
Predicting Missing Values in Survey Data Using Prompt Engineering for Addressing Item Non-Response



Abstract

1. Introduction
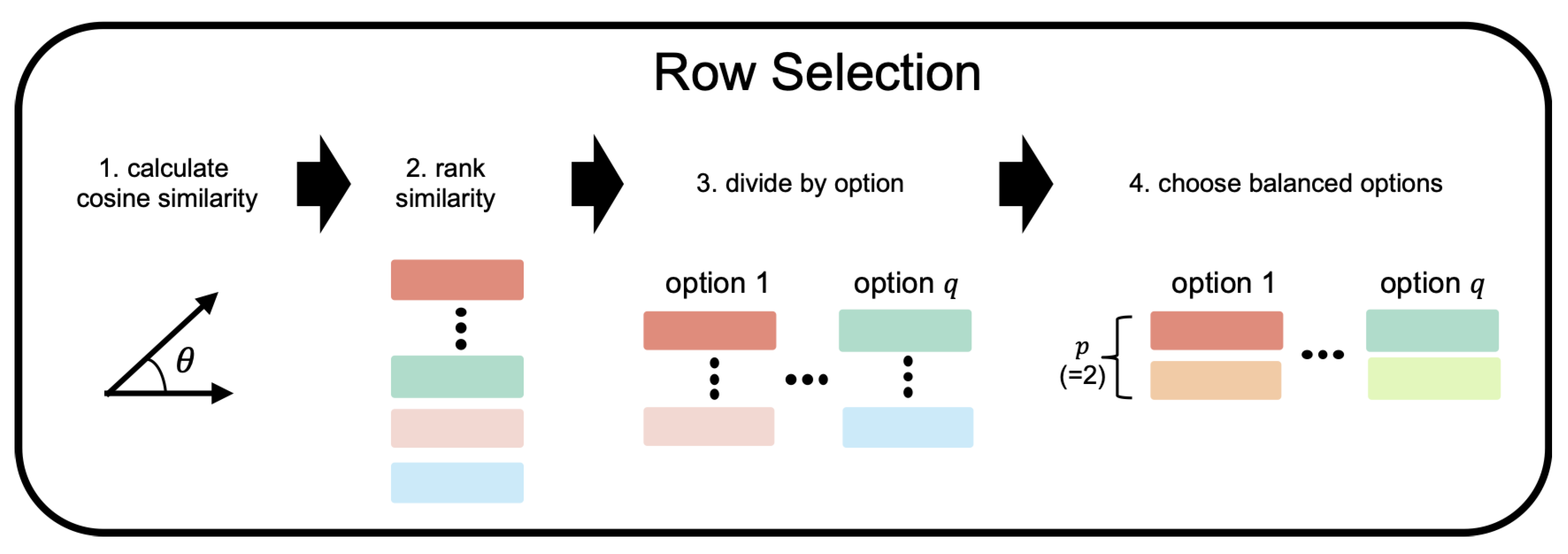
- Row Selection: This involves selecting relevant respondents for the few-shot examples by calculating the cosine similarity between the responses of the current target user and those of other respondents. Respondents whose answers are most similar to the target user’s responses are selected, ensuring that the few-shot examples include balanced options across all possible answer categories for the target question.
- Column Selection: This step is used to include only the most relevant context for answering the target question. First, the LLM is prompted to generate a diverse set of questions designed to elicit responses pertinent to the target question. Subsequently, question–answer pairs corresponding to these generated questions are extracted from the existing dataset by the retriever.
- Our approach consistently achieves high performance across various types of survey questions, effectively leveraging diverse information sources while maintaining robust results.
- We propose a generalized LLM-based method for item non-response prediction that enables rapid inference without requiring complex preprocessing or additional training steps.
- Our method is capable of handling scenarios where existing questions have very few respondents and can address new questions with no prior responses—capabilities that previous methods could not achieve.
- Finally, our approach is scalable, maintaining effectiveness even as new respondents or data points are added in real-time.
2. Related Work
2.1. LLM with Personalized Data
2.2. Retrieval-Augmented Generation (RAG) for In-Context Learning
2.3. Predicting Survey Data Using LLMs
3. Methods
3.1. Problem Definition and Formalization
3.2. Naive Prompt: Methodology and Its Limitations
- 1.
- Vulnerability to Irrelevant Context:The Naive Prompt approach simply selects user question–response pairs that are similar to the target question for context. By relying solely on cosine similarity, this approach is prone to introducing context that may not be semantically relevant to the current target question. This may hinder the performance of LLMs, as unnecessary or off-topic context can lead to lower-quality generation [33].
- 2.
- Inability to Handle Complex Queries:Complex or nuanced queries often require a more sophisticated understanding of the context and nuance, something that simple cosine similarity cannot capture. The Naive Prompt approach struggles in such scenarios, where the absence of a refined selection mechanism leads to suboptimal context assembly.
- 3.
- Underutilization of Survey Data:Because the search is based only on similarity to the target question, the LLM constructs context without fully understanding or utilizing the available survey data. As a result, this method cannot leverage the full potential of survey data for making inferences.
3.3. Our Methods
3.3.1. Row Selection
- 1.
- Cosine Similarity Calculation: the cosine similarity is calculated as follows:where is the set of columns where both the vector and the vector have non-NaN values. By using Equation (3) as a scoring function, this ensures that the similarity is computed based on the commonly answered questions, effectively addressing the issue of missing data.
- 2.
- Ranking Based on Similarity: After calculating the cosine similarity scores for all respondents , the respondents are ranked in descending order of their similarity scores . This ranking allows us to identify the respondents most similar to the target respondents.
- 3.
- Option-Wise Selection: From the top-ranked respondents, p respondents are selected for each answer category of the target question . This step ensures that the few-shot examples include a balanced representation of all possible answer options for the target question.
- 4.
- Balanced Few-Shot Example Selection: Finally, the selected respondents from each answer category are combined to form a balanced few-shot dataset with examples, where q is the number of answer categories (options) for the target question . This balanced dataset is then used to provide context for imputing the missing responses of the target respondent.
3.3.2. Column Selection
- 1.
- Prompting for Related Questions for Enhanced Retrieval:To identify the most relevant questions to the target question , we prompt the LLM to produce alternative phrasings, expansions, or related inquiries that capture different aspects of . Specifically, we use GPT-4 Turbo to generate a set of candidate questions that are semantically related to . This approach allows us to uncover relevant questions that may not be directly similar in wording but are conceptually related, thereby enriching the pool of potential context for the LLM to use in prediction. By using these generated related questions as queries for retrieval, we can capture information that might be missed by using the target question directly, as discussed in Section 3.2.
- 2.
- Embedding with Dense Retriever:Once the candidate questions are generated, each candidate question and each actual question are embedded using a dense retriever model. Specifically, the retriever maps each actual question to an embedding by taking the [CLS] token of the last hidden representation over the tokens in . At query time, the same encoder is applied to the candidate question to obtain a candidate question embedding . This embedding process converts the textual content of the questions into dense vector representations that capture their semantic meaning, enabling more accurate similarity calculations.
- 3.
- Retrieving Similar Questions:After embedding the candidate questions and the actual questions Q using a dense retriever model, we calculate the cosine similarity between the embedded vectors and . For each candidate question , we select the question with the highest cosine similarity:This process yields a set of retrieved questions , where each , selected through Equation (4), is the most similar question to the corresponding candidate question . To ensure that the selected question in does not overlap, each question must be unique. If a question has already been selected for another candidate, it is excluded from the pool of options for subsequent selections, and the next most similar question is selected. This process ensures that all questions in are distinct.
- 4.
- Final Selection of Question–Answer Pairs:From the set of retrieved question–answer pairs , we select the top-k pairs that exhibit the highest relevance to the target question . The relevance is determined by the order of the , which is predetermined by the GPT-4 model per target question. This ensures that the selected pairs provide the most informative context, thereby enabling the LLM to generate more accurate predictions. Additionally, the few-shot respondents selected through the Row Selection process (Section 3.3.1) also undergo the same process of extracting relevant question–answer pairs, ensuring that both row and column selections are optimally aligned to support the LLM’s decision-making process.
3.3.3. Prompt Generation and Answer Extraction
4. Experiments
4.1. Dataset
4.2. Baselines
- 1.
- MICE: Multivariate imputation by chained equations (MICE) [7] is the most common method for imputing missing data. In the MICE algorithm, imputation can be performed using a variety of parametric and nonparametric methods. For our study, we configured MICE to use a non-parametric method, with the number of datasets set to 2 and the number of iterations also set to 2.
- 2.
- Missforest: MissForest [8] is an iterative imputation method that utilizes random forests to predict and fill in missing values within a dataset, capable of handling different types of variables, such as categorical and continuous variables. For our implementation, we configured the random forest using the default settings from the sklearn library [35] and performed 5 iterations.
- 3.
- TabTransformer: TabTransformer [13] is a tabular data modeling architecture that adapts Transformer layers to the tabular domain by applying multi-head attention on parametric embeddings, effectively managing missing values. For our approach, we set all hyperparameters to their default values as referenced in the original paper, with the exception of the epochs, learning rate, and batch size, which were set to 10, 0.0001, and 1, respectively. To handle missing values, we replaced all missing values with 0.
- 4.
- Naive Prompt: In addition to evaluating sophisticated methods, we also implemented a Naive Prompt approach as a baseline. This method is inspired by the Naive RAG [31] approach, where the selection of relevant questions is simplified to assess the impact of more advanced techniques. In the Naive Prompt approach, we performed column selection without leveraging any advanced techniques to rewrite or refine the selected questions. Specifically, during the column selection process, instead of asking the LLM to rewrite relevant questions, we simply selected the questions based on their cosine similarity between the target question and the user’s non-target question–response pairs. These selected questions were then added to the context in descending order of their cosine similarity scores.
4.3. Our Methods
4.3.1. Full Context Method
4.3.2. Non-Row Selection Method
4.4. Results and Discussion
- 1.
- Significant Performance Improvement:The Full Context Method consistently outperforms the baseline models across most survey questions. Specifically, GPT4-turbo outperformed TabTransformer on SATIS questions by a margin of 0.36. As such, GPT4o-mini on DRLEAD and ECON1B achieved F1-Scores of 0.73 and 0.60, respectively, which is a significant gap from the baseline. The Non-Row Selection Method also performed well. GPT4-turbo achieved the highest F1-Scores of 0.91 and 0.65 on the POL1JB question.
- 2.
- Robustness Across Different Question Types:The proposed method demonstrated robustness across various question types, particularly in more complex scenarios. For example, in predicting responses to the DRLEAD question, which requires a deeper understanding of leadership dynamics, GPT4o-mini achieved an F1-score of 0.73, outperforming both the Non-Row Selection Method and all baseline models. This result highlights the method’s ability to handle complex and nuanced survey questions effectively.
- 3.
- Practical Implications and Scalability:The results also underscore the practical benefits of using our approach in survey data analysis. A key advantage is its ability to consistently outperform traditional baselines without requiring complex additional tuning, which can be time-consuming and resource-intensive, particularly in large-scale survey analysis. Unlike MICE and Missforest, which suffer from high computational complexity and require significant time to process large datasets, our method—especially when leveraging LLMs—demonstrates a much more efficient workflow. For instance, MICE and Missforest can take between 4 h 18 min and 5 h 54 min to complete imputation. TabTransformer, on the other hand, requires approximately 4 h of training time per column to achieve the performance observed in our experiments. In stark contrast, our method significantly reduced the time required for predictions. Both LLaMA3 and GPT-based models take only about 4 to 6 min to predict responses for a single question. This substantial reduction in processing time not only makes our approach more practical for real-time or large-scale survey analysis but also highlights its scalability across various survey sizes and complexities.
4.5. Ablation Study
4.5.1. The Impact of Top-k Responses
4.5.2. The Impact of n-Shot Respondents
5. Limitations and Future Works
5.1. Limitations
- 1.
- Challenges with Questions Having Numerous Options:The predictive accuracy of our method decreases when dealing with survey questions that offer a wide range of answer choices. As the number of options increases, the complexity and ambiguity in distinguishing between them can lead to difficulties in accurately predicting the correct response. This is particularly evident in questions where the options are nuanced or overlap in meaning.
- 2.
- Requirement for Hyperparameter Tuning:The optimal values for hyperparameters such as top-k (the number of top relevant questions) and n-shot (the number of few-shot examples) can vary between different survey questions. Each question may require a unique set of hyperparameters to achieve the best performance, necessitating a search process to identify these values.
- 3.
- Dependence of Linguistic Relevance:The effectiveness of our method relies heavily on the linguistic relatedness of the survey questions. For questions that are not semantically rich or lack clear connections to other items in the survey—such as “How did you access this survey?”—our method may struggle to provide accurate predictions. In such cases, the lack of relevant contextual information hinders the model’s ability to infer missing responses effectively.
- 4.
- Limitations with Smaller Language Models and Long ContextsWhen utilizing language models with a smaller number of parameters, such as LLaMA38B, performance issues become more pronounced as the context length increases. These smaller models are more susceptible to decreased accuracy and a higher incidence of hallucinations when processing long prompts.
5.2. Future Works
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Full Prompts
Appendix A.1. Prompt to Generate Candidate Questions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Prompt | |
| Your task is to generate a list of questions based on the provided user input from a survey. Assume the user has completed a survey with various questions, but only one question is provided to you. Here is a description of the survey: {description of the survey} Key sections of the survey include: {key sections} | ||
| Variable Examples | ||
| description of the survey | The ATP W116 survey, conducted by Pew Research Center, is a comprehensive pre-election questionnaire targeting a wide array of political and social issues. It was fielded from 10 October to 16 October 2022. The survey includes questions designed to gauge respondents’ satisfaction with the current state of the country, approval ratings of President Joe Biden, opinions on various institutions, and perspectives on upcoming congressional elections. | |
| key sections | 1. **Political Approval and Satisfaction**: Respondents are asked about their satisfaction with the country’s direction and their approval or disapproval of President Biden’s performance, including the strength of their opinions. … 10. **Personal and Employment Situations**: The survey includes sections on respondents’ current work status, pressures felt in their personal and professional lives, and their perceptions of economic issues affecting the nation and themselves personally. | |
| Few-shot | Prompt | |
| The example of the provided question is: {question} Then you would generate additional questions such as: {additional questions} | ||
| Variable Examples | ||
| question | Thinking about the state of the country these days, would you say you feel... | |
| additional questions | How satisfied are you with the current direction of the country? Do you approve or disapprove of President Biden’s performance? How strongly do you feel about your approval or disapproval of President Biden? … How important is the issue of racial equality in influencing your vote in the upcoming elections? | |
| Target Question | Prompt | |
| Now, generate {number of questions} useful questions for the following question. Provided question is: {provided question} Generate the additional survey questions: | ||
| Variable Examples | ||
| provided question | All in all, are you satisfied or dissatisfied with the way things are going in this country today? | |
| number of questions | 20 | |
Appendix A.2. Prompt to Extract Response
| System | Prompt | |
| You are tasked with predicting responses to targeted user survey questions through given user survey questions-responses. Read the provided user survey questions-responses and use it to select the most appropriate response from the given options to the target question. Ensure that your output includes only the selected response and does not include any additional comments, explanations, or questions. Choose the appropriate answer to the following target question from the following options. Target question: {question} Options: {options} | ||
| Variable Examples | ||
| question | All in all, are you satisfied or dissatisfied with the way things are going in this country today? | |
| options | Satisfied Dissatisfied | |
| Few-shot | Prompt | |
| Here are examples of respondents similar to this user: User n’s survey responses: {responses} Answer: {answer} | ||
| Variable Examples | ||
| responses | Q: How satisfied are you with the choice of candidates for Congress in your district this November? A: Somewhat satisfied … Q: Thinking about the nation’s economy…How would you rate economic conditions in this country today?…A: Only fair | |
| answer | Satisfied | |
| Target User | Prompt | |
| Now, read the following target user survey responses and query, and select the most appropriate response from the given options based on the other responses. Refer to the answers provided by respondents similar to the user provided above. Ensure that your output includes only in Options: User survey responses: {user response} Answer: | ||
| Variable Examples | ||
| user responses | Q: How satisfied are you with the choice of candidates for Congress in your district this November? A: Not too satisfied … Q: Thinking about the nation’s economy… How would you rate economic conditions in this country today?…A: Only fair | |
References
- De Wit, J.R.; Lisciandra, C. Measuring norms using social survey data. Econ. Philos. 2021, 37, 188–221. [Google Scholar] [CrossRef]
- Delfino, A. Student engagement and academic performance of students of partido state university. Asian J. Univ. Educ. 2019, 15, 42–55. [Google Scholar] [CrossRef]
- Khoi Quan, N.; Liamputtong, P. Social Surveys and Public Health. In Handbook of Social Sciences and Global Public Health; Liamputtong, P., Ed.; Springer International Publishing: Cham, Switzerland, 2023; pp. 1–19. [Google Scholar] [CrossRef]
- Brick, J.M.; Kalton, G. Handling missing data in survey research. Stat. Methods Med Res. 1996, 5, 215–238. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Shao, J. Nearest neighbor imputation for survey data. J. Off. Stat. 2000, 16, 113. [Google Scholar]
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A Program for Missing Data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2011, 28, 112–118. [Google Scholar] [CrossRef]
- Lever, J.; Krzywinski, M.; Altman, N. Points of Significance: Logistic regression. Nat. Methods 2016, 13, 541–542. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ke, G.; Xu, Z.; Zhang, J.; Bian, J.; Liu, T.Y. DeepGBM: A Deep Learning Framework Distilled by GBDT for Online Prediction Tasks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 4–8 August 2019; pp. 384–394. [Google Scholar] [CrossRef]
- Huang, X.; Khetan, A.; Cvitkovic, M.; Karnin, Z. TabTransformer: Tabular Data Modeling Using Contextual Embeddings. arXiv 2020, arXiv:2012.06678. [Google Scholar]
- Somepalli, G.; Goldblum, M.; Schwarzschild, A.; Bruss, C.B.; Goldstein, T. SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training. arXiv 2021, arXiv:2106.01342. [Google Scholar]
- Moser, C.; Kalton, G. Question wording. In Research Design; Routledge: Abingdon, UK, 2017; pp. 140–155. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. arXiv 2023, arXiv:2205.11916. [Google Scholar]
- Liu, J.; Liu, C.; Zhou, P.; Lv, R.; Zhou, K.; Zhang, Y. Is ChatGPT a Good Recommender? A Preliminary Study. arXiv 2023, arXiv:2304.10149. [Google Scholar]
- Yang, F.; Chen, Z.; Jiang, Z.; Cho, E.; Huang, X.; Lu, Y. PALR: Personalization Aware LLMs for Recommendation. arXiv 2023, arXiv:2305.07622. [Google Scholar]
- Salemi, A.; Mysore, S.; Bendersky, M.; Zamani, H. LaMP: When Large Language Models Meet Personalization. arXiv 2024, arXiv:2304.11406. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; tau Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv 2021, arXiv:2005.11401. [Google Scholar]
- Izacard, G.; Grave, E. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. arXiv 2021, arXiv:2007.01282. [Google Scholar]
- Xu, P.; Ping, W.; Wu, X.; McAfee, L.; Zhu, C.; Liu, Z.; Subramanian, S.; Bakhturina, E.; Shoeybi, M.; Catanzaro, B. Retrieval meets Long Context Large Language Models. arXiv 2024, arXiv:2310.03025. [Google Scholar]
- Gao, L.; Ma, X.; Lin, J.; Callan, J. Precise Zero-Shot Dense Retrieval without Relevance Labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 1762–1777. [Google Scholar] [CrossRef]
- Asai, A.; Wu, Z.; Wang, Y.; Sil, A.; Hajishirzi, H. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. arXiv 2023, arXiv:2310.11511. [Google Scholar]
- Yan, S.Q.; Gu, J.C.; Zhu, Y.; Ling, Z.H. Corrective Retrieval Augmented Generation. arXiv 2024, arXiv:2401.15884. [Google Scholar]
- Kim, J.; Lee, B. AI-Augmented Surveys: Leveraging Large Language Models and Surveys for Opinion Prediction. arXiv 2024, arXiv:2305.09620. [Google Scholar]
- Simmons, G.; Savinov, V. Assessing Generalization for Subpopulation Representative Modeling via In-Context Learning. arXiv 2024, arXiv:2402.07368. [Google Scholar]
- Plaat, A.; Wong, A.; Verberne, S.; Broekens, J.; van Stein, N.; Back, T. Reasoning with Large Language Models, a Survey. arXiv 2024, arXiv:2407.11511. [Google Scholar]
- Huang, J.; Chang, K.C.C. Towards Reasoning in Large Language Models: A Survey. arXiv 2023, arXiv:2212.10403. [Google Scholar]
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, M.; Wang, H. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv 2024, arXiv:2312.10997. [Google Scholar]
- Ram, O.; Levine, Y.; Dalmedigos, I.; Muhlgay, D.; Shashua, A.; Leyton-Brown, K.; Shoham, Y. In-Context Retrieval-Augmented Language Models. arXiv 2023, arXiv:2302.00083. [Google Scholar] [CrossRef]
- Shi, F.; Chen, X.; Misra, K.; Scales, N.; Dohan, D.; Chi, E.H.; Schärli, N.; Zhou, D. Large Language Models Can Be Easily Distracted by Irrelevant Context. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023, Honolulu, HI, USA, 23–29 July 2023; Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; PMLR: Birmingham, UK, 2023; Volume 202, pp. 31210–31227. [Google Scholar]
- Liu, J.; Shen, D.; Zhang, Y.; Dolan, B.; Carin, L.; Chen, W. What Makes Good In-Context Examples for GPT-3? arXiv 2021, arXiv:2101.06804. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, J.; Xiao, S.; Zhang, P.; Luo, K.; Lian, D.; Liu, Z. BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv 2024, arXiv:2402.03216. [Google Scholar]


| Code | Question | Answers |
|---|---|---|
| SATIS | All in all, are you satisfied or dissatisfied with the way things are going in this country today? | Satisfied Dissatisfied |
| POL10 | Do you think about your vote for Congress this fall as… | A vote FOR Biden A vote AGAINST Biden Biden is not much of a factor |
| POL1JB | Do you approve or disapprove of the way Joe Biden is handling his job as president? | Approve Disapprove |
| DRLEAD | In your view, which party has better political leaders? | The Republican Party The Democratic Party Not sure |
| PERSFNCB | A year from now, do you expect that the financial situation of you and your family will be… | Better Worse About the same as now |
| ECON1B | A year from now, do you expect that economic conditions in the country as a whole will be… | Better Worse About the same as now |
| Method | SATIS | POL1JB | POL10 * | DRLEAD * | PERSFNCB * | ECON1B * |
|---|---|---|---|---|---|---|
| Baselines | ||||||
| MICE | 0.39 | 0.86 | 0.40 | 0.53 | 0.43 | 0.48 |
| Missforest | 0.36 | 0.38 | 0.24 | 0.23 | 0.31 | 0.36 |
| Tabtransformer | 0.48 | 0.85 | 0.78 | 0.54 | 0.44 | 0.42 |
| (NP) LLaMA38B | 0.47 | 0.77 | 0.21 | 0.47 | 0.24 | 0.42 |
| (NP) GPT4o-mini | 0.65 | 0.55 | 0.36 | 0.65 | 0.42 | 0.35 |
| (NP) GPT4-turbo | 0.47 | 0.89 | 0.41 | 0.53 | 0.55 | 0.51 |
| Our method | ||||||
| (FC) LLaMA38B | 0.69 | 0.71 | 0.52 | 0.46 | 0.49 | 0.43 |
| (FC) GPT4o-mini | 0.67 | 0.87 | 0.75 | 0.73 | 0.63 | 0.60 |
| (FC) GPT4-turbo | 0.84 | 0.85 | 0.75 | 0.59 | 0.56 | 0.47 |
| (NRS) LLaMA38B | 0.53 | 0.82 | 0.19 | 0.44 | 0.35 | 0.38 |
| (NRS) GPT4o-mini | 0.53 | 0.53 | 0.55 | 0.70 | 0.46 | 0.31 |
| (NRS) GPT4-turbo | 0.43 | 0.91 | 0.69 | 0.53 | 0.62 | 0.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, J.; Kim, J.; Kim, Y. Predicting Missing Values in Survey Data Using Prompt Engineering for Addressing Item Non-Response. Future Internet 2024, 16, 351. https://doi.org/10.3390/fi16100351
Ji J, Kim J, Kim Y. Predicting Missing Values in Survey Data Using Prompt Engineering for Addressing Item Non-Response. Future Internet. 2024; 16(10):351. https://doi.org/10.3390/fi16100351
Chicago/Turabian StyleJi, Junyung, Jiwoo Kim, and Younghoon Kim. 2024. "Predicting Missing Values in Survey Data Using Prompt Engineering for Addressing Item Non-Response" Future Internet 16, no. 10: 351. https://doi.org/10.3390/fi16100351
APA StyleJi, J., Kim, J., & Kim, Y. (2024). Predicting Missing Values in Survey Data Using Prompt Engineering for Addressing Item Non-Response. Future Internet, 16(10), 351. https://doi.org/10.3390/fi16100351