1. Introduction
Accelerators are specialized processors that have been developed and integrated into computer systems in response to the growing demand for high-performance computing. These accelerators aim to assist the central processing unit (CPU) in executing certain types of computations. Several studies have demonstrated that offloading specific tasks to accelerators can considerably boost the overall system performance [
1]. Hence, the use of accelerators has become a typical approach to handling the high computational demands in various industries and research fields. This has motivated hardware manufacturers to develop a variety of specialized accelerators, including accelerated processing units (APUs), floating-point units (FPUs), digital signal processing units (DSPs), network processing units (NPUs), and graphics processing units (GPUs).
The GPU, which is considered one of the most pervasive accelerators, was initially devised for graphics rendering and image processing. However, in the last few years, its computational power has been increasingly harnessed for parallel number crunching. Nowadays, GPU-accelerated applications are present in many domains that are often unrelated to graphics, such as deep learning, financial analytics, and general-purpose scientific calculations. On the other hand, virtualization plays a fundamental role, as it enables many modern computing concepts. Its primary function is facilitating the sharing and multiplexing of physical resources among different applications. Particularly, virtualization significantly enhances GPU utilization by enabling more efficient allocation of its computational power. In general, the main advantage of virtualizing computing resources lies in reducing energy consumption in data centers, which, in turn, contributes to reducing operational costs. Hence, a variety of new applications that leverage the capabilities of virtual GPUs (vGPUs) have emerged. Examples of such applications that benefit from vGPU acceleration are deep learning, virtual desktop infrastructure (VDI), and artificial intelligence applications.
It is worth noting that virtualizing GPUs presents more complex challenges than the virtualization of CPUs and most I/O devices, as the latter rely on well-established technologies. These challenges stem from several key obstacles. First, there is significant architectural diversity in hardware among GPU brands, complicating the development of a universal virtualization solution. Second, using closed-source drivers from popular GPU brands, such as NVIDIA, poses a significant challenge for third-party developers in developing virtualization technology for these devices. Third, most GPU designs lack inherent sharing mechanisms, leading to a GPU process gaining exclusive access to its resources, thereby blocking other processes from preemption. In addition, several studies have shown that the overhead involved in process preemption is substantially higher in GPUs than in CPUs [
2,
3]. This increased overhead is essentially due to the higher number of cores and context states in GPUs. It is important to note that some recent GPUs, such as the NVIDIA Pascal GPU [
4], include support for preemption at the kernel, thread, and instruction levels to mitigate these challenges.
Before developing advanced GPU virtualization technologies, practitioners used the passthrough technique to enable VMs to access physical GPU (pGPU) resources directly. This approach, however, has limitations, such as the inability to share a GPU among multiple VMs and the lack of support for live migration. Major GPU manufacturers such as NVIDIA, AMD, and Intel have introduced their brand-specific virtualization solutions to address these issues. These include NVIDIA GRID [
5], AMD MxGPU [
6], and Intel’s Graphics Virtualization Technology—Grid generation (GVT-g) [
7]. The first two virtualization solutions are based on hardware virtualization capabilities, whereas the third one, Intel’s GVT-g, provides a software-based solution for full GPU virtualization. GVT-g is open source and has been integrated into the Linux mainline kernel, which makes it a desirable option due to its accessibility and potential for broader integration.
On the other hand, performance analysis tools for GPUs are important for debugging performance issues in GPU-accelerated applications [
8]. These tools help understand how the GPU resources are allocated and consumed, and they facilitate the diagnosis of potential performance bottlenecks. They are particularly crucial in virtualized environments, where resource sharing in vGPUs and its impact on performance need to be better understood. However, developing practical tools for monitoring and debugging vGPUs remains challenging. This is because virtualized environments often present many layers, encompassing hardware, middleware, and host and guest operating systems, which increase the isolation and abstraction of GPU resources, making it difficult to pinpoint the causes of performance issues.
The landscape of GPU performance analysis features diverse tools, with academic contributions tailored to specific GPU programming models or diagnosing particular GPU-related performance issues. For instance, the works in [
9,
10] leveraged library interposition to capture runtime events from OpenCL- and HSA-based programs, respectively. While they enabled the analysis of GPU kernel execution and CPU–GPU interaction, they presented high overhead and faced challenges for broader analysis and portability. On the other hand, vendor-provided options, such as vTune Profiler [
11] and Nsight Systems [
12], leverage dynamic instrumentation and hardware counters to gather performance data and unveil application behavior in various aspects. These tools offer interesting analyses covering kernel execution, memory access patterns, and GPU API call paths. Nevertheless, they are often limited in terms of openness and cross-architecture applicability. In summary, while each of these tools has its strengths and weaknesses, a common shortfall is their lack of support for vGPUs—with the exception of Nsight Systems, which, however, is proprietary and closed-source software.
This paper presents a novel performance analysis framework dedicated to GPUs virtualized with the GVT-g technology. Our framework uses host-based tracing to gather performance data efficiently and with minimal overhead. Tracing is a proven technique for collecting detailed performance data from complex systems. A key advantage of our approach is that it does not necessitate the installation of any agents or tools within the VMs, as tracing is confined to the host operating system’s kernel space. The benefits of this methodology include ease of deployment, preservation of VM owner privacy, and cost-effectiveness. This study’s contributions are as follows:
The remainder of this paper is organized as follows: In
Section 2, we conduct a comprehensive literature review of the methodologies and techniques applied in GPU virtualization.
Section 3 introduces prominent GPU profiling and performance analysis tools.
Section 4 details the design of our proposed framework and outlines several pertinent performance metrics. Next,
Section 5 presents three practical scenarios that demonstrate the effectiveness of our framework. Following this,
Section 6 assesses and discusses the overhead associated with using our framework. Finally, we summarize our findings and contributions in
Section 7.
3. Related Work
As the complexity of GPU-accelerated applications continues to grow, the need for effective performance analysis methods becomes increasingly critical, particularly in vGPU-based systems. Our study of existing GPU performance analysis tools shows that they offer different levels of analysis, and they are mostly dedicated to specific GPU architectures. High-end production-quality tools such as vTune Profiler [
11] and Nsight systems [
12] are notable for their comprehensive approach to analyzing GPU-accelerated applications. They provide a holistic understanding of the application runtime behavior, particularly unveiling the interaction between CPU and GPU, which is crucial for effective optimization. In contrast, tools proposed in academic research are often tailored to specific GPU programming models or addressing particular GPU-related performance issues.
Many vendors offer dedicated software for profiling GPU applications, such as NVIDIA Nsight Systems, Intel vTune Profiler, and AMD Radeon GPU Profiler [
29]. These tools leverage various techniques such as binary instrumentation, hardware counters, and API hooking to gather detailed performance events. Despite providing rich insights into kernel execution, CPU–GPU interaction, memory access patterns, and GPU API call paths, these tools are often limited in terms of openness, flexibility, and cross-architecture applicability. In addition to proprietary offerings, the GPU performance analysis ecosystem encompasses feature-rich open-source tools. For example, HPCToolkit [
30,
31] and TAU [
32] are two versatile tools tailored for analyzing heterogeneous systems’ performance. These tools offer valuable diagnostic capabilities for pinpointing GPU bottlenecks and determining their root causes. For instance, through call path profiling, they provide insights for kernel execution and enable the identification of hotspots in the program’s code.
Aside from the established profilers, academic research also presents many innovative tools for the diagnosis of performance issues in GPU-accelerated applications. Zhou et al. proposed GVProf [
33], a value-aware profiler for identifying redundant memory accesses in GPU-accelerated applications. Their follow-up work [
34] focused on improving the detection of value-related patterns (e.g., redundant values, duplicate writes, and single-valued data). The main objective of their work was to identify diverse performance bottlenecks and provide suggestions for code optimization. GPA (GPU Performance Advisor) [
35] is a diagnostic tool that leverages instruction sampling and data flow analysis to pinpoint inefficiencies in the application code. DrGPU [
36] uses a top-down profiling approach to quantify and decompose stall cycles using hardware performance counters. Based on the stall analysis, it identifies inefficient software–hardware interactions and their root causes, thus helping make informed optimization decisions. CUDAAdvisor [
37], built on top of LLVM, instrumentalizes application code on both the host and device sides. It conducts code- and data-centric profiling to identify performance bottlenecks arising from competition for cache resources and memory and control flow divergence. The main disadvantages of these tools lie in their considerable overhead and exclusive applicability to NVIDIA GPUs. On the other hand, several profiling tools leverage library interposition and userspace tracing to capture runtime events, enabling the correlation of CPU and GPU activities. For example, CLUST [
9] and LTTng-HSA [
10] employ these techniques to profile OpenCL- and HSA-based applications, respectively. However, a substantial drawback of these tools is their tight coupling with specific GPU programming frameworks, which limits their capability to provide a system-wide analysis.
To sum up, the current landscape of GPU performance analysis tools is diverse, with each tool differing in openness, targeted GPU architectures, and depth of analysis. A significant limitation among these tools, with the notable exception of those offered by NVIDIA, is their lack of support for vGPUs (
Table 1). This gap is particularly significant considering the growing importance of GPUs in virtualized environments. Our research aims to address this oversight by proposing a method for analyzing the performance of GPUs virtualized via GVT-g. We detail this method and the framework that it implements in the following section.
4. Proposed Solution
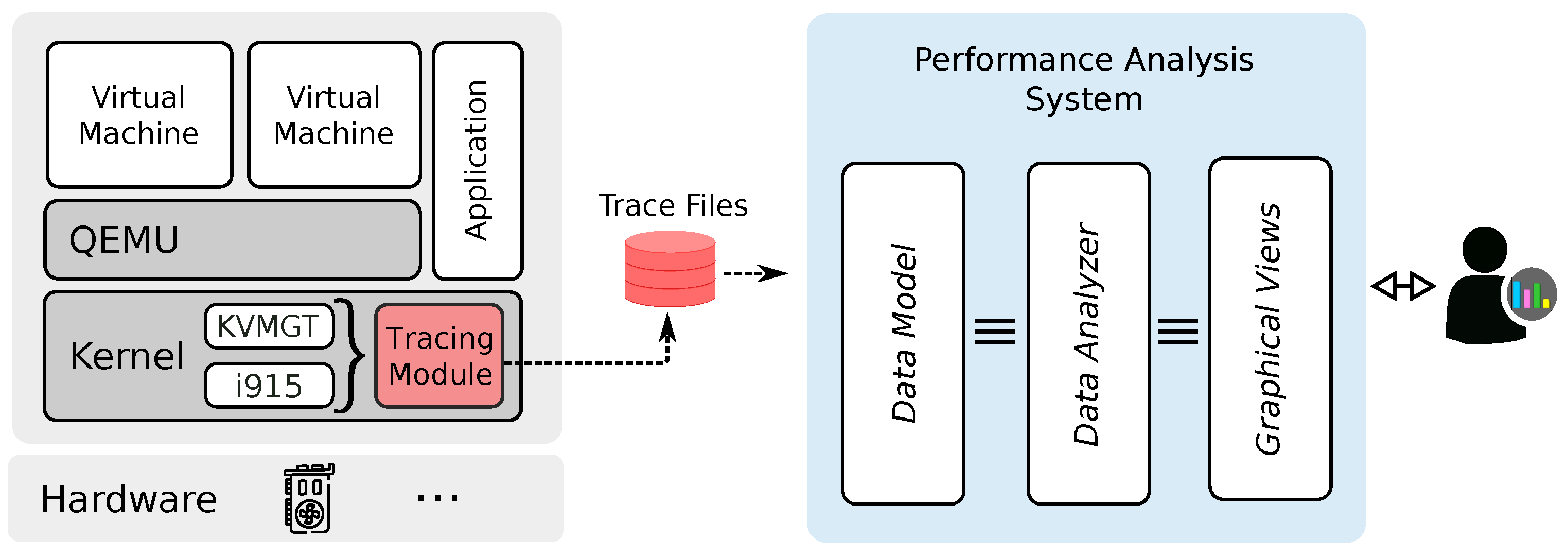
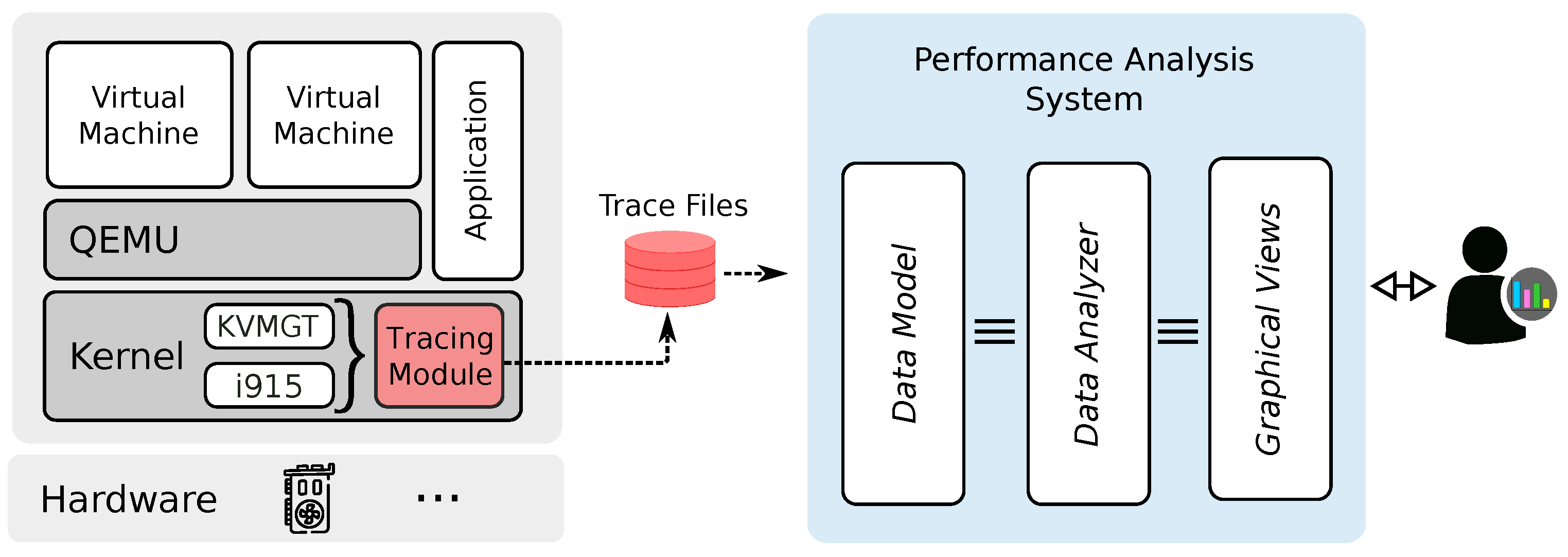
This paper presents a new performance analysis framework for vGPUs managed with GVT-g. The architecture of this framework is depicted in
Figure 1. It comprises three main subsystems: a data collection subsystem, an analysis subsystem, and a visualization subsystem. The first subsystem is in charge of collecting meaningful performance data from GVT-g and the Intel GPU driver. The second subsystem processes the collected data and derives relevant performance metrics. The visualization subsystem consists of several graphical views that display the results of the analysis conducted by the second subsystem. We implemented the visualization and analysis subsystems as extensions of Trace Compass [
15], an open-source trace analyzer. This tool can analyze a massive amount of tracing data to enable the user to diagnose a variety of performance bottlenecks. Moreover, Trace Compass supports interactive graphical interfaces, pre-built analyses, event filtering, and trace synchronization. We present the design details of those subsystems in the following subsections.
In addition, we used KVM [
38] to build our virtualization environment since it is the default hypervisor of Linux. The role of KVM is to enable VMs to leverage the hardware virtualization capabilities of the host machine (e.g., VT-x and AMD-V on Intel and AMD machines, respectively). In Linux, KVM is implemented as three kernel modules: kvm.ko, kvm-intel.ko, and kvm-amd.ko. At the user-space level, we used QEMU [
39] to run the guest OSs of our VMs.
4.1. Data Collection
Logging and tracing are fundamental techniques for collecting runtime data from software. Logging involves recording data in one or more log files and detailing application failures, misbehavior, and the status of its ongoing operations. These high-level human-readable data help in swift bug troubleshooting. In contrast, tracing captures low-level details of software execution, focusing on diagnosing complex functional issues and identifying performance bottlenecks. The resultant data tend to be extensive and detailed. Unlike logging, tracing requires a specialized tool known as a tracer. A multitude of tracers are available for nearly all modern operating systems. For example, in Linux systems, notable tracers include Ftrace [
40], Perf [
41], and LTTng.
Our framework relies on the tracing technique for gathering low-level data for our analysis. It uses LTTng as a tracer because of its versatility and minimal overhead. It is worth noting that we have confined our tracing scope to the host machine to minimize intrusiveness. In addition, as GVT-g is a kernel module (named
kvmgt.ko in Linux systems), our focus is restricted to kernel space tracing. This involves instrumenting the GVT-g module’s source code to introduce new tracepoints and using a selection of existing tracepoints in i915, the host GPU driver.
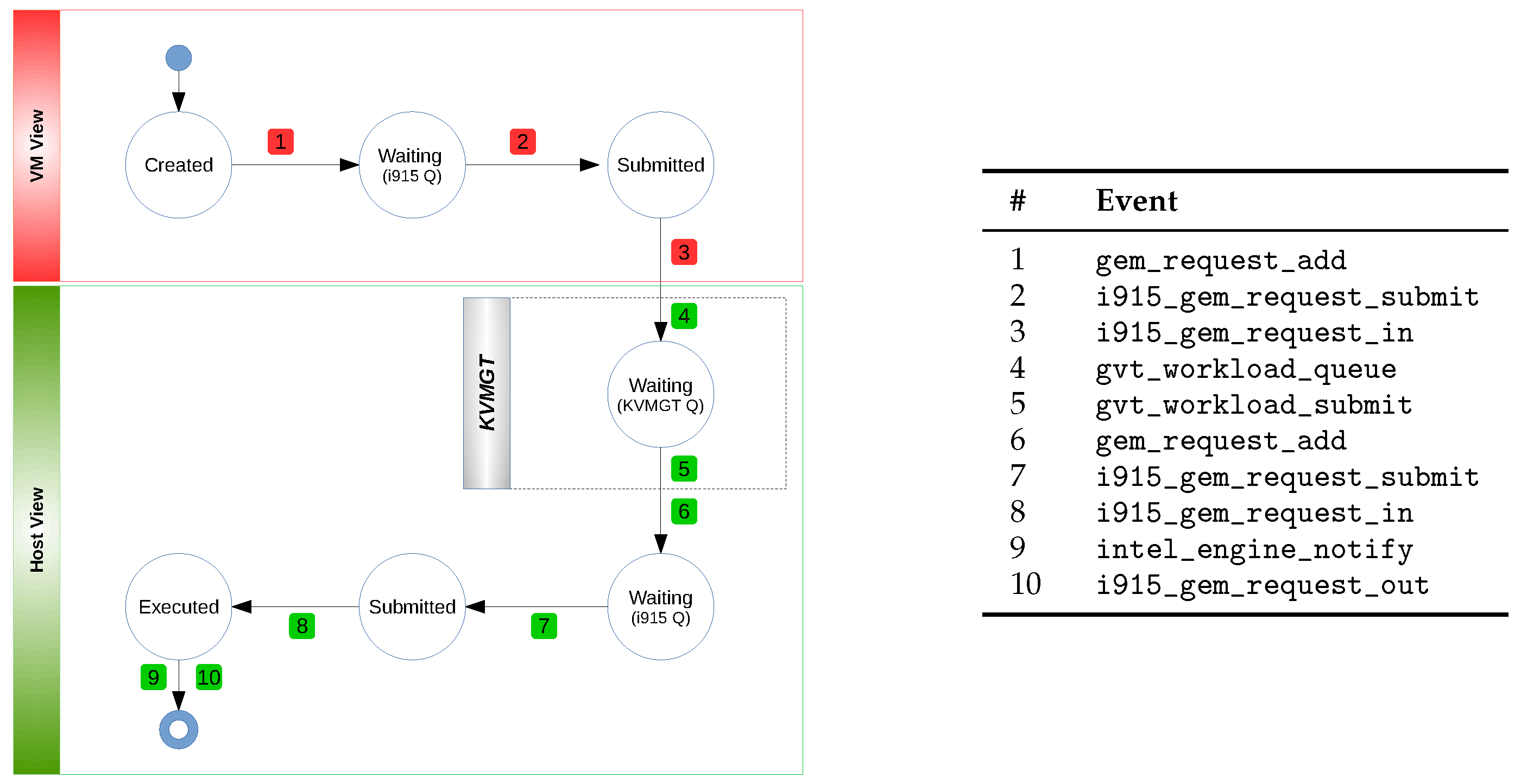
Table 2 details a subset of these tracepoints, which are essential for our analysis.
4.2. Data Analysis
The data generated by tracers are inherently low-level and complex, making any manual analysis very complex. The trace events are semantically interconnected and can be fully understood only within their specific context. Consequently, our principal objective is to develop an automated analysis system that improves the interpretability of the collected data. This system aims to assist practitioners in rapidly identifying performance issues arising from utilizing GPU resources in virtualized environments.
4.2.1. Data Model
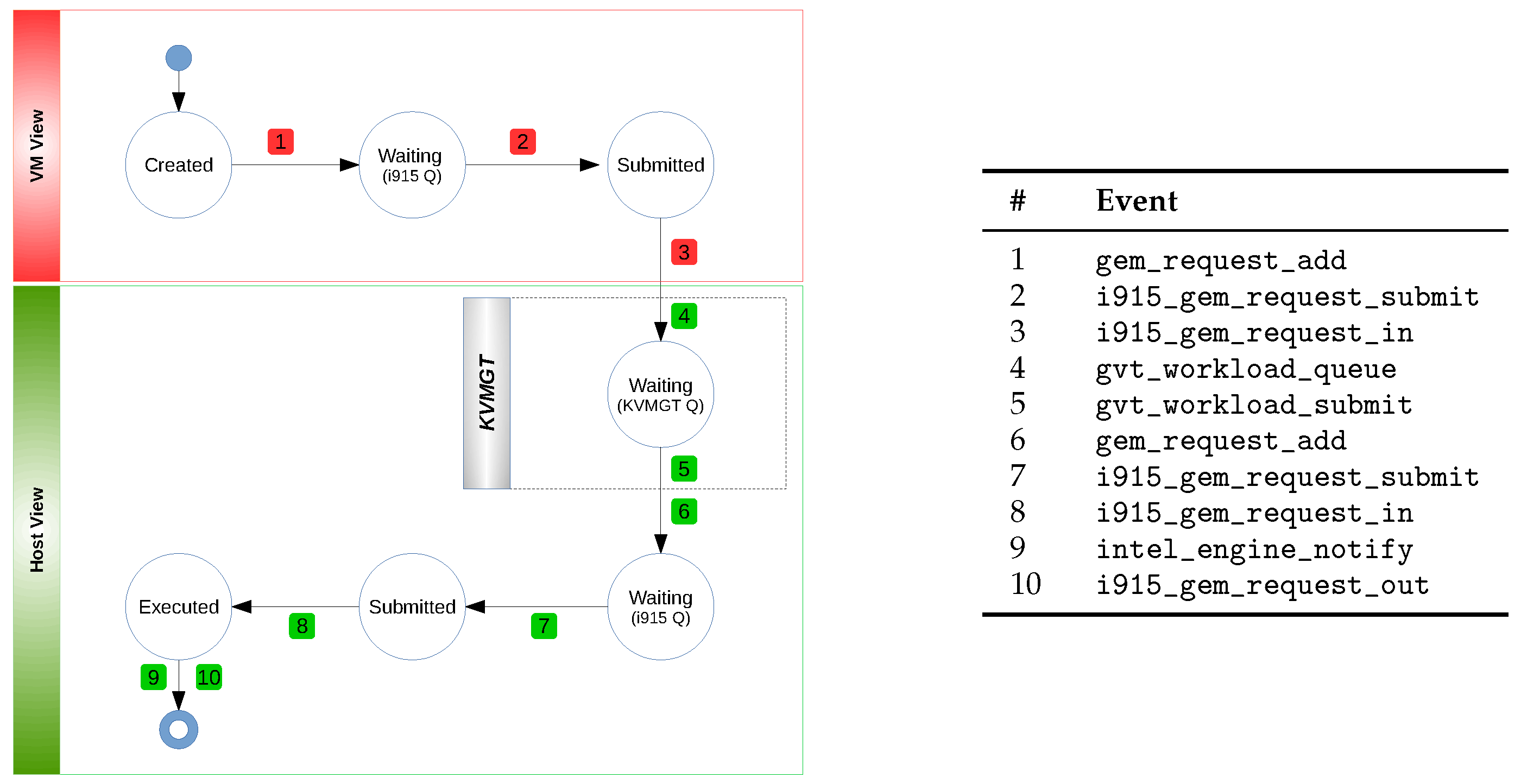
As it is designed for offline analysis, our framework requires a robust data model to organize the data collected from the traced kernel subsystems efficiently. An efficient model is indeed essential for generating metrics and graphical representations effectively. Thus, it is necessary to have a thorough understanding of the GPU request’s lifecycle—from when a VM process initiates a request to the point where the hardware executes it and returns a response. Such a comprehensive insight is paramount for diagnosing intricate performance anomalies effectively.
Figure 2 illustrates the various states that a GPU request undergoes throughout its lifecycle in the system. Initially, a process within a GPU-accelerated VM generates a request for GPGPU or graphics processing operations. This request is first received by the VM’s GPU driver, which places it in a waiting queue (1). As GPU requests often depend on others, these dependencies must be resolved before the request attains the “Submitted” state (2). Once all preceding requests in the queue have been executed, the guest OS’s GPU driver removes the request from its waiting queue and forwards it to the vGPU for execution (3). Subsequently, GVT-g intercepts the request and queues it in the vGPU’s waiting queue associated with the VM (4). When the vGPU’s scheduler allocates time for this vGPU, the request is passed to the host GPU driver (5), which then places it in another waiting queue (6). The request awaits its turn for execution, pending the resolution of its dependencies (7) and completing all prior queued requests. Once these conditions are met, the host GPU driver dispatches the request to the hardware for execution (8). Upon completing the request, GVT-g receives a notification (9) and informs the guest OS via a virtual interrupt.
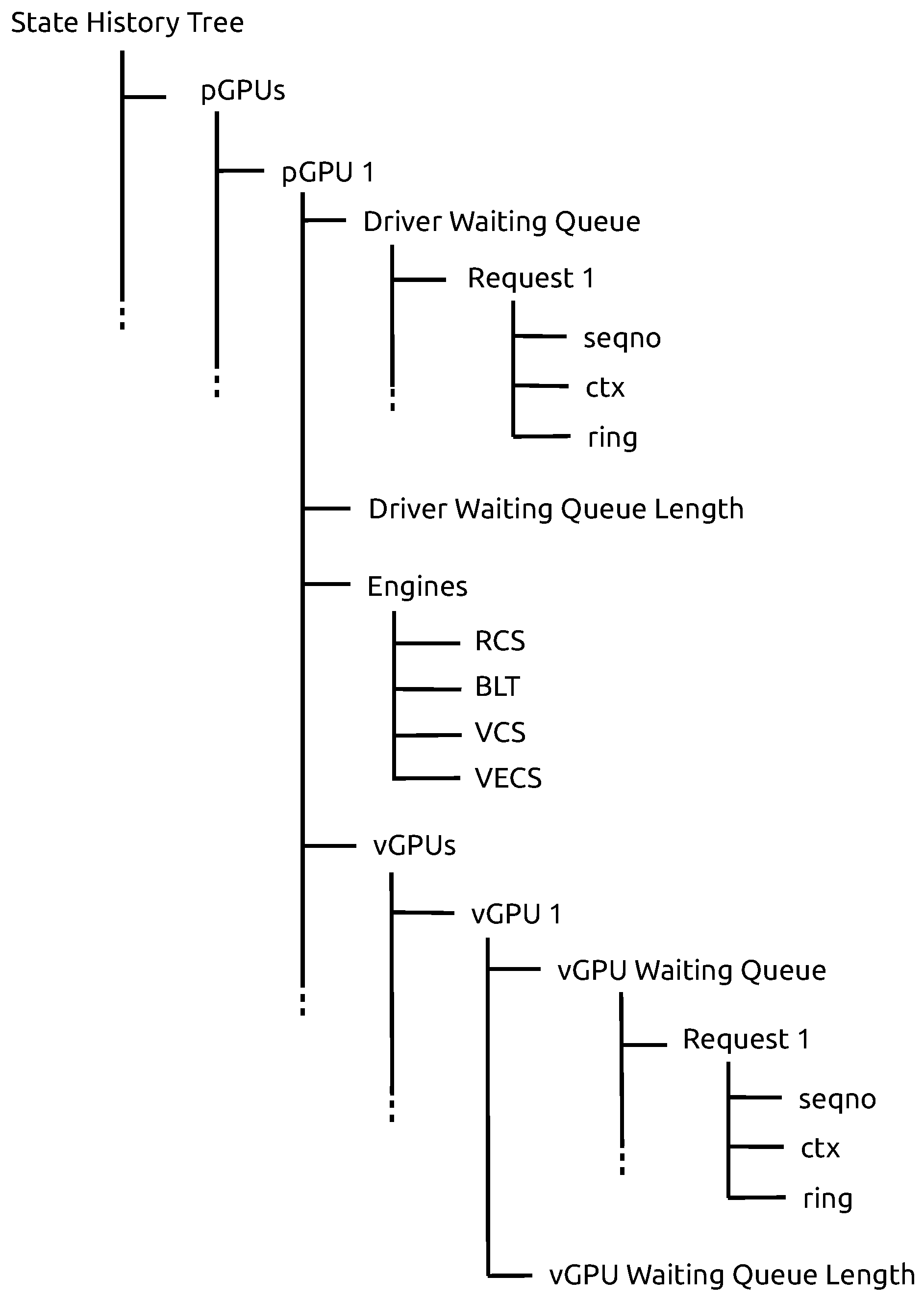
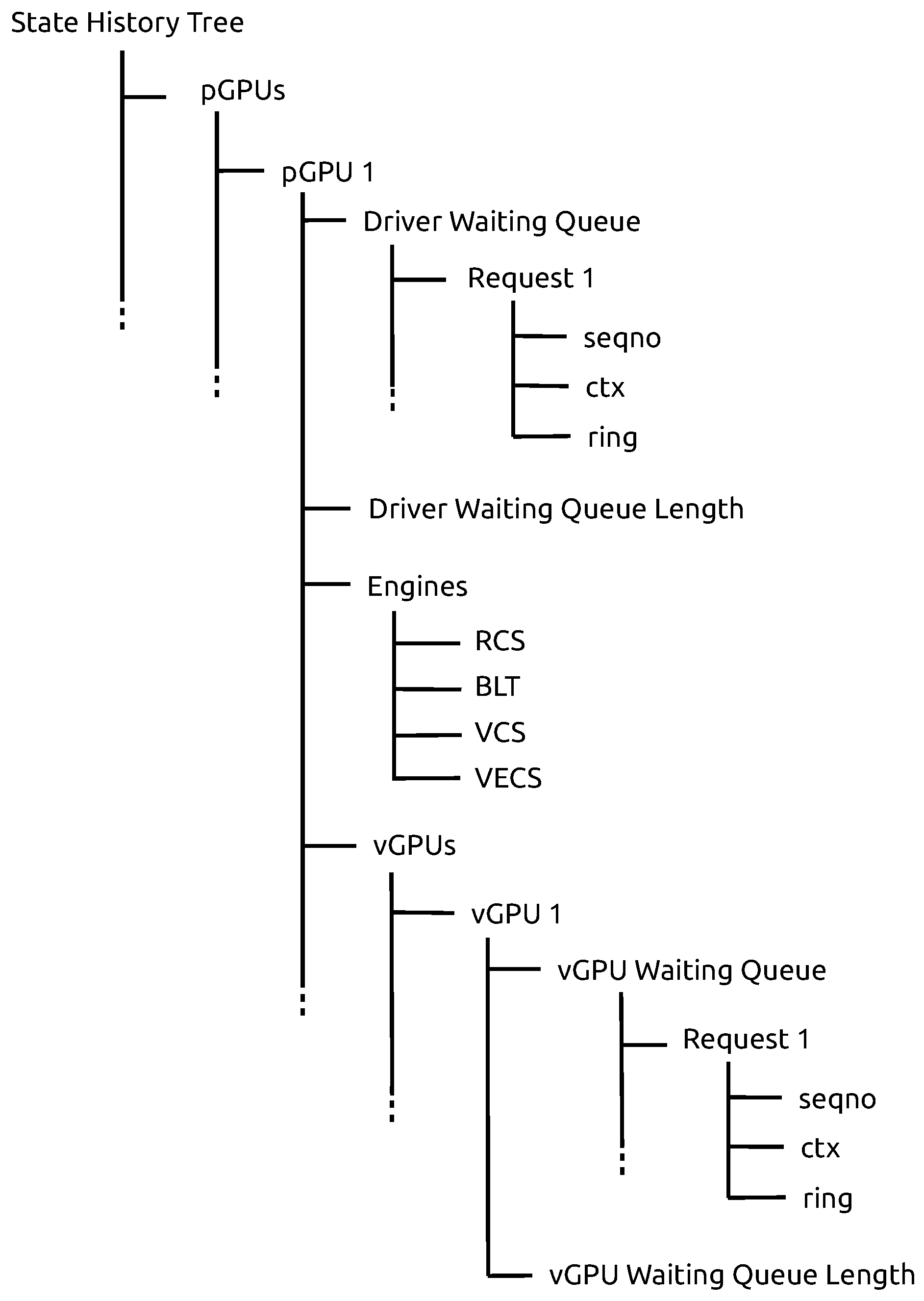
Modeling the collected performance data is mandatory for computing relevant performance metrics, such as the average wait and execution times of requests per vGPU. To this end, we used Trace Compass [
15], a powerful trace analyzer that integrates several interesting pre-built performance analyses. These analyses save the data representing the states of the system to be monitored in a disk-based data structure called a state history tree (SHT) [
42]. We store the states of our system in an attribute–tree data structure (
Figure 3). This data structure exhibits sets of hierarchical attributes, which are updated each time one of the events described in
Section 4.1 is handled. Thus, according to our model, one or many vGPUs can be attached to one pGPU. Both a pGPU and a vGPU each have their own driver waiting queue. A GPU request is identified by its sequence number (
seqno), its context (
ctx), and the engine to which it should be sent for execution (
ring).
4.2.2. Performance Metrics
A performance metric is a quantitative measure of a system’s performance in a specific aspect. Mainly, performance metrics help assess the status of a system and pinpoint potential performance problems. This section introduces several performance metrics that our framework calculates.
GPU Utilization
This metric quantifies the occupancy levels of both the pGPU and the vGPU. It is expressed as the percentage of the time during which the GPU is actively processing requests. Considering that the GPU operates multiple engines to process requests in different queues concurrently, we calculate this metric on a per-engine basis. The formula below uses
and
as markers, representing the start and end timestamps, respectively, for the execution of an individual request denoted by i. Thus, the GPU utilization metric U is calculated as the sum of the execution durations of all requests tracked during T, the observation period. This sum is then divided by T to obtain the utilization percentage.
Waiting Queue Length
This metric indicates the number of requests awaiting execution or processing. It is used by practitioners to identify bottlenecks or performance degradation, especially when examined alongside other metrics. The waiting queue length metric varies based on factors such as the frequency of request issuance, the size of the requests, and the hardware’s execution rate. It functions as a counter that increments with each request added to the queue and decrements when a request is removed.
Average Wait Time
As previously noted, the hardware does not execute GPU requests immediately; they spend some time in various queues, awaiting processing by the pGPU. This delay, or waiting time, starts when a request is queued in the waiting queue of the guest GPU driver and ends when it is dispatched for execution. It is indeed a key factor in evaluating the performance efficiency of the vGPU, as it directly impacts the total time required to process GPU requests. In addition, analyzing the waiting time can provide some insights into potential performance bottlenecks or inefficiencies in the GPU request handling process. Our framework estimates the average wait time (WT) of GPU requests using the formula below. It calculates it by summing the waiting durations (W) of individual requests observed within a specific period and then dividing this sum by n, the total number of requests.
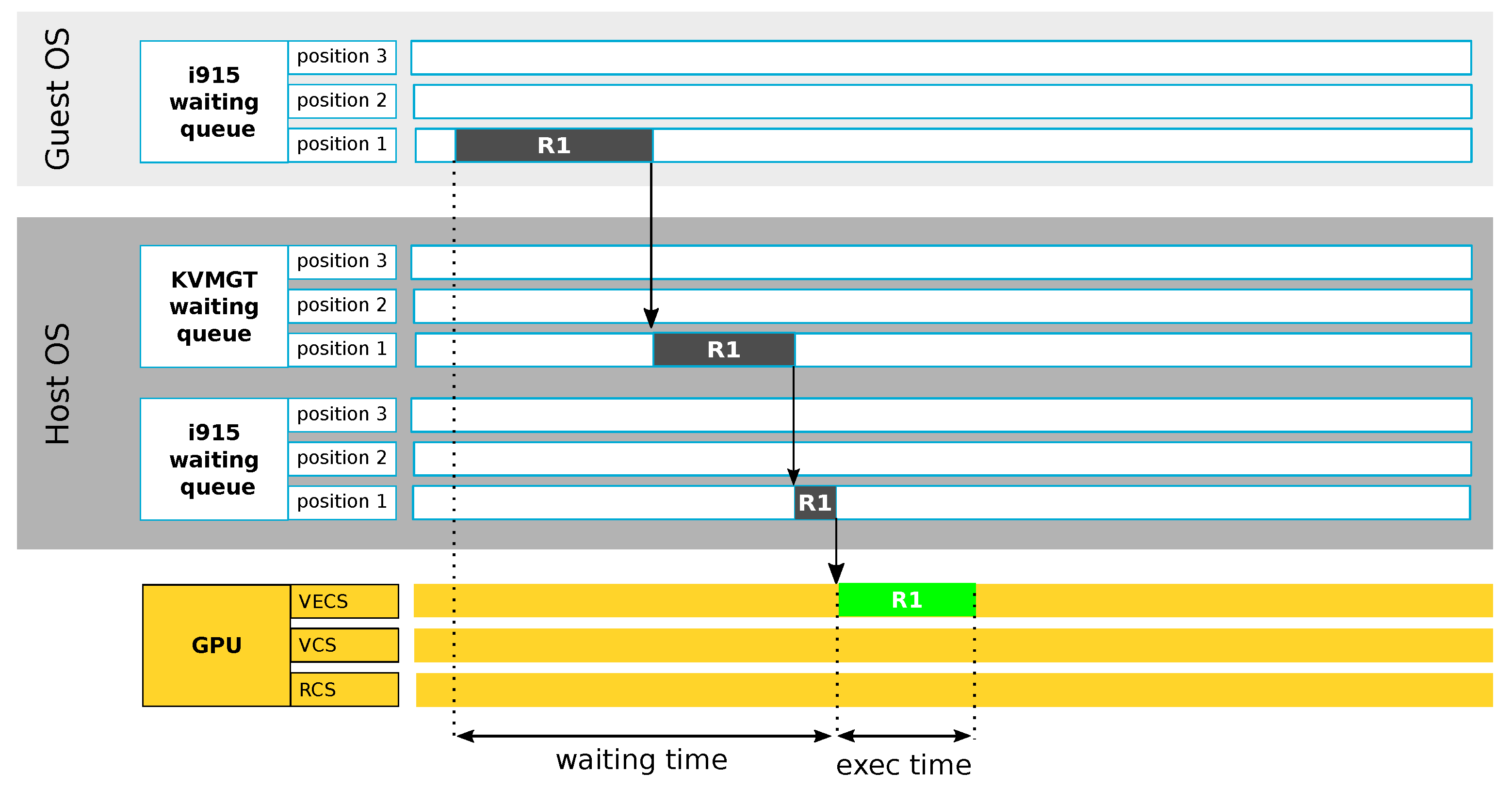
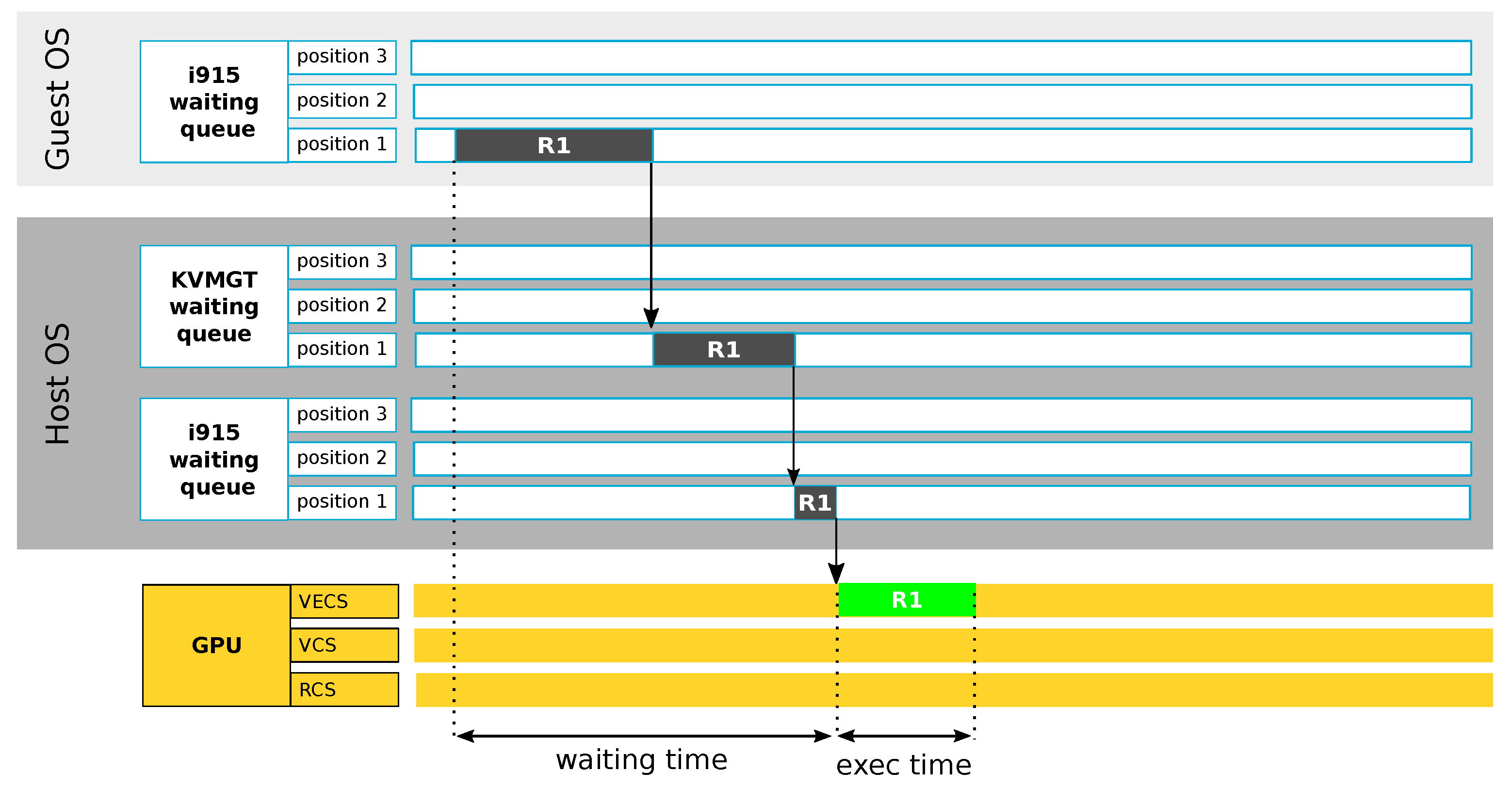
Average Latency
Furthermore, our framework calculates the average time taken to process GPU requests from issuance to completion. As depicted in
Figure 4, this metric encompasses both the waiting time and the execution time. The latter refers to the duration that a GPU engine requires to execute the request. To calculate the average latency, denoted by L in the formula below, our framework sums the waiting (W) and execution (E) times for all requests processed within a given observation period. This sum is then divided by the number of requests, n, to yield the average latency value.
GPU Memory Usage
The i915 GPU driver provides deep insights into memory usage through specific events (e.g., i915_gem_object_create and i915_gem_object_destroy). By tracking these events, we can measure the total memory allocated and subsequently released by Graphics Execution Manager (GEM) objects, representing the dynamic footprint of GPU memory usage. This metric is crucial for understanding how memory allocation and usage impact performance, particularly in virtualized environments where optimizing resource utilization is paramount. Using this metric helps pinpoint potential memory-related bottlenecks and inefficiencies both in the host machine and within VMs.
4.3. Visualization
The presentation of information in a trace analysis framework should be made in a manner that enhances the user’s comprehension of the analyzed system. Hence, our framework provides various views, each tailored to illustrate a specific aspect of GVT-g operations. These views have been integrated as plug-ins within Trace Compass, a versatile open-source trace visualization tool. Examples of the visualizations our framework provides include the GPU usage view, an XY chart that graphically represents the percentage of utilization of vGPUs and pGPUs. Another visualization is the latency view, which displays the durations spent by GPU requests in queues and during execution. This view employs a time graph format, where colored rectangles represent the latencies of individual GPU requests, each marked with its corresponding request ID. Our framework can display the transitions of a request between queues using arrows from the source to the destination.
5. Use Cases
This section aims to demonstrate the practicality and effectiveness of our framework in diagnosing and examining performance issues in GPU-accelerated VMs. We detail the configurations used in our investigations in
Table 3.
5.1. GVT-g Scheduling
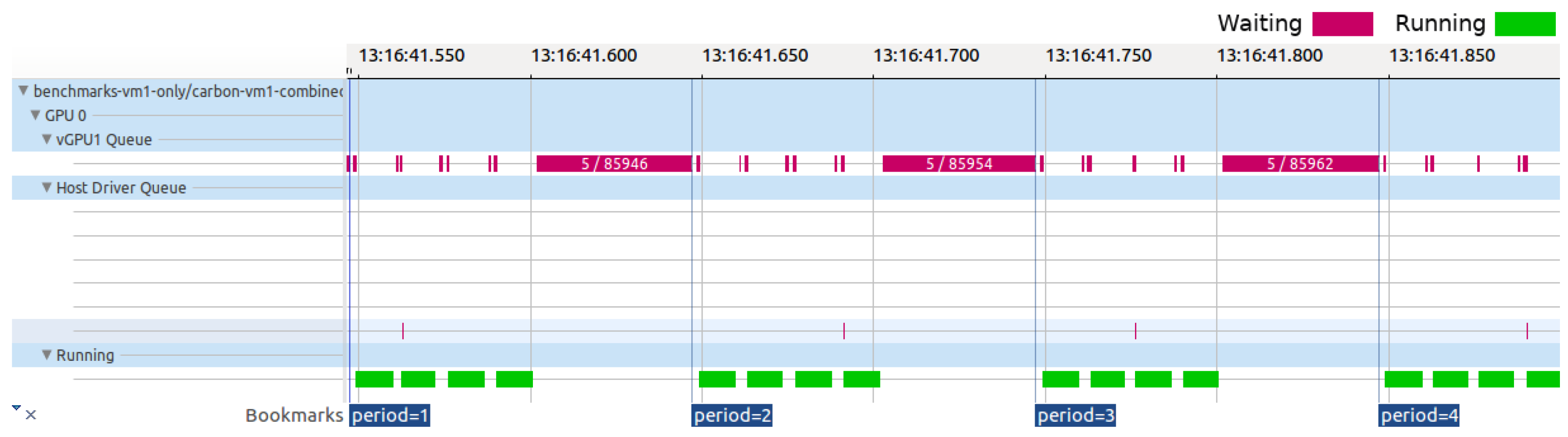
In this case study, we use our framework to examine the internal mechanics of the GVT-g scheduler, as its operations may impact the performance of GPU virtualization solutions. Specifically, GVT-g uses a kernel thread named
gvt_service_thr and multiple additional threads, which are referred to as
workloads thread X, where “X” represents a specific engine supported by the pGPU, such as render or video command streamers. The
gvt_service_thr is responsible for managing vGPU scheduling and context switching, and the
workloads thread X threads are initiated when a vGPU is activated. These threads concurrently monitor the waiting queue, facilitating the transfer of GPU requests to the host GPU driver, as depicted in
Figure 5.
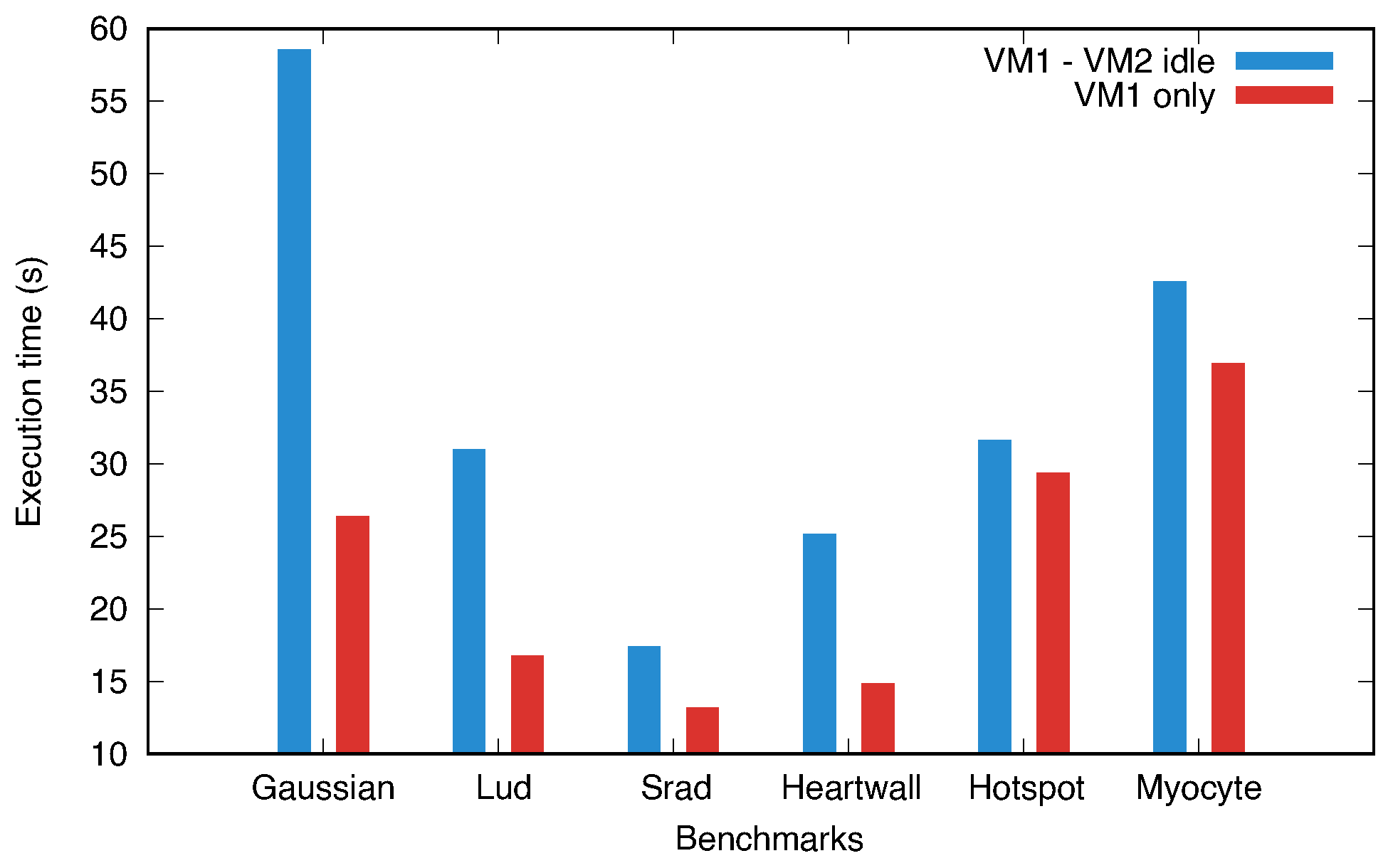
Our initial experiment involved two GPU-accelerated virtual machines (VM1 and VM2) sharing a single pGPU via GVT-g, with each VM hosting a similarly configured vGPU and equal resource allocation weights. These weights, assigned by GVT-g at instantiation, determine each vGPU’s share of pGPU resources. We executed a series of benchmarks from the Rodinia GPU benchmark suite [
43] on VM1. We repeated these benchmarks after completely shutting down VM2.
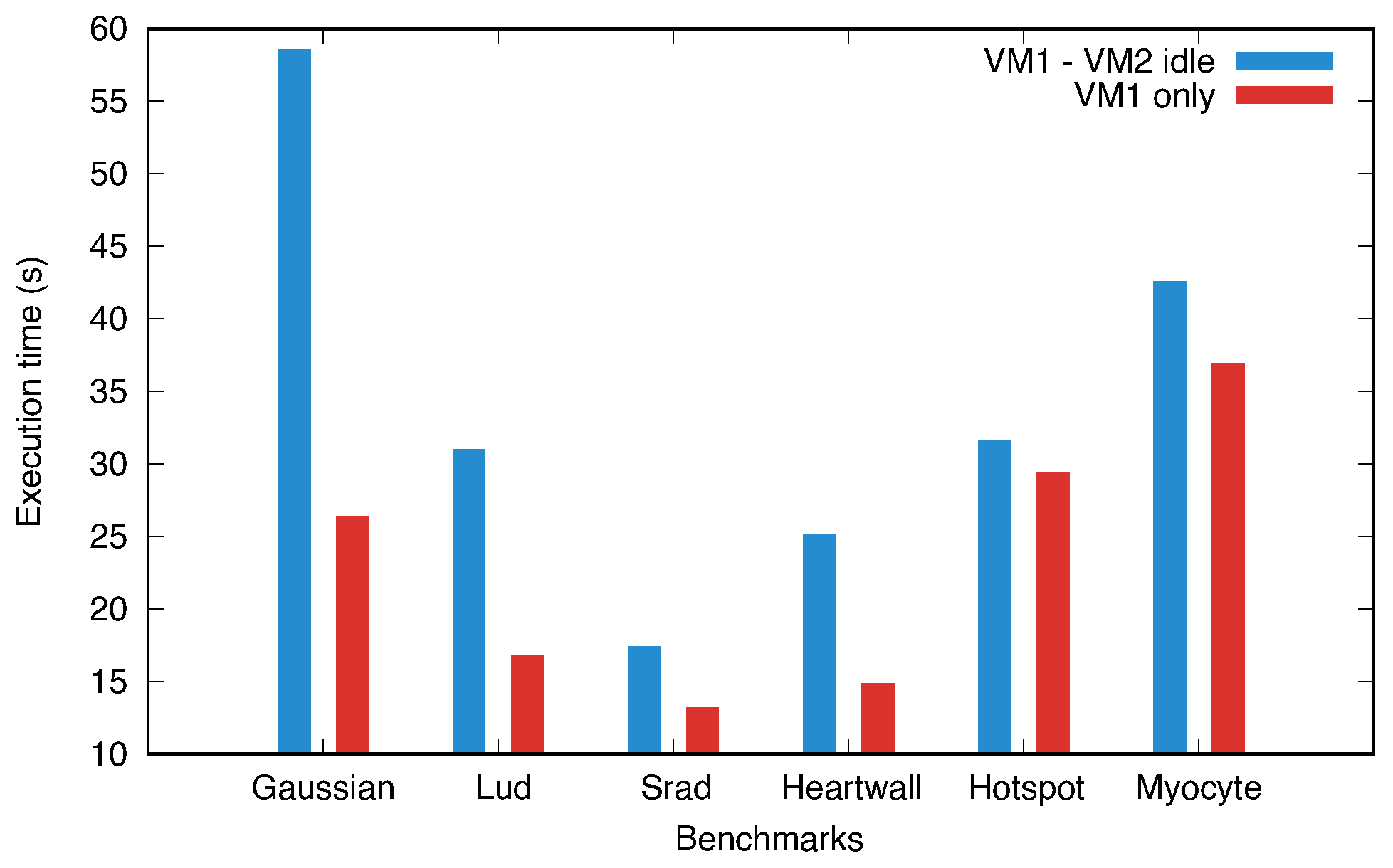
Figure 6 presents histograms comparing the benchmarks’ execution times in both scenarios. Notably, the benchmarks executed slower when VM2 was idle than when it was shut down, with significant time discrepancies in the Gaussian, Lud, and Heartwall benchmarks. This study considered a VM idle if it did not engage in significant GPU workloads.
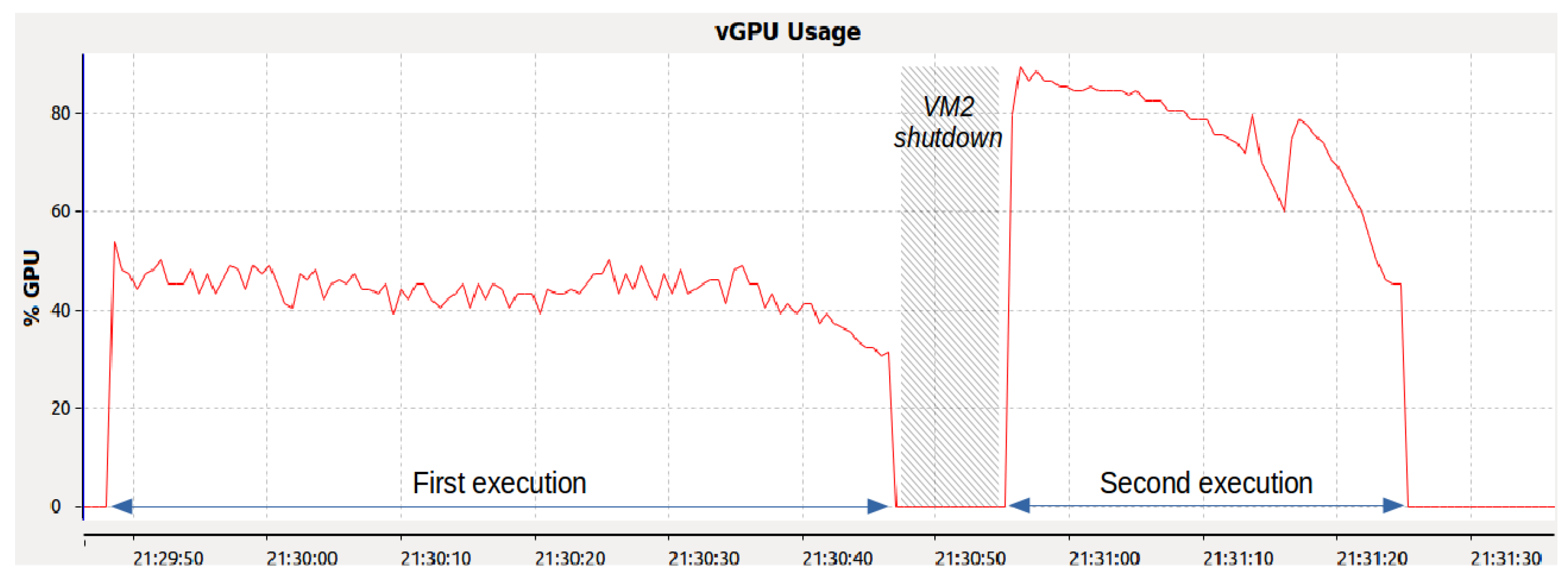
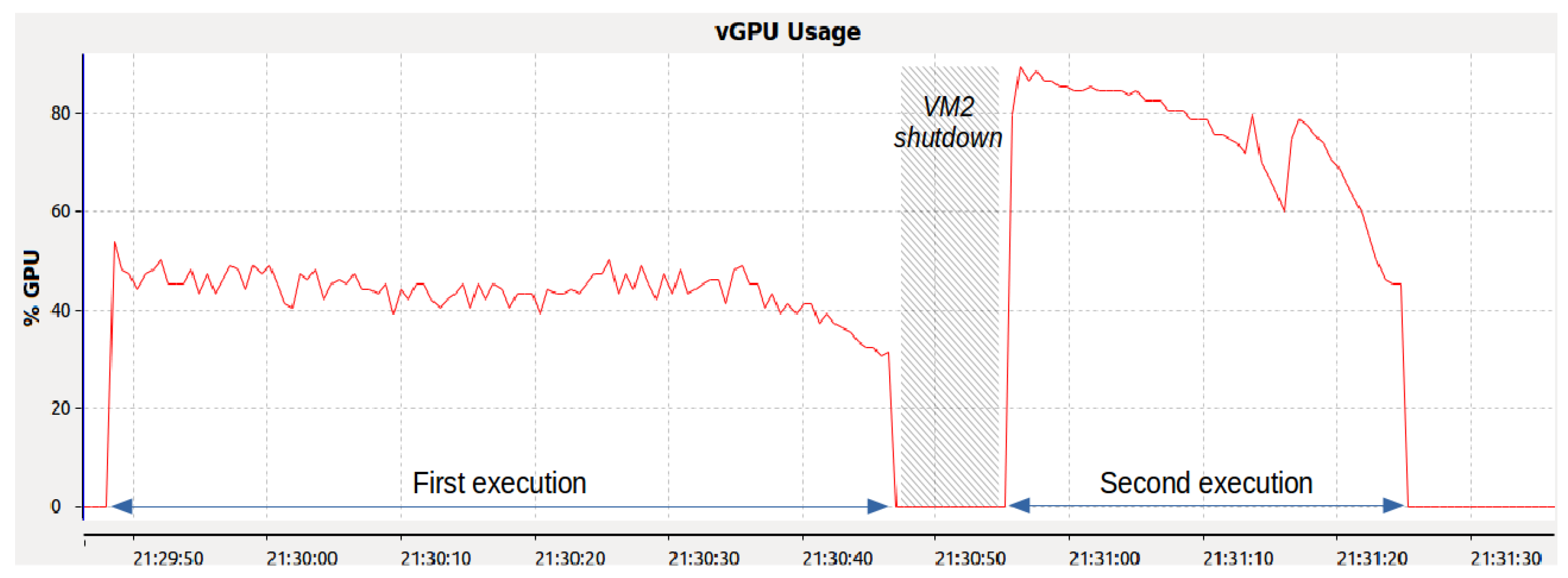
To investigate the performance difference, we analyzed the execution of the Gaussian benchmark on VM1 using our framework.
Figure 7 illustrates the benchmark’s execution duration and GPU utilization. Initially, the benchmark lasted 59 s with an average GPU utilization of about 45%. In contrast, after shutting down VM2, the benchmark was completed in 27 s with a GPU utilization near 80%. This comparison highlights the performance impact of VM2’s concurrent operation, despite it being inactive.
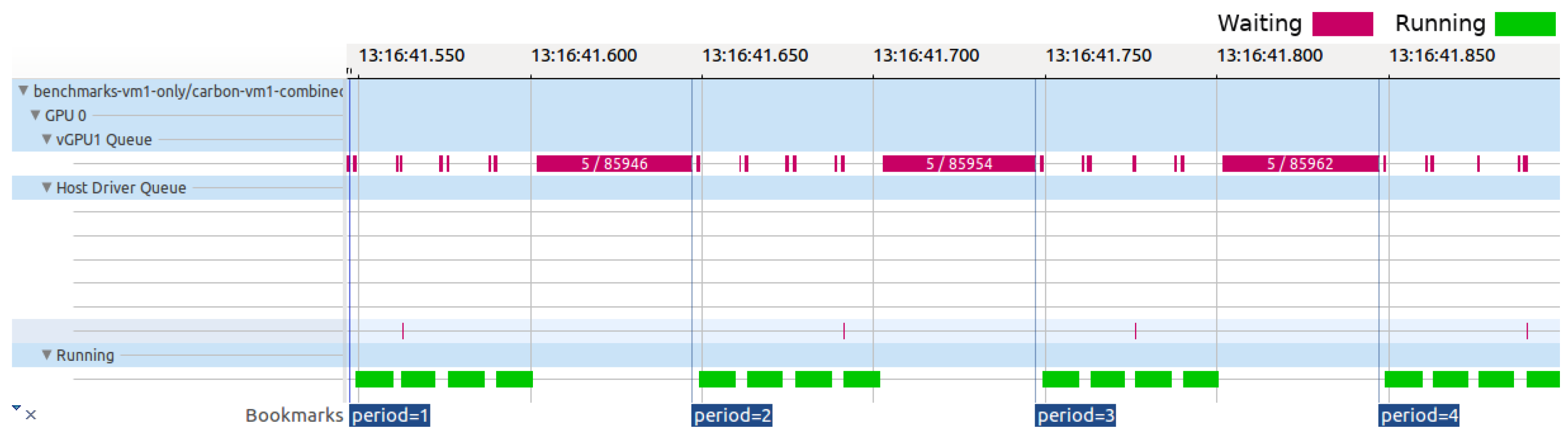
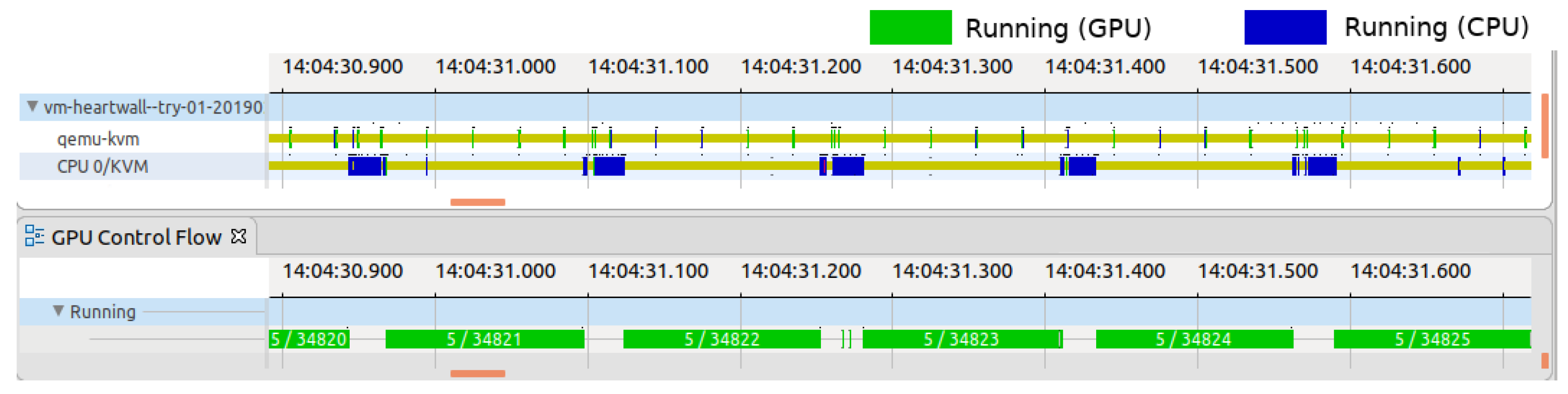
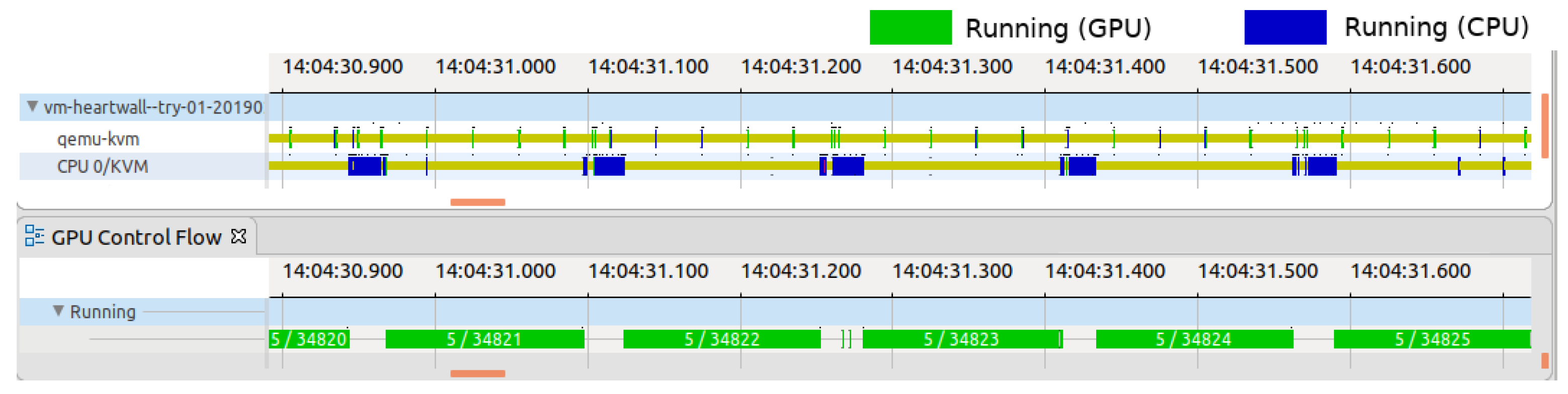
Further examination of the GVT-g scheduler’s operations revealed its reliance on time multiplexing for fair pGPU resource distribution among vGPUs. The scheduler, which was operated via the
gvt_service_thr thread, simultaneously managed all of the GPU engines to minimize scheduling complexity and avoid synchronization bottlenecks. It assigned time slices to vGPUs based on their weights, deducting the aggregate execution time of a vGPU’s requests from its time slice (see the formula below). If a vGPU depletes its time slice within a certain interval (100 ms), the scheduler suspends its operations, recalibrating time slices every ten intervals (one second) and ignoring past debts or credits.
Example 1. Let us consider two vGPUs sharing the host GPU’s resources, and each is assigned an identical weight. In this scenario, the GVT-g scheduler assigns each vGPU a 50 ms time slice per period. If one vGPU is removed, the remaining one receives the entire 100 ms time slice per period, fully utilizing the available resources.
The GVT-g scheduler follows a round-robin policy, cycling every 1 millisecond to inspect vGPU queues for new requests. Upon finding requests, the scheduler activates the underlying vGPU for processing if its time slice remains. Concurrently, the ‘workloads threads X’ handle the active vGPU’s requests and update statistics for the previously active vGPU. If a vGPU exhausts its time slice, the scheduler then schedules another vGPU, as shown in
Figure 5.
In short, our analysis shows that a VM cannot use the idle time slice of another VM due to the GVT-g scheduler policy. While this aligns with typical cloud computing models, it is suboptimal for private cloud data centers seeking to maximize vGPU acceleration. We propose enhancing the GVT-g scheduler with an algorithm that allows a VM to process its GPU workloads when the host GPU resources are unoccupied. A configuration option can be set during startup to allow GVT-g to apply the appropriate scheduling algorithm based on the deployment environment, enabling more efficient GPU resource management.
5.2. Analysis of Contention for Resources
This second use case looks into the extent to which the performance of a vGPU-enabled VM can be affected by the presence of other VMs. In our experiment, two collocated VMs shared host GPU resources via GVT-g, and their vGPUs were configured identically, as detailed in
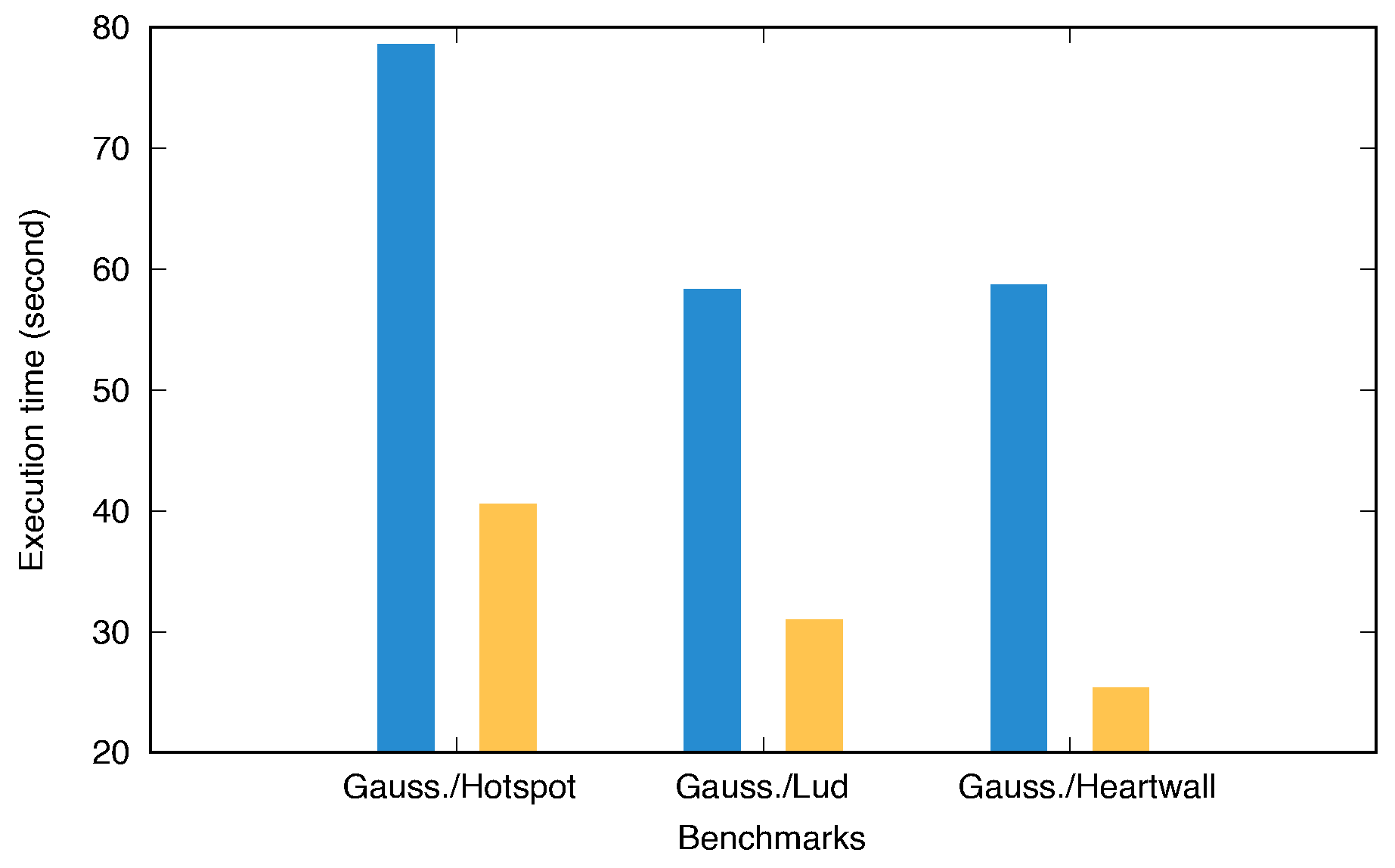
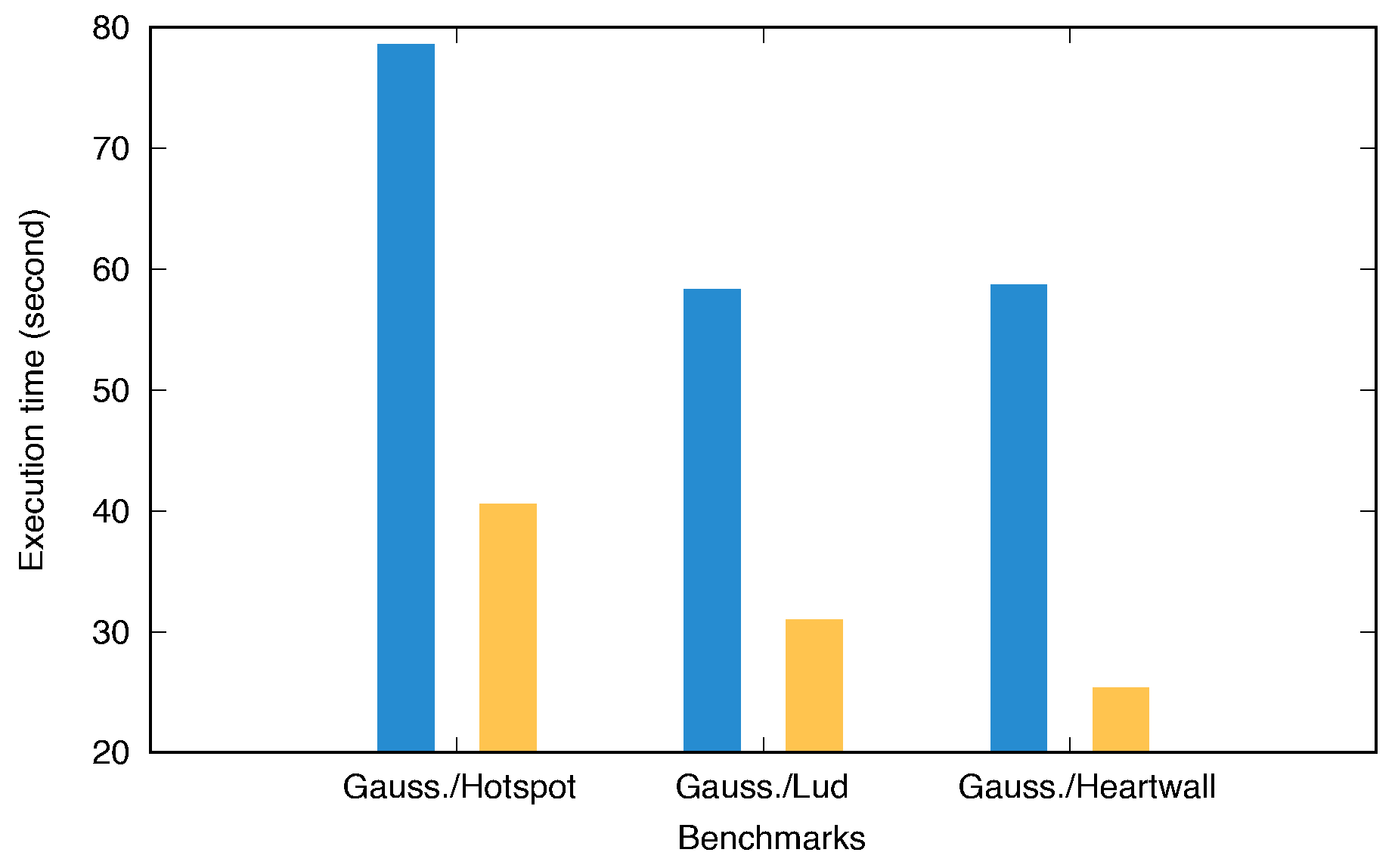
Table 3. On VM1, we ran the Gaussian benchmark, while VM2 executed a variety of benchmarks characterized by various intensities of host GPU resource usage (e.g., varying workload sizes, diverse request frequencies, etc.). For example,
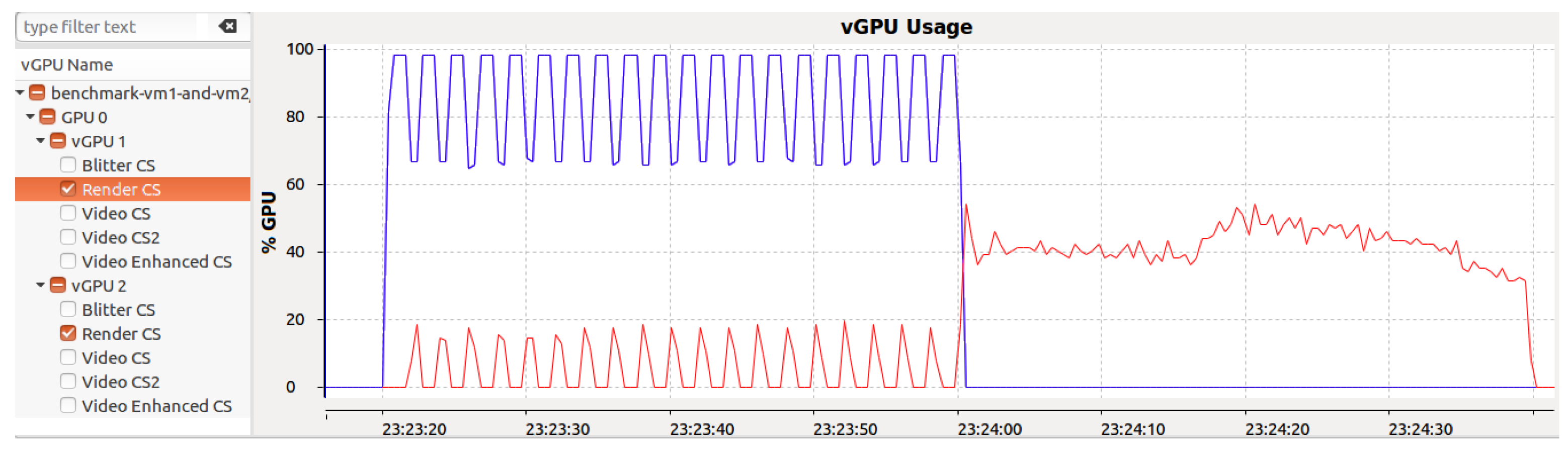
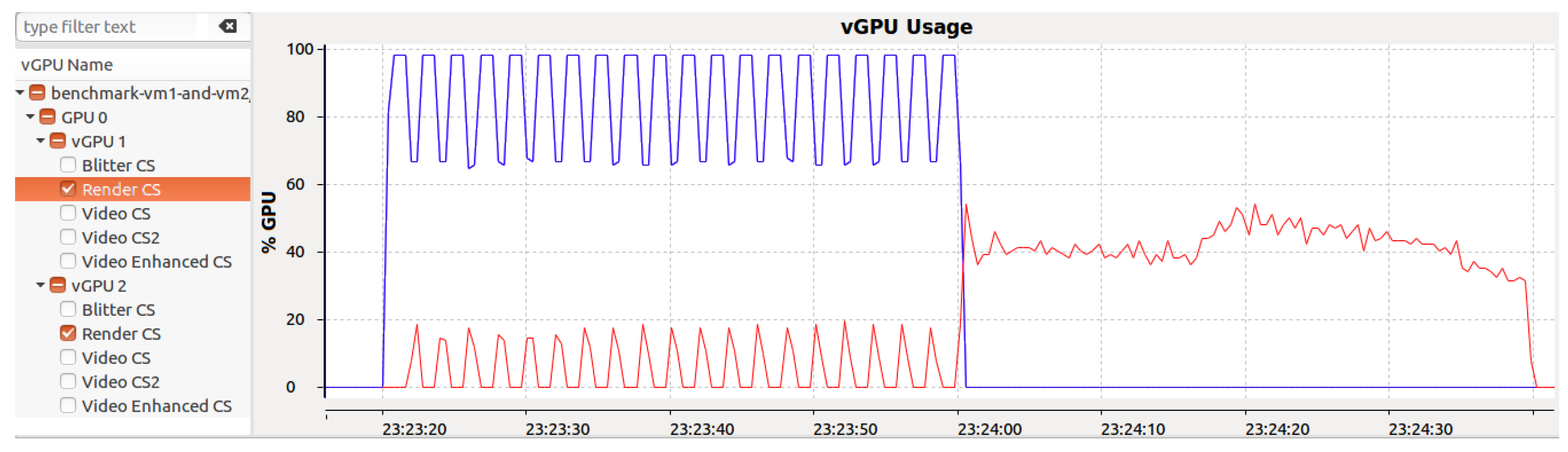
Figure 8 demonstrates the effects of workload sizes from these benchmarks on the Gaussian benchmark’s execution time. Notably, the execution time of the Gaussian benchmark increased significantly when run concurrently with the Hotspot benchmark. Our framework view, which is depicted in
Figure 9, further illustrates that during the Hotspot benchmark’s execution, GPU usage for the Gaussian benchmark did not exceed 20%, but this rose to 40% after the Hotspot benchmark ended.
This experiment shows that the performance of one vGPU can be considerably affected by another vGPU that is co-located. Our analysis indicates that this is primarily caused by the disparity in workload sizes: approximately 18 ms for vGPU1 (Gaussian benchmark) versus 800 ms for vGPU2 (Hotspot benchmark). The i915 GPU driver’s scheduler lacks preemptive multitasking capabilities, meaning that it cannot interrupt an ongoing workload. Thus, the GVT-g scheduler uses a coarse-grained sharing approach for the host GPU time to compensate. Time slices are allocated to vGPUs in proportion to their weights, and the execution times of GPU requests are subtracted from these slices. Outstanding balances (debts and lefts) from previous periods are carried over for up to ten periods, explaining why the large workloads from vGPU2 adversely affected vGPU1’s performance.
Despite enhancing scheduling fairness among vGPUs and, thus, improving VM application responsiveness, this method’s drawback lies in its coarse-grained approach to host GPU time-sharing. This becomes particularly problematic when a vGPU’s workload size exceeds the period length.
In summary, this use case demonstrates that the GVT-g scheduler struggles to maintain fairness between vGPUs under certain conditions, which is largely due to the i915 driver’s lack of preemption support and the implementation of its coarse-grained sharing mechanism. Because the scheduling algorithm’s focus is to maintain interactive program responsiveness, we suggest disabling the debt and leftover management feature when VMs are tasked with running non-interactive tasks.
5.3. Virtual Machine Placement
Live migration, a key feature supported by most modern hypervisors, involves relocating VMs to balance the load on physical host machines. This process not only optimizes physical resource utilization within data centers but also ensures adherence to service-level agreements. VM placement, which is a critical component of VM migration, entails selecting the most suitable physical machine to host a VM. Many placement algorithms have been developed over time to maximize resource utilization in cloud data centers and minimize energy consumption. The efficiency of a placement algorithm is paramount, as studies show a strong correlation between resource optimization and the reduction of operational costs in data centers [
44].
Effective VM placement algorithms often depend on sophisticated monitoring tools. These tools assess VM resource requirements and identify performance issues stemming from resource overcommitment. Overcommitment leads to VMs competing for shared resources, causing frequent interruptions and prolonged execution times for running programs. To mitigate this, several algorithms co-locate VMs with complementary resource demands on the same host. For example, pairing a CPU-intensive VM with a disk or network-intensive VM can optimize resource utilization and enhance overall performance. Similarly, aligning VMs that alternate between CPU and GPU resource demands within the same host proves beneficial. Hence, co-locating CPU- and GPU-bound VMs optimizes the use of both processing units, which lowers the frequency of VM preemption and boosts the overall system performance.
Seeking to optimize VM placement within our private cloud, which was managed via OpenStack [
45], we leveraged our performance analysis framework to incorporate GPU usage data from running VMs as a key input parameter. This optimization involved migrating VMs that exceeded a predefined CPU usage threshold over a certain period to host machines that were mostly engaged with GPU-intensive tasks. This reallocation significantly enhanced the resource utilization across our cloud infrastructure and reduced the execution times of applications within the VMs. The view from our tool in
Figure 10 illustrates this strategy, showcasing a VM that alternates between CPU and GPU computing phases.
To validate our approach, we used the
sched_switch,
kvm_entry, and
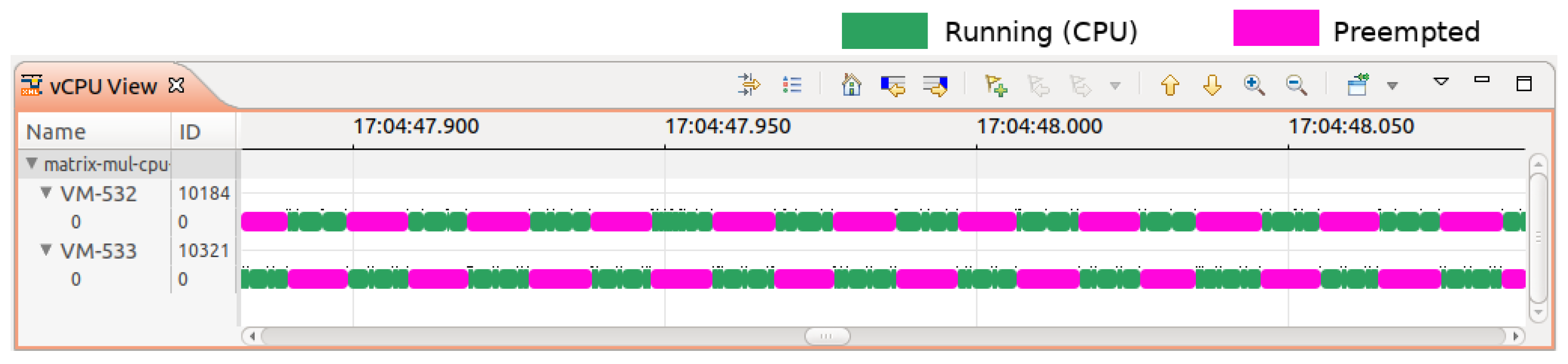
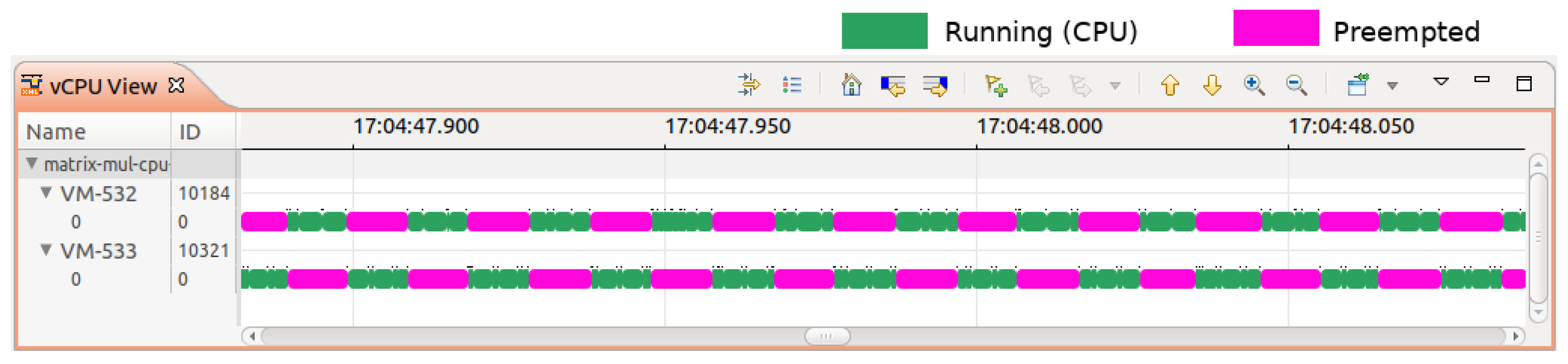
kvm_exit events to compute the number of VM preemptions. Our method involved tracing the operating system kernels of the cloud host machines and categorizing VMs as either GPU-intensive or CPU-intensive using our analysis framework. For example, we observed several CPU-intensive VMs, such as VM-532 and VM-533, co-located on the same host and frequently preempting each other for CPU resources, as depicted in
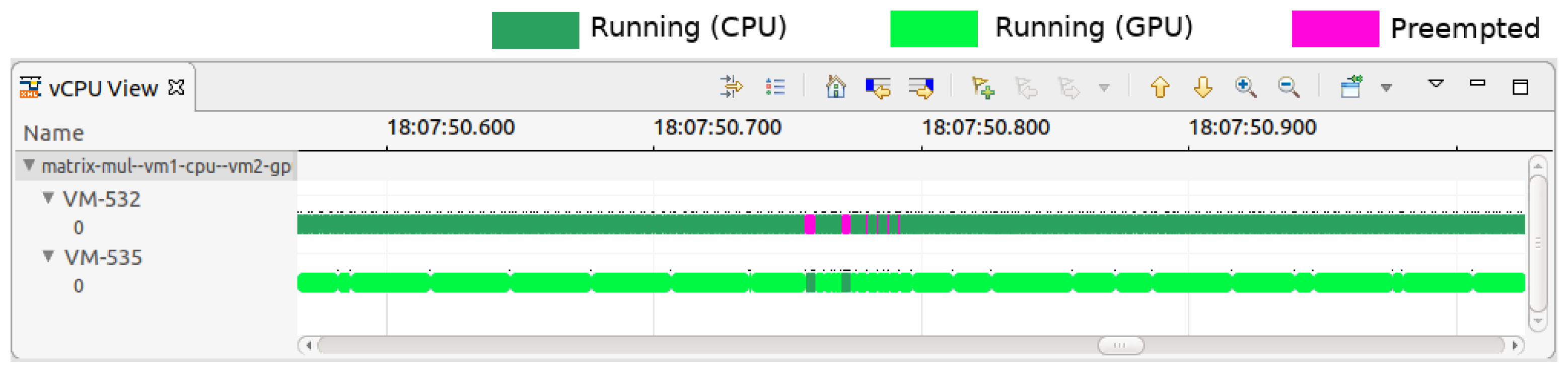
Figure 11. Conversely, other hosts housing VMs primarily running GPU-intensive programs with minimal CPU dependency were identified. We then tagged VMs accordingly as ’CPU-intensive’ and ’GPU-intensive’. Our refined placement algorithm reassigned CPU-intensive VMs to hosts with GPU-intensive VMs when CPU-overcommitment-induced preemptions surpassed a specific threshold. After the implementation of this optimized algorithm, a marked decrease in VM preemptions was observed.
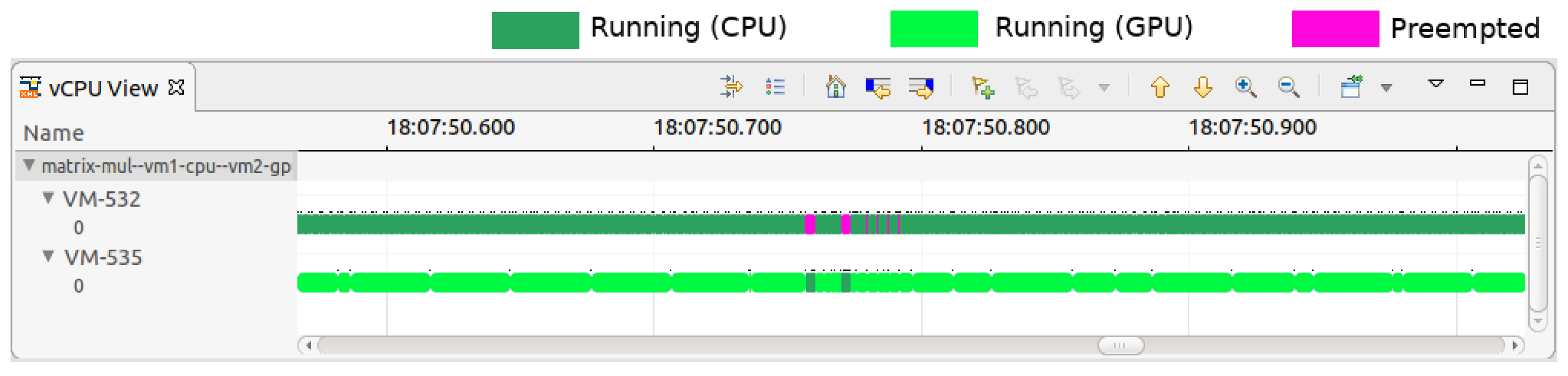
Figure 12 illustrates this improvement, showing a significant reduction in the preemptions of VM-532 after VM-535’s relocation, with preemption counts dropping from 23,125 to 15,087.
6. Tracing Cost Analysis
This section examines the cost implications associated with the use of our framework—particularly the trace data collection phase. As noted before, our approach relies mainly on efficient host kernel tracing. However, the overhead introduced by this tracing must be minimal to prevent any significant impact on the performance or behavior of the system under observation.
To estimate the overhead incurred by our tracing method, we conducted a series of experiments using a VM, the specifications of which are detailed in
Table 3. This VM was utilized to execute selected benchmarks from the Rodinia benchmark suite [
43], which were chosen due to their varied workload sizes and submission frequencies. Our results, as summarized in
Table 4, indicate that the operational overhead from active tracepoints was modest, averaging around 1.01%. This low overhead confirmed the efficiency of our tracing approach in gathering runtime data without significantly burdening the system.
Storing trace files can be problematic for most tracing tools, as they generate data in large amounts. This storage cost is mostly influenced by two factors: the event frequency and the chosen storage format. Our findings, which are illustrated in
Table 4, show that the size of the trace files did not directly correlate with the benchmark execution times. Rather, it was more closely related to the number of events generated, which, in our context, corresponded to the volume of GPU request submissions. Owing to our strategy of selectively activating a limited number of tracepoints, we managed to keep the trace file sizes within reasonable limits, thus mitigating potential storage issues.
7. Conclusions
A GPU is a powerful computing unit with remarkable characteristics, including a highly parallel architecture and energy efficiency. Hence, this device has found extensive application in diverse domains, such as heterogeneous and embedded systems, where it greatly improves application performance. These applications range from autonomous driving to media transcoding and graphics-intensive applications. The interesting attributes of this accelerator have prompted the introduction of vGPU-accelerated VMs, opening up opportunities to address CPU bottlenecks in data centers and enabling end-users to harness the power of high-performance computing devices for a variety of applications.
While our review of the existing literature shows various performance analysis tools for GPUs, support for vGPUs remains a significant gap. Unfortunately, the only tool offering vGPU support, NVIDIA Nsight Systems, is closed-source software and lacks publicly available documentation. To address this gap in research, our study introduces a novel diagnostic tool that is specifically designed to analyze vGPU performance. Utilizing GVT-g, Intel’s virtualization technology for on-die GPUs, as a foundational platform, our framework provides detailed insights into GVT-g operations. It facilitates an exhaustive analysis of VMs equipped with vGPUs, thereby enhancing the understanding and optimization of their performance.
Our approach leverages LTTng, a low-overhead tracer, to collect the low-level data required for our analyses. Through this tool, we traced the host machine kernel to gain a better understanding of vGPU resource utilization. Furthermore, we developed a suite of auto-synchronized views in Trace Compass to unveil the intricate dynamics of vGPU-accelerated VMs as they interact with the host GPU resources. Finally, our analysis reveals that the tracing overhead is minimal at approximately 1.01%. Looking ahead, future iterations of our work will expand this approach to encompass other GPU virtualization technologies, such as MxGPU and NVIDIA Grid. These technologies have gained prominence in the data centers of major cloud providers, making our research even more pertinent and valuable in the evolving landscape of GPU virtualization.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}