
Optimal Proactive Caching for Multi-View Streaming Mobile Augmented Reality


Abstract
:1. Introduction
2. Related Work
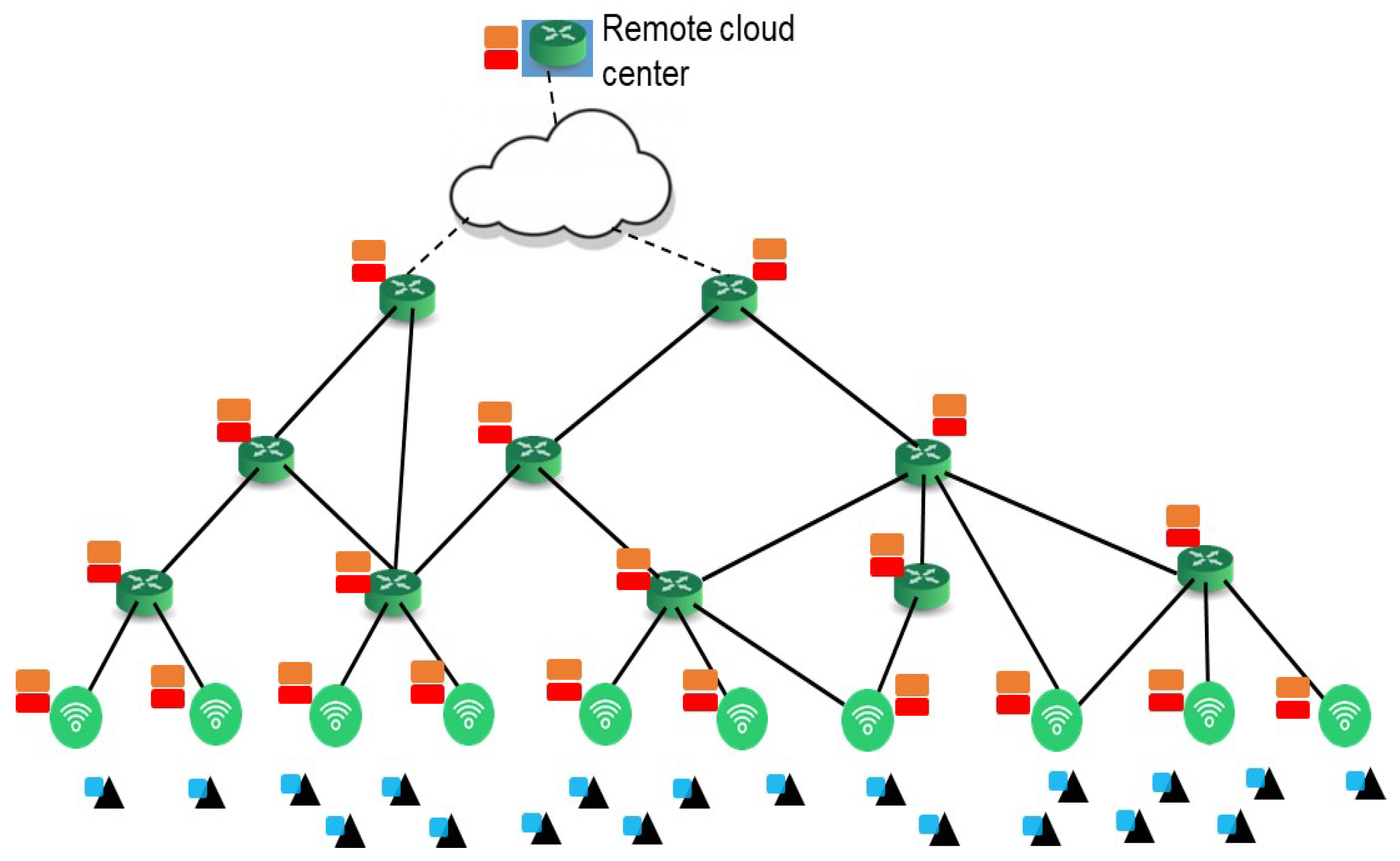
3. System Model
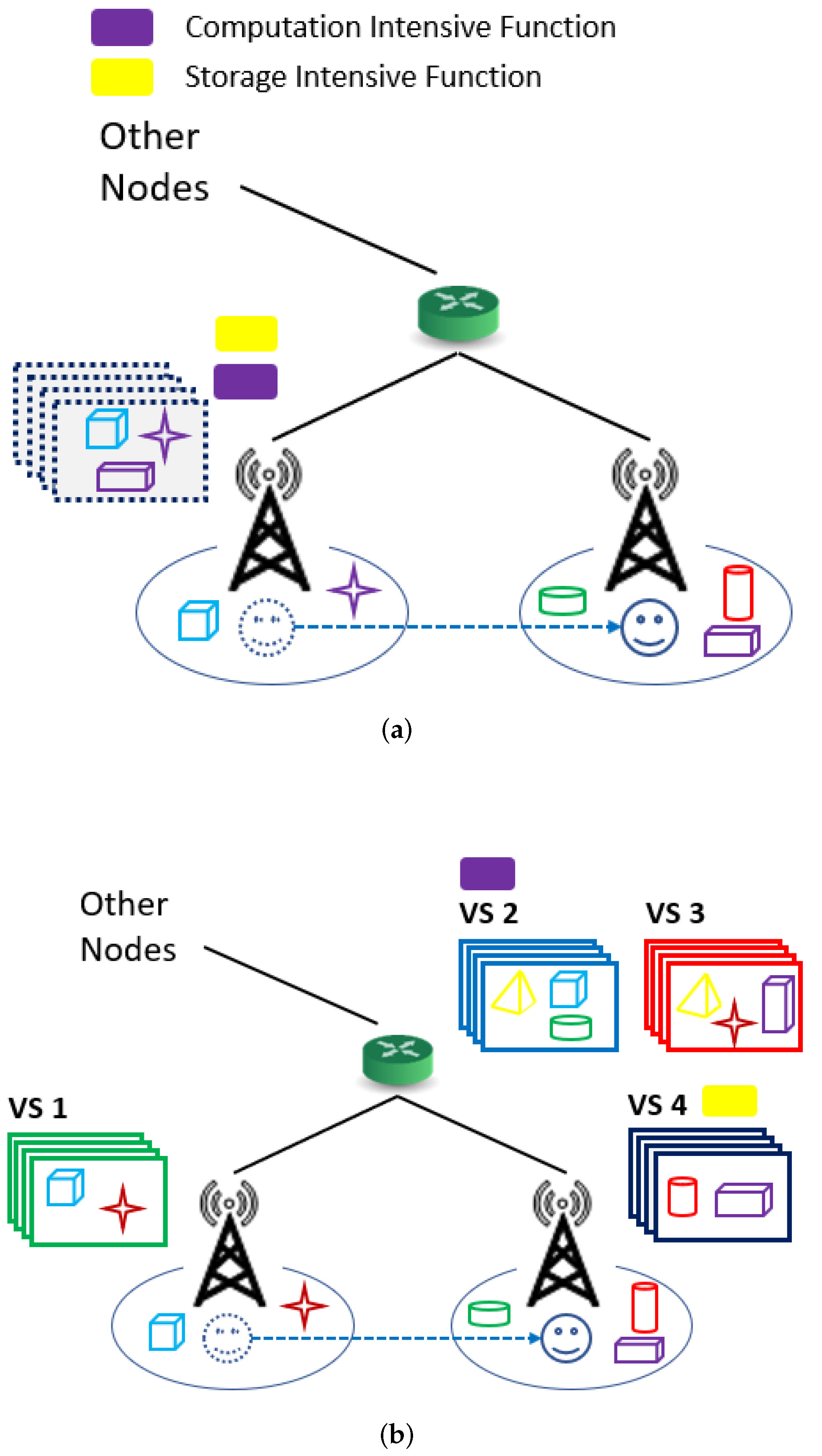
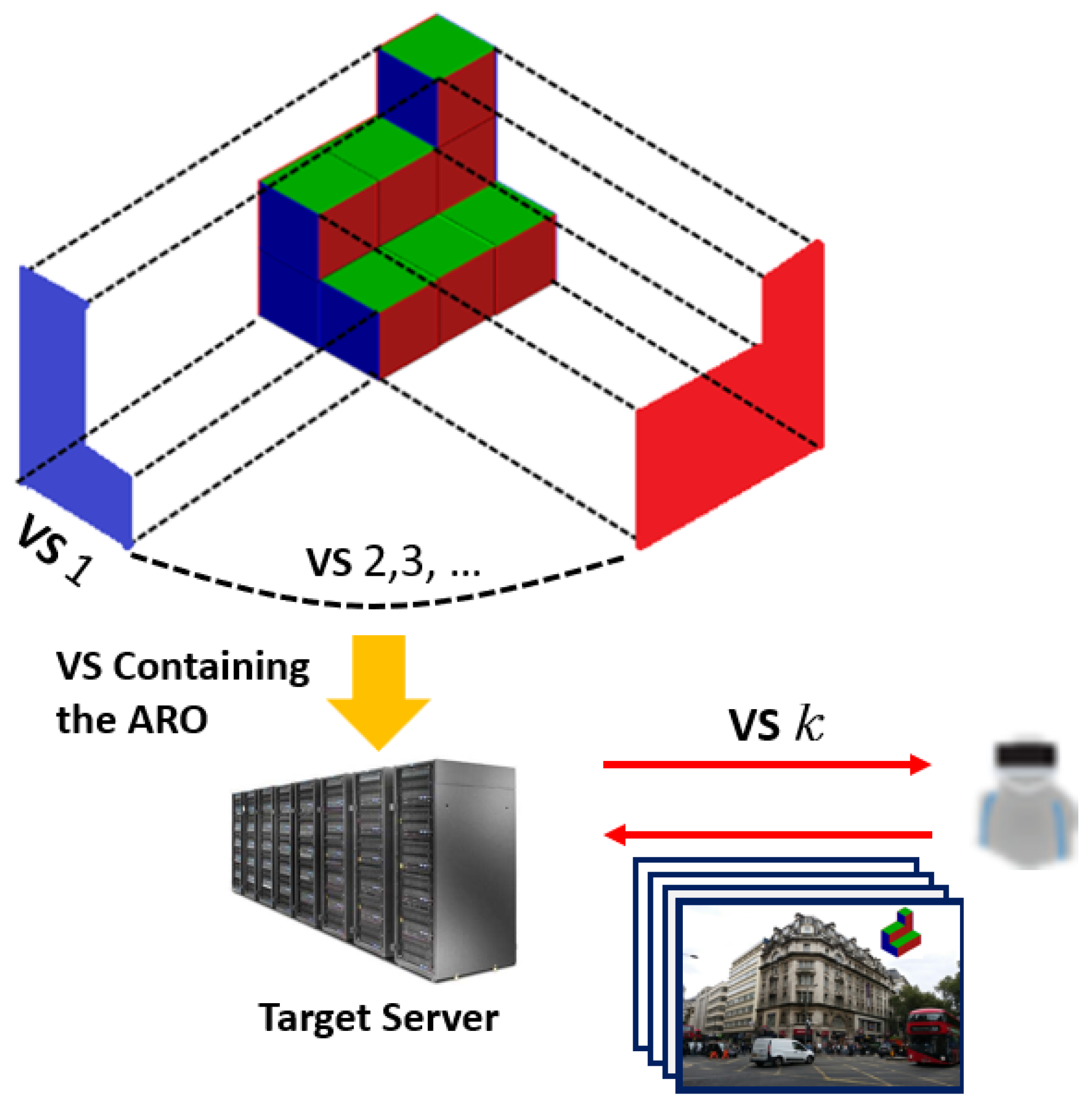
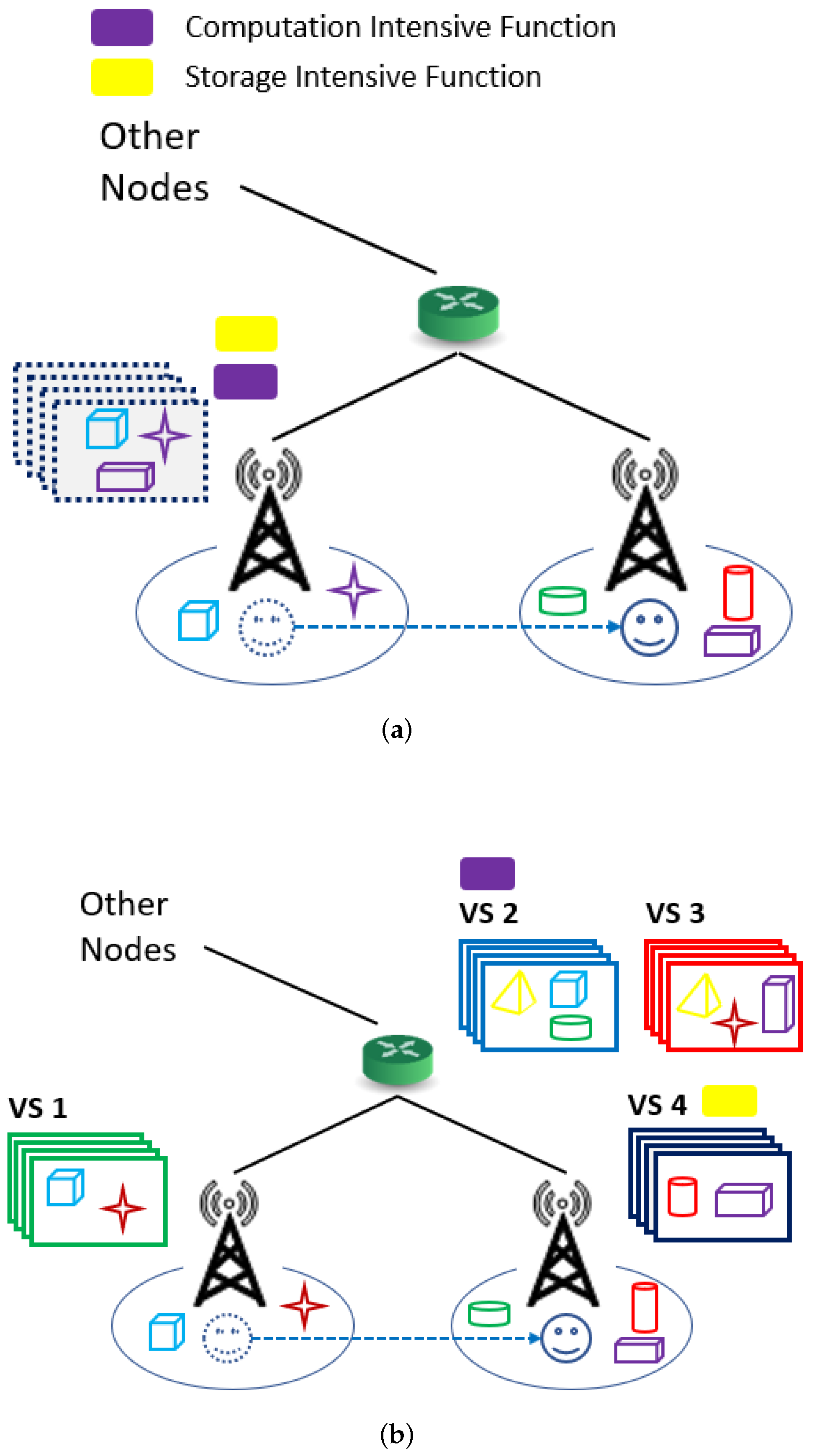
3.1. Multi-View Streaming AR
3.2. Mathematical Programming Formulation
3.2.1. Wireless Channel Modeling and Achievable Data Rate
3.2.2. Latency and Preference
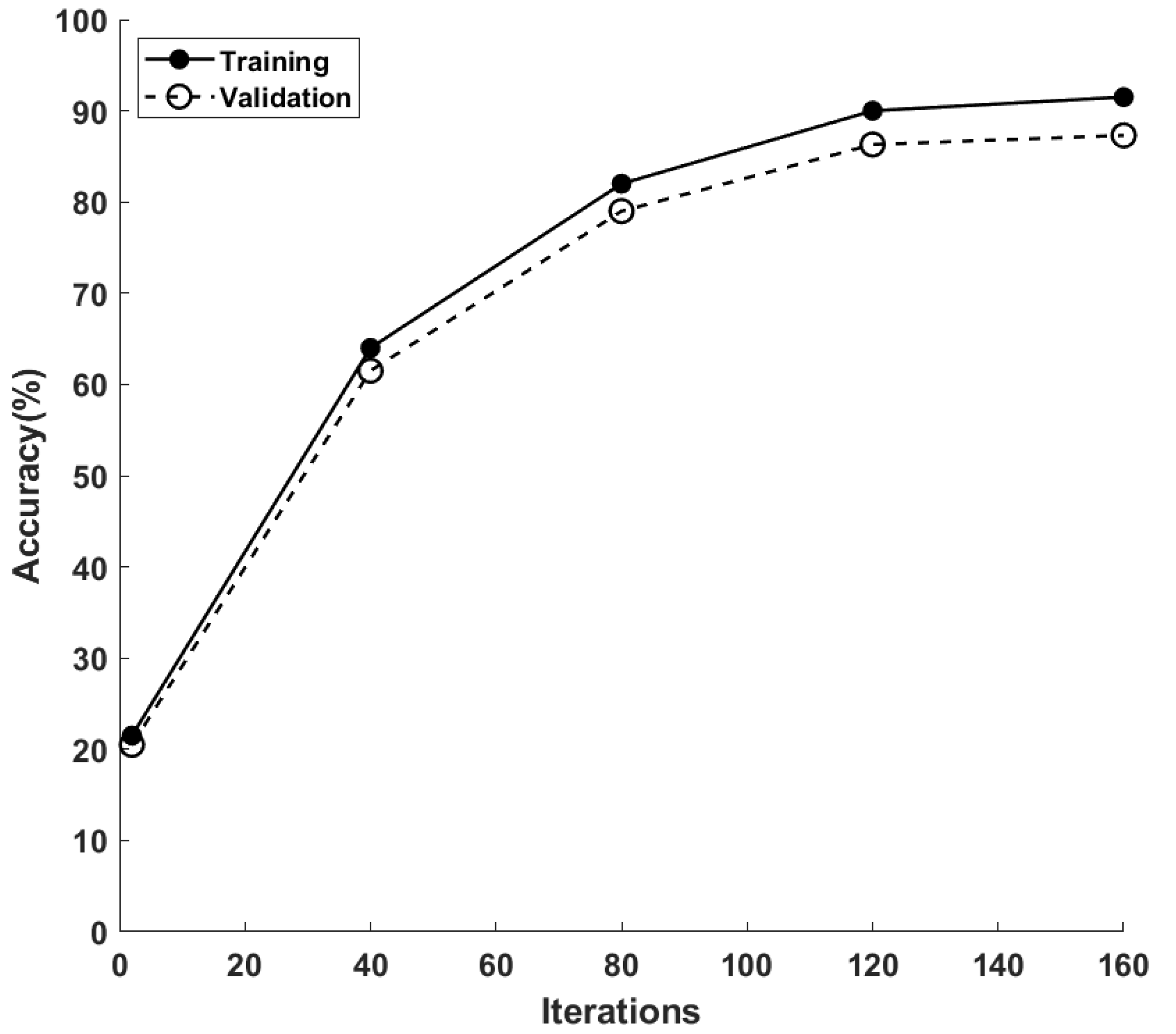
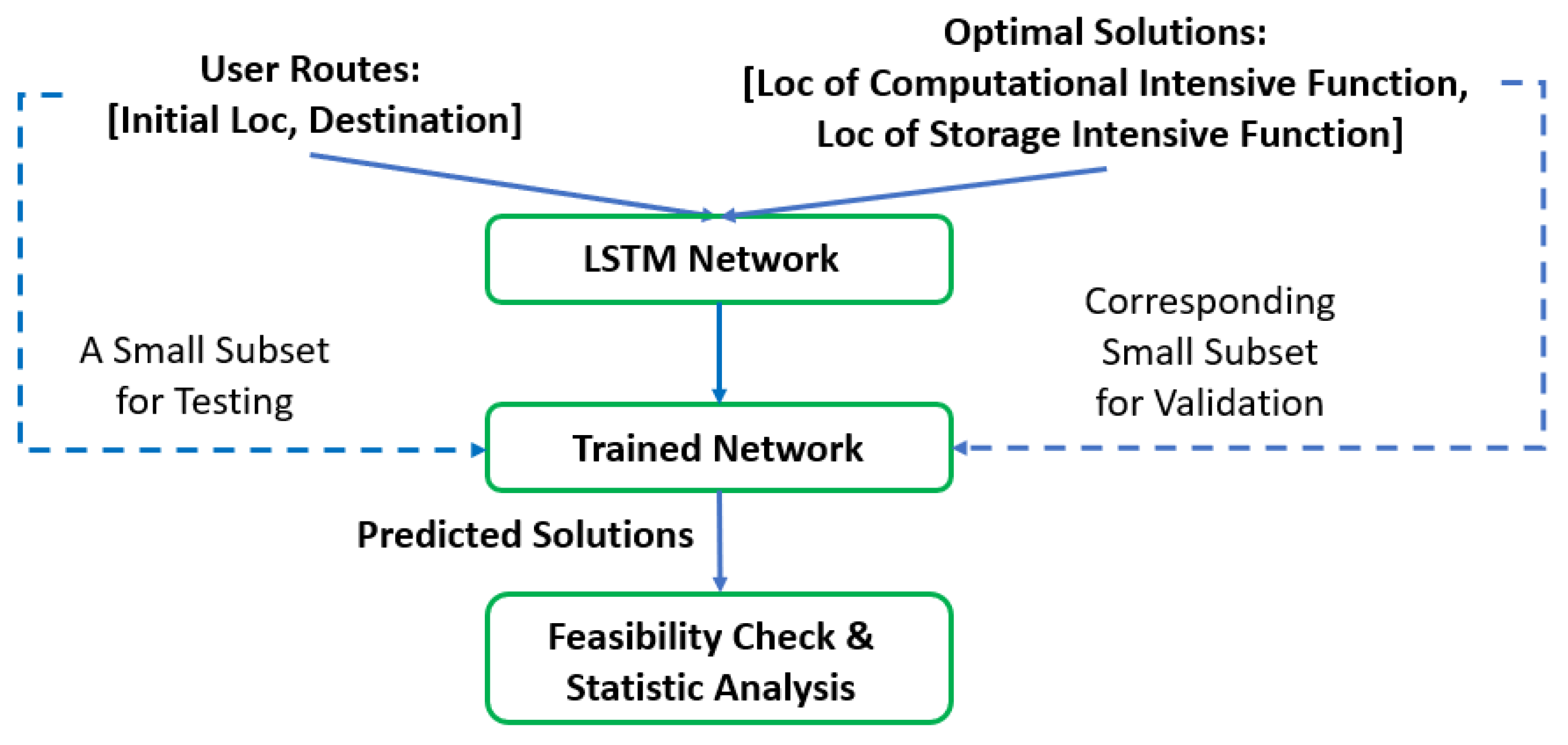
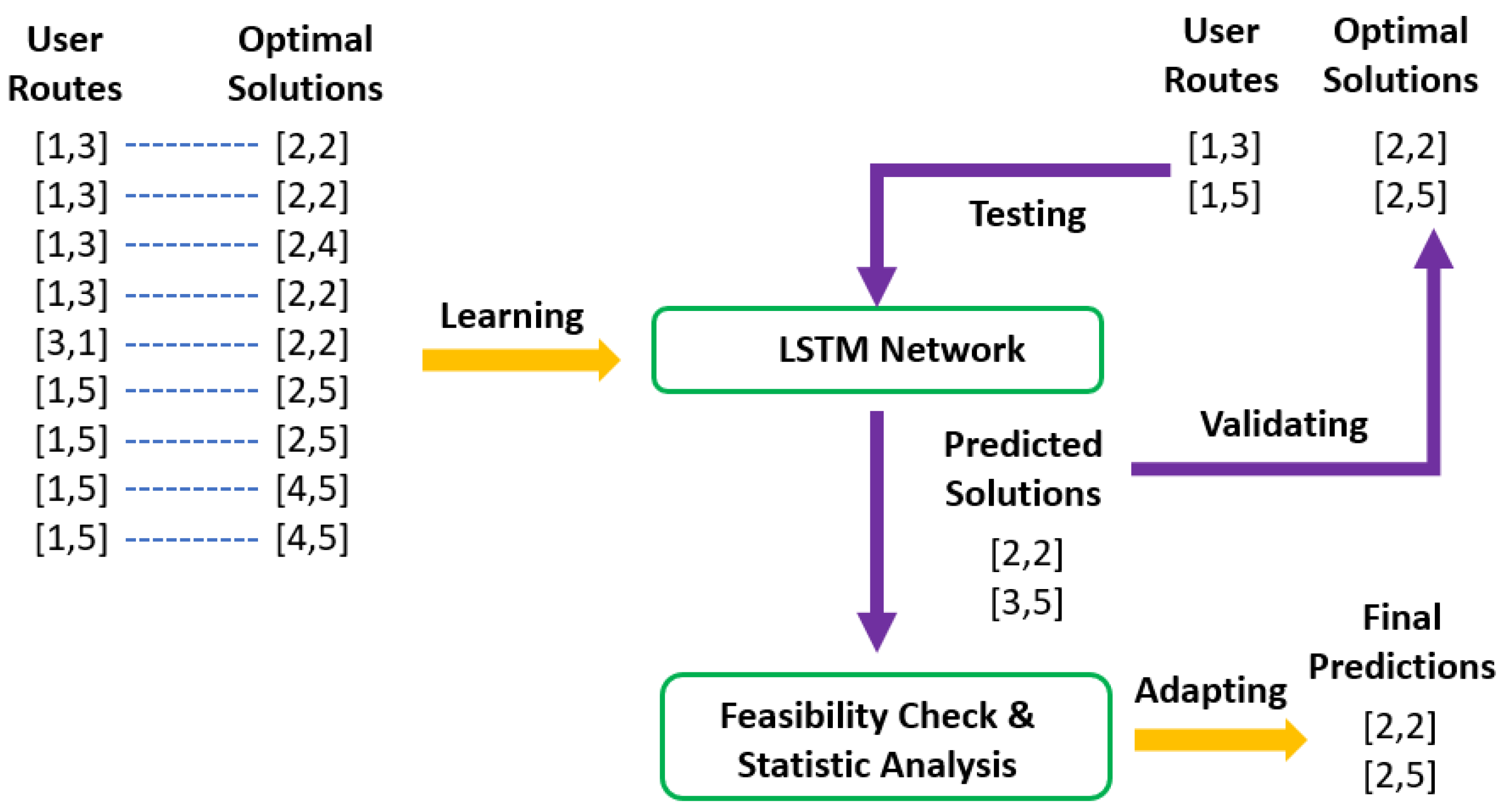
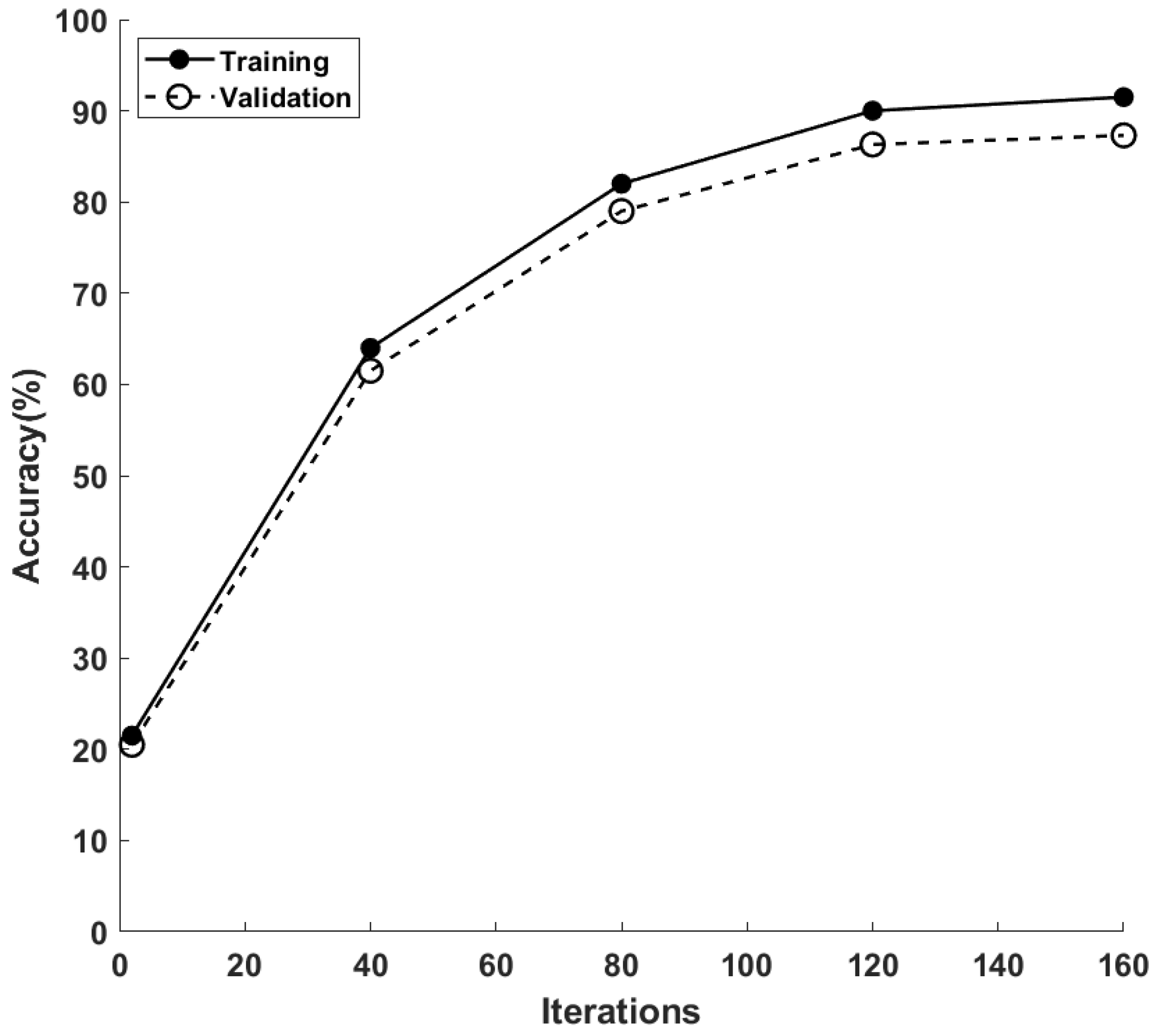
3.3. Heuristic Algorithm Using LSTM
4. Numerical Investigations
4.1. Parameterization
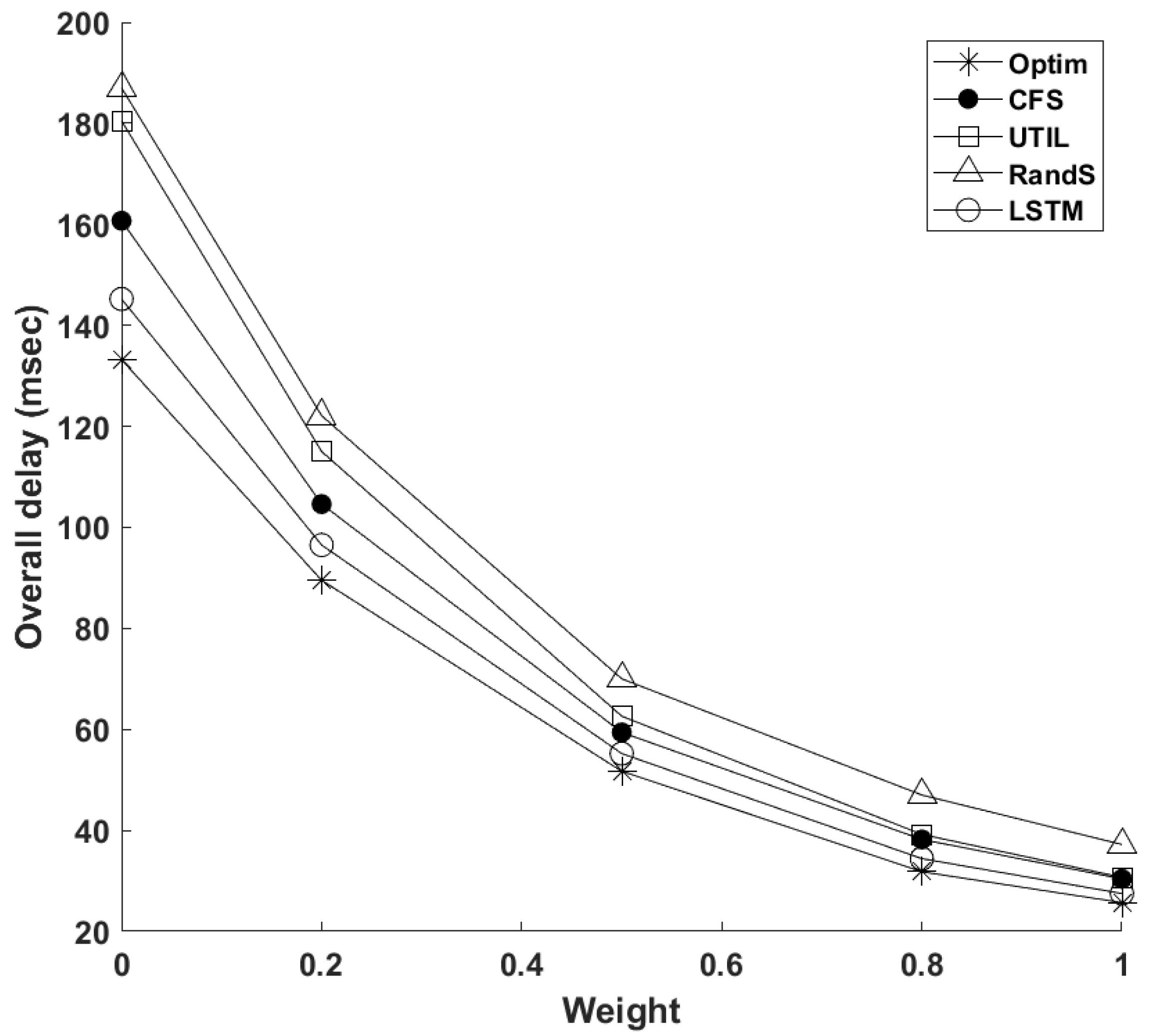
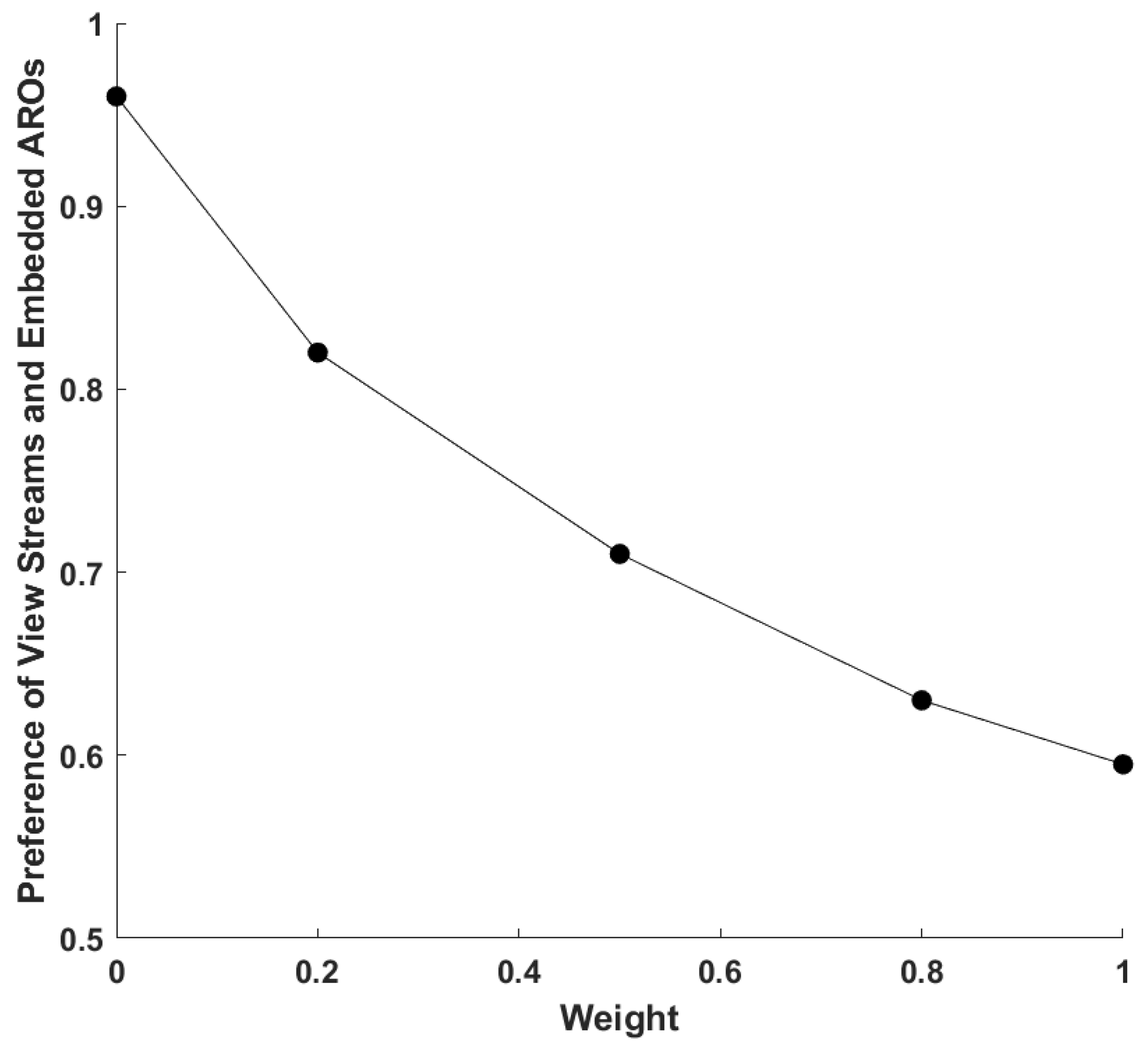
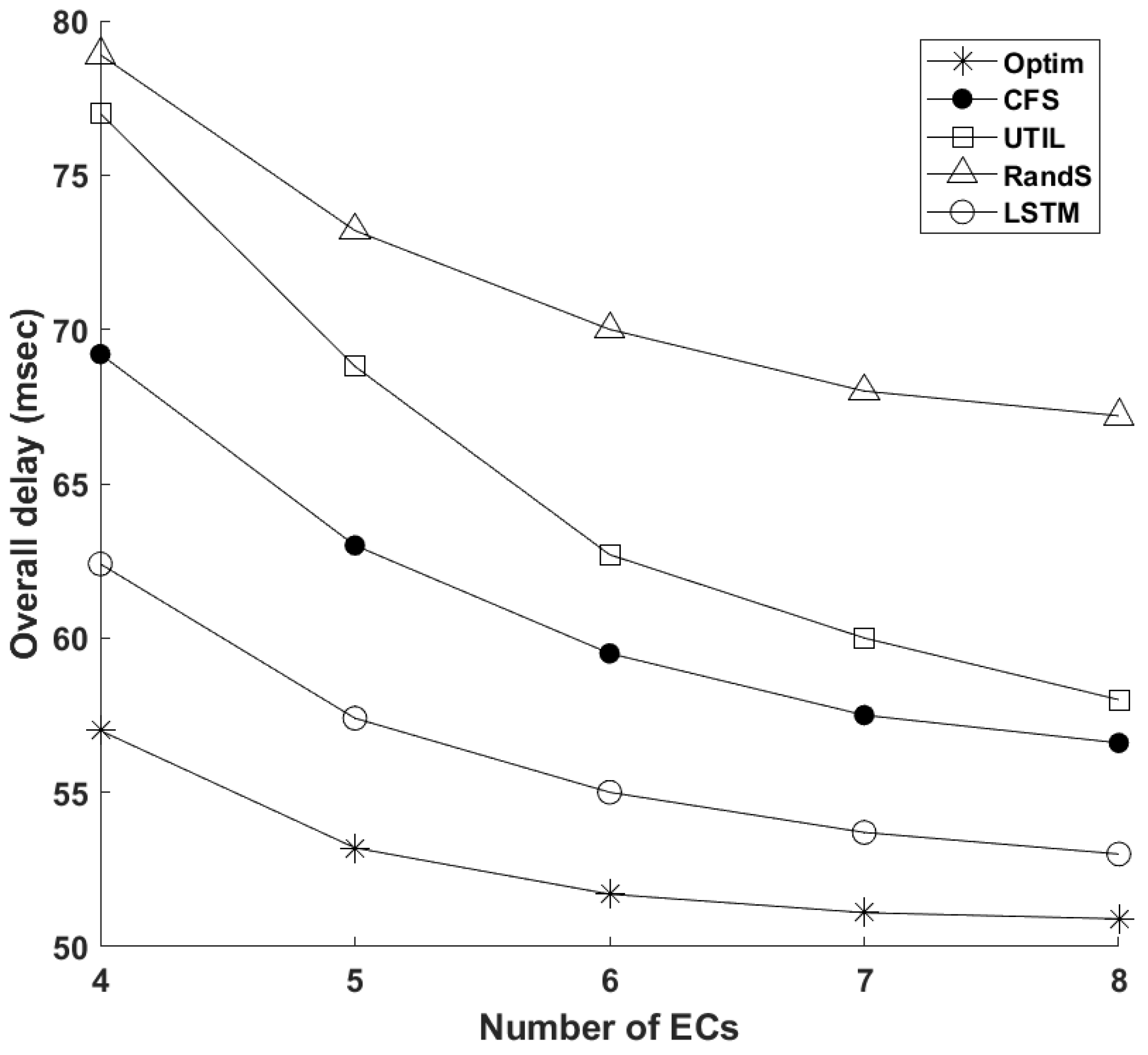
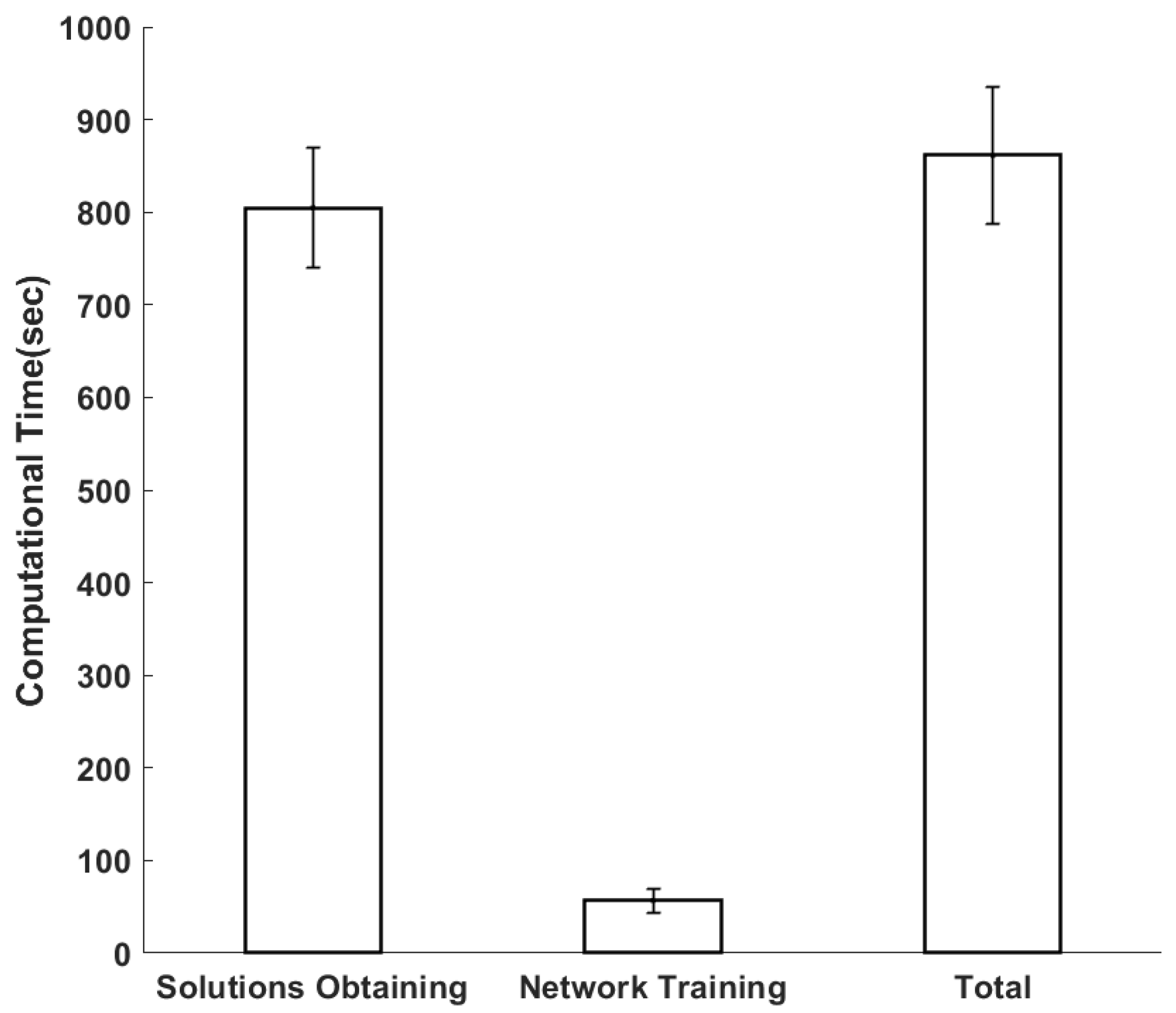
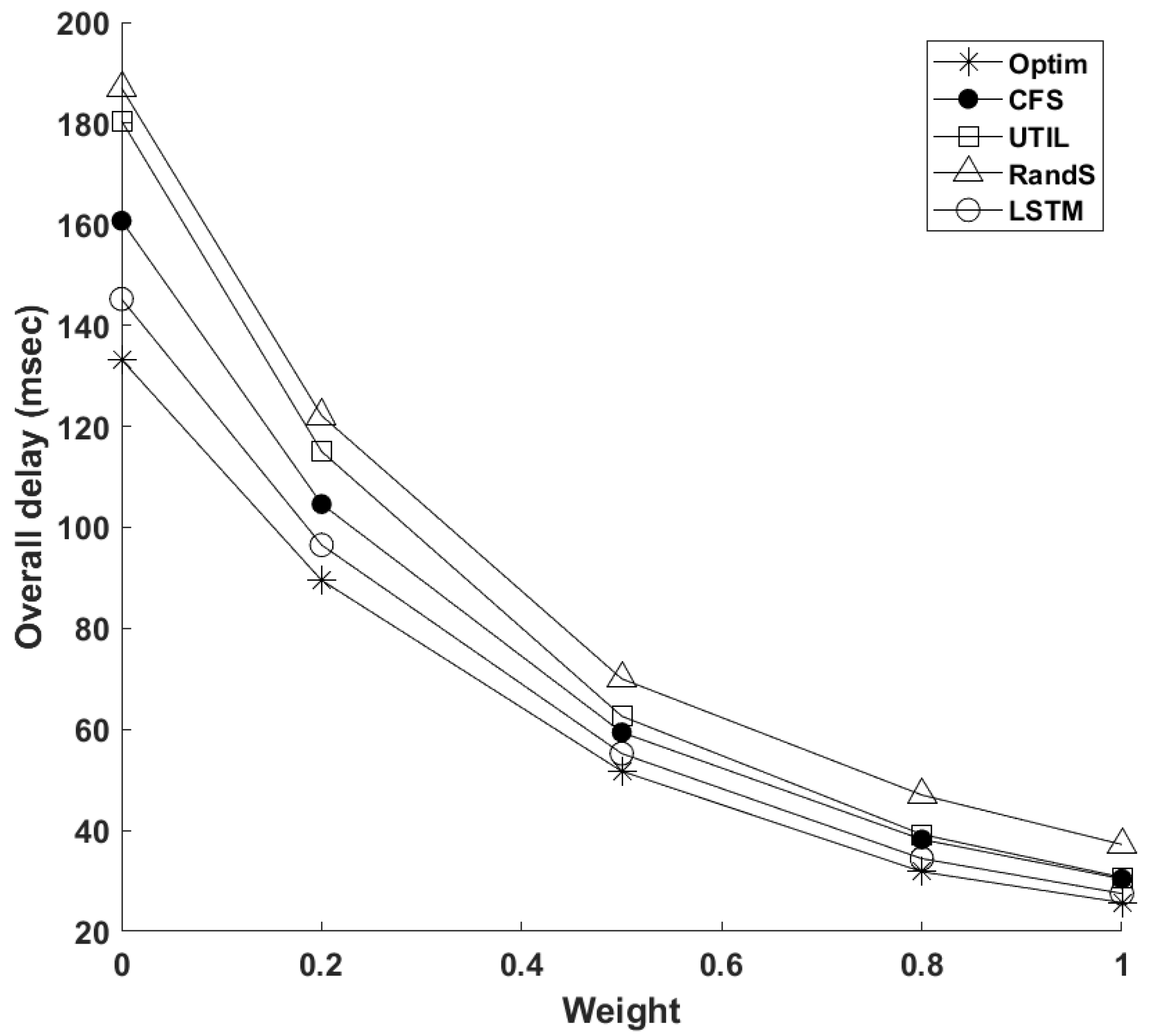
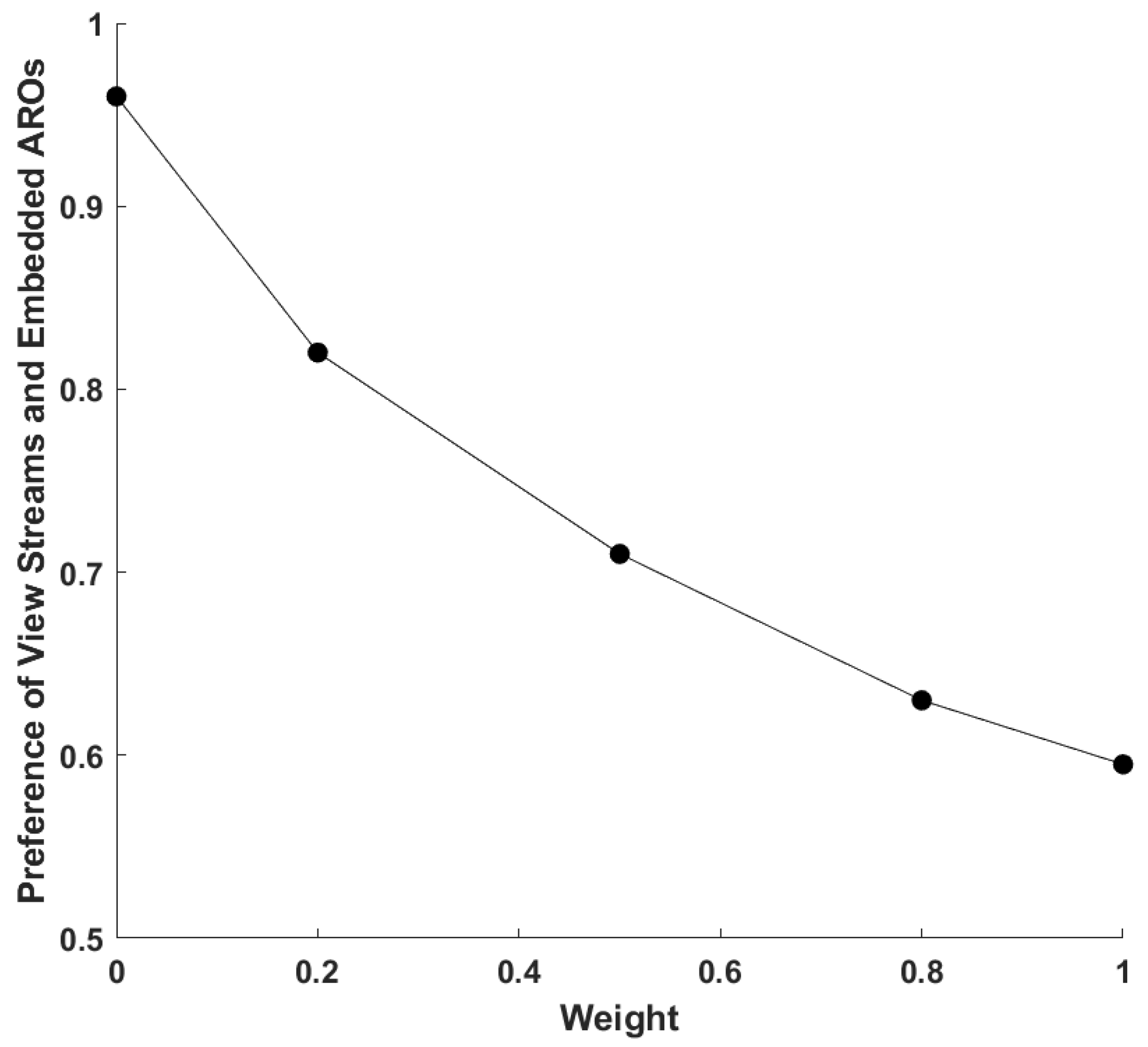
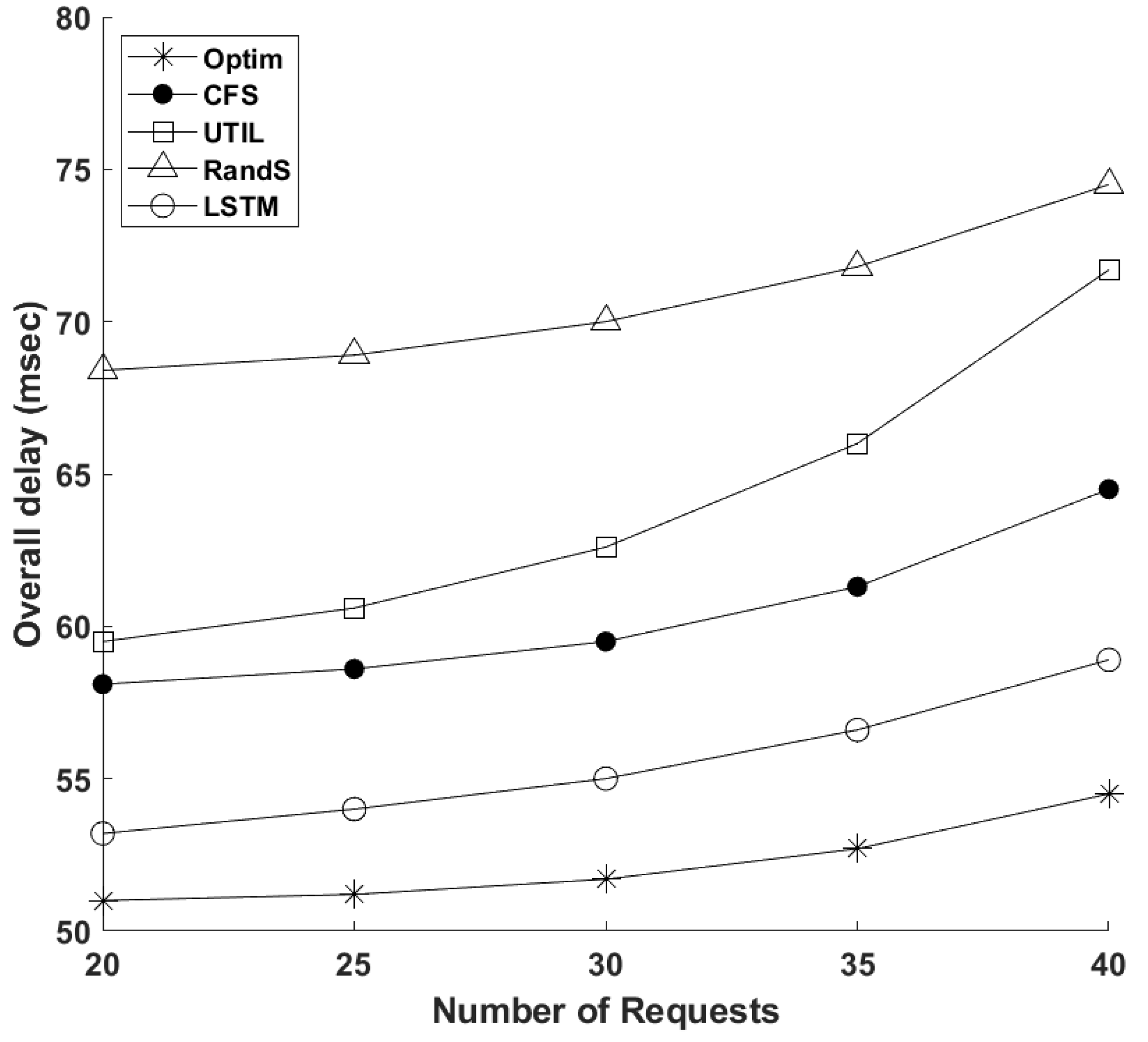
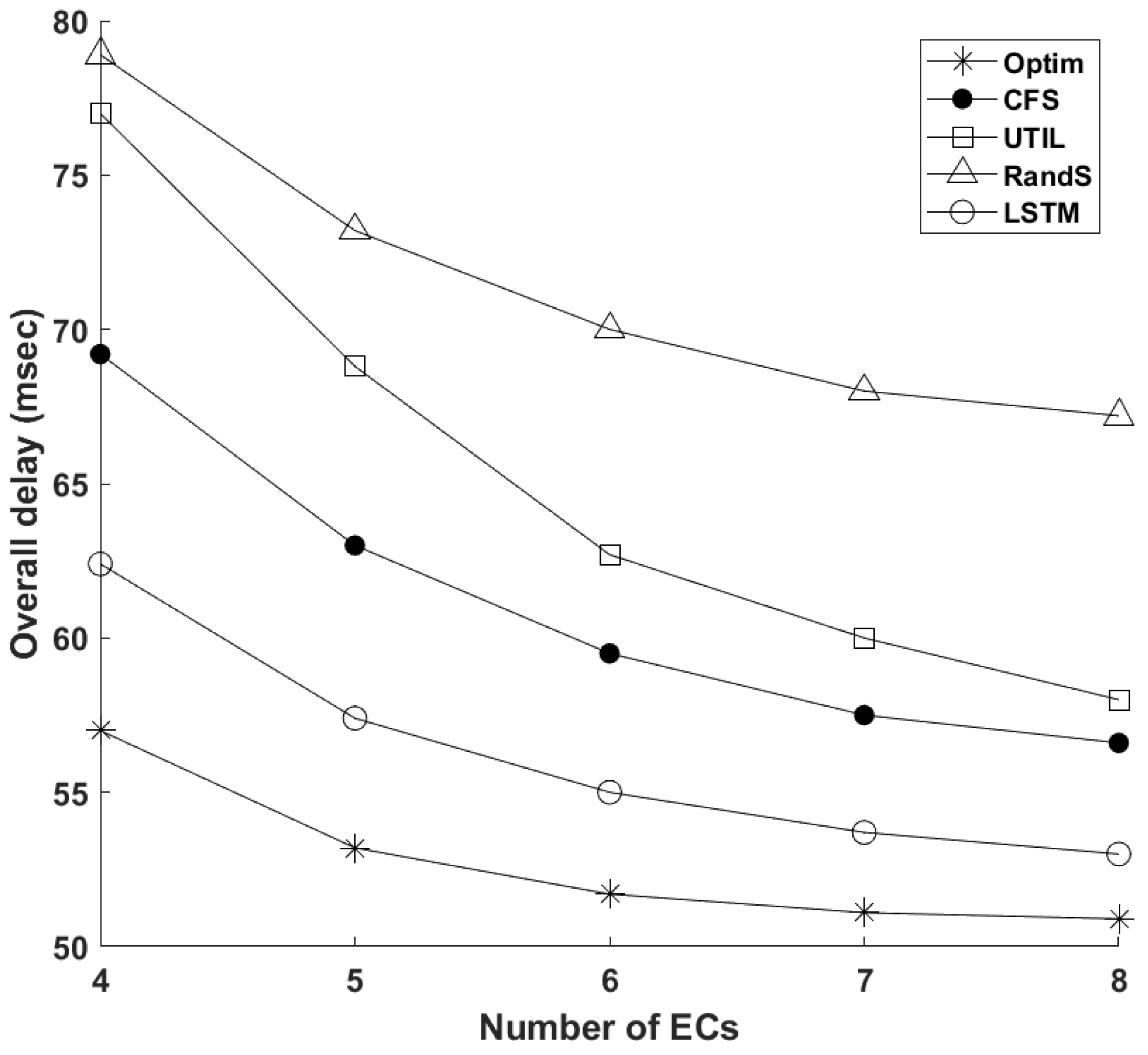
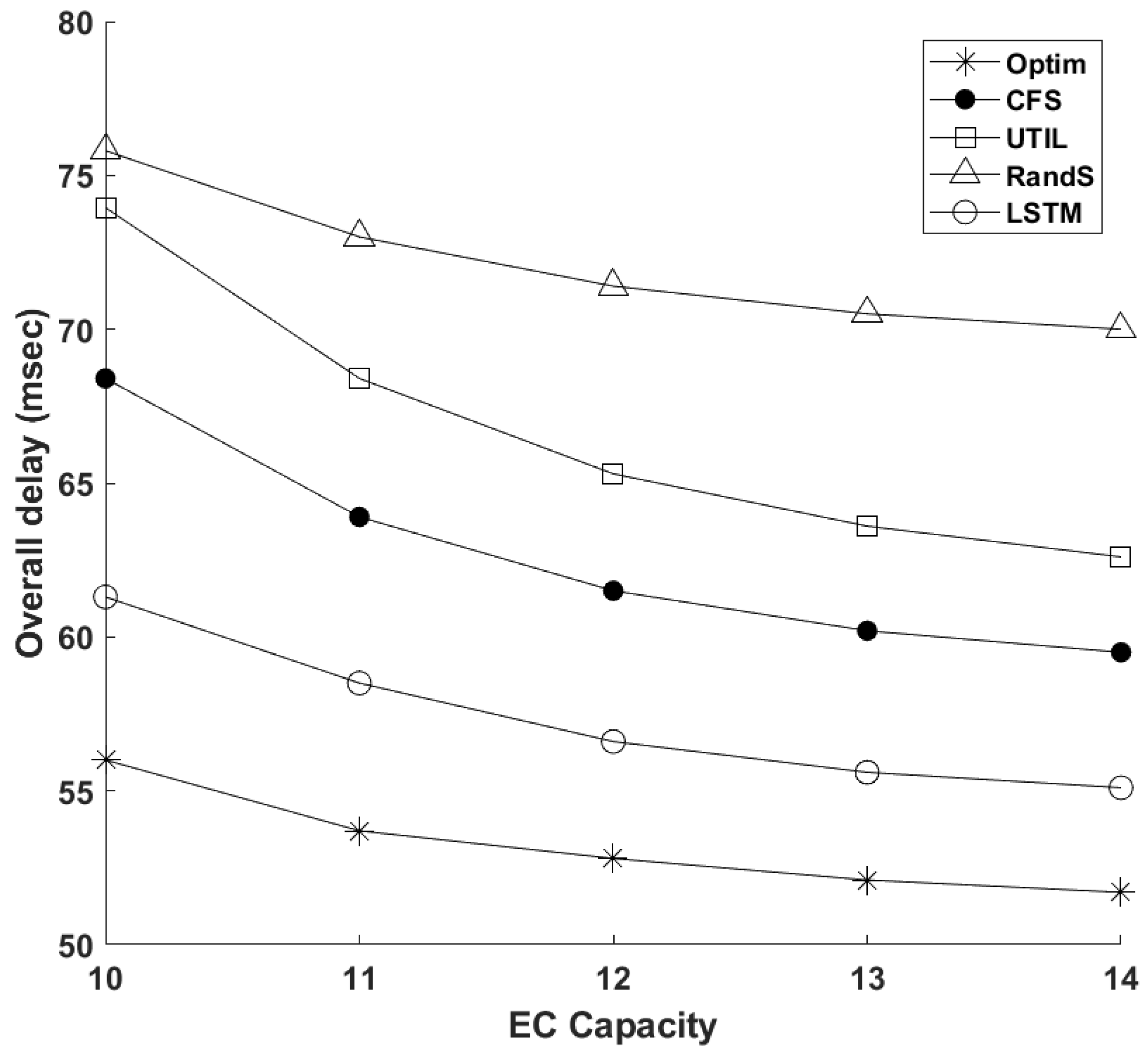
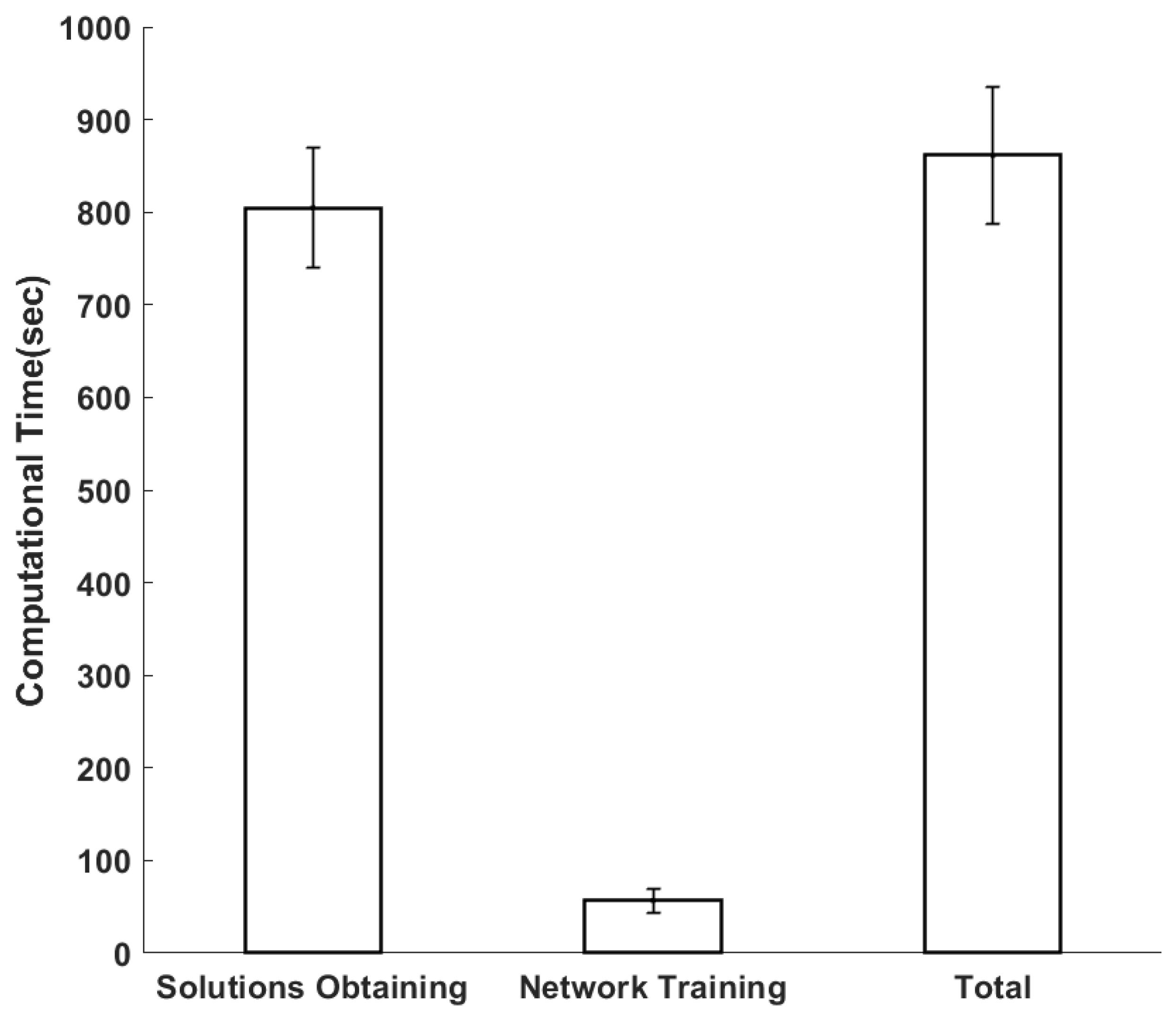
4.2. Simulation Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, L.; Qiao, X.; Lu, Q.; Ren, P.; Lin, R. Rendering Optimization for Mobile Web 3D Based on Animation Data Separation and On-Demand Loading. IEEE Access 2020, 8, 88474–88486. [Google Scholar] [CrossRef]
- Qiao, X.; Ren, P.; Dustdar, S.; Liu, L.; Ma, H.; Chen, J. Web AR: A promising future for mobile augmented reality—State of the art, challenges, and insights. Proc. IEEE 2019, 107, 651–666. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, S.; Opadere, J.; Han, T. An edge network orchestrator for mobile augmented reality. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018. [Google Scholar]
- Zhang, X.; Toni, L.; Frossard, P.; Zhao, Y.; Lin, C. Adaptive streaming in interactive multiview video systems. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1130–1144. [Google Scholar] [CrossRef]
- Avila, L.; Bailey, M. Augment your reality. IEEE Comput. Graph. Appl. 2016, 36, 6–7. [Google Scholar]
- Zhao, M.; Gong, X.; Liang, J.; Guo, J.; Wang, W.; Que, X.; Cheng, S. A cloud-assisted DASH-based scalable interactive multiview video streaming framework. In Proceedings of the 2015 Picture Coding Symposium (PCS), Cairns, QLD, Australia, 31 May–3 June 2015; pp. 221–226. [Google Scholar]
- Chakareski, J.; Velisavljevic, V.; Stankovic, V. View-popularity-driven joint source and channel coding of view and rate scalable multi-view video. IEEE J. Sel. Top. Signal Process. 2015, 9, 474–486. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Friderikos, V. Proactive Edge Cloud Optimization for Mobile Augmented Reality Applications. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Pervez, F.; Raheel, M.S.; Gill, J.; Iqbal, K. Uplink resource allocation of multiple DASH streams for QoE-based real and non-real time viewing over LTE. In Proceedings of the 10th International Conference on Next Generation Mobile Applications, Security and Technologies (NGMAST), Cardiff, UK, 24–26 August 2016. [Google Scholar]
- Zhang, A.; Jacobs, J.; Sra, M.; Höllerer, T. Multi-View AR Streams for Interactive 3D Remote Teaching. In Proceedings of the 27th ACM Symposium on Virtual Reality Software and Technology, Osaka, Japan, 8–10 December 2021; pp. 1–3. [Google Scholar]
- Zhang, R.; Liu, J.; Liu, F.; Huang, T.; Tang, Q.; Wang, S.; Yu, F.R. Buffer-Aware Virtual Reality Video Streaming with Personalized and Private Viewport Prediction. IEEE J. Sel. Areas Commun. 2021, 40, 694–709. [Google Scholar] [CrossRef]
- Bianchini, R.; Fontoura, M.; Cortez, E.; Bonde, A.; Muzio, A.; Constantin, A.M.; Moscibroda, T.; Magalhaes, G.; Bablani, G.; Russinovich, M. Toward ml-centric cloud platforms. Commun. ACM 2020, 63, 50–59. [Google Scholar] [CrossRef]
- Minaee, S.; Liang, X.; Yan, S. Modern Augmented Reality: Applications, Trends, and Future Directions. arXiv 2022, arXiv:2202.09450. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Zuo, Y.; Wu, Y.; Min, G.; Cui, L. Learning-based network path planning for traffic engineering. Future Gener. Comput. Syst. 2019, 92, 59–67. [Google Scholar] [CrossRef]
- Luo, C.; Ji, J.; Wang, Q.; Chen, X.; Li, P. Channel state information prediction for 5G wireless communications: A deep learning approach. IEEE Trans. Netw. Sci. Eng. 2018, 7, 227–236. [Google Scholar] [CrossRef]
- Xie, R.; Wu, J.; Wang, R.; Huang, T. A game theoretic approach for hierarchical caching resource sharing in 5G networks with virtualization. China Commun. 2019, 16, 32–48. [Google Scholar] [CrossRef]
- Halabian, H. Optimal distributed resource allocation in 5G virtualized networks. In Proceedings of the 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Arlington, VA, USA, 8–12 April 2019; pp. 28–35. [Google Scholar]
- Guo, Y.; Wang, S.; Zhou, A.; Xu, J.; Yuan, J.; Hsu, C.H. User allocation-aware edge cloud placement in mobile edge computing. Softw. Pract. Exp. 2020, 50, 489–502. [Google Scholar] [CrossRef]
- Wang, X.; Yang, L.T.; Xie, X.; Jin, J.; Deen, M.J. A cloud-edge computing framework for cyber-physical-social services. IEEE Commun. Mag. 2017, 55, 80–85. [Google Scholar] [CrossRef]
- Wang, Y.; Tao, X.; Zhang, X.; Zhang, P.; Hou, Y.T. Cooperative task offloading in three-tier mobile computing networks: An ADMM framework. IEEE Trans. Veh. Technol. 2019, 68, 2763–2776. [Google Scholar] [CrossRef]
- Ran, X.; Chen, H.; Zhu, X.; Liu, Z.; Chen, J. Deepdecision: A mobile deep learning framework for edge video analytics. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1421–1429. [Google Scholar]
- Chen, K.; Li, T.; Kim, H.S.; Culler, D.E.; Katz, R.H. Marvel: Enabling mobile augmented reality with low energy and low latency. In Proceedings of the 16th ACM Conference on Embedded Networked Sensor Systems, Shenzhen, China, 4–7 November 2018; pp. 292–304. [Google Scholar]
- Bilal, K.; Erbad, A.; Hefeeda, M. Crowdsourced multi-view live video streaming using cloud computing. IEEE Access 2017, 5, 12635–12647. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, H.; Hu, Y. Optimal Power and Bandwidth Allocation for Multiuser Video Streaming in UAV Relay Networks. IEEE Trans. Veh. Technol. 2020, 69, 6644–6655. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, Y.; Hua, M.; Li, C.; Huang, Y.; Yang, L. Proactive caching for vehicular multi-view 3D video streaming via deep reinforcement learning. IEEE Trans. Wirel. Commun. 2019, 18, 2693–2706. [Google Scholar] [CrossRef]
- Cozzolino, V.; Tonetto, L.; Mohan, N.; Ding, A.Y.; Ott, J. Nimbus: Towards Latency-Energy Efficient Task Offloading for AR Services. IEEE Trans. Cloud Comput. 2022. Available online: https://ieeexplore.ieee.org/document/9695282 (accessed on 25 April 2022). [CrossRef]
- Gemici, Ö.F.; Hökelek, İ.; Çırpan, H.A. Modeling Queuing Delay of 5G NR With NOMA Under SINR Outage Constraint. IEEE Trans. Veh. Technol. 2021, 70, 2389–2403. [Google Scholar] [CrossRef]
- Cho, Y.S.; Kim, J.; Yang, W.Y.; Kang, C.G. MIMO-OFDM Wireless Communications with MATLAB; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Wang, Y.; Haenggi, M.; Tan, Z. the meta distribution of the SIR for cellular networks with power control. IEEE Trans. Commun. 2017, 66, 1745–1757. [Google Scholar] [CrossRef]
- Korrai, P.K.; Lagunas, E.; Sharma, S.K.; Chatzinotas, S.; Ottersten, B. Slicing based resource allocation for multiplexing of eMBB and URLLC services in 5G wireless networks. In Proceedings of the 2019 IEEE 24th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Limassol, Cyprus, 11–13 September 2019. [Google Scholar]
- Li, S.; Lin, P.; Song, J.; Song, Q. Computing-Assisted Task Offloading and Resource Allocation for Wireless VR Systems. In Proceedings of the IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020. [Google Scholar]
- Chettri, L.; Bera, R. A comprehensive survey on Internet of Things (IoT) toward 5G wireless systems. IEEE Internet Things J. 2019, 7, 16–32. [Google Scholar] [CrossRef]
- Toczé, K.; Nadjm-Tehrani, S. ORCH: Distributed Orchestration Framework using Mobile Edge Devices. In Proceedings of the IEEE 3rd International Conference on Fog and Edge Computing (ICFEC), Larnaca, Cyprus, 14–17 May 2019; pp. 1–10. [Google Scholar]
- Sonmez, C.; Ozgovde, A.; Ersoy, C. Fuzzy workload orchestration for edge computing. IEEE Trans. Netw. Serv. Manag. 2019, 16, 769–782. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| Set of all AROs | |
| Set of edge clouds | |
| Set of user requests | |
| Set of view streams | |
| Set of user destinations | |
| Set of target AROs for request r in corresponding view stream s | |
| Accessing probability vectors of AROs and view streams | |
| Two types of AR functions (CPU, Cache) | |
| Size of ARO l | |
| 0/1 var.: if ARO l in view stream s for the request r is cached | |
| 0/1 var.: if view stream s is cached at node j | |
| 0/1 var.: if function or for r is set at EC j | |
| 0/1 var.: if a cache hit is spotted for request r | |
| Communication delay between nodes i and j | |
| Input size for functions , in request r | |
| Channel gain for request r at node j | |
| SINR for request r at node j | |
| Resource block bandwidth, power and noise at node j | |
| path loss exponent | |
| Euclidean distance between user r to node j | |
| Initial access point for request r | |
| D | Cache miss penalty |
| Moving probability from initial location to destination k | |
| Computation load and CPU availability at EC j | |
| Processing delay for request r for function , at EC j | |
| Overall latency and user preference | |
| Cache capacity at EC j |
| Parameter | Value |
|---|---|
| Number of available ECs | |
| Number of available VMs per EC (EC Capacity) | |
| Number of requests | |
| Number of view streams per user | 4 |
| AR object size | MByte |
| Total moving probability | |
| Cell radius | 250m |
| Remained cache capacity per EC | MByte |
| CPU frequency | GHz |
| CPU cores | |
| CPU portion per VM | 0.125–0.25 |
| Computation load | 10 cycles/bit |
| Bandwidth of access router | 20 MHz |
| Power of access router | 20 dBm |
| Path loss exponent | 4 |
| Noise power | dBm |
| Number of resource blocks | 100 |
| Average hop’s latency | 2 ms |
| Cache miss penalty | 25 ms |
| Number of user route vectors/optimal decisions | 300 |
| Initial LSTM learning rate | |
| Maximum number of epochs | 160 |
| LSTM dropout probability |
| Scheme | Optim | LSTM | CFS | UTIL | RandS |
|---|---|---|---|---|---|
| Delay (ms) | 25.7 | 27.9 | 30.2 | 31.1 | 37.4 |
| RMSE | - | 2.4 | 8.5 | 3.6 | 5.8 |
| Algorithm | Average Processing Time (s) | STD |
|---|---|---|
| RandS | 0.696 | 0.284 |
| CFS | 0.731 | 0.295 |
| UTIL | 0.753 | 0.308 |
| LSTM | 1.386 | 0.223 |
| Optim | 168.277 | 15.392 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Friderikos, V. Optimal Proactive Caching for Multi-View Streaming Mobile Augmented Reality. Future Internet 2022, 14, 166. https://doi.org/10.3390/fi14060166
Huang Z, Friderikos V. Optimal Proactive Caching for Multi-View Streaming Mobile Augmented Reality. Future Internet. 2022; 14(6):166. https://doi.org/10.3390/fi14060166
Chicago/Turabian StyleHuang, Zhaohui, and Vasilis Friderikos. 2022. "Optimal Proactive Caching for Multi-View Streaming Mobile Augmented Reality" Future Internet 14, no. 6: 166. https://doi.org/10.3390/fi14060166
APA StyleHuang, Z., & Friderikos, V. (2022). Optimal Proactive Caching for Multi-View Streaming Mobile Augmented Reality. Future Internet, 14(6), 166. https://doi.org/10.3390/fi14060166