1. Introduction
The Internet, a complex network facilitating the exchange of information via websites and APIs, has greatly influenced various sectors like email, education, healthcare, and entertainment, optimizing data dissemination [
1,
2,
3]. This evolution gave rise to the Internet of Everything (IoE), an architectural framework that enables access to a vast array of digital content [
4]. Key areas of multimedia consumption include education, cinema, music, literature, gaming, streaming services, and software [
5].
Legal measures, as per the Digital Millennium Copyright Act (DMCA), are essential to protect copyrights on IoE platforms against illegal copying and distribution, also referred to as infringing content [
6,
7]. However, The IoE’s extensive volume poses challenges in monitoring and controlling the distribution of infringing content, despite legal and technical efforts to conduct takedowns [
8,
9]. Historical instances, like the legal actions against Napster in 2001 for pirated music and Megaupload in 2012 for unauthorized downloads, highlight the ongoing struggle against digital unauthorized sharing and its legal consequences [
10,
11].
Despite efforts to combat infringing content, the dissemination of IoE continues to grow. According to [
12], the increased use of information technologies (IT) during the SARS-CoV-19 pandemic led to a significant rise in intellectual property theft, with an estimated
trillion infringed files dispersed by the end of 2021 through websites, video-streaming apps, online social media platforms (OSNs), and instant messaging channels. Data from 2022 [
13] confirm this trend, with search engines like Google Search [
14] generating
million URLs linked to potentially bypassed authorship-claimed digital works.
The UK Government’s Intellectual Property Office [
15,
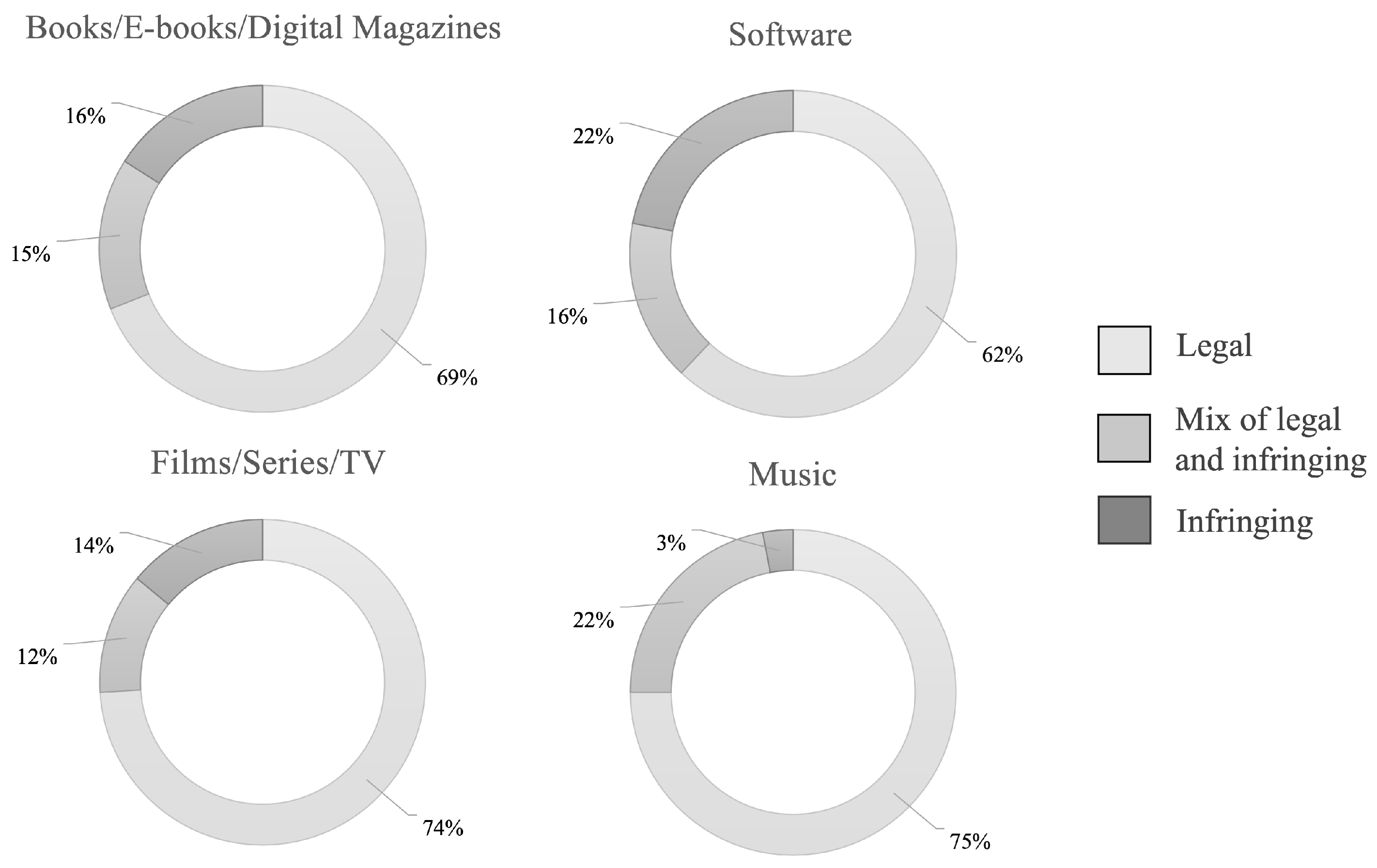
16] annually issues the Online Copyright Infringement Tracking Report, which examines the browsing behavior of a representative sample of users based on their queries in various search engines. This analysis contributes to the classification of websites, guided by the nature and reputation of the content they offer, meticulously evaluating potential infringements of intellectual property rights. Within this framework, the categorization of websites in terms of copyright infringement is segmented into three categories: legal, mixed legal and infringing, and infringing sites. The first category, pertaining to legal sites, is dedicated to promoting, offering, and distributing content endorsed by the authors or their representatives, as well as works belonging to the public domain. The second category, the mixed ones, partially conform to intellectual property regulations, hosting both authorized works and those that are not. The sites in the third category, identified as infringers, engage in a total violation of intellectual property rights, with the reasons for and consequences of such infringement falling under the purview and discretion of the site’s owner and administrator.
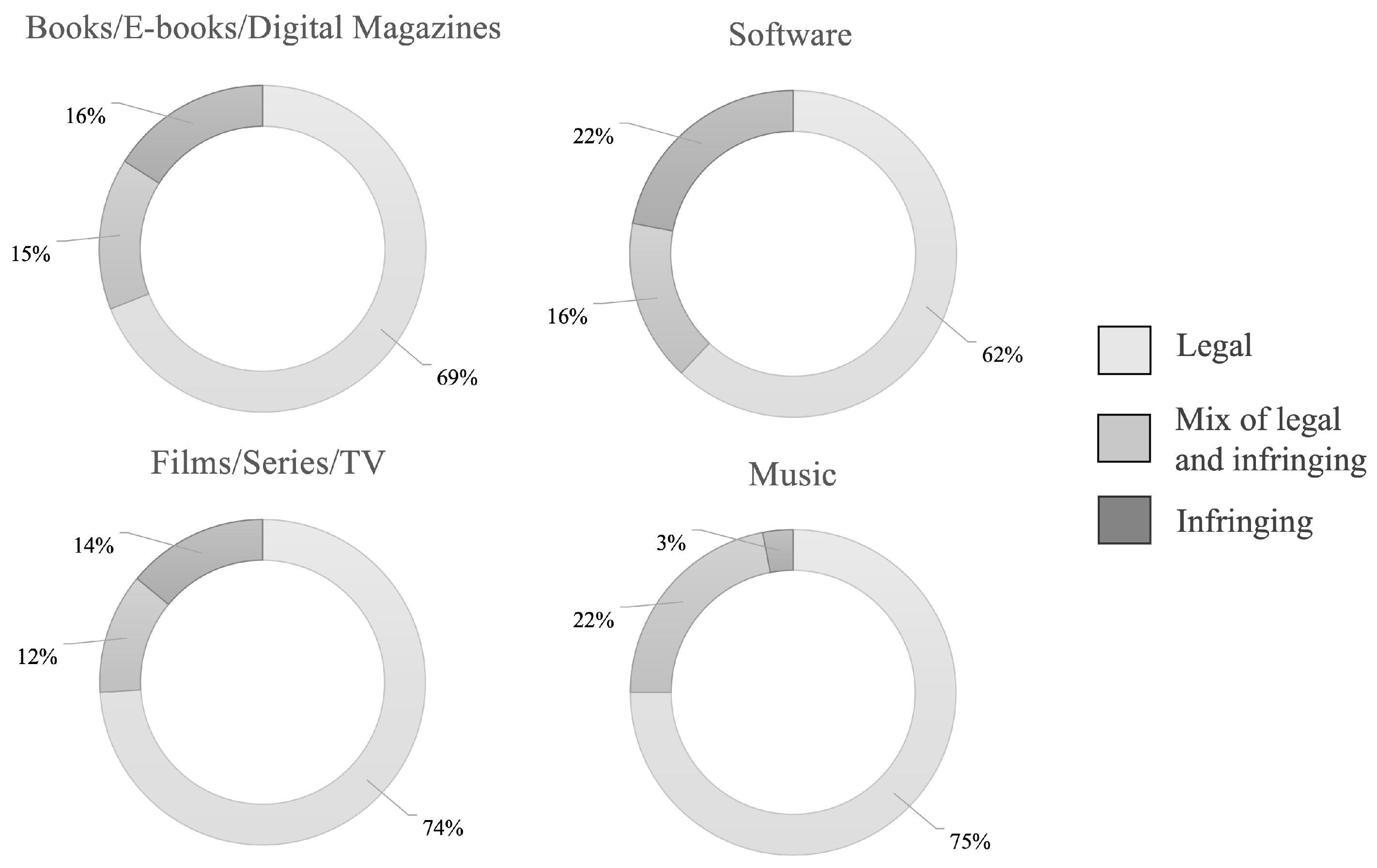
In
Figure 1, the most frequently consumed categories are detailed according to the indices previously mentioned. These, are divided by the type of material and how users accessed the content: books/E-books/digital magazines, software, film/series/TV, and music.
Following this train of thought, there emerges a discernible concern and an overriding need to identify and eliminate materials that infringe copyright in the IoE, through a more efficient and automated process [
12,
13,
15,
16]. According to [
17,
18], in the absence of such measures, the ramifications of these infringements could surpass the mere financial losses currently faced by the industry. These implications include the ethical degradation of work, the introduction of biases in professional training and cultural sectors, a decline in the quality of new creations, and the potential for highly sought-after works to be used as bait in cyber attacks, encompassing malware, phishing, scams, and electronic fraud.
Currently, two primary methods address websites with infringing content over the IoE: legal removal requests and technical tools for scanning and flagging content [
19,
20]. Responsibility for this falls to entities like the DMCA and the World Intellectual Property Organization (WIPO) [
21], who assess these requests. Despite this, the high volume of complaints has led to the rise of private monitoring services, whose detection techniques are often undisclosed due to privacy concerns [
22].
Unfortunately, the policies of Internet Service Providers (ISP) can complicate the removal of infringing content, necessitating monitoring for early detection [
23]. Collaborative efforts across industries and academia are developing solutions like browser extensions to deter visits to infringing sites, perimeter security rules to block malicious links, whitelists, and digital watermarking, focusing primarily on prevention scopes [
24,
25,
26].
Although automated searches in this field have not yet fully matured, the value of Artificial Intelligence (AI), Machine Learning (ML), and particularly Deep Learning (DL) as promising alternatives is increasingly being recognized. The predictive capacity of these technologies to identify patterns indicative of copyright infringement in multimedia content is prematurely being explored [
27]. Indeed, current research focuses on unauthorized video sites, academic plagiarism, and unlicensed software, marking a new frontier in proactive exploration for the detection of sites already engaged in infringement.
Even so, preventive, active, or automated strategies are not yet standardized or uniformly structured, thus creating a significant gap for authors who seek to protect their digital multimedia works or to ascertain if these have been disseminated without their authorization. From this consideration, two research inquiries of crucial importance are raised:
First Research Inquiry: In the context of the diverse and varied existing methodologies for safeguarding and discerning rights-infringing content within the realm of the IoE, how could a meticulously structured taxonomy aid authors in making informed and pertinent decisions within their specific contextual framework?
Second Research Inquiry: Within the evolving sphere of IT and acknowledging the scarcity of preceding research in the domain of ML, is it feasible to develop an advanced methodology in ML, employing tracking techniques in the IoE and sophisticated search algorithms, capable of analyzing, processing, and categorizing sites containing potentially infringing content?
The present study addresses the previously posed research questions, focusing on two fundamental axes: firstly, the design of a detailed taxonomy in the domains of SafeGuarding and Active, aimed at managing infringing sites in the IoE, and secondly, the proposal of an innovative methodology for identifying websites that host multimedia content with potential copyright infringement. This research delves into a field that, so far, has received limited attention in the scientific literature [
28,
29,
30,
31,
32,
33,
34,
35]. The main contributions of this work are as follows:
Point 1: This research introduces a novel taxonomy focused on the dual objectives of protecting multimedia works in the IoE and detecting potentially infringing content, developed through a thorough examination of a wide range of scholarly papers and white papers across various digital libraries.
Point 2: This research introduces an advanced automated search methodology, merging web navigation analysis with multi-engine search capabilities, focusing on key content areas like movies and series, music, software, and books [
16]. By harnessing HTML data from websites, the system detects potential copyright violations, ranging from redirects to JavaScript anomalies. It employs BERT (Bidirectional Encoder Representations from Transformers) [
36], a state-of-the-art pre-trained encoder, for an innovative synthesis of textual and numerical data. Subsequently, the data are processed through a fine-tuned Dense Neural Network (DNN), marking a significant advancement in information retrieval in the IoE domain. Hereafter, this methodology will be referred to as BERT + DNN.
The remainder of this document is structured as follows:
Section 2 outlines the construction of a taxonomy of domains, subdomains, and categories that surround the subject of study—multimedia content and copyright. In
Section 3, related work concerning the detection of copyright-infringing material using AI/ML is discussed, delving into their processes and performance.
Section 4 introduces the methodological BERT + DNN framework, detailing the stages of data collection, preprocessing, transformation, fine-tuning, and classification of websites with infringing multimedia content over the IoE.
Section 5 presents, compares, and discusses the results using quantitative performance metrics. Finally,
Section 6 concludes the paper by listing its significant contributions and emphasizing areas that warrant further exploration in future research endeavors.
2. Taxonomy for the Protection and Detection of Infringing Multimedia Content
In the context of research on copyright infringements within the IoE, multiple studies were discovered, marked by a wide variety of methods, techniques, procedures, and approaches that still lack standardization. This represents a considerable challenge in defining a starting point for projects that are to be implemented. The developed taxonomy offers significant advantages, such as the ability to identify how the dynamics of copyright protection or infringement manifest, the structuring of the techniques used, maintaining coherence between legal and technical tasks, integrating new paradigms in AI/ML, as well as its role as a tool adaptable to emerging information technologies.
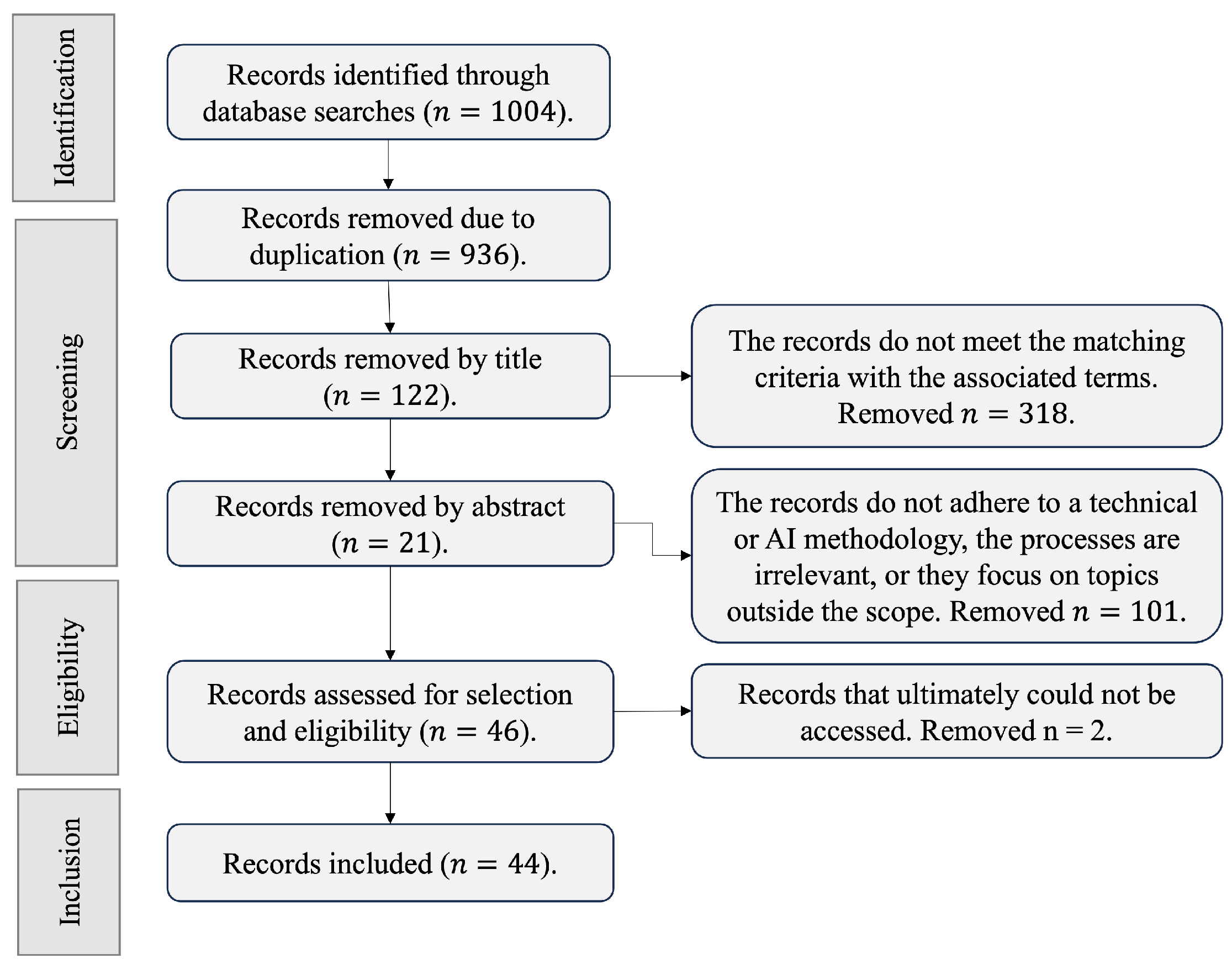
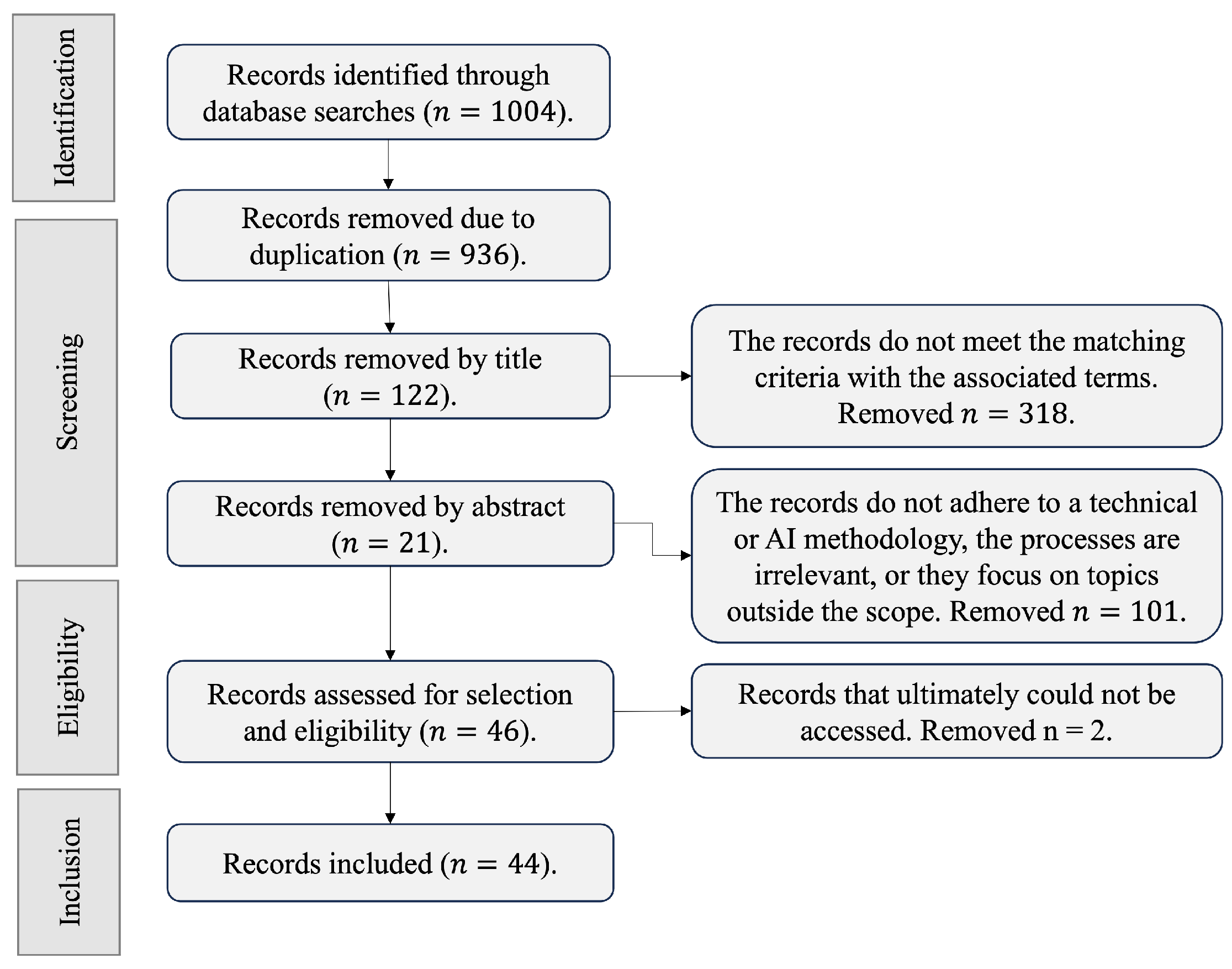
To synthesize the findings, the taxonomic architecture is centered around two primary pillars: the studies that focus on safeguarding digital multimedia materials and those that actively operate by detecting where infringing activity is taking place. The study was directed using a highly effective process for conducting searches of documents about the state-of-the-art, known as Systematic Reviews and Meta-Analyses (PRISMA) [
37]. This method allows for the establishment of a set of explicit criteria to find, filter, and integrate studies, avoiding redundancy or getting sidetracked by searches that lead to irrelevant outcomes. In
Figure 2, the flow of filters used to consolidate the number of relevant records in this research is presented.
To compile an appropriate collection of relevant records, several major scientific publication houses and digital libraries were inspected: EBSCO’s Academic Search [
38], Taylor and Francis Online [
39], Springer Link [
40], Elsevier Science Direct [
41], Oxford Academic [
42], Wiley Online Library [
43], Scopus [
44], IEEE Explore [
45], ACM Digital Library [
46], and MDPI [
47]. This task was undertaken using search terms such as
digital piracy detection,
Machine Learning content protection,
digital rights management with AI,
copyright infringement,
multimedia content tracking,
intellectual property protection, and
digital content protection, to name a few.
In summary, a compilation of 44 studies was achieved, divided into 23 within the safeguarding domain and 21 in the active domain, which are detailed in the following paragraphs:
In the realm of safeguarding digital assets, twenty-three significant research works [
6,
7,
19,
23,
25,
26,
27,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61,
62,
63] have been identified. Of these, nine [
6,
7,
19,
23,
25,
26,
27,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61,
62,
63] focus on the use of legal resources and partially address technical aspects. Ten of these works [
25,
26,
53,
54,
55,
56,
57,
58,
59,
60] adopt a fully technical stance on defensive strategies. However, only four studies [
25,
26,
53,
54,
55,
56,
57,
58,
59,
60] are dedicated to protection models that integrate AI and ML-based technologies.
On the other hand, in the active identification of infringing sites, twenty-one [
25,
28,
29,
30,
31,
32,
33,
34,
35,
64,
65,
66,
67,
68,
69,
70,
71,
72,
73,
74,
75] significant research contributions were compiled. Among these, three [
65,
66,
67] engage in non-technical actions such as manual search and reporting, contributing to the legal takedown of offending sites. Six projects [
28,
29,
68,
69,
70,
71] follow a technical route, involving surveillance and cyber patrolling within the IoE. Regrettably, only twelve initiatives [
28,
29,
30,
31,
32,
33,
34,
35,
72,
73,
74,
75] implement one or more AI/ML techniques for identifying infringing content on the IoE, and of these, only eight [
28,
29,
30,
31,
32,
33,
34,
35] are considered closely related studies. Notably, a single article [
25] stands out for its purely technical approach to the defensive and active aspects.
Taking into account the defined objectives, proposed hypotheses, abstracts reviewed, methodologies applied, and results achieved, the research is categorized into the following domains and subdomains.
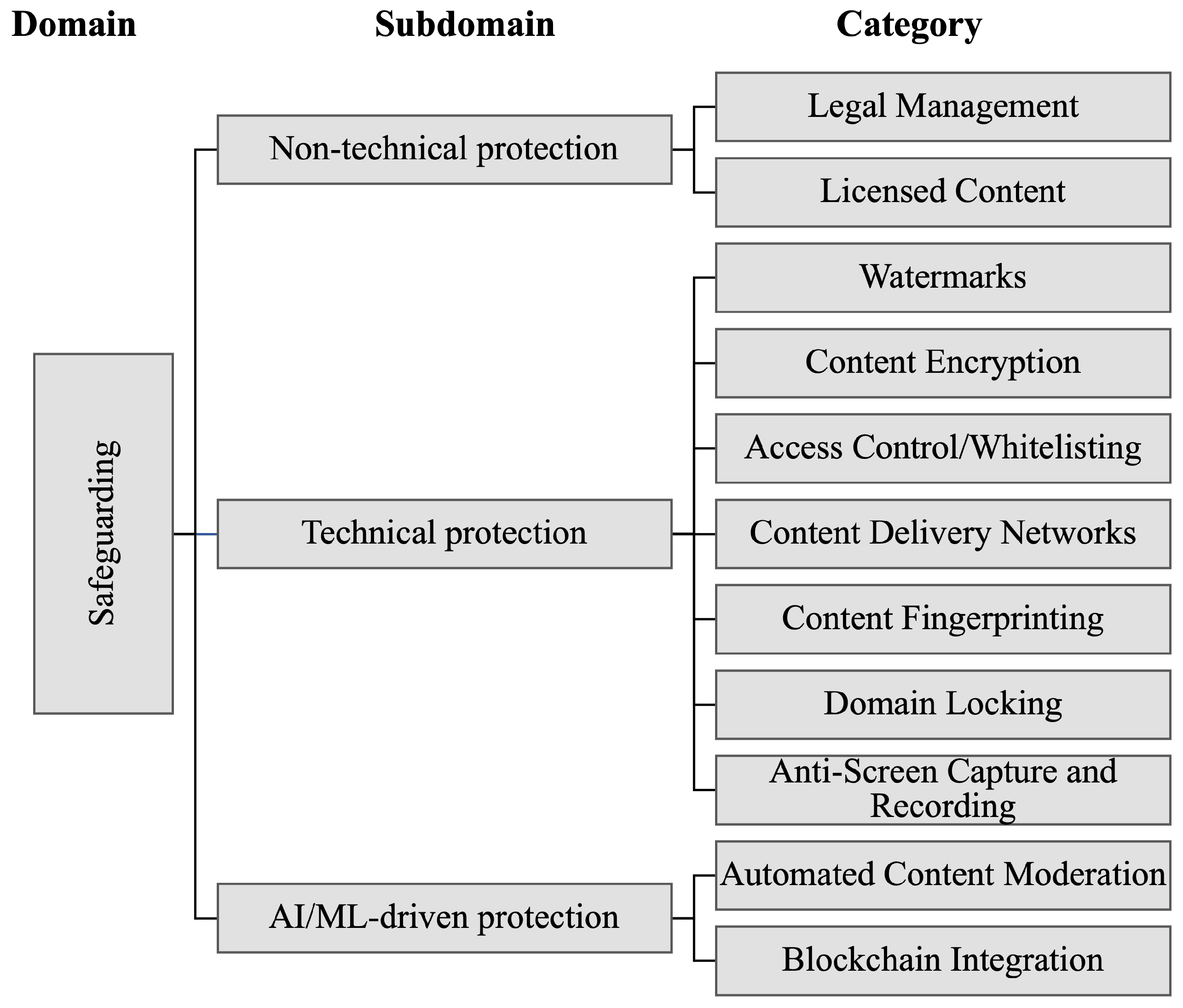
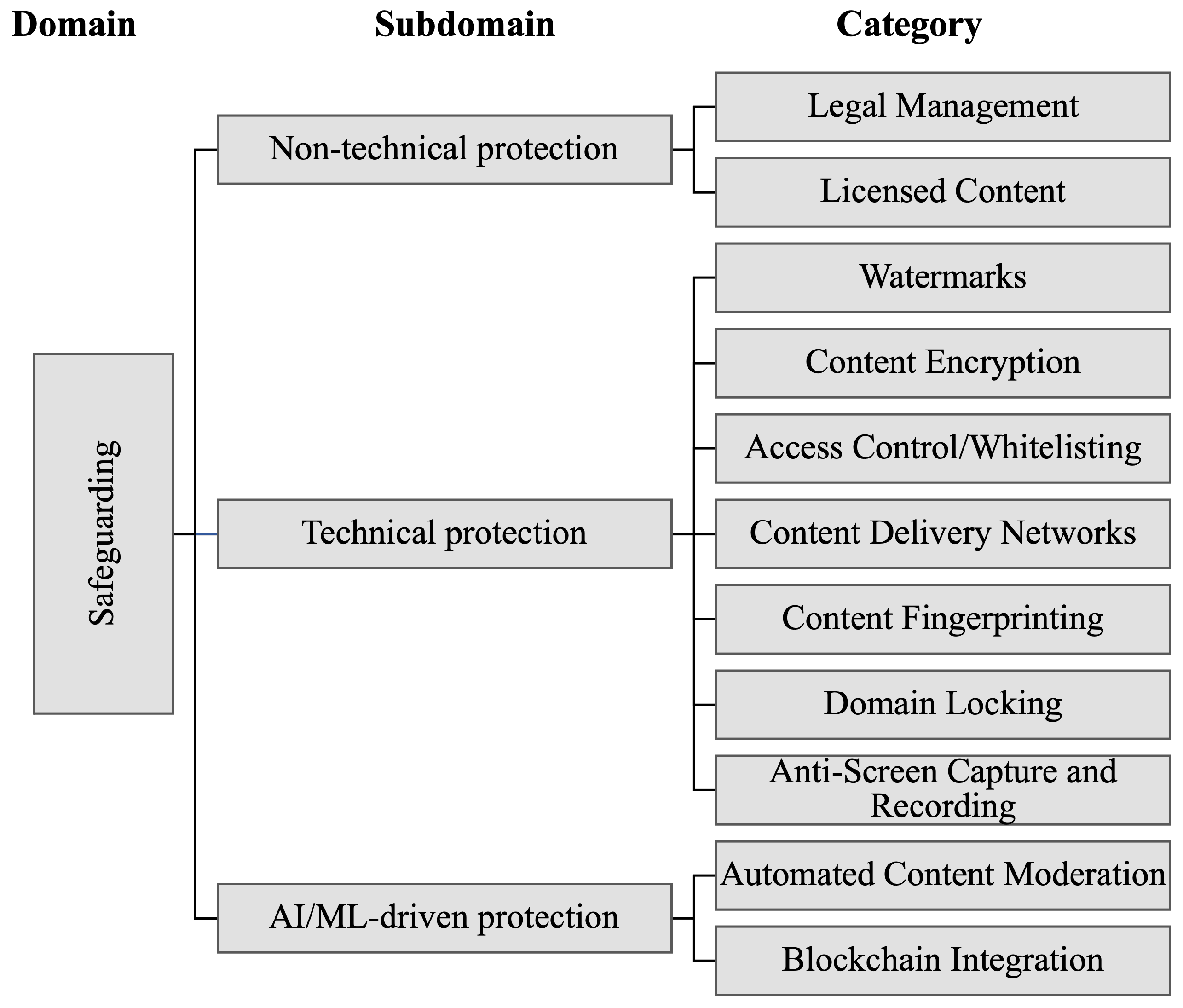
The
safeguarding domain [
6,
7,
19,
23,
48,
49] outlines protection strategies related to copyright laws, international and domestic regulations, legal bodies, global and national benchmarks, as well as technical methods implemented to guarantee that multimedia content on the IoE is used only with the explicit permission of the copyright owners. The research identifies the following specific subdomains
- –
Non-technical protection [
50,
51,
52] involves examining the legal and non-technical domain of jurisdictional frameworks that govern the presentation and regulation of copyrighted material, ensuring it occurs with the consent of the rights holder.
- –
Technical protection [
25,
26,
53,
54,
55,
56,
57,
58,
59,
60] refers to computational techniques known as digital locks or anti-circumvention mechanisms. These are designed to safeguard multimedia works by digitally enforcing copyright laws.
- –
AI/ML-driven protection [
27,
61,
62,
63] is an intelligent scheme that utilizes one or more AI/ML models to enhance the protection of multimedia objects in the IoE, in conjunction with non-technical or technical processes.
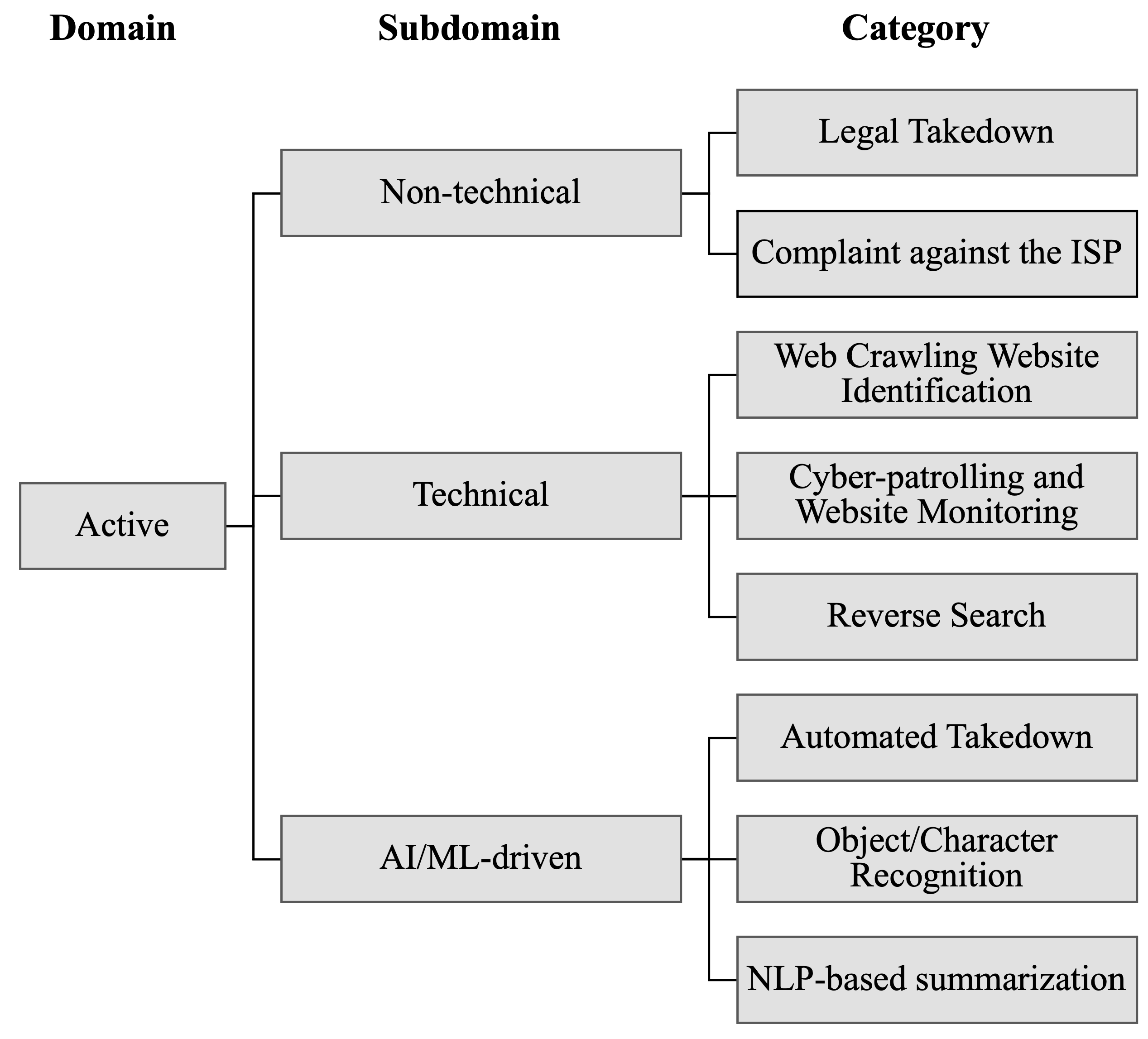
The
active domain [
25,
64] are processes and methodologies that actively seek, either manually or automatically, multimedia files across the IoE, to identify, assess, and address potential infringements to which the given object is bound. From these, the following subdomains emerge:
- –
Non-technical [
65,
66,
67] contains tasks that reside within the DMCA notice-and-take-down process, an act that sets limitations for multimedia content providers on the IoE. If these mandates are not adhered to, it may result in a partial or total removal of the reb resource.
- –
Technical [
28,
29,
68,
69,
70,
71] involves any technical procedure that allows for traversing the IoE to identify websites, links, URLs, P2P platforms, File Transfer Protocol (FTP) endpoints, torrents, and storage clouds where an identified infringing multimedia resource is residing.
- –
AI/ML-driven [
28,
29,
30,
31,
32,
33,
34,
35,
72,
73,
74,
75] includes advanced schemes that harness the power of AI/ML algorithms to efficiently perform cyber patrolling by traversing the IoE using NLP techniques, Supervised Learning (SL), Non-Supervised Learning (NSL), and DL analyses to analyze, discover, and present potential infringing multimedia content.
Figure 3 and
Figure 4 illustrate the taxonomic structure, covering domains, subdomains, and categories, of the research trajectories within the safeguarding and active domains. Hence,
Table 1 and
Table 2 provide a more detailed view of the aforementioned.
3. Related Works
As outlined in
Section 2, eight studies [
28,
29,
30,
31,
32,
33,
34,
35] were identified as closely related works, meeting specific criteria: they employ traversal techniques across the IoE or other related-networks, their methodologies incorporate one or more AI/ML algorithms for identifying websites with potentially infringing multimedia content, and they pertain to key consumption categories as defined in the referenced literature. The following paragraphs provide a detailed overview of each of these publications.
The authors in [
28] introduced a methodology to monitor local network traffic, aiming to identify users leveraging P2P protocols for unauthorized content downloads. Utilizing an audio–video fingerprinting system named The CopySense Appliance, that study demonstrated that by inspecting frames within, P2P, TCP, and UDP protocols, traces of non-original multimedia files can be detected, cross-referencing the DMCA database. The findings suggest an imperative for more advanced mechanisms to bolster similarity-based detections.
Moreover, Ref. [
29] stands as one of the pioneering works leveraging Machine Learning (ML) for infringement content detection. The proposed methodology hinges on metadata and rule engineering to pinpoint re-uploaded videos on unofficial YouTube accounts. By modifying the Jaro–Winkler distance, this study elucidates the feasibility of measuring the similarity between a query and video metadata, facilitating its classification as either original or infringing.
In contrast, Ref. [
30] unveils a technique targeting the unauthorized sale, distribution, and display of various software types. The proposed Ant-Miner trend classification, grounded on the Ant Colony Optimization (ACO) algorithm, is proficient in categorizing the nature of the infringing software.
Expanding on ML applications, Ref. [
31] harnesses the prowess of BERT for text summarization. The paper delineates a framework for classifying YouTube videos by modeling topics embedded in brief video descriptions. Such an approach refines DMCA reporting accuracy.
Simultaneously, Ref. [
32] emphasizes DL potential in detecting infringements. By deploying DL architectures like AlexNet, ResNet, and a tailored eight-layer DNN, the study successfully identifies re-transmitted banners and logos from streaming services across various platforms.
Taking a web-centric perspective, Ref. [
33] champions a web crawling approach coupled with web scraping sensors. The intent is to capture iconography indicative of unauthorized content display or download. Through a marriage of Support Vector Machine (SVM) and Word Embedding techniques, the methodology excels in identifying sites with potentially unauthorized download tendencies based on headers or logos.
In a related vein, Ref. [
34] proposes web monitoring through clusters of web scraping sensors. By extracting text, image, and metadata features, a Multi-Tasking Ensemble Algorithm (MTEA) is trained to ascertain unauthorized video streams.
Lastly, Ref. [
35] further delves into the capabilities of MTEA for pinpointing unauthorized video streams across diverse platforms. The approach considers chat message ratios and sentiment polarities to gauge a video’s popularity vis à vis the original. Complemented by metadata extraction and object recognition, the initial video banner is then compared against the original catalog, earmarking the infringed content.
In order to understand and summarize the capabilities and perspectives of the studies presented in this section, a series of criteria were used, as detailed below:
Data Collection Mechanism: this aspect evaluates whether the study implements a mechanism for gathering data to acquire samples over the IoE.
Use of Known Categories: this study is based on a list, white paper, or report that has assessed the approach as being targeted toward a prevalent issue of infringing multimedia content.
Employment of NLP Methods: it relies in some manner on textual comparison, whether through titles, content, or optical character recognition, to achieve its objective.
AI/ML Algorithm Utilization: One or more AI/ML algorithms are employed for predictive, regression, or classification tasks.
Performance Reporting: at least some measure of performance is documented.
Therefore, in accordance with the criteria previously outlined,
Table 3 sets out the comparison with the methodology (BERT + DNN) presented herein.
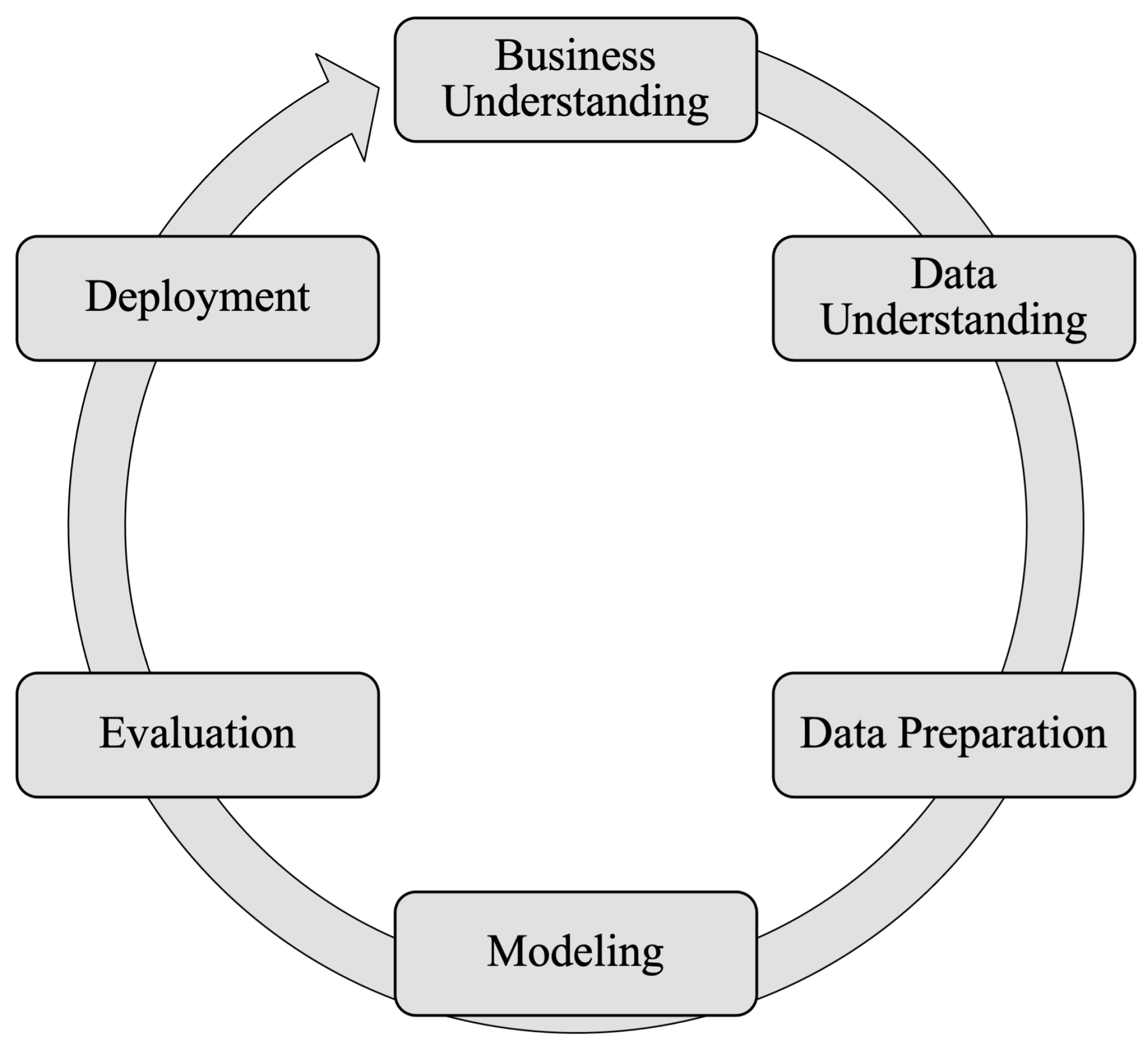
4. Materials and Methods
In the current study, the methodology used is grounded on the principles of the Cross-Industry Standard Process for Data Mining (CRISP-DM) [
79]. CRISP-DM aids in understanding the project’s direction, exploring and navigating the data, identifying key factors for project success, and avoiding the repetition of unnecessary phases.
Figure 5 illustrates the steps for its development.
In the subsequent
Section 4.1,
Section 4.2,
Section 4.3 and
Section 4.4, each step informed by the CRISP-DM framework is contextualized to fulfill the objectives of this project. It should be noted that this project is methodological in nature; therefore, the Deployment phase is omitted, which is referenced in the list of future work presented in
Section 6—Conclusions.
4.1. Business Understanding
In alignment with the CRISP-DM methodology, the process commences with a critical understanding of business needs, leading to a comprehensive series of actions aimed at grasping the project’s objectives. Initially, an exploration of the advantages and disadvantages associated with the active domain category—as delineated in
Section 2—is undertaken, the specifics of which are encapsulated in
Table 4.
Subsequently, the focus shifts to discerning the significance of the identified shortcomings within the non-technical and technical subdomains, thereby revealing the pivotal insights and potential that AI/ML-driven strategies possess for orchestrating a project of this magnitude.
In the ensuing discourse, the investigative intent is accentuated: to rigorously pursue infringing multimedia content by leveraging web crawling techniques across a multitude of search engines within the IoE. The resulting dataset will be engaging advanced NLP algorithms such as BERT and DNN, expanding over a proposed catalog encompassing movies and series, music, software, and books.
Based on the list of advantages and disadvantages of the previously mentioned subdomains and categories, the application of AI/ML algorithms offers a more effective and potent solution in this research domain. In light of this, the following success key points can be presented:
Venturing into the expanse of the IoE, a discerning collection of websites emerges, marked by their propensity to host copyright-infringing multimedia content and their distinct deviation from compliant counterparts. This paves the way for the assembly of a robust dataset, encompassing a diverse array of examples and categories (films and series, music, software, and books) that amalgamate textual features with the intrinsic dynamics of each site.
The depth-first (DF) [
80] pre-processing algorithm enhances traversal through the DOM, effectively capturing text-holding HTML nodes.
Data harvested through this DF approach are standardized and converted into contextually rich semantic vectors via pre-trained BERT encoding.
In the final dataset generation phase, BERT encoding is augmented when merged with additional attributes associated with the unique interactions of each website, thereby amplifying the contextual substance of the samples.
Final samples are subjected to training and evaluation using a fine-tuned DNN, which, unlike other architectures with specific applications, boasts the flexibility to adapt to multiple objectives, such as classification in this instance.
4.2. Data Understanding
To secure pertinent samples for the training and evaluation of the proposed model (BERT + DNN), key websites listed in the esteemed BrightEdge Top 10 ranking [
81] were identified. This ranking is celebrated for its meticulous evaluation, which focuses on recognition, popularity, and traffic within the Internet of Everything (IoE). The selected sites are recognized as the primary platforms where one might encounter notable items within the categories specified by [
16]. The identified sites include the following:
- 1.
Movies and series (
) were sourced from the 2022 Golden Tomato Awards: Best Movies & TV of 2022 by Rotten Tomatoes [
82].
- 2.
Music (
M) was based on the 50 Best Albums of 2022 by Billboard [
83].
- 3.
Software (
S) was obtained from the The List of Most Popular Windows Apps Downloaded in 2022, as described by Microsoft [
84].
- 4.
Books (
B) were referenced from Time magazine’s 100 Must-Read Books of 2022 [
85].
In order to achieve a comprehensive search trough the IoE, a sensor was programmed using Selenium [
86], a browser-side automation tool that enables data grabbing by simulating human browsing. Leveraging the capabilities of Selenium, it is possible to capture the HTML content from HTTP protocol responses, to assess the significance of the headers, and to develop specialized storage modules that allow for the data to be saved in comma-separated values (CSV) format files.
The sensor initiates its search using a combination of specific keywords related to each category (, M, S, and B). For instance, a search might look like download + anti-hero + Taylor + Swift + rar. Here, download and rar are the primary keywords, while anti-hero and Taylor Swift specify the content being sought. In consequence, an array of auxiliary keywords was considered to combine terms, enforcing more accurate queries: free download, full album, full book, free crack, download, online free, rar, zip, compressed, 7z, direct link, unlocked, serial key, free links, online watch, and direct links.
There are several search engines available to navigate a portion of the IoE; in this study, only the five most popular according to The Searching Journal [
87] were used: Google Search [
14], Yandex [
78], Yahoo [
88], Bing [
89], and DuckDuckGo [
90].
The sensor code was outfitted with a generic user-agent header from the automated versions of Firefox and Chromium, with fields that ensure navigation only to the main pages of the previously mentioned search engines, in order to retrieve websites exclusively in American English. In an effort to avoid overloading and mistaking access to already identified non-infringing (NI) websites, a compilation of 17,800 benign URLs was adopted as a whitelist. These URLs are recognized for their impeccable reputation based on the evaluation metrics set forth by Netcraft [
91]. This platform assesses the credibility of websites using a diverse set of benchmarks: visitor count; spam list inclusion; desired cybersecurity features; restrained information; and most importantly, whether they have been the subject of takedowns.
Adopting this method, the sensor was constrained to track 50 items for each category, browsing until reaching a cap of 30 result pages on each search engine. It is important to note that the number of results per page varies by engine: Google fluctuates between 10 and 12 sites, depending on whether they include sponsored links or if the search is related to sales, images, live streams, or news; Yandex consistently displays a steady 10 results per query, regardless of its type; Yahoo provides 5 entries, with the top two links highlighted for their organic relevance; Bing shows between 8 and 10 links sorted by their relevance to current events, social media, and marketing; and DuckDuckGo presents 12, reserving the top 2 spots for the most relevant sites, also featuring links with strong organic positioning.
After obtaining the results, the sensor proceeded to access each of the links, capturing the already-aforementioned features. Within the content context, the title and text embedded in the website’s DOM were extracted. Regarding architectural and behavioral attributes, an initial manual evaluation of several potentially infringing sites was conducted, leading to the conclusion that many share key features to be considered: intrusive advertising, questionable reputation, presence of adware, use of URL shorteners, an abundance of scripts run through JavaScript, CAPTCHAs or access puzzles, frequent redirects, numerous cross-domain and download links, as well as iframes. To illustrate,
Figure 6 displays some examples of records obtained from the search using a specific combination of keywords, and similarly,
Figure 7 details the structure of a website with behavioral patterns that suggest the presence of potential unauthorized multimedia content.
Upon interaction with the sensor, it became evident that there was a need to add an additional tool known as seeker, integrated into the Mechanical Soup library of the Python Programming Language. This tool aids in tracing the internal links of a website, thus revealing the final destinations hidden by URL shorteners and iframes. The advancement has enabled the discernment of various types of sites that could potentially be in violation. Some, of a less professional nature, promote direct downloads; others distribute content through well-known cloud storage platforms; some utilize their site as a channel to generate income through paid advertising; yet others are plagued with adware, which complicates tracking and analysis. Thereupon, an additional component called Access Level has been added to the toolkit, which classifies how each site presents the pattern of multimedia content distribution that may infringe copyright.
- 1.
Level 1: this level included sites that allowed for the downloading of infringing content directly from the homepage.
- 2.
Level 2: the download is located on external sites, typically from massive download repositories or personal storage links such as Google Drive, DropBox, and OneDrive, among others.
- 3.
Level 3: downloads are offered through external sites, often involving URL shorteners, tracking, or survey sites before the actual link is displayed.
- 4.
Level 4: downloads exhibit the characteristics of Level 3, but additionally include challenges, counters, and CAPTCHAs to disclose the displayed content. Many of the sites at this level show signs of adware, poor reputation, or malware components.
In
Table 5, the set of features used to construct the dataset is described.
4.3. Data Preparation
The sensor was able to traverse 51,340 websites pertaining to the IoE; however, some conflicts were encountered: 41 sites were blocked due to anti-DDoS protection, 512 returned HTTP 404 (not found) codes, and 607 returned empty content when an attempt was made to download the HTML payload. Consequently, the final dataset encompassed 50,180 samples, of which 17,800 were non-infringing (including the catalog provided by NetCraft), with the remaining pages potentially infringing: 8780 for the movies and series category, 8401 for the music category, 10,076 for the books category, and 5123 for the software category. In total, 32,380 sites with potential infringing multimedia content were aggregated.
Due to the number of samples and the type of features, there are two main areas to consider in the pre-processing stage. Firstly, the dataset contains binary values (presence of redirects, site reputation, adware, presence of URL shorteners, presence of out-of-domain Javascipt content, and presence of CAPTCHAs), discrete values (level), integer data (number of outbound and download links), and character strings (title and textual content), necessitating transformations and encodings to ensure each feature is on the same scale and context. Secondly, the features must be merged to preserve the necessary latency and to avoid under- or overfitting issues due to bias and variance problems.
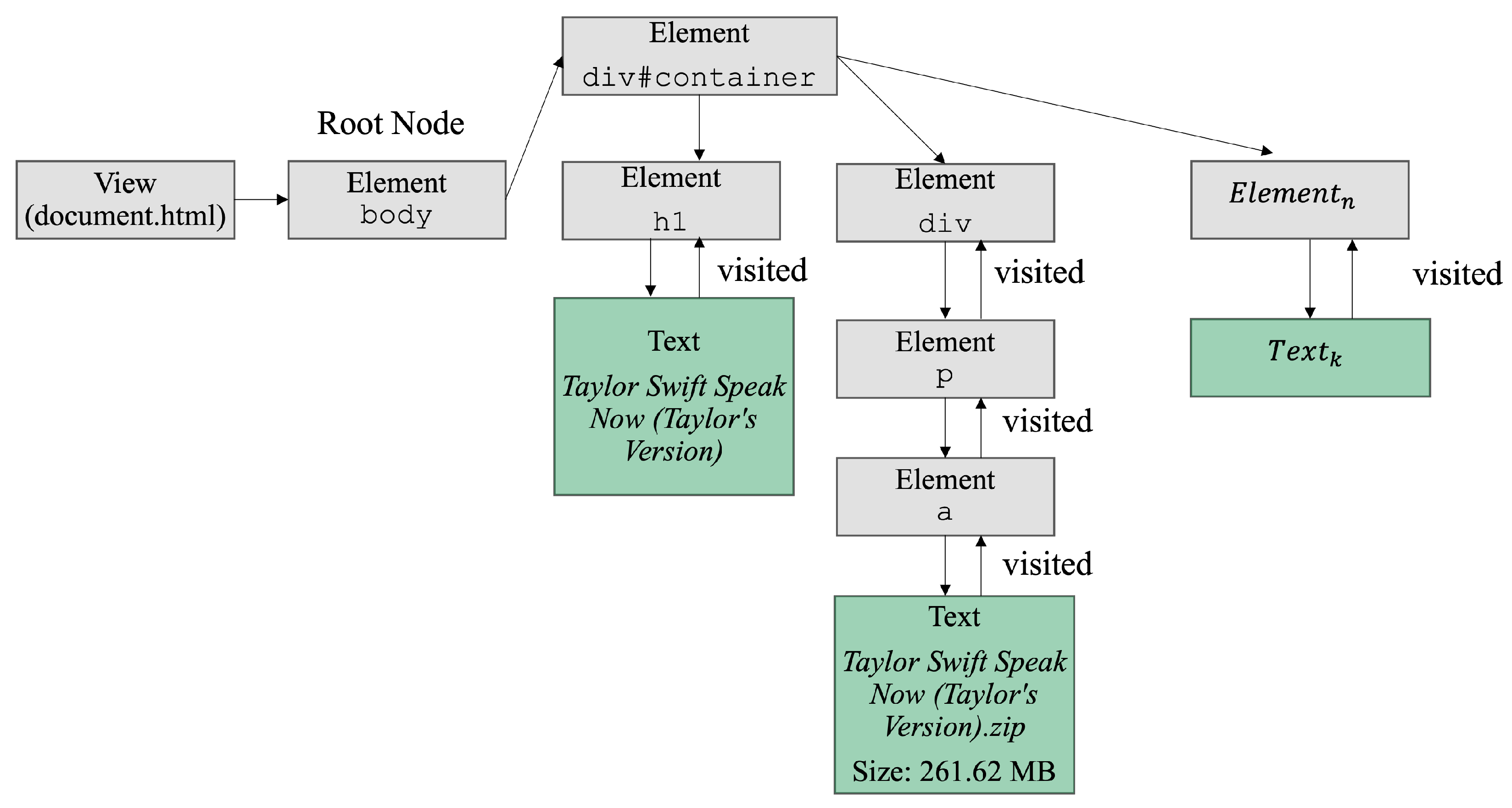
To achieve the aforementioned, the features’ title and textual content were pre-processed by removing HTML tags within the DOM tree, which presents a challenge since most libraries tend to erroneously eliminate significant portions of textual content. To address this, DF is adopted, which examines the tag graph and identifies nodes with content rich in words, marking them as visited once traversed. The algorithm delves deeper, marking both textual and irrelevant nodes through backtracking until no further elements remain to be explored. The result is a compilation of embedded text.
Figure 8 provides a straightforward representation of how the DF approach locates embedded text within the HTML DOM of this project’s dataset.
Ultimately, before adding the title and text as plain text to the dataset, unnecessary white space, emoticons, and any characters outside of the American English UTF-8 encoding were removed, which can then be ingested and transformed by NLP techniques.
4.4. Modeling and Evaluation
This project is marked by the implementation of a fundamental two-phase architecture to compose the BERT + DNN architecture: Initially, contextual vectors are pre-trained, followed by refinement for classification applications. The initial phase is grounded in the use of a pre-existing BERT model, which according to [
94], leads the way in advanced understanding of the dynamics between words and their context, based on a diverse textual corpus. As a cornerstone, BERT
uncased [
95] was chosen, notable for its meticulously adapted Masked Language Model (MLM) designed to analyze lowercase English sentences, equipped with a broad and precise vocabulary. This model, structured with 12 layers of attention and 12 attention heads, along with a 768-dimension vector per sequence, accumulates a total of 110 million parameters, enhancing the adaptability of its parameters for various ML tasks.
The second phase focuses on customizing the embedded representation through the BERT
uncased model, aligning it with the vocabulary derived from HTML tags. This process encompasses the re-calibration of the model’s initial weights and the creation of new vectors, which form the foundation for a fine-tuned DNN, culminating in the development of classification model for the previously mentioned categories:
,
M,
S, and
B.
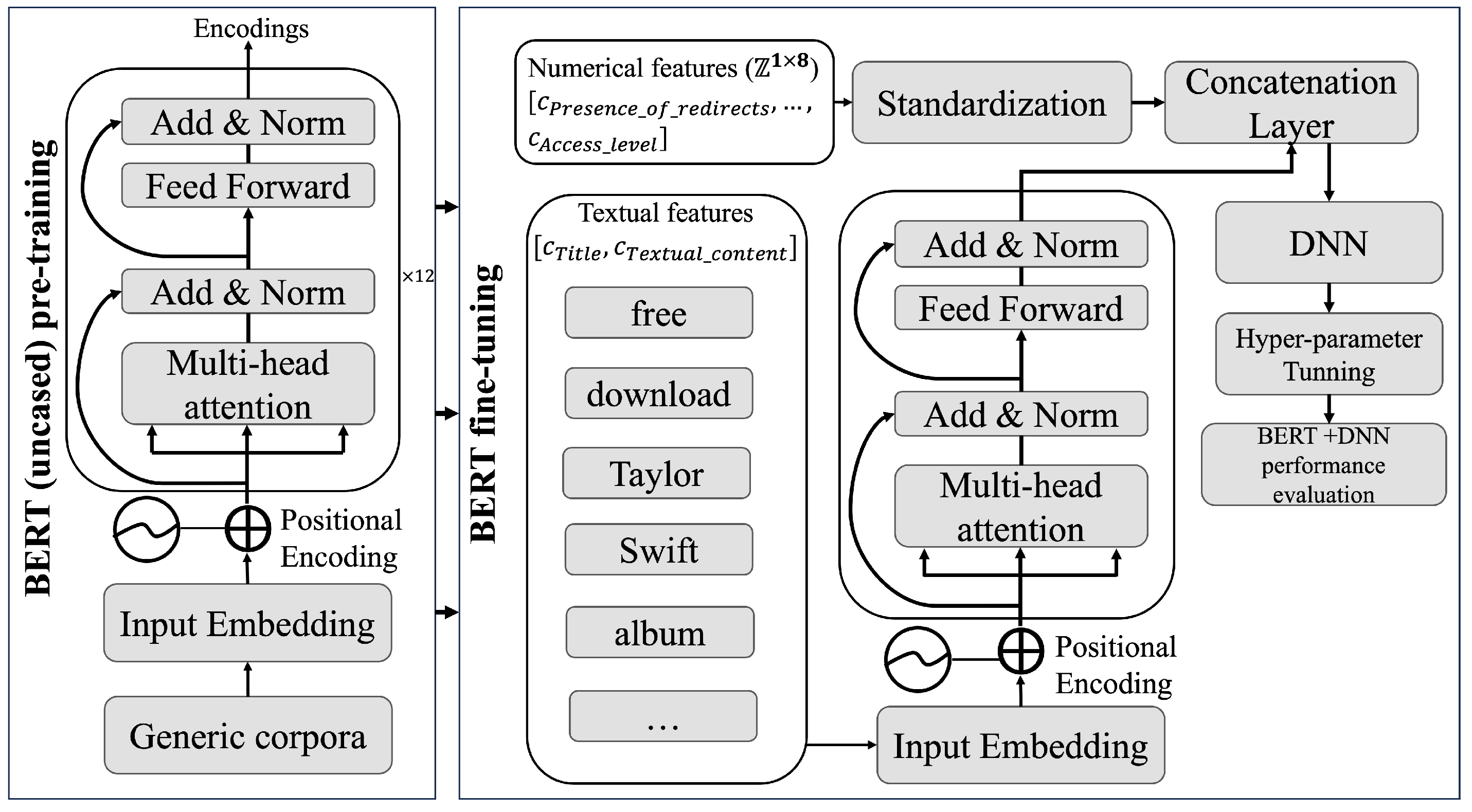
Figure 9 presents a detailed depiction of the proposed architecture.
4.4.1. Pre-Training BERTuncased
In its pre-training phase, the BERTuncased model processes extensive textual data, notably from BookCorpus and Wikipedia, amounting to roughly 250 million words. This corpus undergoes an analysis through three Input Embeddings (E) for Next-Sentence Classification (NSC) and MLM. In NLP, token embeddings methodically segment text into units corresponding to individual words. Positional embeddings assign each token a unique position, integrating this into the embedding layer for improved contextual understanding. Furthermore, segment embeddings are employed to discern between different text sequences, an essential aspect for accurately processing and interpreting linguistic data.
To comprehend the mechanism by which BERTuncased derives weights from E, an examination of the components constituting the basic BERT architecture is delineated in the subsequent enumeration:
- 1.
Concatenation with Positional Encoding: E undergoes integration with the Positional Encoding () layer, thereby infusing information regarding the sequential positioning of each token, resulting in . In this formulation, symbolizes the resultant sequences post-integration, embodying a composite of the tokens’ semantic information and their respective positions within the sequence.
- 2.
Multi-Head Attention (
):
is input into an attention layer for syntactic and semantic analysis of sequences, capturing the language’s context and complexity. This is facilitated by the Multi-Head Attention (
), using matrix-weight tuples. Query matrices
Q identify focus tokens in
, while key matrices
K cover all tokens, crucial for computing attention weights and enabling query comparison. Value matrices (
V) aggregate outputs from
Q and
K interactions. Each of the
heads applies dot-product attention to
Q,
K, and
V, generating scores transformed into probabilities via a softmax function scaled by
(dimension of
K). This scaling stabilizes the softmax function during weight re-calibration in the
,
, and
matrices, preventing gradient reduction. See Equation (
2) for more details.
Consequently, each head
computes and concatenates the attention results
, as detailed in Equation (
2).
where
is the weight matrix responsible for rescaling the outputs of the concatenation layer towards the subsequent stages of the process.
- 3.
Add & Norm: the outputs of the are subjected to a residual connection and normalization prior to entering the Feed Forward (FF) layer. This is integral in any Artificial Neural Network (ANN) to ensure that weights generated during training maintain their significance. This phase emphasizes two crucial processes: addition and normalization.
Addition is crucial in mitigating gradient vanishing, as it preserves input weight information, denoted as
I, across the network. This preservation is maintained irrespective of subsequent layer transformations
, achieved by summing the input and transformed output, resulting in the residual output
. Subsequently, the role of normalization is to standardize
. This standardization is accomplished using the mean-variance normalization method, detailed in Equation (
3).
In this process,
denotes the
i-th value of the input
, with
and
representing its mean and variance, respectively.
E is the stability constant, and
is the standardized output.
then undergoes a Linear Transformation (
), setting the stage for normalization, which optimizes the adaptation of each transformation. See Equation (
4).
where
and
are the parameters to which the
transformation is subjected to improve the coupling of
each time it enters the layer.
- 4.
Feed Forward (FF): this layer processes values from and Add & Norm layers, capturing complex textual characteristics. It employs linear and nonlinear transformations for feature engineering, focusing on key aspects of embedded vectors. These operations occur within BERTuncased’s dimensions () and its FF network (), concluding with the final Add & Norm layer where the model is evaluated, weights are frozen, and pre-training ends.
4.4.2. Fine-Tuning the BERT Model for Classifying Infringing Sites
The refinement procedure is conceptualized as the incorporation of an additional layer to the BERTuncased transformer model, to construct the BERT + DNN architecture. In this phase, the weights are unfrozen and employed to encode the textual samples from the dataset X. Subsequently, the process involves training, optimizing, and evaluating the DNN estimator for the classification of classes . Algorithm 1 outlines the steps involved in this task.
For a better understanding of Algorithm 1, the following paragraphs detail the refinement model.
| Algorithm 1 Fine-tuning and optimization of the BERT + DNN architecture |
- 1:
Inputs: dataset X, BERTuncased model - 2:
Output: BestModel (BERT + DNN) - 3:
Load pre-trained BERTuncased model - 4:
Unfreeze all 768 weights in BERTuncased model - 5:
Pre-process textual features via BERTuncased model - 6:
Preprocess numerical features via Standard Scaling - 7:
for each data point do - 8:
Generate vector from using BERTuncased model - 9:
Concatenate with to form - 10:
end for - 11:
Construct the concatenated training subset - 12:
Partition dataset into training (80%) subset and validation subset (20%) - 13:
Initialize the DNN with Input size - 14:
Initialize the DNN with output size - 15:
Define the subset hyperparameters an values to optimize: learning rate , epochs , batch size and number of hidden layers with their respecipve units U - 16:
Initialize BestModel (BERT + DNN), BestPerformance ← null, 0 - 17:
for each subsetset of hyperparameters () do - 18:
Compute the Excepted Improvement function on BERT + DNN using () - 19:
Compute Sparse Categorical Cross-Entropy loss function () - 20:
Backpropagation to update weights - 21:
if performance of on () > BestPerformance then - 22:
BestModel ←BERT + DNN - 23:
BestPerformance ← performance of - 24:
else Select the next subset of hyperparameters to improve - 25:
end if - 26:
end for - 27:
return BestModel (BERT + DNN) with the best subeset of hyperparameters
|
The parameters of the BERT
uncased model are initialized and subsequently unfrozen, following the recommendations of [
96], for large-volume databases. This approach is suggested as it allows for the re-calibration of these parameters as they adapt to the dataset
X, with the aim of achieving a more efficient adaptation to the classification task.
The textual features Title and Textual Content, incorporated into X as , are processed through a refined procedure of tokenization and subsequent alignment to standardize the length of the tokens before their masking. For this purpose, a maximum length of 300 fixed elements per token has been selected, applying a uniform padding function to complete those sequences that do not reach this maximum limit. The latter generates an embedded output vector code of dimensions for each textual sample.
The numerical samples
which include variables such as
Presence of URL shorteners,
Presence of out-of-domain Javascript content,
Presence of CAPTCHAS,
Number of outbound download links and iframes, and
Access level, undergo to a Standard Scaling (SC) operation. This process involves removing the mean and adjusting each of them to a unit variance, a process detailed in Equation (
5).
where
represents each of the numerical samples,
is the mean, and
is the variance.
The textual embedded vectors
from
corresponding to the
i-th position are merged with their respective standarized numerical vectors
, culminating in the creation of a final set
that harmoniously integrates both characteristics, as detailed in Equation (
6).
is then conformed by samples, composed of fixed-size vectors of 768 elements from the embedding obtained from BERTuncased and the eight remaining standardized numerical features. Afterwards, is divided into three different subsets: , which is used to train the BERT + DNN algorithm; , intended for performance testing; and , which is used for accuracy verification during training. This last step is essential for adjusting the weights of BERT and the hyperparameters of the DNN. These subsets represent, respectively, 70%, 30%, and 20% of the total and are selected randomly and without replacement.
At this stage of development, BERT + DNN has been configured to receive samples and to initiate the training process. This phase involves the integration of DNNs [
97], classified as a category within DL algorithms, distinguished by their proficiency in a range of activities including synthesis, classification, and outlining of concepts in unstructured data, such as those found on websites. The DNNs have solidified their robustness, particularly in operations related to the analysis of information from the IoE, as a case in point, the detection of Denial of Service (DoS) attacks, the identification of internal/external cybersecurity threats, the discernment of web attacks through false data injection, the neutralization of cyber assaults, the containment of phishing attempts, the discovery of piracy activities, and the prevention of the proliferation of malicious software, to name a few.
Various architectures of DNNs exist, distinguished by the quantity of dense hidden layers, the types of activation functions utilized, the optimizers employed to reduce error, and the number of units present in the output layer. Despite the plethora of configurations, the architecture delineated in [
98] has shown exceptional efficacy in the detection of cryptojacking patterns within website payloads when juxtaposed with other neural network models like Convolutional Neural Networks (CNNs), RNNs, and LSTMs.
The BERT + DNN model starts with 776 units for processing the input and 5 for the output, each output representing a different class (). In this method, adjustments are made to several hyperparameters, including the number of epochs (), the learning rate (), the batch size (), and the number of layers (H), along with the number of units in each, forming these adjustments into a series of subsets that integrate into the set . The process is iterative and seeks to optimize these parameters through a function that maximizes the Expected Improvement (), with the goal of achieving the best possible accuracy, namely the . The identification of this optimum, , is carried out by evaluating along with using the best subset of at the conclusion of the training process, resulting in the selection of the most effective model ().
To find the best set of hyperparameters for BERT + DNN in
Table 6, the parameters and ranges used are summarized. It is crucial to highlight that the ReLu activation function is used both in the input layer,
I, and in the hidden layers,
, while the Sigmoid function is employed in the output layer,
O.
For stable operation, a BERT + DNN requires the establishment of several foundational configurations, detailed as follows:
Batch normalization layer: this component ensures the stabilization of the dense layer’s () output by normalizing the values, aiming for a standard deviation near one and a mean approaching zero.
ADAM (Adaptive Moment Estimation)-type optimizer: this mechanism efficiently manages the adjustment of each unit’s weights, utilizing a learning coefficient in conjunction with stochastic gradient descent. It anticipates the estimation of first- and second-order moments, maintaining low computational complexity throughout the process.
Categorical Cross Entropy loss function (): for multi-class classification, where the output layer
O employs a Sigmoid function, the loss can be determined by assessing the difference between the target classes
and the predicted classes
from the validation set
, during the training step. The goal is to minimize this discrepancy by using the divergence between the probability distributions of each class
, as shown in Equation (
7).
The formulation of the optimization problem is presented as follows: Let
be the set of hyperparameters and
be the function aimed at maximizing accuracy.
is modeled through a Gaussian process that calculates the mean of (
) and its covariance function (
), where
. Subsequently,
is subjected to
, as detailed in Equation (
8).
where
represents the expected value of the outcome of the set exhibiting the highest accuracy, calculated from the difference between the current set
and the one that achieved the best value
.
The training process will continue until all hyperparameters next have been optimized to maximize the function, with validation conducted using the tuple . Consequently, the will be acquired and subsequently employed to evaluate the final performance with .
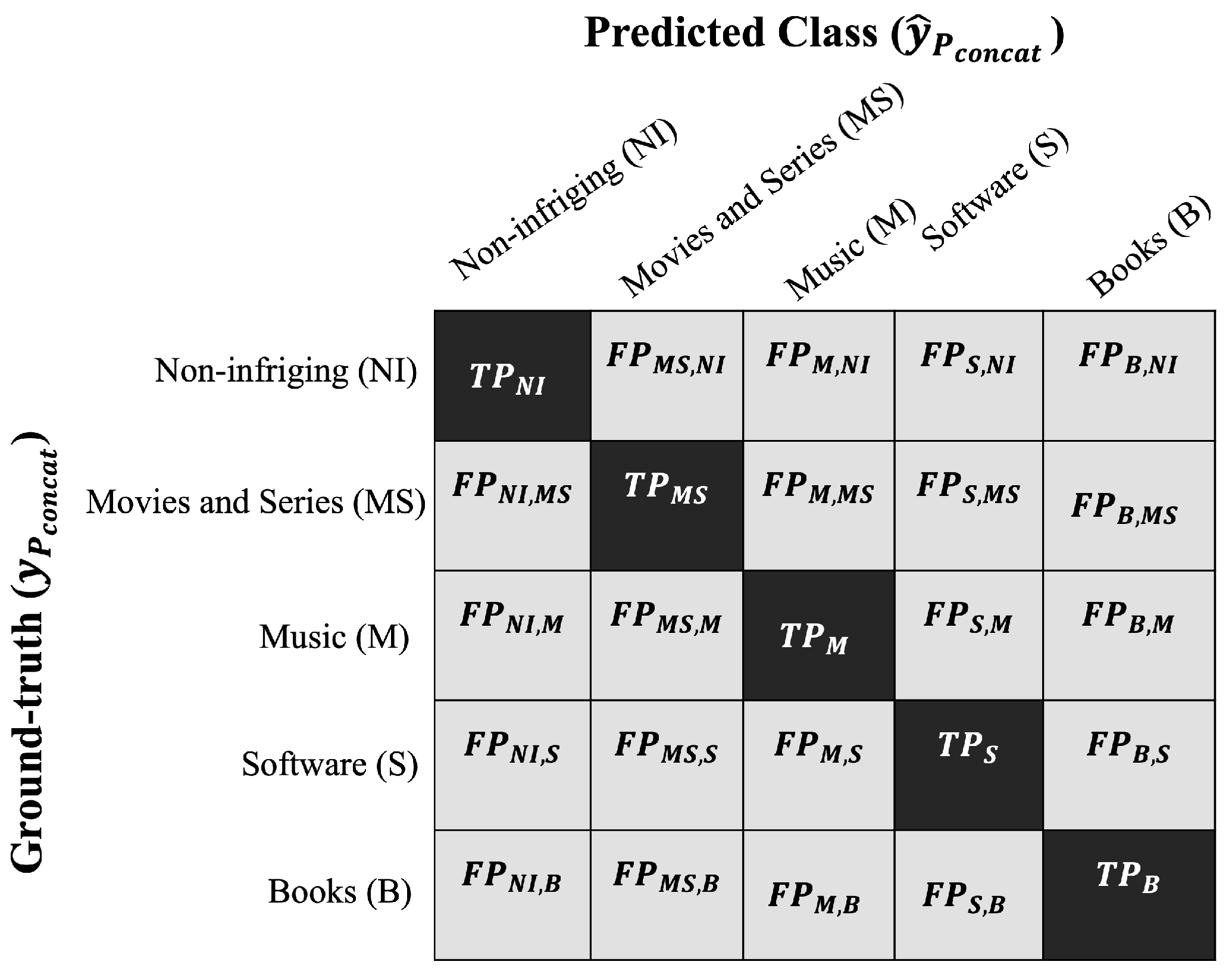
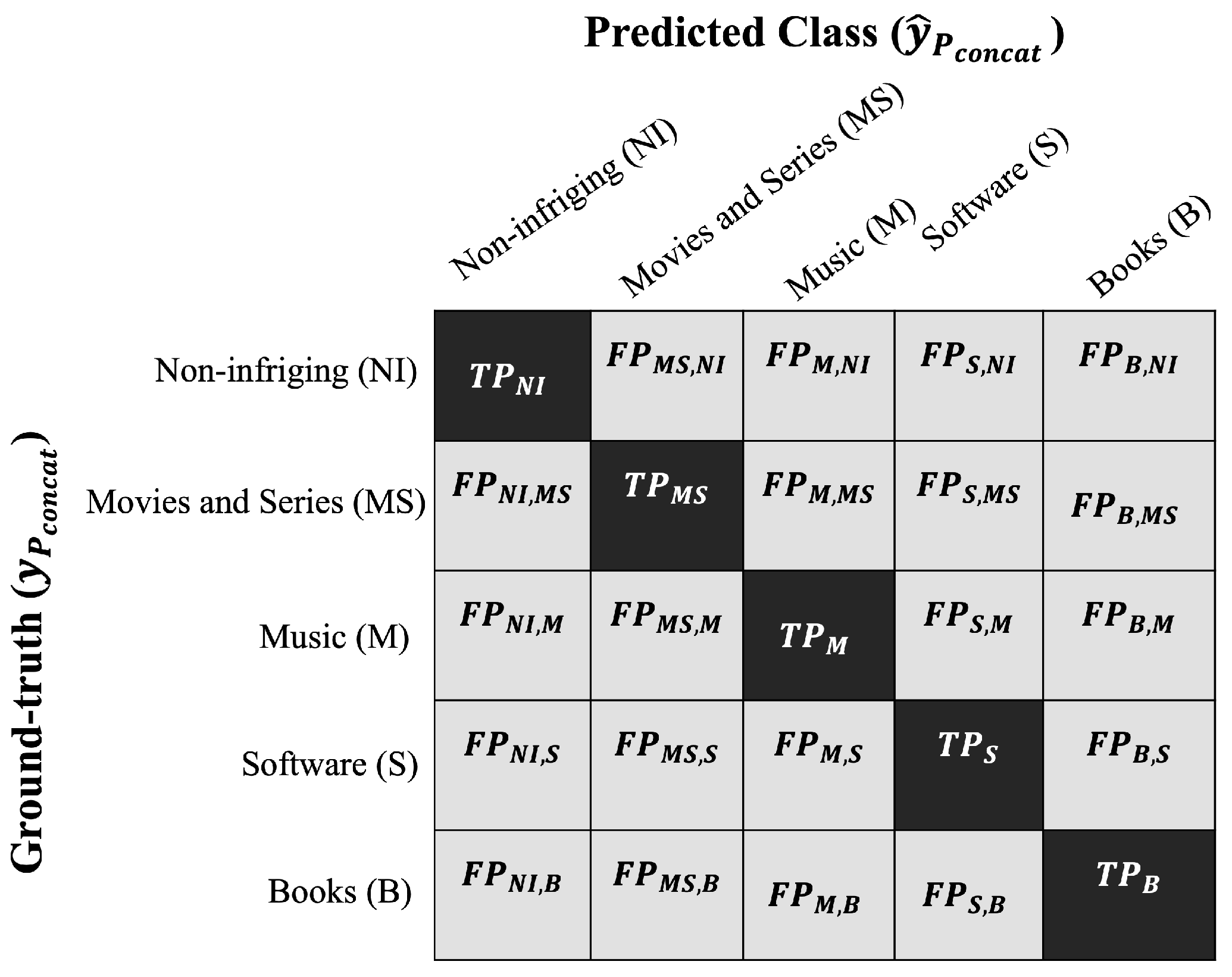
In the context of multi-label classification,
Figure 10 displays a confusion matrix that evaluates the predictive performance of the resultant model
across the selected classes: non-infringing (
), movies and series (
), music (
M), software (
S), and books (
B). The matrix reveals two significant values:
(true positives), indicating the number of correct predictions for the
C-th class compared to the ground truth, as well as
(false positives).
The multi-class performance metrics used to evaluate the BERT + DNN model are described in
Table 7.
5. Results and Discussion
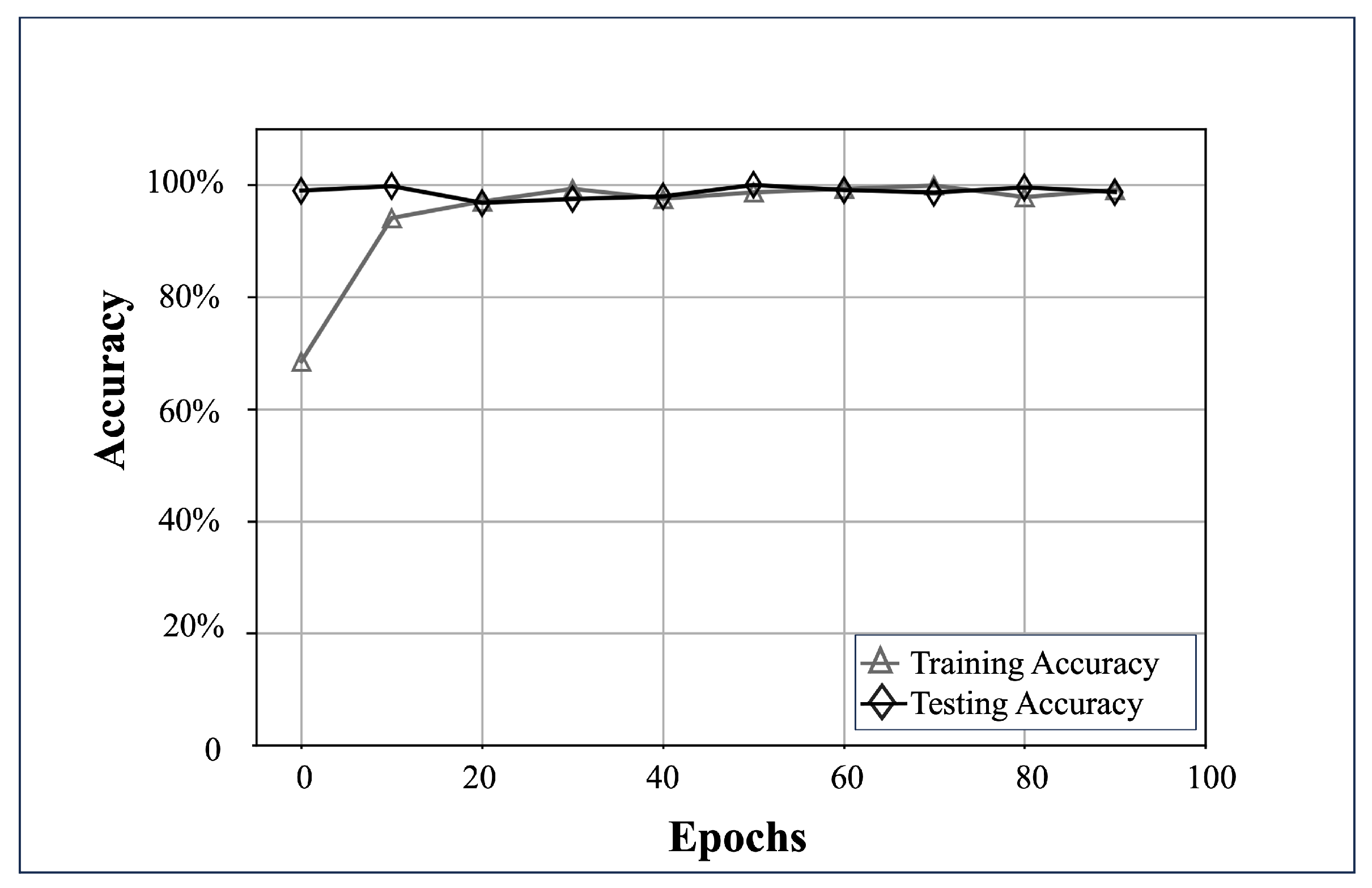
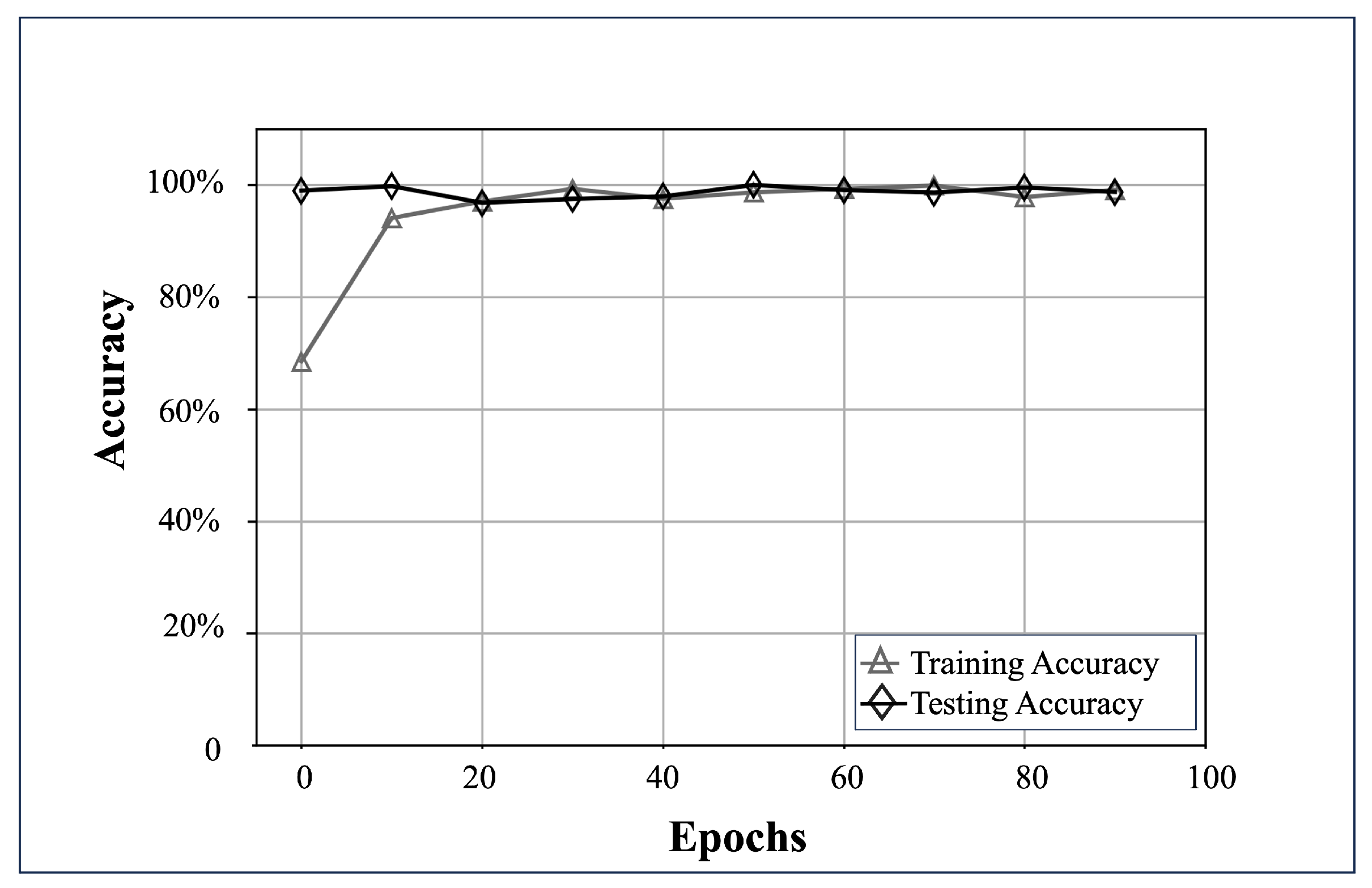
After applying hyperparameter adjustments to the set, validation analyses revealed that the most optimal parameters, , include an of ; a batch size () of 32; a three-layer configuration () with 32, 64, and 128 units (U) respectively; and a total of 100 epochs ().
Using the previously specified values, the test tuple (
,
) was trained using
and subsequently validated with the subset (
,
). Accuracy rates of 95.14% during the training phase and 98.71% in the testing stage were recorded. The convergence of the learning process is evidenced in
Figure 11.
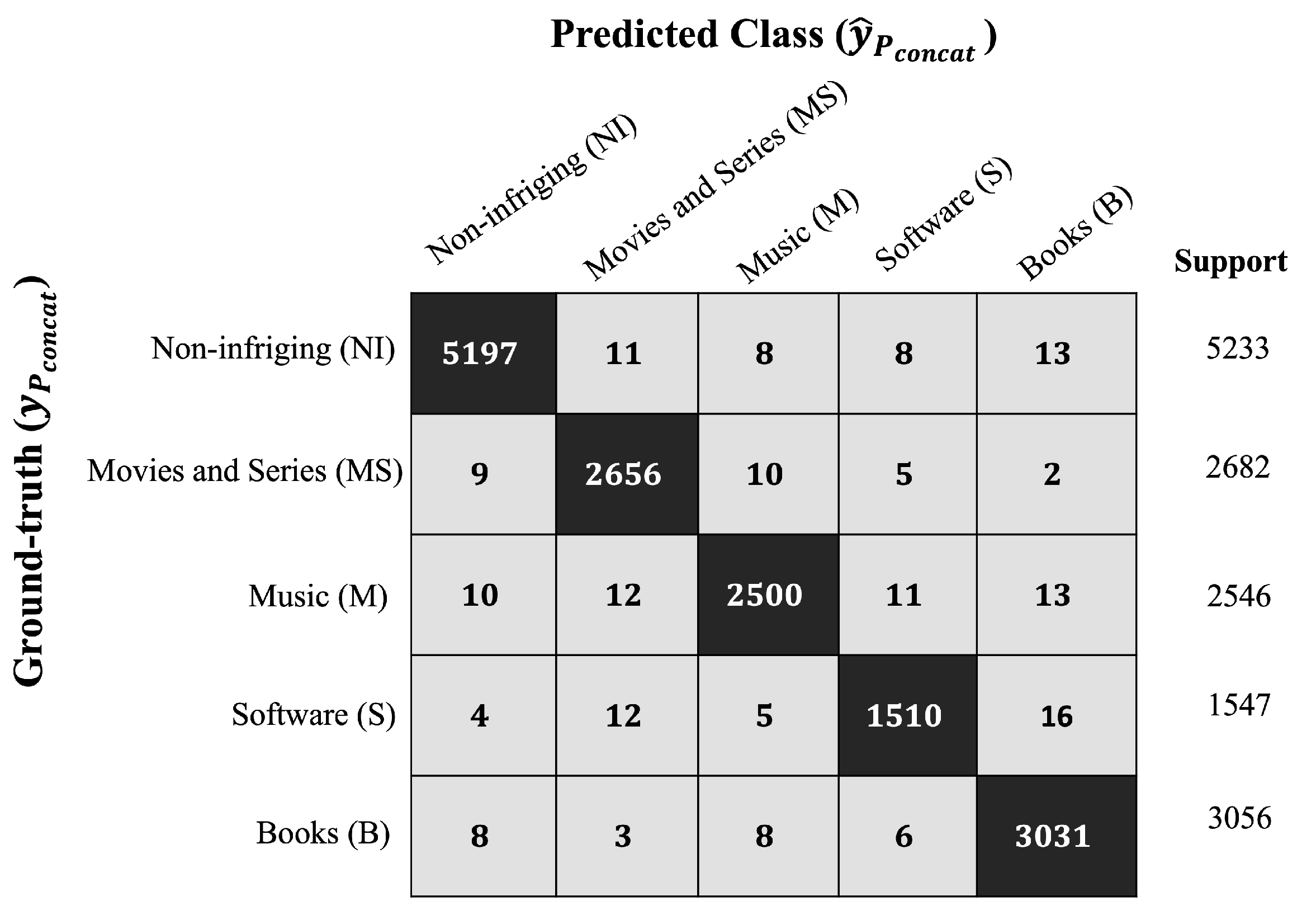
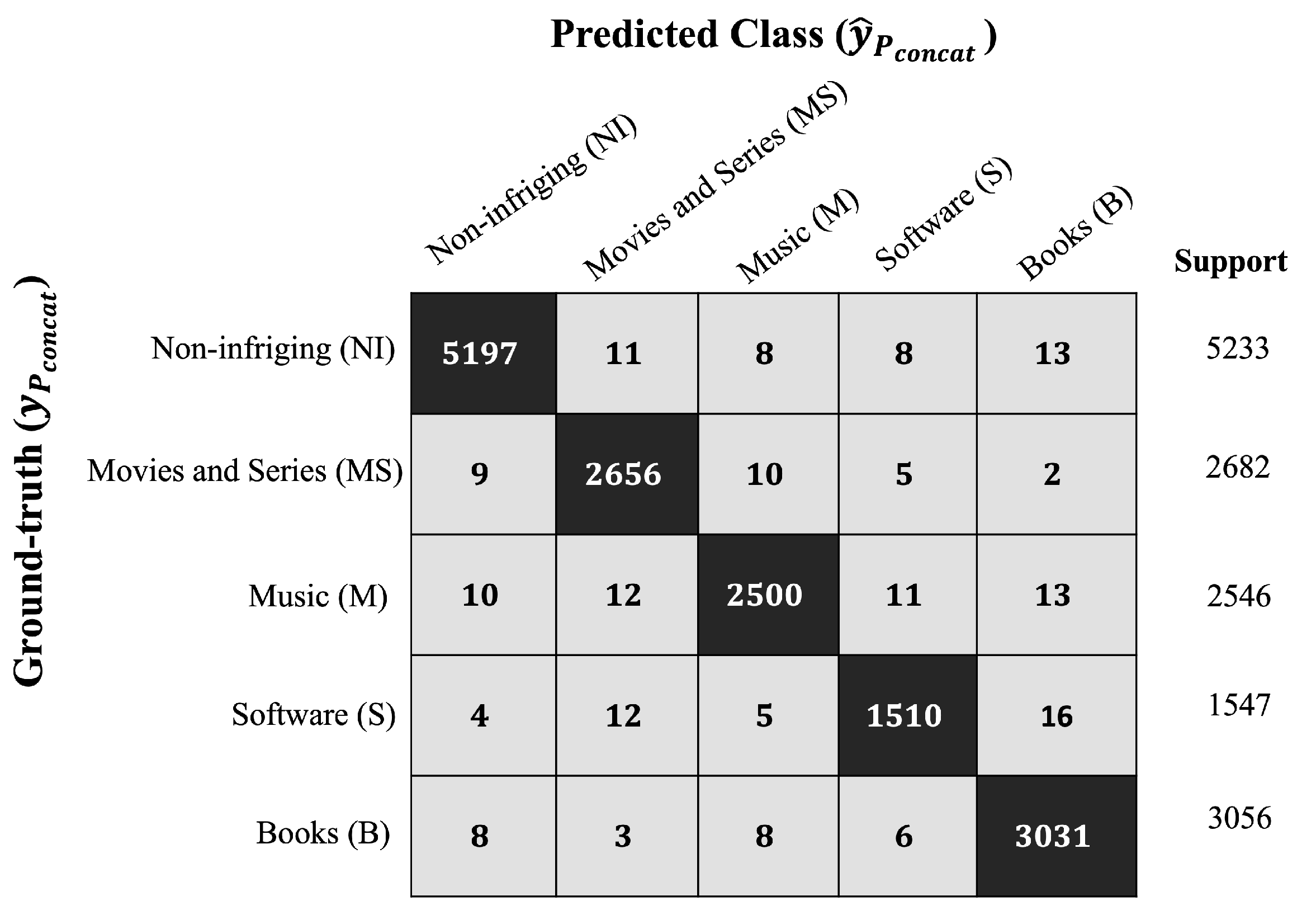
To assess the classification results achieved by the BERT + DNN model,
Figure 12 presents the multi-class confusion matrix, along with the support (number of samples submitted) for each test sample.
Once the composite confusion matrix has been constructed, it is possible to calculate performance metrics, including precision, recall, and the
-score, whose values are referenced in
Table 8.
Although it is not possible to directly compare state-of-the-art studies in terms of their methodology, as they do not use a multi-class classification model like the one employed in this BERT + DNN project, we highlight some of the main disadvantages of these works in the following lines. For the sake of clarity and linguistic conciseness, the related works [
28,
29,
30,
31,
32,
33,
35] will from now on be referred to as studies.
Regarding the exploration of the Internet of Everything (IoE), studies [
28,
30,
32] do not conduct a thorough search for multimedia content at risk of infringement. Study [
28] narrows its focus to the detection of downloads of multimedia objects that have been previously identified and transmitted via a Local Area Network (LAN) at the application layer, identified by a protocol analyzer that targets Peer-to-Peer (P2P) ports. Meanwhile, study [
32] bases its dataset on interviews that investigate the use of potentially infringing software among users of varying ages, genders, ethical beliefs, and economic statuses, without providing details on the aggregation of data over any specific transmission medium. Study [
32] utilizes a pre-established database featuring logos highly susceptible to copyright infringement, depicted in images of well-known commercial brands, and conducts experiments based on this dataset, yet it does not describe the process or location within the IoE from which these data were collected.
Contrary to other methods, studies [
29,
31,
35] conduct selective explorations, opting for web scrapers over search engines to analyze specific sites within the Internet of Everything (IoE) that are directly linked to their research objectives. For instance, Ref. [
31] directs its scraping towards specific YouTube endpoints to retrieve the top
K videos displayed without user consent, solely collecting titles and descriptions. Similarly, Ref. [
29] also gathers data from YouTube, but it uses a more advanced and semantically enriched latent vocabulary that categorizes results based on ethically questionable practices for accessing protected content. Meanwhile, study [
35] employs a hybrid strategy, interspersing the detection of live streams with compromised copyright with a dataset customized for research purposes.
First comparative finding: Compared to the BERT + DNN methodology, which explores a section of the IoE using five search engines, studies [
28,
30,
32] completely restrict their scope without retrieving any information from the IoE; on the other hand, Refs. [
29,
31,
35] only address a fraction of the IoE and fail to achieve a broader spectrum in their collection due to the absence of search engine utilization. Only Ref. [
33] conducts an effective traversal, but its effort is confined to recovering just 98 sites associated with pirated content, a number not considered substantial for a study of this caliber.
In the realm of exploring relevant categories, only the studies [
28,
33] propose a wider spectrum of content for infringement detection. For instance, Ref. [
28] features a collection of music and videos in line with Apple’s rankings, while Ref. [
33] turns to the now-defunct AlexaNet to identify sites likely to be monitored in their data collection, covering areas such as video games, torrents, and sports. In a more generic approach, Ref. [
30] superficially addresses the software category without specifying which programs might be more prone to illicit use. Regarding videos, Refs. [
29,
31,
35] focus on real-time streaming platforms without delving into how to handle TV series, movies, or other streaming content types. In a more limited scope, Ref. [
4] relies on brands from recognized providers without describing their specific fields of expertise. Studies [
28,
29,
30,
31,
32,
33,
35] fail to incorporate additional features that define the behavior and structure of the sites analyzed.
Second comparative finding: In contrast to previous research, this methodology (BERT + DNN) encompasses a wider range of categories ( and B), delving into a more comprehensive analysis of distinctive features of infringing sites. This analysis includes elements such as redirections, reputation assessment, the presence of malicious elements (adware), the use of URL shorteners, and the improper use of JavaScript, among others, factors that have not been addressed by other studies.
In the domain of NLP methods, studies [
30,
32] do not utilize textual analysis methods, erroneously assuming that infringing content can be detected based on specific dependencies. This approach is significantly flawed as it overlooks semantic subtleties, potential issues like case sensitivity, ambiguity, and comprehension limitations, resulting in a final product that cannot be effectively assessed for performance [
99].
Conversely, study [
28] employs the Vector Space Model (VSM). However, this method also faces challenges, as it has been shown that a pure vector representation lacks semantic depth, contributes to an unstable vocabulary dimension, and leads to data dispersion, yielding vector outputs of low quality [
99].
In study [
29], queries based on word similarity are utilized, also through VSM. Such comparisons between sentences risk scale sensitivity in the resulting vectors due to their reliance on the frequency and weight of word occurrences, which can lead to inappropriate similarities [
100].
Study [
33] adopts a more robust representation by combining Optical Character Recognition (OCR) with Word2Vec. Nonetheless, there are risks of mismatch and contextual misinterpretation when using OCR with Word Embeddings, as character misrecognition could lead to incorrectly interpreted words that distort the sense captured by Word2Vec [
101]. Additionally, it is established that Word2Vec cannot recognize the order of words across multiple sentences, which limits understanding [
102].
Moreover, study [
35] proposes extracting sentiment polarity as a feature. This can lead to oversimplification since a user’s text may carry multiple meanings depending on the emotional context, potentially misinterpreting the underlying sentiment [
103]. Furthermore, these features lack context, as polarity does not provide semantic information, only interpretation.
Only study [
31] and the current project employ BERT, which, as discussed throughout the manuscript, reduces the need for extensive feature engineering, preserves the latent context of sentences, and ensures that words maintain their meaning regardless of their position and frequency in the text.
Third comparative finding: In contrast to the previously mentioned research, the methodology presented here (BERT + DNN) harnesses BERT’s pre-trained weights to consolidate, abstract, and more accurately reflect the text embedded within websites. BERT has been meticulously engineered to address the myriad shortcomings prevalent in NLP models, issues that have been reiterated in this section: the lack of semantic depth, the intricacies of composition and connections, the challenges posed by high dimensionality and data dispersion [
28,
29], contextual rigidity [
33], and premises inclined to introduce ambiguity [
35].
In the cutting-edge realm of Artificial Intelligence and Machine Learning (AI/ML), assessing the effectiveness of various models is critical. Study [
28] initially presents RBC, which excels with small and structured datasets. Yet, its rigidity in the face of complex rules diminishes its applicability for the synthesis of textual and numerical features, which is a distinctive feature of this research (BERT + DNN), and restricts its ability to grasp nonlinear dynamics [
104].
While study [
28] stops short of detailing the RBC algorithm’s mathematical underpinnings, the prevailing literature suggests that its linear orientation significantly undermines its utility with nonlinear data types, such as textual content, often leading to error-prone models with subpar performance.
Study [
30] acknowledges the intricacy of ACO, a formidable challenge for amalgamating features in multidimensional contexts, necessitating a thorough search methodology to pinpoint websites likely in breach of copyright laws [
105].
Moreover, the study [
31] endorses LR, an algorithm attuned to predictive tasks involving less complex datasets. However, the process of integrating diverse data characteristics (BERT + DNN) calls for significant regularization trials, potentially detracting from its efficacy in identifying multimedia content within digital lexicons.
Correspondingly, study [
32] employs CNNs, renowned for their proficiency in object detection, yet their performance can be erratic within the heterogeneous IoE. A recalibration of the DOM could potentially refine the detection of illicit multimedia material.
Finally, study [
35] introduces fundamental algorithms like AdaBoost, XG-Boost, RF, SVM, and MLP. Despite the unique challenges each algorithm faces in pinpointing infringing content, they all share the common requirement for meticulous hyperparameter optimization [
106]. AdaBoost risks overfitting without proper classifier baseline selection, XG-Boost may misinterpret features with outlier data, Random Forest necessitates exacting adjustments of its estimators, SVM demands intricate kernel and regularization parameter selection, and MLP grapples with learning rules that could erode the integrity of weight values.
Fourth comparative finding: The BERT + DNN architecture is more versatile and streamlined, effectively managing the fusion of textual and numerical features. It exhibits a classification potential that surpasses the performance metrics of other state-of-the-art studies (precision = %; recall = %, and F1-score = %) in detecting infringing multimedia content, outperforming most the state-of-the-art works.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}