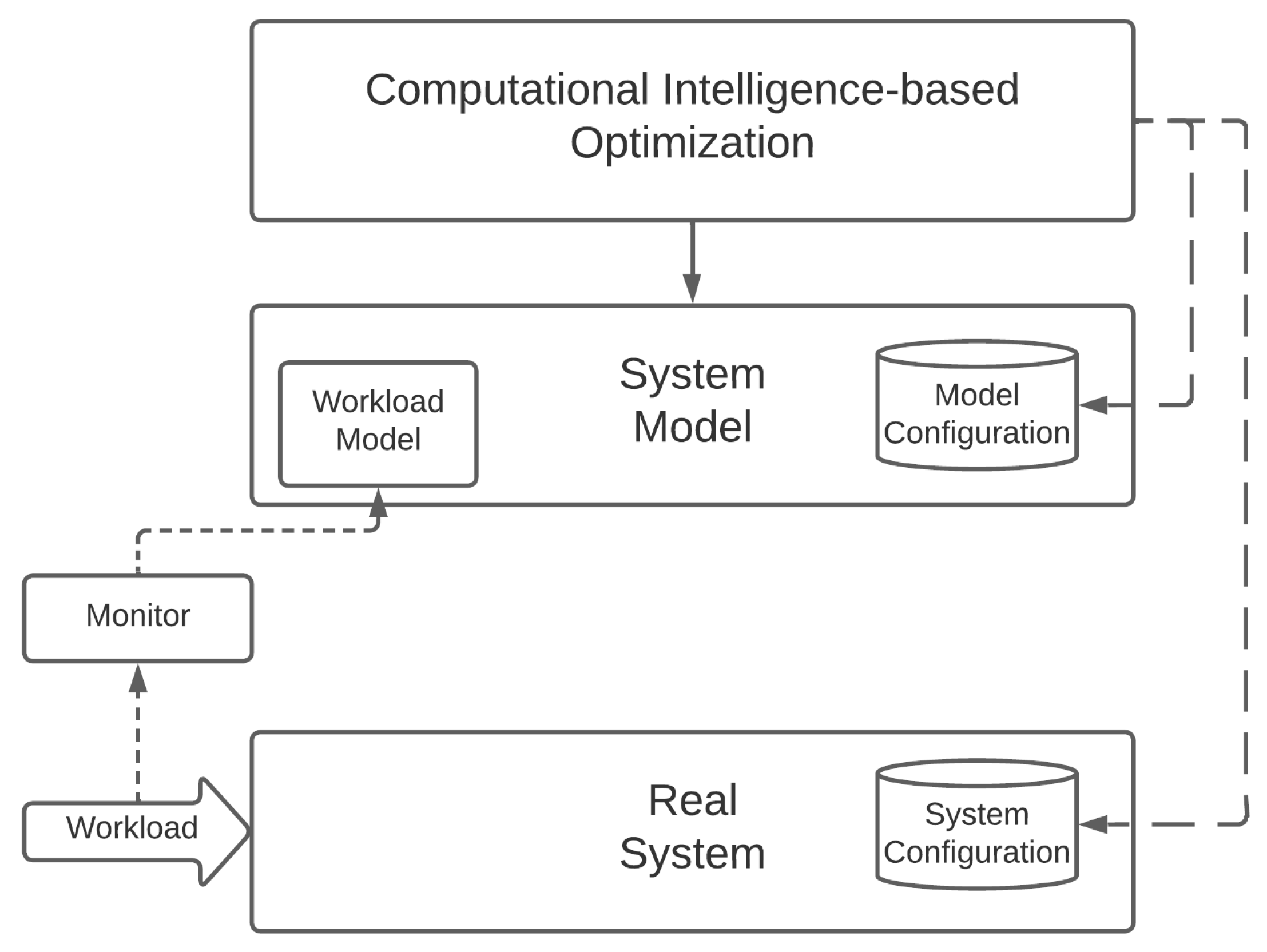
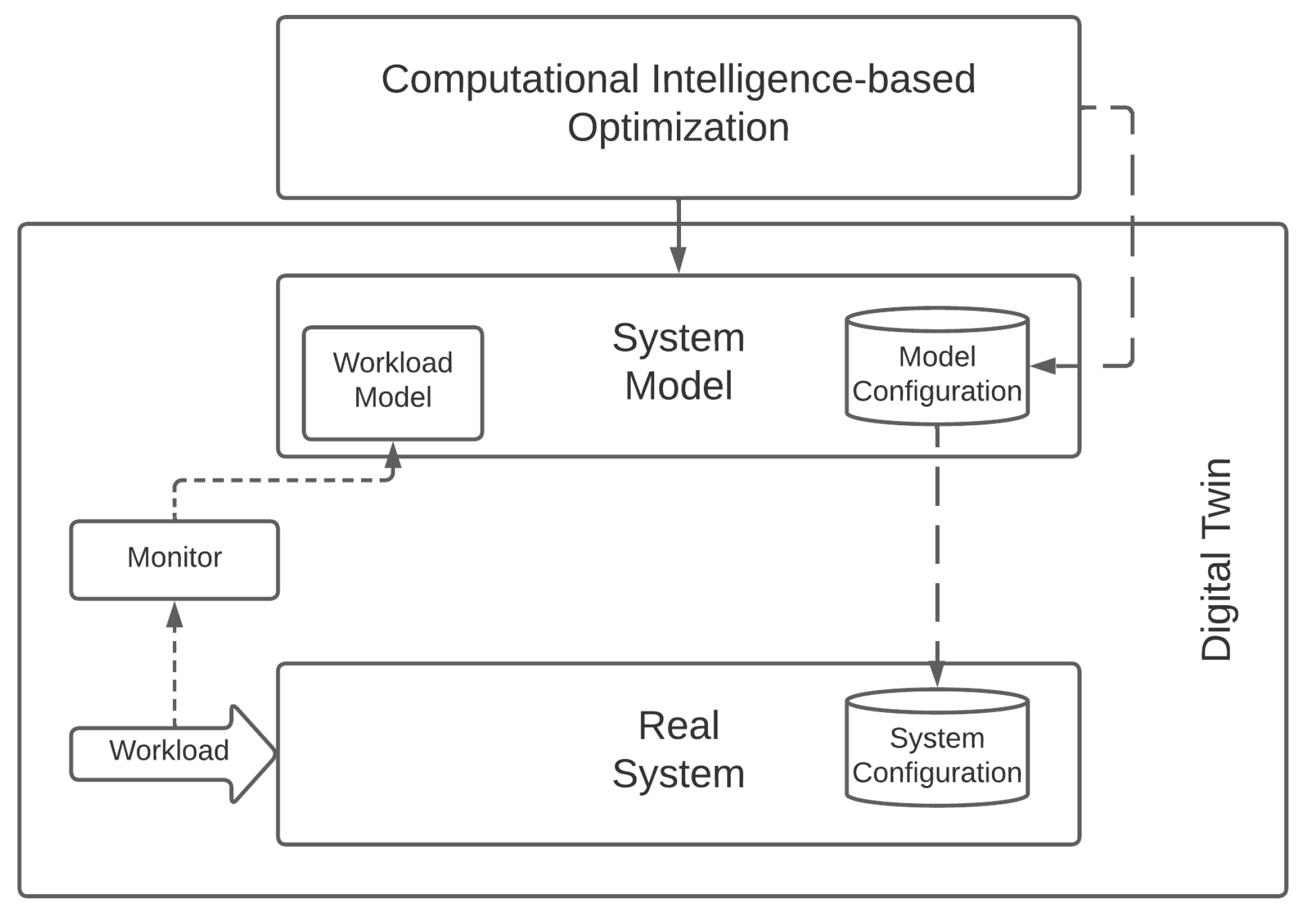
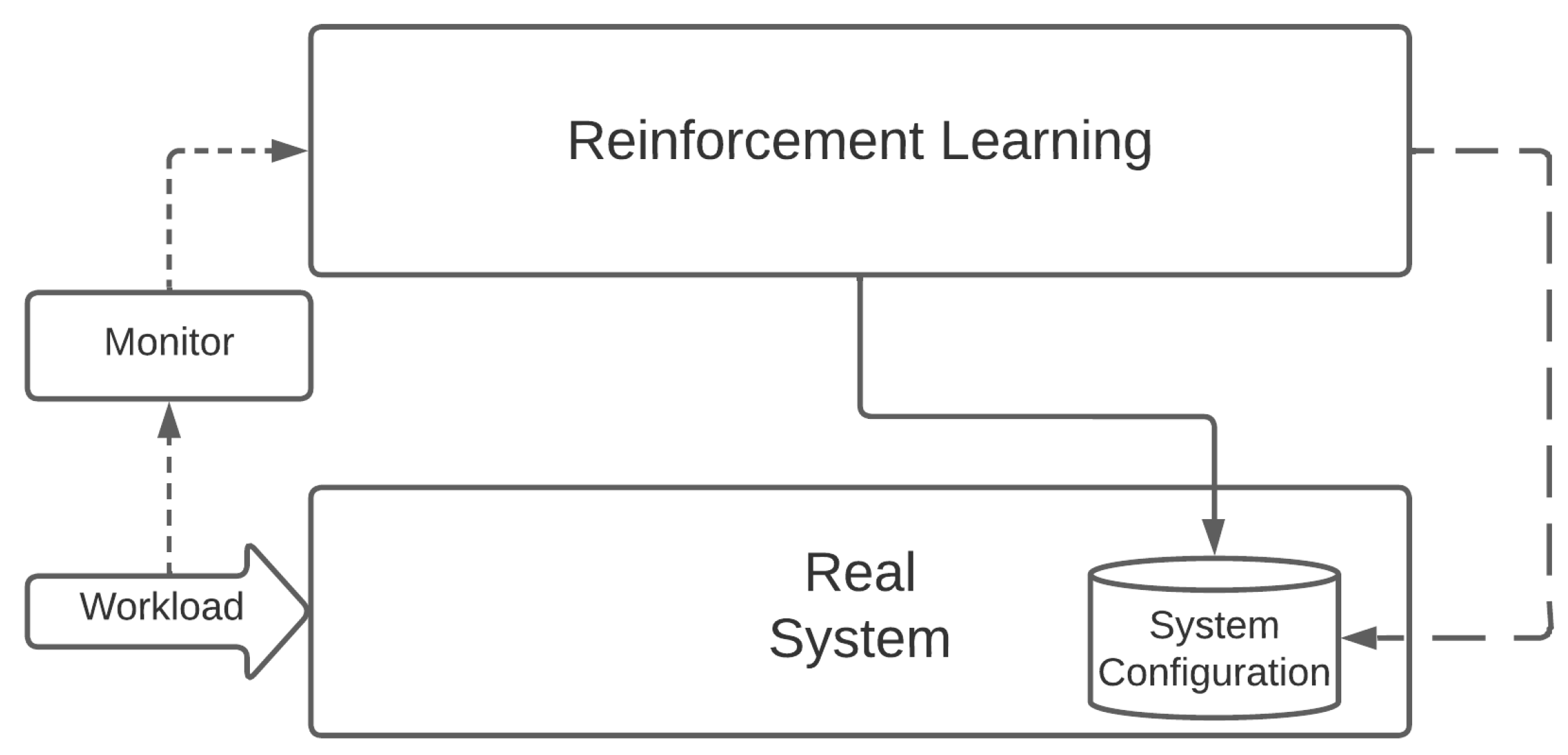
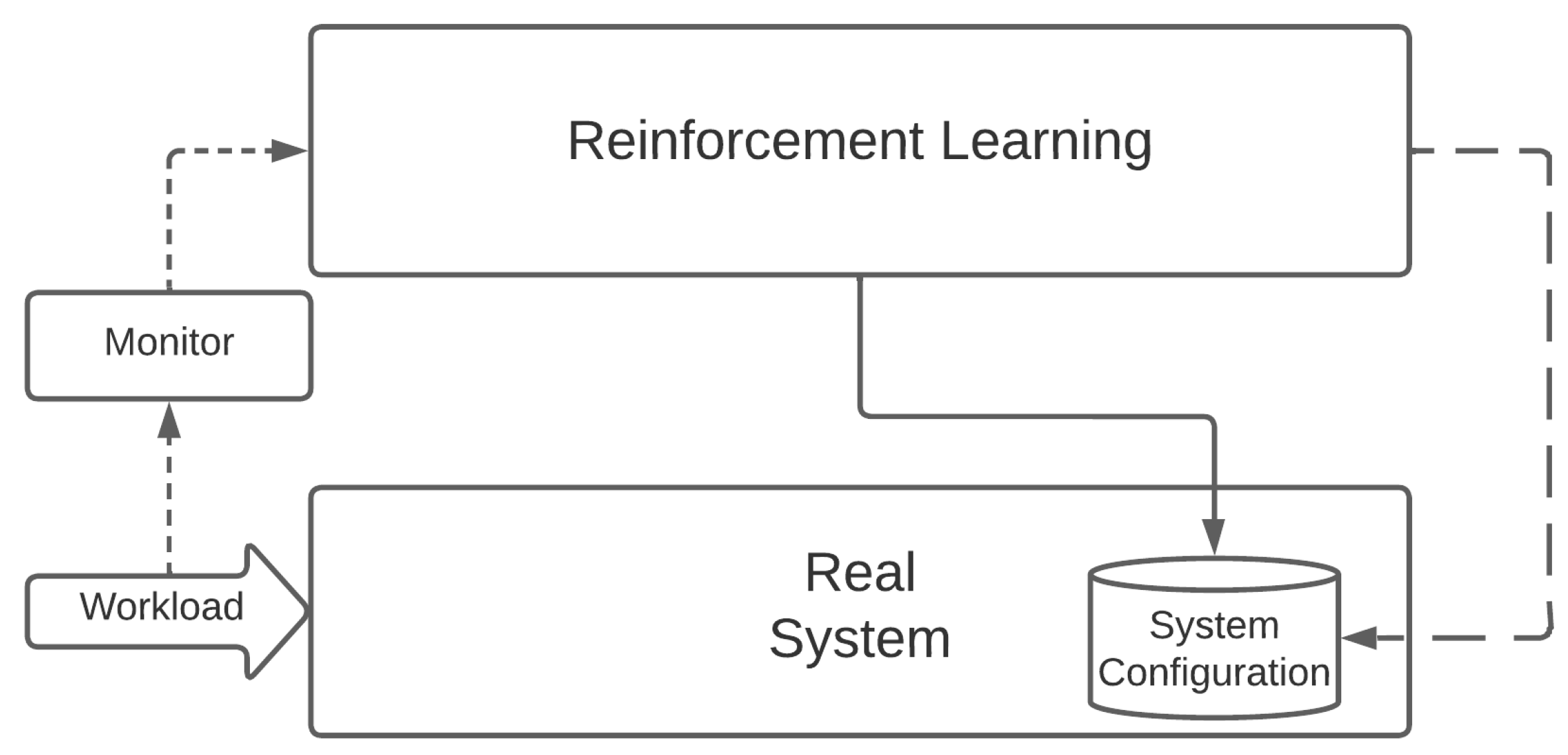
As part of this section, we want to compare the RL and Computational Intelligence approaches in finding the best resource management solution in our proposed scenario. As mentioned before, we argue that metaheuristic approaches could be very effective tools in exploring the parameters’ search space and providing near-optimal configuration solutions. Furthermore, these approaches are less inclined to suffer from the inefficient sampling curse. RL methodologies instead provide autonomous learning and adaptation at the expense of a superior sample inefficiency. Therefore, they do a better job in scenarios characterized by high dynamicity and sudden variations, which often induce metaheuristics to have poor performances, forcing them to a new training phase.
To compare the CI and RL approaches for service management, we define a use case for a simulator capable of reenacting services running in a Cloud Continuum scenario. We built this simulator by extending the Phileas simulator [
73] (
https://github.com/DSG-UniFE/phileas (accessed on 21 September 2023)), a discrete event simulator that we designed to reenact Value-of-Information (VoI)-based services in Fog computing environments. However, even if, in this work, we did not consider the VoI-based management of services, the Phileas simulator represented a good commodity to evaluate different optimization approaches for service management in the Cloud Continuum. In fact, Phileas allows us to accurately simulate the processing of service requests on top of a plethora of computing devices with heterogeneous resources and to model the communication latency between the parties involved in the simulation, i.e., from users to computing devices and vice versa.
6.1. Use Case
For this comparison, we present a scenario to be simulated in Phileas that describes a smart city that provides several applications to its citizens. Specifically, the use case contains the description of a total of 13 devices distributed among the Cloud Continuum: 10 Edge devices, 2 Fog devices, and a Cloud device with unlimited resources to simulate unlimited scalability. Along with the devices’ description, the use case defines 6 different smart city applications, namely: healthcare, pollution-monitoring, traffic-monitoring, video-processing, safety, and audio-processing applications, whose importance is described by the
parameters shown in
Table 3.
To simulate a workload for the described applications, we reenacted 10 different groups of users located at the Edge that generate requests according to the configuration values illustrated in
Table 4. It is worth specifying that the request generation is a stochastic process that we modeled using 10 different random variables with an exponential distribution, i.e., one for each user group. Furthermore,
Table 4 also reports the computed latency for each service type. As for the time between message generation, we modeled the processing time of a task by sampling from a random variable with an exponential distribution. Let us also note that the “compute latency” value does not include queuing time, i.e., the time that a request spends before being processed. Finally, the resource occupancy indicates the number of cores that each service instance requires to be allocated on a computing device.
We set the simulation to be 10 s long, including 1 s of warmup, to simulate the processing of approximately 133 requests per second. Finally, we report the intra-layer communication model in
Table 5, where each element is the configuration for a normal random variable that we used to simulate the transfer time between the different layers of the Cloud Continuum.
Concerning the optimization approaches, we compared the open-source and state-of-the-art DQN and PPO algorithms provided by Stable Baselines3 (
https://github.com/DLR-RM/stable-baselines3 (accessed on 21 September 2023)) with the GA, PSO, QPSO, MPSO, and GWO. For the metaheuristics, we used the implementations of a Ruby metaheuristic library called ruby-mhl, which is available on GitHub (
https://github.com/mtortonesi/ruby-mhl (accessed on 21 September 2023)).
6.2. Algorithms Configurations
To collect statically significant results from the evaluation of the CI approaches, we decided to collect the log of 30 optimization runs. Each optimization run consisted of 50 iterations of the metaheuristic algorithm. This was to ensure the interpretability of the results and to verify if the use of different seeds can significantly change the outcome of the optimization process. At the end of the 30 optimization runs, we measured the average best value found by each approach to verify which one performed better in terms of the value of the objective function and sample efficiency.
Delving into the configuration details of each metaheuristic, for the GA, we used a population of 128 randomly initialized individuals, an integer genotype space, a mutation operator implemented as an independent perturbation of all the individual’s chromosomes sampled from a geometric distribution random variable with a probability of success of 50%, and an extended intermediate recombination operator controlled by a random variable with a uniform distribution in
[
74]. Moreover, we set a lower and an upper bound of 0 and 15, respectively. At each iteration, the GA generates the new population using a binary tournament selection mechanism, in which we applied the configured mutation and recombination. For PSO, we set a swarm size of 40 individuals randomly initialized in the float search space
and the acceleration coefficients C1 and C2 to 2.05. Then, for QPSO, we configured a swarm of 40 individuals randomly initialized in
and a contraction–expansion coefficient
of 0.75. These particular parameter configurations have shown very promising results in different analyses made in the past [
36,
75], so we decided to keep them also for this one.
For GWO, we set the population size to 30 individuals and the same lower and upper bounds of 0 and 15. Then, a different configuration was used for MPSO, where we set the initial number of swarms to 4, each one with 50 individuals, and the maximum number of non-converging swarms to 3. Readers can find a summary table containing the configuration for each CI algorithm provided in
Table 6.
Regarding the DRL algorithms, we implemented two different environments to address the different MDP formulations described above. Specifically, the DQN scans the entire allocation array sequentially twice for 156 time steps, while PPO uses a maximum of 200 time steps, which correspond to their respective episode length. Since the DQN implementation of Stable Baselines3 does not support the multi-discrete action space as PPO does, we chose this training model to ensure the training conditions were as similar as possible for both algorithms. As previously mentioned, during a training episode, the agent modifies how service instances are allocated on top of the Cloud Continuum resources. Concerning the DRL configurations, we followed the guidelines of Stable Baseline3 for one-dimensional observation spaces to define a neural network architecture with 2 fully connected layers with 64 units each and a Rectified Linear Unit (ReLU) activation function for the DQN and PPO. Furthermore, we set for both the DQN and PPO a training period of 100,000 time steps long. Then, to collect statistically significant results comparable to the ones of the CI algorithms, we tested the trained models 30 times.
6.3. Results
For each optimization algorithm, we took note of the solution that maximized the value of (
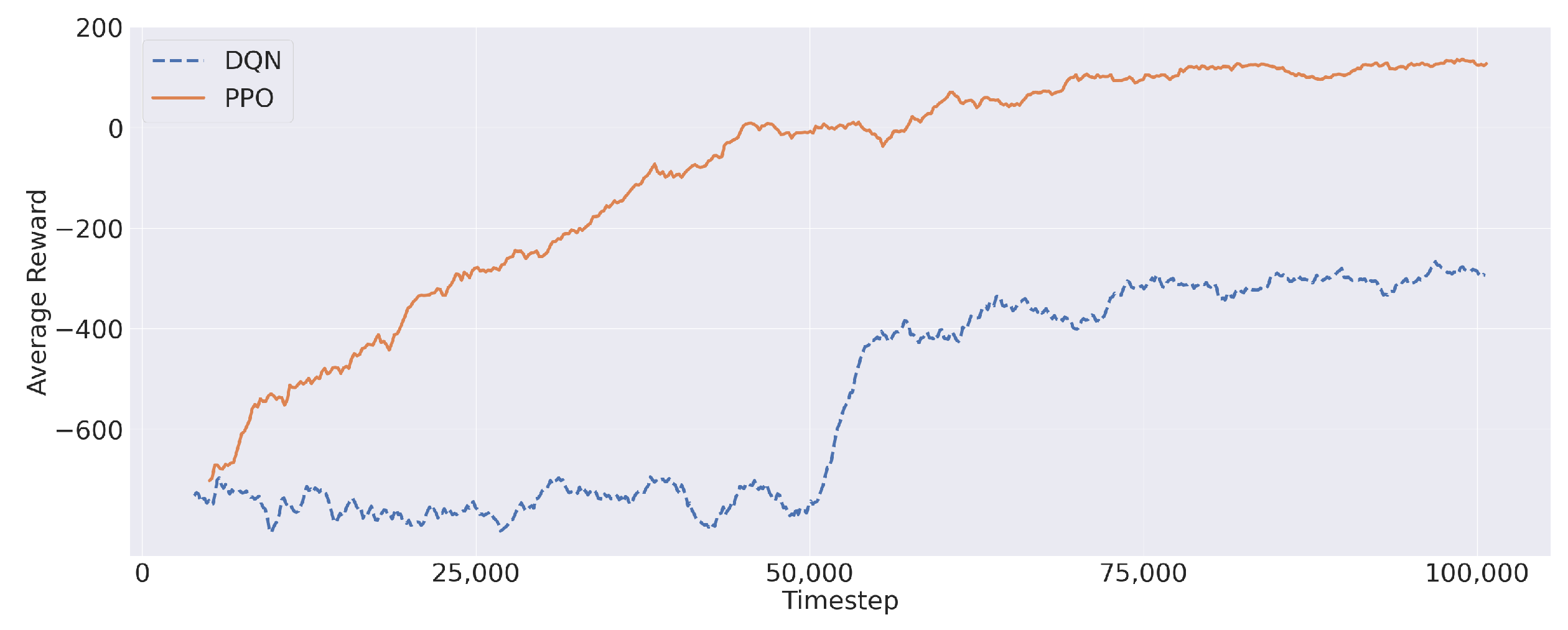
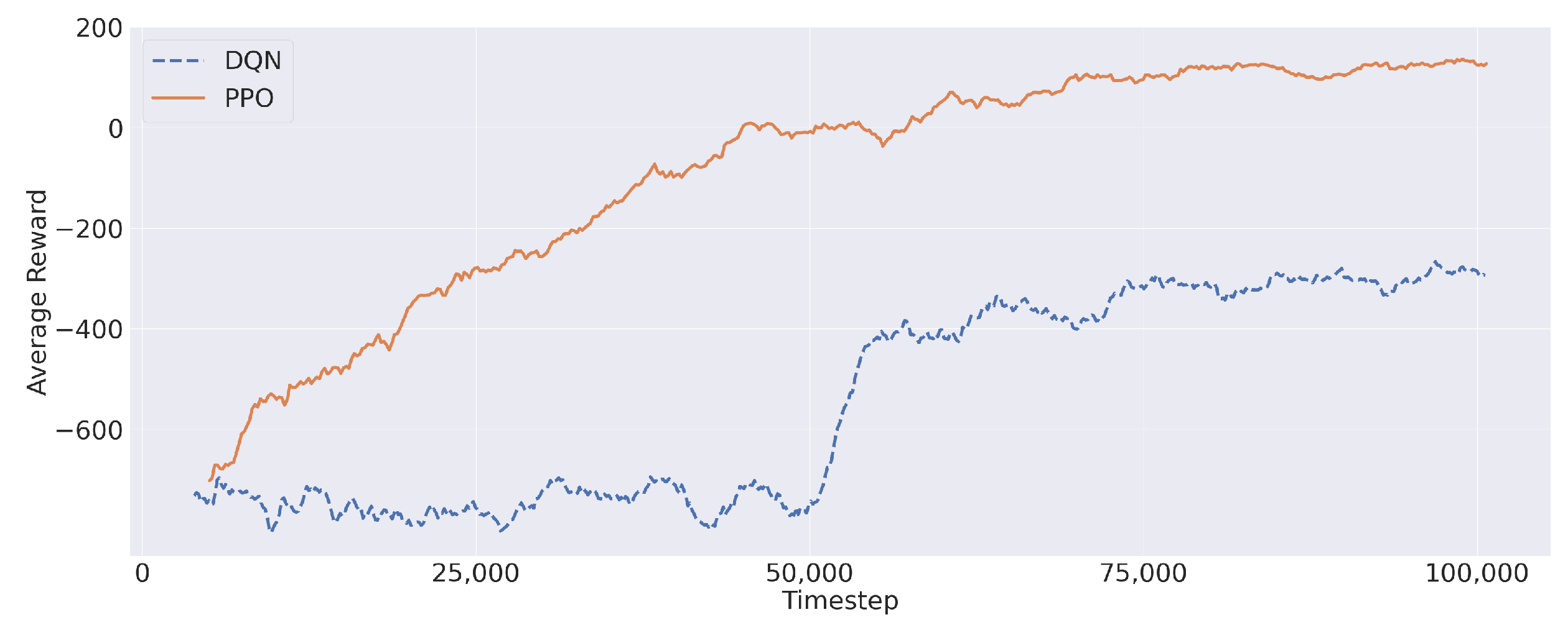
9), also paying particular attention to the percentage of satisfied requests and service latency. Firstly, let us report the average reward during the training process obtained by PPO and the DQN in
Figure 6. Both algorithms showed a progression, in terms of average reward, during the training process. Furthermore,
Figure 6 shows that the average reward converged to a stable value before the end of the training process, thus confirming the validity of the reward structure presented in
Section 3. In this regard, PPO showed a better reward improvement, reaching a maximum near 200. Differently, the DQN remained stuck in negative values despite a rapid reward increase (around Iteration 50,000) during the training session.
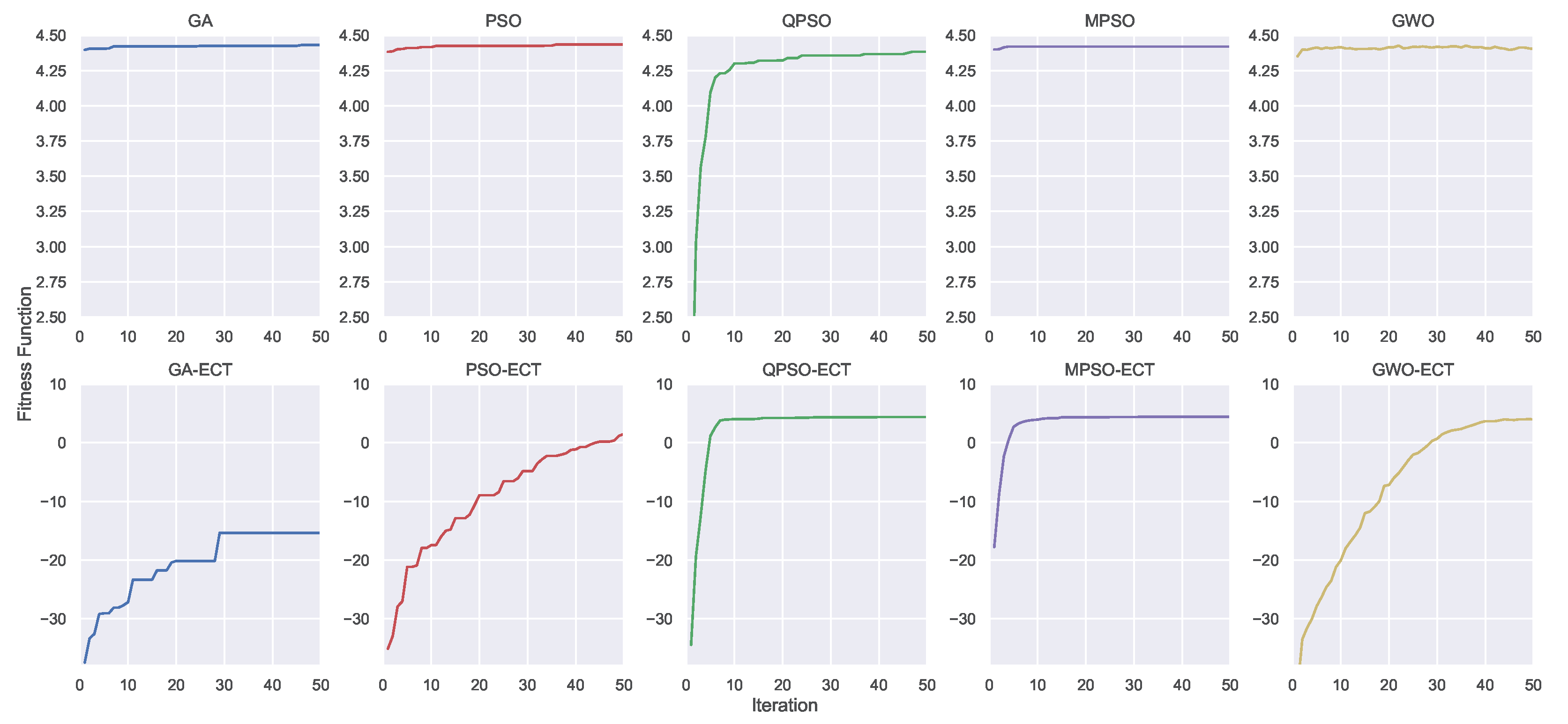
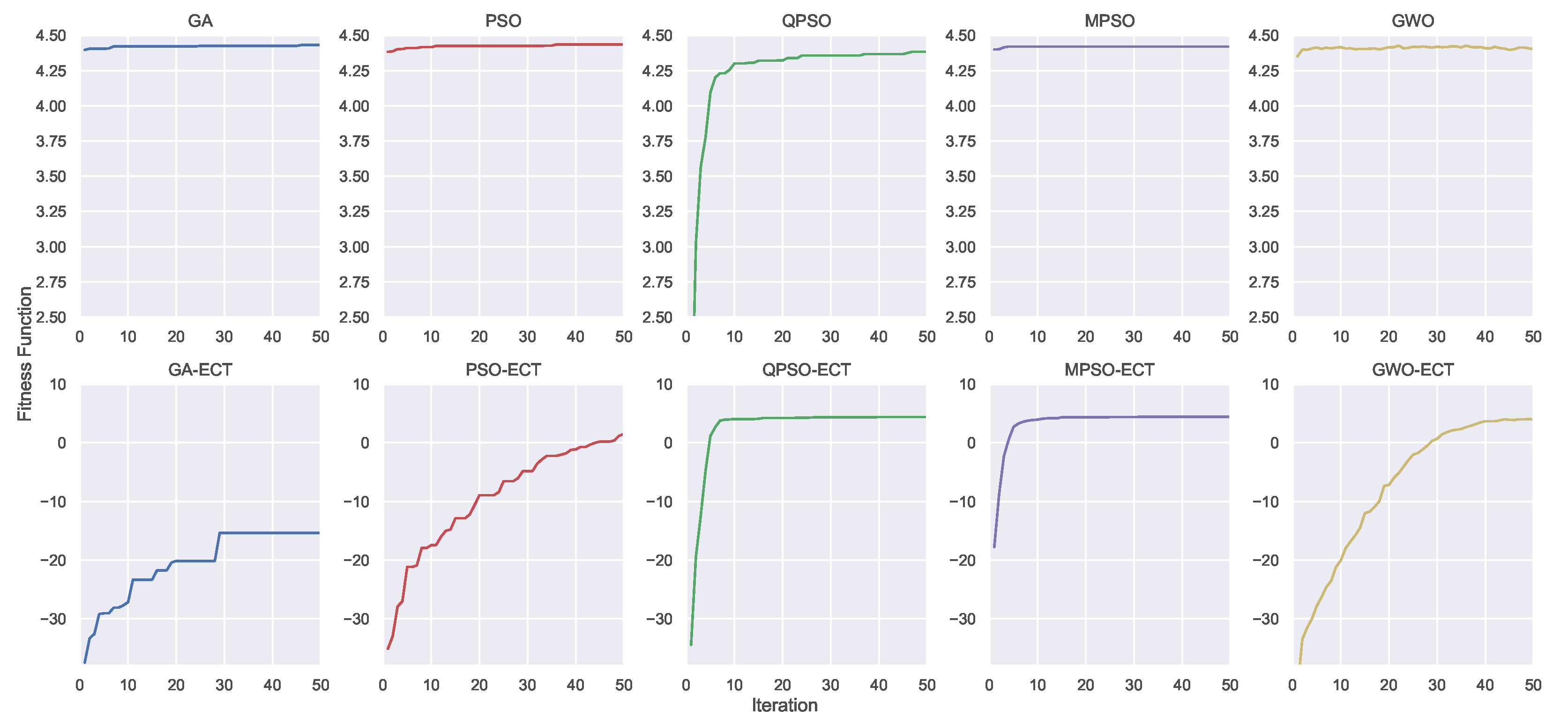
Aside from the DRL training, let us show the convergence process of the CI algorithms in
Figure 7, which is an illustrative snapshot of the progress of the optimization process. Specifically,
Figure 7 shows the convergence process of one of the 30 optimization runs and visualizes on the top the GA, PSO, QPSO, MPSO, and GWO, while on the bottom their constrained versions the GA-ECT, PSO-ECT, QPSO-ECT, MPSO-ECT, and GWO-ECT. For all metaheuristics displayed in the top row, it is easy to note how they can converge very quickly except for QPSO, which showed an increasing trend throughout all 50 iterations. Instead, considering their ECT variants, the GA, PSO, and GWO struggled a bit in dealing with their imposed constraints. In contrast, QPSO-ECT and MPSO-ECT demonstrated very similar performance compared to the previous case. Notably, these two algorithms did not appear to be negatively affected by the introduction of the penalty factor, and they were still able to find the best solution overall without significant difficulty. In this regard, it is worth noting that MPSO makes use of four large swarms of 50 particles, i.e., at each iteration, the number of evaluations of the objective function was even larger than the GA, which was configured with 128 individuals.
To give a complete summary of the performance of the adopted methodologies (CI and DRL), we report in
Table 7 the average and the standard deviation we collected along the 30 optimization runs. More specifically,
Table 7 reports the results for the objective function, the number of generations needed to find the best objective function, and the average number of infeasible allocations associated with the best solutions found. Let us specify that the “Sample efficiency” column in
Table 7 represents for the CI algorithms the average number of samples that were evaluated in order to find the best solution. Specifically, this was approximated by multiplying the number of the average generations with the number of samples evaluated at each generation, e.g, the number of samples at each generation for the GA would be 128 (readers can find this information in
Table 6). Instead, for the DRL algorithms, the “Sample Efficiency” represents the average number of steps, i.e., an evaluation of the objective function that the agent took to achieve the best result—in terms of the objective function—during the 30 episodes.
With regard to the objective function,
Table 7 shows that MPSO was the algorithm that achieved the highest average score for this specific experiment, as opposed to the GA-ECT, which confirmed the poor trend shown in
Figure 7. However, the two versions of MPSO required the highest number of samples to achieve high-quality solutions. It is important to note that all ECT algorithms delivered great solutions in terms of balancing the objective function against the number of infeasible allocations. This trend highlights that using a penalty component to guide the optimization process of CI algorithms can provide higher efficiency in exploring the search space.
On the other hand, the RL algorithms exhibited competitive results compared to the CI algorithms in terms of maximizing the objective function. Specifically, PPO was the quickest to reach its best result, with a great objective function alongside a particularly low number of infeasible allocations (the lowest if we exclude the ECT variants). The DQN was demonstrated to not be as effective as the PPO. Despite requiring the second-fewest generations to find its best solution, all metaheuristic implementations in this analysis outperformed it in both the objective function value and total infeasible allocations. In our opinion, the main reason behind this lies in the implementation of the DQN provided by Stable Baselines3, which does not integrate any prioritized experience replay or improved versions like the Double-DQN. Consequentially, it was not capable of dealing with more-complex observation spaces, such as the multi-discrete action space of PPO. With a sophisticated problem like the one we are dealing with in this manuscript, the Stable Baseline3 DQN implementation appeared to lack the tools to reach the same performance as PPO.
The last step of this experimentation was to analyze the performance of the best solutions presented previously, thus showing how the different solutions perform in terms of the PSR and average latency. Even if the problem formulation does not take into account latency minimization, it is still interesting to analyze how the various algorithms can distribute the service load across the Cloud Continuum and to see which offers the highest-quality solution. It is expected that solutions that make use of Edge and Fog computing devices should be capable of reducing the overall latency. However, given the limited computing resources, there is a need to exploit the Cloud layer for deploying service instances.
Specifically, for each algorithm and each measure, we report both the average and the standard deviation of the best solutions found during the 30 optimization runs grouped by service in
Table 8. From these data, it is easy to note that most of the metaheuristic approaches can find an allocation that nearly maximizes the PSR of the mission-critical services (identified in healthcare, video, and safety as mentioned in
Table 3) and the other as well. Contrarily, both DRL approaches cannot reach PSR performance as competitively as the CI methodologies. This aspect explains why their objective functions visible in
Table 7 ranked among the lowest. Nevertheless, both PPO and the DQN provided very good outcomes in terms of the average latency for each micro-service. Despite certain shortcomings in the PSR of specific services, particularly Audio and Video, PPO consistently outperformed most of them in terms of latency.
On the other hand, looking at the average service latency of the other approaches,
Table 8 shows that the algorithms performed quite differently. Indeed, it is clear how the ECT methodologies consistently outperformed their counterparts in the majority of cases. Among them, QPSO-ECT emerged as the most-efficient overall in minimizing the average latency, particularly for mission-critical services. Specifically, QPSO-ECT overcame the GA-ECT by an average of 50%, PSO-ECT by 37%, GWO-ECT by 48%, and MPSO-ECT by 19% for these services. Oppositely, both variants of the GA registered the worst performance, with a significant number of micro-services registering a latency between 100 and 200 ms.
However, let us specify that minimizing the average service latency was not within the scope of this manuscript, which instead aimed at maximizing the PSR, as is visible in (
9). To conclude, we can suggest that PPO emerged as the best DRL algorithm. It can find a competitive value in terms of the objective function along with the best results in terms of sample efficiency and latency at the price of a longer training procedure—when compared to the CI algorithms. While the ECT variants of the metaheuristics included in this comparison demonstrated great performance as well, they require much more samples to find the best solution.
6.4. What-If Scenario
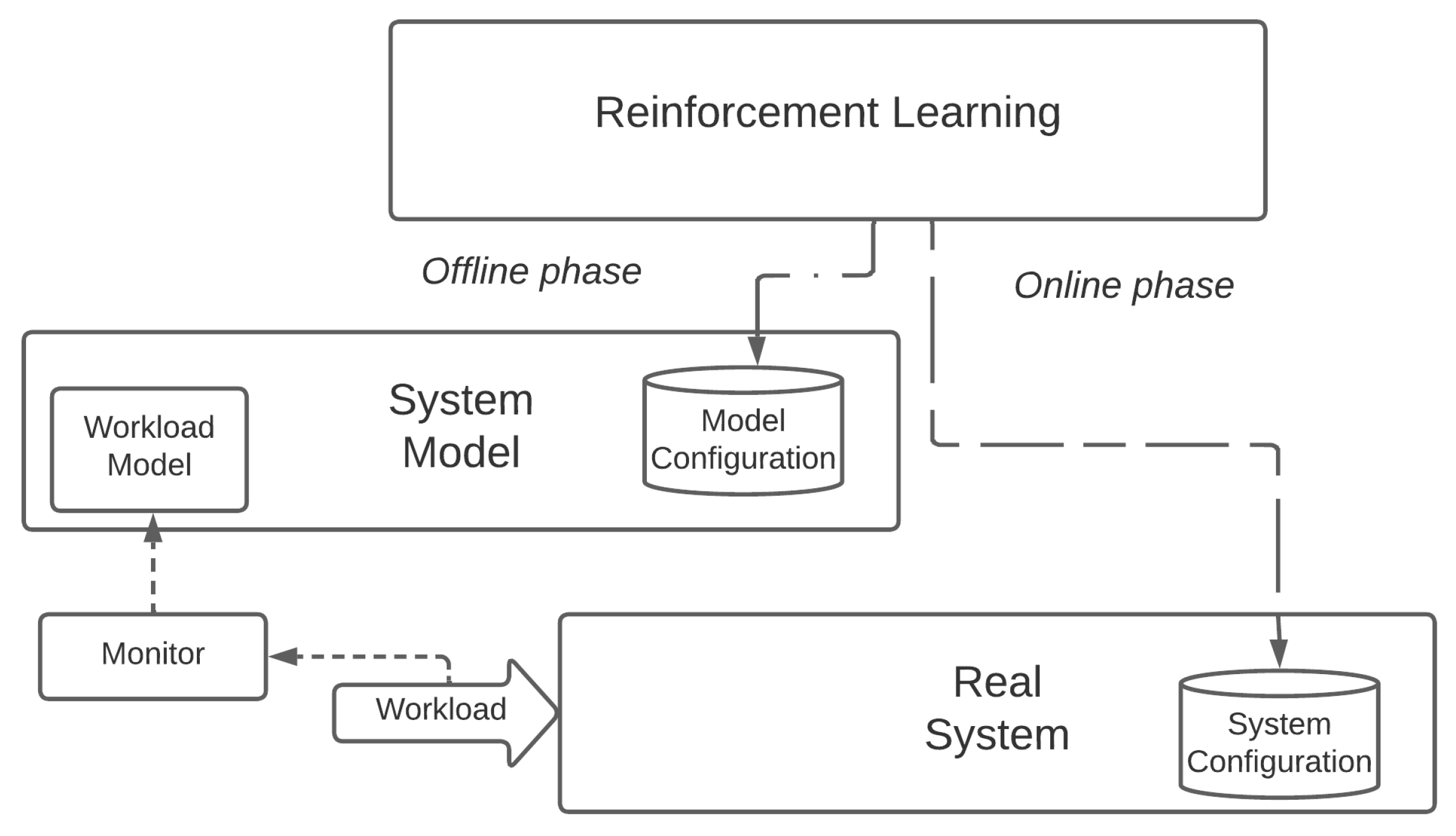
To verify the effectiveness of DRL algorithms in dynamic environments, we conducted a what-if scenario analysis in which the Cloud Computing layer is suddenly deactivated. Therefore, the service instances that were previously running in the Cloud need to be reallocated on the over devices available if there is enough resource availability.
To generate a different service component allocation that takes into account the modified availability of computing resources, we leveraged the same models—trained on the previous scenario—for the DQN and PPO and we used the same models trained on the previous scenario and tested them for 30 episodes. Instead, for the CI algorithms, we used a cold restart technique, consisting of running another 30 optimization runs, each one with 50 iterations. This was to ensure the statistical significance of these experiments. After the additional optimization runs, all CI algorithms should be capable of finding optimized allocations that consider the different availability of computing resources in the modified scenario, i.e., exploiting only the Edge and Fog layers.
As for the previous experiment, we report the statistics collected during the optimization runs to compare the best values of the objective function (
9) and the PSR of services in
Table 9 and
Table 10. Looking at
Table 9, it is easy to note how PPO can still find service component allocations that achieve an objective function score close to 4, without re-training the model. This seems to confirm the good performance of PPO for the service management problem discussed in this manuscript. Moreover, PPO can achieve this result after an average of 36 steps, i.e., each one corresponding to an evaluation of the objective function. This was the result of the longer training procedures that on-policy DRL algorithms require. On the other hand, as is visible in
Table 7, the DQN showed a strong performance degradation, as the best solutions found during the 30 test episodes had an average of 1.60. Therefore, the DQN demonstrated lower adaptability when compared to PPO in solving the problem discussed in this work.
With regard to the CI algorithms, the GA was the worst in terms of the average values of the objective functions, while all the other algorithms achieved average scores higher than 4.0. As for the average number of infeasible allocations, the constrained versions achieved remarkable results, especially QPSO-ECT and MSPO-ECT, where the number of infeasible allocations was zero or close to zero for GWO-ECT. Differently, the GA-ECT and PSO-ECCT could not minimize the number of infeasible allocations to zero. Overall, MPSO was the algorithm that achieved the highest score at the cost of a higher number of iterations.
From a sample efficiency perspective,
Table 9 shows that QPSO was the CI algorithm that achieved the best result in terms of the number of evaluations of the objective function. At the same time, MPSO-ECT showed that it found its best solution with an average of 1493 steps, which was considerably lower than the 7432 steps required by MPSO, which, in turn, found the average best solution overall. Finally, the GA and GA-ECT were the CI algorithms that required a larger number of steps to find their best solutions.
Furthermore, looking at
Table 10, we can see the reasons for the poor performance of the DQN: four out of six services had a PSR less than 50%. More specifically, the PSR for the safety service was 0%, and the one for healthcare was 5%. Even PPO was not great in terms of the PSR in the what-if scenario. On the other hand, all the CI algorithms, excluding the GA and GA-ECT, recorded PSR values above 90% for all services, thus demonstrating that the cold restart technique was effective at exploring the optimal solutions in the modified search space.
Finally, we can conclude that PPO was demonstrated to be effective in exploiting the experience built upon the previous training even in the modified computing scenario. Contrarily, the DQN did not seem to be as effective as PPO in reallocating services’ instances in the what-if experiment. On the other hand, the training of CI algorithms does not create a knowledge base that these algorithms can exploit when the scenario changes remarkably. However, the cold restart technique was effective in re-optimizing the allocation of service instances.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}