
QoE Models for Adaptive Streaming: A Comprehensive Evaluation


Abstract
:1. Introduction
- All considered models yield better performance on H.264-encoded streaming sessions than HEVC-encoded ones. Surprisingly, even the models taking into account HEVC characteristics such as P.1203 and KSQI are not very effective for HEVC-encoded sessions.
- To obtain the high and stable performance for different devices, it is recommended to use Mean Opinion Score (MOS) and Video Multi-method Assessment Fusion (VMAF) to calculate segment quality values.
- Besides quality variations and stalling events, temporal relations between impairment events should be also considered in QoE models.
- The use of multiple statistics as model inputs is indispensable to fully represent quality variations and stalling events in a streaming session. However, it is also found that complex models that contain more statistics do not always lead to better performance.
- Among the considered models, the LSTM model [10] is the best one since it provides the highest and most stable performance across viewing devices and session durations. However, there is still room for improvements of the existing models, especially in the cases of various viewing devices and advanced video codecs.
2. Overview of QoE Models
3. Evaluation Settings
3.1. Selected QoE Models
3.2. Databases
3.3. Evaluation Procedure and Performance Metrics
4. Evaluation Results and Discussion
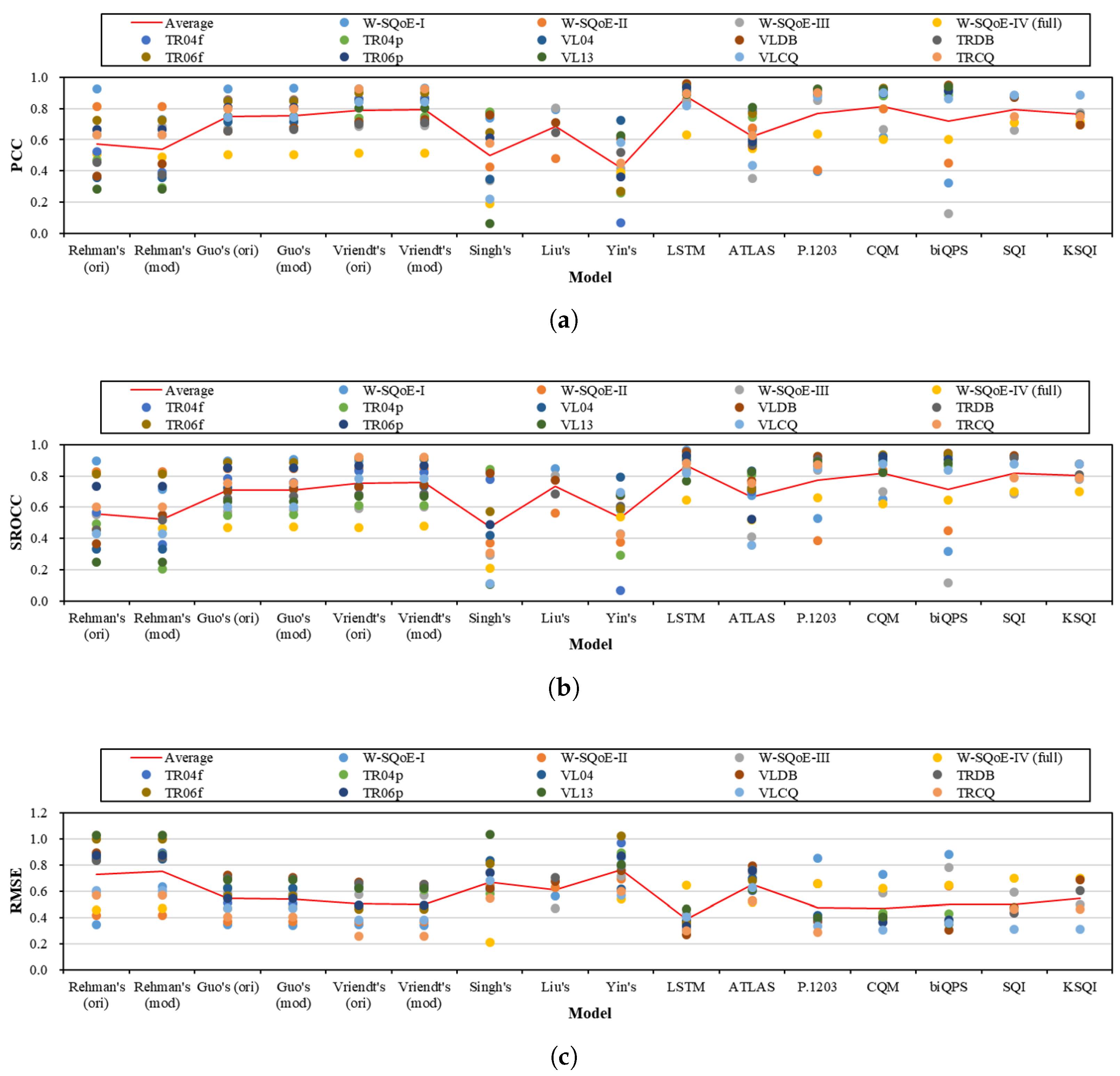
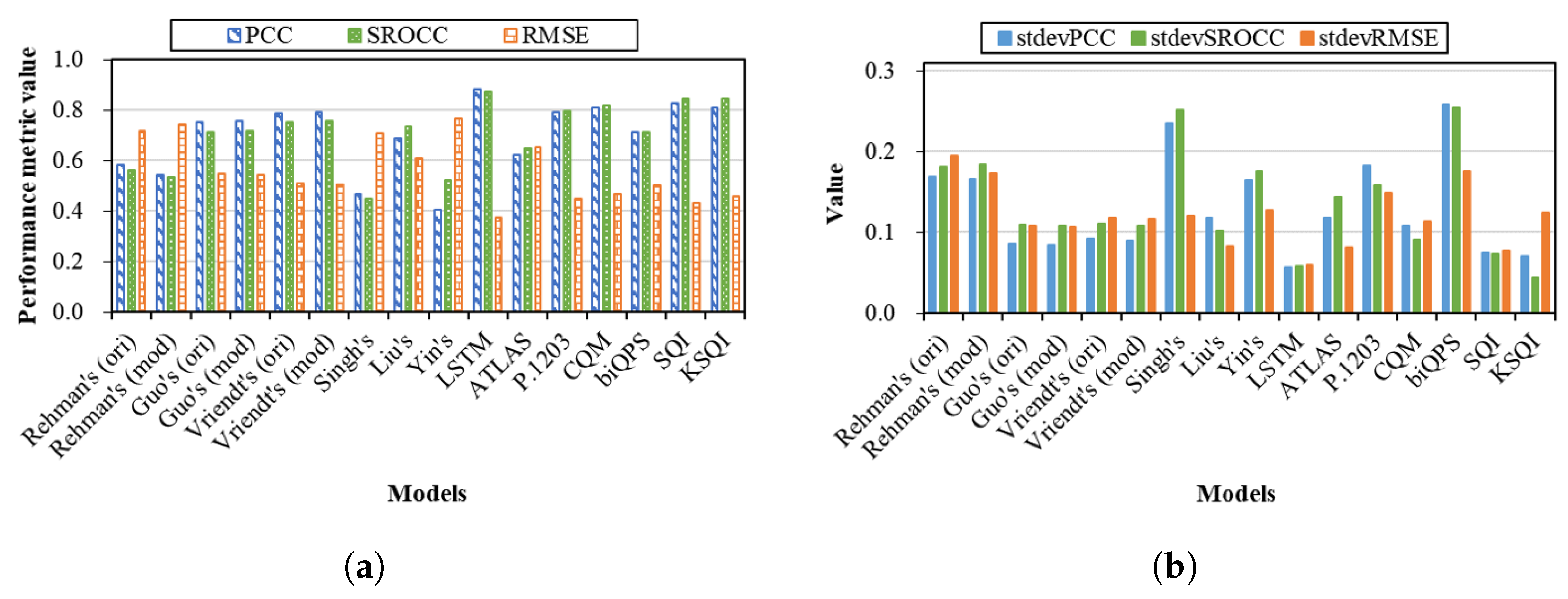
4.1. Performance Variation across Databases
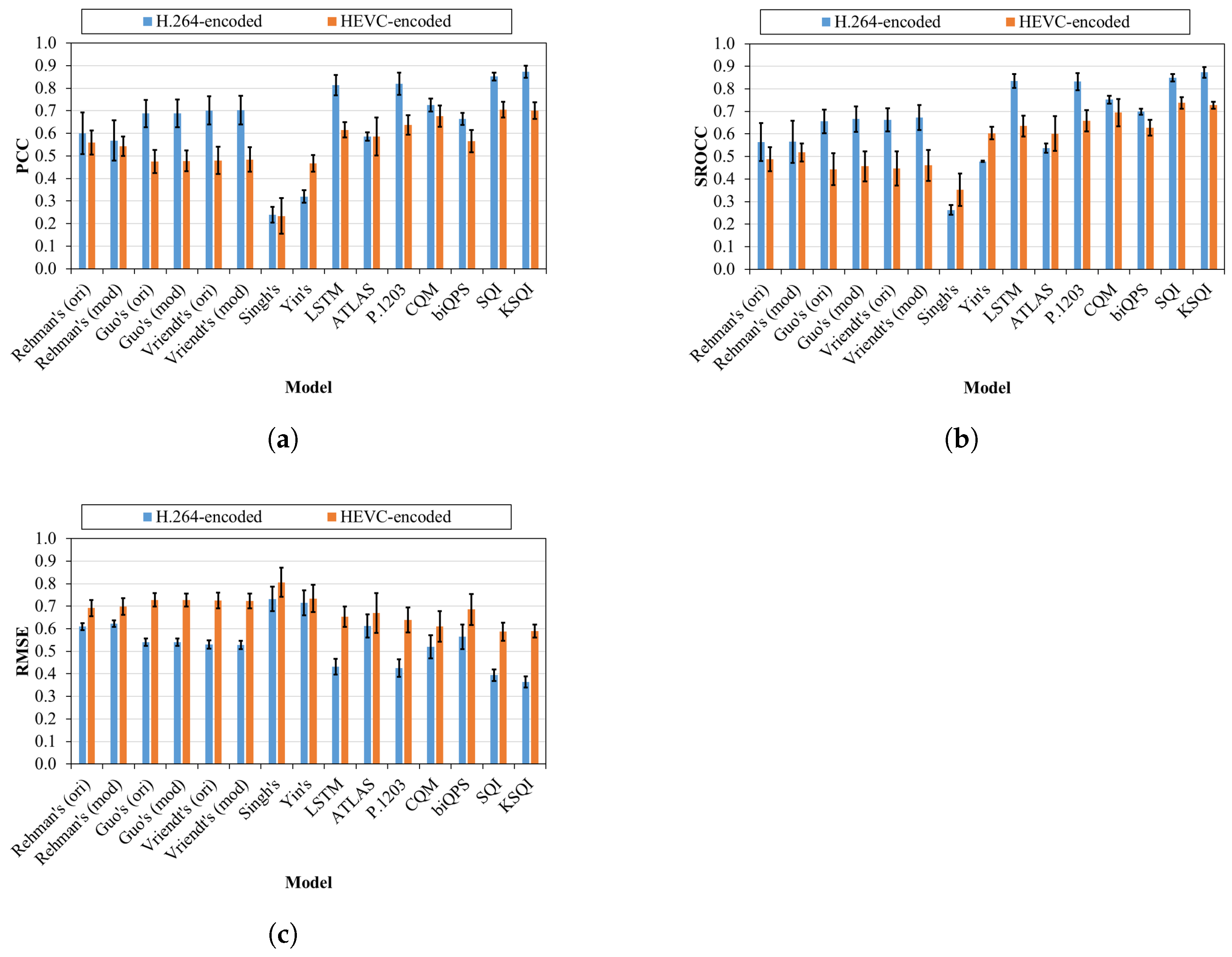
4.2. Performance across Video Codecs
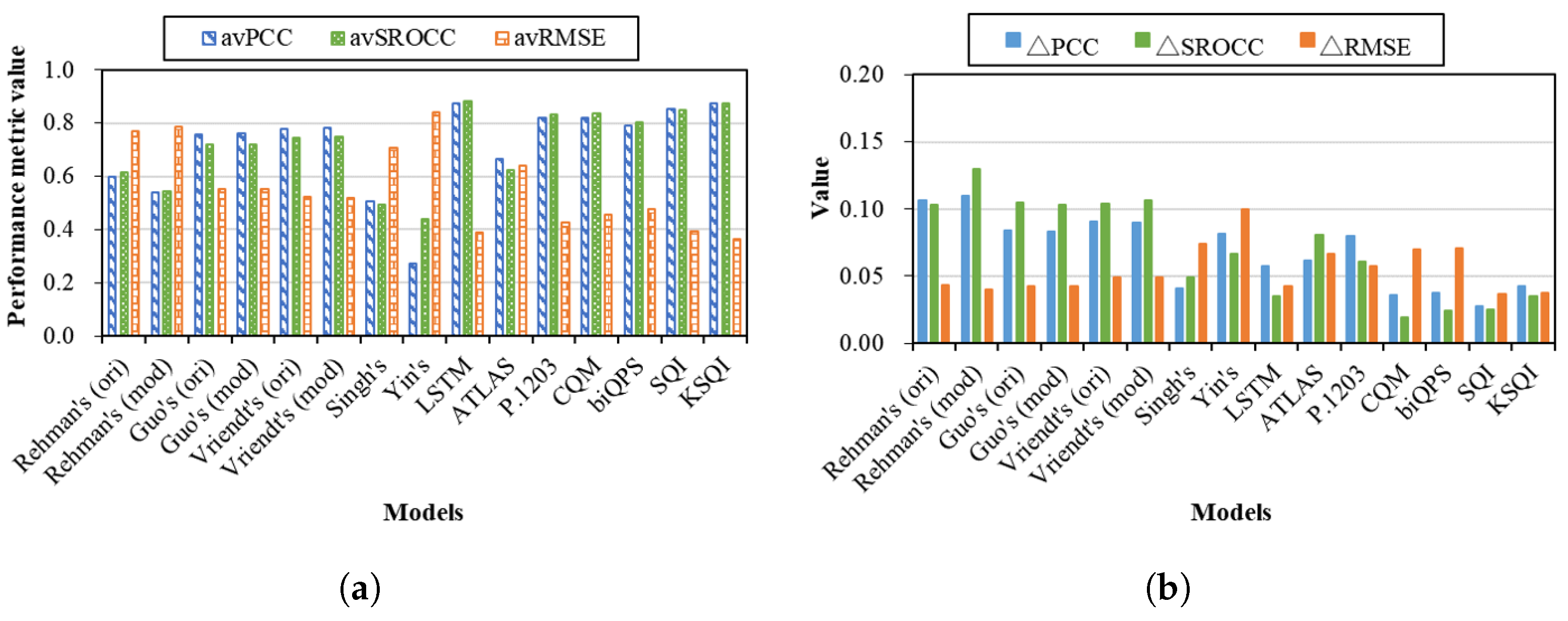
4.3. Performance across Viewing Devices
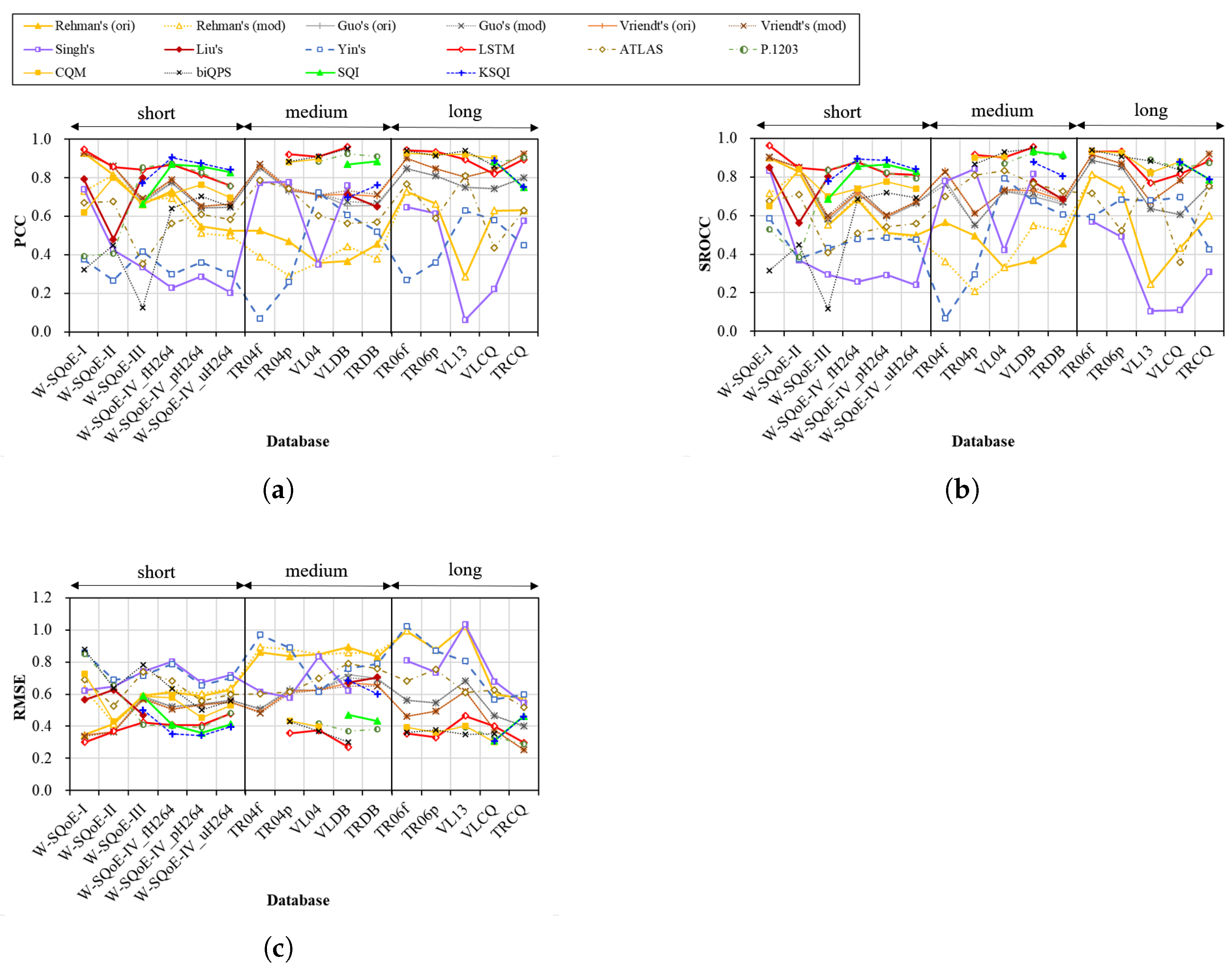
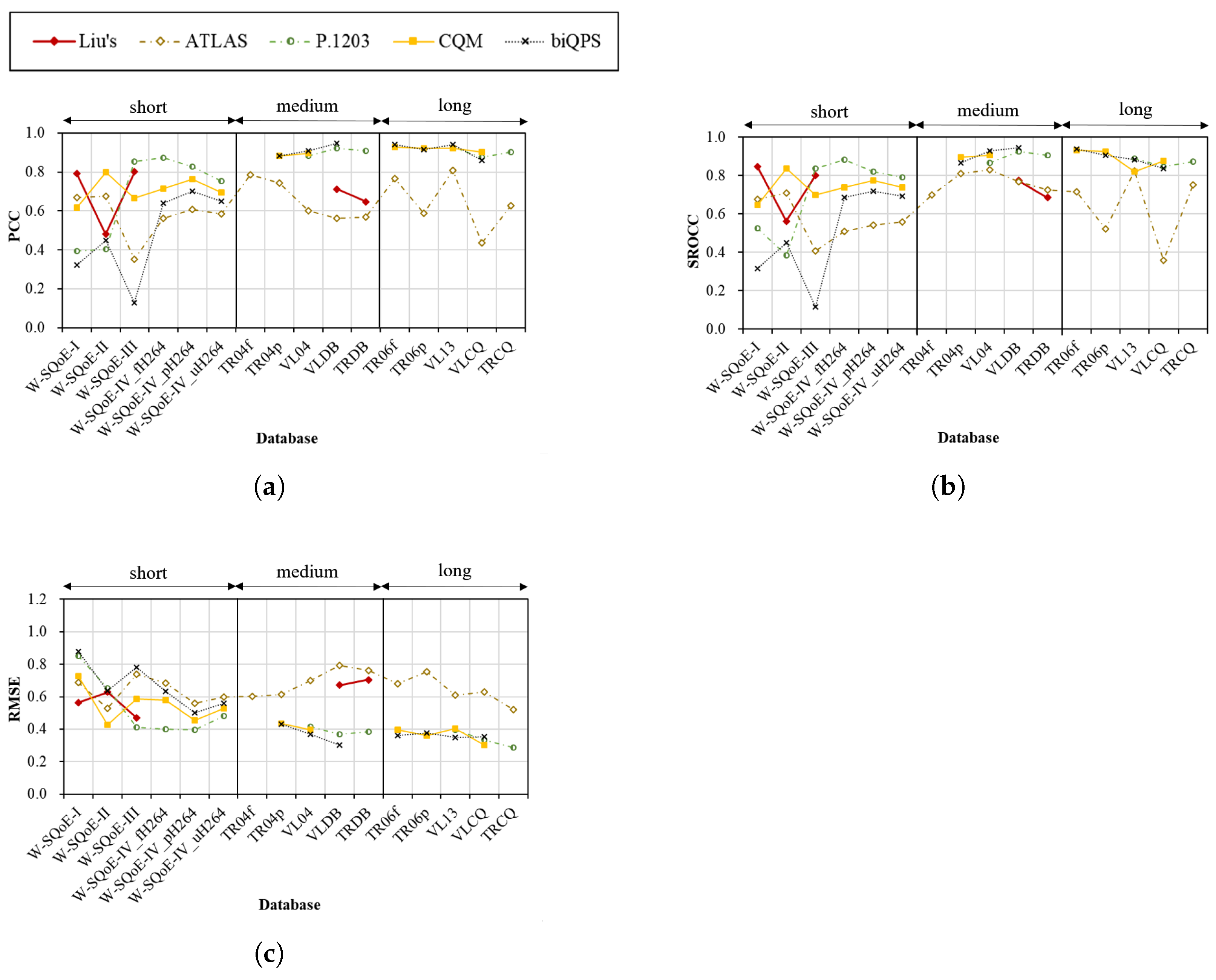
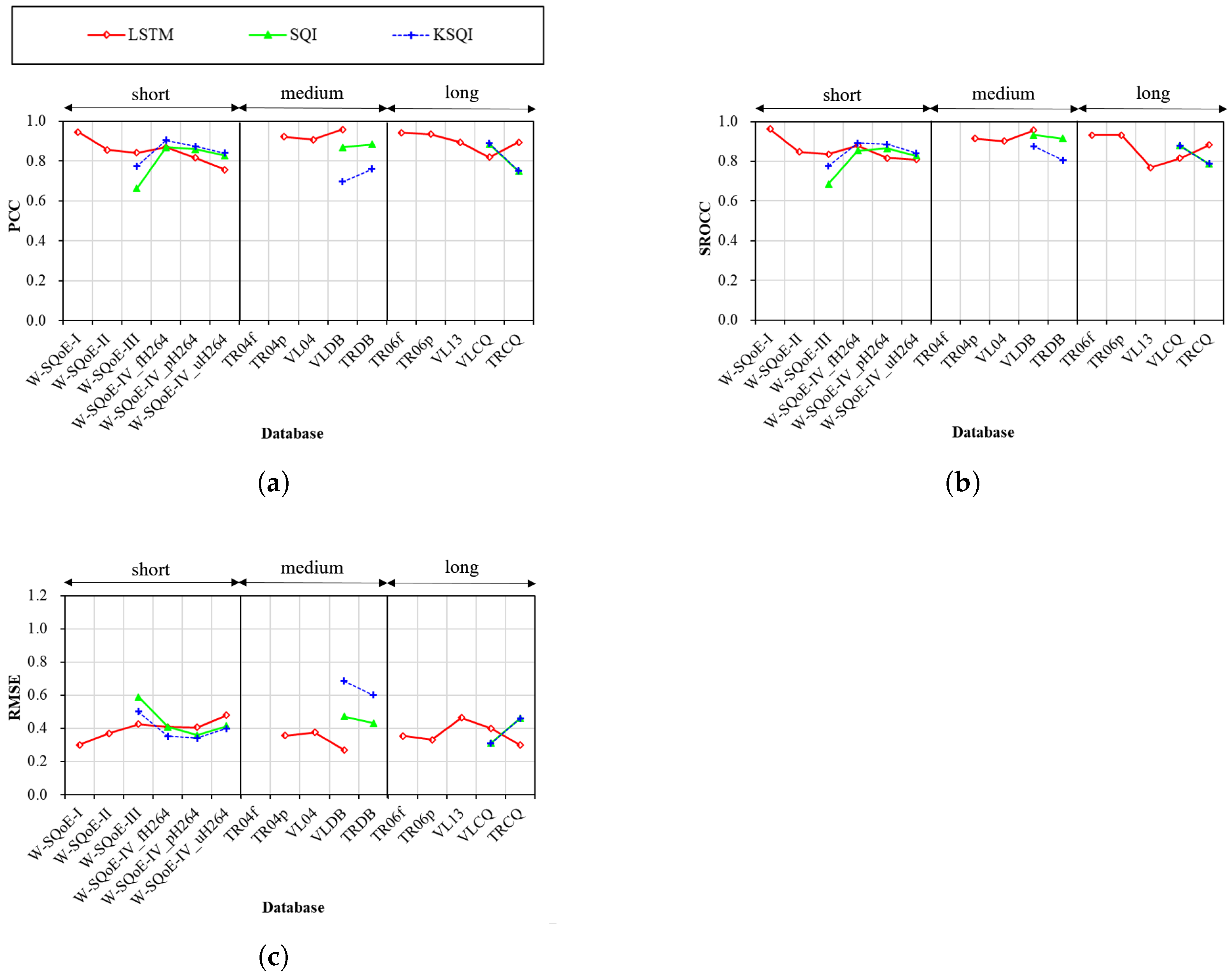
4.4. Performance across Session Durations
4.4.1. First Model Group
4.4.2. Second Model Group
4.4.3. Third Model Group
4.4.4. Fourth Model Group
4.5. Concluding Remarks
- In general, the performances of the models vary significantly across databases. Among them, the three models of LSTM, SQI, and KSQI are found to be the most stable ones.
- Regarding encoding codecs, all the considered models result in better performance on H.264-encoded streaming sessions than HEVC-encoded ones. Surprisingly, even the models taking into account HEVC characteristics such as P.1203 and KSQI have the similar behavior.
- With respect to viewing devices, the use of MOS and VMAF as segment quality metrics is quite effective to help the model perform more consistently. It is suggested that the LSTM, SQI, and KSQI models can be employed for QoE prediction with different viewing devices.
- The models that are developed using short sessions such as the Rehman’s model may result in low and drastically variable performances for medium and long sessions.
- The ability to effectively quantify the impacts of (1) quality variations and (2) stalling events significantly affects the performance of QoE models. Hence, these two factors should be equally considered in order to build an effective model. In addition, it is found that the impact of stalling events can be partially covered by the impact of quality variations as seen in the case of the Vriendt’s model. In addition, it is essential to consider temporal relations between impairment events in QoE models.
- Only one single statistic such as the QP average is insufficient to fully represent quality variations in a streaming session. Combination of several statistics such as the average of segment quality values, the switch frequency, and especially the degrees of quality switches (i.e., switch amplitudes) is found to be indispensable to effectively quantify the impact of quality variations.
- Similarly, the total stalling duration alone, which is employed in most models, is not able to characterize the factor of stalling. Other statistics such as the number of stalling events and the maximum stalling duration should be additionally considered.
- Developing complex models (i.e., more inputs and complicated modeling approaches) does not always result in better performance as found in the case of Yin’s and ATLAS models.
- Among the considered models, the LSTM model is the best one to predict the QoE of streaming sessions with different viewing devices and session durations. To evaluate the QoE of medium and long sessions (i.e., ≥1 min), the three models of P.1203, CQM, and biQPS are also comparable.
- There is still room for improvements of the existing models, especially in the cases of various viewing devices (e.g., ultra high definition TV) and advanced video codecs (e.g., HEVC).
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Conviva. Conviva State of Streaming. 2019. Available online: https://www.conviva.com/state-of-streaming/ (accessed on 15 January 2020).
- Sandvine. The Global Internet Phenomena Report. 2022. Available online: https://www.sandvine.com/phenomena (accessed on 12 April 2022).
- Seufert, M.; Egger, S.; Slanina, M.; Zinner, T.; Hoßfeld, T.; Tran-Gia, P. A survey on quality of experience of HTTP adaptive streaming. IEEE Commun. Surv. Tutor. 2015, 17, 469–492. [Google Scholar] [CrossRef]
- Hoßfeld, T.; Egger, S.; Schatz, R.; Fiedler, M.; Masuch, K.; Lorentzen, C. Initial delay vs. interruptions: Between the devil and the deep blue sea. In Proceedings of the 4th International Workshop on Quality of Multimedia Experience, Melbourne, VIC, Australia, 5–7 July 2012; pp. 1–6. [Google Scholar]
- Tavakoli, S.; Egger, S.; Seufert, M.; Schatz, R.; Brunnström, K.; García, N. Perceptual quality of HTTP adaptive streaming strategies: Cross-experimental analysis of multi-laboratory and crowdsourced subjective studies. IEEE J. Sel. Areas Commun. 2016, 34, 2141–2153. [Google Scholar] [CrossRef] [Green Version]
- Rehman, A.; Wang, Z. Perceptual experience of time-varying video quality. In Proceedings of the 5th International Workshop on Quality of Multimedia Experience (QoMEX), Klagenfurt am Wörthersee, Austria, 3–5 July 2013; pp. 218–223. [Google Scholar]
- Guo, Z.; Wang, Y.; Zhu, X. Assessing the visual effect of non-periodic temporal variation of quantization stepsize in compressed video. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3121–3125. [Google Scholar]
- Liu, Y.; Dey, S.; Ulupinar, F.; Luby, M.; Mao, Y. Deriving and validating user experience model for DASH video streaming. IEEE Trans. Broadcast. 2015, 61, 651–665. [Google Scholar] [CrossRef]
- Singh, K.D.; Hadjadj-Aoul, Y.; Rubino, G. Quality of experience estimation for adaptive HTTP/TCP video streaming using H. 264/AVC. In Proceedings of the IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 14–17 January 2012; pp. 127–131. [Google Scholar]
- Tran, H.T.T.; Nguyen, D.V.; Ngoc, N.P.; Thang, T.C. Overall Quality Prediction for HTTP Adaptive Streaming using LSTM Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3212–3226. [Google Scholar] [CrossRef]
- Vriendt, J.D.; Vleeschauwer, D.D.; Robinson, D. Model for estimating QoE of video delivered using HTTP adaptive streaming. In Proceedings of the IFIP/IEEE International Symposium on Integrated Network Management (IM 2013), Ghent, Belgium, 27–31 May 2013; pp. 1288–1293. [Google Scholar]
- Yin, X.; Jindal, A.; Sekar, V.; Sinopoli, B. A control-theoretic approach for dynamic adaptive video streaming over HTTP. Acm Sigcomm Comput. Commun. Rev. 2015, 45, 325–338. [Google Scholar] [CrossRef]
- Recommendation ITU-T P.1203.3; Parametric bitstream-based quality assessment of progressive download and adaptive audiovisual streaming services over reliable transport-Quality integration module. International Telecommunication Union: Geneva, Switzerland, 2017.
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Duanmu, Z.; Zeng, K.; Ma, K.; Rehman, A.; Wang, Z. A Quality-of-Experience Index for Streaming Video. IEEE J. Sel. Top. Signal Process. 2017, 11, 154–166. [Google Scholar] [CrossRef]
- Duanmu, Z.; Ma, K.; Wang, Z. Quality-of-Experience for Adaptive Streaming Videos: An Expectation Confirmation Theory Motivated Approach. IEEE Trans. Image Process. 2018, 27, 6135–6146. [Google Scholar] [CrossRef] [PubMed]
- Duanmu, Z.; Rehman, A.; Wang, Z. A Quality-of-Experience Database for Adaptive Video Streaming. IEEE Trans. Broadcast. 2018, 64, 474–487. [Google Scholar] [CrossRef]
- Duanmu, Z.; Liu, W.; Li, Z.; Chen, D.; Wang, Z.; Wang, Y.; Gao, W. Assessing the Quality-of-Experience of Adaptive Bitrate Video Streaming. arXiv 2020, arXiv:2008.08804. [Google Scholar]
- Bampis, C.G.; Li, Z.; Katsavounidis, I.; Huang, T.; Ekanadham, C.; Bovik, A.C. Towards Perceptually Optimized End-to-end Adaptive Video Streaming. arXiv 2018, arXiv:1808.03898. [Google Scholar]
- Robitza, W.; Göring, S.; Raake, A.; Lindegren, D.; Heikkilä, G.; Gustafsson, J.; List, P.; Feiten, B.; Wüstenhagen, U.; Garcia, M.N.; et al. HTTP Adaptive Streaming QoE Estimation with ITU-T Rec. P.1203—Open Databases and Software. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018; pp. 466–471. [Google Scholar] [CrossRef]
- Tran, H.T.T.; Nguyen, D.V.; Nguyen, D.D.; Ngoc, N.P.; Thang, T.C. Cumulative Quality Modeling for HTTP Adaptive Streaming. In ACM Transactions on Multimedia Computing Communications and Applications; ACM: New York City, NY, USA, 2020; Volume 17, pp. 1–24. [Google Scholar]
- Le Callet, P.; Möller, S.; Perkis, A. (Eds.) Qualinet White Paper on Definitions of Quality of Experience; Version 1.2; Technical Report: Lausanne, Switzerland, 2013. [Google Scholar]
- Ghadiyaram, D.; Pan, J.; Bovik, A.C. A Subjective and Objective Study of Stalling Events in Mobile Streaming Videos. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 183–197. [Google Scholar] [CrossRef]
- Kougioumtzidis, G.; Poulkov, V.; Zaharis, Z.D.; Lazaridis, P.I. A Survey on Multimedia Services QoE Assessment and Machine Learning-Based Prediction. IEEE Access 2022, 10, 19507–19538. [Google Scholar] [CrossRef]
- Bampis, C.G.; Bovik, A.C. Feature-based prediction of streaming video QoE: Distortions, stalling and memory. Signal Process. Image Commun. 2018, 68, 218–228. [Google Scholar] [CrossRef]
- Tran, H.T.T.; Nguyen, D.V.; Thang, T.C. Open Software for Bitstream-based Quality Prediction in Adaptive Video Streaming. In Proceedings of the ACM Multimedia Systems Conference (MMSys’20), Istanbul, Turkey, 8–11 June 2020; pp. 225–230. [Google Scholar]
- Duanmu, Z.; Liu, W.; Chen, D.; Li, Z.; Wang, Z.; Wang, Y.; Gao, W. A Knowledge-Driven Quality-of-Experience Model for Adaptive Streaming Videos. arXiv 2019, arXiv:1911.07944. [Google Scholar]
- Recommendation ITU-T P.1203.1; Parametric Bitstream-Based Quality Assessment of Progressive Dowload and Adaptive Audiovisual Streaming Services over Reliable Transport-Video Quality Estimation Module. International Telecommunication Union: Geneva, Switzerland, 2017.
- Raake, A.; Garcia, M.N.; Robitza, W.; List, P.; Göring, S.; Feiten, B. A bitstream-based, scalable video-quality model for HTTP adaptive streaming: ITU-T P.1203.1. In Proceedings of the Ninth International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May–2 June 2017; pp. 1–6. [Google Scholar]
- Tran, H.T.T.; Nguyen, D.V.; Nguyen, D.D.; Ngoc, N.P.; Thang, T.C. An LSTM-based Approach for Overall Quality. In Proceedings of the IEEE Conference on Computer Communications Conference (INFOCOM 2019), Paris, France, 29 April–2 May 2019; pp. 702–707. [Google Scholar]
- Bampis, C.G.; Li, Z.; Moorthy, A.K.; Katsavounidis, I.; Aaron, A.; Bovik, A.C. Study of Temporal Effects on Subjective Video Quality of Experience. IEEE Trans. Image Process. 2017, 26, 5217–5231. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Choi, L.K.; De Veciana, G.; Caramanis, C.; Heath, R.W.; Bovik, A.C. Modeling the time-Varying subjective quality of HTTP video streams with rate adaptations. IEEE Trans. Image Process. 2014, 23, 2206–2221. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duanmu, Z.; Ma, K.; Wang, Z. Quality-of-Experience of Adaptive Video Streaming: Exploring the Space of Adaptations. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1752–1760. [Google Scholar]
- Recommendation ITU-T P.1203. ITU-T Rec. P.1203 Standalone Implementation. 2018. Available online: https://github.com/itu-p1203 (accessed on 1 July 2018).
- Tran, H.T.T.; Ngoc, N.P.; Pham, A.T.; Thang, T.C. A Multi-Factor QoE Model for Adaptive Streaming over Mobile Networks. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Rodríguez, D.Z.; Rosa, R.L.; Alfaia, E.C.; Abrahão, J.I.; Bressan, G. Video quality metric for streaming service using DASH standard. IEEE Trans. Broadcast. 2016, 62, 628–639. [Google Scholar] [CrossRef]
- Recommendation ITU-T P.1401; Methods, Metrics and Procedures for Statistical Evaluation, Qualification and Comparison of Objective Quality Prediction Models. International Telecommunication Union: Geneva, Switzerland, 2012.
- Recommendation ITU-T G.1071; Opinion Model for Network Planning of Video and Audio Streaming Applications. International Telecommunication Union: Geneva, Switzerland, 2015.
- Tran, H.T.T.; Ngoc, N.P.; Jung, Y.J.; Pham, A.T.; Thang, T.C. A Histogram-Based Quality Model for HTTP Adaptive Streaming. Ieice Trans. Fundam. Electron. Commun. Comput. Sci. 2017, 100, 555–564. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Modeling Approaches | Segment Quality Parameters | Session Duration (Seconds) | Inputs Used to Represent the Impacts of Factors | |||
|---|---|---|---|---|---|---|---|
| Impact of Initial Delay | Impact of Quality Variations | Impact of Stalling Events | Memory-Related Effects | ||||
| Rehman’s [6] | Analytical functions | Subjective quality metric (i.e., MOS) | 5–15 | — | First segment quality Sum of the impacts of the previous quality switches which is modeled by a piece-wise linear function of the switching amplitudes | — | — |
| Guo’s [7] | Analytical functions | Subjective quality metric (i.e., MOS) | 10 | — | Median segment quality value Minimum segment quality value | — | — |
| Vriendt’s [11] | Analytical functions | Subjective quality metric (i.e., MOS) | 120 | — | Average and standard deviation of segment quality values Number of segment quality switches | — | — |
| Singh’s [9] | Random neural network | Bitstream-level parameter (i.e., QP) | 16 | Initial delay is considered as a stalling event | Average of QP values over all macro- blocks in all frames of the whole session | Total number of stalling events Average of stalling durations Maximum of stalling durations | — |
| Liu’s [8] | Analytical functions | Objective quality metric (i.e., VQM) | 60 | Linear function of initial delay duration | Weighted sum of segment quality values Average of the square of switching amplitudes | Total number of stalling events Sum of stalling durations | — |
| Yin’s [12] | Analytical functions | Bitstream-level parameter (i.e., bitrate) | N/A | Linear function of initial delay duration | Average of segment quality values Average of switching amplitudes | Sum of stalling durations | — |
| LSTM [10] | Long-Short Term Memory (LSTM) | Subjective quality metric (i.e., MOS) | 60–76 | Initial delay is considered as a stalling event | Segment-basis parameters | LSTM network with stalling durations | Segment-basis parameters and stalling durations |
| ATLAS [26] | Support Vector Regression (SVR) | Objective quality metric (e.g., STRRED or VMAF) | 10 and 72 | Initial delay is considered as a stalling event | Average of frame quality values Time per video duration over which a segment quality decrease took place | Total number of stalling events Sum of stalling durations | Time since the last stalling event or segment quality decrease |
| P.1203 [13] | Analytical functions and Random forest | Subjective quality metric (i.e., MOS) or Bitstream-level parameters (i.e., frame types, sizes, and QPs of frames, bitrates, resolutions, and frame-rates of segments) | 60–300 | Initial delay is considered as a stalling event | Number of segment quality switches Number of segment quality direction changes Longest quality switching duration First and fifth percentile of segment quality values Difference between the maximum and minimum segment quality values Average of segment quality values in each interval) | Total number of stalling events Average interval between events Frequency of stalling events Ratio of stalling duration | Weighted sum of segment quality values Weighted sum of stalling durations Time since the last stalling event |
| CQM [22] | Analytical functions | Subjective quality metric (i.e., MOS) | 60–360 | Logarithm function of initial delay duration | Histogram of segment quality values Histogram of switching amplitudes Average window quality value | Histogram of stalling durations | Last window quality value Minimum window quality value Maximum window quality value |
| biQPS [27] | Long-Short Term Memory (LSTM) and Analytical functions | Bitstream-level parameters (i.e., QPs, bitrates, resolutions, frame- rates of segments) | 60–360 | Initial delay is considered as a stalling event | LSTM network with segment-basis parameters Average window quality value | LSTM network with stalling durations | LSTM network with segment-basis parameters and stalling durations Last window quality value Minimum window quality value Maximum window quality value |
| SQI [16] | Analytical functions | Objective quality metric (i.e., VMAF) | 10 | Initial delay is considered as a stalling event | Sum of segment quality values per session duration | A piece-wise function inputted by stalling durations | Using the Hermann Ebbinghaus forgetting curve to estimate the impact of each stalling event A moving average fashion of the previous cumulative quality and the instantaneous quality |
| KSQI [28] | Operator Splitting Quadratic Program solver | Objective quality metric (i.e., VMAF) | 8, 10, 13, and 28 | Initial delay is considered as a stalling event | Impact of each quality switch depends on the instantaneous segment quality and the switching amplitude | Impact of each stalling event depends on the previous segment quality and the stalling duration | A moving average fashion of the previous cumulative quality and the instantaneous quality |
| Original Database | Sub-Database | Viewing Device | Codec |
|---|---|---|---|
| W-SQoE-IV (full) | W-SQoE-IV_pH264 | Smartphone | H.264 |
| W-SQoE-IV_pHEVC | Smartphone | HEVC | |
| W-SQoE-IV_fH264 | FHD | H.264 | |
| W-SQoE-IV_fHEVC | FHD | HEVC | |
| W-SQoE-IV_uH264 | UHD | H.264 | |
| W-SQoE-IV_uHEVC | UHD | HEVC | |
| TR04 (full) | TR04p | Smartphone | H.264 |
| TR04f | FHD | H.264 | |
| TR06 (full) | TR06p | Smartphone | H.264 |
| TR04f | FHD | H.264 |
| Model | Database | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| W-SQoE-I | W-SQoE-II | W-SQoE-III | W-SQoE-IV (full) | TRDB | VLDB | TR04f | TR04p | VL04 | TR06f | TR06p | VL13 | TRCQ | VLCQ | |
| Rehman’s [6] | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test |
| Guo’s [7] | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test |
| Vriendt’s [11] | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test |
| Singh’s [9] | Test | Test | Test | Test | Train | Test | Test | Test | Test | Test | Test | Test | Test | Test |
| Liu’s [8] | Test | Test | Test | Test | Test | Test | NA | NA | NA | NA | NA | NA | NA | NA |
| Yin’s [12] | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test | Test |
| LSTM [10] | Test | Test | Test | Test | Train | Test | Train | Test | Test | Test | Test | Test | Test | Test |
| ATLAS [26] | Test | Test | Test | Test | Test | Test | NA | NA | NA | NA | NA | NA | Test | Test |
| P.1203 [13] | Test | Test | Test | Test | Test | Test | Train | Train | Test | Train | Train | Test | Test | Test |
| CQM [22] | Test | Test | Test | Test | Train | Train | Test | Test | Test | Test | Test | Test | Train | Test |
| biQPS [27] | Test | Test | Test | Test | Train | Test | Train | Test | Test | Test | Test | Test | Train | Test |
| SQI [16] | Train | Train | Test | Test | Test | Test | NA | NA | NA | NA | NA | NA | Test | Test |
| KSQI [28] | Train | Train | Test | Test | Test | Test | NA | NA | NA | NA | NA | NA | Test | Test |
| Database | Rehman’s (ori) | Rehman’s (mod) | Guo’s (ori) | Guo’s (mod) | Vriendt’s (ori) | Vriendt’s (mod) | Singh’s | Liu’s | Yin’s | LSTM | ATLAS | P.1203 | CQM | biQPS | SQI | KSQI |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| W-SQoE-I | 0.93 | 0.73 | 0.93 | 0.93 | 0.93 | 0.93 | 0.74 | 0.79 | 0.38 | 0.95 | 0.67 | 0.39 | 0.62 | 0.32 | N/A | N/A |
| W-SQoE-II | 0.81 | 0.81 | 0.86 | 0.86 | 0.86 | 0.86 | 0.43 | 0.48 | 0.27 | 0.86 | 0.68 | 0.40 | 0.80 | 0.45 | N/A | N/A |
| W-SQoE-III | 0.66 | 0.69 | 0.67 | 0.68 | 0.68 | 0.69 | 0.34 | 0.80 | 0.42 | 0.84 | 0.35 | 0.85 | 0.67 | 0.13 | 0.66 | 0.77 |
| W-SQoE-IV (full) | 0.51 | 0.49 | 0.50 | 0.51 | 0.51 | 0.52 | 0.19 | N/A | 0.39 | 0.63 | 0.54 | 0.64 | 0.60 | 0.60 | 0.71 | 0.71 |
| TR04f | 0.52 | 0.39 | 0.85 | 0.85 | 0.86 | 0.87 | 0.77 | N/A | 0.07 | N/A | 0.79 | N/A | N/A | N/A | N/A | N/A |
| TR04p | 0.47 | 0.29 | 0.73 | 0.74 | 0.74 | 0.75 | 0.78 | N/A | 0.26 | 0.92 | 0.74 | N/A | 0.88 | 0.88 | N/A | N/A |
| VL04 | 0.36 | 0.36 | 0.72 | 0.72 | 0.71 | 0.71 | 0.35 | N/A | 0.72 | 0.91 | 0.60 | 0.88 | 0.90 | 0.91 | N/A | N/A |
| VLDB | 0.37 | 0.44 | 0.65 | 0.68 | 0.71 | 0.73 | 0.76 | 0.71 | 0.61 | 0.96 | 0.56 | 0.92 | N/A | 0.95 | 0.87 | 0.70 |
| TRDB | 0.46 | 0.38 | 0.66 | 0.67 | 0.70 | 0.71 | N/A | 0.65 | 0.52 | N/A | 0.57 | 0.91 | N/A | N/A | 0.88 | 0.76 |
| TR06f | 0.73 | 0.73 | 0.85 | 0.85 | 0.90 | 0.90 | 0.65 | N/A | 0.27 | 0.94 | 0.77 | N/A | 0.93 | 0.94 | N/A | N/A |
| TR06p | 0.66 | 0.66 | 0.81 | 0.81 | 0.85 | 0.85 | 0.61 | N/A | 0.36 | 0.93 | 0.59 | N/A | 0.92 | 0.91 | N/A | N/A |
| VL13 | 0.29 | 0.29 | 0.75 | 0.75 | 0.80 | 0.80 | 0.06 | N/A | 0.63 | 0.89 | 0.81 | 0.92 | 0.92 | 0.94 | N/A | N/A |
| VLCQ | 0.63 | 0.63 | 0.74 | 0.74 | 0.84 | 0.84 | 0.22 | N/A | 0.58 | 0.82 | 0.44 | 0.88 | 0.90 | 0.86 | 0.89 | 0.89 |
| TRCQ | 0.63 | 0.63 | 0.80 | 0.80 | 0.92 | 0.92 | 0.58 | N/A | 0.45 | 0.89 | 0.63 | 0.90 | N/A | N/A | 0.75 | 0.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, D.; Pham Ngoc, N.; Thang, T.C. QoE Models for Adaptive Streaming: A Comprehensive Evaluation. Future Internet 2022, 14, 151. https://doi.org/10.3390/fi14050151
Nguyen D, Pham Ngoc N, Thang TC. QoE Models for Adaptive Streaming: A Comprehensive Evaluation. Future Internet. 2022; 14(5):151. https://doi.org/10.3390/fi14050151
Chicago/Turabian StyleNguyen, Duc, Nam Pham Ngoc, and Truong Cong Thang. 2022. "QoE Models for Adaptive Streaming: A Comprehensive Evaluation" Future Internet 14, no. 5: 151. https://doi.org/10.3390/fi14050151
APA StyleNguyen, D., Pham Ngoc, N., & Thang, T. C. (2022). QoE Models for Adaptive Streaming: A Comprehensive Evaluation. Future Internet, 14(5), 151. https://doi.org/10.3390/fi14050151