1. Introduction
The abundance of information available on the internet has created a challenge for users in sorting through and making decisions among the many options available for services such as restaurants, products, and hotels. This issue, known as information overload, can complicate the decision-making process [
1]. To address this problem, recommendation systems have been developed to filter information and provide customized recommendations to users based on their specific tastes and preferences [
2]. The goal of these systems is to minimize the time users spend searching for information and suggest items they may not have otherwise considered, thereby improving the quality of information access services.
The evolution of e-commerce websites has emphasized the value of recommendation systems in helping customers discover products that are relevant to their needs and preferences. RS has proven to be a useful tool in this context [
3].
Several techniques are used for deciding which items to recommend in RSs, with the three most common techniques being collaborative filtering (CF), content-based filtering (CBF), and hybrid methods combining both [
4]. CF is widely used and can be found on the majority of online shopping sites [
5]. CF systems provide recommendations to a particular user based on the preferences and tastes of other users. These systems can be divided into two types: memory-based (MRB) and model-based (MB). The MRB method utilizes the similarity between items or users to retrieve information for the target user and make recommendations based on the obtained results [
6]. The MB method builds a model to predict the ratings or preferences of the target user for a certain item and makes recommendations based on the estimated ratings. It includes two techniques: user-based and item-based [
7]. In contrast, the CBF approach compares the semantic content of items [
8]. The hybrid technique combines two or more recommendation algorithms or components into an RS [
9]. However, traditional RS methods primarily depend on a single standard rating (overall score) for the recommendation process, which is usually insufficient for precise recommendations, as the overall score cannot provide a detailed analysis of the user’s behavior [
10]. Furthermore, CF faces two main problems, sparsity and gray sheep [
11], which make this method unreliable in some recommender systems. This motivates further research aimed at discovering practical solutions to improve the effectiveness of RS.
Recently, customer reviews have had a significant impact on customers’ decisions to use a service or purchase a product. Many consumers rely on the opinions of others when making decisions, leading to a substantial rise in the number of online customer reviews. Each review reflects the customer’s experience with a particular service, such as watching a movie, buying a product, or booking a room. In this regard, Sentiment Analysis methods can be utilized to deduce the customer’s emotions and opinions on various topics [
12].
The objective of SA is to determine the emotional tone or attitude expressed in user-generated text related to a specific topic or entity [
13]. This is achieved by automatically identifying and extracting information about the discussed entity and assessing whether the language used in the text conveys a negative, positive, or neutral sentiment. SA can be performed at three levels of data extraction [
14]: aspect, sentence, and document level. There are three main approaches for solving the SA problem [
15]: Lexicon-based methods, Machine Learning-based methods, and Hybrid methods. Lexicon-based methods were the first to be employed for SA. They rely on lexicons and linguistic rules and can be classified into two types: corpus-based and dictionary-based [
16]. Machine Learning (ML)-based techniques include traditional and deep learning (DL) methods [
17]. Finally, a hybrid approach combines lexicons and machine learning techniques [
13]. The application of Deep Learning methods has been shown to be more effective than conventional approaches in sentiment analysis [
18]. Deep Learning models such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Deep Neural Networks (DNNs) can be utilized for sentiment classification.
It is common to integrate sentiment analysis methods in recommendation systems to enhance the quality and performance of recommendations [
19]. Integrating SA into RS allows for gathering more information about user feedback and preferences on items, which can improve the effectiveness of the system.
In this work, our aim is to address the challenge of improving the accuracy and personalization of recommendations in e-commerce systems. Specifically, we investigate the impact of integrating sentiment analysis with collaborative filtering methods in the e-commerce domain. By formulating and addressing this research problem, we contribute to the advancement of recommendation systems in the context of e-commerce by leveraging bi-LSTM-based sentiment analysis.
To address our research problem, we conducted a comparative analysis of various recommendation algorithms. We specifically compared their performances under two scenarios: using only ratings to generate recommendations and incorporating both ratings and sentiments for recommendation.
In this study, we propose a novel recommender system that leverages Ensemble learning by combining sentiment analysis and collaborative filtering approaches. In contrast to traditional methods, we propose the utilization of a Bi-LSTM model for sentiment analysis, which represents a significant improvement. The strength of the Bi-LSTM model lies in its ability to capture contextual information and dependencies in sequential data, making it well-suited for sentiment analysis tasks. By integrating sentiment analysis based on Bi-LSTM with the recommendation system, our novel approach aims to improve the accuracy and effectiveness of recommendations.
The results of the empirical study, conducted with two e-commerce datasets, demonstrate that the combination of Bi-LSTM-based sentiment analysis and collaborative filtering techniques leads to a significant improvement in the performance of the recommender system. These results have been compared with baseline models, providing a means to evaluate the validity and superiority of the proposed approach.
The principal contributions of our work are:
We have suggested the use of SA based on the Bi-LSTM model for text data to better understand the opinions, emotions, and attitudes of a user.
We developed and evaluated a novel recommendation system that uses ensemble learning by integrating sentiment analysis of text data with collaborative filtering techniques, which improves the accuracy and personalization of recommendations.
Our proposed system was tested on two real-world datasets and the results showed that it outperforms traditional collaborative filtering techniques in terms of predicting evaluation accuracy.
This paper is structured as follows.
Section 2 presents an overview of the previous research and methods related to the suggested RS.
Section 3 describes the approach and techniques used to develop our recommendation system.
Section 4 provides an examination and presentation of the results obtained from the experiments that we have performed.
Section 5 discusses the results obtained. Lastly,
Section 6 presents the main conclusion and highlights future research directions.
2. Related Work
In recent years, researchers have been actively exploring ways to enhance traditional collaborative filtering techniques in order to overcome challenges such as data sparsity, cold start, and the gray sheep problem. One promising approach to improving collaborative filtering is integrating sentiment analysis into the recommendation process. In this section, we discuss several relevant studies that have employed sentiment analysis in recommender systems, showcasing their unique contributions.
For example, in [
20], Rayan et al. presented a combined learning technique that blends collaborative filtering and CBF for providing customized recommendations for personal well-being services. The research aims to overcome the limitations of conventional collaborative filtering, particularly in the situation of the cold-start issue. The proposed technique is tested using a dataset of personal well-being services and the results show that it surpasses traditional CF techniques.
Another study by the authors of [
21] introduced a hybrid recommendation system that integrated CBF and collaborative filtering using SA based on the Naive Bayes algorithm. The system leveraged microblogging data to enhance the recommendation process. By considering the sentiment expressed in users’ feedback and preferences, the system generated more accurate and personalized recommendations.
The paper [
22] makes a significant contribution to the field of recommender systems by introducing a novel sentiment-based model that tackles the issue of sparse data. Their contribution lies in demonstrating the effectiveness of incorporating sentiment analysis techniques into collaborative filtering-based recommendation algorithms. By leveraging textual reviews, their model enhances the performance of recommender systems by considering the sentiment expressed in user feedback. This integration of sentiment analysis provides valuable insights into improving user satisfaction and the overall quality of recommendations.
Osman et al. [
23] developed a recommender system that incorporated contextual sentiment analysis to improve the precision and personalization of recommendations. By considering the context of users’ feedback and preferences, the system generated more relevant recommendations. This approach addressed the limitations of traditional collaborative filtering methods, which often overlooked the contextual information associated with users’ feedback.
To address the cold-start problem, sentiment analysis of textual data from online communities, such as Twitter and Facebook, has been employed. In one study [
24], the authors proposed a method that integrated sentiment analysis of social network data to enhance the precision and personalization of recommendations. They utilized machine learning methods, including Support Vector Machine (SVM) and Naive Bayes (NB), to perform sentiment analysis and gather additional information about new users or items.
Ziani et al. [
25] introduced a multilingual recommendation system that combined user-based collaborative filtering with sentiment analysis. The system utilized a semi-supervised SVM as a sentiment classification technique to analyze the sentiment of reviews and ratings provided by users. By considering both user preferences and sentiment feedback, the system generated highly accurate and personalized recommendations. The multilingual approach catered to users who spoke different languages, making the system more inclusive and accessible.
In another study [
26], collaborative filtering was combined with sentiment analysis to enhance the performance of a recommender system for groups of users. The authors employed classification methods, such as NBM and Linear Support Vector Classification (LSVC), for sentiment analysis. Additionally, Singular Value Decomposition (SVD) was used to improve the scalability of the recommender system. The findings demonstrated that the proposed technique improved the effectiveness of the system, providing more accurate and personalized recommendations.
In a different approach, authors in [
27] adopted a novel method to enhance the effectiveness of collaborative filtering algorithms. They utilized lexicon-based sentiment analysis to incorporate the emotional content present in the recommended items, resulting in a more precise prediction of users’ preferences.
The work [
28] addresses the limitations of traditional CF techniques by introducing a sentiment digitization modeling framework. The authors emphasize the importance of considering user sentiment in recommendation systems, as it can significantly impact the relevance and personalization of recommendations. They argue that conventional methods often overlook the nuanced emotional aspects of user preferences, leading to suboptimal recommendations. To overcome this limitation, the authors propose a sentiment digitization modeling technique that effectively captures and quantifies the sentiment expressed in user feedback. The framework leverages sentiment analysis algorithms to transform the qualitative sentiment information into quantitative scores, which can be incorporated into the recommendation process. The proposed approach is evaluated using a real-world dataset, and the results demonstrate improved recommendation performance compared to traditional CF methods. The study highlights the potential of sentiment digitization modeling in enhancing recommendation systems by considering the emotional aspect of user preferences.
The work by Devipriya et al. [
29] highlights the effectiveness of different deep learning architectures, specifically RNN and CNN, for recommendations in SA in social applications. The study shows that the RNN architecture demonstrates a better understanding of the relationships between words and achieves improved performance in sentiment label training. On the other hand, the CNN architecture initially struggles with phrase-level labels but can be enhanced by leveraging pre-trained word2vec vectors to address overfitting and enhance performance. The findings of the study imply that deep learning techniques can effectively analyze sentiments in social applications. By utilizing these architectures, recommender systems can be built with improved accuracy and effectiveness in providing recommendations based on user sentiments. The research also suggests potential avenues for further improvements and applications in the field of building recommender systems for various socially relevant domains.
RSs typically depend on explicit user ratings, but this approach becomes impractical in many domains. Additionally, even when explicit ratings are available, their trustworthiness and reliability can pose limitations to the recommender system. To overcome these challenges, analyzing sentiments within textual data, such as reviews and comments, can provide valuable implicit feedback alongside traditional ratings. This approach proves beneficial in improving the accuracy of recommendations for users, especially when there is a large volume of text-based feedback available. While previous studies have incorporated sentiment analysis into recommendation methods, most of them have utilized conventional sentiment techniques.
Our approach, which incorporates the Bi-LSTM model for sentiment analysis in recommendation systems, introduces a novel and promising method to enhance the accuracy and effectiveness of sentiment analysis. Through our experimentation, we have conducted evaluations and confirmed the potential of the Bi-LSTM model in improving sentiment analysis for recommendation systems. By leveraging the unique capabilities of the Bi-LSTM model, such as its ability to capture contextual information and dependencies in sequential data, we have achieved more accurate sentiment analysis and, consequently, enhanced personalized recommendations.
3. Materials and Methods
Our recommendation system integrates collaborative filtering with sentiment analysis based on Bi-LSTM to enhance the precision of user recommendations. The objective is to increase the reliability of the recommendation process by incorporating user review sentiment analysis into traditional recommendation techniques.
As we can see in
Figure 1, the architecture is divided into two parts; one part generates sentiment models, and the other component uses those models to provide recommendations to a specific user. The text data were preprocessed before being utilized to build and train an SA model. Then, a CF technique is combined with a sentiment model to select products to recommend to the user. The Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) are utilized to evaluate the effectiveness of our RS.
3.1. Data Collection
The selection of the datasets was determined by several factors, including the availability and accessibility of the data. In our study, we utilized two distinct datasets to evaluate the performance of our recommendation system.
The first dataset is referred to as the Kindle book review dataset [
30]. This dataset encompasses a diverse range of book categories, allowing us to evaluate the effectiveness of our recommendation system and sentiment analysis model. It consists of detailed information about both users and books, including the ratings and reviews provided by each user for each book. In total, the Kindle book review dataset consists of approximately 12,000 reviews, providing a substantial amount of data for analysis and evaluation.
The second dataset, known as the Amazon digital music dataset, was obtained from a source [
30] and focuses specifically on customer reviews of digital music products available on the Amazon platform. It offers comprehensive information about each review, including the review text, the overall rating assigned by the user, and additional details about the corresponding music product and users involved. The Amazon digital music dataset contains a significantly larger collection of reviews, totaling approximately 64,000 entries. This expanded dataset size allows for a more extensive evaluation of the proposed sentiment analysis approach and the performance of the recommendation system in the context of digital music products. By using these diverse datasets, we aimed to assess the generalizability and robustness of our recommendation system across multiple domains and product categories. The inclusion of both the Kindle book review dataset and the Amazon digital music dataset provides a comprehensive evaluation framework for our proposed system, enabling us to draw meaningful conclusions regarding its effectiveness in delivering accurate and personalized recommendations to users.
3.2. Data Pre-Processing
The preparation of text training data for sentiment analysis, whether through deep learning or traditional machine learning, necessitates cleaning before the induction of the classification model. Because user communication is occasionally informal, the data are noisy and inconsistent, so the data require cleaning and transformation into a format that the classification model can understand.
Data cleaning
The textual data are cleaned by converting all text to lowercase and removing missing values, stop words, punctuation, web links, numbers, special characters, and anything else that is not relevant and therefore can reduce the effectiveness of the sentiment analysis. Some examples of words that are irrelevant and uninformative are shown in
Table 1.
Tokenization
Tokenization is a critical aspect in natural language processing, and it involves the segmentation of simple natural language sentence data into distinct words or individual symbolic tokens [
31]. Following the cleaning process, the text data underwent tokenization, resulting in the decomposition of the data into individual words.
Part Of Speech
The part-of-speech (POS) of a word refers to its categorization in terms of syntax or morphological behavior. In English grammar, some of the widely recognized POS categories include nouns, verbs, adjectives, adverbs, pronouns, prepositions, conjunctions, and interjections. The process of POS tagging involves assigning the appropriate POS label to each word in a text. This step is crucial in opinion mining as it enables the extraction of features and opinion words from reviews. POS tagging can either be performed manually or through the use of a POS tagging tool [
32].
Lemmatization
The individual words were then subjected to lemmatization, which transformed them into their base forms [
33]. Finally, these base forms were transformed into numerical representations.
3.3. Feature Extraction
Once the text data have been cleaned and lemmatized, they need to be transformed into a numerical format that can be utilized as input for deep learning models utilizing techniques such as word embeddings or Term Frequency-Inverse Document Frequency (TF-IDF).
Word embedding [
34] is a language modeling and feature learning technique that maps every word in a vocabulary to a real-valued vector representation. The goal is to have words with similar meanings have similar vector representations. Word embeddings can be learned using neural networks, and one widely used method is Word2vec. the latter includes two models: Skip-Gram (SG) and Continuous Bag-of-Words (CBOW). SG predicts context words given a center word, while CBOW predicts a center word given context words. Another method for learning word embeddings is GloVe. TF-IDF, on the other hand, is a statistical measure that reflects the weight of a word in a corpus or collection of documents, and it is widely utilized in the field of text mining.
DL techniques showed that word embedding vectorizations performed better than TF-IDF across all features and feature selection algorithms [
35,
36]. The GloVe method, as proposed in [
37], has been shown to be a superior approach to word representation learning, outperforming existing methods such as Word2vec on various benchmark tasks.
In our study, we employed GloVe embeddings as the word representation technique for sentiment analysis. By utilizing GloVe embeddings, we aimed to leverage its superior performance and the rich semantic information it captures to enhance the accuracy and effectiveness of our sentiment analysis model.
3.4. Sentiment Analysis Approach
Our methodology involves training and evaluating the BI-LSTM model on two datasets sourced from Amazon.
The BiLSTM model incorporates bidirectional LSTM (Long Short-Term Memory) units. LSTM is an advanced type of Recurrent Neural Network that addresses the issues of gradient explosion and vanishing gradient commonly encountered in traditional RNNs. LSTM is capable of handling sequences of varying lengths and effectively processing sequential data, which helps mitigate the problem of information loss that occurs in recurrent neurons [
38].
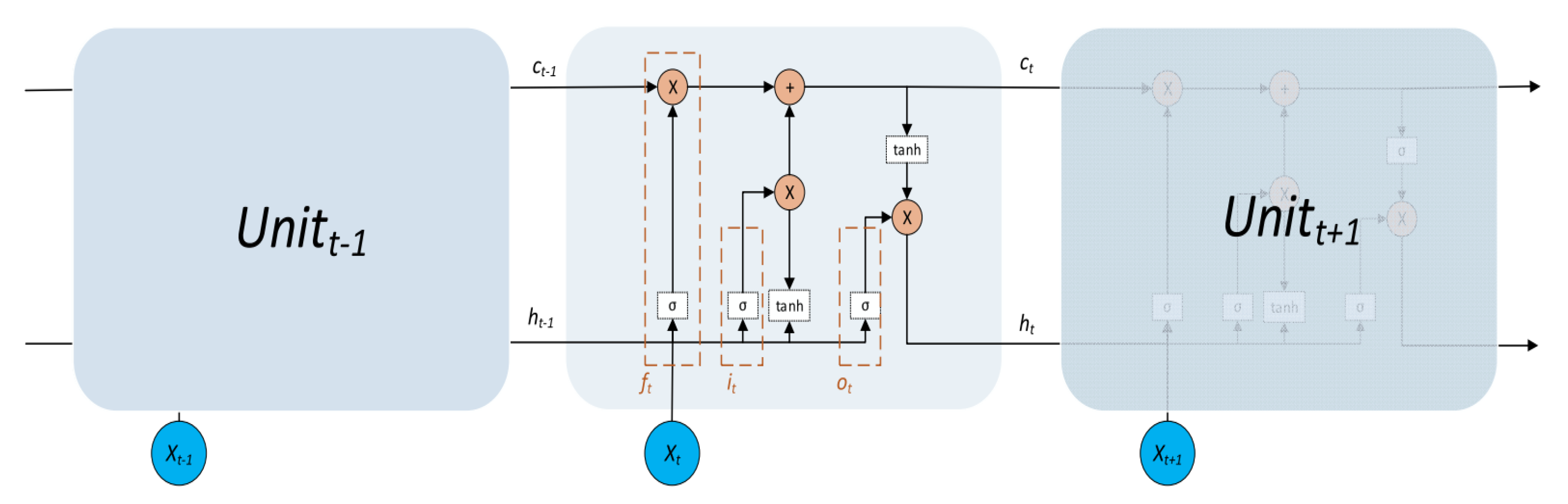
The Long Short-Term Memory (LSTM) architecture consists of several key components, including the input word () at the current time step, the cell state (), the temporary cell state (), the hidden layer state (), the forgetting gate (), the memory gate (), and the output gate (). The LSTM model operates through three main stages: the forgetting stage, the selective memory stage, and the output stage.
In the forgetting stage, the LSTM selectively forgets information stored in the cells, retaining important information. This process is controlled by the forgetting gate (
). Following the forgetting stage is the selective memory stage, where the LSTM selectively “remembers” information from the input cells. Important information is emphasized and retained, while unimportant information is discarded. The memory gate (
) plays a crucial role in controlling this stage. Finally, the output stage determines which information will be selected as the final output. The output gate (
) regulates this stage. The LSTM model operates as a sequential process, with each stage influencing and being influenced by the previous stage. The overall framework of the LSTM model, showcasing these stages and their respective components, is illustrated in
Figure 2.
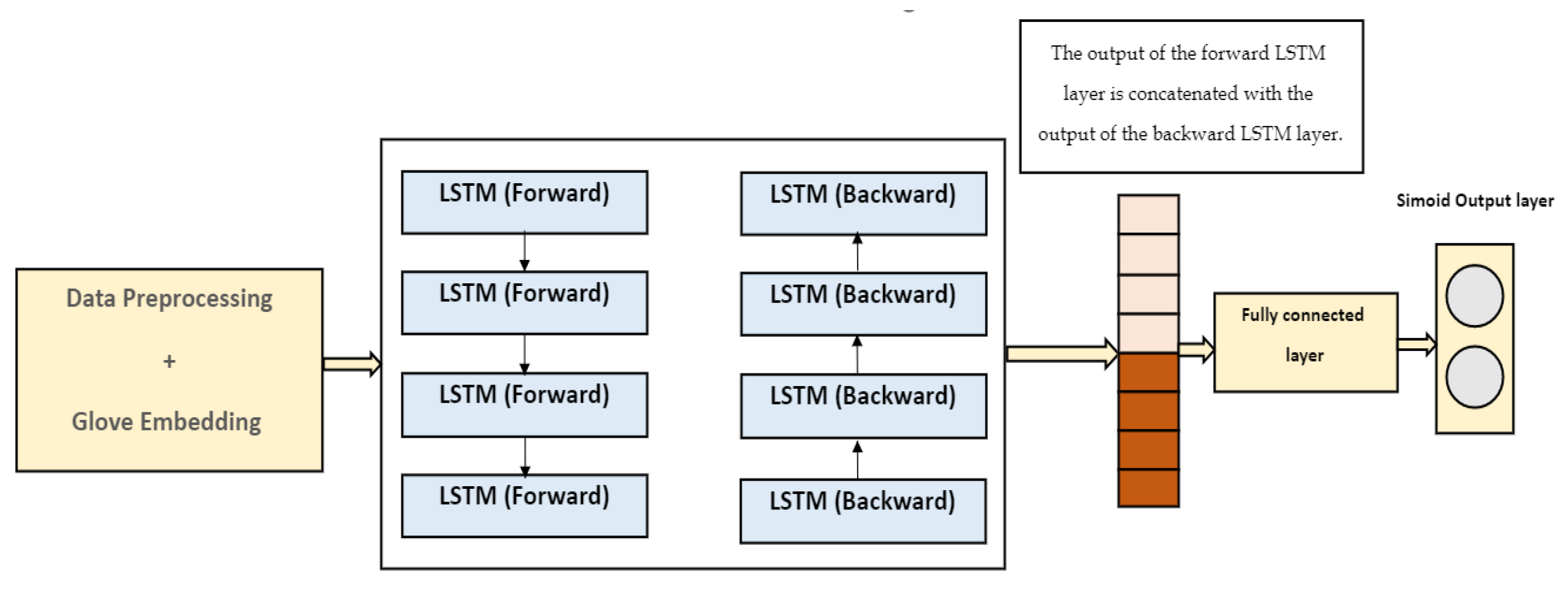
As shown in
Figure 3, the Bi-LSTM architecture consists of two interconnected components: the forward LSTM and the backward LSTM. The forward LSTM processes the input sequence in its original order, while the backward LSTM operates by reversing the input sequence and computes its output in a manner similar to the forward LSTM. By combining the outputs of both LSTMs, the Bi-LSTM model incorporates information from both preceding and subsequent elements in the sequence. Unlike the traditional LSTM, which only considers past context, the Bi-LSTM takes into account both preceding and following information due to the bidirectional processing. This allows the model to capture dependencies and patterns from both directions, enhancing its understanding of the overall sequence. By stacking the outputs of the forward and backward LSTMs, the final result of the BiLSTM model is obtained.
3.4.1. Process for Sentiment Analysis
Sentiment analysis tasks commonly use classification models such as machine learning (ML) and deep learning (DL) models to categorize the sentiment of text data as positive or negative. In our study, we chose to use a Bi-directional Long Short-Term Memory model because of its proven success in sentiment analysis tasks [
39].
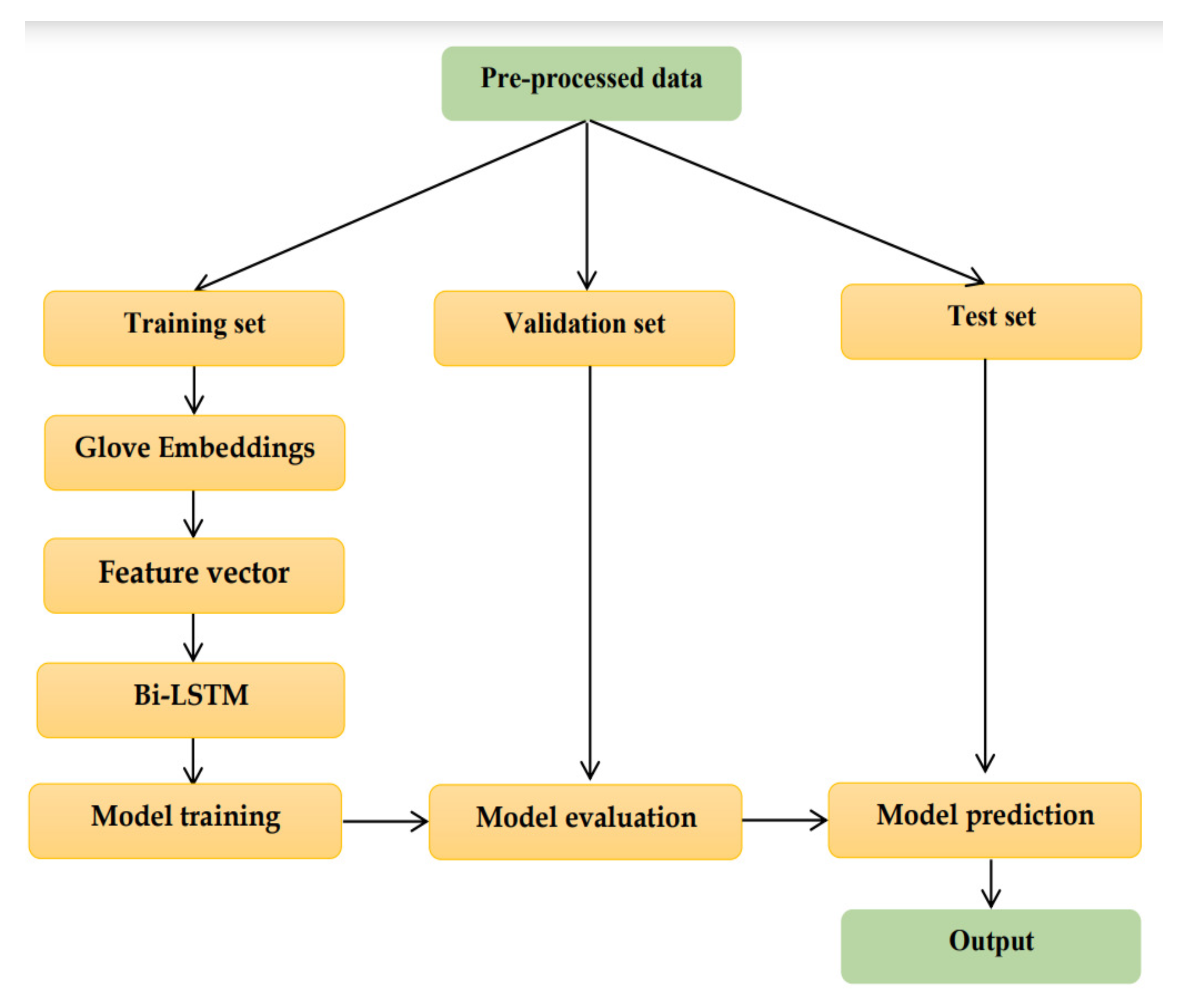
The first step in the model development process was to partition the dataset into three portions: a training set, a validation set, and a test set.
The process employed for conducting sentiment analysis through employment of a Bi-LSTM model is delineated in
Figure 4. The following steps were pursued in order to accomplish this task:
- -
Data Preprocessing: The first step is to clean and preprocess the text data (
Section 3.2).
- -
Glove Embedding: In this step, the tokenized words are converted into dense vectors of fixed size.
- -
Bi-LSTM Model Architecture: The next step is to build a Bi-LSTM model architecture. The input to the model is the sequence of word vectors generated in the previous step. The model consists of two LSTM layers, one in forward and one in backward direction. The output of the LSTM layers is concatenated and passed through a fully connected layer with a sigmoid activation function to obtain the final sentiment label.
- -
Training the Model: The model is trained on the labeled dataset. The loss function used is cross-entropy, and the optimizer used is Adam. In order to apply the dropout regularization technique, a dropout layer is included in the model with a dropout rate of 0.5. This means that in each iteration of the training process, half of the neurons in the previous layer will be randomly deactivated.
- -
Model Evaluation: Once the model is trained, it is evaluated on a test dataset to measure its performance.
- -
Prediction: The final step is to use the trained model to predict the sentiment label for new text data. The input text is preprocessed and converted into word vectors, which are then passed through the Bi-LSTM model to generate the predicted sentiment label.
3.4.2. Evaluation Metrics
Our model was evaluated using various classification metrics, with a focus on accuracy, Area under the ROC Curve (AUC), and F1-score metrics, which are presented in
Table 2.
3.5. Recommendation Algorithms
The recommender system has been implemented using CF methods. The dataset was partitioned into two portions, with the larger part, 80%, utilized for training purposes, while the remaining 20% was utilized as a test set for evaluation purposes.
To prepare the training data for use in a CF model, the data need to be transformed into a specific format. This involves converting the data into a mn × n array where m represents the number of products and n the number of users.
Having transformed the training dataset into a matrix of product features, we constructed our recommender system by utilizing a collaborative filtering method.
To predict products that have not been rated by a particular user, we need a metric to identify similarities between users (user-based) or between items (item-based). One commonly used metric is cosine similarity (Equation (4)) [
40].
where
and
are components of vectors
and
, respectively.
Next, we perform a cosine similarity-based prediction of ratings. The ratings of either the most similar items (in item-based approach) or users (in user-based approach) were utilized to anticipate the rating of a current user for a particular item that has not yet been rated.
where:
- -
is the predicted rating for item j by user i.
- -
denotes the rating provided by user i for item j.
- -
is the average rating by user i.
- -
denotes the similarity between users i and u.
- -
is the predicted rating for user u and item j.
- -
denotes the actual rating that user u gave to item j.
- -
denotes the similarity between items j and i.
Equation (5) is used for user-based collaborative filtering, and Equation (6) is used for item-based collaborative filtering.
Combining sentiment analysis model with traditional collaborative filtering methods for the final prediction:
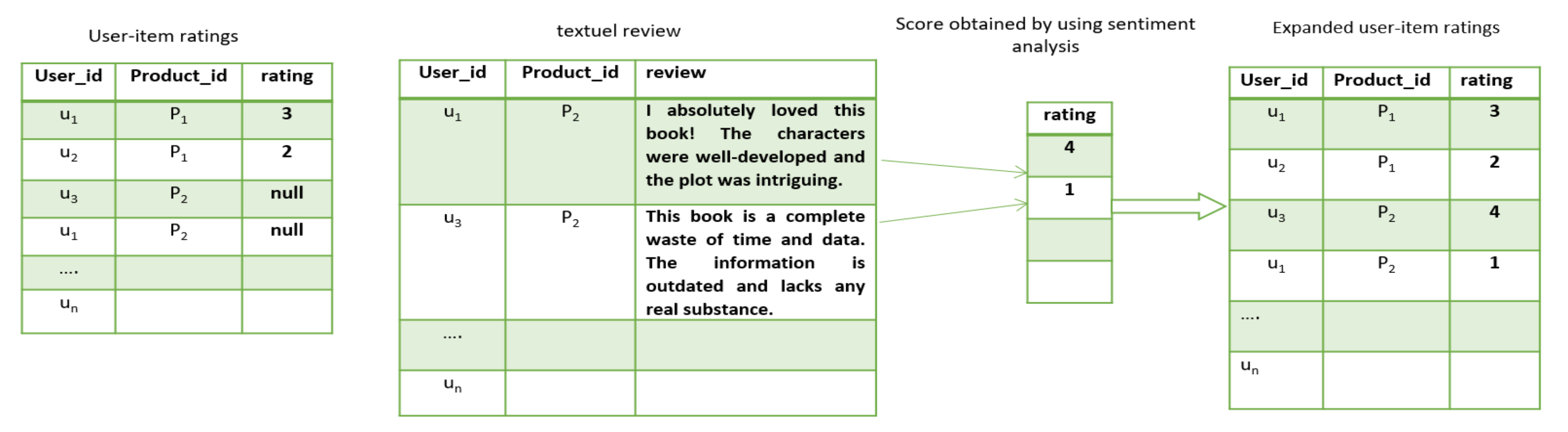
We incorporated sentiment analysis into our recommendation system to classify the sentiment of reviews as negative or positive, and then we used this sentiment information as an additional feature in our system. The goal of incorporating sentiment analysis into the recommendation system is to enhance the predictive accuracy by utilizing the implicit feedback information embedded in the sentiment of the reviews.
Figure 5 displays an illustration of how star ratings can be combined with textual reviews in recommendation systems. This integration can result in an improvement in the overall performance of the recommendation system compared to utilizing star ratings alone.
The integrated result is presented as follows:
where:
- -
R: Predicted rating for a user on a product by CF techniques without using SA.
- -
S: Predicted sentiment score using the Bi-LSTM sentiment model.
- -
: The weight given for each term in the equation.
Evaluation:
The assessment of the efficiency of a recommendation system is conducted through the use of two evaluation metrics, MAE and RMSE. The values of these metrics belong to the interval
and are negatively oriented, i.e., the results are good when the values are small.
where in all these equations,
N is the number of ratings in the test partition, Predicted
is the estimated vote for user
i and item
j, and Actual
represents the real vote.
4. Experimental Results
To test and support our system and proposal, we carried out experiments using two different approaches, one without sentiment analysis and one with it. In the first scenario, recommendations are generated through recommender system techniques that do not take into account sentiment. In the latter, the sentiment analysis-based Bi-LSTM outcomes of the reviews are integrated into the recommendation process.
The initial stage in developing our sentiment model and recommender system involved data preprocessing. Once the data were acquired, we eliminated attributes that did not contribute relevant information for our analysis. Furthermore, we conducted preprocessing steps on the textual data, as outlined in
Section 3.2, prior to constructing our models.
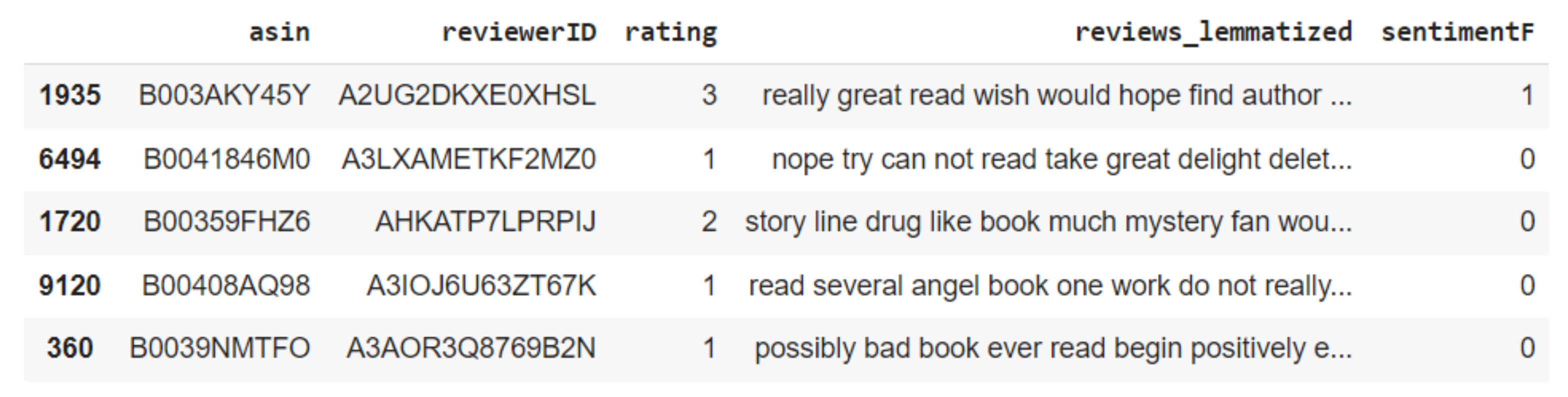
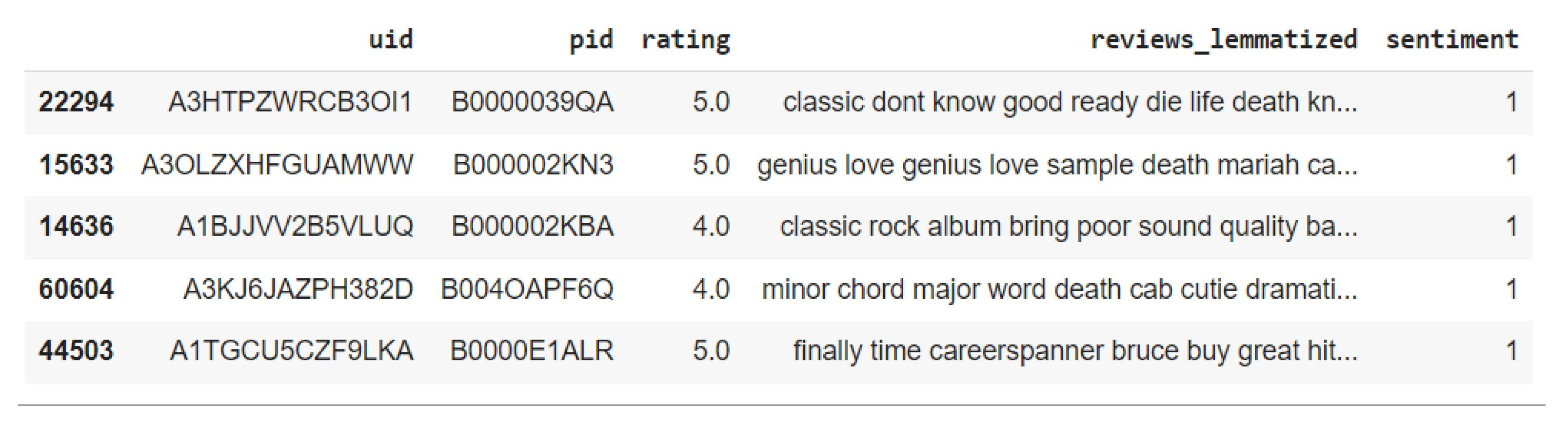
The preprocessed data for the two datasets utilized in this study is illustrated in
Figure 6 and
Figure 7.
where:
- -
asin: ID of the book.
- -
rating: rating of the book.
- -
reviewerID: ID of the reviewer.
- -
review_lemmatized: text of the review preprocessed.
- -
sentimentF: means the polarity of the review; Positive (1) or negative (0).
where:
- -
uid: ID of the user.
- -
pid: ID of the product.
- -
rating: the rating of the product.
- -
review_lemmatized: text of the review preprocessed.
- -
sentiment: means the polarity of the review; Positive (1) or negative (0).
4.1. Sentiment Model
The Glove+Bi-LSTM deep learning model was constructed using the TensorFlow deep learning framework. The dataset employed in the study was divided into three distinct portions: a training set (60% of the dataset), a validation set (20% of the dataset), and a test set (20% of the dataset). The training set served as the basis for training the model. The validation set was utilized for hyperparameter tuning and model selection, with the aim of identifying the best-performing model based on its performance on the validation set. The test set was reserved for the final evaluation of the model’s performance on previously unseen and independent data.
In order to address the issue of overfitting, the deep neural network model employed the dropout technique, allowing certain features to be disregarded during the training process. By systematically applying dropout with varying probabilities ranging from 0.1 to 0.9, the impact of the dropout parameter on the model’s performance was examined.
The accuracy of the model was assessed and recorded for each dropout probability, as depicted in
Table 3. The model’s accuracy reached its highest value when a dropout rate of 0.5 was employed. The comparison of the model’s performance was conducted using three different batch size settings.
Table 4 clearly illustrates that the best performance was achieved when the batch size was set to 32.
Table 5 shows the detailed settings of each parameter in the neural network model.
Various performance metrics such as accuracy, f1-score, and AUC were employed to assess the effectiveness of the model.
4.1.1. First Scenario
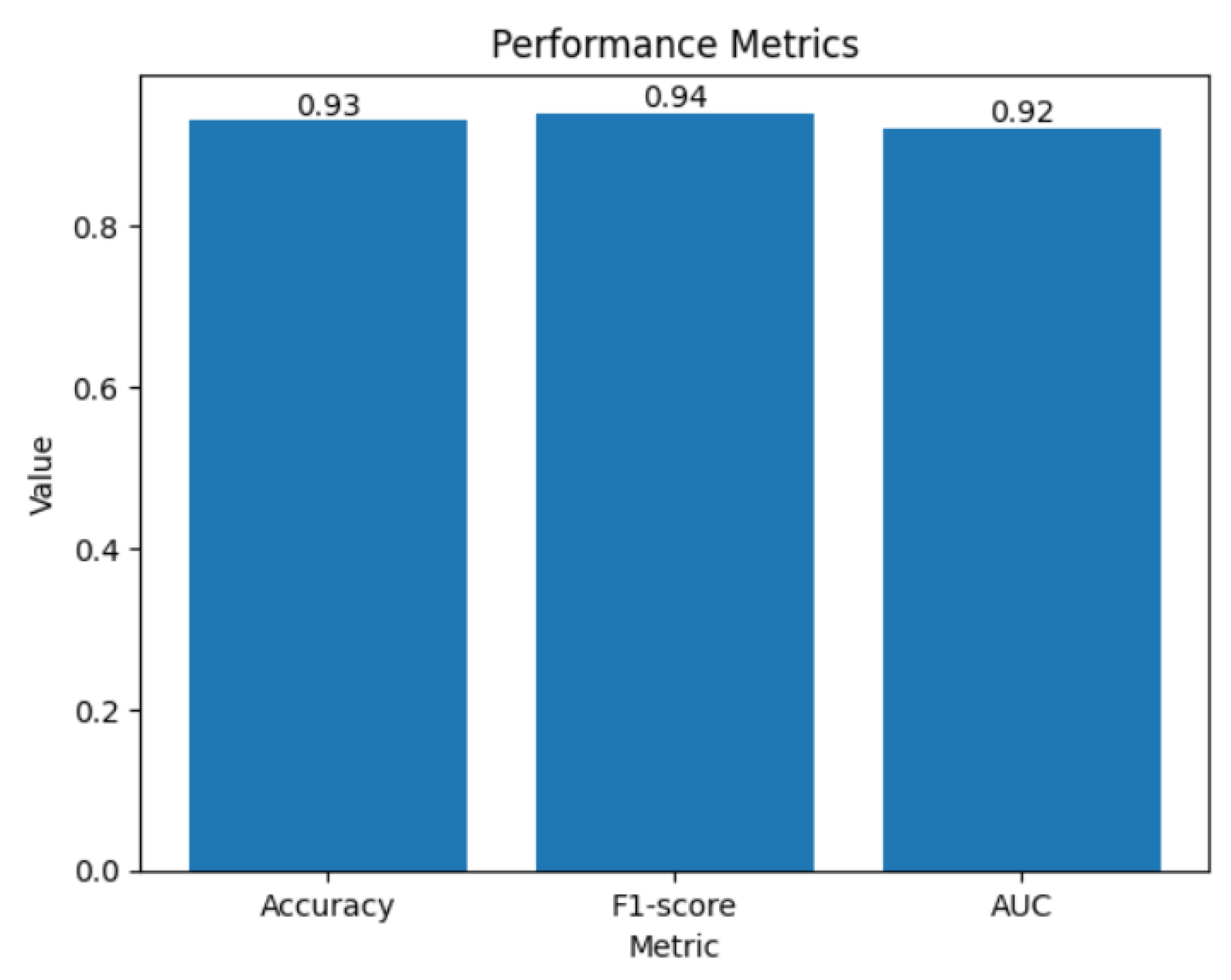
In our initial experiment, we utilized the Kindle book review dataset to evaluate the performance of the proposed Bi-LSTM model.
Figure 8 presents the performance metrics obtained from the first scenario. The accuracy metric indicates the overall correctness of the sentiment classification model, with a value of 0.93, indicating a high level of accuracy in predicting sentiment. The f1-score, with a value of 0.94, provides a balanced measure of the model’s precision and recall, capturing the trade-off between correctly identifying positive and negative sentiments. The AUC metric, with a value of 0.92, reflects the model’s ability to distinguish between positive and negative sentiments, with a higher value indicating a better discriminatory power.
4.1.2. Second Scenario
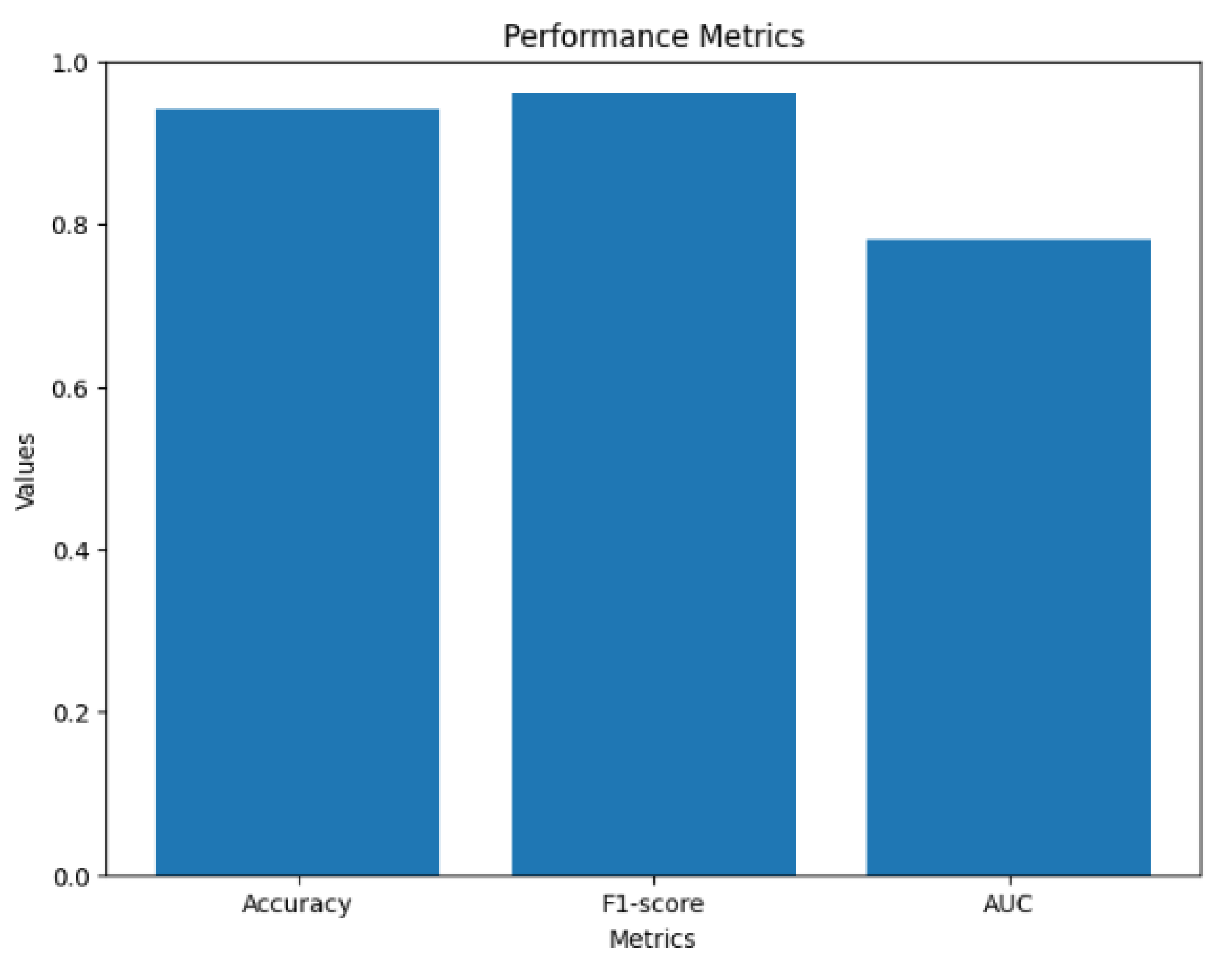
To assess the robustness of our sentiment classification model, we performed an experiment similar to the one described in the initial scenario. However, this experiment was conducted on a larger and distinct dataset.
Figure 9 presents the performance metrics obtained from the second scenario. The accuracy metric achieved a high value of 0.94, indicating a strong level of accuracy in sentiment prediction. Additionally, the f1-score attained a value of 0.96, reflecting a favorable balance between precision and recall. The AUC metric achieved a value of 0.78, indicating a reasonable discrimination capability of the sentiment analysis model.
The collective performance metrics clearly indicate the effectiveness of the sentiment classification model in accurately predicting sentiment in both scenarios.
This model will be utilized for sentiment prediction prior to integrating it with recommendation techniques.
4.2. Recommendation System
For the recommendation model, we tested item-based and user-based CF techniques using cosine similarity. To verify the effectiveness of our proposal, we contrasted the performance of conventional memory-based CF techniques with the same techniques enhanced by our proposal.
Table 6,
Table 7 and
Table 8 and
Figure 10,
Figure 11 and
Figure 12 present the findings of the MAE and RMSE measures for rating prediction on the Amazon Kindle books and Amazon digital music datasets. They were calculated based on the memory-based (item-based and user-based) methods before and after using sentiment analysis based on Bi-LSTM sentiment model. The parameter
is employed to control the significance of the recommendation results with and without sentiment in Equation (8).
Experience 1: User-Based results
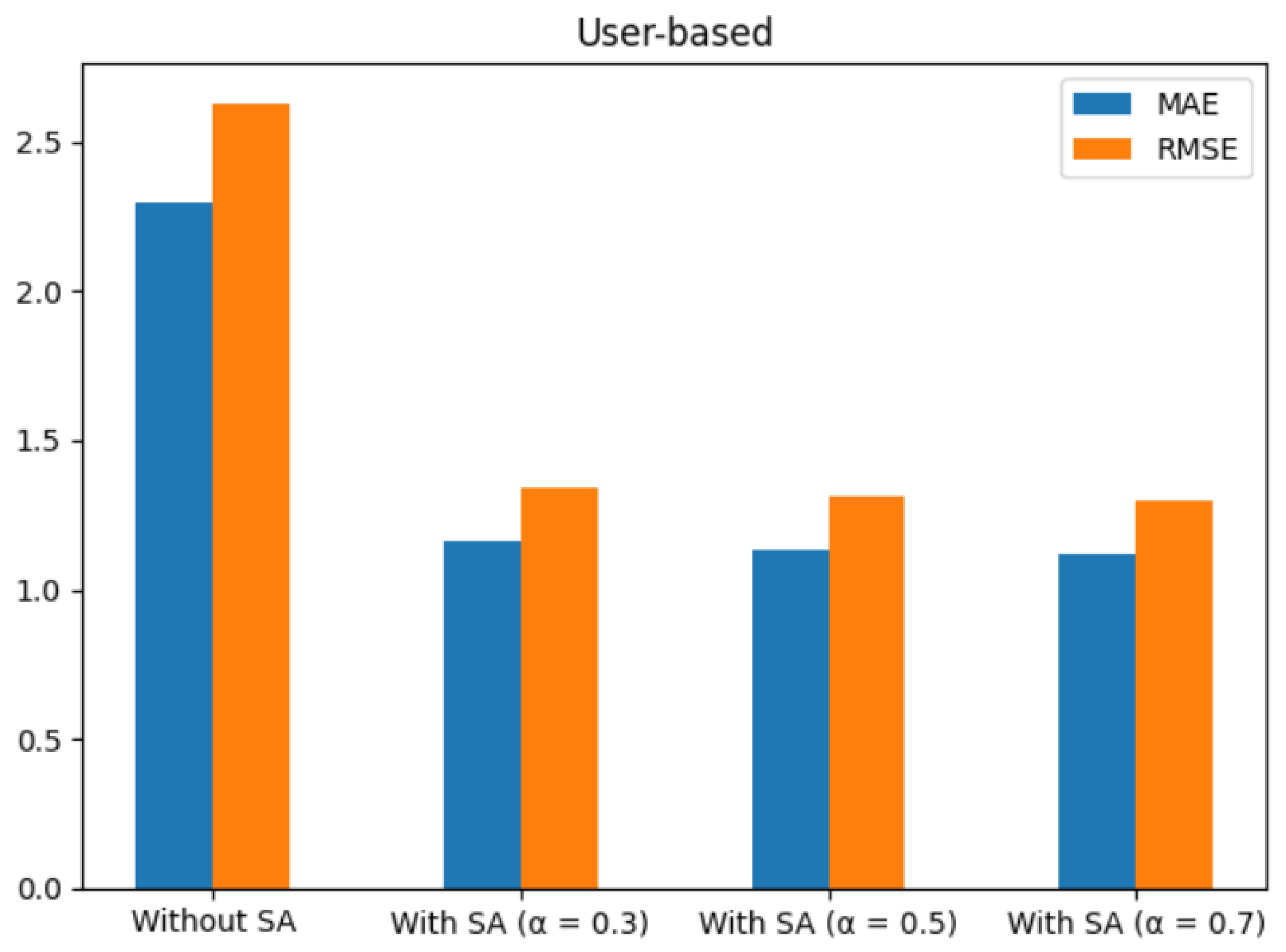
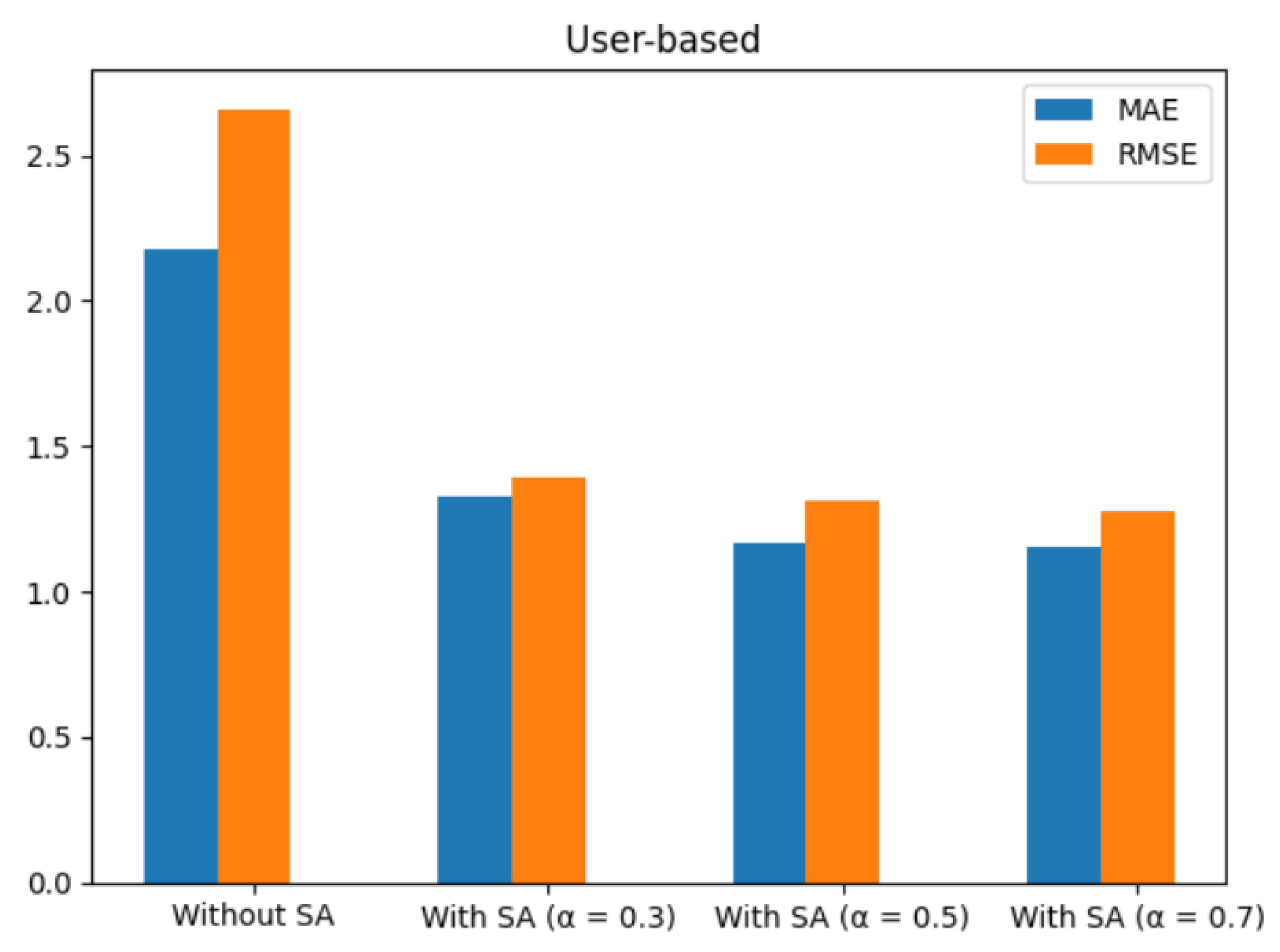
The results from the user-based collaborative filtering technique, presented in
Table 6 and
Table 7, as well as
Figure 10 and
Figure 11, provide insights into the performance of the recommendation system using the Kindle book reviews dataset and the Amazon digital music dataset.
For the Kindle book reviews dataset, when sentiment analysis was incorporated with different values, notable improvements in evaluation metrics were observed compared to the approach without SA. The MAE decreased from 2.30 (without SA) to 1.12 (with SA and = 0.7), while the RMSE decreased from 2.63 to 1.30. This indicates that incorporating sentiment analysis, particularly with = 0.7, resulted in more accurate predictions and reduced errors.
Similar trends were observed for the Amazon digital music dataset. The inclusion of SA with different values led to a reduction in MAE and RMSE. The lowest values were achieved with SA and = 0.7, with MAE of 1.15 and RMSE of 1.28, compared to MAE of 2.18 and RMSE of 2.66 without SA.
Overall, these results demonstrate the effectiveness of incorporating sentiment analysis into the user-based CF technique.
Experience 2: Item-Based results
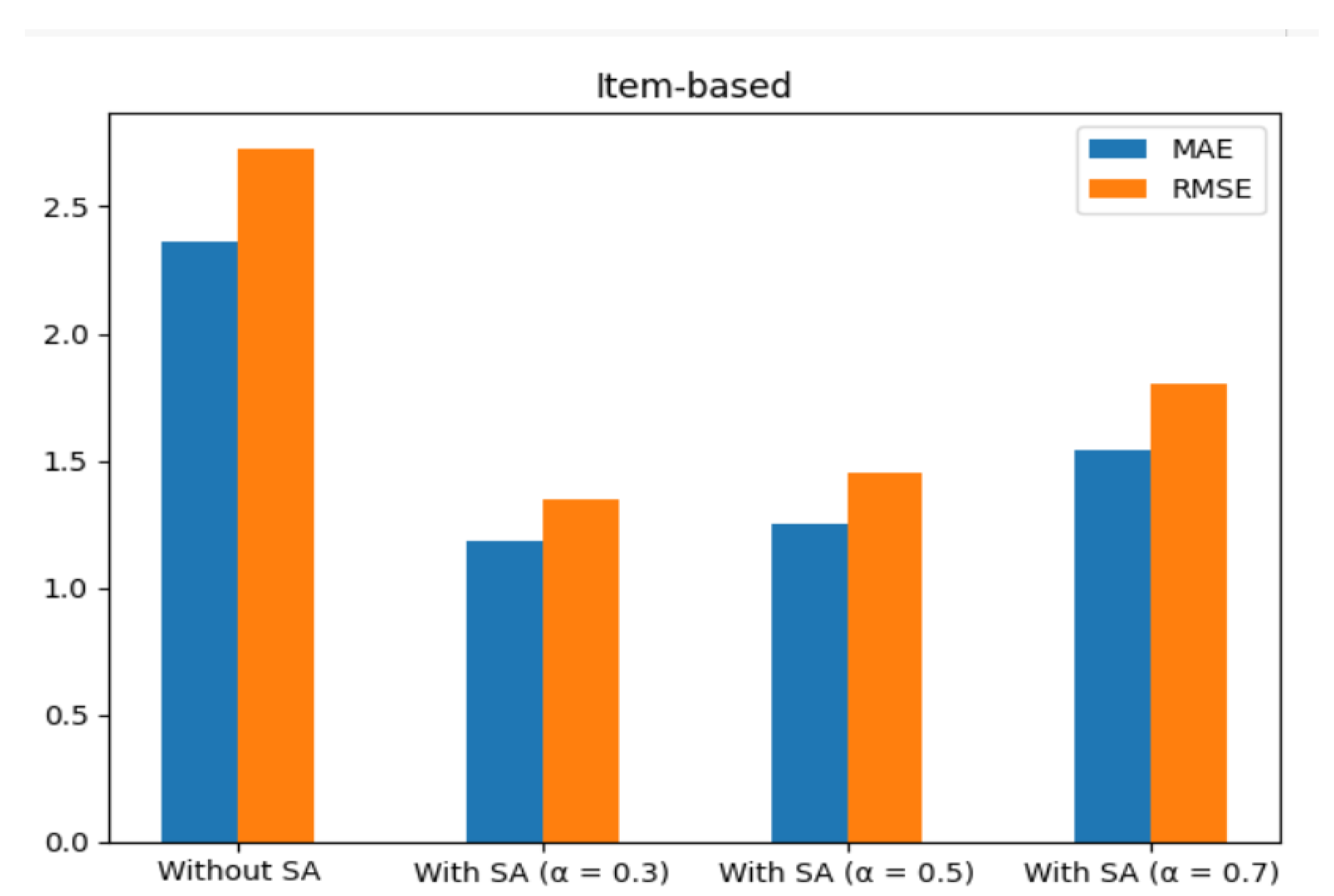
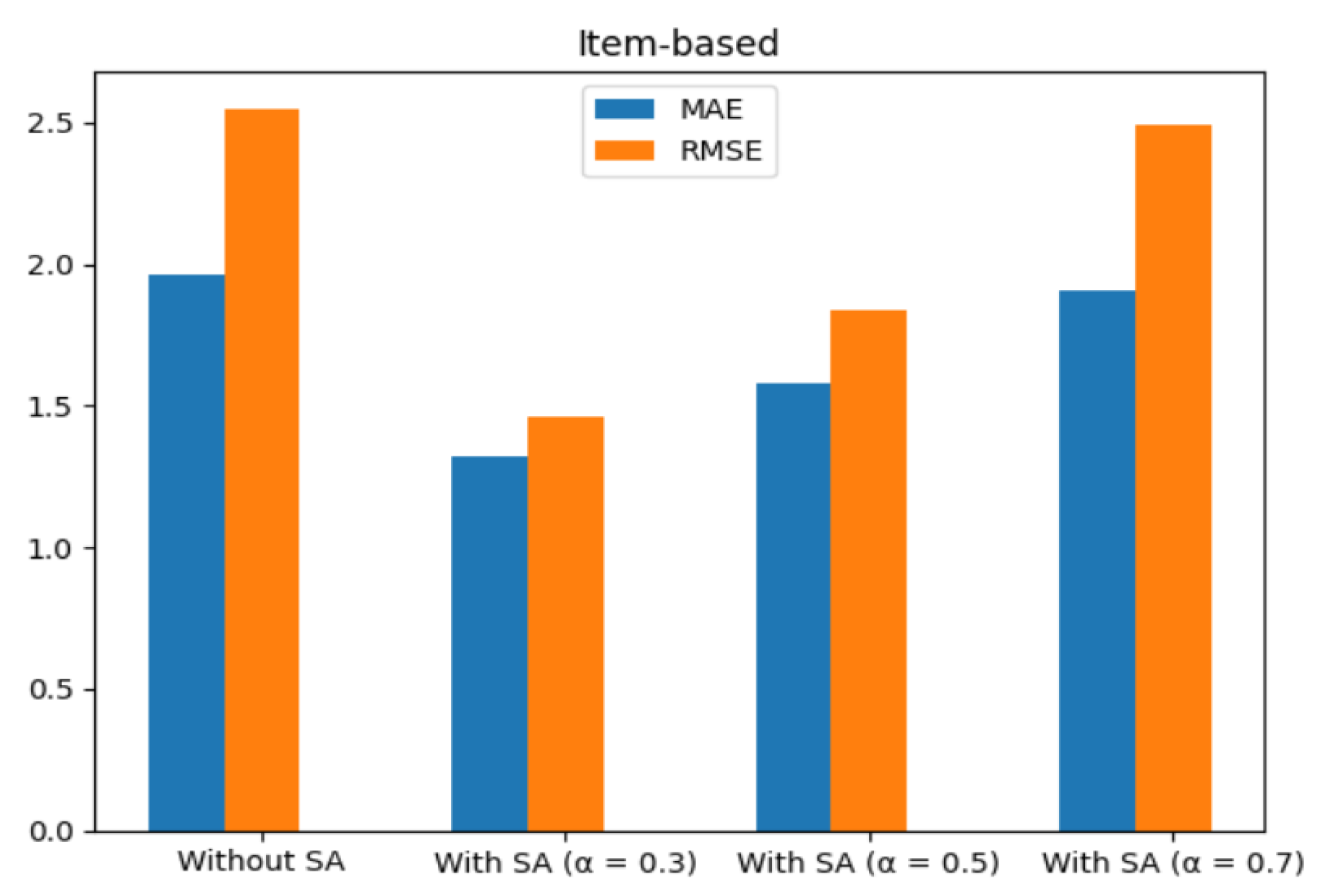
The results from the item-based collaborative filtering technique, as presented in
Table 8 and
Table 9 and
Figure 12 and
Figure 13, provide insights into the performance of the recommendation system using the Kindle book review dataset and the Amazon digital music dataset.
For the Kindle book review dataset, incorporating sentiment analysis with different values resulted in varying effects on the evaluation metrics. While using SA with = 0.3 led to slight improvements in MAE (1.18) and RMSE (1.35) compared to the approach without SA (MAE: 2.36, RMSE: 2.73), value = 0.5 and value = 0.7 led to increased errors.
Similar trends were observed for the Amazon digital music dataset. The inclusion of SA with = 0.3 resulted in improved MAE (1.32) and RMSE (1.46) compared to the approach without SA (MAE: 1.96, RMSE: 2.55). However, = 0.5 and = 0.7 led to larger errors.
4.3. Peformance Comparisons with Baseline Model
In order to assess the effectiveness and validity of the recommender system presented in this paper, we conducted comparative evaluations with existing baseline models. Specifically, we compared the performance of our proposed approach, which combines Glove+Bi-LSTM-based sentiment analysis with CF, with the baseline models already utilized in previous studies. The evaluation was performed using the Kindle book review dataset.
The baseline model employed in the comparative analysis was SVM-based sentiment analysis with CF. The utilization of SVM in the context of sentiment analysis and its integration with CF techniques have been previously explored [
24].
Table 10 illustrates the comparison between the two approaches, highlighting the superior performance and accuracy of our proposed approach compared to other existing methods.
5. Discussion
In the first scenario, employing the Amazon Kindle book dataset, our Bi-LSTM model demonstrated favorable performance metrics. Specifically, it achieved an Area Under the Curve value of 92%, indicating a high level of predictive accuracy. Additionally, the model achieved an accuracy rate of 93%, implying that it correctly classified 93% of the instances in the dataset. The F1-score, which measures the model’s overall precision and recall, reached an impressive 94%. Moving on to the second scenario, where we utilized the Amazon digital music dataset, our Bi-LSTM model yielded slightly different performance results. Although the AUC value decreased to 78%, indicating a comparatively lower predictive accuracy compared to the first scenario, the model still demonstrated a satisfactory level of performance. The accuracy rate remained high at 94%, meaning that 94% of the instances were correctly classified by the model. Moreover, the F1-score reached an outstanding 96%, highlighting the model’s exceptional precision and recall. Overall, these findings underscore the effectiveness of our Bi-LSTM model in both scenarios, albeit with some variations in performance metrics.
The incorporation of model sentiment analysis into collaborative filtering has demonstrated notable enhancements in evaluation metrics when compared to conventional collaborative filtering methods devoid of sentiment analysis across various algorithms and all values examined. In the initial experiment, which employed a user-based approach, optimal performance was achieved by setting to 0.7 for both the Amazon Kindle book dataset and the Amazon digital music dataset. Conversely, in the subsequent experiment utilizing an item-based approach, the most favorable outcomes were observed when was assigned a value of 0.3 for both the Amazon Kindle book dataset and the Amazon digital music dataset.
6. Conclusions & Future Work
In this research paper, we propose a novel recommender system that combines sentiment analysis using the Bi-LSTM deep learning model with collaborative filtering techniques in the e-commerce domain. The objective of this system is to enhance the accuracy and personalization of recommendation systems for online shopping. The proposed architecture offers flexibility in incorporating various techniques, including preprocessing strategies, sentiment analysis with Glove+Bi-LSTM, and different recommender system methods. By leveraging sentiment analysis on user opinions and reviews, the architecture enables the development of a recommender system specifically tailored to e-commerce platforms.
The experiments were conducted using reviews from the Amazon Kindle book and Amazon digital music datasets to evaluate the effectiveness and practicality of the proposed approaches. The results demonstrate the value and applicability of the proposed methods in generating personalized recommendations on e-commerce websites. Specifically, the combination of deep learning-based sentiment analysis and collaborative filtering techniques significantly improves the performance of the recommender system by utilizing the additional information extracted from user reviews and comments.
By incorporating sentiment analysis, the study demonstrates improved performance metrics compared to traditional collaborative filtering methods without sentiment analysis across all tested algorithms. The optimal results were achieved with a value of for the user-based CF technique and for the item-based CF technique for both datasets.
In future work, we plan to further enhance this study by extending the system to handle various types of ratings and comments, thus increasing its adaptability and application. To achieve this goal, we will enhance the sentiment analysis component by employing more advanced algorithms and incorporating additional information for a comprehensive evaluation across different domains, types of ratings and comments, and user characteristics.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}