2. Literature Review
This literature review delves into the realms of e-learning, particularly focusing on student performance assessments and recommendation generations. Recent studies have significantly contributed to understanding and enhancing student engagement and performance through various technological and methodological innovations.
The exploration of emotional engagement in e-learning environments has been a pivotal focus. For instance, the study identified in [
22] employed machine learning algorithms, specifically convolutional neural networks (CNNs), to analyse students’ emotional states through eye movements and facial expressions during online learning sessions. This approach delineates a method for categorising student engagement levels, albeit with challenges, such as overfitting. Similarly, the research presented in [
23] undertakes the classification of human emotions into distinct categories like surprise, anger, and sadness using a Bayesian classifier, underscoring the importance of emotional assessment but also noting limitations when excluding interactive and skill-based parameters.
In the domain of predictive analytics for identifying at-risk students, several methodologies have been employed. The hidden Markov model used in [
24] exemplifies an intelligent approach to predicting student dropout risks, although it notably lacks incorporating demographic features, which could enhance prediction accuracy. Likewise, refs. [
25,
26], have advanced the application of gradient boosting and artificial neural networks (ANN) for early warning systems and performance analysis, respectively, each discussing specific challenges, such as handling large datasets and computational demands. The development of recommendation systems to enhance e-learning experiences has seen innovative applications of machine learning and deep learning techniques.
Studies like [
27,
28] have contributed to this field by utilising ontology and autoencoders for course recommendations, highlighting the balance between leveraging historical data and addressing individual learner needs.
Similarly, the combination of machine learning techniques with fuzzy methodologies in [
29] presents an advanced approach for designing performance prediction systems. By integrating fuzzy logic, this model aims to refine the accuracy of predictions and recommendations, addressing the complexity of student data and learning paths. In the context of adaptive learning environments, ref. [
30] introduces the application of Deep Q-Network (DQN) algorithms from Deep Reinforcement Learning (DRL), proposing a method for distributing learning rules and exercises intelligently. However, this approach is not without its challenges, particularly concerning the security and integrity of the learning system, as highlighted by potential vulnerabilities in the login methodology.
Further, the integration of deep learning for personalised e-learning environments, as discussed in [
31,
32], showcases the shift towards more adaptive and learner-centred approaches, although they also reveal gaps in evaluating and integrating learner information effectively. Learning style identification has also garnered attention, with [
33] employing various machine learning algorithms to detect and cater to different learning preferences, signifying a move towards more personalised education. However, the challenge remains in accurately capturing and responding to the diverse learning modalities of students.
Moreover, the application of machine learning extends into predictive analytics for academic success, with studies like [
34,
35,
36] exploring different algorithms and data preprocessing techniques to forecast student performance. These studies underline the potential of predictive analytics, while also pointing out the limitations of relying solely on historical academic data or a narrow set of predictive factors.
In the domain of Information Retrieval and Natural Language Processing (NLP), a new study [
37] presents a fake news detection model called MST-FaDe. This model utilises a multiscale transformer architecture to accurately identify and categorise fake news across mixed-language content. This research enhances the ability to detect fake news with high precision and recall, especially in environments where content does not adhere to a single language. Integrating this model into educational AI technologies can protect against the spread of misinformation and create a more inclusive and secure learning environment.
In synthesising these works, it becomes evident that while advancements in machine learning and predictive analytics offer significant promise for enhancing e-learning environments, they also present challenges, such as data complexity, model overfitting, and the need for comprehensive feature integration. The emerging trends underscore the importance of holistic and adaptive approaches that consider a wide range of factors affecting student performance and engagement. This review sets the stage for our research into the E-FedCloud platform, which aims to integrate these insights into a cohesive system for improving e-learning outcomes.
By addressing the noted limitations and building on the foundational work reviewed, we aspire to contribute meaningfully to the evolving landscape of educational technology.
Table 1 provides a summary of the literature survey.
3. Problem Definition
Our previous work, AISAR [
38], developed a model using artificial intelligence algorithms to enhance academic performance in e-learning environments. This model encompassed several processes: student authentication, score estimation, clustering, performance prediction, and personalised recommendations. Authentication was conducted through PINs, passwords, and IDs, while student scores were estimated via a recurrent neural network. Students were then categorised into low, average, and excellent groups using a density-based spatial clustering algorithm. Performance prediction employed a threshold-assisted map reduction method to categorise students as very low, low, and normal. For generating recommendations, the State-Action-Reward-State-Action (SARSA) algorithm was implemented. However, this model had several limitations: the authentication approach was susceptible to modern security threats; the clustering method inadequately classified student involvement, leading to high false-positive rates; and the performance prediction lacked real-time data processing capabilities, resulting in reliability and availability issues. Additionally, the SARSA-based recommendation system did not adequately cater to the needs of below-average students requiring personalised support.
The authors in [
39] propose a machine learning-based model for predicting student performance, utilising behaviour and learning information. This process includes data pre-processing, feature extraction, classification, and the development of a machine-based recommendation model. This model is built upon features such as learning behaviour consolidation, interaction, knowledge acquisition, and preparation. However, the study fails to consider crucial factors, such as student interactiveness, participation, emotions, and skills, which could compromise the effectiveness of predictions. Additionally, the study underscores the necessity of addressing issues related to complexity, overfitting, and underfitting to enhance the accuracy of prediction outcomes.
In [
40], the authors proposed using personalised feedback and machine learning algorithms to predict learning behaviours in e-learning modules. Data were collected from performance indicators, educational metrics, and demographic variables. Pre-trained gated recurrent units were employed to classify students into pass or fail categories. Although personalised feedback was provided, these methods did not significantly improve the learning outcomes for struggling students. The study predominantly focused on identifying aspects and behaviours related to students, rather than considering teacher-related aspects that could influence student performance.
The authors in [
41] proposed a deep learning algorithm to predict student performance and generate recommendations based on an early warning system. The data underwent pre-processing, grade prediction, and clustering using the k-nearest neighbour algorithm. The findings indicated that deep neural networks surpassed the performance of other machine learning models. However, the study faced limitations, including the omission of student and teacher legitimacy, the lack of personalised recommendations based on grades, and the lower accuracy and high computational complexity associated with the k-nearest neighbour algorithm.
The study [
42] developed an automated framework to generate recommendations based on student academic performance using machine learning algorithms. This framework employed natural language processing for semantic analysis. Data were collected from user profiles, pre-processed, and analysed using an agent-based methodology. The results demonstrated that agent-based predictive recommendations surpassed the performance of other methods. However, the study did not consider factors such as student engagement results, teacher behaviour, and effective tracing of recommendations for further assistance.
4. Proposed Methods
To enhance the e-learning experience, the proposed E-FedCloud system adopts a comprehensive approach, as depicted in
Figure 1, which outlines the system’s overall architecture. The process begins by ensuring robust authentication for both students and instructors, utilising diverse credentials, such as ID, password, voice, facial data, and keystroke dynamics. This is achieved through federated learning combined with the Cycle GAN algorithm. Following authentication, the system shifts focus to student engagement detection, employing deep learning and threshold-based entropy classification methods. This in-depth evaluation includes analyses of student interactions, academic behaviours, instructor behaviours, and academic emotions. Leveraging deep learning and the Att-CapsNet algorithm, E-FedCloud then generates personalised suggestions for students, tailored according to their assessed levels of participation.
Each student’s performance is taken into account when generating these recommendations, which may include initiatives like scholarships for students at risk of dropping out and additional support for those underperforming, encompassing options like retesting and adjustments to their learning styles. The system employs the ID2QN algorithm, which considers a broad array of factors, including academic achievement, demographics, the teaching methods of course instructors, and students’ prior academic backgrounds, thereby enhancing the accuracy of performance prediction. E-FedCloud also uses majority voting-based clustering algorithms to conduct weekly engagement status assessments, categorising students based on their interactivity, academic behaviour, facial emotions, and instructor actions. Furthermore, the system routinely validates weekly statuses and offers opportunities for retesting to monitor students’ progress. This comprehensive approach ensures a holistic and adaptable e-learning environment, meeting the varied needs of students and consistently fostering their academic development.
The primary focus of this research is to develop an accurate, effective, and secure performance prediction and recommendation model to assess and enhance student academics. To achieve this objective, we have integrated Artificial Intelligence (AI), Federated Learning (FL), and Cloud Computing (CC) technologies.
AI is employed to facilitate automation with high reliability; FL technology is utilised to ensure the privacy of entities; and CC technology is harnessed to provide and store computational resources on-demand without compromising quality.
The entities involved in this study include students, Course Instructors (CIs), Intelligent Software Agents (ISAs), and Cloud Servers (CS).
The detailed process, along with the functioning of each entity, is provided in the following Section. This can be understood by reviewing the sequential research processes outlined below:
Federated learning-based authentication
Majority voting-based multi-objective student engagement clustering
Deep reinforcement learning (DRL)-based early warning system and multi-disciplinary ontology graph construction
Automated personalised recommendation generation and tracking
4.1. Federated Learning-Based Authentication
The study [
43] significantly expands the discussion on data privacy challenges and personalised education solutions, contributing to a richer literature review. It explores a low-latency edge computation offloading strategy for trust evaluation in finance-level Artificial Intelligence of Things (AIoT) environments. The goal is to minimise latency in data processing and decision-making by relocating these processes to edge devices closer to data sources. This approach aims to improve the speed and reliability of AI operations, thus enhancing the efficiency of technology-driven environments.
Similarly, the implementation of federated learning-based authentication in e-learning enhances data privacy and security. This approach allows for the decentralised training of machine learning models across numerous devices without necessitating the sharing of sensitive data, thereby preserving user privacy [
44]. It acts as a safeguard against potential data breaches by decentralising data storage and ensuring adherence to privacy regulations. Moreover, federated learning enables the delivery of personalised learning experiences. It optimises bandwidth usage, establishing it as a bandwidth-efficient methodology. By integrating these advanced techniques, the paper underlines the importance of adopting innovative solutions to overcome the prevalent challenges in e-learning platforms. Federated learning, in particular, plays a pivotal role in maintaining the confidentiality and integrity of data, while facilitating a customised educational experience for learners. This synergy between cutting-edge AIoT strategies and federated learning underscores the evolving landscape of secure, personalised, and efficient e-learning environments. To mitigate malicious activities in the adaptive e-learning environment, a robust and privacy-preserving authentication scheme has been developed for both course instructors (CIs) and students, utilising Federated Learning (FL) technology. This scheme involves CIs, students, and cloud servers (CS).
The authentication process begins with the registration initiated by CIs and students, who send their requests to the CS. The CS comprises two centralised sub-servers, the Student Server (SS) and the Course Instructor Server (CIS), where students and CIs, respectively, register their credentials. The credentials, which include ID, password, face data, voice data, and keystroke dynamics, are treated as local models.
Subsequently, the sub-servers create the global model using a Cycle General Adversarial Network (CGAN). CGAN, consisting of generators (δ) and discriminators (ϵ) for each domain (features from students and course instructors), aims to translate characteristics from one domain to another.
Generators δ
1 and δ
2: convert characteristics between domains. δ
1 transforms SS into CIs, while δ
2 transforms CIs into SS.
Discriminator and : evaluate the resemblance of generated features to real features in their respective domains.
For
(Discriminating SS)
For
(Discriminating CIs)Cycle consistency loss: ensures that a feature translated from one domain to another and back again should resemble the original feature, preserving information. We will refer to the translated features as (SS) and (CIs).
For
(SS to CIs like) and its reverse:
For
(CIs to SS like) and its reverse:
Here,
encourages generated features to resemble the original, while
ensures cycle consistency. Equation (7) represents the generator loss (
.
Here,
encourages the discriminator to correctly identify real features, while
encourages the discriminator to accurately identify generated features as fake. Equation (8) represents the discriminator loss (
.
The process for implementing the Cycle Generative Adversarial Network (CGAN) is detailed in Pseudocode 1. This pseudocode outlines the steps for optimising the generator and discriminator networks over multiple epochs.
| Pseudocode 1: CGAN Implementation |
Input:
for epoch in range
for epoch in range
, batch)
for epoch in range
, batch)
Output: ) |
The generated global models are shared with the students and CIs for authentication purposes. It is important to note that the CI models and student models are swapped between sub-servers to ensure a secure and private environment. By utilising these trained models, issues commonly associated with conventional authentication methods, such as sniffing, spoofing, and shoulder surfing attacks, can be effectively mitigated through the proposed, federated learning-based authentication approach.
4.2. Majority Voting-Based Multi-Objective Student Engagement Clustering
Only authenticated students and course instructors (CIs) are permitted to participate in the adaptive e-learning course. Throughout the online course, through multiple distributed interactions, Intelligent Software Agents (ISAs) are responsible for capturing students’ academic behaviours, interactivity, emotions, and other relevant behaviours, as well as CIs’ behaviours and teaching styles. This information is utilised to determine the weekly engagement status of the students. To be more specific, the responsibilities of ISAs are outlined below:
4.2.1. Student Interactiveness Acquisition
Data quality in an e-learning environment, especially regarding emotional data collected through cameras, is critical. Encouraging camera use, while ensuring informed consent and privacy, involves establishing clear guidelines on camera positioning, lighting, and background. Additionally, setting minimum technical standards for camera resolution and internet connectivity is essential. To technologically enhance data quality, implementing real-time feedback mechanisms is crucial. These mechanisms alert students when the camera is off or if the video quality is compromised due to inadequate lighting or incorrect angles. Furthermore, employing pre-processing algorithms, such as brightness and contrast adjustments, noise reduction, and image stabilisation, can significantly improve the clarity of facial features, ensuring a more accurate analysis of student emotions.
During online courses, course instructors (CIs) engage with students through various methods, such as posing questions, conducting seminars, and administering short quizzes related to lectures, among other interactive activities. Based on these daily interactions, Intelligent Software Agents (ISAs) evaluate the students’ levels of interactivity each week, categorising them into two classes: “highly interactive” and “less interactive”. This evaluation employs the threshold-based Shannon entropy (TSE) method, which quantifies the frequency of interactions exceeding a predefined threshold, thereby assessing engagement levels.
Shannon entropy, denoted as H(ϰ), measures the uncertainty in a dataset. It is calculated for a discrete random variable ϰ with probability distribution P(ϰ) using the formula:
Here,
x represents the possible values of ϰ, and P(ϰ) is the probability of each value occurring. TSE specifically focuses on values exceeding a specified threshold, represented as ℧. The unit of Shannon entropy is bits when using the base-2 logarithm (log
2). To compute TSE (H), it first establishes the probability distribution for interactions surpassing the threshold and then employs the Shannon entropy formula.
Here, ϰ > ℧ represents the set of values exceeding the threshold value. H (ϰ > ℧) denotes the Shannon entropy for values greater than the threshold. TSE is calculated and then utilised to determine each student’s interactiveness grade for the week. For instance, if TSE is below a certain threshold, the student could be categorised as “less interactive” (represented as ϱlow), whereas if TSE is above the threshold, the student could be classified as “highly interactive” (represented as ϱhigh).
The process for calculating the Threshold-based Shannon Entropy (TSE) is outlined in Pseudocode 2. This pseudocode details the steps involved in determining student interactiveness based on daily interaction data and a specified threshold.
| Pseudocode 2: TSE Calculation |
Input: , (threshold)
to 0.0
:
If ℘ (probability or some related metric) > ℧:
Calculate H using Equation (9) for probability above ℧
:
Interactiveness = “Less Interactive” (ϱ_low)
Else:
Interactiveness = “Highly Interactive” (ϱ_high)
Output: |
4.2.2. Student Academic Emotion Acquisition
Enhancing data quality in e-learning platforms can be achieved through advanced technological measures, including real-time feedback systems, pre-processing algorithms, and systematic quality checks. Specifically, the YOLOv6 algorithm [
45] significantly improves the handling of varying image qualities by integrating features from SEC-YOLO and MCE-YOLO [
46], focusing on essential facial regions like the eyes, forehead, and cheeks for emotion analysis. This deep learning approach enables the precise classification of student emotions—frustration, confusion, boredom, and engagement—by leveraging robust feature extraction that remains effective even in lower-quality video streams.
Intelligent Software Agents (ISAs) utilise the YOLOv6 algorithm to monitor and analyse students’ facial emotions daily, employing the threshold-based Shannon Entropy (TSE) method for real-time emotion classification based on the clarity and visibility of key facial features. This dual approach, combining the YOLOv6’s advanced detection capabilities with the TSE method, allows for accurate emotion categorisation and the compilation of weekly emotional insights without compromising data quality or student privacy.
Overall, the integration of YOLOv6, which marries single-channel detection with multi-channel depth for enhanced object recognition, alongside a targeted facial feature analysis, ensures a comprehensive and nuanced understanding of student emotional states. This methodological synergy not only improves the accuracy of emotion detection, but also supports a more personalised and responsive e-learning environment.
To maintain high-quality emotional data collection, providing alternatives for students who are unable or unwilling to use cameras is crucial. Periodic check-ins or mood surveys can supplement or replace camera-based emotional data. Regularly updating and training the YOLOv6 model with new data samples will enhance its accuracy and robustness under varied conditions.
4.2.3. Student Behaviour Acquisition
Student behaviour acquisition is a process that monitors and analyses student behaviours in an e-learning context to improve engagement classification. This involves collecting data on various student behaviours, such as attendance rate, actions (such as frequently pausing the course video), chitchatting, disturbances, and malpractice during exams. Processing these behaviours provides insights into their significance in the learning process. The Threshold-based Shannon Entropy (TSE) method is used to categorise these behaviours into ‘good’ and ‘bad’, based on their entropy values. The ultimate goal is to improve engagement classification results, allowing the e-learning system to assess student engagement levels and tailor the learning experience to enhance both engagement and academic performance. This approach demonstrates a comprehensive effort to use behavioural data to improve the effectiveness of e-learning systems.
4.2.4. CI Behaviours and Teaching Style Acquisition
Finally, the daily behaviours of the course instructors (CIs) and their teaching styles, including their level of interactiveness, course time management, and teaching methods (e.g., PowerPoint presentations, voice, video, etc.), are classified into two categories, acceptable and non-acceptable, using the Threshold-based Shannon Entropy (TSE) method.
Based on the acquisition results mentioned above, the weekly engagement status of the students is computed using the Majority Voting Multi-Objective Clustering (MV-MOC) method. In this context, the multiple objectives pertain to the students’ weekly academic and behavioural status, encompassing interactiveness, academic emotions, and behaviours, respectively.
Multi-Objective Optimisation: MV-MOC extends conventional clustering by optimising multiple objectives concurrently. Each objective corresponds to a distinct clustering solution, and the algorithm aims to find a compromise among these objectives.
Pareto Front: The Pareto Front is a set of solutions that are not dominated. A solution is considered non-dominant if it cannot be improved on one objective without negatively impacting another. The Pareto front illustrates the trade-offs between these objectives.
Majority Voting: MV-MOC assigns data points to clusters based on the consensus of multiple clustering solutions using majority voting. The diversity between Solutions X and Y, based on their cluster assignments, can be calculated. This can be achieved using the Jaccard Index (J), which measures the dissimilarity or diversity between two sets, X and Y.
Here, represents the number of data points assigned to the same cluster in both Solution and Solution (the intersection of sets and ), while represents the total number of unique data points assigned to clusters in Solutions and (the union of sets and ).
The Pareto Dominance Test is performed to determine whether Solution
dominates Solution
based on multiple objectives. Solution
is considered to dominate Solution
if it is equal to or better than Solution
in all objectives. This dominance check can be expressed for each objective
as follows:
Here, represents the value of objective in Solution , and represents the value of objective in Solution . For Solution to dominate Solution , this inequality must hold for all objectives . If it holds for at least one objective, Solution is considered to dominate or be equivalent for some objectives, but not all.
In summary, these equations are used to analyse the diversity between two clustering solutions (Diversity Calculation) and to check if one solution dominates another based on multiple objectives (Pareto Dominance Check). In the final step of the MV-MOC algorithm, the number of times each data point has been assigned to each cluster across all Pareto front solutions is calculated. Subsequently, each data point is assigned to the cluster that receives the majority of votes, determining its final assignment. Optionally, the quality of the clustering solution can be evaluated using cluster validity indices, such as the silhouette score, which measures how well the data points are clustered. represents the Pareto front solutions.
The process for the Majority Voting Multi-Objective Clustering (MV-MOC) is detailed in Pseudocode 3, which outlines the steps for clustering data based on multiple objectives and determining the engagement status of students.
| Pseudocode 3: MV-MOC Calculation |
Input:
Cluster data for each objective separately
Calculate
Verify for all objectives
Generate
A majority vote on
Optionally calculate .
Implement a termination condition
Obtain Final cluster assignments
Output: Engaged not engaged |
To ensure that the algorithm does not operate indefinitely, a termination condition is imposed based on either a fixed number of iterations or convergence. Ultimately, the final clustering solution consists of clusters obtained through majority voting based on Pareto-front solutions, enabling the effective classification of data points according to their engagement status or other relevant objectives. Concerning these objectives, the majority voting method clusters students into classes, such as engaged and non-engaged students. To clarify, students exhibiting good behaviour and positive academic emotions but lower levels of interactiveness would be categorised as engaged students, and vice versa.
4.3. DRL-Based Early Warning System & Multi-Disciplinary Ontology Graph Construction
The Improved Duelling Deep Q Network (ID2QN) serves as an early warning system employing a deep reinforcement learning (DRL) model to forecast student performance. This prediction is based on their engagement status, demographic details, and other pertinent data. Designed to anticipate student performance early, the ID2QN aims to identify students requiring additional support or resources for success. Unlike traditional DRL methods that rely on a table for storing Q-value data, which becomes impractically intensive with growing environmental complexity, ID2QN utilises a neural network for direct state-to-action mapping, negating the need for a Q-value table. The ID2QN algorithm distinguishes between two distinct value functions: the state value function and the action advantage function. The integration of these functions facilitates the determination of the Q-value, assisting in the selection of the most suitable action. The model adopts a dual neural network structure; one network is responsible for generating Q-values for the present state-action pair, while another calculates Q-values for future state-action scenarios. These networks’ parameters are adjusted through a loss function and the stochastic gradient descent algorithm to minimise discrepancies between anticipated and actual Q-values. ID2QN stands out for its capability to efficiently learn the value of each state without the need to explicitly determine the most advantageous action at every juncture. This efficiency renders it a potent model for early performance prediction, particularly within the realm of student engagement and success, especially in environments where accurately assessing the value of actions and states poses significant computational challenges.
The workflow of the Deep Reinforcement Learning System using ID2QN for Early Performance Prediction is as follows:
Input: Collect weekly engagement data, students’ demographic details, and course instructors’ (CIs) behaviours and teaching styles alongside students’ academic histories for input into the neural network.
Process: these inputs are utilised for the early prediction of performance among students showing signs of disengagement.
Implement the DQN algorithm within a neural network framework, formalised by the equation:
Here, ψ represents the state, ϖ denotes potential educational interventions (actions), and φ embodies the network parameters. The strategy eradicates the need for traditional Q-value tables by facilitating state-to-action mappings directly within the neural network. Q-values, ϱ(ψ, ϖ, φ), are estimated to represent the expected rewards of certain actions given specific states.
The Loss Function, L(φ), assesses the gap between predicted and actual rewards, guiding neural network training, and is defined as:
Network parameters (φ) are updated using the stochastic gradient descent to minimise L(φ), thereby refining prediction capabilities.
ID2QN adopts a dual-component structure:
Evaluate Net: Generates current state-action Q-values, ϱ(ψ, ϖ, φ).
Target Net: Outputs future state-action Q-values, ϱ(ψ′, ϖ′, φ′).
The neural network output divides into two distinct functions: the state-value function V(ψ, φ) and the action-advantage function A(ϖ, φ), integrated as:
This delineation enhances decision-making by independently evaluating the current state’s value from the advantages of the specific actions.
Emphasise centralising the advantage function to improve network robustness as:
The model distinctly evaluates the value of each state V(ψ) and the added value of each action A(ϖ), facilitating clearer differentiation between actions.
Early Performance Prediction and Intervention:
- -
Using the ID2QN model to predict student performance and categorise them based on risk levels derived from the neural network’s Q-value output.
- -
Developing targeted interventions based on individual risk assessments indicated by the DRL analysis.
Personalised Recommendation Generation:
- -
Leveraging outputs from the ID2QN model to guide the Att-CapsNet system in crafting personalised educational recommendations.
- -
Continuously refine these recommendations, as per students’ changing engagement and performance metrics.
Evaluation and Feedback Loop:
- -
Evaluate the impact and efficiency of DRL-based interventions on enhancing student outcomes.
- -
Iterate and refine neural network parameters and the entire predictive model based on continuous feedback and observed educational impacts, aiming for ongoing improvement and greater accuracy in early warning predictions.
This refined workflow, supported by detailed equations and methodologies, demonstrates the application of the ID2QN model within an e-learning context to identify students requiring additional support and to customise interventions to improve their educational experiences effectively.
This study illustrates the integration between the Deep Reinforcement Learning (DRL) Early Warning System and Cycle-GAN within an e-learning framework. While Cycle-GAN fortifies the platform’s authentication and privacy measures, the DRL-based early warning system, leveraging the ID2QN model, evaluates student engagement and performance. Their integration underpins a comprehensive e-learning environment where secure and authenticated access, facilitated by federated learning and Cycle-GAN, underwrites the integrity and privacy of data processed by the DRL system. This integration is crucial for the precise and proactive identification of students’ academic needs.
Specifically, the Cycle-GAN (Generative Adversarial Network) technique is deployed for federated learning-based authentication to enhance the platform’s defence against cyber threats, including malicious traffic and vulnerabilities. It simplifies the authentication process within a federated learning framework, safeguarding data integrity during node-to-node transfers. Meanwhile, DRL aims to teach systems to adapt and make informed decisions based on environmental interactions, offering applications in e-learning, such as tailoring educational pathways, allocating resources dynamically, and formulating adaptive assessments.
Therefore, while Cycle-GAN and DRL are both grounded in sophisticated machine learning methodologies, they address distinct needs within the e-learning domain. Cycle-GAN focuses on securing data through enhanced authentication protocols, whereas DRL is utilised to enrich the learning experience, adapting educational content and strategies to align with student preferences and performance. This, in turn, enables accurate and early prediction of student performance.
4.4. Automated Personalised Recommendation Generation and Tracking
The deep learning algorithm, known as the Attention-Based Capsule Network (Att-CapsNet), automatically generates personalised recommendations for students by leveraging the multi-disciplinary ontology graph of student performance. The Att-CapsNet model integrates the capsule network with a channel attention mechanism, specifically the Squeeze-and-Excitation (SE) block, and primarily comprises four layers, described below:
Convolutional Layer: the initial layer is a convolutional layer that employs 3 × 3 convolution kernels, a step size of 1, and the ReLU activation function to extract local information.
Attention Layer: SE blocks, known for their simplicity of implementation, enhance feature extraction within the model and facilitate classification. The squeeze operation in this layer aims to capture the overall features of a channel, with each feature map from the convolutional layer.
Primary Caps Layer: After the SE block, PrimaryCaps receives each feature map and attention weight. The PrimaryCaps layer differs from the standard convolution layer. After this layer, we can produce capsules, also known as vectors, which can store significant information. The SE block then produces attention feature maps by multiplying the original feature maps by the learned channel weights to perform a scale operation.
DigitCaps Layer: The DigitCaps layer stores Ponzi and non-Ponzi capsules. Vectors represent the ultimate result. Capsule networks squash. The likelihood of an entity’s presence is determined by the length of the output vector, while retaining its orientation.
To generate recommendations for a student, the relevant student information is extracted from the multi-disciplinary ontology graph, which illustrates the relationships among various factors influencing student performance and their actual performance outcomes. Using these queried data, the proposed Att-CapsNet recommender system offers a tailored set of recommendations for each student.
For example, a student at risk of dropping out is analysed in conjunction with their performance-affecting factors and may be recommended various options, such as scholarship opportunities, accommodation arrangements, and more, all personalised to their needs. In the case of students facing the risk of failing or achieving lower marks, the system assesses the behaviour of course instructors (CIs) and modifies their teaching styles. This modification may involve simplifying content through animations, incorporating gamified e-learning elements, offering multiple attempts and feedback-based question-and-answer sections (i.e., retests), and so on.
Additionally, the proposed approach continually monitors and tracks student performance on a weekly basis, aiming to enhance performance and provide recommendations to boost student engagement in the course.
In a different context, the lightweight encryption algorithm (LWEA) introduces a secure, computationally efficient encryption method. This encryption method consumes less power due to its reduced key size. The process involves three distinct algorithms:
Secret key generation and text encryption
Secret key encryption and text encryption merging
Text decryption using a secret key
The strategy relies on the one-time pad technique, where a random number generator generates the secret key. Notably, the secret key is transmitted within the encrypted file itself, adding an extra layer of security to the process.
All information, including student authentication details, engagement status, performance status, ontology graph data, and recommendation outcomes, is securely stored within the blockchain in an encrypted format utilising the Lightweight Encryption Algorithm (LWEA) [
47]. This approach ensures the utmost security and confidentiality, making the data unreadable to anyone without the proper decryption key. The use of LWEA, known for its efficiency in environments with limited computational resources, alongside blockchain technology, provides a robust and tamper-resistant solution, ensuring sensitive information remains protected from unauthorised access, breaches, or tampering, thereby enhancing the overall security and integrity of the e-learning platform.
5. Experimental Results
To simulate the proposed research method, JDK 1.8, Netbeans 12.3, and Wamp Server 2.0 (MySQL 5.1.36) were utilised. These tools are efficient and provide all the necessary specifications for the proposed technique.
In evaluating the system, the study used the Open University Learning Analytics dataset (OULAD), developed by Kuzilek et al. in 2017 [
48], specifically designed for e-learning testing environments. This VLE-based dataset includes a wide array of data, featuring information on 32,593 students across 22 courses, coupled with detailed records of click activities totalling 10,655,280 entries. The OULAD-VLE dataset is extensive, encompassing three distinct types of data: demographics, performance, and learning behaviour.
The dataset features a range of information categories, including course details, student demographics, registration data, assessments, VLE interactions, student results, and student assessment scores. Course information comprises the code name, presentation duration, and semester offering. Demographic details cover student identification numbers, regional locations, and age groups. Registration data reveal enrolment patterns and dropout rates. The assessment section offers a comprehensive view of each course’s evaluation methods, including the type of assessment, its weight, and the students’ final scores. Logs of VLE interactions provide an in-depth look at student engagement with the online platform, which is crucial for measuring engagement levels and understanding how they correlate with learning outcomes. Student results detail the final outcomes for each course attempt, facilitating analyses against demographic and engagement metrics. Lastly, student assessment scores give a clearer picture of individual performances across different assessment types and stages within each course.
The OULAD enables in-depth learning analytics studies focused on identifying factors contributing to student success and developing predictive models to improve educational outcomes. Researchers can use this dataset to explore relationships between student engagement, assessment performance, demographic factors, and final results, enhancing their understanding of effective online learning practices.
This work utilised a variety of data types to assess the model’s effectiveness. Student demographic data (e.g., age, gender, nationality, and socio-economic status) were used to assess the model’s generalisability across diverse populations, and academic history data (grades, test scores, and assignment completion rates) were analysed to understand student performance patterns and trends. Engagement metrics (login frequency, time spent on materials, forum participation, and quiz/assignment completion) measured student interaction with the e-learning platform. For instance, data might show that students who log in daily and actively participate in forums tend to have higher academic performance.
Additionally, multi-modal biometric data (e.g., facial expressions, eye movements, and keystroke dynamics) [data reflecting physiological and behavioural responses] were captured to identify emotional states, like confusion or disengagement, triggering support mechanisms. For example, a student’s frequent eye movements away from the screen might indicate a lack of focus. Behavioural data (number of video pauses, replays, and multitasking instances) provided insights into students’ learning behaviours. Frequent pausing of lecture videos, for instance, might indicate difficulty understanding the material.
By incorporating these diverse types of data, our evaluation process demonstrates how the DRL-based early warning system can accurately predict student performance and provide personalised recommendations to enhance their academic success. This comprehensive data approach ensures a robust evaluation and validation of our model’s effectiveness.
5.1. Comparative Analysis
This section compares the proposed method with several existing ones, including PCT [
43], MST-FaDe [
37], Fuzzy SVM [
29], and Artificial Intelligence-Based Student Assessment and Recommendation (AISAR) [
38]. It evaluates its effectiveness using performance metrics, such as accuracy, precision, recall, F1-scores, true positive rates, false positive rates, true negative rates, and false negative rates.
5.1.1. No. of Epochs vs. Accuracy
Certainly, a simple linear equation can be used to represent the link between the number of training epochs and accuracy (∀):
Here,
represents the number of training epochs, and the rate of change in accuracy per epoch is given by ℘. It indicates how much accuracy increases with each additional epoch.
is the starting accuracy, often known as the intercept, which represents the accuracy at epoch 0.
Figure 2 and
Table 2 present the number of epochs vs. accuracy.
As the number of epochs increases, the accuracy rate also increases. Choosing five epochs as a comparison point in machine learning model training can indicate early performance, assess model efficiency, and benchmark against standard practices. It also highlights resource efficiency, as fewer epochs mean less computational time and energy usage. For example, in several epochs (e.g., 5), the accuracy of the proposed method reaches 65%, while existing methods, such as PCT, achieve 15%, MST-FaDe achieves 25%, Fuzzy SVM achieves 35%, and AISAR achieves 45%. With a higher number of epochs (e.g., 25), the proposed method attains an accuracy level of 73%, while PCT reaches 39%, MST-FaDe reaches 49%, Fuzzy SVM reaches 59%, and AISAR reaches 61%. Ultimately, the proposed method demonstrates a higher accuracy level compared to existing ones.
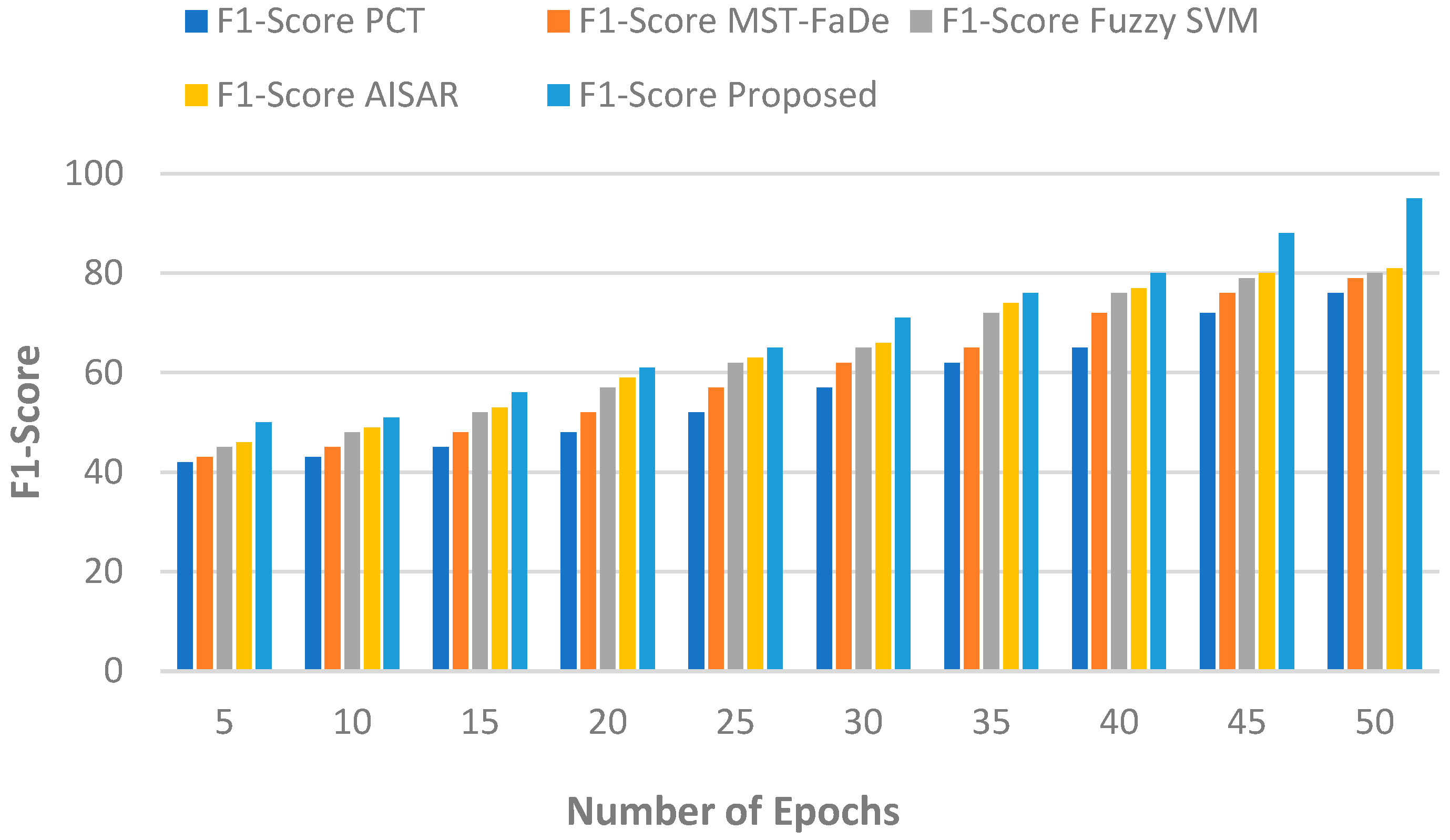
5.1.2. No of Epochs vs. F1-Score
Certainly, the relationship between the number of training epochs and the F1-Score can be succinctly explained through a simple equation. The F1-Score is a widely used metric for evaluating the balance between precision and recall in classification problems. The formula is traditionally expressed as:
The F1-Score (F) is the harmonic mean of precision (E) and recall (K)). Precision (E) is defined as the ratio of true positives to the sum of true positives and false positives, while recall (K) is defined as the ratio of true positives to the sum of true positives and false negatives. Consequently, the F1-Score provides a single value that encapsulates model performance, considering both false positives and false negatives. This offers a balanced perspective, particularly useful in scenarios with uneven class distributions.
Table 3 represents numerical outcomes, and
Figure 3 illustrates the relationship between the number of epochs and the F1-score. As the number of epochs increases, the F1-score correspondingly rises. In the proposed method, F1-scores of 50%, 65%, and 95% are achieved with 5, 25, and 50 epochs, respectively. Conversely, the PCT method yields F1-scores of 42%, 52%, and 76%; the MST-FaDe method yields F1-scores of 43%, 57%, and 79%; and the fuzzy SVM method yields F1-scores of 45%, 62%, and 80% for the same respective epochs. Meanwhile, AISAR registers F1-scores of 46%, 63%, and 81% for the corresponding epochs. Existing approaches demonstrate lower F1-scores when compared to the proposed method.
5.1.3. Precision vs. Recall Rate
A single equation can succinctly represent the relationship between precision and recall as:
Here, precision ) is a metric representing the accuracy of a classification model, defined as the ratio of true positives () to the total predicted positives ( + ). True positives () refer to instances correctly identified as positive by the model, while false positives () denote instances that are incorrectly labelled as positive.
In contrast,
can be expressed using a different equation:
Here, recall
of a classification model is represented as the ratio of true positives to total actual positives (
). False negatives (
) are instances that the model fails to identify as positive.
Table 4 illustrates the numerical outcomes and
Figure 4 illustrates the relationship between precision and recall.
PCT initiates with a low precision of 0.08, gradually improving precision as the recall rate rises, reaching an accuracy of 0.85 and a recall rate of 1.0; MST-FaDe initiates with a low precision of 0.10, increasing accuracy over time while maintaining a constant recall rate, reaching an accuracy of 0.90 and a recall rate of 1.0; Fuzzy SVM initiates with a low precision of 0.11, steadily enhancing precision as the recall rate ascends, achieving an accuracy of 0.95 and a recall rate of 1.0. AISAR begins with a reasonable precision of 0.12, which rapidly improves alongside the recall rate, attaining a precision of 0.96 at a recall rate of 1.0. The proposed model demonstrates the highest precision among the five models, commencing at 0.13 and progressively improving, culminating in a precision of 0.99 at a recall rate of 1.0.
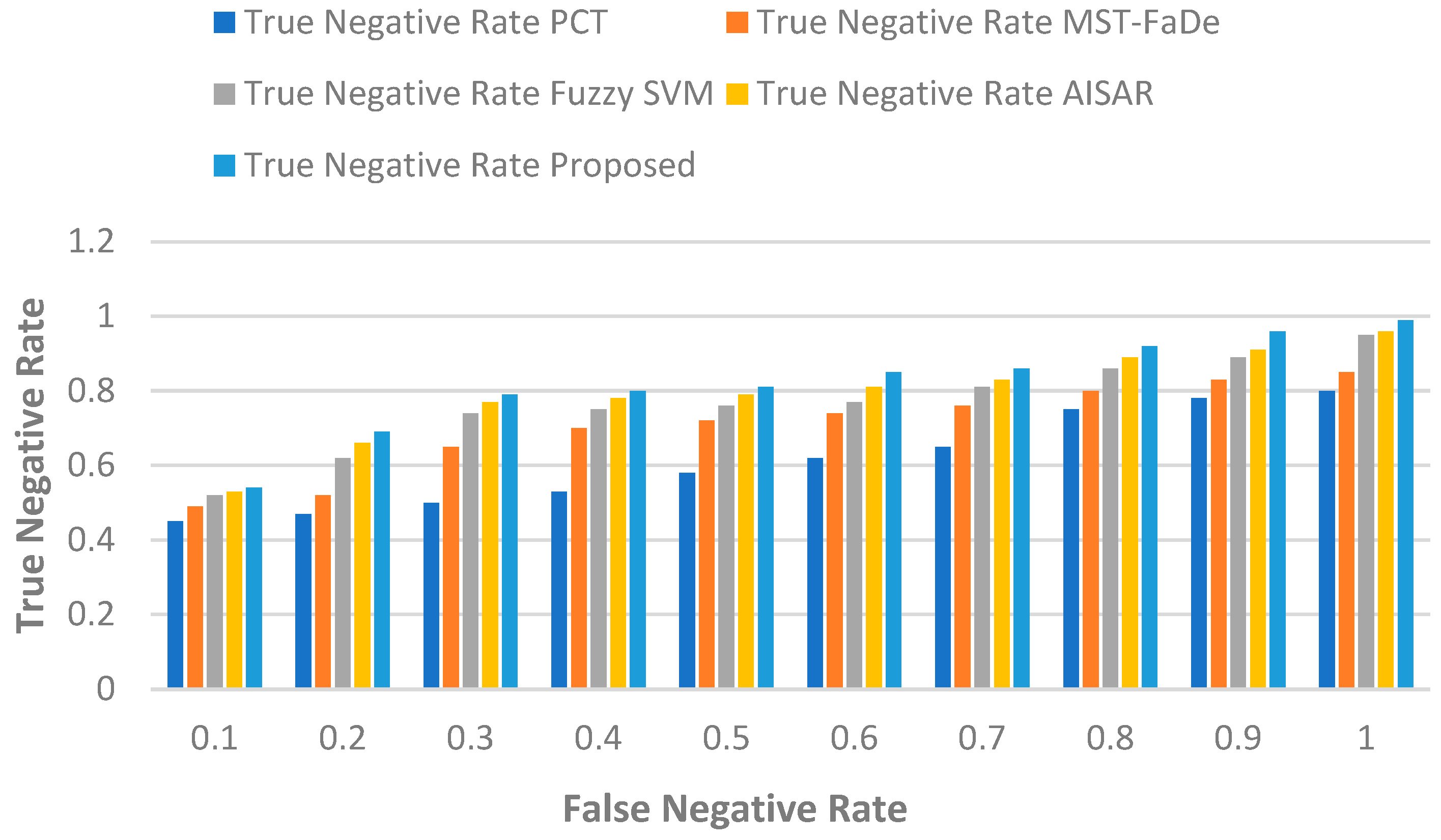
5.1.4. True Negative Rate vs. False Negative Rate
The true negative rate (
) and false negative rate (
) are pivotal metrics used in binary classification to assess a classifier’s performance. Typically, these rates are computed using the confusion matrix, which is a table that summarises the classifier’s predictions.
, Specificity, represents the fraction of actual negatives (class 0) that the classifier correctly predicts as negatives. Here is the
equation, along with a brief explanation:
represents the proportion of true negatives (class 0) that the classifier incorrectly predicts as positives and can be calculated using the following equation:
At a false negative rate (FNR) of 0.1, PCT has a true negative rate (TNR) of 50 (1–0.50) and gradually enhances its TNR as the FNR increases, reaching 0.05 at a FNR of 1.0. MST-FaDe has a true negative rate (TNR) of 49 (1–0.51) at a false negative rate (FNR) of 0.1. Its TNR steadily improves as the FNR rises, reaching 0.05 with a false negative rate of 1.0 at an FNR of 0.1. Fuzzy SVM has a TNR of 0.48 (1–0.52) and gradually enhances its TNR as the FNR increases, reaching 0.05 at an FNR of 1.0. AISAR exhibits a similar pattern, beginning with a slightly higher TNR of 0.47 (1–0.53) at an FNR of 0.1 and improving to 0.04 at an FNR of 1.0.
The proposed model starts with the highest initial TNR of 0.46 (1–0.54) at an FNR of 0.1 and consistently outperforms the other models, achieving the highest TNR of 0.01 at an FNR of 1.0.
Table 5 represents the numerical results and
Figure 5 illustrates the trade-off between TNR and FNR for each of the five models, demonstrating that the proposed model optimally balances minimising false negatives and maximising true negatives.
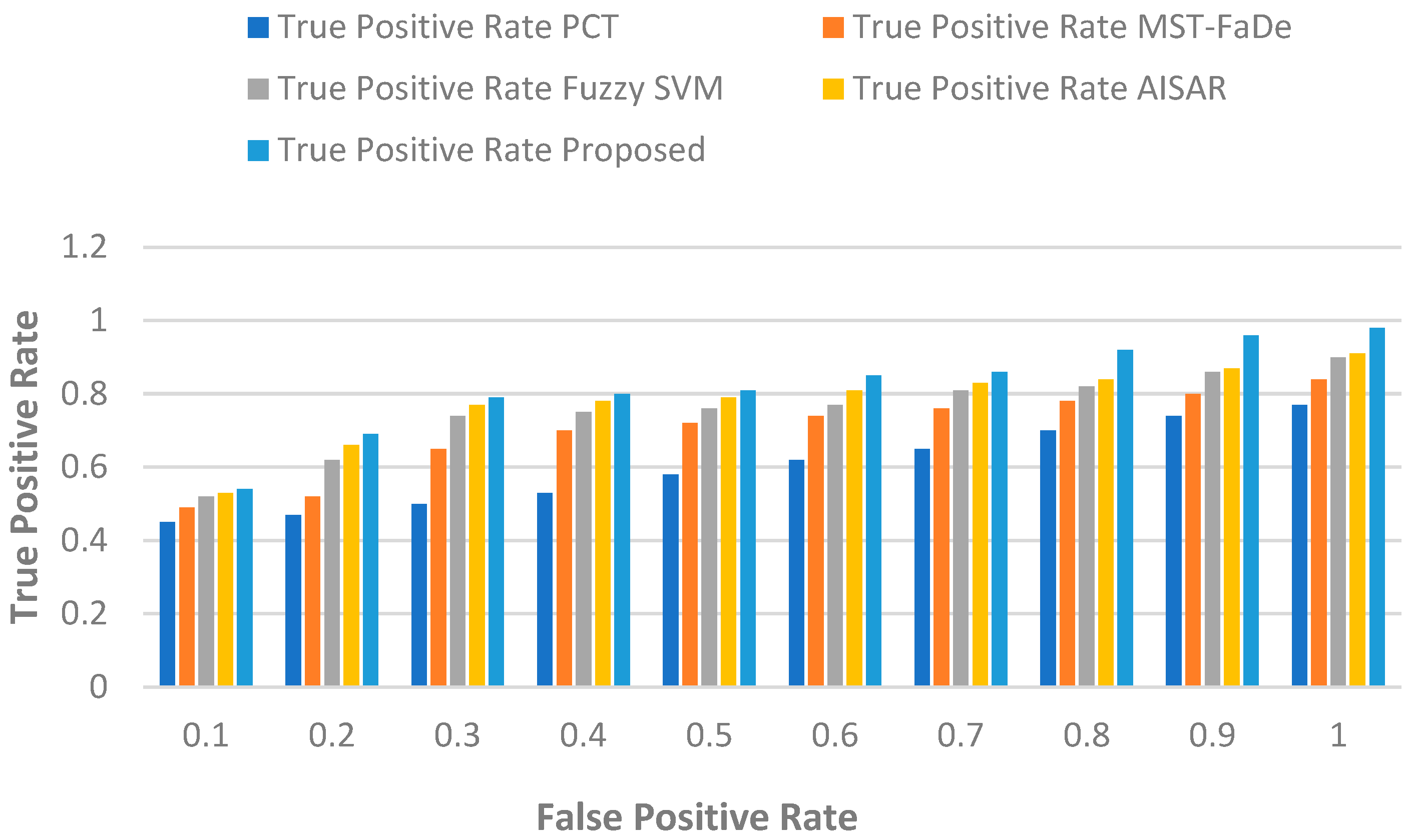
5.1.5. True Positive Rate vs. False Positive Rate
The true positive rate (), also recognised as sensitivity or recall, and the false positive rate () are critical metrics in binary classification utilised to evaluate a classifier’s performance. Both rates can be derived using the confusion matrix.
signifies the proportion of actual positives (class 1) that are accurately predicted as positives, as detailed in Equation (20). On the other hand,
represents the proportion of actual negatives (class 0) that the classifier erroneously predicts as positives. The relationship for s can be described as:
In practical terms, PCT starts with a true positive rate (TPR) of 0.45 and gradually elevates the TPR with a rising false positive rate (FPR), achieving 0.77 at an FPR of 1.0. The true positive rate (TPR) of MST-FaDe is initially set at 0.49, and it is progressively increased with an increasing false positive rate (FPR) to reach 0.84 at an FPR of 1.0. Fuzzy SVM starts with a TPR of 0.52 and gradually elevates the TPR with a rising FPR, achieving 0.90 at an FPR of 1.0. AISAR exhibits a similar trajectory, initiating with a TPR of 0.53 at an FPR of 0.1 and escalating to 0.91 at an FPR of 1.0. The proposed model begins with a TPR of 0.54 at an FPR of 0.1, consistently outperforming the prior models, and achieves the highest TPR of 0.98 at an FPR of 1.0.
Table 6 represents the numerical outcomes, and
Figure 6 illustrates the trade-off between TPR and FPR for all models, demonstrating that the proposed model consistently sustains a higher TPR while managing FPR, indicative of enhanced classification task performance.
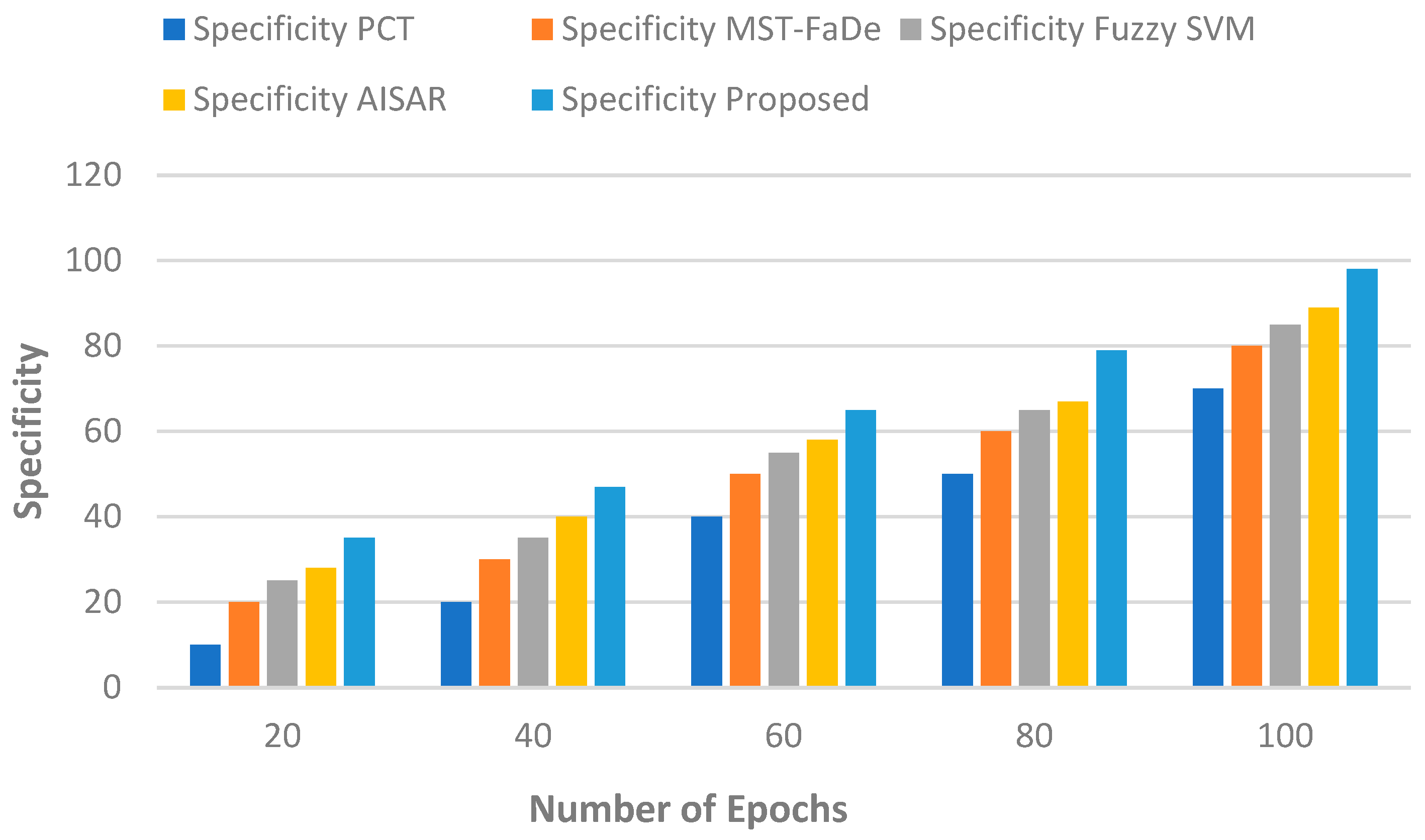
5.1.6. Specificity vs. Number of Epochs
A statistic called the specificity metric is used in classification tasks to assess a model’s accuracy in identifying negative situations. It is expressed as the ratio of true negatives (
) to the total of false positives (
) and true negatives (
). The specificity formula is as follows in mathematics:
stands for True Negatives, or the quantity of negative situations that are accurately detected. stands for False Positives, or the quantity of positive instances that were mistakenly recognised.
Figure 7 displays the specificity, while
Table 7 shows the specificity’s numerical results. When compared to other current techniques, like PCT, MST-FaDe, fuzzy SVM, and AISAR, the recommended approach provides exceptional specificity. That is the overall utility as the number of epochs increases. The greatest specificity of the suggested methods is 98% in terms of epochs; by comparison, the maximum specificities of PCT, MST-FaDe, fuzzy SVM, and AISAR are 70, 80, 85, and 89 bits per second, respectively. Our suggested strategy outperforms the current ones in terms of specificity.
5.2. Research Summary
Students and Course Instructors (CIs) are initially enrolled in matching sub-servers using credentials such as ID, password, face data, voice data, and keystroke dynamics. The credentials of students and CIs are treated as local models. Once these local models are established, the sub-servers employ CGAN to construct the global model and perform authentication based on this model. The TSE approach is employed to assess students’ interactiveness, academic emotions, and behaviour, as well as the behaviours and teaching styles of CIs. The weekly engagement status of the students is then determined using the MV-MOC approach. The performance of non-engaged students is subsequently predicted early using the ID2QN. Personalised recommendations for students are automatically generated using a deep learning technique called Att-CapsNet and are stored on the blockchain using the LWEA.
Table 8 presents the numerical evaluation of the current and proposed strategies.
6. Conclusions
In conclusion, this research establishes a detailed framework for the management of both students and course instructors, enhancing engagement assessment within the educational sphere. It lays down a solid groundwork for user authentication, incorporating multi-modal biometric data to ensure security. The application of the Threshold-based Shannon Entropy (TSE) method allows for a nuanced analysis of student behaviour, emotional responses, and instructional strategies, shedding light on diverse aspects of the educational process. Utilising the MV-MOC technique, the study enables educators to closely monitor and stimulate student participation on a weekly basis, fostering a more engaged learning environment. Furthermore, the integration of predictive modelling, exemplified by the ID2QN algorithm, aids in the timely identification of students in need of additional academic support. Additionally, this study innovates by offering personalised recommendations through the Att-CapsNet system, further secured by blockchain technology via the Lightweight Encryption Algorithm (LWEA), marking a significant step towards a more integrated and individualised educational approach.
Performance-wise, the proposed model outperforms existing systems, such as PCT, MST-FaDe, Fuzzy SVM, and AISAR, exhibiting significant improvements in accuracy (97%), F1-score (95%), precision-recall balance (0.99), and true positive rates, while simultaneously minimising false negatives and positives. This system has been refined to enhance agility, personalisation, and security, operating effectively without added complexity. These qualities underscore its robustness and efficiency across a range of classification and prediction scenarios, markedly enhancing the quality and responsiveness of e-learning platforms.
However, the proposed work has its limitations, which should be addressed. These may include the dependency on high-quality, multi-modal biometric data, which may not be readily available or may raise privacy concerns among users. Additionally, the complexity of the ID2QN and Att-CapsNet algorithms may require substantial computational resources, potentially limiting their applicability in resource-constrained environments. Furthermore, the effectiveness of the proposed model in diverse educational settings, with varying curricula and student populations, needs to be thoroughly evaluated. Future work could focus on addressing these limitations, exploring the scalability of the system, and extending its applicability to broader educational contexts.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}