



Target-Oriented Data Annotation for Emotion and Sentiment Analysis in Tourism Related Social Media Data


Abstract
1. Introduction
2. Literature Review
2.1. Sentiment Analysis and Its Application in Tourism
2.2. Emotion Analysis and Its Application in Tourism
2.3. Target-Oriented Sentiment Analysis
3. Methodology
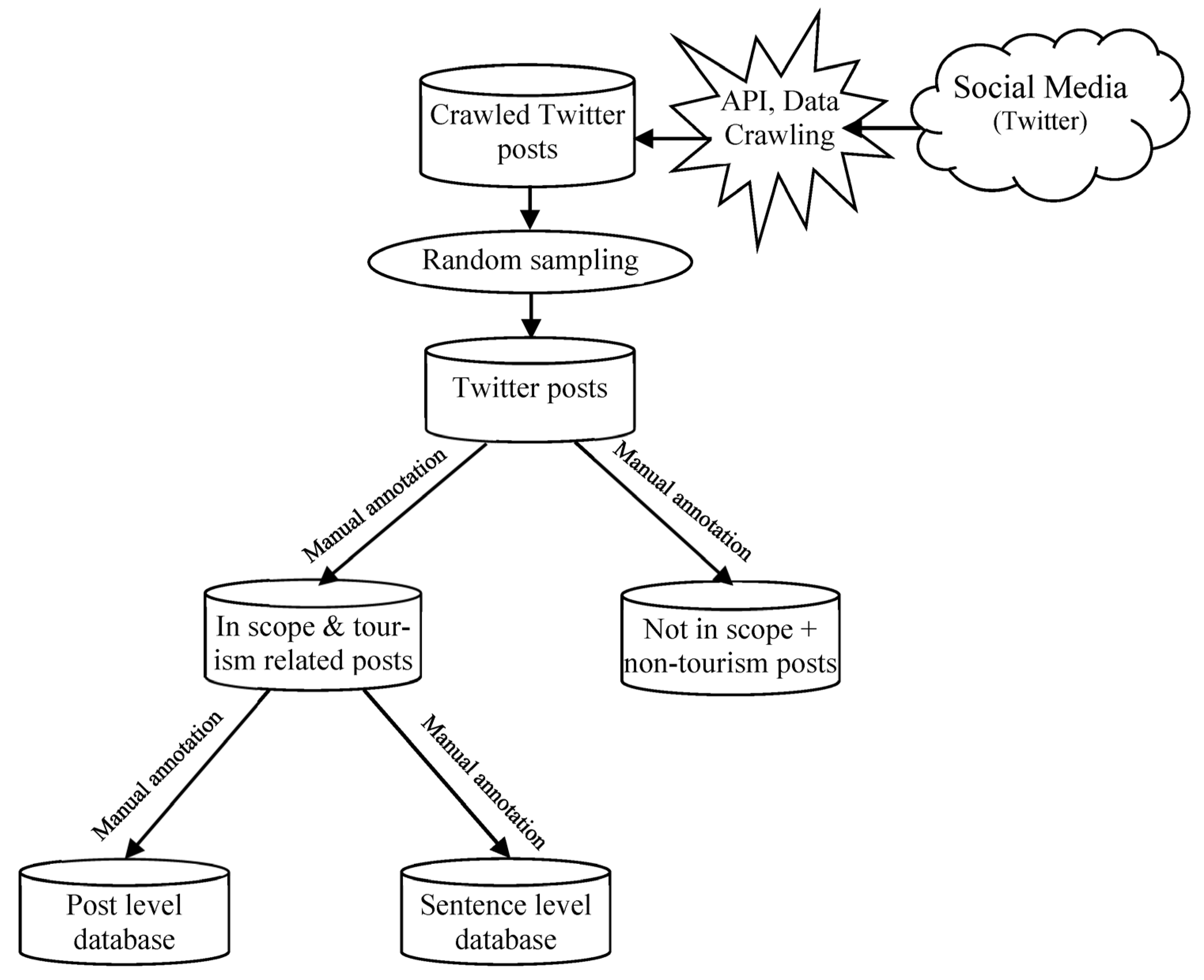
3.1. Methodology for Post Collection and Annotation
3.1.1. Annotation Scheme and Key Definitions
3.1.2. Annotation Procedure
3.1.3. Instructions for Coding Tweets
 , :(, :-(,
, :(, :-(,  , !!!, ???, hahaha, lol) as these provide insight into the intensity and emotion, as well as when the vocabulary is not matching the markers (instances of sarcasm).
, !!!, ???, hahaha, lol) as these provide insight into the intensity and emotion, as well as when the vocabulary is not matching the markers (instances of sarcasm).3.1.4. Post and Sentence Level Annotation
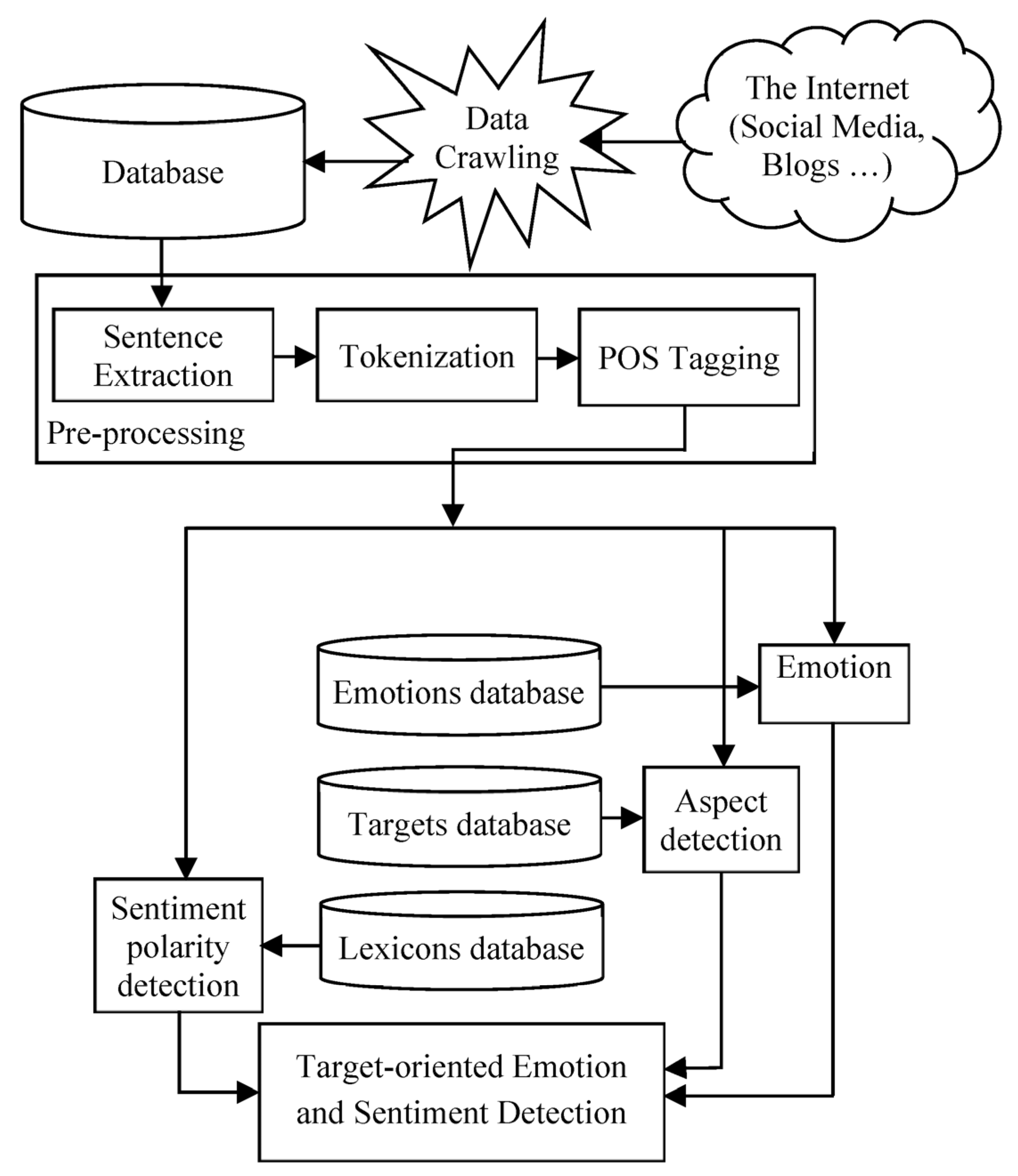
3.2. Proposed Target-Oriented Emotion and Sentiment Analysis
4. A Pilot Study
4.1. Data Collection
4.1.1. Annotation Agreement
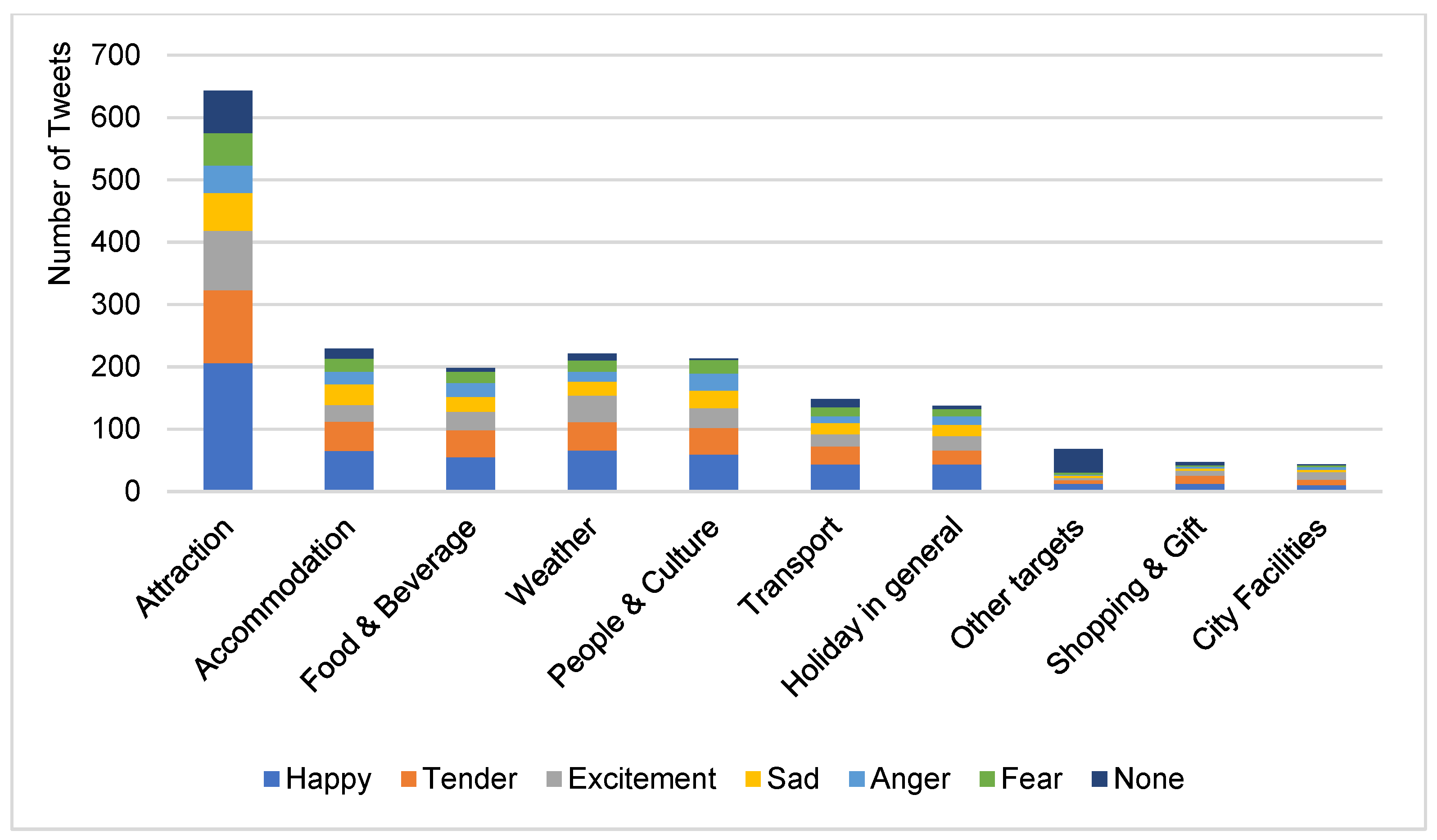
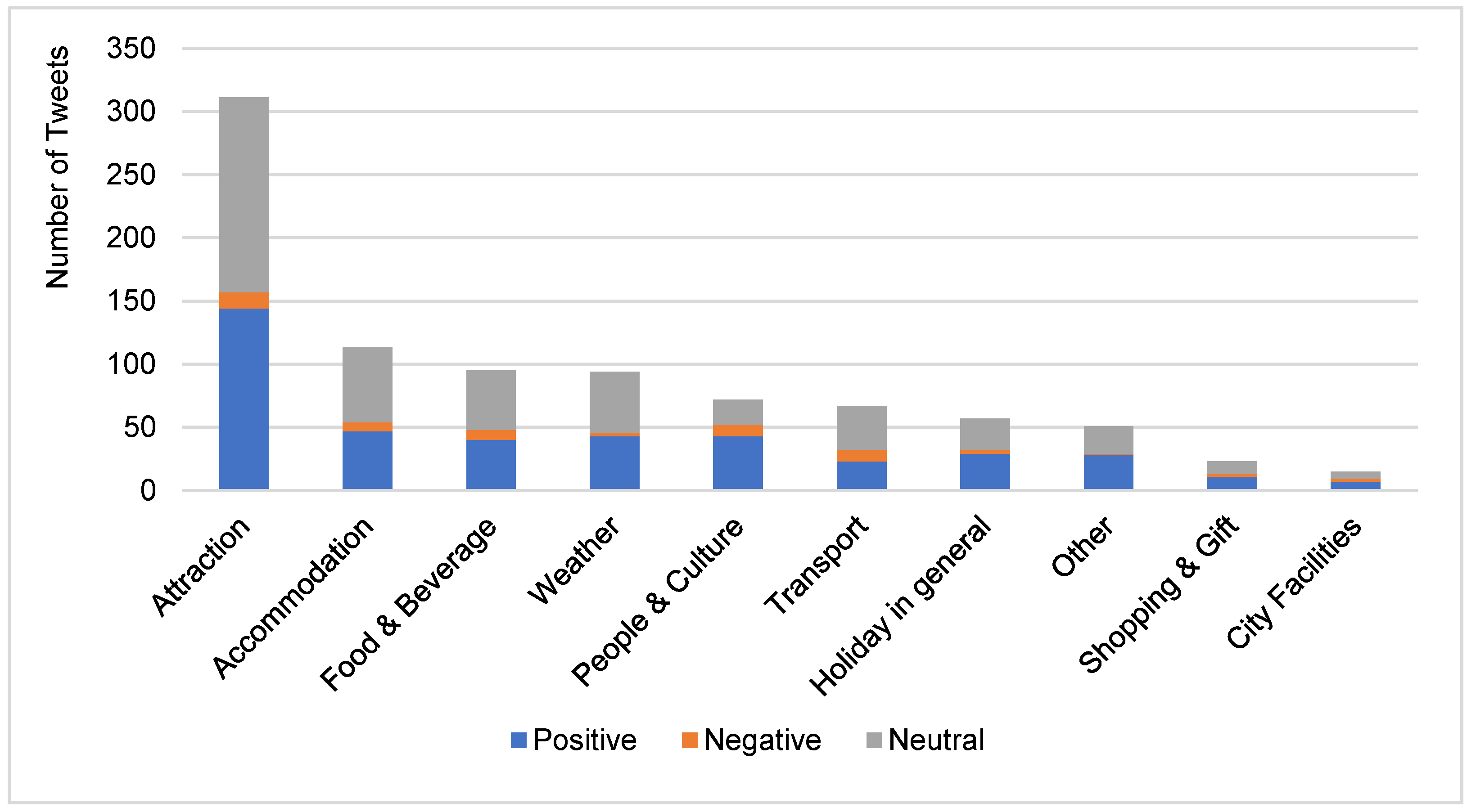
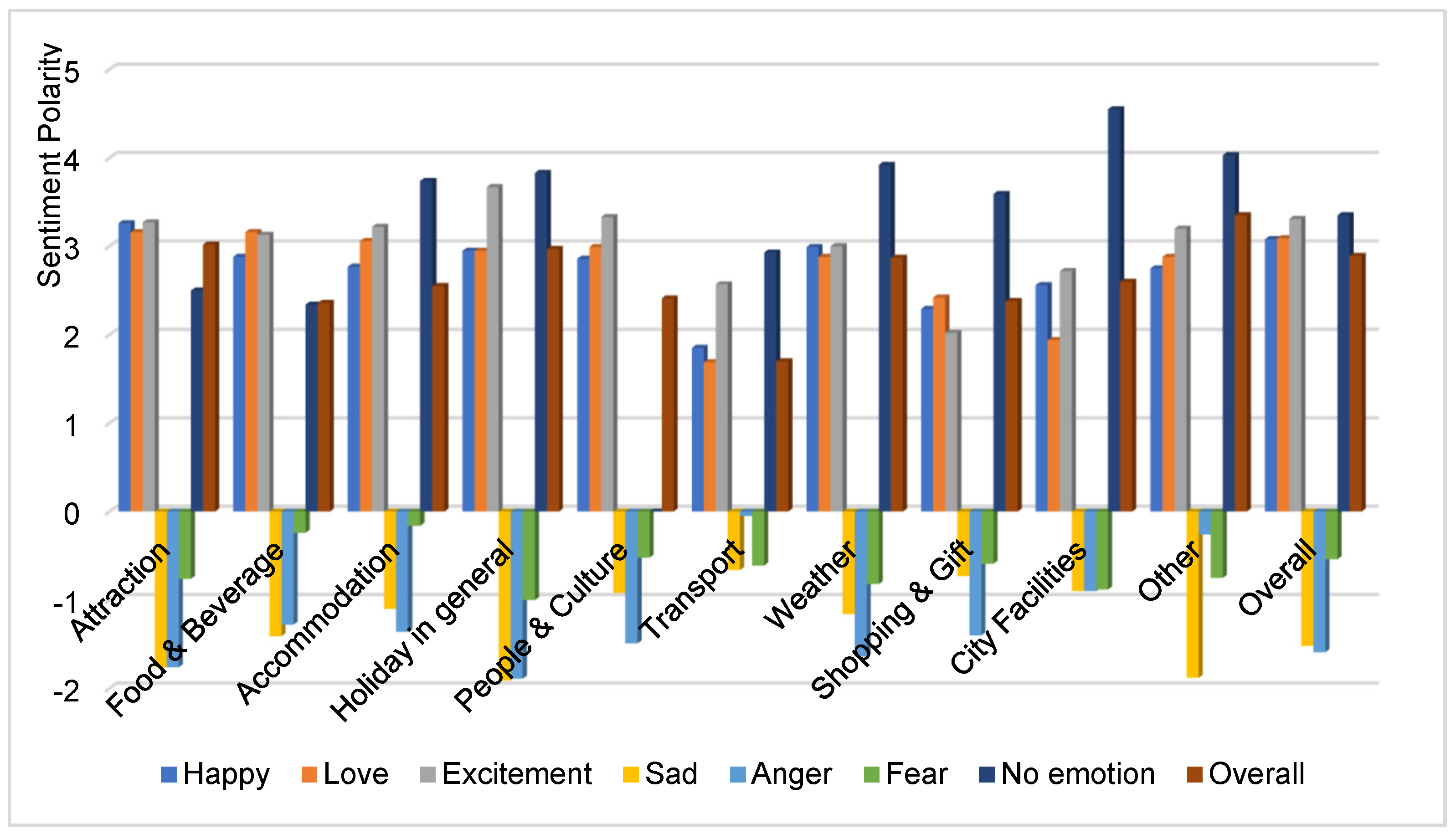
4.2. Discussion on the Annotated Data
4.3. Performance of the Proposed Sentiment Analysis System
5. Conclusions and Future Work
Future Research Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Y. More Important than ever: Measuring Tourist Satisfaction. Griffith Institute for Tourism Research Report No 10. 2016. Available online: https://www.griffith.edu.au/__data/assets/pdf_file/0029/18884/Measuring-Tourist-Satisfaction.pdf (accessed on 12 April 2023).
- Ladhari, R.; Michaud, M. eWOM effects on hotel booking intentions, attitudes, trust, and website perceptions. Int. J. Hosp. Manag. 2015, 46, 36–45. [Google Scholar] [CrossRef]
- Nieto-García, M.; Muñoz-Gallego, P.A.; González, Ó. Tourists’ willingness to pay for an accommodation: The effect of eWOM and internal reference price. Int. J. Hosp. Manag. 2017, 62, 67–77. [Google Scholar] [CrossRef]
- Chiu, C.; Chiu, N.-H.; Sung, R.-J.; Hsieh, P.-Y. Opinion mining of hotel customer-generated contents in Chinese weblogs. Curr. Issues Tour. 2015, 18, 477–495. [Google Scholar] [CrossRef]
- Confente, I. Twenty-five years of word-of-mouth studies: A critical review of tourism research. Int. J. Tour. Res. 2015, 17, 613–624. [Google Scholar] [CrossRef]
- Becken, S.; Alaei, A.; Wang, Y. Benefits and pitfalls of using tweets to assess destination sentiment. J. Hosp. Tour. Technol. 2019, 11, 19–34. [Google Scholar] [CrossRef]
- Alaei, A.R.; Becken, S.; Stantic, B. Sentiment Analysis in Tourism: Capitalizing on Big Data. J. Travel Res. 2019, 58, 175–191. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Wenyu, C.; Nunoo-Mensah, H. Text-based emotion detection: Advances, challenges, and opportunities. Eng. Rep. 2020, 2, e12189. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Mohammad, S.M. Sentiment analysis: Automatically detecting valence, emotions, and other affectual states from text. In Emotion Measurement; Woodhead Publishing: Cambridge, UK, 2021; pp. 323–379. [Google Scholar]
- Wolny, W. Emotion Analysis of Twitter Data That Use Emoticons and Emoji Ideograms. In Proceedings of the 25th International Conference on Information Systems Development (ISD2016 POLAND), Katowice, Poland, 24–26 August 2016; pp. 476–483. Available online: https://aisel.aisnet.org/isd2014/proceedings2016/CreativitySupport/5/ (accessed on 12 April 2023).
- Xiang, Z.; Schwartz, Z.; Gerdes Jr, J.H.; Uysal, M. What can big data and text analytics tell us about hotel guest experience and satisfaction? Int. J. Hosp. Manag. 2015, 44, 120–130. [Google Scholar] [CrossRef]
- Liu, C.-C.; Yang, T.-H.; Hsieh, C.-T.; Soo, V.-W. Towards Text-based Emotion Detection: A Survey and Possible Improvements. In Proceedings of the International Conference on Information Management and Engineering, Kuala Lumpur, Malaysia, 3–5 April 2009; pp. 70–74. [Google Scholar]
- Toprak CJakob, N.; Gurevych, I. Sentence and expression level annotation of opinions in user-generated discourse. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, ACL ’10, Uppsala, Sweden, 13 July 2010; pp. 575–584. [Google Scholar]
- Ribeiro, F.N.; Araujo, M.; Goncalves, P.; Goncalves, M.A.; Benevenuto, F. A Benchmark Comparison of State-of-the-Practice Sentiment Analysis Methods. EPJ Data Sci. 2016, 23. Available online: https://epjdatascience.springeropen.com/articles/10.1140/epjds/s13688-016-0085-1 (accessed on 12 April 2023).
- Rossetti, M.; Stella, F.; Zanker, M. Analyzing user reviews in tourism with topic models. Inf. Technol. Tour. 2016, 16, 5–21. [Google Scholar] [CrossRef]
- Kessler, J.S.; Eckert, M.; Clark, L.; Nicolov, N. The 2010 ICWSM JDPA sentiment corpus for the automotive domain. In Proceedings of the 4th International AAAI Conference on Weblogs and Social Media Data Workshop Challenge, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Tubishat, M.; Idris, N.; Abushariah, M.A.M. Implicit aspect extraction in sentiment analysis: Review, taxonomy, oppportunities, and open challenges. Inf. Process. Manag. 2018, 54, 545–563. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 271–278. [Google Scholar]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Brob, J. Aspect-Oriented Sentiment Analysis of Customer Reviews Using Distant Supervision Techniques. Ph.D. Thesis, University of Berlin, Berlin, Germany, 2013. [Google Scholar]
- Bjorkelund, E.; Burnett, T.H.; Norvag, K. A study of opinion mining and visualization of hotel reviews. In Proceedings of the 14th International Conference on Information Integration and Web-based Applications & Services, Bali, Indonesia, 3–5 December 2012; pp. 229–238. [Google Scholar] [CrossRef]
- Gräbner, D.; Zanker Fliedl, M.G.; Fuchs, M. Classification of customer reviews based on sentiment analysis. In Information and Communication Technologies in Tourism; Springer: New York, NY, USA, 2012; pp. 460–470. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the 8th International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Misopoulos, F.; Mitic, M.; Kapoulas, A.; Karapiperis, C. Uncovering customer service experiences with Twitter: The case of airline industry. Manag. Decis. 2014, 52, 705–723. [Google Scholar] [CrossRef]
- Claster, W.B.; Pardo, P.; Cooper, M.; Tajeddini, K. Tourism, travel and tweets: Algorithmic text analysis methodologies in tourism. Middle East J. Manag. 2013, 1, 81–99. [Google Scholar] [CrossRef]
- Kasper, W.; Vela, M. Sentiment analysis for hotel reviews. In Proceedings of the Computational Linguistics-Applications Conference, Jachranka, Poland, 17–19 October 2011; Volume 231527, pp. 45–52. [Google Scholar]
- Jeon, W.; Lee, Y.; Geum, Y. Airline Service Quality Evaluation Based on Customer Review Using Machine Learning Approach and Sentiment Analysis. J. Soc. e-Bus. Stud. 2021, 26, 15–36. [Google Scholar]
- Duan, W.; Cao, Q.; Yu, Y.; Levy, S. Mining online user-generated content: Using sentiment analysis technique to study hotel service quality. In Proceedings of the 46th System Sciences (HICSS), Hawaii International Conference, Maui, HI, USA, 7–10 January 2013; pp. 3119–3128. Available online: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6480220 (accessed on 12 April 2023).
- Park, E.; Kang, J.; Choi, D.; Han, J. Understanding customers’ hotel revisiting behaviour: A sentiment analysis of online feedback reviews. Curr. Issues Tour. 2020, 23, 605–611. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, X. World Cup 2014 in the Twitter World: A big data analysis of sentiments in US sports fans’ tweets. Comput. Hum. Behav. 2015, 48, 392–400. [Google Scholar] [CrossRef]
- Strapparava, C.; Mihalcea, R. SemEval-2007 task 14: Affective text. In Proceedings of the 4th International Workshop on Semantic Evaluations (SemEval ‘07), Association for Computational Linguistics, Prague, Czech Republic, 23–24 June 2007; pp. 70–74. [Google Scholar]
- Holzman, L.E.; Pottenger, W.M. Classification of Emotions in Internet Chat: An Application of Machine Learning Using Speech Phonemes. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=420ddd737833e808965e051a8af20d8bcd76f423 (accessed on 12 April 2023).
- Alm, C.O.; Roth, D.; Sproat, R. Emotions from Text: Machine Learning for Text-based Emotion Prediction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 579–586. [Google Scholar]
- Aman, S.; Szpakowicz, S. Identifying Expressions of Emotion in Text. Available online: http://saimacs.github.io/pubs/2007-TSD-paper.pdf (accessed on 12 April 2023).
- Ding, X.; Liu, B.; Yu, P.S. A holistic lexicon-based approach to opinion mining. In Proceedings of the International Conference on Web Search and Web Data Mining, Palo Alto, CA, USA, 11–12 February 2008; pp. 231–240. [Google Scholar] [CrossRef]
- Buhalis, D. Marketing the competitive destination of the future. Tour. Manag. 2000, 21, 97–116. [Google Scholar] [CrossRef]
- Chen, J.; Becken, S.; Stantic, B. Assessing destination satisfaction by social media: An innovative approach using Importance-Performance Analysis. Ann. Tour. Res. 2022, 93, 103371. [Google Scholar] [CrossRef]
- Tourism Research Australia. Chinese Visitor Satisfaction. 2014. Available online: https://www.tourism.australia.com (accessed on 12 April 2023).
- Maedche, A.; Staab, S. Ontology Learning for the Semantic Web. IEEE Intell. Syst. 2001, 16, 72–79. [Google Scholar] [CrossRef]
- Ganu, G.; Elhadad, N.; Marian, A. Beyond the Stars: Improving Rating Predictions Using Review Text Content. In Proceedings of the 12th International Workshop on the Web and Databases (WebDB 2009), Providence, RI, USA, 28 June 2009; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.150.140&rep=rep1&type=pdf (accessed on 12 April 2023).
- Wan, H.; Yang, Y.; Du, J.; Liu, Y.; Qi, K.; Pan, J.Z. Target-Aspect-Sentiment Joint Detection for Aspect-Based Sentiment Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9122–9129. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation, Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Al-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; Clercq, O.D.; et al. Semeval-2016 task 5: Aspect based sentiment analysis. In ProWorkshop on Semantic Evaluation (SemEval-2016); Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 19–30. [Google Scholar]
- Li, S.; Scott, N.; Walters, G. Current and potential methods for measuring emotion in tourism experiences: A review. Curr. Issues Tour. 2015, 18, 805–827. [Google Scholar] [CrossRef]
- D’Mello, S.; Picard, R.W.; Graesser, A. Toward an Affect-Sensitive AutoTutor. IEEE Intell. Syst. 2007, 22, 53–61. [Google Scholar] [CrossRef]
- McLaren, K. (n.d.) Your Emotional Vocabulary List. Dynamic Emotional Integration. Available online: https://karlamclaren.com/wp-content/uploads/2016/05/Emotional-Vocabulary-List-Color.pdf (accessed on 12 April 2023).
- Plutchik, R. Emotion: A Psychoevolutionary Synthesis; Harper and Row: New York, NY, USA, 1980. [Google Scholar]
- Elbagir, S.; Yang, J. Sentiment Analysis on Twitter with Python’s Natural Language Toolkit and VADER Sentiment Analyzer. In IAENG Transactions on Engineering Sciences; 2020; pp. 63–80. [Google Scholar]
- Fleiss, J.L. Statistical Methods for Rates and Proportions, 2nd ed.; John Wiley: New York, NY, USA, 1981. [Google Scholar]
- Altman, D.G. Practical Statistics for Medical Research; Chapman & Hall/CRC Press: New York, NY, USA, 1999. [Google Scholar]
- Volo, S. Bloggers’ reported tourist experiences: Their utility as a tourism data source and their effect on prospective tourists. J. Vacat. Mark. 2010, 16, 297–311. [Google Scholar] [CrossRef]
- Dodds, P.S.; Clark, E.M.; Desu, S. Human language reveals a universal positivity bias. Proc. Natl. Acad. Sci. USA 2015, 112, 2389–2394. [Google Scholar] [CrossRef]
- Vishnubhotla, K.; Mohammad, S.M. Tweet Emotion Dynamics: Emotion Word Usage in Tweets from US and Canada. In Proceedings of the 13th Language Resources and Evaluation Conference (LREC-2022), Marseille, France, 20–25 June 2022. [Google Scholar]
- Pappas, N.; Popescu-Belis, A. Sentiment Analysis of User Comments for OneClass Collaborative Filtering over TED Talks. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; ACM: New York, NY, USA; pp. 773–776. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Number |
|---|---|
| Total number of posts | 475 |
| Positive posts | 279 |
| Negative posts | 28 |
| Neutral posts | 168 |
| Total number of sentences | 585 |
| Positive sentences | 342 |
| Negative sentences | 43 |
| Neutral sentences | 200 |
| Tweets composed of 1 sentence | 382 |
| Tweets composed of 2 sentences | 76 |
| Tweets composed of 3 sentences | 17 |
| Emotion | ||||||||
| Happiness | Love | Excitement | Sadness | Anger | Fear | No Emotion | Total No of Tweets (95% CI) | |
| Attraction | 206 | 117 | 95 | 61 | 44 | 52 | 68 | 311 (65.47 ± 4.28%) |
| Accommodation | 65 | 47 | 27 | 33 | 20 | 21 | 16 | 113 (23.79 ± 3.60%) |
| Food & Beverage | 55 | 43 | 30 | 24 | 22 | 18 | 6 | 95 (20.00 ± 3.23%) |
| Weather | 66 | 45 | 43 | 22 | 16 | 18 | 11 | 94 (19.79 ± 2.92%) |
| People & Culture | 59 | 43 | 32 | 28 | 27 | 22 | 2 | 72 (15.16 ± 1.57%) |
| Transport | 43 | 29 | 20 | 18 | 11 | 14 | 13 | 67 (14.11 ± 4.28%) |
| Holiday in general | 43 | 23 | 23 | 18 | 14 | 11 | 5 | 57 (12.00 ± 3.83%) |
| Shopping & Gift | 12 | 13 | 8 | 4 | 3 | 2 | 5 | 23 (4.84 ± 3.60%) |
| City Facilities | 10 | 9 | 12 | 4 | 4 | 3 | 1 | 15 (3.16 ± 3.23%) |
| Other targets | 12 | 6 | 4 | 3 | 2 | 3 | 38 | 51 (10.74 ± 2.92%) |
| Total No of tweets (95% CI) | 278 (58.53 ± 4.43%) | 163 (34.32 ± 4.27%) | 126 (26.53 ± 3.97%) | 96 (20.21 ± 3.61%) | 70 (14.74 ± 3.19%) | 71 (14.95 ± 3.21%) | 141 (29.68 ± 4.11%) | |
| Target | Number | |||
| Positive | Negative | Neutral | Total | |
| Attraction | 144 | 13 | 154 | 311 |
| Food & Beverage | 40 | 8 | 47 | 95 |
| Accommodation | 47 | 7 | 59 | 113 |
| Holiday in general | 29 | 3 | 25 | 57 |
| People & Culture | 43 | 9 | 20 | 72 |
| Transport | 23 | 9 | 35 | 67 |
| Weather | 43 | 3 | 48 | 94 |
| Shopping & Gift | 11 | 2 | 10 | 23 |
| City Facilities | 7 | 2 | 6 | 15 |
| Other | 28 | 1 | 22 | 51 |
| Overall (95% CI) | 279 (58.73% ± 4.43%) | 28 (5.89% ± 2.12%) | 168 (35.37% ± 4.30%) | |
| Emotion | Sentiment Polarity (%) | |||||||
| Happy | Love | Excitement | Sad | Anger | Fear | None | Average | |
| NRC Emotion Lexicon | 52.85 | 54.55 | 46.15 | 56.25 | 41.10 | 43.75 | 80.74 | 64.84 |
| Overall | 70.04 | 69.58 | 68.87 | 59.52 | 58.95 | 63.77 | 64.83 | 65.59 |
| Target | Sentiment Polarity (%) |
| Attraction | 66.19 |
| Food & Beverage | 65.39 |
| Accommodation | 66.36 |
| Holiday in general | 64.96 |
| People & Culture | 66.07 |
| Transport | 65.90 |
| Weather | 66.13 |
| Shopping & Gift | 62.96 |
| City Facilities | 65.17 |
| None | 66.84 |
| Overall | 65.59 |
| Metric Method | Neutral | Positive | Negative | Overall Accuracy (%) | Correlation (Proposed System vs. Human) | ||||||
| Precision (%) | Recall (%) | F-Measure (%) | Precision (%) | Recall (%) | F-Measure (%) | Precision (%) | Recall (%) | F-Measure (%) | |||
| Sentence Level | 53.8 | 89.5 | 67.2 | 90.0 | 55.3 | 68.5 | 42.9 | 41.9 | 42.4 | 66.0 | 0.631 |
| Post Level | 57.0 | 89.3 | 69.6 | 89.0 | 57.7 | 70.0 | 32.3 | 35.7 | 33.9 | 67.6 | 0.625 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alaei, A.; Wang, Y.; Bui, V.; Stantic, B. Target-Oriented Data Annotation for Emotion and Sentiment Analysis in Tourism Related Social Media Data. Future Internet 2023, 15, 150. https://doi.org/10.3390/fi15040150
Alaei A, Wang Y, Bui V, Stantic B. Target-Oriented Data Annotation for Emotion and Sentiment Analysis in Tourism Related Social Media Data. Future Internet. 2023; 15(4):150. https://doi.org/10.3390/fi15040150
Chicago/Turabian StyleAlaei, Alireza, Ying Wang, Vinh Bui, and Bela Stantic. 2023. "Target-Oriented Data Annotation for Emotion and Sentiment Analysis in Tourism Related Social Media Data" Future Internet 15, no. 4: 150. https://doi.org/10.3390/fi15040150
APA StyleAlaei, A., Wang, Y., Bui, V., & Stantic, B. (2023). Target-Oriented Data Annotation for Emotion and Sentiment Analysis in Tourism Related Social Media Data. Future Internet, 15(4), 150. https://doi.org/10.3390/fi15040150