


Advanced Techniques for Geospatial Referencing in Online Media Repositories


Abstract
1. Introduction
2. Related Work
3. Methodology
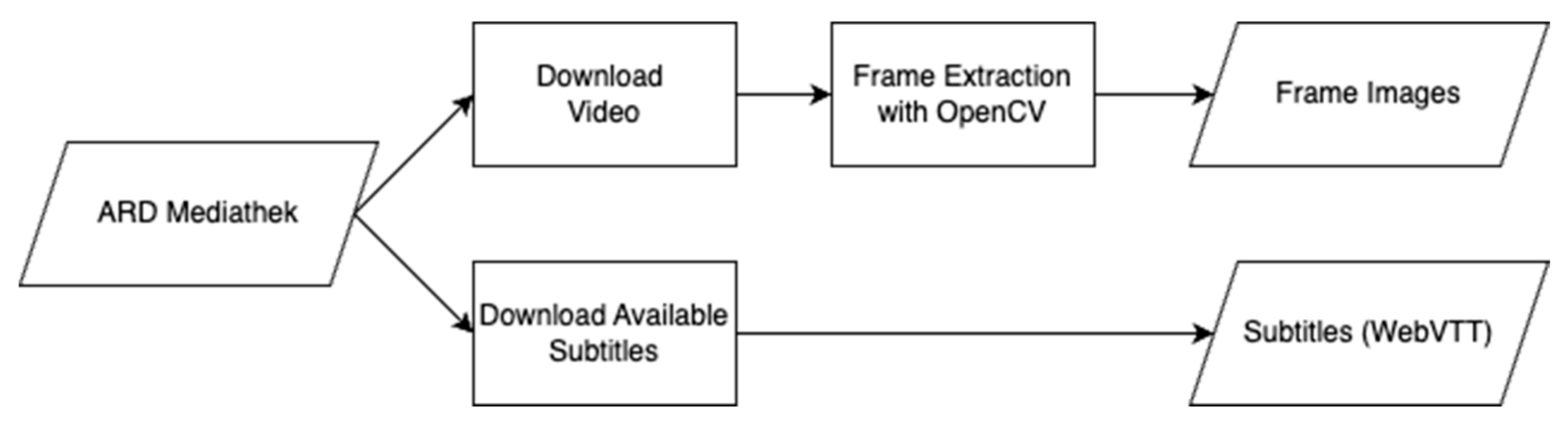
3.1. Data Acquisition
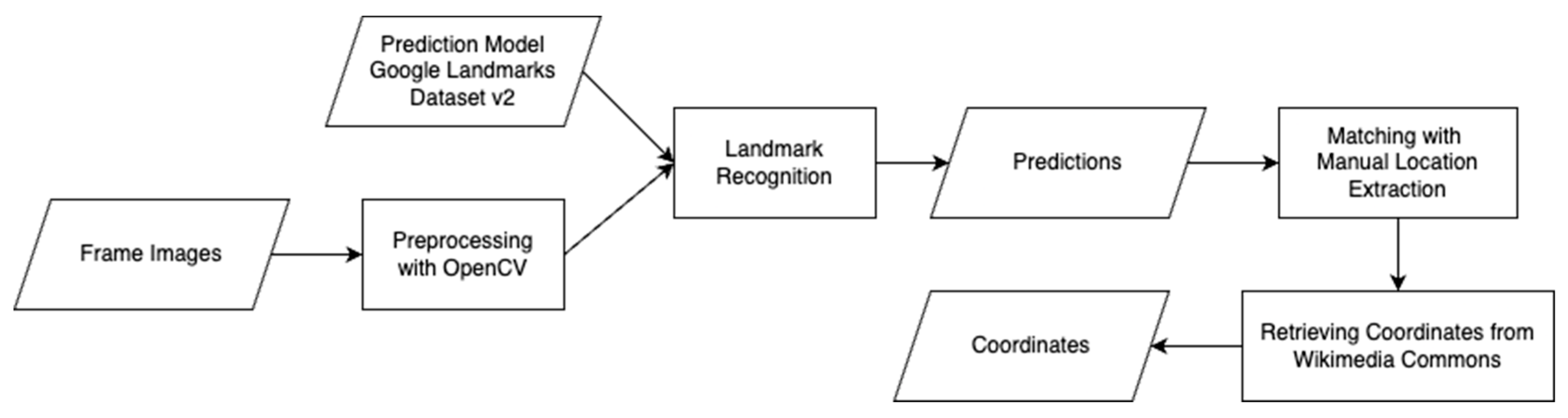
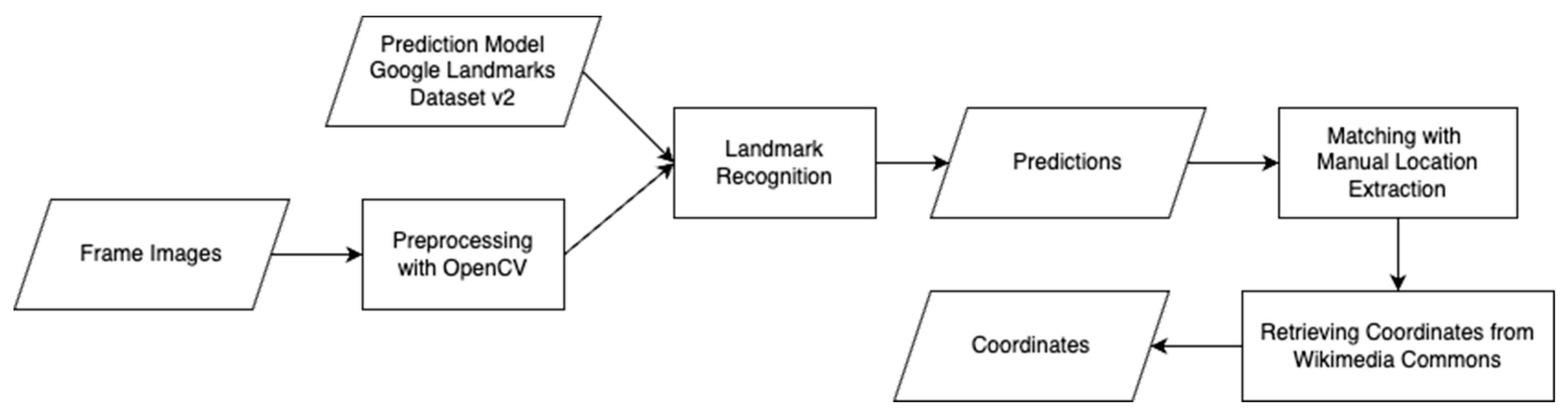
3.2. Analyzing the Visible Image
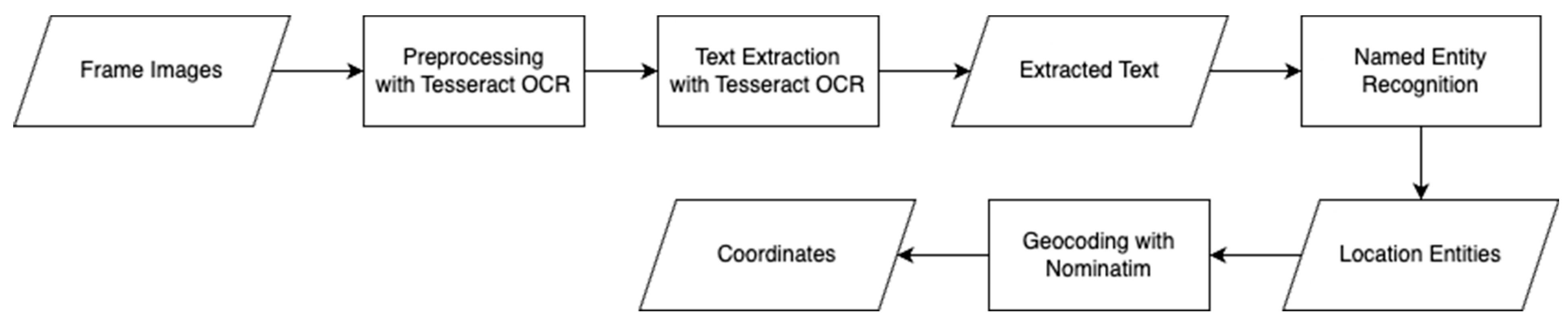
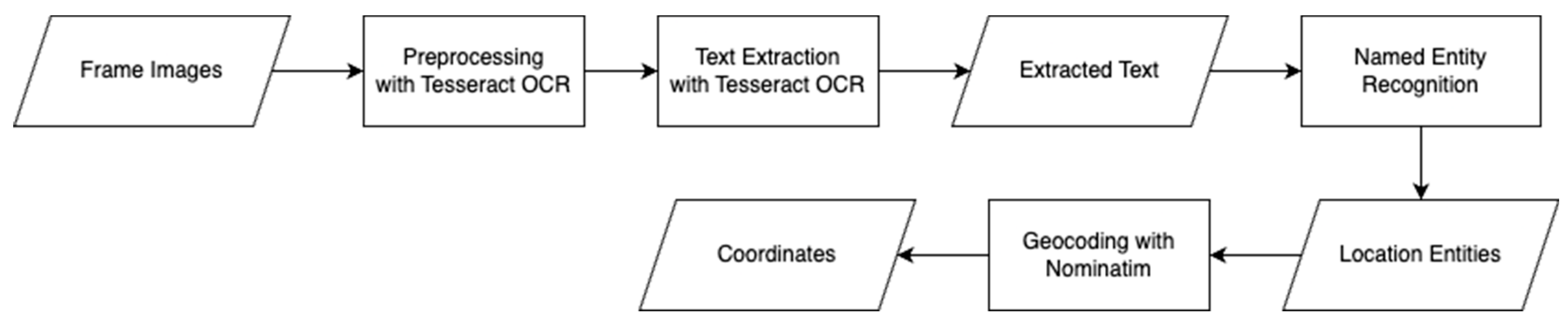
3.3. Analyzing Text in the Visible Image
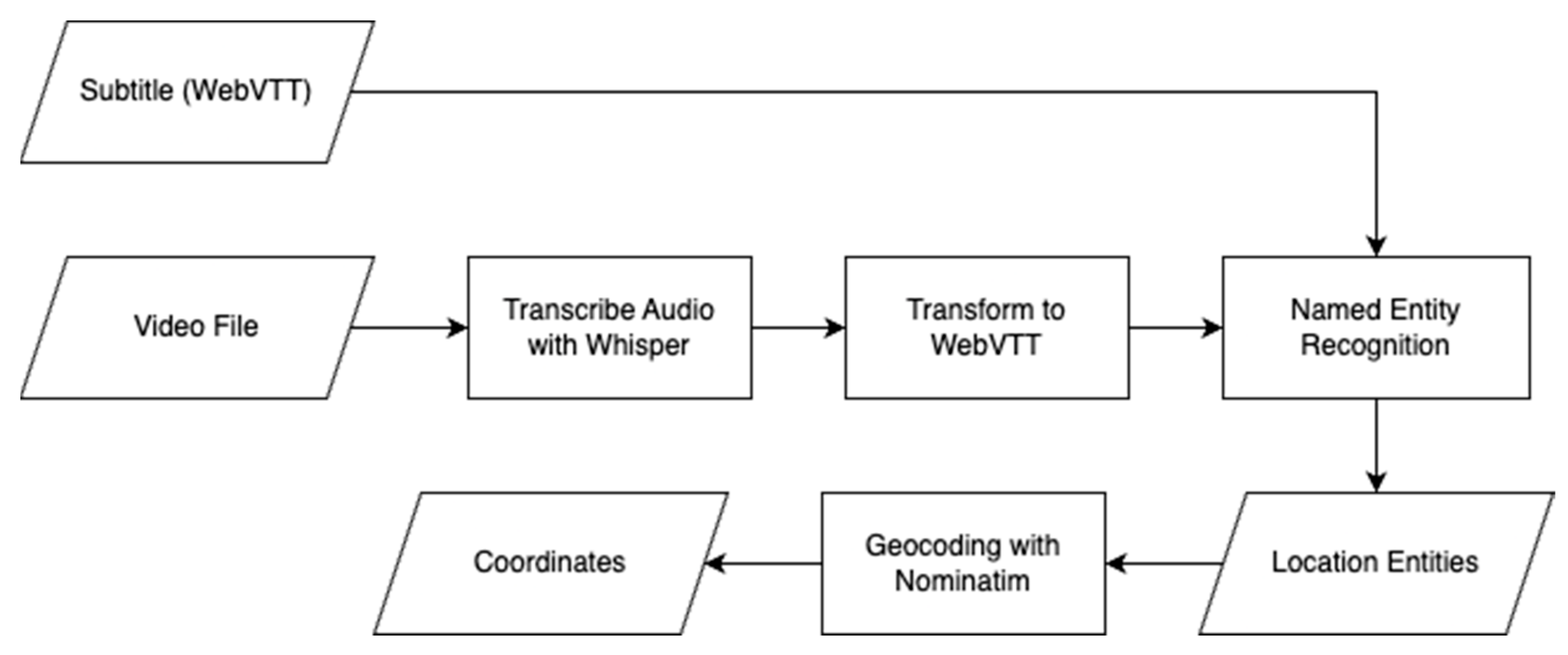
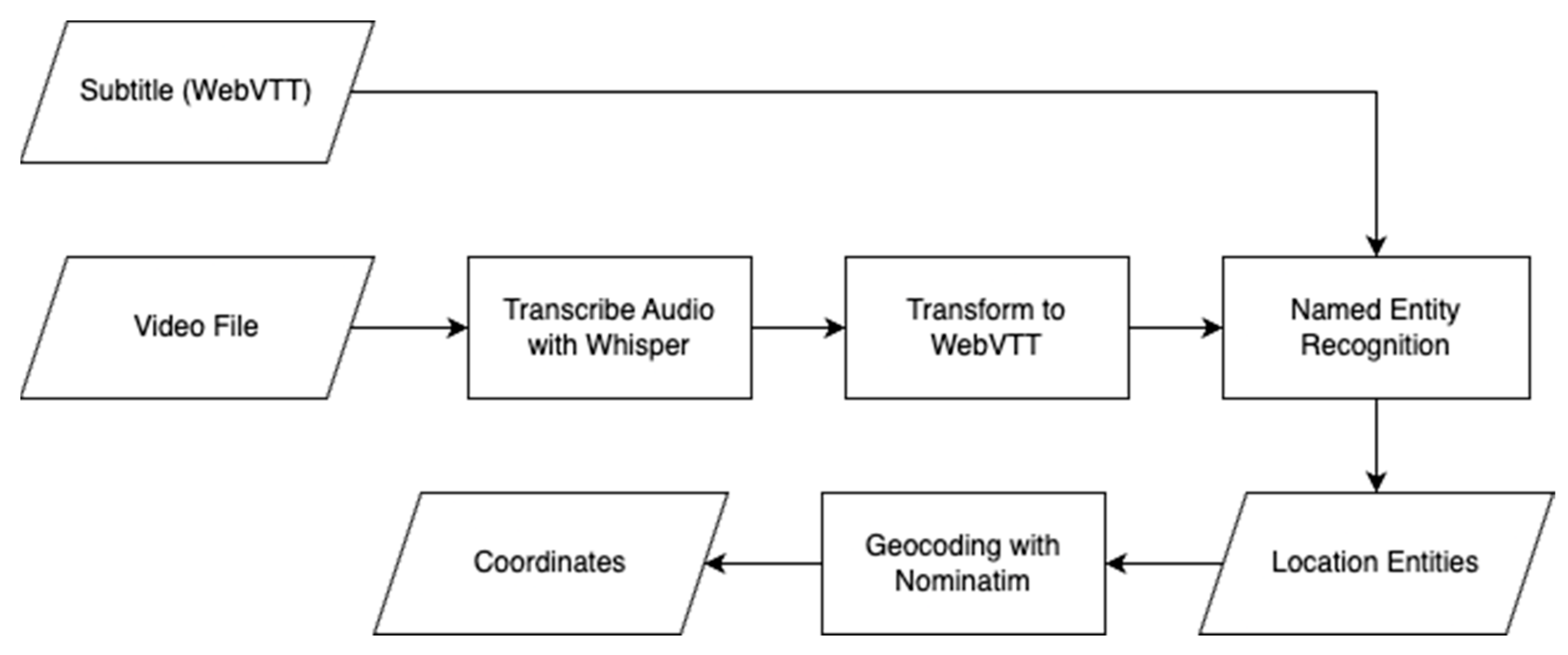
3.4. Analyzing Audio and Subtitles
4. Analysis
- gpt-3.5-turbo: gpt-3.5-turbo is a large language model developed by OpenAI and optimized for chatbots [72]. The prompt was defined to output locations in the text in a standardized and parsable format to extract location references.
- GeoTxt: GeoTxt recognizes and extracts location references from text [75].
- spaCy: It is a general NLP tool. The model de_core_news_md was used, and the LOC entities recognized by spaCy were kept as locations [76].
- Stanford Core NLP: This Java implementation of a CRF-based NER was developed and maintained by the Stanford Natural Language Processing Group [77]. It is used via the official Stanza package. The LOC (location) entities recognized by the Stanford NER were retained as locations.
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hopfgartner, F.; Schöffmann, K. Interactive Search in Video & Lifelogging Repositories. In Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, Oslo, Norway, 7–11 March 2017; pp. 421–423. [Google Scholar]
- Rupapara, V.; Thipparthy, K.R.; Gunda, N.K.; Narra, M.; Gandhi, S. Improving Video Ranking on Social Video Platforms. In Proceedings of the 2020 7th International Conference on Smart Structures and Systems (ICSSS), Chennai, India, 23–24 July 2020; pp. 1–5. [Google Scholar]
- Westphal, C.; Melodia, T.; Zhu, W.; Timmerer, C. Guest Editorial Video Distribution over Future Internet. IEEE J. Select. Areas Commun. 2016, 34, 2061–2062. [Google Scholar] [CrossRef]
- Jamonnak, S.; Zhao, Y.; Curtis, A.; Al-Dohuki, S.; Ye, X.; Kamw, F.; Yang, J. GeoVisuals: A Visual Analytics Approach to Leverage the Potential of Spatial Videos and Associated Geonarratives. Int. J. Geogr. Inf. Sci. 2020, 34, 2115–2135. [Google Scholar] [CrossRef]
- Chen, Z.; Shi, C. Analysis of Algorithm Recommendation Mechanism of TikTok. Int. J. Educ. Humanit. 2022, 4, 12–14. [Google Scholar] [CrossRef]
- Hyvönen, E. Publishing and Using Cultural Heritage Linked Data on the Semantic Web; Synthesis Lectures on Data, Semantics, and Knowledge; Springer International Publishing: Cham, Switzerland, 2012. [Google Scholar]
- Goldberg, D.W.; Wilson, J.P.; Knoblock, C.A. From Text to Geographic Coordinates: The Current State of Geocoding. Urisa J. 2007, 19, 33. [Google Scholar]
- Nadeau, D.; Sekine, S. A Survey of Named Entity Recognition and Classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Gelernter, J.; Balaji, S. An Algorithm for Local Geoparsing of Microtext. Geoinformatica 2013, 17, 635–667. [Google Scholar] [CrossRef]
- Leidner, J.L.; Lieberman, M.D. Detecting Geographical References in the Form of Place Names and Associated Spatial Natural Language. Sigspatial Spec. 2011, 3, 5–11. [Google Scholar] [CrossRef]
- Hu, Y.; Mao, H.; McKenzie, G. A Natural Language Processing and Geospatial Clustering Framework for Harvesting Local Place Names from Geotagged Housing Advertisements. Int. J. Geogr. Inf. Sci. 2018, 33, 714–738. [Google Scholar] [CrossRef]
- Stenetorp, P.; Pyysalo, S.; Topic, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. Brat: A Web-Based Tool for NLP-Assisted Text Annotati-on. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012. [Google Scholar]
- Wang, W.; Stewart, K. Spatiotemporal and Semantic Information Extraction from Web News Reports about Natural Hazards. Comput. Environ. Urban Syst. 2015, 50, 30–40. [Google Scholar] [CrossRef]
- Ling, X.; Singh, S.; Weld, D.S. Design Challenges for Entity Linking. Trans. Assoc. Comput. Linguist. 2015, 3, 315–328. [Google Scholar] [CrossRef]
- Hu, X.; Zhou, Z.; Li, H.; Hu, Y.; Gu, F.; Kersten, J.; Fan, H.; Klan, F. Location Reference Recognition from Texts: A Survey and Comparison. ACM Comput. Surv. 2023, 56, 112. [Google Scholar] [CrossRef]
- Gregory, I.; Donaldson, C.; Murrieta-Flores, P.; Rayson, P. Geoparsing, GIS, and Textual Analysis: Current Developments in Spatial Humanities Research. Int. J. Humanit. Arts Comput. 2015, 9, 1–14. [Google Scholar] [CrossRef]
- Melo, F.; Martins, B. Automated Geocoding of Textual Documents: A Survey of Current Approaches. Trans. GIS 2017, 21, 3–38. [Google Scholar] [CrossRef]
- Leetaru, K.H. Fulltext Geocoding versus Spatial Metadata for Large Text Archives: Towards a Geographically Enriched Wikipedia. D-Lib Mag. 2012, 18. [Google Scholar] [CrossRef]
- Gritta, M.; Pilehvar, M.T.; Limsopatham, N.; Collier, N. What’s Missing in Geographical Parsing? Lang. Resour. Eval. 2018, 52, 603–623. [Google Scholar] [CrossRef] [PubMed]
- Purves, R.S.; Clough, P.; Jones, C.B.; Hall, M.H.; Murdock, V. Geographic Information Retrieval: Progress and Challenges in Spatial Search of Text. FNT Inf. Retr. 2018, 12, 164–318. [Google Scholar]
- Li, L.T.; Pedronette, D.C.G.; Almeida, J.; Penatti, O.A.B.; Calumby, R.T.; Da, S.; Torres, R. Multimedia Multimodal Geocoding. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 474–477. [Google Scholar]
- Penatti, O.A.B.; Li, L.T.; Almeida, J.; Da, S.; Torres, R. A Visual Approach for Video Geocoding Using Bag-of-Scenes. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieval, Hong Kong, China, 5–8 June 2012; pp. 1–8. [Google Scholar]
- Paris, S.; Halkias, X.; Glotin, H. Beyond SIFT for Image Categorization by Bag-of-Scenes Analysis. In Pattern Recognition Applications and Methods; Fred, A., De Marsico, M., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2015; Volume 318, pp. 191–207. [Google Scholar]
- Trevisiol, M.; Jégou, H.; Delhumeau, J.; Gravier, G. Retrieving Geo-Location of Videos with a Divide & Conquer Hierarchical Multimodal Approach. In Proceedings of the 3rd ACM Conference on International Conference on Multimedia Retrieval, Dallas, TX, USA, 16–20 April 2013; pp. 1–8. [Google Scholar]
- Van Laere, O.; Schockaert, S.; Dhoedt, B. Georeferencing Flickr Resources Based on Textual Meta-Data. Inf. Sci. 2013, 238, 52–74. [Google Scholar] [CrossRef]
- Horbach, F.; Visca, D.; Pagel, S.; Neis, P. Methods for Georeferencing Linear and Non-Linear Media Content. GI_Forum 2023, 10, 66–72. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2013, 580–587. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Jiang, Y.-G.; Wu, Z.; Tang, J.; Li, Z.; Xue, X.; Chang, S.-F. Modeling Multimodal Clues in a Hybrid Deep Learning Framework for Video Classification. IEEE Trans. Multimed. 2018, 20, 3137–3147. [Google Scholar] [CrossRef]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL Based Multimodal Emotion Recognition and Sentiment Analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detec-tion Using Convolutional Networks. arXiv 2014, arXiv:1312.6229. [Google Scholar]
- Chen, Z.; Lam, O.; Jacobson, A.; Milford, M. Convolutional Neural Network-Based Place Recognition. arXiv 2014, arXiv:1411.1509. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the Performance of ConvNet Features for Place Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Hou, Y.; Zhang, H.; Zhou, S. Convolutional Neural Network-Based Image Representation for Visual Loop Closure Detection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 2238–2245. [Google Scholar]
- Panphattarasap, P.; Calway, A. Visual Place Recognition Using Landmark Distribution Descriptors. In Computer Vision–ACCV 2016, Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016, Revised Selected Papers, Part IV 13; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Bai, D.; Wang, C.; Zhang, B.; Yi, X.; Yang, X. CNN Feature Boosted SeqSLAM for Real-Time Loop Closure Detection. Chin. J. Electron. 2018, 27, 488–499. [Google Scholar] [CrossRef]
- Chen, Z.; Jacobson, A.; Sunderhauf, N.; Upcroft, B.; Liu, L.; Shen, C.; Reid, I.; Milford, M. Deep Learning Features at Scale for Visual Place Recognition. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3223–3230. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Neubert, P.; Protzel, P. Beyond Holistic Descriptors, Keypoints, and Fixed Patches: Multiscale Superpixel Grids for Place Recog-nition in Changing Environments. IEEE Robot. Autom. Lett. 2016, 1, 484–491. [Google Scholar] [CrossRef]
- Chen, Z.; Maffra, F.; Sa, I.; Chli, M. Only Look Once, Mining Distinctive Landmarks from ConvNet for Visual Place Recogni-tion. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 9–16. [Google Scholar]
- Chen, Z.; Liu, L.; Sa, I.; Ge, Z.; Chli, M. Learning Context Flexible Attention Model for Long-Term Visual Place Recognition. IEEE Robot. Autom. Lett. 2018, 3, 4015–4022. [Google Scholar] [CrossRef]
- Radenović, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [CrossRef]
- Kim, H.J.; Dunn, E.; Frahm, J.-M. Learned Contextual Feature Reweighting for Image Geo-Localization. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3251–3260. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recogni-tion. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Weyand, T.; Araujo, A.; Cao, B.; Sim, J. Google Landmarks Dataset v2—A Large-Scale Benchmark for Instance-Level Recognition and Retrieval. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2572–2581. [Google Scholar]
- Hausler, S.; Garg, S.; Xu, M.; Milford, M.; Fischer, T. Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 14136–14147. [Google Scholar]
- Smith, R. An Overview of the Tesseract OCR Engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, PR, Brazil, 23–26 September 2007; pp. 629–633. [Google Scholar]
- Islam, N.; Islam, Z.; Noor, N. A Survey on Optical Character Recognition System. arXiv 2017, arXiv:1710.05703. [Google Scholar]
- Mittal, R.; Garg, A. Text Extraction Using OCR: A Systematic Review. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; pp. 357–362. [Google Scholar]
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic Speech Recognition: A Survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Su-pervision. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Sato, T.; Kanade, T.; Hughes, E.K.; Smith, M.A. Video OCR for Digital News Archive. In Proceedings of the 1998 IEEE International Workshop on Content-Based Access of Image and Video Database, Bombay, India, 3 January 1998; pp. 52–60. [Google Scholar]
- Saluja, R.; Maheshwari, A.; Ramakrishnan, G.; Chaudhuri, P.; Carman, M. OCR On-the-Go: Robust End-to-End Systems for Reading License Plates & Street Signs. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 154–159. [Google Scholar]
- Priambada, S.; Widyantoro, D.H. Levensthein Distance as a Post-Process to Improve the Performance of OCR in Written Road Signs. In Proceedings of the 2017 Second International Conference on Informatics and Computing (ICIC), Jayapura, Indonesia, 1–3 November 2017; pp. 1–6. [Google Scholar]
- Paiders, J.; Plume, E. Use of Place Names in the Subtitle Corpus of Highest-Grossing Movies of the Past 20 Years. J. Int. Symp. Stud. Engl. Croat. Ital. Stud. 2018, 1, 43–60. [Google Scholar]
- ARD Mediathek. Available online: https://www.ardmediathek.de/ (accessed on 7 January 2024).
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2020, 25, 120–125. [Google Scholar]
- Cao, B.; Araujo, A.; Sim, J. Unifying Deep Local and Global Features for Image Search. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XX 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 726–743. [Google Scholar]
- Wikimedia Commons. Available online: https://commons.wikimedia.org/wiki/Main_Page (accessed on 7 January 2024).
- ABBYY FineReader PDF. Available online: https://pdf.abbyy.com/ (accessed on 9 February 2024).
- Adobe Acrobat: Easily Edit Your Scanned PDF Documents with OCR. Available online: https://www.adobe.com/acrobat/how-to/ocr-software-convert-pdf-to-text.html (accessed on 9 February 2024).
- Google Cloud Vision API: Detect Text in Images. Available online: https://cloud.google.com/vision/docs/ocr (accessed on 9 February 2024).
- Microsoft Azure AI Vision Documentation: OCR—Optical Character Recognition. Available online: https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/overview-ocr (accessed on 9 February 2024).
- Amazon Textract: Automatically Extract Printed Text, Handwriting, Layout Elements and Any Data from Any Document. Available online: https://aws.amazon.com/textract (accessed on 9 February 2024).
- Nominatim: Open-Source Geocoding with OpenStreetMap Data. Available online: https://nominatim.org/ (accessed on 7 January 2024).
- OpenStreetMap. Available online: https://openstreetmap.org/ (accessed on 7 January 2024).
- Akbik, A.; Bergmann, T.; Blythe, D.; Rasul, K.; Schweter, S.; Vollgraf, R. FLAIR: An Easy-to-Use Framework for State-of-the-Art NLP. In Proceedings of the NAACL 2019, 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Online, 6–11 June 2019; pp. 54–59. [Google Scholar]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual String Embeddings for Sequence Labeling. In Proceedings of the COLING 2018, 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Karimzadeh, M.; Pezanowski, S.; MacEachren, A.M.; Wallgrün, J.O. GeoTxt: A Scalable Geoparsing System for Unstructured Text Geolocation. Trans. GIS 2019, 23, 118–136. [Google Scholar] [CrossRef]
- spaCy: Industrial-Strength Natural Language Processing. Available online: https://spacy.io/ (accessed on 7 January 2024).
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. arXiv 2020, arXiv:2003.07082. [Google Scholar]
- Benikova, D.; Biemann, C.; Reznicek, M. NoSta-D Named Entity Annotation for German: Guidelines and Dataset. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 2524–2531. [Google Scholar]
- OpenAI GPT-3.5 Turbo Fine-Tuning and API Updates. Available online: https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates (accessed on 7 January 2024).
- Hossain, M.M.; Labib, M.F.; Rifat, A.S.; Das, A.K.; Mukta, M. Auto-Correction of English to Bengali Transliteration System Using Levenshtein Distance. In Proceedings of the 2019 7th International Conference on Smart Computing & Communications (ICSCC), Sarawak, Malaysia, 28–30 June 2019; pp. 1–5. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Precision | Recall | F1 Score |
|---|---|---|---|
| gpt-3.5-turbo | 0.61 | 0.79 | 0.67 |
| Flair NER | 0.85 | 0.80 | 0.83 |
| GeoText | 0.57 | 0.11 | 0.19 |
| spaCy | 0.63 | 0.46 | 0.53 |
| Stanford Core NLP | 0.67 | 0.55 | 0.60 |
| Stanza | 0.78 | 0.78 | 0.78 |
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Visible Image (Landmark Recognition) | 0.01 | 0.01 | 0.01 |
| Text in the Visible Image (OCR) | 0.38 | 0.16 | 0.23 |
| Audio/Subtitles | 0.74 | 0.71 | 0.72 |
| Total | 0.35 | 0.40 | 0.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Warch, D.; Stellbauer, P.; Neis, P. Advanced Techniques for Geospatial Referencing in Online Media Repositories. Future Internet 2024, 16, 87. https://doi.org/10.3390/fi16030087
Warch D, Stellbauer P, Neis P. Advanced Techniques for Geospatial Referencing in Online Media Repositories. Future Internet. 2024; 16(3):87. https://doi.org/10.3390/fi16030087
Chicago/Turabian StyleWarch, Dominik, Patrick Stellbauer, and Pascal Neis. 2024. "Advanced Techniques for Geospatial Referencing in Online Media Repositories" Future Internet 16, no. 3: 87. https://doi.org/10.3390/fi16030087
APA StyleWarch, D., Stellbauer, P., & Neis, P. (2024). Advanced Techniques for Geospatial Referencing in Online Media Repositories. Future Internet, 16(3), 87. https://doi.org/10.3390/fi16030087