
Towards an Optimal Cloud-Based Resource Management Framework for Next-Generation Internet with Multi-Slice Capabilities


Abstract
:1. Introduction
2. Related Works and Research Problem
- Investigate the current allocation techniques in 5G C-RAN, such as static and dynamic resource allocation algorithms.
- Design a system for resource allocation at the slice level and then implement a system that has combined functions, such as admission control, resource allocation, and slice isolation. Initially, the system will implement admission control to admit the users to existing slices. Then, the system will dynamically allocate the RBs to the different slices, such as eMBB, URLLC, and mMTC, in the C-RAN based on the priority and the QoS of the slices. The system will also implement isolation between the network slices to protect the minimum QoS requirements for the slices while increasing system utilization.
- Implement a performance evaluation and develop a simulation model to evaluate the performance of the proposed system against the static slice allocation (SSA) system. We will compare the result to the SSA system by considering some performance measures such as resource utilization, average waiting time, and the total blocking probability (TBP).
3. System Model and Assumptions
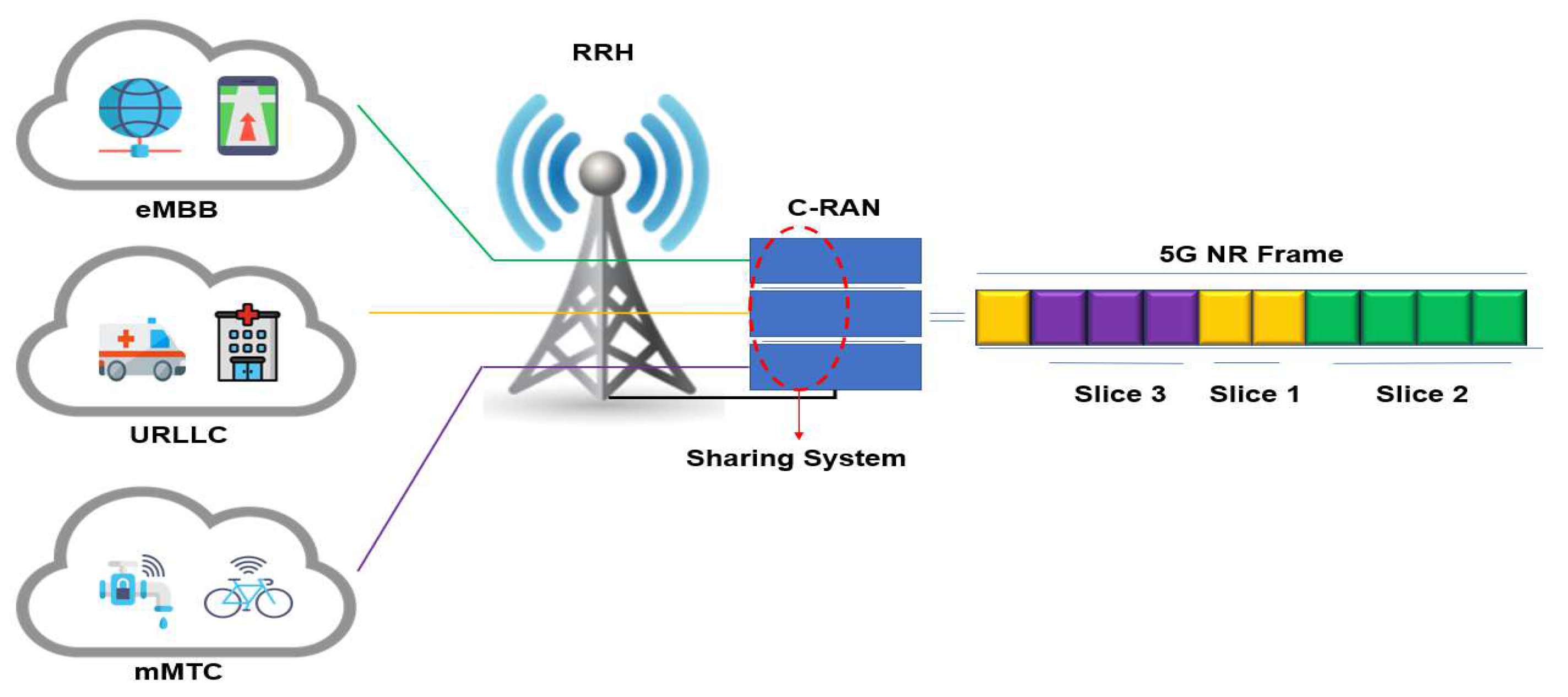
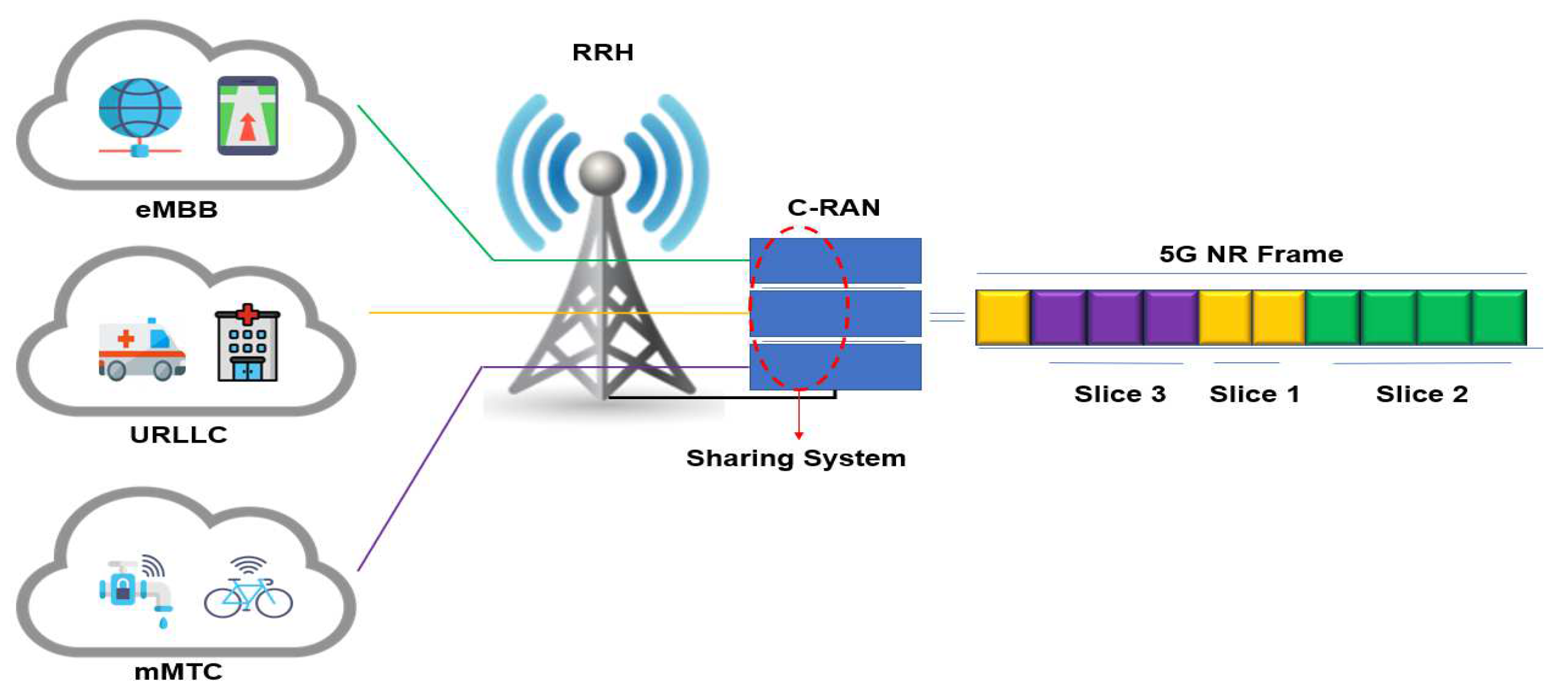
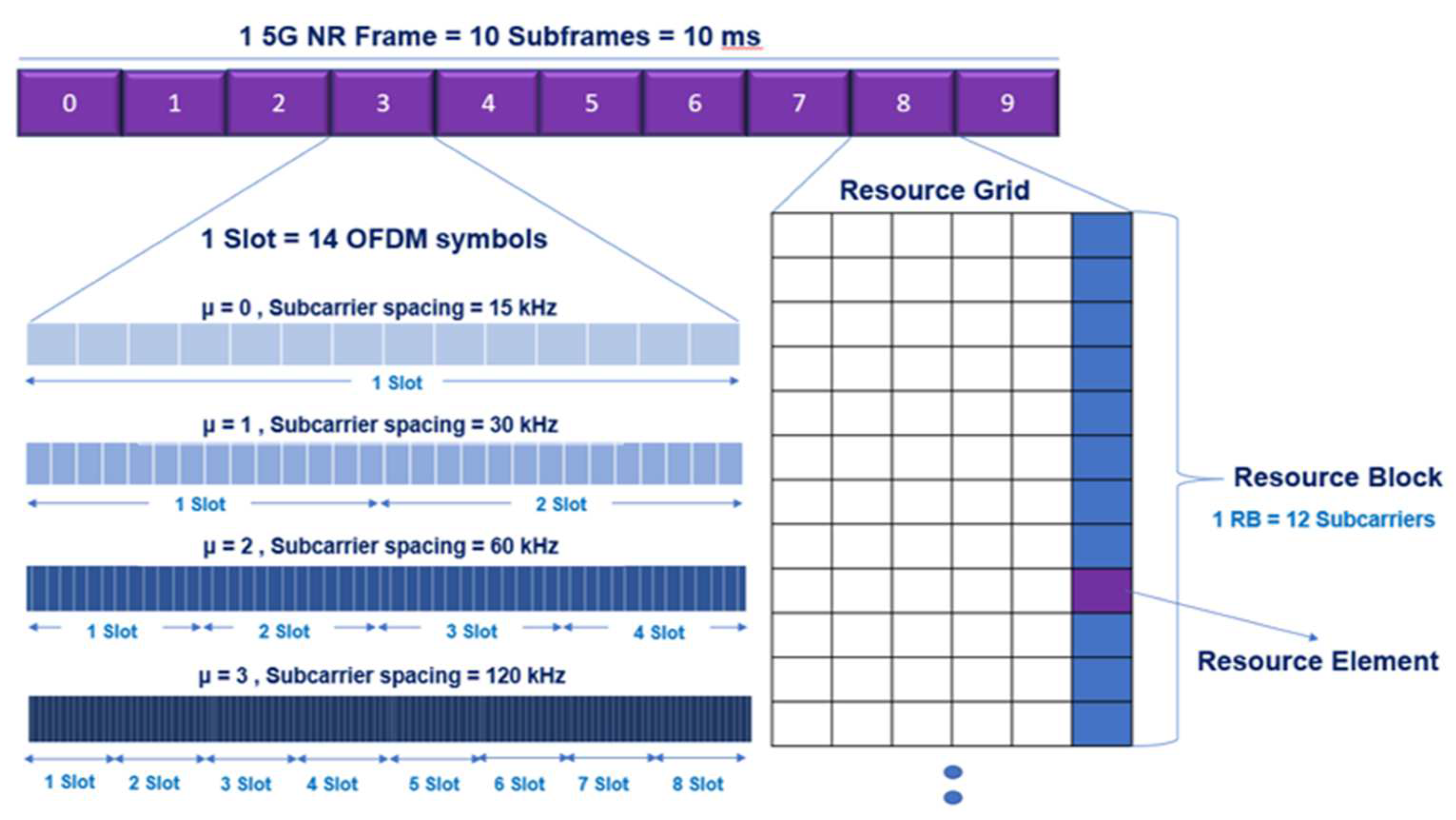
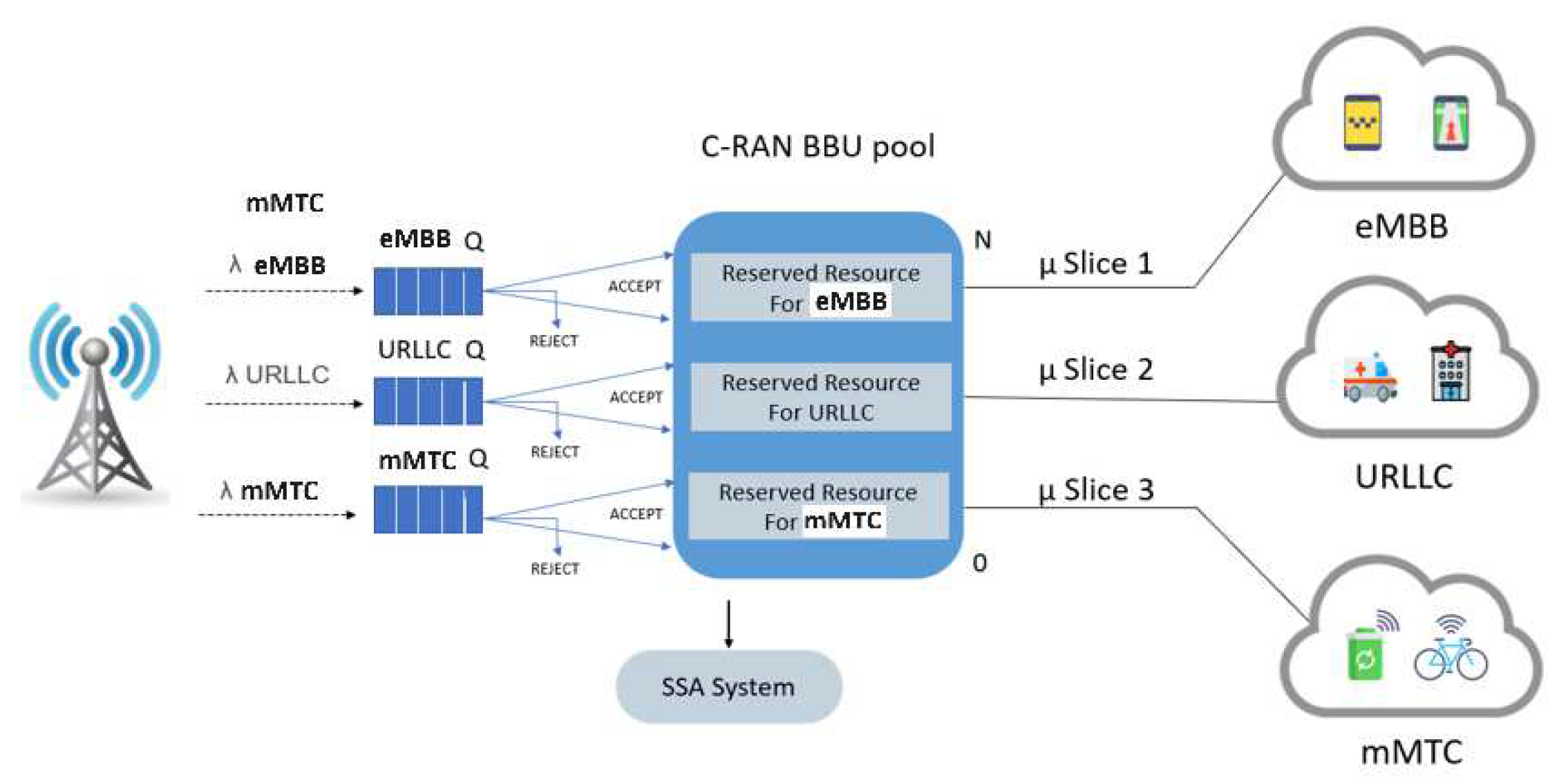
3.1. 5G C-RAN Architecture Model and Resource Allocation
- (1)
- for URLLC connection requests:
- (2)
- for eMBB connection requests:
- (3)
- for mMTC connection requests:
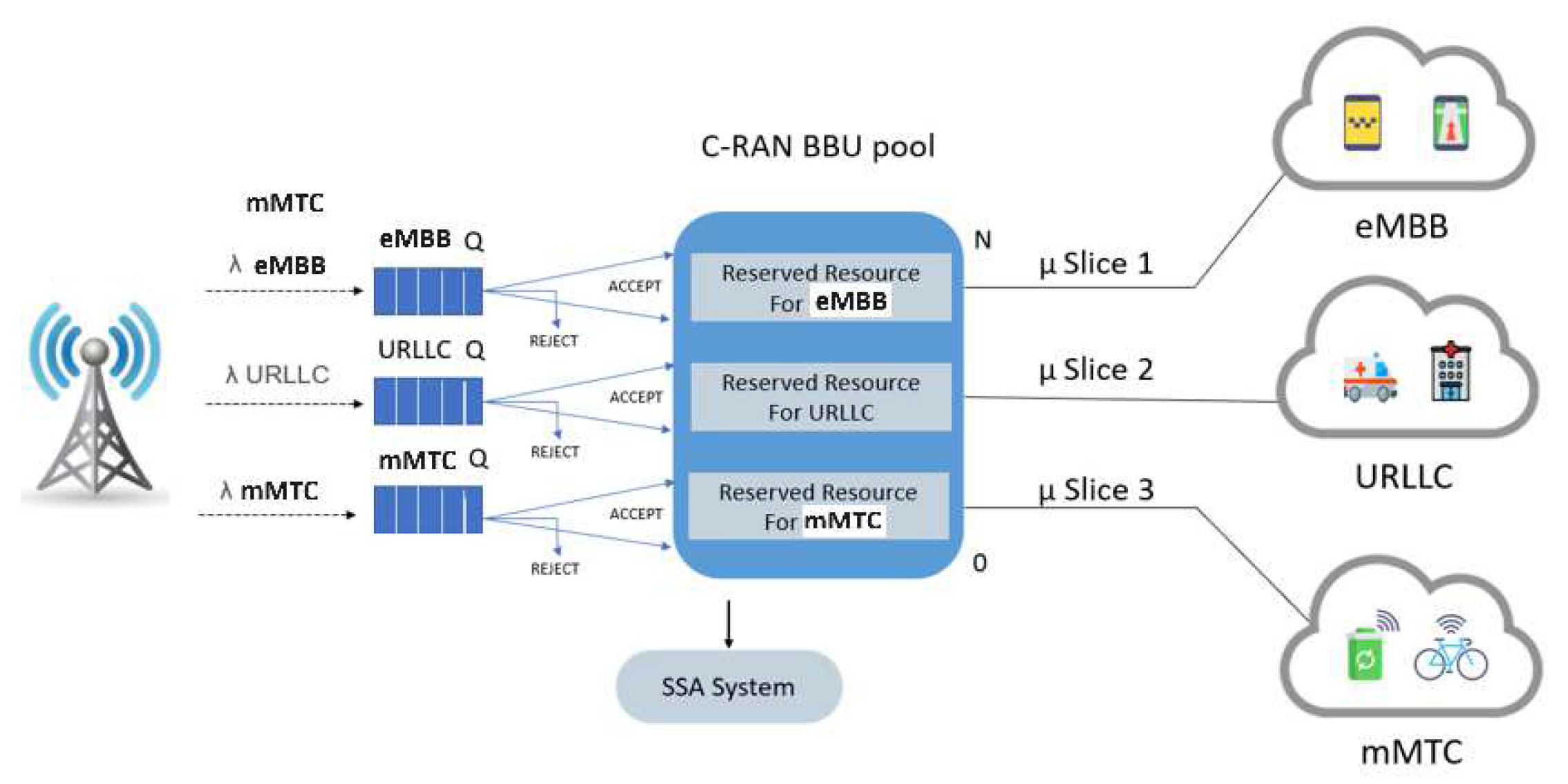
3.2. Proposed Slice Allocation System
3.2.1. Static Slice Allocation System (SSA)
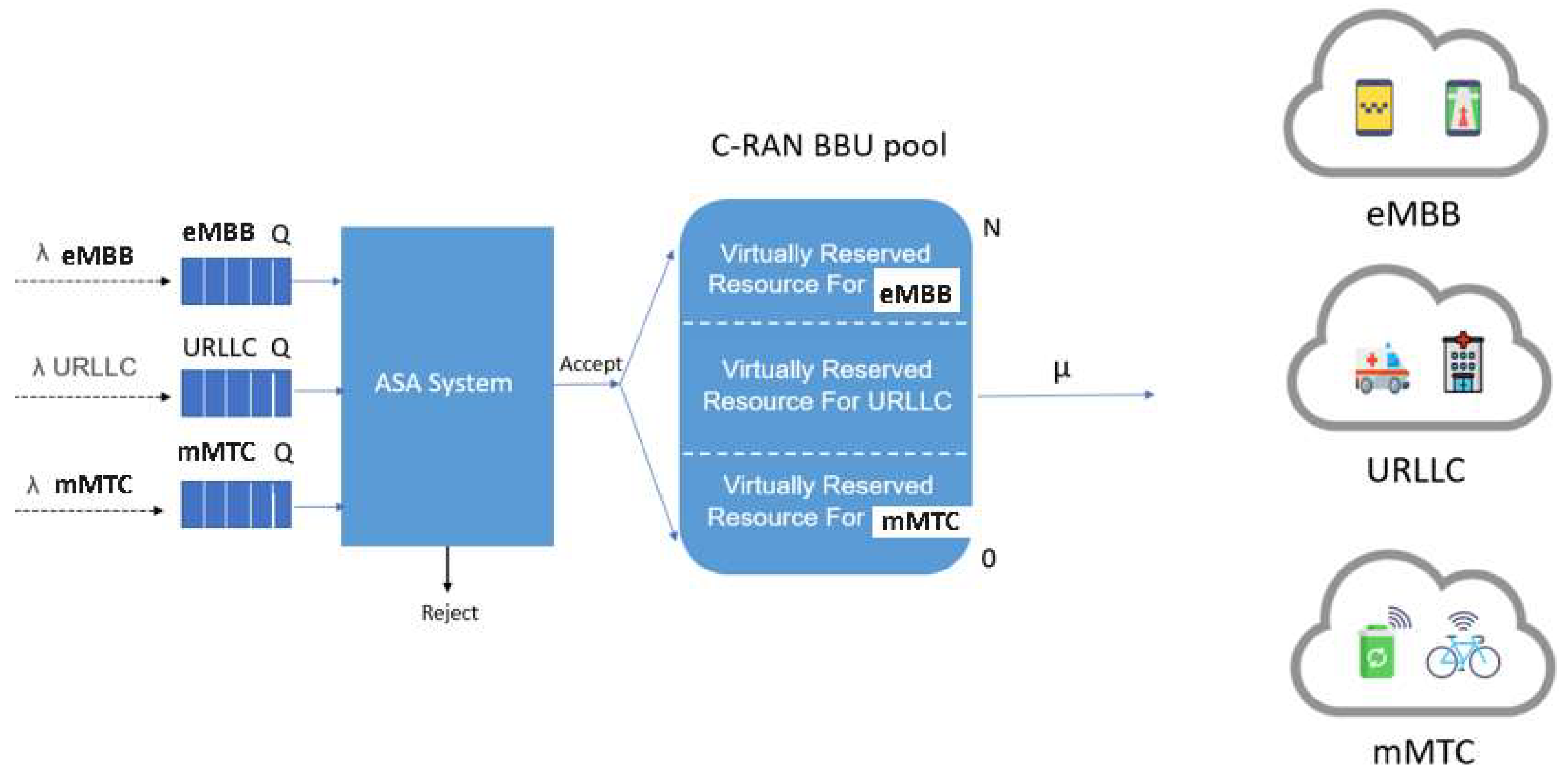
3.2.2. Proposed Adaptive Slice Allocation System (ASA)
- The arrived slice’s request i is accepted if the following criterion is satisfied:
- When all system RBs are utilized, an arriving slice’s request i is inserted into its corresponding queue or blocked if it is full.
- If a slice’s request i exceeds its queuing time limit, it will be dropped from its queue.
- When a slice’s request i departs, its corresponding occupied RBs are released, and the ASP is computed for all queued slices requests that have non-empty queues. Then, the queue with the lowest ASP value, which indicates that it has the highest priority, is served first based on the FIFO policy.
- The total number of RBs that are currently utilized by all active users of the slice, denoted as .
- The number of RBs that are virtually reserved for the ith slice, denoted as Therefore, the ASP value for slice’s request i is given by
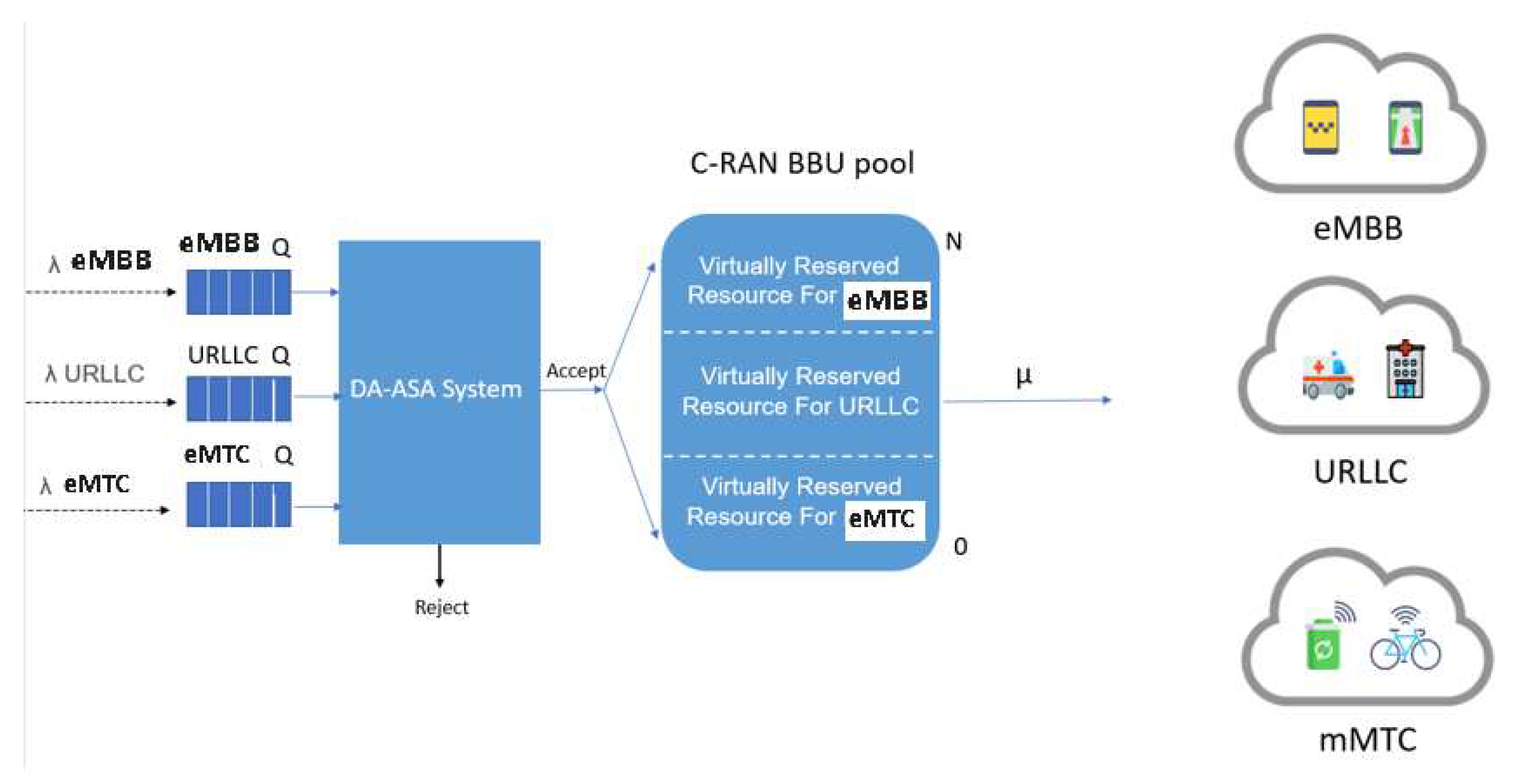
3.2.3. Proposed Delay Aware Adaptive Slice Allocation System (DA-ASA)
- The total number of RBs that are currently utilized by all active users of the slice, denoted as .
- The number of RBs that are virtually reserved for the slice, denoted as .
- The maximum tolerable delay limit for a user request in the ith slice, denoted as .
- The current delay for a request in the slice, denoted as .
4. Simulation Results and Discussions
4.1. Performance Measures
- System utilization (U)
- Average waiting time (W)
- Total Blocking Probabilities (TBP)
4.2. Simulation Setup
4.3. Results and Discussions
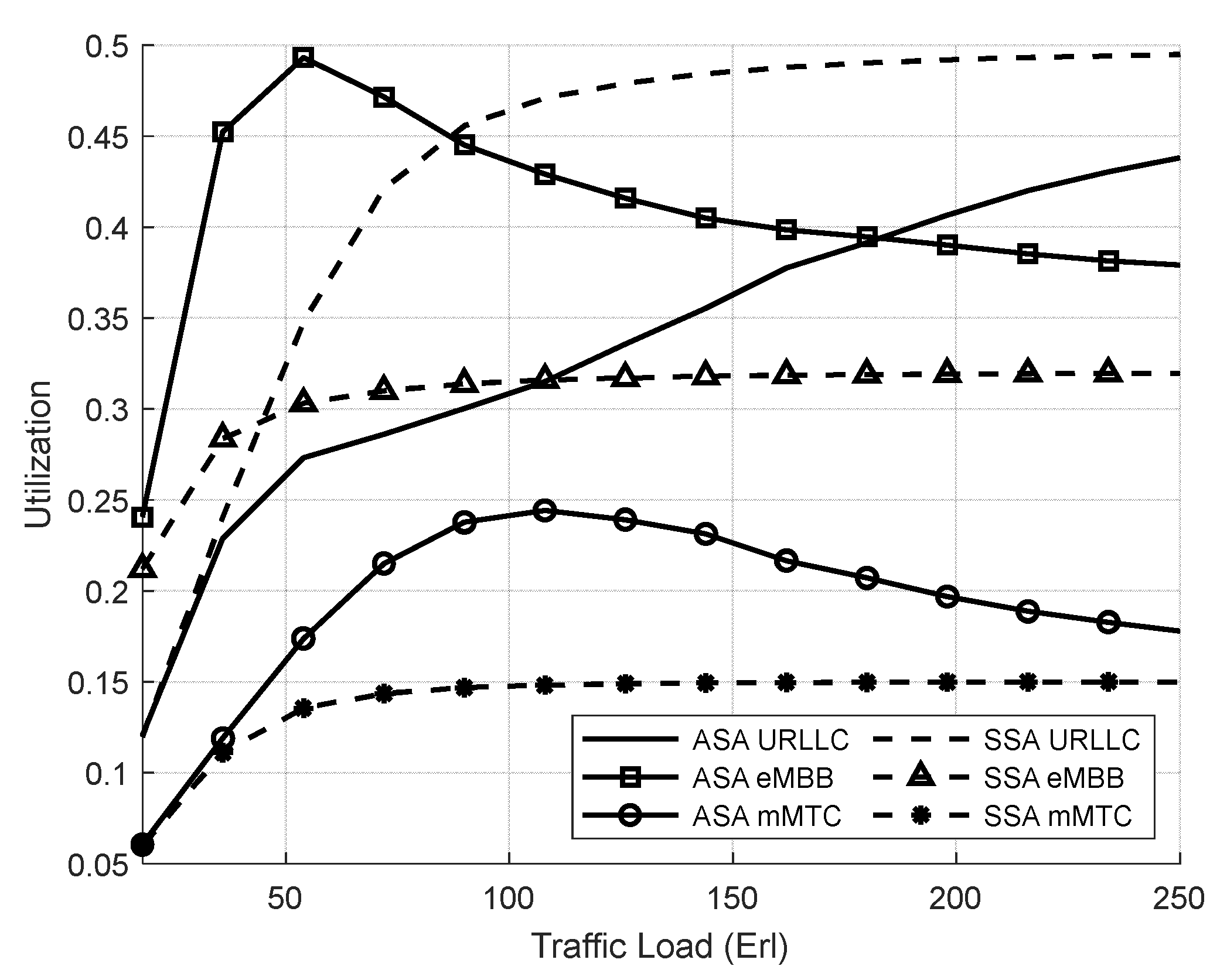
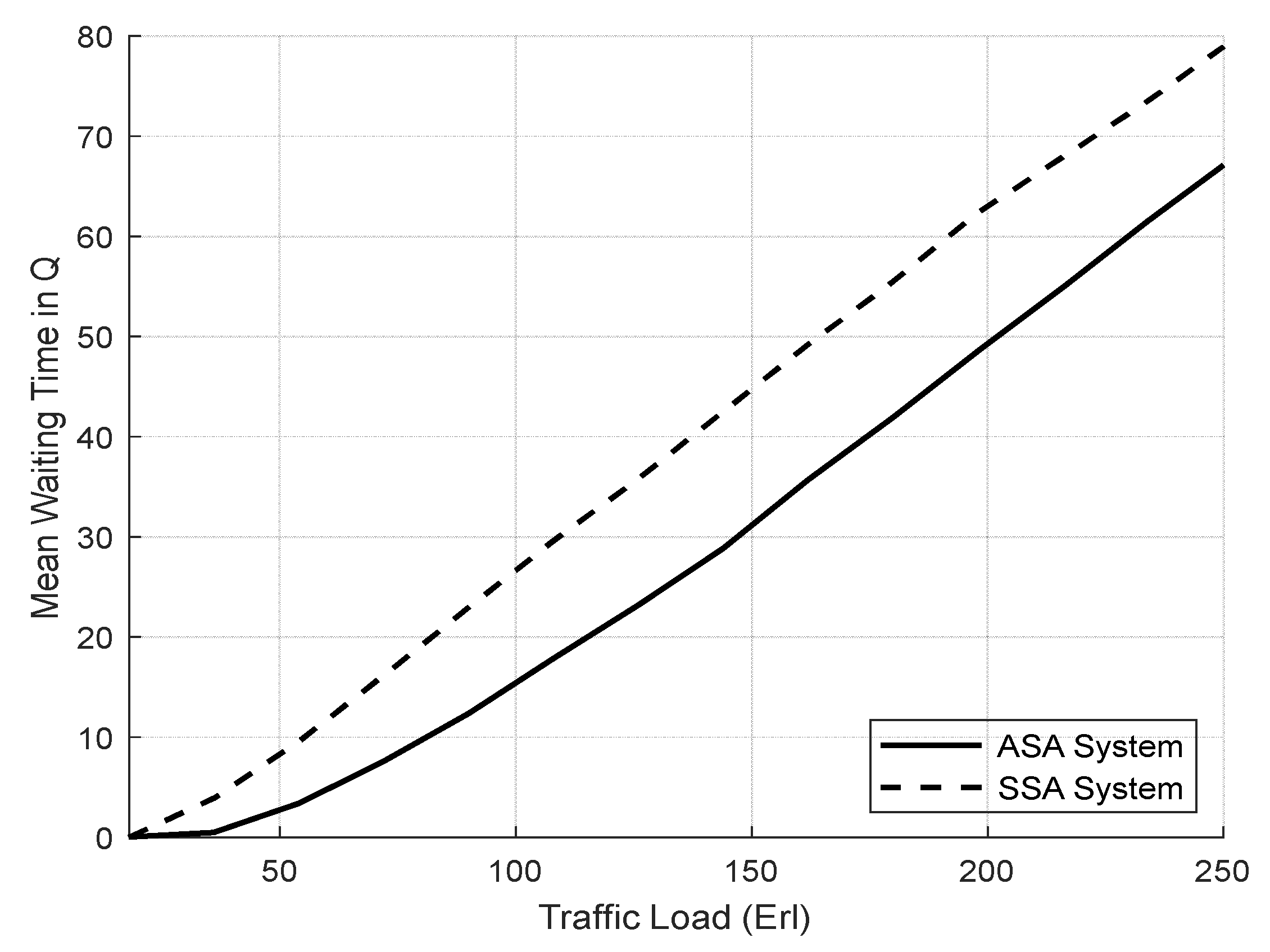
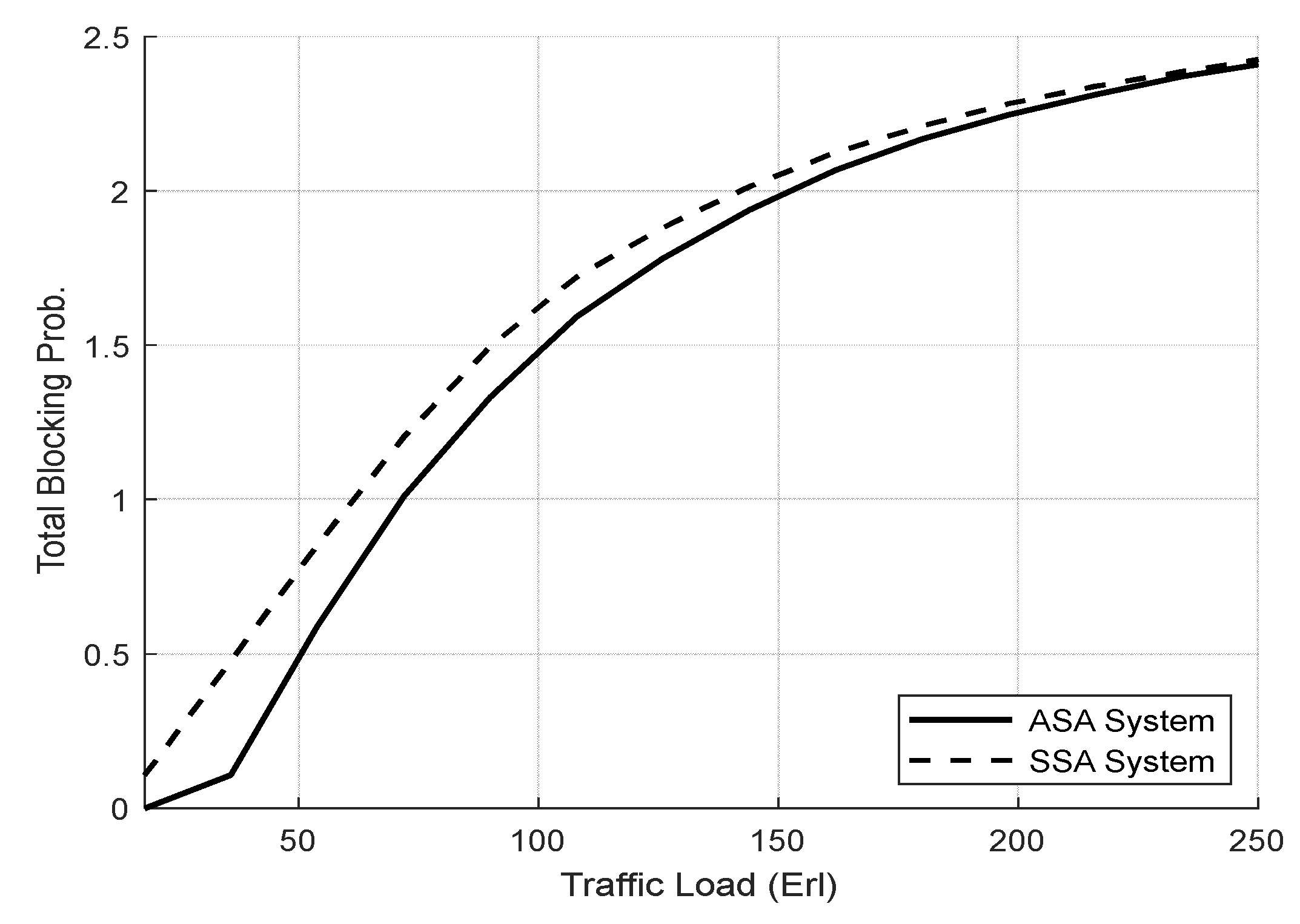
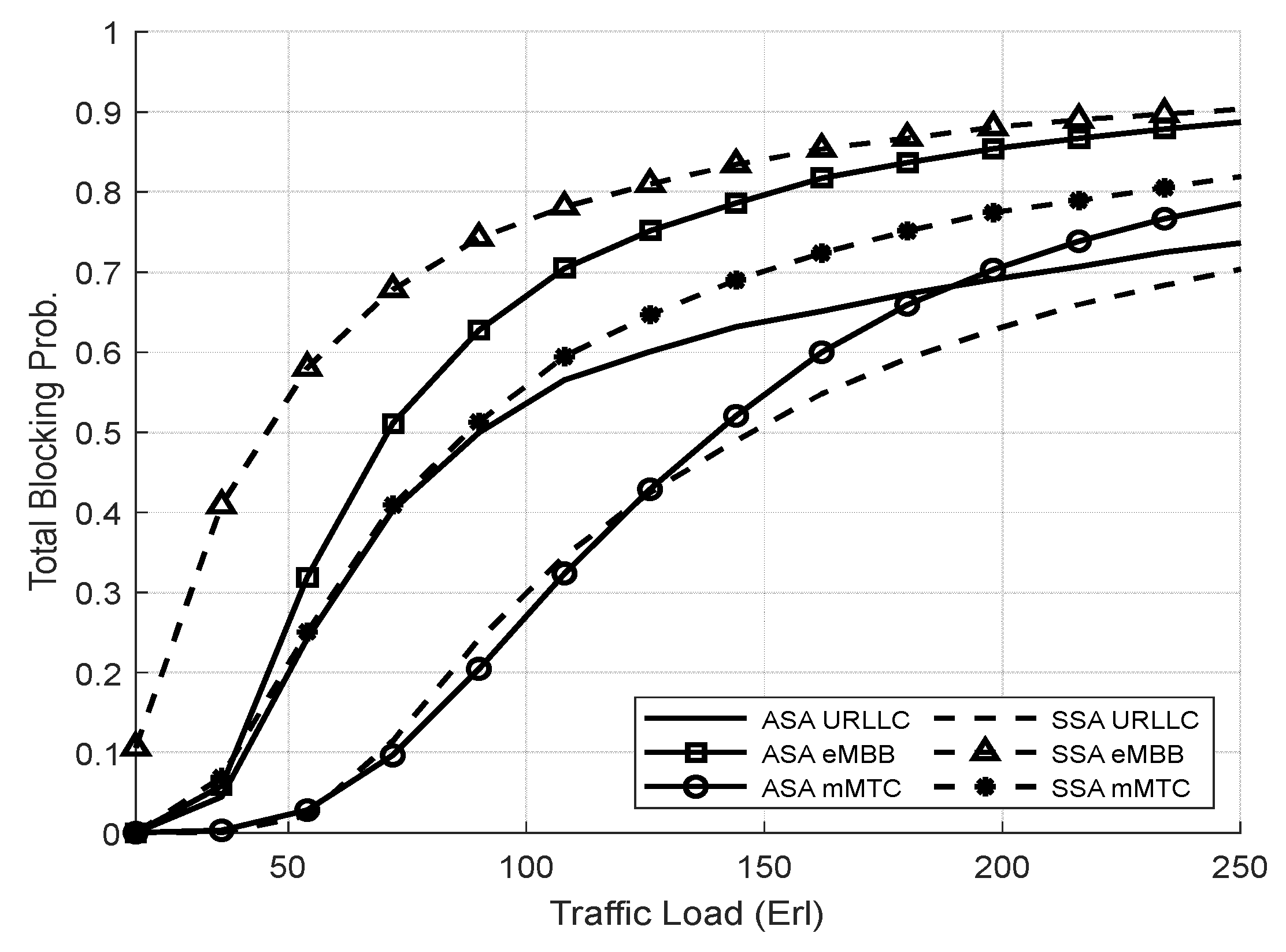
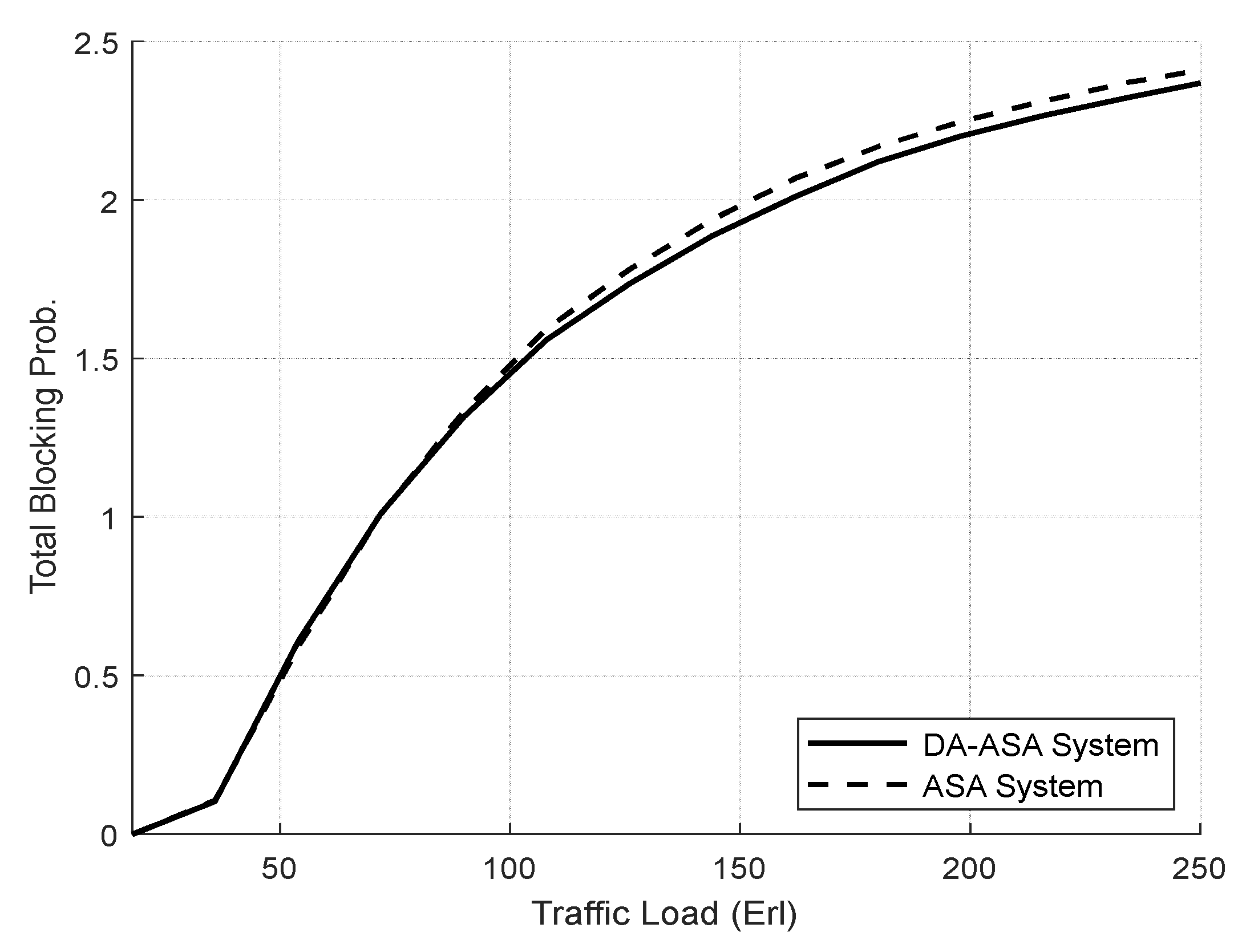
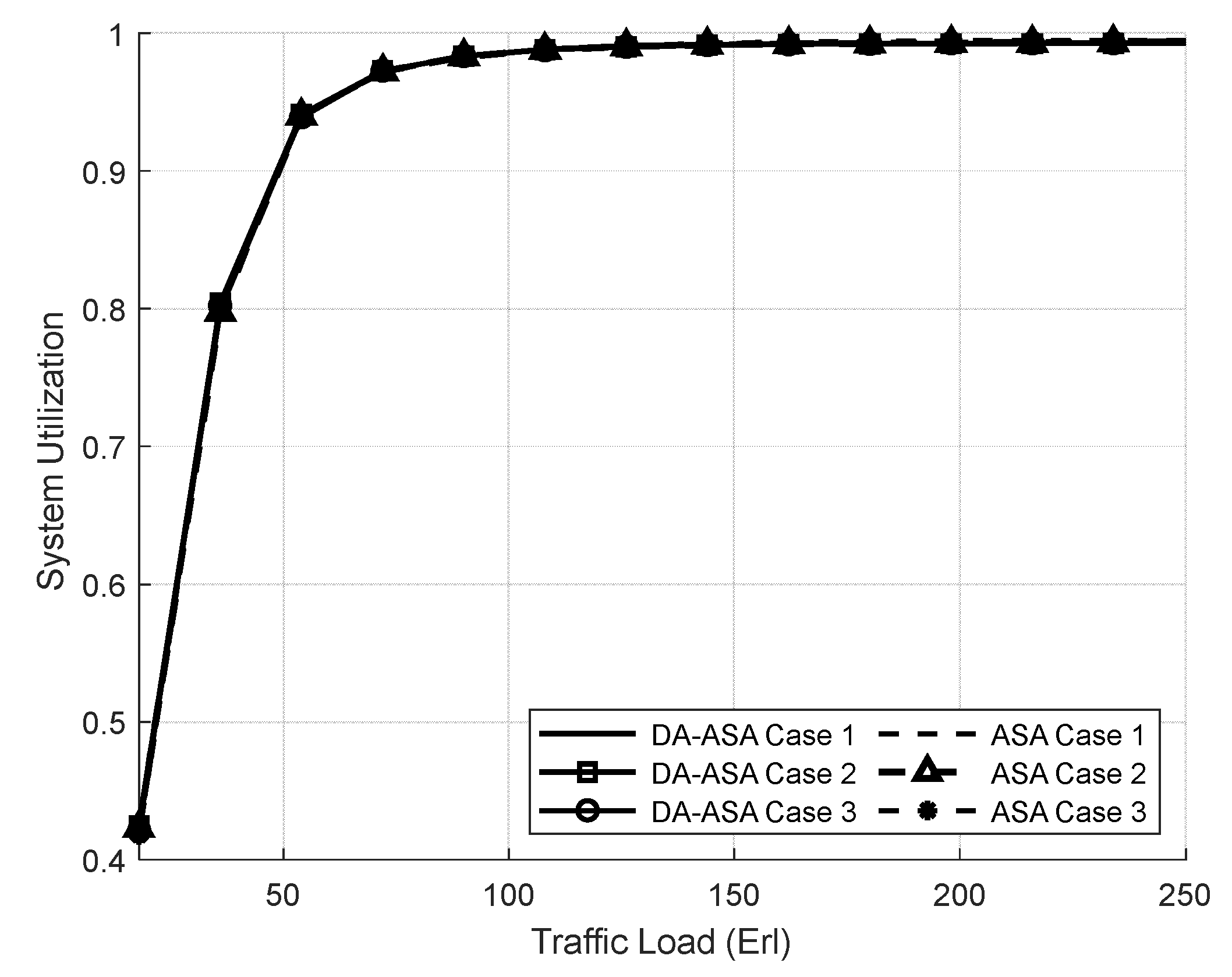
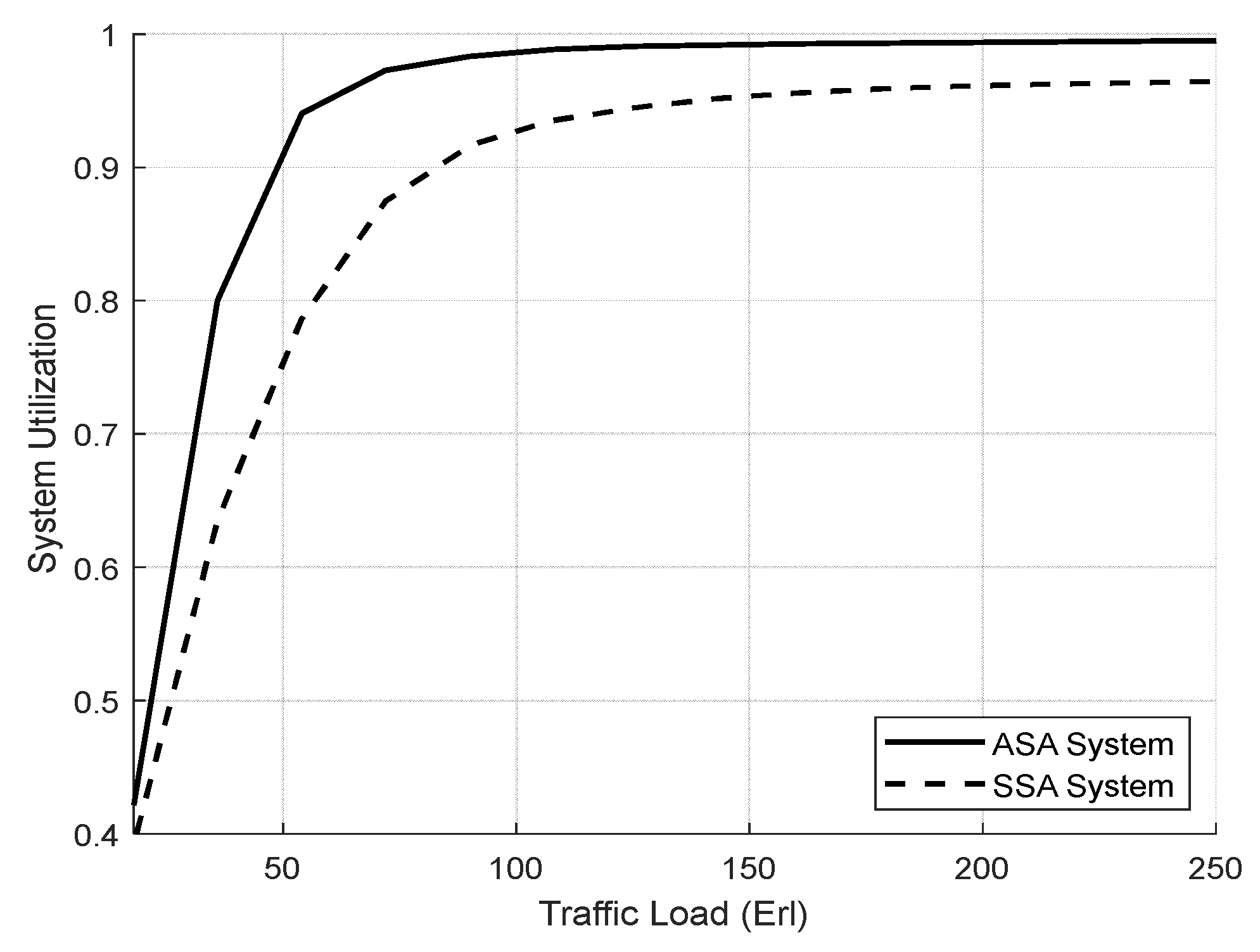
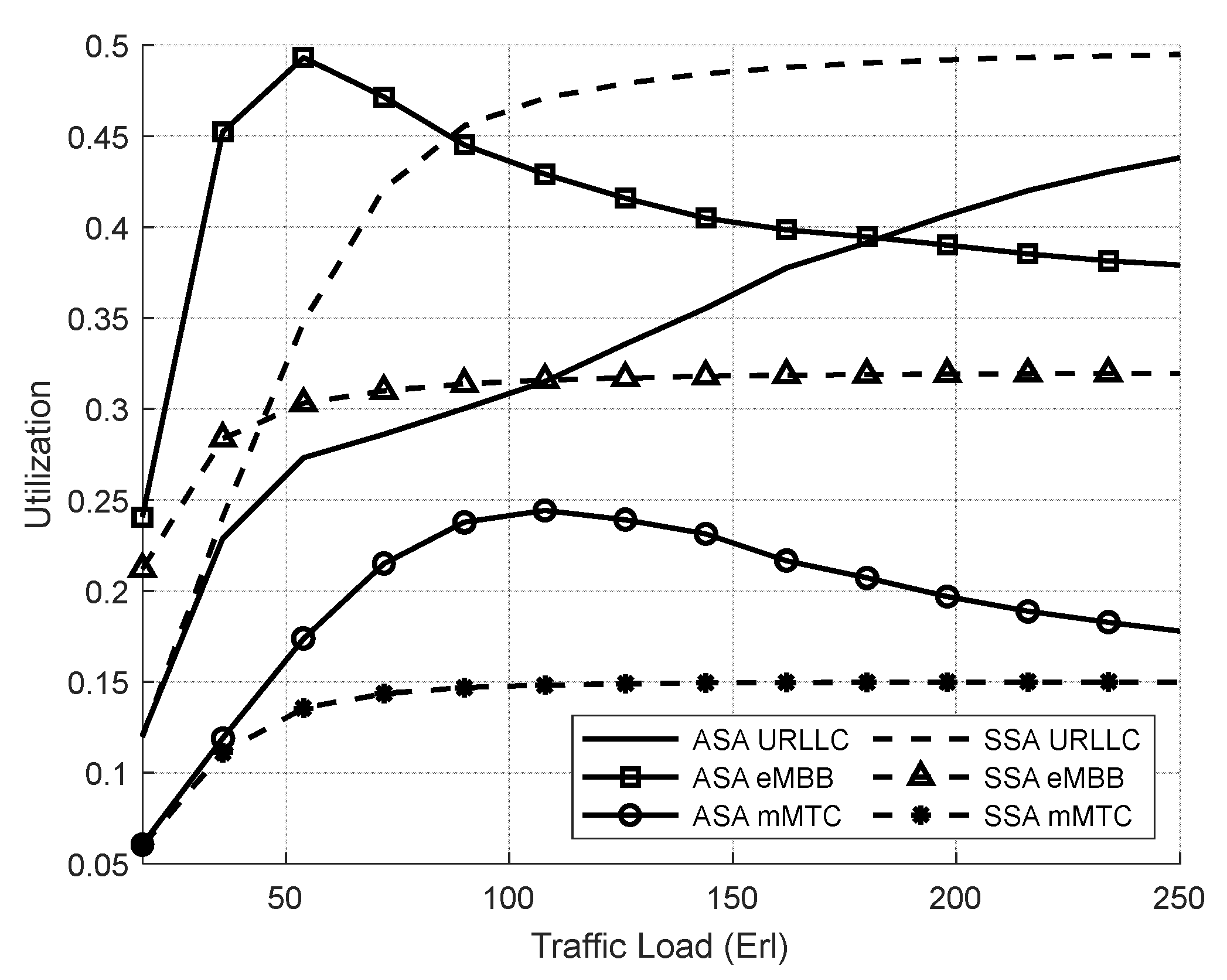
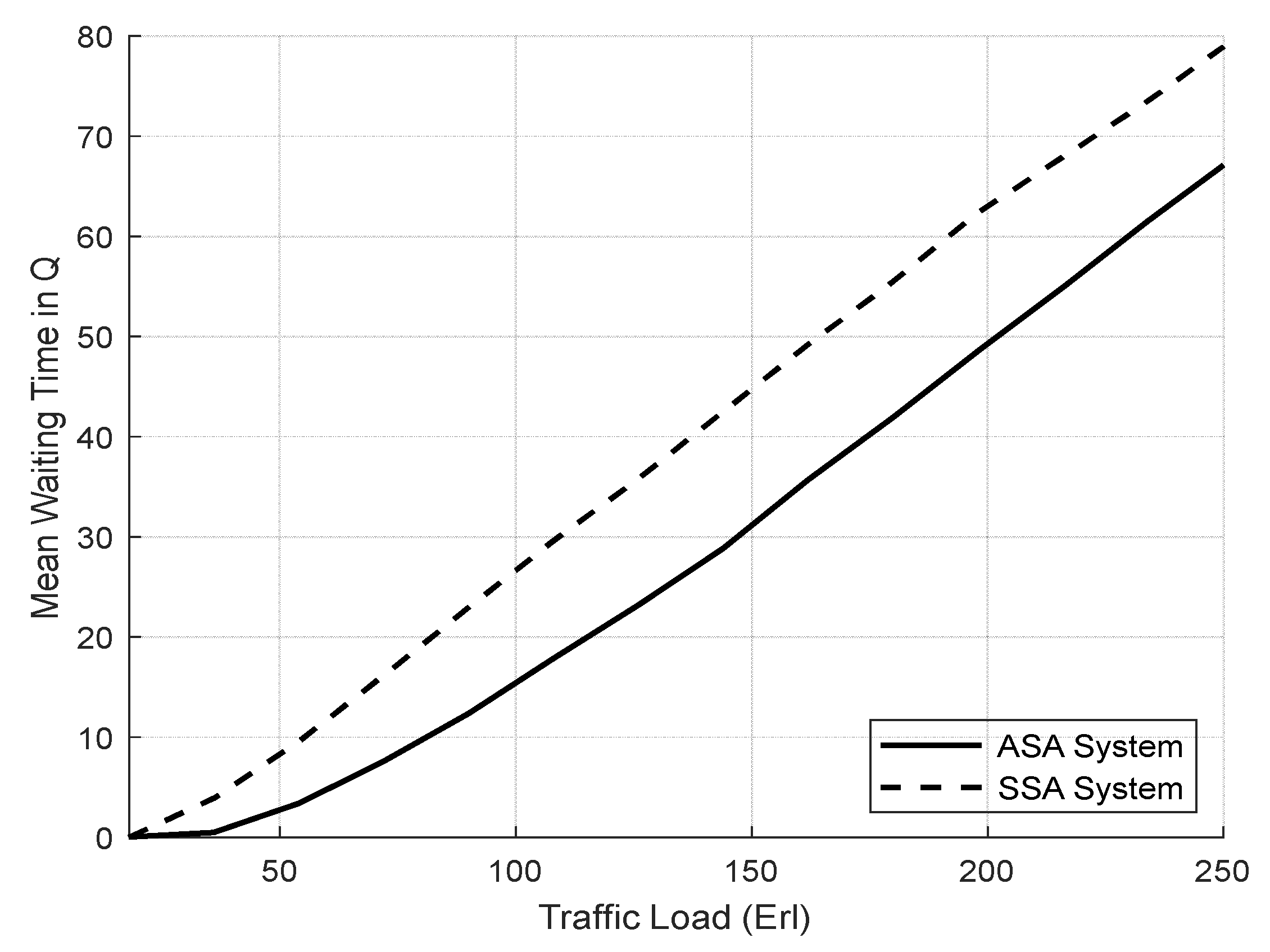
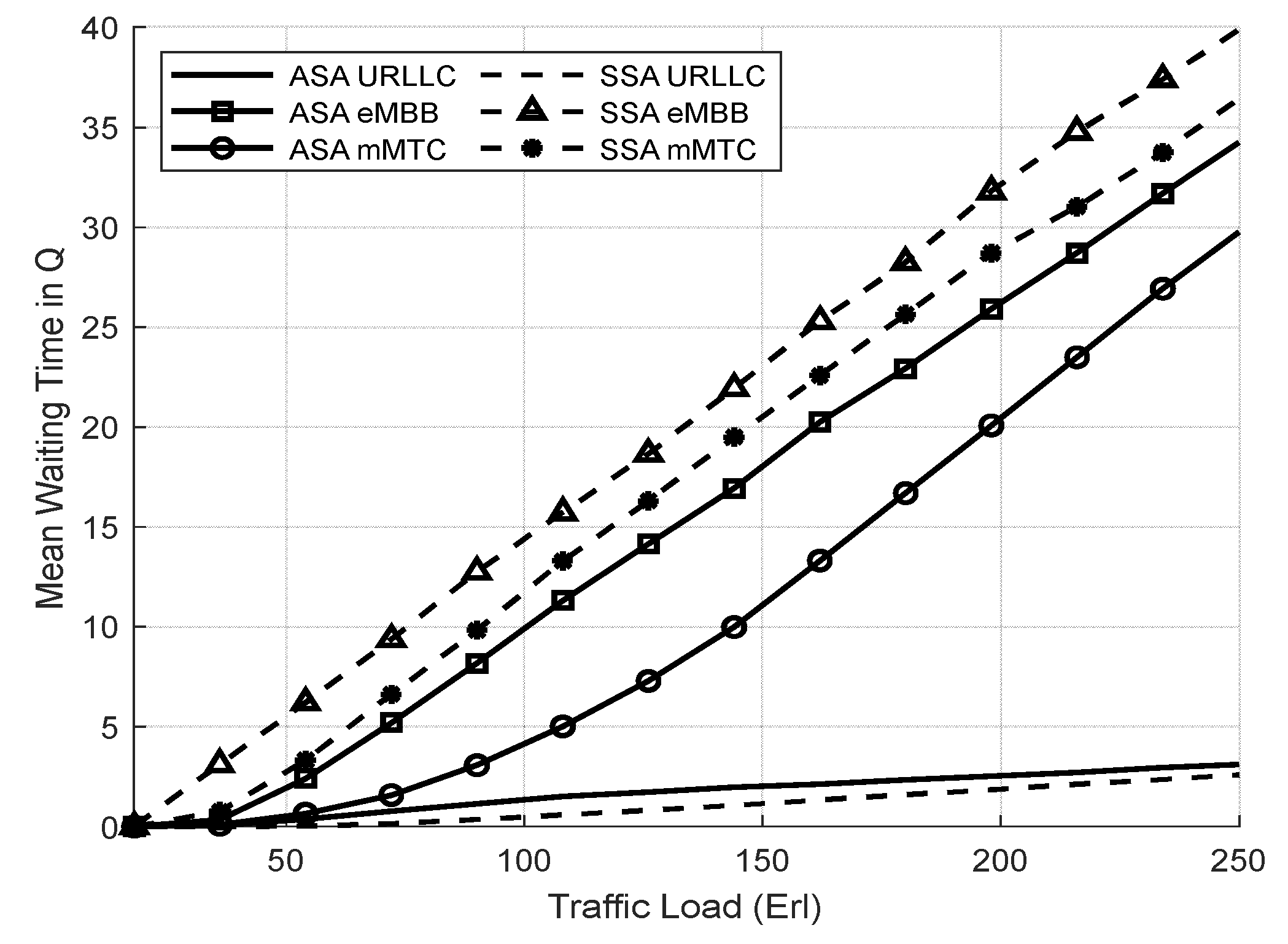
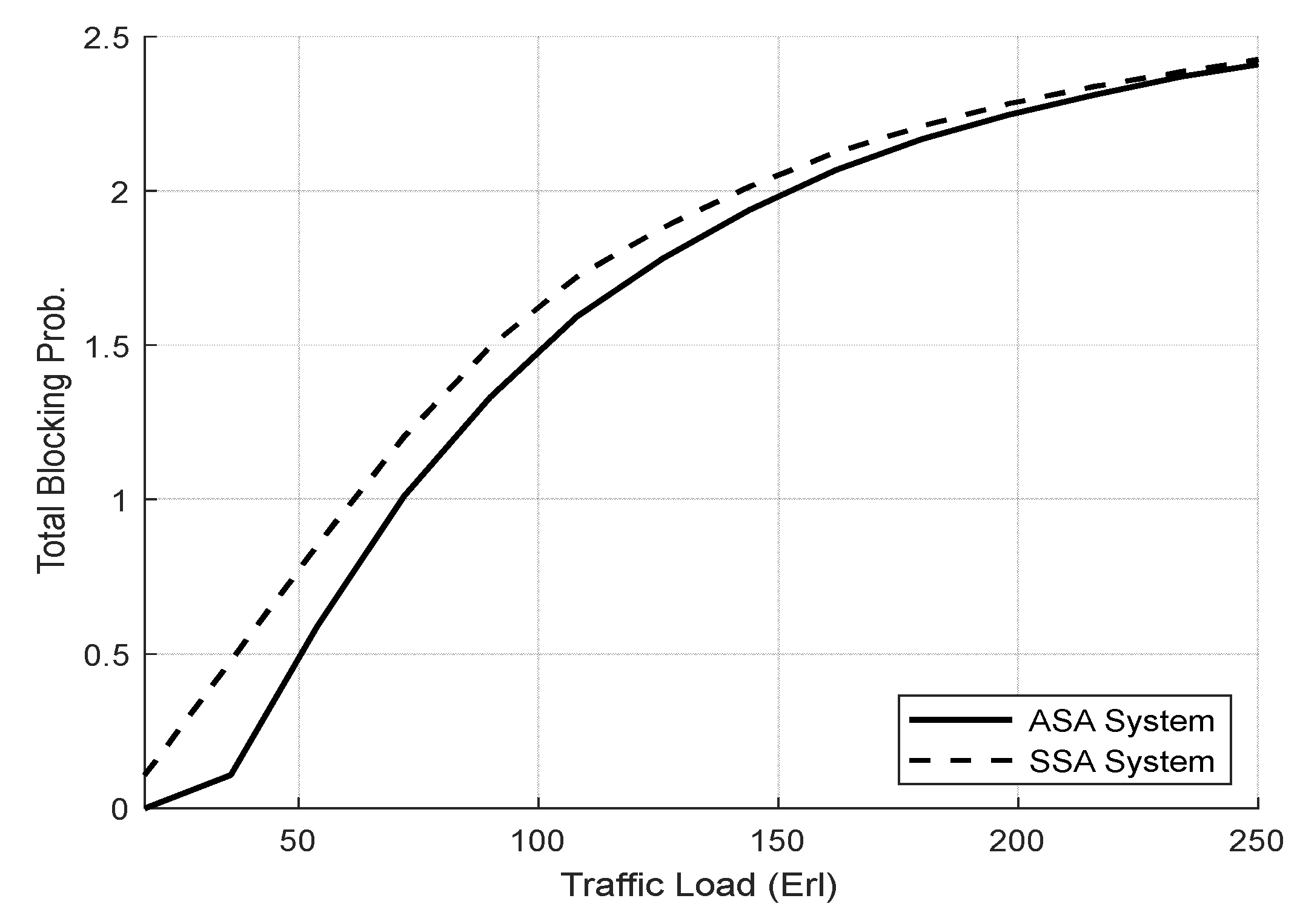
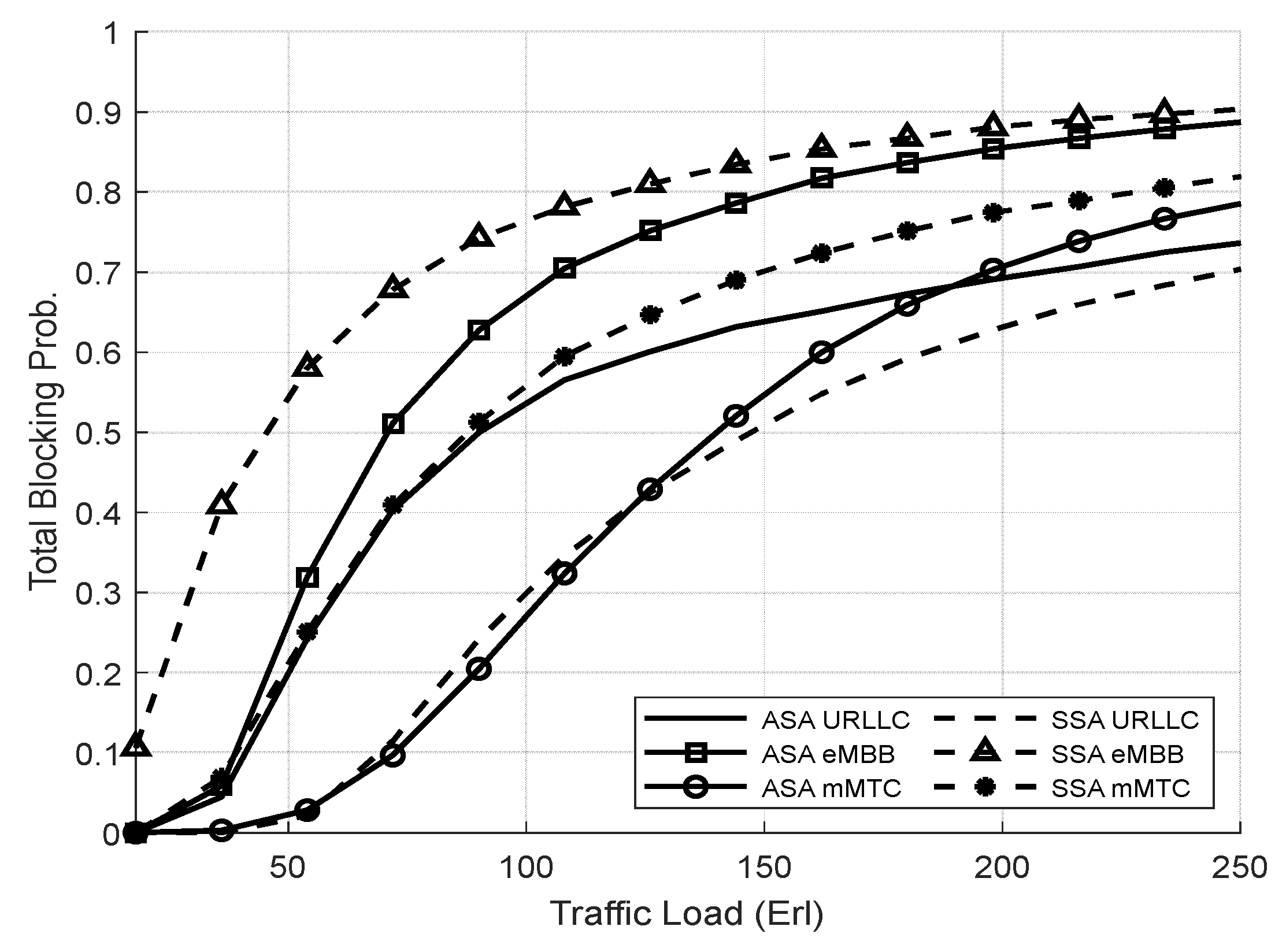
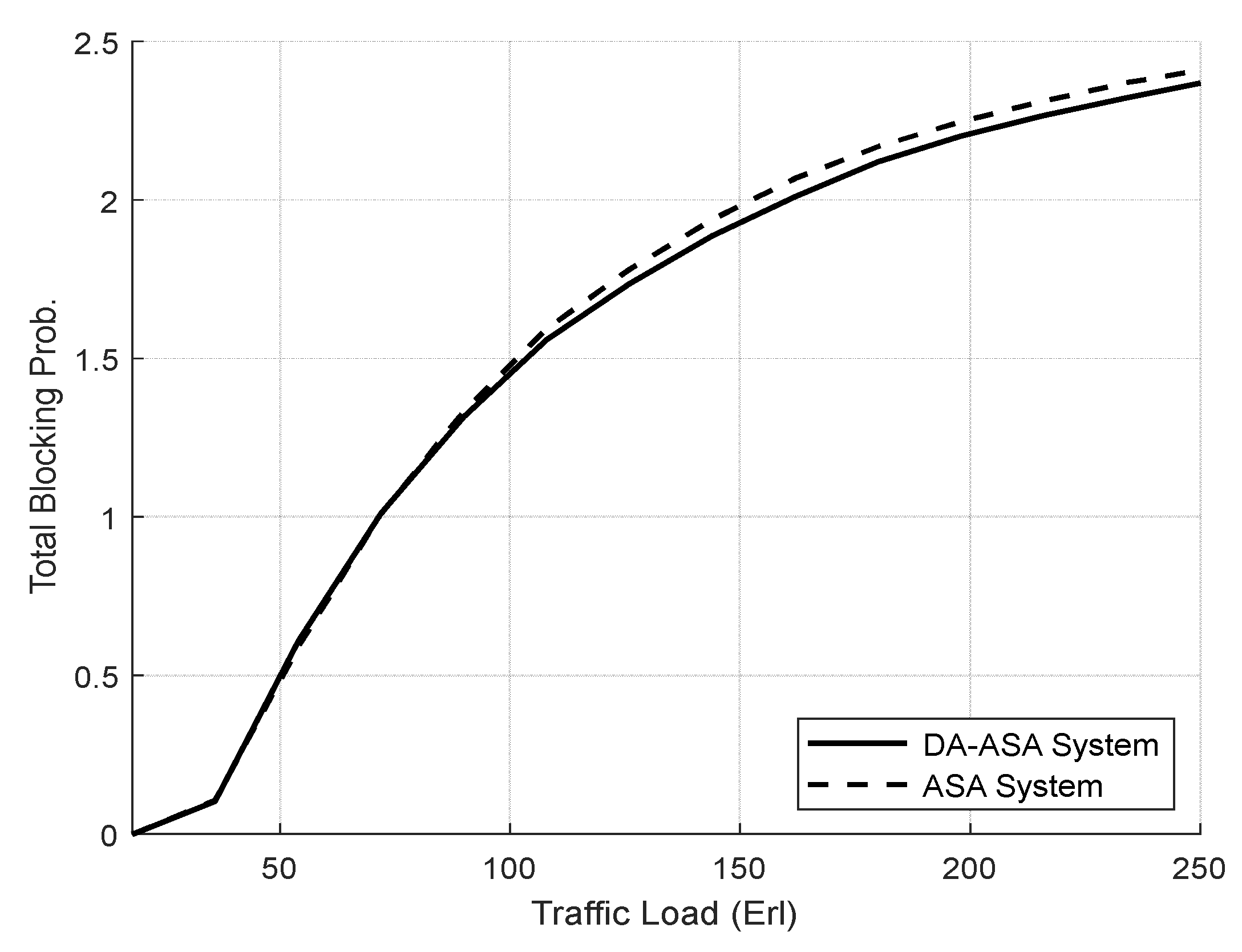
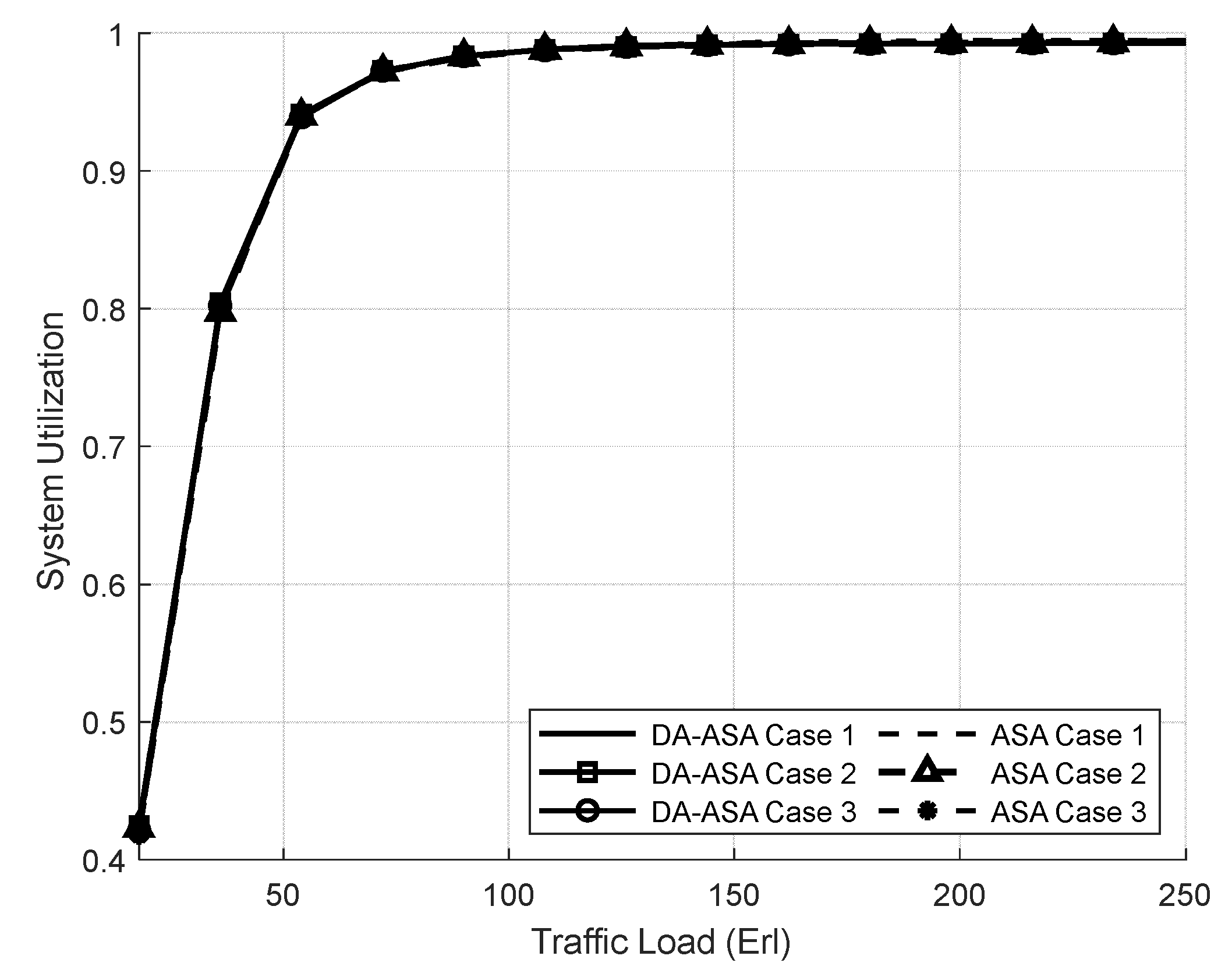
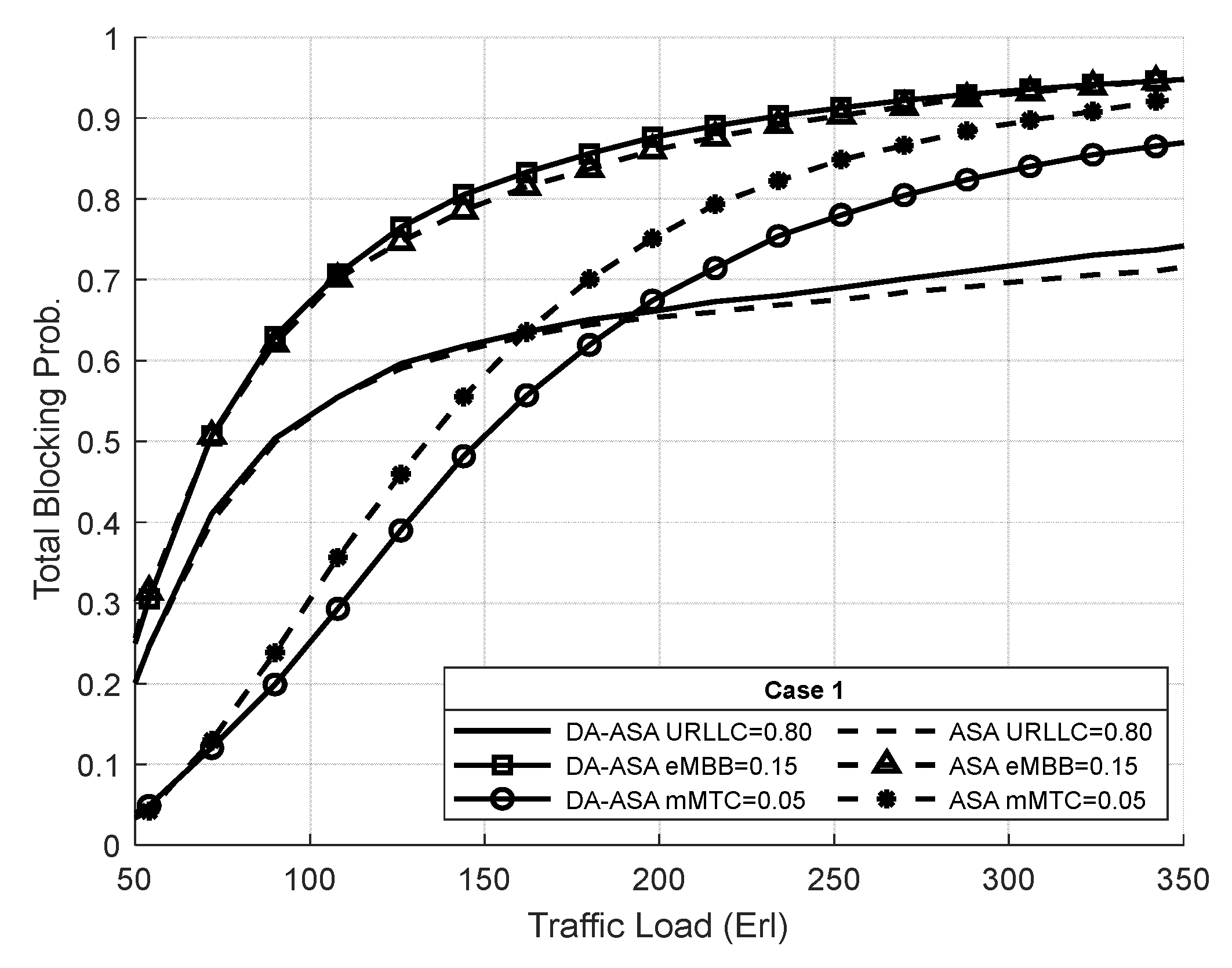
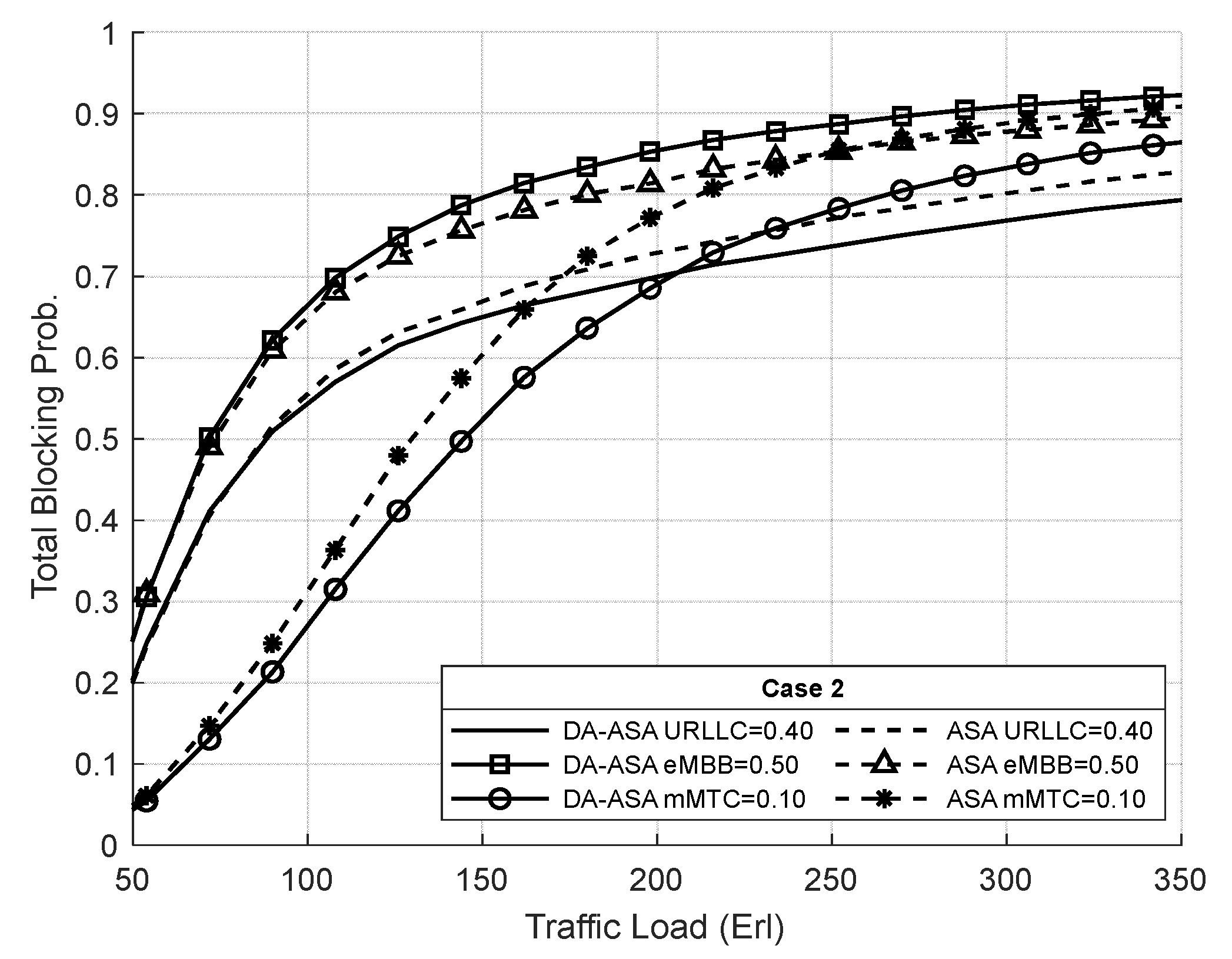
4.3.1. Evaluation Result of the SSA and the ASA Systems
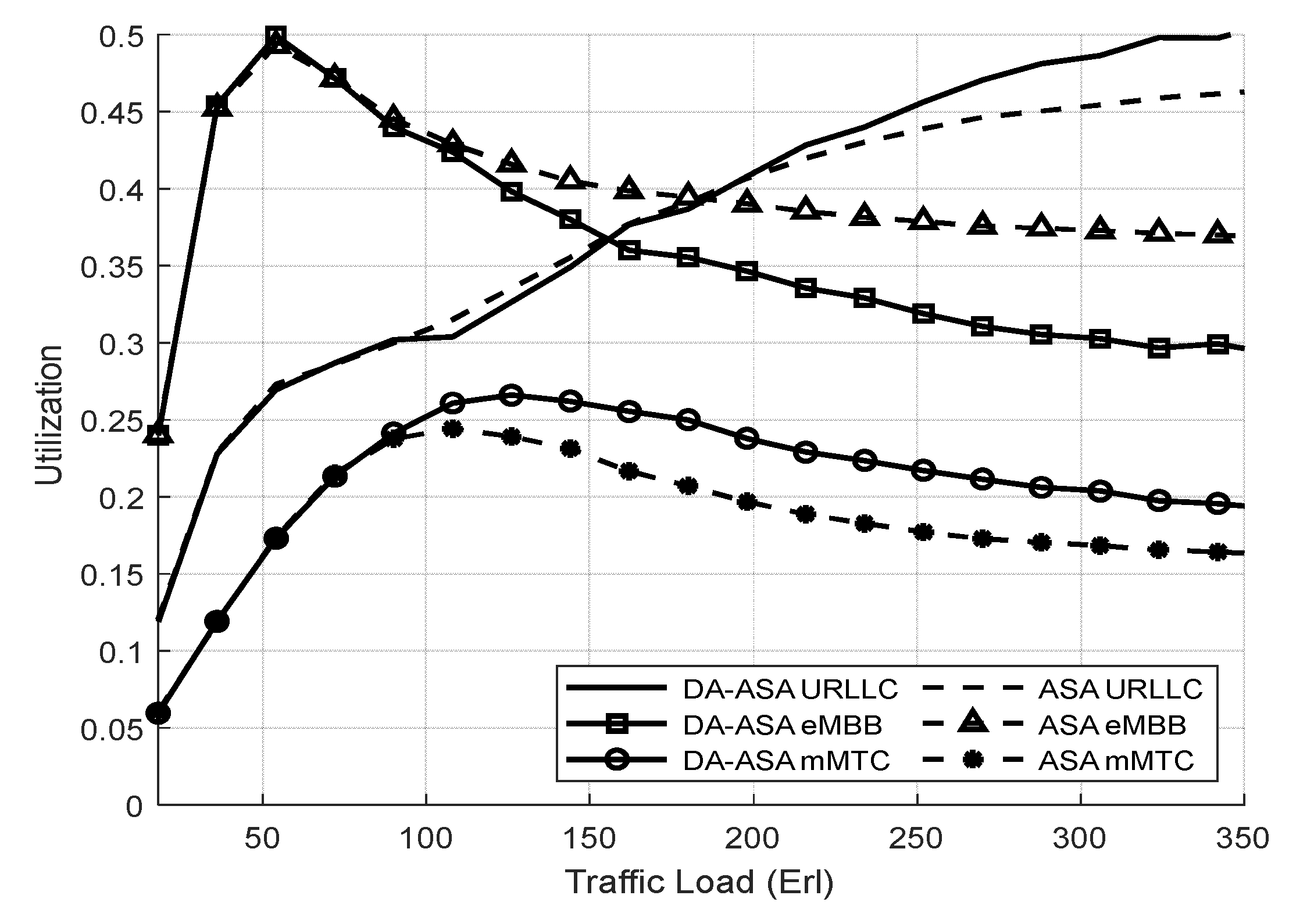
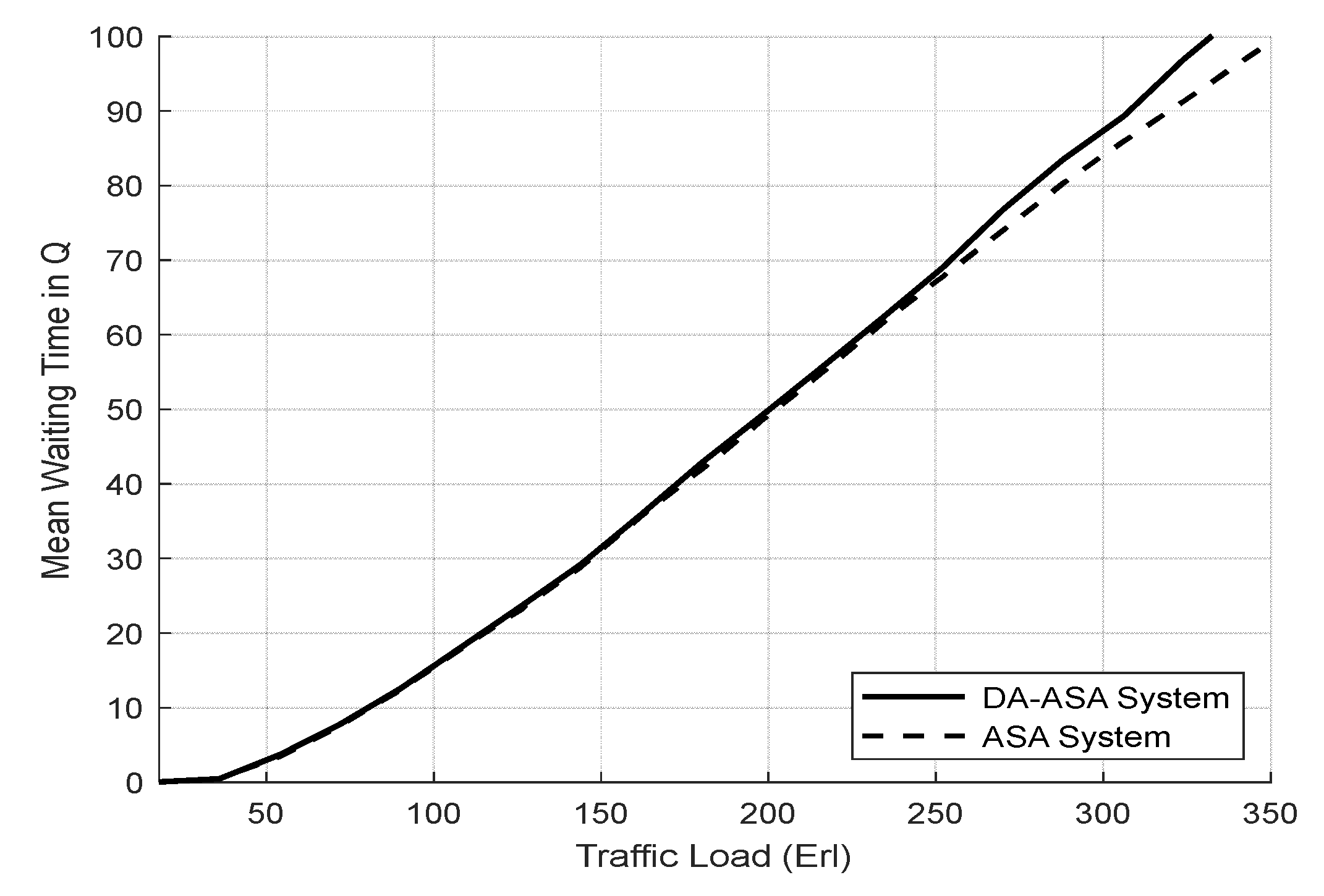
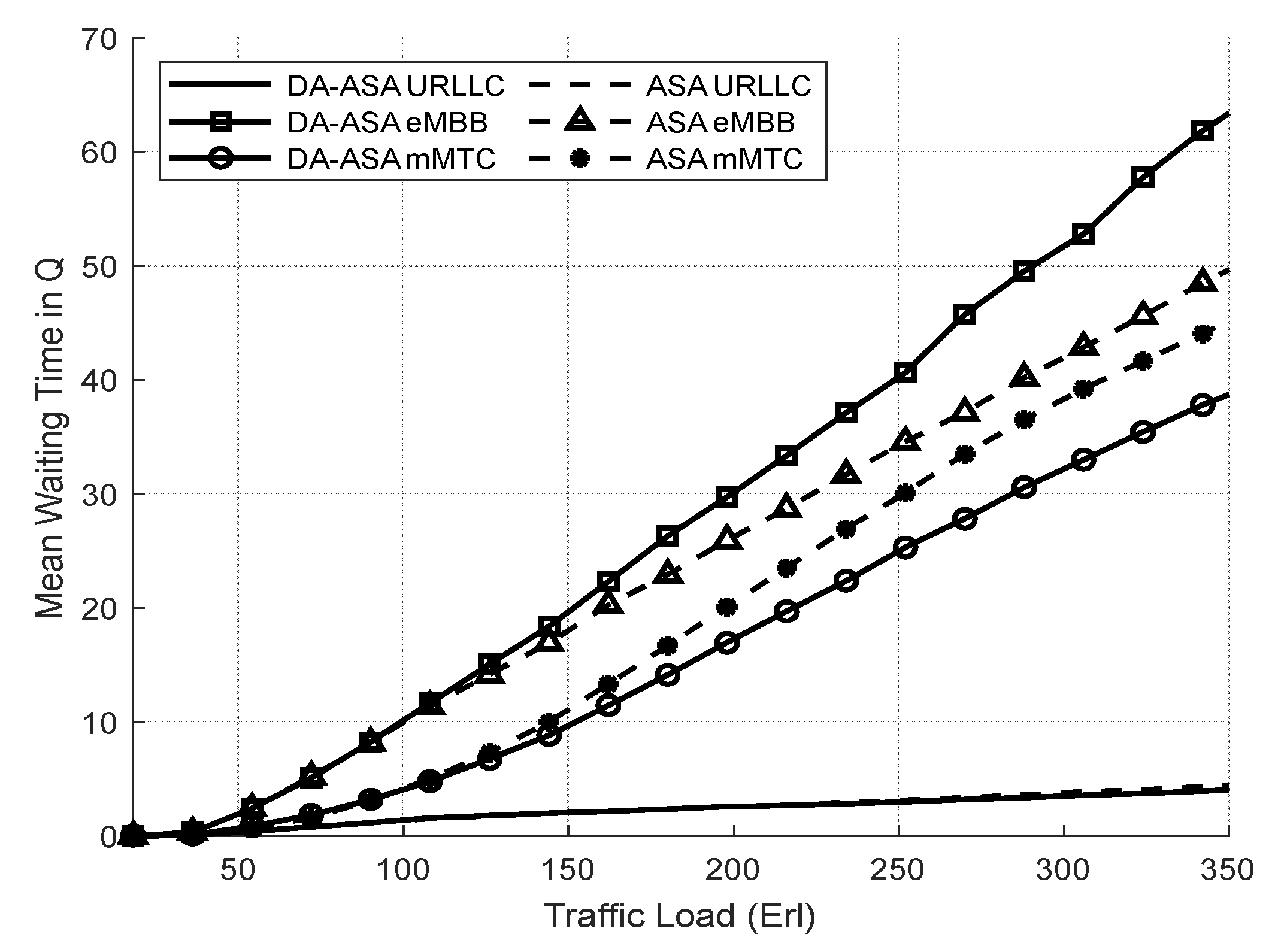
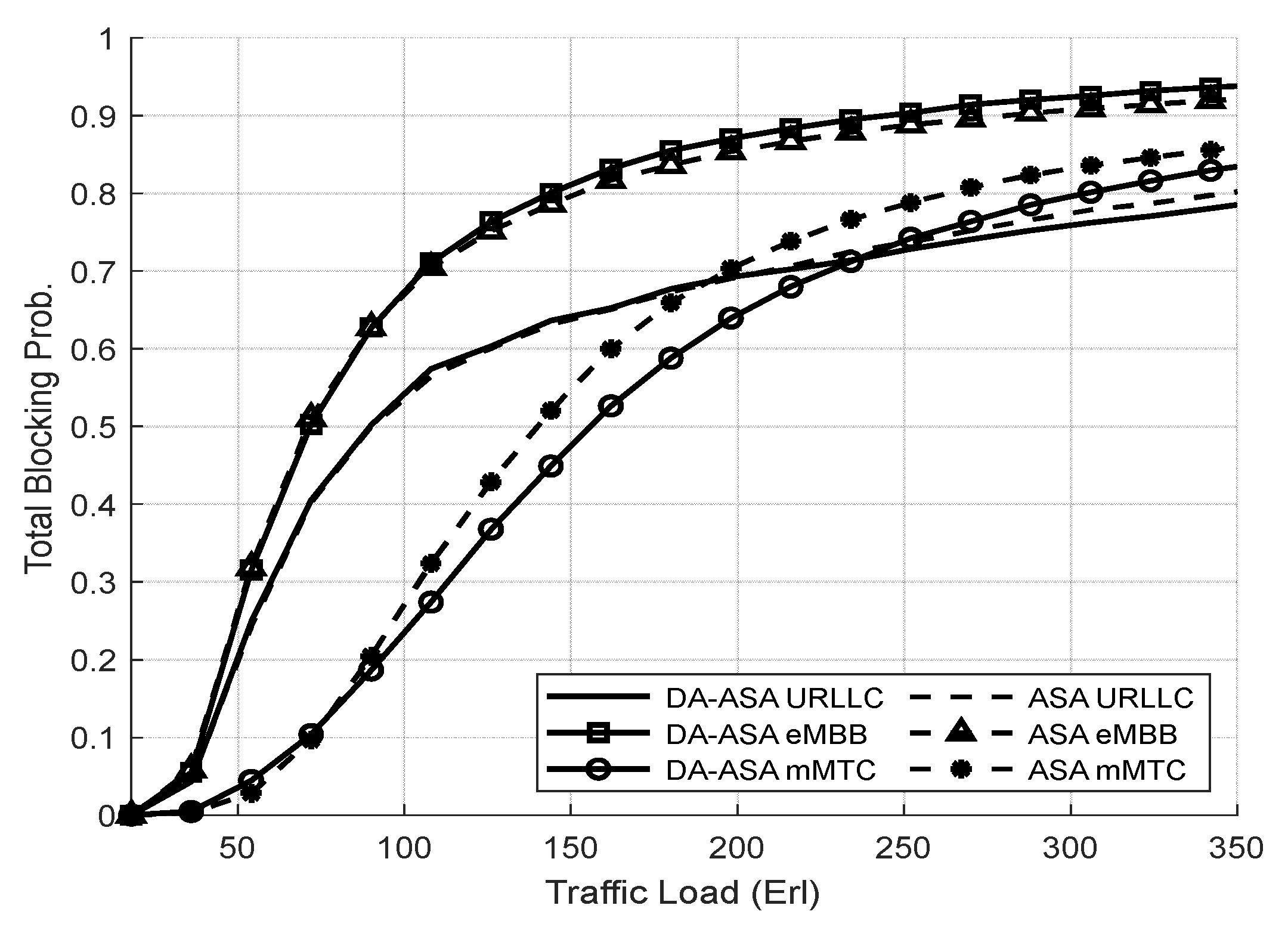
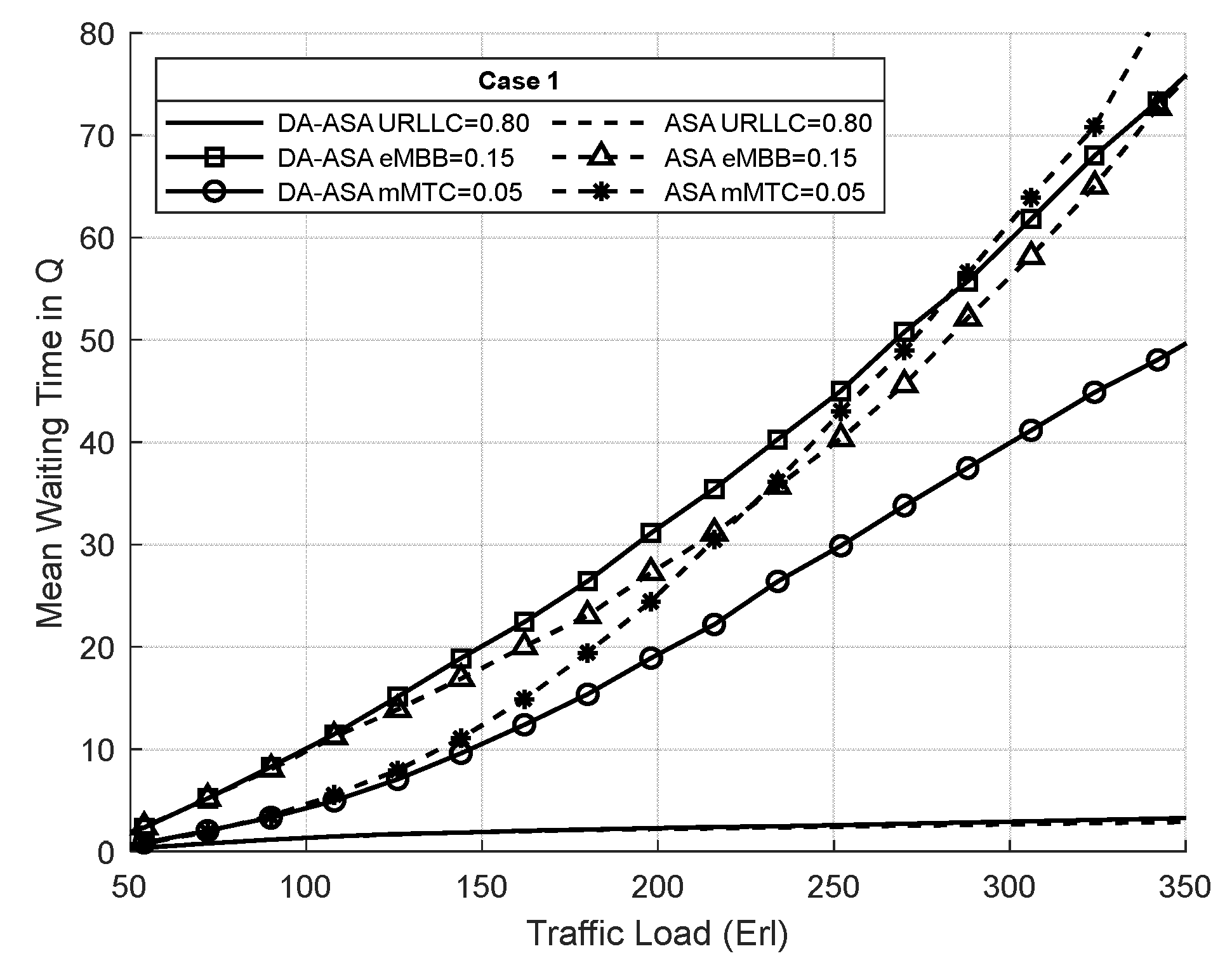
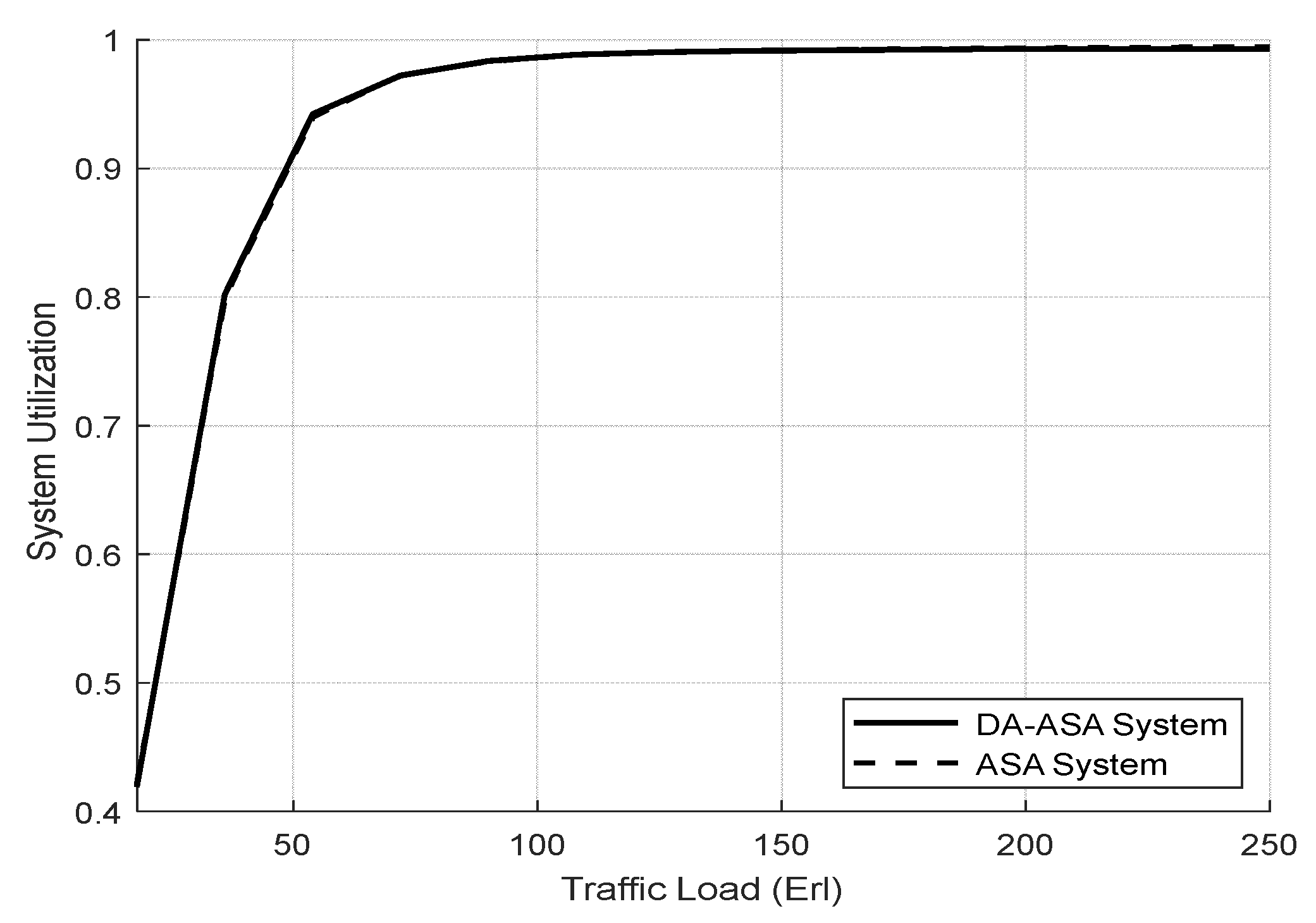
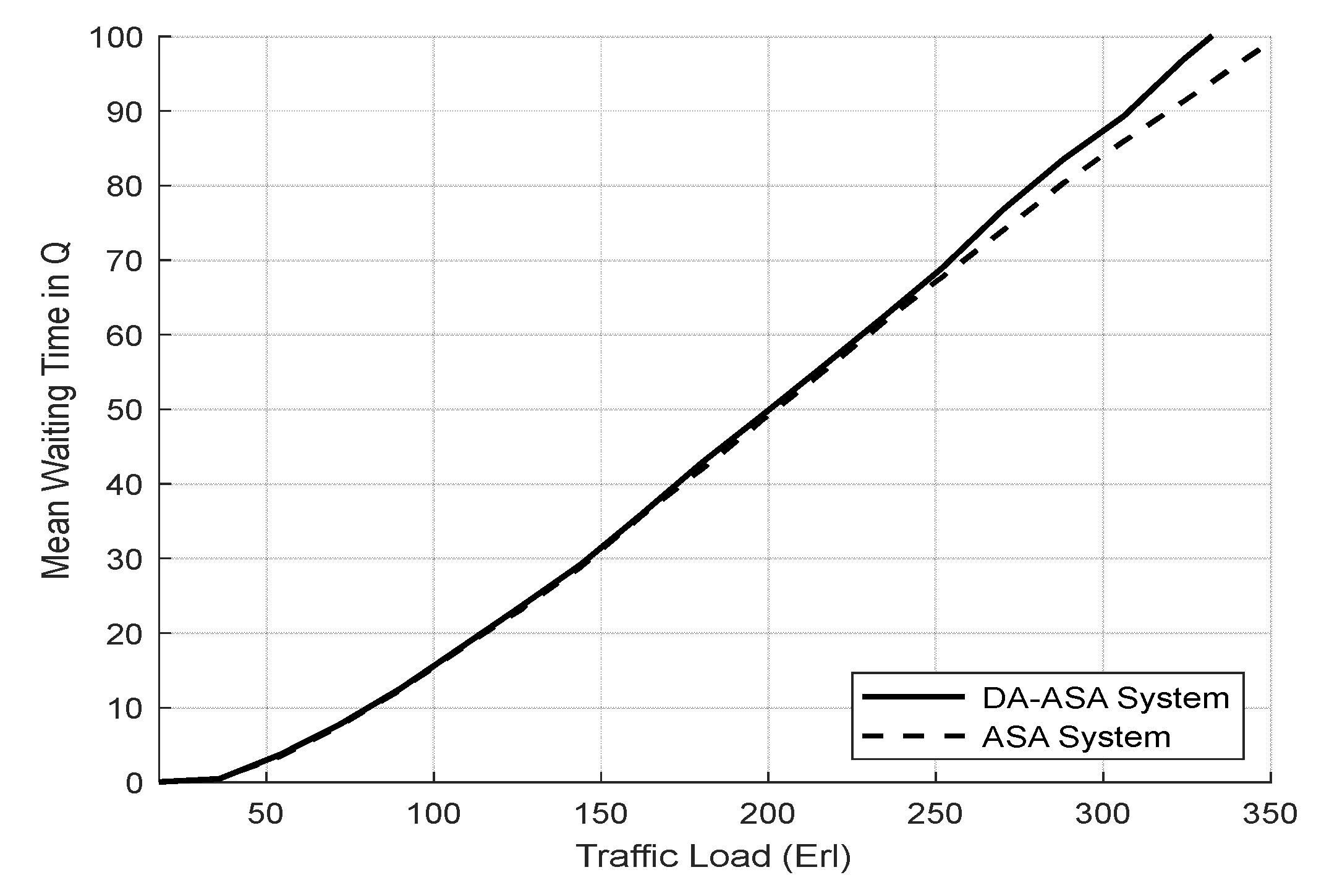
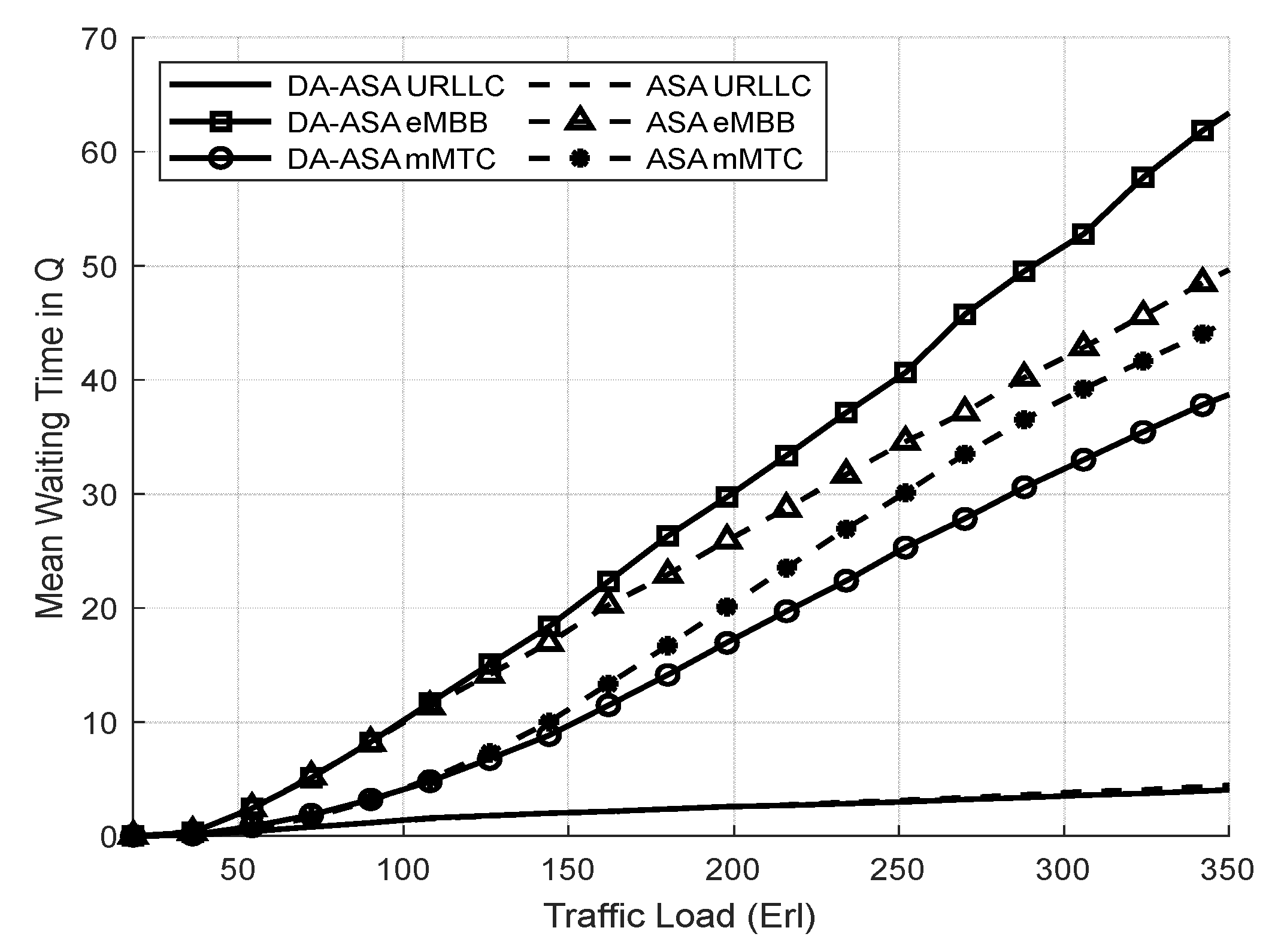
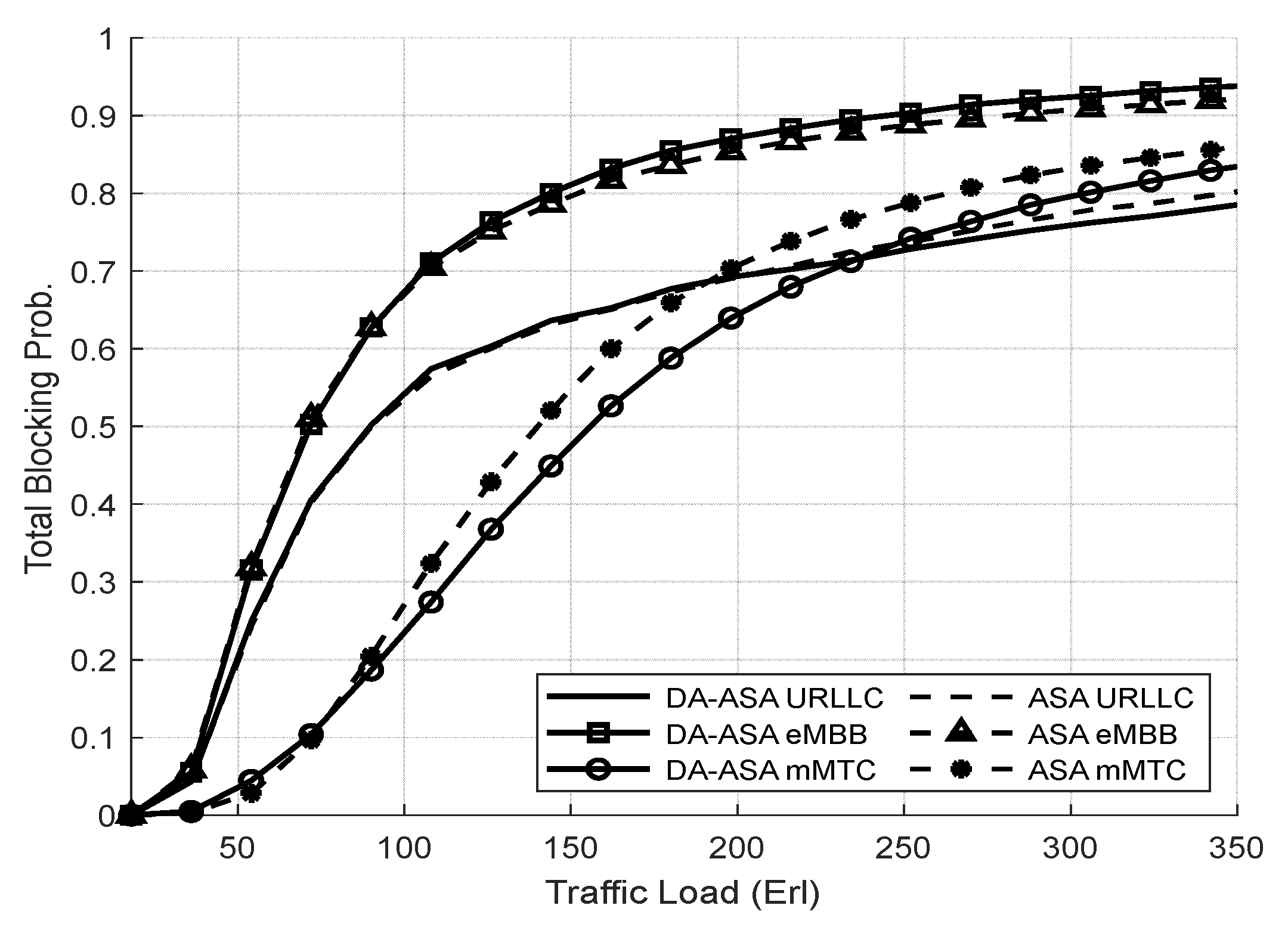
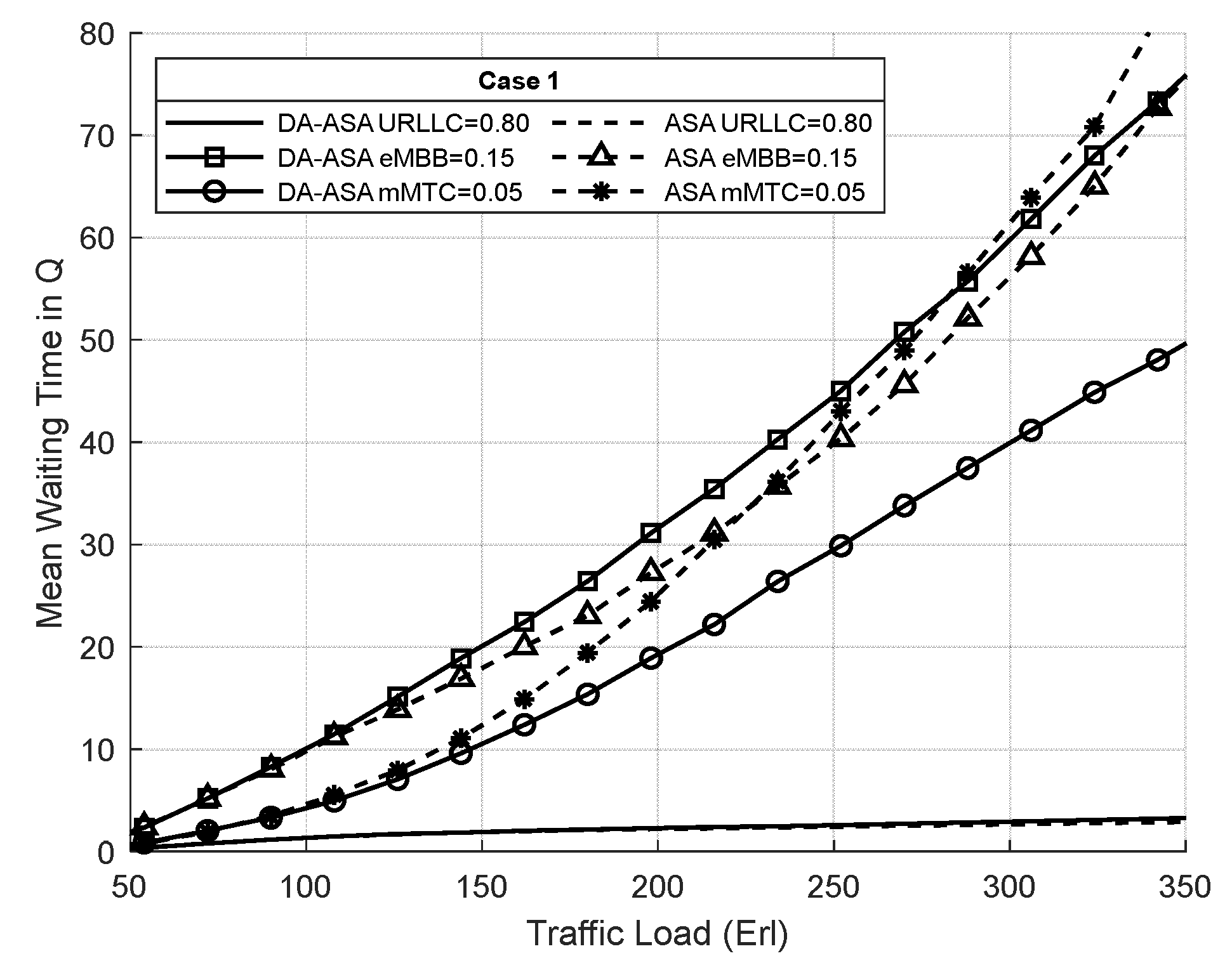
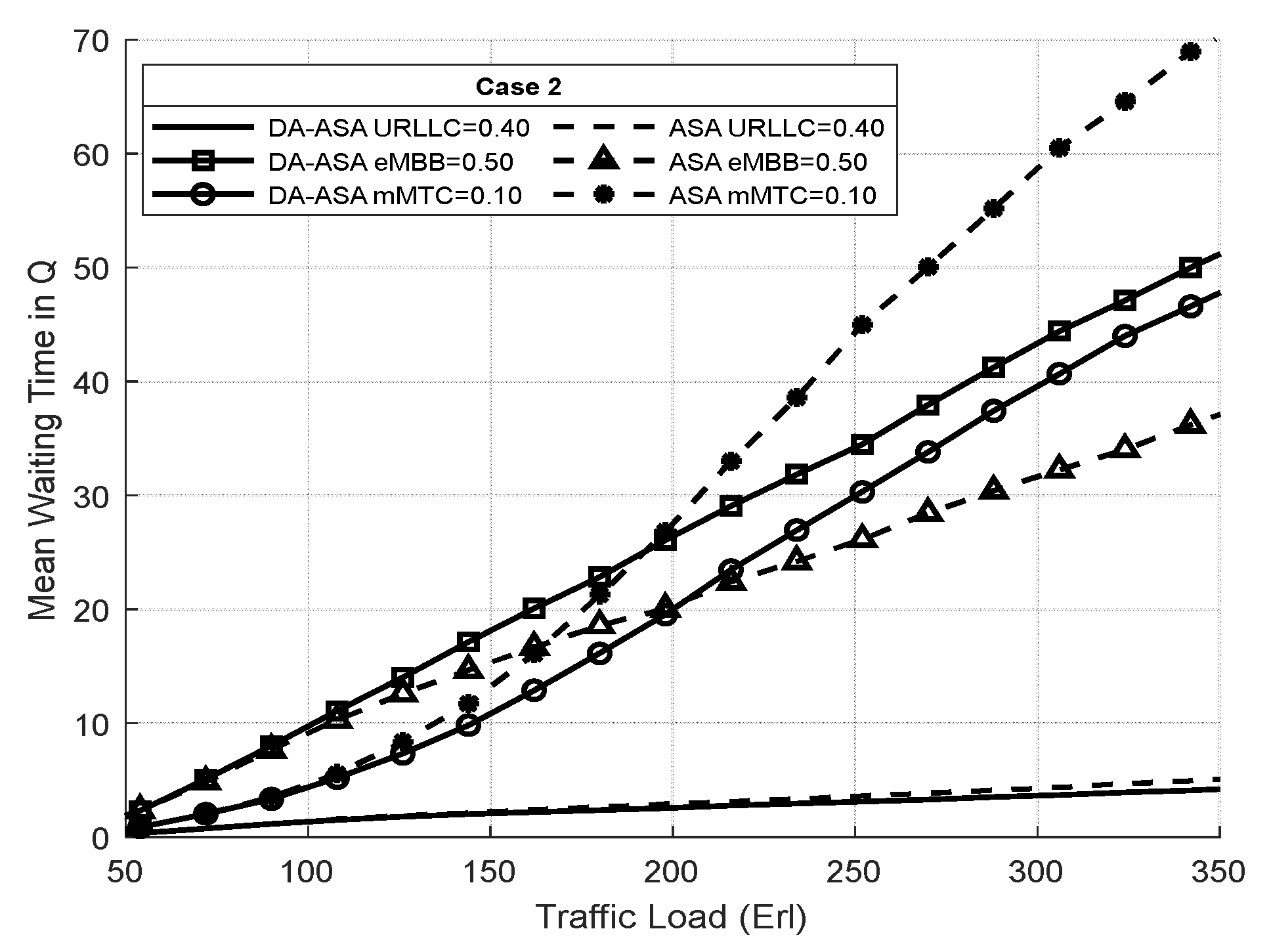
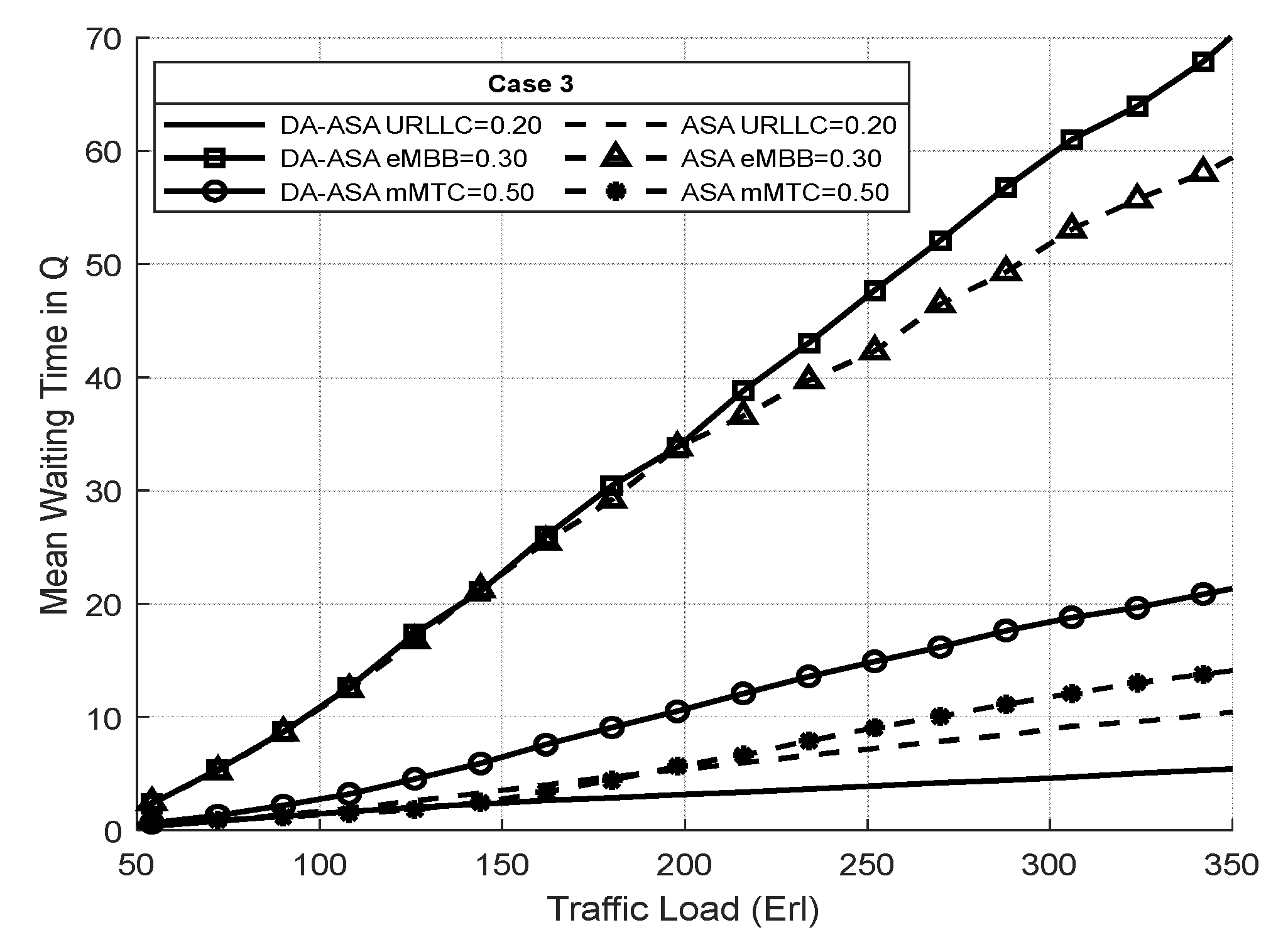
4.3.2. Evaluation Result of the Delay-Aware on the Adaptive Slicing System
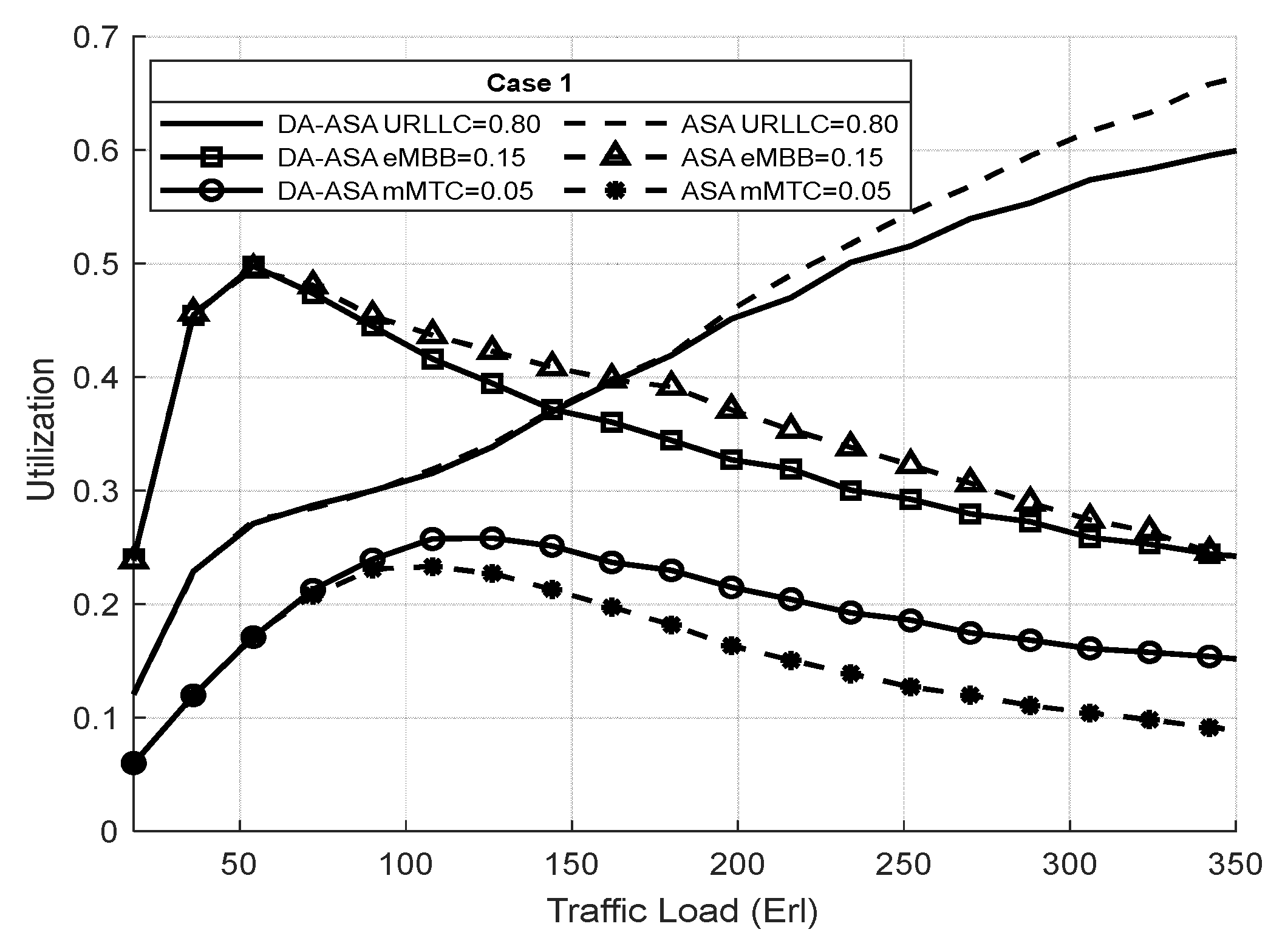
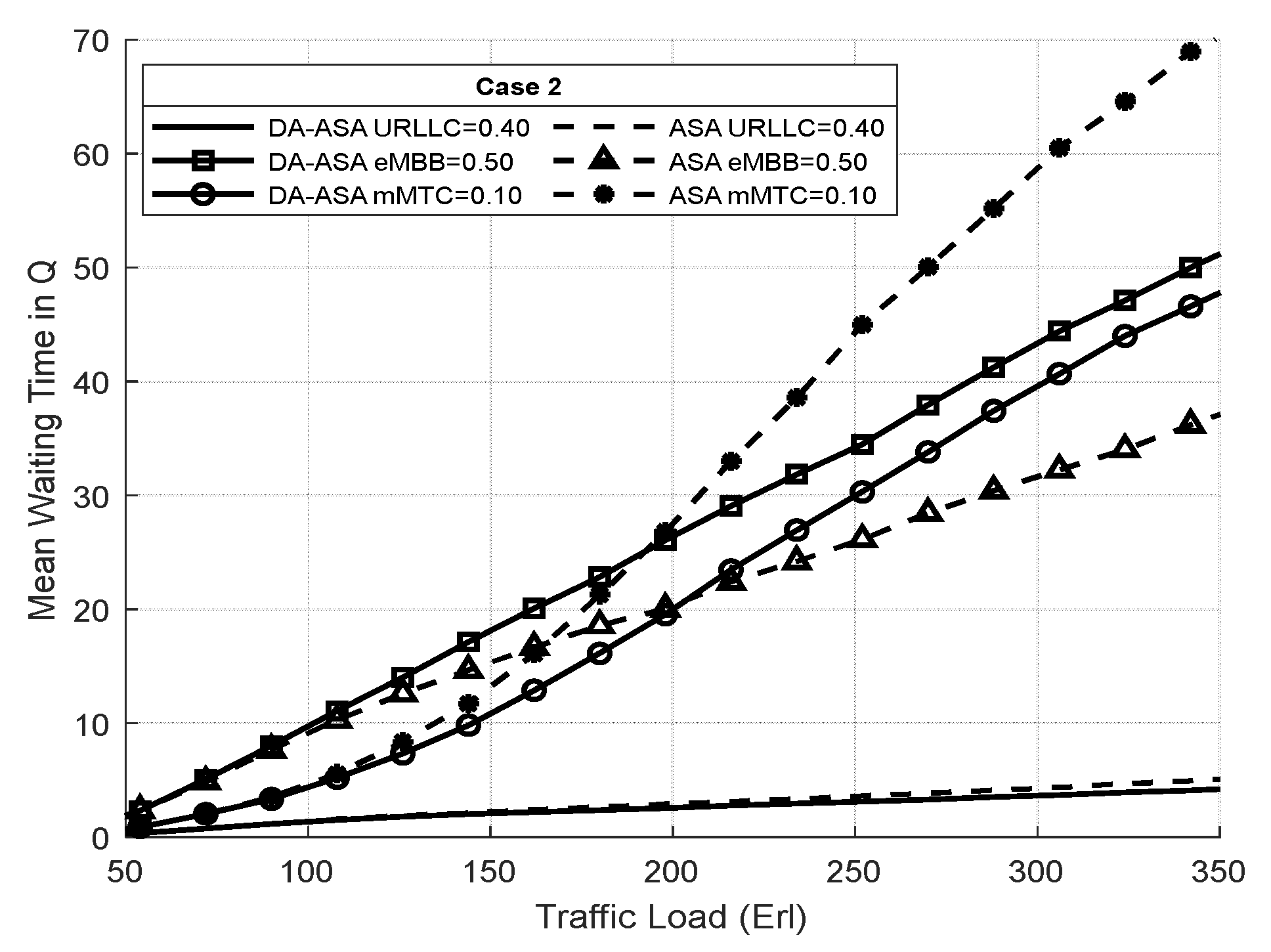
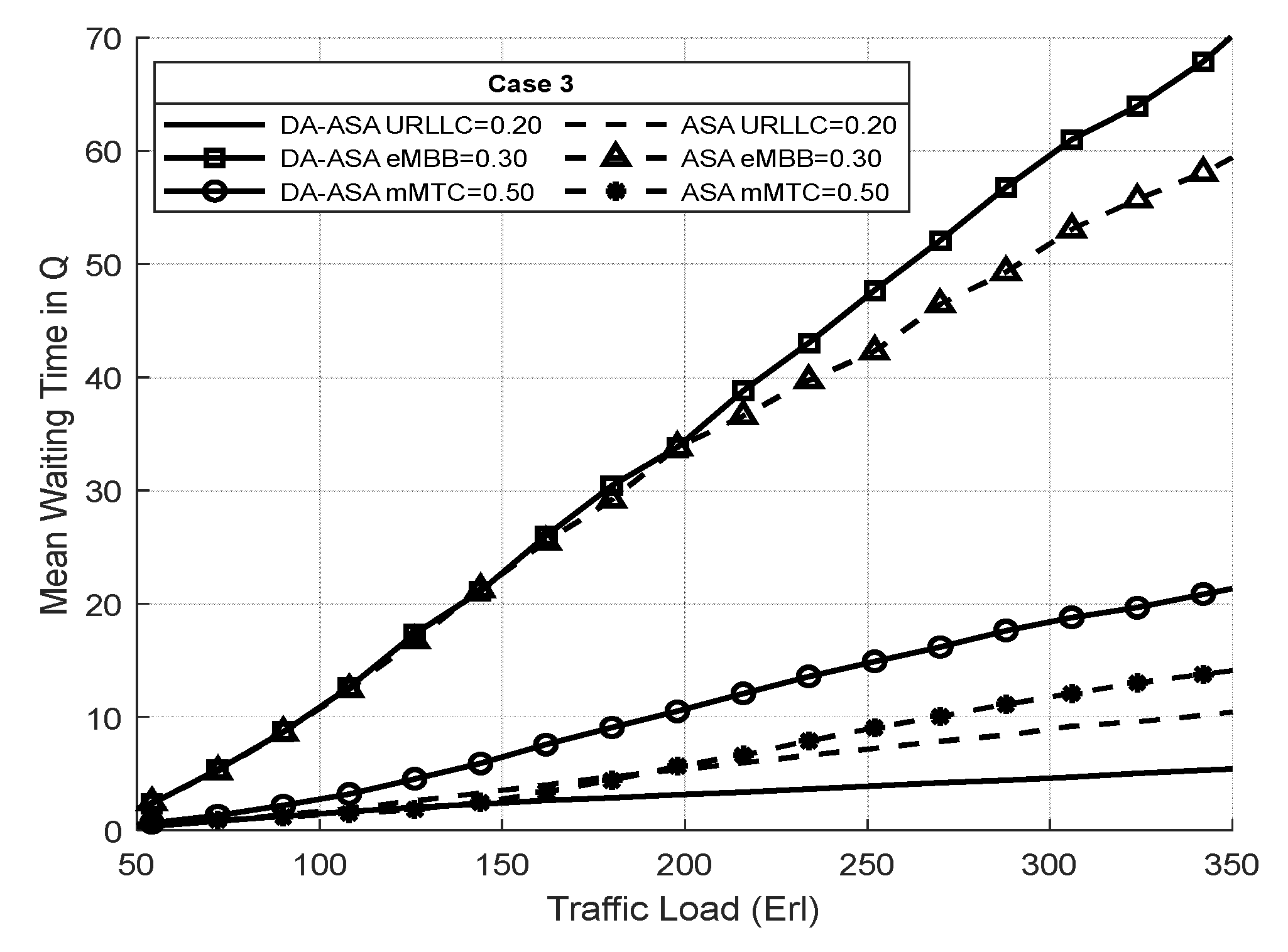
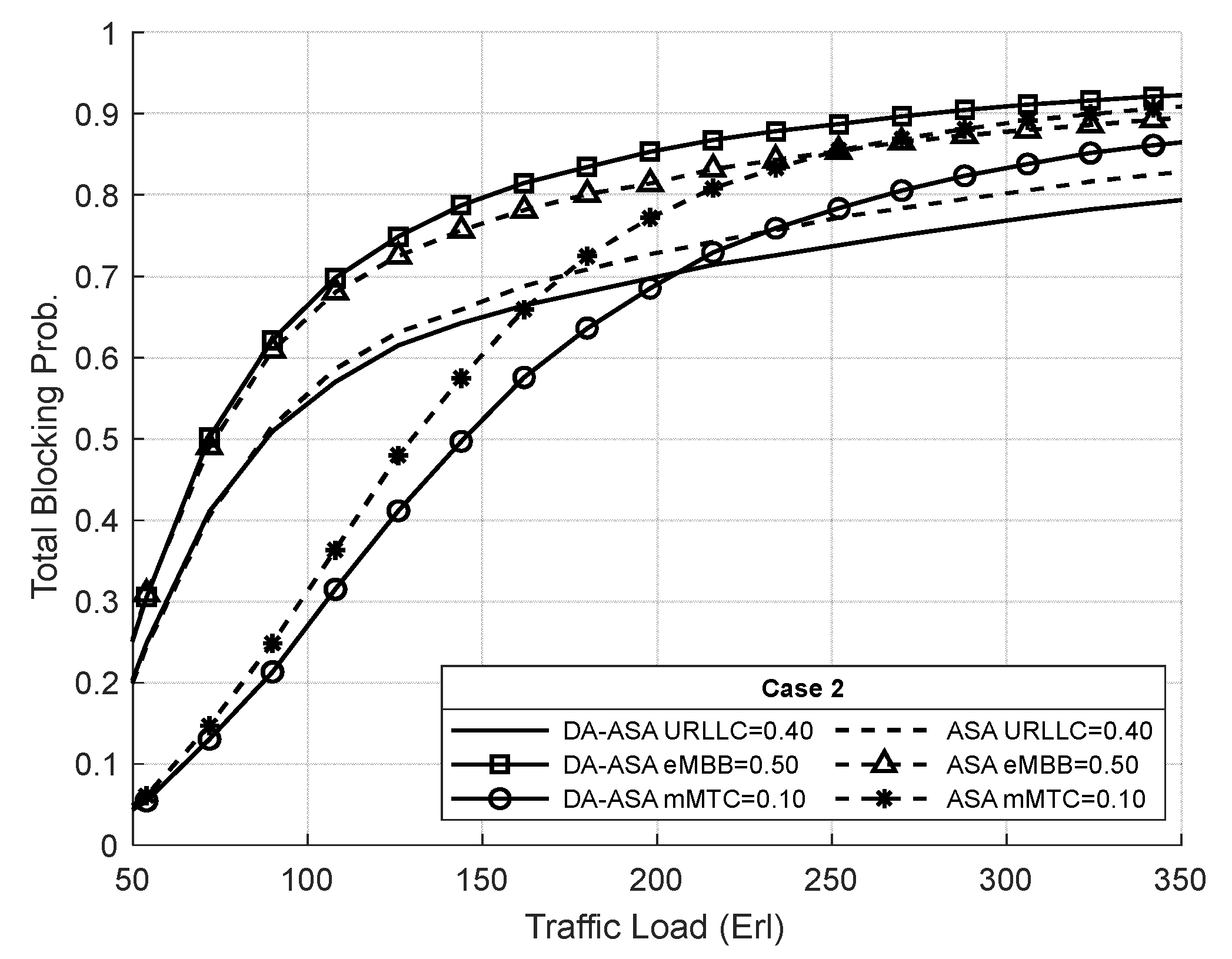
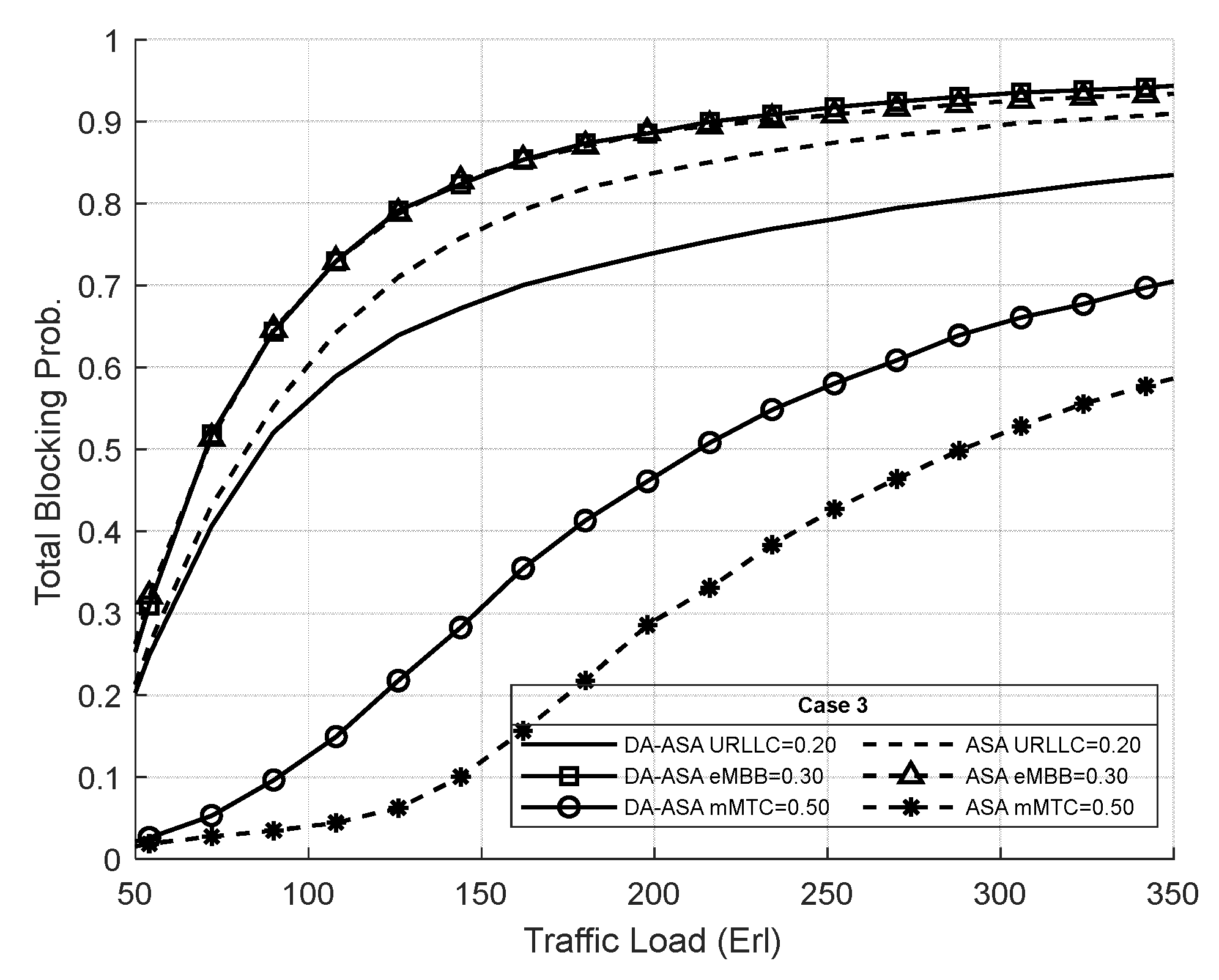
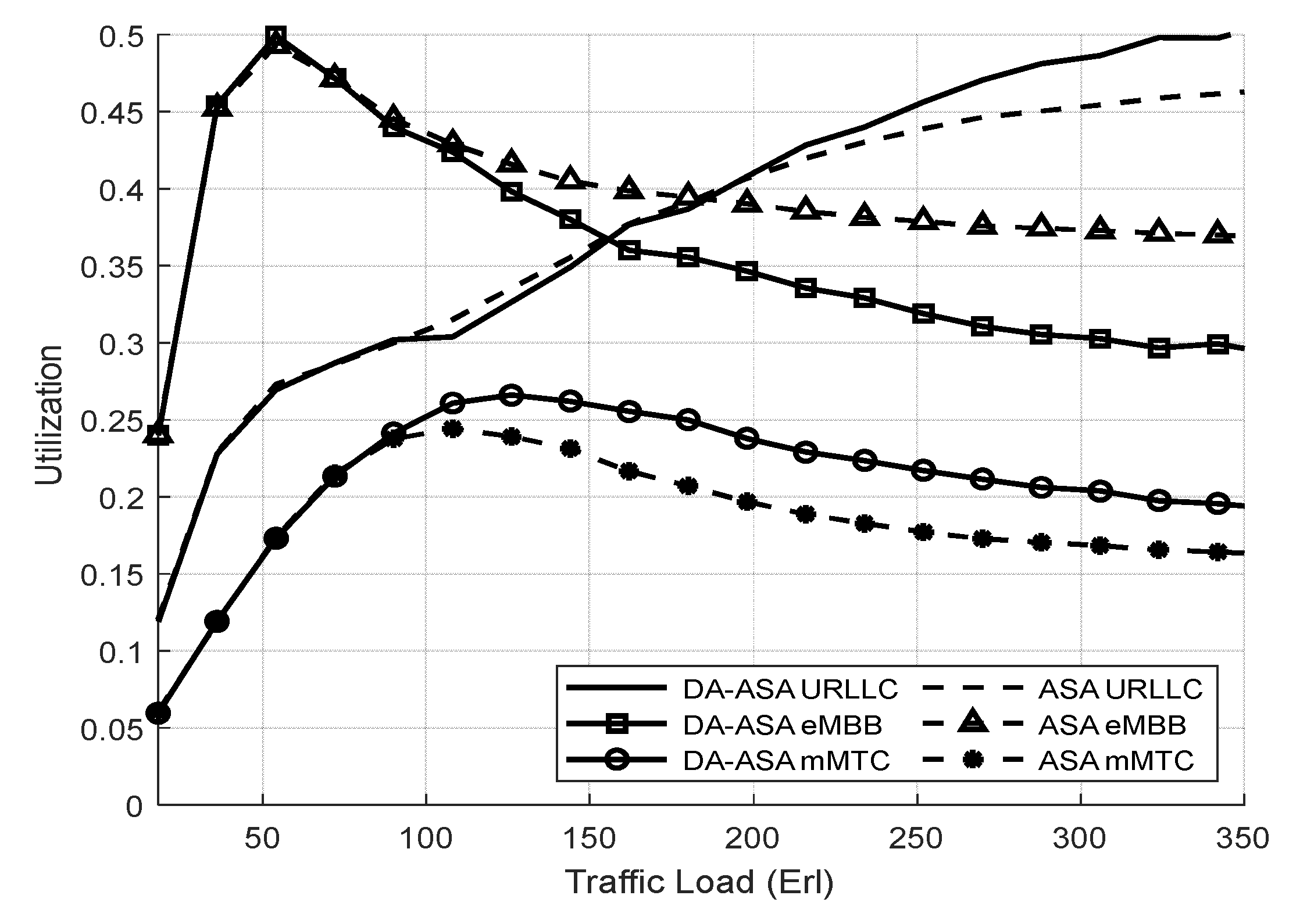
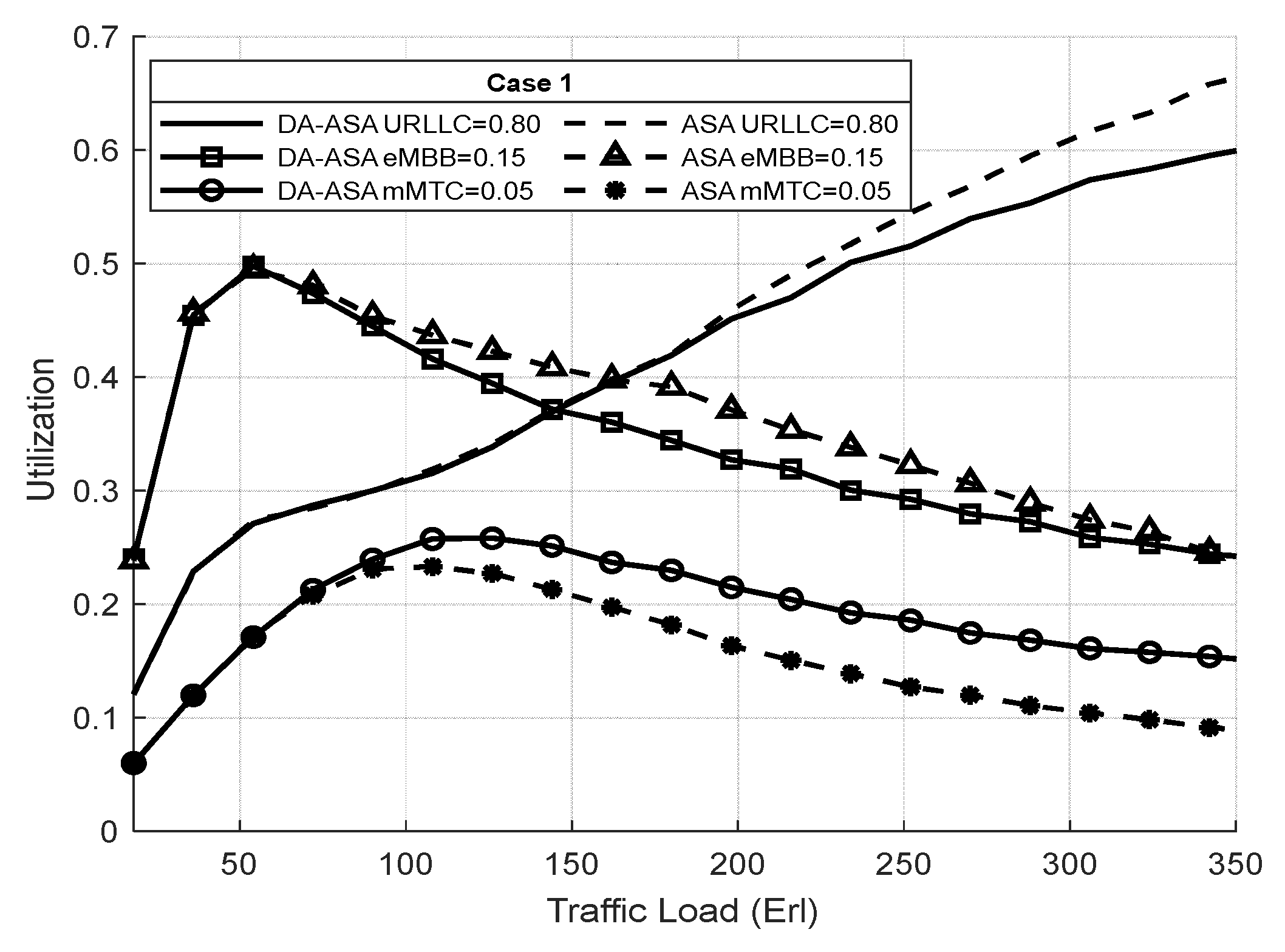
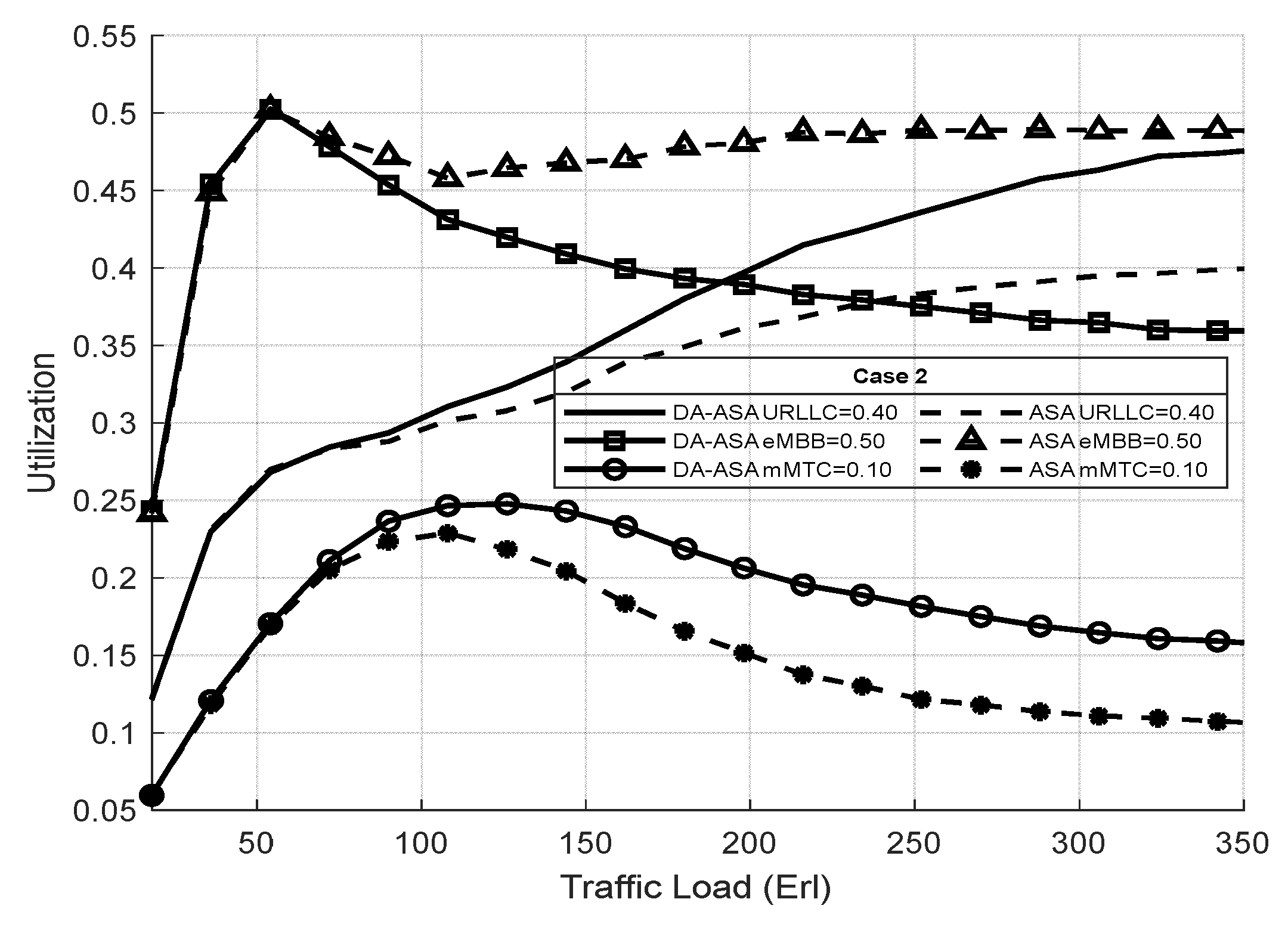
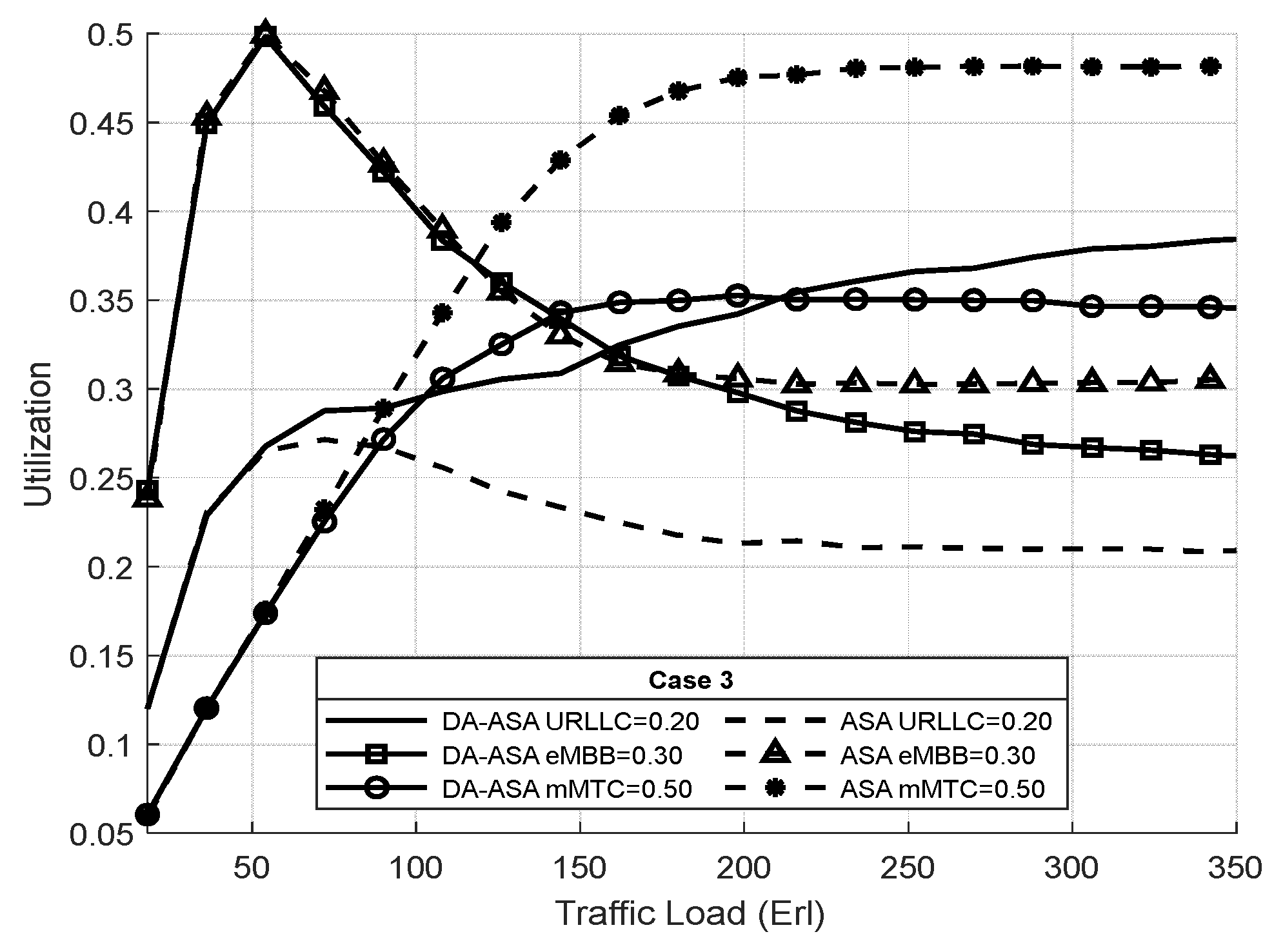
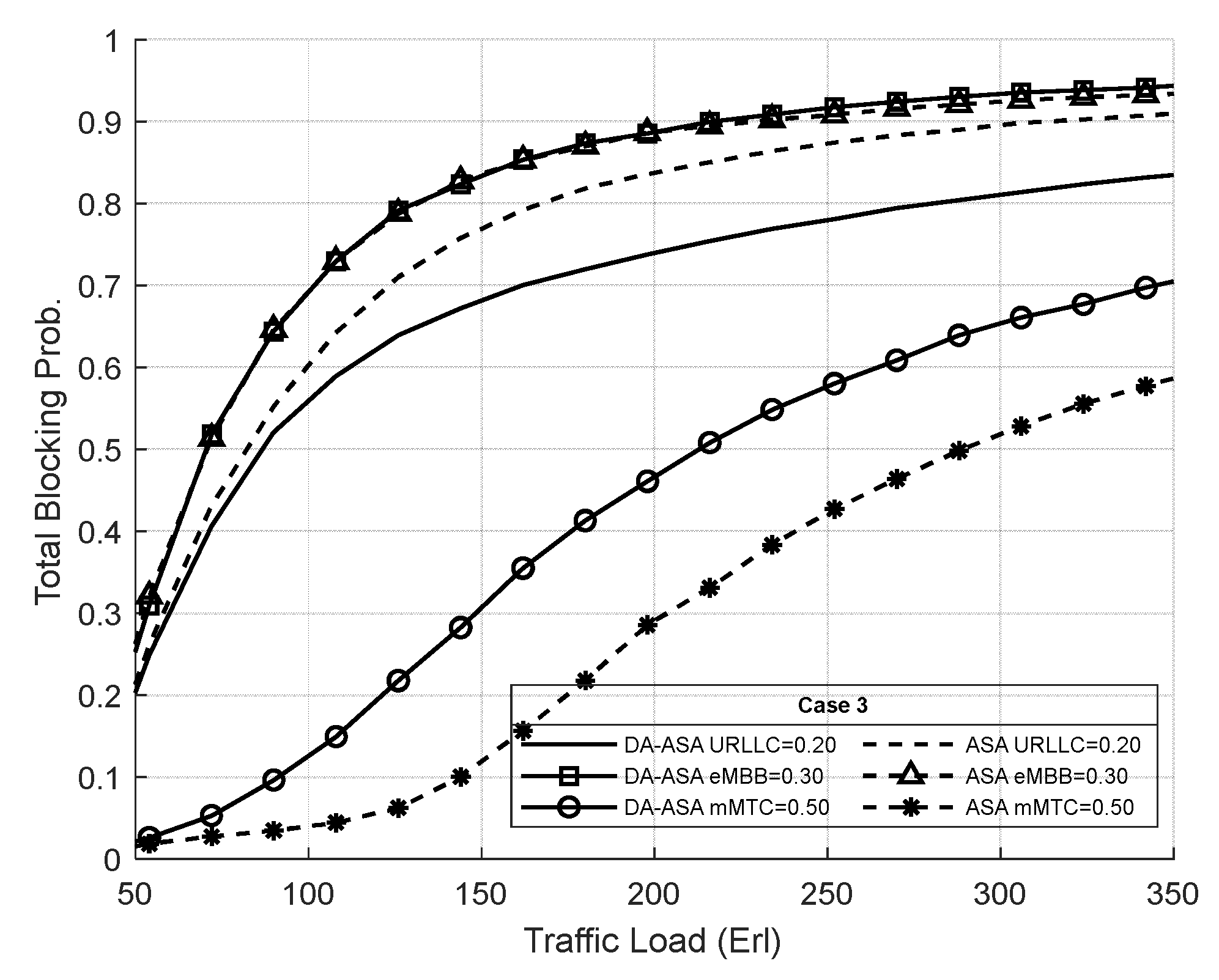
4.3.3. Evaluation Result of the ASA and the DA-ASA with Different Priority Ratio
5. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Statista. Global Mobile Data Traffic 2023|Statistic. 2023. Available online: https://www.statista.com/statistics/271405/global-mobile-data-traffic-forecast/ (accessed on 14 August 2023).
- Ficzere, D. Complex network theory to model 5G Network Slicing. In Proceedings of the NOMS 2022-2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; pp. 1–4. [Google Scholar]
- Lin, X. An Overview of 5G Advanced Evolution in 3GPP Release 18. IEEE Commun. Stand. Mag. 2022, 6, 77–83. [Google Scholar] [CrossRef]
- Shehab, M.J.; Kassem, I.; Kutty, A.A.; Kucukvar, M.; Onat, N.; Khattab, T. 5G Networks Towards Smart and Sustainable Cities: A Review of Recent Developments, Applications and Future Perspectives. IEEE Access 2022, 10, 2987–3006. [Google Scholar] [CrossRef]
- Salman, T.; Jain, R. Cloud RAN: Basics, advances and challenges. Washington University in St. Louis. April 2016. Available online: https://www.cse.wustl.edu/~jain/cse574-16/ftp/cloudran.pdf (accessed on 18 September 2023).
- Baranda, J.; Mangues-Bafalluy, J. End-to-End Network Service Orchestration in Heterogeneous Domains for Next-Generation Mobile Networks. In Proceedings of the NOMS 2022-2022 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 25–29 April 2022; pp. 1–6. [Google Scholar]
- Gomes, R.; Vieira, D.; de Castro, M.F. Application of Meta-Heuristics in 5G Network Slicing: A Systematic Review of the Literature. Sensors 2022, 22, 6724. [Google Scholar] [CrossRef]
- Habibi, M.A.; Nasimi, M.; Han, B.; Schotten, H.D. A Comprehensive Survey of RAN Architectures Toward 5G Mobile Communication System. IEEE Access 2019, 7, 70371–70421. [Google Scholar] [CrossRef]
- Pana, V.S.; Babalola, O.P.; Balyan, V. 5G radio access networks: A survey. Array 2022, 14, 100170. [Google Scholar] [CrossRef]
- Mamane, A.; Fattah, M.; El Ghazi, M.; El Bekkali, M.; Balboul, Y.; Mazer, S. Scheduling Algorithms for 5G networks and beyond: Classification and Survey. IEEE Access 2022, 10, 51643–51661. [Google Scholar] [CrossRef]
- Ojijo, M.O.; Falowo, O.E. A Survey on Slice admission Control Strategies and Optimization Schemes in 5G Network. IEEE Access 2020, 8, 14977–14990. [Google Scholar] [CrossRef]
- Yarkina, N.; Correia, L.M.; Moltchanov, D.; Gaidamaka, Y.; Samouylov, K. Multi-tenant resource sharing with equitable-priority-based performance isolation of slices for 5G cellular systems. Comput. Commun. 2022, 188, 39–51. [Google Scholar] [CrossRef]
- Li, W.; Liu, R.; Dai, Y.; Wang, D.; Cai, H.; Fan, J.; Li, Y. Research on Network Slicing for Smart Grid. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020. [Google Scholar] [CrossRef]
- Setayesh, M.; Bahrami, S.; Wong, V.W.S. Joint PRB and Power Allocation for Slicing eMBB and URLLC Services in 5G C-RAN. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020. [Google Scholar] [CrossRef]
- Sun, Y.; Feng, G.; Zhang, L.; Yan, M.; Qin, S.; Imran, M.A. User Access Control and Bandwidth Allocation for Slice-Based 5G-and-Beyond Radio Access Networks. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019. [Google Scholar] [CrossRef]
- Vila, I.; Perez-Romero, J.; Sallent, O.; Umbert, A. Characterization of Radio Access Network Slicing Scenarios with 5G QoS Provisioning. IEEE Access 2020, 8, 51414–51430. [Google Scholar] [CrossRef]
- Hua, Y.; Li, R.; Zhao, Z.; Chen, X.; Zhang, H. GAN-Powered Deep Distributional Reinforcement Learning for Resource Management in Network Slicing. IEEE J. Sel. Areas Commun. 2020, 38, 334–349. [Google Scholar] [CrossRef]
- Song, F.; Li, J.; Ma, C.; Zhang, Y.; Shi, L.; Jayakody, D.N.K. Dynamic virtual resource allocation for 5g and beyond network slicing. IEEE Open J. Veh. Technol. 2020, 1, 215–226. [Google Scholar] [CrossRef]
- Canpolat, C.; Schmidt, E.G. Dynamic User Count Aware Resource Allocation for Network Slicing in Virtualized Radio Access Networks. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020. [Google Scholar] [CrossRef]
- Feng, L.; Zi, Y.; Li, W.; Zhou, F.; Yu, P.; Kadoch, M. Dynamic Resource Allocation with RAN Slicing and Scheduling for uRLLC and eMBB Hybrid Services. IEEE Access 2020, 8, 34538–34551. [Google Scholar] [CrossRef]
- Lieto, A.; Malanchini, I.; Mandelli, S.; Moro, E.; Capone, A. Strategic Network Slicing Management in Radio Access Networks. IEEE Trans. Mob. Comput. 2022, 21, 1434–1448. [Google Scholar] [CrossRef]
- Li, J.; Shi, W.; Yang, P.; Ye, Q.; Shen, X.S.; Li, X.; Rao, J. A Hierarchical Soft RAN Slicing Framework for Differentiated Service Provisioning. IEEE Wirel. Commun. 2020, 27, 90–97. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, T.; Li, J.; Zhu, Y. Radio Resource Allocation for RAN Slicing in Mobile Networks. In Proceedings of the 2020 IEEE/CIC International Conference on Communications in China (ICCC), Chongqing, China, 9–11 August 2020. [Google Scholar] [CrossRef]
- Ha, V.N.; Nguyen, T.T.; Le, L.B.; Frigon, J.F. Admission Control and Network Slicing for Multi-Numerology 5G Wireless Networks. IEEE Netw. Lett. 2019, 2, 5–9. [Google Scholar] [CrossRef]
- Tang, J.; Shim, B.; Quek, T.Q.S. Service Multiplexing and Revenue Maximization in Sliced C-RAN Incorporated with URLLC and Multicast eMBB. IEEE J. Sel. Areas Commun. 2019, 37, 881–895. [Google Scholar] [CrossRef]
- Sun, Y.; Qin, S.; Feng, G.; Zhang, L.; Imran, M.A. Service Provisioning Framework for RAN Slicing: User Admissibility, Slice Association and Bandwidth Allocation. IEEE Trans. Mob. Comput. 2021, 20, 3409–3422. [Google Scholar] [CrossRef]
- Zou, H.; Zhou, M.; Cui, Y.; He, P.; Zhang, H.; Wang, R. Service provisioning in sliced cloud radio access networks. Wirel. Commun. Mob. Comput. 2022, 2022, 7326172. [Google Scholar] [CrossRef]
- Xie, Y.; Kong, Y.; Huang, L.; Wang, S.; Xu, S.; Wang, X.; Ren, J. Resource allocation for network slicing in dynamic multi-tenant networks: A deep reinforcement learning approach. Comput. Commun. 2022, 195, 476–487. [Google Scholar] [CrossRef]
- Degambur, L.N.; Mungur, A.; Armoogum, S.; Pudaruth, S. Resource Allocation in 4G and 5G Networks: A Review. Int. J. Commun. Netw. Inf. Secur. 2021, 13, 5116. [Google Scholar] [CrossRef]
- Awad, A.M.; Shehata, M.; Gasser, S.M.; EL-Badawy, H. CoMP-Aware BBU Placements for 5G Radio Access Networks over Optical Aggregation Networks. Appl. Sci. 2022, 12, 8586. [Google Scholar] [CrossRef]
- Adda, S.; Aureli, T.; Coltellacci, S.; D’Elia, S.; Franci, D.; Grillo, E.; Pasquino, N.; Pavoncello, S.; Suman, R.; Vaccarono, M. A methodology to characterize power control systems for limiting exposure to electromagnetic fields generated by massive MIMO antennas. IEEE Access 2020, 8, 171956–171967. [Google Scholar] [CrossRef]
- 3GPP Specification Series: 38 Series. Available online: https://www.3gpp.org/dynareport?code=38-series.htm (accessed on 17 October 2022).
- 5G Flexible Numerology—What Is It? Why Should You Care?—Technical Support Knowledge Center Open. Available online: https://edadocs.software.keysight.com/kkbopen/5g-flexible-numerology-what-is-it-why-should-you-care-598781627.html (accessed on 17 October 2022).
- 5G NR Resource block—Gaussian Waves. Available online: https://www.gaussianwaves.com/2022/02/5g-nr-resource-block/ (accessed on 17 October 2022).
- Floor and Ceiling Functions—Wikipedia. Available online: https://en.wikipedia.org/wiki/Floor_and_ceiling_functions (accessed on 17 October 2022).
- Alotaibi, D. Survey on Network Slice Isolation in 5G Networks: Fundamental Challenges. Procedia Comput. Sci. 2021, 182, 38–45. [Google Scholar] [CrossRef]
- Demirovic, S.; Kis, P.; Jankovic, J.; Ilic, Z. Resource Utilization—QoS Isolation Trade-Off in 5G Networks Considering Network Slicing Reconfiguration Interval. In Proceedings of the 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Requirements | eMBB | mMTC | uRLLC |
|---|---|---|---|
| Average throughput | 0.1–1 Gbps | Up to 1 Mbps | 25 Mbps |
| Latency | 10 ms | >1 h | 1 ms |
| Availability | 0.97% | 0.999% | 0.99999% |
| Other | Mobility up to 500 km/h | Battery life up to 10 years | Reliability up to 0.99999% |
| Num. of Slots in a Subframe | Slot Time Length | Subcarrier Spacing | |
|---|---|---|---|
| 0 | 1 | 1 ms | 15 kHz |
| 1 | 2 | 0.5 ms | 30 kHz |
| 2 | 4 | 0.25 ms | 60 kHz |
| 3 | 8 | 0.125 ms | 120 kHz |
| Description | Equation |
|---|---|
| Number of virtual reserved RBs for all user of the URLLC slice | |
| Number of virtual reserved RBs for all user of the eMBB slice. | |
| Number of virtual reserved RBs for all user of the mMTC slice. |
| Symbol | Description |
|---|---|
| The priority ratio for serving URLLC slice traffic, specified as a real number between 0 and 1, where 1 means highest priority. | |
| The priority ratio for serving eMBB slice traffic, specified as a real number between 0 and 1, where 1 means highest priority. | |
| The priority ratio for serving mMTC slice traffic, specified as a real number between 0 and 1, where 1 means highest priority. | |
| slice, specified as a real number between 0 and 1, where 0 means highest priority. | |
| The total number of RBs. An integer count of physical resource blocks. | |
| The total number of RBs that are currently utilized by all active users. | |
| slice. Where i is a number ranging from 1 to 3 for URLLC, eMBB, and mMTC slices, respectively. | |
| Total number of RBs allocated for transmission control overhead. | |
| slice. | |
| slice. | |
| slice. | |
| The required average data rates for each connection request. Unit: integer. | |
| The maximum number of RBs required. | |
| The required number of RBs. | |
| Minimum number of RBs required. | |
| slice. | |
| Number of active connections for each slice’s request i. Unit: integer. | |
| slice. Unit: integer value in ms. | |
| slice. Unit: ms. |
| 5G Slice | |
|---|---|
| URLLC | |
| eMBB | |
| mMTC |
| Arrival Event of Request i | Departure Event of Request i |
|---|---|
| if) | if is full) |
| Admit request i | |
| else | with the lowest ASP value. |
| not reaches its limits) | if () Admit request i |
| else Release the resource. end if | |
| else Reject request i | else Release the resource |
| end if end if | end if |
| 5G Slice | |
|---|---|
| URLLC | |
| eMBB | |
| mMTC |
| Arrival Event of Request i | Departure Event of Request i |
|---|---|
| ) | is full) |
| Admit request i | |
| else | with the lowest ASP value. |
| not reaches its limits) | ) Admit request i |
| else Release the resource. end if | |
| else Reject request i | else Release the resource |
| end if end if | end if |
| Parameter | Assumption |
|---|---|
| System bandwidth | 20 MHz (100 PRBs, 180 kHz per PRB) |
| TTI | 1 ms |
| Number of PRBs for data transmission | 96 |
| Number of PRBs for control transmission | 4 |
| User arrival | Poisson process |
| Number of admitted calls simulated | 1,000,000 |
| Call duration | Exponential 120 sec. |
| Calls Queue size | 10 |
| 5G Slice | Priority Ratio | Delay Budget | Rate Budget |
|---|---|---|---|
| URLLC | = 50% | 1 ms | 128 Kbps |
| eMBB | = 35% | 4 ms | 256 Kbps |
| mMTC | = 15% | 7 ms | 64 Kbps |
| Priority Ratio | Case No. 1 | Case No. 2 | Case No. 3 |
|---|---|---|---|
| 80% | 40% | 20% | |
| 15% | 50% | 30% | |
| 5% | 10% | 50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlQahtani, S.A. Towards an Optimal Cloud-Based Resource Management Framework for Next-Generation Internet with Multi-Slice Capabilities. Future Internet 2023, 15, 343. https://doi.org/10.3390/fi15100343
AlQahtani SA. Towards an Optimal Cloud-Based Resource Management Framework for Next-Generation Internet with Multi-Slice Capabilities. Future Internet. 2023; 15(10):343. https://doi.org/10.3390/fi15100343
Chicago/Turabian StyleAlQahtani, Salman Ali. 2023. "Towards an Optimal Cloud-Based Resource Management Framework for Next-Generation Internet with Multi-Slice Capabilities" Future Internet 15, no. 10: 343. https://doi.org/10.3390/fi15100343
APA StyleAlQahtani, S. A. (2023). Towards an Optimal Cloud-Based Resource Management Framework for Next-Generation Internet with Multi-Slice Capabilities. Future Internet, 15(10), 343. https://doi.org/10.3390/fi15100343