
A Multipath Data-Scheduling Strategy Based on Path Correlation for Information-Centric Networking

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We introduce a multipath transmission method applied to ICN which establishes multiple end-to-end relay paths by treating ICN routers as relays between the source and the destination.
- We propose a relay-node-selection algorithm based on path correlation to minimize the impact of overlapping links. Moreover, we comprehensively calculate the path state value by combining round-trip time (RTT) and packet loss rate and propose a multipath data-scheduling algorithm based on the path state value.
- We evaluate the proposed method through a series of simulation experiments. Experimental results show that the proposed method can maintain high bandwidth utilization while reducing the number of out-of-order packets.
2. Related Works
2.1. Multipath Transmission Technology
2.2. Multipath Data-Scheduling Strategy
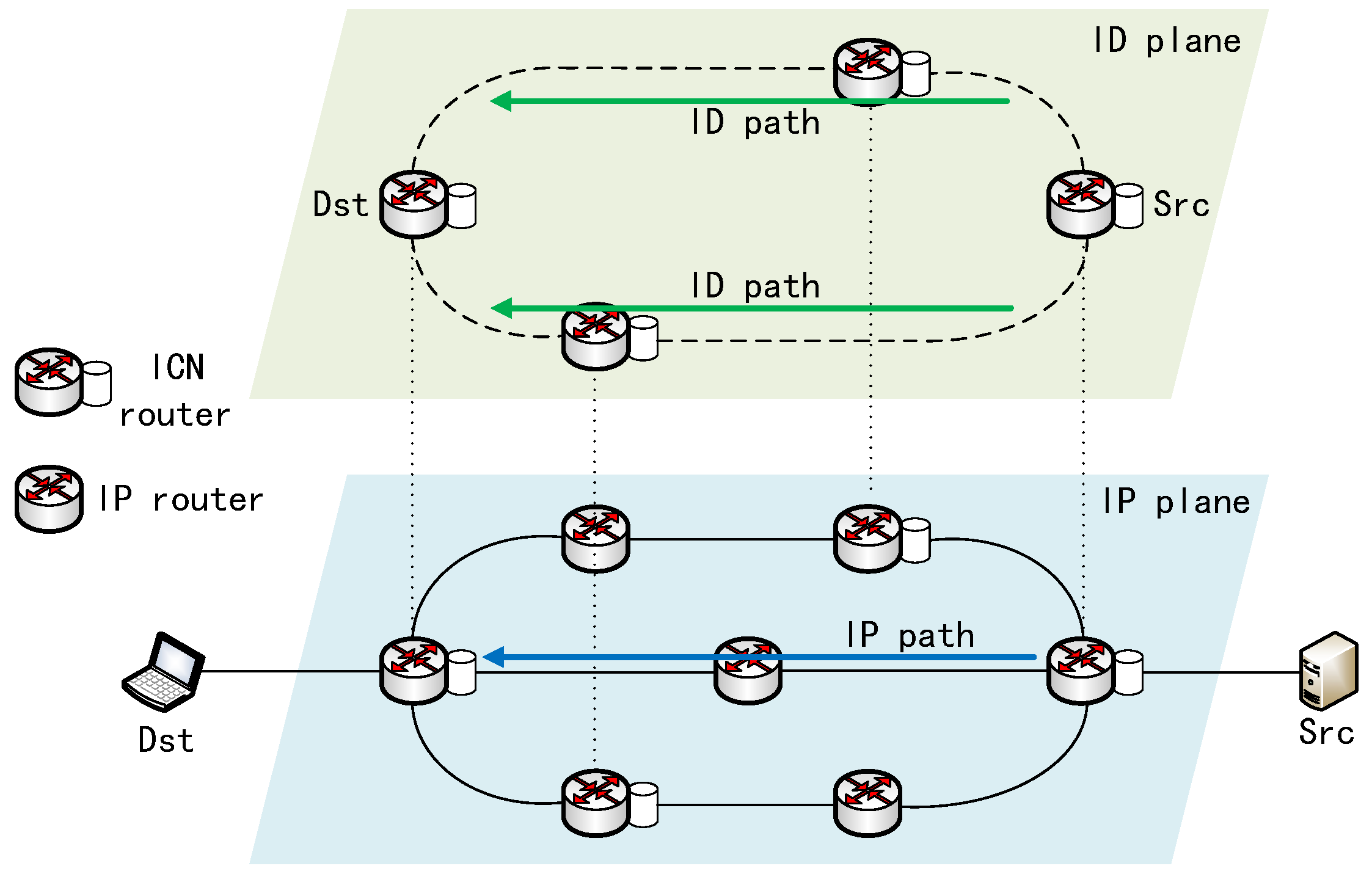
3. System Design
Multipath Transmission Mechanism
4. Multipath Data Scheduling
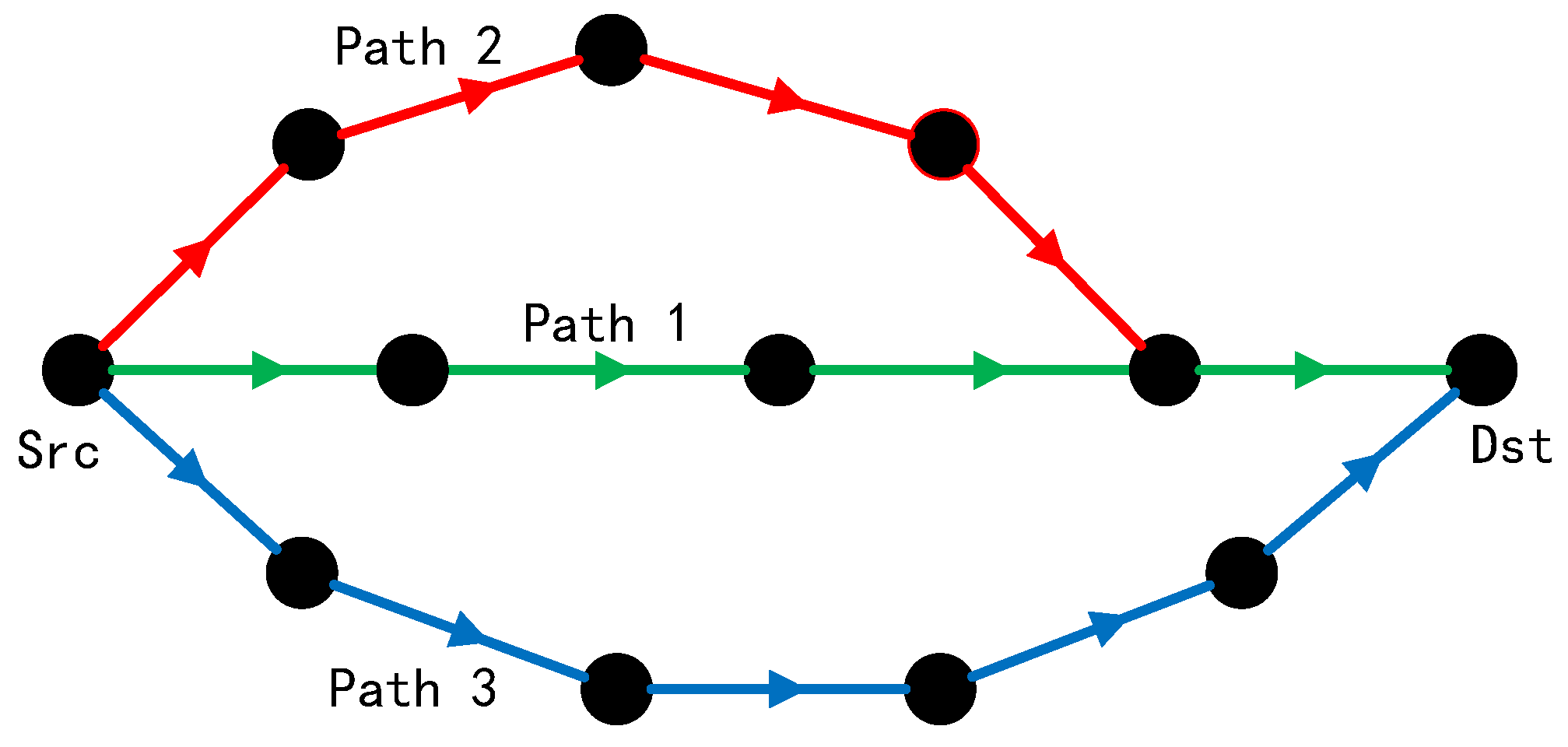
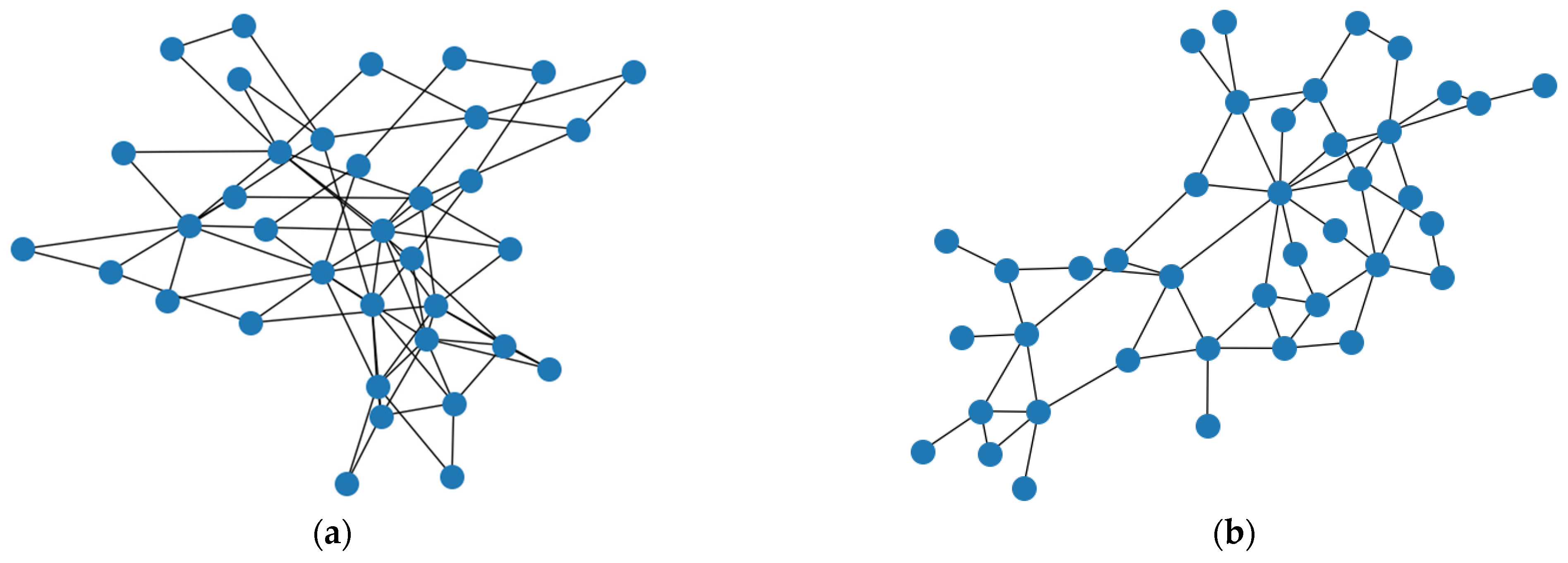
4.1. Path Correlation Analysis
| Algorithm 1 Relay-Node-Selection Algorithm |
| 1: Input: G(V,E), src, dst, k, MPSID 2: Output: S, P 3: R = QueryFromNRS(MPSID) 4: defaultPath = dijkstra_path(src,dst) 5: P.add(defaultPath) 6: if hit (src, dst) cache then 7: determine S and P based on the path correlation information 8: else if 9: for i = 1 to M do 10: if relayPath(i) is independent of the path in P then 11: P.add(relayPath(i)) 12: S.add(Node(i)) 13: end if 14: if |S| = k then 15: break; 16: end if 17: end for 18: end if 19: return S, P |
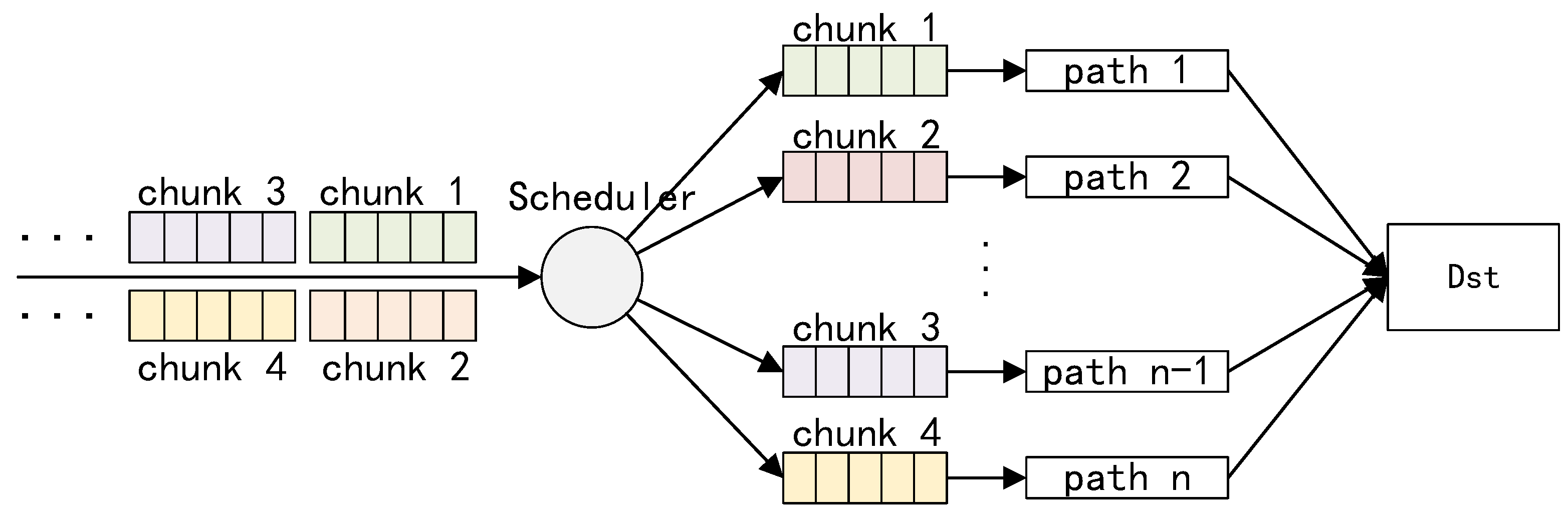
4.2. Data Scheduling
| Algorithm 2 Data-Scheduling Algorithm |
| 1: Initialization: , , , 2: for every scheduling cycle during transmission do 3: for each sub-path do 4: count the and of selected path 5: if then 6: 7: end if 8: if then 9: 10: end if 11: if then 12: 13: end if 14: if then 15: 16: end if 17: calculate and according to Formula (9) and (10) 18: calculate according to Formula (8) 19: end for 20: distribute the chunk to the sub-path with the best state value 21: end for |
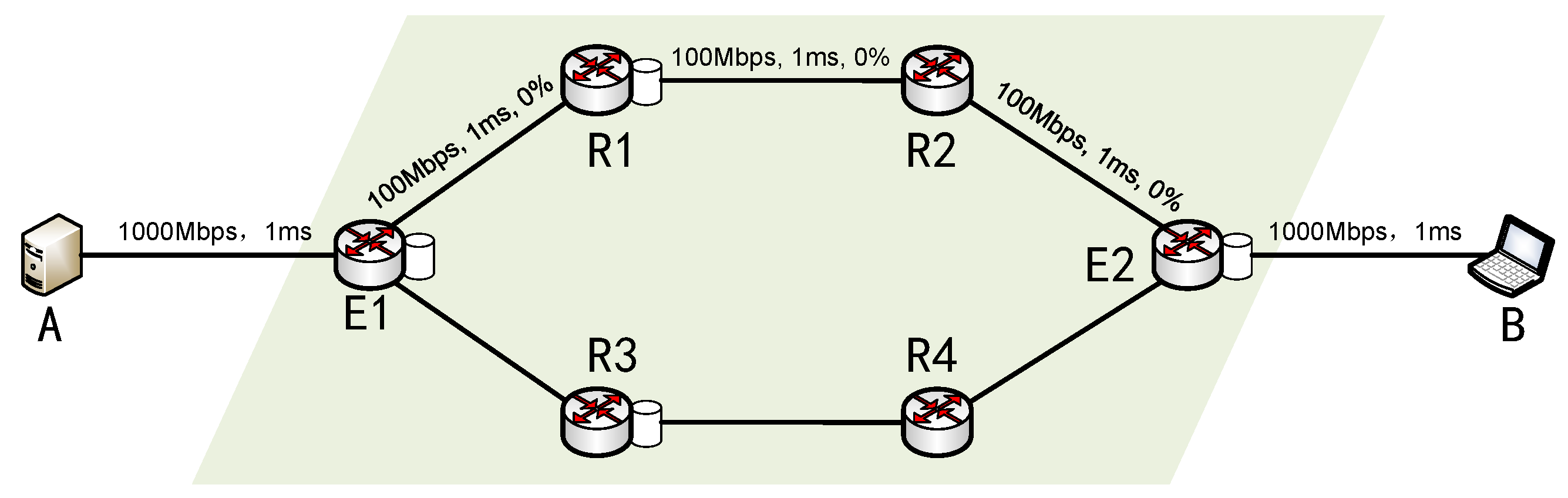
5. Evaluation
5.1. Basic Performance Evaluation
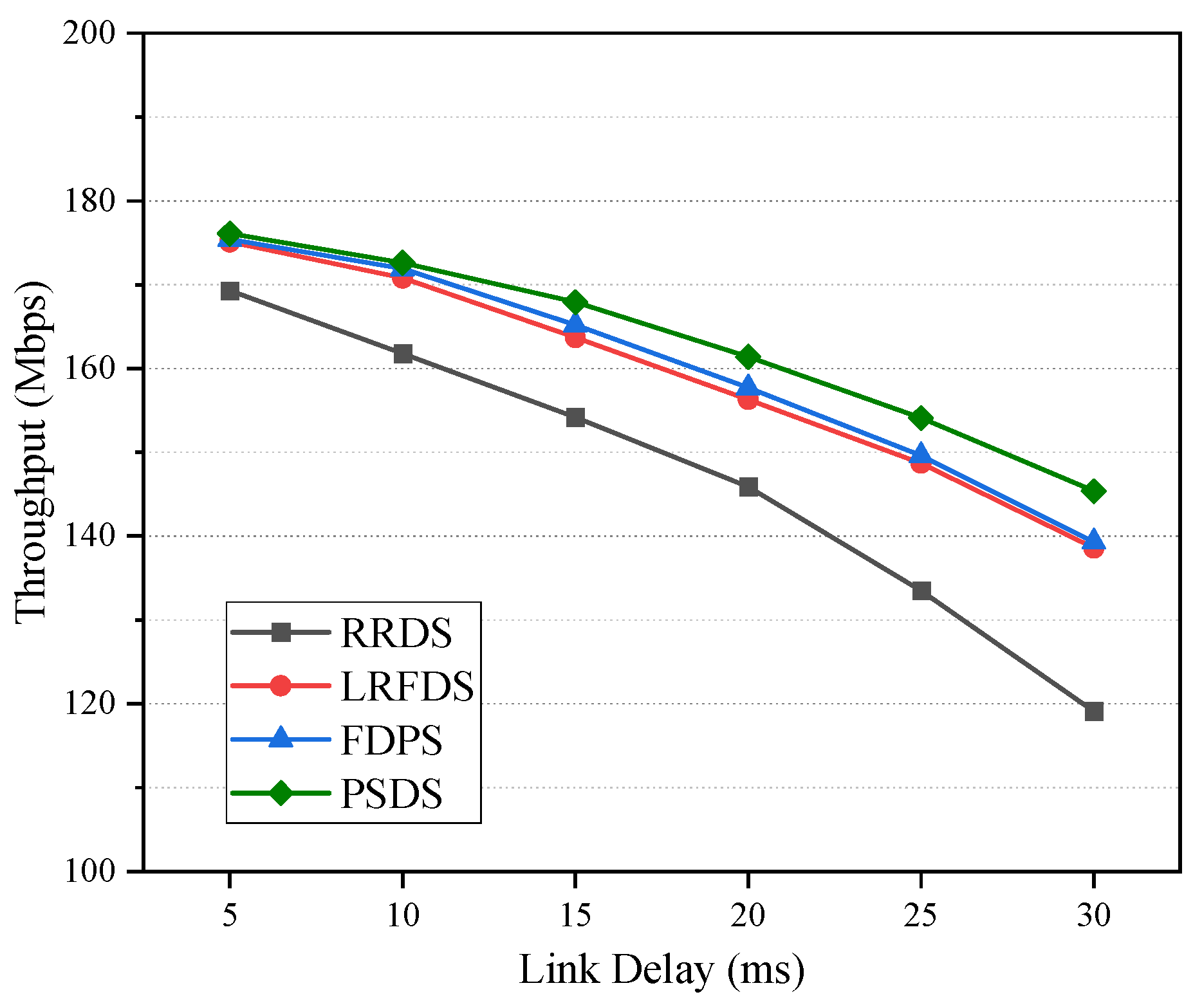
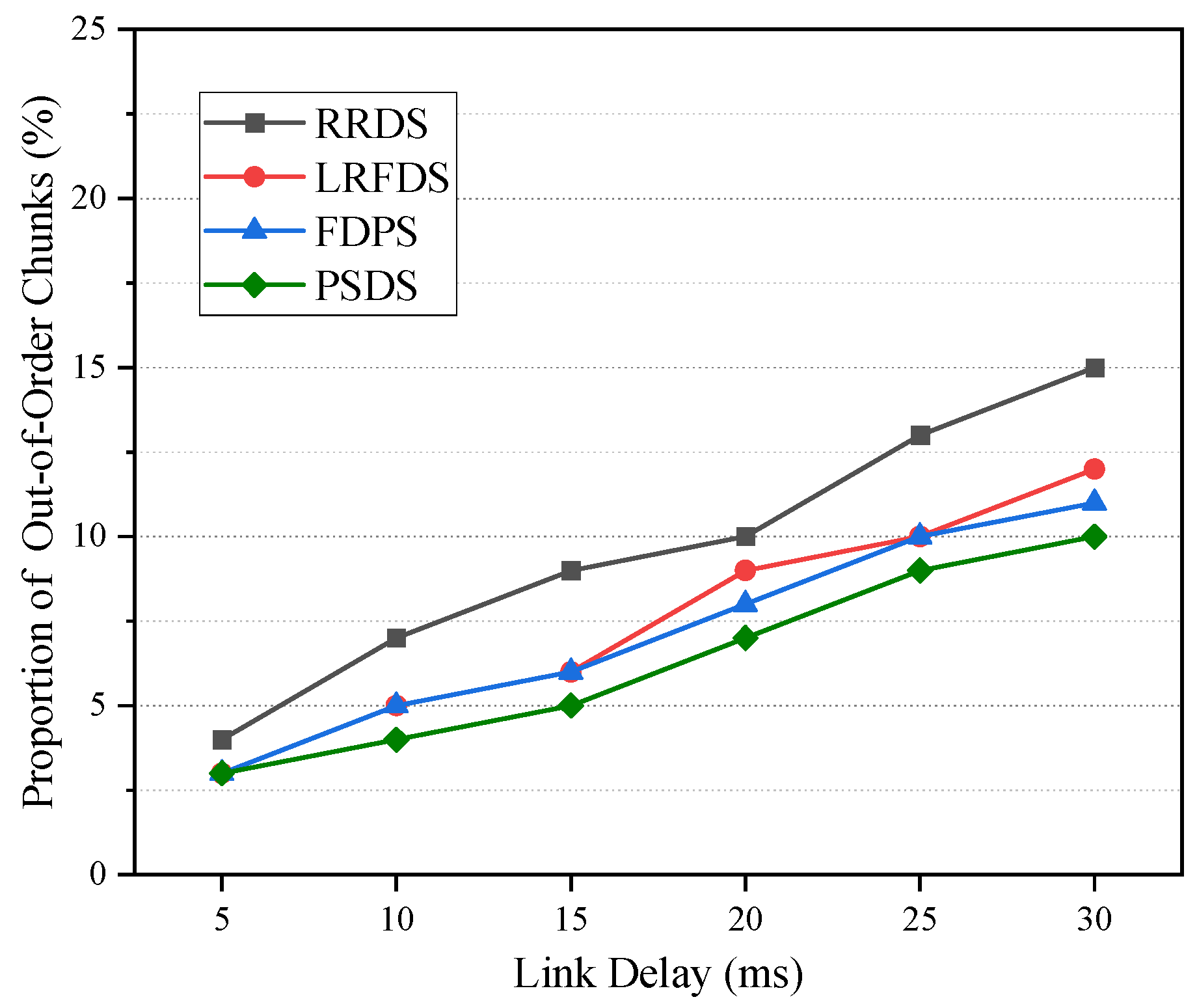
5.1.1. The Effect of Delay on Performance
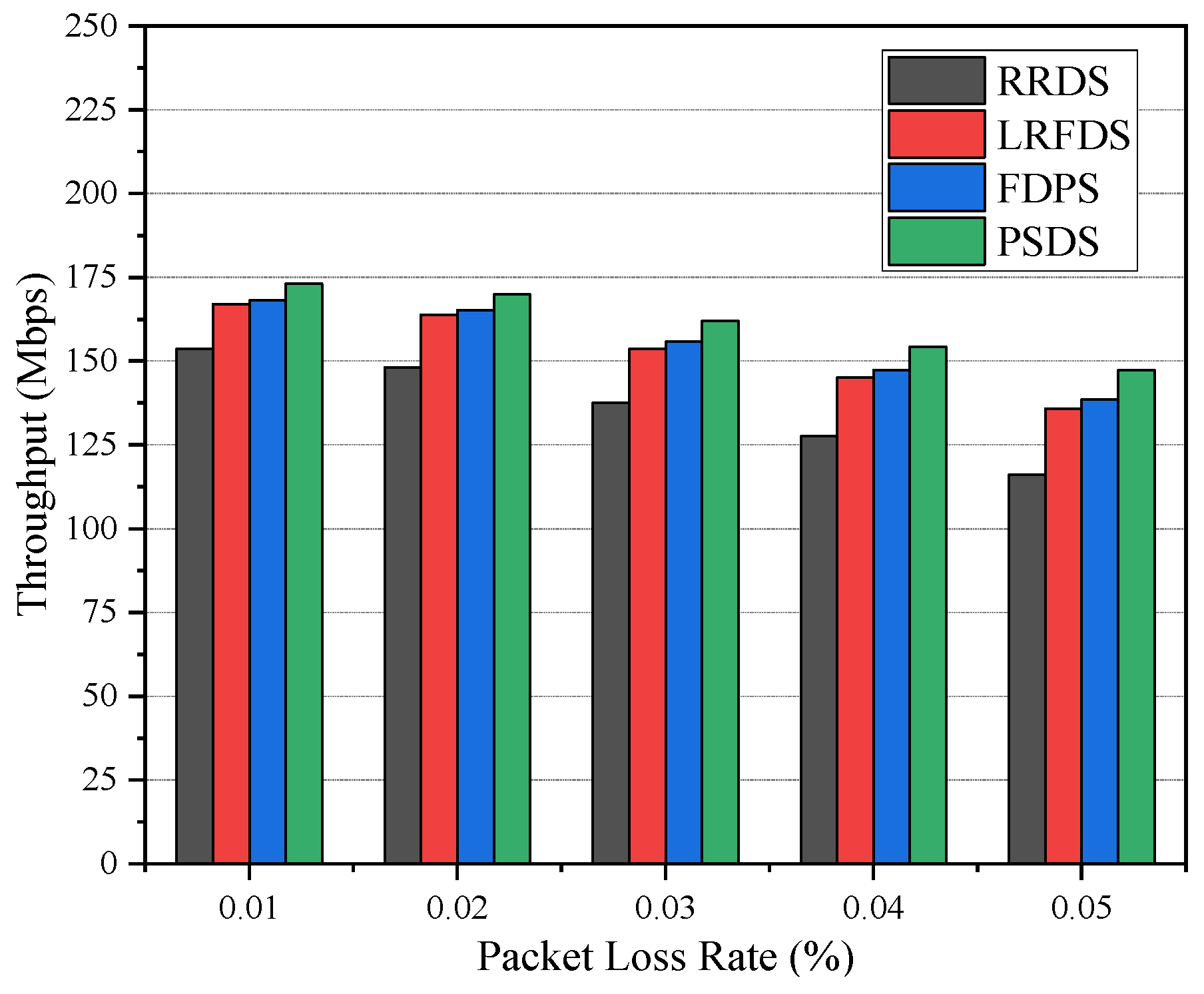
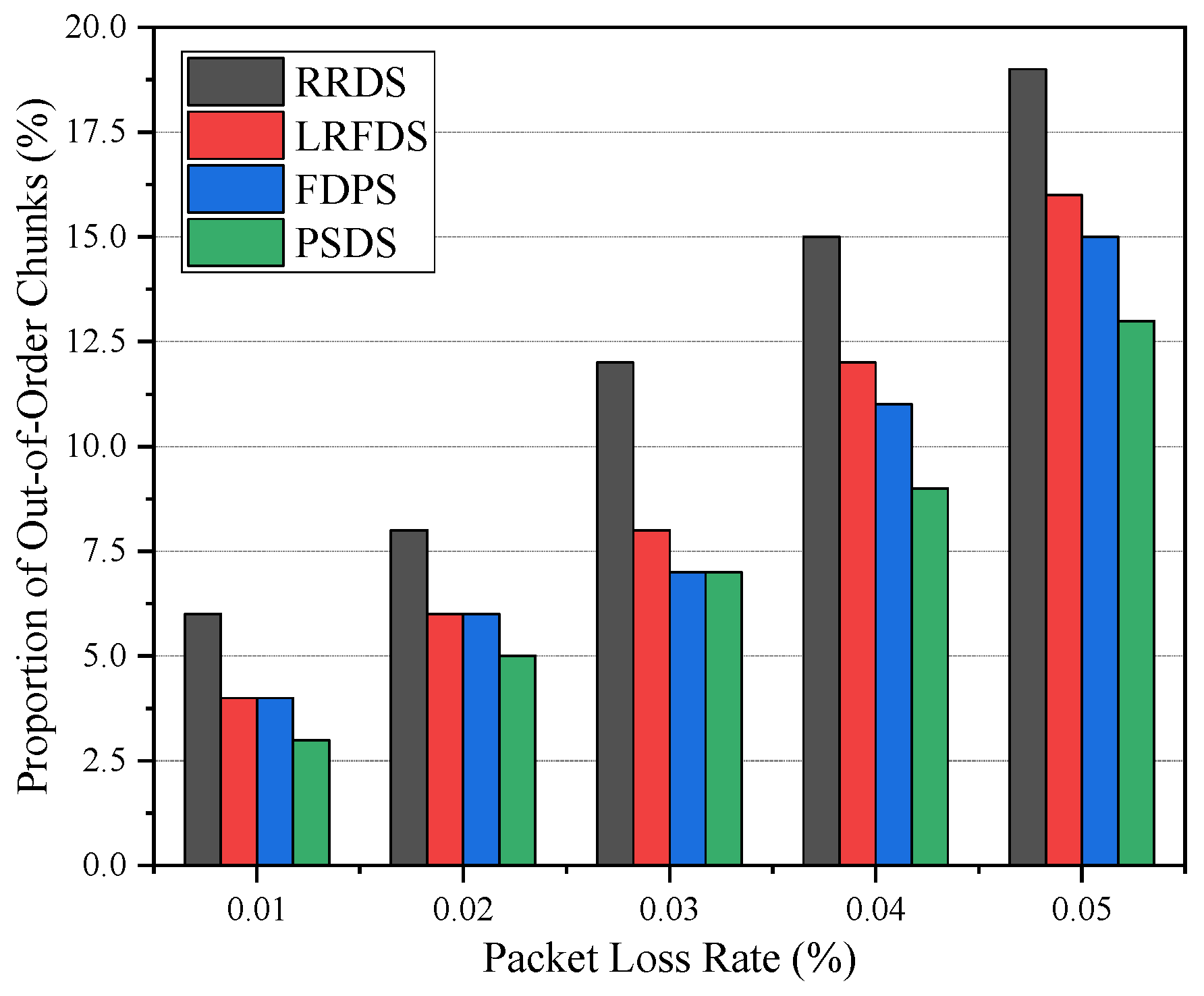
5.1.2. The Effect of Loss Rate on Performance
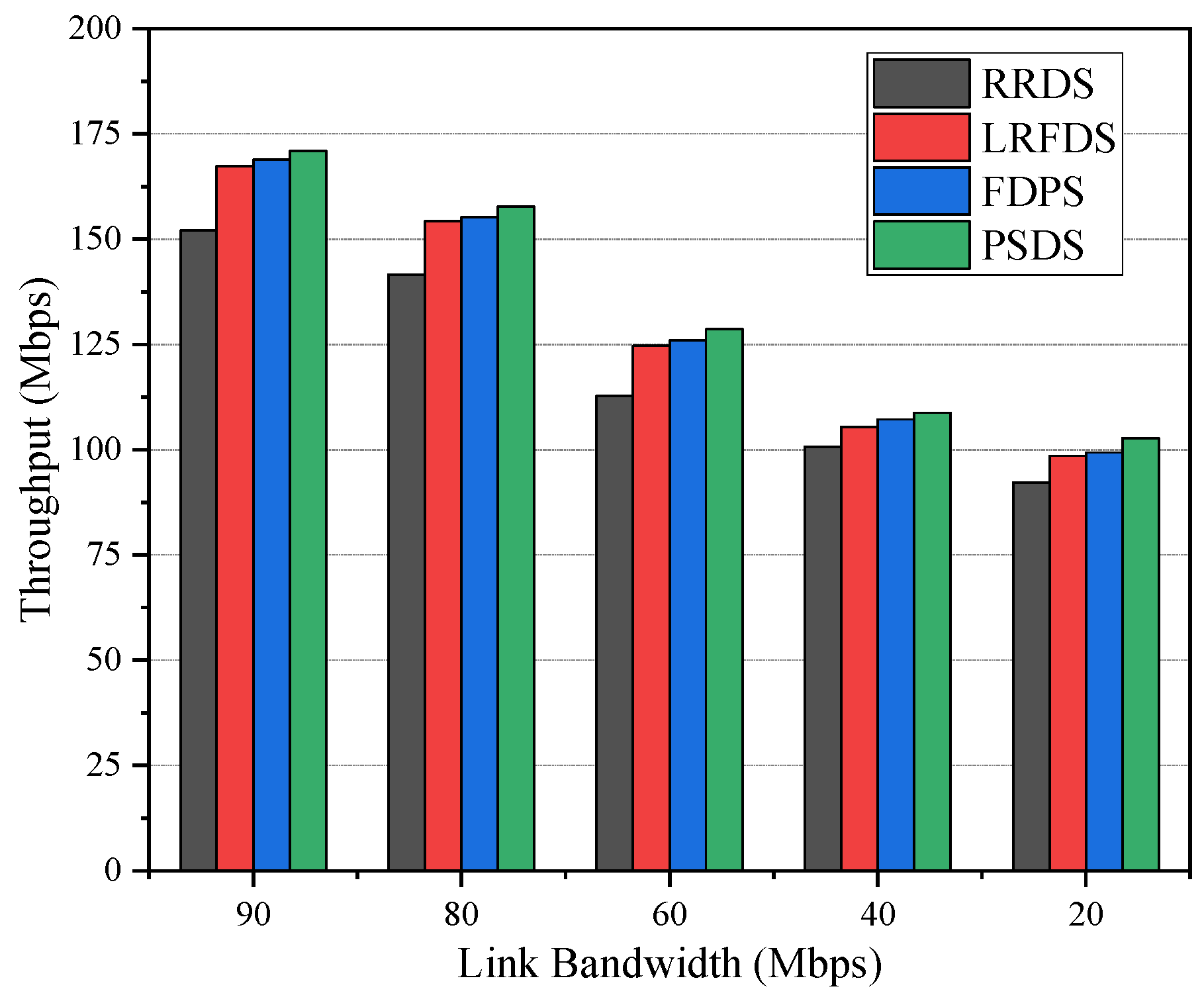
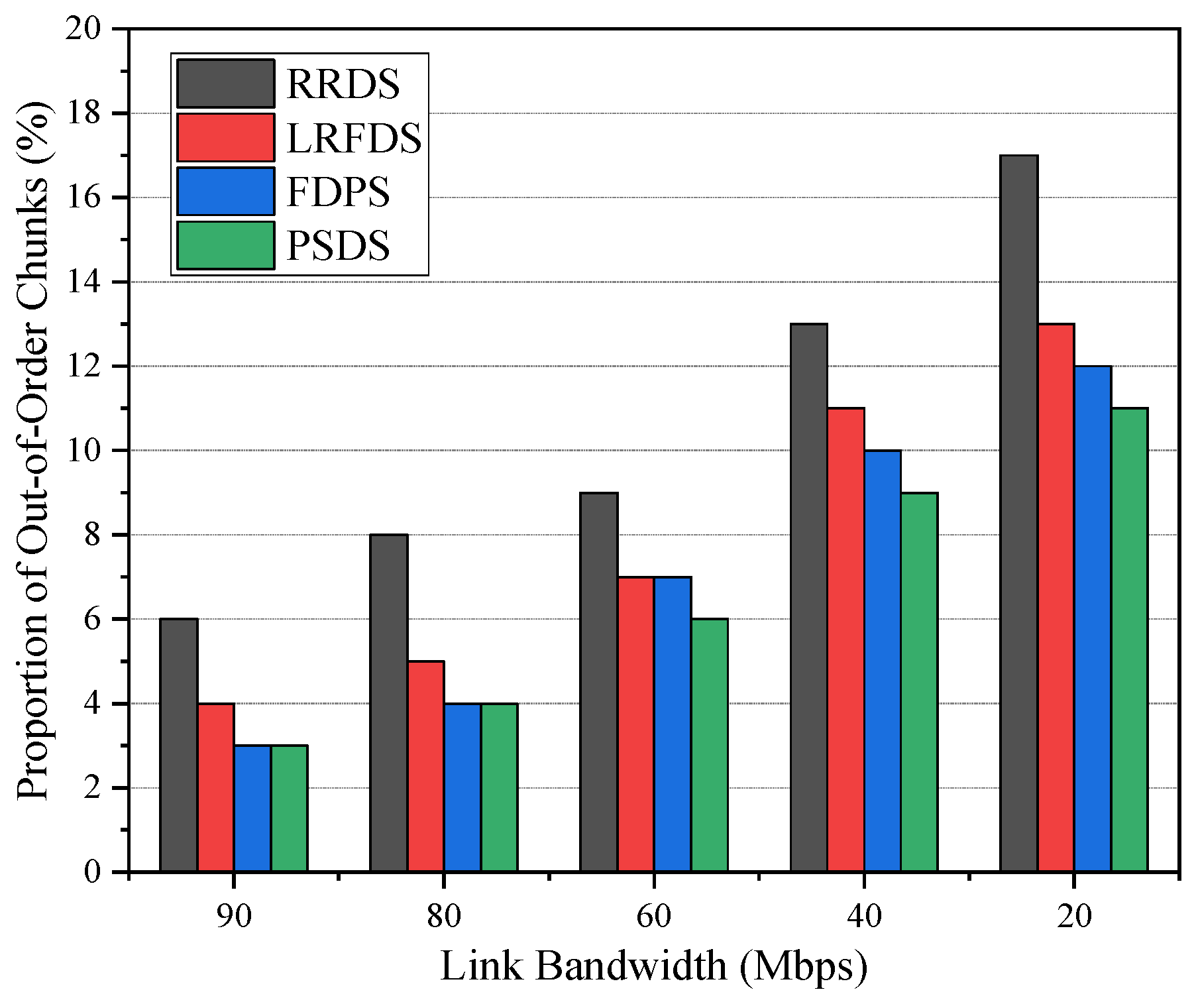
5.1.3. The Effect of Bandwidth on Performance
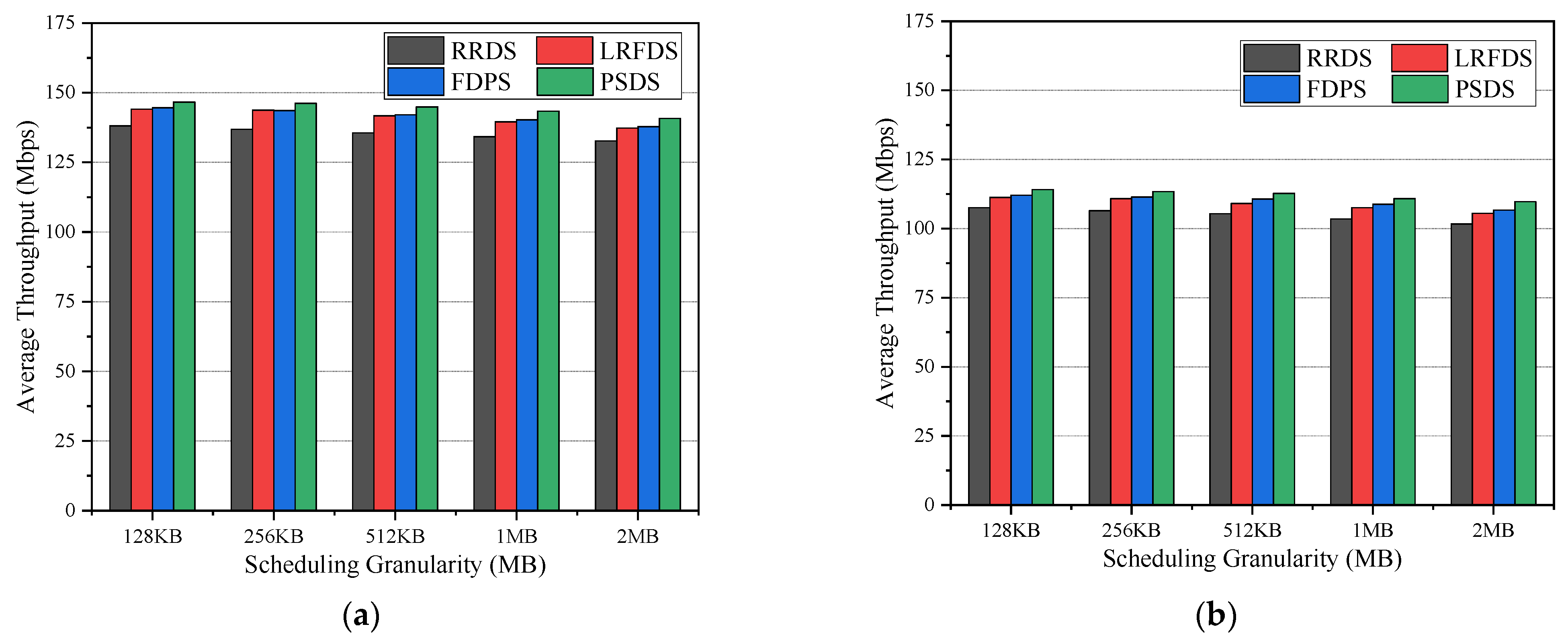
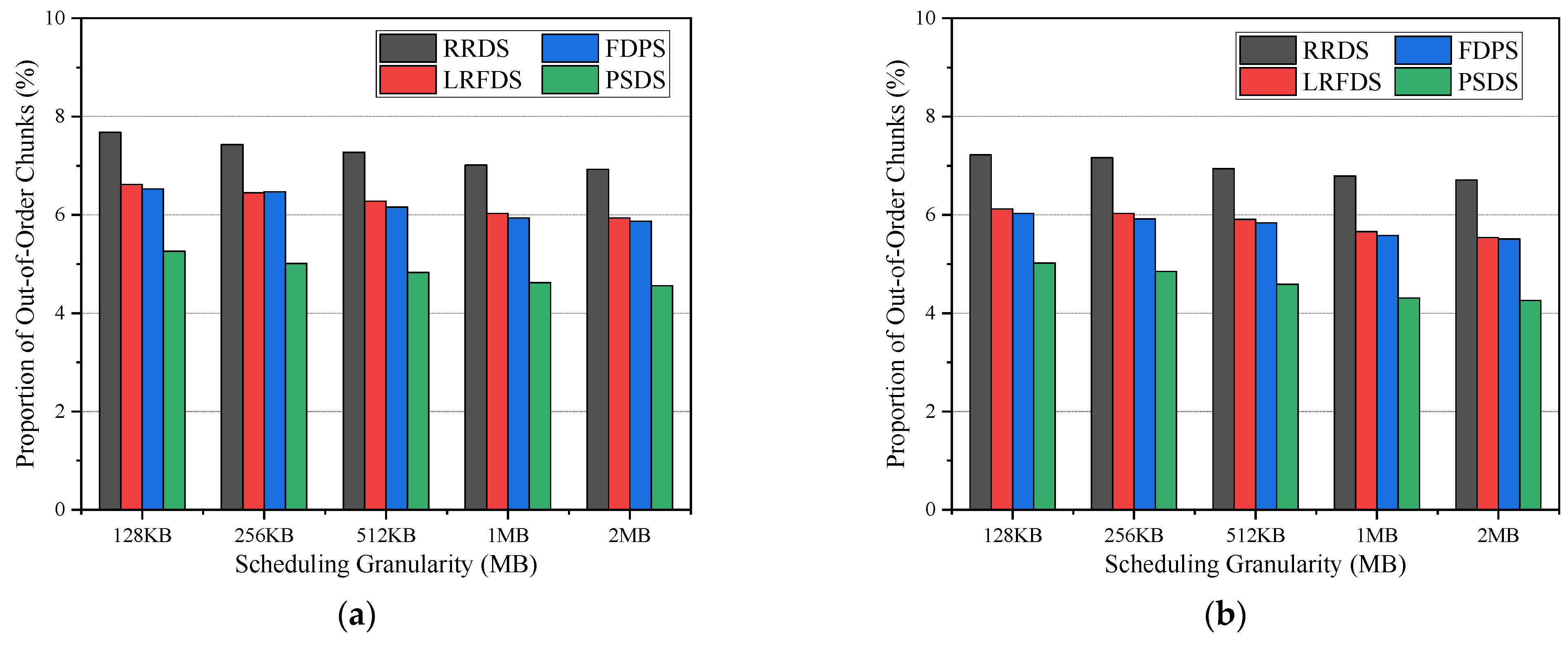
5.2. Comprehensive Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Passarella, A.J.C.C. A survey on content-centric technologies for the current Internet: CDN and P2P solutions. Comput. Commun. 2012, 35, 1–32. [Google Scholar] [CrossRef]
- Ahlgren, B.; Dannewitz, C.; Imbrenda, C.; Kutscher, D.; Ohlman, B.J.I.C.M. A survey of information-centric networking. IEEE Commun. Mag. 2012, 50, 26–36. [Google Scholar] [CrossRef]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking named content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 1–12. [Google Scholar]
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Claffy, K.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B.J.A.S.C.C.R. Named data networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Saxena, D.; Raychoudhury, V.; Suri, N.; Becker, C.; Cao, J.J.C.S.R. Named data networking: A survey. Comput. Sci. Rev. 2016, 19, 15–55. [Google Scholar] [CrossRef]
- Trossen, D.; Parisis, G.J.I.C.M. Designing and Realizing an Information-Centric Internet. IEEE Commun. Mag. 2012, 50, 60–67. [Google Scholar] [CrossRef]
- Raychaudhuri, D.; Nagaraja, K.; Venkataramani, A.J.A.S.M.C.; Review, C. Mobilityfirst: A robust and trustworthy mobility-centric architecture for the future internet. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2012, 16, 2–13. [Google Scholar] [CrossRef]
- Dannewitz, C.; Kutscher, D.; Ohlman, B.; Farrell, S.; Ahlgren, B.; Karl, H.J.C.C. Network of Information (NetInf)—An informationcentric networking architecture. Comput. Commun. 2013, 36, 721–735. [Google Scholar] [CrossRef]
- Wang, J.; Chen, G.; You, J.; Sun, P. SEANet: Architecture and Technologies of an On-Site, Elastic, Autonomous Network. J. Netw. New Media 2020, 9, 1–8. [Google Scholar]
- Hopps, C. Analysis of an Equal-Cost Multi-Path Algorithm. Available online: https://datatracker.ietf.org/doc/html/rfc2992 (accessed on 9 February 2023).
- Filsfils, C.; Previdi, S.; Ginsberg, L.; Decraene, B.; Litkowski, S.; Shakir, R. Segment Routing Architecture. Available online: https://www.rfc-editor.org/rfc/rfc8402 (accessed on 9 February 2023).
- Ventre, P.L.; Tajiki, M.M.; Salsano, S.; Filsfils, C. SDN architecture and southbound APIs for IPv6 segment routing enabled wide area networks. IEEE Trans. Netw. Serv. 2018, 15, 1378–1392. [Google Scholar] [CrossRef]
- Scharf, M.; Ford, A. Multipath TCP (MPTCP) Application Interface Considerations. Available online: https://www.rfc-editor.org/rfc/rfc6897 (accessed on 9 February 2023).
- Stewart, R.; Metz, C. SCTP: New transport protocol for TCP/IP. IEEE Internet Comput. 2001, 5, 64–69. [Google Scholar] [CrossRef]
- Savage, S.; Anderson, T.; Aggarwal, A.; Becker, D.; Cardwell, N.; Collins, A.; Hoffman, E.; Snell, J.; Vahdat, A.; Voelker, G.J.I.M. Detour: Informed Internet routing and transport. IEEE Micro 1999, 19, 50–59. [Google Scholar] [CrossRef]
- Andersen, D.; Balakrishnan, H.; Kaashoek, F.; Morris, R. Resilient overlay networks. In Proceedings of the Eighteenth ACM Symposium on Operating Systems Principles, Banff Alberta, AB, Canada, 21–24 October 2001; pp. 131–145. [Google Scholar]
- Luo, J.; Hu, J.; Wu, D.; Li, R. Opportunistic routing algorithm for relay node selection in wireless sensor networks. IEEE Trans. Ind. Inform. 2014, 11, 112–121. [Google Scholar] [CrossRef]
- Tuah, N.; Ismail, M. Extending lifetime of heterogenous wireless sensor network using relay node selection. In Proceedings of the 2013 International Conference of Information and Communication Technology (ICoICT), Bandung, Indonesia, 20–22 March 2013; pp. 17–21. [Google Scholar]
- Romanov, A.; Myachin, N.; Sukhov, A. Fault-tolerant routing in networks-on-chip using self-organizing routing algorithms. In Proceedings of the IECON 2021–47th Annual Conference of the IEEE Industrial Electronics Society, Toronto, ON, Canada, 13–16 October 2021; pp. 1–6. [Google Scholar]
- Zhou, J.; Tewari, M.; Zhu, M.; Kabbani, A.; Poutievski, L.; Singh, A.; Vahdat, A. WCMP: Weighted cost multipathing for improved fairness in data centers. In Proceedings of the Ninth European Conference on Computer Systems, Amsterdam, The Netherlands, 14–16 April 2014; pp. 1–14. [Google Scholar]
- Moy, J. OSPF Version 2. Available online: https://www.rfc-editor.org/rfc/rfc2178 (accessed on 9 February 2023).
- Han, J.; Watson, D.; Jahanian, F. Topology aware overlay networks. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; pp. 2554–2565. [Google Scholar]
- Jin, J.; Nahrstedt, K. QoS service routing in one-to-one and one-to-many scenarios in next-generation service-oriented networks. In Proceedings of the IEEE International Conference on Performance, Computing, and Communications, Phoenix, AZ, USA, 15–17 April 2004; pp. 503–510. [Google Scholar]
- Roy, S.; Pucha, H.; Zhang, Z.; Hu, Y.C.; Qiu, L. On the placement of infrastructure overlay nodes. IEEE/ACM Trans. Netw. 2009, 17, 1298–1311. [Google Scholar] [CrossRef]
- Cha, M.; Moon, S.; Park, C.-D.; Shaikh, A. Placing relay nodes for intra-domain path diversity. In Proceedings of the 25th IEEE International Conference on Computer Communications, Barcelona, Spain, 23–29 April 2006; pp. 1–12. [Google Scholar]
- Paasch, C.; Ferlin, S.; Alay, O.; Bonaventure, O. Experimental evaluation of multipath TCP schedulers. In Proceedings of the 2014 ACM SIGCOMM Workshop on Capacity Sharing Workshop, Chicago, IL, USA, 18 August 2014; pp. 27–32. [Google Scholar]
- Le, T.-A.; Bui, L.X. Forward delay-based packet scheduling algorithm for multipath TCP. Mob. Netw. Appl. 2018, 23, 4–12. [Google Scholar] [CrossRef]
- Vu, V.A.; Walker, B. Redundant multipath-tcp scheduling with desired packet latency. In Proceedings of the 14th Workshop on Challenged Networks, Los Cabos, Mexico, 21–25 October 2019; pp. 7–12. [Google Scholar]
- Cao, Z.; Wang, Z.; Zegura, E. Performance of hashing-based schemes for internet load balancing. In Proceedings of the IEEE INFOCOM 2000. Conference on Computer Communications. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies, Tel Aviv, Israel, 26–30 March 2000; pp. 332–341. [Google Scholar]
- Mirani, F.H.; Boukhatem, N.; Tran, M.A. A data-scheduling mechanism for multi-homed mobile terminals with disparate link latencies. In Proceedings of the 2010 IEEE 72nd Vehicular Technology Conference-Fall, Ottawa, ON, Canada, 6–9 September 2010; pp. 1–5. [Google Scholar]
- Ni, D.; Xue, K.; Hong, P.; Shen, S. Fine-grained forward prediction based dynamic packet scheduling mechanism for multipath TCP in lossy networks. In Proceedings of the 2014 23rd International Conference on Computer Communication and Networks (ICCCN), Shanghai, China, 4–7 August 2014; pp. 1–7. [Google Scholar]
- Shafiee, M.; Ghaderi, J. A simple congestion-aware algorithm for load balancing in datacenter networks. IEEE/ACM Trans. Netw. 2017, 25, 3670–3682. [Google Scholar] [CrossRef]
- Perry, J.; Ousterhout, A.; Balakrishnan, H.; Shah, D.; Fugal, H. Fastpass: A centralized” zero-queue” datacenter network. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; pp. 307–318. [Google Scholar]
- Xu, Y.; Ni, H.; Zhu, X. An Effective Transmission Scheme Based on Early Congestion Detection for Information-Centric Network. Electronics 2021, 10, 2205. [Google Scholar] [CrossRef]
- Liao, J.; Tian, S.; Wang, J.; Li, T.; Qi, Q. Load-balanced one-hop overlay multipath routing with path diversity. KSII Trans. Internet Inf. Syst. 2014, 8, 443–461. [Google Scholar]
- Brandes, U. On variants of shortest-path betweenness centrality and their generic computation. Soc. Netw. 2008, 30, 136–145. [Google Scholar] [CrossRef]
- Cohen, R.; Raz, D. Cost-effective resource allocation of overlay routing relay nodes. IEEE/ACM Trans. Netw. 2013, 22, 636–646. [Google Scholar] [CrossRef]
- Bui, V.; Zhu, W.; Bui, L. Optimal relay placement for maximizing path diversity in multipath overlay networks. In Proceedings of the 2008 IEEE Global Telecommunications Conference, New Orleans, LA, USA, 30 November–4 December 2008; pp. 1–6. [Google Scholar]
- ns-3 Network Simulator. Available online: https://www.nsnam.org (accessed on 1 April 2023).
- Knight, S.; Nguyen, H.X.; Falkner, N.; Bowden, R.; Roughan, M. The internet topology zoo. IEEE J. Sel. Areas Commun. 2011, 29, 1765–1775. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Ni, H.; Zhu, X. A Multipath Data-Scheduling Strategy Based on Path Correlation for Information-Centric Networking. Future Internet 2023, 15, 148. https://doi.org/10.3390/fi15040148
Xu Y, Ni H, Zhu X. A Multipath Data-Scheduling Strategy Based on Path Correlation for Information-Centric Networking. Future Internet. 2023; 15(4):148. https://doi.org/10.3390/fi15040148
Chicago/Turabian StyleXu, Yong, Hong Ni, and Xiaoyong Zhu. 2023. "A Multipath Data-Scheduling Strategy Based on Path Correlation for Information-Centric Networking" Future Internet 15, no. 4: 148. https://doi.org/10.3390/fi15040148
APA StyleXu, Y., Ni, H., & Zhu, X. (2023). A Multipath Data-Scheduling Strategy Based on Path Correlation for Information-Centric Networking. Future Internet, 15(4), 148. https://doi.org/10.3390/fi15040148