
Evaluation of a New-Concept Secure File Server Solution




Abstract
1. Introduction
2. Background
2.1. Review of File System-Related Security Solutions and Research
2.2. State-of-the-Art Malware Prevention Techniques
3. Research Methodology
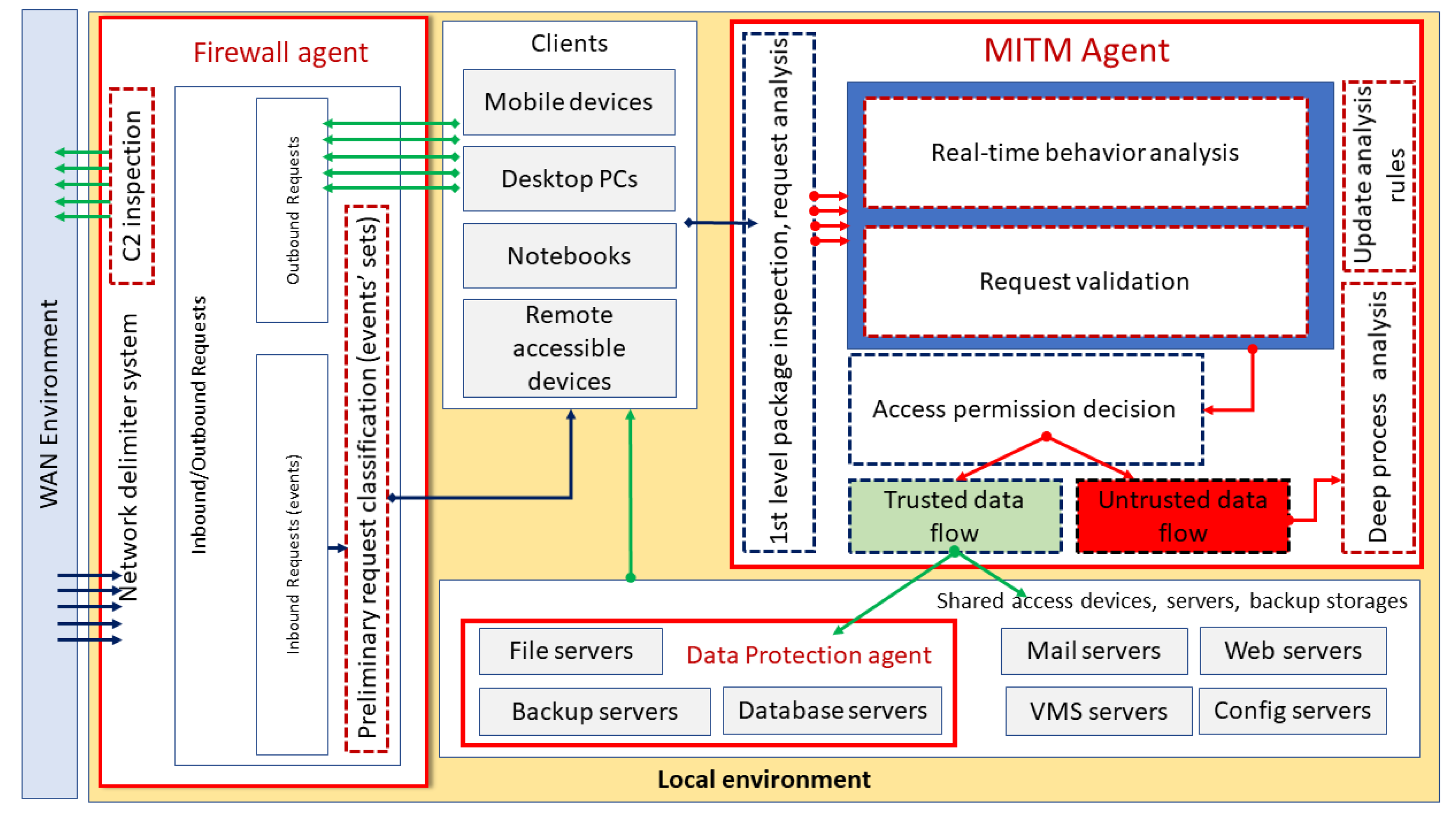
3.1. The ARDS System and Study Questions
3.2. Methodology of the Performance Tests
3.2.1. Examined Structures
- {TE-01}: Windows 7 client—ARDS TestServer
- {TE-02}: Windows 7 client—Windows 2019 Server
- {TE-03}: Windows 10 client—ARDS TestServer
- {TE-04}: Windows 10 client—Windows 2019 Server
- {TE-05}: Ubuntu 22.04 client—ARDS TestServer
- {TE-06}: Ubuntu 22.04 client—Windows 2019 Server
3.2.2. Defining the Data Set to Be Used for Measurement
- 1 × 1 GiB
- 4 × 256 MiB
- 256 × 4 MiB
- 2097 × 500 kiB
3.2.3. Reducing the Uncertainty of the Measurements and Filtering Out Measurement Errors
- Read/write buffer management (filling up, emptying);
- Initial indexing of files;
- The network throughput sometimes exceeded the theoretical maximal bandwidth of the SATA3 interface (10 Gbit/s vs. 6 Gbit/s), which could lead to uncertainty due to different caching mechanisms;
- Minor fluctuations in read/write speed of SSD drives;
- The performance impact of other running processes.
3.2.4. Ensuring Reproducibility
3.2.5. Methodology for Evaluating the Results
4. Results
4.1. Results on 1 Gbit/s Connection
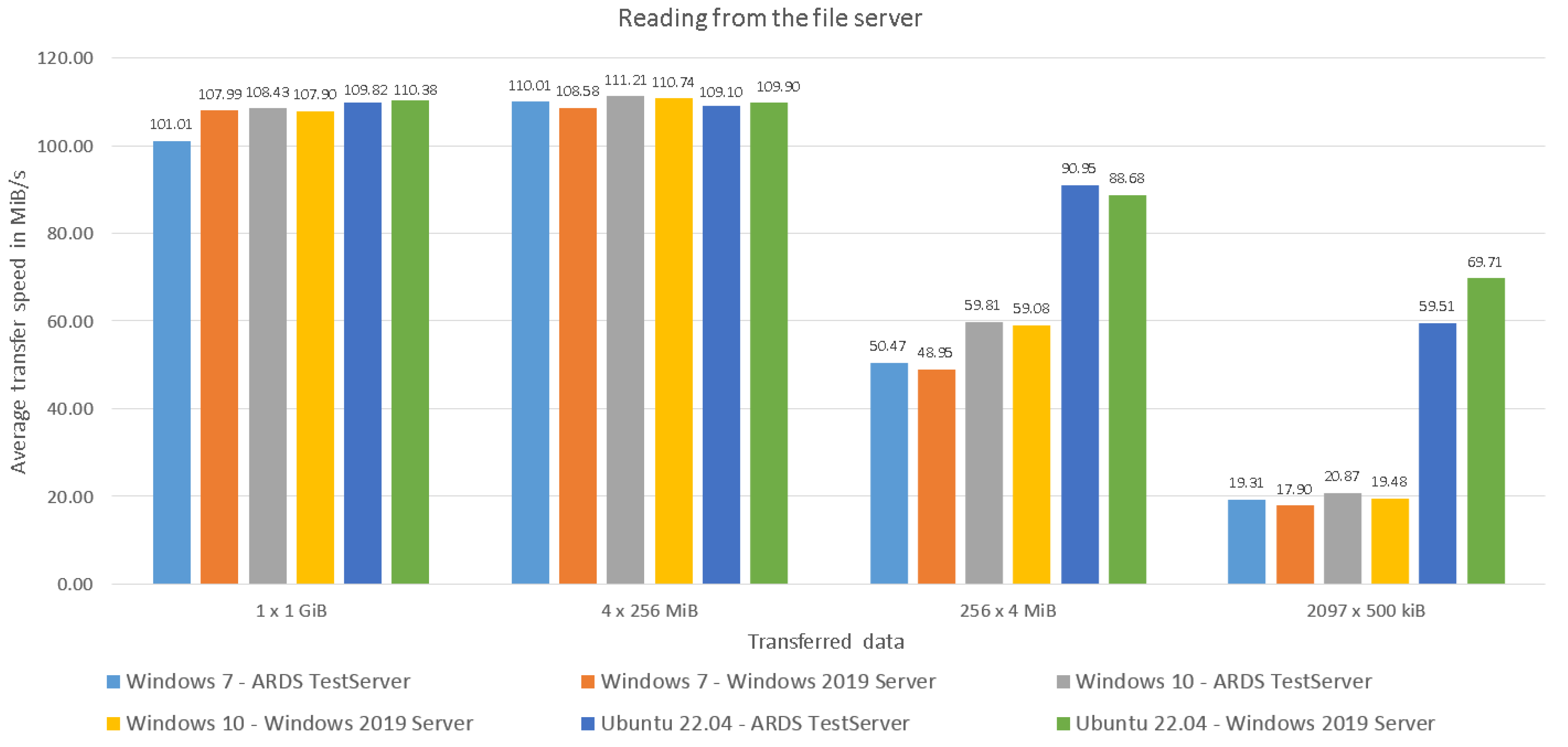
4.1.1. Results of Reading Performance Tests on 1 Gbit/s Connection
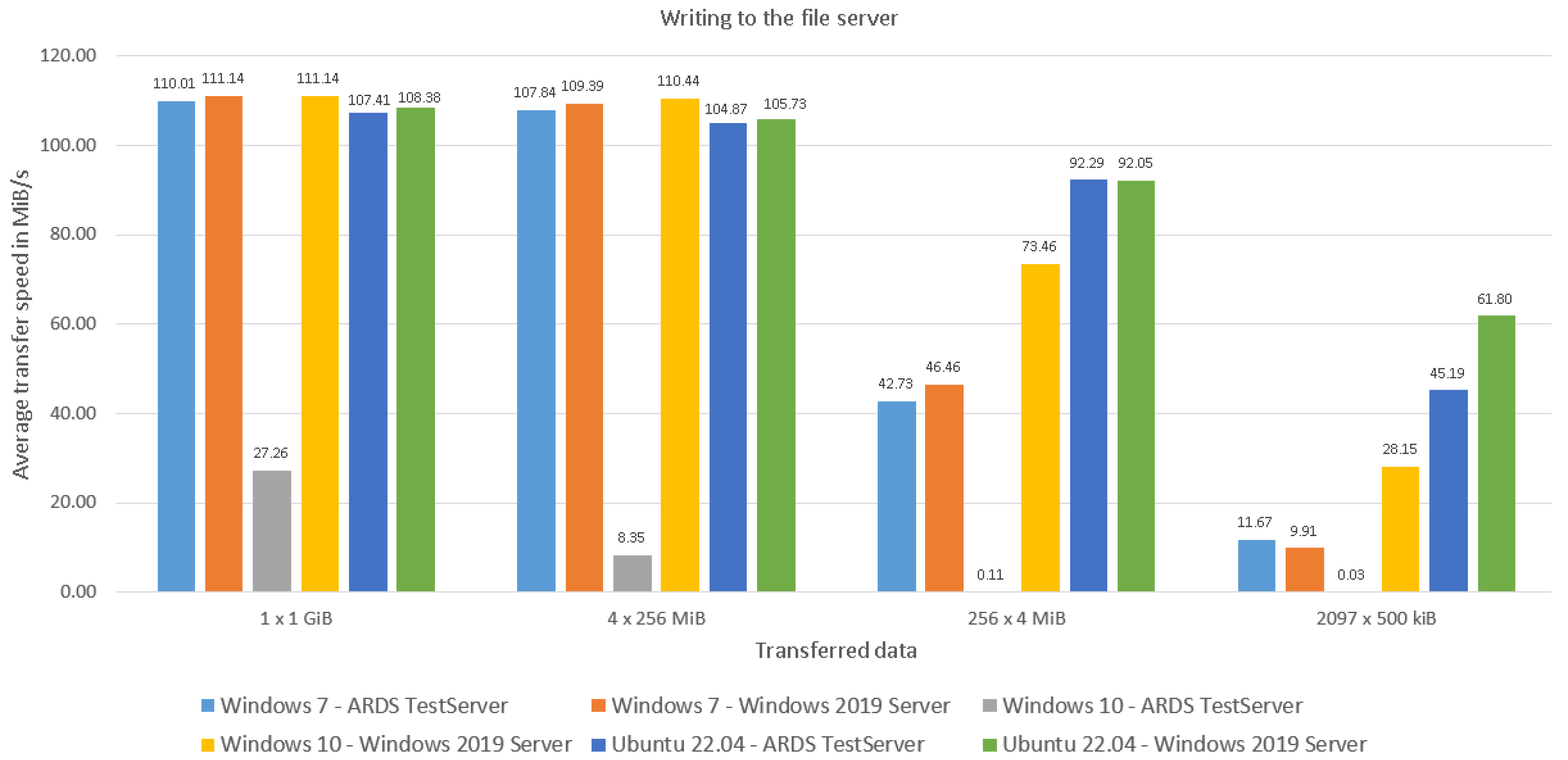
4.1.2. Results of Writing Performance Tests on 1 Gbit/s Connection
4.2. Results for 10 Gbit/s Connection
4.2.1. Results of Reading Tests on 10 Gbit/s Connection
4.2.2. Results of Writing Tests on 10 Gbit/s Connection
4.3. Reference-Based Performance Evaluation
5. Discussion
6. Summary
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ARDS | Anti-Ransomware Defense System |
| CPU | Central Processing Unit |
| DAC | Direct Attached Cable |
| ECC-RAM | Error Correction Code Random Access Memory |
| GPO | Group Policy Object |
| HDFS | Hadoop Distributed File System |
| ICN | Information Centered Networking |
| LIRS | Low Inter-reference Recency Set |
| NDN | Named Data Networking |
| NIC | Network Interface Card |
| OS | Operating System |
| RaaS | Ransomware-as-a-Service |
| SATA | Serial Advanced Technology Attachment |
| SFP | Small Form-factor Pluggable network interface |
| SMB | Server Message Block |
| SME | Small and Medium-sized Enterprises |
| SSD | Solid State Drive |
| VSS | Volume Shadow Copy Service |
Appendix A. Scripts
Appendix A.1. Script to Generate Sample Files for Measurements
Appendix A.2. Script to Manage File Transfer on Windows Clients
Appendix A.3. Script to Manage File Transfer on Ubuntu Clients
References
- Ferdous, J.; Islam, R.; Mahboubi, A.; Islam, M.Z. A Review of State-of-the-Art Malware Attack Trends and Defense Mechanisms. IEEE Access 2023, 11, 121118–121141. [Google Scholar] [CrossRef]
- Ngo, F.T.; Agarwal, A.; Govindu, R.; MacDonald, C. Malicious Software Threats. In The Palgrave Handbook of International Cybercrime and Cyberdeviance; Holt, T.J., Bossler, A.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 793–813. [Google Scholar] [CrossRef]
- Vanness, R.; Chowdhury, M.M.; Rifat, N. Malware: A Software for Cybercrime. In Proceedings of the 2022 IEEE International Conference on Electro Information Technology (eIT), Mankato, MN, USA, 19–21 May 2022; pp. 513–518. [Google Scholar] [CrossRef]
- Microsoft. Troubleshooting Slow File Copying in Windows. 2022. Available online: https://learn.microsoft.com/en-us/troubleshoot/windows-client/performance/troubleshooting-slow-file-copying-in-windows (accessed on 28 February 2023).
- FBI. Ransomware. 2023. Available online: https://www.fbi.gov/how-we-can-help-you/safety-resources/scams-and-safety/common-scams-and-crimes/ransomware (accessed on 28 February 2023).
- Gabrielle, H.; Mikiann, M. Healthcare Ransomware Attacks: Understanding the Problem and How to Protect Your Organization. LogRhythm. 2024. Available online: https://logrhythm.com/blog/healthcare-ransomware-attacks/ (accessed on 22 August 2024).
- Liang, J.; Guan, X. A virtual disk environment for providing file system recovery. Comput. Secur. 2006, 25, 589–599. [Google Scholar] [CrossRef]
- Gaonkar, S.; Keeton, K.; Merchant, A.; Sanders, W. Designing dependable storage solutions for shared application environments. In Proceedings of the International Conference on Dependable Systems and Networks (DSN’06), Philadelphia, PA, USA, 25–28 June 2006; pp. 371–382. [Google Scholar] [CrossRef]
- Van Oorschot, P.C.; Wurster, G. Reducing Unauthorized Modification of Digital Objects. IEEE Trans. Softw. Eng. 2012, 38, 191–204. [Google Scholar] [CrossRef]
- Chervyakov, N.; Babenko, M.; Tchernykh, A.; Kucherov, N.; Miranda-López, V.; Cortés-Mendoza, J.M. AR-RRNS: Configurable reliable distributed data storage systems for Internet of Things to ensure security. Future Gener. Comput. Syst. 2019, 92, 1080–1092. [Google Scholar] [CrossRef]
- Verma, R.; Mendez, A.; Park, S.; Mannarswamy, S.; Kelly, T.; Morrey, C.B., III. Failure-Atomic Updates of Application Data in a Linux File System. In Proceedings of the 13th USENIX Conference on File and Storage Technologies (FAST ’15), Santa Clara, CA, USA, 16–19 February 2015; pp. 606–614. [Google Scholar]
- Newberry, E.; Zhang, B. On the Power of In-Network Caching in the Hadoop Distributed File System. In Proceedings of the 6th ACM Conference on Information-Centric Networking, New York, NY, USA, 24–26 September 2019; ICN ’19. pp. 89–99. [Google Scholar] [CrossRef]
- Makris, A.; Kontopoulos, I.; Psomakelis, E.; Xyalis, S.N.; Theodoropoulos, T.; Tserpes, K. Performance Analysis of Storage Systems in Edge Computing Infrastructures. Appl. Sci. 2022, 12, 8923. [Google Scholar] [CrossRef]
- IBM. IBM Security QRadar XDR. 2023. Available online: https://www.ibm.com/qradar (accessed on 28 February 2023).
- Bitdefender GravityZone Business Security Premium. 2023. Available online: https://www.bitdefender.com/business/products/gravityzone-premium-security.html (accessed on 28 February 2023).
- The Industry’s Most Sophisticated Endpoint Security Solution. Available online: https://www.sophos.com/en-us/products/endpoint-antivirus (accessed on 22 August 2024).
- Trend Micro Incorporated. Propel Security Operations Forward. 2023. Available online: https://www.trendmicro.com/en_us/business/products/security-operations.html (accessed on 28 February 2023).
- Szücs, V.; Arányi, G.; Dávid, Á. Introduction of the ARDS—Anti-Ransomware Defense System Model—Based on the Systematic Review of Worldwide Ransomware Attacks. Appl. Sci. 2021, 11, 6070. [Google Scholar] [CrossRef]
- KnowBe4. What Is Phishing? 2022. Available online: https://www.phishing.org/ (accessed on 28 February 2023).
- Vaas, L. Widespread, Easily Exploitable Windows RDP Bug Opens Users to Data Theft. 2022. Available online: https://threatpost.com/windows-bug-rdp-exploit-unprivileged-users/177599/ (accessed on 28 February 2023).
- GeekPage. Fix Slow File Copy Speed in Windows 10/11. 2022. Available online: https://thegeekpage.com/fix-slow-file-copy-speed-in-windows-10/ (accessed on 28 February 2023).
- AOMEI. Windows 10 File Copy/Transfer Very Slow. 2022. Available online: https://www.ubackup.com/windows-10/windows-10-file-copy-slow-1021.html (accessed on 28 February 2023).
- Natalie, P. Remote Desktop Protocol Use in Ransomware Attacks. 2021. Available online: https://rhisac.org/ransomware/remote-desktop-protocol-use-in-ransomware-attacks/ (accessed on 28 February 2023).
- Synology. What Can I Do When the File Transfer via Windows (SMB/CIFS) Is Slow? 2022. Available online: https://kb.synology.com/hu-hu/DSM/tutorial/What_can_I_do_when_the_file_transfer_via_Windows_SMB_CIFS_is_slow (accessed on 28 February 2023).
- Ye, X.; Zhai, Z.; Li, X. ZDC: A Zone Data Compression Method for Solid State Drive Based Flash Memory. Symmetry 2020, 12, 623. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solution/Working Environ. | Capabilities/Services of Proposed Solutions | ||||||
|---|---|---|---|---|---|---|---|
| Full File System Recovery | Single File Recovery | Operation Validation | Error Correction/Detection | Overhead | Recovery Speed | ||
| Liang, J. et al. [7] | FSR VDE | yes yes | no yes | no no | no no | high low | low high |
| Gaonkar, S. et al. [8] | Automated approach | no | yes | no | no | medium | config. depend. |
| Van Oorschot, P.C. et al. [9] | Rootkit resistant mechanism | no | no | yes | yes | medium | no data |
| Chervyakov N. et al. [10] | RRNS—AR-RRNA | no | yes | yes (file op./enc.) | yes | medium | high |
| Verma, R. et al. [11] | AdvFS—CMADD solution | no | yes | yes | error detection | medium | tolerable |
| Files | ||||
|---|---|---|---|---|
| 1 × 1 GiB | 4 × 256 MiB | 256 × 4 MiB | 2097 × 500 kiB | |
| Test ID | Average Transfer Speed in MiB/s | |||
| Windows 7—ARDS TestServer | 101.01 | 110.01 | 50.47 | 19.31 |
| Windows 7—Windows 2019 Server | 107.99 | 108.58 | 48.95 | 17.90 |
| Windows 10—ARDS TestServer | 108.43 | 111.21 | 59.81 | 20.87 |
| Windows 10—Windows 2019 Server | 107.90 | 110.74 | 59.08 | 19.48 |
| Ubuntu 22.04—ARDS TestServer | 109.82 | 109.10 | 90.95 | 59.51 |
| Ubuntu 22.04—Windows 2019 Server | 110.38 | 109.90 | 88.68 | 69.71 |
| Files | ||||
|---|---|---|---|---|
| 1 × 1 GiB | 4 × 256 MiB | 256 × 4 MiB | 2097 × 500 kiB | |
| Test ID | Average Transfer Speed in MiB/s | |||
| Windows 7—ARDS TestServer | 110.01 | 107.84 | 42.73 | 11.67 |
| Windows 7—Windows 2019 Server | 111.14 | 109.39 | 46.46 | 9.91 |
| Windows 10—ARDS TestServer | 27.26 | 8.35 | 0.11 | 0.03 |
| Windows 10—Windows 2019 Server | 111.14 | 110.44 | 73.46 | 28.15 |
| Ubuntu 22.04—ARDS TestServer | 107.45 | 104.87 | 92.29 | 45.15 |
| Ubuntu 22.04—Windows 2019 Server | 108.38 | 105.73 | 92.05 | 61.80 |
| Files | ||||
|---|---|---|---|---|
| 1 × 1 GiB | 4 × 256 MiB | 256 × 4 MiB | 2097 × 500 kiB | |
| Test ID | Average Transfer Speed in MiB/s | |||
| Windows 10—ARDS TestServer | 961.41 | 796.50 | 144.62 | 39.97 |
| Windows 10—Windows 2019 Server | 759.98 | 689.00 | 184.00 | 42.87 |
| Ubuntu 22.04—ARDS TestServer | 1020.51 | 998.14 | 620.99 | 208.60 |
| Ubuntu 22.04—Windows 2019 Server | 630.24 | 634.34 | 304.59 | 154.75 |
| Files | ||||
|---|---|---|---|---|
| 1 × 1 GiB | 4 × 256 MiB | 256 × 4 MiB | 2097 × 500 kiB | |
| Test ID | Average Transfer Speed in MiB/s | |||
| Windows 10—ARDS TestServer | 268.08 | 252.94 | 180.35 | 75.64 |
| Windows 10—Windows 2019 Server | 810.08 | 816.61 | 234.18 | 59.35 |
| Ubuntu 22.04—ARDS TestServer | 303.69 | 328.22 | 233.43 | 150.84 |
| Ubuntu 22.04—Windows 2019 Server | 843.81 | 844.27 | 558.02 | 322.65 |
| Files | ||||
|---|---|---|---|---|
| 1 × 1 GiB | 4 × 256 MiB | 256 × 4 MiB | 2097 × 500 kiB | |
| Reading test results | ||||
| Windows 7—ARDS TestServer/ | ||||
| Windows 7—Windows 2019 Server | 1.0723 (=) | 0.9872 (+) | 0.9703 (+) | 0.9078 (+) |
| Windows 10—ARDS TestServer/ | ||||
| Windows 10—Windows 2019 Server | 0.9958 (+) | 0.9957 (+) | 0.9873 (+) | 0.9363 (+) |
| Ubuntu 22.04—ARDS TestServer/ | ||||
| Ubuntu 22.04—Windows 2019 Server | 1.0043 (=) | 1.0075 (−) | 0.9749 (+) | 1.1715 (−) |
| Writing test results | ||||
| Windows 7—ARDS TestServer/ | ||||
| Windows 7—Windows 2019 Server | 1.0109 (=) | 1.0150 (=) | 1.0947 (=) | 0.8491 (+) |
| Windows 10—ARDS TestServer/ | ||||
| Windows 10—Windows 2019 Server | 4.0782 (−) | 13.2265 (−) | 683.8709 (−) | 878.7343 (−) |
| Ubuntu 22.04—ARDS TestServer/ | ||||
| Ubuntu 22.04—Windows 2019 Server | 1.0085 (=) | 1.0072 (=) | 0.9973 (+) | 1.3681 (−) |
| Files | ||||
|---|---|---|---|---|
| 1 × 1 GiB | 4 × 256 MiB | 256 × 4 MiB | 2097 × 500 kiB | |
| Reading test results | ||||
| Windows 10—ARDS TestServer/ | ||||
| Windows 10—Windows 2019 Server | 0.7809 (+) | 0.8672 (+) | 1.2733 (−) | 1.0728 (=) |
| Ubuntu 22.04—ARDS TestServer/ | ||||
| Ubuntu 22.04—Windows 2019 Server | 0.6134 (+) | 0.6199 (+) | 0.4947 (+) | 0.7620 (+) |
| Writing test results | ||||
| Windows 10—ARDS TestServer/ | ||||
| Windows 10—Windows 2019 Server | 3.0263 (−) | 3.2113 (−) | 1.2903 (−) | 0.7893 (+) |
| Ubuntu 22.04—ARDS TestServer/ | ||||
| Ubuntu 22.04—Windows 2019 Server | 2.8602 (−) | 2.7480 (−) | 2.4110 (−) | 2.1825 (−) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arányi, G.; Vathy-Fogarassy, Á.; Szücs, V. Evaluation of a New-Concept Secure File Server Solution. Future Internet 2024, 16, 306. https://doi.org/10.3390/fi16090306
Arányi G, Vathy-Fogarassy Á, Szücs V. Evaluation of a New-Concept Secure File Server Solution. Future Internet. 2024; 16(9):306. https://doi.org/10.3390/fi16090306
Chicago/Turabian StyleArányi, Gábor, Ágnes Vathy-Fogarassy, and Veronika Szücs. 2024. "Evaluation of a New-Concept Secure File Server Solution" Future Internet 16, no. 9: 306. https://doi.org/10.3390/fi16090306
APA StyleArányi, G., Vathy-Fogarassy, Á., & Szücs, V. (2024). Evaluation of a New-Concept Secure File Server Solution. Future Internet, 16(9), 306. https://doi.org/10.3390/fi16090306