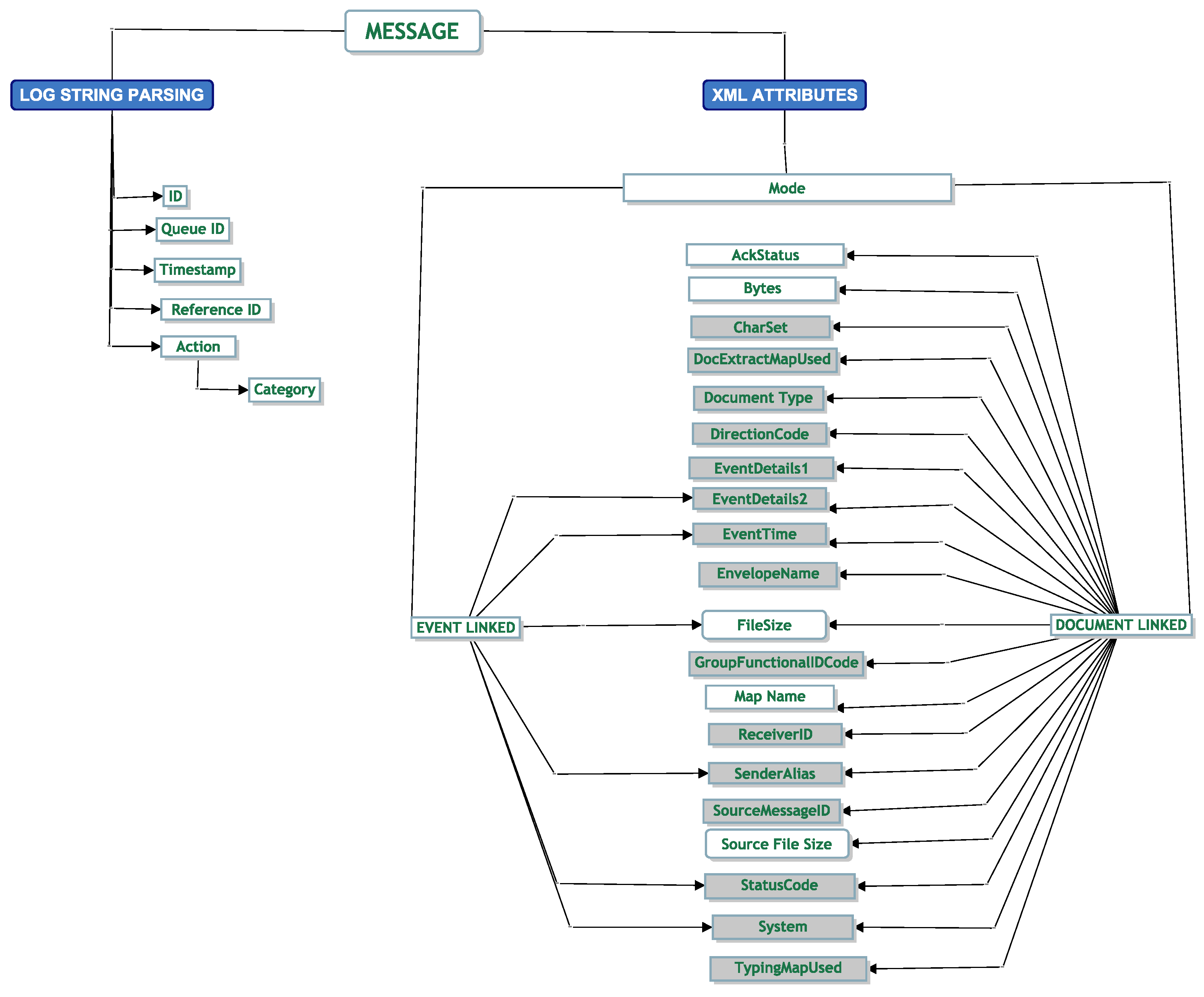
3.2.1. Parametric Modelling
For queue modelling, correlation is a feature that needs to be identified to see if it exists, as queueing models assume no correlation. We have applied extensive studies on these EDI messages around correlation. Please refer to our paper for further reading [
11].
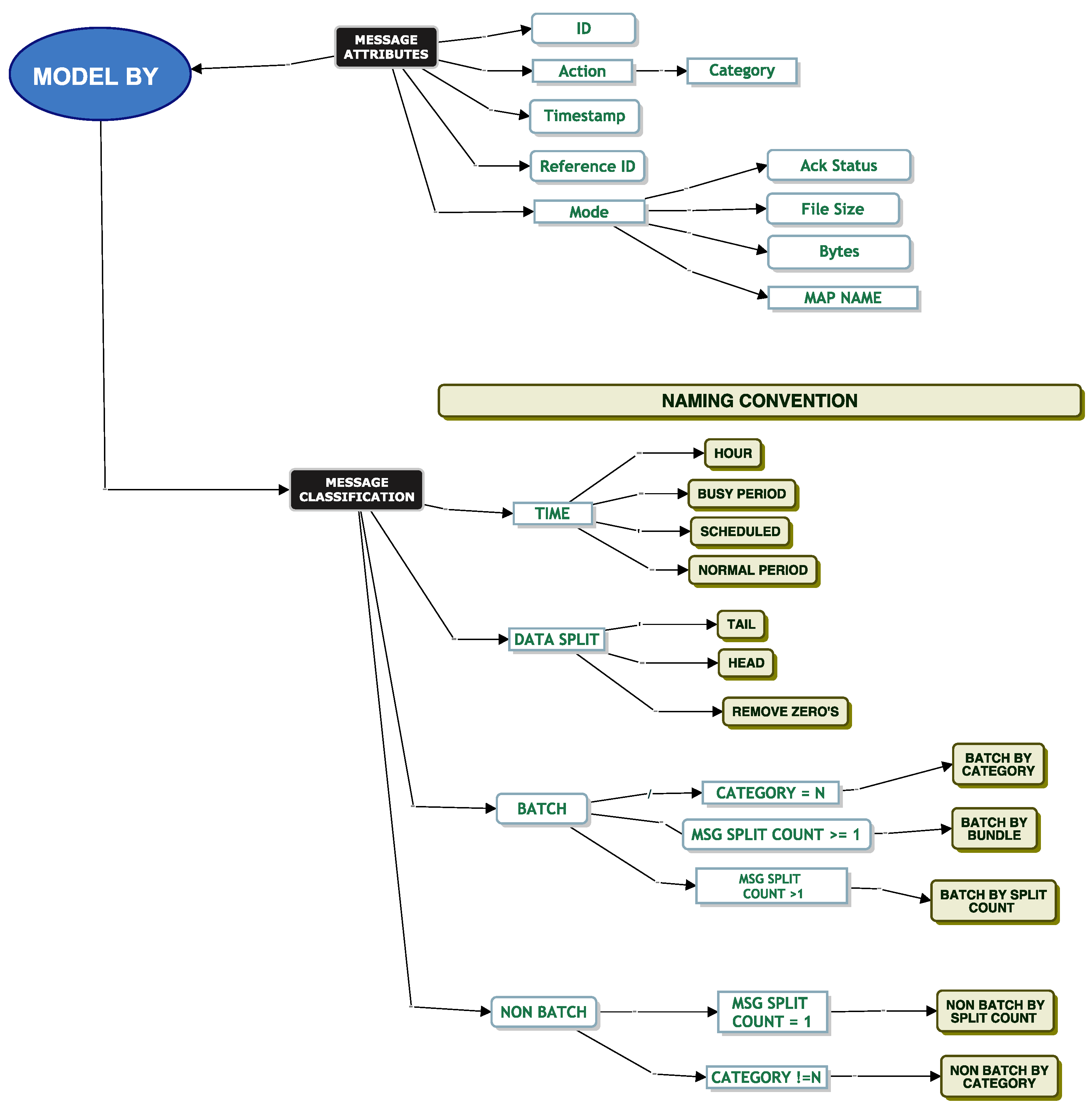
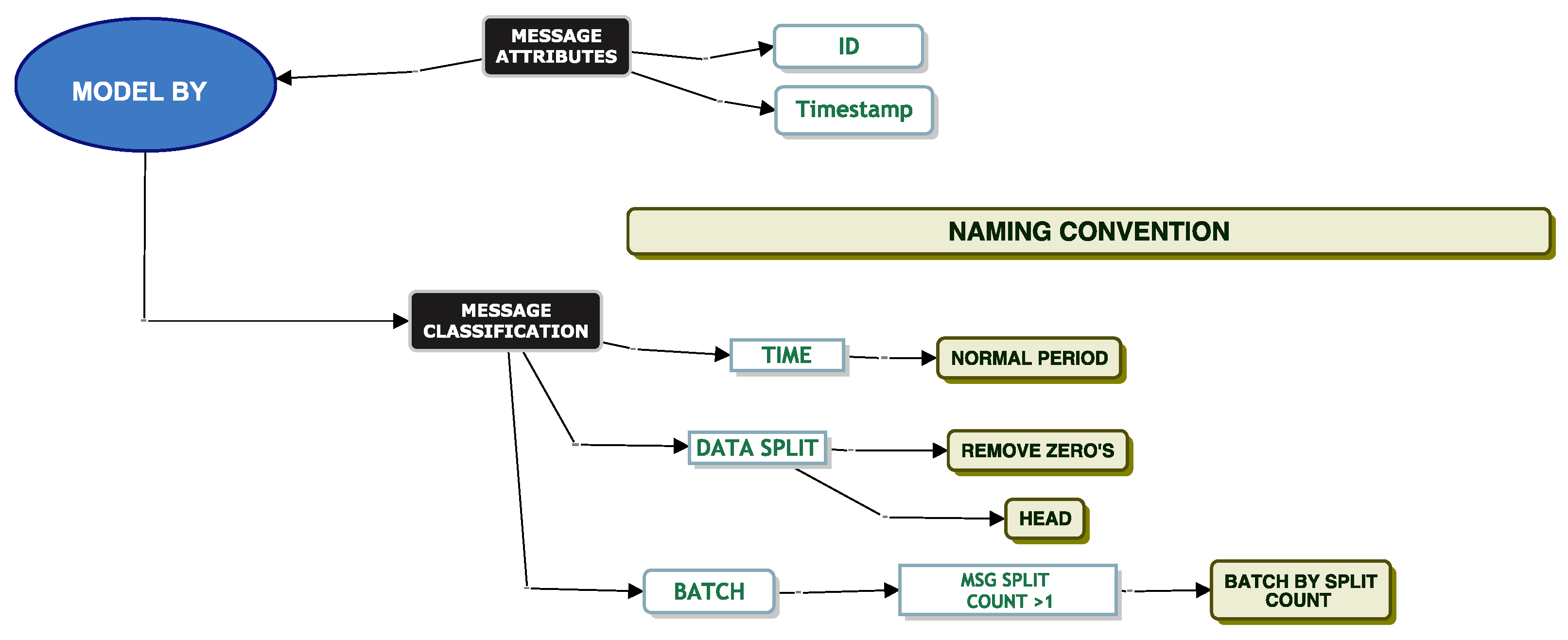
When modelling EDI messages, we found many challenges. From these challenges, the classification model was born. The different elements of the classification model helped us answer a challenge we faced. For example, we could not tell what happened to a message as it was being translated. We did not know if a message was dependent on another message. We were challenged with modelling the data with a continuous distribution. We faced many challenges around the removal of correlation and trying to break the head and tail of the data at a suitable point to help parametric fitting.
The classification model helped us iterate through the different techniques to help us address the challenges we faced. Our next set of sections will help bring the reader through our techniques based on these challenges.
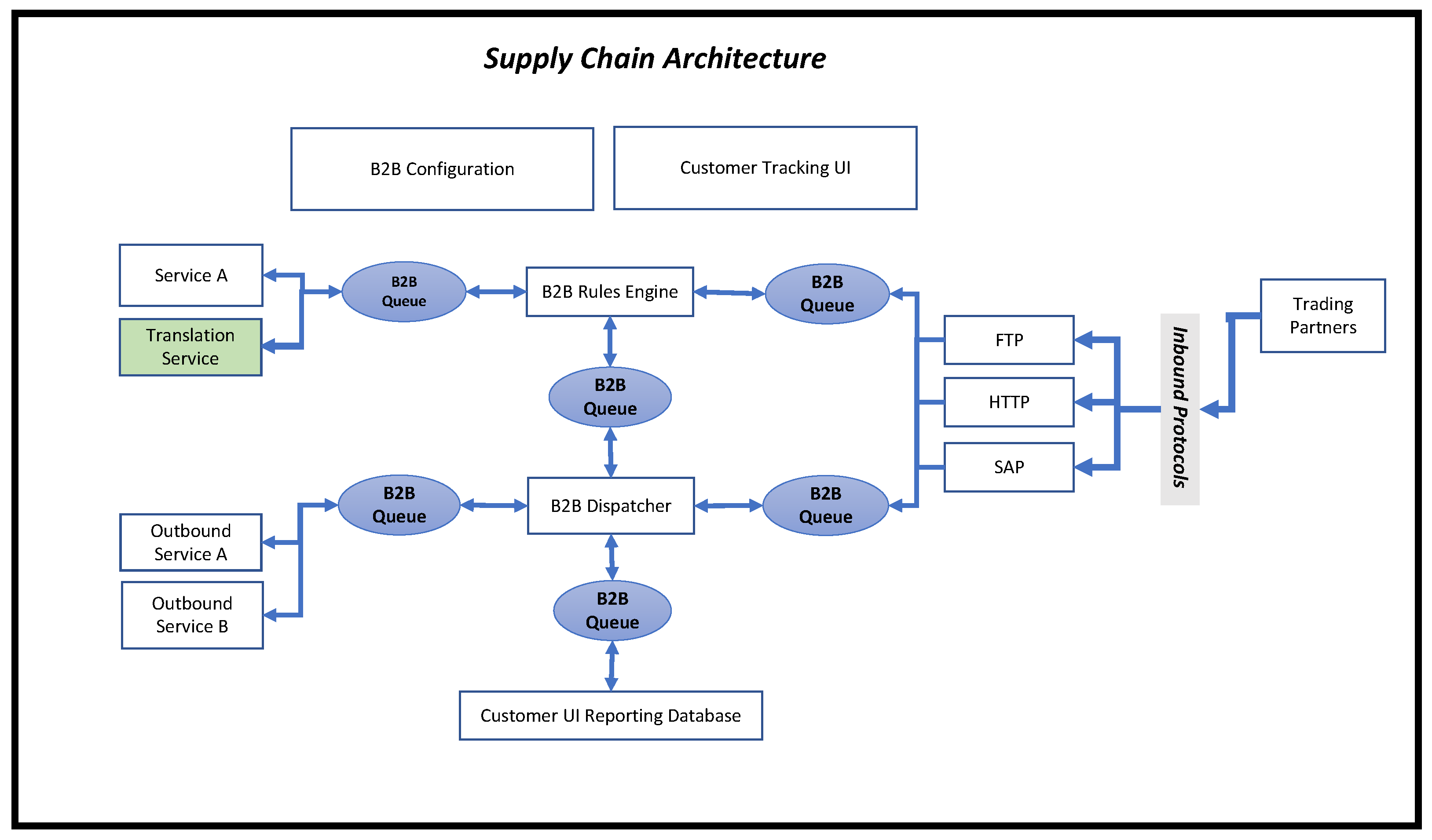
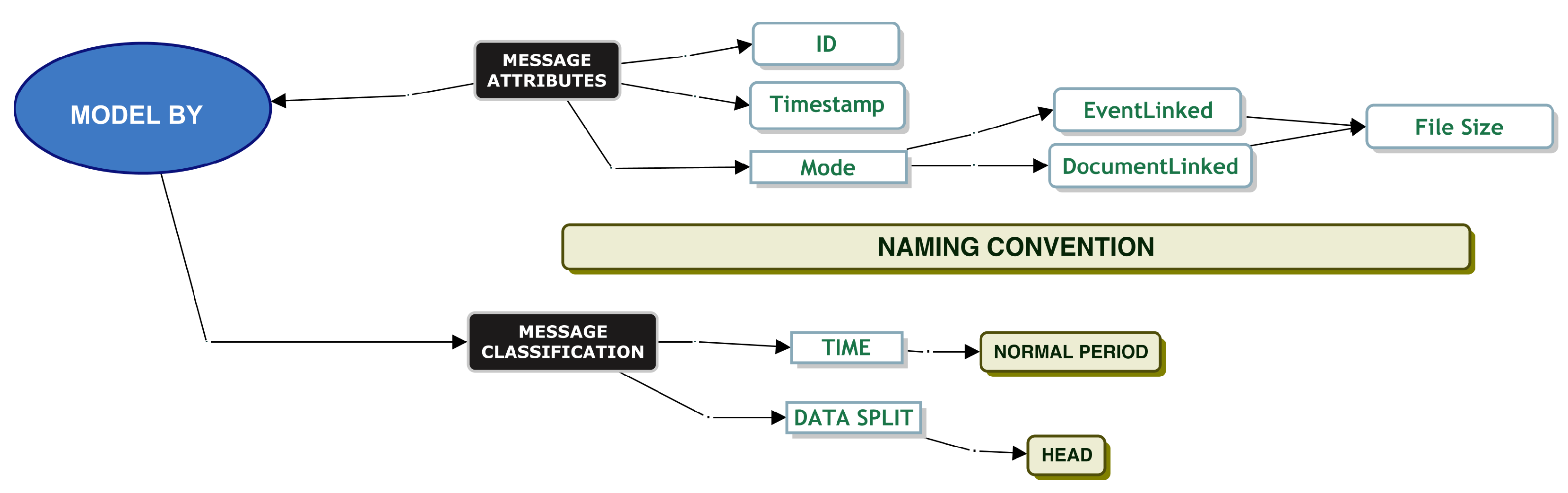
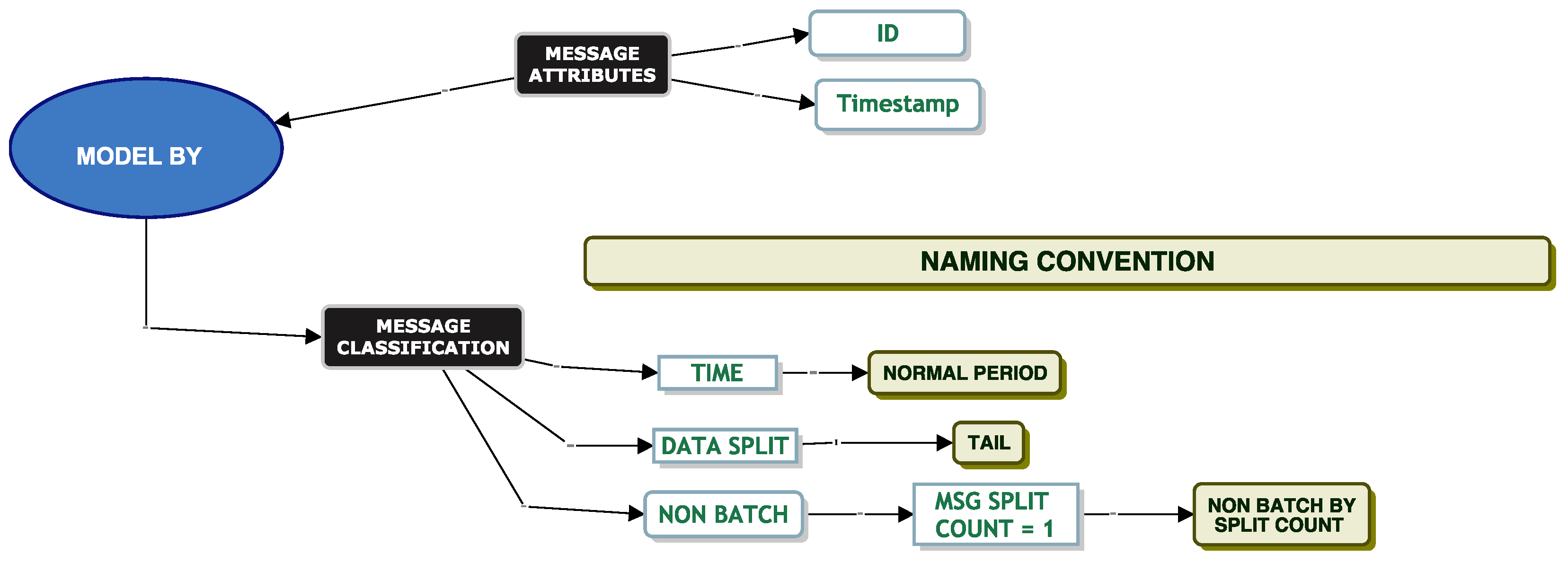
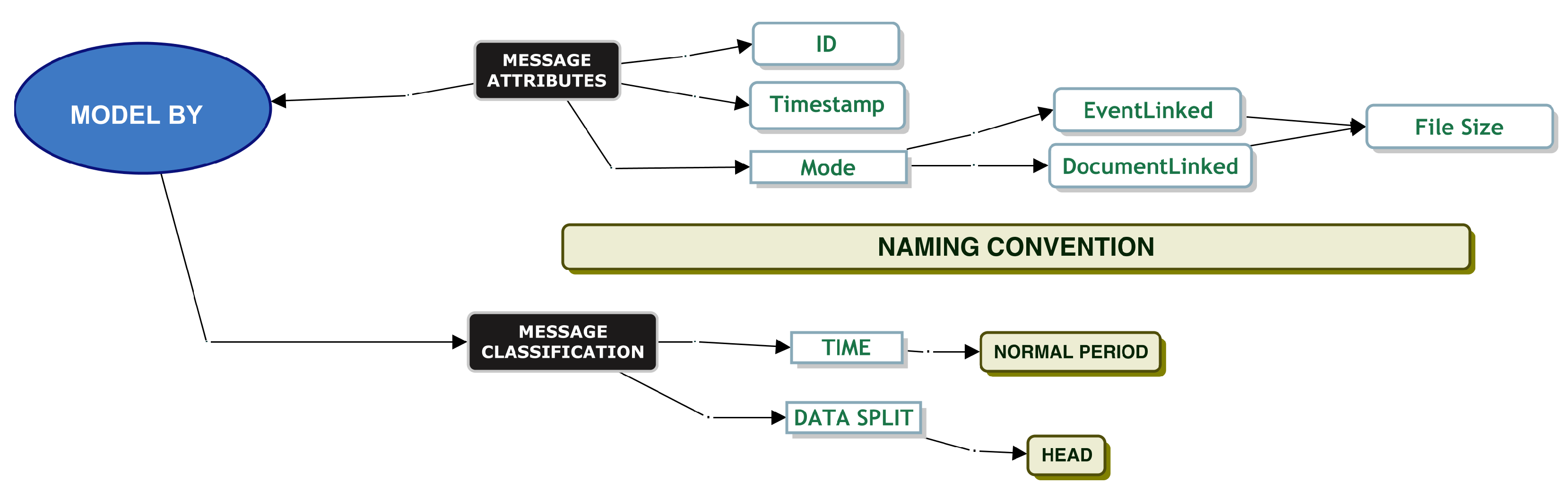
Model By File Size
When testing a system, it is important to understand each message’s file size, as it gives an indication as to whether the message needs to be split for queue ingestion and the amount of disk space required. File size may influence service times. DevOps informed us that one of the inbound connectors does not allow a file size greater than 100 MB, and most file sizes are approximately 20 kilobytes in size.
When modelling by file size, we applied the classification model to our data as per
Figure 5.
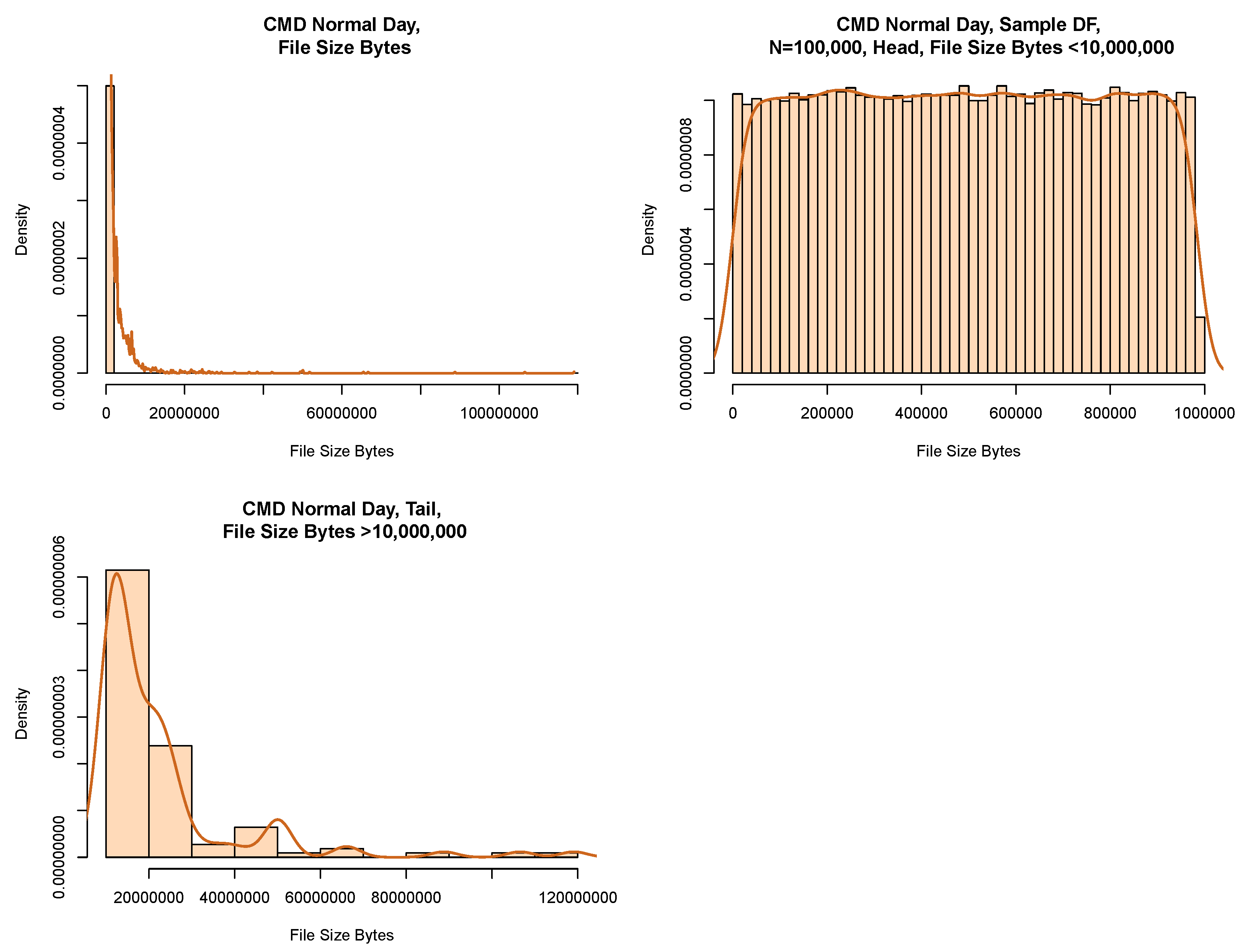
Figure 7 displays the model chosen that allowed us to successfully fit a parametric distribution to our data. We picked data from the “Normal Period” and partitioned the data into its head and tail using a size of 10,000,000 B as the boundary. We then took a random sample from the dataset.
Table 7 gives the count of data per partition before we implemented a random sample on the model. We note that we captured the majority of the data in the head.
Figure 8 shows a histogram of our data both before and after the partition. The plot to the top left shows the data before partitioning. The plot to the top right shows the results of a random sample from the head. We can see that the shape of the histogram shows signs of fitting into a uniform distribution. The plot to the bottom left shows the tail of the data.
We use a Chi-square GoF test for the head of the data (see
Table 8). This indicates that with
<
p-value 0.05, it appears that a uniform distribution may be a reasonable model for the head of the distribution.
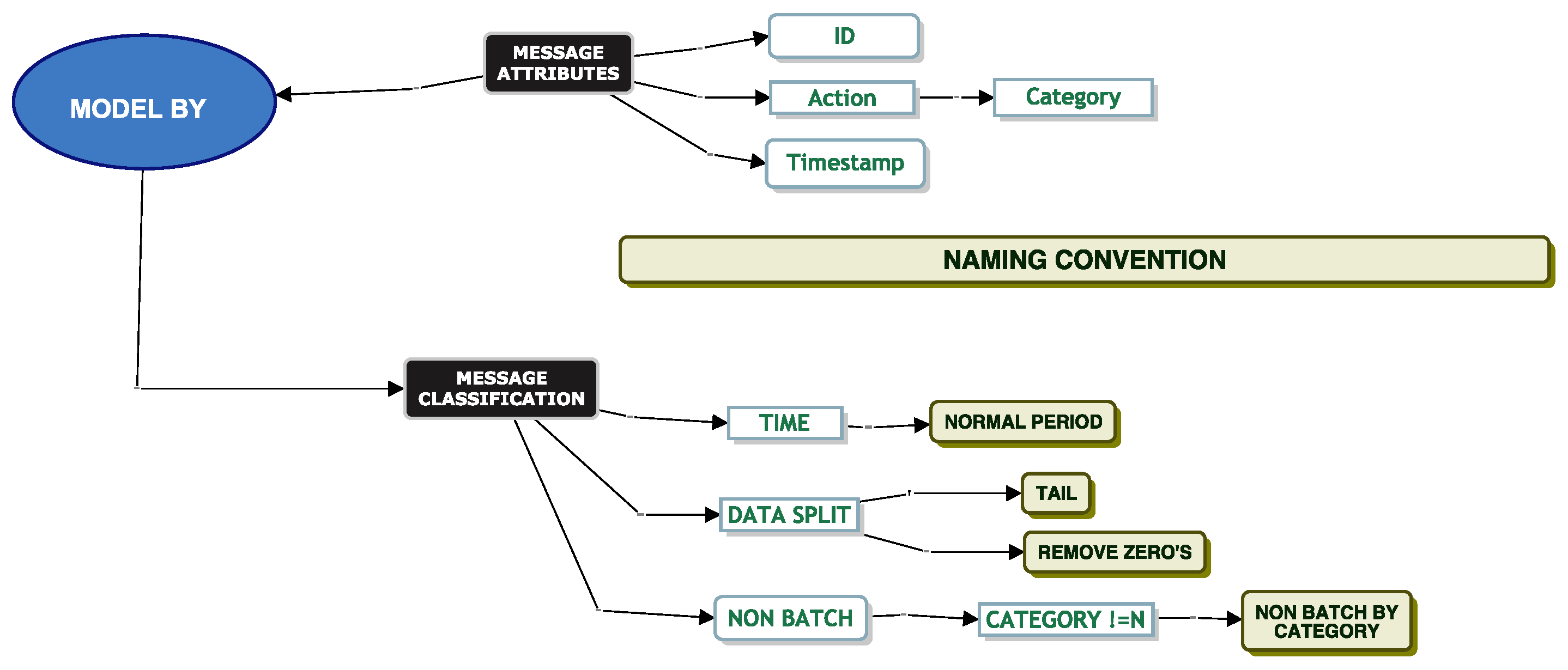
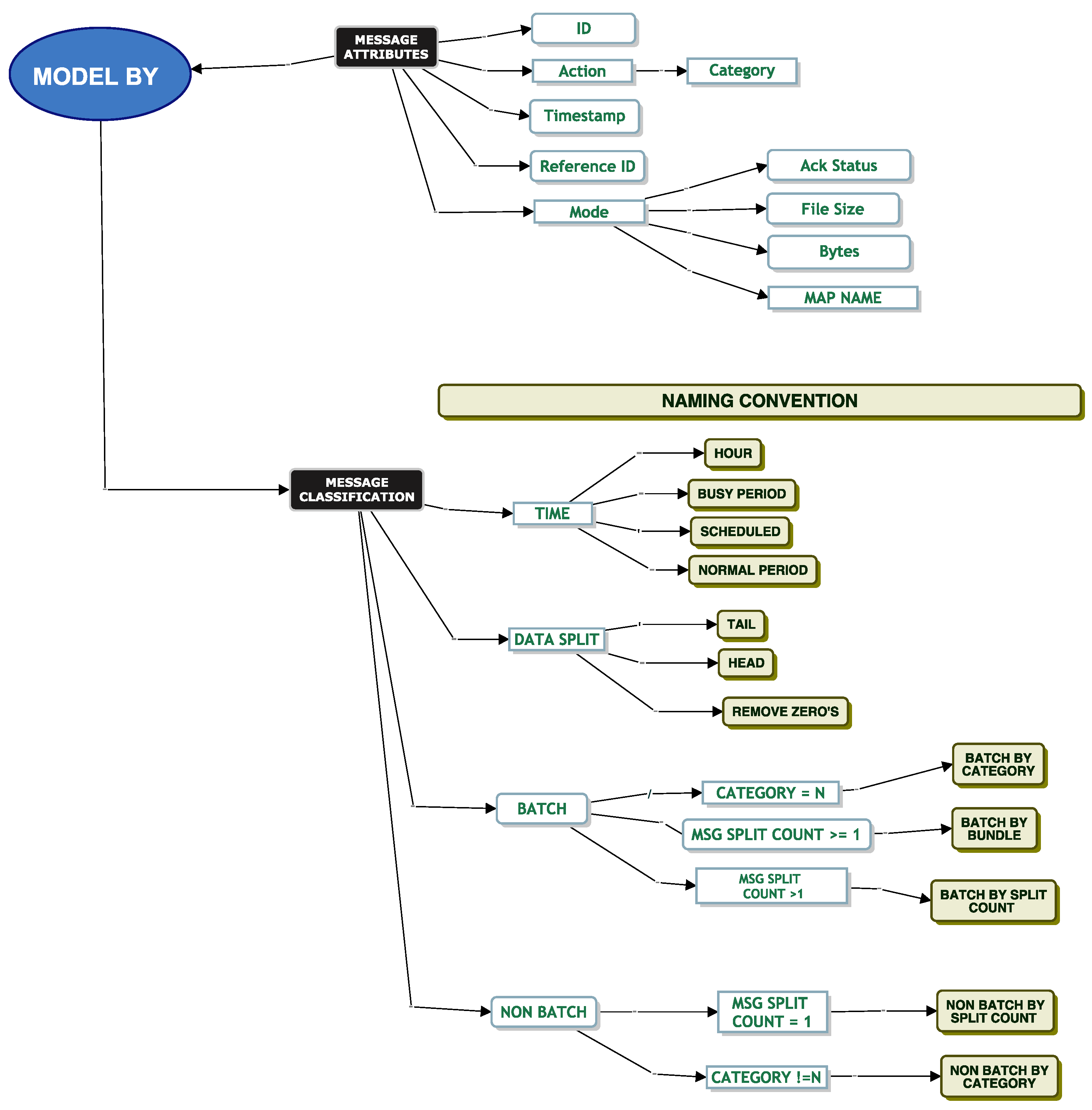
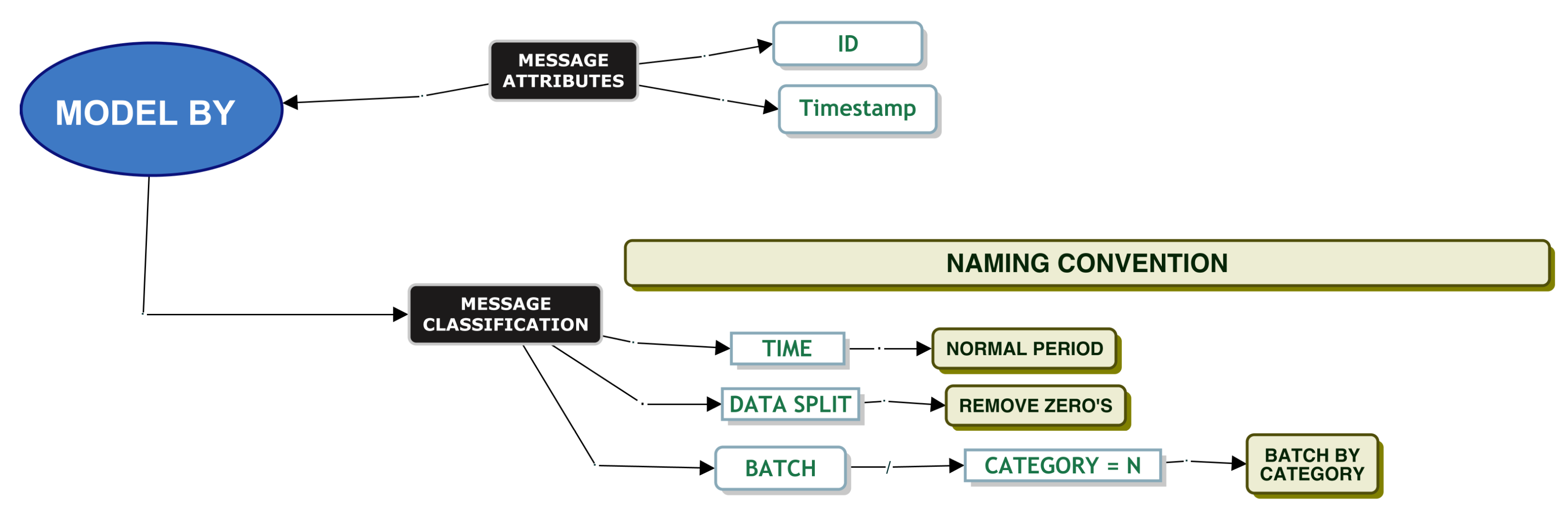
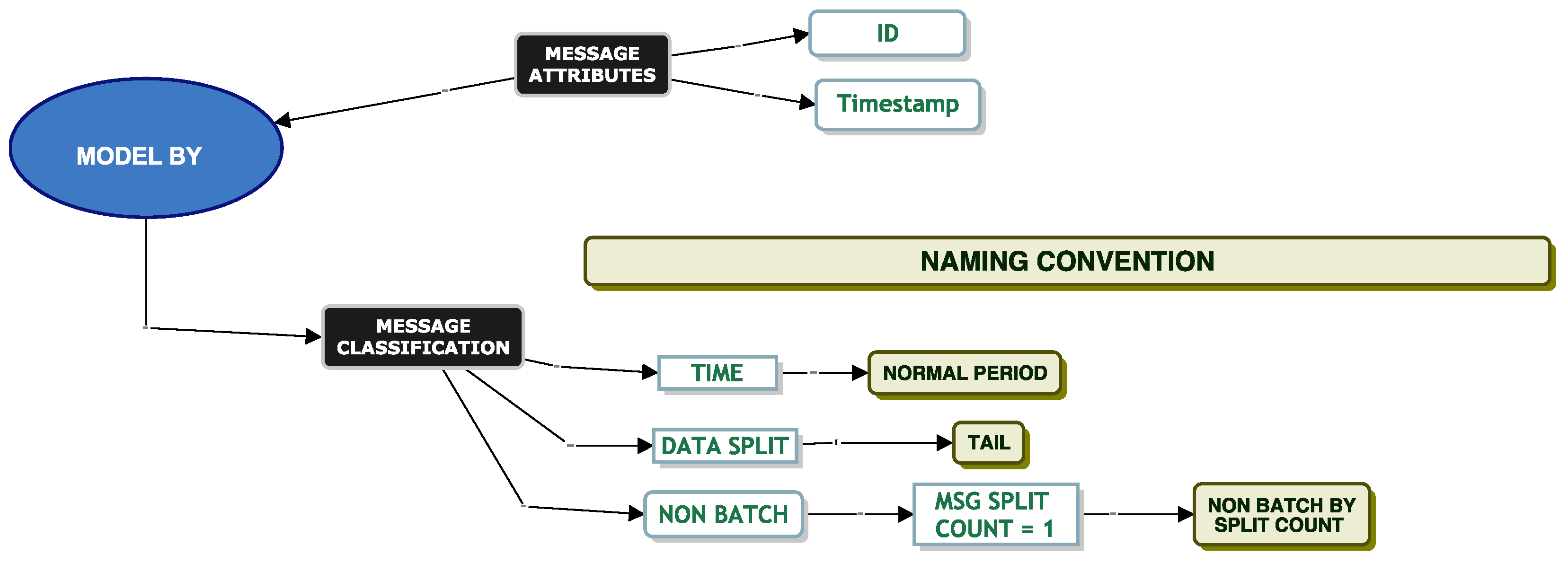
Model Batch By Category
Service Time Modelling
When simulating service and inter-arrival times, it is important to know if the queue will ingest a message as a single message or as a batch of messages. This is because a batch arrival would be a clear type of interdependence between messages that would be relevant for queue modelling. DevOps informed us that certain messages (“Flat Translation” or “Batch Translation”) should be considered batch messages based on their “Category” attribute. These messages should be split into smaller files and sent into the system as a batch. All other messages should be considered non-batch type messages. When we inspected the data, we found evidence that the messages for flat translation and batch translation were both single messages and batch-type messages. Based on these initial comments from DevOps, we went ahead and modelled the service times of these messages.
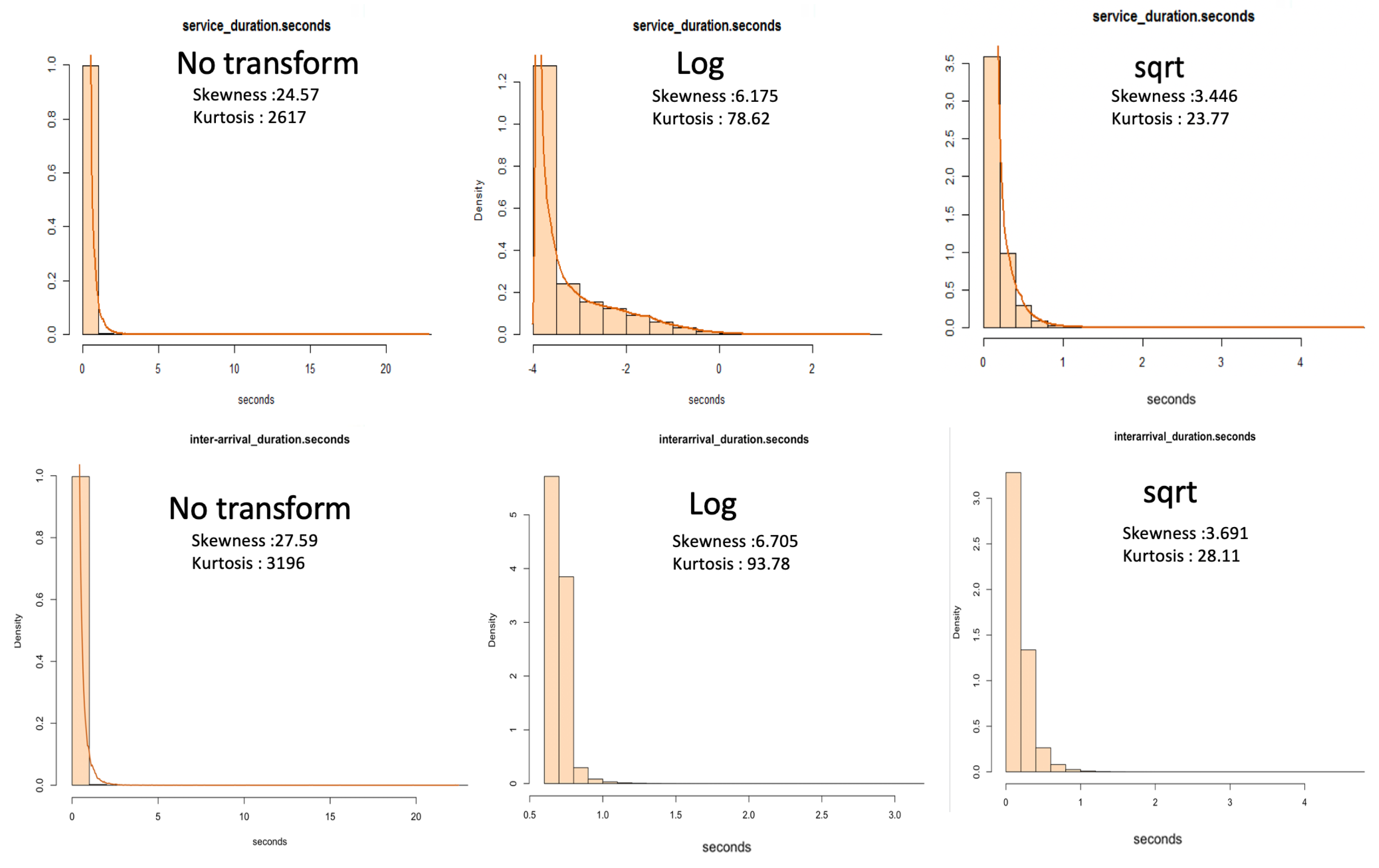
Before attempting to model the service times of the dataset, we analysed measures of dispersion. From
Table 9, we note that of the total batch messages, half of the messages were removed when we removed messages of zero duration. We also observe that these data are heavy-tailed with a skewness greater than 20 and high kurtosis. There is a 0.10 s difference in the 95th percentile between the service times of both batch messages and batch messages where zeros are removed. Messages greater than zero seconds in service times are likely to take less than 0.26 s to process.
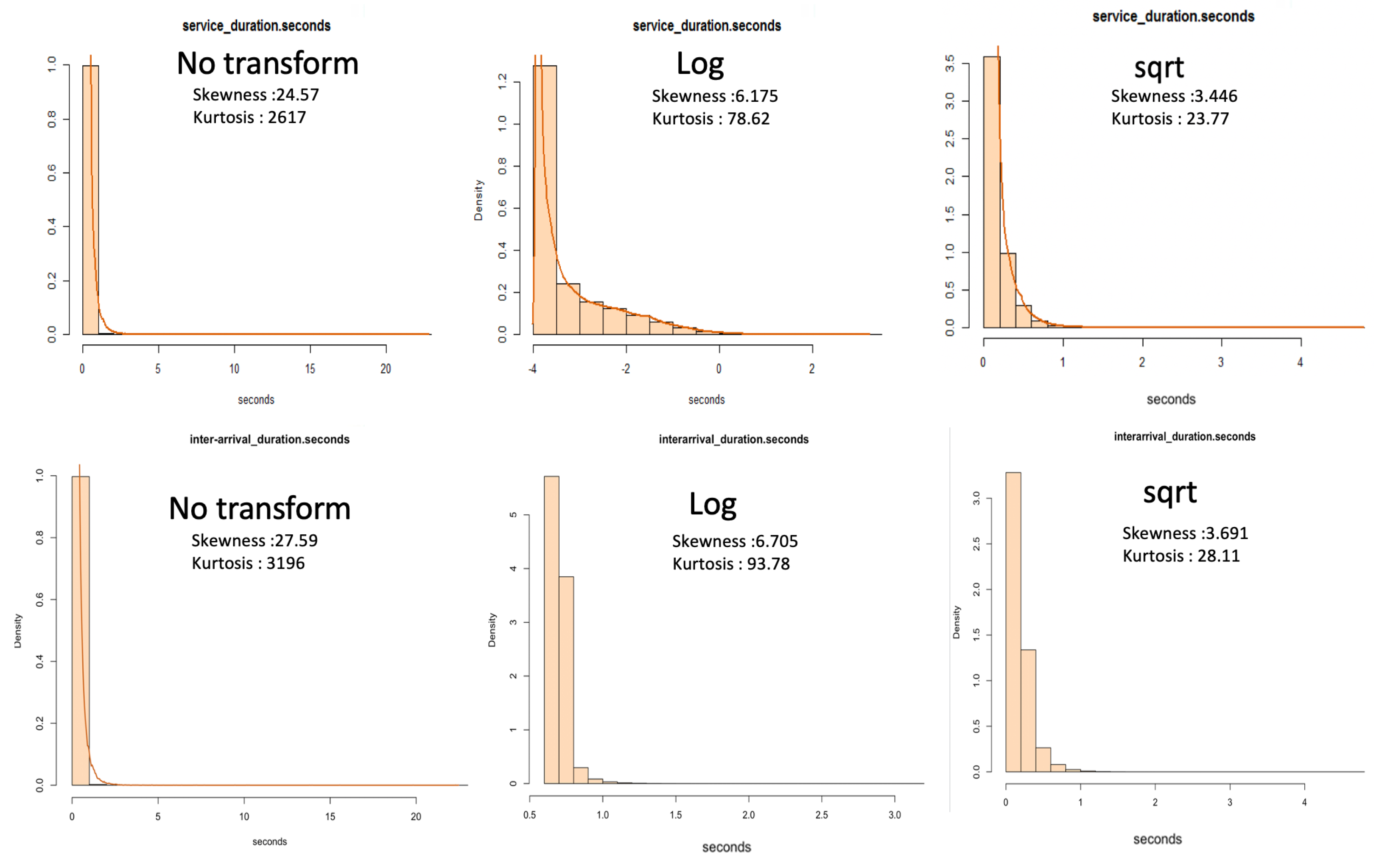
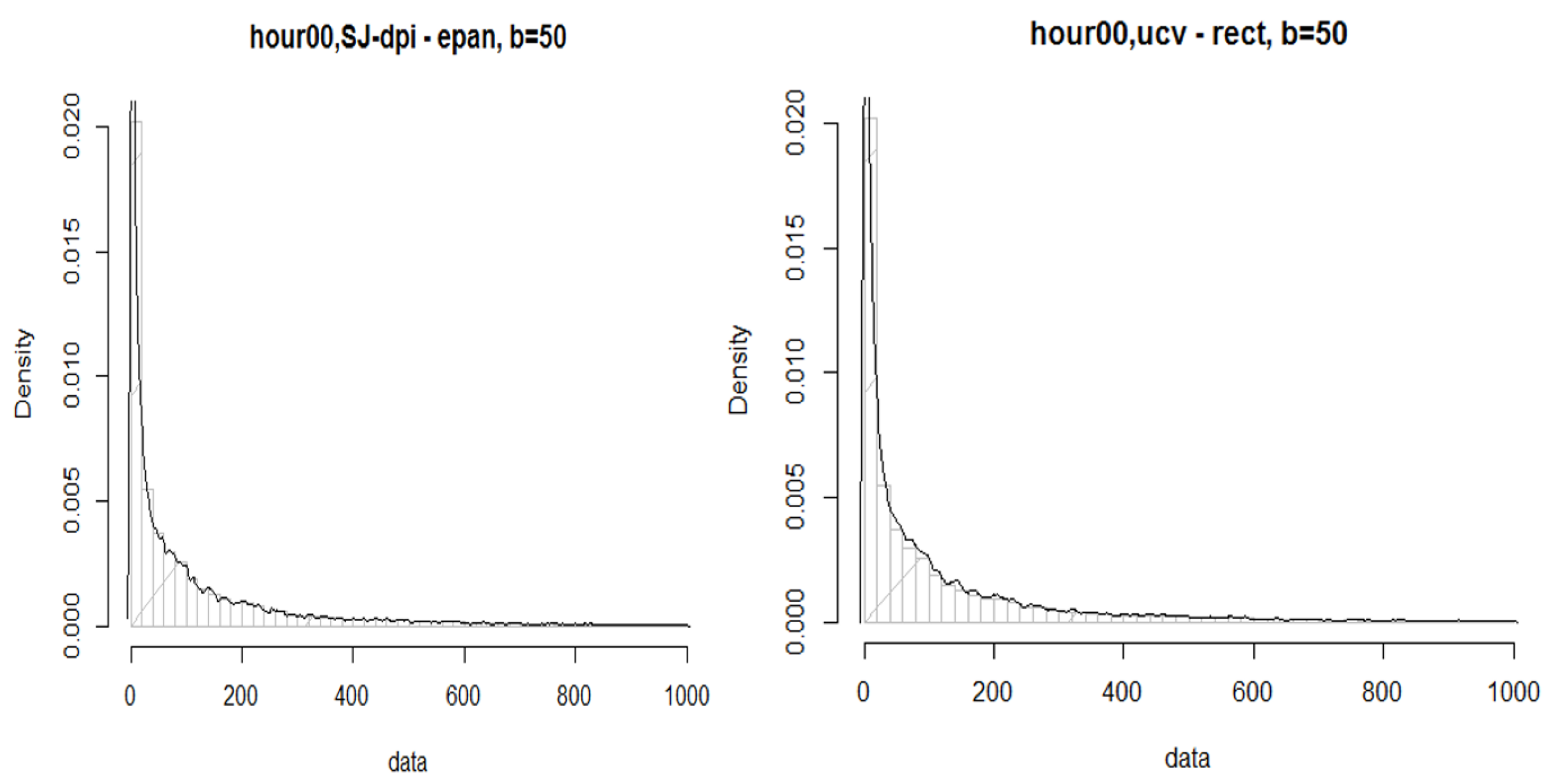
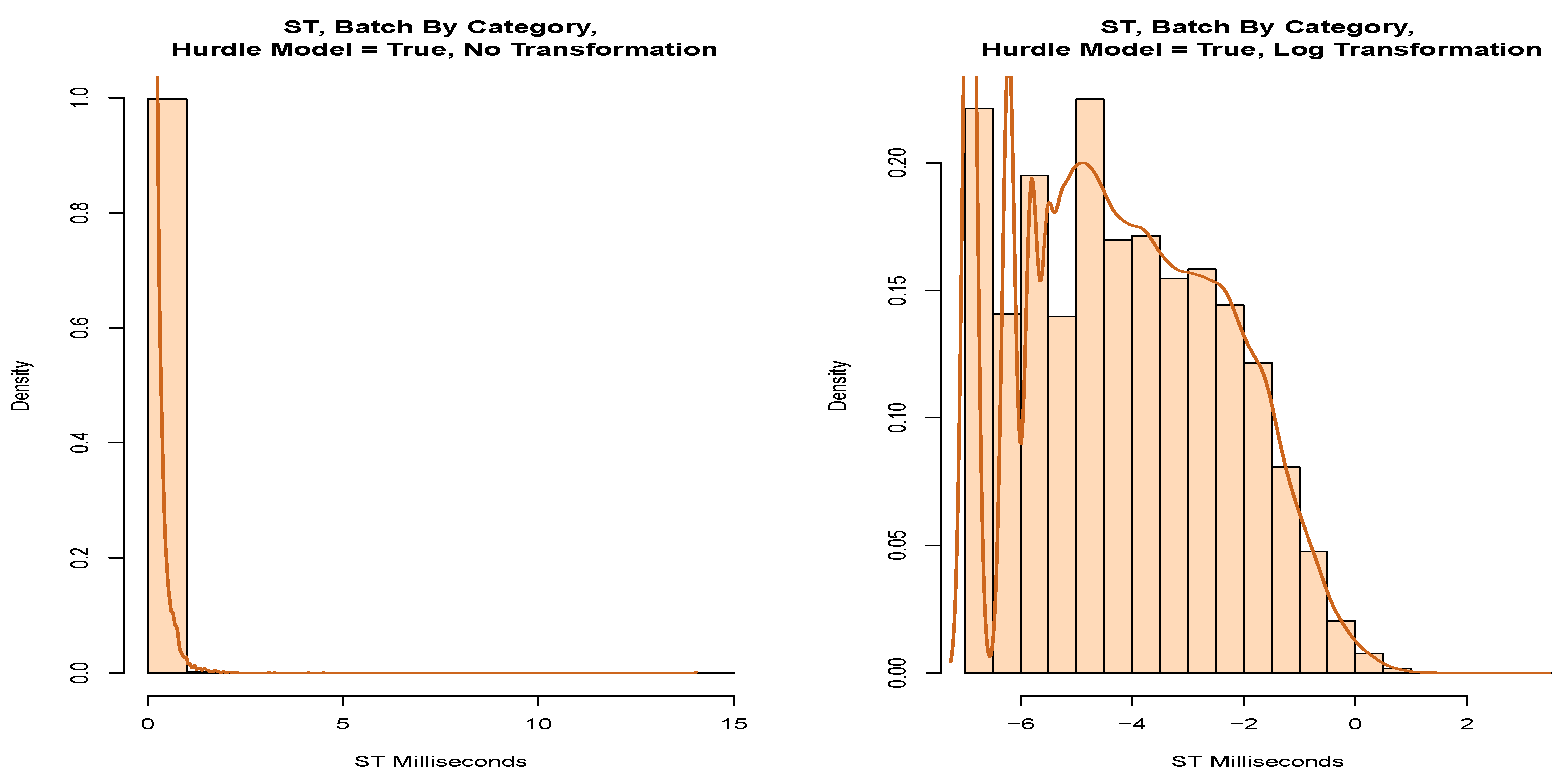
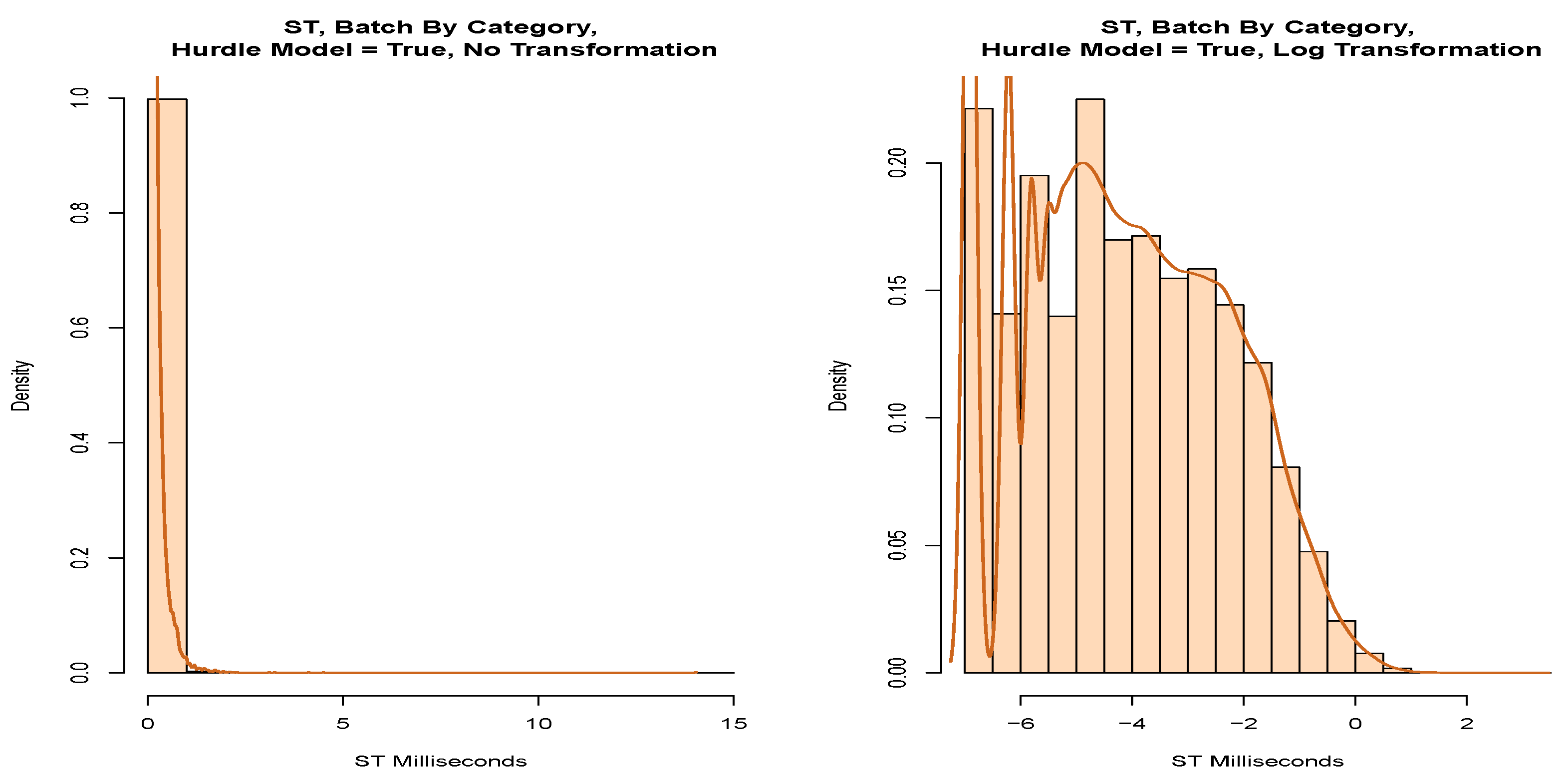
We applied the model from
Figure 9 without partitioning the data by head or tail.
Table 10 shows the top two models with the lowest AD score. We note that these data are close to a log-normal distribution but significantly fail the AD test.
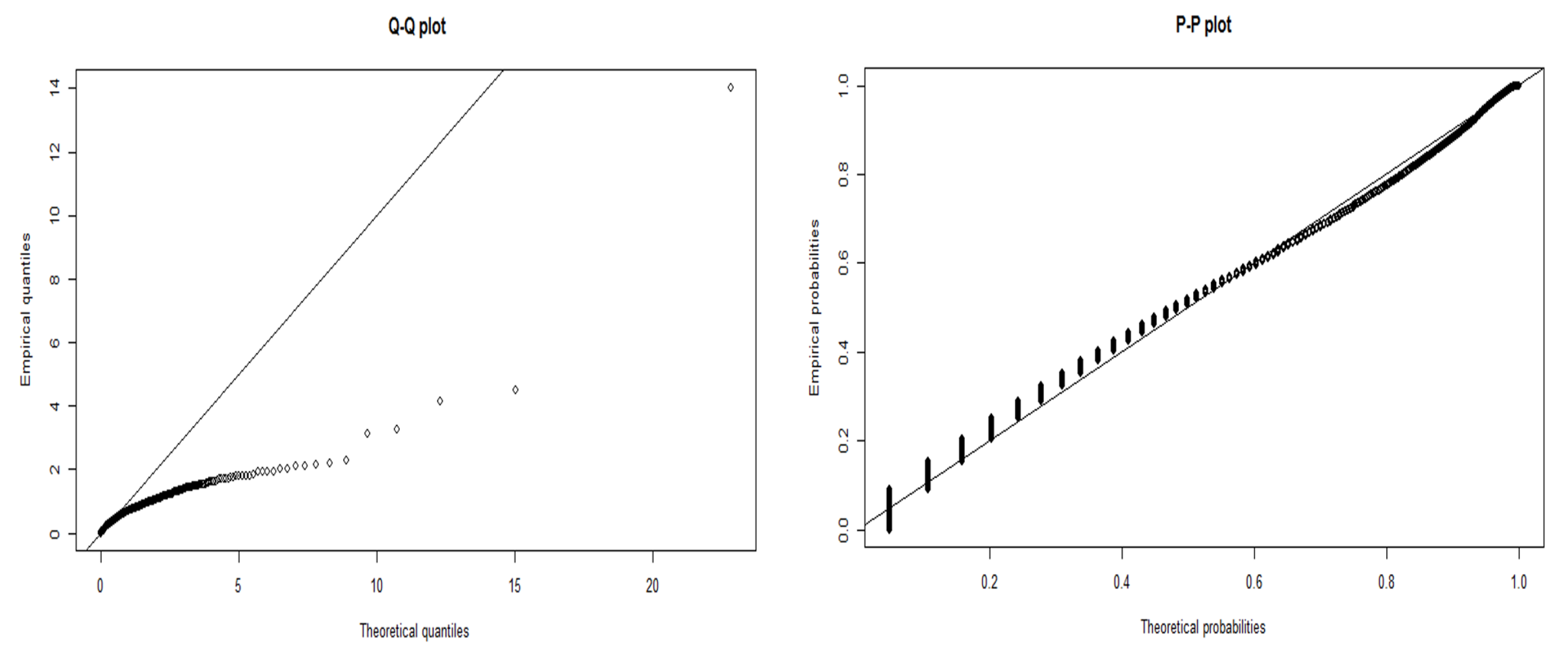
To further understand our results, in
Figure 10, we compare the data after a square root transform to the modelled log-normal distribution. The Q-Q plot shows that the data tail off at the start of the quantile line. We observe from the P-P plot that while the data appear continuous on the right-hand side of the plot, there are many discrete values on the lower probabilities.
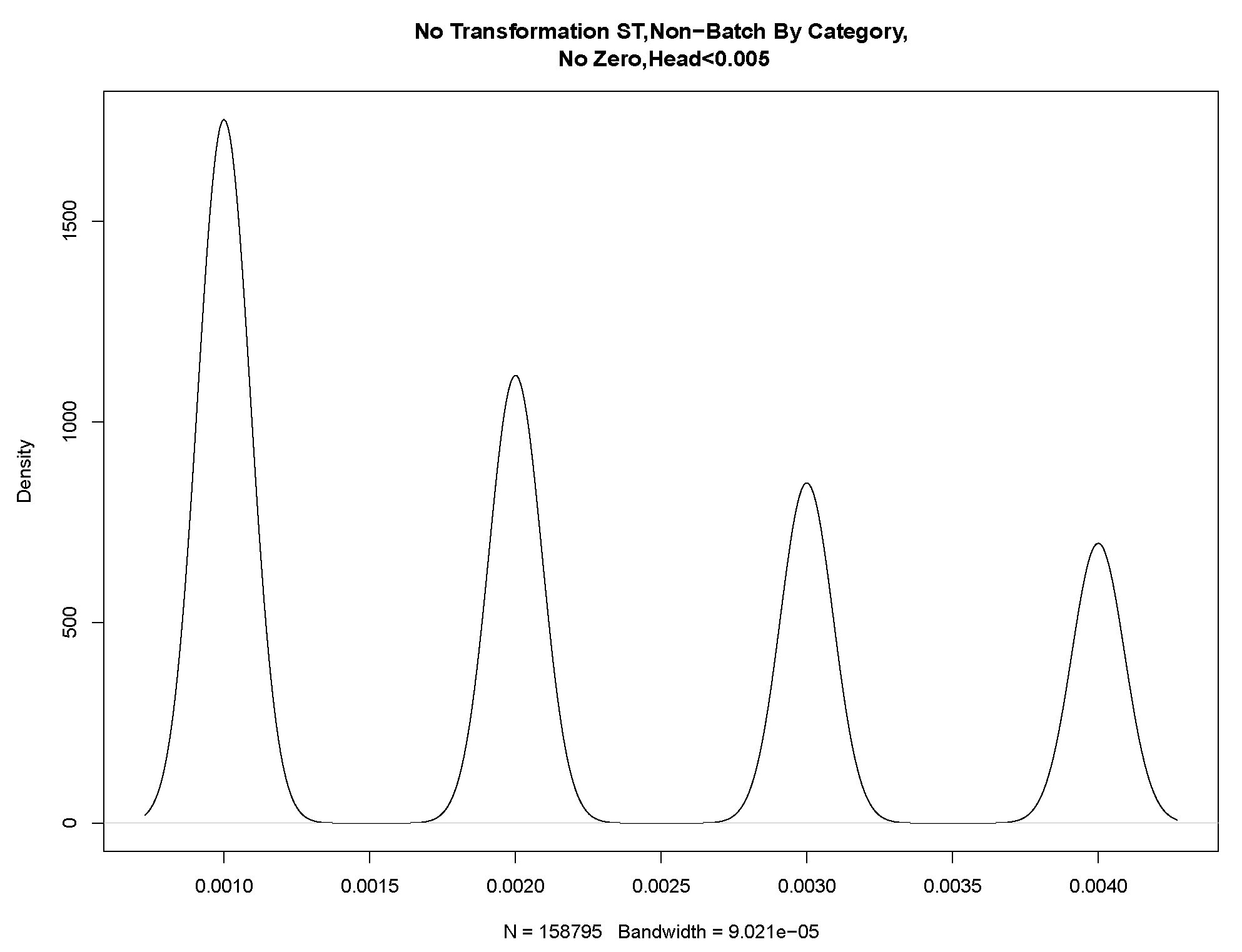
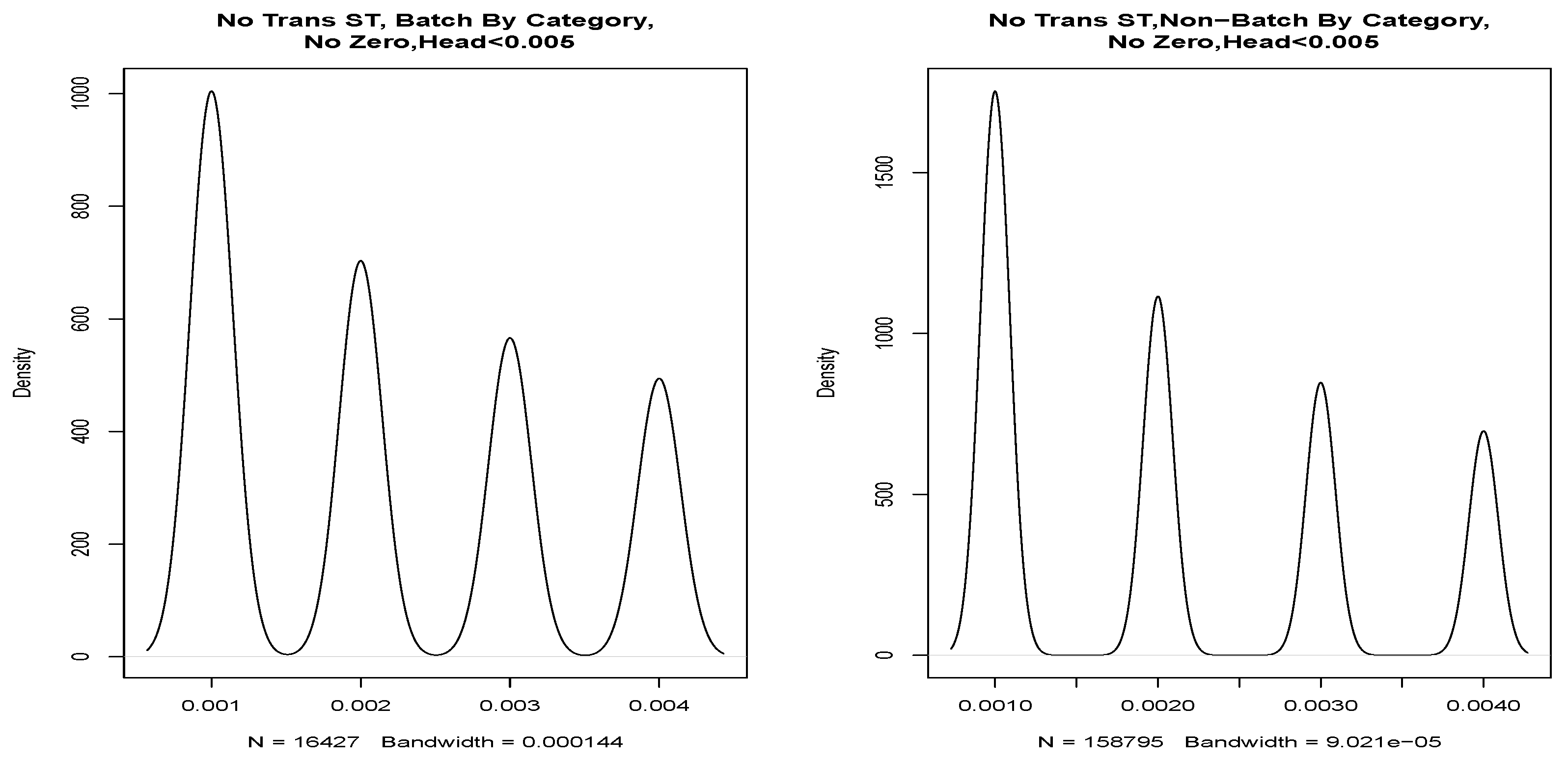
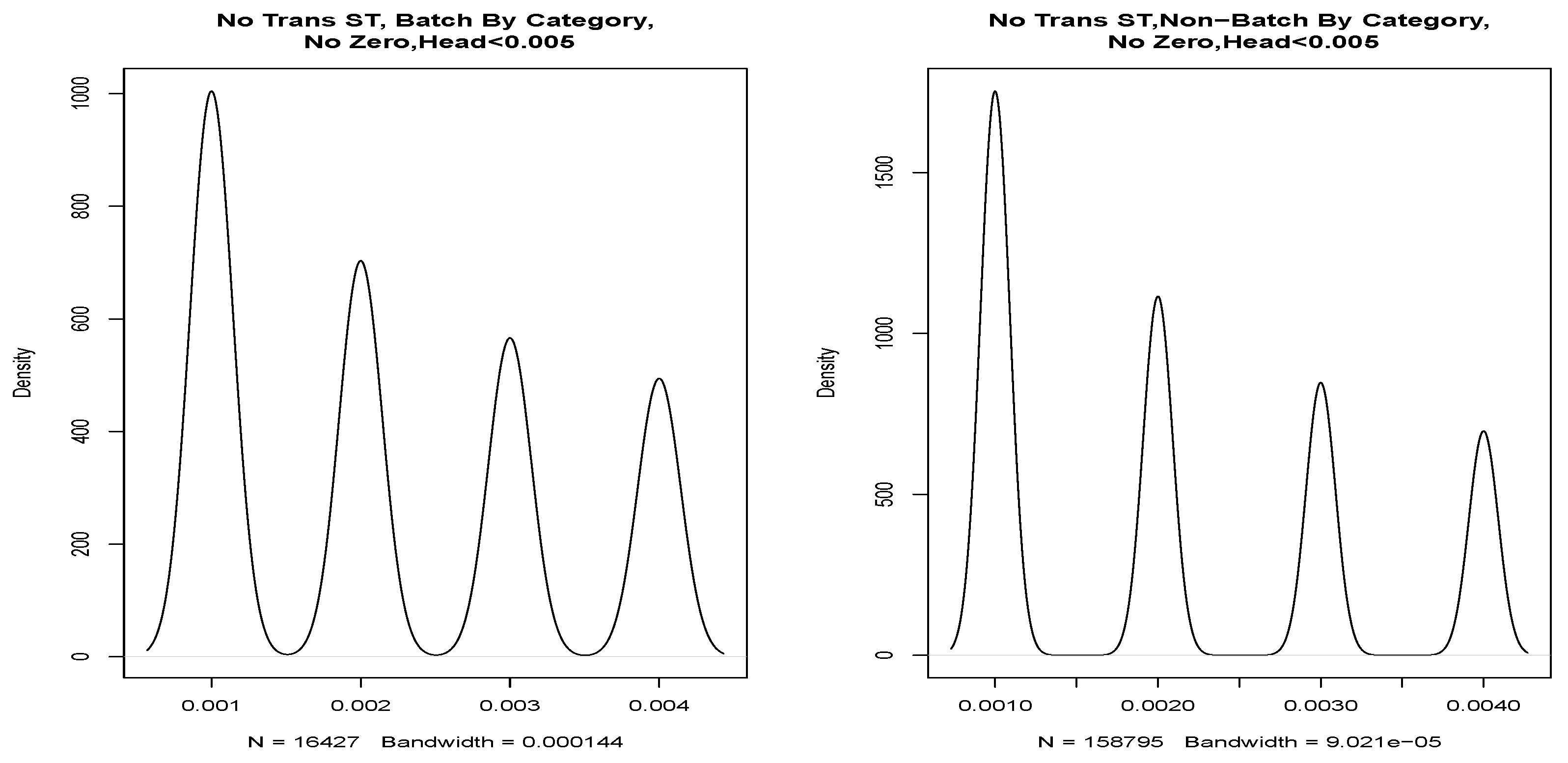
If we partition these data into a head and tail, we find clear evidence of discrete values in the P-P plot shown in
Figure 11. From these values, we were able to draw four discrete Gaussian distributions. These four Gaussian distributions result from KDE estimation applied to the discrete data and are not a feature of our data but a feature of the underlying system in the way that the mantissa is set on the message timestamp. We expect our data to be continuous, and this figure and data are not a true representation. We discuss this further in
Section 4.4.
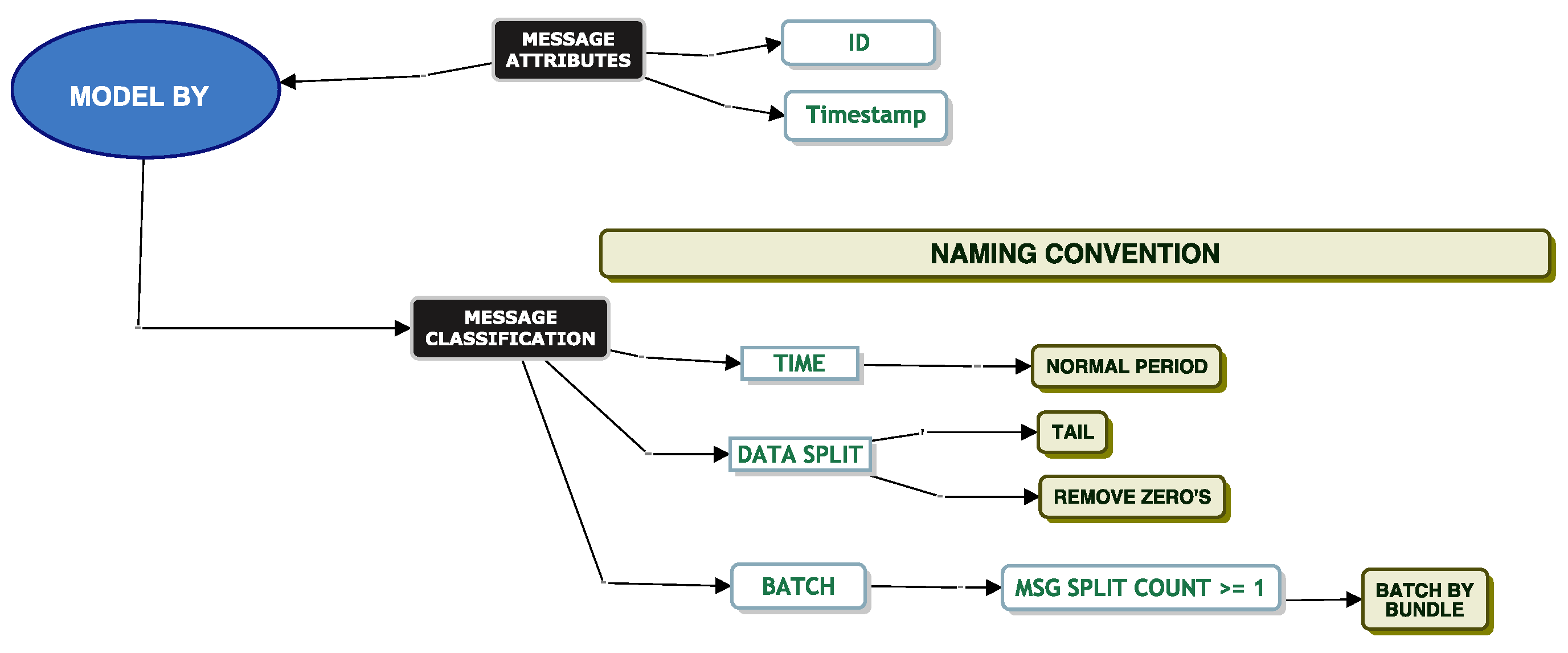
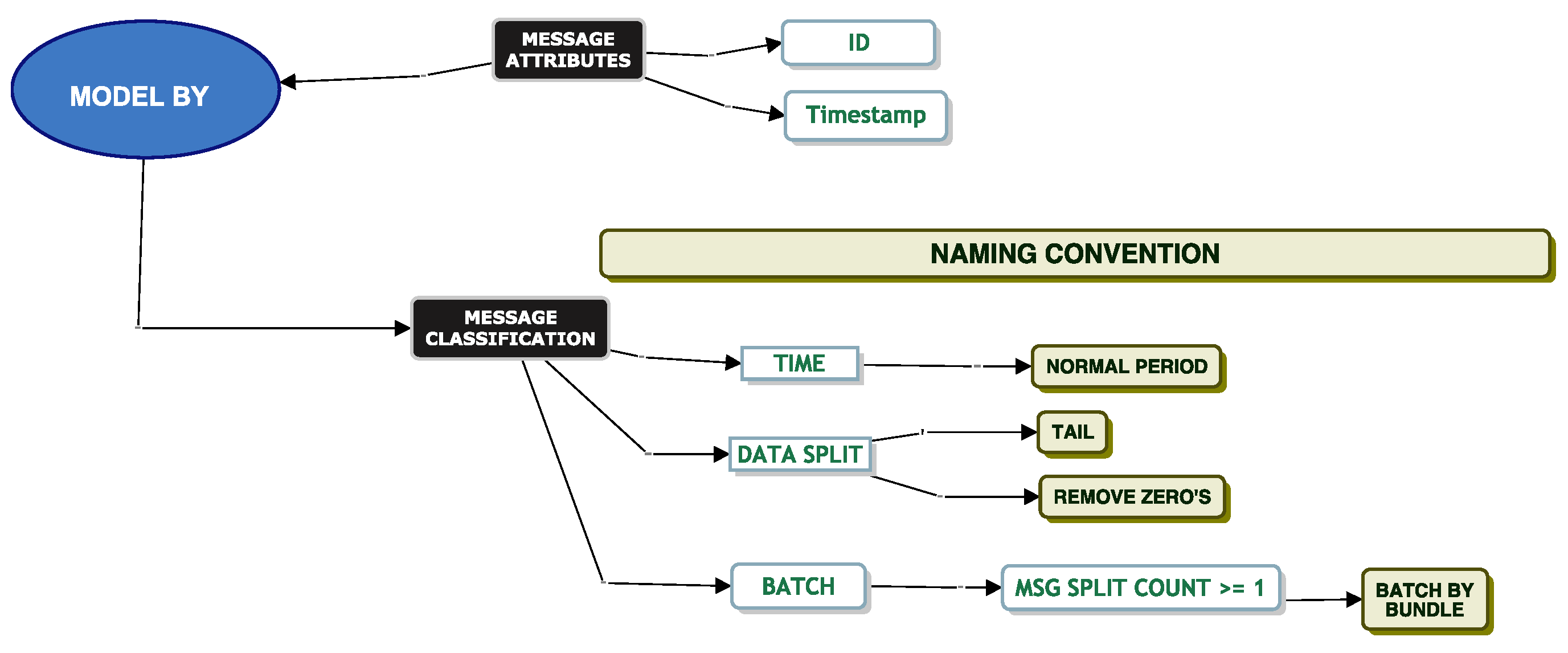
Model Batch By Bundle
Service Time Modelling
In this section, we consider messages that correspond to a bundle of XML documents, which we call “Batch By Bundle”. Our aim is to investigate the fitting of a parametric distribution to the service times accounting for these “Batch by Bundle” messages.
To recap on modelling “Batch By Bundle”, we take all messages and count the number of XML documents associated with a message. If a message has only one XML document, we take the service times for these messages for modelling. For any messages where the XML document count associated with a message is greater than one, we take the first and last message of this bundle and discard all messages in between. We note that all messages in between are all zero seconds in duration.
Using the model in
Figure 12, we applied data from the “normal period” using the tail of the data and removing zeros from the model. Our model came close to fitting a log-normal parametric distribution but failed the AD GoF test.
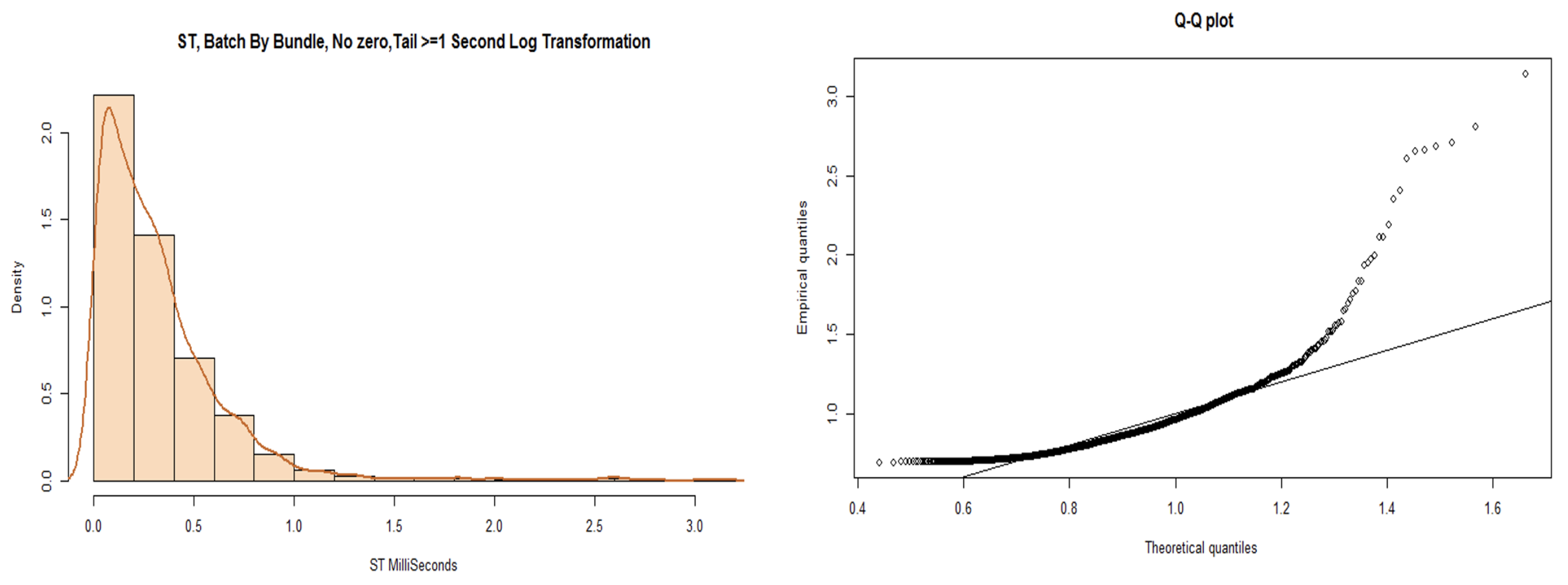
We partitioned the data into a head and tail, using a boundary of 1 s. The model results of fitting the log-normal distribution to the tail of the data are shown in the chart to the left of
Figure 13. The histogram represents a shape close to a log-normal distribution but again fails the AD test. The chart to the right shows the results of the Q-Q plot for log-normal distribution fitting. We observe from the Q-Q plot that the lower quantile regions are more fitting to the line than the upper quantile regions, but there are clear systematic mismatches.
Table 11 shows our best AD test result. We applied a constant of 1 to the tail of the service times and applied a log transform on the data to improve the fit.
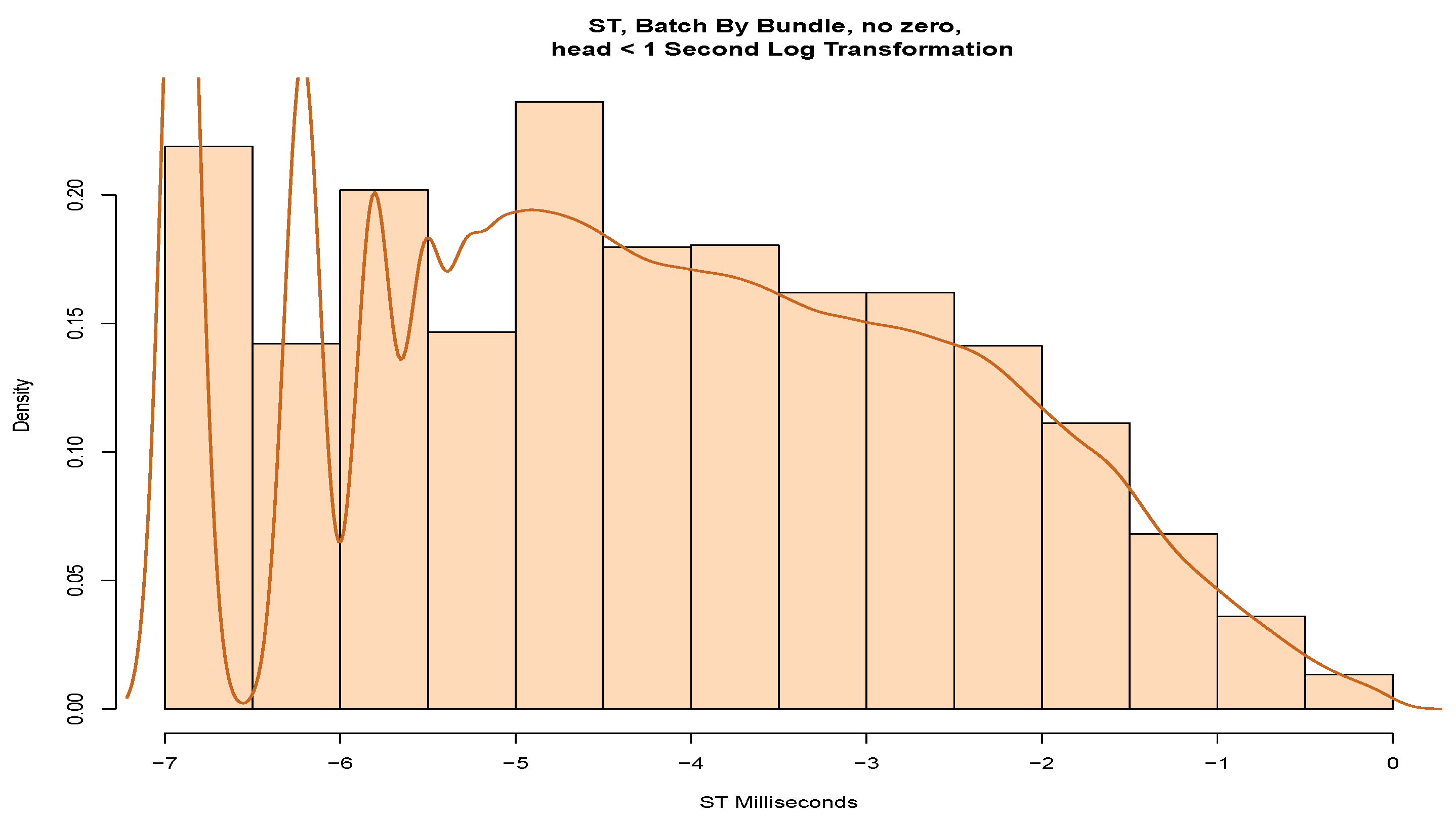
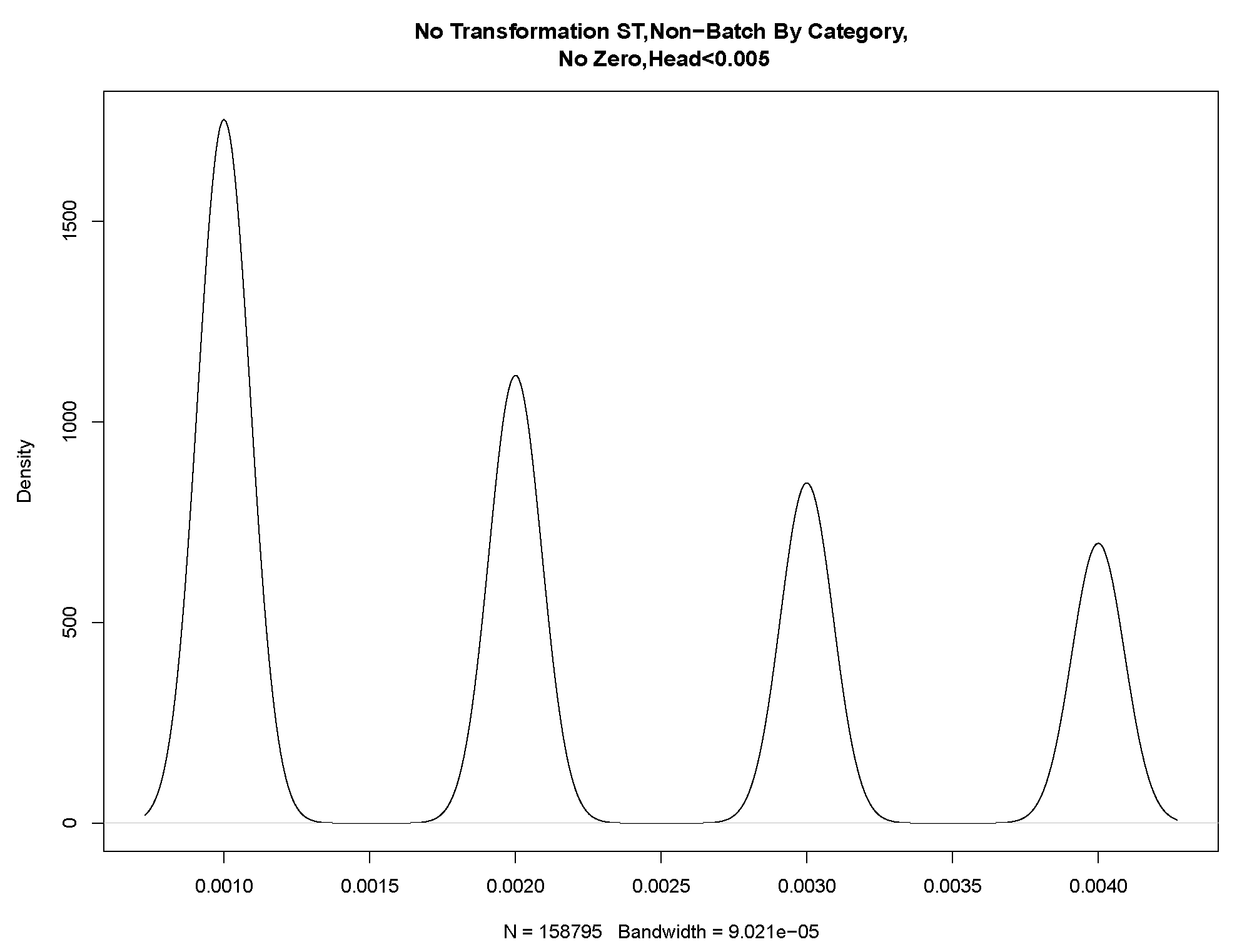
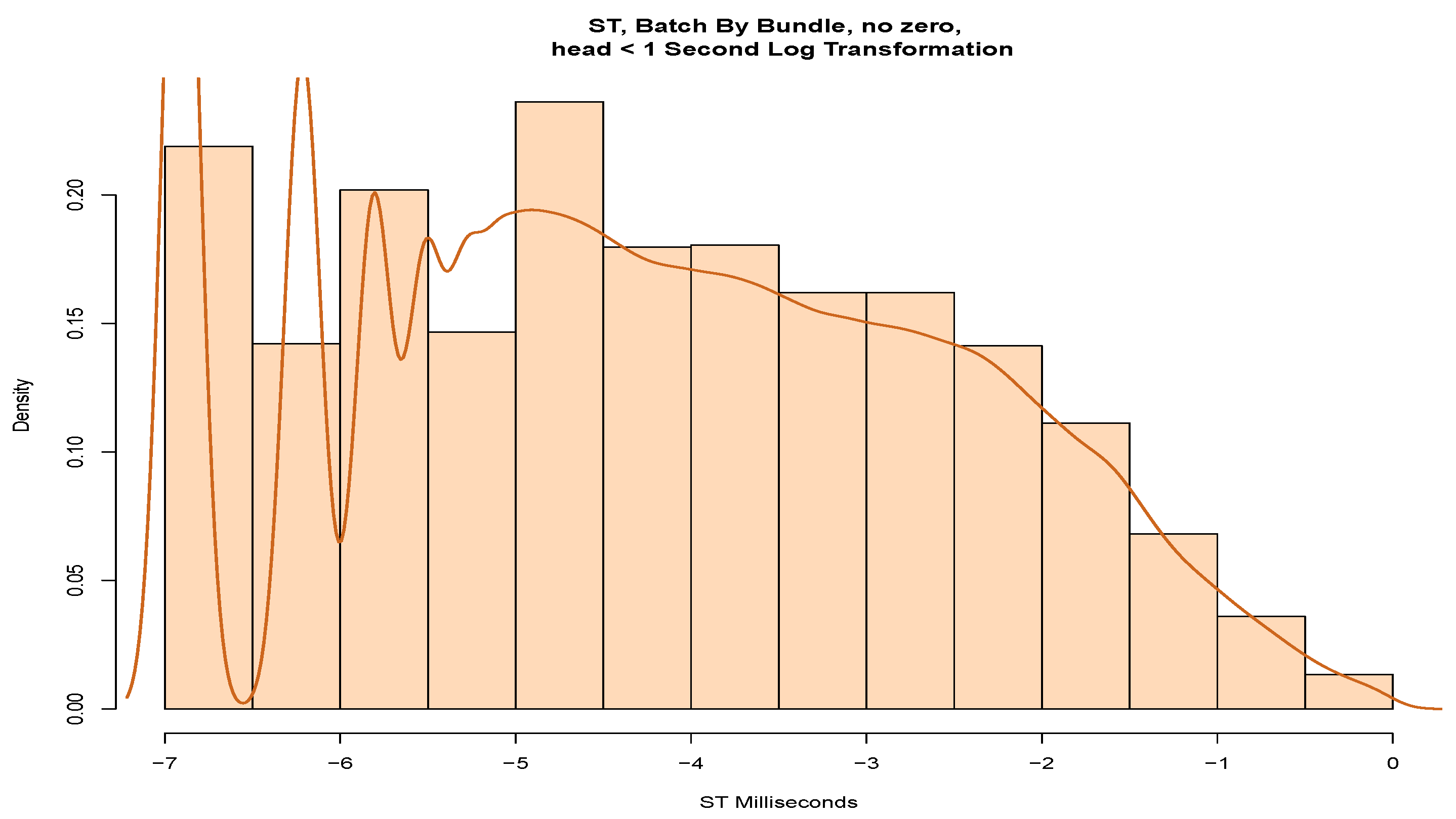
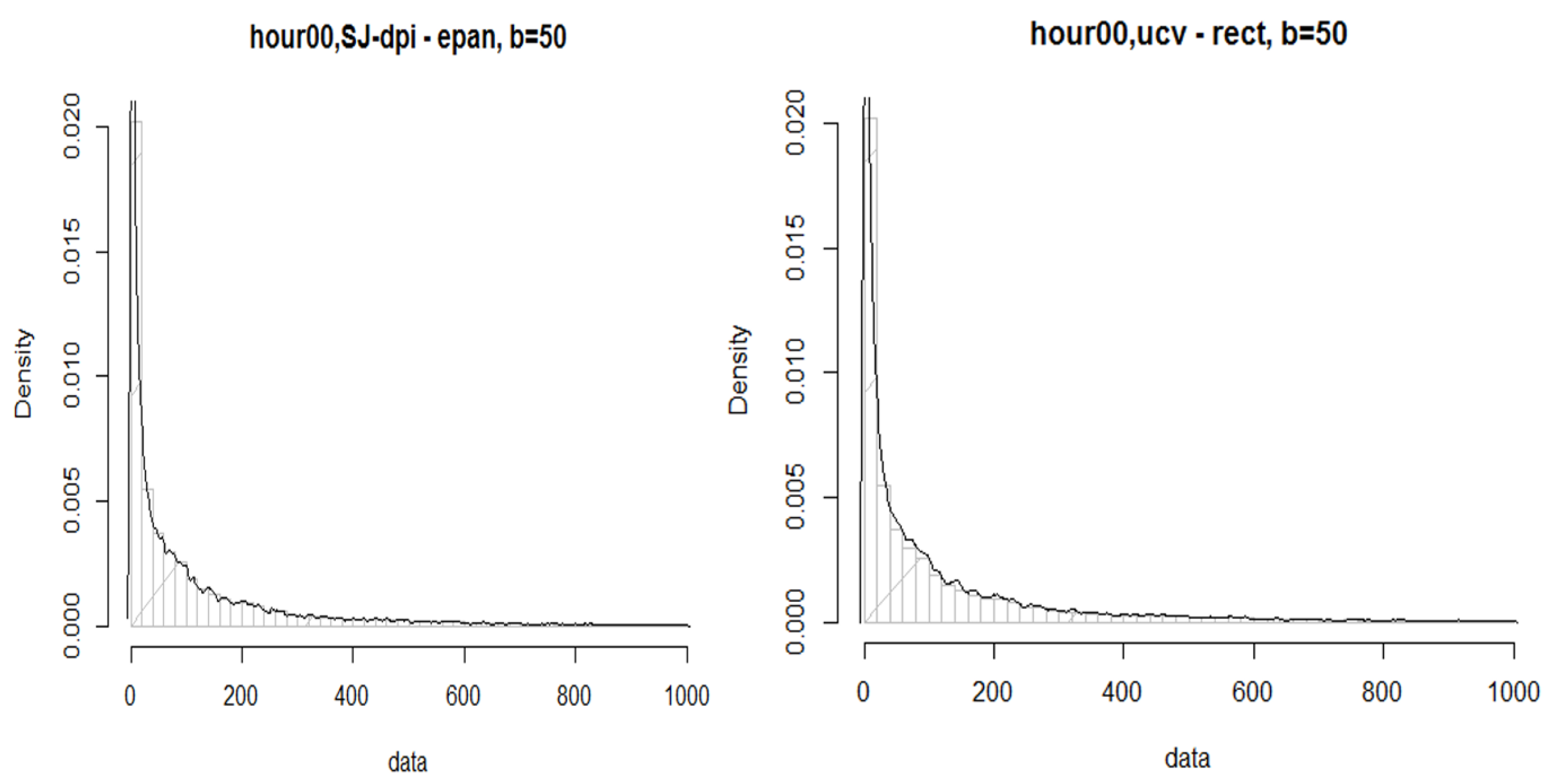
To model the head of the data,
Figure 14 shows a histogram with a probability density drawn on the service times. We note several peaks at the left of the estimated density that again suggests quantisation. Consequently, it is unlikely that these data would fit a parametric distribution. Possibly, it could be further partitioned, KDE could be applied, or adjustments could be made for quantisation.
We now attempt to model our data using “Batch By Split Count”.
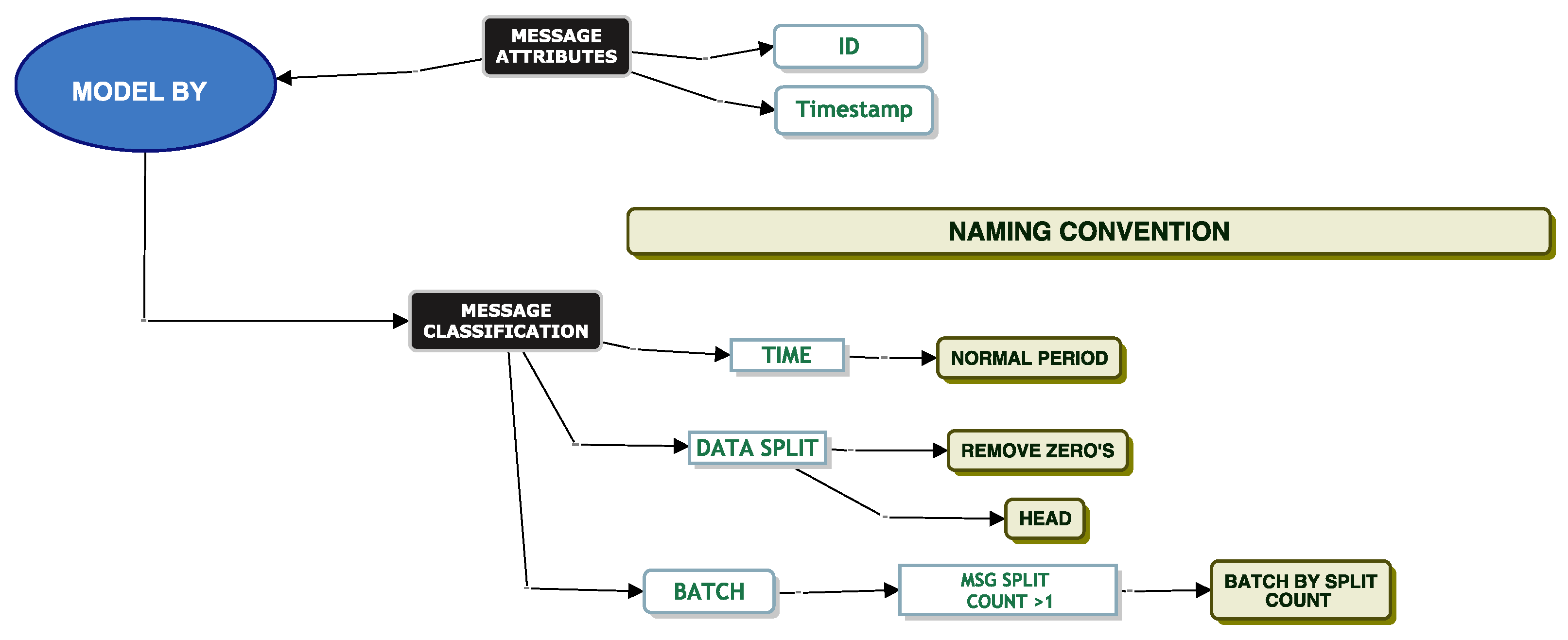
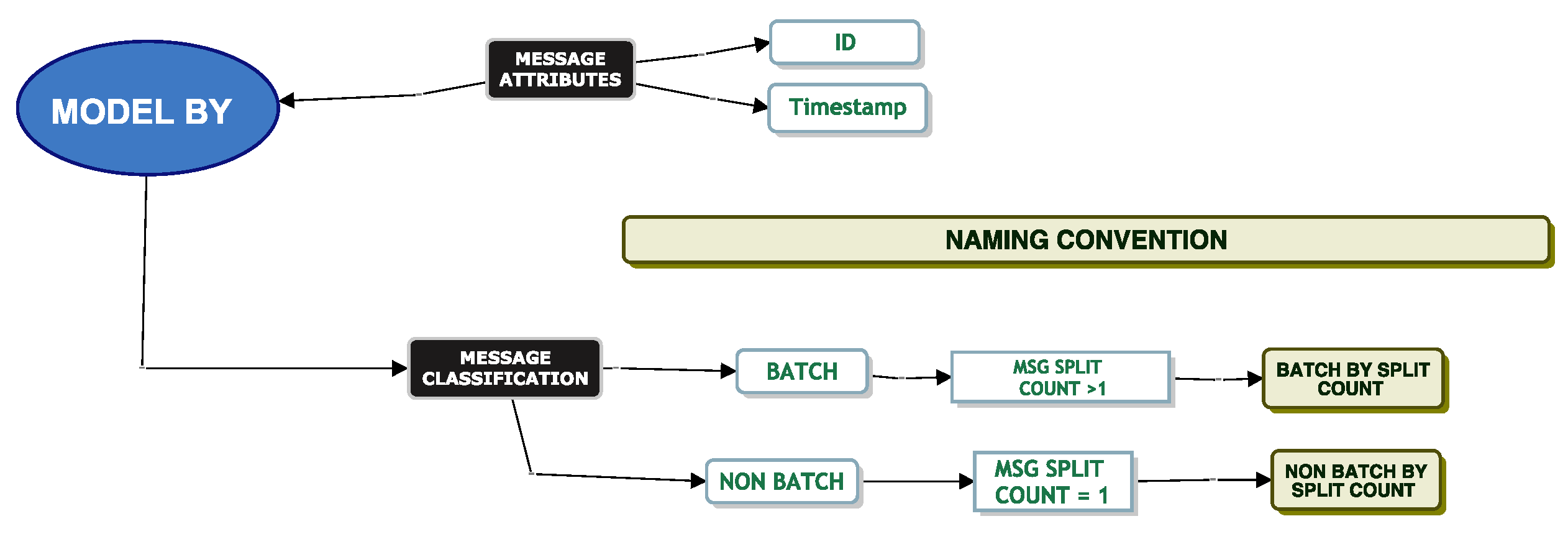
Model Batch By Split Count
We classify messages using a “Batch By Split Count”. As mentioned previously, one single message may be split into multiple smaller messages and sent to the queue as a batch. A “Batch By Split Count” is one where the XML document count is
. Again, we attempt to fit a parametric distribution to the service times of these messages. We then model the messages using three different partitioning techniques. We model messages where the XML count is
, where the XML count
and where the XML count
as per
Figure 15.
Regardless of the transformation and partitioning technique applied, we could not fit our data to a parametric distribution to the service times of these batch messages.
Table 12 shows the top two distributions with the lowest AD score. If we model the head of the service times, where the split count is >2, the service times is ≤1 s, no transformation is applied, and zeros are removed, our model comes close to fitting a log-normal distribution with an AD score of 39 and also comes close to fitting a Burr distribution with an AD score of 41.
Based on the observations in
Table 12, and looking at the results of the applied model for a log-normal distribution in
Figure 16, our data do not fit a parametric distribution for the head of the data.
We note that we were also not able to fit the tail of the data to a parametric distribution.
We now focus our efforts on modelling by “Non-Batch By Split Count”.
Model Non-Batch By Split Count
Service Time And Inter-Arrival Time Modelling
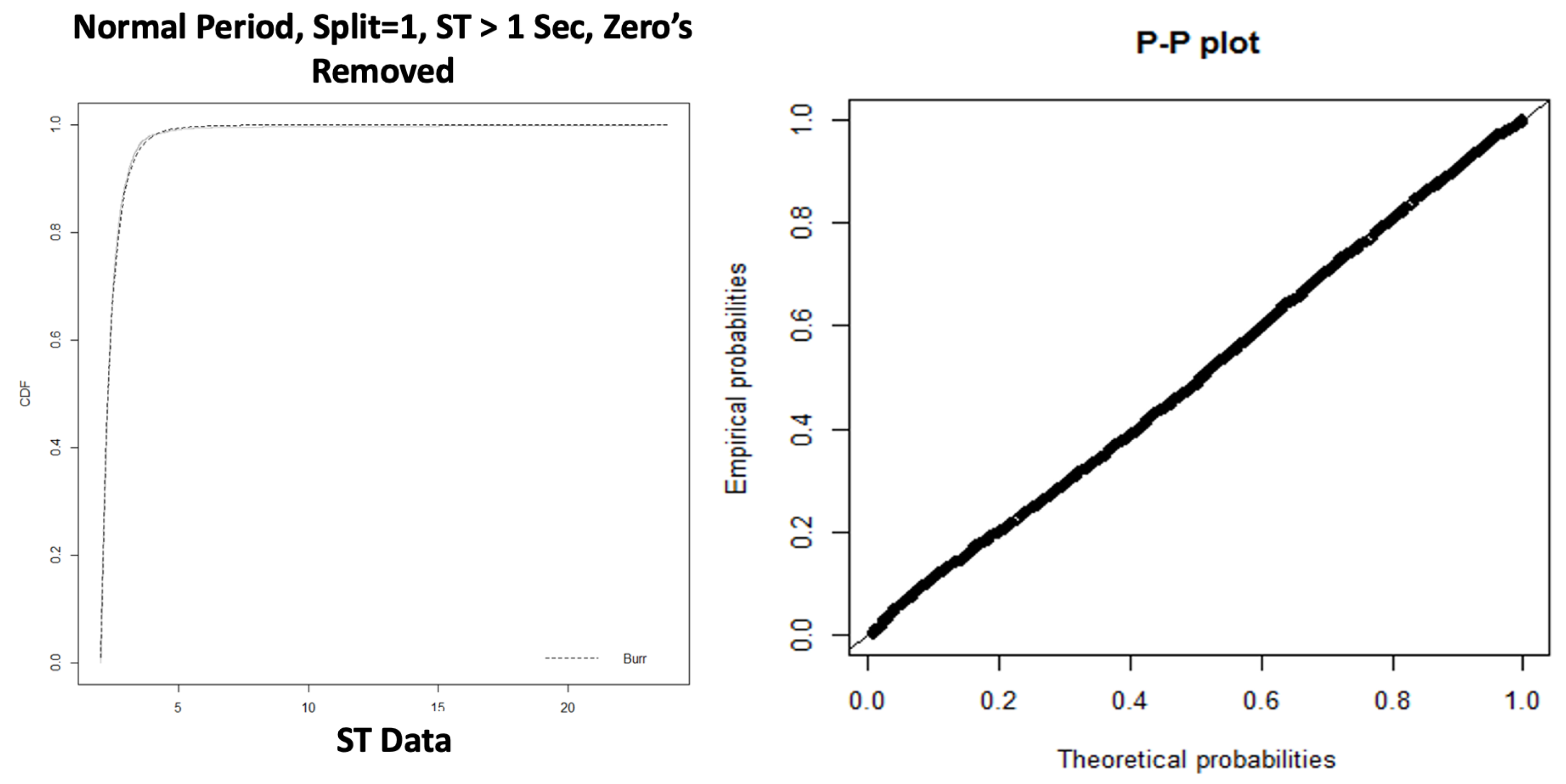
“Non-Batch By Split Count” is the complement of “Batch By Split Count”; it considers the messages where exactly one XML document is associated with the message. We modelled the service and the inter-arrival times by applying different techniques of the classification model. The results of our analysis indicate that we could only fit a Burr distribution to the tail of the data, as per
Figure 17.
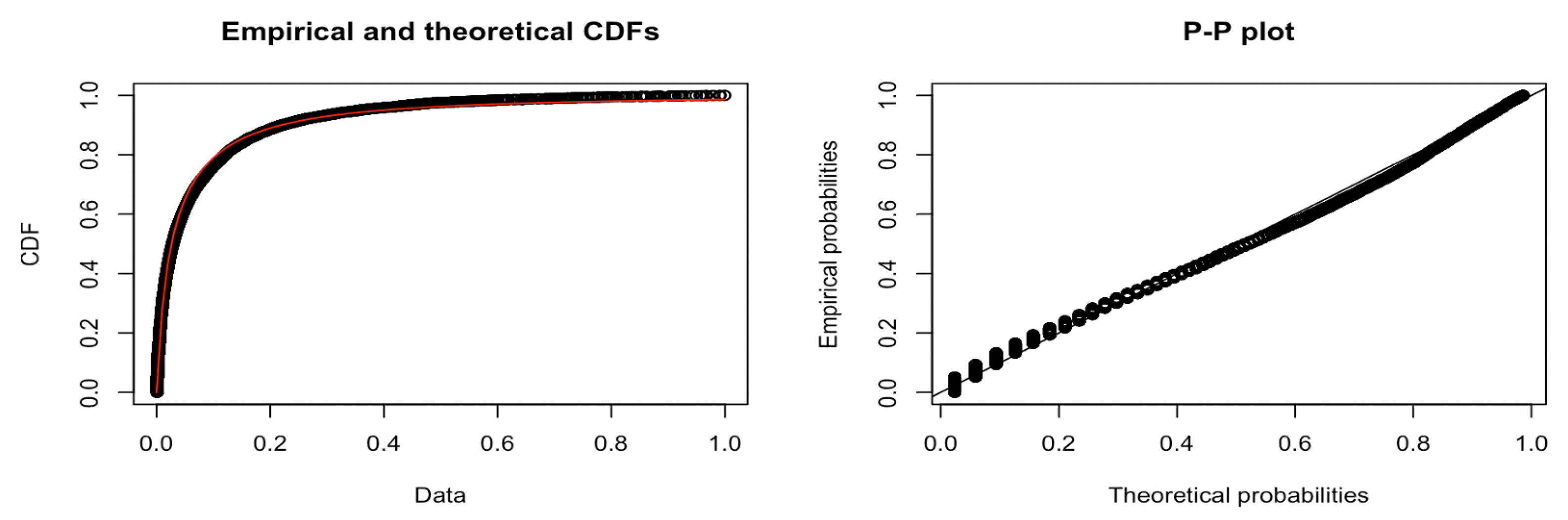
The results of the Anderson–Darling test in
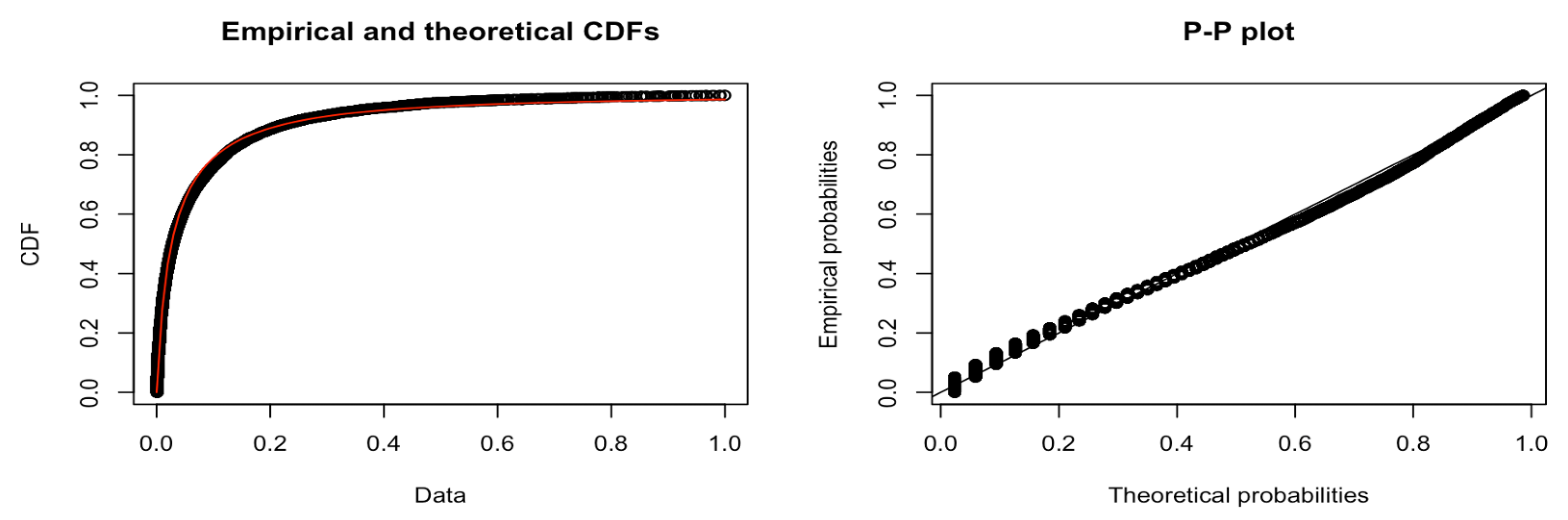
Table 13 confirm that we can fit the tail of the service times to a Burr distribution. Note that we applied a constant offset of 1 to the dataset when it passed the AD GoF test. The CDF plot in
Figure 18 shows both the empirical distribution and the fitted Burr distribution. From the P-P plot, we note that no observations appear to deviate significantly from the line.
For the head of the service times data (service times s), we could not parametrically fit the data to a parametric distribution, irrespective of transformation or implementing partitioning methods.
Now we consider inter-arrival times partitioned into the head and a tail with a boundary of 1 s. For the tail (>1 s), the results of the AD tests conclude (
Table 14) that these filtered data do not fit a parametric distribution. However, we observe that a no-transform and a square root transform (highlighted in bold) are a relatively close fit to a Burr distribution but do not pass the AD test.
Table 14 shows only the closest model to a parametric distribution. When modelling the head of the inter-arrival times, we found evidence of correlation, which is included in our conference paper [
11].
Model Non-Batch By Category
Service Time Modelling
To recap on the importance of modelling by “Non-Batch By Category”, we refer the reader back to
Section 3.2.1. We now try and fit a parametric distribution to our data using different techniques from the classification model. First, we analyse the measures of dispersion using the “Non-Batch By Category” model. We note from
Table 15 that for the service times, one-third of the messages are removed when we remove messages of zero duration. We also note a slight difference in the service times in the 95th percentile between non-batch messages and when zeros are removed from the dataset. Our dataset is highly skewed, with a reporting skewness greater than 20. With the zeros removed from the dataset, the lowest service time is 0.001 s.
Our closest model to fit a parametric distribution is in
Figure 19. We apply the model to the “Normal Period” using the “Tail” of the data and removing messages that are zero seconds in duration.
Table 16 shows the top two best models for parametric fitting. We note a large AD score and ascertain that even the best fitting model is not particularly good, and so we have not identified a suitable parametric model.
When modelling the head of our data, we again found evidence of discrete values leading to quantisation noise. We refer to
Section 4.4 for a discussion around the effects of quantisation.
Using the classification model, we attempt to fit our data to a parametric distribution. We now focus our efforts on non-parametric modelling.
3.2.3. Message Interdependence
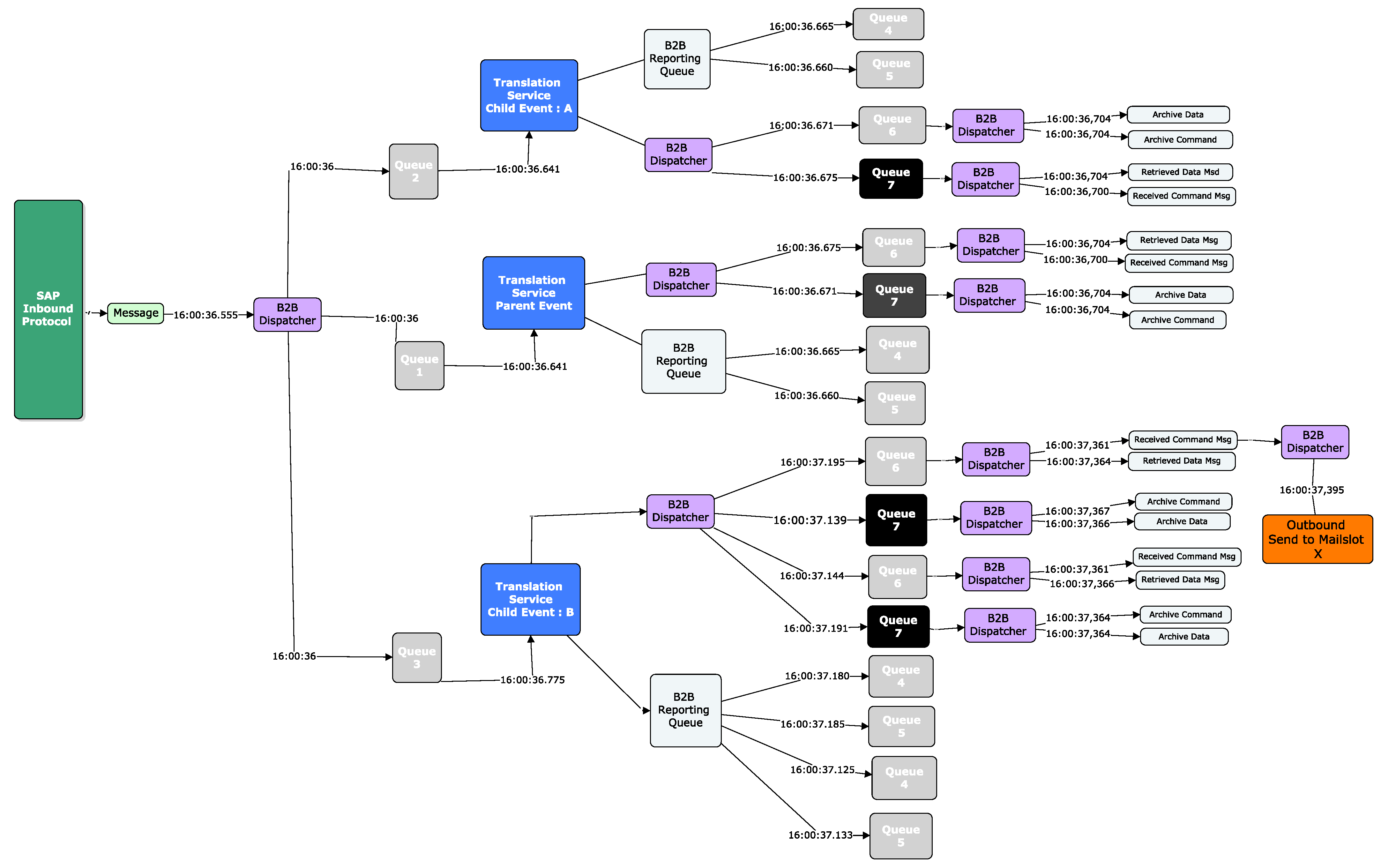
Message interdependence is critical when simulating a queueing system. Modelling single message behaviour through a queueing system is less complicated than modelling messages where there is a parent–child relationship, and the relationship may be one too many. The service times of a batch message may not be determined until the last child message arrives and is processed in the queueing system. Using the classification model, we attempted to understand if we could easily identify a parent–child relationship within our dataset. Applying the models from
Figure 21, we observe that we were able to determine if a message was dependent on previous messages based on the “Batch By Split Count” model and the “Non-Batch By Split Count” model.
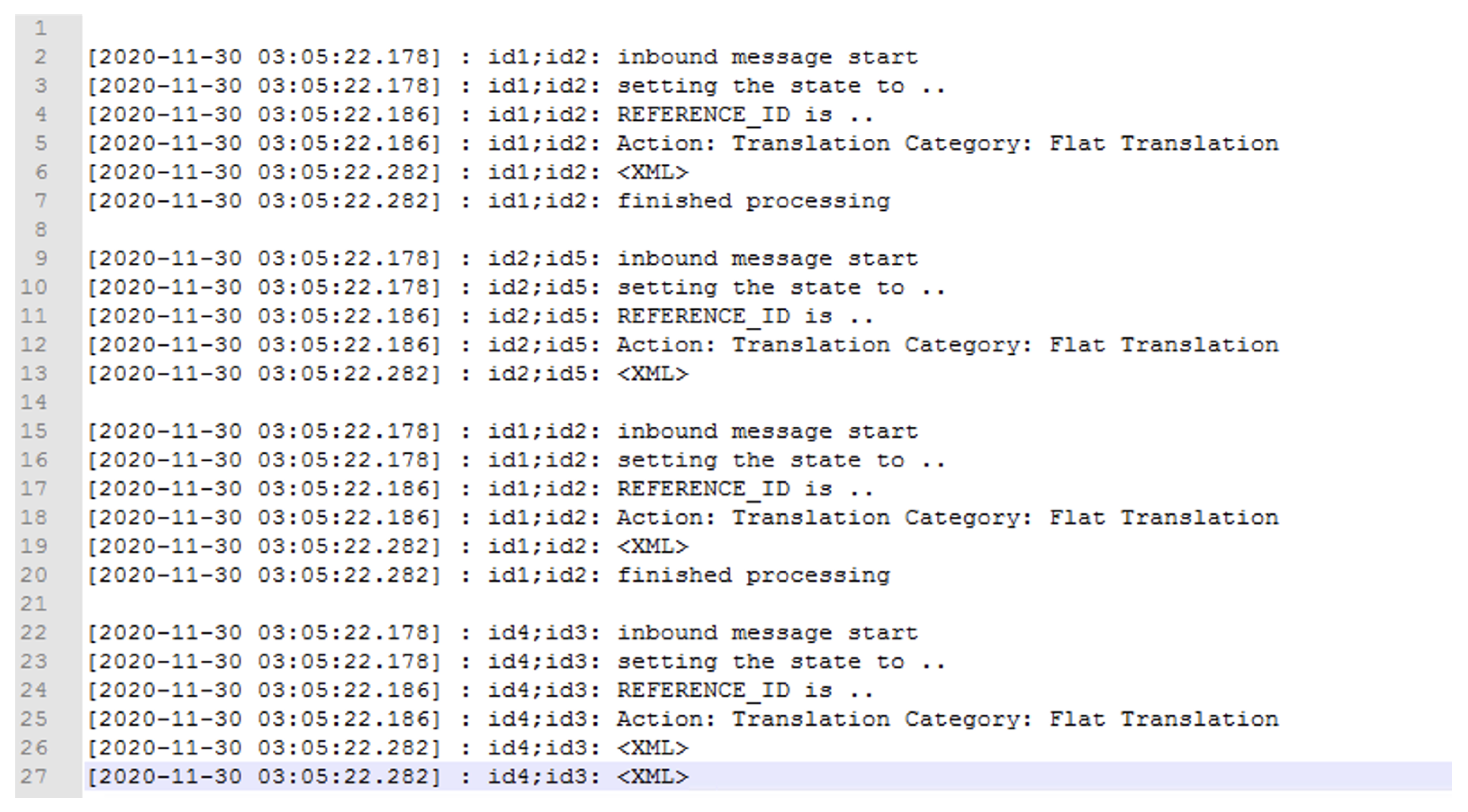
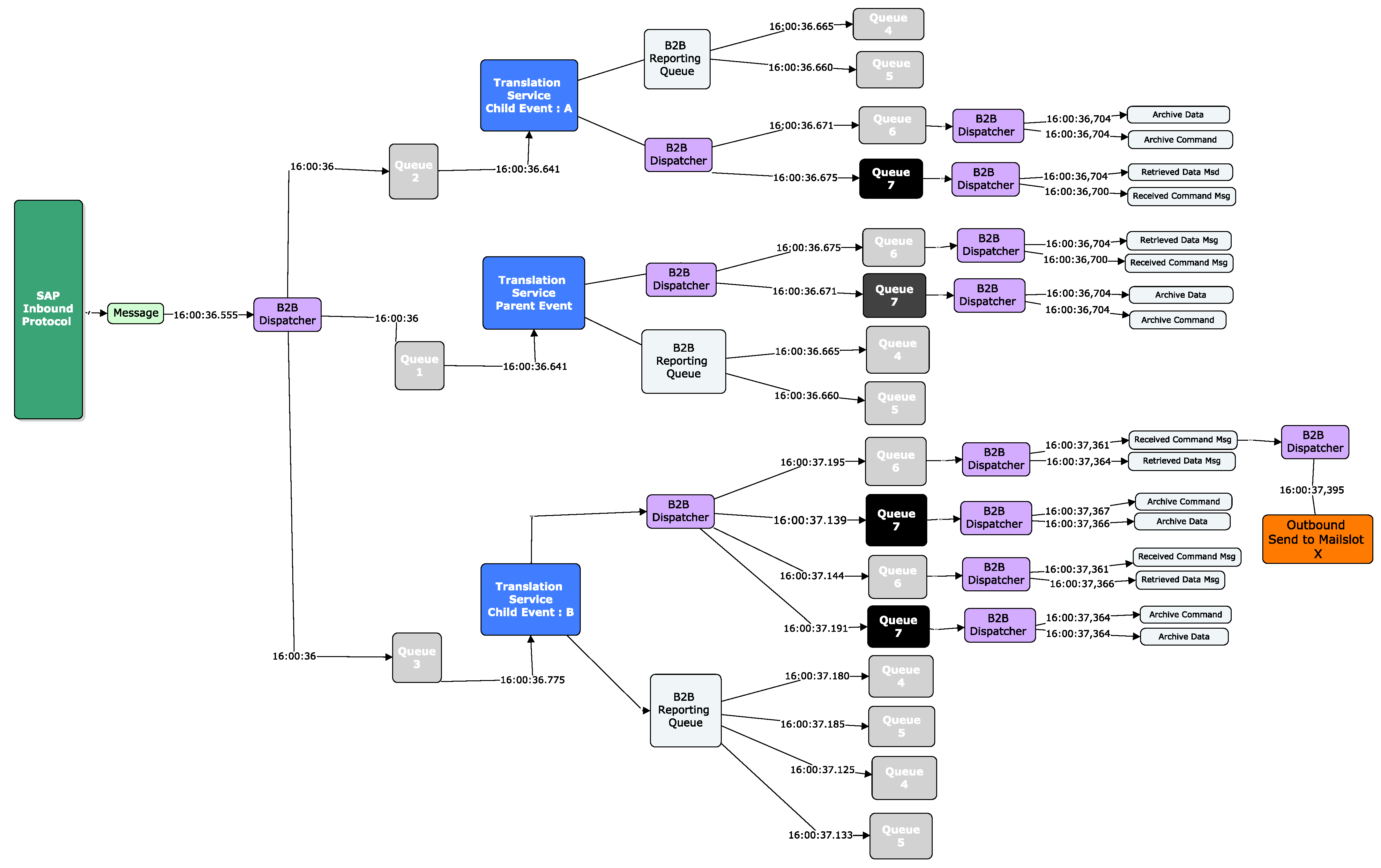
We now explore the text in
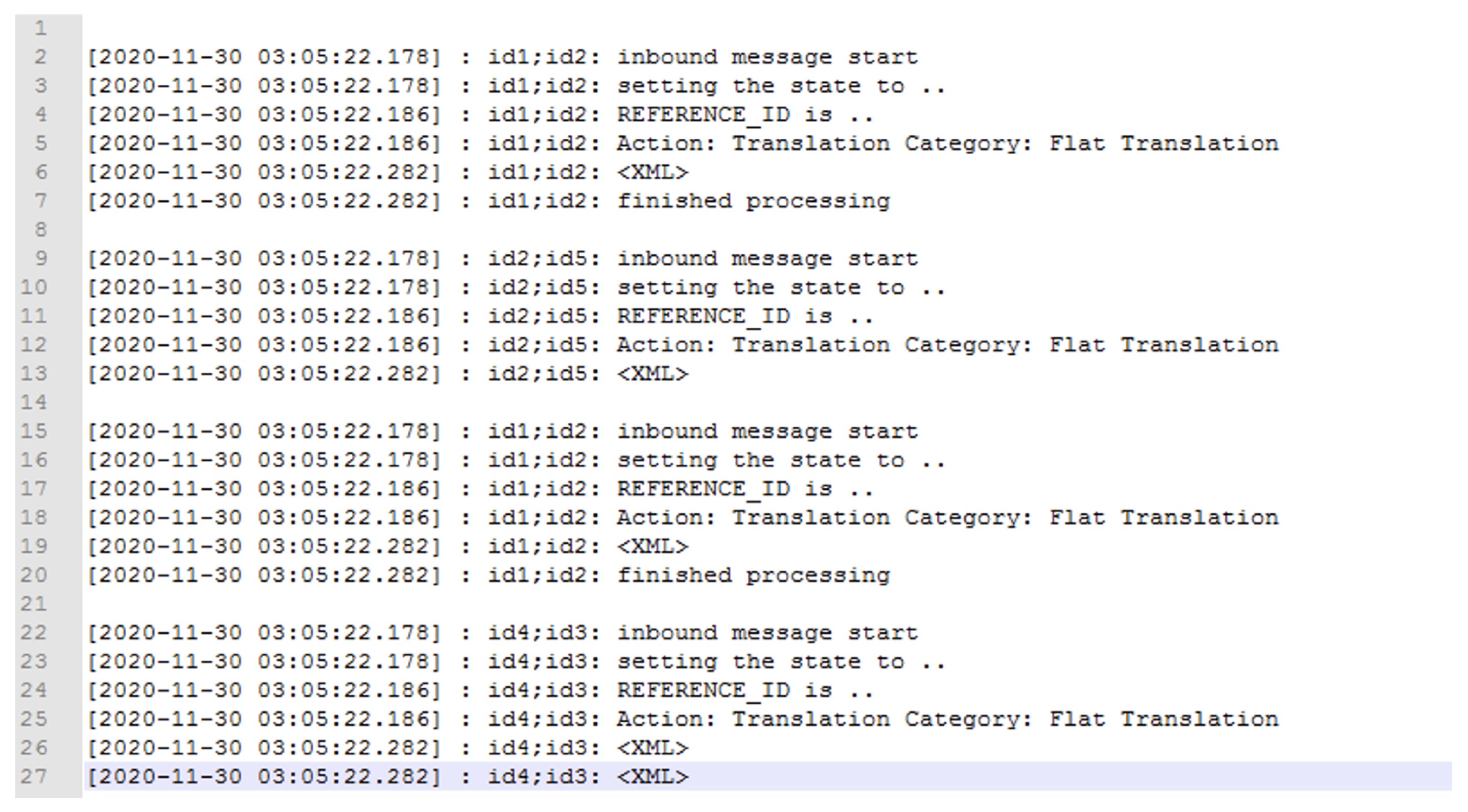
Figure 22 to give some context on how we came to this conclusion.
At a high-level view, a message first arrives in line 2. The message is set to an associated state defined by a map associated with the message as per line 3, and the customer name is associated in line 4 using a Reference ID. The message is then sent for translation in line 5, and the XML for the message is produced in line 6. The message is then completed processing in line 7. A subset of this message is then processed again starting from line 15 and is finished at line 20. This means that this message is split into two messages and is fully complete at line 20.
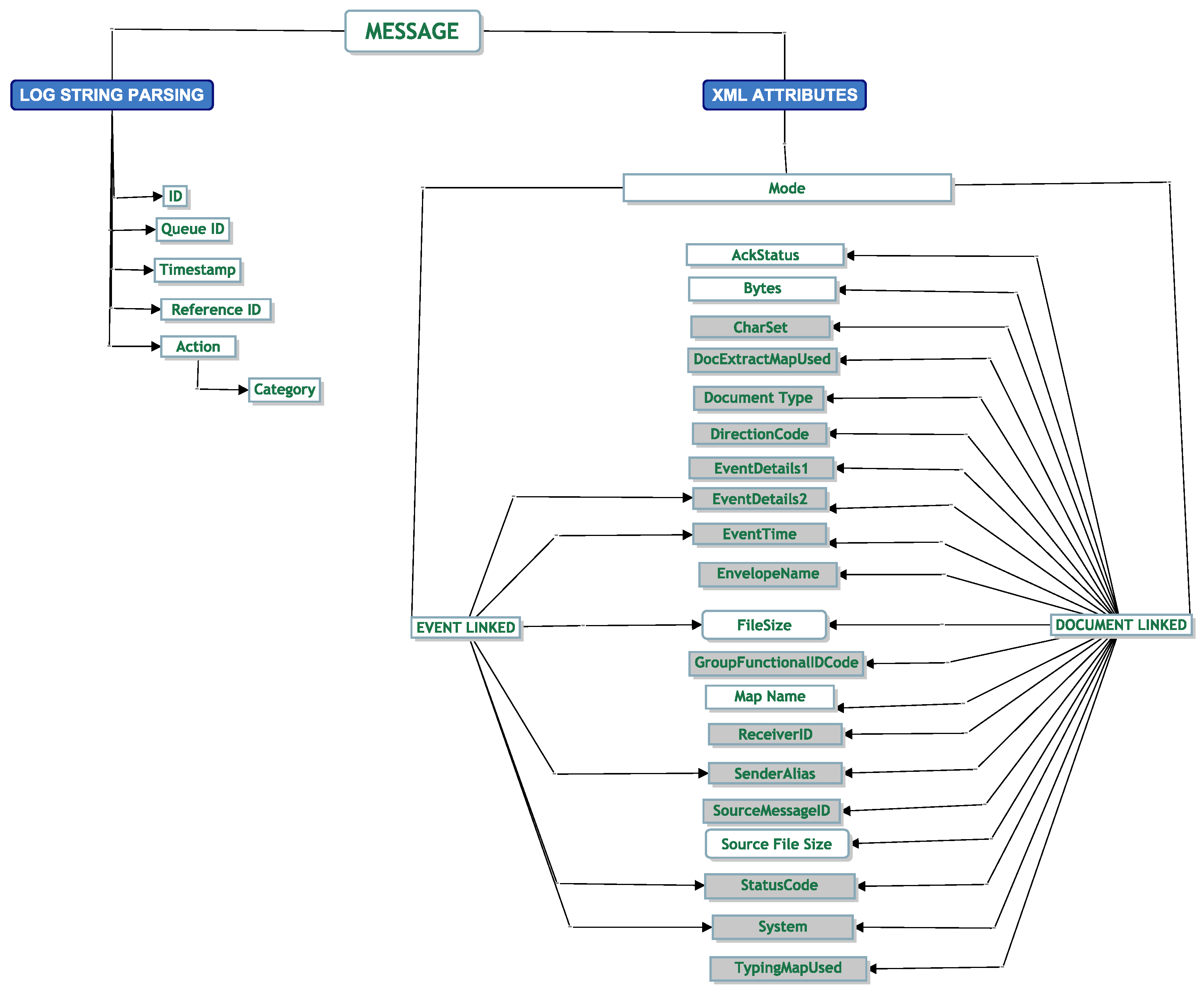
In more detail, we took the ID of the message and split the string in two (id1:id2). The first string was the Company ID (id1), and the second string was the Message-ID (id2). Consider the hypothetical example in
Figure 22. Using the second part of the ID in the second delimited column (id2), we counted the number of times the message had a string tag of <XML>. We note that the message first enters the system on line 2. It then has an <XML> tag on line 6. We count this as 1 XML document. We then note the message arrives in the system again at line 15, and at line 19, it has another <XML> tag. We count this as 2 XML documents for id2. We iterate through all the log data until the last part of the message comes into the system, and we aggregate the count of <XML> tags.
It is important to note that if there were 2 <XML> tags, i.e., if we had one on lines 26 and 27, we would only take the first <XML> tag as a count. Although we never saw this behaviour in the wild, we note this in case it happens on other systems.
Using the signature, we can now determine if a single arrival will send an influx of messages into the queueing system.
We also seek to understand if there is a dependence between the service times of these independent and non-independent messages. To explore this, we split the messages into messages where the service time exceeds 1 s or 2 s (see
Table 17). We chose these values, as they reflect the tail of our data, and it would be useful to know if these messages are more likely to be in the tail.
We perform a Fisher’s exact test on our data to check for independence.
Table 18 of the Fisher’s exact test indicates that there is no significant association [
p < 0.05] between independent and non-independent messages, where the service times exceed 1 or 2 s in duration.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}