
Predictive Maintenance Based on Identity Resolution and Transformers in IIoT


Abstract
1. Introduction
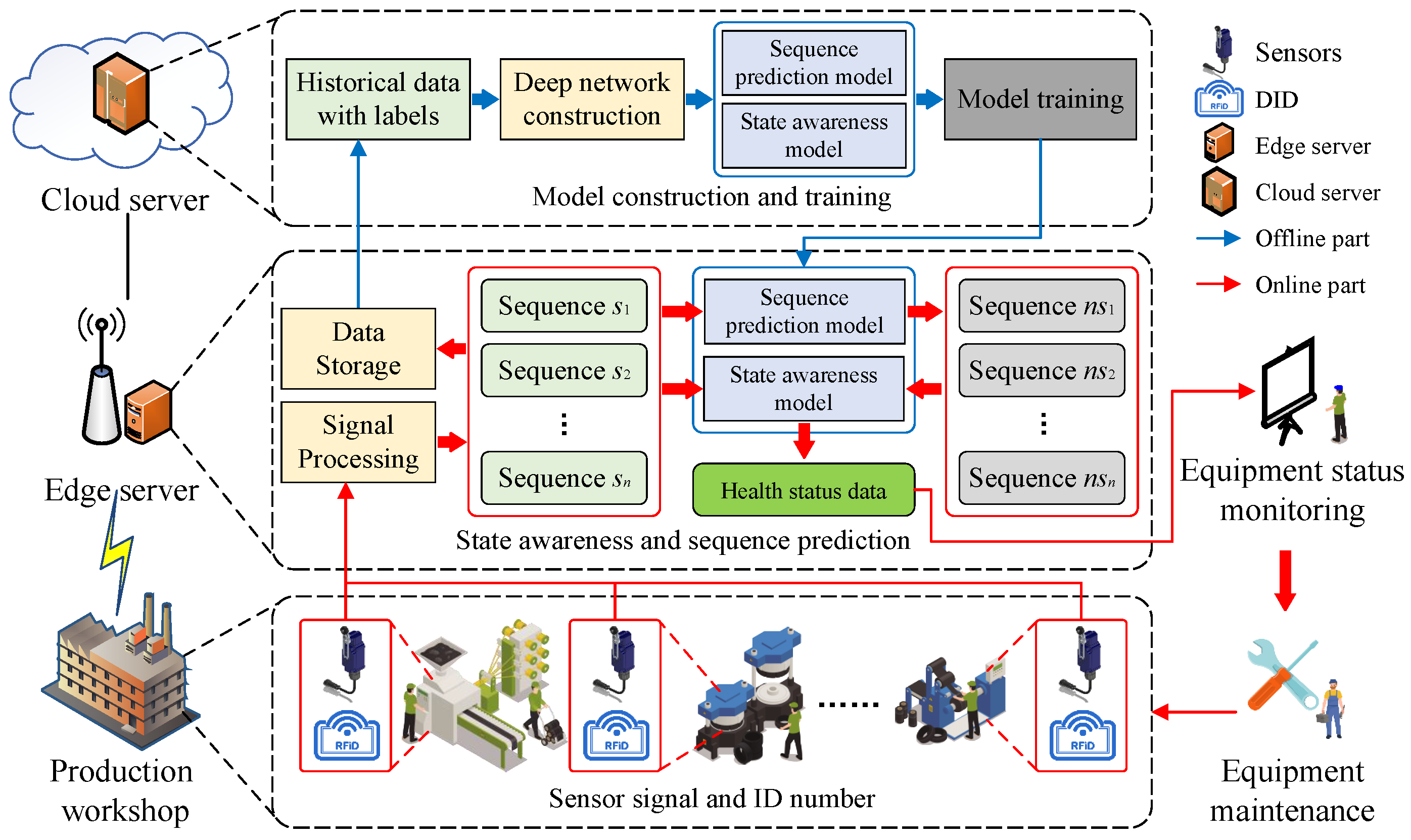
- This paper presents a real-time predictive maintenance framework ITPM based on the transformer model and outlines its implementation. The ITPM consists of two main components: the state awareness model (SAM) and the sequence prediction model (SPM). These models work collaboratively to analyze the current sensor data of equipment and predict future states, enabling proactive maintenance decisions and preventing machine breakdowns.
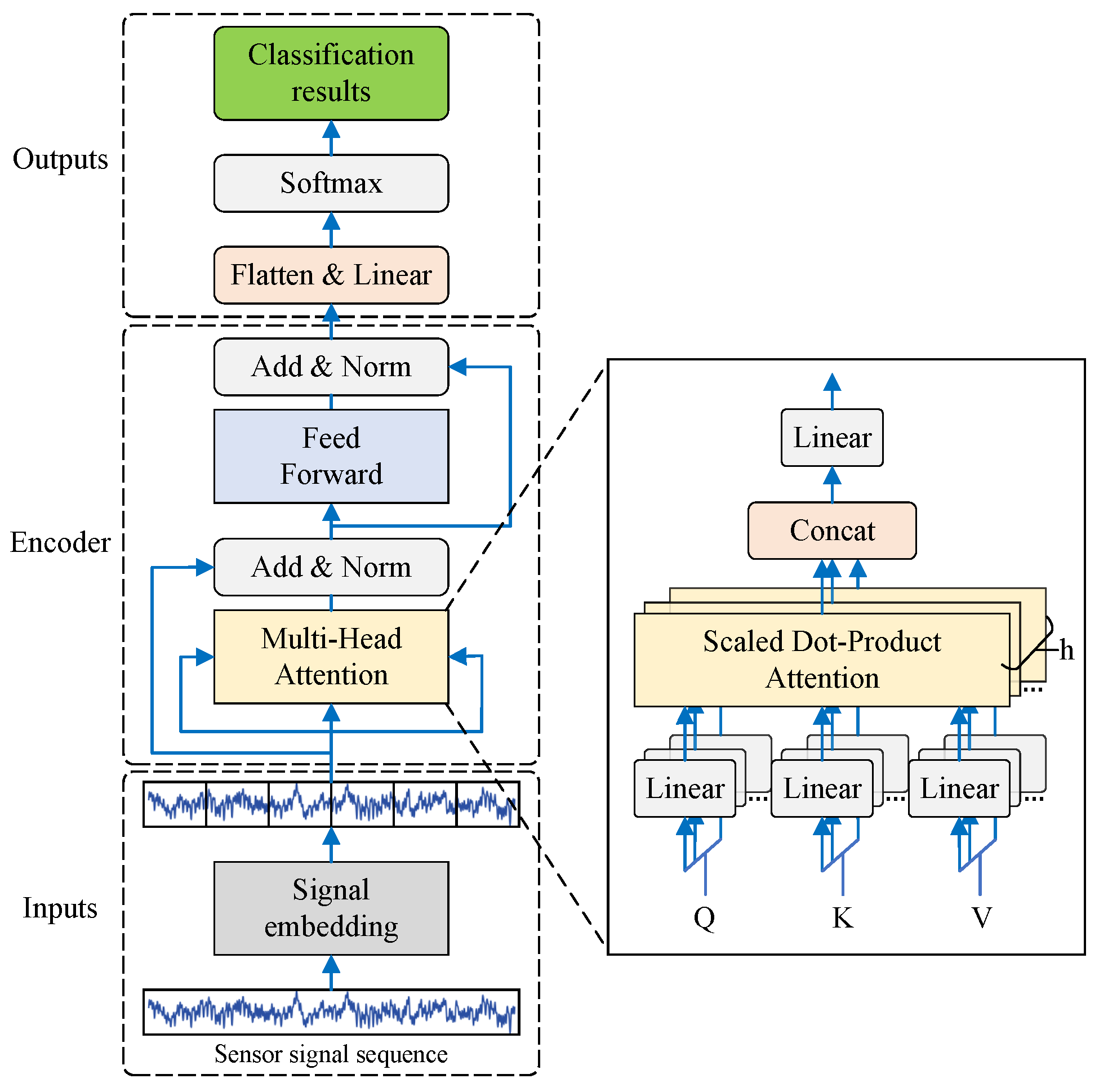
- The SAM utilizes a self-attention structure to evaluate the states of equipment in a production workshop. The input sequence comprises the data collected from sensors attached to the equipment. These data are fed into the model, which employs self-attention to weigh the significance of different parts of the input sequence. The output of the SAM is a classification category that reflects the states of equipment.
- By leveraging the self-attention mechanism, the SPM can detect patterns and dependencies in the input data that may be difficult for other models to capture. The predicted sequences are subsequently utilized by a state-sensing model that performs pre-sensing to monitor the current condition of the facility and predict future states.
2. Related Works
2.1. Equipment Condition Detection
2.2. Equipment Condition Prediction
3. System Overview and Identity Resolution
3.1. System Environment
3.2. Identity Resolution
4. Proposed Framework for Predictive Maintenance
4.1. State Awareness Model
4.2. Sequence Prediction Model
4.3. Association between SAM and SPM
5. Evaluation
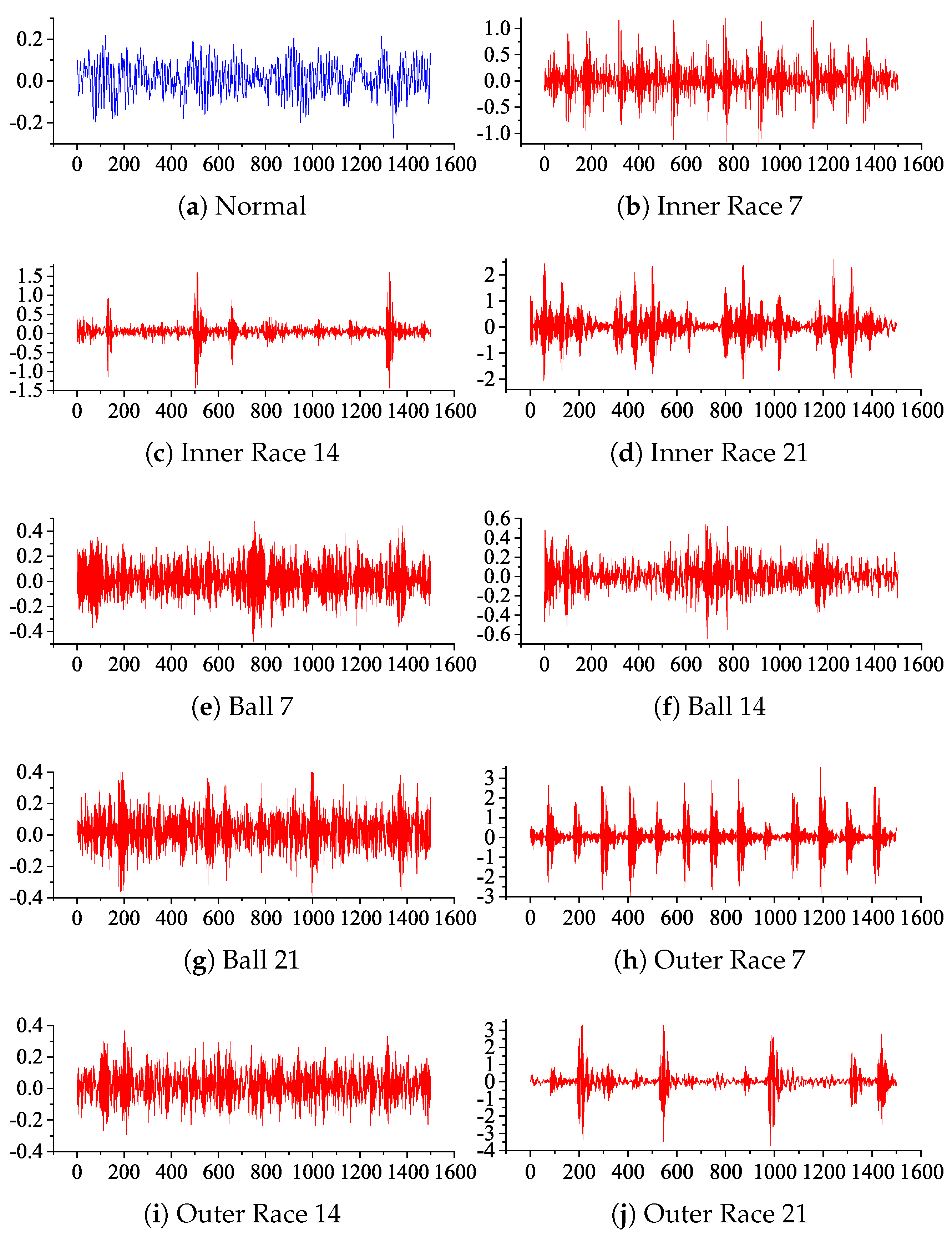
5.1. Dataset Construction
5.2. Experimental Settings
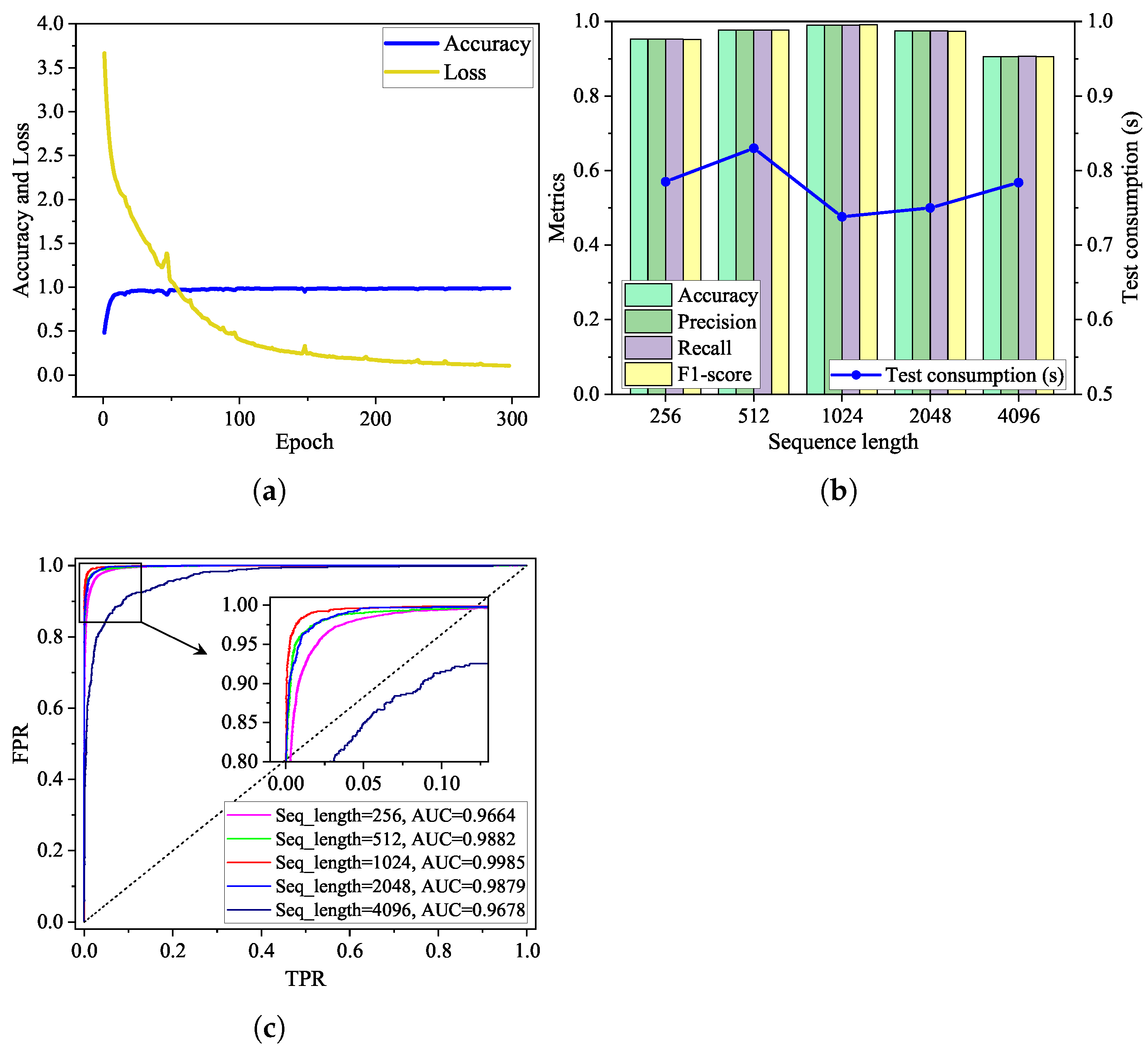
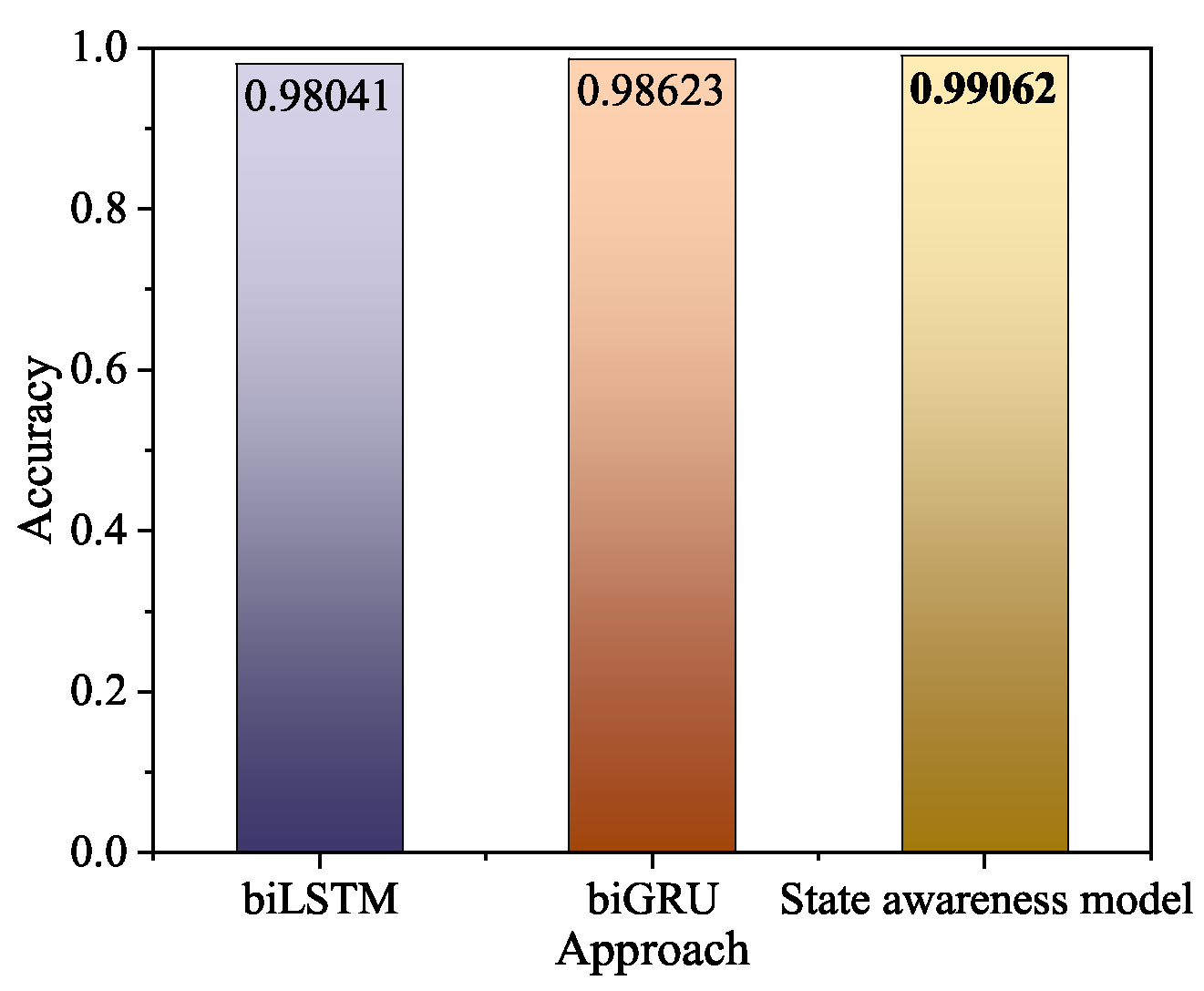
5.3. Experiments on State Awareness Model
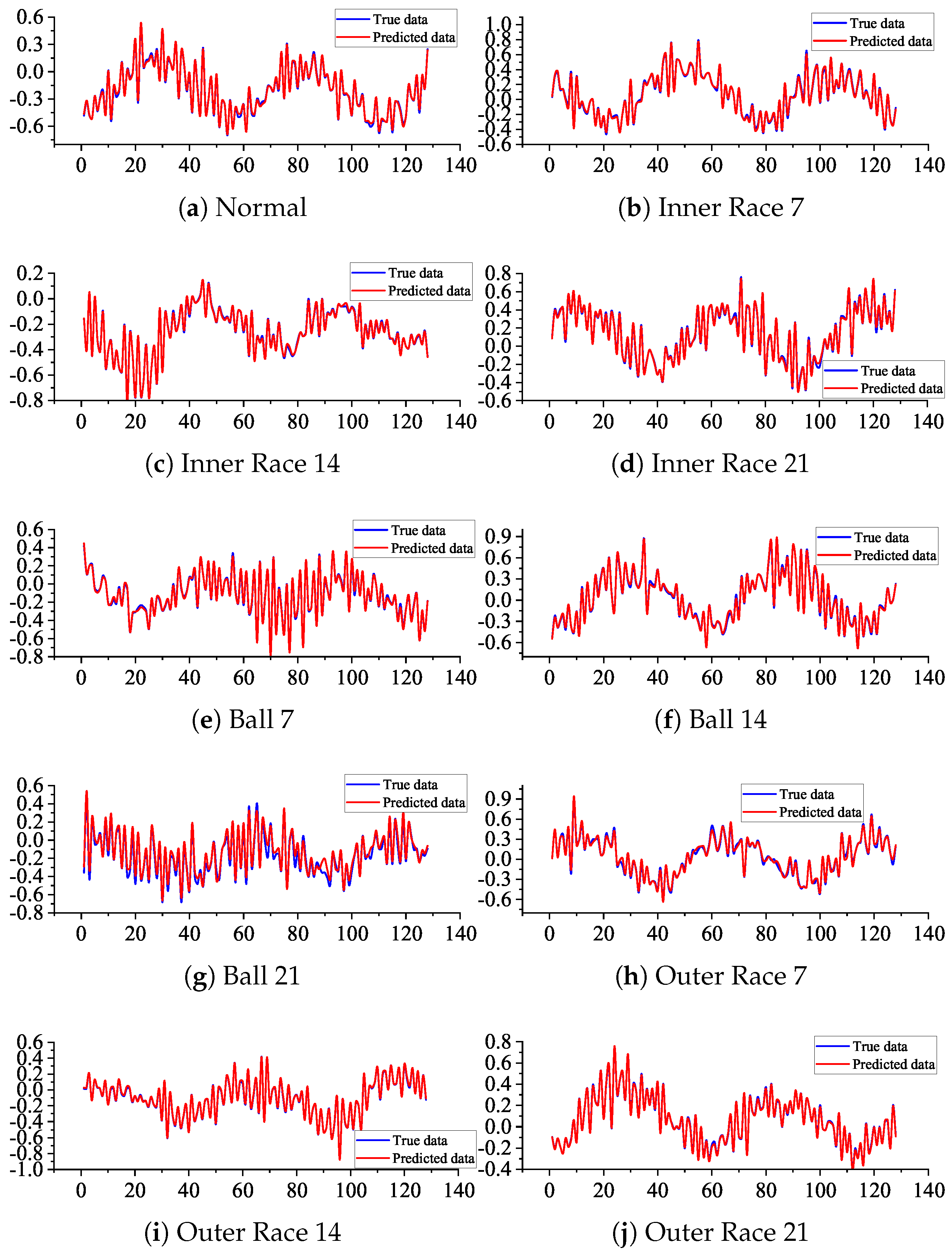
5.4. Experiments on Sequence Prediction Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Zhang, W.; Yang, D.; Wang, H. Data-Driven Methods for Predictive Maintenance of Industrial Equipment: A Survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Wei, D.; Liu, D.; Xiao, Z.; Xia, X.; Malik, O.P. Fault diagnosis for rotor based on multi-sensor information and progressive strategies. Meas. Sci. Technol. 2023, 34, 065111. [Google Scholar] [CrossRef]
- Wang, Z.; Wen, C.; Dong, Y. A method for rolling bearing fault diagnosis based on GSC-MDRNN with multi-dimensional input. Meas. Sci. Technol. 2023, 34, 055901. [Google Scholar] [CrossRef]
- de Rezende, S.W.F.; Barella, B.P.; Moura, J.R.V.; Tsuruta, K.M.; Cavalini, A.A.; Steffen, V. ISHM for fault condition detection in rotating machines with deep learning models. J. Braz. Soc. Mech. Sci. Eng. 2023, 45, 212. [Google Scholar] [CrossRef]
- Demetgul, M.; Zihan, M.; Heider, I.; Fleischer, J. Misalignment detection on linear feed axis using sensorless motor current signals. Int. J. Adv. Manuf. Technol. 2023, 126, 2677–2691. [Google Scholar] [CrossRef]
- Feng, R.; Du, H.; Du, T.; Wu, X.; Yu, H.; Zhang, K.; Huang, C.; Cao, L. Fault diagnosis for wind turbines based on LSTM and feature optimization strategies. Concurr. Comput. Pract. Exp. 2024, 36, e7886. [Google Scholar] [CrossRef]
- Xu, X.; Guo, H.; Zhang, Z.; Shi, P.; Huang, W.; Li, X.; Brunauer, G. Fault diagnosis method via one vs. rest evidence classifier considering imprecise feature samples. Appl. Soft Comput. 2024, 161, 111761. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Curran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 27730–27744. [Google Scholar] [CrossRef]
- Teoh, Y.K.; Gill, S.S.; Parlikad, A.K. IoT and Fog-Computing-Based Predictive Maintenance Model for Effective Asset Management in Industry 4.0 Using Machine Learning. IEEE Internet Things J. 2023, 10, 2087–2094. [Google Scholar] [CrossRef]
- Wang, B.; Qiu, W.; Hu, X.; Wang, W. A rolling bearing fault diagnosis technique based on recurrence quantification analysis and Bayesian optimization SVM. Appl. Soft Comput. 2024, 156, 111506. [Google Scholar] [CrossRef]
- Liu, X.; Cai, B.; Yuan, X.; Shao, X.; Liu, Y.; Akbar Khan, J.; Fan, H.; Liu, Y.; Liu, Z.; Liu, G. A hybrid multi-stage methodology for remaining useful life prediction of control system: Subsea Christmas tree as a case study. Expert Syst. Appl. 2023, 215, 119335. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Y.; Huang, Q.; Zhou, Y. Intelligent Fault Prognosis Method Based on Stacked Autoencoder and Continuous Deep Belief Network. Actuators 2023, 12, 117. [Google Scholar] [CrossRef]
- Liu, J.; Hao, R.; Liu, Q.; Guo, W. Prediction of remaining useful life of rolling element bearings based on LSTM and exponential model. Int. J. Mach. Learn. Cybern. 2023, 14, 1567–1578. [Google Scholar] [CrossRef]
- Zheng, G.; Li, Y.; Zhou, Z.; Yan, R. A Remaining Useful Life Prediction Method of Rolling Bearings Based on Deep Reinforcement Learning. IEEE Internet Things J. 2024, 11, 22938–22949. [Google Scholar] [CrossRef]
- Cen, Z.; Hu, S.; Hou, Y.; Chen, Z.; Ke, Y. Remaining useful life prediction of machinery based on improved Sample Convolution and Interaction Network. Eng. Appl. Artif. Intell. 2024, 135, 108813. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, H. Quantile regression network-based cross-domain prediction model for rolling bearing remaining useful life. Appl. Soft Comput. 2024, 159, 111649. [Google Scholar] [CrossRef]
- Ren, Y.; Xie, R.; Yu, F.R.; Huang, T.; Liu, Y. Potential Identity Resolution Systems for the Industrial Internet of Things: A Survey. IEEE Commun. Surv. Tutorials 2021, 23, 391–430. [Google Scholar] [CrossRef]
- Huo, R.; Zeng, S.; Di, Y.; Cheng, X.; Huang, T.; Yu, F.R.; Liu, Y. A Blockchain-Enabled Trusted Identifier Co-Governance Architecture for the Industrial Internet of Things. IEEE Commun. Mag. 2022, 60, 66–72. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Liu, Y.; Jia, X.; Shen, L.; Ming, Z.; Duan, J. Local Normalization Based BN Layer Pruning. In Artificial Neural Networks and Machine Learning-ICANN 2019: DEEP LEARNING, PT II, Lecture Notes in Computer Science, Proceedings of the 28th International Conference on Artificial Neural Networks (ICANN), Tech Univ Munchen, Klinikum Rechts Isar, Munich, Germany, 17–19 September 2019; Tetko, I., Kurkova, V., Karpov, P., Theis, F., Eds.; Springer: Cham, Switzerland, 2019; Volume 11728, pp. 334–346. [Google Scholar] [CrossRef]
- Hendriks, J.; Dumond, P.; Knox, D.A. Towards better benchmarking using the CWRU bearing fault dataset. Mech. Syst. Signal Process. 2022, 169, 108732. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Significance |
|---|---|
| F | The set of facilities |
| E | The edge server |
| T | The set of time periods |
| The ID set of devices | |
| The embedded matrix of sensor signals | |
| The inputs of scaled dot-product attention | |
| Sdp | The outputs of scaled dot-product attention |
| Multi-head | The outputs of multi-head attention |
| FF | The outputs of feed forward layer |
| The health condition | |
| R | The residual connection |
| The means and variances of layer normalization |
| Sequence Length | Data Volume | Time Consumption (s) | Metrics (Testing) | ||||
|---|---|---|---|---|---|---|---|
| Train | Test | Accuracy | Precision | Recall | F1-Score | ||
| 256 | 18,880 | 36,223.014 | 0.785 | 95.306% | 95.252% | 95.227% | 0.952 |
| 512 | 16,100 | 4538.319 | 0.830 | 97.696% | 97.753% | 97.705% | 0.977 |
| 1024 | 16,080 | 1511.606 | 0.738 | 99.062% | 99.049% | 99.053% | 0.991 |
| 2048 | 16,050 | 1526.244 | 0.750 | 97.438% | 97.448% | 97.473% | 0.974 |
| 4096 | 15,980 | 2110.378 | 0.784 | 90.598% | 90.613% | 90.681% | 0.906 |
| Method | Epoch | Number of Species | Accuracy |
|---|---|---|---|
| biLSTM | 300 | 10 | 98.041% |
| biGRU | 98.623% | ||
| SAM | 99.062% |
| Sequence Length | Data Volume | Time Consumption (s) | Metrics (Testing) | ||
|---|---|---|---|---|---|
| Train | Test | RMSE | MAE | ||
| 256 | 18,880 | 9656.101 | 1.418 | 25.050 | 0.629 |
| 512 | 16,100 | 10,699.200 | 1.416 | 17.986 | 1.088 |
| 1024 | 16,080 | 3081.609 | 1.268 | 14.522 | 2.235 |
| 2048 | 16,050 | 4527.055 | 1.382 | 21.917 | 4.637 |
| 4096 | 15,980 | 6093.705 | 1.392 | 33.890 | 8.693 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Z.; Du, L.; Huo, R.; Huang, T. Predictive Maintenance Based on Identity Resolution and Transformers in IIoT. Future Internet 2024, 16, 310. https://doi.org/10.3390/fi16090310
Qi Z, Du L, Huo R, Huang T. Predictive Maintenance Based on Identity Resolution and Transformers in IIoT. Future Internet. 2024; 16(9):310. https://doi.org/10.3390/fi16090310
Chicago/Turabian StyleQi, Zhibo, Lei Du, Ru Huo, and Tao Huang. 2024. "Predictive Maintenance Based on Identity Resolution and Transformers in IIoT" Future Internet 16, no. 9: 310. https://doi.org/10.3390/fi16090310
APA StyleQi, Z., Du, L., Huo, R., & Huang, T. (2024). Predictive Maintenance Based on Identity Resolution and Transformers in IIoT. Future Internet, 16(9), 310. https://doi.org/10.3390/fi16090310