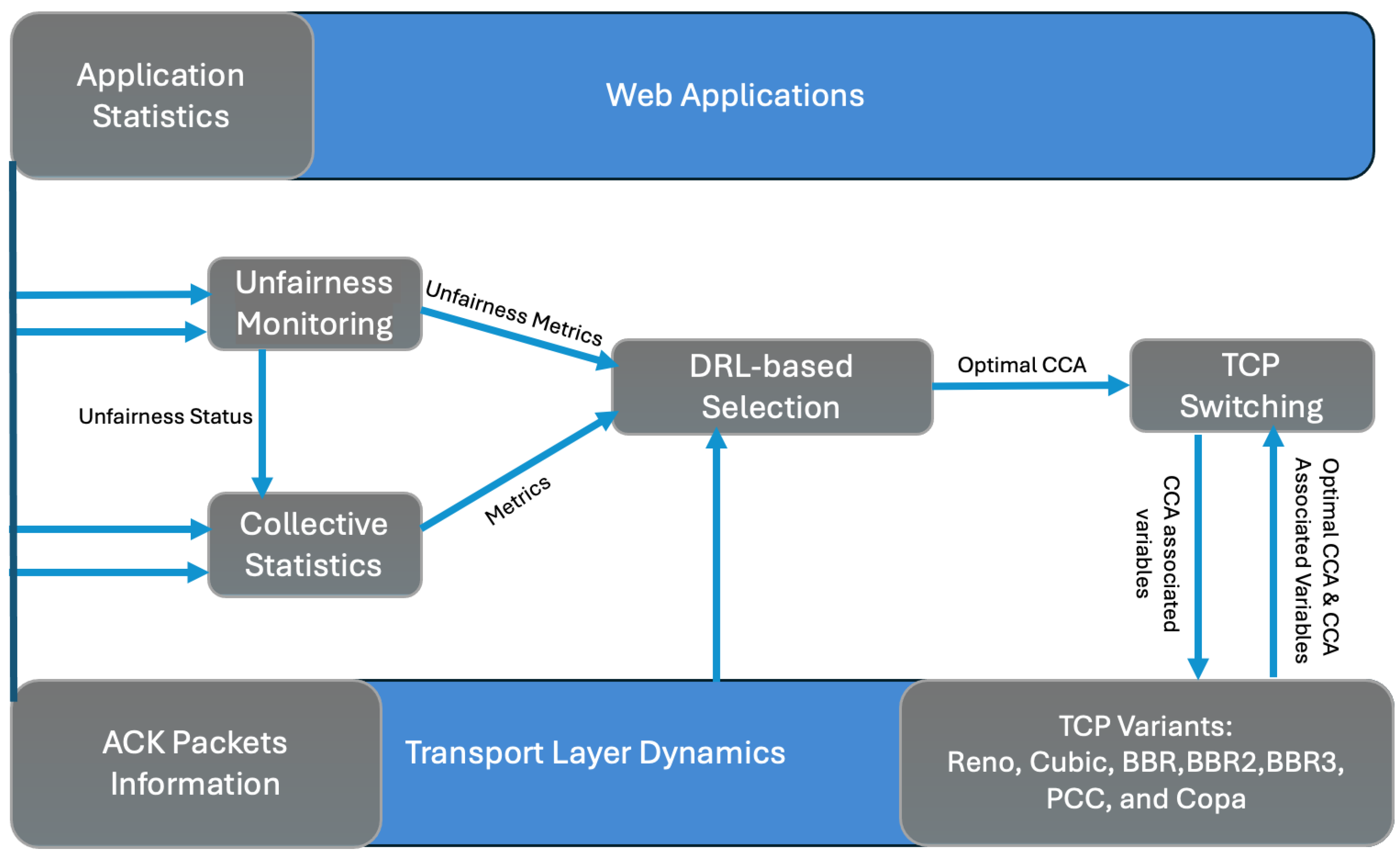
This section details the design of our TCP-switching mechanism, which utilizes DRL to optimize CCAs. The model integrates four key components, Unfairness Monitoring, Collective Statistics, DRL-based Selection, and TCP Switching, each contributing to a dynamic and responsive network management system.
Before presenting the details of our system model, we outline a set of metrics in
Table 2 and
Table 3 for monitoring unfairness and Collective Statistics in CCAs, respectively. Analyzing these metrics allows us to assess CCA fairness and identify the need for adjustments or switching.
Selecting effective CCAs requires addressing flow unfairness, which is pivotal for optimizing QoS and QoE. We assert that CCAs failing to distribute bandwidth fairly among all flows will not adequately enhance QoS and QoE. Our approach involves evaluating and addressing the fairness of CCAs through various metrics and employing DRL to switch CCAs based on these evaluations dynamically.
To detect unfairness in CCAs, we use a fixed-point approach that compares throughput across different flows. If one flow consistently receives a higher throughput than others, it indicates that the CCA may be unfair. This approach involves defining a fairness function that evaluates the throughput ratio between flows and iteratively adjusting it until it reaches a fixed point, reflecting an equitable bandwidth distribution. For example, one possible function could be the ratio of the throughput of the flow to the average throughput of all flows:
where
is the throughput of flow 1, a is the number of flows, and
is the average throughput of all flows.
The fixed-point approach then iteratively adjusts the throughput of each flow until the function
reaches a fixed point. A fixed point is a value of the function that does not change when the throughput of the flows is adjusted. The fixed-point approach can be shown in the following equation:
where
is the throughput of flow 1 in iteration
x,
is the throughput of flow 1 in iteration
, and
is the value of the function
in iteration
x. If the fixed-point approach converges to a value where all flows have the same throughput, then the congestion control algorithm is fair. However, if the fixed-point approach converges to a value where one flow has more throughput than the others, then the congestion control algorithm is unfair.
CCAs are deployed in the transport layer that settles behaviors of data transformation, which rigorously affects the user experience [
3]. The improvisation in QoS does not improve the Quality of Experience. The gap between QoE and QoS must be filled; if not, it must be minimized. Here, we do not upgrade any CCAs directly; however, we attempt to develop a model between the transport layer and the application layer that assists in selecting the right CCAs and ultimately provides better QoE. There is no such CCA that fits in every situation and functions perfectly in all scenarios. Thus, the alternative for better QoE is to autonomously select the effective and efficient CCA in varying scenarios.
However, it is challenging to select the right CCAs and to form the CCA-selection policies [
3] by observing the network conditions and QoE metrics. One of the main challenges is to adapt to the dynamic network conditions. The networks are affected by various factors [
3] such as the overflow of traffic into the networks, the fading of wireless channels, and user movement activities. The network’s condition does not stay stable. Another difficulty in choosing the right CCA is the empirical characteristics of CCAs [
51,
52]. The latest CCAs [
14,
16] are seriously difficult to model and characterize, as the existing understanding of CCAs is empirical [
51,
52].
Another notable challenge is the difficulty in smooth switching. As [
3] mentioned, there is a very strong possibility of taking the place of CCA switching while the transmission is happening because of unstable network conditions. Here, we have implemented unrestricted switching. Unrestricted switching allows the new CCA to inherit all CCA-related variables, encompassing connection-level variables (such as congestion window/sending rate and RTT-related values), and private state variables of the CCA (e.g., minimum RTT, CWND increment, etc.). Limited sSwitching, on the other hand, only inherits connection-level variables. The private state variables of the new CCA are initialized from default values.
4.1. Model Interpretation
As shown in
Figure 2, Collective Statistics aggregates data from the transport and application layers. These metrics are integrated with inputs from unfairness monitoring. The DRL-based selection then evaluates the fairness status of CCAs using these data, maps the metrics provided by Collective Statistics, selects an optimal CCA, and recommends TCP switching. Upon receiving the optimal CCA recommendation, TCP switching initiates the transition from the current CCA to the newly selected optimal CCA, considering the network dynamism and environments.
4.1.1. Proposed DRL-Based CCA Switching
Our DRL framework utilizes a Deep Q-Network (DQN) to dynamically select and switch CCAs based on real-time network conditions. DQN was chosen over other DRL algorithms, such as DDPG, Double DQN, and DeepSARSA due to its superior performance in fairness analysis, as highlighted by [
53], and its effectiveness in handling large discrete action spaces, which is relevant for CCA selection [
54]. Furthermore, ref. [
55] demonstrated the ability of DQN to manage complex decision-making tasks, further supporting its suitability for our research.
State Space (S)
The state space captures key network metrics influencing the performance of CCA, including throughput, RTT, loss rate, and jitter. These parameters allow the DQN to assess and adjust the CCA based on real-time conditions.
Action Space (A)
The action space consists of selecting between different CCAs, such as Cubic, BBR, or PCC, where each action represents a potential CCA switch.
Reward Function (R)
The reward function is designed to improve network performance by addressing disparities in metrics and promoting beneficial CCA switches. For simplicity, we use
but the constants can be tuned to encourage actions that emphasize throughput and reduce RTT and the loss rate differently.
Q-Function (Q)
The Q function estimates the expected cumulative reward for each pair of state actions, which guides the selection of the optimal CCA:
with
balancing immediate and future rewards. This function helps determine actions that maximize long-term network performance. DRL trains a neural network to solve problems to optimize our proposed approach, predicting and responding to congestion indicators, effectively using the available bandwidth, and switching to the optimal CCA. Due to current dependencies on user-space libraries, DRL implementations must run in the user space (not in the kernel). The proposed DRL-Based TCP Switching Algorithm is shown in Algorithm 1.
Given time and resource constraints, network environment complexity, data preprocessing needs, and real-time modeling challenges, we implemented offline DRL as the sole method for switching CCAs in this paper. The process was as follows.
Data Collection: Historical network traffic data were gathered using tools like iperf3 and Wireshark, capturing metrics such as throughput, packet loss, RTT, and congestion levels.
Offline Training: The DRL model was trained offline with the collected data, learning to identify network behavior patterns and select suitable CCAs. Validation: The model was validated with separate datasets to ensure its effectiveness and generalization to unseen network conditions, fine-tuning parameters as needed.
Validation The DRL model was validated with separate datasets to ensure its effectiveness and generalization to unseen network conditions, fine-tuning parameters as needed.
| Algorithm 1 DRL-Based TCP Switching Algorithm |
Input: Historical network data, Real-time network metrics Output: CCA selection and smooth switching Step 1: Data Collection Collect historical network traffic data using tools (e.g., iperf3, Wireshark) Gather metrics: throughput, packet loss, RTT, congestion levels Step 2: Offline Training Train DRL model with collected historical data Model learns to identify patterns and select suitable CCA DRL model analyzes historical network metrics (e.g., throughput, packet loss, RTT, congestion levels) The model identifies patterns and correlations within these metrics that impact network performance The model learns to predict the best-performing CCA under a different network Select the optimal perfroming CCA Step 3: Validation Validate the DRL model with separate validation datasets Fine-tune model parameters to improve generalization Step 4: Real-time Monitoring while network is operational do Continuously monitor real-time network metrics Update network condition variables Input real-time metrics to the trained DRL model Predict the optimal CCA for current network conditions end while Step 5: Algorithm Selection Policy Develop policy based on the DRL model’s decision-making Determine appropriate CCA based on observed conditions Step 6: Prepare for Switching Retrieve parameters of the predicted optimal CCA Analyze potential disruptions during the transition Save the current state of network traffic Step 7: Execute Switching Communicate new CCA parameters to the transport layer Migrate CCA variables smoothly, ensuring minimal disruption Apply the new CCA and monitor initial performance Step 8: Post-Switch Evaluation Continue monitoring network metrics post-switch Compare performance with pre-switch metrics if performance improves then Confirm new CCA selection else Revert to the previous CCA or select an alternative end if
|
Realtime Monitoring: The continuous monitoring of real-time network metrics was conducted to update network condition variables. These metrics were inputted into the trained DRL model to predict the optimal CCA for current network conditions.
Algorithm Selection Policy: A policy was developed based on the DRL model’s decisions, determining CCA selection based on observed network conditions.
Simulation: The DRL-based congestion control mechanism was simulated in an offline environment, evaluating performance and the ability to mitigate unfairness.
Optimization: The DRL model and selection policy were refined based on simulation results and validation feedback, enhancing decision-making accuracy and robustness.
Preparation for Switching: The parameters of the predicted optimal CCA were retrieved, potential disruptions during the transition were analyzed, and the current state of network traffic was saved to facilitate a smooth migration to the new CCA.
Execution of Switching: New CCA parameters were communicated to the transport layer, variables were migrated smoothly to minimize disruption, and the new CCA was applied while monitoring initial performance.
5. Experimental Methodology, Results, and Discussion
In this section, we present our experimental methodology, including our experimental testbed setup and test scenario design. We then present the result analysis and discussion of each experiemtal scenario accordingly.
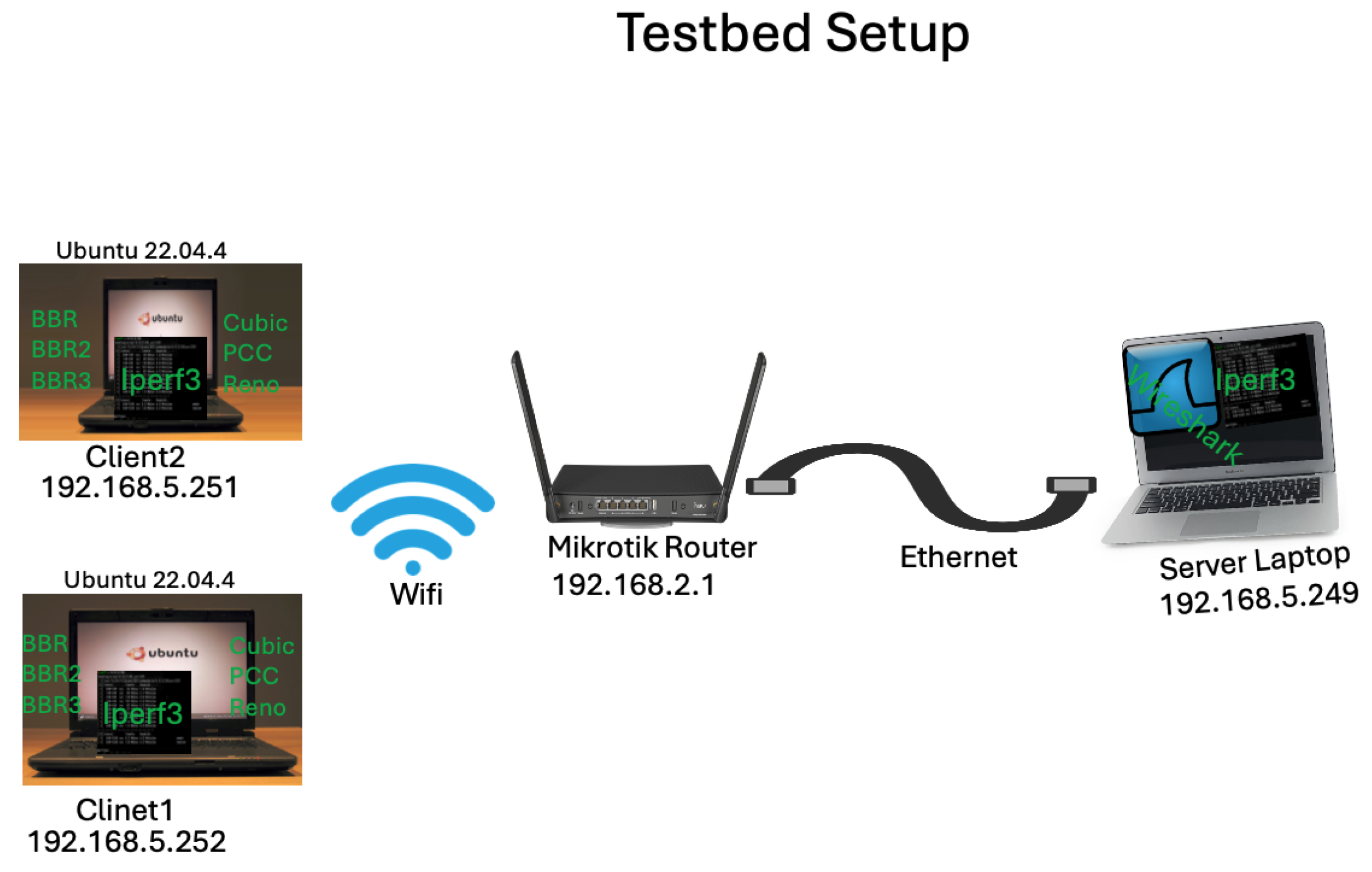
5.1. Experimental Testbed Setup
In our experimental testbed setup, as demonstrated in
Figure 3, we configured the client, router, and server components to facilitate comprehensive experimentation. As shown in the
Table 4, MikroTik RouterOS v6.49.4 serves as the network gateway, complemented by Ubuntu 22.04.4 deployed on both client machines. Network traffic generation is managed using Iperf3, while Wireshark captures data for detailed analysis. Our WiFi hAP ax (see
https://mikrotik.com/product/hap_ax3, accessed on 27 June 2024, for details) network configuration includes a 100 Mbps bottleneck and a queue buffer of 50 packets, utilizing the Pfifo queuing discipline. Clients connect via WiFi, ensuring flexibility and mobility, while the server maintains a stable Ethernet connection for robust data transmission. This setup allows us to rigorously test and analyze various algorithms such as CUBIC, BBR, PCC, BB2, and BBR3 over a duration of 100 s, focusing on metrics like throughput, throughout fairness
, sending rate, packet loss ratio, RTT, and jitter.
We first observed the disparities in throughput within and between the CCAs (throughout fairness ) and explored the RTT, jitter, and packet loss ratio within and between the different CCAs before and after switching in both line graphs and box plots. The aim was to minimize flow unfairness, optimize overall performance, and prevent flow starvation. Our investigation encompassed a range of CCAs, including CUBIC, BBR, Reno, PCC, BBR2, and BBR3. Each algorithm’s behavior was thoroughly scrutinized across various experimental scenarios, evaluating the network stability, throughput, jitter, RTT, and packet loss ratio under different configurations. We conducted experiments involving specific intervals of CCA switching, such as transitioning from CUBIC, BBR, PCC, BBR2, and BBR3, to capture the intricate interactions between CCAs. Throughout our experiments, spanning 100 s with 1 s intervals, data collection and analysis using Wireshark and iperf3 statistics enabled us to identify performance disparities and fairness issues among the tested algorithms. This rigorous analysis contributed insights toward optimizing and selecting algorithms tailored to diverse networking requirements.
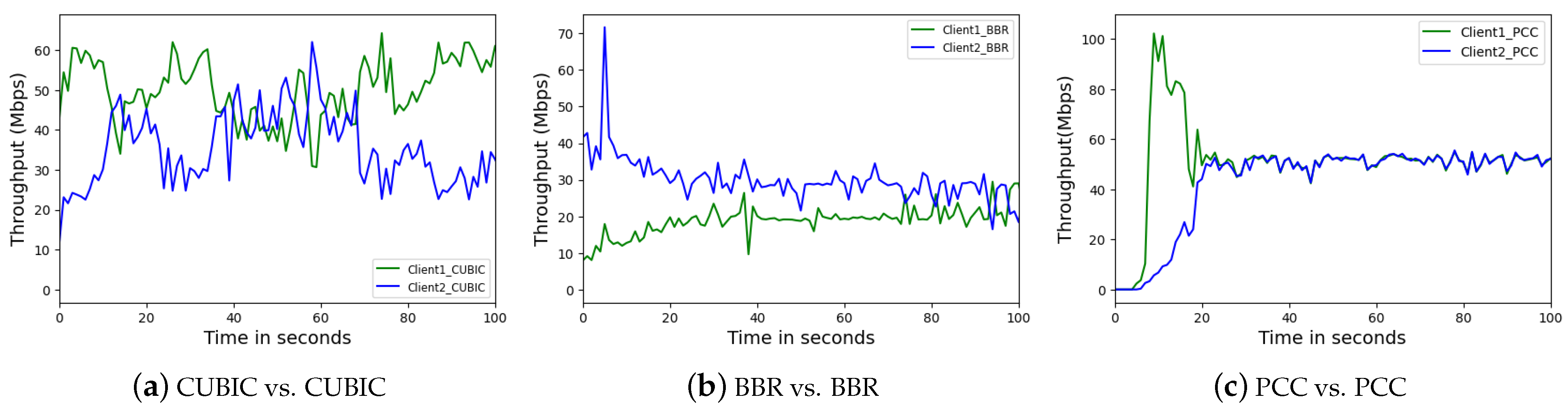
The plots in
Figure 4 highlight the behaviors of flows using the same CCA flows competing for bandwidth.
Figure 4a, two CUBIC flows, and
Figure 4b, two BBR flows, demonstrate that throughput disparities are prevalent within CCA flows, unlike in the case of PCC flows as shown in
Figure 4c. Such throughput unfairness (quantifying throughout fairness using
) observed in BBR and CUBIC flows suggests that both CCAs inherit complex and sensitive congestion mechanisms, which cannot always prevent unfairness among flows. Moreover, flow fairness varies in the real world as network conditions dynamically change, affecting each flow unevenly over time. PCC’s focus on fairness through learning mechanisms explains its lower unfairness compared to other competitive CCAs.
Results in
Section 5.2,
Section 5.3 and
Section 5.4 show the complexities of fairness in multi-CCA network traffic. While all flows initially experience a slow throughput rise due to network learning (latency, jitter, bandwidth), different CCAs exhibit varying behaviors due to their inherent design philosophies. These design principles lead to unfairness when non-identical CCAs compete. Additionally, factors like differing responsiveness to network changes (e.g., sudden congestion events) and varying interpretations of “fairness” by different algorithms can further exacerbate unfairness. Understanding these dynamics is crucial for optimizing network performance. One potential avenue for improvement could be the development of “fairness-aware” CCAs or “switching” for fairer CCAs that can dynamically adjust their behavior based on the presence of other algorithms, promoting a more cooperative approach to resource allocation.
In
Figure 5, CUBIC and BBR are competing, the throughput variation slightly improves over time. The influencing factor behind this is the adaptive nature of CCAs, which improves the estimation of available bandwidth. However, throughput imbalance remains unacceptably high in flows like in
Figure 5. Not only do CCA flows such as CUBIC vs. BBR and PCC vs. BBR show disparities flattening out over time as CCAs adjust their data transfer aggressiveness, but distinct behaviors of CCAs with other CCA flows validate the hypothesis that no two CCA flows are perfectly fair to each other. Thus, intelligently assessing and switching available CCAs while studying changing network conditions would be very beneficial.
Motivation to Choose the Scenarios
The selected scenarios CUBIC vs. BBR-CUBIC, PCC vs. BBR-PCC, and BBR vs. PCC-BBR were chosen to highlight the dynamic interplay between different CCAs under varying network conditions. These scenarios were selected due to their representative nature in demonstrating how dynamically switching between CCAs can optimize network performance, fairness, and resource utilization. CUBIC and BBR were chosen for their distinct approaches to congestion control, with CUBIC being widely used and BBR offering a newer, bandwidth-centric methodology. PCC was included for its adaptive nature and ability to handle diverse network conditions. By focusing on these specific pairings and transitions, the paper aims to illustrate practical benefits and challenges of dynamic CCA switching, providing insights into improving network performance and fairness in real-world scenarios.
5.2. Scenario 1: CUBIC vs. BBR-CUBIC
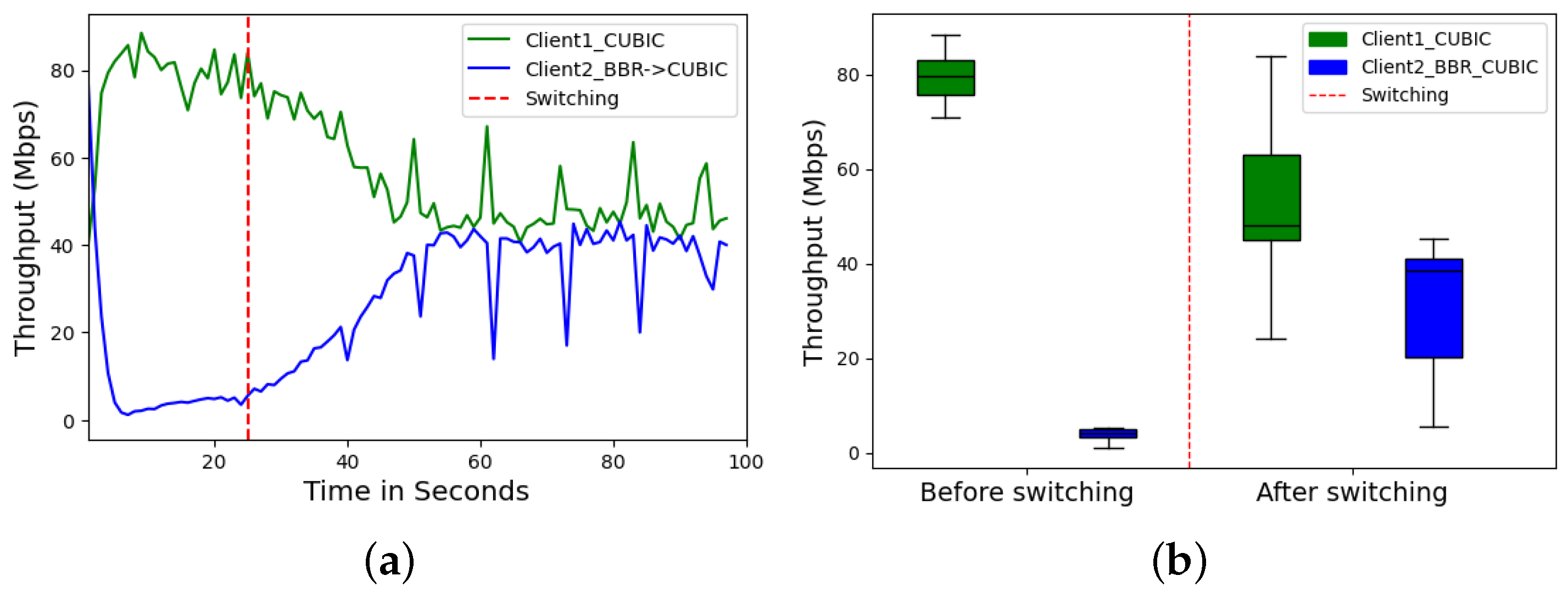
Dynamically switching CCAs based on network conditions significantly enhanced network performance and fairness among flows. The throughput graphs in
Figure 5a clearly illustrate this improvement. After switching Client 2 from BBR to CUBIC at the 25 s mark, the throughput surged from near 0 Mbps (starvation) to approximately 40 Mbps by the 60 s mark and remained stable thereafter. This contrasts with the initial BBR behavior, which exhibited lower and more fluctuating throughput. Moreover, the box plot in
Figure 5b confirms the significant increase in median throughput and reduced variability for Client 2 post-switching. This indicates a more equitable distribution of bandwidth among flows.
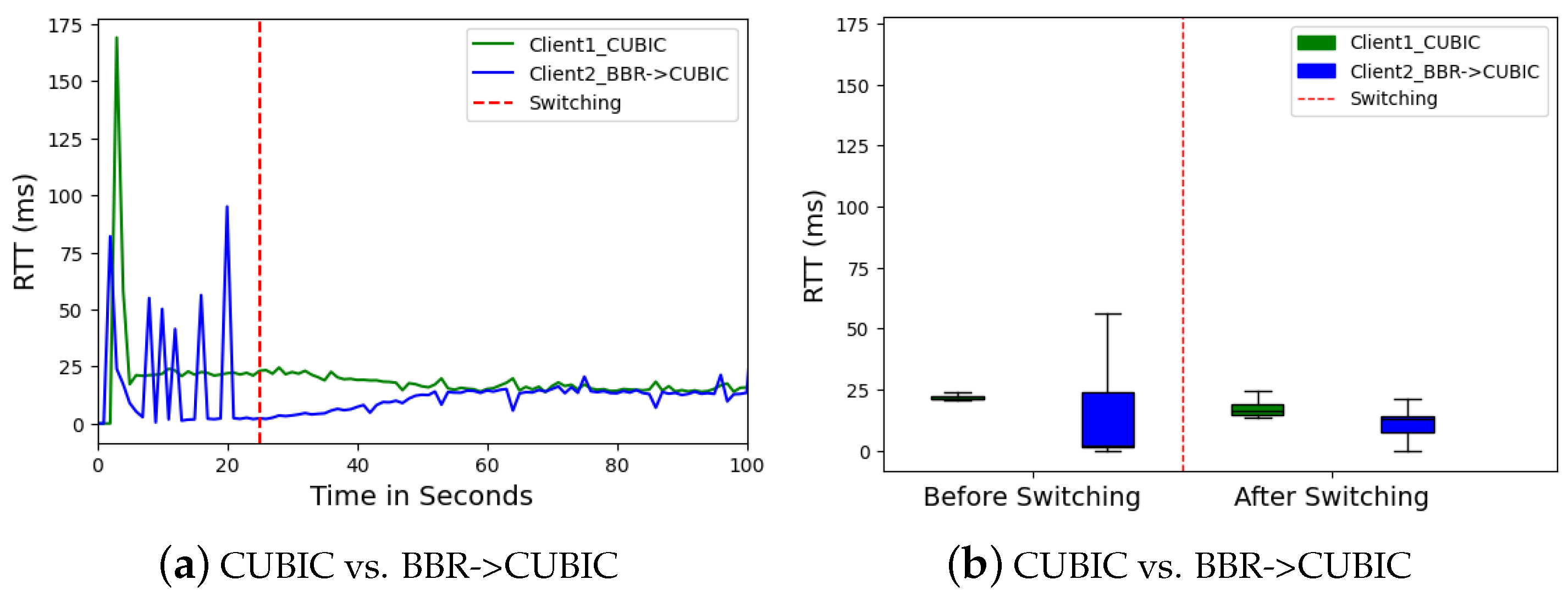
RTT is a critical factor influencing network fairness and congestion avoidance, which directly impacts throughput and sending rate. Despite a higher RTT, Client 1 achieved higher throughput at 30 s compared to 80 s in
Figure 6a. This suggests that algorithms such as BBR and CUBIC optimize bandwidth utilization, mitigating the impact of high RTT on throughput. However, significant RTT fluctuations causes higher jitter variation as shown in
Figure 7 degrade performance, as observed in the variability of throughput for Client 2 using BBR before switching in the
Figure 5 and
Figure 6a,b.
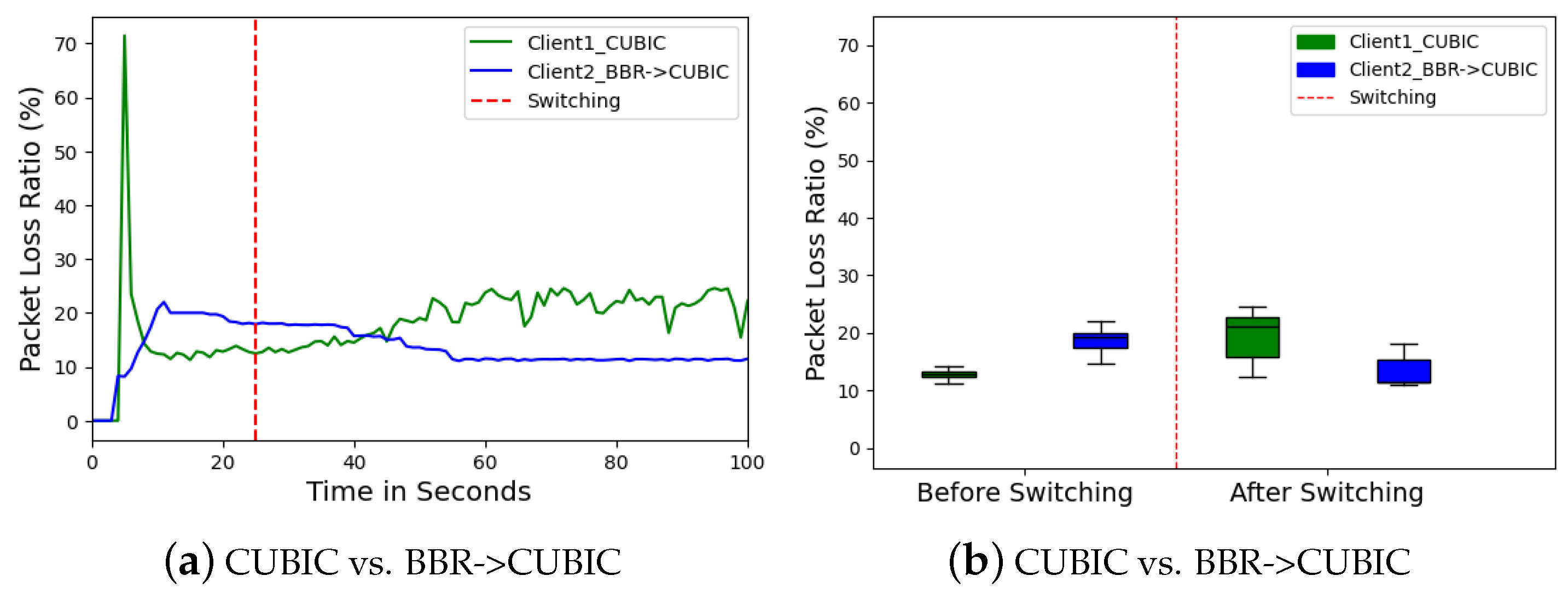
The packet loss ratio reflects an algorithm’s ability to manage congestion, showing a clear trend in
Figure 8a. Before switching, BBR exhibited higher packet loss rates compared to CUBIC, despite sending fewer bytes. This indicates BBR’s struggle to efficiently utilize available bandwidth under varying network conditions. After switching
Figure 8b, Client 2 experienced reduced packet loss with CUBIC, while the competing flow saw a slight increase, suggesting CUBIC’s better adaptability and congestion control capabilities.
Low jitter indicates stable network conditions without noticeable variation in packet arrival time. Inconsistent and higher jitter variations negatively impact the network, resulting in lower throughput. The relationship between jitter and throughput is illustrated in graphs (a) and (b) of
Figure 5 and
Figure 6, respectively. It is noted that Client 2 experienced higher variations in RTT and packet arrival times before switching to CUBIC and received minimal throughput.
5.3. Scenario 2: PCC vs. BBR-PCC
Similar to CUBIC and BBR, PCC and BBR exhibited competitive behavior when contending for bandwidth under specific network conditions. Before the switch, Client 1 (PCC) generally outperformed Client 2 (BBR) in terms of throughput by observing throughout fairness . PCC’s adaptive nature effectively adjusts to bandwidth and latency variations and contributed to its superior performance. Conversely, BBR demonstrated challenges in maintaining fairness, particularly in networks with varying RTTs.
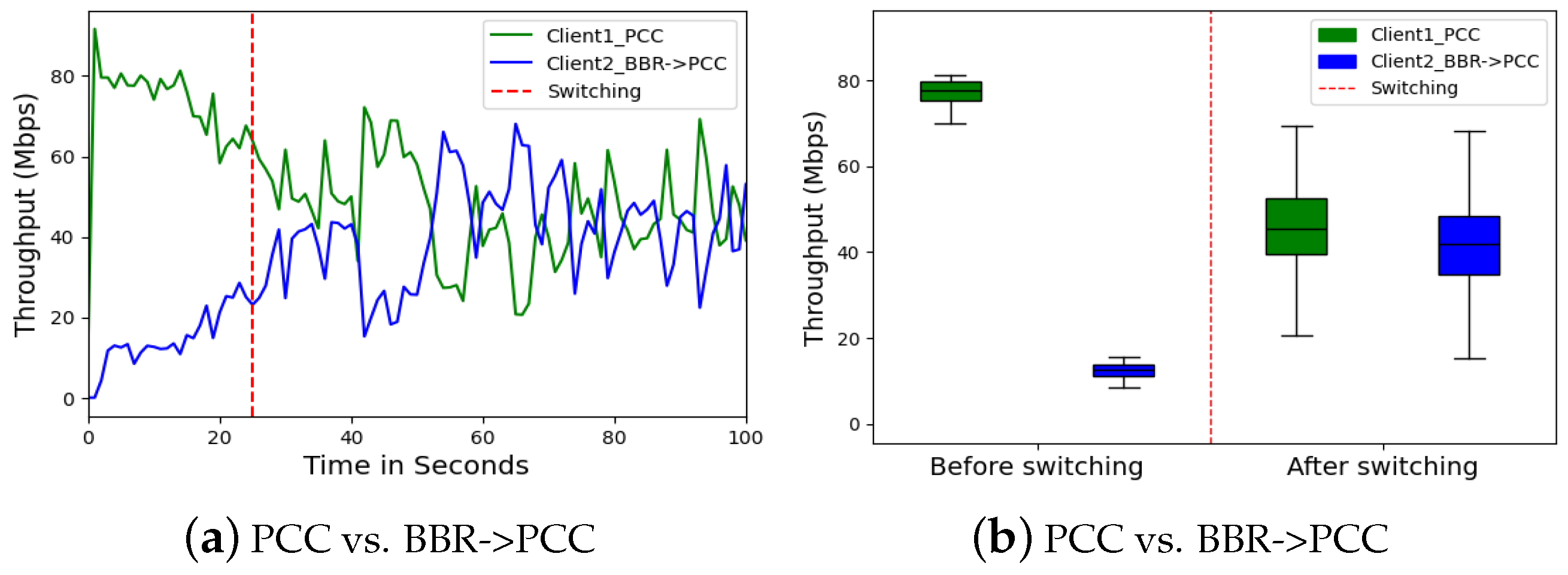
In Scenario 2, we investigated the impact of Client 2 switching from BBR to PCC at 25 s. Client 2 using BBR initially averaged throughput of 12.32 Mbps, but this surged to 40.40 Mbps after the switch to PCC in
Figure 9a,b. This suggests that PCC offered a more efficient way to utilize bandwidth under these specific network conditions. BBR’s congestion control strategy might not have been ideal, leading to underutilized resources.
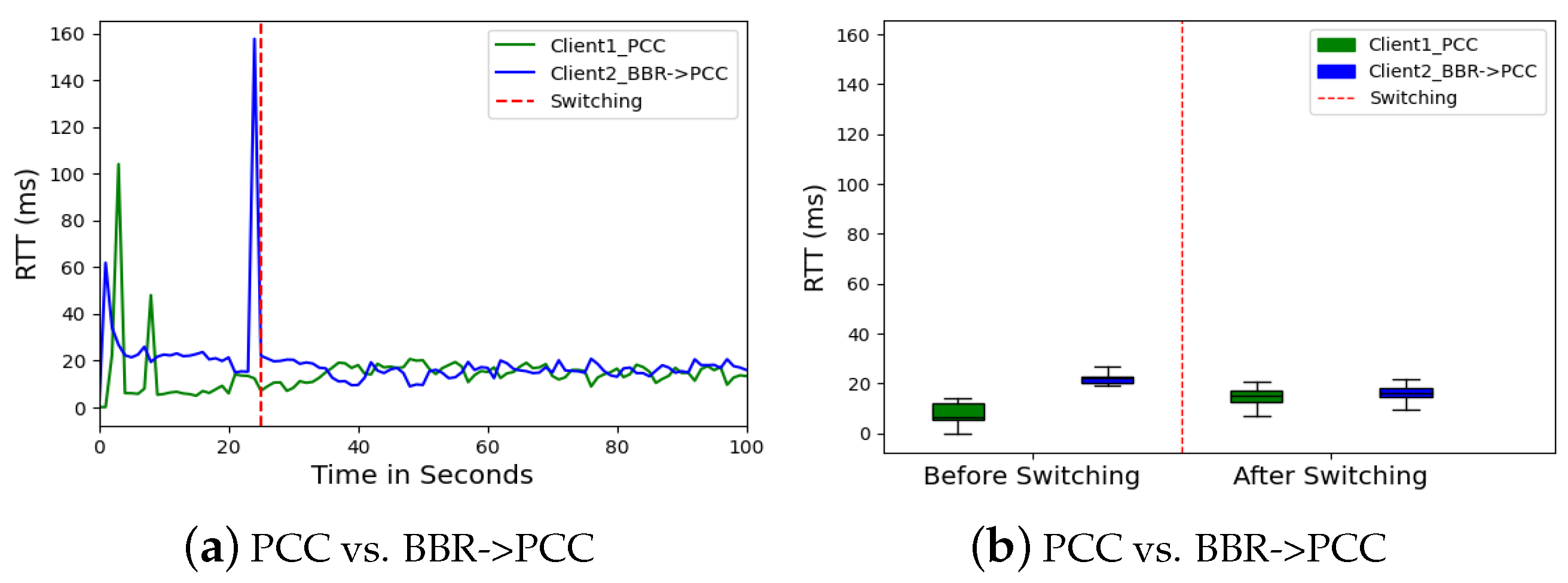
Nevertheless, significant improvements were observed in latency and data loss. Client 2 (BBR) initially experienced high variations in RTT (
Figure 10a). This variability suggests that BBR struggled to maintain consistent latency. Switching to PCC led to a decrease in these variations, with both clients maintaining RTTs below 20 ms. Similarly, jitter (variation in RTT) for Client 2 also decreased post-switch, as seen in
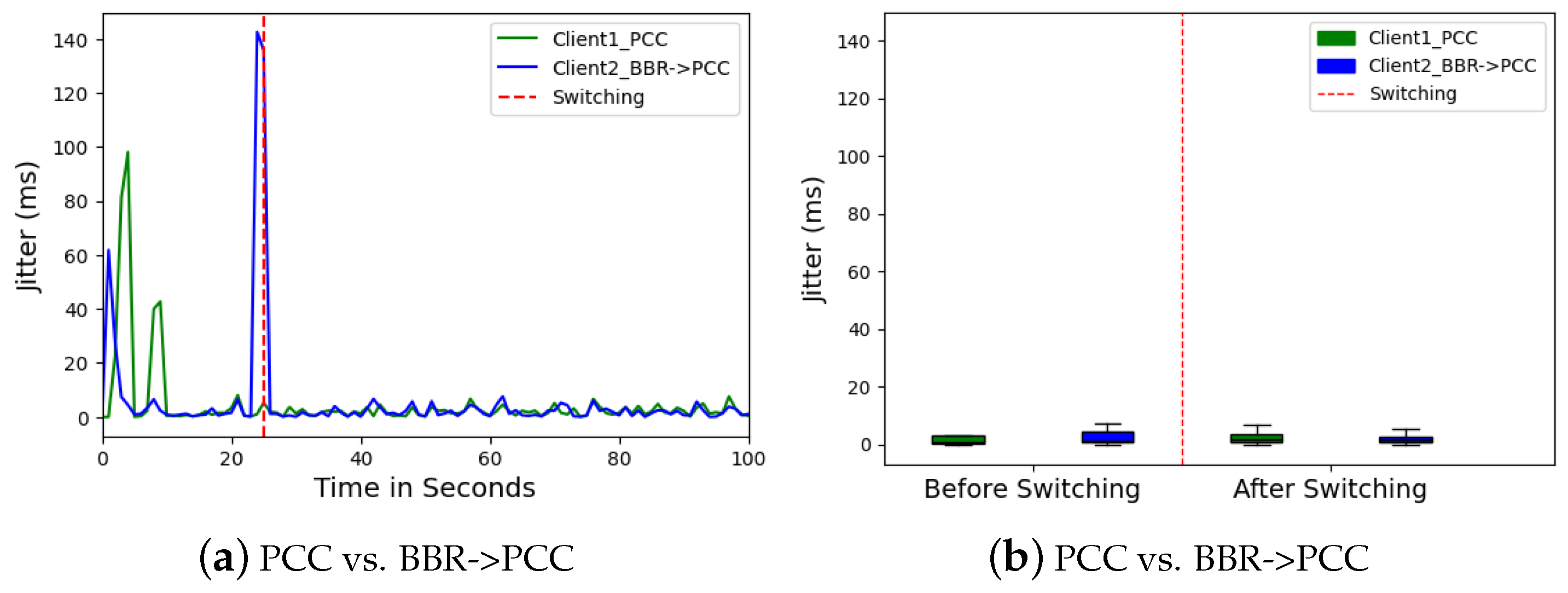
Figure 11. These improvements suggest PCC’s approach resulted in smoother data flow and lower latency for Client 2, possibly due to better congestion management.
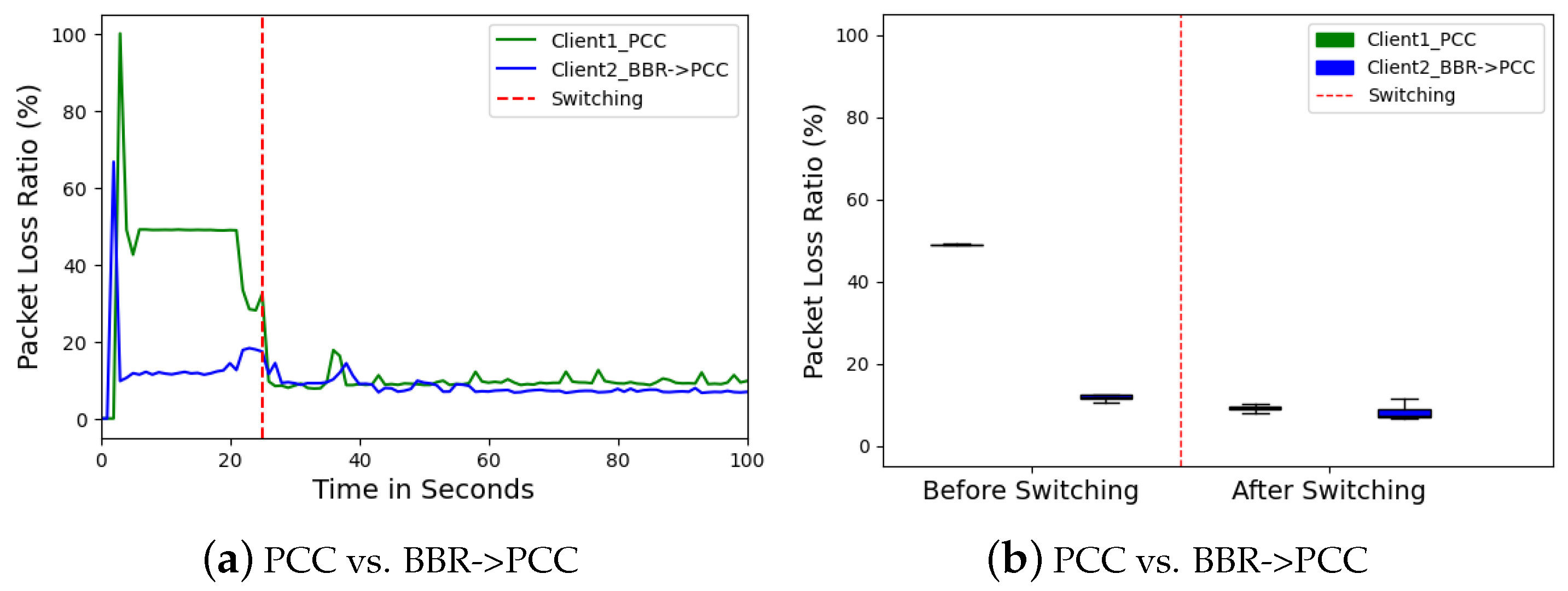
Packet loss measurements also saw a dramatic improvement. Client 2 (BBR) displayed a high initial packet loss ratio (48.97%) (
Figure 12a,b). This indicates significant data loss. Interestingly, Client 1 (PCC) also experienced a high initial packet loss. However, after the switch, the packet loss ratio for both clients dropped significantly. Client 2’s median packet loss dropped to nearly 10%, while Client 1’s (PCC) also improved to 7%. This suggests PCC’s congestion control strategy effectively mitigated packet loss for both clients, likely by optimizing resource allocation and reducing network congestion.
5.4. Scenario 3: BBR vs. PCC-BBR
This analysis explores Scenario 3, where PCC and BBR compete for bandwidth. While PCC initially offered higher throughput for Client 2 (infer throughout fairness ), significant fluctuations indicated potential instability. Switching Client 2 to BBR resulted in more stable performance for both clients across key metrics: throughput, RTT, jitter, and packet loss.
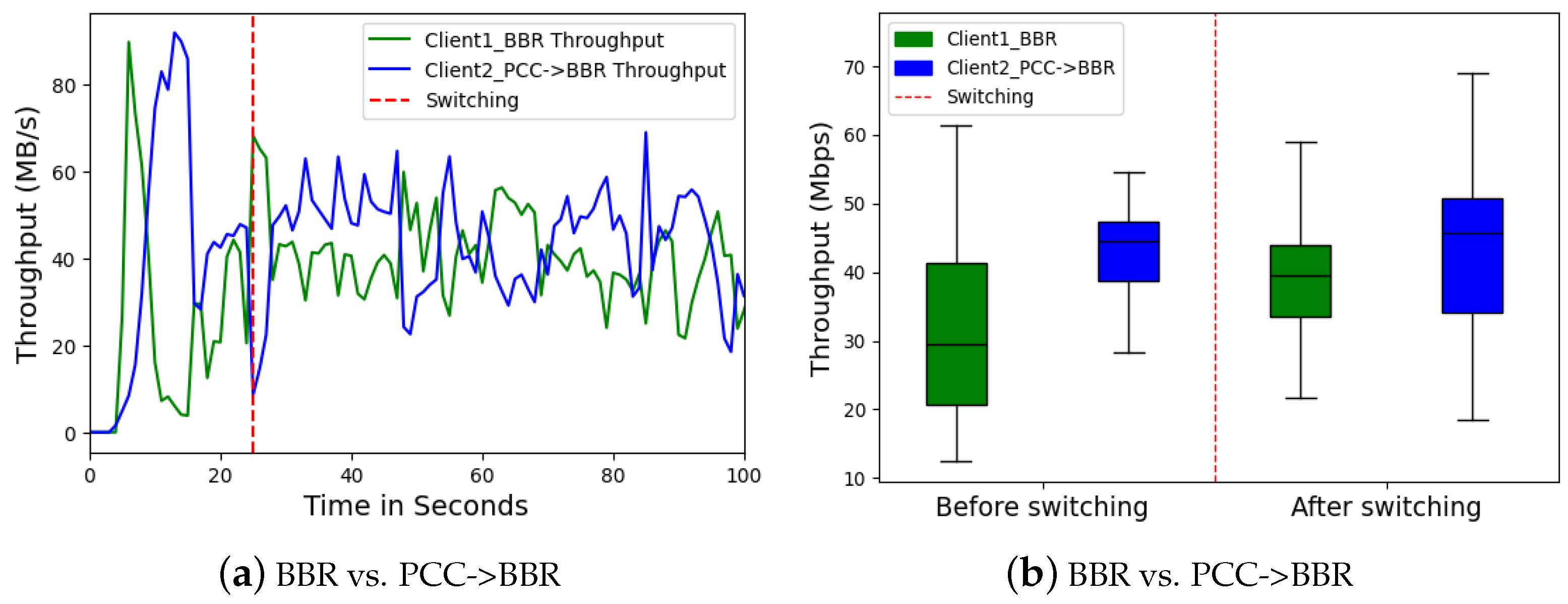
Initially, the competing CCA, PCC, provided Client 2 with significantly higher throughput, exceeding 44 Mbps on average, as seen in
Figure 13a. However, this advantage came with substantial fluctuations in PCC’s throughput, hinting at potential instability in its congestion control mechanism.
Client 2 switched from PCC to BBR, yielding positive impacts on network performance for both clients across several key metrics. Notably, Client 2 (BBR) maintained a stable throughput above 40 Mbps, demonstrating the effectiveness of BBR in achieving good throughput while ensuring stability. Interestingly, considering
Figure 13b, even Client 1 (BBR) experienced improvement, with its median throughput rising to 40 Mbps. This suggests that the overall network congestion was better managed after the switch, potentially due to BBR’s identical strategy to adapt network variation and optimize resource allocation.
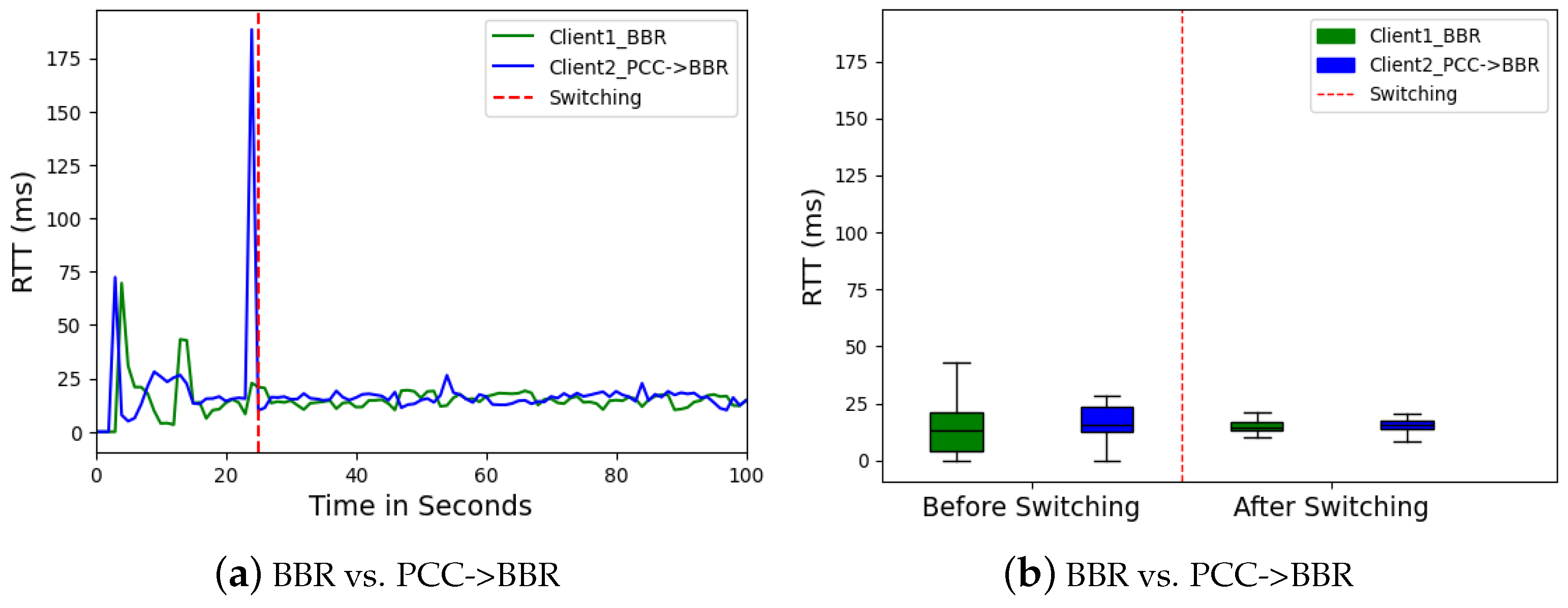
Prior to the switch, Client 2 (PCC) exhibited significant spikes in RTT in
Figure 14a, reaching as high as 104 ms at times. These fluctuations likely stemmed from the instability in PCC’s throughput. After the switch, both clients displayed consistently lower and more stable RTTs under 15 ms. Similarly, jitter in
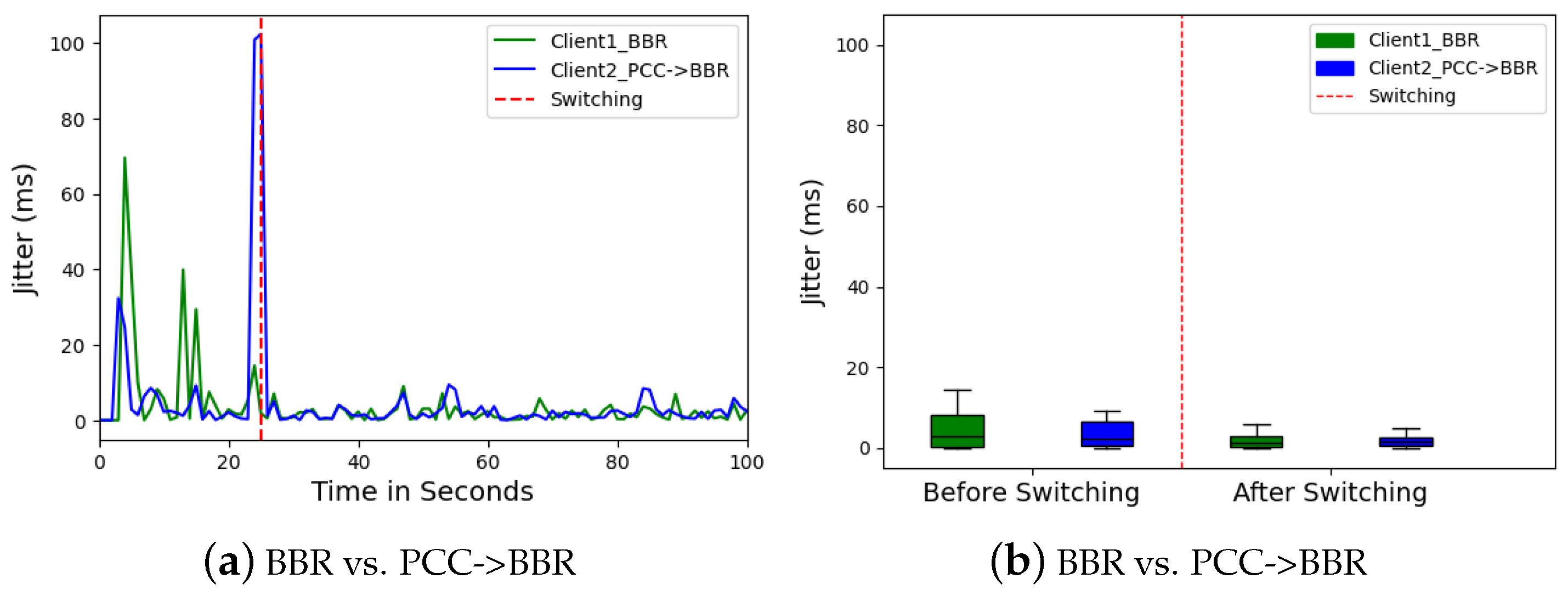
Figure 15, which measures the variation in RTT, decreased significantly for both clients, with Client 2 (BBR) dropping to below 2 ms. This jitter reduction highlighted the benefit of stable throughput in maintaining consistent data flow and minimizing delays.
The observed improvements can be explained by considering the interrelationships between network performance metrics. High and unstable throughput in PCC could lead to buffer overflows, causing packet drops in
Figure 16 and increased jitter in
Figure 15. BBR’s focus on congestion avoidance likely contributed to its lower initial throughput but resulted in greater stability across all metrics. This aligns with the established principle that stable throughput, even if slightly lower than the peak offered by an unstable CCA, leads to more efficient data flow and minimizes negative impacts on other metrics.
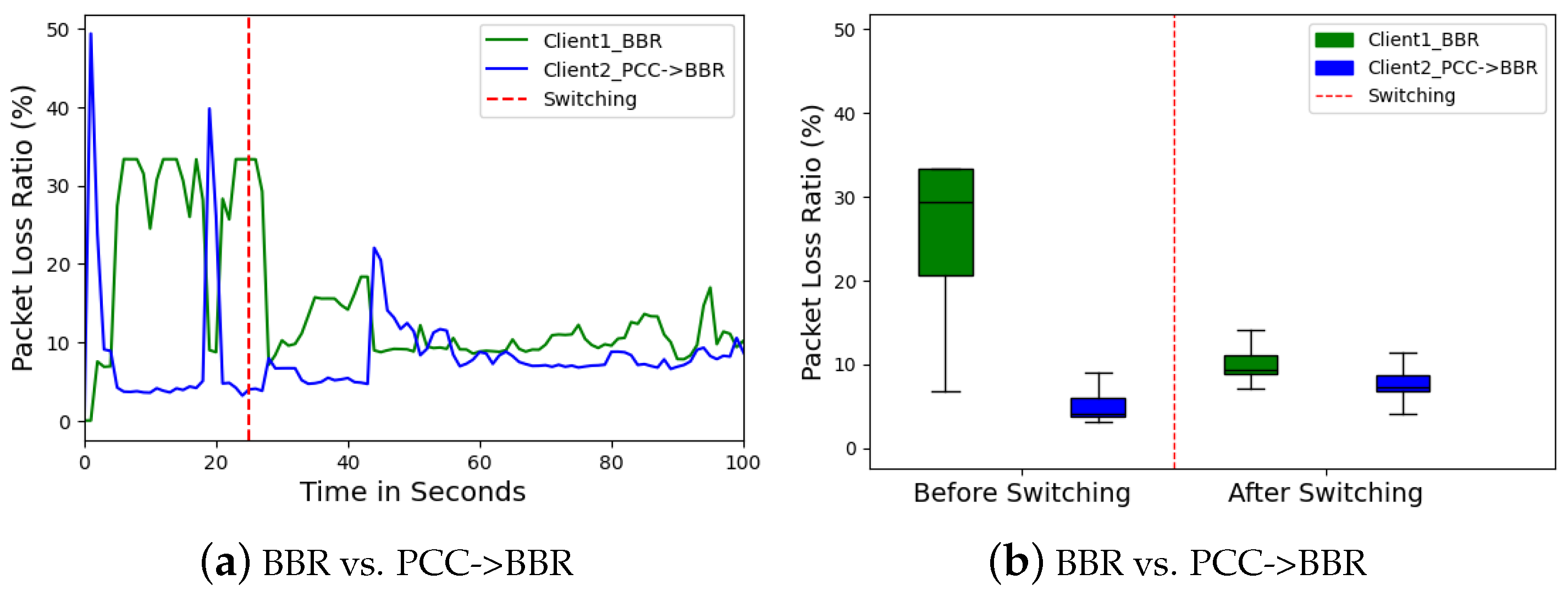
Client 2 (PCC) also experienced a higher packet loss ratio compared to Client 1 (BBR) before the switch. This is likely because the unstable throughput of PCC could have resulted in buffer overflow and packet drops. Both clients benefited from reduced packet loss after the switch. Client 1 (BBR) displayed a more significant improvement, with median packet loss dropping from around 29% to near 10% in
Figure 16. This further emphasizes the positive impact of BBR’s congestion-avoidance strategy, which helps minimize packet drops by ensuring a smoother and more predictable data flow.
RTT and Jitter
Analyzing Scenarios 1, 2, and 3 reveals the critical role dynamic CCA selection plays in achieving fair resource allocation. Static CCAs can struggle to adapt, leading to underutilized bandwidth or flow starvation. A DRL model, when coupled real-time network data analysis, can choose the most suitable CCA for each flow, which prevents these issues.
Furthermore, fairness is crucial in ensuring a smooth user experience. A DRL model trained with fairness objectives can select CCAs that optimize individual flow performance while promoting fair resource distribution. This dynamic adaptation based on network conditions ensures optimal performance and user experience across all connections.
5.5. DRL Model
In the framework, we have employed a Deep Q-network (DQN) to optimize the switching of CCAs based on network performance metrics. The environment constructed using the OpenAI Gym framework has a state space comprising four key metrics: throughput, latency, packet loss rate, and sending rate. The action space was discrete, with only two possible actions: switch the CCA or maintain the current CCA.
The training data consisted of various network performance metrics recorded over time, representing different network states. Our custom environment, CongestionControlEnv, was designed to reset at the beginning of each episode, initializing the state with the current network conditions. At each step, the agent could either choose to switch the CCA based on an evaluation function or continue with the current CCA.
The evaluation function determines the best CCA by combining the current network state with historical data. It scores each available CCA based on weighted metrics of 70% for throughput, 20% for latency, and 10% for loss rate and selects the CCA with the highest score as the optimal choice for managing network congestion. This approach ensures that the most suitable algorithm is selected, effectively adapting to the dynamic nature of the network.
The agent was trained over 1000 episodes, with each episode allowing the agent to perform actions based on an epsilon-greedy policy, balancing exploration and exploitation. Experiences were stored in a replay buffer, from which the agent sampled mini-batches to train the Q-network. The Q-network, built using TensorFlow, consisted of two hidden layers with 64 neurons each, followed by an output layer corresponding to the action space. The training was performed using the mean squared error (MSE) loss function and the Adam optimizer. The reward function penalized high disparities in network performance metrics and the act of switching the CCA, encouraging the agent to maintain stable and optimal network conditions.
After training, the DQN model was evaluated using a separate test dataset to validate its performance. The test environment was configured similarly to the training environment, with network states derived from the test dataset. The trained model was loaded, and the agent’s actions were recorded over 200 test episodes. The evaluation focused on the total reward, loss, and accuracy of the agent’s actions.
In this paper, the DQN agent’s neural network predicts actions by computing Q-values for each possible action given the current state. The action with the highest Q-value is selected as the predicted action. These predicted actions are then executed by the agent in the environment, which responds by transitioning to a new state and providing a reward based on the action taken. This dynamic interaction between the agent and the environment allows the DQN to tackle the complex task of selecting the most suitable CCA in ever-changing network environments.
To evaluate the performance of our DQN, we primarily focused on cumulative reward as a metric. However, we also incorporated accuracy as a supplementary metric, following the approach of [
56]. Accuracy is calculated by comparing the predicted actions of the DQN agent to the actual actions taken by the environment, providing insight into how closely the agent’s decisions align with a reference policy during training.
Additionally, loss is computed as the mean squared error between the predicted Q-values and the target Q-values. These target Q-values are derived from the reward received and the maximum predicted Q-values of the next state, ensuring the DQN learns effectively over time. This approach not only monitors the agent’s learning process but also provides a more comprehensive evaluation of the DQN’s effectiveness, as emphasized by [
57], in real-time TCP congestion control scenarios.
5.5.1. Training Reward
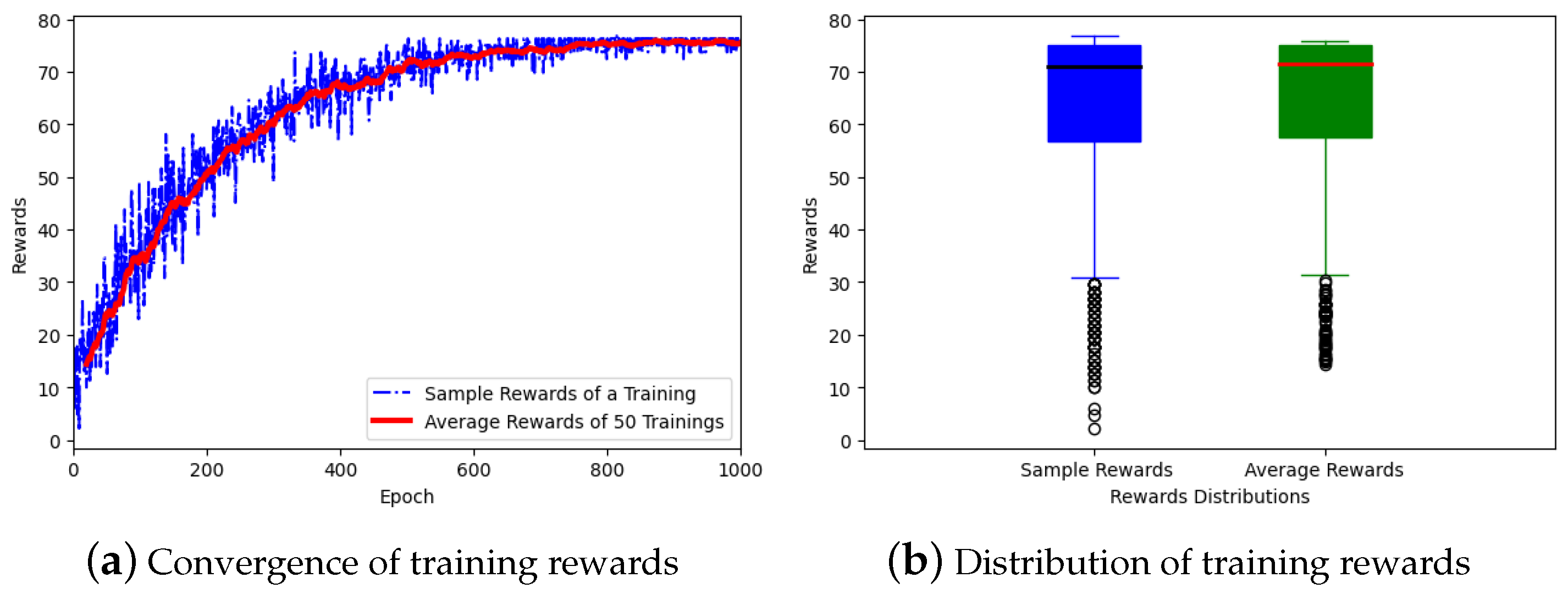
Figure 17a, showing the convergence of training rewards, illustrates the evolution of training rewards over 1000 epochs during the training of the DRL agent. The y-axis represents the convergence rewards accumulated by the agent in each epoch, while the x-axis corresponds to the number of training epochs. The blue curve shows the sample rewards from a single training run, reflecting the variability in the agent’s learning process, while the red curve represents the average rewards over 50 training runs, providing a smoothed view of the agent’s performance over time.
The curves indicate a general upward trend, signifying the agent’s progress towards a near-optimal policy. As the epochs increase, the total rewards rise, demonstrating that the agent is improving its decision-making capabilities. However, the blue curve exhibits fluctuations and occasional plateaus, suggesting that the learning process involves an exploration of the state–action space, which is inherent to DRL algorithms. The eventual stabilization of the red curve toward the latter epochs suggests that the agent is converging towards an optimal policy, where further improvements become marginal.
Figure 17b, showing the distribution of training rewards, visualizes the distribution of rewards across different training episodes. The blue boxplot represents the sample rewards from a single training run, while the green boxplot illustrates the average rewards across 50 training runs.
The median reward, located around 70, signifies the typical performance level of the agent during training. The small inter-quartile range (IQR) suggests that the agent’s performance was consistent across episodes, with the rewards generally clustering around the median. There are a few outliers visible at the lower end of the range, indicating instances where the agent received significantly lower rewards. However, the presence of these outliers is limited, suggesting that the agent was mostly successful in selecting high-performing CCAs that matched the current network conditions. This consistency in performance highlights the model’s effectiveness in minimizing network issues like unfairness and flow starvation.
5.5.2. Training Loss
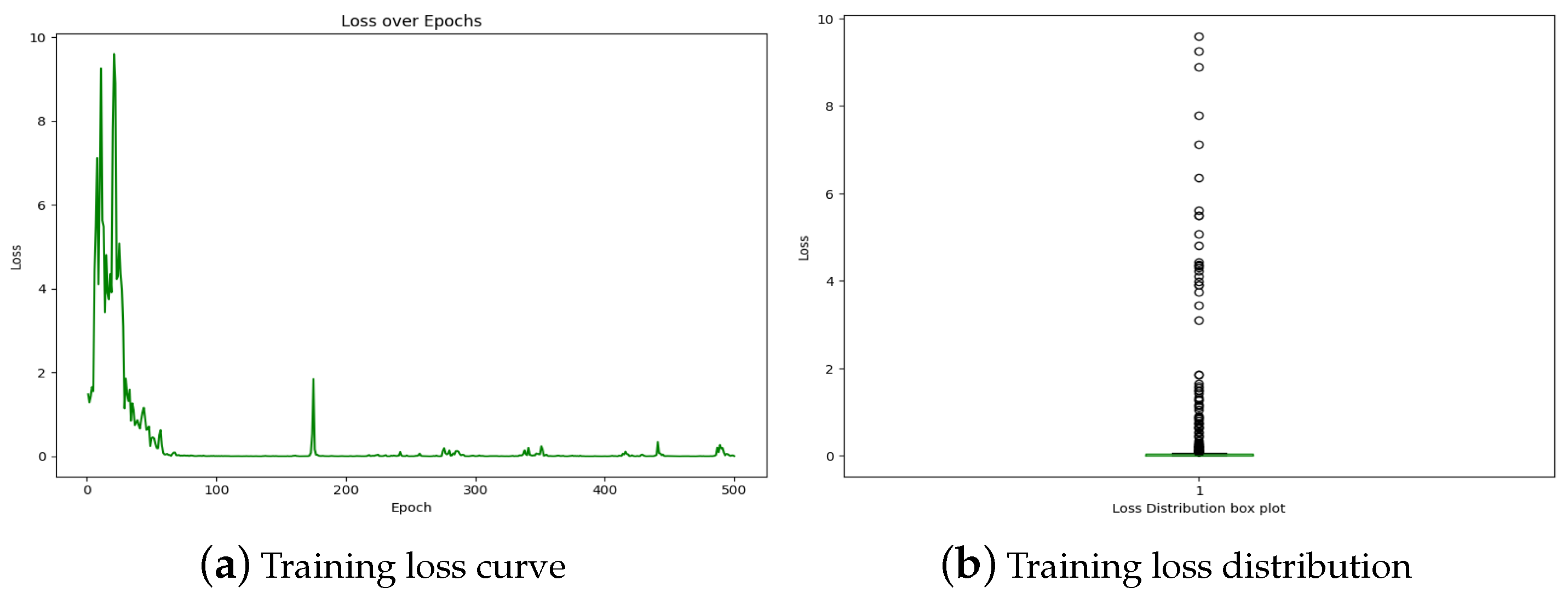
The downward trajectory of the loss curve in
Figure 18a indicates successful learning by the DRL agent, progressively minimizing prediction errors over the training epochs. Specifically, after 58 epochs, the loss becomes minimal, hovering close to zero with slight fluctuations observed between epochs 176 to 179. This pattern suggests that the trained model effectively identified and switched between the most suitable congestion control algorithms (CCAs) for current network conditions, thereby maintaining flow fairness and preventing starvation.
The corresponding box plot in
Figure 18b illustrates fluctuations in loss values, indicating challenges encountered during training. However, the fact that 88% of the loss distribution is negligible (close to zero) underscores the agent’s ability to develop a robust policy.
5.5.3. Training Accuracy
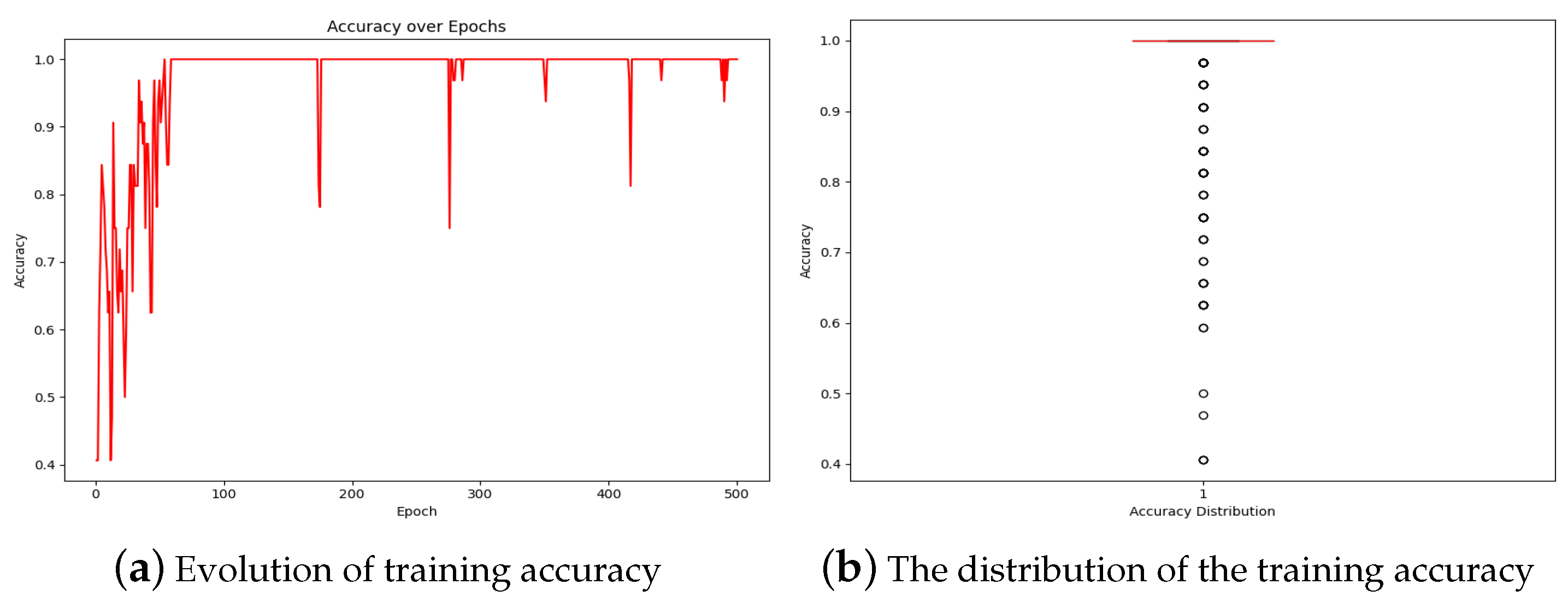
The accuracy graph in
Figure 19a shows an exponential upward trend, indicating highly accelerated improved decision-making by the DRL agent over time, with the model reaching 100% accuracy after the 60-epoch mark. As depicted in
Figure 19b, minor fluctuations and outliers were typical during training and did not significantly detract from the overall upward trajectory. The fact that 96.8% of epochs achieved 100% accuracy highlights the model’s capability to make precise decisions and switch to the best available CCAs. This trend suggests effective learning and policy improvement by the agent. However, the fluctuations in accuracy during training indicate that there is still room for improvement, which represents a limitation of this model.
5.6. Our Key Findings
Table 5 summarizes our key findings with the performance metrics of various CCAs over WiFi, comparing scenarios before and after switching the congestion control.
In Scenario 1, Client 1 (CUBIC) demonstrates superior throughput (79.44 Mbps) compared to Cleint 2 (BBR) before switching (4.08 Mbps), but at the cost of higher RTT (21.44 ms vs. 2.32 ms) and jitter (0.75 ms vs. 23.99 ms), with a packet loss of 12.8% versus BBR’s 19.35%. After switching, Client 1’s throughput decreased to 40.64 Mbps, while Client 2’s improved to 38.72 Mbps, with RTTs of 16.30 ms and 13.01 ms, respectively. In Scenario 2, Cleint 1 (PCC) exhibited higher throughput (77.36 Mbps) before switching compared to Client 2 (BBR) (12.32 Mbps) but sufferd from greater packet loss (48.97% vs. 11.83%). After switching, Client 1’s throughput decreased to 44 Mbps, while its packet loss improved to 9.22%, compared to Client 2’s throughput of 40.4 Mbps and loss of 7.21%. In Scenario 3, Client 1 (BBR) before switching shows a throughput of 20.48 Mbps and RTT of 13.40 ms, with a packet loss of 29.44%. Post-switching, BBR’s performance dramatically improved to 42.56 Mbps in throughput, 15.78 ms in RTT, and 7.20% in packet loss.
Table 5 highlights the varied impacts of different CCAs and switching on throughput, RTT, jitter, and packet loss, demonstrating the need for dynamic adaptation to optimize network performance. Upon reviewing several rigorous CCA studies in the field, including their driving principles, behaviors, and performance in different network conditions summarized in
Table 5, we draw the following findings:
Mitigating Non-Congestive Delay Variations: Delay-bounding CCAs aim to manage non-congestive delay variations by ensuring that delay adjustments comprise at least half the expected non-congestive jitter along the network path [
18]. If the delay oscillations fall below this threshold, the CCA may struggle to maintain high throughput, bounded delays, and fairness, potentially leading to inefficient network performance.
Characteristics and Thresholds for Network Design: CCAs should adjust delays by at least half the expected non-congestive delays to differentiate between congestion-related and other delays. Failing to meet this threshold can cause the CCA to struggle with throughput, delay management, and fairness [
18].
Dynamic Switching of CCAs and Insights into Fairness and Stability: This study reveals that throughput unfairness persists within the same CCA, influenced by network path characteristics. Dynamically switching between CCAs based on network conditions can improve fairness and stability. These findings highlight the potential of using Deep Reinforcement Learning to adapt CCAs dynamically for better network performance and fairness.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}