
Artificial Intelligence in Adaptive and Intelligent Educational System: A Review

 , ,
, ,
Abstract
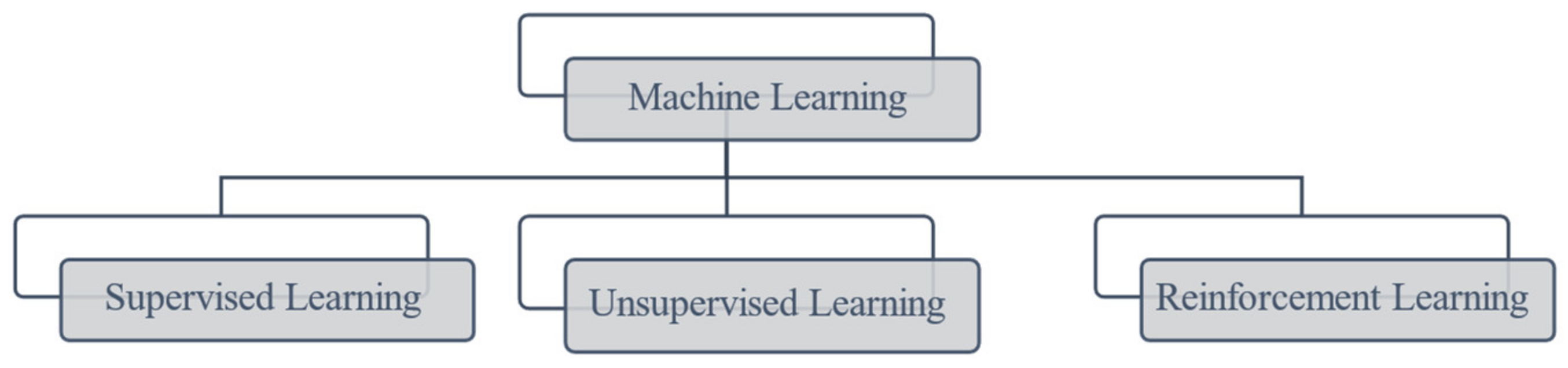
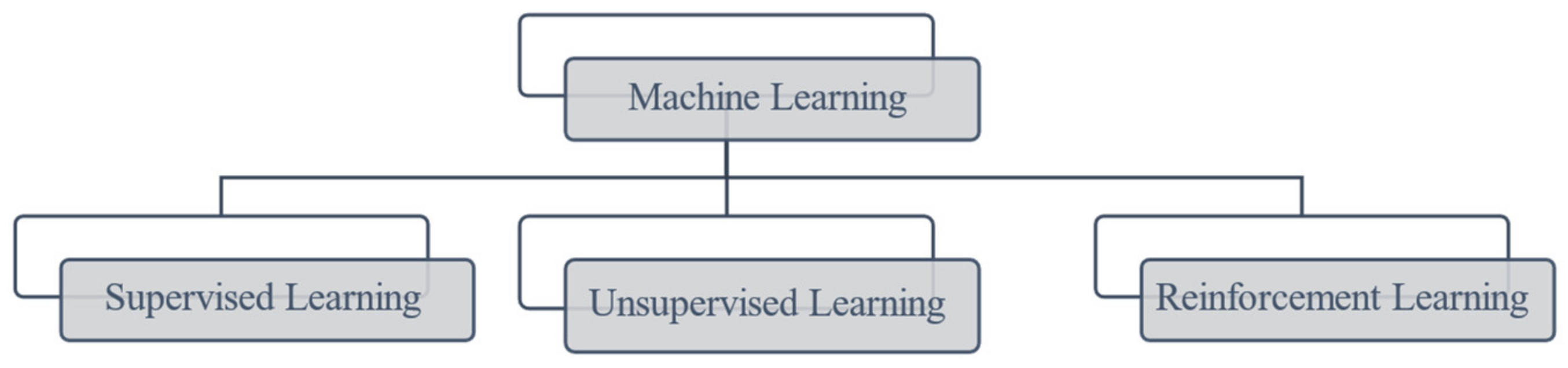
:1. Introduction
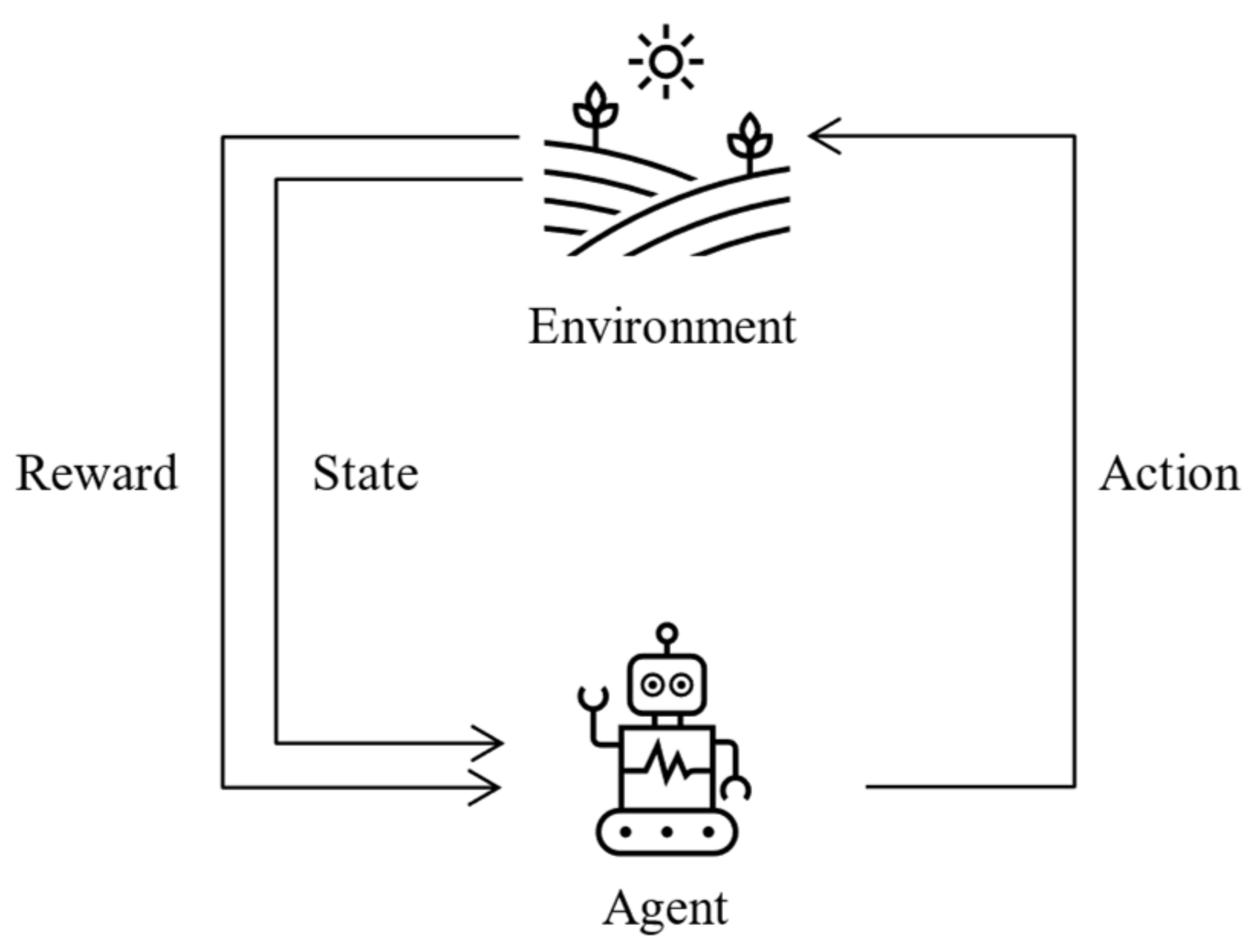
2. Reinforcement Learning
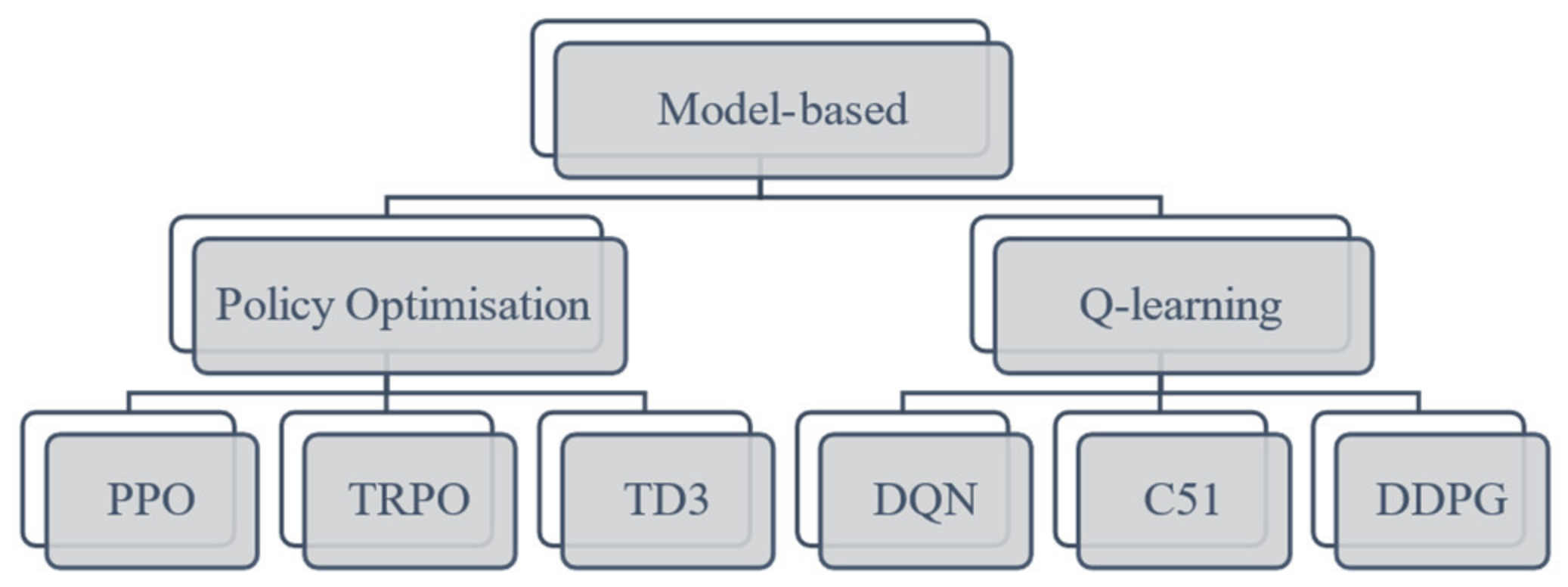
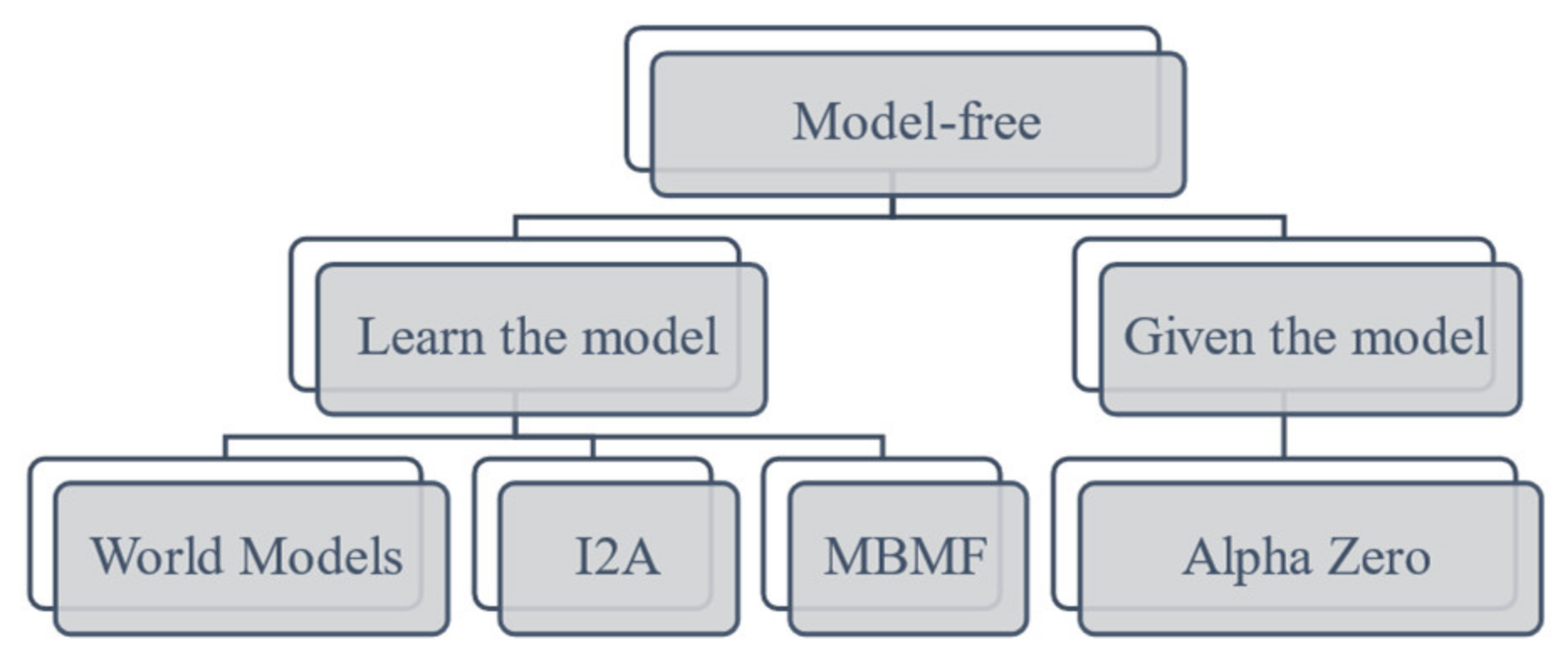
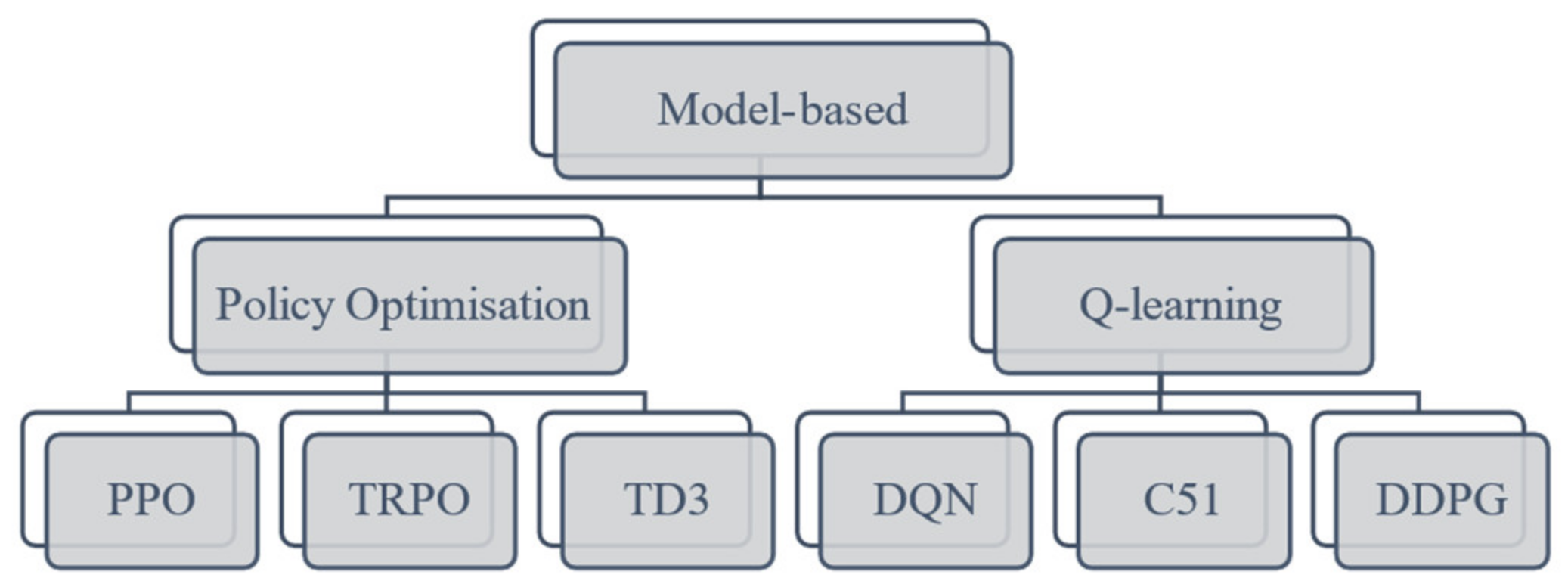
2.1. Model-Based and Model-Free Reinforcement Learning
2.2. Markov Decision Processes
2.3. Q-Learning
2.4. Deep Q-Network and Double Deep Q-Network
2.5. Comparison with Bayesian Network
3. Reinforcement Learning in Adaptive and Intelligent Educational System (RLATES)
3.1. Current Research
3.2. Applied Reinforcement Learning in RLATES
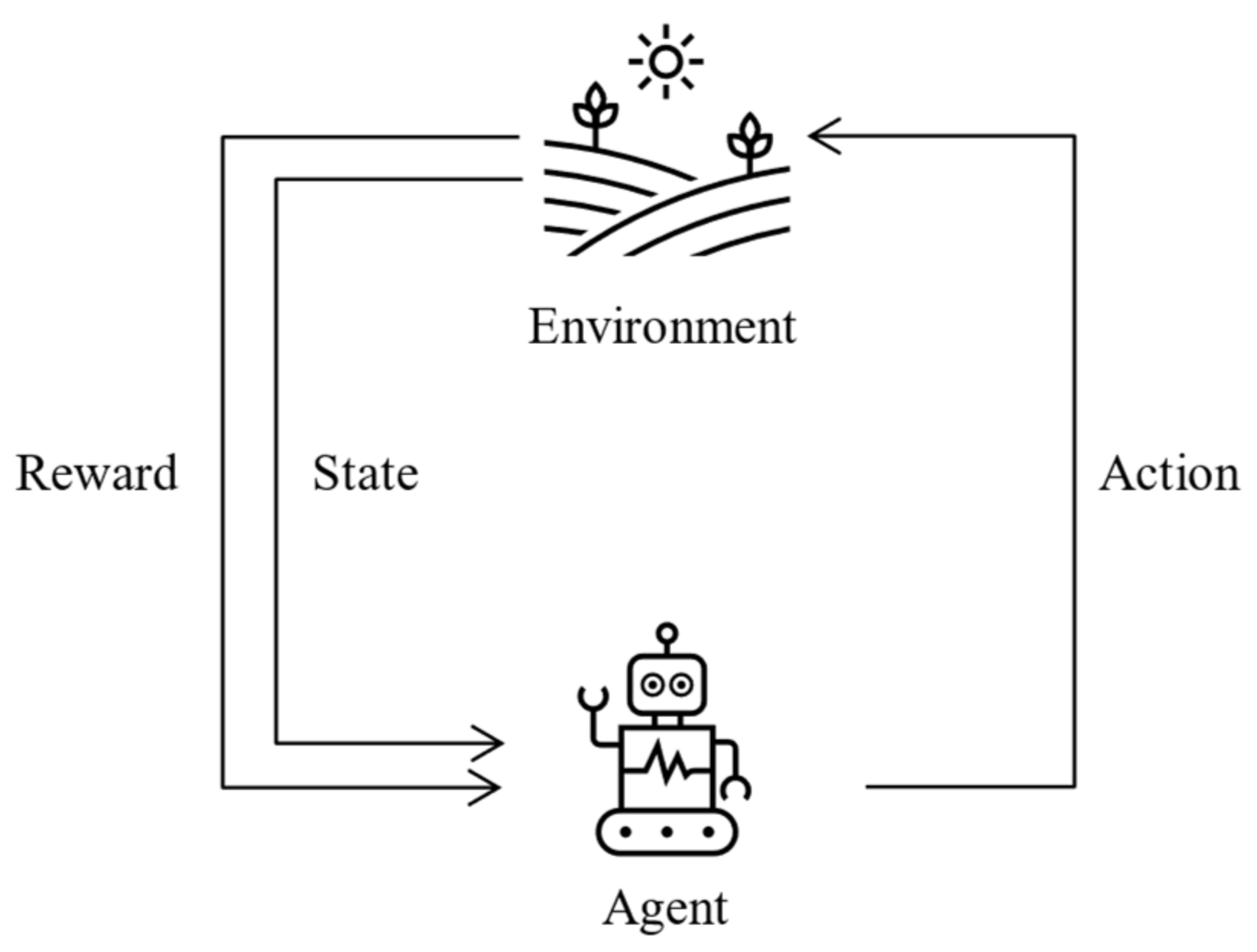
- Agent: In RLATES, the agent refers to the student. The learning system is used through the student interacting with the system for subsequent processes; therefore, the student corresponds to the agent in the reinforcement learning algorithm.
- Environment: In a broad sense, the environment is the entire knowledge structure of the system, and it collects information on the characteristics of the students and tests their knowledge through exams and quizzes distributed throughout the knowledge modules.
- Action: Actions are the selections that an agent needs to take at each step, so in RLATES, the actions correspond to the knowledge modules, each of which represents an action.
- State: In reinforcement learning algorithms, the state refers to the state that the environment returns to when the agent performs an action. Therefore, in RLATES, the state corresponds to the student’s learning state, i.e., how the student mastered the knowledge. Here, a vector is used to store the data, and all state values are in the range of 0–1. For a student, if the knowledge has been fully mastered and correctly understood, the state value is set at 1. If the knowledge has not been mastered by the student, then the state value is set at 0.
- Reward: For reinforcement learning algorithms, each selection returns a different reward value, and similarly, in RLATES, each knowledge module corresponds to a different reward according to the significance. Moreover, in RLATES, the intention is to maximize the cumulative value of this reward.
| Algorithm 1 Apply reinforcement learning algorithm to RLATES |
| Initialize Q (s, a) for s ∈ S and a ∈ A Test the current situation of student’s knowledge s Loop for each episode, Pick a knowledge module a, show this module to the student, by using the ε-greedy policy Get the reward r, while the RLATES goal is achieved, a positive r will be obtained, else a null r will be obtained. Test the current situation of student’s knowledge s’ Update Q (s, a): s ← s’ until s reaches the goal state |
4. Conclusions
- Due to the features of intelligent educational systems, reinforcement learning is appropriate for application in the construction of a system and can be very helpful in providing proper teaching strategies for students with the same characteristics.
- Although many scholars have worked on how to integrate reinforcement learning into intelligent instructional systems, the majority still only adopt classical Q-learning algorithms, and the application of the more sophisticated reinforcement learning algorithms to the field of intelligent instructional systems has rarely been conducted. When evaluating the system performance, most studies use similar evaluation metrics, which facilitates scholars to make comparisons between different studies. However, some studies have developed their own evaluation metrics, which can better evaluate the experimental results for future optimization, but the disadvantage is that they cannot compare the experimental results with other studies, which has limitations.
- Research on the application of reinforcement learning to intelligent instructional systems has rarely been conducted in recent years, but as online learning is increasingly required by students, research in this area is expected to increase in popularity in the future. Although online education cannot completely replace offline education, the combination of computer technology and education can make education gradually online, which is the trend of future development.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Canhoto, A.I.; Clear, F. Artificial intelligence and machine learning as business tools: A framework for diagnosing value destruction potential. Bus. Horiz. 2020, 63, 183–193. [Google Scholar] [CrossRef]
- Jones, D.T. Setting the standards for machine learning in biology. Nat. Rev. Mol. Cell Biol. 2019, 20, 659–660. [Google Scholar] [CrossRef]
- Sidey-Gibbons, J.A.M.; Sidey-Gibbons, C.J. Machine learning in medicine: A practical introduction. BMC Med. Res. Methodol. 2019, 19, 64. [Google Scholar] [CrossRef] [PubMed]
- Loftus, M.; Madden, M.G. A pedagogy of data and Artificial Intelligence for student subjectification. Teach. High. Educ. 2020, 25, 456–475. [Google Scholar] [CrossRef]
- Xu, J.; Moon, K.H.; van der Schaar, M. A Machine Learning Approach for Tracking and Predicting Student Performance in Degree Programs. IEEE J. Sel. Top. Signal Process. 2017, 11, 742–753. [Google Scholar] [CrossRef]
- Williamson, B. Digital education governance: Data visualization, predictive analytics, and ‘real-time’ policy instruments. J. Educ. Policy 2016, 31, 123–141. [Google Scholar] [CrossRef]
- Tseng, J.C.R.; Chu, H.-C.; Hwang, G.-J.; Tsai, C.-C. Development of an adaptive learning system with two sources of personalization information. Comput. Educ. 2008, 51, 776–786. [Google Scholar] [CrossRef]
- Erümit, A.K.; Çetin, İ. Design framework of adaptive intelligent tutoring systems. Educ. Inf. Technol. 2020, 25, 4477–4500. [Google Scholar] [CrossRef]
- Dorça, F.A.; Lima, L.V.; Fernandes, M.A.; Lopes, C.R. Comparing strategies for modeling students learning styles through reinforcement learning in adaptive and intelligent educational systems: An experimental analysis. Expert Syst. Appl. 2013, 40, 2092–2101. [Google Scholar] [CrossRef]
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Learning teaching strategies in an Adaptive and Intelligent Educational System through Reinforcement Learning. Appl. Intell. 2009, 31, 89–106. [Google Scholar] [CrossRef]
- Iglesias, A.; Martínez, P.; Aler, R.; Fernández, F. Reinforcement learning of pedagogical policies in adaptive and intelligent educational systems. Knowl.-Based Syst. 2009, 22, 266–270. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, The Twenty-Eighth Conference on Innovative Applications of Artificial Intelligence, The Sixth Symposium on Educational Advances in Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar] [CrossRef]
- Shawky, D.; Badawi, A. Towards a Personalized Learning Experience Using Reinforcement Learning. In Machine Learning Paradigms: Theory and Application; Studies in Computational Intelligence; Hassanien, A.E., Ed.; Springer International Publishing: Cham, Switzerland, 2019; Volume 801, pp. 169–187. ISBN 978-3-030-02356-0. [Google Scholar]
- Bassen, J.; Balaji, B.; Schaarschmidt, M.; Thille, C.; Painter, J.; Zimmaro, D.; Games, A.; Fast, E.; Mitchell, J.C. Reinforcement Learning for the Adaptive Scheduling of Educational Activities. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems; ACM: Honolulu, HI, USA, 2020; pp. 1–12. [Google Scholar]
- Thomaz, A.L.; Breazeal, C. Reinforcement learning with human teachers: Evidence of feedback and guidance with implications for learning performance. In Proceedings of the AAAI; American Association for Artificial Intelligence: Boston, MA, USA, 2006; Volume 6, pp. 1000–1005. [Google Scholar]
- Zhang, P. Using POMDP-based Reinforcement Learning for Online Optimization of Teaching Strategies in an Intelligent Tutoring System. Ph.D. Thesis, University of Guelph, Guelph, ON, Canada, 2013. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Atkeson, C.G.; Santamaria, J.C. A comparison of direct and model-based reinforcement learning. In Proceedings of the International Conference on Robotics and Automation, Albuquerque, NM, USA, 25 April 1997; Volume 4, pp. 3557–3564. [Google Scholar]
- Pal, C.-V.; Leon, F. A Modified I2A Agent for Learning in a Stochastic Environment. In Proceedings of the Computational Collective Intelligence; Nguyen, N.T., Hoang, B.H., Huynh, C.P., Hwang, D., Trawiński, B., Vossen, G., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 388–399. [Google Scholar]
- Ha, D.; Schmidhuber, J. World Models. arXiv 2018, arXiv:1803.10122. [Google Scholar] [CrossRef]
- Akanksha, E.; Jyoti; Sharma, N.; Gulati, K. Review on Reinforcement Learning, Research Evolution and Scope of Application. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 1416–1423. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2019, arXiv:1509.02971. [Google Scholar]
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 449–458. [Google Scholar]
- Hoey, J.; Poupart, P.; Bertoldi, A.v.; Craig, T.; Boutilier, C.; Mihailidis, A. Automated handwashing assistance for persons with dementia using video and a partially observable Markov decision process. Comput. Vis. Image Underst. 2010, 114, 503–519. [Google Scholar] [CrossRef]
- Yu, X.; Fan, Y.; Xu, S.; Ou, L. A self-adaptive SAC-PID control approach based on reinforcement learning for mobile robots. Int. J. Robust Nonlinear Control 2021. early view. [Google Scholar] [CrossRef]
- van Otterlo, M.; Wiering, M. Reinforcement Learning and Markov Decision Processes. In Reinforcement Learning; Adaptation, Learning, and Optimization; Wiering, M., van Otterlo, M., Eds.; Springer Berlin Heidelberg: Berlin, Heidelberg, 2012; Volume 12, pp. 3–42. ISBN 978-3-642-27644-6. [Google Scholar]
- Girard, J.; Reza Emami, M. Concurrent Markov decision processes for robot team learning. Eng. Appl. Artif. Intell. 2015, 39, 223–234. [Google Scholar] [CrossRef]
- Srinivasan, R.; Parlikad, A.K. Semi-Markov Decision Process With Partial Information for Maintenance Decisions. IEEE Trans. Reliab. 2014, 63, 891–898. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Mason, K.; Grijalva, S. A review of reinforcement learning for autonomous building energy management. Comput. Electr. Eng. 2019, 78, 300–312. [Google Scholar] [CrossRef]
- Thrun, S.; Schwartz, A. Issues in using function approximation for reinforcement learning. In Proceedings of the 1993 Connectionist Models Summer School; Lawrence Erlbaum: Mahwah, NJ, USA, 1993; Volume 6, pp. 1–9. [Google Scholar]
- Van Hasselt, H.P. Insights in Reinforcement Learning; van Hasselt, H.P., Ed.; Wöhrmann Print Service, B.V.: Zutphen, The Netherlands, 2011; ISBN 978-90-393-5496-4. [Google Scholar]
- Ramírez-Noriega, A.; Juárez-Ramírez, R.; Martínez-Ramírez, Y. Evaluation module based on Bayesian networks to Intelligent Tutoring Systems. Int. J. Inf. Manag. 2017, 37, 1488–1498. [Google Scholar] [CrossRef]
- Burhan, M.I.; Sediyono, E.; Adi, K. Intelligent Tutoring System Using Bayesian Network for Vocational High Schools in Indonesia. E3S Web Conf. 2021, 317, 05027. [Google Scholar] [CrossRef]
- Chen, S.H.; Pollino, C.A. Good practice in Bayesian network modelling. Environ. Model. Softw. 2012, 37, 134–145. [Google Scholar] [CrossRef]
- Mousavinasab, E.; Zarifsanaiey, N.; Niakan Kalhori, S.R.; Rakhshan, M.; Keikha, L.; Ghazi Saeedi, M. Intelligent tutoring systems: A systematic review of characteristics, applications, and evaluation methods. Interact. Learn. Environ. 2021, 29, 142–163. [Google Scholar] [CrossRef]
- Suebnukarn, S. Intelligent Tutoring System for Clinical Reasoning Skill Acquisition in Dental Students. J. Dent. Educ. 2009, 73, 1178–1186. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Model-Free | Model-Based |
|---|---|---|
| SpringerLink | 93 | 99 |
| ScienceDirect | 122 | 81 |
| IEEE Xplore | 25 | 27 |
| Total | 240 | 207 |
| MDP Versions | System Form | State Characteristic | Reference |
|---|---|---|---|
| Fully Observable MDP (FOMDP) | Discrete | All observable | [29] |
| Partially Observable MDP (POMDP) | Discrete | Partially observable | [16] |
| Semi-MDP(SMDP) | Continuous | All observable | [30] |
| No. | Author and Year | Algorithm | Assessment Metrics | Description |
|---|---|---|---|---|
| 1 | Dorça et al. [9] | Q-learning | Performance value (PFM)/distance between learning style (DLS) | Three different automated control strategies are proposed to detect and learn from students’ learning styles. |
| 2 | Iglesias et al. [10] | Q-learning | Number of actions/number of students | Apply the RL in AIESs with database design. |
| 3 | Iglesias et al. [11] | Q-learning | Time consumption/number of students | Apply the reinforcement learning algorithm in AIESs. |
| 4 | Shawky and Badawi [13] | Q-learning | Number of actions/number of steps/cumulative rewards | The system can update states and adding new states or actions automatically. |
| 5 | Thomaz and Breazeal [15] | Q-learning | Number of actions/state/trials | Modify the RL algorithm to separate guidance and feedback channel. |
| 6 | Bassen et al., 2020 [14] | PPO (Proximal Policy Optimization) | Course completion rate/learning gains | Applied neural network to reduce number of samples required for the algorithm to converge. |
| 7 | Zhang, 2013 [16] | POMDP (Partially Observable Markov Decision Process) | Rejection rate | The model provides local access to the information when selecting the correct answer to a student’s question. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, J.; Mohd Rum, S.N.; Kasmiran, K.A.; Mohd Aris, T.N.; Mohamed, R. Artificial Intelligence in Adaptive and Intelligent Educational System: A Review. Future Internet 2022, 14, 245. https://doi.org/10.3390/fi14090245
Dong J, Mohd Rum SN, Kasmiran KA, Mohd Aris TN, Mohamed R. Artificial Intelligence in Adaptive and Intelligent Educational System: A Review. Future Internet. 2022; 14(9):245. https://doi.org/10.3390/fi14090245
Chicago/Turabian StyleDong, Jingwen, Siti Nurulain Mohd Rum, Khairul Azhar Kasmiran, Teh Noranis Mohd Aris, and Raihani Mohamed. 2022. "Artificial Intelligence in Adaptive and Intelligent Educational System: A Review" Future Internet 14, no. 9: 245. https://doi.org/10.3390/fi14090245
APA StyleDong, J., Mohd Rum, S. N., Kasmiran, K. A., Mohd Aris, T. N., & Mohamed, R. (2022). Artificial Intelligence in Adaptive and Intelligent Educational System: A Review. Future Internet, 14(9), 245. https://doi.org/10.3390/fi14090245