
Machine Learning: Models, Challenges, and Research Directions



Abstract
:1. Introduction
- Brief discussion of data pre-processing;
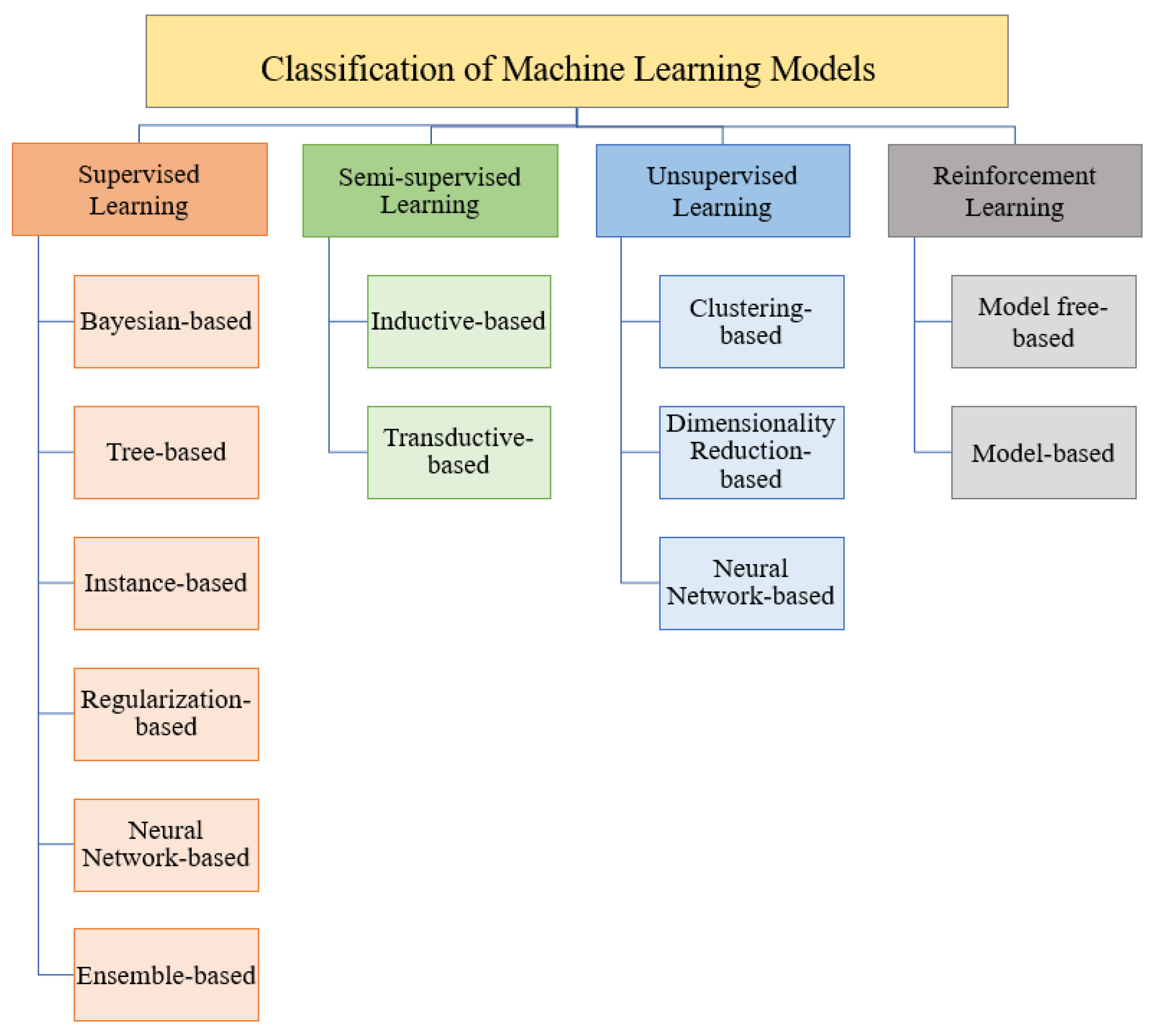
- Detailed classification of supervised, semi-supervised, unsupervised, and reinforcement learning models;
- Study of known optimization techniques;
- Challenges of machine learning in the field of cybersecurity.
2. Related Work and Research Methodology

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Study Highlights | Coverage of Data Pre-Processing and Hyperparameter Tuning | Coverage of Machine Learning | ||||
|---|---|---|---|---|---|---|---|---|
| Data Pre-Processing | Hyperparameter Tuning Approach | Supervised Learning | Unsupervised Learning | Semi-Supervised Learning | Reinforcement Learning | |||
| [34] | 2021 | Describes the known deep learning models, their principles, and characteristics. | ✓ | ✓ | ||||
| [41] | 2019 | Focuses on limited machine learning techniques on only software-defined networking. | ✓ | ✓ | ✓ | ✓ | ||
| [39] | 2022 | Investigates the known issues in the field of system designs that can be solved using machine learning techniques. | ✓ | ✓ | ✓ | |||
| [26] | 2021 | Presents a detailed description of a few supervised models and their optimization techniques. | ✓ | ✓ | ||||
| [32] | 2021 | Provides an overview of semi-supervised machine learning techniques with their existing algorithms. | ✓ | |||||
| [38] | 2022 | Provides the state of the art, challenges, and limitations of supervised models in the field of maritime risk analysis. | ✓ | |||||
| [33] | 2022 | Reviews hardware architecture of reinforcement learning algorithms. | ✓ | |||||
| [28] | 2022 | Presents the existing algorithm for wireless sensor networks and describes the existing challenges of using such techniques. | ✓ | |||||
| [29] | 2016 | Describes most of the known supervised algorithms for classification problems. | ✓ | |||||
| [35] | 2019 | Provides a description of known supervised and unsupervised models. | ✓ | ✓ | ||||
| [36] | 2021 | Discusses supervised and unsupervised deep learning models for intrusion detection systems. | ✓ | ✓ | ||||
| [37] | 2021 | Surveys existing supervised and unsupervised techniques in smart grid. | ✓ | ✓ | ||||
| [40] | 2021 | Explains known algorithms for image classifications. | ✓ | ✓ | ✓ | |||
| [31] | 2022 | Illustrates the unsupervised deep learning models and summarizes their challenges. | ✓ | |||||
| [42] | 2023 | Discusses techniques for energy usage in future | ✓ | ✓ | ✓ | ✓ | ||
| [43] | 2020 | Reviews various ML techniques in the security of the Internet of Things. | ✓ | ✓ | ✓ | ✓ | ||
| [44] | 2020 | Proposes a taxonomy of machine learning techniques in the security of Internet of Things. | ✓ | ✓ | ✓ | ✓ | ||
| [38] | 2019 | Surveys the taxonomy of machine learning models in intrusion detection systems. | ✓ | ✓ | ✓ | |||
| [45] | 2022 | Gives ML techniques in industrial control systems. | ✓ | ✓ | ✓ | ✓ | ✓ | |
| [30] | 2022 | Proposes the taxonomy of intrusion detection systems for supervised models. | ✓ | |||||
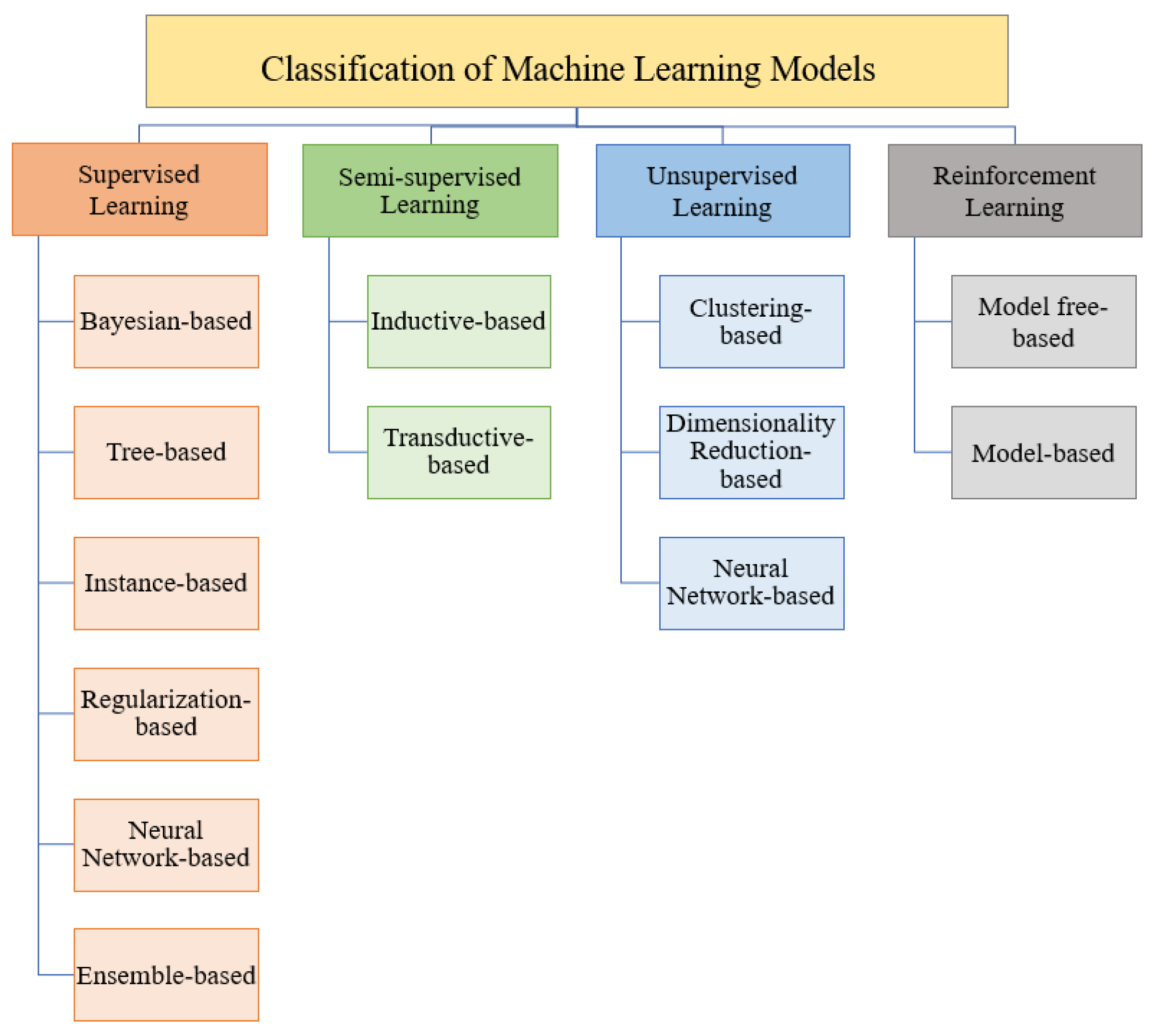
3. Machine Learning Models
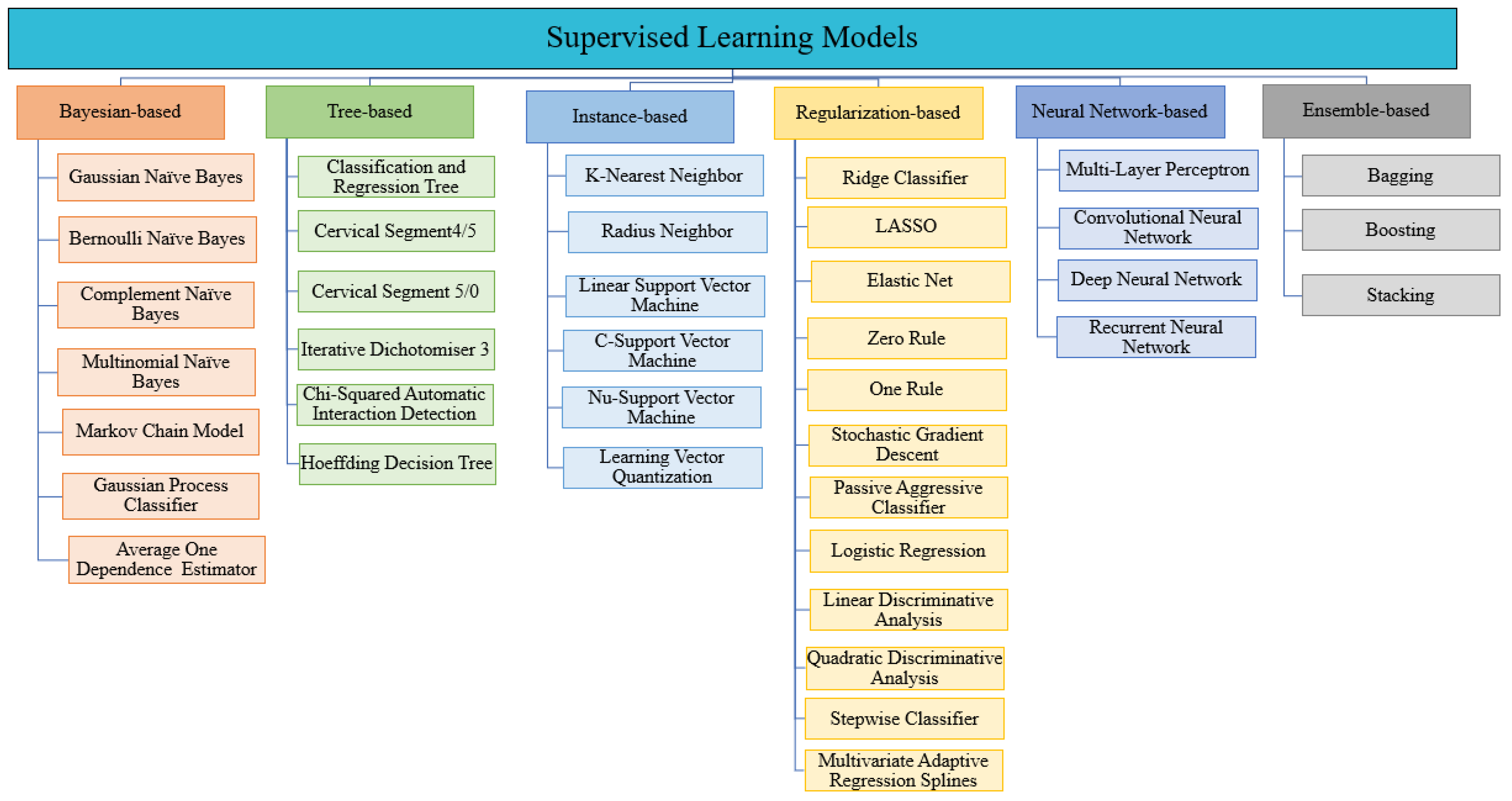
3.1. Supervised Learning
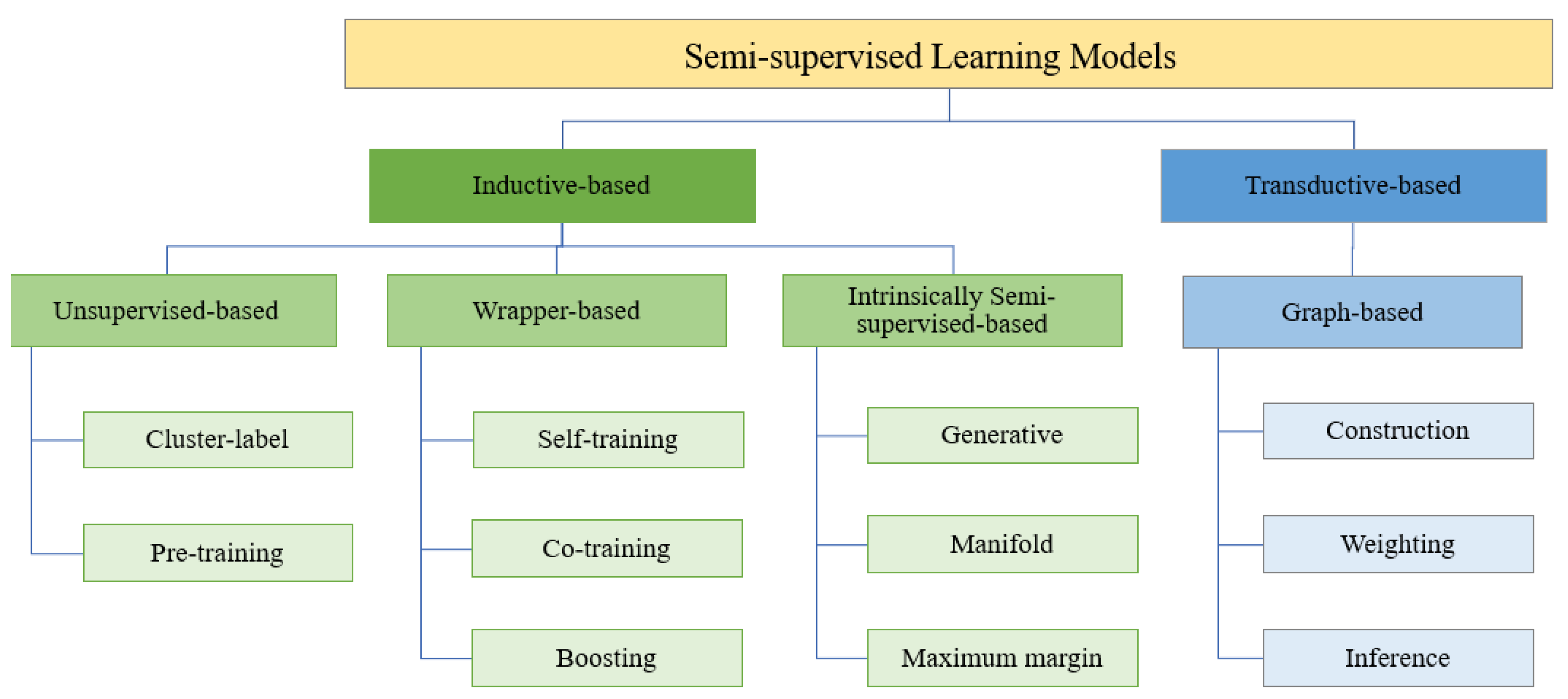
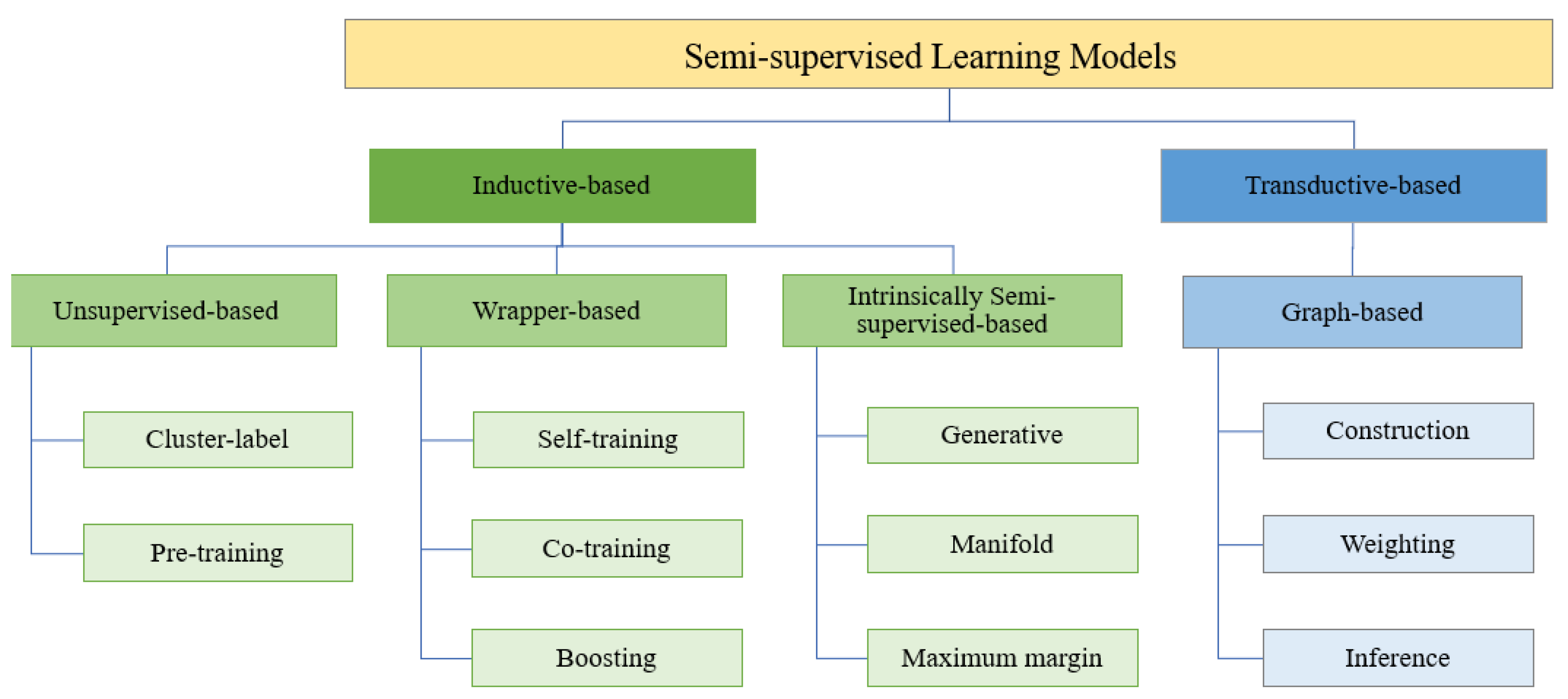
3.2. Semi-Supervised Learning
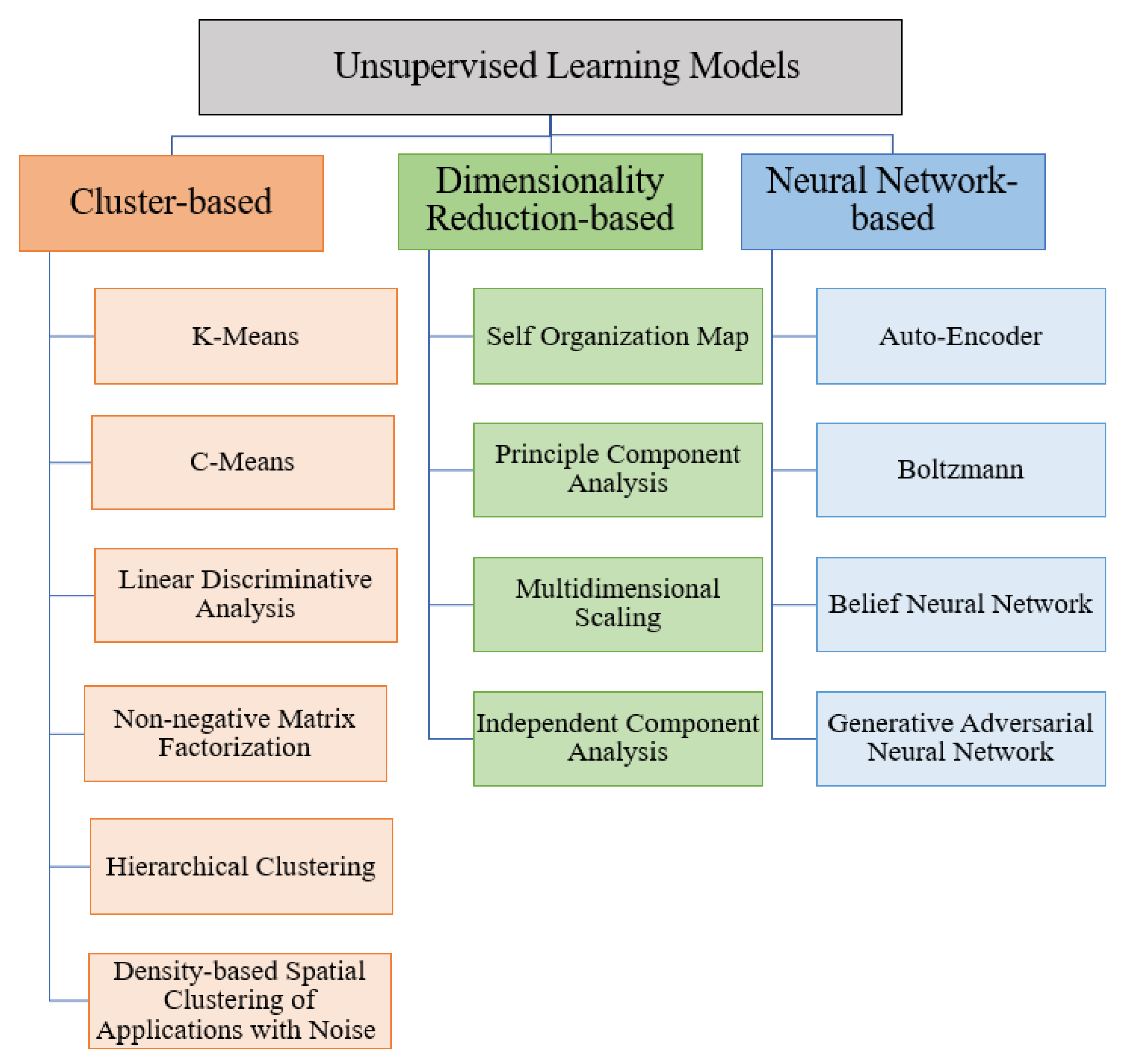
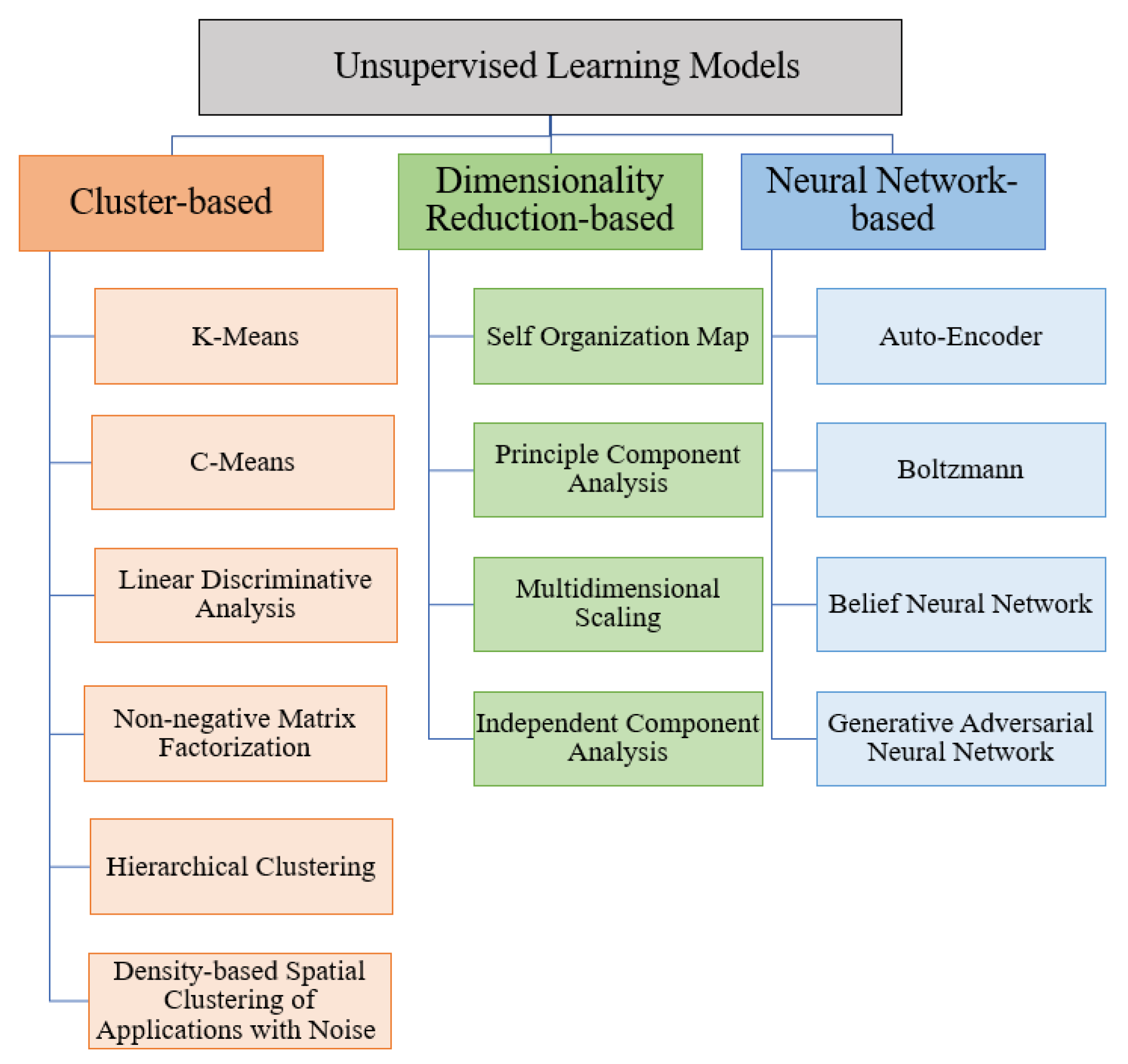
3.3. Unsupervised Learning
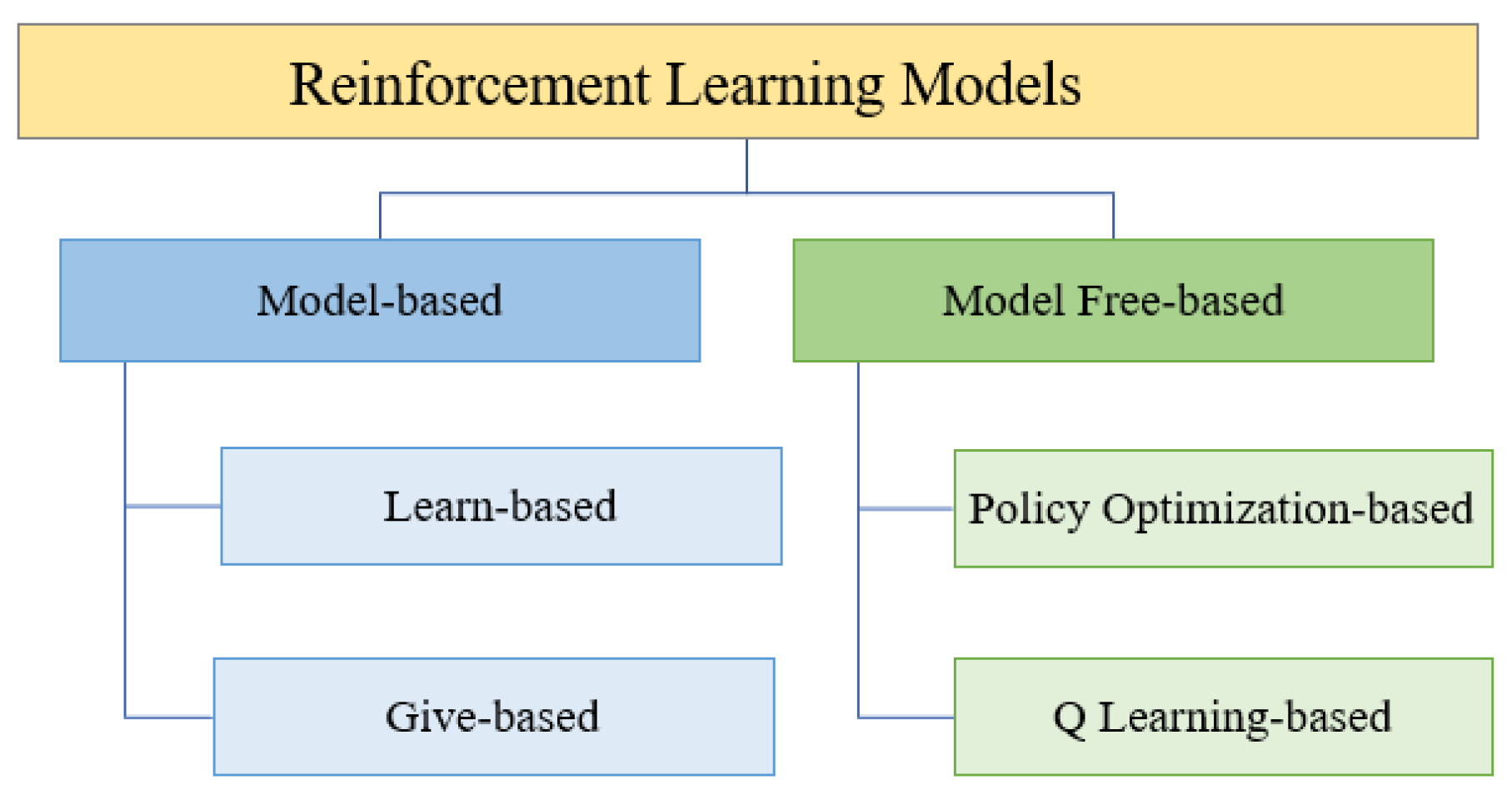
3.4. Reinforcement Learning
4. Machine Learning Processes
4.1. Data Pre-Processing
4.2. Tuning Approaches
4.3. Evaluation Metrics
4.3.1. Evaluation Metrics for Supervised Learning
4.3.2. Evaluation Metrics for Unsupervised Learning Models
4.3.3. Evaluation Metrics for Semi-Supervised Learning Models
4.3.4. Evaluation Metrics for Reinforcement Learning Models
5. Challenges and Future Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sarker, I.H. Machine Learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Vinuesa, R.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Felländer, A.; Langhans, S.D.; Tegmark, M.; Nerini, F.F. The role of artificial intelligence in achieving the sustainable development goals. Nat. Commun. 2020, 11, 233. [Google Scholar] [CrossRef] [PubMed]
- Ullah, Z.; Al-Turjman, F.; Mostarda, L.; Gagliardi, R. Applications of artificial intelligence and machine learning in smart cities. Comput. Commun. 2020, 154, 313–323. [Google Scholar] [CrossRef]
- Ozcanli, A.K.; Yaprakdal, F.; Baysal, M. Deep learning methods and applications for electrical power systems: A comprehensive review. Int. J. Energy Res. 2020, 44, 7136–7157. [Google Scholar] [CrossRef]
- Zhao, S.; Blaabjerg, F.; Wang, H. An Overview of Artificial Intelligence Applications for Power Electronics. IEEE Trans. Power Electron. 2021, 36, 4633–4658. [Google Scholar] [CrossRef]
- Mamun, A.A.; Sohel, M.; Mohammad, N.; Sunny, M.S.H.; Dipta, D.R.; Hossain, E. A Comprehensive Review of the Load Fore-casting Techniques Using Single and Hybrid Predictive Models. IEEE Access 2020, 8, 134911–134939. [Google Scholar] [CrossRef]
- Massaoudi, M.; Darwish, A.; Refaat, S.S.; Abu-Rub, H.; Toliyat, H.A. UHF Partial Discharge Localization in Gas-Insulated Switch-gears: Gradient Boosting Based Approach. In Proceedings of the 2020 IEEE Kansas Power and Energy Conference (KPEC), Manhattan, KS, USA, 13–14 July 2020; pp. 1–5. [Google Scholar]
- Ali, S.S.; Choi, B.J. State-of-the-Art Artificial Intelligence Techniques for Distributed Smart Grids: A Review. Electronics 2020, 9, 1030. [Google Scholar] [CrossRef]
- Yin, L.; Gao, Q.; Zhao, L.; Zhang, B.; Wang, T.; Li, S.; Liu, H. A review of machine learning for new generation smart dispatch in power systems. Eng. Appl. Artif. Intell. 2020, 88, 103372. [Google Scholar] [CrossRef]
- Peng, S.; Sun, S.; Yao, Y.-D. A Survey of Modulation Classification Using Deep Learning: Signal Representation and Data Prepro-cessing. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: New York, NY, USA, 2021. [Google Scholar]
- Arjoune, Y.; Kaabouch, N. A Comprehensive Survey on Spectrum Sensing in Cognitive Radio Networks: Recent Advances, New Challenges, and Future Research Directions. Sensors 2019, 19, 126. [Google Scholar] [CrossRef]
- Meng, T.; Jing, X.; Yan, Z.; Pedrycz, W. A survey on machine learning for data fusion. Inf. Fusion 2020, 57, 115–129. [Google Scholar] [CrossRef]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Khoei, T.T.; Ismail, S.; Kaabouch, N. Boosting-based Models with Tree-structured Parzen Estimator Optimization to Detect Intrusion Attacks on Smart Grid. In Proceedings of the 2021 IEEE 12th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 1–4 December 2021; pp. 165–170. [Google Scholar] [CrossRef]
- Hutter, F.; Lücke, J.; Schmidt-Thieme, L. Beyond manual tuning of hyperparameters. KI-Künstliche Intell. 2015, 29, 329–337. [Google Scholar] [CrossRef]
- Khoei, T.T.; Aissou, G.; Hu, W.C.; Kaabouch, N. Ensemble Learning Methods for Anomaly Intrusion Detection System in Smart Grid. In Proceedings of the IEEE International Conference on Electro Information Technology (EIT), Mt. Pleasant, MI, USA, 14–15 May 2021; pp. 129–135. [Google Scholar] [CrossRef]
- Waubert de Puiseau, C.; Meyes, R.; Meisen, T. On reliability of reinforcement learning based production scheduling systems: A comparative survey. J. Intell. Manuf. 2022, 33, 911–927. [Google Scholar] [CrossRef]
- Moos, J.; Hansel, K.; Abdulsamad, H.; Stark, S.; Clever, D.; Peters, J. Robust Reinforcement Learning: A Review of Foundations and Recent Advances. Mach. Learn. Knowl. Extr. 2022, 4, 276–315. [Google Scholar] [CrossRef]
- Latif, S.; Cuayáhuitl, H.; Pervez, F.; Shamshad, F.; Ali, H.S.; Cambria, E. A survey on deep reinforcement learning for audio-based applications. Artif. Intell. Rev. 2022, 56, 2193–2240. [Google Scholar] [CrossRef]
- Passah, A.; Kandar, D. A lightweight deep learning model for classification of synthetic aperture radar images. Ecol. Inform. 2023, 77, 102228. [Google Scholar] [CrossRef]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A survey on distributed machine learning. ACM Comput. Surv. 2020, 53, 1–33. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Pitropakis, N.; Panaousis, E.; Giannetsos, T.; Anastasiadis, E.; Loukas, G. A taxonomy and survey of attacks against machine learning. Comput. Sci. Rev. 2019, 34, 100199. [Google Scholar] [CrossRef]
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A survey of human-in-the-loop for machine learning. Futur. Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A comprehensive survey of loss functions in machine learning. Ann. Data Sci. 2022, 9, 187–212. [Google Scholar] [CrossRef]
- Choi, H.; Park, S. A Survey of Machine Learning-Based System Performance Optimization Techniques. Appl. Sci. 2021, 11, 3235. [Google Scholar] [CrossRef]
- Rawson, A.; Brito, M. A survey of the opportunities and challenges of supervised machine learning in maritime risk analysis. Transp. Rev. 2022, 43, 108–130. [Google Scholar] [CrossRef]
- Ahmad, R.; Wazirali, R.; Abu-Ain, T. Machine Learning for Wireless Sensor Networks Security: An Overview of Challenges and Issues. Sensors 2022, 22, 4730. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1310–1315. [Google Scholar]
- Abdallah, E.E.; Eleisah, W.; Otoom, A.F. Intrusion Detection Systems using Supervised Machine Learning Techniques: A survey. Procedia Comput. Sci. 2022, 201, 205–212. [Google Scholar] [CrossRef]
- Dike, H.U.; Zhou, Y.; Deveerasetty, K.K.; Wu, Q. Unsupervised Learning Based On Artificial Neural Network: A Review. In Proceedings of the 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS), 25–27 October 2018; pp. 322–327. [Google Scholar]
- van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Rothmann, M.; Porrmann, M. A Survey of Domain-Specific Architectures for Reinforcement Learning. IEEE Access 2022, 10, 13753–13767. [Google Scholar] [CrossRef]
- Dong, S.; Wang, P.; Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 2020, 40, 100379. [Google Scholar] [CrossRef]
- Ray, S. A Quick Review of Machine Learning Algorithms. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 35–39. [Google Scholar]
- Lansky, J.; Ali, S.; Mohammadi, M.; Majeed, M.K.; Karim, S.H.T.; Rashidi, S.; Hosseinzadeh, M.; Rahmani, A.M. Deep Learning-Based Intrusion Detection Systems: A Systematic Review. IEEE Access 2021, 9, 101574–101599. [Google Scholar] [CrossRef]
- Massaoudi, M.; Abu-Rub, H.; Refaat, S.S.; Chihi, I.; Oueslati, F.S. Deep Learning in Smart Grid Technology: A Review of Recent Advancements and Future Prospects. IEEE Access 2021, 9, 54558–54578. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Wu, N.; Xie, Y. A survey of machine learning for computer architecture and systems. ACM Comput. Surv. 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Schmarje, L.; Santarossa, M.; Schröder, S.-M.; Koch, R. A Survey on Semi-, Self- and Unsupervised Learning for Image Classification. IEEE Access 2021, 9, 82146–82168. [Google Scholar] [CrossRef]
- Xie, J.; Yu, F.R.; Huang, T.; Xie, R.; Liu, J.; Wang, C.; Liu, Y. A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Issues and Challenges. In IEEE Communications Surveys & Tutorials; IEEE: New York, NY, USA, 2019; Volume 21, pp. 393–430. [Google Scholar]
- Yao, Z.; Lum, Y.; Johnston, A.; Mejia-Mendoza, L.M.; Zhou, X.; Wen, Y.; Aspuru-Guzik, A.; Sargent, E.H.; Seh, Z.W. Machine learning for a sustainable energy future. Nat. Rev. Mater. 2023, 8, 202–215. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.K.; Du, X.; Ali, I.; Guizani, M. A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security. In IEEE Communications Surveys & Tutorials; IEEE: New York, NY, USA, 2020; Volume 22, pp. 1646–1685. [Google Scholar]
- Messaoud, S.; Bradai, A.; Bukhari, S.H.R.; Quang, P.T.A.; Ahmed, O.B.; Atri, M. A survey on machine learning in internet of things: Algorithms, strategies, and applications. Internet Things 2020, 12, 100314. [Google Scholar] [CrossRef]
- Umer, M.A.; Junejo, K.N.; Jilani, M.T.; Mathur, A.P. Machine learning for intrusion detection in industrial control systems: Ap-plications, challenges, and recommendations. Int. J. Crit. Infrastruct. Prot. 2022, 38, 100516. [Google Scholar] [CrossRef]
- Von Rueden, L.; Mayer, S.; Garcke, J.; Bauckhage, C.; Schuecker, J. Informed machine learning–towards a taxonomy of explicit integration of knowledge into machine learning. Learning 2019, 18, 19–20. [Google Scholar]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef]
- Wang, H.; Lv, L.; Li, X.; Li, H.; Leng, J.; Zhang, Y.; Thomson, V.; Liu, G.; Wen, X.; Luo, G. A safety management approach for Industry 5.0′ s human-centered manufacturing based on digital twin. J. Manuf. Syst. 2023, 66, 1–12. [Google Scholar] [CrossRef]
- Reuther, A.; Michaleas, P.; Jones, M.; Gadepally, V.; Samsi, S.; Kepner, J. Survey and Benchmarking of Machine Learning Accelerators. In Proceedings of the 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA USA, 24–26 September 2019; pp. 1–9. [Google Scholar]
- Kaur, B.; Dadkhah, S.; Shoeleh, F.; Neto, E.C.P.; Xiong, P.; Iqbal, S.; Lamontagne, P.; Ray, S.; Ghorbani, A.A. Internet of Things (IoT) security dataset evolution: Challenges and future directions. Internet Things 2023, 22, 100780. [Google Scholar] [CrossRef]
- Paullada, A.; Raji, I.D.; Bender, E.M.; Denton, E.; Hanna, A. Data and its (dis)contents: A survey of dataset development and use in machine learning research. Patterns 2021, 2, 100336. [Google Scholar] [CrossRef] [PubMed]
- Slimane, H.O.; Benouadah, S.; Khoei, T.T.; Kaabouch, N. A Light Boosting-based ML Model for Detecting Deceptive Jamming Attacks on UAVs. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 328–333. [Google Scholar]
- Manesh, M.R.; Kenney, J.; Hu, W.C.; Devabhaktuni, V.K.; Kaabouch, N. Detection of GPS spoofing attacks on unmanned aerial systems. In Proceedings of the 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–6. [Google Scholar]
- Sharifani, K.; Amini, M. Machine Learning and Deep Learning: A Review of Methods and Applications. World Inf. Technol. Eng. J. 2023, 10, 3897–3904. [Google Scholar]
- Obaid, H.S.; Dheyab, S.A.; Sabry, S.S. The Impact of Data Pre-Processing Techniques and Dimensionality Reduction on the Ac-curacy of Machine Learning. In Proceedings of the 2019 9th Annual Information Technology, Electromechanical Engineering and Microelectronics Conference (IEMECON), Jaipur, India, 13–15 March 2019; pp. 279–283. [Google Scholar]
- Liu, B.; Ding, M.; Shaham, S.; Rahayu, W.; Lin, Z. When machine learning meets privacy: A survey and outlook. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Singh, S.; Gupta, P. Comparative study ID3, cart and C4. 5 decision tree algorithm: A survey. Int. J. Adv. Inf. Sci. Technol. (IJAIST) 2014, 27, 97–103. [Google Scholar]
- Zhang, M.-L.; Zhou, Z.-H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Musavi, M.T.; Ahmed, W.; Chan, K.H.; Faris, K.B.; Hummels, D.M. On the training of radial basis function classifiers. Neural Netw. 1992, 5, 595–603. [Google Scholar] [CrossRef]
- Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics. Electronics 2021, 10, 593. [Google Scholar] [CrossRef]
- Jiang, T.; Fang, H.; Wang, H. Blockchain-Based Internet of Vehicles: Distributed Network Architecture and Performance Analy-sis. IEEE Internet Things J. 2019, 6, 4640–4649. [Google Scholar] [CrossRef]
- Jia, W.; Dai, D.; Xiao, X.; Wu, H. ARNOR: Attention regularization based noise reduction for distant supervision relation classifi-cation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1399–1408. [Google Scholar]
- Abiodun, O.I.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Izeboudjen, N.; Larbes, C.; Farah, A. A new classification approach for neural networks hardware: From standards chips to embedded systems on chip. Artif. Intell. Rev. 2014, 41, 491–534. [Google Scholar] [CrossRef]
- Wang, D.; He, H.; Liu, D. Intelligent Optimal Control With Critic Learning for a Nonlinear Overhead Crane System. IEEE Trans. Ind. Informatics 2018, 14, 2932–2940. [Google Scholar] [CrossRef]
- Wang, S.-C. Artificial Neural Network. In Interdisciplinary Computing in Java Programming; Springer: Berlin/Heidelberg, Germany, 2003; pp. 81–100. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017. [Google Scholar]
- Khoei, T.T.; Slimane, H.O.; Kaabouch, N. Cyber-Security of Smart Grids: Attacks, Detection, Countermeasure Techniques, and Future Directions. Commun. Netw. 2022, 14, 119–170. [Google Scholar] [CrossRef]
- Gunturi, S.K.; Sarkar, D. Ensemble machine learning models for the detection of energy theft. Electr. Power Syst. Res. 2021, 192, 106904. [Google Scholar] [CrossRef]
- Chafii, M.; Bader, F.; Palicot, J. Enhancing coverage in narrow band-IoT using machine learning. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Bithas, P.S.; Michailidis, E.T.; Nomikos, N.; Vouyioukas, D.; Kanatas, A.G. A Survey on Machine-Learning Techniques for UAV-Based Communications. Sensors 2019, 19, 5170. [Google Scholar] [CrossRef] [PubMed]
- Benos, L.; Tagarakis, A.C.; Dolias, G.; Berruto, R.; Kateris, D.; Bochtis, D. Machine Learning in Agriculture: A Comprehensive Updated Review. Sensors 2021, 21, 3758. [Google Scholar] [CrossRef]
- Wagle, P.P.; Rani, S.; Kowligi, S.B.; Suman, B.H.; Pramodh, B.; Kumar, P.; Raghavan, S.; Shastry, K.A.; Sanjay, H.A.; Kumar, M.; et al. Machine Learning-Based Ensemble Network Security System. In Recent Advances in Artificial Intelligence and Data Engineering; Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–15. [Google Scholar]
- Sutton, C.D. Classification and regression trees, bagging, and boosting. Handb. Stat. 2005, 24, 303–329. [Google Scholar]
- Zaadnoordijk, L.; Besold, T.R.T.; Cusack, R. Lessons from infant learning for unsupervised machine learning. Nat. Mach. Intell. 2022, 4, 510–520. [Google Scholar] [CrossRef]
- Khoei, T.T.; Kaabouch, N. A Comparative Analysis of Supervised and Unsupervised Models for Detecting Attacks on the Intrusion Detection Systems. Information 2023, 14, 103. [Google Scholar] [CrossRef]
- Kumar, P.; Gupta, G.P.; Tripathi, R. An ensemble learning and fog-cloud architecture-driven cyber-attack detection framework for IoMT networks. Comput. Commun. 2021, 166, 110–124. [Google Scholar] [CrossRef]
- Hady, M.; Abdel, A.M.F.; Schwenker, F. Semi-supervised learning. In Handbook on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1–21. [Google Scholar]
- Luo, Y.; Zhu, J.; Li, M.; Ren, Y.; Zhang, B. Smooth neighbors on teacher graphs for semi-supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lake City, UT, USA, 18–22 June 2018; pp. 8896–8905. [Google Scholar]
- Park, S.; Park, J.; Shin, S.; Moon, I. Adversarial dropout for supervised and semi-supervised learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3917–3924. [Google Scholar]
- Khoei, T.T.; Kaabouch, N. ACapsule Q-learning based reinforcement model for intrusion detection system on smart grid. In Proceedings of the IEEE International Conference on Electro Information Technology (eIT), Romeoville, IL, USA, 18–20 May 2023; pp. 333–339. [Google Scholar]
- Polydoros, A.S.; Nalpantidis, L. Survey of model-based reinforcement learning: Applications on robotics. J. Intell. Robot. Syst. 2017, 86, 153–173. [Google Scholar] [CrossRef]
- Degris, T.; Pilarski, P.M.; Sutton, R.S. Model-Free reinforcement learning with continuous action in practice. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 2177–2182. [Google Scholar] [CrossRef]
- Cao, D.; Hu, W.; Zhao, J.; Zhang, G.; Zhang, B.; Liu, Z.; Chen, Z.; Blaabjerg, F. Reinforcement learning and its applications in modern power and energy systems: A review. J. Mod. Power Syst. Clean Energy 2020, 8, 1029–1042. [Google Scholar] [CrossRef]
- Zhang, J.M.; Harman, M.; Ma, L.; Liu, Y. Machine Learning Testing: Survey, Landscapes and Horizons. In IEEE Transactions on Software Engineering; IEEE: New York, NY, USA, 2022; Volume 48, pp. 1–36. [Google Scholar]
- Salahdine, F.; Kaabouch, N. Security threats, detection, and countermeasures for physical layer in cognitive radio networks: A survey. Phys. Commun. 2020, 39, 101001. [Google Scholar] [CrossRef]
- Ramírez, J.; Yu, W.; Perrusquía, A. Model-free reinforcement learning from expert demonstrations: A survey. Artif. Intell. Rev. 2022, 55, 3213–3241. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Dev, K.; Maddikunta, P.K.R.; Gadekallu, T.R.; Bhattacharya, S.; Hegde, P.; Singh, S. Energy Optimization for Green Communication in IoT Using Harris Hawks Optimization. In IEEE Transactions on Green Communications and Networking; IEEE: New York, NY, USA, 2022; Volume 6, pp. 685–694. [Google Scholar]
- Khodadadi, N.; Snasel, V.; Mirjalili, S. Dynamic Arithmetic Optimization Algorithm for Truss Optimization Under Natural Fre-quency Constraints. IEEE Access 2022, 10, 16188–16208. [Google Scholar] [CrossRef]
- Cummins, C.; Wasti, B.; Guo, J.; Cui, B.; Ansel, J.; Gomez, S.; Jain, S.; Liu, J.; Teytaud, O.; Steinerm, B.; et al. CompilerGym: Robust, Performant Compiler Optimization Environments for AI Research. In Proceedings of the 2022 IEEE/ACM In-ternational Symposium on Code Generation and Optimization (CGO), Seoul, Republic of Korea, 2–6 April 2022; pp. 92–105. [Google Scholar]
- Zhang, W.; Gu, X.; Tang, L.; Yin, Y.; Liu, D.; Zhang, Y. Application of machine learning, deep learning and optimization algo-rithms in geoengineering and geoscience: Comprehensive review and future challenge. Gondwana Res. 2022, 109, 1–17. [Google Scholar] [CrossRef]
- Mittal, S.; Vaishay, S. A survey of techniques for optimizing deep learning on GPUs. J. Syst. Arch. 2019, 99, 101635. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Oyelade, O.N.; Ezugwu, A.E.-S.; Mohamed, T.I.A.; Abualigah, L. Ebola Optimization Search Algorithm: A New Nature-Inspired Metaheuristic Optimization Algorithm. IEEE Access 2022, 10, 16150–16177. [Google Scholar] [CrossRef]
- Blank, J.; Deb, K. Pymoo: Multi-Objective Optimization in Python. IEEE Access 2020, 8, 89497–89509. [Google Scholar] [CrossRef]
- Qiao, K.; Yu, K.; Qu, B.; Liang, J.; Song, H.; Yue, C. An Evolutionary Multitasking Optimization Framework for Constrained Multi-objective Optimization Problems. IEEE Trans. Evol. Comput. 2022, 26, 263–277. [Google Scholar] [CrossRef]
- Riaz, M.; Ahmad, S.; Hussain, I.; Naeem, M.; Mihet-Popa, L. Probabilistic Optimization Techniques in Smart Power System. Energies 2022, 15, 825. [Google Scholar] [CrossRef]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on deep semi-supervised learning. arXiv 2021, arXiv:2103.00550. [Google Scholar] [CrossRef]
- Gibson, B.R.; Rogers, T.T.; Zhu, X. Human semi-supervised learning. Top. Cogn. Sci. 2013, 5, 132–172. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef]
- Canese, L.; Cardarilli, G.C.; Di Nunzio, L.; Fazzolari, R.; Giardino, D.; Re, M.; Spanò, S. Multi-Agent Reinforcement Learning: A Review of Challenges and Applications. Appl. Sci. 2021, 11, 4948. [Google Scholar] [CrossRef]
- Du, W.; Ding, S. A survey on multi-agent deep reinforcement learning: From the perspective of challenges and applications. Artif. Intell. Rev. 2020, 54, 3215–3238. [Google Scholar] [CrossRef]
- Salwan, D.; Kant, S.; Pareek, H.; Sharma, R. Challenges with reinforcement learning in prosthesis. Mater. Today Proc. 2022, 49, 3133–3136. [Google Scholar] [CrossRef]
- Narkhede, M.S.; Chatterji, S.; Ghosh, S. Trends and challenges in optimization techniques for operation and control of Mi-crogrid—A review. In Proceedings of the 2012 1st International Conference on Power and Energy in NERIST (ICPEN), Nirjuli, India, 28–29 December 2012; pp. 1–7. [Google Scholar]
- Khoei, T.T.; Ismail, S.; Kaabouch, N. Dynamic Selection Techniques for Detecting GPS Spoofing Attacks on UAVs. Sensors 2022, 22, 662. [Google Scholar] [CrossRef]
- Khoei, T.T.; Ismail, S.; Al Shamaileh, K.; Devabhaktuni, V.K.; Kaabouch, N. Impact of Dataset and Model Parameters on Machine Learning Performance for the Detection of GPS Spoofing Attacks on Unmanned Aerial Vehicles. Appl. Sci. 2022, 13, 383. [Google Scholar] [CrossRef]
- Khoei, T.T.; Kaabouch, N. Densely Connected Neural Networks for Detecting Denial of Service Attacks on Smart Grid Network. In Proceedings of the IEEE 13th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 26–29 October 2022; pp. 0207–0211. [Google Scholar]
- Khan, A.; Khan, S.H.; Saif, M.; Batool, A.; Sohail, A.; Khan, M.W. A Survey of Deep Learning Techniques for the Analysis of COVID-19 and their usability for Detecting Omicron. J. Exp. Theor. Artif. Intell. 2023, 1–43. [Google Scholar] [CrossRef]
- Gopinath, M.; Sethuraman, S.C. A comprehensive survey on deep learning based malware detection techniques. Comput. Sci. Rev. 2023, 47, 100529. [Google Scholar]
- Gheisari, M.; Ebrahimzadeh, F.; Rahimi, M.; Moazzamigodarzi, M.; Liu, Y.; Pramanik, P.K.D.; Heravi, M.A.; Mehbodniya, A.; Ghaderzadeh, M.; Feylizadeh, M.R.; et al. Deep learning: Applications, architectures, models, tools, and frameworks: A com-prehensive survey. In CAAI Transactions on Intelligence Technology; IET: Stevenage, UK, 2023. [Google Scholar]
- Morgan, D.; Jacobs, R. Opportunities and challenges for machine learning in materials science. Annu. Rev. Mater. Res. 2020, 50, 71–103. [Google Scholar] [CrossRef]
- Phoon, K.K.; Zhang, W. Future of machine learning in geotechnics. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2023, 17, 7–22. [Google Scholar] [CrossRef]
- Krishnam, N.P.; Ashraf, M.S.; Rajagopal, B.R.; Vats, P.; Chakravarthy, D.S.K.; Rafi, S.M. Analysis of Current Trends, Advances and Challenges of Machine Learning (Ml) and Knowledge Extraction: From Ml to Explainable AI. Ind. Qualif.-Stitute Adm. Manag. UK 2022, 58, 54–62. [Google Scholar]
- Li, Z.; Yoon, J.; Zhang, R.; Rajabipour, F.; Srubar, W.V., III; Dabo, I.; Radlińska, A. Machine learning in concrete science: Applications, challenges, and best practices. NPJ Comput. Mater. 2022, 8, 127. [Google Scholar] [CrossRef]
- Houssein, E.H.; Abohashima, Z.; Elhoseny, M.; Mohamed, W.M. Machine learning in the quantum realm: The state-of-the-art, challenges, and future vision. Expert Syst. Appl. 2022, 194, 116512. [Google Scholar] [CrossRef]
- Khan, T.; Tian, W.; Zhou, G.; Ilager, S.; Gong, M.; Buyya, R. Machine learning (ML)-centric resource management in cloud computing: A review and future directions. J. Netw. Comput. Appl. 2022, 204, 103405. [Google Scholar] [CrossRef]
- Esterhuizen, J.A.; Goldsmith, B.R.; Linic, S. Interpretable machine learning for knowledge generation in heterogeneous catalysis. Nat. Catal. 2022, 5, 175–184. [Google Scholar] [CrossRef]
- Bharadiya, J.P. Leveraging Machine Learning for Enhanced Business Intelligence. Int. J. Comput. Sci. Technol. 2023, 7, 1–19. [Google Scholar]
- Talaei Khoei, T.; Ould Slimane, H.; Kaabouch, N. Deep learning: Systematic review, models, challenges, and research directions. In Neural Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–22. [Google Scholar]
- Ben Amor, S.; Belaid, F.; Benkraiem, R.; Ramdani, B.; Guesmi, K. Multi-criteria classification, sorting, and clustering: A bibliometric review and research agenda. Ann. Oper. Res. 2023, 325, 771–793. [Google Scholar] [CrossRef]
- Valdez, F.; Melin, P. A review on quantum computing and deep learning algorithms and their applications. Soft Comput. 2023, 27, 13217–13236. [Google Scholar] [CrossRef]
- Fihri, W.F.; Arjoune, Y.; Hassan El Ghazi, H.; Kaabouch, N.; Abou El Majd, A.B. A particle swarm optimization based algorithm for primary user emulation attack detection. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 823–827. [Google Scholar]
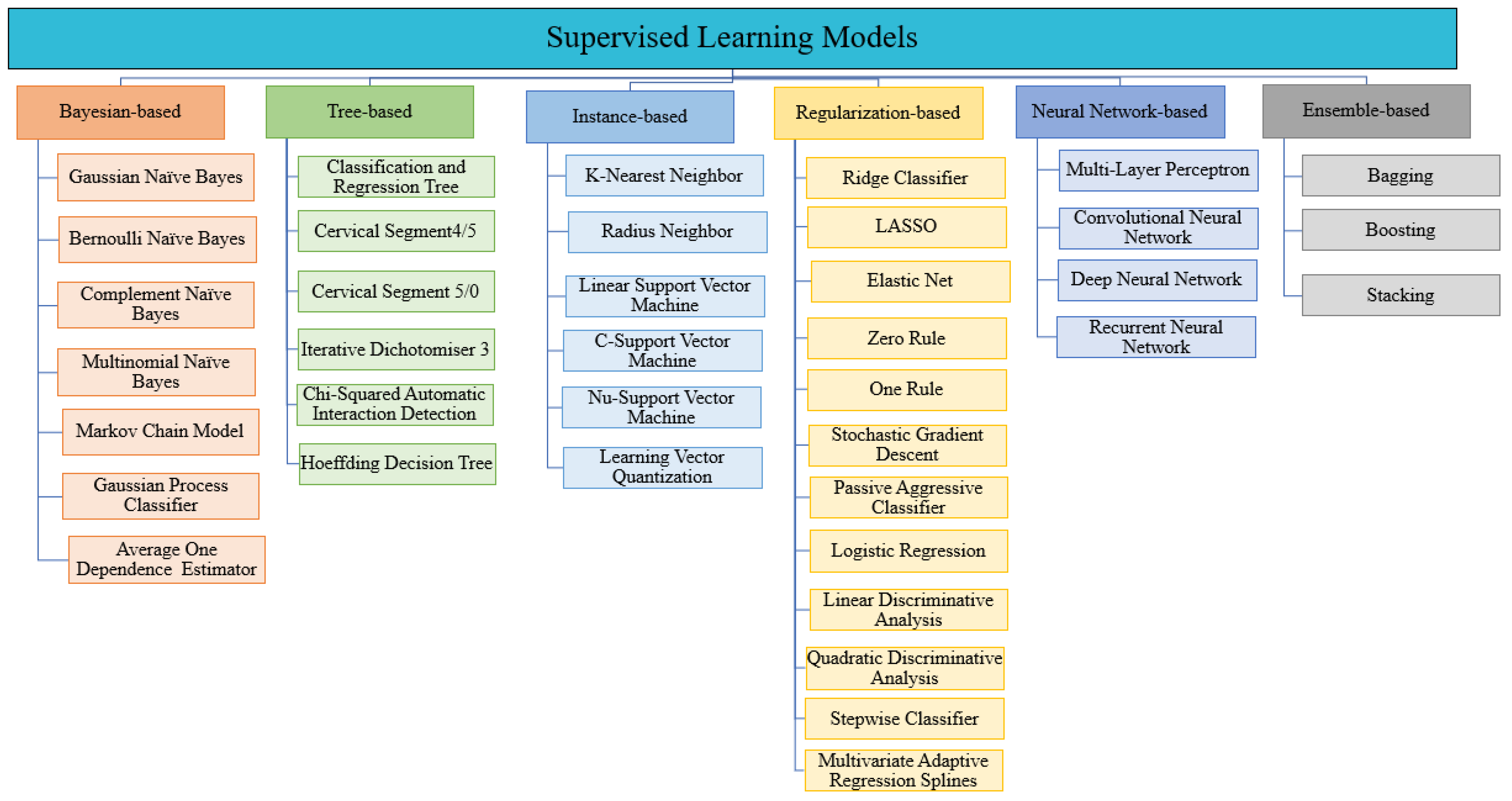


| Classification Category | Characteristics | Advantages | Disadvantages |
|---|---|---|---|
| Bayesian- Based |
|
|
|
| Tree- based |
|
|
|
| Instance- based |
|
|
|
| Regularization-based |
|
|
|
| Neural network-based |
|
|
|
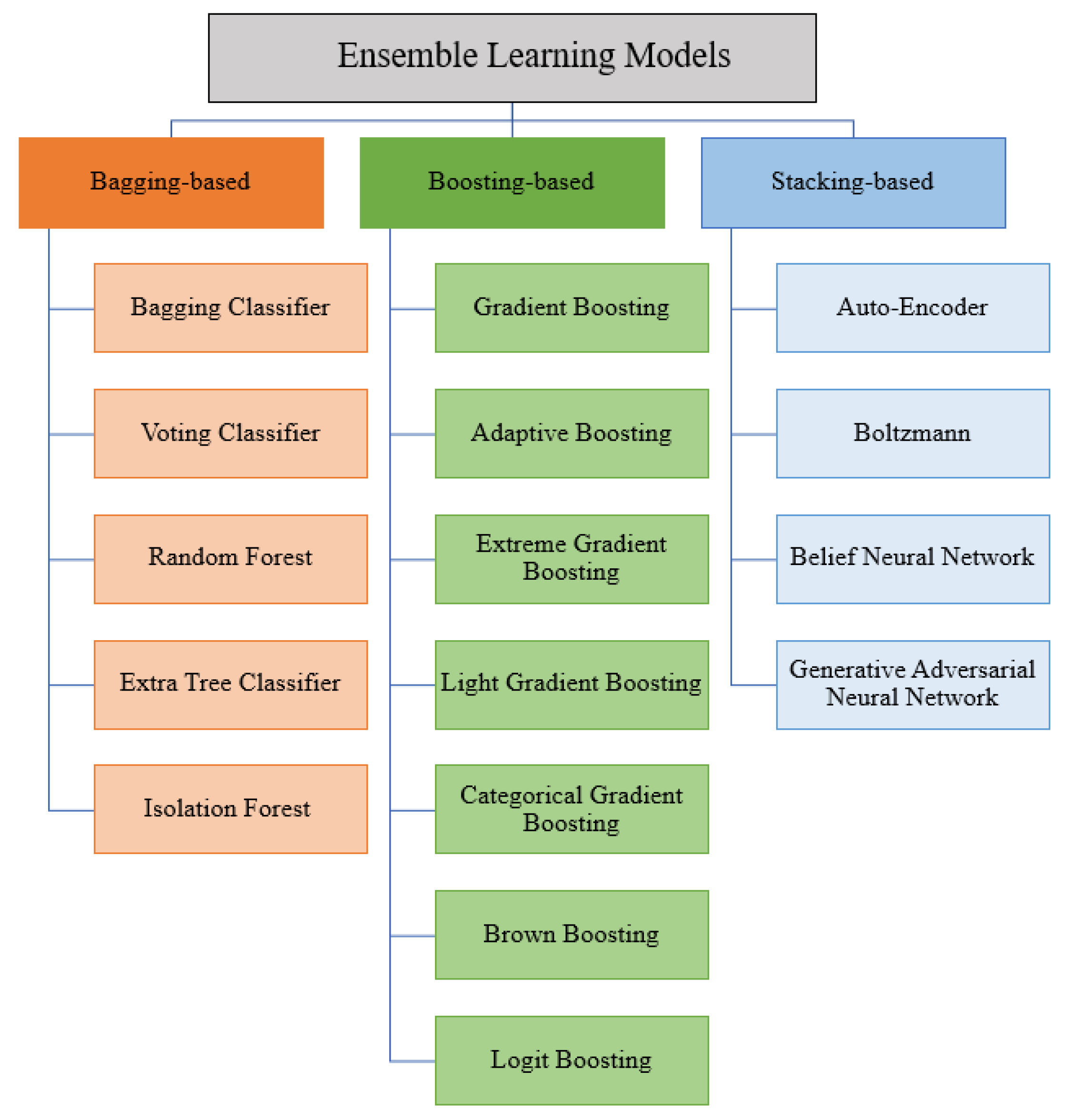
| Ensemble-based |
|
|
|
| Classification Category | Characteristics | Advantage | Disadvantage |
|---|---|---|---|
| Inductive- Based | Generates a model that can create predictions for any sample in the input space | The predictions of new samples are independent of old samples | The same model can be used in training and predicting new data samples |
| Transductive- based | Predictive strengths are limited to objects that are processed during the training steps | No difference between the training and testing steps | No distinction between the transductive algorithms in a supervised manner |
| Classification Category | Characteristics | Advantages | Disadvantages |
|---|---|---|---|
| Cluster-based | Divides uncategorized data into similar groups; |
|
|
| Dimensionality reduction-based | Decreases the number of features in the given dataset; |
|
|
| Neural network-based | Inspiration of human brains. |
|
|
| Classification Category | Characteristics | Advantage | Disadvantage |
|---|---|---|---|
| Model-based | Optimal actions are learned via a model |
|
|
| Model free-based | No transition of a probability distribution or reward associated with the Markov decision process |
|
|
| Data Preprocessing Steps | Methodology | Technique | Highlights |
|---|---|---|---|
| Data transformation | Standardization and normalization | Unit vector normalization | Extract the given data, and convert them to a usable format |
| Max abs scalar | |||
| Quantile transformer scalar | |||
| Robust scalar Min-max scaling | |||
| Power transformer scalar | |||
| Unit vector normalization | |||
| Standard scalar | |||
| Data cleaning | Missing value imputation | Complete case analysis | Loss of efficiency, strong bias, and complications in handling data. |
| Frequent category imputation | |||
| Mean/median imputation | |||
| Mode imputation | |||
| End of tail imputation | |||
| Nearest neighbor imputation | |||
| Iterative imputation | |||
| Hot and cold deck imputation | |||
| Exploration imputation | |||
| Interpolation imputation | |||
| Regression-based imputation | |||
| Noise treatment | Data polishing | ||
| Noise filters | |||
| Data reduction/ increasing | Feature selection | Wrapper | Decrease or increase the number of samples or features that are not important in the process of training |
| Filter | |||
| Embedded | |||
| Feature extraction | Principle component analysis | ||
| Linear discriminative analysis | |||
| Independent component analysis | |||
| Partial least square | |||
| Multifactor dimensionality reduction | |||
| Nonlinear dimensionality reduction | |||
| Autoencoder | |||
| Tensor decomposition | |||
| Instance generation | Condensation algorithms | ||
| Edition algorithms | |||
| Hybrid algorithms | |||
| Discretization | Discretization-based | Chi-squared discretization | Loss of information, simplicity, readability, and faster learning process |
| Efficient discretization | |||
| Imbalanced learning | Under-sampling | Random under-sampling | Presents true evaluation results |
| Tomek links | |||
| Condensed nearest neighbor | |||
| Edited nearest neighbor | |||
| Near-miss under-sampling | |||
| Oversampling | Random oversampling | ||
| Synthetic minority oversampling technique | |||
| Adaptive synthetic | |||
| Borderline-synthetic minority oversampling technique |
| Hyperparameter Methods | Strengths | Limitations |
|---|---|---|
| Grid search |
|
|
| Random search |
|
|
| Genetic algorithm |
|
|
| Gradient-based techniques |
|
|
| Bayesian optimization-Gaussian process |
|
|
| Particle swarm optimization |
|
|
| Bayesian optimization-tree structure parzen estimator |
|
|
| Hyperband |
|
|
| Bayesian optimization-SMAC |
|
|
| Population-based |
|
|
| Category | Metric Name |
|---|---|
| Supervised Learning |
|
| Unsupervised Learning |
|
| Semi-Supervised Learning |
|
| Reinforcement Learning |
|
| Challenges | Descriptions |
|---|---|
| Interpretability and Explain-ability |
|
| Bias and Fairness |
|
| Adversarial Robustness |
|
| Privacy and Security |
|
| Reinforcement Learning |
|
| Quantum Computing |
|
| Multi-Criteria Models |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talaei Khoei, T.; Kaabouch, N. Machine Learning: Models, Challenges, and Research Directions. Future Internet 2023, 15, 332. https://doi.org/10.3390/fi15100332
Talaei Khoei T, Kaabouch N. Machine Learning: Models, Challenges, and Research Directions. Future Internet. 2023; 15(10):332. https://doi.org/10.3390/fi15100332
Chicago/Turabian StyleTalaei Khoei, Tala, and Naima Kaabouch. 2023. "Machine Learning: Models, Challenges, and Research Directions" Future Internet 15, no. 10: 332. https://doi.org/10.3390/fi15100332
APA StyleTalaei Khoei, T., & Kaabouch, N. (2023). Machine Learning: Models, Challenges, and Research Directions. Future Internet, 15(10), 332. https://doi.org/10.3390/fi15100332