
Enhancing IoT Device Security through Network Attack Data Analysis Using Machine Learning Algorithms




Abstract
1. Introduction
- A novel IoT device dataset was introduced, based on a smart health service testbed, that included both attack and normal network traffic. The dataset was preprocessed and feature-engineered using advanced machine-learning techniques, enabling the models to achieve higher accuracy;
- The generated dataset was cross-evaluated with an existing IoT intrusion detection system dataset using various machine learning algorithms. The results demonstrated the competency of the generated dataset in improving the performance of intrusion detection systems and revealed unique features that make it a valuable addition to the field of IoT intrusion detection;
- Nine popular machine learning model classifiers were applied to the dataset to classify attack and normal network traffic. The models utilized advanced approaches to detect anomalies and patterns in the network traffic, resulting in better classification accuracy;
- The study demonstrated the competency of advanced machine learning techniques for detecting and classifying botnet attacks and showed that machine learning models could effectively differentiate between normal and attack traffic. These techniques and insights can be instrumental in the improvement of the security of IoT devices, networks, and systems, thereby serving techniques in preventing botnet attacks.
2. State of the Art
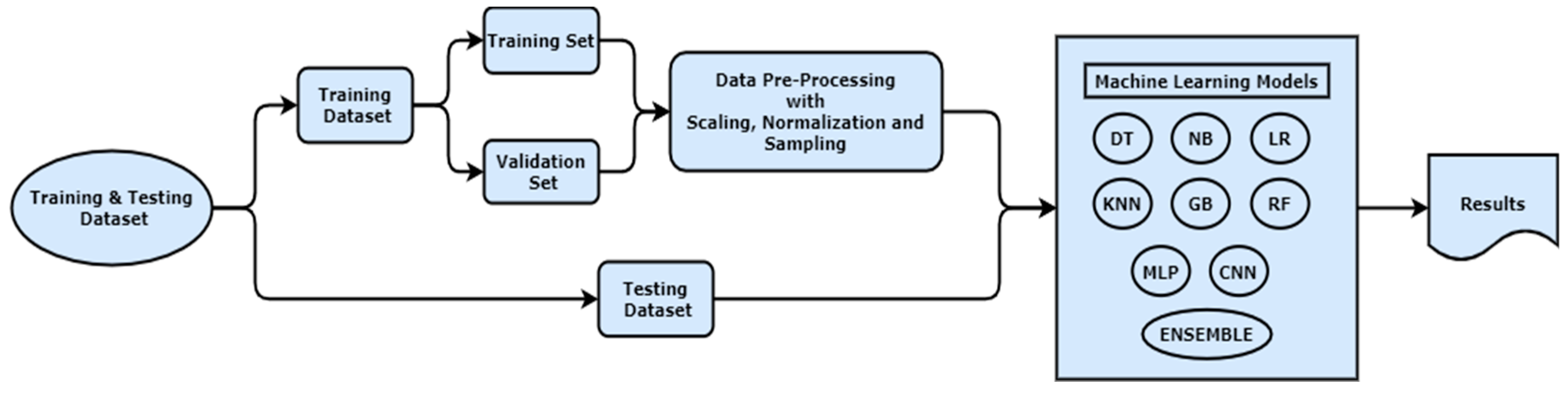
3. Materials and Methods
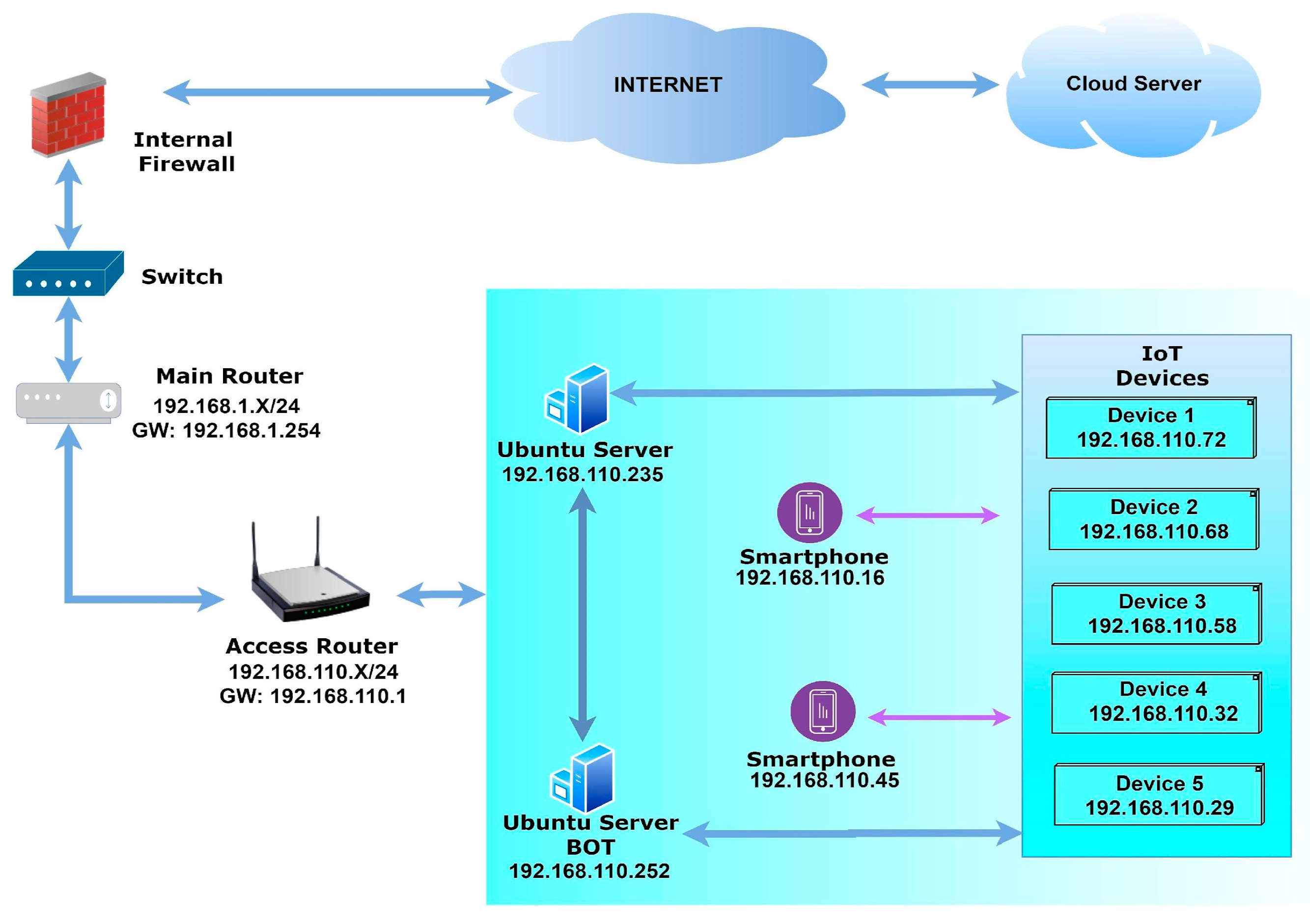
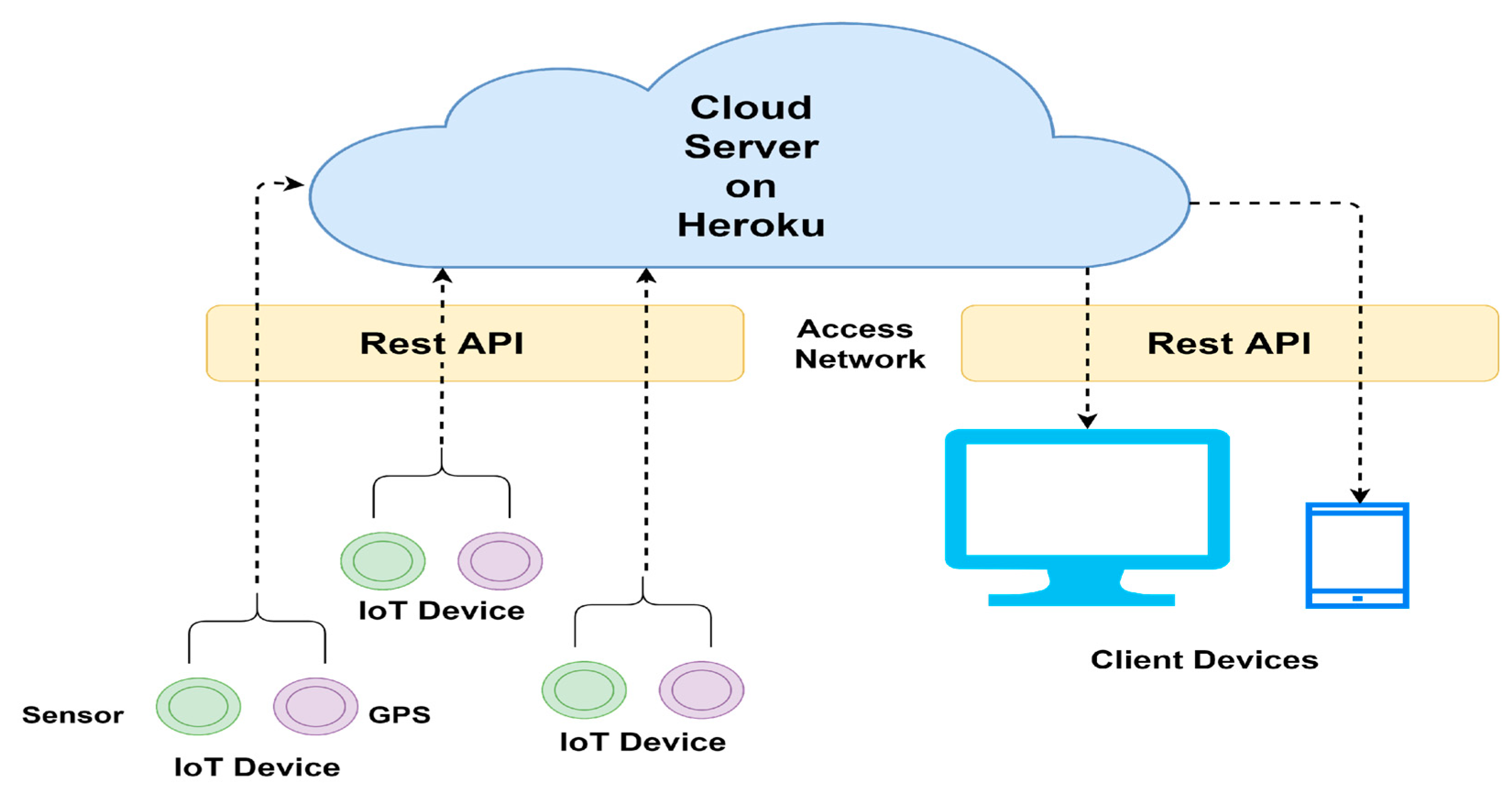
3.1. Details of the Testbed
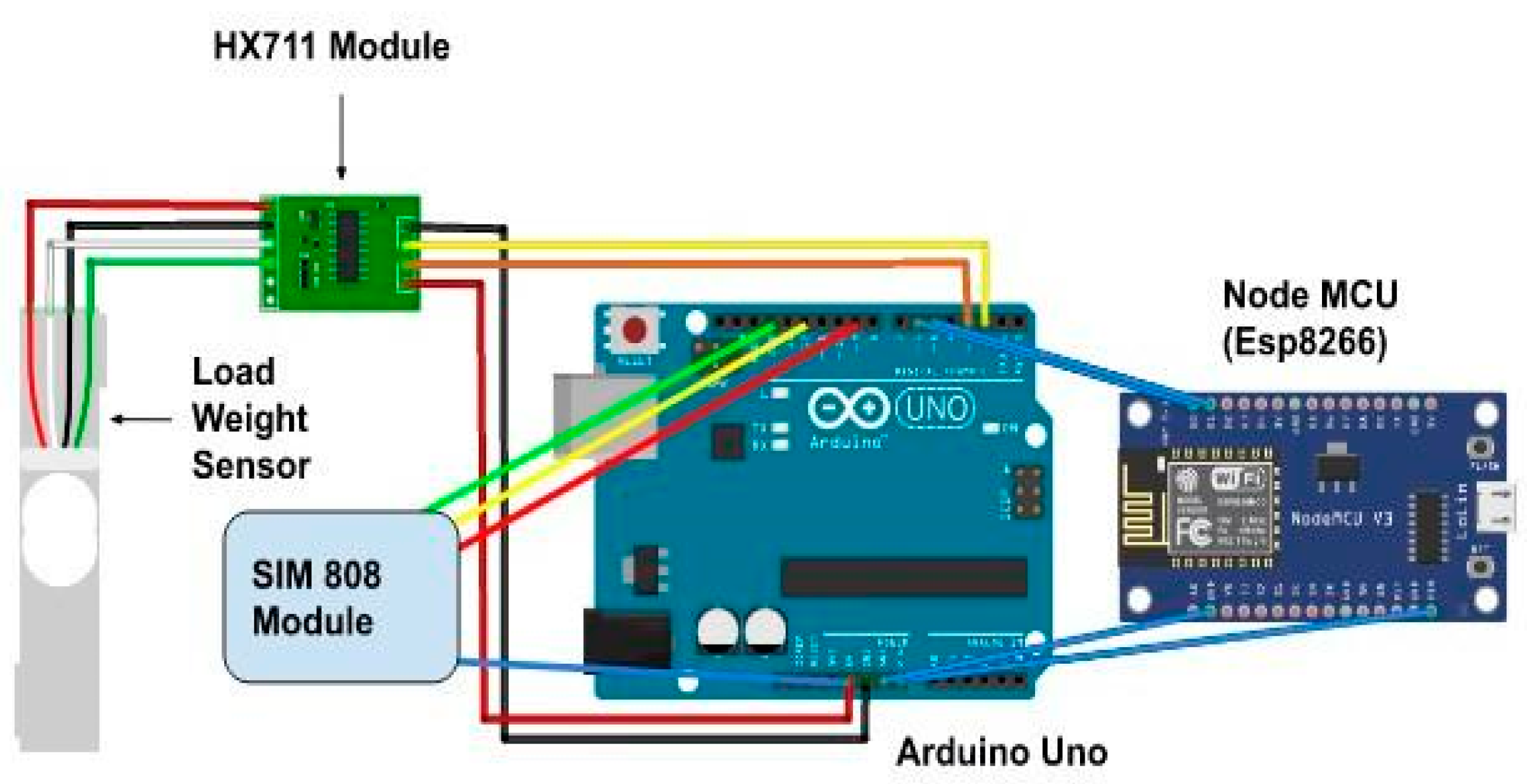
- Arduino Uno’s communication with all four components and supporting accessories;
- Sim808 Module for GPS location-based information retrieval and GSM (Global System for Mobile Communication) utilization for cellular network use;
- Esp8266, which helps the WiFi network communication to initialize the communication between the IoT device with the cloud network;
- The Load Cell Sensor and HX711 Module help generate the sensor data based on an object’s weight over the sensor. The HX711 module converts the analog signal from the sensor and amplifies the voltage output from the load sensor so that Arduino Uno can read the output. Algorithm 1 outlines the procedure utilized for the communication of cloud network with developed IoT devices.
| Algorithm 1 Transmitting data from SIM808 to cloud network |
| 1: Connect the SIM808 module to the Arduino Uno using the appropriate pins and connectors |
| 2: Configure the SIM808 module with the appropriate settings and credentials for the cloud network |
| 3: Use the Arduino Uno’s serial communication functions to establish a connection with the SIM808 module |
| 4: Use the SIM808 module’s API to obtain the data that you want to transmit |
| 5: Use the Arduino Uno’s networking functions (such as WiFiClient or EthernetClient) to establish a connection with the cloud network |
| 6: Use the Arduino Uno’s HTTP or MQTT libraries to send the data to the cloud network |
| 7: Disconnect from the cloud network and the SIM808 module when the transmission is complete |
3.2. Data Generation
3.2.1. Flow-Based Approach
3.2.2. Packet Conversion
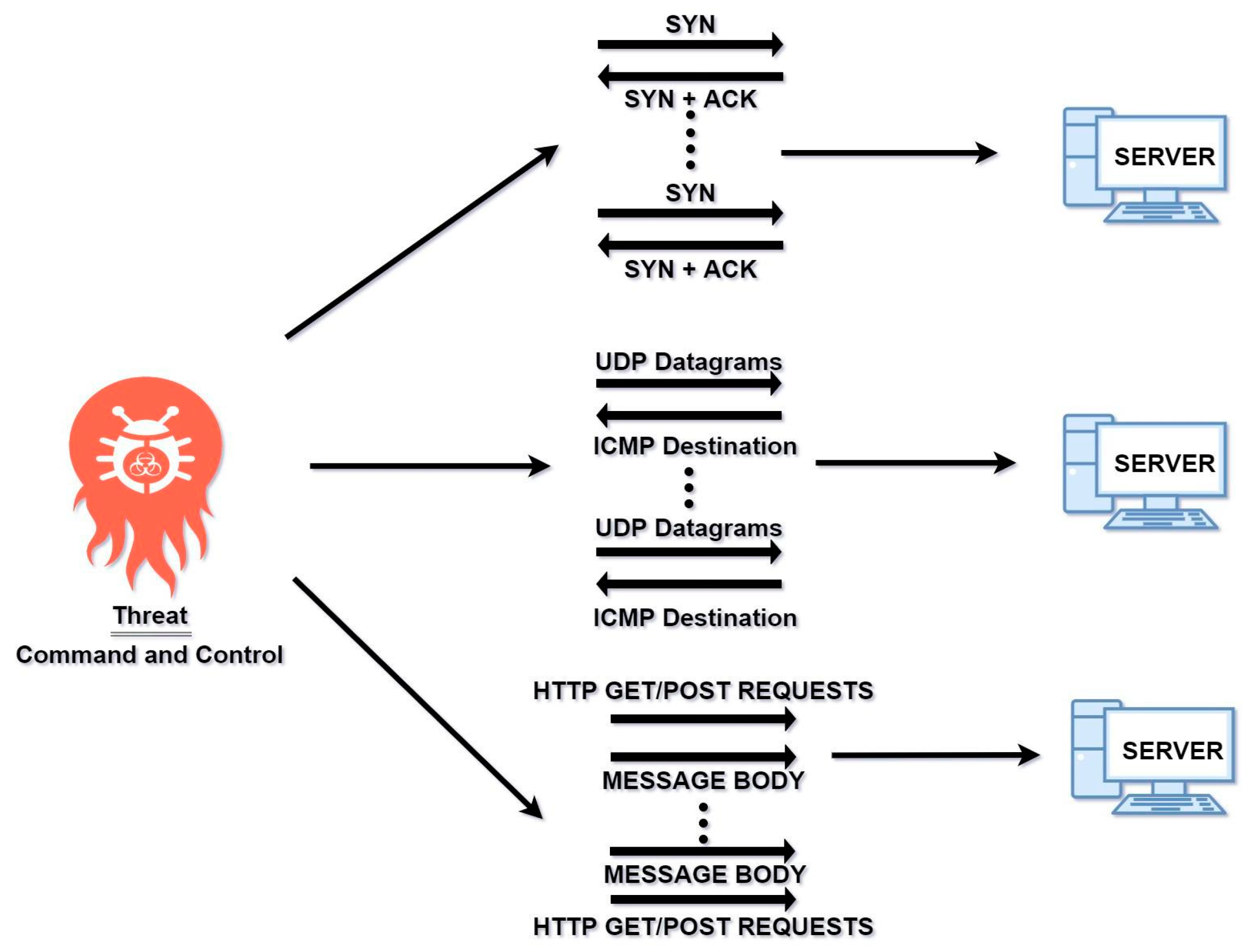
3.3. Initiation of Botnet Attack
3.3.1. Denial of Service
3.3.2. Network Discovery/Reconnaissance Attack
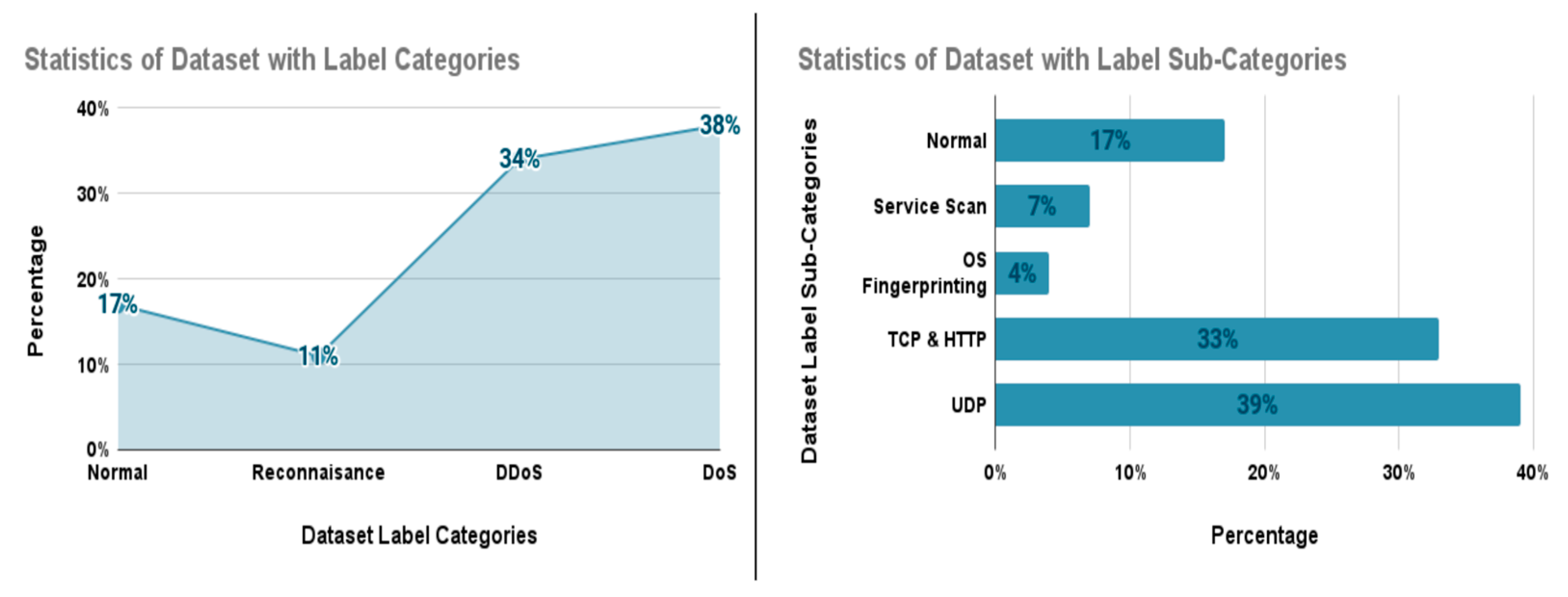
3.4. Labeling of Dataset
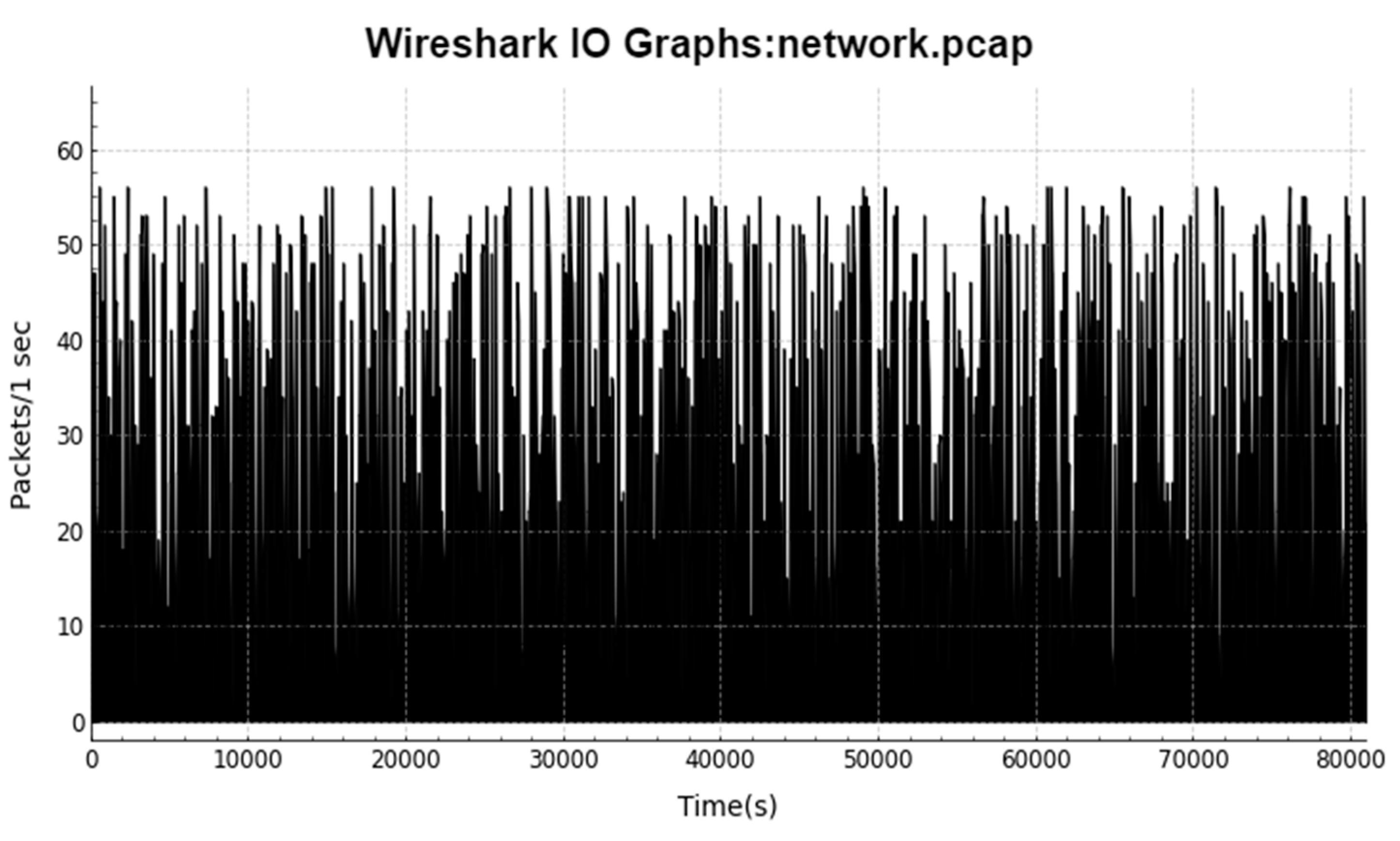
3.5. Analyzing the Dataset
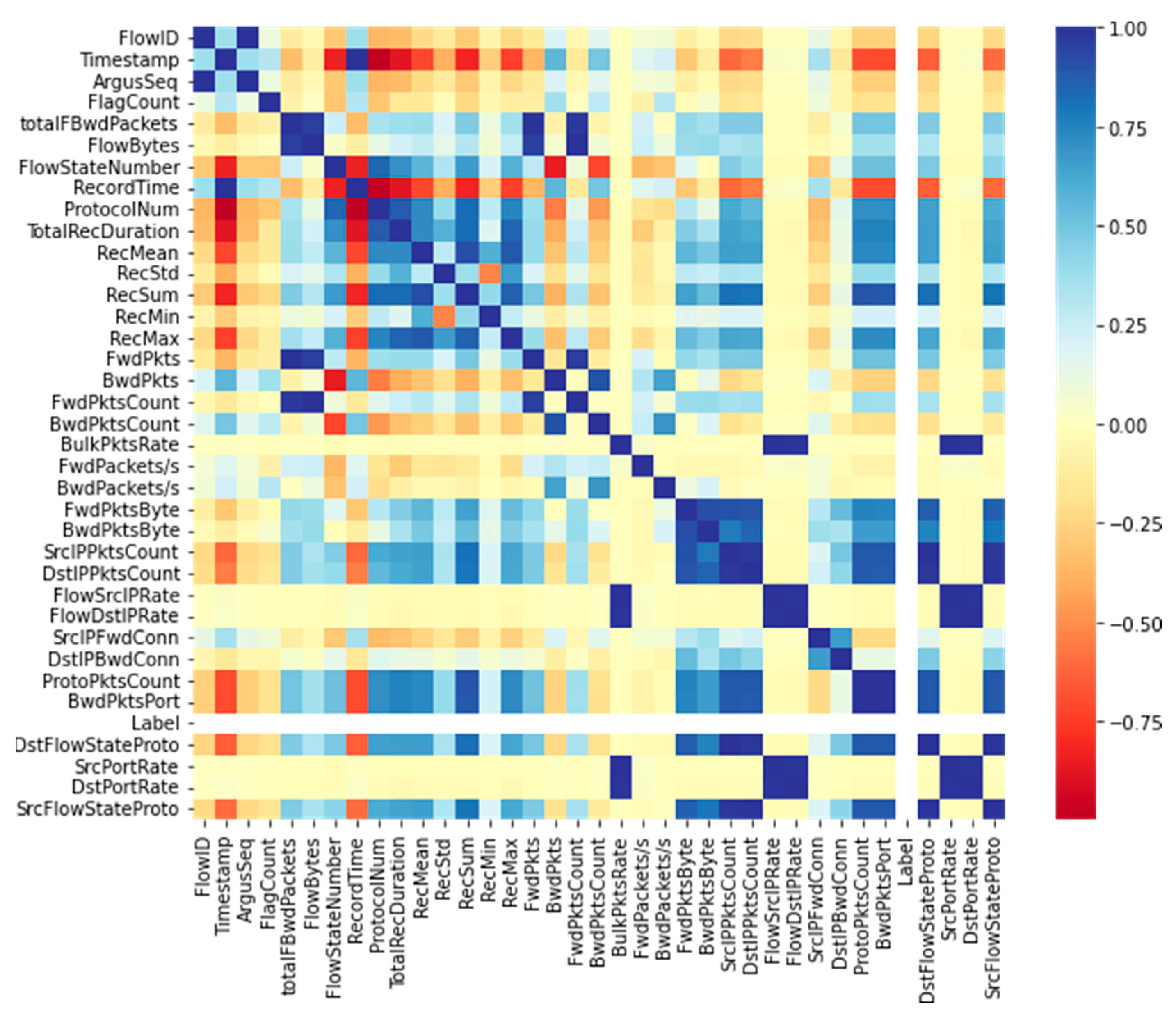
3.5.1. Pearson Correlation Coefficient
3.5.2. Entropy
3.5.3. Data Scaling and Normalization
3.5.4. Sampling of Data
4. Results
4.1. Performance Measuring Metrics
4.2. Model Parameters
4.2.1. Decision Tree
4.2.2. Naive Bayes
4.2.3. Logistic Regression
4.2.4. KNN
4.2.5. Gradient Boost
4.2.6. Random Forest
4.2.7. MLP
4.2.8. CNN
4.2.9. Ensemble Method
| Algorithm 2 Hybrid Voting Ensemble using Hard and Soft Voting |
| Require: Training data D = (x1, y1), (x2, y2),…, (xn, yn), test data T = x’1, x’2,…, x’m |
| Ensure: Ensemble predictions ŷ = ŷ1, ŷ2,…, ŷm |
| 1: Train K models on the training data D: M = M1, M2,…, MK |
| 2: for each test instance x’i do |
| 3: for each model Mj ∈ M do |
| 4: Make a prediction ŷi,j = Mj(x’i) |
| 5: end for |
| 6: Compute the average of class probabilities avg(y) = (1/K) Σj = 1K pi,j(y), where pi,j(y) is the probability estimate for class y given by model Mj for instance x’i |
| 7: Compute the majority vote prediction ŷivote = argmaxy Σj = 1K [ŷi,j = y] |
| 8: Compute the average prediction confidence Ciavg = (1/K) * Σj = 1K maxy pi,j(y) |
| 9: Set a threshold α ∈ [0, 1] |
| 10: if the average prediction confidence Ciavg ≥ α then |
| 11: Set the ensemble prediction to be the average prediction: ŷi = arg maxy pˆiavg(y) |
| 12: else |
| 13: Set the ensemble prediction to be the majority vote prediction: ŷi = ŷvotei |
| 14: end if |
| 15: end for |
| 16: return ŷ = 0 |
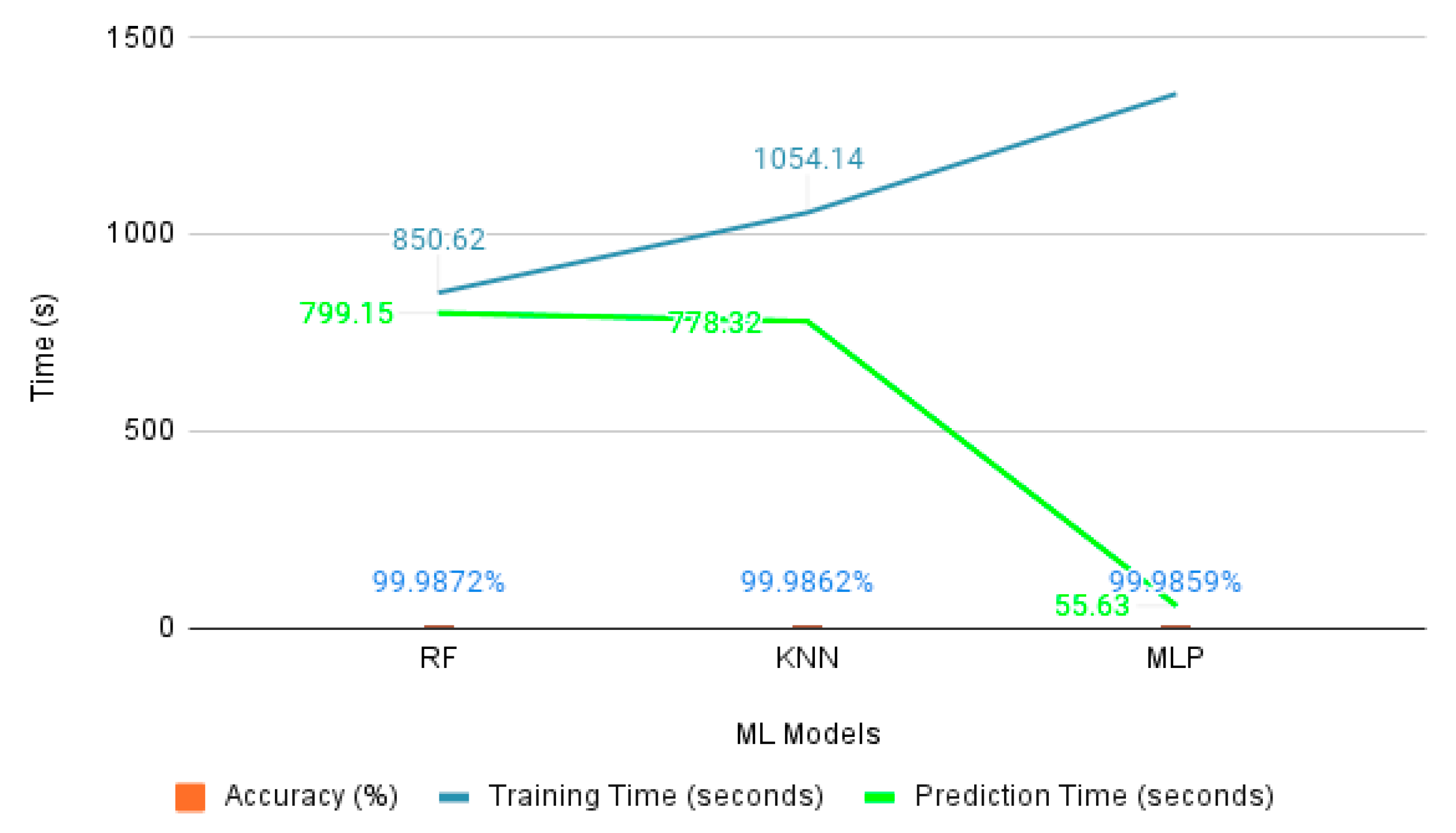
4.3. Binary Classification for Generated Dataset
4.3.1. Best 10 Features
4.3.2. Best 20 Features
4.3.3. Performance Evaluation Regarding Number of Features
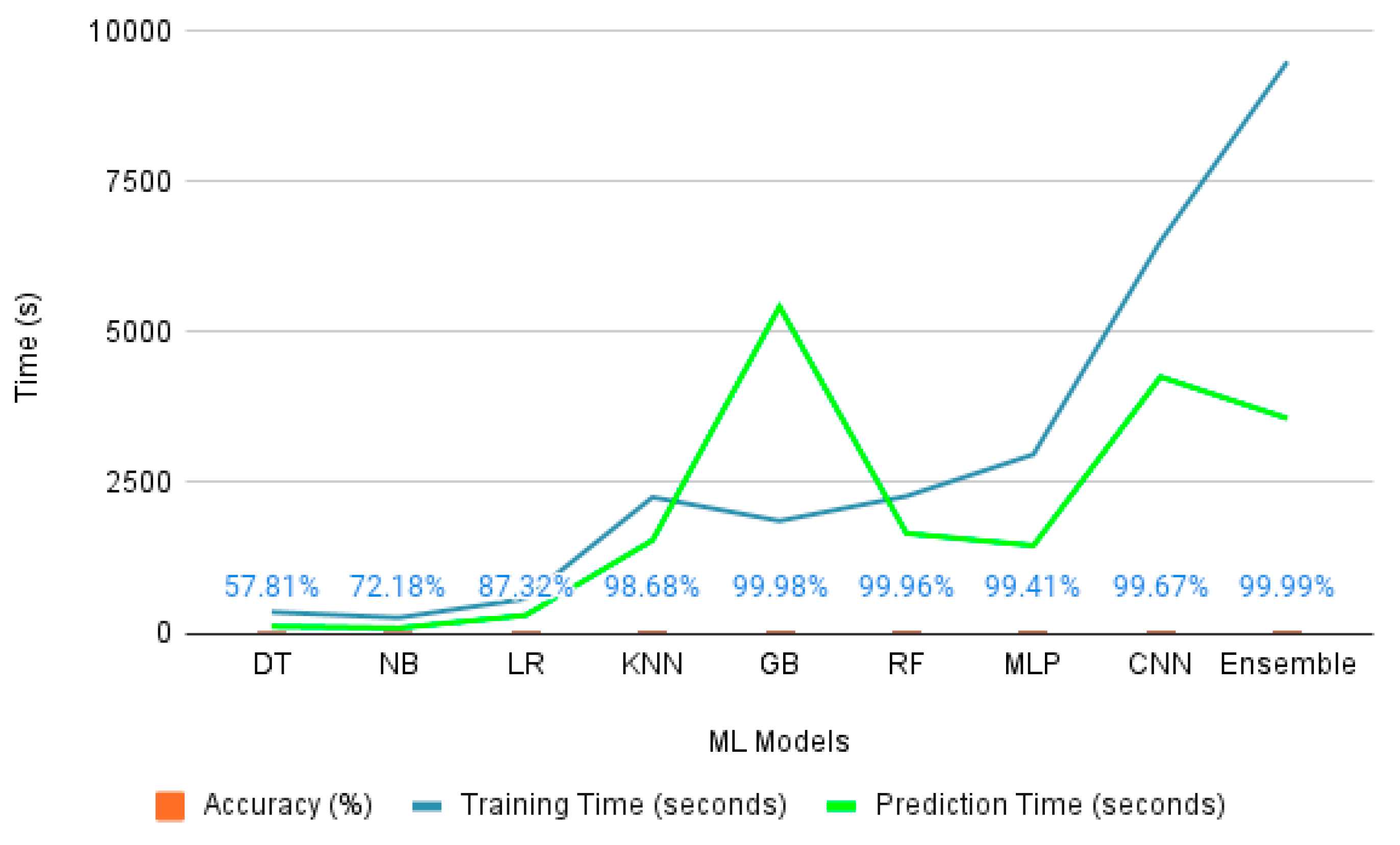
4.4. Cross-Dataset MultiClass Classification
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Feature from Generated Dataset |
|---|---|
| Flow data id | FlowID |
| Source IP address identification | SrcIp |
| Source port number value | SrcPort |
| Destination IP address identification | DstIp |
| Destination port number value | DstPort |
| Start time for the record | Timestamp |
| Argus flow number | ArgusSeq |
| Flags according to the flow state | flgs |
| Numerical value of flag | FlagCount |
| Transaction protocol in string | Protocol |
| Numerical value of protocol | ProtocolNum |
| Total packet count | totalFBwdPackets |
| Total number of bytes | FlowBytes |
| Flow State | FlowState |
| Numerical value for flow state | FlowStateNumber |
| End record time | RecordTime |
| Count of packets per protocol | ProtoPktsCount |
| Count of packets per dport | BwdPktsPort |
| Avg rate per protocol per Source IP | FlowSrcIPRate |
| Avg rate per protocol per Destination IP | FlowDstIPRate |
| Count of inbound connections per source IP | SrcIPFwdConn |
| Count of inbound connections per destination IP | DstIPBwdConn |
| Mean frequency per protocol per source port | SrcPortRate |
| Mean frequency per protocol per dport | DstPortRate |
| Count of packets organized based on flow state and protocol per source IP | SrcFlowStateProto |
| Count of packets organized based on flow state and protocol per destination IP | DstFlowStateProto |
| Total record duration time | TotalRecDuration |
| Mean length of combined data records | RecMean |
| Standard deviation of combined data records | RecStd |
| Total duration of combined data records | RecSum |
| Minimum duration of combined data records | RecMin |
| Maximum duration of combined data records | RecMax |
| Total source-to-destination packet | FwdPkts |
| Total destination-to-source packet | BwdPkts |
| Total Source-to-destination byte | FwdPktsCount |
| Total destination-to-source byte | BwdPktsCount |
| Total packets per second in flow | BulkPktsRate |
| Source to destination packets per second | FwdPackets/s |
| Destination to source packets per second | BwdPackets/s |
| Count of bytes per source IP | FwdPktsByte |
| Count of bytes per Destination IP | BwdPktsByte |
| Count of packets per source IP | SrcIPPktsCount |
| Count of packets per Destination IP | DstIPPktsCount |
References
- Nord, J.H.; Koohang, A.; Paliszkiewicz, J. The Internet of Things: Review and theoretical framework. Expert Syst. Appl. 2019, 133, 97–108. [Google Scholar] [CrossRef]
- Kumar, A.; Lim, T.J. EDIMA: Early Detection of IoT Malware Network Activity Using Machine Learning Techniques. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT’19), Limerick, Ireland, 15–18 April 2019. [Google Scholar]
- Ali, I.; Ahmed, A.I.A.; Almogren, A.; Raza, M.A.; Shah, S.A.; Khan, A.; Gani, A. Systematic Literature Review on IoT-Based Botnet Attack. IEEE Access 2020, 8, 212220–212232. [Google Scholar] [CrossRef]
- Al-Othman, Z.; Alkasassbeh, M.; Baddar, S.A.-H. A State-of-the-Art Review on IoT botnet Attack Detection (Version 1). arXiv 2019, arXiv:2010.13852. [Google Scholar] [CrossRef]
- Vengatesan, K.; Kumar, A.; Parthibhan, M.; Singhal, A.; Rajesh, R. Analysis of Mirai Botnet Malware Issues and Its Prediction Methods in Internet of Things. In Proceedings of the Lecture Notes on Data Engineering and Communications Technologies, Madurai, India, 19–20 December 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 120–126. [Google Scholar]
- Awadelkarim Mohamed, A.M.; Abdallah, M.; Hamad, Y. IoT Security: Review and Future Directions for Protection Models. In Proceedings of the 2020 International Conference on Computing and Information Technology (ICCIT-1441), Tabuk, Saudi Arabia, 9–10 September 2020. [Google Scholar] [CrossRef]
- Mukhopadhyay, S.; Suryadevara, N.; Nag, A. Wearable Sensors and Systems in the IoT. Sensors 2021, 21, 7880. [Google Scholar] [CrossRef] [PubMed]
- Trajanovski, T.; Zhang, N. An Automated and Comprehensive Framework for IoT Botnet Detection and Analysis (IoT-BDA). IEEE Access 2021, 9, 124360–124383. [Google Scholar] [CrossRef]
- Al-Hadhrami, Y.; Hussain, F.K. Real time dataset generation framework for intrusion detection systems in IoT. Future Gener. Comput. Syst. 2020, 108, 414–423. [Google Scholar] [CrossRef]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2016, 18, 1153–1176. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep Learning for IoT Big Data and Streaming Analytics: A Survey (Version 2). arXiv 2017, arXiv:1712.04301. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Ottawa, ON, Canada, 8–10 July 2009. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018. [Google Scholar] [CrossRef]
- Sivanathan, A.; Gharakheili, H.H.; Loi, F.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Classifying IoT Devices in Smart Environments Using Network Traffic Characteristics. IEEE Trans. Mob. Comput. 2019, 18, 1745–1759. [Google Scholar] [CrossRef]
- Hamza, A.; Gharakheili, H.H.; Benson, T.A.; Sivaraman, V. Detecting Volumetric Attacks on loT Devices via SDN-Based Monitoring of MUD Activity. In Proceedings of the 2019 ACM Symposium on SDN Research, SOSR ’19: Symposium on SDN Research, San Jose, CA, USA, 3–4 April 2019. [Google Scholar] [CrossRef]
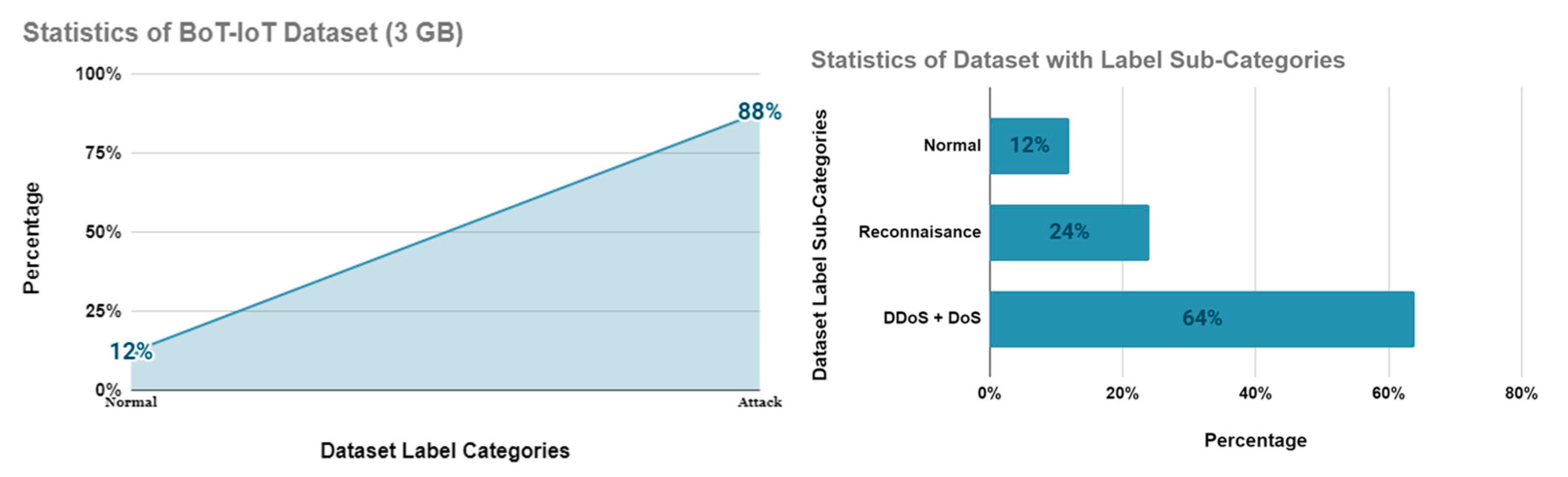
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the Internet of Things for network forensic analytics: Bot-IoT dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion Detection in 802.11 Networks: Empirical Evaluation of Threats and a Public Dataset. IEEE Commun. Surv. Tutor. 2015, 18, 184–208. [Google Scholar] [CrossRef]
- Zolanvari, M.; Teixeira, M.A.; Gupta, L.; Khan, K.M.; Jain, R. Machine Learning-Based Network Vulnerability Analysis of Industrial Internet of Things. IEEE Internet Things J. 2019, 6, 6822–6834. [Google Scholar] [CrossRef]
- Al-Hawawreh, M.; Sitnikova, E.; Aboutorab, N. X-IIoTID: A Connectivity-Agnostic and Device-Agnostic Intrusion Data Set for Industrial Internet of Things. IEEE Internet Things J. 2022, 9, 3962–3977. [Google Scholar] [CrossRef]
- Dinculeană, D.; Cheng, X. Vulnerabilities and Limitations of MQTT Protocol Used between IoT Devices. Appl. Sci. 2019, 9, 848. [Google Scholar] [CrossRef]
- Wireshark Download. Wireshark. Available online: https://wireshark.org/download.html (accessed on 9 March 2023).
- Cloud Application Platform—Heroku. Available online: https://www.heroku.com/ (accessed on 9 March 2023).
- Umer, M.F.; Sher, M.; Bi, Y. Flow-based intrusion detection: Techniques and challenges. Comput. Secur. 2017, 70, 238–254. [Google Scholar] [CrossRef]
- Holman, R.; Stanley, J. The history and technical capabilities of Argus. Coast. Eng. 2007, 54, 477–491. [Google Scholar] [CrossRef]
- Kali Linux Tools’. Kali Linux. Available online: https://www.kali.org/tools/goldeneye/ (accessed on 9 March 2023).
- Kali Linux Tools’. Kali Linux. Available online: https://www.kali.org/tools/hping3/ (accessed on 9 March 2023).
- Nmap: The Network Mapper—Free Security Scanner. Available online: https://nmap.org/ (accessed on 9 March 2023).
- Gvozdenovic, S.; Becker, J.K.; Mikulskis, J.; Starobinski, D. IoT-Scan: Network Reconnaissance for the Internet of Things (Version 1). arXiv 2022, arXiv:2204.02538. [Google Scholar] [CrossRef]
- Kali Linux Tools’. Kali Linux. Available online: https://www.kali.org/tools/xprobe/ (accessed on 9 March 2023).
- Ostinato Traffic Generator for Network Engineers’. Ostinato Traffic Generator for Network Engineers. Available online: https://ostinato.org/ (accessed on 9 March 2023).
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Komazec, T.; Gajin, S. Analysis of flow-based anomaly detection using Shannon’s entropy. In Proceedings of the 2019 27th Telecommunications Forum (TELFOR), Belgrade, Serbia, 26–27 November 2019. [Google Scholar] [CrossRef]
- Patro, S.G.K.; Sahu, K.K. Normalization: A Preprocessing Stage (Version 1). arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Lemaitre, G. Imbalanced-Learn. Scikit-Learn-Contrib. Available online: https://github.com/scikit-learn-contrib/imbalanced-learn (accessed on 11 February 2021).











| Dataset | Year | Comprehensive IoT Simulation | Multi Attack Scenarios | Telemetry Data | Label | IoT/IIoT |
|---|---|---|---|---|---|---|
| KDDCUP99/NSL-KDD [12] | 1998 | No | No | No | Yes | IoT |
| UNSW NB15[13] | 2015 | No | Yes | No | Yes | IoT |
| AWID [18] | 2015 | Yes | Yes | No | Yes | IoT |
| ISCX [14] | 2017 | No | Yes | No | Yes | IoT |
| UNSW-IoT Trace [15] | 2018 | Yes | No | No | N/A | IoT |
| BoT-IoT [17] | 2018 | Yes | Yes | No | Yes | IoT |
| UNSW-IoT [16] | 2019 | Yes | Yes | No | Yes | IoT |
| WUSTL-IIoT-2021 [19] | 2021 | Yes | Yes | No | Yes | IIoT |
| Reconnaissance | Denial of Service |
|---|---|
| Service Scanning-nmap, hping3 | DDoS-hping3, goldeneye |
| OS Fingerprinting-nmap, Xprobe2 | DoS-hping3, goldeneye |
| TrafficCategory | SubCategory |
|---|---|
| Normal | Normal |
| DoS | TCP, UDP, and HTTP |
| DDoS | TCP, UDP, and HTTP |
| Reconnaissance | ServiceScan and OSFingerprint |
| Best 10 Features | Remaining 10 Features for Best 20 |
|---|---|
| RecMean | FlowSrcIPRate |
| RecMin | FlowDstIPRate |
| RecMax | SrcPortRate |
| FwdPackets/s | DstPortRate |
| BwdPackets/s | SrcIpPktsCount |
| SrcIPFwdConn | DstIpPktsCount |
| DstIPBwdConn | BwdPktsCount |
| FlowID | ProtocolNum |
| FlowState | RecordTime |
| ArgusSeq | FwdPktsCount |
| Best 10 Features | Remaining 10 Features for Best 20 |
|---|---|
| seq | AR_P_Proto_P_Dport |
| stddev | AR_P_Proto_P_DstIP |
| N_IN_Conn_P_SrcIP | AR_P_Proto_P_Sport |
| min | AR_P_Proto_P_SrcIP |
| state number | TnP_PSrcIP |
| mean | TnP_Per_Dport |
| N_IN_Conn_P_DstIP | TnP_PDstIP |
| drate | flgs_number |
| srate | Pkts_P_State_P_Protocol_P_SrcIP |
| max | Pkts_P_State_P_Protocol_P_DestIP |
| Classes | Nature |
|---|---|
| 0 | DDoS-HTTP |
| 1 | DDoS-TCP |
| 2 | DDoS-UDP |
| 3 | DoS-HTTP |
| 4 | DoS-TCP |
| 5 | DoS-UDP |
| 6 | Normal |
| 7 | ServiceScan |
| 8 | OSFingerprint |
| Classifiers | Binary Parameter | Multiclass Parameter | Approach | Scikit Classifier |
|---|---|---|---|---|
| Random Forest | n_estimators = 10 criterion = ‘entropy’ | n_estimators = 100 criterion = ‘entropy’ | Multiclass = ‘OVR’ | RandomForestClassifier |
| KNN | n_neighbors = 30 | n_neighbors = 30 | Multiclass = ‘OVR’ | KNeighborsClassifier |
| MLP | 1 hidden layer and 100 neurons, alpha = 0.0001 | 3 hidden layers (100, 100, 50), alpha = 0.0001 | Multiclass = ‘OVR’ | MLPClassifier |
| Decision Tree | Only Multiclass Classification | max_depth = 2, criterion = ‘gini’ | OVR | DecisionTreeClassifier |
| Gradient Boost | Only Multiclass Classification | random_state = 42 | One-vs-Rest approach (OVR) | XGBClassifier |
| Naive Bayes | Only Multiclass Classification | var_smoothing = 1 × 10−9 | OVR | GaussianNB |
| Logistic Regression | Only Multiclass Classification | solver = ‘liblinear’ | OVR | LogisticRegression |
| CNN | Only Multiclass Classification | 7 dense layers, 6 dropout layers, 1500 nodes, epochs: 50, activation function: ‘relu’, loss_function: ‘categorical_crossentropy’ optimizer: ‘adam’ | Categorical | Tensorflow-Sequential Model |
| Ensemble | Only Multiclass Classification | voting = ‘soft’ and ‘hard’, estimators = ‘7’, sklearn.ensemble technique | OVR | VotingClassifier |
| Model | 0/1 | Precision | Recall | F1-Score | Accuracy | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|---|
| Random Forest | 0 1 | 0.5525 0.9999 | 0.9983 0.9681 | 0.7135 0.9834 | 0.974125 | 825.36 | 729.16 |
| KNN | 0 1 | 0.9992 0.9998 | 0.9954 1.0000 | 0.9973 0.9998 | 0.999812 | 996.15 | 562.12 |
| MLP | 0 1 | 0.9989 0.9998 | 0.9965 0.9999 | 0.9976 0.9999 | 0.999816 | 1256.21 | 24.25 |
| Model | 0/1 | Precision | Recall | F1-Score | Accuracy | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|---|
| Random Forest | 0 1 | 0.9989 0.9999 | 0.9976 1.0000 | 0.9983 0.9999 | 0.999872 | 850.62 | 799.15 |
| KNN | 0 1 | 0.9999 0.9999 | 0.9966 1.0000 | 0.9982 0.9999 | 0.999862 | 1054.14 | 778.32 |
| MLP | 0 1 | 0.9998 0.9999 | 0.9988 1.0000 | 0.9992 0.9999 | 0.999859 | 1356.14 | 55.63 |
| Model | Class | Precision | Recall | F1 Score | Accuracy | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|---|
| Decision Tree | 0 1 2 3 4 5 6 7 8 | 0.00 0.39 0.58 0.00 0.00 0.51 0.00 0.00 0.57 | 0.00 1.00 0.57 0.00 0.00 0.89 0.00 0.00 0.27 | 0.00 0.56 0.58 0.00 0.00 0.65 0.00 0.00 0.37 | 0.428093 | 307.40 | 102.76 |
| Naive Bayes | 0 1 2 3 4 5 6 7 8 | 0.09 0.66 1.00 0.00 0.99 0.55 0.73 0.51 0.57 | 0.96 0.52 1.00 0.00 0.67 0.91 0.12 0.89 0.27 | 0.17 0.58 1.00 0.00 0.80 0.68 0.20 0.65 0.37 | 0.553320 | 212.16 | 55.24 |
| Logistic Regression | 0 1 2 3 4 5 6 7 8 | 0.31 0.20 0.95 1.00 0.99 0.69 0.38 0.55 0.38 | 0.89 0.06 1.00 1.00 0.67 0.91 0.13 0.91 0.13 | 0.46 0.09 0.97 1.00 0.80 0.78 0.20 0.68 0.20 | 0.846680 | 567.21 | 268.12 |
| KNN | 0 1 2 3 4 5 6 7 8 | 0.99 0.97 1.00 1.00 0.96 0.91 0.80 0.97 0.99 | 0.98 0.83 1.00 1.00 0.99 0.90 0.81 0.83 0.98 | 0.99 0.89 1.00 1.00 0.98 0.91 0.80 0.89 0.99 | 0.972670 | 2182.4 | 1136.56 |
| Gradient Boost | 0 1 2 3 4 5 6 7 8 | 0.58 0.91 1.00 0.72 0.86 1.00 0.62 0.76 1.00 | 0.57 0.91 1.00 0.45 0.96 1.00 0.64 0.73 1.00 | 0.58 0.92 1.00 0.56 0.91 1.00 0.63 0.75 1.00 | 0.873166 | 1657.5 | 4400.12 |
| Random Forest | 0 1 2 3 4 5 6 7 8 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.95 0.99 | 1.00 0.99 1.00 1.00 1.00 1.00 1.00 0.99 0.97 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.97 0.98 | 0.994109 | 2167.15 | 1354.12 |
| MLP | 0 1 2 3 4 5 6 7 8 | 0.98 0.99 1.00 0.99 0.99 1.00 1.00 0.98 0.91 | 1.00 0.99 1.00 1.00 1.00 1.00 1.00 0.94 0.96 | 0.99 0.99 1.00 1.00 1.00 1.00 1.00 0.96 0.94 | 0.982880 | 2856.12 | 1274.12 |
| CNN | 0 1 2 3 4 5 6 7 8 | 1.00 0.97 1.00 1.00 0.96 0.89 0.90 0.99 0.99 | 0.98 0.83 1.00 1.00 1.00 0.96 0.72 0.67 0.99 | 0.99 0.99 1.00 1.00 0.99 0.98 0.97 0.99 0.99 | 0.975160 | 5815.22 | 3514.5 |
| Ensemble Approach | 0 1 2 3 4 5 6 7 8 | 1.00 1.00 0.99 1.00 1.00 0.99 1.00 1.00 1.00 | 1.00 1.00 0.99 1.00 1.00 0.99 1.00 1.00 1.00 | 1.00 1.00 0.99 1.00 1.00 0.911 1.00 1.00 1.00 | 0.99967 | 9232.4 | 3201.12 |
| Model | Class | Precision | Recall | F1 Score | Accuracy | Training Time (s) | Prediction Time (s) |
|---|---|---|---|---|---|---|---|
| Decision Tree | 0 1 2 3 4 5 6 7 8 | 0.00 0.39 0.90 0.00 0.00 0.70 0.00 0.00 0.57 | 0.00 1.00 0.87 0.00 0.00 0.92 0.00 0.00 0.68 | 0.00 0.56 0.89 0.00 0.00 0.80 0.00 0.00 0.62 | 0.578093 | 350.40 | 112.76 |
| Naive Bayes | 0 1 2 3 4 5 6 7 8 | 0.34 0.85 0.87 0.73 0.51 1.00 1.00 0.57 0.94 | 0.96 0.54 1.00 0.52 0.89 0.85 1.00 0.27 0.47 | 0.50 0.66 0.93 0.61 0.65 0.92 1.00 0.37 0.63 | 0.721787 | 257.32 | 85.67 |
| Logistic Regression | 0 1 2 3 4 5 6 7 8 | 0.58 0.91 1.00 0.72 0.86 1.00 1.00 0.62 0.76 | 0.57 0.91 1.00 0.45 0.96 1.00 1.00 0.64 0.73 | 0.58 0.92 1.00 0.56 0.91 1.00 1.00 0.63 0.75 | 0.873166 | 569.23 | 296.55 |
| KNN | 0 1 2 3 4 5 6 7 8 | 0.98 0.99 1.00 0.99 0.99 1.00 1.00 0.91 0.98 | 1.00 0.99 1.00 1.00 1.00 1.00 1.00 0.96 0.94 | 0.99 0.99 1.00 1.00 1.00 1.00 1.00 0.94 0.96 | 0.986780 | 2256.54 | 1542.26 |
| Gradient Boost | 0 1 2 3 4 5 6 7 8 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 0.999840 | 1864.25 | 5421.87 |
| Random Forest | 0 1 2 3 4 5 6 7 8 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 0.999594 | 2274.39 | 1656.34 |
| MLP | 0 1 2 3 4 5 6 7 8 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.95 0.99 | 1.00 0.99 1.00 1.00 1.00 1.00 1.00 0.99 0.97 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.97 0.98 | 0.994109 | 2967.15 | 1454.12 |
| CNN | 0 1 2 3 4 5 6 7 8 | 0.99 0.99 1.00 1.00 0.99 0.98 0.98 0.99 0.99 | 0.99 0.99 1.00 1.00 1.00 0.99 0.96 0.99 0.99 | 0.99 0.99 1.00 1.00 0.99 0.98 0.97 0.99 0.99 | 0.996718 | 6504.15 | 4254.12 |
| Ensemble Approach | 0 1 2 3 4 5 6 7 8 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 | 0.999936 | 9487.25 | 3565.21 |
| Dataset | Year | Comprehensive IoT Simulation | Multi Attack Scenarios | Telemetry Data | Label | IoT/IIoT |
|---|---|---|---|---|---|---|
| KDDCUP99/NSL-KDD [12] | 1998 | No | No | No | Yes | IoT |
| UNSW NB15 [13] | 2015 | No | Yes | No | Yes | IoT |
| AWID [18] | 2015 | Yes | Yes | No | Yes | IoT |
| ISCX [14] | 2017 | No | Yes | No | Yes | IoT |
| UNSW-IoT Trace [15] | 2018 | Yes | No | No | N/A | IoT |
| BoT-IoT [17] | 2018 | Yes | Yes | No | Yes | IoT |
| UNSW-IoT [16] | 2019 | Yes | Yes | No | Yes | IoT |
| WUSTL-IIoT-2021 [19] | 2021 | Yes | Yes | No | Yes | IIoT |
| Proposed Dataset | 2022 | Yes | Yes | Yes | Yes | IoT |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koirala, A.; Bista, R.; Ferreira, J.C. Enhancing IoT Device Security through Network Attack Data Analysis Using Machine Learning Algorithms. Future Internet 2023, 15, 210. https://doi.org/10.3390/fi15060210
Koirala A, Bista R, Ferreira JC. Enhancing IoT Device Security through Network Attack Data Analysis Using Machine Learning Algorithms. Future Internet. 2023; 15(6):210. https://doi.org/10.3390/fi15060210
Chicago/Turabian StyleKoirala, Ashish, Rabindra Bista, and Joao C. Ferreira. 2023. "Enhancing IoT Device Security through Network Attack Data Analysis Using Machine Learning Algorithms" Future Internet 15, no. 6: 210. https://doi.org/10.3390/fi15060210
APA StyleKoirala, A., Bista, R., & Ferreira, J. C. (2023). Enhancing IoT Device Security through Network Attack Data Analysis Using Machine Learning Algorithms. Future Internet, 15(6), 210. https://doi.org/10.3390/fi15060210