1. Introduction
The rapid innovation in Internet of Things (IoT) technology has accelerated data-driven strategies, harnessing vast volumes of data originating from a tremendous number of IoT devices in various domains, including digital healthcare [
1], smart factories [
2], industrial control systems [
3], and transportation systems [
4]. The IoT service market is poised to reach
$575 billion in 2027 with an impressive annual growth rate of 18.8% [
5]. Nevertheless, the ubiquitous deployment of IoT devices poses numerous threats to IoT networks, such as Distributed Denial-of-Service (DDoS), Botnets, and Backdoors, echoing the security concerns commonly encountered in traditional networked systems [
6]. Unfortunately, the conventional Network Intrusion Detection Systems (NIDSs) based on Deep Packet Inspection (DPI) with pre-defined rulesets to address vulnerabilities within IoT networks are gradually losing their efficacy. Such ineffectiveness is attributable to the growing prevalence of zero-day attacks and the widespread adoption of encryption protocols [
7].
To address this problem, researchers have leveraged machine learning algorithms on intrusion detection systems to analyze incoming network traffic to identify suspicious or anomalous activities in IoT environments [
8,
9,
10,
11,
12]. Based on the labeled data categorizing packets as either benign or malicious, these models acquire the ability to discern patterns associated with different types of attacks. Throughout the training phase, relevant features representing various aspects of network behavior (e.g., inter-arrival time and flow rates) are used [
13,
14,
15]. One of the remarkable advantages of ML-based intrusion detection mechanisms is their capacity to detect unforeseen attacks and adapt to varying IoT network environments.
Nonetheless, there are several obstacles to building an effective intrusion detection model. Unlike rule-based Deep Packet Inspection (DPI), the ML-based approach is susceptible to generating false alarms, potentially misidentifying legitimate activities as malicious. The quality and completeness of the training data profoundly impact the model’s performance, particularly its ability to detect unseen attacks. In practice, obtaining sufficient labeled data for various attack types is challenging. Furthermore, the class imbalance (e.g., benign data substantially outweighing malicious ones) within the training data can introduce bias into the model, and, consequently, overfitting becomes a risk in such scenarios. These limitations become even more pronounced in the diverse and dynamic landscapes of IoT networks and environments, accentuating the challenges faced in developing robust intrusion detection systems.
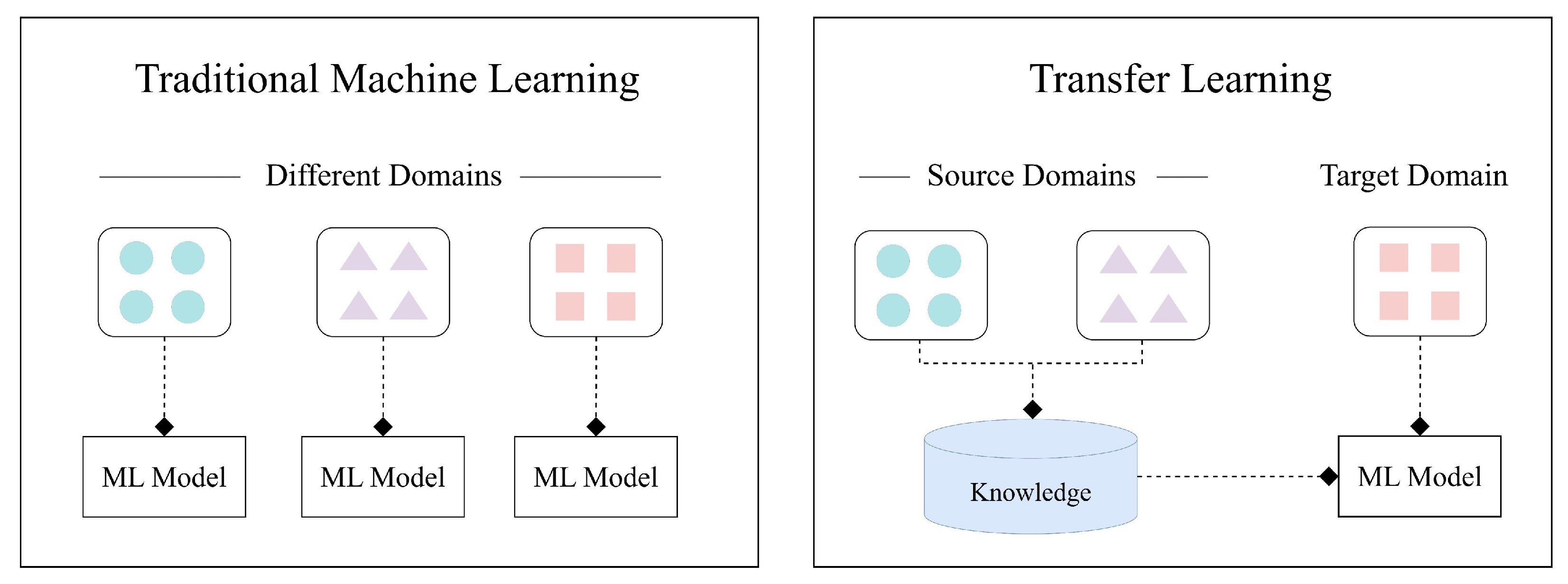
Notably, the emergence of Transfer Learning [
16] helps IDSs improve the detection performance in the context of IoT environments. Transfer learning entails the process of addressing a new problem, known as the target domain, by leveraging knowledge gleaned from a previously well-understood domain, termed the source domain. This approach capitalizes on the wealth of knowledge from the source domain to bolster performance and expedite the learning process in the target domain. Researchers have elaborated on enhancing the detection accuracy of IDSs in IoT environments by utilizing various machine learning and deep learning models with knowledge transfer [
17,
18,
19]. These endeavors have predominantly focused on enhancing the models themselves by exploring knowledge transfer strategies. However, there remains a gap when it comes to determining which data sets are suitable as source domains. From the perspective of the target domain, it remains unclear which data set is appropriate as a source domain to optimize the margin of improvement and contribute most effectively to the transfer learning process.
In this paper, we propose a novel framework to identify the most analogous source domain to a given target domain, leveraging deep learning as our foundational approach. Through a meticulous comparative analysis of the outcomes of similarity assessments and intrusion detection based on deep transfer learning, we significantly enhance the overall rigor of our experimental methodology. To explain in detail, similarity assessment consists of a framework that uses deep learning to determine which source domains are most similar to the target domain when there are multiple source domains. Furthermore, in intrusion detection based on deep transfer learning, we conduct an accuracy experiment, which exists to make sure that the results obtained in a similarity assessment are appropriate. Then, by comparing the results of these two steps, the source domain that is most similar to the target domain is finally selected. This study can provide a guide for identifying which data sets are best suited to the source domain in the transfer learning process and, in turn, contribute to improving the detection accuracy of IDSs in IoT environments. By utilizing four public intrusion detection data sets, we demonstrate the effectiveness of our framework in successfully choosing a fitting source domain data set, ultimately achieving the highest performance in transfer learning.
The organizational structure of this paper is outlined as follows:
Section 2 is dedicated to substantiating the research’s necessity through an exhaustive examination of the relevant literature.
Section 3 systematically organizes crucial contextual information. Subsequently, in
Section 4, we delve into an intricate exposition of the framework conceived by our research team, accompanied by a detailed presentation of the experimental methodology executed within this framework.
Section 5 adeptly illustrates the results obtained through the proposed experimental approach. Lastly,
Section 6 summarizes our research findings and delineating prospective avenues for future research endeavors.
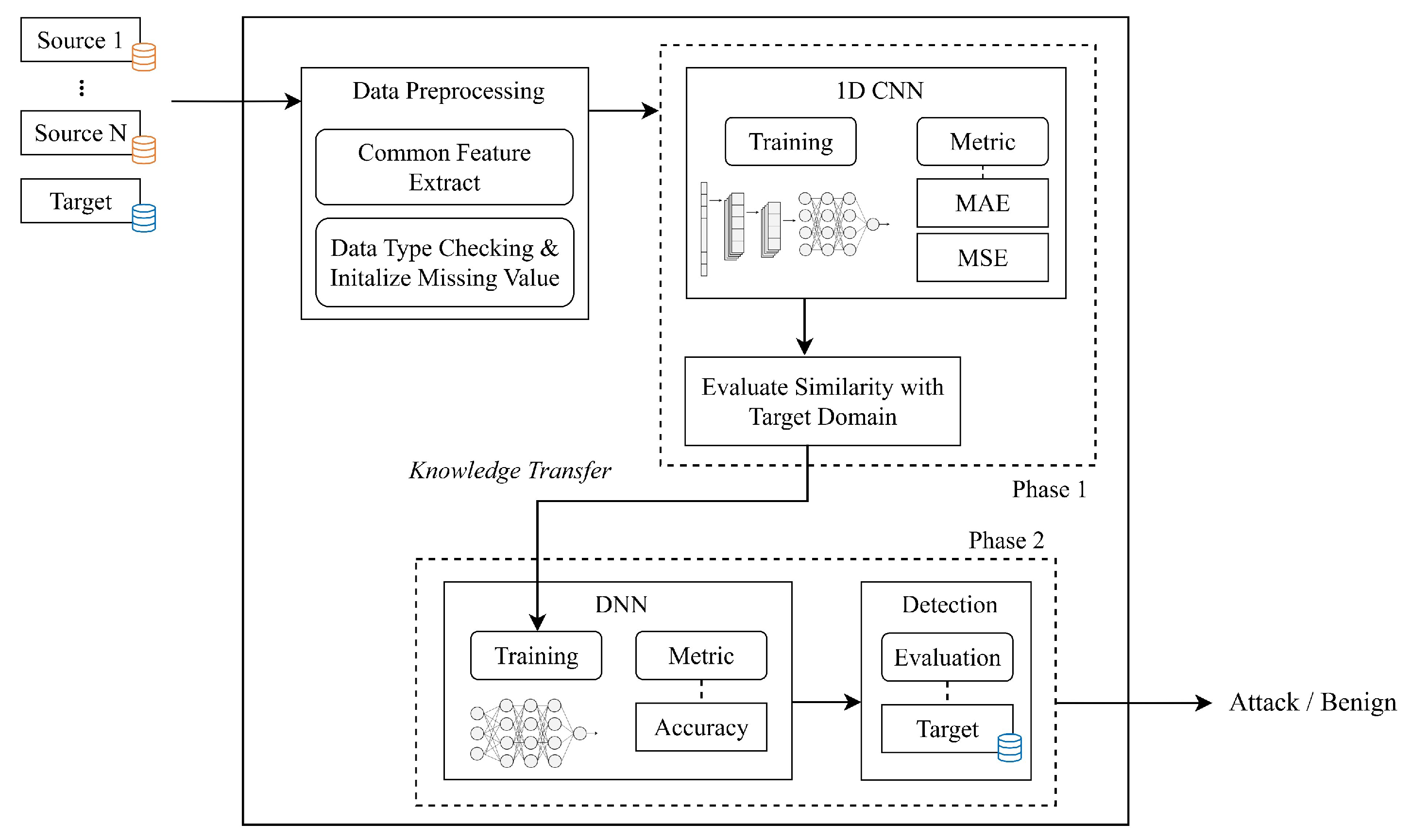
4. Framework Design
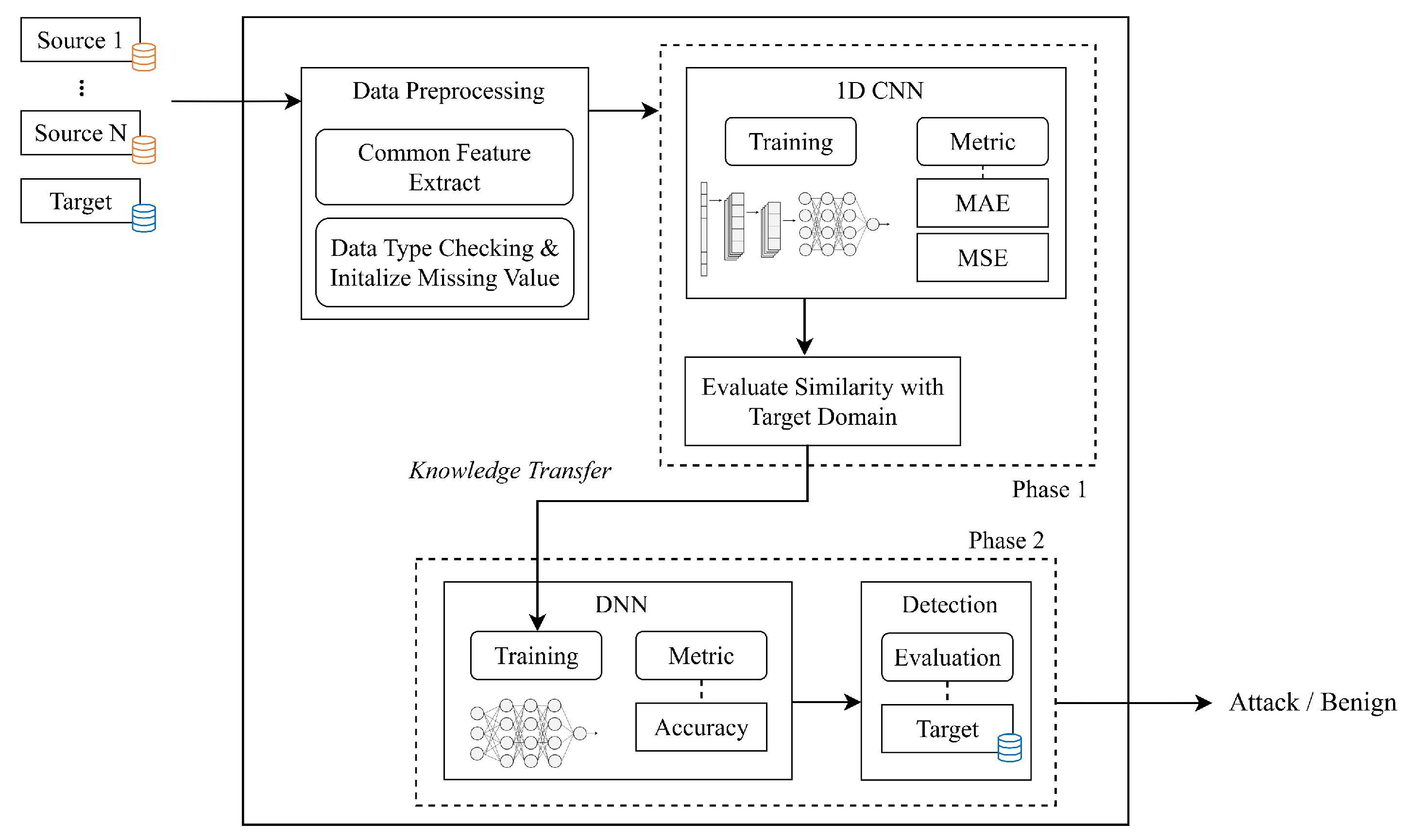
This section outlines the proposed framework for knowledge transfer, aimed at identifying an appropriate source domain for intrusion detection in the IoT environment. The ultimate goal is to build a binary classifier for determining whether the given flow from the target domain is malicious or benign based on the knowledge transfer. The framework is structured around two key phases: (1) similarity assessment with the target domain (Phase 1) and (2) the application of deep transfer learning for intrusion detection (Phase 2). An overview of the entire process is depicted in
Figure 2.
First, candidate source data sets, along with the target domain data set, undergo a preprocessing phase. Then, a metric is employed to assess the similarity between these data-sets. This evaluation serves to determine which source domain exhibits the highest degree of similarity with the target domain. The insights achieved from Phase 1 are then leveraged in Phase 2, where a model is constructed for handling inference data originating from the target domain.
4.1. Preprocessing
Given the diverse deployment scenarios and specialized devices inherent in the IoT ecosystem, it is essential to acknowledge that the data collection environments for each candidate source data set can significantly vary. These differences manifest in various ways, including variations in the number of features, data set composition, and the quantities of attack and benign instances. Consequently, preprocessing is necessarily required to unify the feature configurations across multiple data sets and address uninitialized values before embarking on the knowledge transfer process. This ensures that the source and target domains are effectively aligned, evaluating the similarity between data sets and facilitating a seamless transfer of knowledge between them.
Based on a feature analysis of the four data sets that we utilized, we first identified a common set of 12 features shared among all the source domain candidates and the target domain data set.
Table 2 summarizes the result.
To acquire common features across the four data sets, we focused on unifying features whose names were different but virtually identical in representing flow aspects (e.g., sbytes in Bot-IoT and Fwd_Pkt_Len_Mean in IoT Intrusion data sets). We note that the four data sets used in our study are representative and widely used data sets with extensive flow characteristics, which means that our approach can be extended to apply to other IoT intrusion detection data sets. The remaining features include ‘Source IP’, ‘Source Port’, ‘Destination IP’, ‘Destination Port’, ‘Protocol’, ‘Flow Duration’, ‘Fwd Packet Length Mean’, ‘Bwd Packet Length Average’, ‘Total Delivered Packets’, ‘Total Bandwidth Packets’, ‘Timestamp’, and ‘Label’, which signify the maliciousness of the data. We also note that the previous studies showed that anomaly detection performance is affected by feature importance (e.g., the weight of the information gain) rather than the sheer number of features [
36]. In a comparative analysis, previous studies grouped features into sets of 4, 15, and 22, demonstrating a consistently high accuracy ranging from 96% to 99%. We confirmed that our evaluation result aligns with such a result to distinguish benign and malicious traffic, as our proposed framework delivers a 97–99% accuracy (see
Section 5.3). To ensure a balanced representation among the source data sets, we employed a sampling strategy for the number of attack instances in each attack type. Specifically, we adjusted the total count of benign and attack instances in each data set to align with 625,783, which is the smallest instance number among the data sets (IoT Intrusion data set).
4.2. Phase 1: Similarity Assessment
In our study, we based our approach on
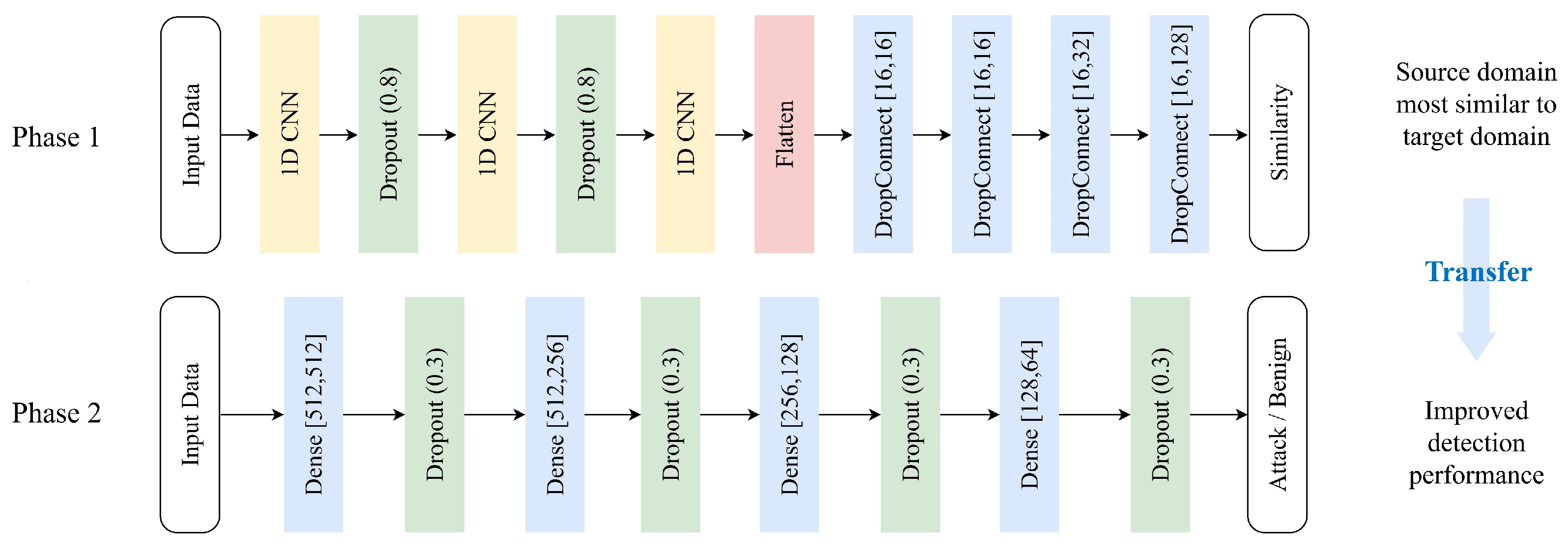
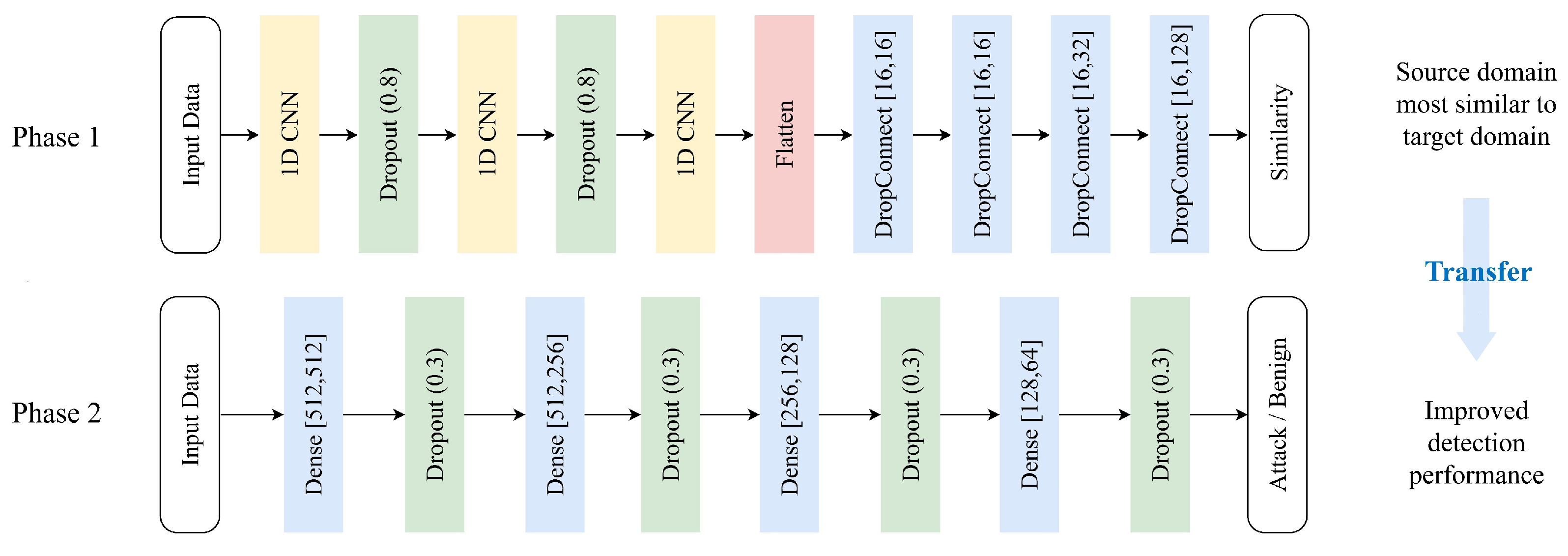
similarity to select the optimal source domain to enhance the attack detection performance in the target domain. We designed the similarity assessment based on the following intuition: the closer the data are to the target domain, the better the detection performance will be during transfer learning. In phase 1, we evaluate the similarity between each source domain and the target domain. The deep learning model used for this has layers as illustrated in
Figure 3, consisting of three 1D CNN layers and five Dense layers.
All 1D CNN layers and Dense layers use the LeakyReLU activation function, and a Flatten layer is added between the 1D CNN and Dense to match dimensions. The dropout layer is one of the regularization techniques used to prevent overfitting in deep learning models. The reason the dropout layer parameter was set to 0.8 was to deactivate neurons with a 20% probability during training, preventing the network from being overly dependent on specific neurons. Thus, 0.8 was the optimal parameter value obtained through experimentation. The rationale for layer selection and arrangement lies in the hierarchical nature of deep neural networks in transfer learning. In the context of transfer learning, lower layers are known to capture more fundamental knowledge from the input data of network traffic, while upper layers specialize in learning higher-level abstractions by combining or synthesizing these basic features, respectively. In our approach, we maintain the lower layer (1DCNN) in a fixed state and manipulate the parameters of the upper layer (Dense and Dropconnect). Additionally, we employ batch normalization to standardize the data distribution. Batch normalization adjusts data distribution within each batch, enhancing the stability of the learning process. Finally, to prevent overfitting, early stopping is implemented based on the point where the validation loss starts increasing. This layered configuration aims to leverage the specialized capabilities of each layer, facilitating the effective transfer of knowledge across varying domains.
In phase 1, we use the Mean Squared Error (MSE) loss function and the Mean Absolute Error (MAE) loss sum to conduct similarity assessments between the source and target domains. MSE and MAE are representative metrics for regression problems, and both are based on the difference between the actual and predicted values, which has the advantage of being intuitive and involving less computational complexity. In addition, the MSE loss function is typically used in deep learning models that train the closest value to the actual label to be predicted. Because it averages the square of the errors, large errors are more emphasized, which is useful for evaluating the overall performance of the model. Mean Squared Error (MSE) is defined as follows:
Through the MSE loss function, we calculate the mean squared error, where represents the predicted values, represents the actual values, and N denotes the number of training samples.
To evaluate the performance of the regression model and determine how well it has learned, we utilize the MAE evaluation metric. MAE measures the absolute differences between the actual ground truth values and the predicted values, averaging these absolute differences. A lower MAE indicates a higher similarity of the model’s predictions to the actual values. MAE is defined as follows:
In this context, represents the actual values, while denotes the predicted values. The error is calculated by subtracting the predicted value from the actual value. This difference is then taken in absolute terms. The resulting value is divided by the number of training samples, N, to compute the average.
Algorithm 1 describes the detailed workflow of phase 1.
| Algorithm 1: Similarity evaluation between source and target domains
|
![Futureinternet 16 00080 i001]() |
The goal is to evaluate the similarity between source domains () and a target domain (T) before conducting knowledge transfer. After the preprocessing and sampling procedure, our framework conducts deep learning with the aforementioned network layers for similarity assessment. Note that we use LeakyReLU as an activation function to evaluate which of the source domain is most similar to the target. The MSE and MAE loss functions are used as performance evaluation indicators of the regression model to compare the performance of the trained model (). The training is repeated until the epoch reaches 100, and the appearance of each epoch is observed at 20, 40, 60, 80, 100. If there is overfitting at this time, the training undergoes early stopping to prevent overfitting.
4.3. Phase 2: Transfer Learning
In phase 2, our framework acquires a training model for intrusion detection against the target domain by utilizing the knowledge transferred from phase 1. For evaluation, the Binary Cross Entropy (BCE) loss function is employed to assess the accuracy of malicious traffic detection for source domains with a high similarity. We selected BCE because it measures the difference between the predictive probability of the model and the actual class and is a suitable loss function for binary classification. During the experiment, the binary classifier is trained by setting malicious traffic to 1 and positive traffic to 0. The BCE loss function is defined as follows:
Here,
represents the actual label (either 0 or 1), and
is the predicted binary probability (0
1) for the data. As the prediction becomes more accurate, the loss decreases. Our aim is to minimize the total loss through training.
To prevent overfitting, we introduce five Dense layers and four Dropout layers (see
Figure 3). The Dropout layer deactivates random neurons during training to enhance generalization capabilities. To reduce the model’s complexity and enhance generalization, a Dropout rate of 0.3 is applied. In the phase 2 experiments, a ratio of 0.3 showed the most optimal results. Additionally, to simplify the model, we reduce the number of units in the deep learning model and utilize DropConnect in the Dense layers. For binary classification, the Leaky ReLU activation function is used in the four Dense layers excluding the last Dense layer, which requires a Sigmoid activation function. This choice effectively controls the model complexity and mitigates overfitting.
As shown in Algorithm 2, the goal of phase 2 is to acquire a binary classifier (K) to judge whether the given target domain instance is benign or malicious. Like the typical architecture composition in a binary classification problem, we use LeakyReLU as an activation function for four dense layers and Sigmoid for the last one. Comparing the Accuracy value, the result obtained from this experiment allows us to determine the highest accuracy when using any of the three s as the source domain. As a result, phase 2 demonstrates the correlation of similarity and performance between data sets based on the accuracy of the target-domain-like source domain identified in phase 1.
| Algorithm 2: Transfer learning with source and target domains |
![Futureinternet 16 00080 i002]() |
5. Evaluation
5.1. Experimental Environment
To evaluate the performance of our proposed framework, we used four public data sets mentioned above. The Bot-IoT data set and IoT Intrusion data set were selected as target domains, which were collected from real IoT environments. The experiment included the number of both cases in which each of these two data sets (Bot-IoT and IoT Intrusion) was set as the target domain, and, in each case, the source domain was the other three except that data set. These source domains contain various types of network attacks and provide appropriate data to evaluate their similarities with the target domain. Note that each source domain consists of 70% of the three data sets and 30% of the data set selected as the target domain. As an experimental environment, we used a Windows 11 Pro 64-bit operating system, equipped with an Intel(R) Core(TM) i7-1065G7 CPU @ 1.30 GHz 1.50 GHz processor, 16 GB of RAM, and an Intel Iris Plus Graphics graphics card. We utilized Python 3.11.4 64-bit and leveraged the Pandas, Scikit-learn, and Numpy libraries.
Table 3 summarizes our evaluation environment.
5.2. Similarity Assessment
First, we measured the MAE and MSE of each source domain candidate for knowledge transfer to figure out the source domain most adventurous to the target domain. The result acquired from phase 1 was further used in the subsequent phase, phase 2, to conduct a more accurate and effective transfer learning. The experimental results are shown in
Table 4 and
Table 5. We confirmed that the Bot-IoT data set was the IoT Intrusion data set with the lowest MAE and MSE metric values, which means that it was the most similar to the target domain. This suggests that the IoT Intrusion data set has similar features and patterns to the Bot-IoT data set. Likewise, even when the IoT Intrusion data set was a target, it was confirmed that the MAE and MSE of the Bot-IoT data set were the lowest. As a next step, we verified that intrusion detection based on deep transfer learning in each case utilizing IoT Intrusion data set and Bot-IoT data set delivered the best inference performance for the source data set conducted in phase 2.
5.3. Intrusion Detection Performance
To verify the assessment result, we constructed multiple models for each source domain combined with the target domain data set, a typical way of instance-based transfer learning. For this, three training data sets were constructed by combining 100% of the source data set and 70% of the target data set for each of the three source data sets. Note that the remaining 30% of the target data set was used as a test data set. The accuracy evaluation index employed in the performance assessment was derived from a confusion matrix and adhered to the following standard measurements:
Here, TP (True Positive) represents the count of inference results in which the model correctly predicted a malicious flow as an attack class. In essence, the accuracy metric serves as an indicator of how precise the model’s predictions are, with a higher value approaching 1 signifying superior performance.
As expected, the highest Accuracy value and the lowest loss value were identified in the case of using the IoT Intrusion data set as the source data set. To cross-check whether the selected source domain based on the assessment and the target domain were indeed similar, we performed a qualitative analysis by scrutinizing the data sets, for example, by examining the number of attack types and the instance ratio of common attack types.
First, when the number of common attack types between the target and source domains was examined, UNSW-NB15 overlapped the most with two types: DoS and Reconnaissance. Meanwhile, IoT Intrusion and CIC-IDS2017 had only DoS in common. Considering that all three source domains shared the DoS attack type with the target domain, similarity was assessed based on the number of DoS instances. The counts for each source domain were as follows: IoT Intrusion with 59,391 instances, UNSW-NB15 with 16,353 instances, and CIC-IDS2017 with 252,661 instances, out of a total of 625,783 instances across the domains. The percentage of DoS instances from the total for each source domain was calculated as follows: IoT Intrusion at 9.48%, UNSW-NB15 at 2.61%, and CIC-IDS2017 at 40.35%. Interestingly, this reveals that CIC-IDS2017 significantly had the highest number of instances for the common attack type.
Then, we reviewed the data collection environment for each public data set. The data sets used as source domains were collected from diverse environments ranging from actual IoT setups to virtual networks. The IoT Intrusion data set originated from a smart home environment, specifically from SKT NUGU (NU 100) and the EZVIZ Wi-Fi Camera (C2C Mini O Plus 1080P). The UNSW-NB15 data set is a hybrid blend of genuine modern network traffic and synthesized modern attack behaviors. The CIC-IDS2017 data set was collected in a virtual environment designed to emulate real PCAP data. Lastly, the Bot-IoT data set comprises data from five IoT devices, including smart fridges, garage doors, weather monitors, lights, and thermostats.
While UNSW-NB15 dominated in terms of the number of attack types and CIC-IDS2017 led in the instance ratio of shared attack types with the target domain, ultimately, the IoT Intrusion data set, generated from the same smart home environment, demonstrated the highest performance. This underscores the significant influence of the data collection environment on the target domain’s performance. In situations requiring the selection of a source domain for transfer learning, it is recommended, as evidenced by our paper, to prioritize the collection environment over the shared attack types for better effectiveness.
5.4. Overfitting Mitigation
To address overfitting in the model training, we employed various techniques. First, we utilized the dropout layer and empirically determined the dropout rate to mitigate overfitting. For mild overfitting, a dropout rate between 0.2 and 0.5 is recommended, and for severe cases, a rate of 0.8 is beneficial. Therefore, we applied a rate of 0.8 to ensure a robust prevention of overfitting. Additionally, as the complexity of the model increases, it becomes more prone to overfitting. Hence, we adjusted the number of layers and parameters in the model. Finally, we incorporated the BatchNormalization() layer into the deep learning model to further mitigate overfitting. The BatchNormalization() Layer normalizes the output value of the activation function to distribute it appropriately. If the weights are not appropriate, the model may become sensitive to even small changes in the input data, which may lead to overfitting. In this case, BatchNormalization() improves the learning speed and suppresses overfitting by maintaining good weight values and appropriately distributing activation values without depending on the initial weight value. Finally, it is worth noting that existing overfitting mitigation methods, including the aforementioned mitigation strategies, can be also leveraged to our proposed framework.
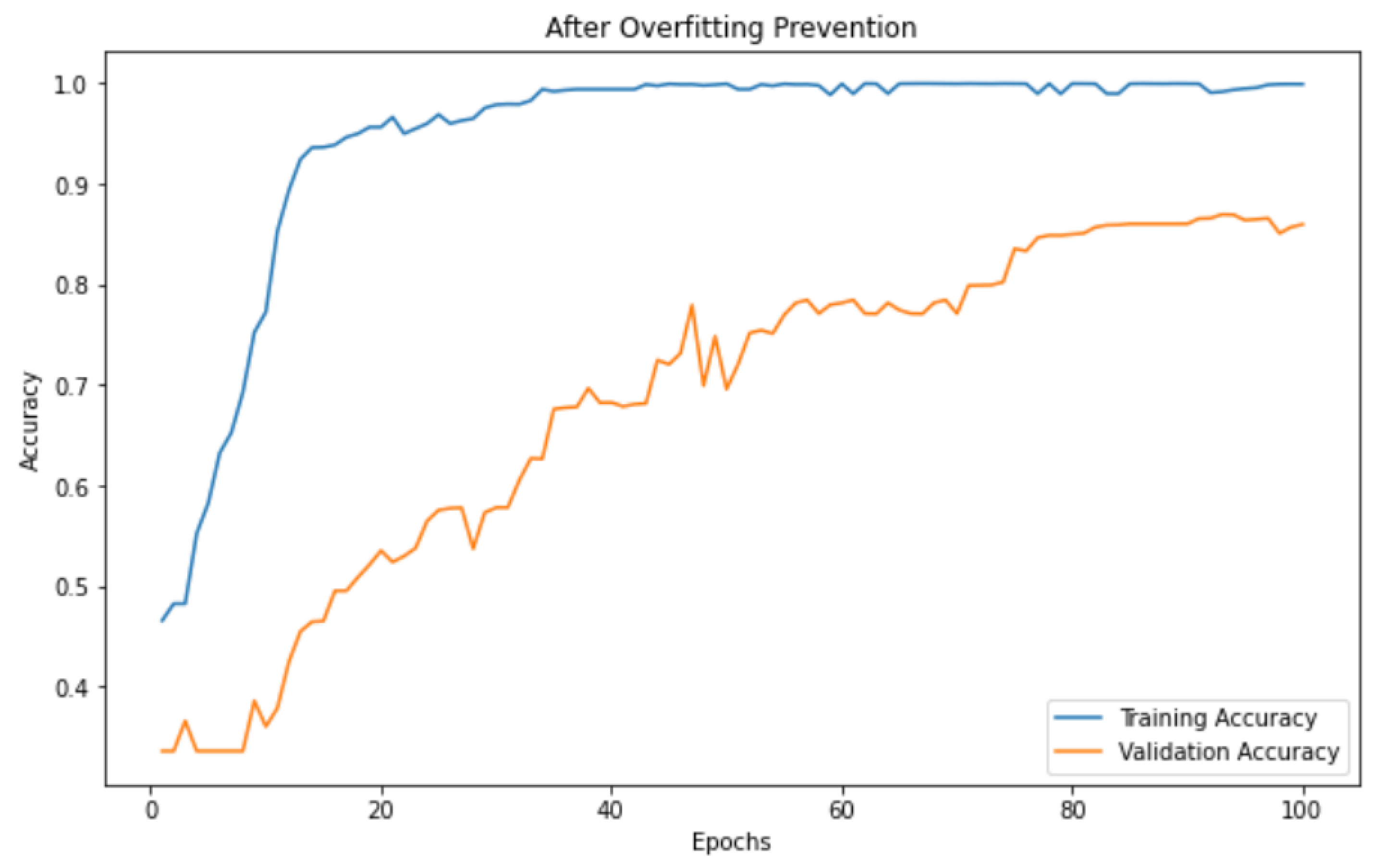
To validate the overfitting mitigation strategies applied in our framework, we measured the trend of training and validation accuracies in phase 2 for the IoT Intrusion data set while varying the epochs until 100.
Figure 4 shows the result after adopting the aforementioned mitigation methods.
Typically, a model is likely to be overfitted when the slope of training and validation accuracy gradually decrease, reaching a floor. In our observation, we noted a smooth increase in both training and validation accuracy, with a consistent plateau observed from epoch 20 onwards, maintaining a stable shape. This is interpreted as the effective contribution of the overfitting technique mentioned above.
5.5. Discussion and Limitations
Our research emphasizes the importance of choosing the right source domain for transfer learning, as this choice impacts learning performance. This perspective, which highlights the significance of selecting an appropriate source domain, has yet to be explored in existing research. The effectiveness of our framework is demonstrated through our evaluation results on the IoT Intrusion and Bot-IoT data set case studies. Remarkably, these data sets, sharing similar collection environments and attack labels compared to other data sets, exhibited the best accuracy as a source domain to each other when processed using our framework. This result highlights the framework’s efficacy when collection environments and attack labels align closely.
Compared to previous studies, our approach sets itself apart by not only focusing on the types and frequencies of attacks but also taking into account the environmental context of data collection based on the inherent similarity with the target domain. While existing approaches are primarily focused on the technical enhancement of trained intrusion detection models by utilizing diverse machine learning techniques, we recognize the importance of providing practical implications and insights for knowledge distillation. These insights are particularly valuable for practitioners and researchers in IoT security, who face challenges posed by diverse and heterogeneous IoT network environments. We believe the importance of our research lies not only in developing an effective intrusion detection model but also in emphasizing the crucial role of selecting an appropriate source domain based on its similarity to the target domain.
However, our knowledge distillation strategy based on data set similarity would be inefficient in scenarios where the intersection across the source domain candidates and the target domain are limited and scarce. As our framework relies on a subset of shared features from varied candidate data set pools in the preprocessing phase, it might fail to accurately identify all the attacks specified within the data sets. We note that information loss due to the common feature extraction can be ameliorated if the raw packet data (e.g., PCAP files) are accessible. By utilizing the same flow analyzer (e.g., CICFlowMeter [
34]) against candidate data set pools to acquire the flow information from the raw packet data, it is possible to fairly utilize all the flow features for transfer learning.
If raw packet data are not provided, the number of common features could be drastically reduced when using datasets with vastly different characteristics, which could lead to performance degradation. However, these concerns can be alleviated primarily through screening by security operators before performing intrusion detection. For example, they can conduct qualitative analysis to ensure the collection environment is similar or the considered attack label is being targeted. Subsequently, they might encounter a situation in which it is hard to intuitively determine the most suitable source dataset among the filtered candidate data set pools. In such cases, we believe leveraging the proposed framework is considered best practice for comparing datasets and resolving uncertainties.
In addition, the aforementioned limitation aligns with the inherent constraints of knowledge distillation based on data set similarity, particularly in scenarios involving the detection of unforeseen attack patterns (e.g., zero-day attacks). We believe such limitation can be addressed by leveraging the state-of-the-art ML techniques. For example, recent approaches that enhances the calibration of neural network confidence by leveraging outlier exposure [
37] can be applicable to phase 2 in our framework to detect false alarms raised by zero-day attacks.







{kind=link}
{kind=link}
{kind=link}
{kind=link}