1. Introduction
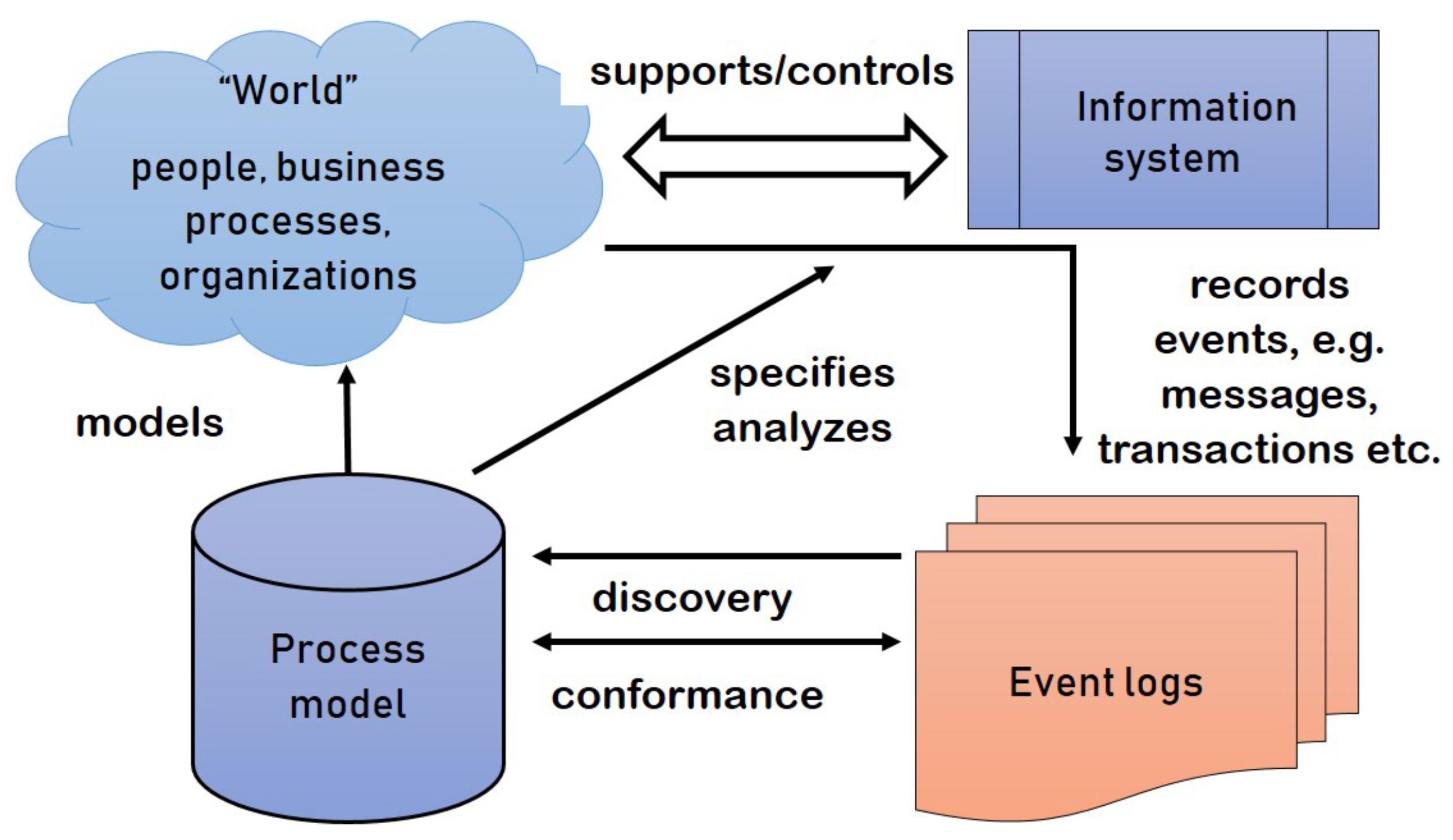
Modern information systems diligently maintain a record of operational events in the form of an event log. Historically, these system logs served primarily as a reference point to retrospectively trace the sequence of events and identify any potential errors. However, with the rapid progression of technology in today’s era, the focus has broadened significantly. The challenge now lies not just in detecting errors but also in deriving valuable insights from these event logs. In the modern era, information systems have become an integral part of various sectors, including business, healthcare, and education, among others. These systems generate a vast number of data, providing a rich source of information for understanding and improving processes. It is necessary to monitor, analyse, and improve a process to keep the business environment running smoothly. However, the complexity and number of these data present significant challenges to extracting meaningful insights.
Process mining [
1] has emerged as a promising approach to address these challenges. As an intersection between data mining and business process management, process mining is about discovering, monitoring, analysing, and improving real-world business processes through knowledge extraction from event logs provided by information systems [
2].
Real-world examples of event logs include loan applications in banking systems [
3], an application of a patient’s medical billing report in hospital [
4], logs used to detect customer behaviour based on logged clicks [
5], and there are more examples.
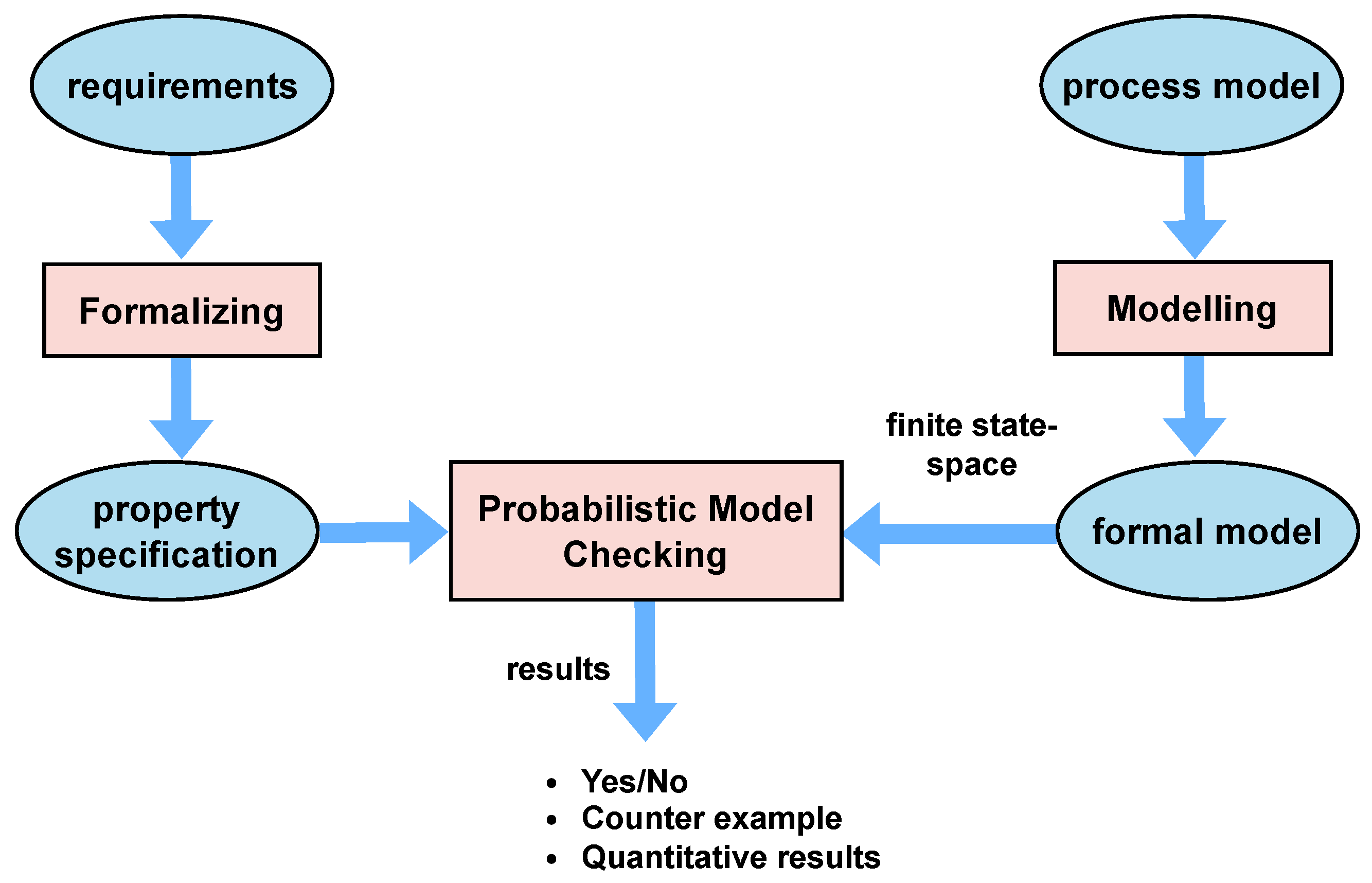
Real-world processes are often influenced by a number of unpredictable factors, from machine breakdowns to human decision variability. Process-mining techniques might fall short in capturing these peculiarities, leading to models that are overly simplified or not representative of the actual system behaviour. Formal verification has emerged as an effective strategy to verify process correctness. Formal verification is a method used in computer science to verify and/or analyse the properties of finite-state systems, and it is a powerful technique for verifying concurrent and distributed systems. The work presented by [
6] introduces BProVe, a verification framework dedicated to
business process model and notation (BPMN). This framework was created to address the lack of formal semantics in BPMN, which creates obstacles for the automated verification of relevant properties. The work in [
7] proposes an approach, termed model mining, which facilitates the creation of abstract, concise, and functionally structured models from event logs. In [
8], a methodology for conducting temporal analysis on mobile service-based business processes is introduced with a concentrated emphasis on the specification and validation of temporal constraints.
Model checking is an often-utilised technique of formal verification that involves the creation of a model of the system, specifying desirable properties in a logical language and then using algorithms to determine whether the model satisfies these properties [
9]. According to [
10], the model-checking approach model processes as transition systems and express properties as formulas in temporal logic. These properties signify the requirements that a particular process needs to fulfill to be deemed correct. Linear temporal logic (LTL) is one of the languages that allows users to define properties for verification. The objective of model checking is to ascertain whether a process model demonstrates particular desirable behaviour. In some cases where the process model fails to exhibit the necessary behaviour, model-checking techniques provide a counterexample. This assists in identifying the areas of the model that require correction, ensuring that the final model is robust and fit for its intended purpose. The application of model-checking techniques in process mining is a relatively new and promising research area [
11]. The integration of these two fields can provide a more robust and comprehensive analysis of operational processes. By applying model-checking techniques to the models discovered in process mining, we can verify whether certain properties hold, detect discrepancies between the intended and actual process, and even predict future process behaviour [
12,
13,
14].
Historically, the verification of software and hardware systems was largely deterministic. Yet, as systems have become more complex and have begun to account for randomness and uncertainty, deterministic methods have been found lacking in comprehensiveness. The traditional binary output (YES or NO) of model checking may not be enough for real-world processes ranging from financial [
15] to automotive [
16] and healthcare [
17] sectors having stochastic behaviour.
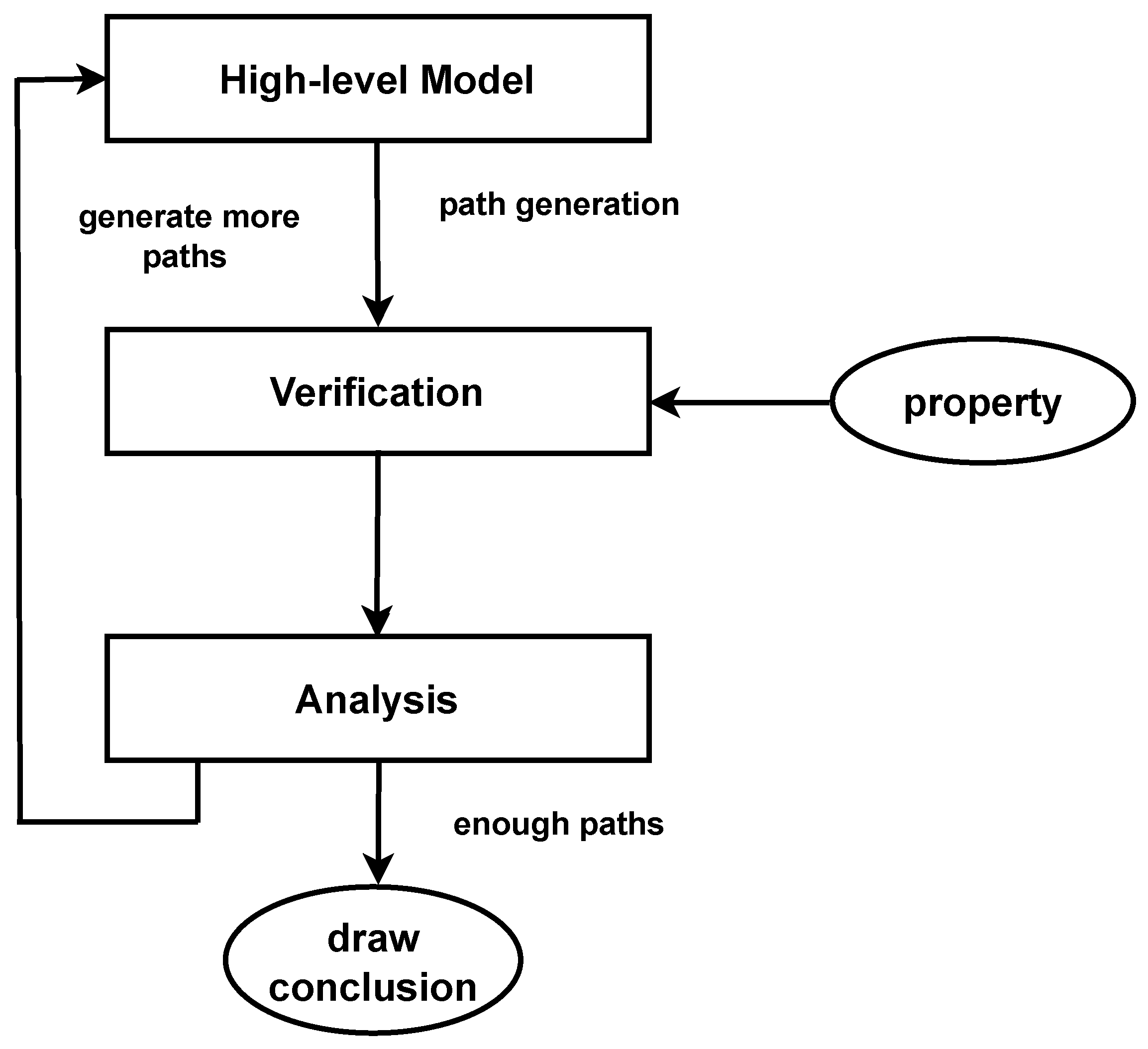
Probabilistic model checking has risen to prominence in this context, providing a means to verify systems that incorporate probabilistic behaviours, with probabilistic models being intended to quantitatively assess system performance and precision [
18]. In recent times, probabilistic model checking has established itself as a powerful method for verifying both hardware and software. This technique is recognised for its broad applications, notably in the assessment of reliability, dependability, and performance [
19,
20]. A noteworthy collaboration was achieved by combining probabilistic model checking and process mining. This was implemented using discrete- and continuous-time Markov chain models, as detailed in [
21,
22]. The authors proposed a framework to verify whether a discovered model satisfies certain desired properties or constraints and provided answers to questions of how likely, how long, and what factors influence possible paths in a process.
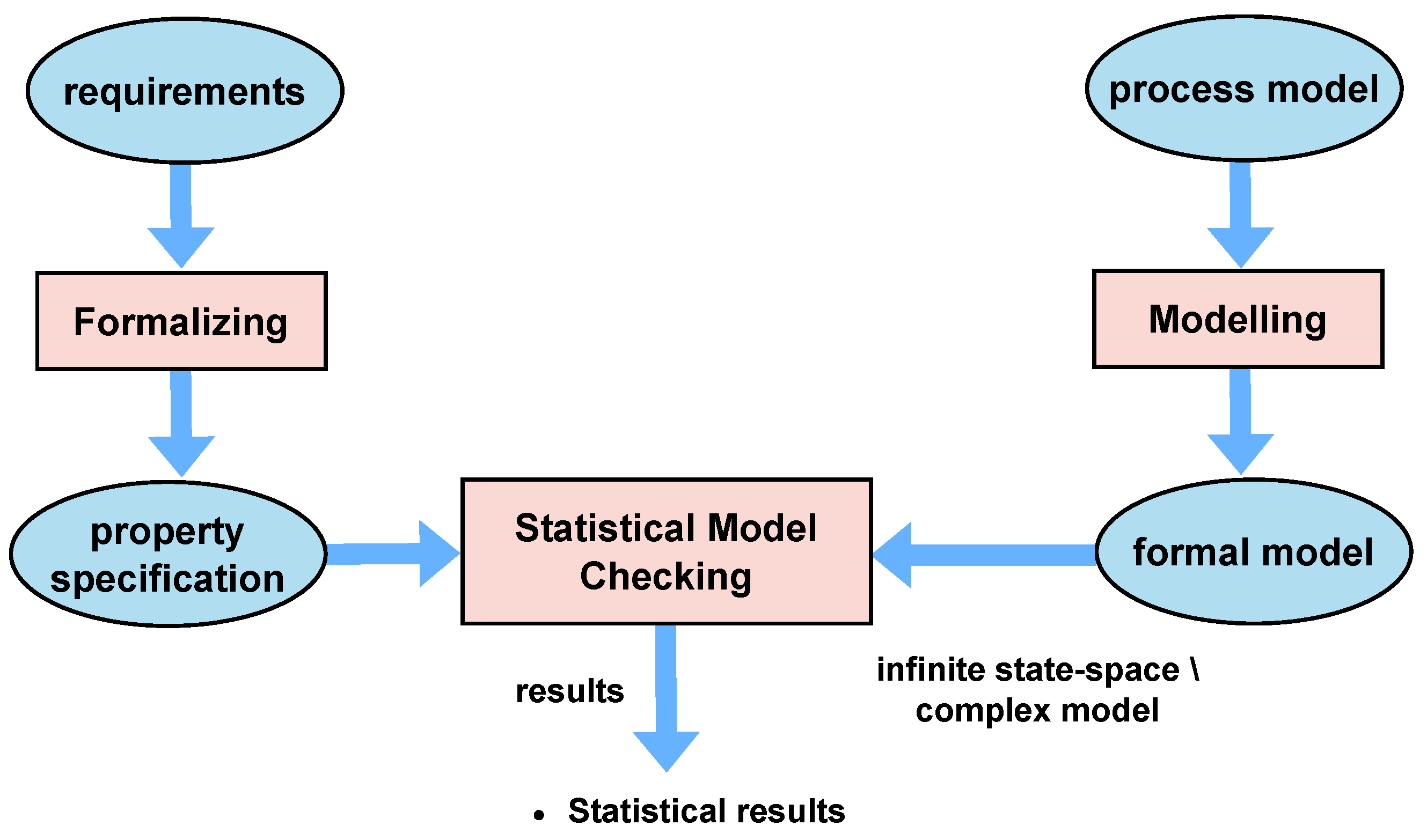
Figure 1 illustrates the probabilistic model-checking method for process-mining models.
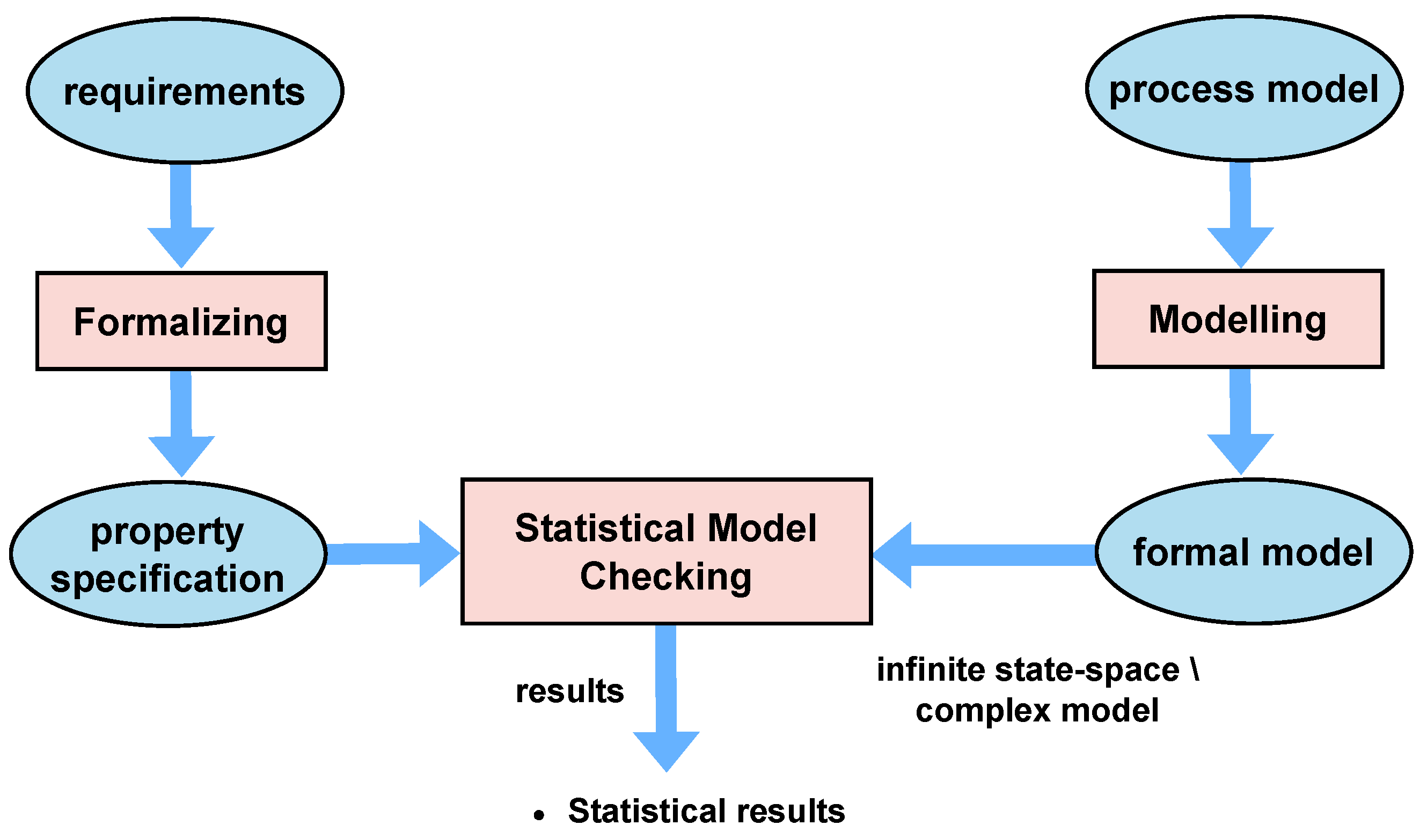
While probabilistic model checking has made significant advancements in the field of software model checking, showcasing its effectiveness and robustness in approach, the persistent challenge of the state explosion problem continues to require innovative strategies to be overcome. One such solution is the application of statistical model checking (SMC), utilising simulation methods, particularly discrete-event simulation (DES), as a mitigation strategy.
SMC represents a methodology rooted in simulation for validating properties relevant to stochastic systems. It serves as an alternative to conventional model-checking techniques, notably the probabilistic ones, which often struggle with systems that exhibit large or infinite state space—a scenario that usually presents challenges for standard methods [
23]. Within the scope of SMC, a system is conceptualised as a stochastic process, and the properties are expressed using temporal logic. The fundamental concept supporting SMC is the estimation of the likelihood that a system complies with a specific property. This research article aims to explore the application of statistical-model-checking techniques in process mining.
The methodology presented in this article aims to extend the current process-mining techniques by introducing statistical model checking. In this study, we propose a novel methodology that integrates SMC and PM by formally modelling discovered and replayed process models and applying statistical methods to estimate the results. Our approach offers an efficient, automated evaluation to determine the alignment of a process model with user specifications, aiding users in choosing the most suitable process model. The proposed approach enables the validation of qualitative and quantitative properties of complex systems and/or systems with large state space, where it is difficult to perform probabilistic model checking. The aforementioned process is accomplished by executing several discrete simulations of the system under study, where each simulation trace is individually examined for the property of interest. The final result can be understood as a statistical representation of the given probability, supplemented by a confidence interval. This interval serves to quantify the level of uncertainty embedded in the estimation, thereby providing a comprehensive measure of the probable accuracy of the results.
The novelty of this work lies in the statistical methods utilised, which allow for the analysis of large logs and complex models by using sampling and statistical inference, thus making PM scalable to enterprise-level applications. SMC can provide a formal method to verify business processes against desired properties. This is novel, because traditional PM techniques focus on discovering, monitoring, and improving processes based on historical data without formal verification. By using SMC, the accuracy of discovered process could be improved. SMC-based formal methods in business processes can help in identifying not just the paths taken in a process, but also those that are possible yet never taken. This provides a complete picture of the process capabilities. SMC can be used to predict future states of a process. Such predictive capability could significantly contribute to PM, allowing organisations to foresee and minimise potential issues before they occur.
Figure 2 illustrates the statistical-model-checking method for process-mining models. We believe that our research will contribute to the advancement of process-mining techniques and will provide valuable insights for organisations to improve their processes.
The structure of this research article is as follows:
Section 2 presents background material related with this research.
Section 3 offers a thorough analysis of the relevant work. In
Section 4, the proposed framework is presented; it is divided in three stages, and each stage is discussed in detail. The implementation details of a case study and discussion of the results are presented in
Section 5, and finally,
Section 6 concludes the article, summarising the findings and implications of this research.
3. Related Work
The advent of process mining has revolutionised the way organisations understand and optimise their operational processes. The advancements in this field have led to significant improvements, enabling experts in their field to understand highly complex processes [
38] and non-technical users to easily retrieve relevant information and insights about their processes [
39]. By extracting knowledge from event logs, process mining provides a data-driven lens to analyse and improve business processes. However, the accuracy and reliability of the models generated through process mining are critical for effective decision making. This underscores the need for a robust verification technique to validate these models. Concurrently, the field of formal verification, particularly model checking, has seen substantial advancements. The integration of these two fields, however, is a relatively new area of exploration. This integration can offer a higher degree of confidence in the validity of the models and the insights derived from them.
Formal verification methods are used to prove or disprove the correctness of a system with respect to certain formal specifications or properties. Model checking is an automated method that checks whether a model of a system meets a given specification by exploring all possible states of the system. The work on model checking by [
40] serves as a comprehensive overview of the evolution and advancements in model checking, an automatic verification technique for state transition systems, over the past several years. Model checking as a technique has proven to be a valuable tool in the identification and resolution of problems within computer hardware, communication protocols, and software applications. Furthermore, it has begun to find its use in evaluating cyber–physical, biological, and financial systems. However, this approach encounters a significant obstacle, often referred to as the state explosion problem. In simple terms, this issue arises when the sheer number of states within a system becomes too large to be managed effectively [
40].
Expanding the scope of model checking, the authors [
41] took it into the domain of financial risk assessment. They devised a probabilistic model that provides an assessment of potential risks in financial production. The authors approach is unique, as it relies on computing probabilities to estimate users’ behaviours, hence quantifying the likelihood of their actions. The authors recognised for their prior work on process discovery [
12] presented a complementary approach by proposing a method to verify whether a specific property holds true for a system, given an event log of the system’s behaviour [
13]. They accomplish this through the development of a language based on LTL and the use of a standard XML format to store event logs. Furthermore, the authors present an LTL checker that can confirm whether the behaviour observed in an event log complies with the properties defined in the LTL language. The LTL checker was implemented in the process-mining ProM framework [
42], and the results can be further analysed using various process-mining tools. This work lays the foundation for the need of verification and model checking of mined models.
In [
14], the authors presented an approach that employs temporal logic query checking, which bridges the gap between process discovery and conformance checking. This method facilitates the identification of business rules based on LTL that are consistent with the log by assessing them against a set of user-defined rules. In the study [
19,
43], the focus was on conformance checking, emphasising the role of alignments, and in [
44], they focused on anti-alignments. Such conformance checking provides enhanced diagnostic tools to detect variances between a trace and its associated process model.
The work in [
45] advances runtime verification through a comprehensive examination of flexible, constraint-based process models based on LTL on finite traces. In [
46], the authors presented a new probabilistic approach to conformance checking by incorporating stochastic process models, considering routing probabilities and frequencies. The work in [
47] proposed a runtime verification technique called predictive runtime verification. The unique aspect of this work is that instead of assuming the availability of a system model, the authors describe a runtime verification workflow where the model is learned and incrementally refined using process-mining techniques. The authors in [
48] presented an approach for the automatic analysis of business process models discovered through the application of process-mining techniques.
Formal verification techniques such as model checking, however, often encounter a common problem known as the state explosion problem, where the number of states in a model may grow exponentially with the size of the model. Hence, alternative approaches that can handle large models are needed. A unique algorithm that employs Monte Carlo simulation [
33] and hypothesis testing for non-explosive, stochastic discrete-event systems was proposed in [
32] and further elaborated in [
49]. Monte Carlo simulation—a statistical method—permits the modelling of random variables and their potential outcomes. This approach has significantly improved probabilistic model checking capabilities and highlighted the potential of using simulations to strengthen model-checking methodologies. The authors in [
32] presented a model-independent method for verifying properties of discrete-event systems, which often have complex dynamics that are difficult to analyse. The uniqueness of this approach lies in its model independence, making it versatile for any discrete-event system. The sole model-dependent aspect is the establishment of sample execution paths and the probability measure on these path sets. In [
50], the algorithm of [
32] was extended to statistically verify black-box systems. The paper [
50] presents a novel statistical methodology for analysing stochastic systems against specifications specified in a sub-logic of continuous stochastic logic. The system under study behaves as a black-box that is already deployed, from which sample traces can be passively observed but cannot be manipulated. More applications of SMC in stochastic systems can be found in [
28,
29,
30].
A comprehensive overview of the SMC methodology, its real-world implementations, and its applications in various domains can be found in the literature reviews conducted in [
31,
51]. These surveys explain how SMC emerges as a formidable strategy for approximating the probability that a system adheres to a certain temporal property. The methodology of SMC involves the examination of a finite collection of system executions, followed by the application of statistical techniques to generalise the findings. The outcomes of this process adhere to a confidence level that can be predefined by the user, thereby allowing for control over the precision of the results. The work emphasises SMC’s capacity to alleviate the state-space explosion problem, along with its ability to manage requirements that surpass the expressiveness of traditional temporal logics. The work in [
52] introduces a research direction that merges statistical model checking and process mining. The research aims to augment SMC by explaining the reasons behind specific estimates, which can assist in model validation or recommend improvements (enhancement). The integration of SMC and PM results in an approach to white-box behavioural model validation and enhancement. With this methodology, PM can detect discrepancies in the model by examining the simulations generated through SMC. Importantly, since SMC can determine the necessary number of simulations for a given analysis, it produces statistically reliable event logs suitable for PM applications.
The work performed so far in the verification of process models suggests that process models must be validated for accuracy and precision to ensure their effectiveness. This validation is achieved by defining the semantics of the models and applying various logic and formal methods for verification, including model checking. Applications of model checking in process mining are still in their infancy; nevertheless, it is a promising research field and can be extended with the application of statistical model checking in process mining to handle complex systems with stochastic behaviour.
4. Proposed Framework
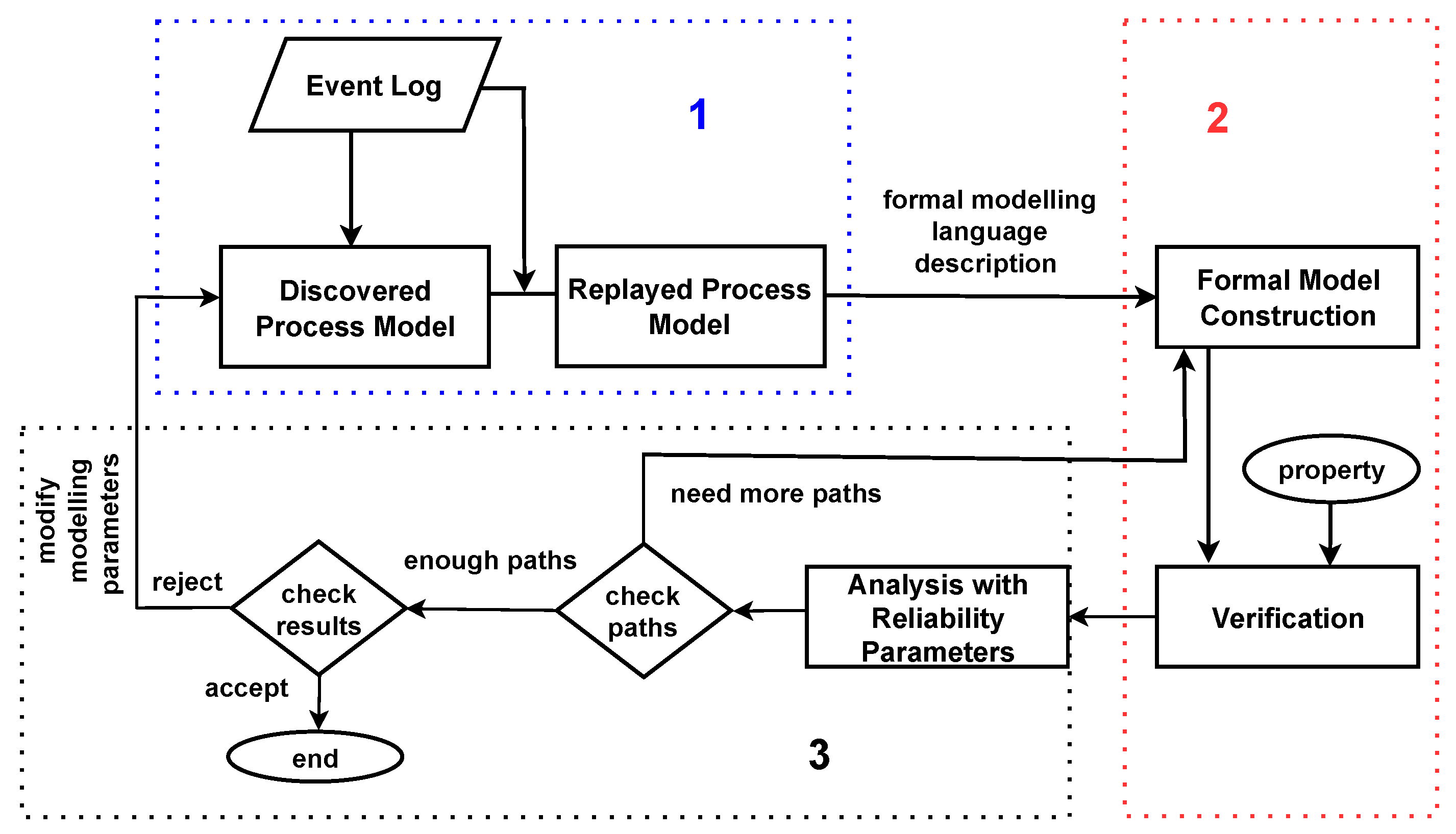
Statistical model checking concentrates on performing the right number of simulations to obtain statistically reliable estimations, such as the probability of success in reaching a goal state. On the other hand, process mining focuses on constructing and/or optimising a system model using logs of its traces. Drawing on the strengths of these two methodologies, as shown in
Figure 3 and
Figure 4, we propose a framework that integrates SMC and PM. This fusion aids in identifying anomalies and areas of concern within models discovered through PM. Notably, it addresses complex business processes, which are often challenging to model comprehensively.
Figure 5 illustrates the proposed framework.
SMC, with its capacity to manage the state-space explosion problem and its ability to handle complex process behaviours, is a powerful tool for process mining. The application of SMC could greatly aid in understanding, optimising, and controlling complex business processes, thus offering significant value for organisations striving for efficiency and reliability. Furthermore, it could recommend improvements based on the statistically robust results estimated through SMC. The proposed framework is divided into three major parts, as shown below:
4.1. Process-Mining Model
In the initial stage, the focus lies in the discovery and replay of the process model. Process discovery is a technique in process mining whereby a process model is constructed from an event log, which is an unstructured sequence of events captured from the execution of a process, while in the replay method, an algorithm operates by replaying event logs in the process model, aiming to reproduce the observed behaviour and evaluate its alignment with the expected process flow. Replay can also provide valuable insights, including the frequency of execution of different paths and performance metrics such as waiting times and execution times for activities. Dotted block 1 in
Figure 5 illustrates the initial step of the proposed framework.
4.1.1. Process Discovery
Process discovery entails utilising an event log as an initial data source and generating a model that effectively captures the observed behaviour within the log. The objective of process discovery techniques extends beyond merely constructing models that depict the control flow of activities; they also encompass uncovering additional dimensions, such as revealing the social network connections among the resources involved in executing these activities [
53]. The utilisation of process discovery techniques is highly valuable for gaining insights into real-world processes.
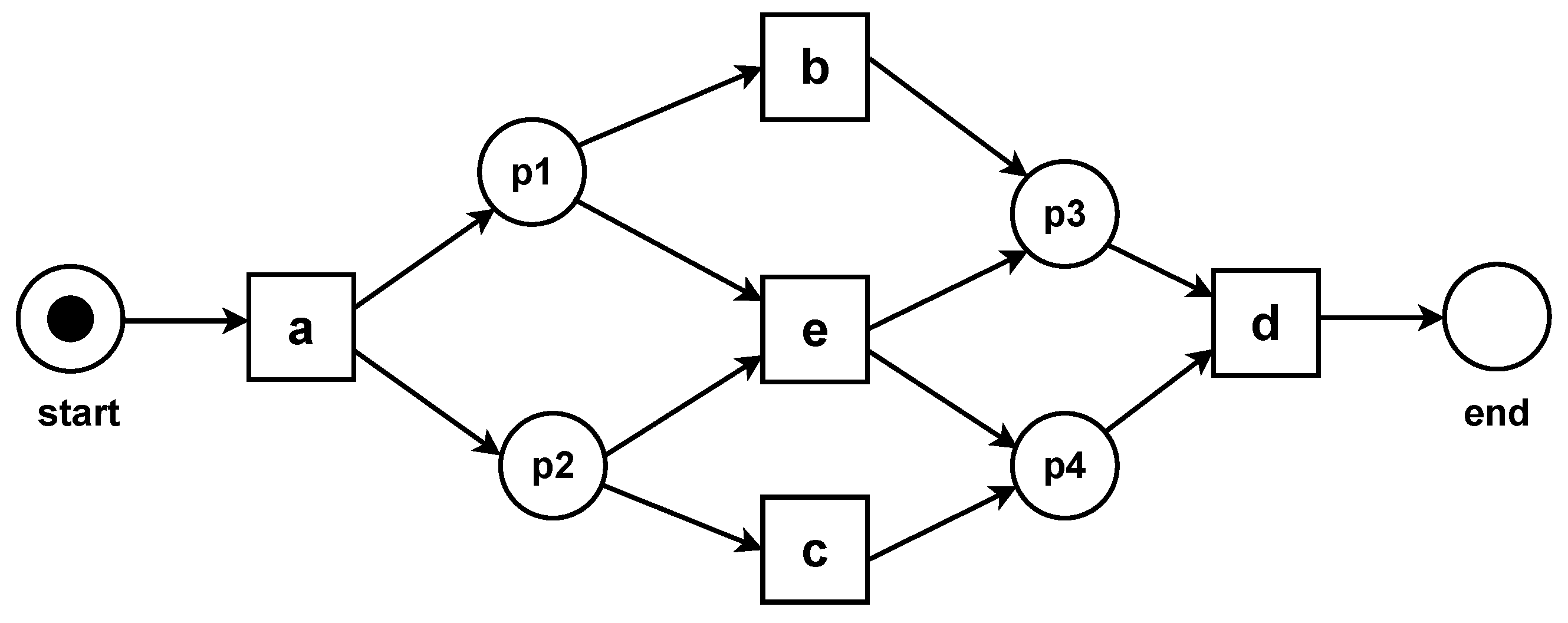
Process discovery algorithm: Let
I denote the set of process discovery algorithms. In a formal sense, a process discovery algorithm can be defined as a function that maps an event log to a process model. Specifically, for each
, we have
, where
L represents the set of event logs and
represents the resulting process model. The primary objective is to ensure that the discovered process model accurately reflects the observed behaviour within the event log.
Figure 6 shows a model of log
L discovered using a simple discovery algorithm,
Alpha Miner.
Alpha Miner, one of the first and simplest process discovery algorithms, is utilised for its capability to discover a process model that is easier to understand compared with other discovery algorithms, which may generate complex models.
4.1.2. Conformance Checking
Conformance checking involves the examination of both a process model and an event log associated with the specific process. The purpose of conformance analysis is to compare the observed behaviour recorded in the log against the behaviour permitted by the model [
54,
55]. When the observed behaviour deviates from what is allowed by the model or vice versa, it indicates non-conformance between the log and the model.
Alignment: It refers to the pairwise comparison or the quantification of the similarity between observed event logs and a reference process model. It measures the level of agreement between the recorded behaviour and the expected behaviour specified by the model. Alignment provides insights into the degree of compliance, accuracy, and fitness of the observed process execution traces with respect to the modelled process.
Replay algorithm: A replay algorithm refers to a computational procedure that operates on an event log, denoted by L, and a process model, represented as , as its input. The objective of the algorithm is to produce a set of alignments that establish the correspondence between the event log and the process model, denoted by . Here, represents a set of alignments that establish a correspondence between the events in the log and the states of a Petri net.
4.2. Modelling and Verification
In this step, the primary focus lies in constructing a model and ensuring its validity for the system under investigation. A model is built to accurately represent the behaviour of the real-world system. The construction of this model typically involves formalising the processes obtained in the first step (
Section 4.1), translating them into a formal language that can be used for further analysis. Dotted block 2 in
Figure 5 illustrates the modelling and verification step.
In this step, one can build a complete model of a system or can generate paths to perform verification. The formal model is generated with the help of a set of alignments,
, which results from the replayed process model, as shown in
Figure 5. Set of alignments
is used to create a transition probability matrix and/or rate matrix depending on the type of model we consider (i.e., discrete-time or continuous-time Markov model). In a formal model of type discrete-time Markov chain (DTMC)
(where
is a finite set of states,
is the initial state,
is the labelling function,
is the transition probability matrix), where
for all
, each element
of the transition probability matrix gives the probability of making a transition from state
s to
[
56]. And in a formal model of the type continuous-time Markov chain (CTMC)
,
S is a finite set of states;
is the initial state;
is the labelling function; and
is the transition rate matrix [
56]. The logic used to express the properties of the formal
model is
probabilistic computation tree logic (PCTL), while for
, it is
continuous stochastic logic (CSL). The syntax and semantics defined below are for CSL (excluding the
S operator), and if we change the time domain from
to
, we obtain PCTL [
57]. Let
represent a
state formula and
represent a
path formula; then,
where
is an atomic proposition,
(set of atomic propositions),
, and
. The operators (¬, ∧) represent logical
and
, respectively, while
X (“next”),
(“bounded next”),
U (“until”), and
(“bounded until”) are standard operators in temporal logic. Note that we use bounded and unbounded
X and
U operators. The notion that a state
s (or a path
) satisfies a formula
is denoted by
(or
) and is defined as follows [
57]:
This step involves generating a finite number of system simulations and leveraging statistical methods to determine whether the collected samples provide statistical proof of the system either meeting or failing to meet the specified requirements. The key principle here is that the sample runs of a stochastic system are generated in accordance with the system’s defined distribution. This allows for the estimation of the probability measure on the system’s executions. A formal model of the discovered process, as shown in
Figure 6, is presented along with its defined properties below.
![Futureinternet 15 00378 i001]()
![Futureinternet 15 00378 i002]()
4.3. Analysis
The analysis phase within SMC plays an integral role, addressing the results derived from the process and analysing them using a range of key determinants, i.e.,
reliability parameters. A deeper understanding of these reliability parameters provides the ability to closely examine the dependability of the SMC results. Typically, these parameters find associations with the statistical confidence and accuracy of the outcomes obtained from the model-checking procedure. Among the reliability parameters, the concept of
confidence interval finds prominence, with its elements being confidence level and width. A significant feature within this context is the
statistical test. An instance of such a test is the sequential probability ratio test (SPRT) [
34].
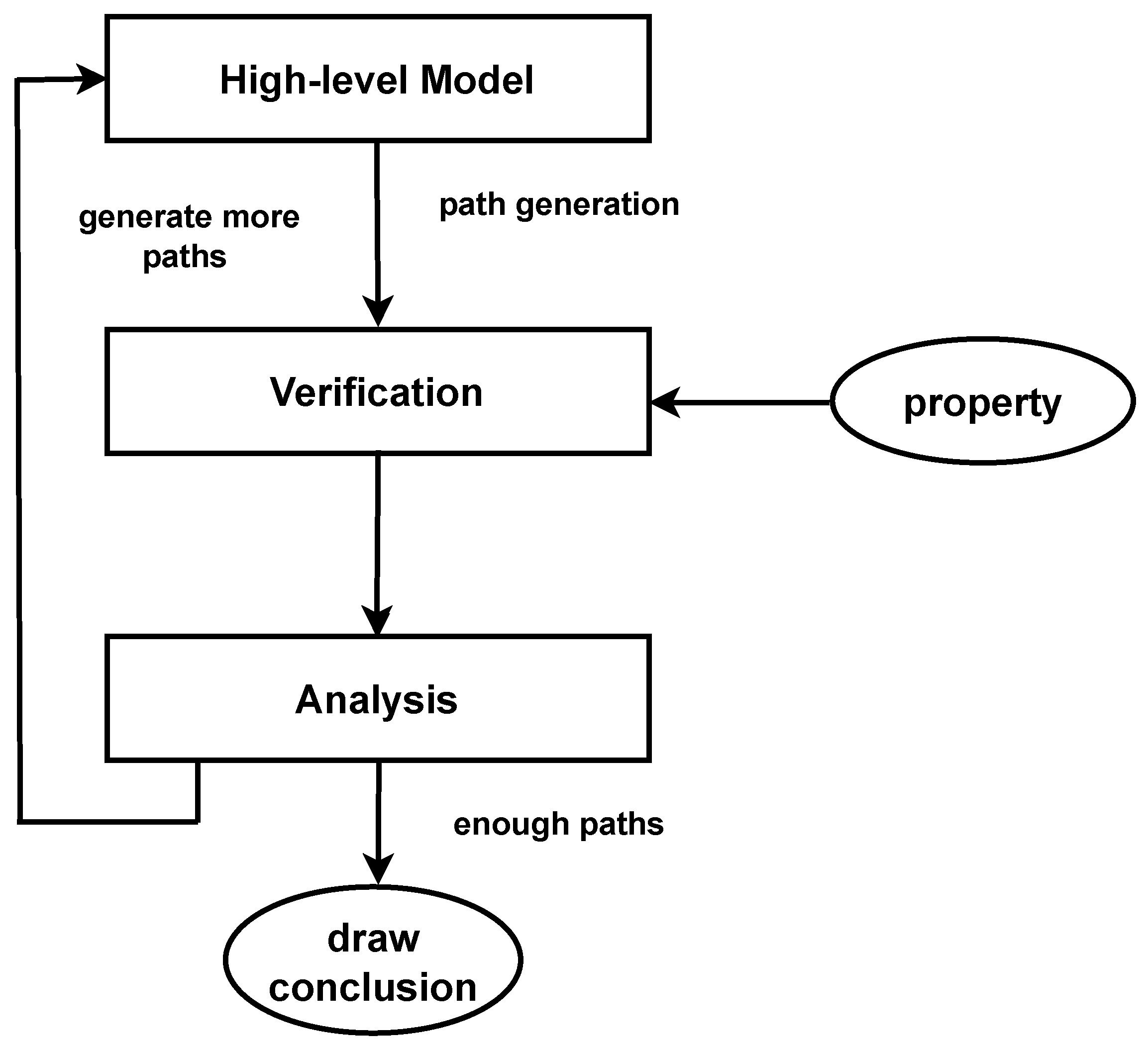
As illustrated in dotted block 3 in
Figure 5, the first assessment criterion is the count of paths. This criterion is essential to evaluating the results. If the execution traces or paths are insufficient for making a conclusive decision, additional paths are generated from the established formal model. Conversely, when there are adequate paths executed, the next step involves reviewing the results and proceeding towards making a decision on whether to accept or reject these results. The basis for such decision making, whether to accept or reject the results, resides in the user requirements, serving as the determining factor for the application of statistical-model-checking techniques to process models.
The implication of a user rejecting the acquired results denotes that alterations can be made to the modelling parameters of the process model’s discovery and replay. Let us consider a formal model represented by , and let represent a temporal logic property. In this scenario, the task of the SMC algorithm is to approximate the value of , where denotes the probability that satisfies . To achieve this, the algorithm generates multiple random paths or samples, denoted by , in . For every , the algorithm checks if holds. This results in a sequence of Bernoulli random variables defined as if holds for and otherwise.
The SMC algorithm uses the generated samples to estimate . The estimate is then validated against the user-defined acceptance/rejection criteria that are defined using the reliability parameters. If the estimate falls within acceptable limits, it is accepted. Otherwise, the algorithm iterates, either generating more samples or modifying the model or the property, until a satisfactory estimate is obtained.
5. Case Study
5.1. Event Log and Process-Mining Algorithms
The implementation of the proposed approach is based on a dataset of a loan application process performed in a financial institution [
3]. The data contain all applications filed on an online system in 2016 and their subsequent events until February 2017. There are 31,509 applications filed in total, and for these applications, 42,995 offers were created in total. The events in this dataset represent real-life events captured by the institute’s operational processes. The event log contains 26 types of activities, which are divided into 3 types:
Application events,
Offer events, and
Workflow events. To showcase the application of the suggested method, we employed a range of process discovery algorithms, including
Alpha Miner, Discover using Decomposition, Mine for Heuristic Net, and Mine Transition System. And, for each discovered process model, we implemented various replay algorithms,
Heuristic cost-based fitness with Integer Linear Programming (ILP), A* cost-based fitness with ILP, Best first search simple string distance (SSD) calculation, Dijkstra-based replayer, ILP-based replayer, LP-based replayer, Prefix-based A* cost-based fitness, and Splitting replayer [
58].
5.2. Verification
For each of the four process discovery algorithms and each of the eight replay algorithms, we built a DTMC model in the PRISM model checker [
59].
Table 1 presents a description of the generated DTMC models grouped by process-mining algorithm. The table is divided into three columns, in which the first column shows process discovery algorithms, the second column is about the number of states for each discovered and replayed algorithm, and the third column presents the lowest and highest values of transitions for each algorithm. In the second column, we can observe variations in the number of states among discovery algorithms. The discovery algorithm
Mine for Heuristic Net has 27 states, while the others have 26. The reason is that the
Mine for Heuristic Net algorithm generates a discovery model that includes all (observable and unobservable) activities. A
(tau) transition, also known as a silent or invisible transition, represents unobservable activities. It does not correspond to any observable operation or event in the modelled process. It is used to represent internal actions or events that are unobservable or irrelevant to the analysis at hand. For example, in a workflow process, you might have actions like “approve document” or “send email” that are represented by observable transitions. However, there might be internal system checks or data processing steps that are not directly observable from the outside. These are modelled using
transitions, indicating that something happens, but it is not necessary to specify what that something is for the purposes of the model. These transitions can change the state of the Petri net without producing any visible outcome.
As mentioned in
Section 5.1, there are eight different replay algorithms, which were utilised to generate a formal model. Therefore, the number of transitions varies in each discovery algorithm, depending on the nature of the respective replay algorithm, except for
Discover using Decomposition. The reason behind this is that the
Discover using Decomposition algorithm has consistent performance in each replay algorithm. In other words, the
Discover using Decomposition algorithm maintains consistent behaviour across different scenarios.
The verification procedure is divided into two main steps. Firstly, we undertake estimation exercises at confidence levels of 99% and 95%. This part of the study fundamentally focuses on the statistical evaluation of the properties under investigation within these confidence intervals. The choices of these specific confidence levels allows us to assess the robustness and reliability of our findings under different degrees of statistical certainty. The 95% confidence level is commonly used in research, as it offers a standard balance between statistical power and confidence. It implies that if the study were repeated multiple times, 95 out of 100 similar studies would produce results within this interval, suggesting a high level of reliability. However, to further strengthen our conclusions and to account for potential variations in the data, we also consider the 99% confidence level. By comparing results at these two levels, we aim to demonstrate the consistency of our findings. If the results remain significant at both the 95% and 99% confidence levels, it indicates a higher degree of certainty in our conclusions. On the other hand, discrepancies between these levels may suggest areas where further investigation is needed or where conclusions are more tentative.
The second part of our verification procedure comprises hypothesis testing applied to selected properties. By incorporating these two complementary approaches, we seek to provide a comprehensive evaluation of the properties under investigation. Estimation at different confidence levels allows us to assess the reliability of the results across a range of statistical significance levels. Hypothesis testing, on the other hand, facilitates the rigorous validation of the underlying assumptions and predictions regarding the properties in question. The proposed framework, therefore, offers a multifaceted and robust evaluation of the model.
5.2.1. Estimation with Confidence Level of 99%
In
Table 2,
Table 3,
Table 4 and
Table 5, the derived results demonstrate the probabilistic estimates for the examined properties at a confidence level of 99%. In order to obtain reliable results, we conducted a sequence of 100 simulations for each property.
Table 2 presents a comprehensive overview of the estimated results specific to each process discovery algorithm, inclusive of the corresponding replay algorithm. The focal property investigated here is expressed as
. In simpler terms, this property seeks to explore the
likelihood of arriving at state x (where x denotes a target state) within a time frame of 10 units. The property is particularly useful in scenarios where timely completion or response is critical. It allows stakeholders to assess risks and make informed decisions with high-level confidence based on the likelihood of events within relevant time frames. For example, it can verify requirements such as a task’s completion within a specified time frame or the prevention of system failures within a certain period.
The findings pertaining to the particular property expressed as
are presented in
Table 3. This property represents an exploratory question inquiring about whether the
probability that state x does not occur before state y is encountered within a temporal window of 5 time units. Essentially, we are investigating the constraint-based temporal behaviour of the model’s transitions, imposing a bounded time limit on the
until (U) operator. The importance of this property lies in its ability to model circumstances where the occurrence of state
y takes precedence and should be reached before state
x. This form of probabilistic property allows for the study of the ordered temporal relationships between different states within a fixed time constraint, offering valuable insights into the temporal dynamics of the system.
Table 4 outlines the derived outcomes associated with the verification of the property
. In essence, this property investigates the
accumulated reward, represented in this context as a
cost required to transition to a designated state
x. It is important to note that state
x could represent various scenarios, such as the
target state, a
deadlock state that halts progression, or any other significant state within the system model.
The estimation of such a property is essential, as it facilitates a quantifiable understanding of the resource expenditure needed to transition within the system, thus providing crucial insights into the process model’s performance. By quantifying the cost to reach specific states, we are better equipped to evaluate the model’s performance under different conditions and make informed decisions. The summary presented in
Table 5 offers an analytical exploration of the property
, a construct defined to answer the question
what is the likelihood that the subsequent state following the initial state is x? In this property, we utilise the
NEXT operator, denoted by
X, which signifies the next reachable state from the current position in the sequence. The state labelled
x is an arbitrary state of interest within the model, subject to the specific requirements or investigative focus of the analysis. This table, therefore, provides a quantitative estimation, offering a calculated probability that the model will transition into specified state
x immediately after leaving the initial state. Specific state
x is selected based on the research objectives or the specific characteristics of the process under investigation.
5.2.2. Estimation with Confidence Level of 95%
Table 6,
Table 7,
Table 8 and
Table 9 present the findings derived from our probabilistic analysis of the properties under investigation. Each of these results provides an estimation with a confidence level of 95%. To ensure a robust set of data, a series of 100 simulations were carried out for each property. Specifically,
Table 6 provides a detailed analysis of the projected results, differentiating between a variety of process discovery algorithms and their associated replay algorithms. The focus of our evaluation is the property
. This property queries the
probability of attaining target state x within a predetermined temporal boundary of 10 units. A 95% confidence level offers a slightly broader margin for uncertainty compared with the 99% confidence level for the same property, as presented in
Table 2. This might be suitable for scenarios where the implications of the outcome are less critical.
The results linked to the specific property expressed as
can be found in
Table 7. This property represents an investigative query about
the likelihood that condition x does not appear before condition y within a defined period of 5 time units. The property refers to an examination of model transitions within specific temporal constraints. It captures a restricted duration on the
until operator, essentially quantifying the time-bound behaviour of these transitions. This property can be used to validate if a system behaves as expected. For instance, in a business process, it can be used to check if a certain undesirable state
is avoided until a desired state
is reached within a certain time frame. The comparison between
Table 3 and
Table 7 highlights the impact of confidence levels on the same property, with
Table 3 yielding higher confidence results.
Table 8 presents the results obtained from the verification of the property
. Essentially, this property explores the aggregate
reward, characterised as a
cost in this scenario, in relation to the transition to a specified state (
x). Understanding the expected cost until a certain state is reached is crucial for process optimisation. For instance, if
s represents a specific state in a process, the property can provide insights into the total cost of reaching state
s at a 95% confidence level.
Table 9 provides an in-depth evaluation of the property
, a construct designed to estimate
the probability of transitioning into specific state x immediately following the initial state. This property involves the use of the
NEXT operator, denoted by
X, which indicates the subsequent reachable state in the model’s sequence. The specific state, denoted by
x, represents a chosen state in the model. This property can be used to verify the likelihood of transitioning from one state to another in the very next step. This is particularly useful in processes where immediate transitions are critical, as it aids in understanding the short-term behaviours and immediate consequences of the current state.
5.2.3. Hypothesis Testing
Hypothesis testing, an essential tool in statistical analysis, can be performed on a set of collected samples. This process involves two distinct methodologies: fixed-size sampling and sequential testing.
In the context of fixed-size sampling, the total number of samples required is determined in advance. This process is systematic, calculating the sample quantity according to risk functions corresponding to error probabilities denoted by
and
[
60]. It is a predetermined approach where the sample size is set before the commencement of the experiment.
Sequential testing, on the other hand, contrasts with the fixed-size sampling method. In this approach, samples are successively assembled, and statistical analyses are performed concurrently [
34]. The process continues iteratively until sufficient information to make a decision with the necessary confidence level is acquired. This method provides flexibility, since the total number of required observations is not set in advance.
The
sequential probability ratio test (SPRT), based on
acceptance-sampling techniques [
32], was performed to determine how many samples were needed for the defined property to return a true result within a given bound on the
P operator.
Table 10 outlines the derived outcomes associated with the verification of the property
, which states
what is the probability that state x is not reached until ‘visited’ is/are reached (where
‘visited’ refers to one or more states defined in the model). This property can be used to determine how many samples are needed to validate whether the system behaves as expected, with a threshold of 50% or more. For instance, in a business process, it can be used to check if a certain undesirable state
is avoided until number of desired states
visited is reached with a probability of 50% or more. To obtain reliable results, we conducted a series of 100 simulations for the defined property. Note that the values of
(
type I error),
(
type II error), and
(
half-width of an indifference region) were set to
.
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 illustrate a comprehensive exploration of the application of SMC techniques to process models. The analysis focuses on verifying various properties at different
confidence levels, specifically,
99% and 95%, and
hypothesis testing, specifically, SPRT. Various statistical outcomes are obtained from different models, each demonstrating varied results for multiple properties, as shown in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. In this context,
Table 2,
Table 3,
Table 4 and
Table 5 illustrate the estimation results at a 99% confidence level;
Table 6,
Table 7,
Table 8 and
Table 9 highlight the results at a 95% confidence level; and
Table 10 presents the hypothesis-testing results for each process model.
5.3. Discussion
In the research conducted, we utilised statistical-model-checking methods to verify properties associated with a complex system. The outcomes demonstrated significance, highlighting the value of such methods when delving into complex systems based on probability. Initially, our analysis involved the successful implementation of a formal model (DTMC, in this case) to represent the system under consideration. This model then underwent verification against various properties expressed using PCTL, spanning from simple reachability to complex bounded until properties. Subsequently, we embarked on an exhaustive statistical model evaluation of these properties. The checking process yielded a series of results, providing valuable insights into the system’s behaviour. These insights paved the way for deducing probabilistic metrics significant for informed decisions about system management and control.
During the analysis of properties described in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10, which were utilised in the conducted case study, certain observations were made regarding the model’s performance, specifically the model discovered through the application of the
Mine for Heuristic Net technique. The model exhibited better performance in its estimations, irrespective of whether the confidence level was set to
99% or
95%. It can be observed from
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9 that the
Mine for Heuristic Net discovery algorithm yielded better results in most of the replay algorithms compared with other process discovery algorithms. When considering probabilistic properties where a user desires higher probabilistic values,
Mine for Heuristic Net provided better results. Similarly, for cost-related properties where the objective is to minimise values, the specified discovery algorithm performed better. During the
hypothesis-testing phase, all four models under consideration demonstrated varied performance with different replay algorithms. As seen in
Table 10, the first replay algorithm required fewer samples for
Mine for Heuristic Net to return a true result. In contrast, for the second replay algorithm, both
Alpha Miner and
Mine for Heuristic Net required a fewer (or the same) number of samples. Additionally, the results vary when moving from left to right in
Table 10. Therefore, it is not possible to definitively select one discovery algorithm as superior.
However, it is noteworthy to mention that these results are fundamentally statistical. Despite this statistical nature, the findings indicate that the Mine for Heuristic Net model offers certain advantages. Particularly, it appears to be more beneficial in relation to reward- or cost-associated properties, as well as in the estimation of probabilistic properties.
The statistical-model-checking techniques were found to be remarkably effective in handling the inherent randomness of the DTMC model. Notably, these techniques offered a practical alternative to traditional, exhaustive model-checking approaches, which are often obstructed by the state-space explosion problem. Moreover, the statistical-model-checking techniques provided both upper and lower bounds to the property probabilities, thereby providing quantifiable uncertainty measures for each result. One critical aspect observed is this study is the trade-off between the accuracy of results and computational cost. While increasing the number of samples in the statistical-model-checking process could enhance the precision of results, it simultaneously led to an increase in the computational load. Therefore, determining an optimal balance between accuracy and computational efficiency is a significant challenge.
In conclusion, the work in this article demonstrates the practicality and efficiency of using statistical-model-checking techniques for verifying the properties of complex models. The results obtained provide a solid foundation for the further use of these methods in more complex and larger probabilistic systems. Our findings also highlight the need for additional research to optimise the balance between result accuracy and computational effort in the model-checking process.
6. Conclusions
In this work, we integrate statistical model checking into the domain of process mining. The presented work demonstrates the feasibility and effectiveness of employing SMC to analyse process models extracted from event logs. By applying statistical techniques, we are able to assess complex process behaviours without yielding to the state-space explosion problem, a prevalent issue in traditional model checking. The methodology enables the verification of various properties in a more scalable and efficient manner. Through the combination of SMC and PM, robust tools are provided for businesses to analyse, optimise, and control their processes.
The proposed methodology helps in the continuous monitoring and verification of business processes, ensuring that they meet the desired quality standards. As the methodology sets a new standard for process analysis, it encourages the adoption of forward-thinking approaches to process management. By staying ahead of the curve with such innovative methodologies, businesses can future-proof their processes against evolving operational challenges. The case study presented in this work further solidified the applicability and effectiveness of the proposed approach across different scenarios.
However, this work is not without its limitations and challenges. The tuning of parameters in SMC, such as the confidence level and error margin (), requires careful consideration and a deep understanding of the underlying processes and statistical principles. Further research may focus on developing more user-friendly methods for non-experts to utilise the power of SMC in process mining. Moreover, while our approach has proven successful in handling various properties and models, certain highly complex or specialised scenarios may require further refinement and extension of our techniques.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}